

L1 Japanese Perceptual Drift in Late Learners of L2 English
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Materials
2.3. Procedure
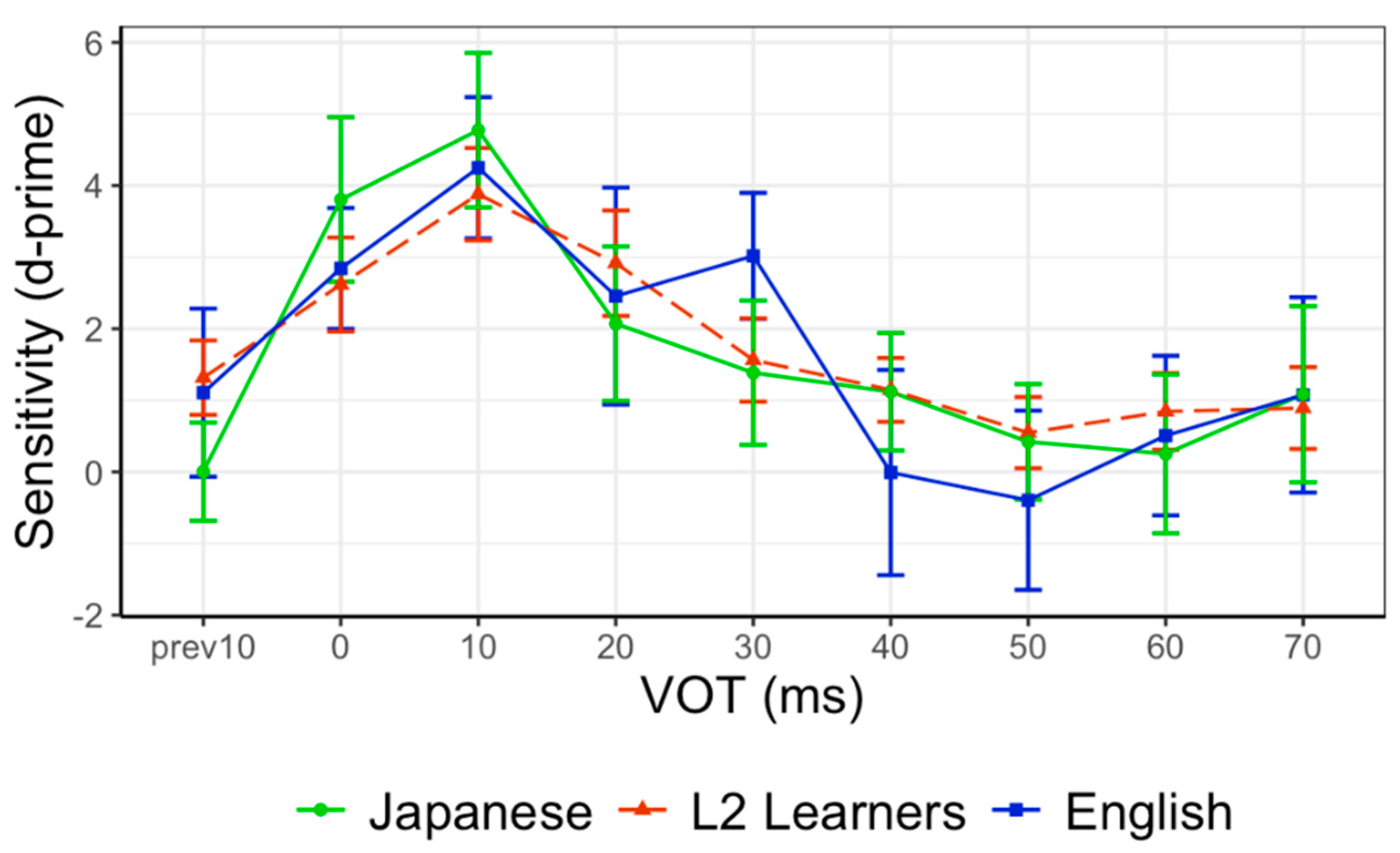
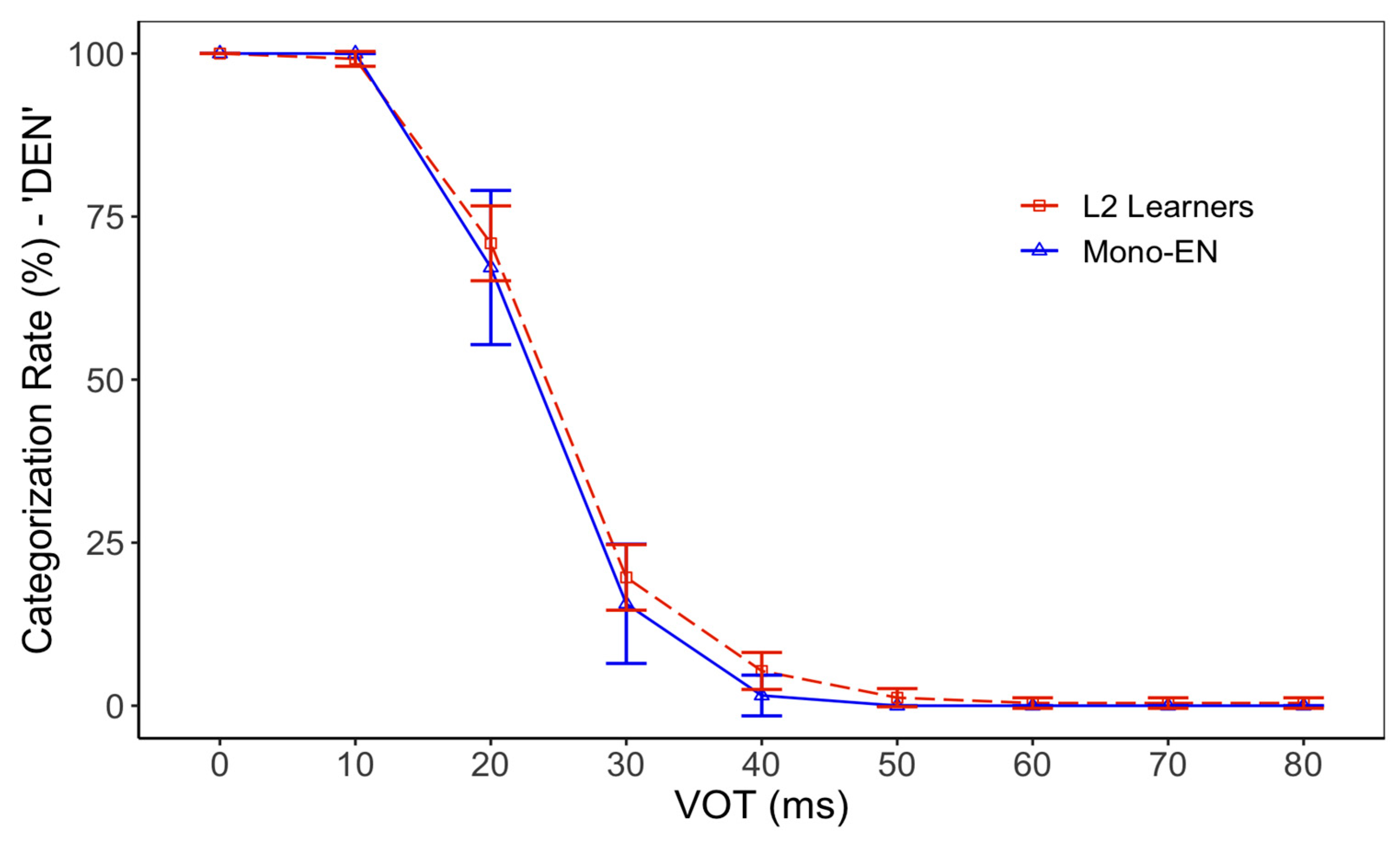
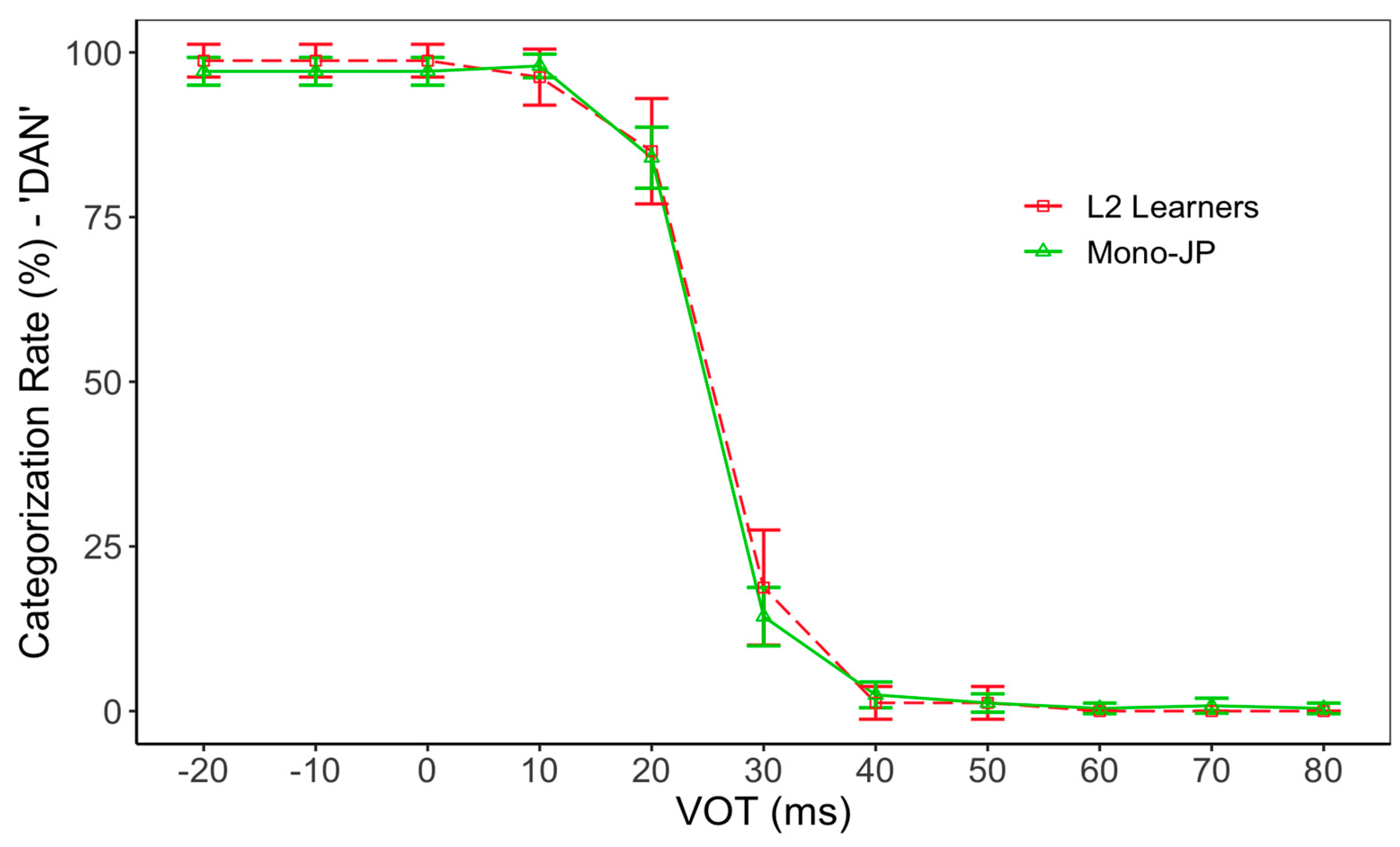
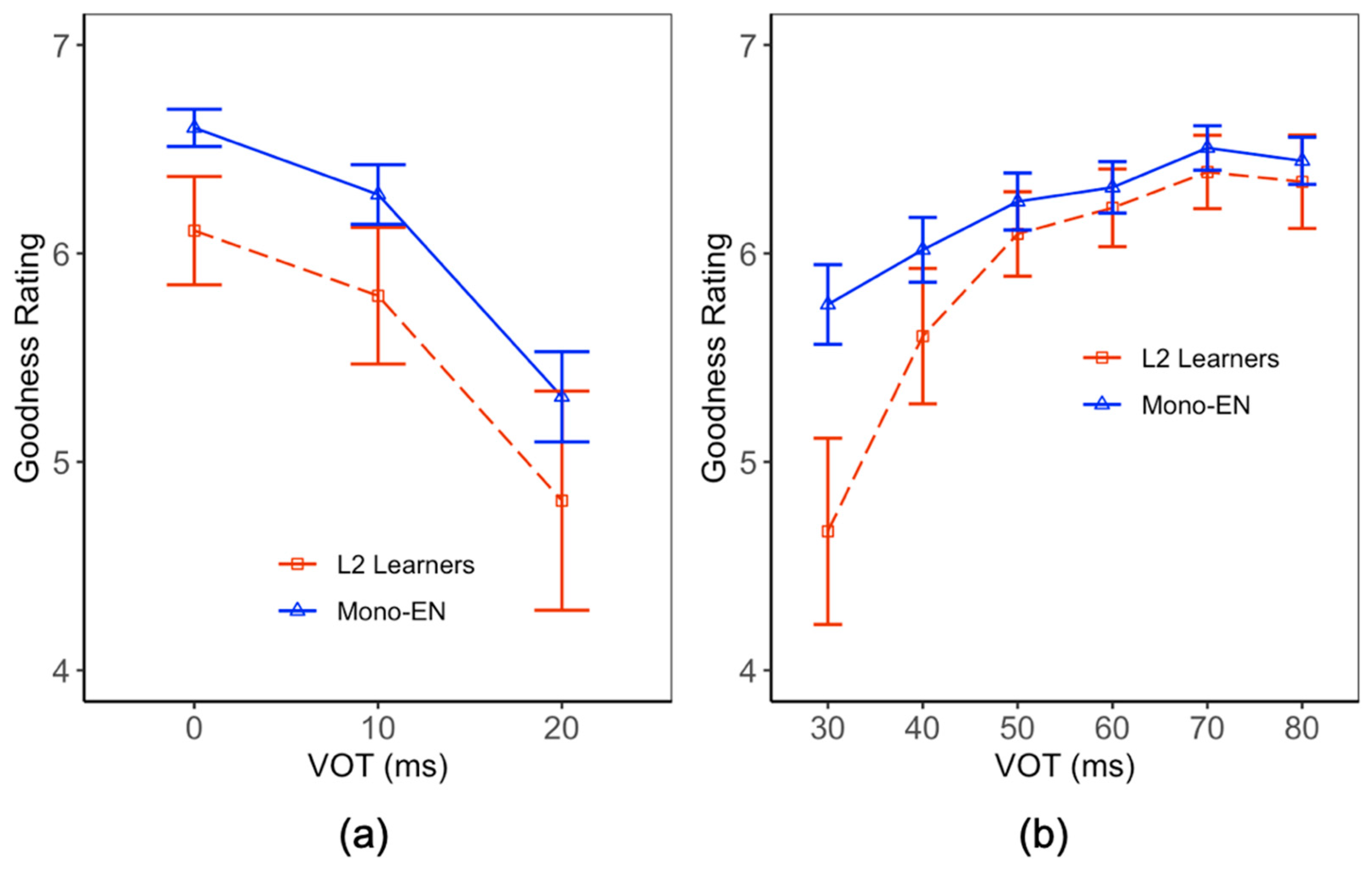
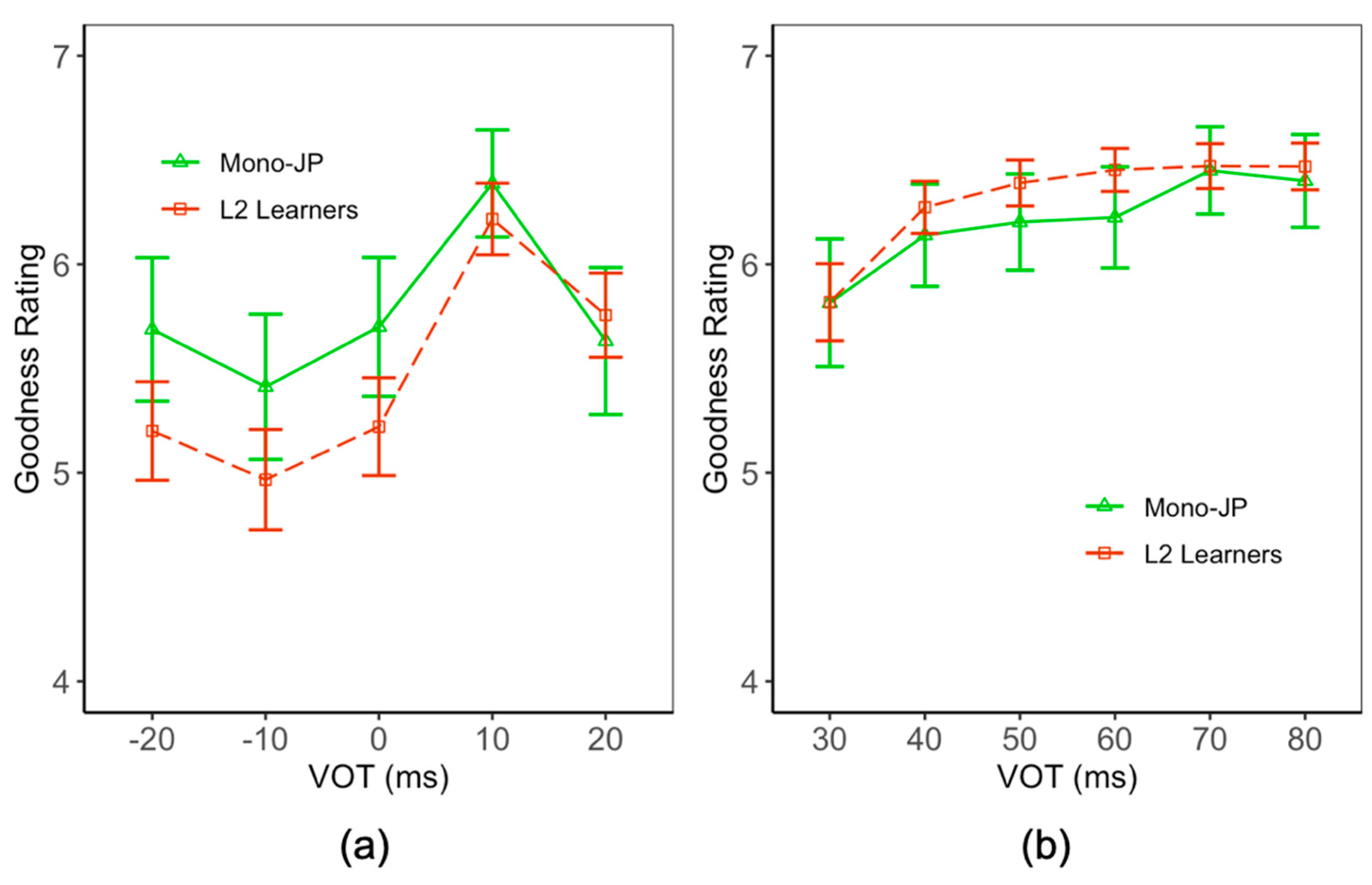
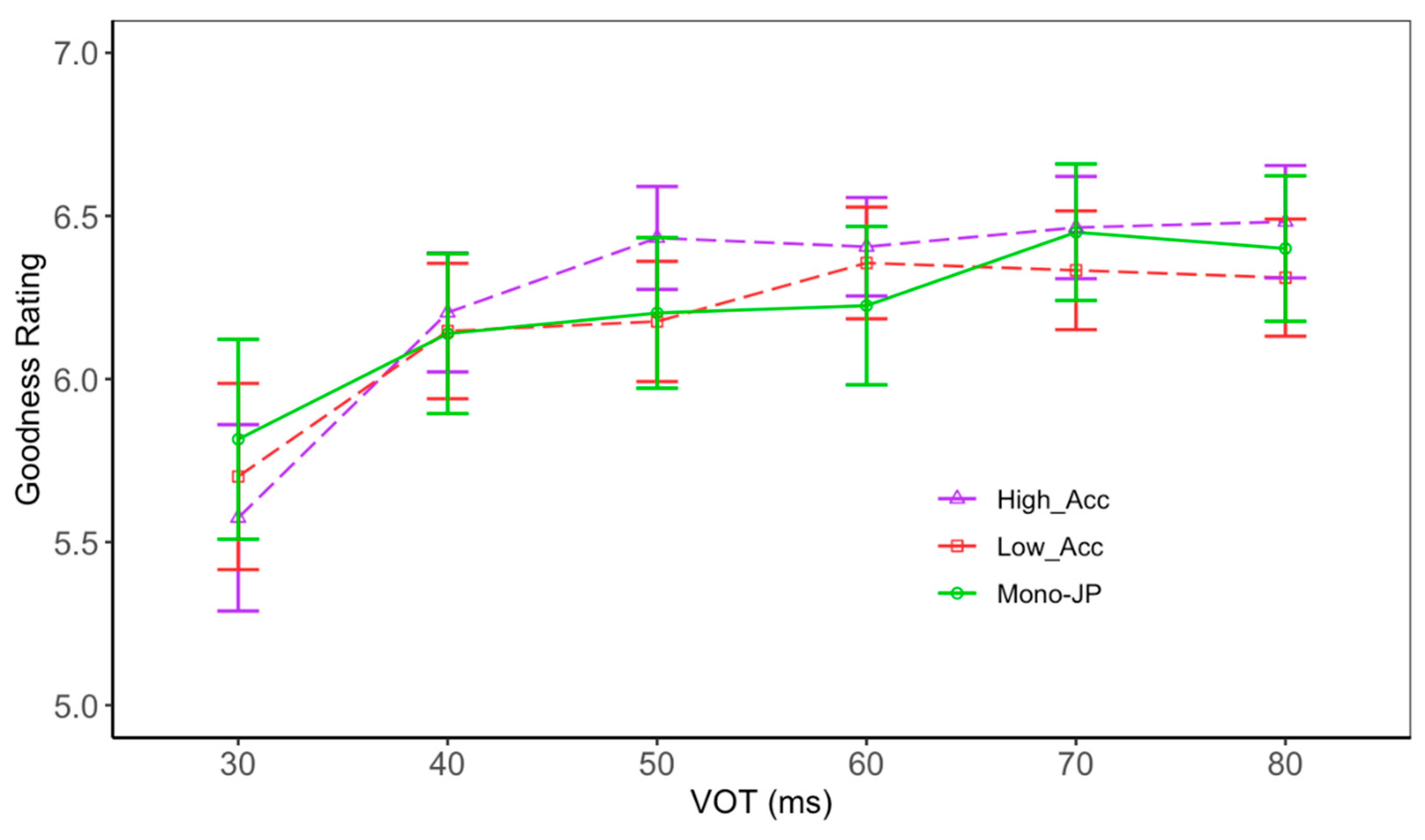
3. Results
3.1. VOT Perception
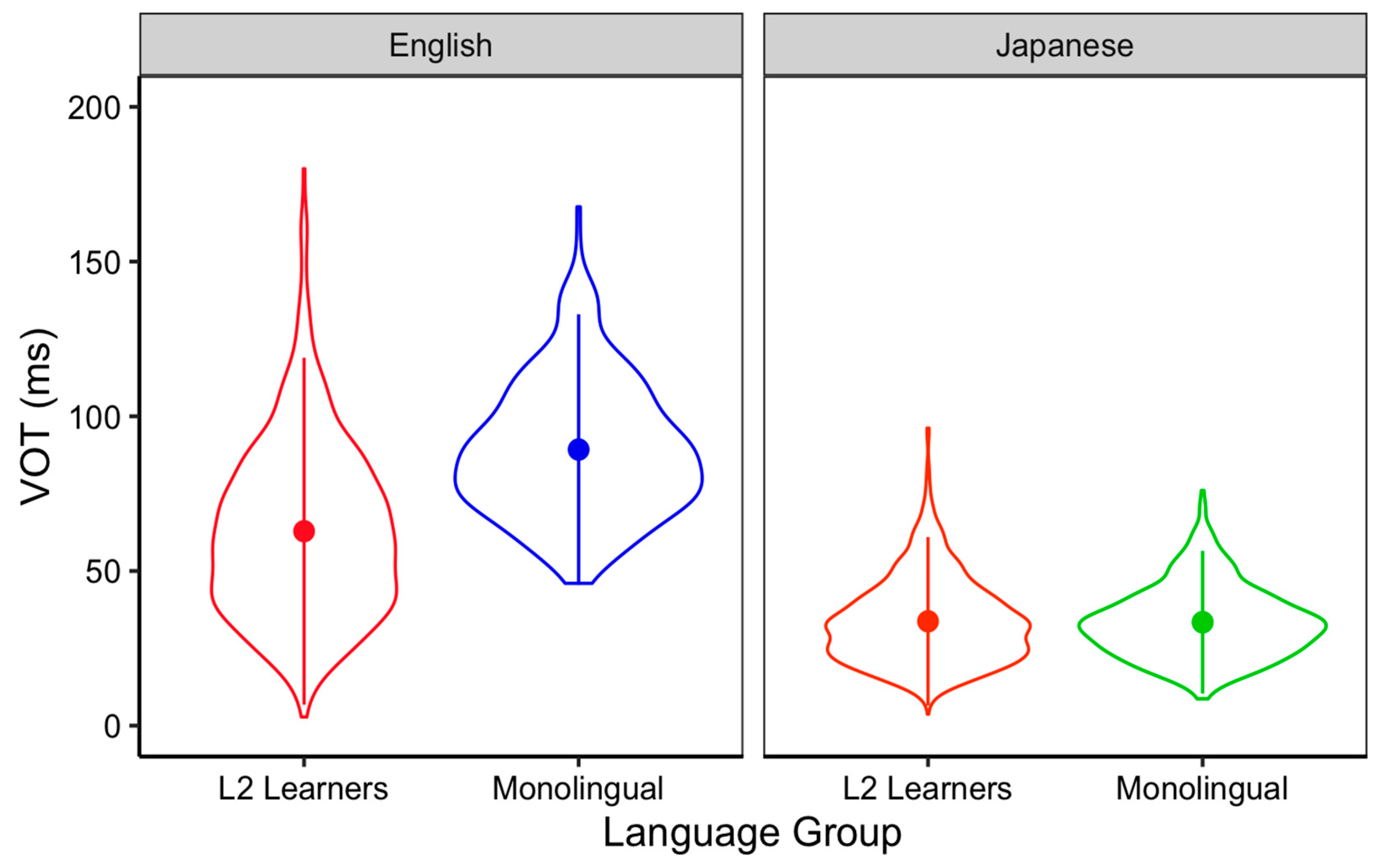
3.2. VOT Production
4. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | |
