The Sound Pattern of Heritage Spanish: An Exploratory Study on the Effects of a Classroom Experience




Abstract
1. Introduction
2. Background
2.1. Basics of Spanish Sound System
2.2. Key Studies of Segmental Material in Heritage Spanish in the US
2.3. Discourse Measures
3. Materials and Methods
3.1. Informants
3.2. Data Elicitation Procedure
3.3. Acoustic Analysis
4. Results
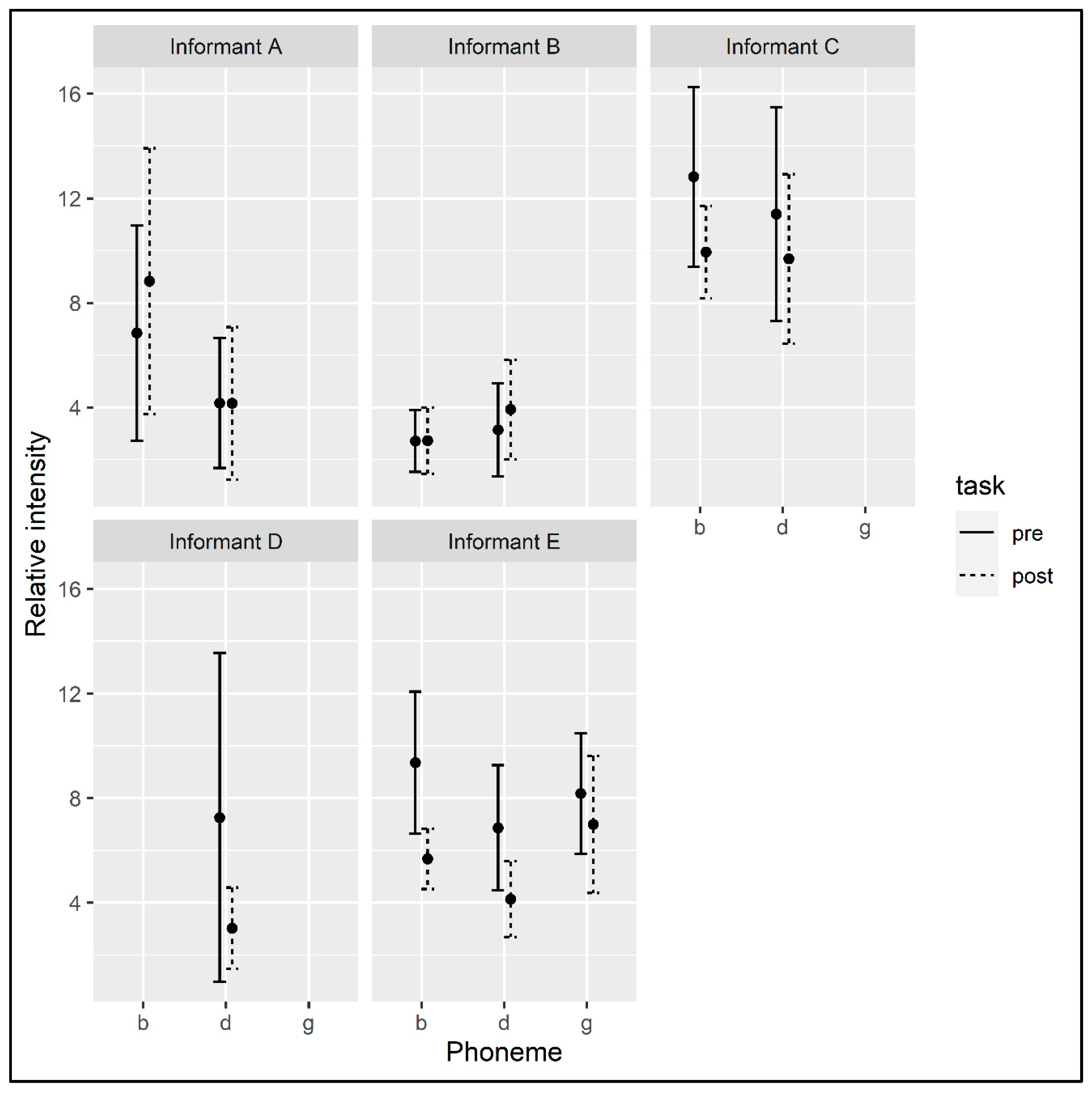
4.1. Consonants
