

How Good Does This Sound? Examining Listeners’ Second Language Proficiency and Their Perception of Category Goodness in Their Native Language


Abstract
1. Introduction
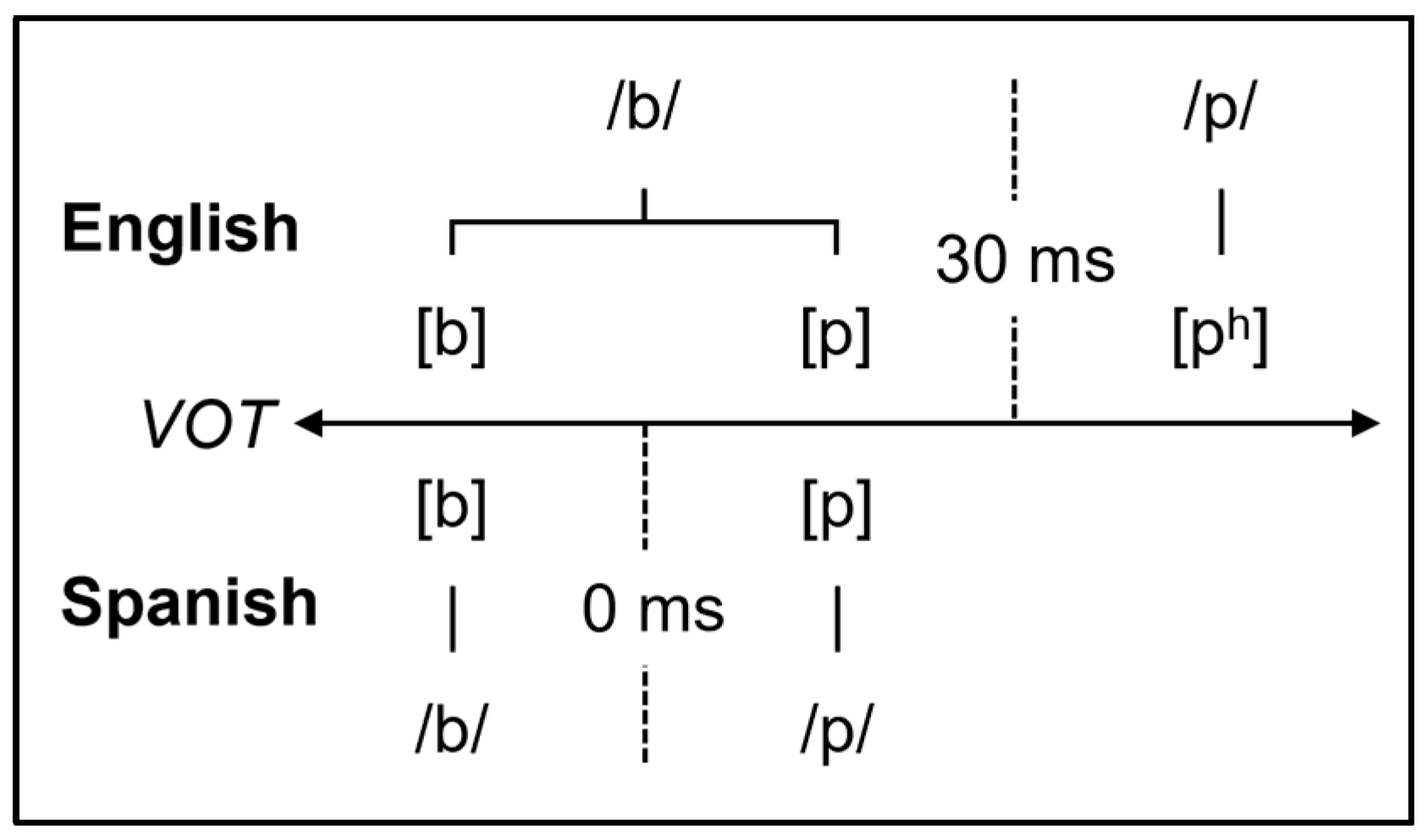
1.1. Speech Learning Models
1.2. Crosslinguistic Influence in Speech Production
1.3. Crosslinguistic Influence in Speech Perception
1.4. The Current Study
- To what extent does L2 proficiency shape participants’ perception of L1 category goodness?We predicted that participants who were more proficient in Spanish would perceive prevoiced variants as better exemplars of the English voiced category than individuals who were less proficient in Spanish. For voiceless stops, we predicted that with increasing proficiency, listeners would rate stops with shorter VOT values as better examples of English voicelessness but that the level of acceptability would diminish at or near the boundary of voicing thresholds in English (~30 ms VOT).
- To what extent does this effect depend on place of articulation?We hypothesized that the effect of L2 proficiency on the category goodness ratings would be stronger for bilabial than for coronal stops because bilabial stops share the same place of articulation in both languages whereas coronal stops are alveolar in English but dental in Spanish.
