
Regularization and Innovation: A Usage-Based Approach to Past Participle Variation in Brazilian Portuguese

Abstract
1. Introduction
| (1) | O | livro | impresso/imprimido | terá | características | únicas. |
| the | book | printed.m.sg | have.3sg.fut | characteristics | unique.f.pl | |
| ‘The printed book will have unique characteristics.’ | ||||||
| (2) | O | documento | está | impresso/imprimido | em | papel | grosso. |
| The | document | be.3sg.pres | printed.m.sg | on | paper | thick | |
| ‘The document is printed on thick paper.’ | |||||||
| (3) | O | livro | foi | impreso/imprimido | por | uma | só | editorial. |
| The | book | be.3sg.pret | printed.m.sg | by | one | only | publisher | |
| ‘The book was published by only one publisher.’ | ||||||||
| (4) | Ele | já | tinha | impresso/imprimido | o | documento. |
| He | already | have.3sg.imp | printed.m.sg | the | document | |
| ‘He had already printed the document.’ | ||||||
| (5) | Eles | recebem | uma | moeda | para | cada | ponto | ganhado/ganho. |
| They | receive.3pl.pres | a | coin | for | every | point | won.m.sg | |
| ‘They receive a coin for every point won.’ | ||||||||
2. Background
2.1. Previous Work on Portuguese Past Participles
| (6) | E | sera | abrido | a | vos. |
| and | be.3sg.fut | open.part | to | you | |
| ‘And it will be opened to you.’ | |||||
| Livro de vita Christi (1446) | |||||
| (7) | Tinha | morrido | o | Rey | do | Egypto. |
| have.3sg.imp | die.part | the | King | of | Egypt. | |
| ‘The king of Egypt had died.’ | ||||||
| Promptuario historico II, Frei Manoel da Mealhada (1760) | ||||||
2.2. Usage-Based Grammar and Linguistic Analogy
2.3. Frequency and Probability
3. Materials and Methods
3.1. Corpus Description
3.2. Data Collection Procedures
3.3. Statistical Methods
4. Results and Discussion
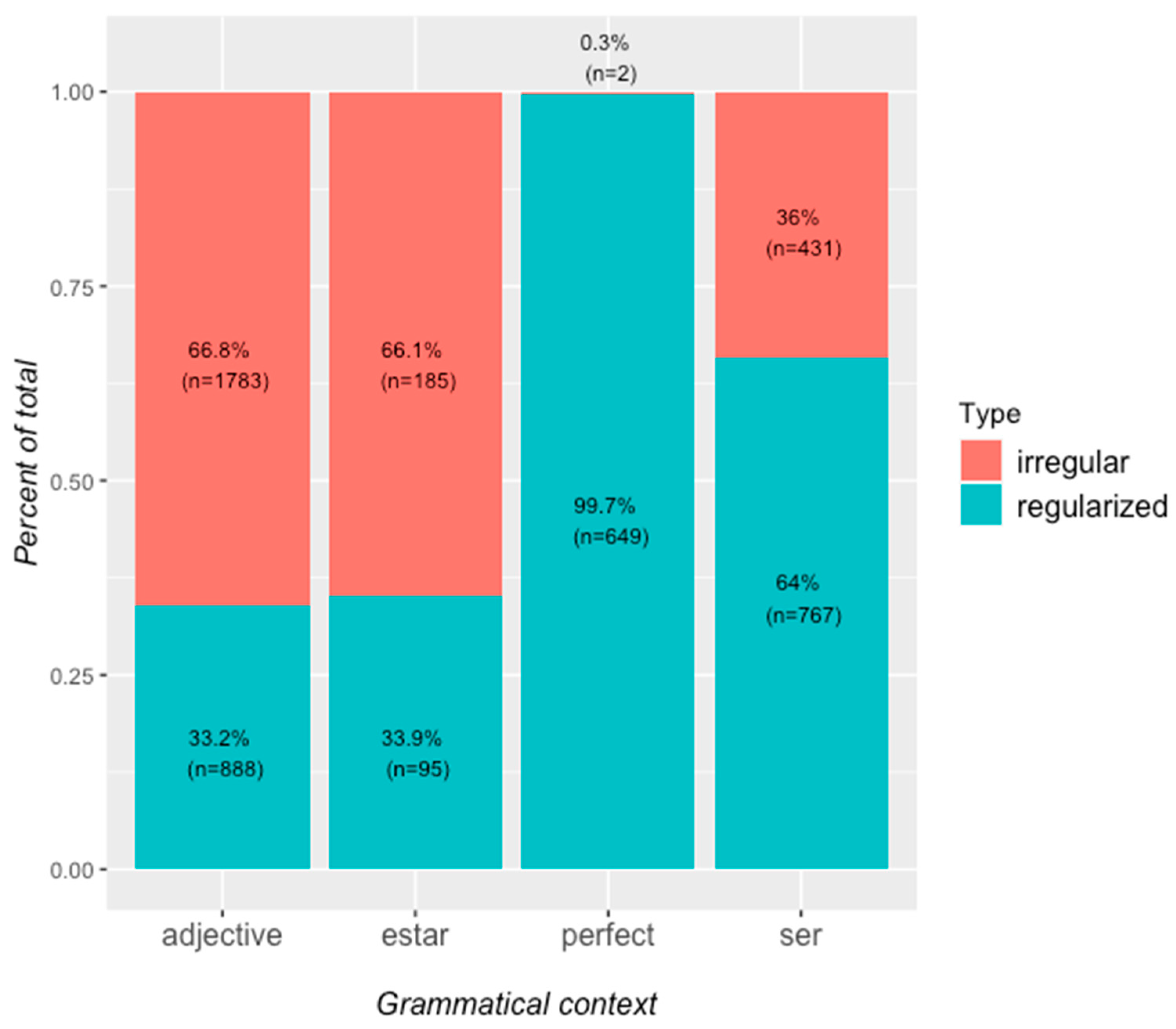
