
Reanalyzing Variable Agreement with tu Using an Online Megacorpus of Brazilian Portuguese
Abstract
1. Introduction: The Phenomenon
| (1a) | Tu | és (2SG) |
| You | be.PRES:2SG | |
| ‘You are’ | ||
| (1b) | Tu | é (3SG) |
| you | be.PRES:3SG | |
| ‘You are’ | ||
| (2a) | Tu | comeste (2SG) |
| you | eat.PRET:2SG | |
| ‘You ate’ | ||
| (2b) | Tu | comeu |
| you | eat.PRET:3SG | |
| ‘You ate’ | ||
| (3a) | Tu | escrevias (2SG) |
| you | write.IMPF:2SG | |
| ‘You wrote/were writing’ | ||
| (3b) | Tu | escrevia (3SG) |
| you | write.IMPF:3SG | |
| ‘You wrote/were writing’ | ||
| (4a) | (Se) | tu | achares (2SG) |
| if | you | believe.FUTSUBJ.2SG | |
| ‘(If) you believe’ | |||
| (4b) | (Se) | tu | achar (3SG) |
| if | you | believe.FUTSUBJ.3SG | |
| ‘(If) you believe’ | |||
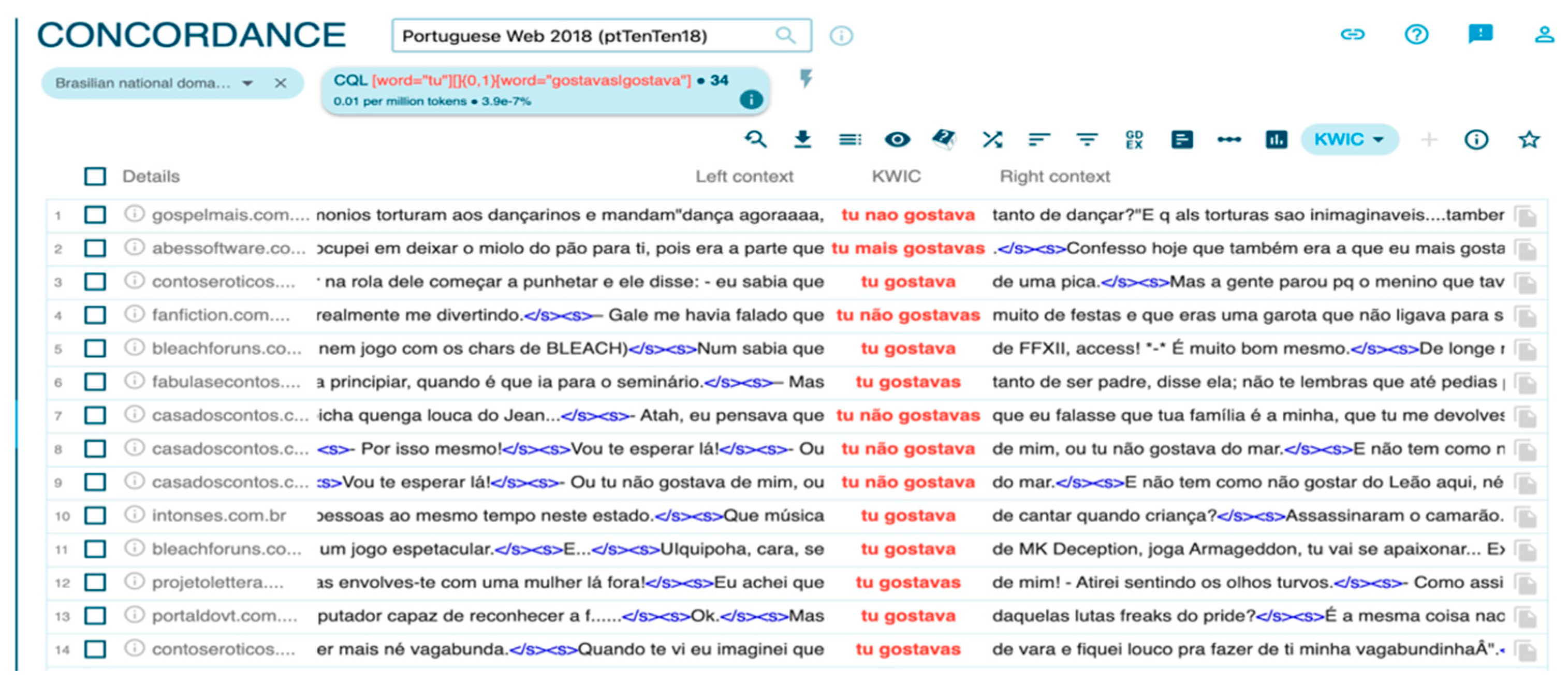
2. Methods
3. Results
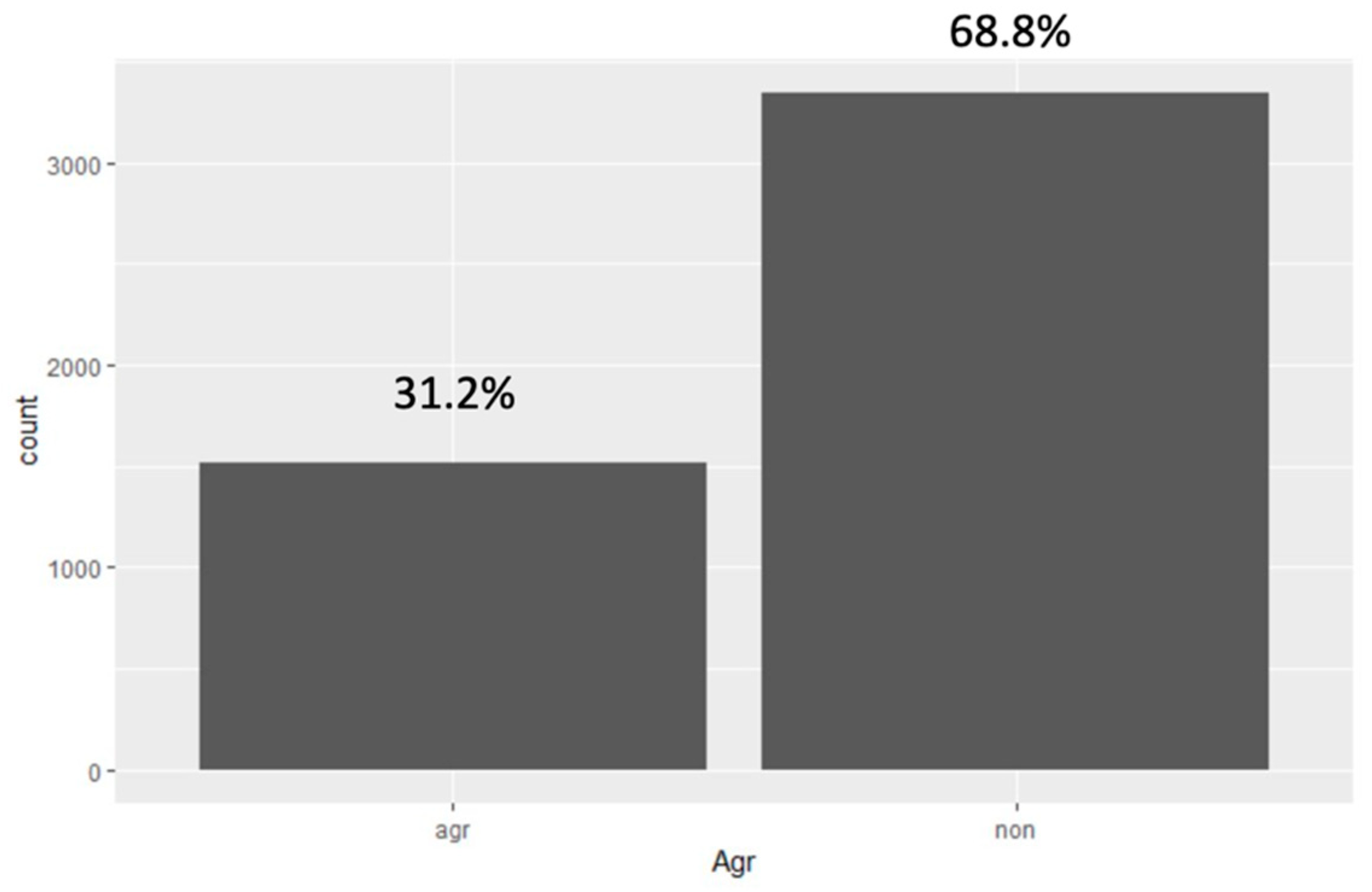
3.1. Descriptive Statistics
| (5) | Eu estou > Eu tô |
| ‘I am’ | |
| (6) | Tu estava(s) > Tu tava(s) |
| ‘You were’ | |
| (7) | Ela esteve > Ela teve |
| ‘She was’ |
- Low Phonic Salience: Present (tu fala/falas) and Imperfect (tu falava/falavas)
- Mid Phonic Salience: Future Subjunctive (tu falar/falares)
- High Phonic Salience: Preterit (tu falou/falaste)
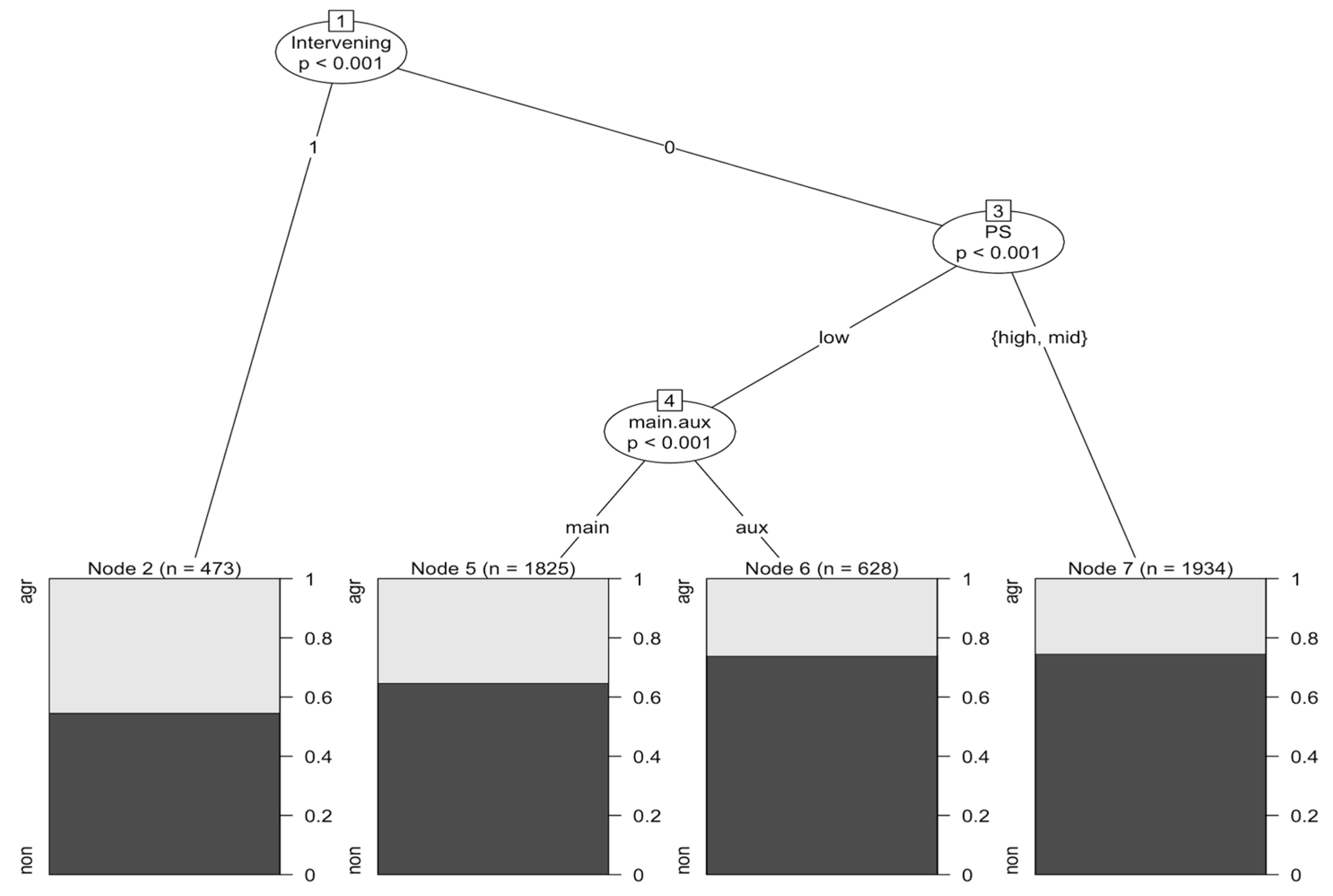
3.2. Inferential Statistical Analysis