- To what extent do participants’ L1 and L2 production patterns affect their perception of L1 category goodness?We did not have a strong a priori prediction for this research question beyond an exploratory hypothesis that participants’ perception might be aligned with their production, especially if L2 production patterns are conceptualized as a measure of phonological proficiency in the L2 (Flege et al. 1994). Regarding the perception of L1 voiced stops, we reasoned that participants who produced L1 and L2 stops with prevoicing might be more likely to endorse higher ratings for prevoiced variants. With respect to the perception of L1 voiceless stops, we reasoned that participants who produced stops with shorter VOT, particularly in L2, would be more likely to endorse higher ratings for short-lag variants.
2. Materials and Methods
2.1. Materials
2.2. Participants
2.3. Procedure
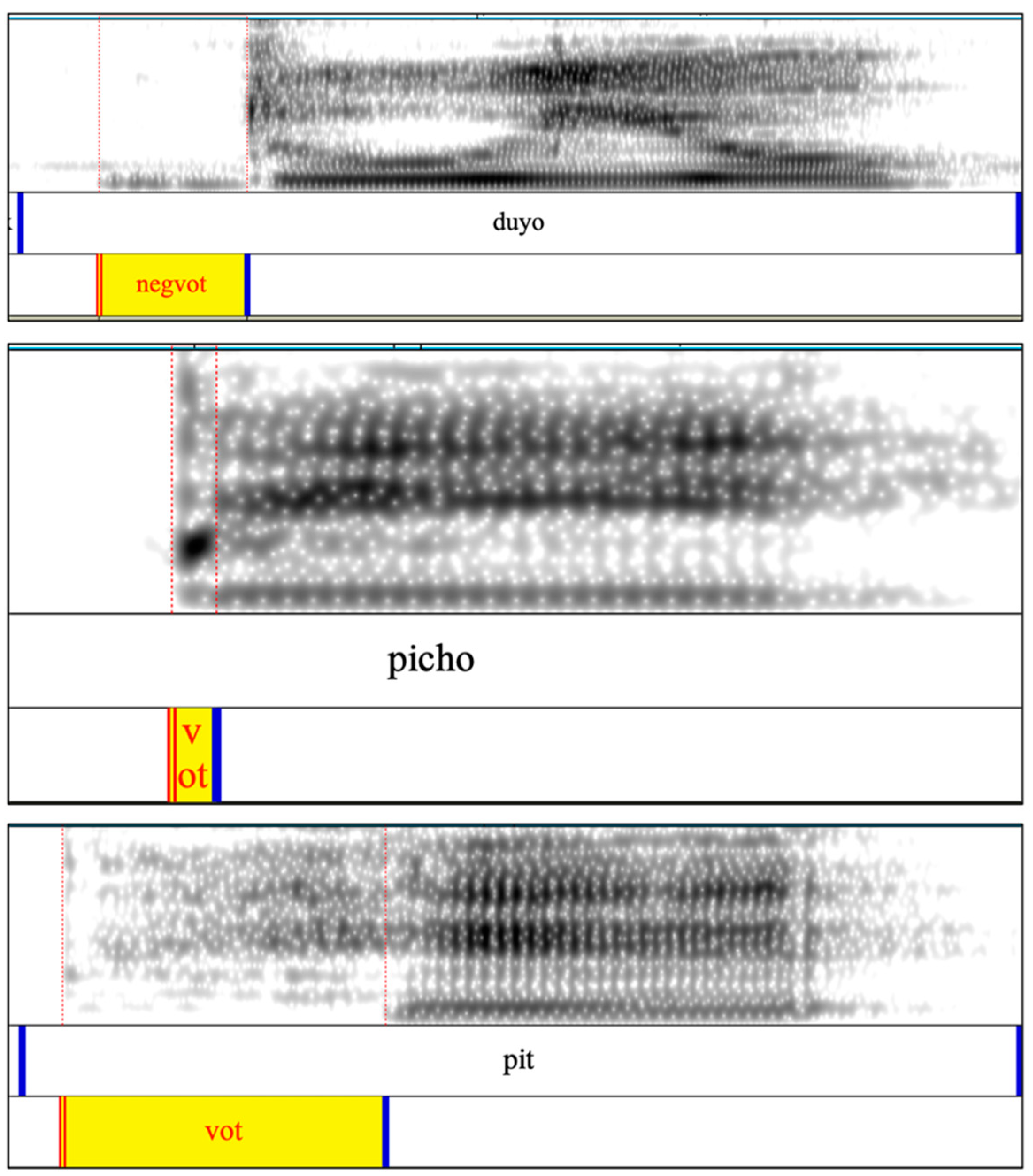
2.4. Measurement and Scoring
3. Results
3.1. Stop Consonant Production
3.1.1. Voiced Stop Production
3.1.2. Voiceless Stop Production
3.2. L1 Category Goodness Ratings
3.2.1. Approach to Analysis
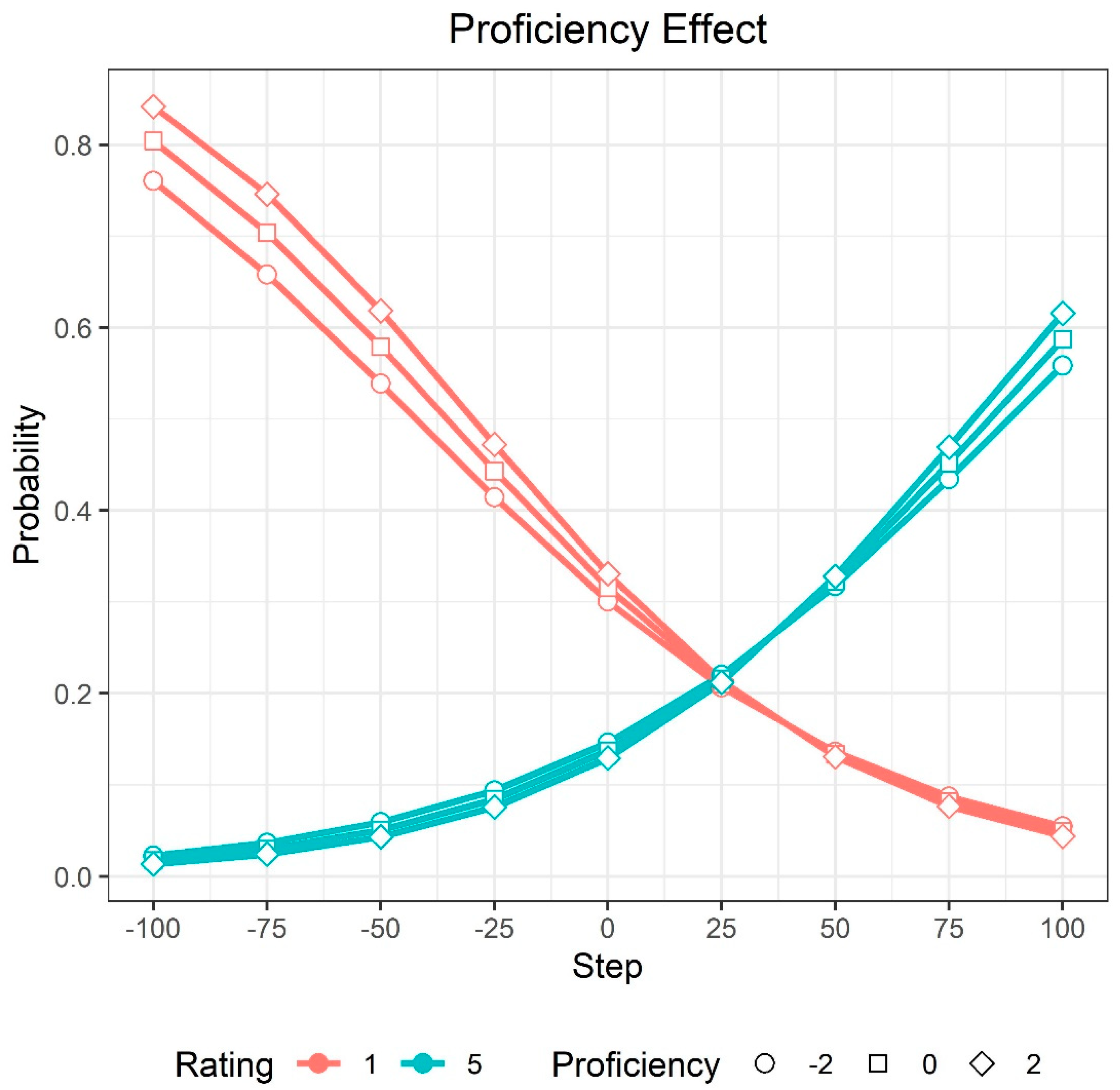
3.2.2. Voiced Stop Targets