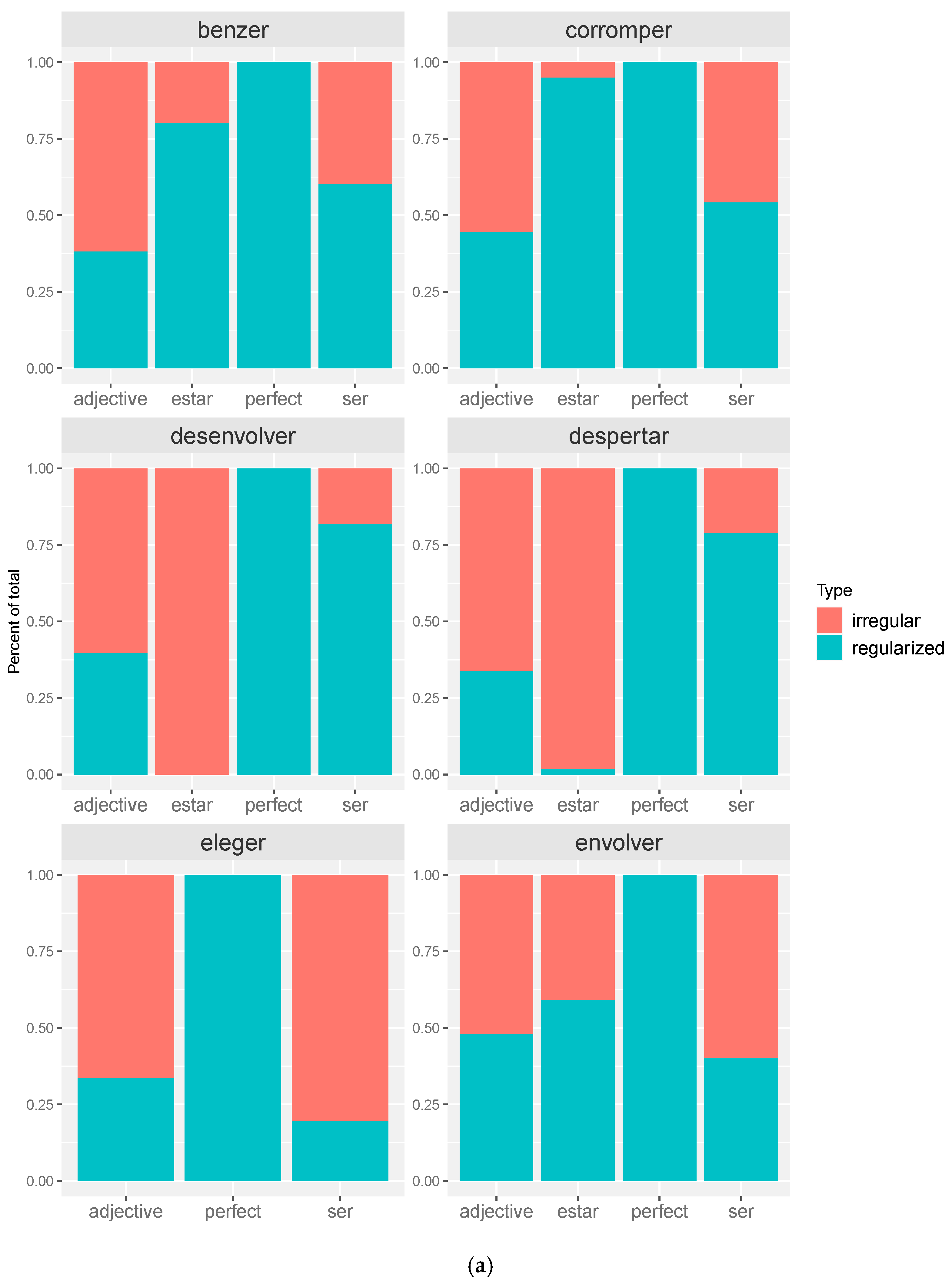
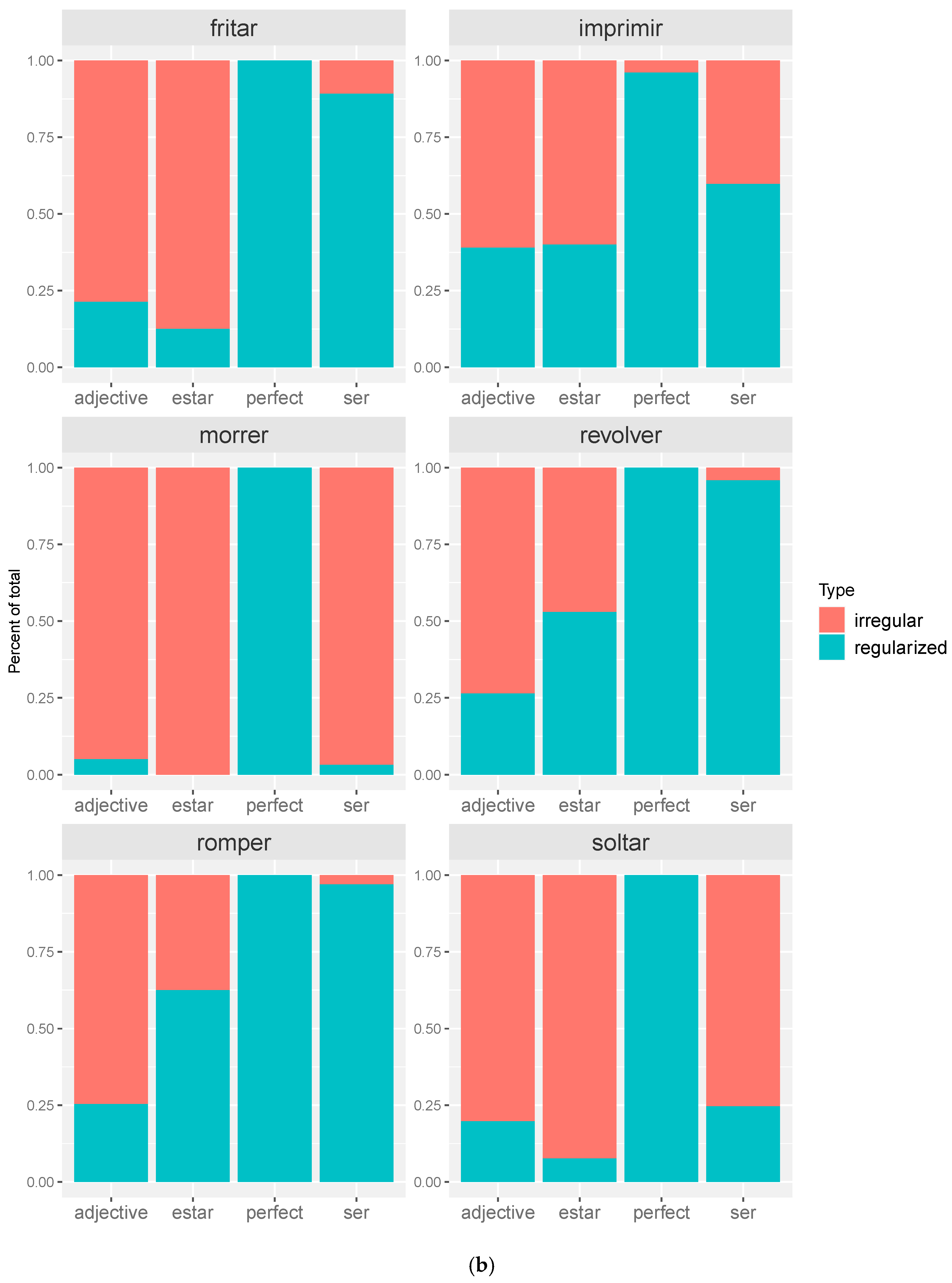
4.1. Long-Form Latinate Irregulars
4.1.1. Description of the Data
4.1.2. Inferential Analysis of Long-Form Latinate Irregulars
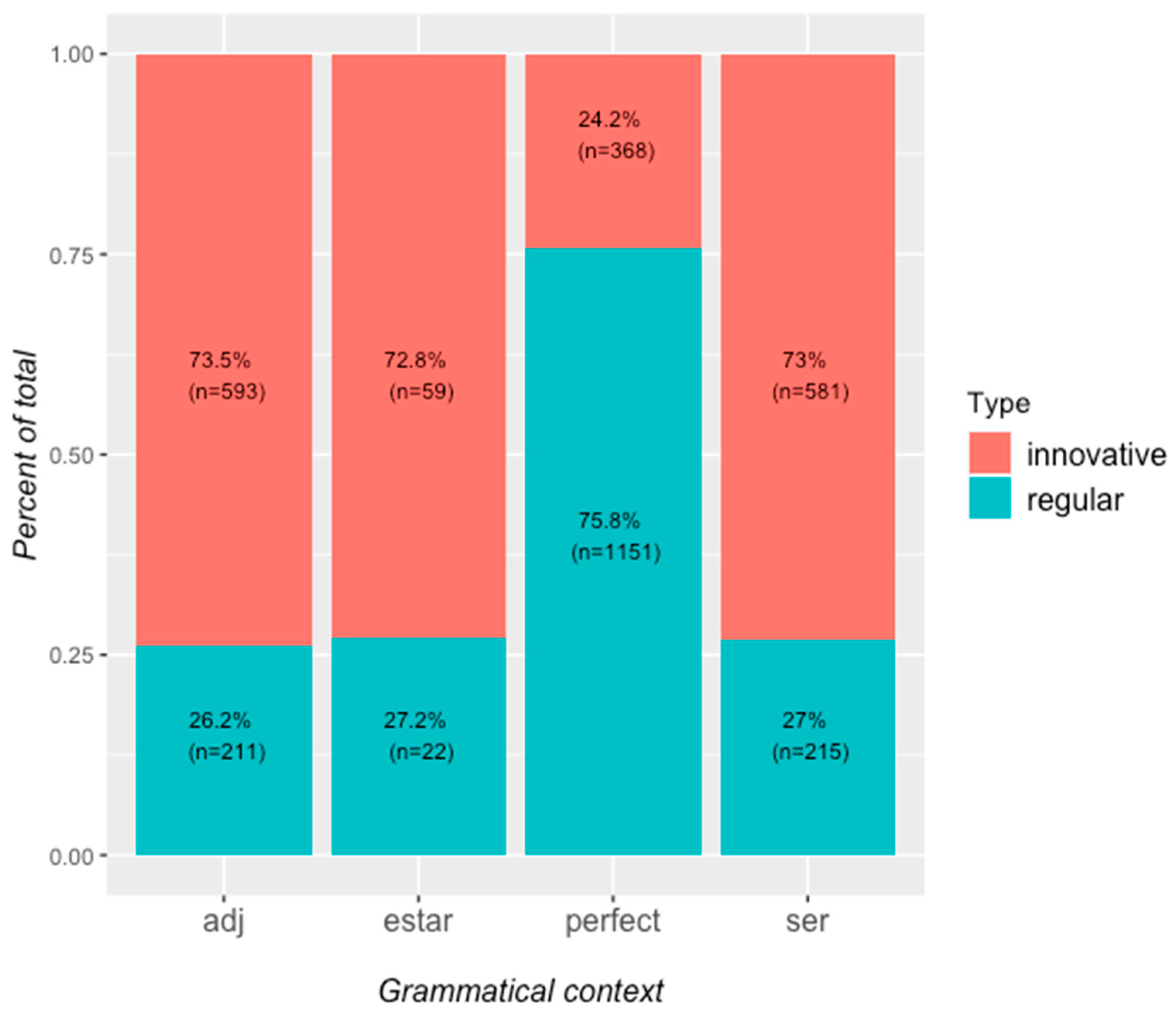
4.2. Short-Form Participles
4.2.1. Description of the Data
4.2.2. Inferential Analysis of Short-Form Participles
4.3. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Verb | Irregular Form | Total Irregular | Regularized Form | Total Regularized | Use across Contexts |
|---|---|---|---|---|---|
| abrir | aberto | 447,921 | abrido | 111 | variable |
| absolver | absolto | 31 | absolvido | 10,014 | variable |
| bendizer | bendito | 10,081 | bendizido | 1 | variable |
| benzer | bento | 2237 | benzido | 442 | variable |
| cobrir | coberto | 81,254 | cobrido | 41 | variable |
| contradizer | contradito | 553 | contradizido | 3 | variable |
| corromper | corrupto | 25,754 | corrompido | 8798 | variable |
| descobrer | descoberto | 61,744 | descobrido | 86 | variable |
| descrever | descrito | 111,788 | descrevido | 35 | variable |
| desenvolver | desenvolto | 685 | desenvolvido | 517,521 | variable |
| desfazer | desfeito | 8896 | desfazido | 1 | variable |
| despertar | desperto | 12,746 | despertado | 10,699 | variable |
| devolver | devolto | 0 | devolvido | 30,740 | no irreg. |
| dissolver | dissolto | 0 | dissolvido | 12,128 | no irreg. |
| dizer | dito | 217,670 | dizido | 33 | variable |
| eleger | eleito | 200,553 | elegido | 1072 | variable |
| envolver | envolto | 9514 | envolvido | 324,280 | variable |
| escrever | escrito | 425,412 | escrevido | 105 | variable |
| extinguir | extinto | 54,329 | extinguido | 667 | variable |
| fazer | feito | 1,997,297 | fazido | 32 | variable |
| fixar | fixo | 125,943 | fixado | 77,117 | categorical |
| fritar | frito | 17,060 | fritado | 544 | variable |
