1. Introduction
What is the relation between categories and frequent items? Categories or classes are variously conceived, but there is growing support for exemplar categories with a high-frequency central member. Consistent with this view, categories have been shown to be gradient rather than discrete; to derive from experienced tokens rather than abstract features; and to have central and marginal, rather than equally uniform, members. Evidence comes from diachronic studies of new constructions, which generalize from specific exemplars (e.g.,
Bybee and Torres Cacoullos 2009); from acceptability judgements, which are influenced by similarity to frequent tokens (e.g.,
Bybee and Eddington 2006); and from the acquisition of argument structure constructions, which are easier to learn when the input is skewed toward a high-frequency member (e.g.,
Goldberg et al. 2004) (cf.,
Bybee 2010, Chapters 4 and 5).
In this paper, we add novel evidence from spontaneous speech, to demonstrate that usage-based categories are defined by variation patterns. Categories or classes are those sets of items that share
contextual constraints—linguistic factors conditioning the selection of one variant over its alternative in discourse (
Poplack and Torres Cacoullos 2015, pp. 268–270); and
contextual distributions—the relative frequency with which those factors occur in discourse. The shared variation patterns defining a category in turn display some differences from the constraints and distributions of the more general variable structure. Variation patterns, furthermore, contribute evidence for
lexically anchored categories, in which one or more forms stand out for their high frequency but share patterns with other members of the category considered in the aggregate.
Subject expression in Spanish and the unresolved discussion of whether verb class or lexical frequency makes a contribution is a handy arena for revisiting categories and their underpinnings. A widely reported language-particular constraint on Spanish subject expression is the favoring effect of cognition verbs such as ‘think’ and ‘know’, which show higher than average rates of subject pronouns (vs. unexpressed subjects). However, the coherence of the semantic classes apparently conditioning variable Spanish subject expression has been discussed in view of both skewed distributions toward a few high frequency verbs such as
creer ‘to think’ and
saber ‘to know’, and differences in subject pronoun rate among individual verbs within a class (e.g.,
Bayley et al. 2013;
Erker and Guy 2012;
Orozco and Hurtado 2021).
The study of morphosyntactic variation has established that lexical effects (which reflect memory storage of speakers’ experience with words and phrases) can outweigh online effects of the morphosyntactic or phonetic features constituting the context in which speakers make choices between variants. For example, in complement clause mood selection in French, the identity of the matrix verb (a lexical effect) determines the presence of an embedded subjunctive more than contextual (or online) factors such as the variable presence of the complementizer
que (
Poplack 1992, pp. 255–56). However, acknowledging lexical effects need not detract from semantic classes. An example from English is the favoring effect of motion verbs in choice of the present tense (vs.
will or
be going to) as a future expression (e.g.,
she’s going on the day after Thanksgiving). Just two verb types (
go and
come) represent half the number of tokens of the present as a future expression, but the favoring of the present holds for motion verbs overall, even when these two frequent verbs are set aside (
Torres Cacoullos and Walker 2009b, pp. 334–35).
We also know that there are verb forms or collocations—verb-person-tense-polarity combinations—the very frequency of which justifies singling them out as lexically particular constructions but which show parallels in linguistic conditioning with the general variable structure. Consider complement-taking predicates in speech corpora of English (cf.,
Torres Cacoullos and Walker 2009a).
I think,
I guess,
I remember and a handful of other subject-verb combinations make up a large proportion of complement-taking predicate tokens as well as large proportions of their respective lexical types (e.g.,
I think alone makes up a quarter of all the data and more than half the tokens of all forms of
think). They also show lower than average rates of complementizer
that, or higher rates of occurrence with no complementizer. However, the linguistic conditioning of variable
that in frequent forms parallels its conditioning in the general main-and-complement clause structure (for example, in that lexical vs. pronominal complement clause subjects favor the presence of
that across the board).
To address lexically anchored categories, here we show the relevance of lexically particular constructions such as
(yo) creo ‘I think’ to Spanish subject expression. We adapt the variationist comparative method (
Poplack and Meechan 1998, pp. 130–32;
Torres Cacoullos and Travis 2019, p. 656;
Torres Cacoullos and Walker 2009a, p. 31), to compare the subject expression patterns of frequently co-occurring combinations with those of other cognition verbs and with non-cognition verbs. Analyses using mixed effects logistic regression models, first with individual verb as a random effect and then also incorporating frequent verb forms as fixed effects, reveal similar conditioning for these constructions as for other cognition verbs. Also shared is an association with non-coreferential contexts. Contextual constraints and distributions thus provide evidence that cognition verbs in Spanish variable subject expression form a category anchored in lexically particular constructions.
2. Variable Subject Expression in Spontaneous Speech
The spontaneous speech data for this study come from face-to-face conversation from the Corpus of Conversational Colombian Spanish, collected in 1997 and 2004 in the city of Cali (CCCS, cf.,
Travis 2005, pp. 9–25). A total of 37 speakers were recorded, 24 women and 13 men, most in their 20s and 30s (age range: 24 to 60). Participants were primarily from the middle class, recruited through the social network of two research assistants, an undergraduate student and a professor at a university in Cali. A total of 30 recordings were made of two- to five-party conversations between couples, friends and family members. They took place during naturally arising interactions such as while eating dinner, cooking, doing homework, or waiting for friends, and ranged from 7 to 40 min long, with an average of 18 min. This provided a total of nine hours of speech and nearly 100,000 words for analysis.
Variable Spanish subject expression in speech concerns the choice between pronominal and unexpressed subjects as a grammatical means of referring to an accessible subject. Lexical noun phrases fall outside the envelope of variation, as they are a site for introducing new, or inaccessible, information (
Travis and Torres Cacoullos 2018, p. 83). We focus on first person and third person singular subjects (1sg and 3sg), as the most frequent to occur in spontaneous speech data. The competing variants are pre-verbal subject pronouns and null, or unexpressed, subjects. Non-human and non-specific subjects are set aside as they are rarely realized by personal pronouns. Also outside the envelope of variation are post-verbal subject pronouns, which are subject to distinct linguistic conditioning, and
wh-interrogatives, where the variation in this variety is between post-verbal and unexpressed subjects (on the variable context for Spanish subject expression, see
Torres Cacoullos and Travis 2018, pp. 138–41).
We extracted all instances of variable 3sg subjects in the corpus, and a comparable number of 1sg subjects from a portion of the corpus, giving a total of 2802 tokens with an overall rate of expression of 41%. Example (1) illustrates this variability, with the relevant 1sg and 3sg subject instances marked in bold, and unexpressed subjects with a Ø in the Spanish original and the subject in parentheses in the translation on the right. (See
Appendix A for the transcription conventions.)
| (1) |
| (re a health insurance policy Ángela is taking out for her husband, as a surprise for him) |
| 1. | Ángela: | ... Ay, | ‘… Oh, |
| 2. | | qué pecado con Santi. | I feel so bad about Santi. |
| 3. | | Yoquisiera que él supie=ra, | I’d like him to know,
(lit. ‘that hesanti knows’) |
| 4. | | porque -- | because -- |
| 5. | | ... Pues, | … Well, |
| 6. | | para que Ø la [pueda usa = r]. | So that (hesanti) [can use it].’ |
| 7. | Sara: | [@@@] | [@@@] |
| 8. | Ángela: | ... Qué hago? | ‘… What should I do?’ |
| 9. | Sara: | Y si le dices? | ‘And if you tell him? |
| 10. | | .. Ø Dice [que no] -- | .. (Hesanti) will say [no] --’ |
| 11. | Ángela: | [No le va a gustar]. | ‘[It won’t please him]. |
| 12. | | A él no le va a gustar. | It won’t please him. |
| 13. | | ... Yo después le digo. | … I’ll tell him later. |
| 14. | | Yocreo que yo no me aguanto. | I think that I won’t be able to resist. |
| 15. | | es que yo no me aguanto. | It’s that I won’t be able to resist.’ |
| (4 Seguro, 68–82) |
3. Factors in Variable Subject Expression
Subject person is often reported as the strongest constraint conditioning subject expression in Spanish when all persons are considered, with pronouns favored for 1sg over 3sg subjects. While the relatively higher rate has been attributed to the egocentric nature of the first person (e.g.,
Silva-Corvalán and Enrique-Arias 2017, p. 184), the difference between 1sg and 3sg diminishes if we consider also lexical subjects as a means of expression (
Travis and Torres Cacoullos 2018, p. 78). What is important for the problem of defining the category under consideration here, as we will see, is that 1sg subjects show a greater tendency than 3sg to occur in environments that favor pronominal expression (in non-coreferential contexts and with cognition verbs).
A cross-linguistic effect is that of accessibility in accordance with the generalization that more accessible referents, that is, those which have been recently activated in the discourse, or represent given information, tend to be realized with less “coding material” (here, as unexpressed subjects), and less accessible referents with more “coding material” (here, pronouns) (
Givón 1983a, p. 18). While accessibility has been operationalized in terms of distance from previous mention (e.g., in the papers in
Givón 1983b), in Spanish, it is typically equated with coreferentiality, with pronominal subjects most likely to occur when there has been a switch in subject from the previous clause. This can be seen in example (1) above. In line 3, the subject referent (Santi) of the second clause is not coreferential with that of the preceding clause, and is expressed with the pronoun
él, while in line 6, this same subject is retained, and is unexpressed.
A robust effect conditioning morphosyntactic variation in general is that of structural priming, as the tendency to repeat a previously used variant is observed in virtually every study that tests for it. For Spanish subject pronoun expression, priming was first examined across adjacent clauses (
Cameron 1994), and it has more recently been demonstrated to occur most strongly between subjects with the same referent, even when separated by up to 10 clauses, in what is termed coreferential subject priming (
Torres Cacoullos and Travis 2018, pp. 88-91). This phenomenon is illustrated in lines 14 and 15 in example (1) where, despite the coreferential contexts, the pronoun
yo is repeated.
TAM is also often reported to have an effect, with subject pronouns tending to be favored in imperfective over perfective contexts. This is typically attributed either to ambiguity resolution (for example, 1sg and 3sg are ambiguous in the imperfect), or to the backgrounding function of some imperfective TAMs in discourse. Most consistent is the disfavoring effect of the perfective (preterit), which is tied to its greater tendency than imperfectives to be used in temporally sequential contexts in narratives and to occur with dynamic verbs (
Torres Cacoullos and Travis 2018, pp. 97–101). Cognition verbs, on the other hand, occur proportionally more in the present tense than other verbs, as we discuss below, and it is this uneven distribution of TAMs across verb classes that is pertinent here, as present tense turns out to be a component of the cognition verb construction.