| 2 | Takada et al. (2015) show an ongoing generational change in word-initial voiced stop VOTs from heavily prevoiced variants to less voiced ones. |
| 3 | It is possible that the L2 participants were in bilingual mode during the entire session as it is difficult to make sure a participant is completely in a “unilingual mode”. However, by giving all the written and spoken instructions in the language of the current task, we aimed to help participants stay in the mode of the language of the given task. |
| 4 | The d-prime score of 0 indicates hit rate = false alarm rate. A positive score indicates better sensitivity, while a negative d-prime score reflects a higher false alarm rate compared to the hit rate. |
| 5 | Normality and homogeneity of variance were checked using the Shapiro–Wilk test and Levene’s test using an R package, rstatix (version 0.7.2; Kassambara 2023). |
| 6 | The data were analyzed using the orginal package (Christensen 2019). |
| 7 | The relationship between L2 learners’ production VOTs and goodness rating can also be examined by looking at their correlation. However, no significant correlation was found between them. |
| 8 | Two standard deviations of the native speaker group mean were chosen as the criterion for determining nativelikeness based on several previous studies (e.g., Flege et al. 1995; Munro et al. 1996). |
| 9 | bAs it was pointed out by the anonymous reviewer, it is also possible that the strength of the perceptual measure might depend on the task. |
References
- Abramson, Arthur S., and Leigh Lisker. 1973. Voice-timing perception in Spanish word-initial stops. Journal of Phonetics 1: 1–8. [Google Scholar] [CrossRef]
- Barlow, Jessica A. 2014. Age of Acquisition and Allophony in Spanish-English Bilinguals. Frontiers in Psychology 5: 288. [Google Scholar] [CrossRef] [PubMed]
- Benkí, José R. 2001. Place of articulation and first formant transition pattern both affect perception of voicing in English. Journal of Phonetics 29: 1–22. [Google Scholar] [CrossRef]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and Second-Language Speech Perception: Commonalities and Complementarities. In Language Learning & Language Teaching. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam: John Benjamins Publishing Company, vol. 17, pp. 13–34. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2020. Praat: Doing Phonetics by Computer [Computer Program]. Available online: http://www.praat.org/ (accessed on 31 October 2018).