| imprimir | impresso | 96,505 | imprimido | 1654 | variable |
| inscrever | inscrito | 139,499 | inscrevido | 6 | variable |
| juntar | junto | 63,831 | juntado | 7834 | categorical |
| maldizer | maldito | 17,585 | maldizido | 3 | variable |
| morrer | morto | 183,516 | morrido | 15,348 | variable |
| possuir | posseso | 11 | possuído | 6481 | variable |
| predizer | predito | 1640 | predizido | 0 | no reg. |
| prover | provisto | 24 | provido | 16,180 | variable |
| recobrir | recoberto | 5247 | recobrido | 2 | variable |
| resolver | resolto | 6 | resolvido | 91,165 | variable |
| revolver | revolto | 6431 | revolvido | 595 | variable |
| romper | roto | 3749 | rompido | 10,053 | variable |
| satisfazer | satisfeito | 103,785 | satisfazido | 2 | variable |
| soltar | solto | 59,925 | soltado | 1145 | variable |
| transcrever | transcrito | 12,898 | transcribido | 2 | variable |
| ver | veido | 28 | visto | 445,431 | variable |
| voltar | volto | 9 | voltado | 323,281 | variable |
| 1 | Importantly, uses of participle forms with ser may correspond to different structures. Specifically, they can be used adjectivally (e.g., As comidas são feitas de milho ‘The foods are made with corn’), as well as in passive constructions (e.g., A comida foi feita pela cozinheira ‘The food was prepared by the cook’). Though there are potentially important semantic differences in these uses, the present analysis groups them together as uses with ser, in order to provide initial analysis of the role of grammatical context. Nevertheless, future analysis will endeavor to analyze potential distinctions between the two usage types. |
| 2 | In the present work, ‘Latinate’ is used as an umbrella term to refer to participles whose irregularity can be traced to influence from forms in Classical Latin. These are to be distinguished from other irregular participle forms which arose as innovations via other historical processes. |
