

Spanish in the Southeast: What a Swarm of Variables Can Tell Us about a Newly Forming Bilingual Community


Abstract
1. Introduction
2. Background Studies
2.1. The Southeast as a New Dialect Region/“New Destination” Community
2.2. New Dialect Formation in Language Contact Settings
2.3. The Initial Variable Swarm
2.3.1. Realization of Intervocalic /bdg/
2.3.2. Vowel Space and Convex Hull Area (CHA)
2.3.3. Prosodic Rhythm (nPVI)
2.3.4. Bilingual Discourse Markers (DMs)
2.3.5. Summary of the Initial Swarm
2.4. New Swarm Variables
2.4.1. Subject Pronoun Expression (SPE)
2.4.2. Code Switching
- Single word switch: Ella estaba bien surprised ‘She was very surprised’.
- Intersentential switch: ¿Cómo te puedo decir? The right path ‘How can I say it (for you)? The right path’.
- Intrasentential switch: O como cuando van hunting in the woods ‘Or like when they go hunting in the woods’.
2.4.3. Filled Pauses
2.4.4. The Realization of Orthographic b~v
2.4.5. Growing the Swarm
3. Materials and Methods
3.1. General Methods
3.2. Methodology: Subject Pronoun Realization (SPE)
3.3. Methodology: Code Switching (CS)
3.4. Methodology: Filled Pauses (FP)
3.5. Methodology: The Realization of Orthographic <b/v>
4. Results
4.1. Subject Pronoun Expression (SPE)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Log Odds | N | % Overt Pro | p-Value |
|---|---|---|---|---|
| Person/Number and Definiteness | <0.001 * | |||
| él-ella.definite | 1.902 | 267 | 38.2 | |
| 1st singular—yo | 0.847 | 1214 | 21.6 | |
| 3rd plural—ellos-ellas.definite | 0.567 | 209 | 18.2 | |
| 2nd singular—tú.definite | −0.352 | 58 | 8.6 | |
| 2nd singular—tú.indefinite | −0.494 | 151 | 6.6 | |
| 1st plural—nosotros-nosotras | −0.589 | 292 | 8.6 | |
| 3rd plural—ellos-ellas.indefinite | −1.881 | 74 | 2.7 | |
| Switch Reference | <0.001 * | |||
| Complete switch | 0.643 | 945 | 25.5 | |
| Partial switch | −0.284 | 181 | 18.2 | |
| No switch | −0.359 | 1139 | 15.0 | |
| Reflexivity | <0.001 * | |||
| Non-reflexive | 0.392 | 1997 | 20.7 | |
| Reflexive | −0.392 | 268 | 11.6 | |
| Distinctiveness of TAM | <0.001 * | |||
| Non-distinctive | 0.248 | 475 | 26.1 | |
| Distinctive | −0.248 | 1790 | 17.9 | |
| Lexical Content | 0.002 * | |||
| Estimative | 0.676 | 99 | 43.4 | |
| Stative | −0.132 | 562 | 22.0 | |
| External activity | −0.220 | 1229 | 17.4 | |
| Mental activity | −0.324 | 375 | 17.1 | |
| Generation | 0.094 | |||
| G1 | 0.238 | 1173 | 19.9 | |
| G2 | −0.238 | 1092 | 19.2 | |
| Sex | 0.24 | |||
| Female | 0.173 | 1282 | 21.6 | |
| Male | −0.173 | 983 | 17 | |
| Region | 0.60 | |||
| Central America | 0.08 | 686 | 24.2 | |
| Mexico | −0.08 | 1579 | 17.6 |
| N | df | intercept | overall prop | AIC | R2.fixed | R2.random | R2.total |
| 2265 | 18 | −2.348 | 0.196 | 1970.175 | 0.224 | 0.063 | 0.287 |
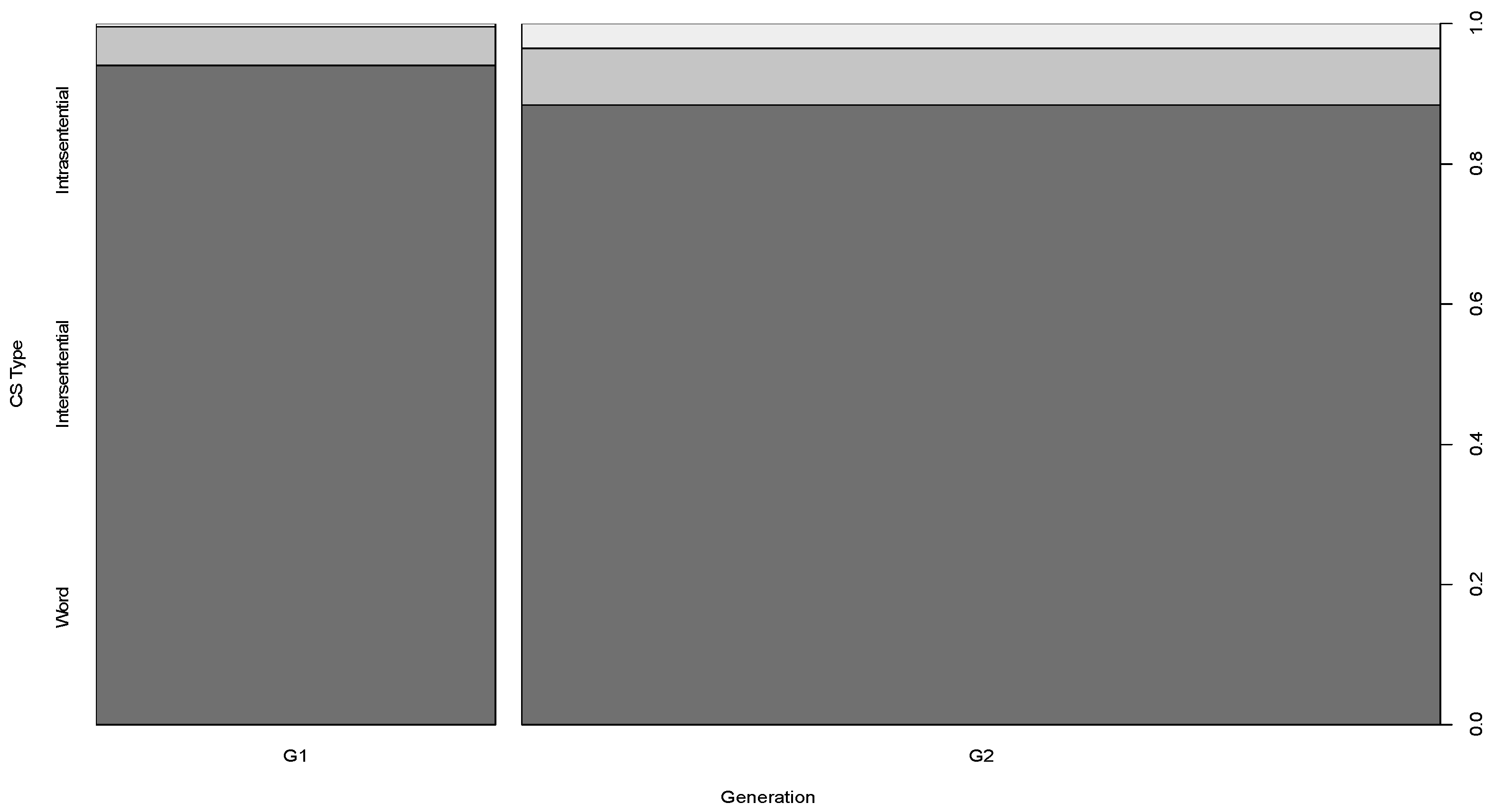
4.2. Code Switching
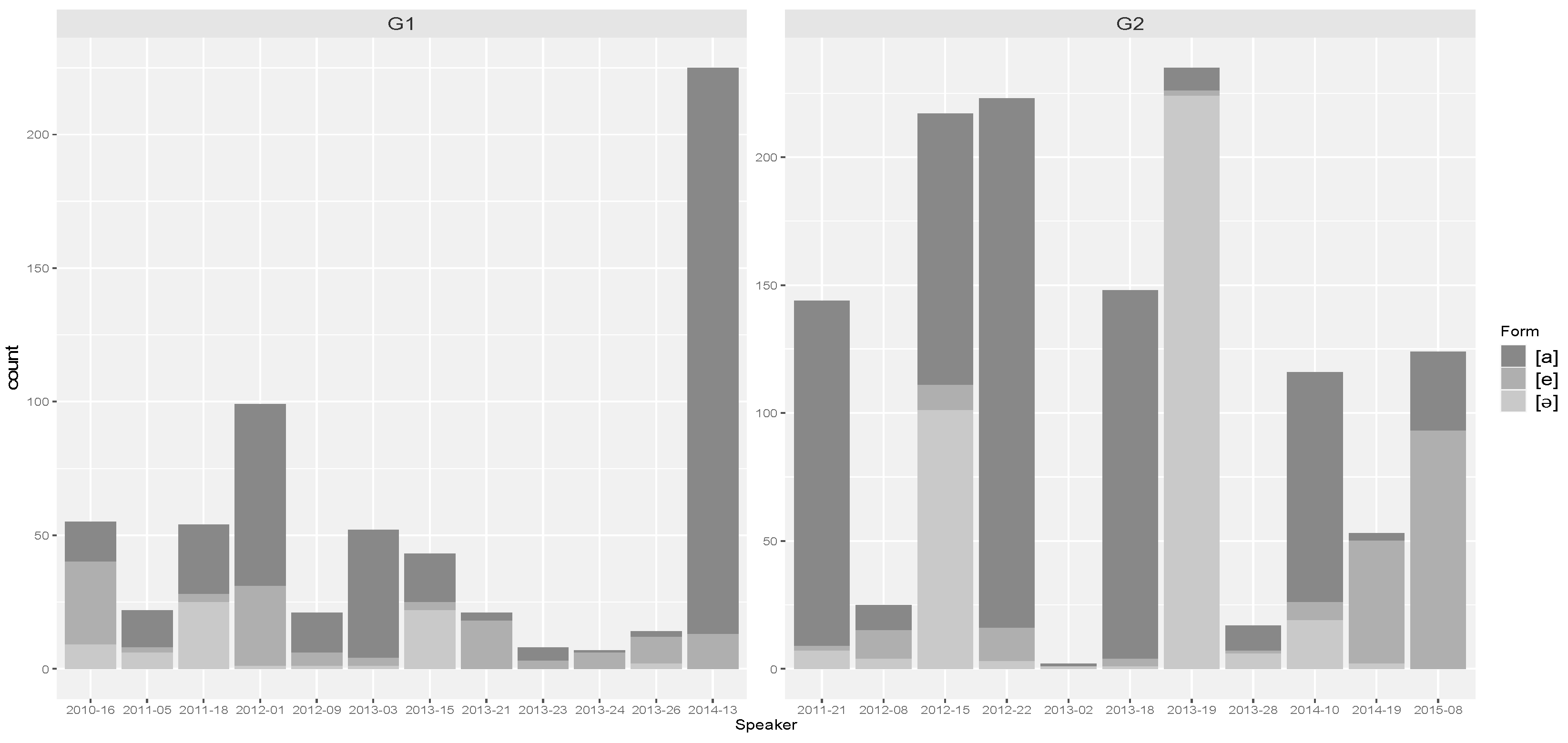
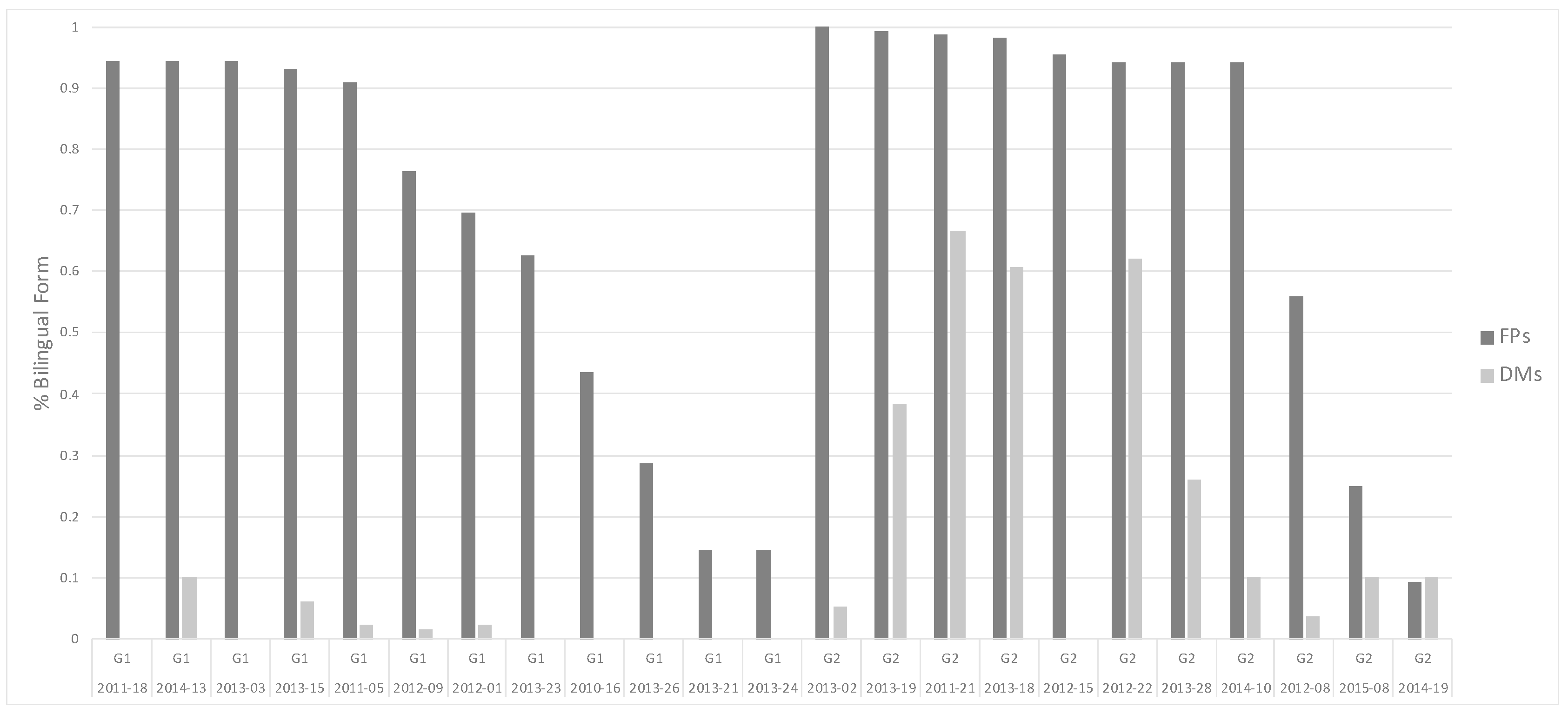
4.3. Filled Pauses (FPs)
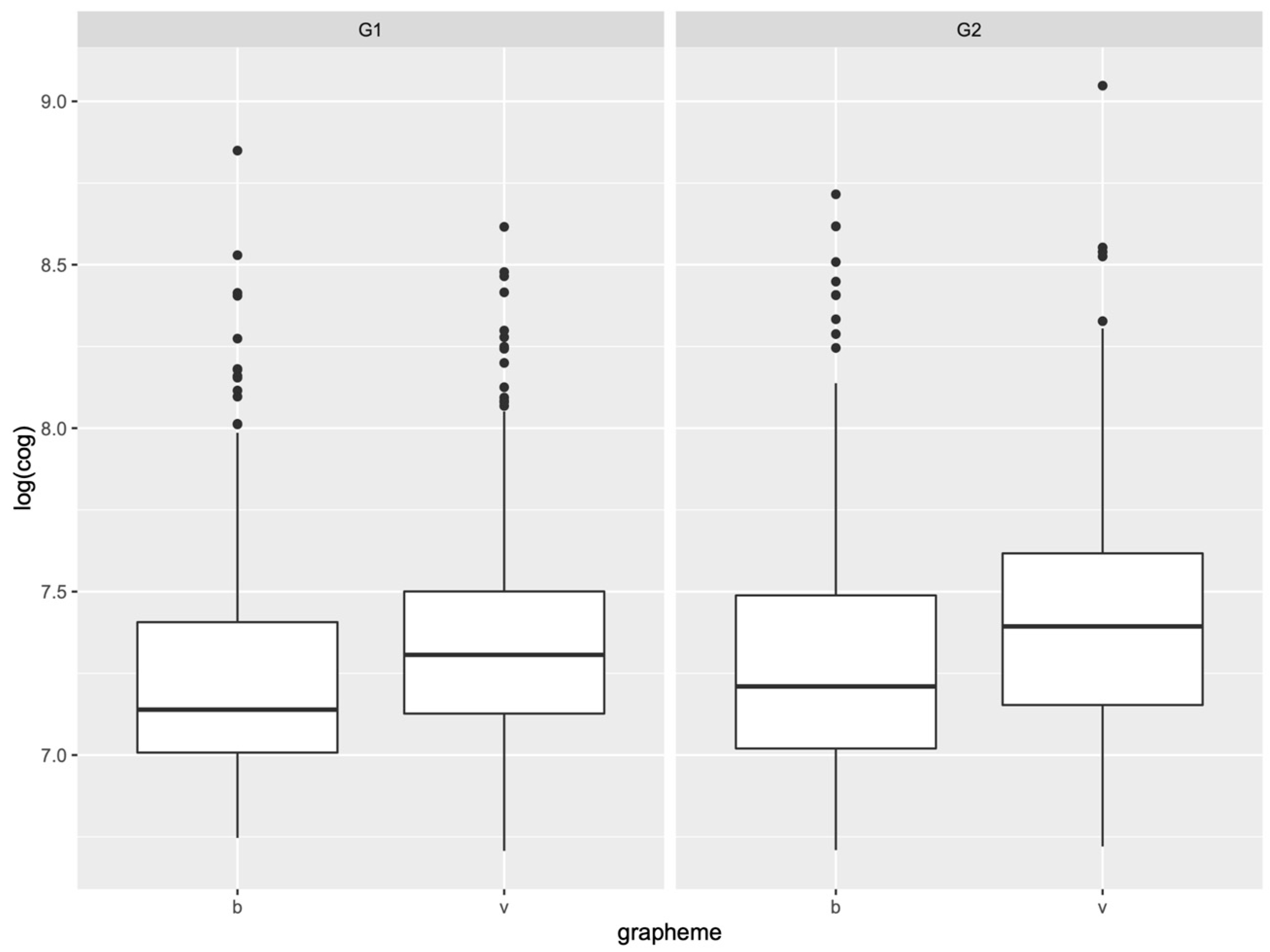
4.4. The Realization of Orthographic <b/v>
5. Discussion: The Swarm Analysis