Of most interest for the relevance of lexically anchored categories is the widely reported constraint of verb class, with effects identified for dynamic verbs, which tend to favor unexpressed subjects more than stative verbs do (e.g., in example (1),
decir ‘to say’ in lines 10 and 13 vs.
querer ‘to want’ in line 3). Singled out in virtually all studies is the semantically rather than aspectually defined class of cognition verbs, which tends to favor expressed subjects the most (e.g.,
que él supiera ‘that he knows’ in line 3 and
yo creo ‘I think’, in line 14). The favoring effect with cognition verbs has been attributed to the role of the pronoun to mark an utterance as the speaker’s personal opinion (
Aijón Oliva and Serrano 2010, p. 8), or “a higher level of speaker commitment” (
Posio 2014, p. 14). Such pragmatic considerations, verified by quantitative patterns, may be part of what defines a construction (cf.,
Travis and Torres Cacoullos 2020;
Vázquez Rozas and Enríquez Ovando 2020, pp. 225–26; see
Section 7 below).
In sum, the same effects in Spanish subject expression have been repeatedly found, including for verb class. Nevertheless, the role of highly frequent verbs remains a topic of controversy and misunderstanding as to locus (frequency of what?) and direction (favoring or disfavoring?). What we highlight here is that lexical item and category need not be opposed. Rather, variation patterns reveal that lexically particular, frequent expressions act synergistically with the general verb class, in the case of cognition verbs, to favor subject pronouns.
4. Conditioning of Subject Pronoun Expression
We begin with an analysis of the constraints on subject expression in order to ascertain the impact of verb class alongside the set of predictors described above. To do this, we ran a series of regression analyses using generalized linear mixed effects models with the glmer() function in R (
Bates et al. 2019;
R Development Core Team 2019). Models were fit with subject pronoun realization (pronoun/zero) as the dependent variable, and person, accessibility, priming, TAM and verb class as independent variables. TAM was found not to be significant and was pruned from the model. We tested two-way interactions between each of the predictors, and of these, only subject person by accessibility was found to be statistically significant and included in the final model.
Speaker and verb (as lemma) were included as random intercepts. Including speaker as a random intercept is intended to ensure that the model considers individual differences so that inferences can be drawn beyond the study participants (see
Guy 1980 on individual differences and the speech community). Including verb as a random intercept is intended to take account of lexical effects. It is, however, important to bear in mind that it is common in corpora for a large proportion of the data to be made up of items that occur only once. Such
hapax legomena typically represent “roughly half the vocabulary size” by one account (
Baayen 2001, p. 17). This is the case here, where 40% (122/294) of all verb lemmas present just one token.
1 Such low-frequency words cannot carry their own lexically specific probabilities, but rather must be associated with “lexicon-wide probabilities, which are based on data pooled across individual words” (
Barth and Kapatsinski 2018, p. 103). From a modeling perspective, pooling such low-frequency words “avoid[s] making the random effect structure too sensitive to particularities” (