| 3 | Interestingly, Schwenter et al. (2019) found greater use of short-form forms in European Portuguese as compared to Brazilian Portuguese. Though of great interest, this is beyond the scope of the present analysis. |
| 4 | There are different grammatical constructions with ter and participle forms. For example, the participle form can be part of a perfect construction like the Pretérito Perfeito Composto (tenho preparado a comida ‘I have prepared the food’), or function as an adjective as in tenho a comida preparada (‘I have a prepared food’). In the present data, instances of the first case were coded as perfect constructions with ter, while instances of the second were coded as adjectives modifying nouns. |
| 5 | The corpus data for long-form Latinate irregulars does not indicate a linear relationship between verb frequency and relative frequency of regularized past participles. Unexpectedly, results of a two-tailed t-test show a significant direct positive relationship between verb frequency and the relative frequency of regularized participles for these 35 verbs that show variation (t = 6.151, df = 34, p-value = 5.487 × 10−7). However, the Pearson’s correlation coefficient for these measures, which indicates the strength of association between the two continuous variables, shows only a very slight, if not negligible positive correlation (r = 0.01). |
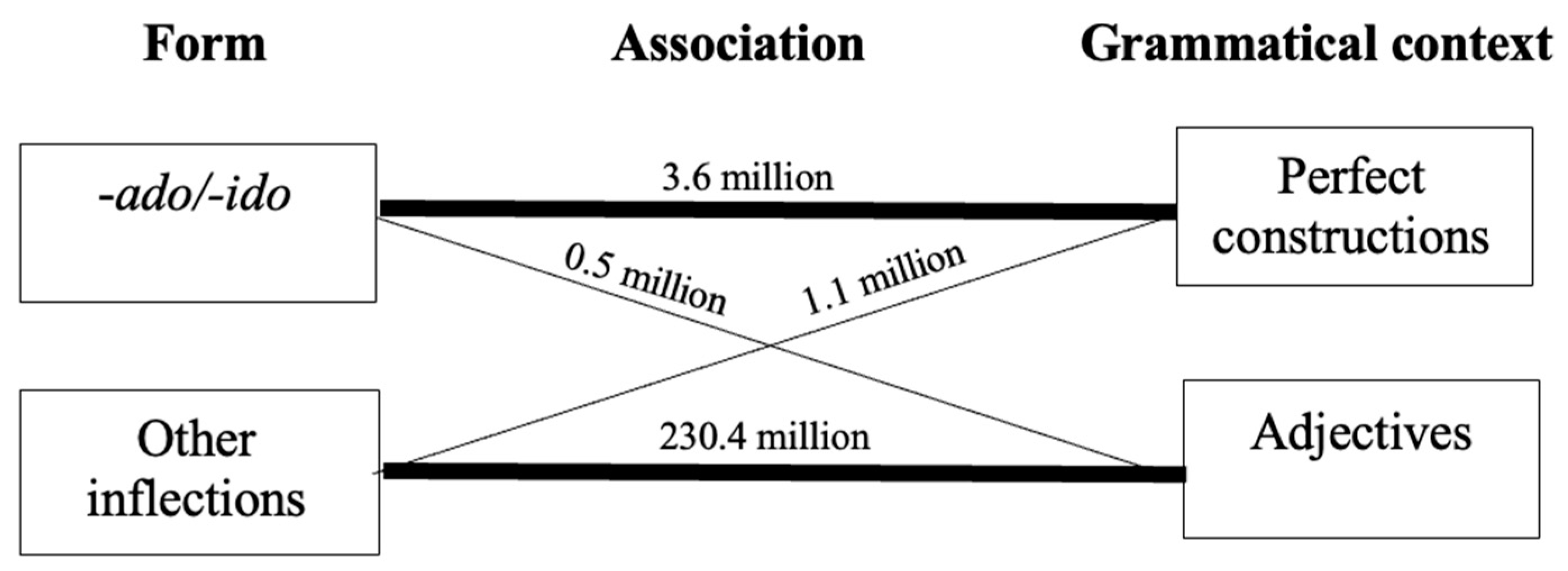
| 6 | Though verb lexeme frequency in all grammatical contexts under analysis was calculated and taken into consideration in all statistical models, a significant contextual effect was seen only with regard to frequency in perfect constructions for short-form participles. |