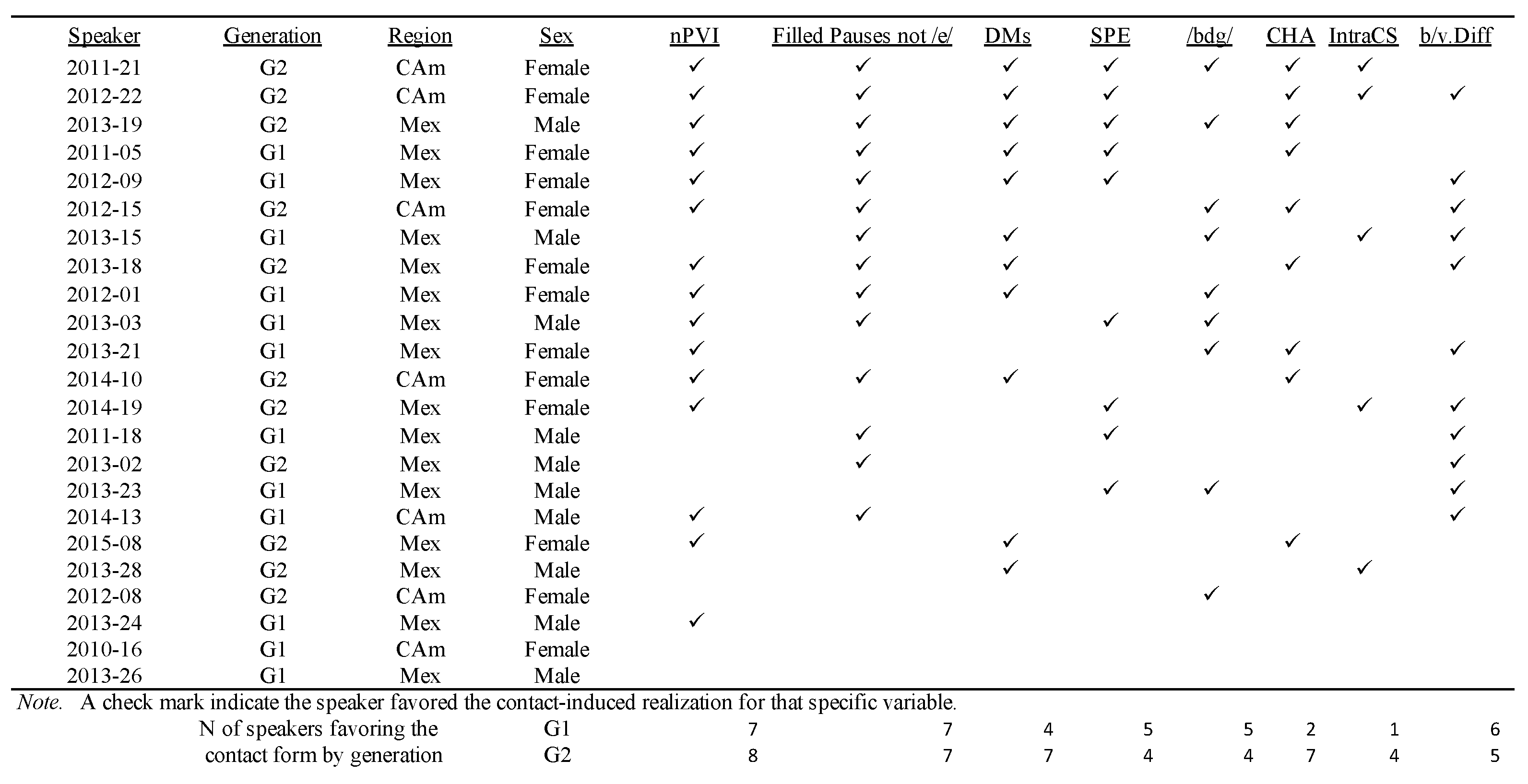
5.1. Speaker Rankings
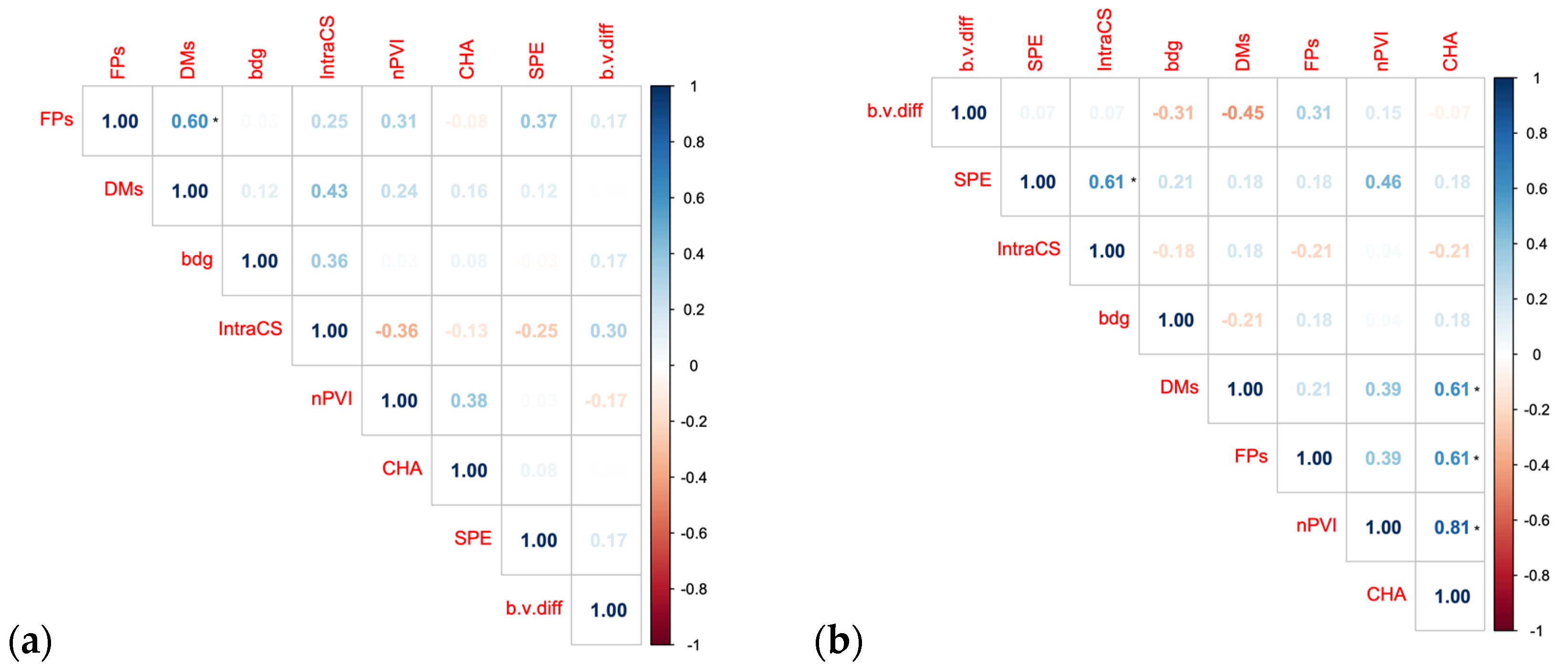
5.2. Correlations across Variables
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Participant | Sex | Birth Year | Generation | Region | Years in U.S. |
|---|---|---|---|---|---|
| 2010-16 | F | 1957 | G1 | CAm | 25 |
| 2014-13 | M | 1985 | G1 | CAm | 19 |
| 2012-01 | F | 1957 | G1 | Mex | 33 |
| 2013-21 | F | 1983 | G1 | Mex | 1 |
| 2011-05 | F | 1988 | G1 | Mex | 10 |
| 2013-03 | M | 1993 | G1 | Mex | 10 |
| 2012-09 | F | 1992 | G1 | Mex | 9 |
| 2013-15 | M | 1962 | G1 | Mex | 35 |
| 2013-24 | M | 1984 | G1 | Mex | 2 |
| 2013-23 | M | 1981 | G1 | Mex | 2 |
| 2011-18 | M | 1992 | G1 | Mex | 3 |
| 2013-26 | M | 1982 | G1 | Mex | 1 |
| 2015-08 | F | 1992 | G2 | Mex | 20 |
| 2011-21 | F | 1989 | G2 | CAm | Since birth |
| 2014-10 | F | 1992 | G2 | CAm | Since birth |
| 2012-15 | F | 1988 | G2 | CAm | Since birth |
| 2012-22 | F | 1992 | G2 | CAm | Since birth |
| 2012-08 | F | 1989 | G2 | CAm | Since birth |
| 2013-19 | M | 1989 | G2 | Mex | Since birth |
| 2013-18 | F | 1993 | G2 | Mex | Since birth |
| 2014-19 | F | 1992 | G2 | Mex | Since birth |
| 2013-28 | M | 1991 | G2 | Mex | Since birth |
| 2013-02 | M | 1992 | G2 | Mex | Since birth |
Appendix B
| Factor | Log Odds | N | % Overt Pro | p-Value |
|---|---|---|---|---|
| Person/Number and Definiteness | <0.001 * | |||
| él-ella.definite | 3.659 | 92 | 38.0 | |
| yo | 2.971 | 502 | 24.7 | |
| ellos-ellas.definite | 2.594 | 50 | 20.0 | |
| tú.definite | 1.860 | 30 | 13.3 | |
| nosotros-nosotras | 1.773 | 157 | 10.2 | |
| tú.indefinite | 0.883 | 104 | 3.8 | |
| ellos-ellas.indefinite | −13.740 | 46 | 0.0 | |
| Switch Reference | <0.001 * | |||
| Complete switch | 0.693 | 421 | 24.5 | |
| No switch | −0.210 | 480 | 16.0 | |
| Partial switch | −0.484 | 80 | 16.2 | |
| Lexical Content | 0.0047 * | |||
| Estimative | 0.916 | 46 | 52.2 | |
| Stative | −0.164 | 221 | 23.1 | |
| External activity | −0.358 | 555 | 16.2 | |
| Mental activity | −0.393 | 159 | 17.6 | |
| Distinctiveness of TAM | 0.013 * | |||
| Non-distinctive | 0.27 | 176 | 26.7 | |
| Distinctive | −0.27 | 805 | 18.1 | |
| Reflexivity | 0.0185 * | |||
| Non-reflexive | 0.36 | 865 | 20.7 | |
| Reflexive | −0.36 | 116 | 12.1 |
| n | df | intercept | overall proportion | AIC | R2.fixed | R2.random | R2.total |
| 981 | 15 | −4.187 | 0.197 | 859.63 | 0.781 | 0.012 | 0.793 |
| Factor | Log Odds | N | % Overt Pro | p-Value |
|---|---|---|---|---|
| Person/Number and Definiteness | <0.001 * | |||
| él-ella.definite | 8.721 | 25 | 56.0 | |
| yo | 7.637 | 107 | 20.6 | |
| ellos-ellas.definite | 6.251 | 21 | 9.5 | |
| nosotros-nosotras | 5.868 | 25 | 12 | |
| tú.definite | −8.910 | 3 | 0.0 | |
| ellos-ellas.indefinite | −9.191 | 10 | 0.0 | |
| tú.indefinite | −10.376 | 1 | 0.0 | |
| Switch Reference | <0.001 * | |||
| Partial switch | 0.613 | 17 | 35.3 | |
| Complete switch | 0.567 | 87 | 28.7 | |
| No switch | −1.180 | 88 | 11.4 | |
| Lexical Content | 0.009 * | |||
| Stative | 5.187 | 62 | 37.1 | |
| External activity | 4.158 | 98 | 16.3 | |