- Caramazza, A., and G. H. Yeni-Komshian. 1974. Voice Onset Time in Two French Dialects. Journal of Phonetics 2: 239–45. [Google Scholar] [CrossRef]
- Casillas, Joseph V. 2020. Phonetic Category Formation Is Perceptually Driven During the Early Stages of Adult L2 Development. Language and Speech 63: 550–81. [Google Scholar] [CrossRef] [PubMed]
- Chang, Charles B. 2012. Rapid and Multifaceted Effects of Second-Language Learning on First-Language Speech Production. Journal of Phonetics 40: 249–68. [Google Scholar] [CrossRef]
- Chang, Charles B. 2013. A Novelty Effect in Phonetic Drift of the Native Language. Journal of Phonetics 41: 520–33. [Google Scholar] [CrossRef]
- Chang, Charles B. 2019. Phonetic Drift. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Christensen, Rune H. B. 2019. Ordinal: Regression Models for Ordinal Data. R Package. Available online: https://CRAN.R-project.org/package=ordinal (accessed on 20 November 2023).
- Crawford, Clifford James. 2009. Adaptation and Transmission in Japanese Loanword Phonology. Ph.D. dissertation, Cornell University, Ithaca, NY, USA. [Google Scholar]
- de Leeuw, Esther, Linnaea Stockall, Dimitra Lazaridou-Chatzigoga, and Celia Gorba Masip. 2021. Illusory Vowels in Spanish–English Sequential Bilinguals: Evidence That Accurate L2 Perception Is Neither Necessary nor Sufficient for Accurate L2 Production. Second Language Research 37: 587–618. [Google Scholar] [CrossRef]
- Dmitrieva, Olga. 2019. Transferring Perceptual Cue-Weighting from Second Language into First Language: Cues to Voicing in Russian Speakers of English. Journal of Phonetics 73: 128–43. [Google Scholar] [CrossRef]
- Flege, James Emil. 1982. Laryngeal timing and phonation onset in utterance-initial English stops. Journal of Phonetics 10: 177–92. [Google Scholar] [CrossRef]
- Flege, James Emil. 1987. The Production of ‘New’ and ‘Similar’ Phones in a Foreign Language: Evidence for the Effect of Equivalence Classification. Journal of Phonetics 15: 47–65. [Google Scholar] [CrossRef]
- Flege, James Emil. 1995. Second Language Speech Learning: Theory, Findings, and Problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 233–72. [Google Scholar]
- Flege, James Emil. 2007. Language Contact in Bilingualism: Phonetic System Interactions. In Laboratory Phonology. Edited by Jennifer Cole and José Ignacio Hualde. Berlin and New York: Mouton de Gruyter, vol. 9, pp. 353–81. [Google Scholar]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The Revised Speech Learning Model (SLM-r). In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar]
- Flege, James Emil, and Wieke Eefting. 1987a. Production and Perception of English Stops by Native Spanish Speakers. Journal of Phonetics 15: 67–83. [Google Scholar] [CrossRef]
- Flege, James Emil, and Wieke Eefting. 1987b. Cross-Language Switching in Stop Consonant Perception and Production by Dutch Speakers of English. Speech Communication 6: 185–202. [Google Scholar] [CrossRef]
- Flege, James Emil, Carlo Schirru, and Ian R. A. MacKay. 2003. Interaction between the Native and Second Language Phonetic Subsystems. Speech Communication 40: 467–91. [Google Scholar] [CrossRef]
- Flege, James Emil, Ian R. A. MacKay, and Diane Meador. 1999. Native Italian Speakers’ Perception and Production of English Vowels. The Journal of the Acoustical Society of America 106: 2973–87. [Google Scholar] [CrossRef]
- Flege, James Emil, Murray J. Munro, and Ian R. A. MacKay. 1995. Factors affecting strength of perceived foreign accent in a second language. The Journal of the Acoustical Society of America 97: 3125–34. [Google Scholar] [CrossRef] [PubMed]
- Guion, Susan G. 2003. The Vowel Systems of Quichua-Spanish Bilinguals. Phonetica 60: 98–128. [Google Scholar] [CrossRef] [PubMed]
- Harada, Tetsuo. 2003. L2 Influence on L1 Speech in the Production of VOT. Paper presented at the 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; pp. 1085–88. [Google Scholar]
- Harada, Tetsuo. 2007. The Production of Voice Onset Time (VOT) by English-Speaking Children in a Japanese Immersion Program. International Review of Applied Linguistics in Language Teaching 45: 353–78. [Google Scholar] [CrossRef]
- Herd, Wendy. 2020. Sociophonetic Voice Onset Time Variation in Mississippi English. The Journal of the Acoustical Society of America 147: 596–605. [Google Scholar] [CrossRef]
- Hitchcock, Elaine, and Laura L. Koenig. 2021. Adult perception of stop consonant voicing in American-English-learning toddlers: Voice onset time and secondary cues. Journal of the Acoustical Society of America 150: 460–77. [Google Scholar] [CrossRef]
- Iverson, Paul, and Patricia K. Kuhl. 1995. Mapping the Perceptual Magnet Effect for Speech Using Signal Detection Theory and Multidimensional Scaling. The Journal of the Acoustical Society of America 97: 553–62. [Google Scholar] [CrossRef] [PubMed]
- Jong, Kenneth J. de, Noah H. Silbert, and Hanyong Park. 2009. Generalization Across Segments in Second Language Consonant Identification. Language Learning 59: 1–31. [Google Scholar] [CrossRef]
- Kartushina, Natalia, Alexis Hervais-Adelman, Ulrich Hans Frauenfelder, and Narly Golestani. 2016a. Mutual Influences between Native and Non-Native Vowels in Production: Evidence from Short-Term Visual Articulatory Feedback Training. Journal of Phonetics 57: 21–39. [Google Scholar] [CrossRef]
- Kartushina, Natalia, Ulrich H. Frauenfelder, and Narly Golestani. 2016b. How and When Does the Second Language Influence the Production of Native Speech Sounds: A Literature Review: L2 Influences on L1: A Literature Review. Language Learning 66: 155–86. [Google Scholar] [CrossRef]
- Kassambara, Alboukadel. 2023. rstatix: Pipe-Friendly Framework for Basic Statistical Texts. R Package Version 0.7.2. Available online: https://rpkgs.datanovia.com/rstatix/ (accessed on 1 July 2023).