| 7 | It is important to acknowledge that the data that comprise this corpus are from 2011, and it is likely that there have been changes since that time, in particular, on social media and other informal written genres. After the analysis of these data, Sketch Engine published a newer Portuguese copora (ptTenTen18 and ptTenTen20). This work represents only a preliminary view of this type of variation in Brazilian Portuguese past participles in the ptTenTen11 corpus and will continue to be developed. |
| 8 | Overall lexeme frequency was also considered as a potential predictor of degree of participle innovation, but was not found to be a statistically significant independent variable for these data and was not included in the best-fit model. |
| 9 | Due to the limitations on the current data set, teasing apart potential differences in participle selection between ter and haver was not possible, and most of the tokens occur with the former. Future research will endeavor to explore the the degree to which haver participates in regular perfect constructions as compared to ter. |
References
- Anttila, Raimo. 1977. Analogy. New York: Mouton Publishers. [Google Scholar]
- Baayen, R. Harold. 2010. Demythologizing the word frequency effect: A discriminative learning perspective. The Mental Lexicon 5: 436–61. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Blevins, James P., and Juliette Blevins. 2009. Introduction: Analogy in grammar. In Analogy in Grammar: Form and Acquisition. Edited by James P. Blevins and Juliette Blevins. Oxford: Oxford University Press, pp. 1–12. [Google Scholar]
- Bybee, Joan. 1985. Morphology: A Study of the Relation between Meaning and Form. Amsterdam: John Benjamins. [Google Scholar]
- Bybee, Joan. 1995. Regular morphology and the lexicon. Language and Cognitive Processes 10: 425–55. [Google Scholar] [CrossRef]