| Mental activity | 3.310 | 28 | 7.1 | |
| Estimative | −12.655 | 4 | 0.0 | |
| Distinctiveness of TAM | 0.849 | |||
| Non-distinctive | 0.049 | 53 | 26.4 | |
| Distinctive | −0.049 | 139 | 119.4 | |
| Reflexivity | 0.144 | |||
| Non-reflexive | 0.463 | 158 | 23.4 | |
| Reflexive | −0.463 | 34 | 11.8 |
| n | df | intercept | overall proportion | AIC | R2.fixed | R2.random | R2.total |
| 192 | 15 | −13.359 | 0.214 | 173.926 | 0.88 | 0.0 | 0.88 |
| Factor | Log Odds | N | % Overt Pro | p-Value |
|---|---|---|---|---|
| Person/Number and Definiteness | <0.001 * | |||
| él-ella.definite | 5.596 | 13 | 15.4 | |
| yo | 5.137 | 396 | 17.9 | |
| ellos-ellas.definite | 5.076 | 60 | 15.0 | |
| ellos-ellas.indefinite | 4.999 | 12 | 8.3 | |
| tú.indefinite | 3.910 | 41 | 4.9 | |
| tú.definite | −11.768 | 24 | 0.0 | |
| nosotros-nosotras | −12.951 | 52 | 0.0 | |
| Distinctiveness of TAM | <0.001 * | |||
| Non-distinctive | 0.564 | 106 | 20.8 | |
| Distinctive | −0.564 | 492 | 12.8 | |
| Lexical Content | 0.00144 * | |||
| Estimative | 1.269 | 34 | 50.0 | |
| Mental activity | −0.247 | 125 | 15.2 | |
| External activity | −0.348 | 310 | 10.6 | |
| Stative | −0.674 | 129 | 12.4 | |
| Reflexivity | 0.00163 * | |||
| Non-reflexive | 1.151 | 535 | 15.7 | |
| Reflexive | −1.151 | 63 | 1.6 | |
| Switch Reference | 0.0431 * | |||
| Complete switch | 0.646 | 236 | 18.2 | |
| No switch | 0.101 | 315 | 12.7 | |
| Partial switch | −0.747 | 47 | 4.3 |
| n | df | intercept | overall proportion | AIC | R2.fixed | R2.random | R2.total |
| 598 | 15 | −7.662 | 0.142 | 420.84 | 0.905 | 0.013 | 0.918 |
| Factor | Log Odds | N | % Overt Pro | p-Value |
|---|---|---|---|---|
| Person/Number and Definiteness | <0.001 * | |||
| tú.definite | 10.809 | 1 | 100.0 | |
| tú.indefinite | 2.161 | 5 | 80.0 | |
| él-ella.definite | −0.570 | 137 | 37.2 | |
| ellos-ellas.definite | −2.268 | 78 | 21.8 | |
| yo | −2.424 | 209 | 21.5 | |
| ellos-ellas.indefinite | −3.632 | 6 | 16.7 | |
| nosotros-nosotras | −4.077 | 58 | 10.3 | |
| Switch Reference | <0.001 * | |||
| Complete switch | 0.885 | 201 | 34.8 | |
| Partial switch | −0.127 | 37 | 32.4 | |
| No switch | −0.757 | 256 | 16.8 | |
| Lexical Content | 0.481 | |||
| External activity | 0.404 | 266 | 28.2 | |
| Stative | 0.162 | 150 | 22.0 | |
| Mental activity | 0.053 | 63 | 23.8 | |
| Estimative | −0.619 | 15 | 13.3 | |
| Distinctiveness of TAM | 0.713 | |||
| Non-distinctive | 0.05 | 140 | 29.3 | |
| Distinctive | −0.05 | 354 | 23.7 | |
| Reflexivity | 0.428 | |||
| Non-reflexive | 0.153 | 439 | 25.7 | |
| Reflexive | −0.153 | 55 | 21.8 |
| n | df | intercept | overall proportion | AIC | R2.fixed | R2.random | R2.total |
| 494 | 15 | 0.308 | 0.253 | 485.02 | 0.322 | 0.133 | 0.455 |
| 1 | Note that many lexical FPs are also analyzable as discourse markers. |