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | This summary of the (non)agreement rates across Brazil is consonant with folk ideas about where agreement with tu is found, especially with regard to the phenomenon in Maranhão, which is often considered by laypersons to be the Brazilian state where the “best” Portuguese is spoken (Bagno 2009). |
| 2 | We created an additional conditional inference tree testing interaction between the significant factors seen in Figure 4 as well as Log Frequency (binary division) and Polarity. It appeared there was a boosting effect of Frequency on Polarity, such that only those verbs with high frequency showed a sensitivity to Polarity (cf. Erker and Guy 2012). There appeared to be a further interaction effect of Frequency and main vs. auxiliary verb, but given the low number of low frequency auxiliary tokens with high/mid PS (n = 11), this potential interaction appeared dubious. Further testing of these potential interactions in a regression model, however, revealed that they were not statistically significant. |
| 3 | It is not possible to access a large amount of the prior (or following) context in the Portuguese Web corpus (2018 or 2020 versions). However, there is a finite set of characters available for analysis before each target token, and this would provide an inherent limit on the distance between the prime (e.g., a prior token with 2SG agreement) and the target (a following token with 2SG agreement). While this limit on context is not ideal, it would at least offer a basis for consistent analysis across the full set of data (cf. Rosemeyer and Schwenter 2019). |