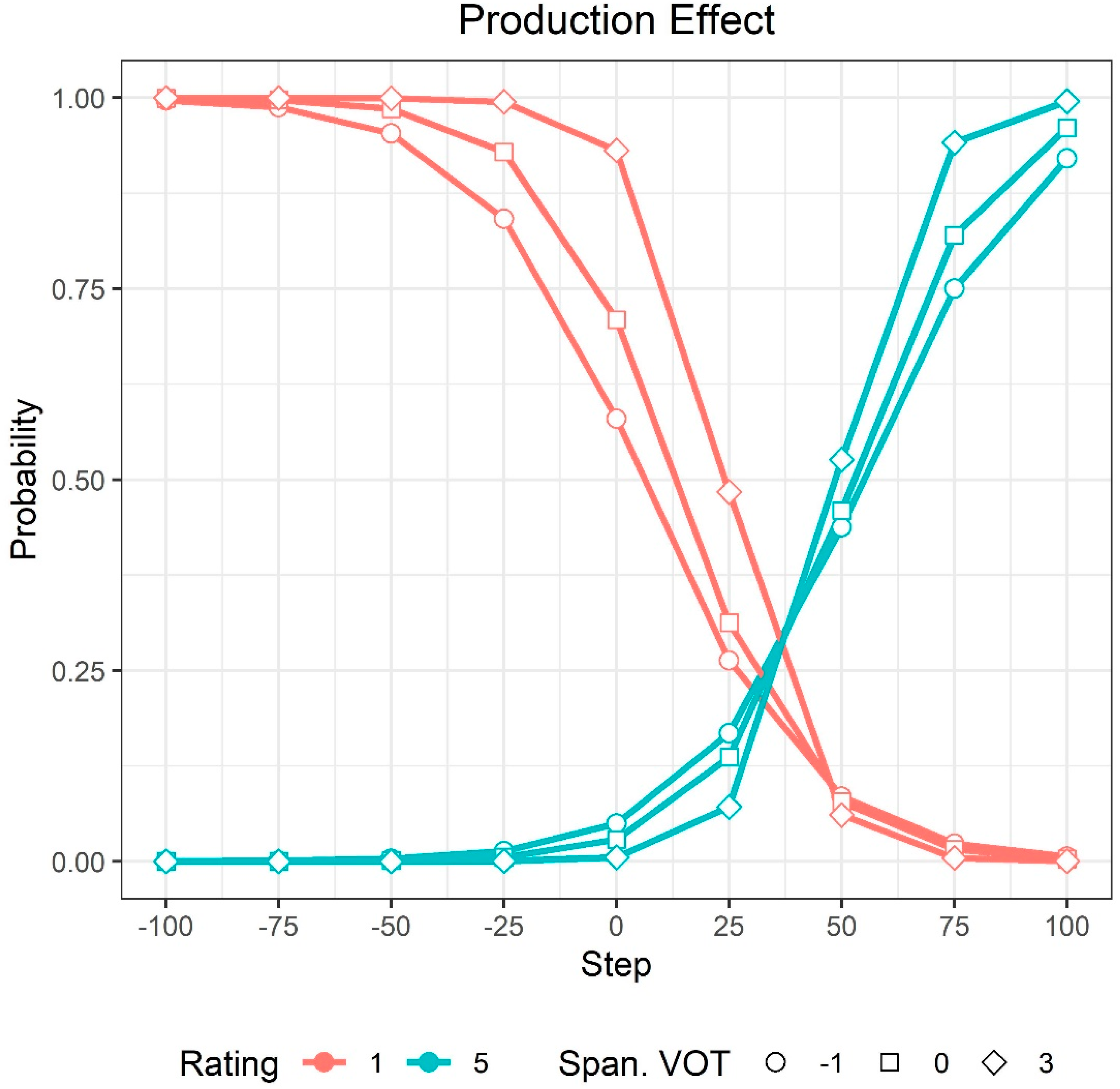
3.2.3. Voiceless Stop Targets
3.2.4. Summary of L1 Rating Results
4. Discussion
4.1. Effect of L2 Proficiency on L1 Category Goodness
4.2. Effect of L1 and L2 Production
4.3. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. English and Spanish Target Words
| /p/-/b/ | /t/-/d/ | ||
| pan-ban | /pæn/-/bæn/ | tab-dab | /tæb/-/dæb/ |
| pet-bet | /pɛt/-/bɛt/ | tech-deck | /tɛk/-/dɛk/ |
| pit-bit | /pɪt/-/bɪt/ | tip-dip | /tɪp/-/dɪp/ |
| push-bush | /pʊʃ/-/bʊʃ/ | teal-deal | /til/-/dil/ |
| pair-bear | /pɛr/-/bɛr/ | tuck-duck | /tʌk/-/dʌk/ |
| /p/-/b/ | /t/-/d/ | ||
| pala-bala | /pala/-/bala/ | taño-daño | /taɲo/-/daɲo/ |
| peso-beso | /peso/-/beso/ | tela-dela | /tela/-/dela/ |
| picho-bicho | /piʧo-/biʧo/ | tilo-dilo | /tilo/-/dilo/ |
| puso-buzo | /puso/-/buso/ | tuyo-duyo | /tuʝo/-/duʝo/ |
| 1 | Our participant sample included individuals who learned Spanish predominantly through instruction (n = 16) as well as individuals who had learned Spanish at home from family members and could therefore be considered heritage speakers (n = 20). As reviewers pointed out, it is possible that different patterns could emerge for instructed L2 learners and heritage speakers. To evaluate this possibility, we refit the models with a contrast-coded Context of Learning predictor (−0.5 = instructed, 0.5 = heritage) and relevant interaction terms. The associated terms never reached statistical significance in any of the models, and model estimates changed very little as a result of its integration. The full analysis can be accessed in the R code for this paper. |
References
- Amengual, Mark. 2011. Interlingual influence in bilingual speech: Cognate status effect in a continuum of bilingualism. Bilingualism: Language and Cognition 15: 517–30. [Google Scholar] [CrossRef]
- Antoniou, Mark, Catherine T. Best, Michael D. Tyler, and Christian Kroos. 2011. Inter-language interference in VOT production by L2-dominant bilinguals: Asymmetries in phonetic code-switching. Journal of Phonetics 39: 558–570. [Google Scholar] [CrossRef] [PubMed]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Philadelphia: John Benjamins, pp. 13–24. [Google Scholar]
- Boersma, Paul, and David Weenink. 2022. Praat: Doing Phonetics by Computer (Version 6.2.14). Available online: http://www.praat.org/ (accessed on 30 January 2023).