| 2 | It should be noted that in our own data, the majority of the auditorily labiodental tokens were also approximants rather than fricatives. Thus, the presence of the labiodental approximant [ʋ] complicates the classification of potential contact forms, as a bilingual speaker could produce a hybrid form that utilizes the labiodental point of articulation from English alongside the approximant mode of articulation from Spanish. In this way, bilingual labiodentals may not correspond exactly with English fricative /v/. |
| 3 | Technical aspects regarding FASE are described in greater depth in Wilbanks (2015) and Ronquest et al. (2020). Regarding the reliability of automatic alignment with FASE, Wilbanks (2015) compares FASE alignment to the alignment produced by trained human phoneticians. He finds that the refined, adapted FASE segmentation was similar to human segmentation: boundary differences between the two human coders had a mean of 14.47 ms, compared to a mean difference of 20.81 ms between the human coders and the trained FASE model. |
| 4 | For example, the full model AIC was compared to the AIC of a model with all variables except one (e.g., Switch Reference). The difference in AIC values indicates the importance of the variable in the full model, with larger differences denoting a stronger effect on the model. Kapatsinski (2012) demonstrates why this method is superior to the range of coefficients, the traditional method of determining the constraint hierarchy in sociolinguistic studies, which can be biased towards variables/factors with more levels. |
| 5 | An acoustic analysis of phonological filled pauses, as well as an examination of lexical pauses (e.g., sea, este) and silent pauses is forthcoming. |
| 6 | Data are frequently skewed to the right when there is a lower boundary to the measurement; in this case, COG cannot be a negative number. See https://www.itl.nist.gov/div898/handbook/eda/section3/histogr6.htm, accessed on 4 March 2023. |
| 7 | There are only two Central American G1 speakers in the present corpus, and some of these variables may achieve significance in a larger sample. Still, the match between Mexican and Central American G1 speakers speaks to the robustness of these constraints across Spanish varieties, even when few speakers are analyzed. |
| 8 | However, in some contexts, bilinguals have been found to produce fewer FPs than monolinguals but higher rates of silent pauses, which were not studied here (García-Amaya 2022). Additionally, although not coded in our data, impressionistically some monolinguals may have compensated for lower rates of phonological FPs by using more lexical FPs (pues, este, etc.). Further study is warranted and underway. |
| 9 | A more detailed analysis of <b> and <v> in NC Spanish is forthcoming. |
| 10 | http://www.sthda.com/english/wiki/correlation-matrix-an-r-function-to-do-all-you-need, accessed on 4 March 2023. |
References
- Abreu, Laurel. 2012. Subject pronoun expression and priming effects among bilingual speakers of Puerto Rican Spanish. In Selected Proceedings of the 14th Hispanic Linguistics Symposium. Edited by Kimberly Geeslin and Manuel Díaz-Campos. Somerville: Cascadilla Proceedings Project, pp. 1–8. [Google Scholar]
- Alvord, Scott, and Brandon Rogers. 2014. Miami-Cuban Spanish vowels in contact. Sociolinguistic Studies 8: 139–70. [Google Scholar] [CrossRef]