References
- Azevedo, Milton M. 2005. Portuguese: A Linguistic Introduction. Cambridge: Cambridge University Press. [Google Scholar]
- Baayen, R. Harald. 2008. Analyzing Linguistic Data: A Practical Introduction to Statistics Using R. Cambridge: Cambridge University Press. [Google Scholar]
- Bagno, Marcos. 2009. Não é errado falar assim! São Paulo: Parábola. [Google Scholar]
- Bhat, D. N. Shankara. 2004. Pronouns. Oxford: Oxford University Press. [Google Scholar]
- Bybee, Joan L., Revere Perkins, and William Pagliuca. 1994. The Evolution of Grammar. Chicago: University of Chicago Press. [Google Scholar]
- Davet, Julie, and Paula Isaias Campos-Antoniassi. 2014. Variação na concordância verbal de segunda pessoa do singular—Um estudo de fala florianopolitana. UFSC Working Papers em Linguística 15: 95–111. [Google Scholar] [CrossRef]
- Dickinson, Kendra V. 2022. Past Participles in Spanish and Brazilian Portuguese: A Usage-Based Approach to Grammatical and Social Variation. Ph.D. dissertation, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Dickinson, Kendra V. 2024. Regularization and innovation: A usage-based approach to past participle variation in Brazilian Portuguese. Languages 9: 52. [Google Scholar] [CrossRef]