- Bybee, Joan. 2002. Word frequency and context of use in the lexical diffusion of phonetically conditioned sound change. Language Variation and Change 14: 261–90. [Google Scholar] [CrossRef]
- Bybee, Joan. 2003. Mechanisms of change in grammaticization: The role of frequency. In The Handbook of Historical Linguistics. Edited by Brian D. Joseph and Richard D. Janda. Oxford: Blackwell, pp. 602–23. [Google Scholar]
- Bybee, Joan. 2006. From usage to grammar: The mind’s response to repetition. Language 82: 711–33. [Google Scholar] [CrossRef]
- Bybee, Joan. 2010. Language, Usage and Cognition. Cambridge: Cambridge University Press. [Google Scholar]
- Bybee, Joan. 2013. Usage-based theory and exemplar representations of constructions. In The Oxford Handbook of Construction Grammar. Edited by Thomas Hoffman and Graeme Trousdale. Oxford: Oxford University Press, pp. 49–69. [Google Scholar]
- Bybee, Joan, and Clay Beckner. 2010. Usage-based theory. In The Oxford Handbook of Linguistic Analysis. Edited by Bernd Heine and Heiko Narrog. Oxford: Oxford University Press, pp. 953–80. [Google Scholar]
- Chagas de Souza, Paulo. 2007. Athematic participles in Brazilian Portuguese: A syncretism in the making. Acta Linguistica Hungarica 54: 119–28. [Google Scholar] [CrossRef]
- Chagas de Souza, Paulo. 2011. Particípios atemáticos no PB: Um processo paradigmático. ReVEL 5: 176–85. [Google Scholar]
- Croft, William. 2003. Typology and Universals, 2nd ed. Cambridge: Cambridge University Press. [Google Scholar]
- Croft, William. 2012. Verbs: Aspect and Causal Structure. Oxford: Oxford University Press. [Google Scholar]
- Cunha, Celso, and Lindley Cintra. 2016. Nova Gramática do Português Contemporâneo. Rio de Janeiro: Lexicon Editora Digital. [Google Scholar]
- Davies, Mark. 2004. Corpus do Português: Genre/Historical (Corpus). Available online: https://www.corpusdoportugues.org/hist-gen/ (accessed on 1 January 2022).