- Anderson, Tyker Kimball, and Almeida Jacqueline Toribio. 2007. Attitudes towards lexical borrowing and intra-sentential code-switching among Spanish-English bilinguals. Spanish in Context 4: 217–40. [Google Scholar] [CrossRef]
- Aaron, Jessi Elana. 2004. The Gendered Use of salirse in Mexican Spanish: Si me salía yo con las amigas, se enojaba. Language in Society 33: 585–607. [Google Scholar] [CrossRef]
- Bayley, Robert, and Lucinda Pease-Alvarez. 1997. Null pronoun variation in Mexican-descent children’s narrative discourse. Language Variation and Change 9: 349–71. [Google Scholar] [CrossRef]
- Bayley, Robert, Norma L. Cárdenas, Belinda Treviño Schouten, and Carlos Martin Vélez Salas. 2012. Spanish dialect contact in San Antonio, Texas: An exploratory study. In Selected Proceedings of the 14th Hispanic Linguistics Symposium. Edited by Kimberly Geeslin and Manuel Díaz-Campos. Somerville: Cascadilla Proceedings Project, pp. 48–60. [Google Scholar]
- Boersma, Paul, and David Weenink. 2022. Praat: Doing Phonetics by Computer [Computer Program], Version 6.3.02; Available online: https://www.praat.org/ (accessed on 29 November 2022).
- Boomershine, Amanda, and Rebecca Ronquest. 2019. Teaching pronunciation to Spanish heritage speakers. In Key Issues in the Teaching of Spanish Pronunciation. Edited by Rajiv Rao. London: Routledge, pp. 288–303. [Google Scholar]
- Britain, David, and Peter Trudgill. 1999. Migration, new-dialect formation and sociolinguistic refunctionalisation: Reallocation as an outcome of dialect contact. Transactions of the Philological Society 97: 245–56. [Google Scholar] [CrossRef]
- Carolina Demography. 2021. North Carolina’s Hispanic Community: Snapshot (2021). Available online: https://www.ncdemography.org/ (accessed on 24 February 2023).
- Carter, Phillip M. 2005. Prosodic variation in SLA: Rhythm in an urban North Carolina Hispanic community. University of Pennsylvania Working Papers in Linguistics 11: 59–71. [Google Scholar]
- Carter, Phillip M. 2007. Phonetic Variation and Speaker Agency: Mexicana Identity in a North Carolina Middle School. Penn Working Papers in Linguistics 13: 1–15. [Google Scholar]
- Carter, Phillip M. 2013. Shared spaces, shared structures: Latino social formation and African American English in the U.S. South. Journal of Sociolinguistics 17: 66–92. [Google Scholar] [CrossRef]
- Carter, Phillip M., and Andrew Lynch. 2015. Multilingual Miami: Current trends in sociolinguistic research. Language and Linguistics Compass 9: 369–85. [Google Scholar] [CrossRef]
- Carter, Phillip M., and Tonya Wolford. 2016. Cross-generational prosodic convergence in South Texas Spanish. Spanish in Context 13: 29–52. [Google Scholar] [CrossRef]
- Chetty, Sarah. 2018. To /b/ or not to /b/: On the production of the graphemes <bv> in heritage Spanish [Poster presentation]. In The 2018 Graduate Research Symposium. Raleigh: NC State University. Available online: https://grad.ncsu.edu/wp-content/uploads/2018/04/sarahchettyposter.pdf (accessed on 24 February 2023).