Szmrecsanyi et al. 2016, p. 9). Accordingly, we pooled all
hapax legomena into a single level in the random intercept for verb.
Table 1 provides the summary of the final model, with overall pronoun rates and token numbers for each linguistic context (level) presented in the first two columns; rows presenting the glmer model are shaded, and reference levels appear in unshaded rows. There are no surprises, as results are consistent with other studies—subject pronouns are favored by 1sg over 3sg subjects; by stative and cognition verbs over dynamic verbs, particularly so by cognition verbs; in non-coreferential over coreferential contexts; and for priming (measured as a coreferential mention in the previous 10 clauses), in the contexts of a previous pronoun and no previous mention (that is, in the absence of a prime) over the context of a previous unexpressed subject. In addition, as reflected in the significant interaction, the accessibility effect is weaker for 3sg than it is for 1sg. This is consistent with differential effects for 1sg vs. 3sg. As we have previously reported, the impact of distance from the previous mention is larger and becomes operative at shorter distances for 1sg than for 3sg subjects (
Travis and Torres Cacoullos 2018, pp. 75–77).
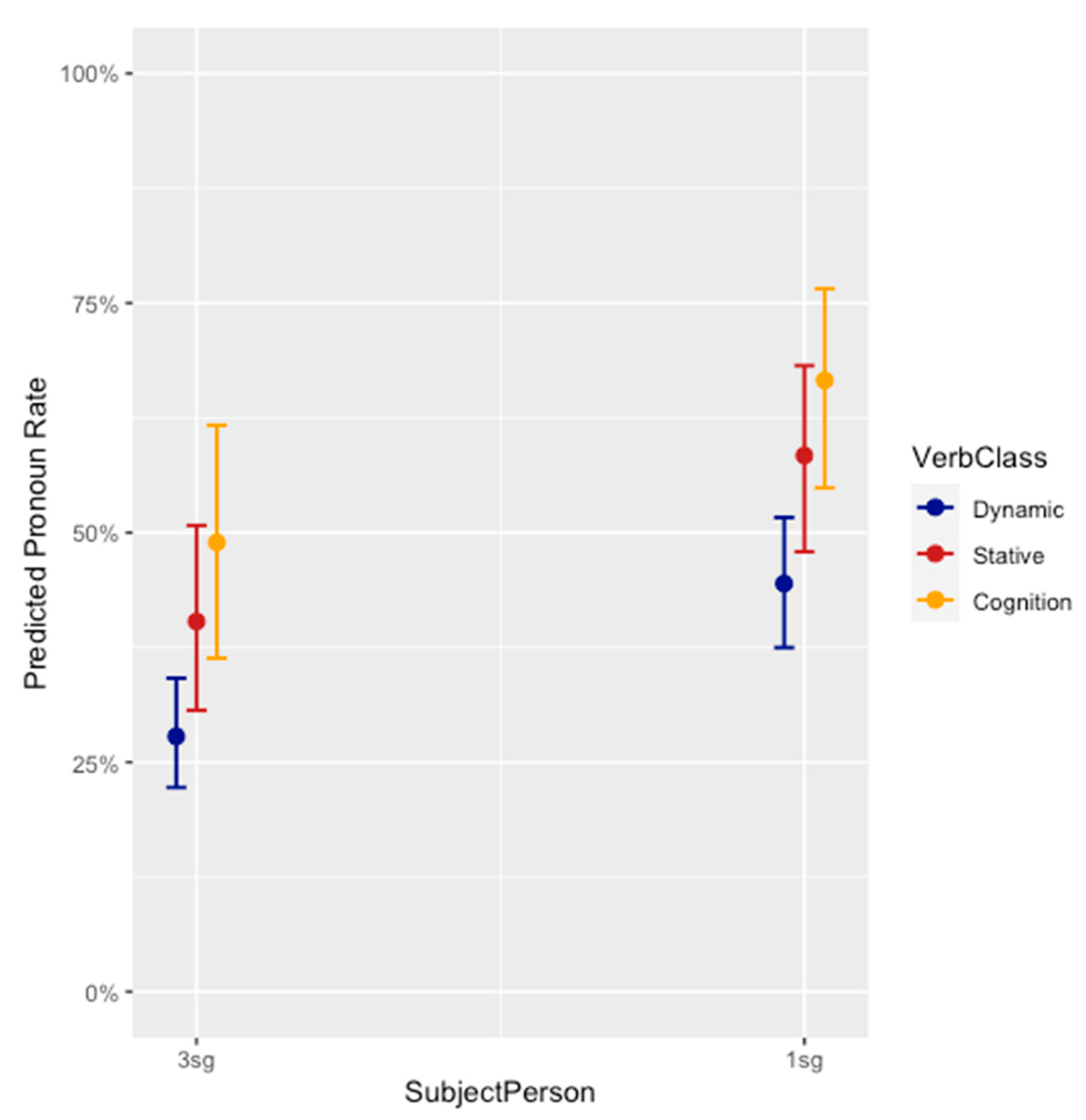
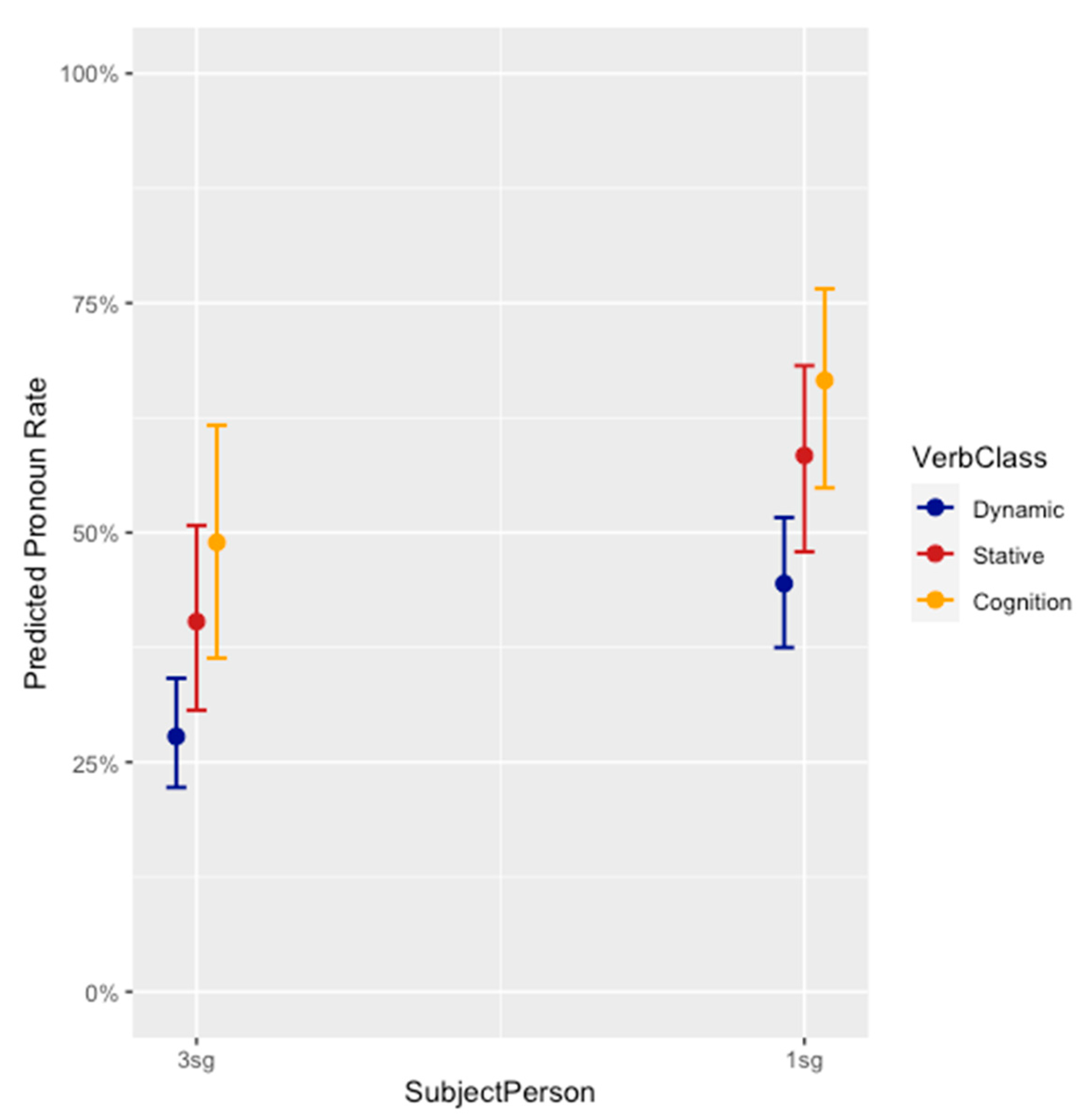
Figure 1 presents the predicted rate of pronominal subjects by person and verb class, based on the output of the model in
Table 1, and illustrates why a model including an interaction between person and verb class did not return a significant result for this interaction—the favoring of pronominal subjects most by cognition verbs holds for both 1sg and 3sg subjects, and the favoring of pronouns by 1sg over 3sg subjects holds for each verb class. But to understand the interplay between person and verb class, consider
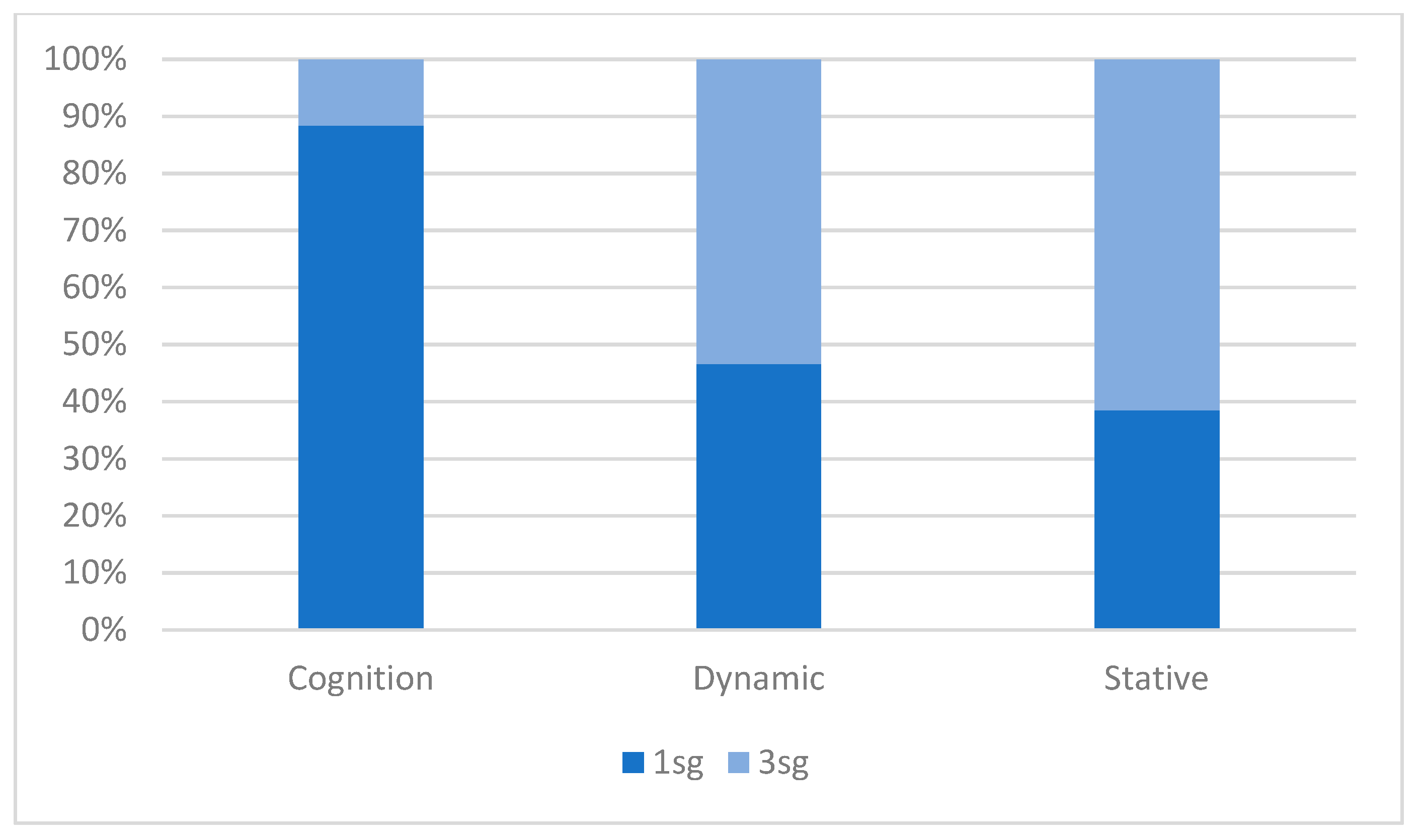
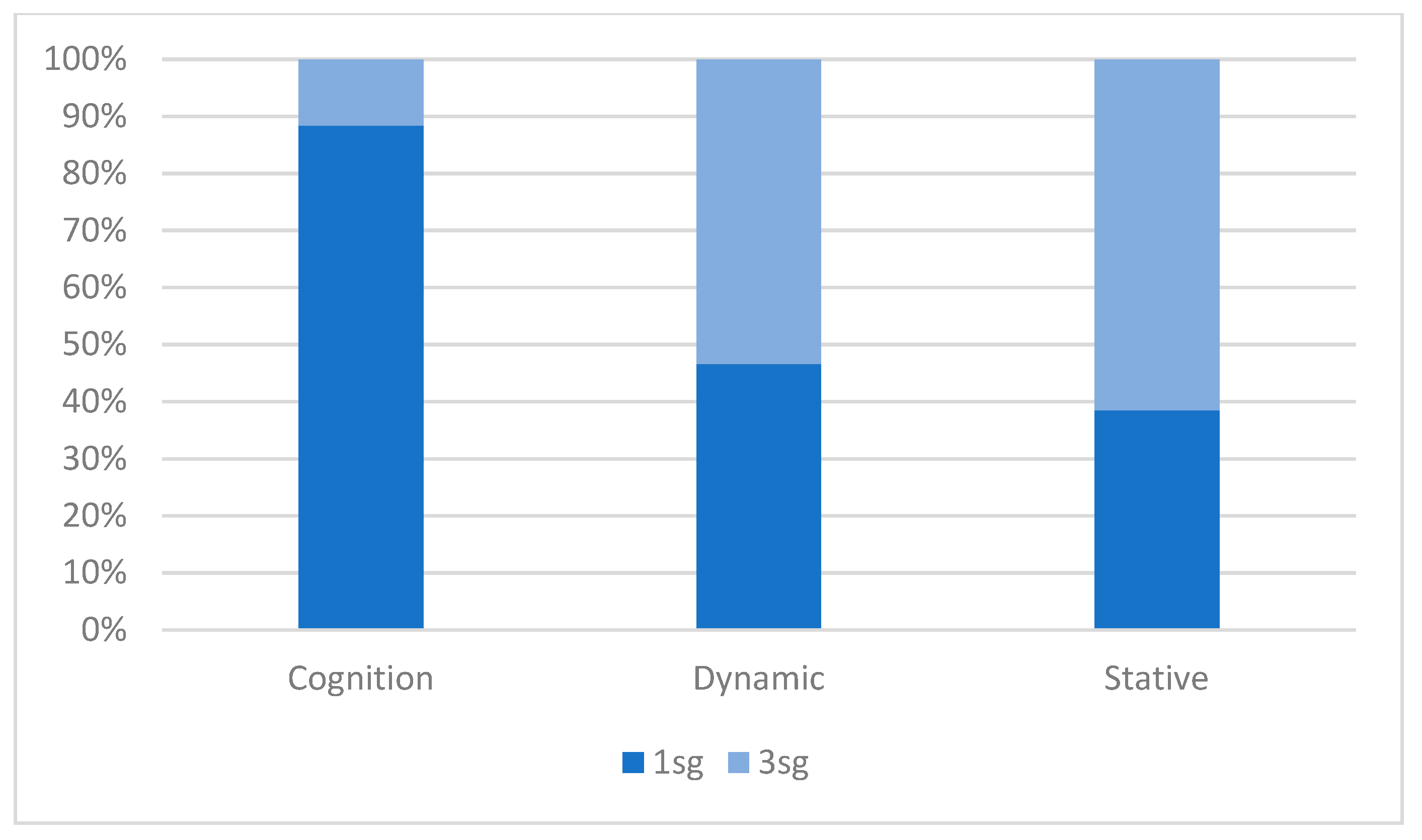
Figure 2, which breaks down each verb class by person. Here we observe that cognition verbs are overwhelmingly made up of 1sg subjects, which account for a full 88% of all instances, compared with 47% of dynamic, and 39% of stative, verbs. The converse also holds—over one fifth of 1sg subjects occur with cognition verbs, but under 3% of 3sg subjects do. Thus, though absence of a significant interaction in the model would indicate that 1sg and 3sg subjects pattern similarly with respect to verb class, this result should not be overinterpreted, given the relatively low number of 3sg cognition verbs (
n = 39 vs.
n = 296 for 1sg). Furthermore, other studies have reported a lack of a verb class effect for 3sg subjects (
Shin 2014, p. 311).
The very robust finding reported in the Spanish subject expression literature for cognition verbs, then, is actually accounted for by cognition verbs
with 1sg subjects, as observed by
Torres Cacoullos and Travis (
2018, p. 102). The favoring of subject pronouns with specifically 1sg cognition verbs suggests a 1sg cognition verb construction, which we can represent as [(
yo) +
cognition verb1sg]. Constructions, generally defined as pairings of form and meaning (e.g.,
Goldberg 2013), are operationalizable quantitatively as items tending to co-occur in particular contexts (
Travis and Torres Cacoullos 2020, p. 140). Let us now explore the makeup of the 1sg cognition verb construction.