- Fox, John, and Sanford Weisberg. 2018. An R Companion to Applied Regression. California: Sage Publications. [Google Scholar]
- Hock, Hans Henrich. 1991. Principles of Historical Linguistics. Berlin: Mouton de Gruyter. [Google Scholar]
- Hopper, Paul J. 1987. Emergent grammar. Annual Meeting of the Berkeley Linguistics Society 13: 139–57. [Google Scholar] [CrossRef]
- Hricsina, Jan. 2019. The Periphrasis Formed by the Verb ir + Infinitive in the History of the Portuguese language. Etudes Romanes de Brno 40: 81. [Google Scholar] [CrossRef]
- Huber, Joseph. 1933. Altportugiesisches Elementarbuch. Heidelberg: Carl Winters Universitätsbuchhandlung, (Portuguese translation Gramática do Português Antigo. Traslated by Maria Manuela Delille. Lisboa: Fundação Calouste Gulbenkian, 1986). [Google Scholar]
- Kilgarriff, Adam, Miloš Jakubíček, Jan Pomikalek, Tony Berber Sardinha, and Pete Whitelock. 2014. PtTenTen: A corpus for Portuguese lexicography. In Working with Portuguese Corpora. Bloomsbury: Bloomsbury Academic, pp. 111–30. [Google Scholar]
- Langacker, Ronald W. 1987. Foundations of Cognitive Grammar: Theoretical Prerequisites. Stanford: Stanford University Press. [Google Scholar]
- Laurent, Richard. 1999. Past Participles from Latin to Romance. Berkeley: University of California Press. [Google Scholar]
- Liaw, Andy, and Matthew Wiener. 2002. Classification and Regression by randomForest. R News 2: 18–22. Available online: https://CRAN.R-project.org/doc/Rnews/ (accessed on 1 January 2022).
- Lobato, Lucia. 1999. Sobre a forma do particípio do português e o estatuto dos traços formais. DELTA: Documentação de Estudos em Lingüística Teórica e Aplicada 15: 113–40. [Google Scholar] [CrossRef]
- MacWhinney, Brian. 1978. The acquisition of morphophonology. Monographs of the Society for Research in Child Development 43: 1–123. [Google Scholar] [CrossRef]
- Miara, Fernanda Lima Jardim, and Izete Lehmkuhl Coelho. 2015. Particípios duplos: Norma, avaliação e uso escrito. Cadernos de Letras da UFF 25: 217–37. [Google Scholar] [CrossRef]
- Mohr, Gordon, Michael Stack, Igor Rnitovic, Dan Avery, and Michele Kimpton. 2004. An Introduction to Heritrix. Paper presented at 4th International Web Archiving Workshop, Bath, UK, September 16; pp. 109–15. [Google Scholar]
- Padró, Lluís, Miquel Collado, Samuel Reese, Marina Lloberes, and Irene Castellon. 2010. Freeling 2.1: Five years of open-source language processing tools. Paper presented at 7th Language Resources and Evaluation Conference, Valletta, Malta, May 17–23. [Google Scholar]
- Perini, Mário. 2002. Modern Portuguese: A Reference Grammar. New Haven: Yale University Press. [Google Scholar]
- R Core Team. 2022. R: A Language and Environment for Statistical Computing. Software. Vienna: R Foundation for Statistical Computing. Available online: http://www.R-project.org/ (accessed on 1 January 2022).