- Erker, Danny, and Gregory R. Guy. 2012. The role of lexical frequency in syntactic variability: Variable subject personal pronoun expression in Spanish. Language 88: 526–57. [Google Scholar] [CrossRef]
- Faraco, Carlos. 1996. O tratamento “você” em português: Uma abordagem histórica. Fragmenta 13: 51–82. [Google Scholar] [CrossRef]
- Guimarães, Ana Maria Mattos. 1979. A Ocorrência de 2” Pessoa: Estudo Comparativo Sobre o Uso de tu e Você na Linguagem Escrita. Ph.D. dissertation, Universidade Federal do Rio Grande do Sul, Porto Alegre, Brazil. [Google Scholar]
- Heine, Bernd. 1993. Auxiliaries: Cognitive Forces and Grammaticalization. Oxford: Oxford University Press. [Google Scholar]
- Johnson, Daniel Ezra. 2009. Getting off the GoldVarb standard: Introducing RBrul for mixed-effects variable rule analysis. Language and Linguistics Compass 3: 359–83. [Google Scholar] [CrossRef]
- Kato, Mary, Ana Maria Martins, and Jairo Nunes. 2022. Português Brasileiro e Português Europeu: Sintaxe Comparada. São Paulo: Editora Contexto. [Google Scholar]
- Kilgarriff, Adam, Vít Baisa, Jan Bušta, Miloš Jakubíček, Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý, and Vít Suchomel. 2014. The Sketch Engine: Ten years on. Lexicography 1: 7–36. [Google Scholar] [CrossRef]
- Loregian, Loremi. 1996. Concordância Verbal Com o Pronome tu na Fala do Sul do Brasil. Master’s thesis, Universidade Federal de Santa Catarina, Florianópolis, Brazil. [Google Scholar]