- Caramazza, Alfonso, Grace H. Yeni-Komshian, Edgar B. Zurif, and Ettore Carbone. 1973. The acquisition of a new phonological contrast: The case of stop consonants in French–English bilinguals. Journal of the Acoustical Society of America 54: 421–28. [Google Scholar] [CrossRef]
- Casillas, Joseph V., and Miquel Simonet. 2018. Perceptual categorization and bilingual language modes: Assessing the double phonemic boundary in early and late bilinguals. Journal of Phonetics 71: 51–64. [Google Scholar] [CrossRef]
- Cebrián, Juli. 2006. Experience and the use of non-native duration in L2 vowel categorization. Journal of Phonetics 34: 372–87. [Google Scholar] [CrossRef]
- Chang, Charles B. 2012. Rapid and multifaceted effects of second-language learning on first-language speech production. Journal of Phonetics 40: 249–68. [Google Scholar] [CrossRef]
- Chang, Charles B. 2013. A novelty effect in phonetic drift of the native language. Journal of Phonetics 41: 520–33. [Google Scholar] [CrossRef]
- Chang, Charles B. 2018. Perceptual attention as the locus of transfer to nonnative speech perception. Journal of Phonetics 68: 85–102. [Google Scholar] [CrossRef]
- Chládková, Kateřina, and Václav J. Podlipský. 2011. Native dialect matters: Perceptual assimilation of Dutch vowels by Czech listeners. Journal of the Acoustical Society of America 130: EL186–192. [Google Scholar] [CrossRef]
- Christensen, Rune H. B. 2019. Ordinal: Regression Models for Ordinal Data. R Package. Available online: https://CRAN.R-project.org/package=ordinal (accessed on 30 January 2023).
- Crosswhite, Katherine. 2003. Duration Logging Script. Available online: http://web.archive.org/web/20030620172734/ling.rochester.edu/people/cross/scripts.html (accessed on 30 January 2023).
- de Leeuw, Esther, Aurela Tusha, and Monika S. Schmid. 2018. Individual phonological attrition in Albanian–English late bilinguals. Bilingualism: Language and Cognition 21: 278–95. [Google Scholar] [CrossRef]
- de Leeuw, Esther, Ineke Mennen, and James M. Scobbie. 2012. Singing a different tune in your native language: First language attrition of prosody. International Journal of Bilingualism 16: 101–16. [Google Scholar] [CrossRef]
- de Leeuw, Esther, Monika S. Schmid, and Ineke Mennen. 2010. The effects of contact on native language pronunciation in an L2 migrant setting. Bilingualism: Language and Cognition 13: 33–40. [Google Scholar] [CrossRef]
- de Leeuw, Esther. 2019. Native speech plasticity in the German-English late bilingual Stefanie Graf: A longitudinal study over four decades. Journal of Phonetics 73: 24–39. [Google Scholar] [CrossRef]
- Dimitrieva, Olga. 2019. Transferring perceptual cue-weighting from second language into first language: Cues to voicing in Russian speakers of English. Journal of Phonetics 73: 128–43. [Google Scholar] [CrossRef]
- Escudero, Paola. 2007. Second-language phonology: The role of perception. In Phonology in Context. Edited by Martha C. Pennington. New York: Palgrave Macmillan, pp. 109–34. [Google Scholar]
- Fabra, Lucrecia R. 2005. Predicting ease of acquisition of L2 speech sounds. A perceived dissimilarity test. Vigo International Journal of Applied Linguistics 2: 75–92. [Google Scholar]
- Flege, James E. 1987. The production of “new” and “similar” phones in a foreign language: Evidence for the effect of equivalence classification. Journal of Phonetics 15: 47–65. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second language speech learning: Theory, findings, problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Baltimore: York Press, pp. 233–77. [Google Scholar]
- Flege, James E., and Ocke-Schwen Bohn. 2021. The revised Speech Learning Model. In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. New York: Cambridge University Press, pp. 3–83. [Google Scholar]
- Flege, James E., and Wieke Eefting. 1987a. Cross-language switching in stop consonant perception and production by Dutch speakers of English. Speech Communication 6: 185–202. [Google Scholar] [CrossRef]
- Flege, James E., and Wieke Eefting. 1987b. Production and perception of English stops by native Spanish speakers. Journal of Phonetics 15: 67–83. [Google Scholar] [CrossRef]