- Schmid, Hans-Jörg. 2015. A blueprint of the entrenchment-and-conventionalization model. Yearbook of the German Cognitive Linguistics Association 3: 3–26. [Google Scholar] [CrossRef]
- Schwenter, Scott A., Mark Hoff, Eleni Christodulelis, Chelsea Pflum, and Ashlee Dauphinais. 2019. Variable past participles in Portuguese perfect constructions. Language Variation and Change 31: 69–89. [Google Scholar] [CrossRef]
- Villalva, Alina, and Fernanda Jardim. 2018. Particípios atemáticos no Português: Tipologia, distribuição e avaliação. Estudios de Lingüística del Español 39: 279–303. [Google Scholar] [CrossRef]
- Queriquelli, Luiz Henrique Milani. 2018. Os particípios rizotônicos emergentes no português brasileiro e sua gênese histórica. Filologia e Linguística Portuguesa 20: 47–59. [Google Scholar] [CrossRef]
- Williams, Edwin B. 2016. From Latin to Portuguese: Historical Phonology and Morphology of the Portuguese Language. Philadelphia: University of Pennsylvania Press. [Google Scholar]


| Verb | Meaning | Long-Form Latinate Irregular | Regularized Form |
|---|---|---|---|
| aceitar | ‘to accept’ | aceito 1 | aceitado |
| explusar | ‘to expel’ | expulso | explusado |
| expresser | ‘to express’ | expresso | expressado |
| Verb | Meaning | Regular Participle | 1SG | Innovative Participle |
|---|---|---|---|---|
| pagar | ‘to pay’ | pagado | pago | pago |
| chegar | ‘to arrive’ | chegado | chego | chego |
| falar | ‘to talk’ | falado | falo | falo |
| Verb | Meaning | Regular Participle | 1SG | Innovative Participle |
|---|---|---|---|---|
| trazer | ‘to bring’ | trazido | trago | trago |
| pedir | ‘to arrive’ | pedido | peço | peço |
| vender | ‘to sell’ | vendido | vendo | vendo |
| Verb | Stem | Standard Participle | Innovative Participle |
|---|---|---|---|
| pagar | pag- | pagado | pago |
| vender | vend- | vendido | vendo |
| falar | fal- | falado | falo |
| Factor Value | Estimate | Std. Error | z-Value | p-Value | |
|---|---|---|---|---|---|
| Intercept | −0.96060 | 0.25364 | −3.787 | 0.000152 | |
| Grammatical Context Reference level = adjective | estar | 0.08089 | 0.13890 | 0.582 | 0.5603 |
| perfect | 8.37183 | 0.75619 | 11.071 | <2 × 10−16 | |
| ser | 1.59433 | 0.07885 | 20.220 | <2 × 10−16 |
| Verb | Lexeme Freq./Million | Regular Form | Total Regular | % Regular | Short-Form | Total Short-Form | % Short-Form |
|---|---|---|---|---|---|---|---|
| limpar | 20.43 | limpado | 1099 | 0.80% | limpo | 137,864 | 99.20% |
| empregar | 36.25 | empregado | 102,684 | 92.80% | emprego | 7989 | 7.20% |
| gastar | 51.33 | gastado | 1292 | 2.50% | gasto | 51,352 | 97.50% |
| entregar | 89.95 | entregado | 197,788 | 98.90% | entregue | 2150 | 1.10% |
| pegar | 97.04 | pegado | 21,587 | 70.70% | pego | 8943 | 29.30% |
| pagar | 140.17 | pagado | 1336 | 1.20% | pago | 107,008 | 98.80% |
| pedir | 207 | pedido | 25,102 | 99.80% | peço | 57 | 0.20% |
| trazer | 231.4 | trazido | 66,442 | 99.80% | trago | 104 | 0.10% |
| ganhar | 280.65 | ganhado | 10,346 | 81.30% | ganho | 2373 | 18.70% |
| chegar | 481.75 | chegado | 55,500 | 97.70% | chego | 1323 | 2.30% |
| Factor Value | Estimate | Std. Error | z | p-Value | |
|---|---|---|---|---|---|
| Intercept | 0.3451 | 0.0845 | 4.084 | <0.001 | |
| Grammatical Context Reference level = adjective | estar | 0.43139 | 0.26649 | 1.619 | 0.105 |
| perfect | −0.71328 | 0.09933 | −7.181 | <0.001 | |
| ser | −0.08327 | 0.12968 | −0.642 | 0.521 | |
| Grammatical Context * Freq. in Perfect Constructions | estar * freq. | −0.77875 | 0.55394 | −1.0406 | 0.16 |
| perfect * freq. | −1.35474 | 0.17782 | −7.619 | <0.001 | |
| ser * freq. | −2.70295 | 0.25577 | −10.568 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dickinson, K.V. Regularization and Innovation: A Usage-Based Approach to Past Participle Variation in Brazilian Portuguese. Languages 2024, 9, 52. https://doi.org/10.3390/languages9020052
Dickinson KV. Regularization and Innovation: A Usage-Based Approach to Past Participle Variation in Brazilian Portuguese. Languages. 2024; 9(2):52. https://doi.org/10.3390/languages9020052
Chicago/Turabian StyleDickinson, Kendra V. 2024. "Regularization and Innovation: A Usage-Based Approach to Past Participle Variation in Brazilian Portuguese" Languages 9, no. 2: 52. https://doi.org/10.3390/languages9020052
APA StyleDickinson, K. V. (2024). Regularization and Innovation: A Usage-Based Approach to Past Participle Variation in Brazilian Portuguese. Languages, 9(2), 52. https://doi.org/10.3390/languages9020052