5. Straddling Lexical Types and Classes: Lexically Particular Constructions
What is the evidence for cognition verbs as a class within a [(
yo) +
cognition verb1sg] construction? Semantically, cognition verbs—also referred to as “knowledge” and “propositional attitude” predicates—express knowledge about, or attitude to, a proposition, and syntactically, they are characterized by their status as complement-taking predicates (
Noonan 2007, pp. 124–30) (cf. also
Givón 1984, p. 119). In actual usage, they also share a particular morphosyntactic profile in their tendency to occur with 1sg subjects as we have just seen, which has been related to the semantics of these verbs, since “the speaker must have access to the mental state to which the verb refers” (
Weber and Bentivoglio 1991, p. 200). Cognition verbs are also mostly in the present tense (78%, 261/335 of the time, compared with just 50%, 897/1783, of dynamic verbs). A similar profile has been found in speech data from other varieties of Spanish (e.g.,
Shin 2014, p. 311;
Torres Cacoullos and Travis 2018, pp. 101–2;
Weber and Bentivoglio 1991, p. 203), and other languages, such as Swedish, Finnish, English and Mandarin (
Dahl 2000, p. 5;
Helasvuo 2014, p. 66;
Scheibman 2001, p. 69;
Tao 1996, p. 151). We can think of these semantic-morphosyntactic features as characterizing the class.
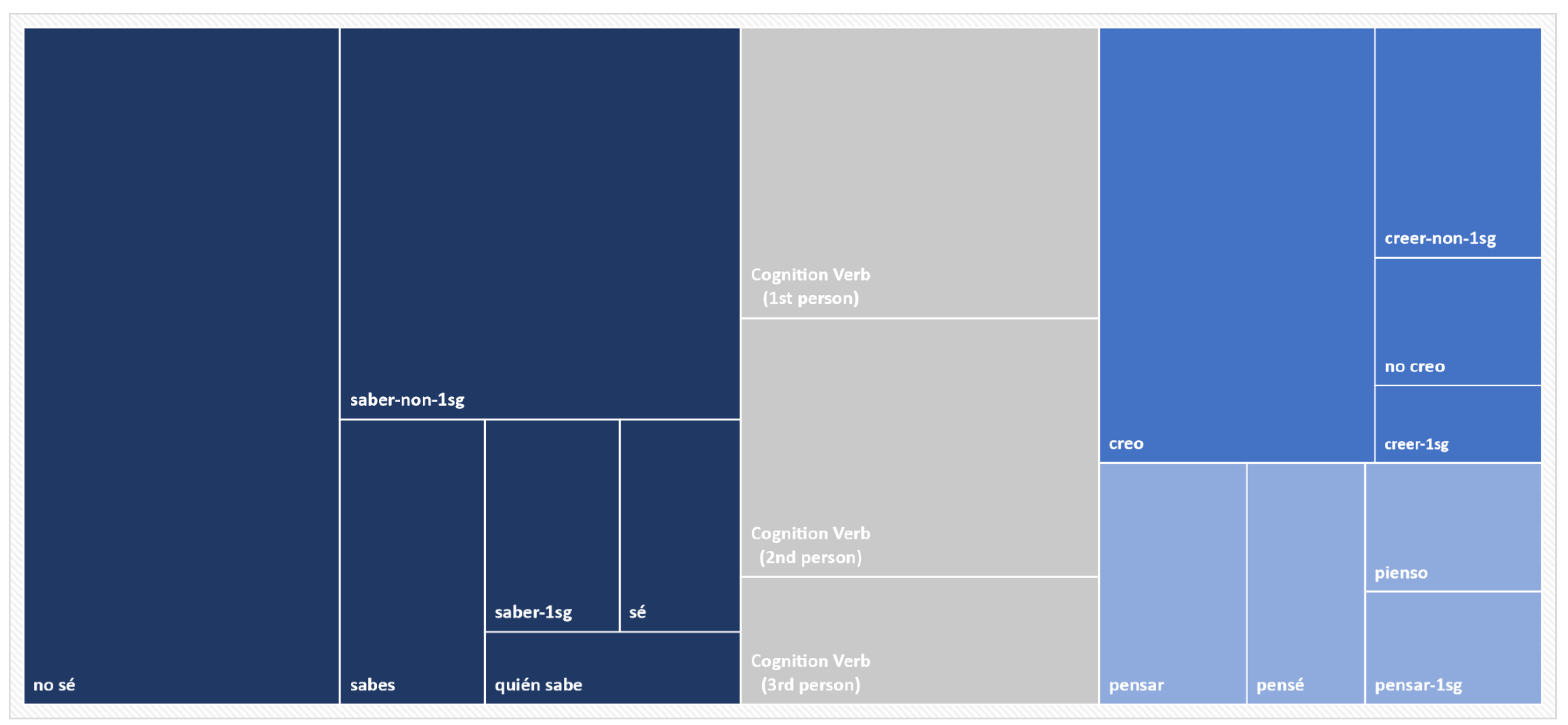
Despite these shared characteristics, the distribution of the verbs themselves is quite skewed, with a small number of verb types representing the majority of cognition verb tokens. For a view of this skewed distribution, we draw on a larger sample from the CCCS, which comprises all cognition verbs and all grammatical persons (
n = 720).
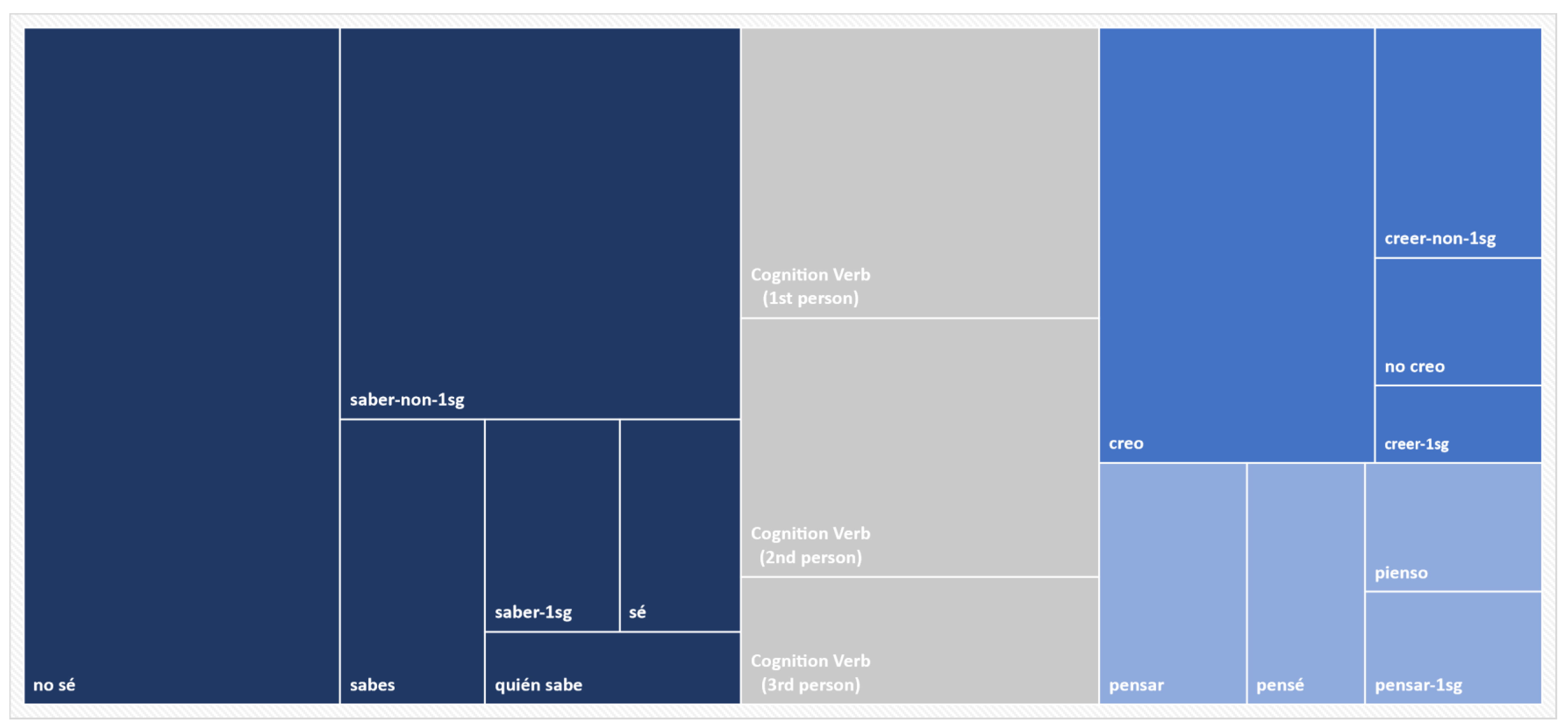
Figure 3 presents the distribution of this sample according to the most frequently occurring verb types and the most frequent forms in which those verbs occur, arranged by frequency of occurrence. Just two verbs constitute two thirds of all cognition verb tokens,
saber ‘to know’ and
creer ‘to believe/think’.
2 Furthermore, two specific constructions from these verbs represent close to one third of all cognition verb tokens,
(yo) no sé ‘I don’t know’ and
(yo) creo ‘I think’. The third most frequent cognition verb,
pensar ‘to think’, makes up only 10%, centered on two forms,
(yo) pensé ‘I thought’ and
(yo) pienso ‘I think’. All other cognition verbs combined (a total of 12 verb types, e.g.,
acordarse ‘to remember’ (
n = 40),
imaginarse ‘to imagine’ (
n = 47),
darse cuenta ‘realize’ (
n = 23),
entender ‘understand’ (
n = 23)) make up just one quarter of the data; these are collapsed in
Figure 3, but grouped by person.
3| saber ‘to know (n = 340): | (yo) no sé ‘I don’t know’, (tú) sabes ‘you know’, |
| | (yo) sé ‘I know’, quién sabe ‘who knows’ |
| creer ‘to think/believe’ (n = 135): | (yo) creo ‘I think’, (yo) no creo ‘I don’t think’ |
| pensar ‘to think’ (n = 75): | (yo) pensé ‘I thought’, (yo) pienso ‘I think’ |
| Cognition verbs (other) (n = 170) | |
Cross-linguistically, 1sg cognition verb combinations are recognized to have a specialized meaning, for example in English, related to “degrees of certainty or commitment to a proposition” (
Noonan 2007, p. 125). This is consistent with the proposal that a main function of complement-taking predicate phrases is to “frame a clause in subjective epistemic terms” (
Thompson 2002, p. 138). Thus,
(yo) no sé ‘I don’t know’ can be used to express lack of knowledge, but also as a discourse marker, for example to soften a statement as in (2) (
Rivas and Brown 2009;
Travis 2006, pp. 93–95). And though
(yo) creo ‘I think’ derives from a verb meaning ‘to believe’, both it and
(yo) pienso ‘I think’ are said to be “basic methods of expressing the epistemic-evidential stance of speakers”, with
(yo) creo being preferred in modern-day Spanish across varieties (in contrast to French, where, despite the existence of cognate verbs,
je pense is the form that has won out for this epistemic use) (
Vázquez Rozas 2015, pp. 579–580).
| (2) |
| (re friends who made a poor business choice) |
| 1. | Ángela: | Pero es que tan -- | ‘But they are such -- |
| 2. | | .. ay, | .. oh, |
| 3. | | yo no sé, | I don’t know, |
| 4. | | tan bobos. | such silly people.’ |
| (3 Familia, 959–962) |
Just what, then, is the relationship between these lexically particular constructions and the set of lower frequency items? Does evidence of a class of cognition verbs remain once we take into account the behavior of these highly frequent expressions?