- Flege, James E., Murray J. Munro, and Robert A. Fox. 1994. Auditory and categorical effects on cross-language vowel perception. Journal of the Acoustical Society of America 95: 3623–3641. [Google Scholar] [CrossRef]
- Flege, James E., Ocke-Schwen Bohn, and Sunyoung Jang. 1997. Effects of experience on non-native speakers’ production and perception of English vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Fox, John, and Sanford Weisberg. 2018. Visualizing fit and lack of fit in complex regression models with predictor effect plots and partial residuals. Journal of Statistical Software 87: 1–27. [Google Scholar] [CrossRef]
- Fox, John, and Sanford Weisberg. 2019. An R Companion to Applied Regression, 3rd ed. Los Angeles: Sage. [Google Scholar]
- Garcia, Dalia L., and Tamar H. Gollan. 2021. The MINT Sprint: Exploring a fast administration procedure with an expanded multilingual naming test. Journal of the International Neuropsychological Society 28: 845–61. [Google Scholar] [CrossRef] [PubMed]
- Gorba, Celia, and Juli Cebrián. 2021. The role of L2 experience in L1 and L2 perception and production of voiceless stops by English learners of Spanish. Journal of Phonetics 88: 101094. [Google Scholar] [CrossRef]
- Gorba, Celia. 2019. Bidirectional influence on L1 Spanish and L2 English stop perception: The role of L2 experience. Journal of the Acoustical Society of America 145: EL587. [Google Scholar] [CrossRef] [PubMed]
- Hopp, Holger, and Monika S. Schmid. 2013. Perceived foreign accent in first language attrition and second language acquisition: The impact of age of acquisition and bilingualism. Applied Psycholinguistics 34: 361–94. [Google Scholar] [CrossRef]
- Kapnoula, Efthymia C., Matthew B. Winn, Eun Jong Kong, Jan Edwards, and Bob McMurray. 2017. Evaluating the sources and functions of gradiency in phoneme categorization: An individual differences approach. Journal of Experimental Psychology: Human Perception and Performance 43: 1594–611. [Google Scholar] [CrossRef]
- Kartushina, Natalia, Ulrich H. Frauenfelder, and Narly Golestani. 2016. How and when does the second language influence the production of native speech sounds: A literature review. Language Learning 66: 155–86. [Google Scholar] [CrossRef]
- Kim, Donghyun, Meghan Clayards, and Heather Goad. 2018. A longitudinal study of individual differences in the acquisition of new vowel contrasts. Journal of Phonetics 67: 1–20. [Google Scholar] [CrossRef]
- Kuhl, Particia K., Barbara T. Conboy, Sharon Coffey-Corina, Denise Padden, Maritza Rivera-Gaxiola, and Tobey Nelson. 2008. Phonetic learning as a pathway to language: New data and native language magnet theory expanded (NLM-e). Philosophical Transactions of the Royal Society of London B Biological Sciences 363: 979–1000. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Lang, Benjamin, and Lisa Davidson. 2019. Effects of exposure and vowel space distribution on phonetic drift: Evidence from American English learners of French. Language and Speech 62: 30–60. [Google Scholar] [CrossRef] [PubMed]
- Linck, Jared A., and Ian Cunnings. 2015. The utility and application of mixed-effects models in second language research. Language Learning 65: 185–207. [Google Scholar] [CrossRef]
- Lüdecke, Daniel. 2022. sjPlot: Data Visualization for Statistics in Social Science. R Package Version 2.8.11. Available online: https://CRAN.R-project.org/package=sjPlot (accessed on 30 January 2023).
- Mayr, Robert, and Paola Escudero. 2010. Explaining individual variation in L2 perception: Rounded vowels in English learners of German. Bilingualism: Language and Cognition 13: 279–97. [Google Scholar] [CrossRef]
- Peng, Z. Ellen, Sebastian Waz, Emily Buss, Yi Shen, Virginia Richards, Hari Bharadwaj, G. Christopher Stecker, Jordan A. Beim, Adam K. Bosen, Meredith D. Braza, and et al. 2022. Remote testing for psychological and physiological acoustics. The Journal of the Acoustical Society of America 151: 3116–28. [Google Scholar] [CrossRef]
- R Core Team. 2022. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 30 January 2023).