- Loregian-Penkal, Loremi. 2004. (Re)análise da Referência de Segunda Pessoa na Fala da Região Sul. Ph.D. dissertation, Universidade Federal do Paraná, Curitiba, Brazil. [Google Scholar]
- Mendes, Ronald Beline, and Lívia Oushiro. 2015. Variable number agreement in Brazilian Portuguese: An overview. Language and Linguistics Compass 9: 358–68. [Google Scholar] [CrossRef]
- Naro, Anthony Julius. 1981. The social and structural dimensions of a syntactic change. Language 57: 63–98. [Google Scholar] [CrossRef]
- Paredes Silva, Vera Lúcia. 2003. O retorno do tu ao falar carioca. In Português Brasileiro: Contato Linguístico, Heterogeneidade e História. Edited by Cláudia Roncarati and Jussara Abraçado. Rio de Janeiro: 7Letras, pp. 160–69. [Google Scholar]
- Perini, Mário. 2002. Modern Portuguese Grammar. New Haven: Yale University Press. [Google Scholar]
- Poplack, Shana, Rena Torres Cacoullos, Nathalie Dion, Rosane Berlinck, Salvatore Digesto, Dora LaCasse, and Jonathan Steuck. 2018. Variation and grammaticalization in Romance: A cross-linguistic study of the subjunctive. In Manuals in Linguistics: Romance Sociolinguistics. Edited by Wendy Ayres-Bennett and Janet Carruthers. Berlin and Boston: de Gruyter, pp. 217–52. [Google Scholar]
- R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org (accessed on 14 March 2024).