- Chládková, Kateřina, Paola Escudero, and Paul Boersma. 2011. Context-specific acoustic differences between Peruvian and Iberian Spanish vowels. JASA 130: 416–28. [Google Scholar] [CrossRef]
- Cobb, Katherine, and Miquel Simonet. 2015. Adult Second Language Learning of Spanish Vowels. Hispania 98: 47–60. [Google Scholar] [CrossRef]
- Colantoni , Laura, and Irina I. Marinescu. 2010. The scope of stop weakening in Argentine Spanish. In Selected Proceedings of the 4th Conference on Laboratory Approaches to Spanish Phonology. Edited by Marta Ortega-Llebaria. Somerville: Cascadilla Proceedings Project, pp. 100–14. [Google Scholar]
- Coloma, Germán. 2012. The Importance of Ten Phonetic Characteristics to Define Dialect Areas in Spanish. Dialectologia: Revista Electrònica, pp. 1–26. [Google Scholar]
- Dodsworth, Robin, and Richard A. Benton. 2017. Social network cohesion and the retreat from Southern vowels in Raleigh. Language in Society 46: 371–405. [Google Scholar] [CrossRef]
- Drager, Katie, and Jennifer Hay. 2012. Exploiting random intercepts: Two case studies in sociophonetics. Language Variation and Change 24: 59–78. [Google Scholar] [CrossRef]
- Eckert, Penelope. 2005. Variation, Convention, and Social Meaning [Plenary Address]. Oakland: The Annual Meeting of the Linguistic Society of America. Available online: http://www.justinecassell.com/discourse09/readings/EckertLSA2005.pdf (accessed on 19 May 2023).
- Eckert, Penelope. 2012. Three waves of variation study: The emergence of meaning in the study of sociolinguistic variation. Annual Review of Anthropology 41: 87–100. [Google Scholar] [CrossRef]
- Erker, Daniel. 2017. The limits of named language varieties and the role of social salience in dialectal contact: The case of Spanish in the United States. Language and Linguistics Compass 11: 1–20. [Google Scholar] [CrossRef]
- Erker, Daniel, and Joana Bruso. 2017. Uh, bueno, em…: Filled pauses as a site of contact-induced change in Boston Spanish. Language Variation and Change 29: 205–44. [Google Scholar] [CrossRef]
- Escobar, Anna María, and Kim Potowski. 2015. El español de los Estados Unidos. Cambridge: Cambridge University Press. [Google Scholar]
- File-Muriel, Richard J., and Eearl K. Brown. 2011. The gradient nature of s-lenition in Caleño Spanish. Language Variation and Change 23: 223–43. [Google Scholar] [CrossRef]
- García-Amaya, Lorenzo. 2009. New findings on fluency measures across three different learning contexts. In Selected Proceedings of the 11th Hispanic Linguistics Symposium. Edited by Joseph Collentine, Maryellen García, Barbara Lafford and Francisco Marcos Marín. Somerville: Cascadilla Press, pp. 68–80. [Google Scholar]
- García-Amaya, Lorenzo. 2022. An investigation into utterance-fluency patterns of advanced LL bilinguals: Afrikaans and Spanish in Patagonia. Linguistic Approaches to Bilingualism 12: 163–90. [Google Scholar] [CrossRef]
- Grabe, Esther, and Ee Ling Low. 2002. Durational variability in speech and the rhythm class hypothesis. Papers in Laboratory Phonology 7: 515–46. [Google Scholar]
- Hernández, José Esteban. 2002. Accommodation in a Dialect Contact Situation. San José: Revista de filología y lingüística de la Universidad de Costa Rica, pp. 93–110. [Google Scholar]
- Howe, Chad, and Philip Limerick. 2020. Perceptions of Spanish among Spanish Heritage Speakers in the Southeastern United States through Computer-Mediated Communication. In Spanish in the United States and across Domains. Edited by Francisco Salgado-Robles and Edwin Lamboy. Leiden: Brill, pp. 364–87. [Google Scholar]
- Hualde, José Ignacio. 2005. The Sounds of Spanish. Cambridge: Cambridge University Press. [Google Scholar]
- Hualde, José Ignacio, Miquel Simonet, and Marianna Nadeu. 2011. Consonant lenition and phonological recategorization. Laboratory Phonology 2: 301–29. [Google Scholar] [CrossRef]
- Johnson, Daniel Ezra. 2009. Getting off the GoldVarb standard: Introducing Rbrul for mixed-effects variable rule analysis. Language and Linguistics Compass 3: 359–83. [Google Scholar] [CrossRef]
- Kapatsinski, Vsevolod. 2012. Towards a de-Ranged Study of Variation [Conference Presentation]. Washington, DC: Georgetown University Round Table on Linguistics, Measured Language: Quantitative Approaches to Acquisition, Assessment, Processing, and Variation. Available online: http://pages.uoregon.edu/vkapatsi/DerangedPaper.pdf (accessed on 24 February 2023).
- Kerswill, Paul. 2013. Koineization. In The Handbook of Language Variation and Change. Edited by J. K. Chambers and Natalie Schilling. Oxford: John Wiley & Sons. [Google Scholar]
- Knightly, Leah, SunAh Jun, Janet Oh, and Terry Kit-fong Au. 2003. Production benefits of childhood overhearing. JASA 114: 465–74. [Google Scholar] [CrossRef] [PubMed]
- Knouse, Stephanie M., Renee Neves, Erk Ortiz, and Daria Acosta-Rua. 2022. “Le está haciendo un disservice”: Overt Attitudes toward Language Contact Phenomena in the Upstate of South Carolina. Hispania 105: 173–94. [Google Scholar] [CrossRef]
- Labov, William. 1963. The social motivation of a sound change. Word 19: 273–309. [Google Scholar] [CrossRef]
- Labov, William, Ingrid Rosenfelder, and Josef Fruehwald. 2013. One hundred years of sound change in Philadelphia: Linear incrementation, reversal, and reanalysis. Language 89: 30–65. [Google Scholar] [CrossRef]
- Ladefoged, Peter, and Sandra Disner. 2012. Vowels and Consonants. Chichester: John Wiley and Sons. [Google Scholar]
- Limerick, Pilip P. 2019. The discursive distribution of subject pronouns in Spanish spoken in Georgia: A weakening of pragmatic constraints? Studies in Hispanic and Lusophone Linguistics 12: 97–126. [Google Scholar] [CrossRef]
- Limerick, Philip P. 2021. First-person plural subject pronoun expression in Mexican Spanish spoken in Georgia. Studies in Hispanic and Lusophone Linguistics 14: 411–32. [Google Scholar] [CrossRef]
- Lipski, John M. 1994. Latin American Spanish. London: Longman. [Google Scholar]
- Lipski, John M. 2005. Code-switching or borrowing? No sé so no puedo decir, you know. In Selected Proceedings of the Second Workshop on Spanish Sociolinguistics. Edited by Lotfi Sayahi and Maurice Westmoreland. Somerville: Cascadilla Proceedings Project, pp. 1–15. [Google Scholar]
- Lipski, John M. 2008. Varieties of Spanish in the United States. Washington, DC: Georgetown University Press. [Google Scholar]
- Lipski, John M. 2014. Spanish-English code-switching among low-fluency bilinguals: Towards an expanded typology. Sociolinguistic Studies 8: 23. [Google Scholar] [CrossRef]
- Lipski, John M. 2020. Equatorial Guinea Spanish non-continuant /d/: More than a generic L2 trait. In Spanish Phonetics and Phonology in Contact: Studies from Africa, the Americas, and Spain. Edited by Rajiv Rao. Amsterdam: John Benjamins, pp. 13–32. [Google Scholar]
- Low, Ee-Ling, and Esther Grabe. 1995. Prosodic patterns in Singapore English. In Proceedings of the International Congress of Phonetic Sciences, Stockholm. Edited by Kjell Elenius and Peter Branderud. Stockholm: KTH and Stockholm University Press, pp. 636–39. [Google Scholar]
- Mariano, Paolo. 2014. Correlatore [Computer Program]. Available online: http://www.lfsag.unito.it/correlatore/readme_en.html (accessed on 14 September 2022).