- Rosner, Burton S., Luis E. López-Bascuas, José E. García-Albea, and Richard P. Fahey. 2000. Letter to the Editor: Voice-onset times for Castilian Spanish initial stops. Journal of Phonetics 28: 217–24. [Google Scholar] [CrossRef]
- Sancier, Michele L., and Carol A. Fowler. 1997. Gestural drift in a bilingual speaker of Brazilian Portuguese and English. Journal of Phonetics 25: 421–36. [Google Scholar] [CrossRef]
- Schoonmaker-Gates, Elena. 2015. On voice-onset time as a cue to foreign accent in Spanish: Native and nonnative perception. Hispania 98: 779–91. [Google Scholar] [CrossRef]
- van Leussen, Jan-Willem, and Paolo Escudero. 2015. Learning to perceive and recognize a second language: The L2LP model revised. Frontiers in Psychology 6: 1000. [Google Scholar] [CrossRef]
- Winn, Matthew B. 2020. Make VOT Continuum (version 32). Praat Script. Available online: https://github.com/ListenLab/VOT (accessed on 30 January 2023).
- Winn, Matthew B., Monita Chatterjee, and William J. Idsardi. 2013. Roles of voice onset time and f0 in stop consonant voicing perception: Effects of masking noise and low-pass filtering. Journal of Speech, Language, and Hearing Research 56: 1097–107. [Google Scholar] [CrossRef]
- Zampini, Mary, and Kerry P. Green. 2001. The voicing contrast in English and Spanish: The relationship between perception and production. In One Mind, Two Languages: Bilingual Language Processing. Edited by Janet Nichol. Malden: Wiley-Blackwell, pp. 23–48. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English | Spanish | |||
|---|---|---|---|---|
| M (SD) | Range1 | M (SD) | Range1 | |
| VOT /b/ | −61.75 (54.27) | −215–15 | −60.83 (45.27) | −165–13 |
| VOT /p/ | 79.65 (20.15) | 41–123 | 24.71 (15.61) | 10–68 |
| % prevoicing /b/ | 55.91 (33.06) | 0–100 | 69.55 (25.89) | 11–100 |
| % prevoicing /p/ | 0.21 (1.28) | 0–8 | 0.38 (1.77) | 0–10 |
| VOT /d/ | −43.06 (55.45) | −206–34 | −62.38 (39.90) | −142–28 |
| VOT /t/ | 93.32 (21.23) | 57–171 | 30.80 (19.96) | 11–90 |
| % prevoicing /d/ | 45.98 (32.85) | 0–100 | 73.98 (27.50) | 0–100 |
| % prevoicing /t/ | 0.00 (0.00) | na 3 | 0.77 (4.06) | 0–25 |
| Proficiency 2 | 68.56 (6.50) | 45–79 | 46.56 (14.96) | 15–77 |
| Fixed Effects | Odds Ratio | SE | 95% CI | p |
|---|---|---|---|---|
| Intercept | 1.971 | 0.586 | [1.101, 3.529] | 0.022 |
| Language | 4.191 | 1.420 | [2.157, 8.143] | <0.001 |
| Place | 0.796 | 0.176 | [0.516, 1.228] | 0.302 |
| Proficiency | 0.760 | 0.224 | [0.427, 1.353] | 0.351 |
| Language × Prof. | 1.146 | 0.330 | [0.652, 2.015] | 0.636 |
| Random Effects | SD | Correlation | ||
| By-subject | ||||
| Intercepts | 1.719 | |||
| Slopes: Language | 1.612 | −0.51 | ||
| Slopes: Place | 0.496 | −0.08 | 0.16 | |
| By-word | ||||
| Intercepts | 0.387 |
| Fixed Effects | Estimate | SE | 95% CI | p |
|---|---|---|---|---|
| Intercept | −100.662 | 4.590 | [−109.664, −91.660] | <0.001 |
| Language | 23.809 | 4.817 | [14.362, 33.257] | <0.001 |
| Place | 2.266 | 3.898 | [−5.378, 9.910] | 0.561 |
| Proficiency | −1.281 | 3.703 | [−8.544, 5.982] | 0.729 |
| Language × Prof. | 3.137 | 3.248 | [−3.233, 9.506] | 0.334 |
| Random Effects | SD | Correlation | ||
| By-subject | ||||
| Intercepts | 25.765 | |||
| Slopes: Language | 18.064 | −0.13 | ||
| Slopes: Place | 8.140 | −0.70 | 0.32 | |
| By-item | ||||
| Intercepts | 7.102 |
| Fixed Effects | Estimate | SE | 95% CI | p |
|---|---|---|---|---|
| Intercept | 64.157 | 7.565 | [49.325, 78.990] | <0.001 |