- Rosemeyer, Malte, and Scott A. Schwenter. 2019. Entrenchment and persistence in language change: The Spanish past subjunctive. Corpus Linguistics and Linguistic Theory 15: 167–204. [Google Scholar] [CrossRef]
- Scherre, Maria Marta Peireira, and Maria Eugênia Lammoglia Duarte. 2016. Main current processes of morphosyntactic variation. In The Handbook of Portuguese Linguistics. Edited by W. Leo Wetzels, João Costa and Sergio Menuzzi. New York: Wiley and Sons, pp. 526–43. [Google Scholar]
- Scherre, Maria Marta Peireira, Anthony Julius Naro, and Carolines Rodrigues Cardoso. 2007. O papel do tipo de verbo na concordância verbal no português brasileiro. DELTA 23: 283–317. [Google Scholar] [CrossRef]
- Scherre, Maria Marta Peireira, Carolina Queiroz Andrade, and Rafael de Castro Catão. 2020. Redesenhando o mapa dos pronomes tu/você/cê/ocê no português brasileiro falado. In Conquistas e Desafios dos Estudos Linguísticos na Contemporaneidade: Trabalhos do V Congresso Nacional de Estudos Linguísticos—V CONEL. Edited by Pedro Henrique Witchs, Lucyenne Matos da Costa Vieira-Machado, CláudIA Jotto Kawachi Furlan and Mayara de Oilveira Nogueira. Porto Alegre: Editora Fi, pp. 270–76. [Google Scholar]
- Scherre, Maria Marta Peireira, Edilene Patrícia Dias, Carolina Queiroz Andrade, and Germano Ferreira Martins. 2015. Variação dos pronomes “tu” e “você”. In Mapeamento Sociolinguístico do Português Brasileiro. Edited by Marco Antonio Martins and Jussara Abraçado. São Paulo: Contexto, pp. 133–72. [Google Scholar]
- Schwenter, Scott A., and Mark Hoff. 2020. Cross-dialectal productivity of the Spanish subjunctive in nominal clause complements. In Variation and Evolution. Aspects of Language Contact and Contrast across the Spanish-Speaking World. Edited by Sandro Sessarego, Juan J. Colomina-Almiñana and Adrián Rodríguez-Riccelli. Amsterdam: John Benjamins, pp. 11–31. [Google Scholar]
- Schwenter, Scott A., Mark Hoff, Eleni Christodulelis, Chelsea Pflum, and Ashlee Dauphinais. 2019. Variable past participles in Portuguese perfect constructions. Language Variation and Change 31: 69–89. [Google Scholar] [CrossRef]
- Schwenter, Scott A., Mark Hoff, Kendra V. Dickinson, Justin Bland, and Luana Lamberti. 2018. Experimental evidence for 2SG direct object pronoun preferences in Brazilian Portuguese. Revista LinguíStica 14: 259–90. [Google Scholar] [CrossRef]