- Mata, Rodolfo. 2022. Bilingualism is good but codeswitching is bad: Attitudes about Spanish in contact with English in the Tijuana-San Diego border area. Critical Inquiry in Language Studies, 1–22. [Google Scholar] [CrossRef]
- Mendoza-Denton, Norma. 2002. Language and Identity. In The Handbook of Language Variation and Change. Edited by J. K. Chambers, Peter Trudgill and Natalie Schilling-Estes. Oxford: Blackwell, pp. 475–99. [Google Scholar]
- Mendoza-Denton, Norma. 2010. Individuals and communities. In The Sage Handbook of Sociolinguistics. Edited by Ruth B. Wodak, Barbara Johnstone and Peter Kerswill. Los Angeles: Sage Publications, pp. 181–91. [Google Scholar]
- Menke, Mandy R., and Timothy L. Face. 2010. Second language Spanish vowel production: An acoustic analysis. Studies in Hispanic and Lusophone Linguistics 3: 181–214. [Google Scholar] [CrossRef]
- Michnowicz, Jim. 2015. Subject Pronoun Expression in Contact with Maya in Yucatan Spanish. In Subject Pronoun Expression in Spanish: A Cross-Dialectal Perspective. Edited by Ana Carvalho, Rafael Orozco and Naomi Lapidus Shin. Washington, DC: Georgetown University Press, pp. 103–22. [Google Scholar]
- Michnowicz, Jim, Alex Hyler, James Shepherd, and Sonya Trawick. 2018. Spanish in North Carolina: English-origin loanwords in a newly forming Hispanic community. In Language Diversity in the New South. Edited by Jeffrey Reaser, Eric Wilbanks, Walt Wolfram and Karissa Wojcik. Chapel Hill: University of North Carolina Press, pp. 289–305. [Google Scholar]
- Michnowicz, Jim, Rebecca Ronquest, Bailey Ambrister, Hannah Bain, Nick Chisholm, Rebecca Greene, Lindsey Bull, and Anne Elkins. 2023a. Perceptions of Inclusive Language in the Spanish of the Southeast: Data from a Large Classroom Project. Spanish in Context. Available online: https://www.jbe-platform.com/content/journals/10.1075/sic.00084.mic (accessed on 6 July 2023).
- Michnowicz, Jim, Sonya Trawick, and Ronquest Ronquest. 2023b. Spanish language maintenance and shift in a newly-forming community in the southeastern United States: Insights from a large-class survey. Hispanic Studies Review 7. Available online: https://hispanicstudiesreview.cofc.edu/article/77601-spanish-language-maintenance-and-shift-in-a-newly-forming-community-in-the-southeastern-united-states-insights-from-a-large-class-survey (accessed on 7 July 2023).
- Montes-Alcalá, Cecilia, and Lindsey Sweetnich. 2014. Español en el sureste de EE. UU.: El papel de las actitudes lingüísticas en el mantenimiento o pérdida de la lengua. Revista Internacional de Lingüística Iberoamericana 23: 77–92. [Google Scholar] [CrossRef]
- Myers-Scotton, Carol. 1995. Social Motivations for Codeswitching: Evidence from Africa. Oxford: Oxford University Press. [Google Scholar]
- Navarro Tomás, Tomás. 1918. Manual de Pronunciación Española, 12th ed. Madrid: CSIC. [Google Scholar]
- O’Rourke, Erin, and Kim Potowski. 2016. Phonetic accommodation in a situation of Spanish dialect contact: Coda/s/and//in Chicago. Studies in Hispanic and Lusophone Linguistics 9: 355–99. [Google Scholar] [CrossRef]
- Otheguy, Ricardo, Ana Celia Zentella, and David Livert. 2007. Language and dialect contact in Spanish in New York: Toward the formation of a speech community. Language 83: 770–802. [Google Scholar] [CrossRef]
- Otheguy, Ricardo, and Ana Celia Zentella. 2012. Spanish in New York: Language Contact, Dialectal Leveling, and Structural Continuity. Oxford: Oxford University Press. [Google Scholar]
- Pew Research Center. 2014. Demographic Profile of Hispanics in North Carolina. Available online: http://www.pewhispanic.org/states/state/nc (accessed on 2 October 2022).
- Poplack, Shana. 1978. Dialect acquisition among Puerto Rican bilinguals. Language in Society 7: 89–103. [Google Scholar] [CrossRef]
- Poplack, Shana. 1980. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of code-switching. Linguistics 18: 581–618. [Google Scholar] [CrossRef]
- Poplack, Shana. 1988. Contrasting patterns of code-switching in two communities. Codeswitching: Anthropological and sociolinguistic Perspectives 48: 215–44. [Google Scholar]
- Quilis, Antonio, and Manuel Esgueva. 1983. Realización de los fonemas vocálicos españoles en posición fonética normal. In Estudios de fonética. Edited by Manuel Esgueva and Margarita Cantarero. Madrid: Consejo Superior de Investigaciones Científicas, pp. 159–251. [Google Scholar]
- Rangel, Natalie, Verónica Loureiro-Rodríguez, and María Irebe Moyna. 2015. “Is that what I sound like when I speak?”: Attitudes towards Spanish, English, and code-switching in two Texas border towns. Spanish in Context 12: 177–98. [Google Scholar] [CrossRef]
- Rao, Rajiv. 2014. On the status of the phoneme /b/ in heritage speakers of Spanish. Sintagma 26: 37–54. [Google Scholar]
- Rao, Rajiv. 2015. Manifestations of /bdg/ in heritage speakers of Spanish. Heritage Language Journal 12: 48–74. [Google Scholar] [CrossRef]
- Rao, Rajiv, and Rebecca Ronquest. 2015. The heritage Spanish phonetic/phonological system: Looking back and moving forward. Studies in Hispanic and Lusophone Linguistics 8: 403–14. [Google Scholar] [CrossRef]
- R Core Team. 2022. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 3 October 2022).
- Ronquest, Rebecca. 2012. An Acoustic Analysis of Heritage Spanish Vowels. Ph.D. thesis, Indiana University, Bloomington, Indiana. [Google Scholar]
- Ronquest, Rebecca, Jim Michnowicz, Eric Wilbanks, and Cortés Claudia. 2020. Examining the (mini-)variable swarm in the Spanish of the Southeast. In Hispanic Linguistics: Current Issues and New Directions. Edited by Alfonso Morales-Front, Michael Ferreira, Ronald Leow and Cristina Sanz. Amsterdam: John Benjamins, pp. 303–25. [Google Scholar]
- Shin, Naomi Lapidus. 2013. Women as leaders of language change: A qualification from the bilingual perspective. In Selected Proceedings of the 6th Workshop on Spanish Sociolinguistics. Edited by Ana M. Carvalho and Sara Beaudrie. Somerville: Cascadilla Proceedings Project, pp. 135–47. [Google Scholar]
- Shin, Naomi Lapidus, and Ricardo Otheguy. 2009. Shifting sensitivity to continuity of reference: Subject pronoun use in Spanish. In Español en Estados Unidos y en otros contextos: Cuestiones sociolingüìsticas, políticas, y pedagógicas. Edited by Manel Lacorte and Jennifer Leeman. Madrid: Iberoamericana/Vervuert Verlag, pp. 111–36. [Google Scholar]
- Shin, Naomi Lapidus, and Ricardo Otheguy. 2013. Social class and gender impacting change in bilingual settings: Spanish subject pronoun use in New York. Language in Society 42: 429–52. [Google Scholar] [CrossRef]
- Shousterman, Cara. 2014. Speaking English in Spanish Harlem: The role of rhythm. University of Pennsylvania Working Papers in Linguistics 20: 18. [Google Scholar]
- Silva-Corvalán, Carmen. 1994. The gradual loss of mood distinctions in Los Angeles Spanish. Language Variation and Change 6: 255–72. [Google Scholar] [CrossRef]
- Silva-Corvalán, Carmen. 2008. The limits of convergence in language contact. Journal of Language Contact 2: 213–24. [Google Scholar] [CrossRef]
- Sorace, Antonella. 2004. Native language attrition and developmental instability at the syntax-discourse interface: Data, interpretations and methods. Bilingualism Language and Cognition 7: 143–5. [Google Scholar] [CrossRef]
- Sorace, Antonella. 2005. Selective Optionality in Language Development. In Syntax and Variation: Reconciling the Biological and the Social. Edited by Leonie Cornips and Karen Corrigan. Amsterdam: John Benjamins, pp. 55–80. [Google Scholar]
- Tagliamonte, Sali A. 2011. Variationist Sociolinguistics: Change, Observation, Interpretation. Hoboken: John Wiley and Sons. [Google Scholar]
- Thomas, Erik. 2015. What a swarm of variables tells us about the formation of Mexican American English [Conference presentation]. Paper presented at LAVIS IV, Raleigh, NC, USA, August 28; Available online: https://www.academia.edu/15228944/What_a_Swarm_of_Variables_Tells_Us_about_the_Formation_of_Mexican_American_English (accessed on 1 November 2022).