6. Classes and Lexically Particular Constructions: The Test of Variation Patterns
We test the status of cognition verbs as a class in relation to variable subject expression with 1sg subjects, singling out lexically particular constructions. One source of evidence comes from rates of subject pronoun expression. Here, we also bring to bear another source of evidence, which comes from variation patterns: linguistic constraints and contextual distribution of the data.
We first consider rates of subject pronoun expression.
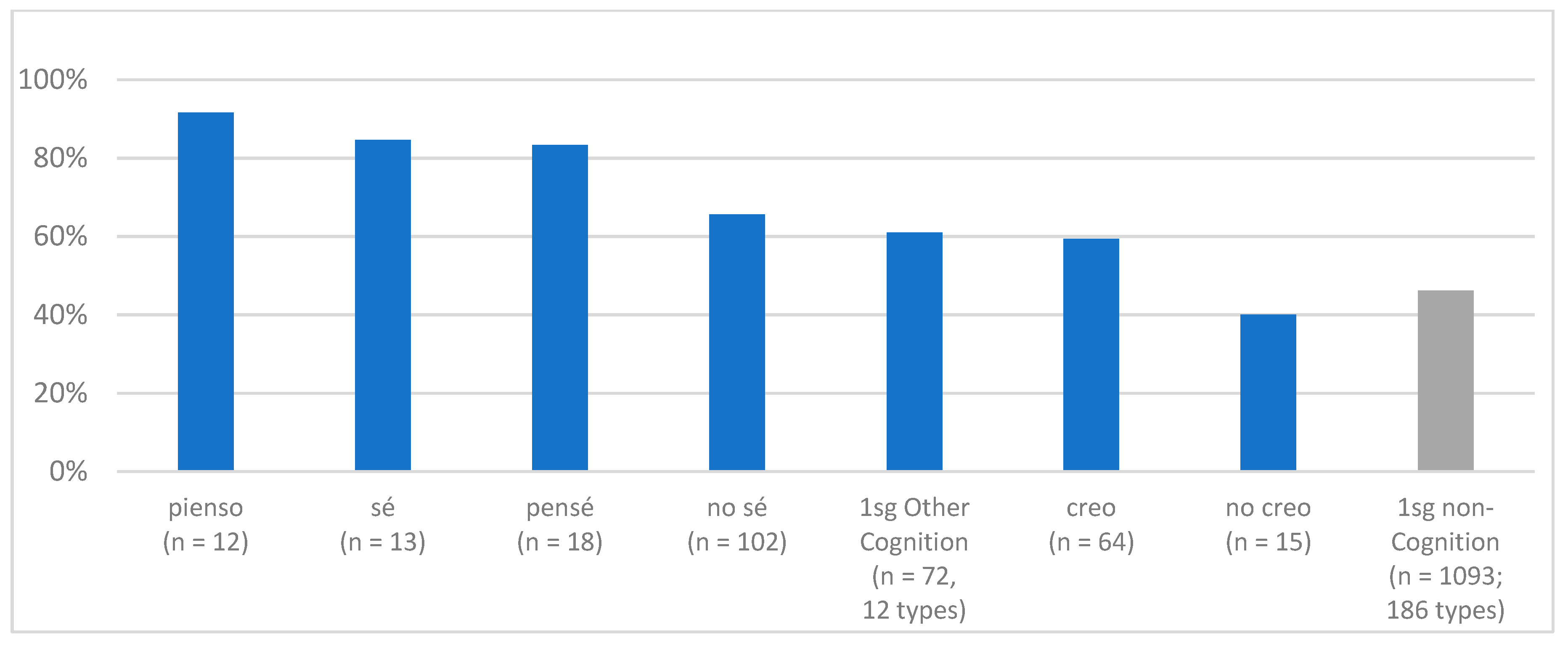
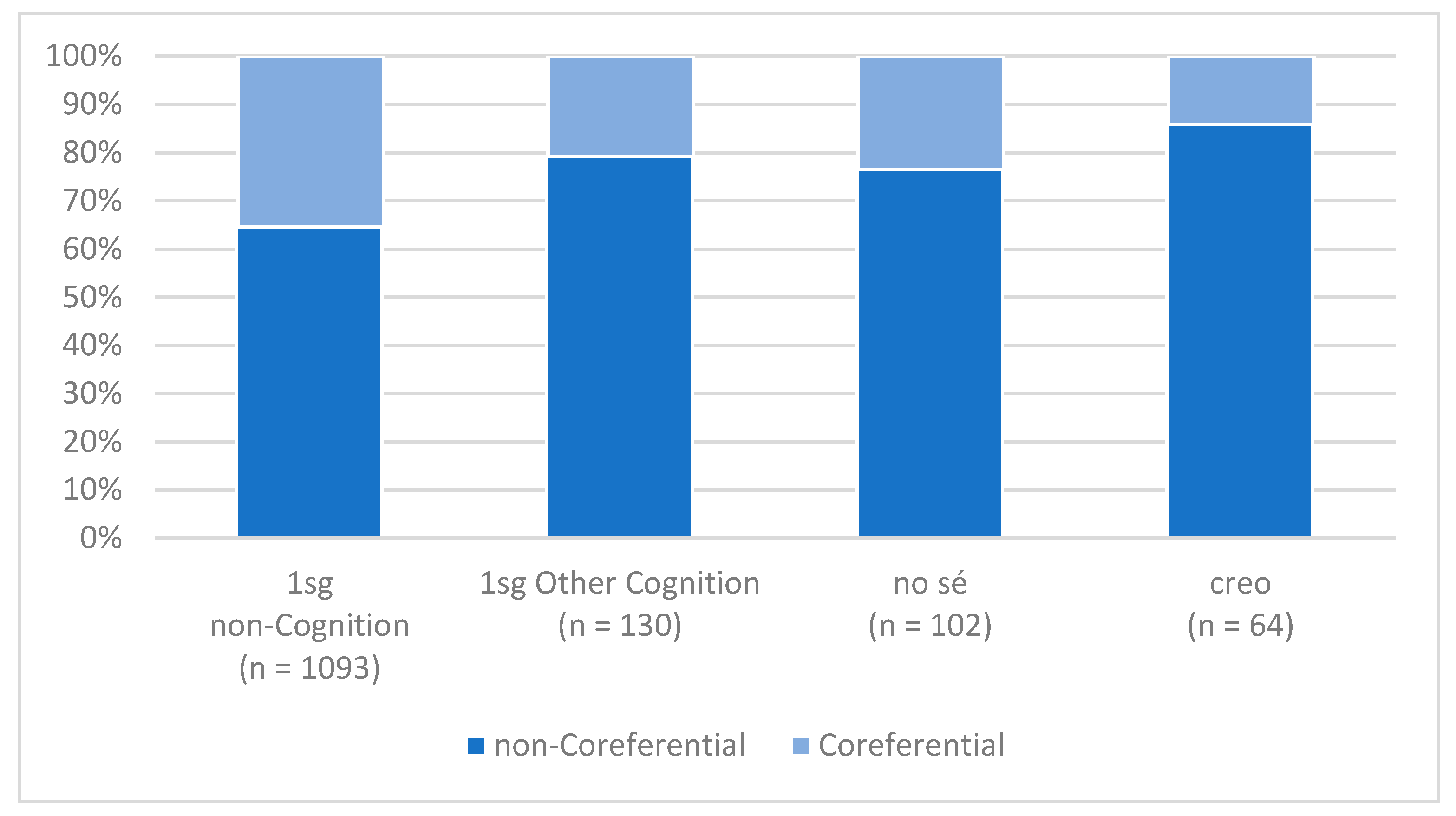
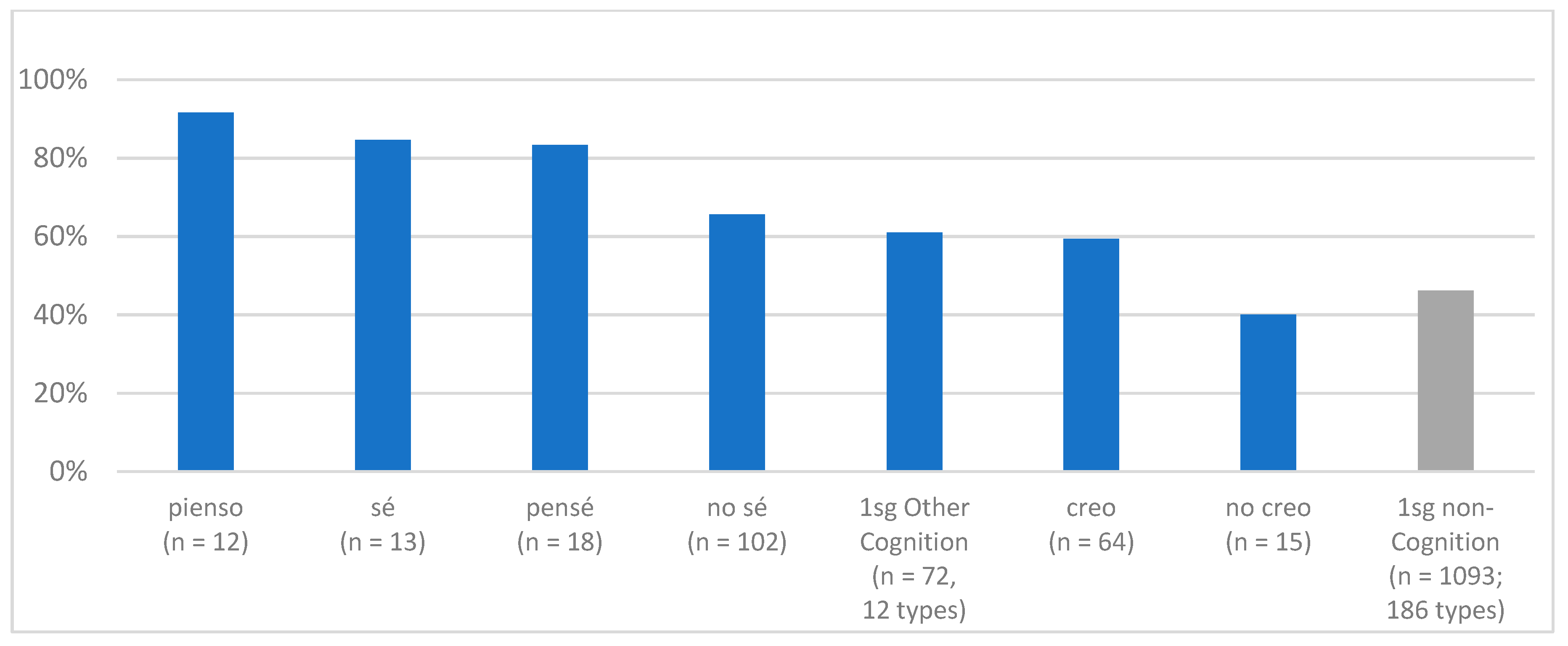
Figure 4 presents these for each of the 1sg forms identified in
Figure 3, for 1sg other cognition verbs combined, and for 1sg non-cognition verbs. As can be seen, the favoring of subject pronouns is widely shared across the class. The subject pronoun rate for cognition verb forms ranges from 59% for
(yo) creo to 92% for
(yo) pienso, and as a set, 1sg other cognition verbs have a rate of 61%, substantially higher than 1sg non-cognition verbs at 46% (with the one exception of
(yo) no creo ‘I don’t think’, at 40%). We can verify, then, that the favoring of subject pronouns is not idiosyncratic behavior of frequent verbs, but generally holds across 1sg cognition verb items.