- Keating, Patricia, Michael J. Mikoś, and William F. Ganong. 1981. A cross-language study of range of voice onset time in the perception of initial stop voicing. The Journal of the Acoustical Society of America 70: 1261. [Google Scholar] [CrossRef]
- Lang, Benjamin, and Lisa Davidson. 2019. Effects of Exposure and Vowel Space Distribution on Phonetic Drift: Evidence from American English Learners of French. Language and Speech 62: 30–60. [Google Scholar] [CrossRef] [PubMed]
- Lev-Ari, Shiri, and Sharon Peperkamp. 2013. Low Inhibitory Skill Leads to Non-Native Perception and Production in Bilinguals’ Native Language. Journal of Phonetics 41: 320–31. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1964. A Cross-Language Study of Voicing in Initial Stops: Acoustical Measurements. Word 20: 384–422. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1967a. Some Effects of Context on Voice Onset Time in English Stops. Language and Speech 10: 1–28. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1967b. The voicing dimension: Some experiments in comparative phonetics. Paper presented at the 6th International Congress of Phonetic Sciences, Prague, Czech Republic, September 7–13; Edited by Bohuslav Hála, Milan Romportl and Přmysl Janota. pp. 563–67. [Google Scholar]
- Long, Michael H. 1990. Maturational Constraints on Language Development. Studies in Second Language Acquisition 12: 251–85. [Google Scholar] [CrossRef]
- Mack, Molly. 1989. Consonant and Vowel Perception and Production: Early English-French Bilinguals and English Monolinguals. Perception & Psychophysics 46: 187–200. [Google Scholar] [CrossRef]
- MacKay, Ian R. A., James Emil Flege, Thorsten Piske, and Carlo Schirru. 2001. Category Restructuring during Second-Language Speech Acquisition. The Journal of the Acoustical Society of America 110: 516–28. [Google Scholar] [CrossRef] [PubMed]
- Macmillan, Neil A., and C. Douglas Creelman. 2005. Detection Theory: A User’s Guide, 2nd ed. Mahwah: Lawrence Erlbaum Associates. [Google Scholar]
- Major, Roy C. 1992. Losing English as a First Language. The Modern Language Journal 76: 190–208. [Google Scholar] [CrossRef]
- Mora, Joan C., and Marianna Nadeu. 2012. L2 Effects on the Perception and Production of a Native Vowel Contrast in Early Bilinguals. International Journal of Bilingualism 16: 484–500. [Google Scholar] [CrossRef]
- Mora, Joan C., James L. Keidel, and James E. Flege. 2015. Effects of Spanish Use on the Production of Catalan Vowels by Early Spanish-Catalan Bilinguals. In Current Issues in Linguistic Theory. Edited by Joaquín Romero and María Riera. Amsterdam: John Benjamins Publishing Company, vol. 335, pp. 33–54. [Google Scholar] [CrossRef]
- Munro, Murray, James Emil Flege, and Ian R. A. Mackay. 1996. The effects of age of second language learning on the production of English vowels. Applied Psycholinguistics 17: 313–34. [Google Scholar] [CrossRef]
- Nasukawa, Kuniya. 2008. Place-Dependent VOT in L2 Acquisition. In Selected Proceedings of the 2008 Second Language Research Forum. Edited by Matthew T. Prior, Yukiko Watanabe and Sang-Ki Lee. Somerville: Cascadilla Proceedings Project, pp. 197–210. [Google Scholar]
- Ogasawara, Naomi. 2011. Acoustic Analysis of Voice-Onset Time in Taiwan Mandarin and Japanese. Concentric: Studies in Linguistics 37: 155–78. [Google Scholar]
- Pailler, Christophe. 2003. Computation of the Sensitivity Parameter (d’) of SDT [R Script]. Available online: http://www.pallier.org/computing-discriminability-a-d-and-bias-with-r.html (accessed on 1 July 2019).
- Riney, Timothy James, Naoyuki Takagi, Kaori Ota, and Yoko Uchida. 2007. The Intermediate Degree of VOT in Japanese Initial Voiceless Stops. Journal of Phonetics 35: 439–43. [Google Scholar] [CrossRef]
- Ruben, Robert J. 1999. A Time Frame of Critical/Sensitive Periods of Language Development. Acta Oto-Laryngologica 117: 202–5. [Google Scholar] [CrossRef]
- Sancier, Michele L., and Carol A. Fowler. 1997. Gestural Drift in a Bilingual Speaker of Brazilian Portuguese and English. Journal of Phonetics 25: 421–36. [Google Scholar] [CrossRef]
- Sheldon, Amy, and Winifred Strange. 1982. The Acquisition of /r/ and /l/ by Japanese Learners of English: Evidence That Speech Production Can Precede Speech Perception. Applied Psycholinguistics 3: 243–61. [Google Scholar] [CrossRef]
- Schertz, Jessamyn. 2014. klatt_synthesize_vot_f0_series.praat. Available online: http://individual.utoronto.ca/jschertz/scripts.shtml (accessed on 25 July 2018).