- Silva, Gláucia V. 2001. Word Order in Brazilian Portuguese. Berlin: Mouton de Gruyter. [Google Scholar]
- Souza, Christiane Maria Nunes de, and Raquel Gomes Chaves. 2015. A avaliação da concordância verbal com o pronome tu em Florianópolis. UFSC Working Papers em Linguística 16: 170–89. [Google Scholar] [CrossRef]
- Tagliamonte, Sali, and R. Harald Baayen. 2012. Models, forests, and trees of York English: Was/were variation as a case study of statistical practice. Language Variation and Change 24: 135–78. [Google Scholar] [CrossRef]
- Tarallo, Fernando. 1996. Turning different at the turn of the century: 19th century Brazilian Portuguese. In Towards a Social Science of Language: Papers in Honor of William Labov. Edited by Gregory R. Guy, Crawford Feagin, Deborah Schiffrin and John Baugh. Amsterdam: John Benjamins, vol. 1, pp. 199–220. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Independent Variables | Values |
|---|---|
| Verb Lexeme | verb (labeled by infinitive) |
| Phonic Salience | low, mid, high |
| Verb Lemma Frequency | tokens per million |
| Verb Type | main or auxiliary |
| Intervening Words | 0 or 1 |
| Polarity | affirmative, negative |
| Verb Form | present, preterit, imperfect, future subjunctive |
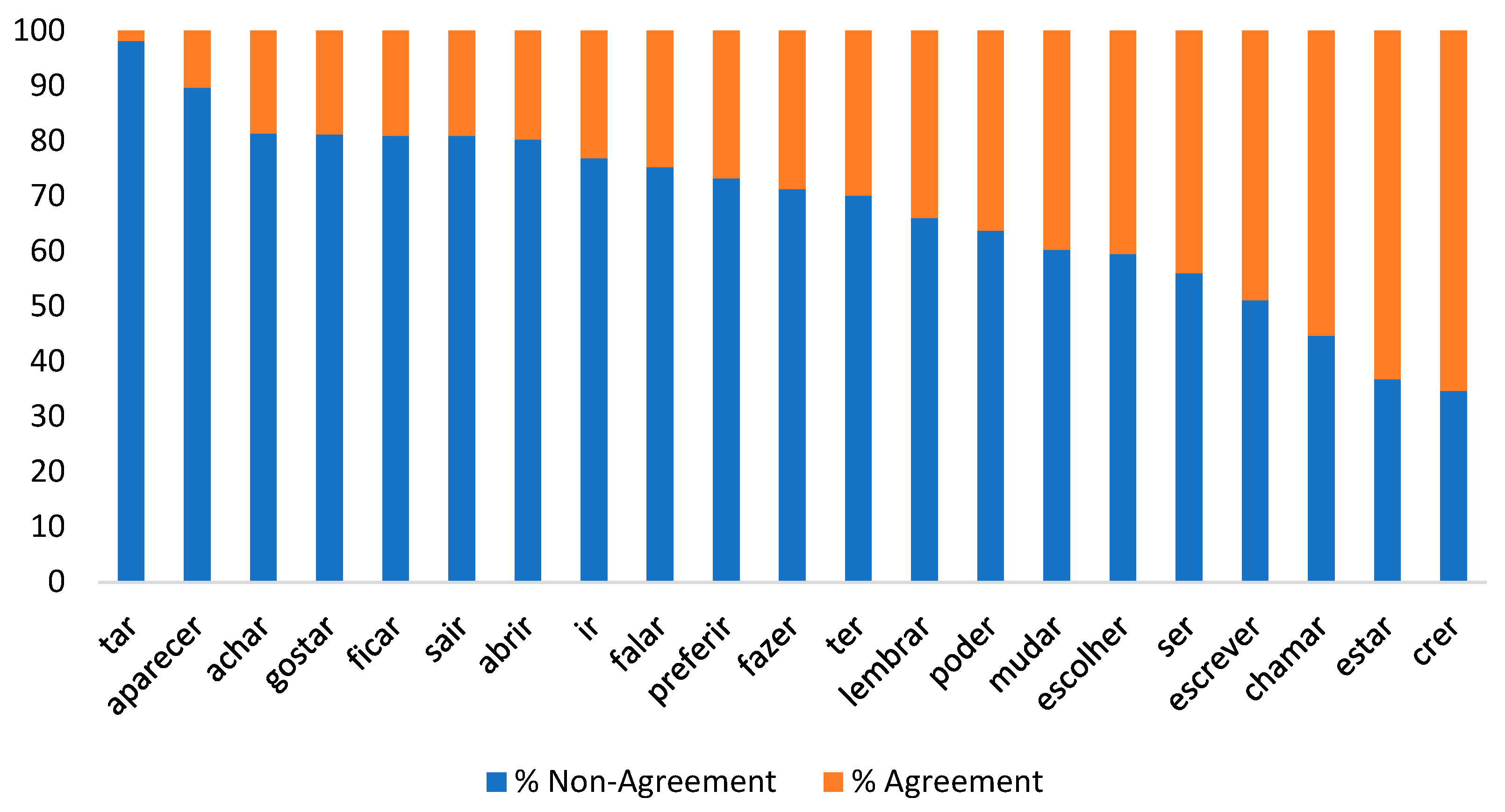
| ser | estar | tar | poder | ter | fazer | ir | ficar | falar | achar | chamar | |
| Freq/million | 17,426.63 | 4007.25 | N/A | 3217.78 | 2503.25 | 2258.97 | 1720.42 | 1212.86 | 606.29 | 412.89 | 377.94 |
| Agr | 150 (44.0%) | 199 (63.2%) | 4 (1.9%) | 95 (36.3%) | 109 (29.9%) | 103 (28.7%) | 95 (23.1%) | 48 (19.1%) | 64 (24.7%) | 88 (18.6%) | 88 (55.3%) |
| Non-Agr | 191 (56.0%) | 116 (36.8%) | 204 (98.1%) | 167 (63.7%) | 255 (70.1%) | 256 (71.3%) | 317 (76.9%) | 203 (80.9%) | 195 (75.3%) | 385 (81.4%) | 71 (44.7%) |
| gostar | sair | lembrar | escrever | abrir | mudar | escolher | aparecer | preferir | crer | ||
| Freq/million | 330.87 | 323.6 | 265.65 | 236.05 | 220.9 | 205.93 | 198.46 | 189.27 | 93.25 | 92.05 | |
| Agr | 51 (18.8%) | 48 (19.1%) | 51 (34%) | 108 (48.9%) | 15 (19.7%) | 69 (39.7%) | 49 (40.5%) | 7 (10.3%) | 19 (26.8%) | 64 (65.3%) | |
| Non-Agr | 221 (81.2%) | 203 (80.9%) | 99 (66%) | 113 (51.1%) | 61 (80.3%) | 105 (60.3%) | 72 (50.5%) | 61 (89.7%) | 52 (73.2%) | 34 (34.7%) |
| Estar | Tar | |
|---|---|---|
| Agreement | 199 (63.2%) | 4 (1.9%) |