Furthermore, subject pronoun rates may be associated less with the lexical verb, and rather with particular verb-tense-subject-polarity combinations, most notably,
(yo) creo and
(yo) no sé. This too we verify in
Figure 4, which shows that individual lexical types do not show uniformly high rates. For
saber ‘to know’, positive polarity
(yo) sé ‘I know’ has among the highest rates, at 85%, while
(yo) no sé ‘I don’t know’ is in the middle, at 66%. The converse is so for
creer ‘to think/believe’, for which
(yo) creo ‘I think’ has a higher rate than
(yo) no creo ‘I don’t think’ (59% vs. 40%).
Next, we consider variation patterns. We propose to test the relevance of the cognition verb class and lexically particular constructions to subject expression by zooming in on the linguistic conditioning of variability. To do this, we ran a second generalized linear mixed effect model, this time on 1sg subjects only, again with subject pronoun realization (pronoun/zero) as the dependent variable; with accessibility, priming, and verb class as independent variables; and with speaker and verb as random intercepts (as previously, pooling verbs that occur only once). To compare cognition verbs and specific constructions, we reconfigure the predictor of verb class as one of verb class–construction, treating the two most frequently occurring forms—(yo) creo and (yo) no sé—as separate levels in this predictor, collapsing dynamic and stative verbs into one level of non-cognition verbs, and comparing with other cognition verbs as the reference level. In this way, instead of a blanket random effect for verb to account for lexical idiosyncrasies, we incorporate the most frequent forms as fixed effects in the model to directly test their relationship with other cognition verbs.
Table 2 presents the final model summary. Evidence for the role of lexically particular expressions in contouring the more general construction is seen in that, first, even when we separate out
(yo) creo and
(yo) no sé, the shared patterning of cognition verbs holds: non-cognition verbs have a significantly lower rate of pronoun expression than other cognition verbs. And second, there is no significant difference between other cognition verbs and neither
(yo) creo nor
(yo) no sé.
4 These results thus support cognition verbs as a class that is distinct from non-cognition verbs, with
(yo) creo and
(yo) no sé as members.
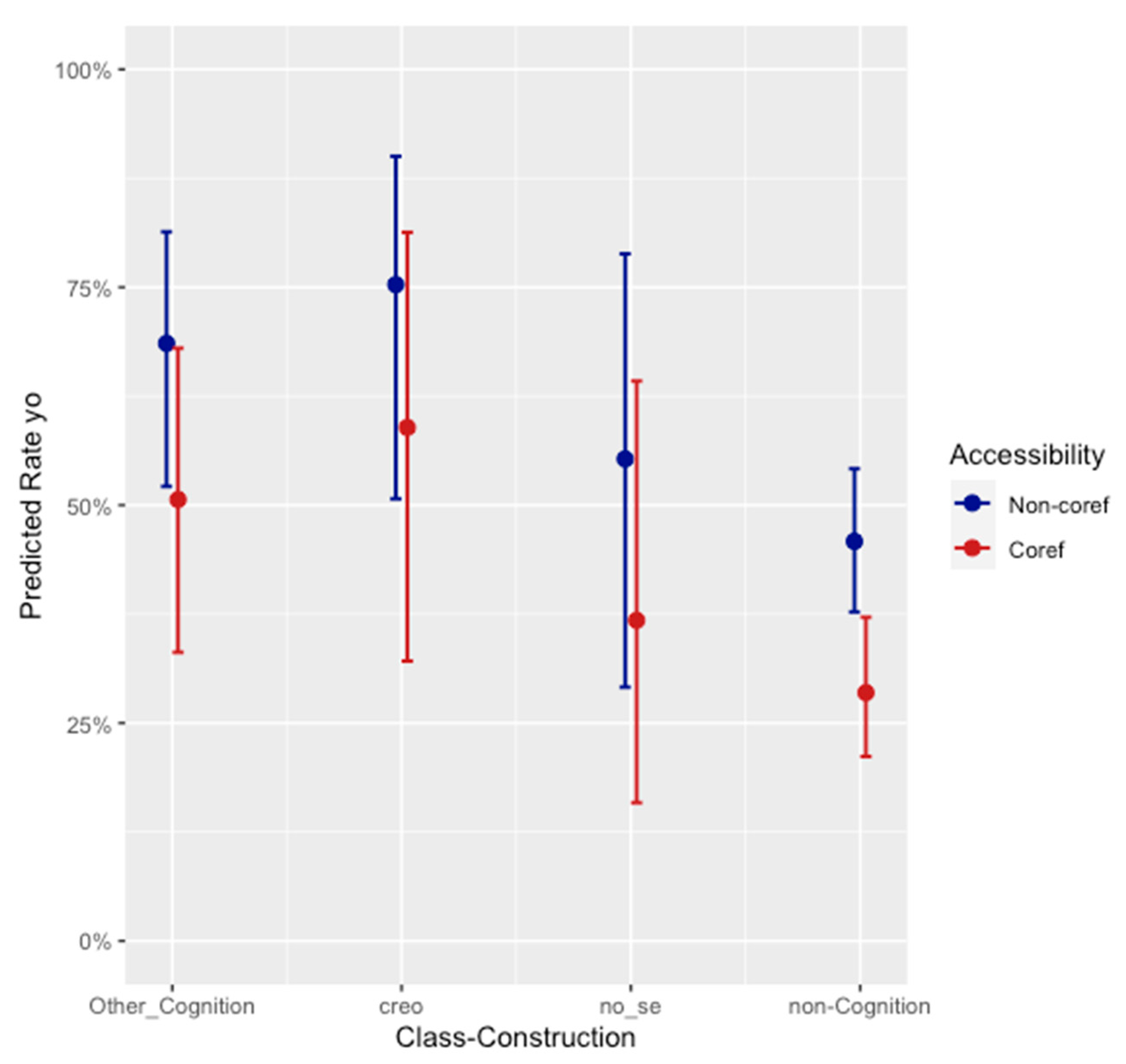
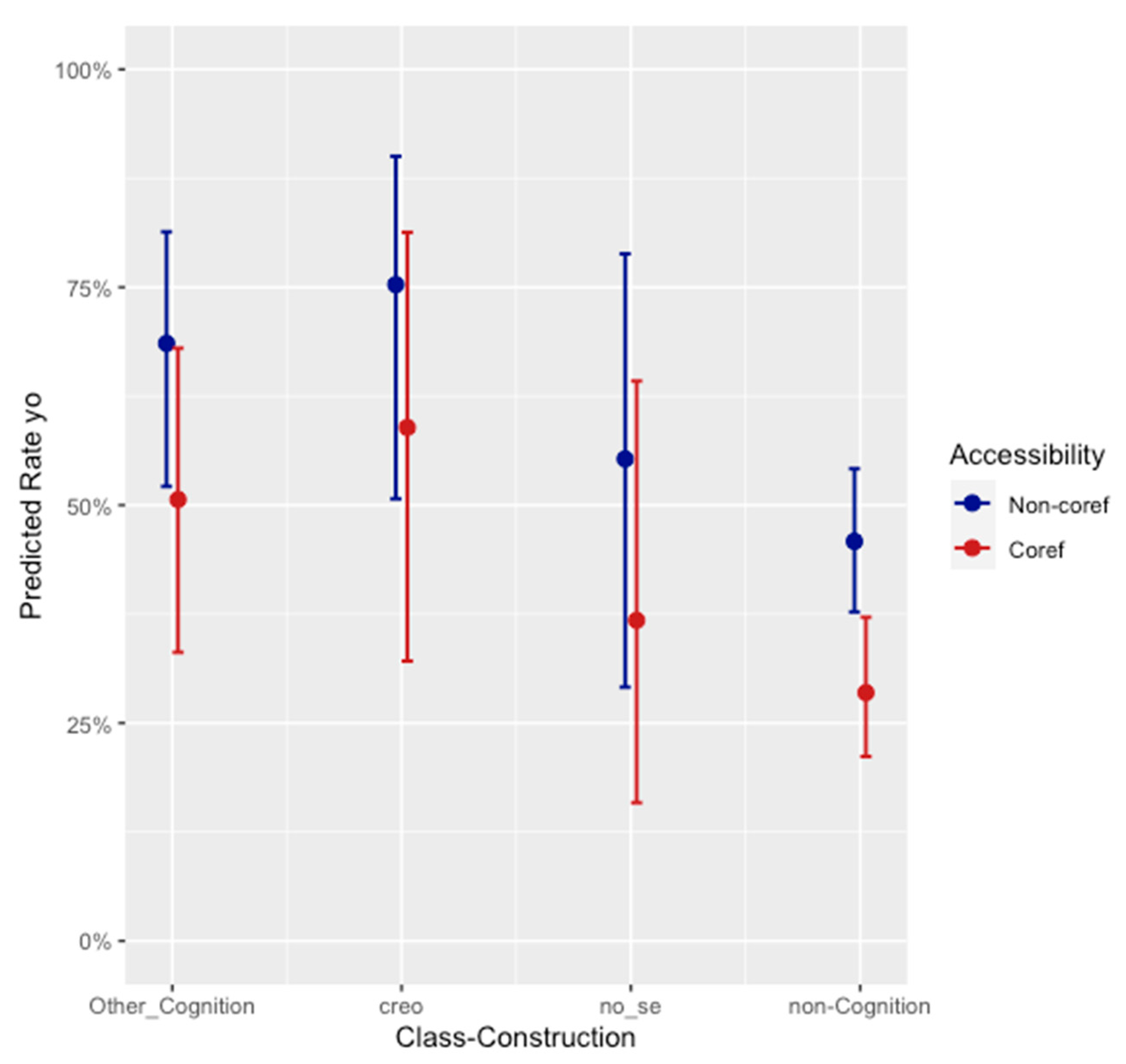
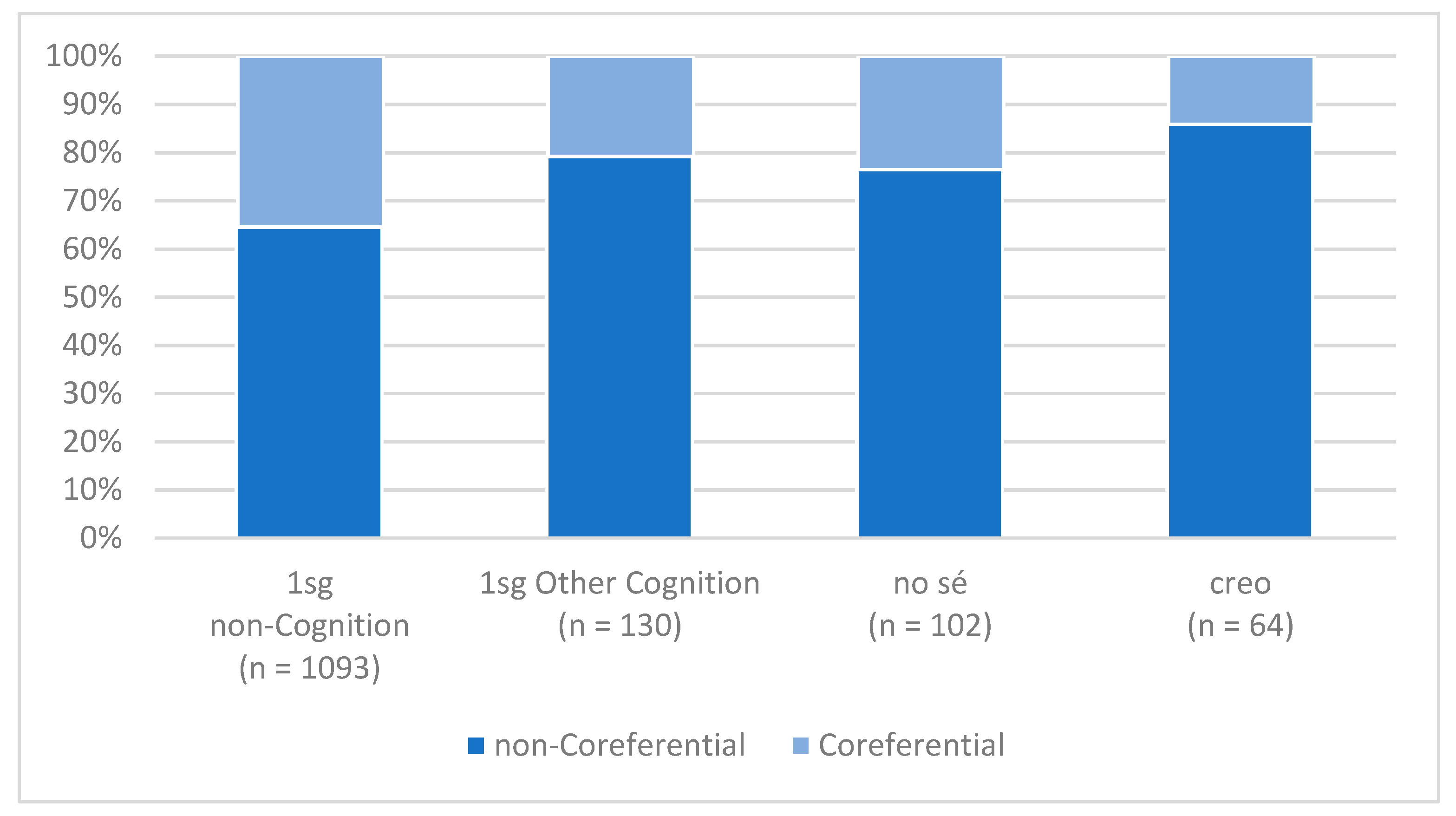
Close examination of the contextual distribution for verb class–construction according to accessibility reveals that there is a linguistically significant relationship of “dependence” between the two predictors (
Sankoff 1988, p. 986), in that cognition verbs are disproportionately used in non-coreferential contexts. This can be seen in
Figure 6, which presents the proportion of the data occurring in coreferential vs. non-coreferential contexts for the four levels of the verb class–construction predictor in
Table 2 and
Figure 5: the proportion of the data occurring in non-coreferential contexts is lowest for 1sg non-cognition verbs at 64%, substantially lower than any of the cognition verbs categories, which are at 79% for 1sg other cognition verbs, 76% for
(yo) no sé, and as high as 86% for
(yo) creo. Some of the few instances of
(yo) creo in a coreferential context are seen in line 14 in example (1) above. In contrast, 50% (711/1413) of 3sg subjects occur in non-coreferential contexts (not shown here). (On the distinct distribution for 1sg and 3sg by distance and differences in the workings of accessibility according to grammatical person, see
Travis and Torres Cacoullos 2018, pp. 79–81).
We now come to contextual distribution, which must be recognized as a component of variation patterns in spontaneous speech. Consider the numbers presented in the “Overall
n” column in
Table 2, which show that 1sg verbs occur twice as often in non-coreferential vs. coreferential contexts (compared with 1.4 times as often for 1sg and 3sg combined, seen in
Table 1). Might higher pronoun rates for 1sg cognition verbs merely reflect disproportionate occurrence in non-coreferential contexts? It was not possible to include an interaction for accessibility by verb class–construction in the model reported in
Table 2 because of the skewed data distributions, which we turn to shortly. But a visualization of the effect of accessibility broken down by verb class–construction in
Figure 5 shows that the higher pronoun rate in non-coreferential than coreferential contexts holds across cognition and non-cognition verbs, and that the favoring with cognition verbs holds across coreferential and non-coreferential contexts. Thus, the favoring of subject pronouns is a genuine effect for 1sg cognition verbs, that applies irrespective of coreferentiality (cf.,
Posio 2013, p. 283). Though the effect may appear to be stronger for non-cognition verbs, the vastly smaller token numbers for the other three levels in this predictor (see
Table 2) must be taken into account in comparing the differences in the confidence intervals returned in the model.