- Toribio, Almeida Jacqueline. 2004. Spanish/English speech practices: Bringing chaos to order. International Journal of Bilingual Education and Bilingualism 7: 133–54. [Google Scholar] [CrossRef]
- Toribio, Almeida Jacqueline. 2011. Code-Switching among US Latinos. In The Handbook of Hispanic Sociolinguistics. Hoboken: Wiley, pp. 530–52. [Google Scholar]
- Torres, Lourdes. 2002. Bilingual discourse markers in Puerto Rican Spanish. Language in Society 31: 65–83. [Google Scholar] [CrossRef]
- Torres, Lourdes. 2011. Spanish in the United States: Bilingual discourse markers. In The Handbook of Hispanic Sociolinguistics. Edited by Manuel Díaz-Campos. Malden: Wiley-Blackwell, pp. 491–503. [Google Scholar]
- Torres, Lourdes, and Kim Potowski. 2008. A comparative study of bilingual discourse markers in Chicago Mexican, Puerto Rican, and MexiRican Spanish. International Journal of Bilingualism 12: 263–79. [Google Scholar] [CrossRef]
- Trovato, Adriano. 2017. A Sociophonetic Analysis of Contact Spanish in the United States: Labiodentalization and Labial Consonant Variation. Ph.D. thesis, University of Texas, Austin, TX, USA. [Google Scholar]
- Trudgill, Peter. 1986. Dialects in Contact. Oxford: Blackwell. [Google Scholar]
- U.S. Census Bureau. 2020. Hispanic or Latino Origin by Specific Origin. 2016–20 American Community Survey 5-Year Estimates. Available online: https://data.census.gov/cedsci/table?q=Latino%20Origin%20NC&tid=ACSDT5Y2020.B03001 (accessed on 31 October 2022).
- Wei, Taiyun, and Viliam Simko. 2021. R Package ‘Corrplot’: Visualization of a Correlation Matrix (Version 0.92). Available online: https://github.com/taiyun/corrplot (accessed on 5 November 2022).
- Wilbanks, Eric. 2015. The Development of FASE (Forced Alignment System for Español) and Implications for socioli guistic research. Paper presented at New Ways of Analyzing Variation 44, Toronto, ON, Canada, October 22–25; Available online: https://ericwilbanks.github.io/files/wilbanks_nwav_2015.pdf (accessed on 20 May 2023).
- Willis, Erik. 2005. An Initial Examination of Southwest Spanish Vowels. Southwest Journal of Lingusitics 24: 185–98. [Google Scholar]
- Wolfram, Walt, Mary Kohn, and Erin Callahan-Price. 2011. Southern-Bred Hispanic English: An Emerging Socioethnic Variety. In Selected Proceedings of the 5th Workshop on Spanish Sociolinguistics. Edited by Jim Michnowicz and Robin Dodsworth. Somerville: Cascadilla Proceedings Project, pp. 1–13. [Google Scholar]
- Wolfram, Walt, Phillip Carter, and Beckie Morello. 2004. Emerging Hispanic English: New dialect formation in the American South. Journal of Sociolinguistics 8: 339–58. [Google Scholar] [CrossRef]
- Woolard, Kathryn A. 1999. Strategies of simultaneity and bivalency in bilingual communication. Journal of Linguistic Anthropology 8: 3–29. [Google Scholar] [CrossRef]
- Zentella, Ana Celia. 1990. Lexical leveling in four New York City Spanish dialects: Linguistic and social factors. Hispania 73: 1094–105. [Google Scholar] [CrossRef]
- Zentella, Ana Celia. 1997. Growing up Bilingual: Puerto Rican Children in New York. Malden: Blackwell Publishers. [Google Scholar]
- Zúñiga, Victor, and Rubén Hernández-León, eds. 2005. New Destinations: Mexican Immigration in the United States: Community Formation, Local Responses and Inter-Group Relations. New York: Russell Sage Foundation. [Google Scholar]






| Variable | Levels |
|---|---|
| Dependent | |
| SPE | Overt Null |
| Independent | |
| Person/number/definiteness | Yo Tú (definite) Tú (indefinite) Él/ella (definite) Nosotros/nosotras Ellos/ellas (definite) Ellos/ellas (indefinite) |
| Distinctiveness of TAM | Distinctive Non-distinctive |
| Switch reference | Complete switch Partial switch No switch |
| Lexical content | External activity Mental activity Estimative Stative |
| Generation | G1 G2 |
| Sex | Male Female |
| Region of origin | Mexico Central America |
| Speaker | Random intercept |
| Variable | Levels |
|---|---|
| Dependent | |
| Code-switch type | Sentence-level code switching (Intrasentential + intersentential) (analysis 1) Word Intrasentential (analysis 2) Intersentential + Word |
| Independent | |
| Generation | G1 G2 |
| Sex | Male Female |
| Region of origin | Mexico Central America |
| Speaker | Random intercept |
| Variable | Levels |
|---|---|
| Dependent | |
| Filled pause vowel | [ə] + [a] [e] |
| Independent | |
| Generation | G1 G2 |
| Sex | Male Female |
| Region of origin | Mexico Central America |
| Speaker | Random Intercept |
| Variable | Levels |
|---|---|
| Dependent | |
| COG | Continuous variable (analysis 1) COG difference <v>—<b> (analysis 2) |
| Independent | |
| Following vowel | [i] [e] [a] [o] [u] |
| Word position | Initial Medial |
| Grapheme | <b> <v> |
| Generation | G1 G2 |
| Sex | Male Female |
| Region of origin | Mexico Central America |
| Speaker | Random intercept |
| Word | Random intercept |
| Mexican G1 | Central American G1 | Mexican G2 | Central American G2 |
|---|---|---|---|
| 1. Person/Number * | 1. Person/Number * | 1. Person/Number * | 1. Person/Number * |
| 2. Switch * | 2. Switch * | 2. Lexical Content * | 2. Switch * |
| 3. Lexical Content * | 3. Lexical Content * | 3. TMA Distinctive * | 3. Lexical Content |
| 4. TMA Distinctive * | 4. TMA Distinctive | 4. Reflexivity * | 4. TMA Distinctive |
| 5. Reflexivity * | 5. Reflexivity | 5. Switch * | 5. Reflexivity |
| Switch Type | N | % of Data |
|---|---|---|
| Single word | 702 | 90.1% |
| Intersentential | 57 | 7.3% |
| Intrasentential | 20 | 2.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michnowicz, J.; Ronquest, R.; Chetty, S.; Green, G.; Oliver, S. Spanish in the Southeast: What a Swarm of Variables Can Tell Us about a Newly Forming Bilingual Community. Languages 2023, 8, 168. https://doi.org/10.3390/languages8030168
Michnowicz J, Ronquest R, Chetty S, Green G, Oliver S. Spanish in the Southeast: What a Swarm of Variables Can Tell Us about a Newly Forming Bilingual Community. Languages. 2023; 8(3):168. https://doi.org/10.3390/languages8030168
Chicago/Turabian StyleMichnowicz, Jim, Rebecca Ronquest, Sarah Chetty, Georgia Green, and Stephanie Oliver. 2023. "Spanish in the Southeast: What a Swarm of Variables Can Tell Us about a Newly Forming Bilingual Community" Languages 8, no. 3: 168. https://doi.org/10.3390/languages8030168
APA StyleMichnowicz, J., Ronquest, R., Chetty, S., Green, G., & Oliver, S. (2023). Spanish in the Southeast: What a Swarm of Variables Can Tell Us about a Newly Forming Bilingual Community. Languages, 8(3), 168. https://doi.org/10.3390/languages8030168