| Non-agreement | 116 (36.8%) | 204 (98.1%) |
| Present | Past | Imperfect | Future Subjunctive | |
|---|---|---|---|---|
| Agreement | 644 (32.2%) | 384 (28.4%) | 303 (37.7%) | 183 (26.2%) |
| Non-agreement | 1359 (67.8%) | 970 (71.6%) | 501 (62.3%) | 516 (73.8%) |
| Low | Mid | High | |
|---|---|---|---|
| Agreement | 928 (34.3%) | 202 (25.2%) | 384 (28.4%) |
| Non-agreement | 1776 (65.7%) | 600 (74.8%) | 970 (71.6%) |
| Main | Auxiliary | |
|---|---|---|
| Agreement | 1271 (32.0%) | 243 (27.3%) |
| Non-agreement | 2699 (68.0%) | 647 (72.7%) |
| Main | Auxiliary | |
|---|---|---|
| Agreement | 390 (31.5%) | 152 (23.8%) |
| Non-agreement | 848 (68.5%) | 487 (76.2%) |
| 0 Intervening Elements | 1 Intervening Element | |
|---|---|---|
| Agreement | 1299 (29.7%) | 215 (45.5%) |
| Non-agreement | 3088 (70.3%) | 258 (54.5%) |
| Affirmative | Negative | |
|---|---|---|
| Agreement | 1399 (32.0%) | 115 (28.8%) |
| Non-agreement | 3062 (68.0%) | 284 (71.2%) |
| High | Low | |
|---|---|---|
| Agreement | 803 (32.0%) | 711 (30.3%) |
| Non-agreement | 1709 (68.0%) | 1637 (69.7%) |
| Estimate | Std. Error | Z-Value | p-Value | |
|---|---|---|---|---|
| (Intercept) | 0.17242 | 0.26360 | 4.944 | <0.001 |
| PS (High) | 0.33152 | 0.08051 | 4.118 | <0.001 * |
| PS (Mid) | 0. 70859 | 0. 10377 | 6.829 | <0.001 * |
| Intervening (1 element) | −0.54970 | 0.11013 | −4.991 | <0.001 * |
| Main.aux (Main) | −0.44254 | 0.13753 | −3.218 | 0.00129 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schwenter, S.A.; Miranda, L.; Pérez, I.; Cataloni, V. Reanalyzing Variable Agreement with tu Using an Online Megacorpus of Brazilian Portuguese. Languages 2024, 9, 197. https://doi.org/10.3390/languages9060197
Schwenter SA, Miranda L, Pérez I, Cataloni V. Reanalyzing Variable Agreement with tu Using an Online Megacorpus of Brazilian Portuguese. Languages. 2024; 9(6):197. https://doi.org/10.3390/languages9060197
Chicago/Turabian StyleSchwenter, Scott A., Lauren Miranda, Ileana Pérez, and Victoria Cataloni. 2024. "Reanalyzing Variable Agreement with tu Using an Online Megacorpus of Brazilian Portuguese" Languages 9, no. 6: 197. https://doi.org/10.3390/languages9060197
APA StyleSchwenter, S. A., Miranda, L., Pérez, I., & Cataloni, V. (2024). Reanalyzing Variable Agreement with tu Using an Online Megacorpus of Brazilian Portuguese. Languages, 9(6), 197. https://doi.org/10.3390/languages9060197