A greater preponderance of 1sg cognition verbs in non-coreferential contexts may be a general tendency, not specific to this dataset. A similar distribution is observed in the New Mexico Spanish-English Bilingual corpus and in the Santa Barbara Corpus of Spoken American English,
5 and appears to hold for Peninsular Spanish and European Portuguese spoken data (
Posio 2013, pp. 283–84). Thus, contextual distribution is itself part of the variation patterns characterizing 1sg cognition verbs as a class, and
(yo) creo and
(yo) no sé as members of that class.
Contextual distribution may have a cumulative effect in enhancing the impact of favoring contexts. Here, the association with non-coreferential contexts may contribute to the higher pronoun rate overall for 1sg cognition verbs. This is because variation is conditioned not only by online, context-dependent factors (such as accessibility and priming for subject expression), but also by “usage history”, reflecting speakers’ cumulative prior experience with a form’s contextual distribution (
Bybee 2010, p. 43). Especially relevant is frequency of occurrence in a favorable context, according to which, high frequency of occurrence in a context that favors one variant over another may, via a cumulative effect, promote the choice of that variant across the board (
Brown 2004;
Bybee 2002).
The effect of frequency of occurrence in a favorable context has been observed in both phonology and morphosyntax. An example from phonology is variable word-initial [s] realization in New Mexican Spanish (
Brown 2004). Reduction to [h] is favored in the phonetic environment of a preceding non-high vowel (an online, context-dependent factor). In this favoring environment, such as when following
no ‘no’, a word like
señora ‘lady’ is more likely to reduce than its masculine counterpart,
señor ‘gentleman’. This can be explained by the more frequent occurrence of the former in this favorable preceding non-high vowel context, often following feminine articles
la ‘the’ and
una ‘an’, compared with the corresponding
el and
un for the masculine
señor (a storage, experience-dependent factor). Thus, word-initial [s] reduction is impacted by a word’s overall frequency of occurrence in contexts that favor reduction.
An example from morphosyntax is the variable pluralization of Spanish
haber ‘there is/are’ when the single argument is a plural noun (prescriptively, existential
haber is always singular, the opposite of English) (
Brown and Rivas 2012). One of the factors favoring plural verb morphology with
haber is preponderance of the plural noun form in subject role. For example, among animate nouns, pluralization is more likely with
maestros ‘teachers’ than with
abogados ‘lawyers’ and among inanimate nouns, with
chismes ‘gossip tales’ than with
ventanas ‘windows’. The first of each pair occurs more often than the second as a subject, thus more frequently agreeing with plural verbal morphology. This effect of grammatical relation probabilities is another example of how contextual distribution functions as a cumulative usage-based factor that impacts selection of variants in online production. For variable subject expression, the higher rate of occurrence in non-coreferential contexts may result in an overall higher rate of pronominal vs. unexpressed subjects for 1sg cognition verbs, which holds across the class—for
(yo) creo, (yo) no sé and the set of less frequent verbs (
Brown 2020).
7. Unravelling Frequency Effects: Conventionalized Chunks
The patterns of variation we examined above have allowed us to establish the internal coherence of the class of verbs in the [(
yo) +
cognition verb1sg] construction. Though some frequent forms make up the bulk of tokens of the class, those lexically specific constructions and the set of other cognition verbs exhibit shared patterns of favoring subject pronoun expression (
Table 2) and association with non-coreferential contexts (
Figure 6).
At the same time, frequency propels the conventionalization, or chunking, of these lexically particular constructions. Let us consider
(yo) creo, which has received a lot of attention as the most frequent manifestation of cognition verbs and as strongly favoring subject pronoun expression across varieties of Latin American (e.g.,
Erker and Guy 2012, p. 539) and Peninsular Spanish (e.g.,
Aijón Oliva and Serrano 2010;
Posio 2015, p. 67). For a broad overview, we go to the oral portion of the “Genre/Historical” sub-corpus of the Corpus del Español (
Davies 2002).
Two frequency measures are pertinent to lexically particular expressions. Most obvious is
overall token frequency. In the Corpus del Español, the form
creo is the most frequent 1sg verb form, occurring nearly twice as often as the next most frequent form
sé (
creo n = 9215,
sé n = 5885) (cf.,
Travis and Torres Cacoullos 2012, pp. 739–740). Complementary to overall token frequency is
relative frequency, or the frequency of an expression relative to the component parts that make it up. The special status of
(yo) creo is evident in its frequency relative to both the verb and the pronoun.