- Shimizu, Katsumasa. 1977. Voicing features in the perception and production of stop consonants by Japanese speakers. Studia Phonologica 11: 25–34. [Google Scholar]
- Shimizu, Katsumasa. 1989. A Cross-Language Study of Voicing Contrasts of Stops. Studia Phonologica 23: 1–12. [Google Scholar]
- Shimizu, Katsumasa. 1990. A Cross-Language Study of Voicing Contrasts of Stop Consonants in Asian Languages. Ph.D. dissertation, University of Edinburgh, Edinburgh, UK. [Google Scholar]
- Takada, Mieko, Eun Jong Kong, Kiyoko Yoneyama, and Mary E. Beckman. 2015. Loss of Prevoicing in Modern Japanese /g, d, b/. Paper presented at the 18th International Congress of Phonetic Sciences, Glasgow, UK, August 10–14; pp. 1–5. [Google Scholar]
- Takahashi, Chikako. 2020. The Interaction between L1 and L2 Phonetic Learning. Ph.D. dissertation, Stony Brook University, New York, NY, USA. [Google Scholar]
- Tice, Marisa, and Melinda Woodley. 2012. Paguettes & Bastries: Novice French Learners Show Shifts in Native Phoneme Boundaries. UC Berkeley Phonology Lab Annual Report. Available online: http://journals.linguisticsociety.org/proceedings/index.php/ExtendedAbs/article/view/589 (accessed on 1 July 2019).
- Williams, Lee. 1977. The Perception of Stop Consonant Voicing by Spanish-English Bilinguals. Perception & Psychophysics 21: 289–97. [Google Scholar] [CrossRef]
- Xu, Yisheng, and Alexander L. Francis. 2006. Effects of language experience and stimulus complexity on the categorical perception of pitch direction. The Journal of the Acoustical Society of America 120: 1063–74. [Google Scholar] [CrossRef]
- Yusa, Noriaki, Kuniya Nasukawa, Masatoshi Koizumi, Kim Jungho, Naoki Kimura, and Kensuke Emura. 2010. Unexpected effects of the second language on the first. Paper presented at the New Sounds 2010: Proceedings of the 6th International Symposium on the Acquisition of Second Language Speech, Poznan, Poland, May 1–3; pp. 580–84. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ms | Prevoicing (−20) | End (+80) |
|---|---|---|
| F1 | 250 | 720 |
| F2 | 500 | 1240 |
| F3 | 1500 | 2500 |
| F4 | 3600 | 3600 |
| F5 | 3850 | 3850 |
| B1 | 90 | 90 |
| B2 | 500 | 70 |
| B3 | 500 | 110 |
| B4 | 250 | 250 |
| B5 | 200 | 200 |
| AF | 0 | 0 |
| AV | 45 | 55 |
| Japanese | English | |
|---|---|---|
| p | Pisutoru (pistol), piza (pizza), pikaso (picaso), pasu (pass), papa (papa), pagu (pug) | Peak, peace, peach, papa, pipe, pie, pile |
| t | Tiffanii (Tiffany), tisshu (tissue), tiikappu (tea cup), tafu (tough), tasuku (task), tate (vertical), tesuto (test), tefuron (teflon), tetorisu (tetris) | Tease, teach, tea, type, tile, tight |
| k | Kigu (instrument), kiba (fang), kisu (a type of fish), kasu (sediment), kaba (hippopotamous) | Keep, kiwi, key, kite, Cairo, king |
| Language Groups | Mean | Median | SD |
|---|---|---|---|
| English monolinguals | 24.21 | 10 | 23.87 |
| L2 learners | 18.55 | 10 | 19.87 |
| Japanese monolinguals | 9.0 | 10 | 12.93 |
| β | SE | z | p (>/z/) | |
|---|---|---|---|---|
| (Intercept) | 8.45 | 0.78 | 10.79 | |
| Language group | 1.04 | 0.64 | 1.6 | 0.01 |
| Steps | −0.36 | 0.03 | −10.36 | <0.001 |
| Language group *steps | −0.05 | 0.02 | −1.81 | 0.06 |
| β | SE | z | p (>/z/) | |
|---|---|---|---|---|
| (Intercept) | 8.62 | 0.9 | 9.55 | |
| Language group | −0.14 | 0.71 | −0.2 | 0.8 |
| Steps | −0.33 | 0.03 | −10.34 | <0.001 |
| Language group * steps | 0.009 | 0.02 | 0.3 | 0.7 |
| Fixed Effect | Odds Ratio | SE | z | p (>/z/) |
|---|---|---|---|---|
| Language group | 1.97 | 0.67 | 2.91 | <0.005 |
| Steps | −1.38 | 00.21 | −6.59 | <0.001 |
| Language group * steps | −0.44 | 0.23 | −1.88 | 0.05 |
| Fixed Effect | Odds Ratio | SE | z | P (>/z/) |
|---|---|---|---|---|
| Language group | 2.16 | 0.78 | 2.77 | 0.005 |
| Steps | 0.6 | 0.06 | 9.06 | <0.001 |
| Language group * steps | −0.14 | 0.07 | −1.99 | <0.04 |
| Fixed Effect | Odds Ratio | SE | z | P (>/z/) |
|---|---|---|---|---|
| Language group | −1.65 | 0.63 | −2.61 | <0.005 |
| Steps | 0.20 | 0.07 | 2.76 | 0.005 |
| Language group * steps | 0.28 | 0.08 | 3.24 | <0.005 |
| Fixed Effects | Odds Ratio | SE | z | p (>/z/) |
|---|---|---|---|---|
| Language group | 0.008 | 0.55 | 0.01 | 0.98 |
| Steps | 0.22 | 0.05 | 4.06 | <0.001 |
| Language group * steps | −0.004 | 0.06 | −0.07 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takahashi, C. L1 Japanese Perceptual Drift in Late Learners of L2 English. Languages 2024, 9, 23. https://doi.org/10.3390/languages9010023
Takahashi C. L1 Japanese Perceptual Drift in Late Learners of L2 English. Languages. 2024; 9(1):23. https://doi.org/10.3390/languages9010023
Chicago/Turabian StyleTakahashi, Chikako. 2024. "L1 Japanese Perceptual Drift in Late Learners of L2 English" Languages 9, no. 1: 23. https://doi.org/10.3390/languages9010023
APA StyleTakahashi, C. (2024). L1 Japanese Perceptual Drift in Late Learners of L2 English. Languages, 9(1), 23. https://doi.org/10.3390/languages9010023