| Language | −61.656 | 13.112 | [−87.364, −35.947] | <0.001 |
| Place | 10.064 | 2.894 | [4.390, 15.737] | 0.001 |
| Proficiency | −0.143 | 0.152 | [−0.442, 0.155] | 0.346 |
| Language × Prof. | 0.069 | 0.263 | [−0.446, 0.584] | 0.792 |
| Random Effects | SD | Correlation | ||
| By-subject | ||||
| Intercepts | 14.026 | |||
| Slopes: Language | 23.876 | −0.13 | ||
| Slopes: Place | 6.455 | 0.16 | −0.01 | |
| By-word | ||||
| Intercepts | 5.600 |
| Fixed Effects | Odds Ratio | SE | 95% CI | p |
|---|---|---|---|---|
| Place | 1.551 | 0.558 | [0.766, 3.138] | 0.222 |
| Step | 0.080 | 0.070 | [0.014, 0.451] | 0.004 |
| Prof. | 1.009 | 0.013 | [0.983, 1.036] | 0.492 |
| Step × Prof. | 0.983 | 0.018 | [0.949, 1.019] | 0.350 |
| Place × Step | 1.188 | 0.370 | [0.645, 2.188] | 0.581 |
| Place × Prof. | 0.994 | 0.005 | [0.983, 1.004] | 0.256 |
| Place × Step × Prof. | 1.005 | 0.007 | [0.992, 1.018] | 0.490 |
| Production covariates | ||||
| Eng. Prevoicing | 1.080 | 0.323 | [0.602, 1.941] | 0.796 |
| Span. Prevoicing | 0.831 | 0.249 | [0.462, 1.497] | 0.538 |
| Eng. Prevoicing × Step | 0.774 | 0.317 | [0.347, 1.725] | 0.531 |
| Span. Prevoicing × Step | 1.272 | 0.522 | [0.569, 2.845] | 0.557 |
| Random Effects | SD | Correlation | ||
| By-subject | ||||
| Intercepts | 1.213 | |||
| Slopes: Step | 1.659 | −0.94 | ||
| By-word | ||||
| Intercepts | 0.397 |
| Fixed Effects | Odds Ratio | SE | 95% CI | p |
|---|---|---|---|---|
| Place | 0.991 | 0.363 | [0.483, 2.031] | 0.980 |
| Step | 4.819 | 5.508 | [0.513, 45.263] | 0.169 |
| Prof. | 0.954 | 0.015 | [0.924, 0.985] | 0.004 |
| Step × Prof. | 1.070 | 0.026 | [1.021, 1.121] | 0.005 |
| Place × Step | 0.491 | 0.212 | [0.21, 1.146] | 0.100 |
| Place × Prof. | 0.994 | 0.008 | [0.979, 1.009] | 0.406 |
| Place × Step × Prof. | 1.010 | 0.009 | [0.992, 1.028] | 0.278 |
| Production covariates | ||||
| Eng. VOT | 1.099 | 0.249 | [0.705, 1.715] | 0.676 |
| Span. VOT | 0.496 | 0.119 | [0.31, 0.794] | 0.003 |
| Eng. VOT × Step | 0.899 | 0.303 | [0.465, 1.739] | 0.753 |
| Span. VOT × Step | 2.433 | 0.860 | [1.217, 4.865] | 0.012 |
| Random Effects | SD | Correlation | ||
| By-subject | ||||
| Intercepts | 1.285 | |||
| Slopes: Step | 1.929 | −0.91 | ||
| By-word | ||||
| Intercepts | 0.224 | |||
| Slopes: Step | 0.296 | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagle, C.; Baese-Berk, M.M.; Diantoro, C.; Kim, H. How Good Does This Sound? Examining Listeners’ Second Language Proficiency and Their Perception of Category Goodness in Their Native Language. Languages 2023, 8, 43. https://doi.org/10.3390/languages8010043
Nagle C, Baese-Berk MM, Diantoro C, Kim H. How Good Does This Sound? Examining Listeners’ Second Language Proficiency and Their Perception of Category Goodness in Their Native Language. Languages. 2023; 8(1):43. https://doi.org/10.3390/languages8010043
Chicago/Turabian StyleNagle, Charlie, Melissa M. Baese-Berk, Carissa Diantoro, and Haeun Kim. 2023. "How Good Does This Sound? Examining Listeners’ Second Language Proficiency and Their Perception of Category Goodness in Their Native Language" Languages 8, no. 1: 43. https://doi.org/10.3390/languages8010043
APA StyleNagle, C., Baese-Berk, M. M., Diantoro, C., & Kim, H. (2023). How Good Does This Sound? Examining Listeners’ Second Language Proficiency and Their Perception of Category Goodness in Their Native Language. Languages, 8(1), 43. https://doi.org/10.3390/languages8010043