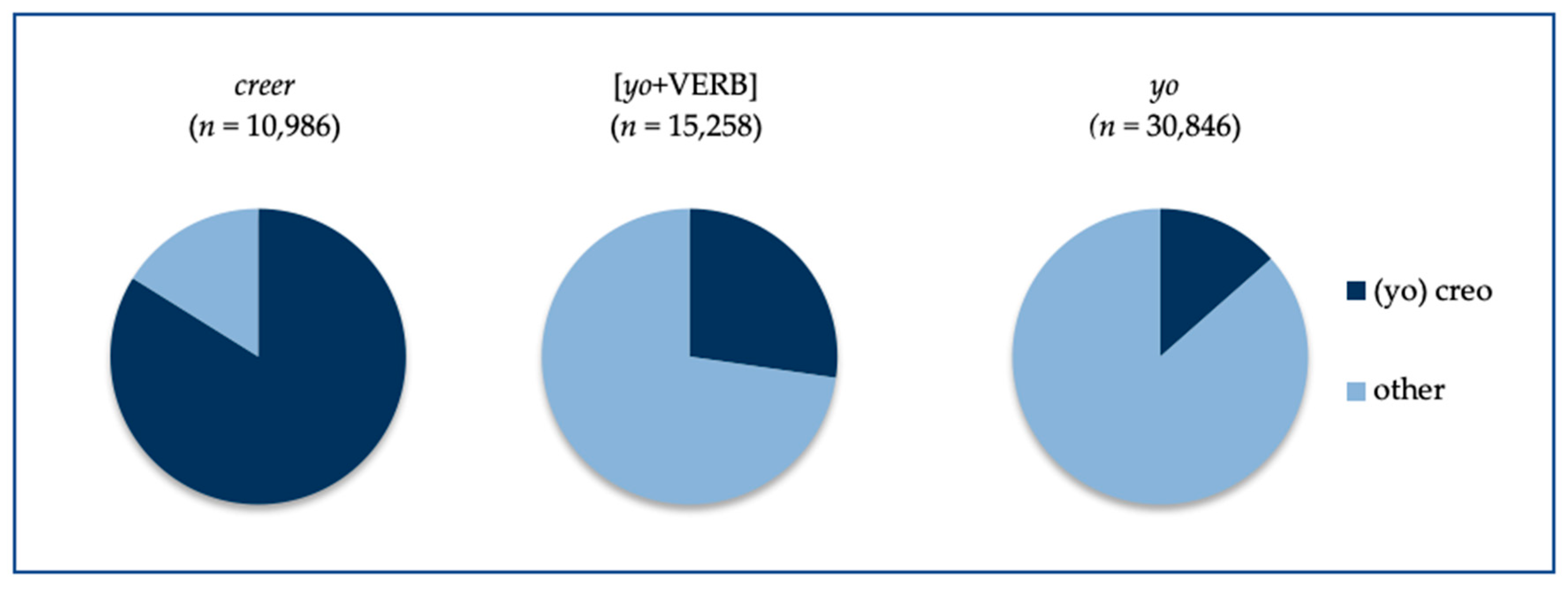
Figure 7 shows, first, that
(yo) creo (
n = 4165, in the darker shade) represents a large proportion of its corresponding lexical type, a full 84% of all instances of
creer (pie chart on the left). In accounting for such a large proportion of
creer,
(yo) creo may be accessed independently as a unit, given that relative frequency affects degree of compositionality. Such chunking can be seen synchronically, for example, in that derived forms that are more frequent than the base word are more likely to be accessed whole (without being decomposed into affix + base), such that
impatient, which is more frequent than
patient, is more likely to be accessed directly than
imperfect, which is less frequent than
perfect (
Hay 2001, pp. 1047, 1061). Diachronically, relative frequency is likewise important, for example, in the creation of complex prepositions such as
a pesar de ‘in spite of’, which has become more frequent than
pesar (originally, ‘sorrow’) (
Torres Cacoullos 2006) (see
Bybee 2010, pp. 138–46 on ‘in spite of’).
Second, the frequency of the string
yo creo relative to other instances of the 1sg subject pronoun
yo reveals a strong association between
creo and
yo.
Yo creo represents over one quarter of the instances of
yo immediately followed by a verb (27%, second chart in
Figure 7). This proportion stands out in particular when we consider that the next most frequent verbs are the present perfect auxiliary
haber ‘to have’ and the light verb
tener ‘to have’, each of which occurs approximately one sixth as often as
yo creo (just over 700 times).
6 Even considering all instances of
yo, yo creo still represents a substantial proportion, 14% (third chart), followed by
yo no (
n = 3387). Compare this with the most frequent items to follow
I in English conversation,
am and
don’t, each accounting for around 10% of all instances of
I (
n = 414), and leading to contraction (
I’m) and phonetic reduction (especially in
I don’t know) (
Bybee and Scheibman 1999, pp. 590–92).
A consequence of its token and relative frequency would be to promote access of
yo creo as a chunk. With chunking, the component parts of an expression become less analyzable and more independent of other instances of the same units (
Bybee 2010, pp. 33–56). Thus, (
yo) creo may be processed directly as a chunked unit, rather than through the paradigm of the verb
creer or as the combination of pronoun and verb.
Chunking and conventionalization of
(yo) creo as a lexically particular construction has developed over time. In pre-modern Spanish texts
creo was neither frequent nor did it favor
yo (
Ramos 2016, p. 120;
Vázquez Rozas 2015, p. 594). There has also been a generalization in meaning of the construction (
Vázquez Rozas and Enríquez Ovando 2020). While
(yo) creo is still used to mean ‘believe in something’, most frequent is the construction with a clausal complement in which
creo has a general meaning of ‘think’ (
Posio 2014, p. 7). Even as a complement-taking predicate,
(yo) creo may function more as an epistemic adverbial than a main clause, as can be seen in the two tokens of
creo in lines 1 and 3 in (3) (
Travis 2006, pp. 97–98). The loss of specific meaning features is accompanied by morphosyntactic decategorialization seen in its occurrence as a parenthetical (as in (4)), and internal fixedness, seen in the rarity of intervening elements such as adverbs (
Posio 2014, pp. 10–11).
| (3) |
| 1. | Nury: | Porque creo que ella se casa
con él, | ‘because (I) think she’s going to
marry him, |
| 2. | | y se viene a vivir acá. | and come and live here. |
| 3. | | .. Creo. | .. (I) think. |
| 4. | | No estoy segura. | (I)’m not sure.’ |
| [11 Estudios, 825–828] |
| (4) |
| 1. | Rocío: | y a eso está en la cevichería
en Guapi, | ‘and that’s what it costs in the
seafood restaurant in Guapi, |
| 2. | | yo creo. | I think.’ |
| [18 Tumaco, 1340–1341] |
Lexically particular constructions may differ across speech communities. While
(yo) creo appears to be a pan-Hispanic phenomenon, the same is not so for other expressions. For example, in these data from Cali, Colombia,
(yo) no sé ‘I don’t know’ stands out, both for its frequent occurrence and for its favoring of subject expression. While the same is so in New Mexican Spanish (
Torres Cacoullos and Travis 2018, pp. 169–70), in other varieties,
no sé tends to occur without a subject pronoun (e.g.,
Cameron 1992, p. 102;
Erker and Guy 2012, p. 539) (cf.
Rivas and Brown 2009 for comparison of
no sé across three varieties of Spanish). Similarly,
sabes ‘you know’ has a low rate of subject pronoun expression in these data (just 10%, 3/29), but studies of other dialects have noted
tú sabes, with the pronoun, as a fixed expression (
Bayley et al. 2013, p. 25;
Claes 2011, p. 196). Thus, lexically particular constructions “represent the conventional way of expressing an idea” (
Bybee 2010, p. 81), and they conventionalize differently in accordance with community norms.
Recognition of lexically specific constructions helps us understand why token frequency as such does not have a uniform effect (cf.,
Bayley et al. 2013;
Erker and Guy 2012). It has been suggested that frequency operates in interaction with other factors, so that “high frequency either activates or amplifies” other factors. For example, in the case of Spanish subject pronoun expression, person and verb class effects appear only among frequent verbs (
Erker and Guy 2012, p. 545). This result, however, likely reflects the behavior of the lexically particular constructions, which are defined precisely by subject person and verb class. Moreover, there is no usage-based reason for an “expectation of consistent favoring of pronoun occurrence” by high frequency (
Erker and Guy 2012, p. 539). High frequency promotes reductive sound change but has a “conserving effect” for regularization and analogical change (
Bybee 2010, pp. 24, 75) and, therefore, with lexically particular constructions, conventionalization may go in either direction, of elevated
or depressed pronoun rates.
8. Conclusions
We conclude that lexically particular construction and general class effects are synergistic: highly frequent, particular expressions contribute to shaping general patterns, as the center of classes to which they attract members with shared semantic-morphosyntactic characteristics. These shared characteristics are seen in quantitative variation patterns in discourse, which are constituted by both contextual constraints and contextual distributions.
Lexically particular constructions are pertinent to the linguistic conditioning of variation and thus should be taken into account for interpretation of results (regardless of whether our statistical models include lexical item as a random effect;
Torres Cacoullos and Travis 2019, p. 686). Decades of study of variable Spanish subject pronoun expression have established broad agreement on the conditioning factors. These are replicated here, but when we consider the relationships between predictors, it is clear that cognition verbs are overwhelmingly used in the first person singular, such that the widely reported cognition verb effect is really one of 1sg cognition verbs. While discussions on the priority of frequent verbs as opposed to semantic classes have recognized strikingly different frequencies of lexical types, there are also strikingly different frequencies of particular verb-tense-subject-polarity combinations. The role of such particular expressions is overlooked in analyses of subject expression focusing on either cognition verbs as a class or on specific frequent verb types.
Variation patterns provide a measure of category status. If there is a cognition class, patterns of 1sg subject expression will be shared across cognition verbs, distinguishing them from other verbs, and this will apply to high-frequency lexically particular instances as it will to other members. Here, we have shown that (yo) creo and (yo) no sé have shared patterns with other cognition verbs, including the favoring of subject pronouns and an association with non-coreferential contexts. At the center of the class is (yo) creo: on the strength of high token and relative frequencies in addition to the favoring of subject pronoun expression, it is best considered a chunked unit which, nevertheless, contours the class. Thus, semantic classes of verbs are centered on high-frequency members. For Spanish variable subject expression, cognition verbs form a category anchored in 1sg lexically particular constructions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}