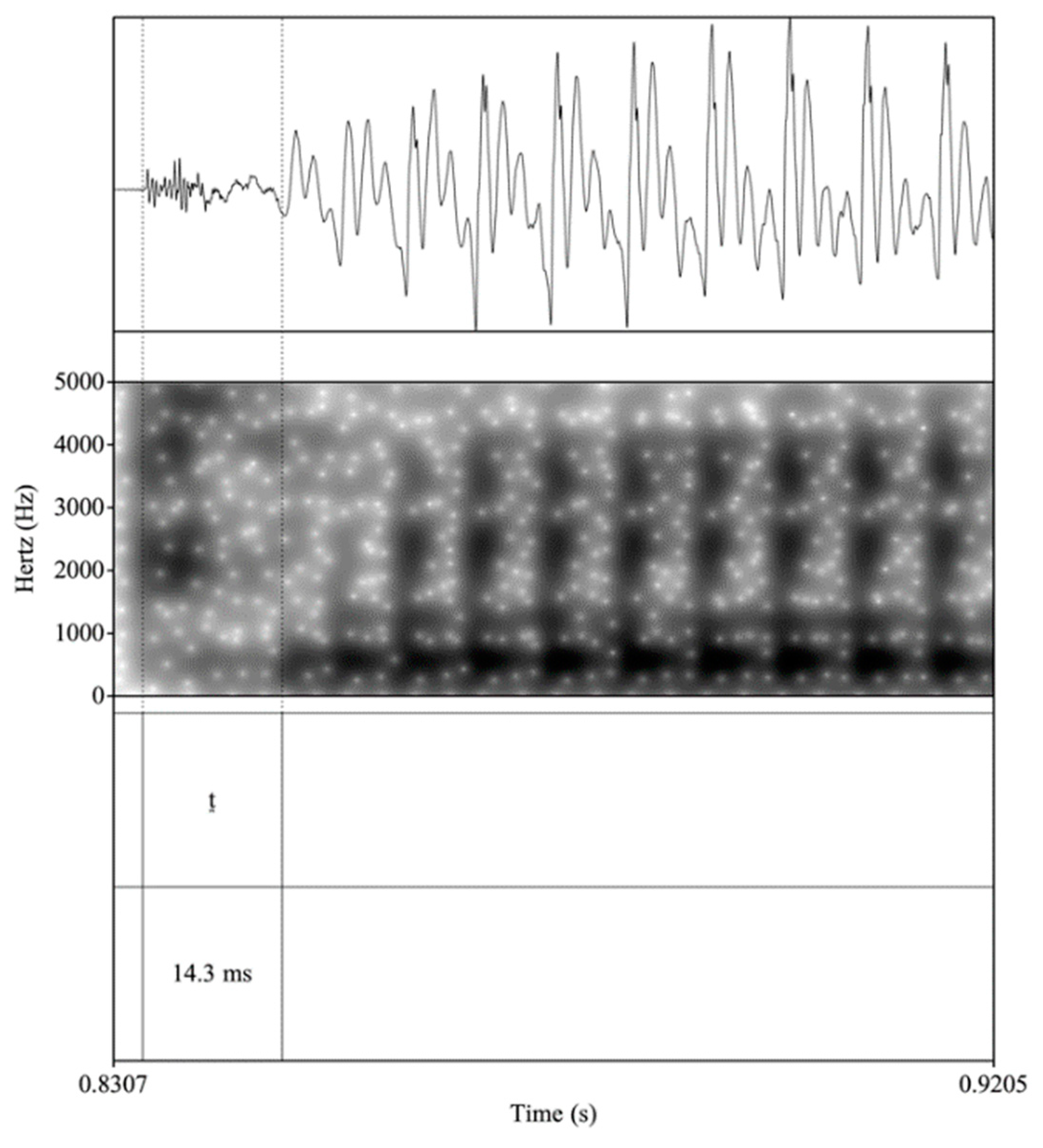
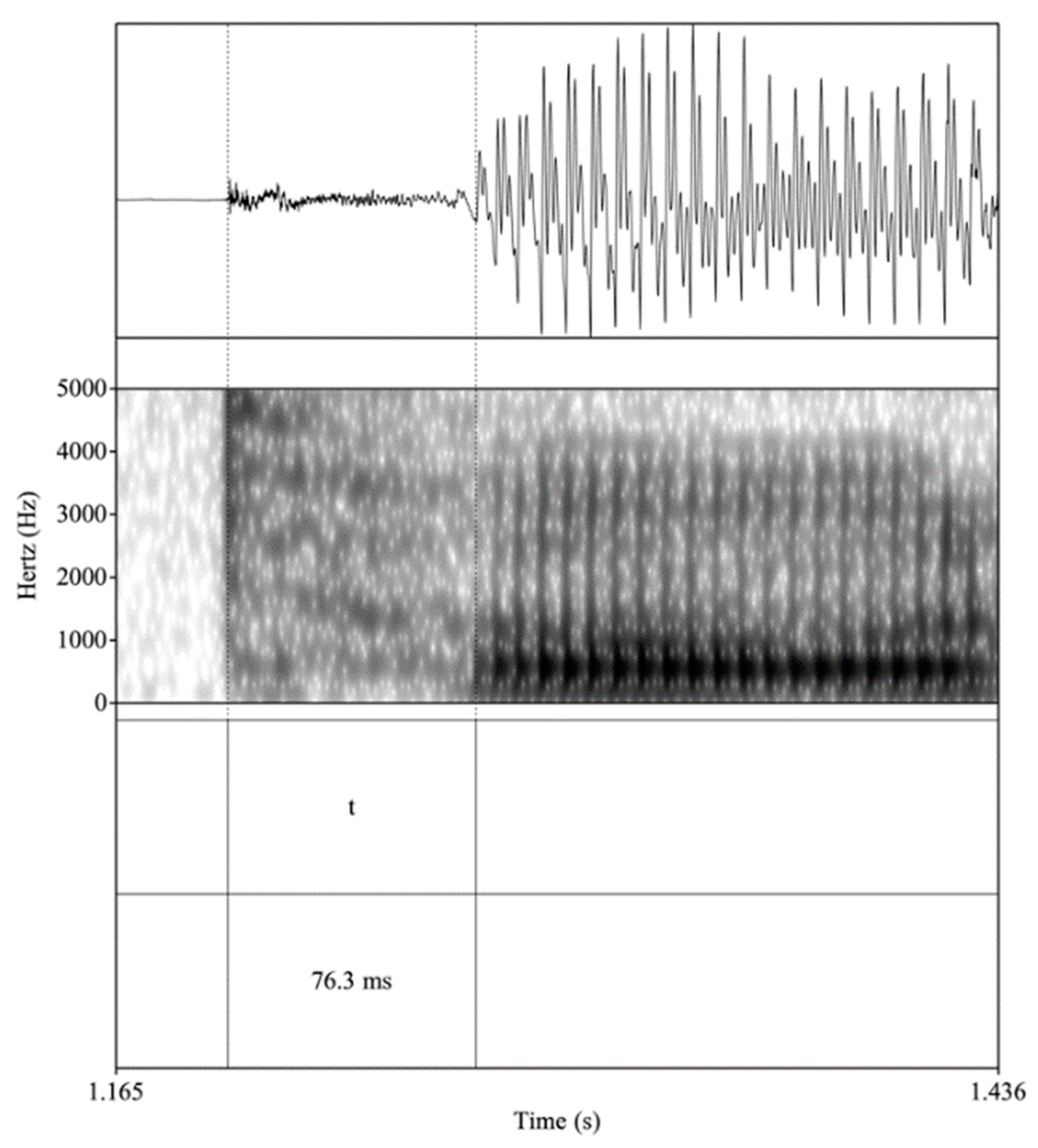
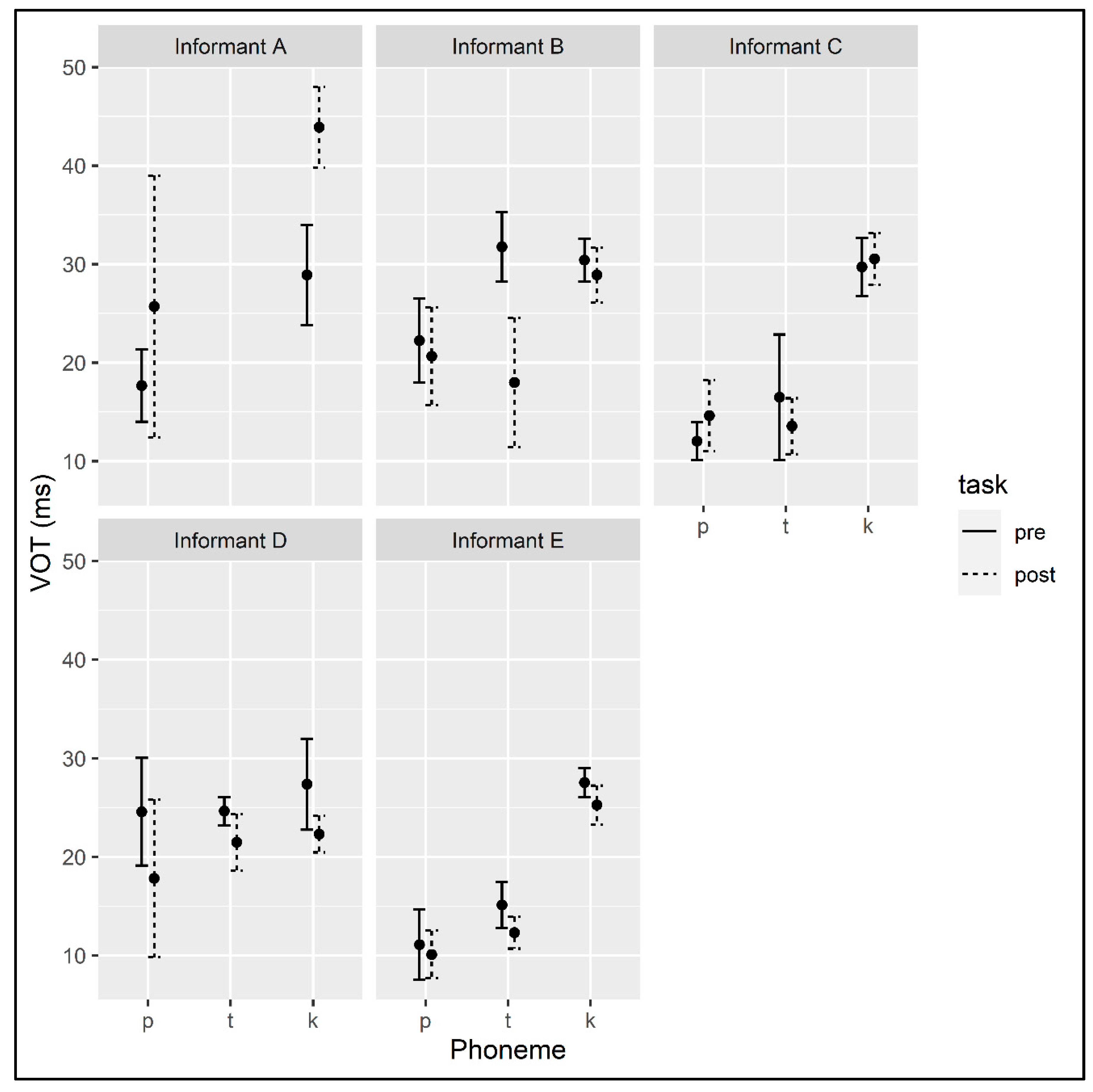
4.1.1. Voiceless Consonants
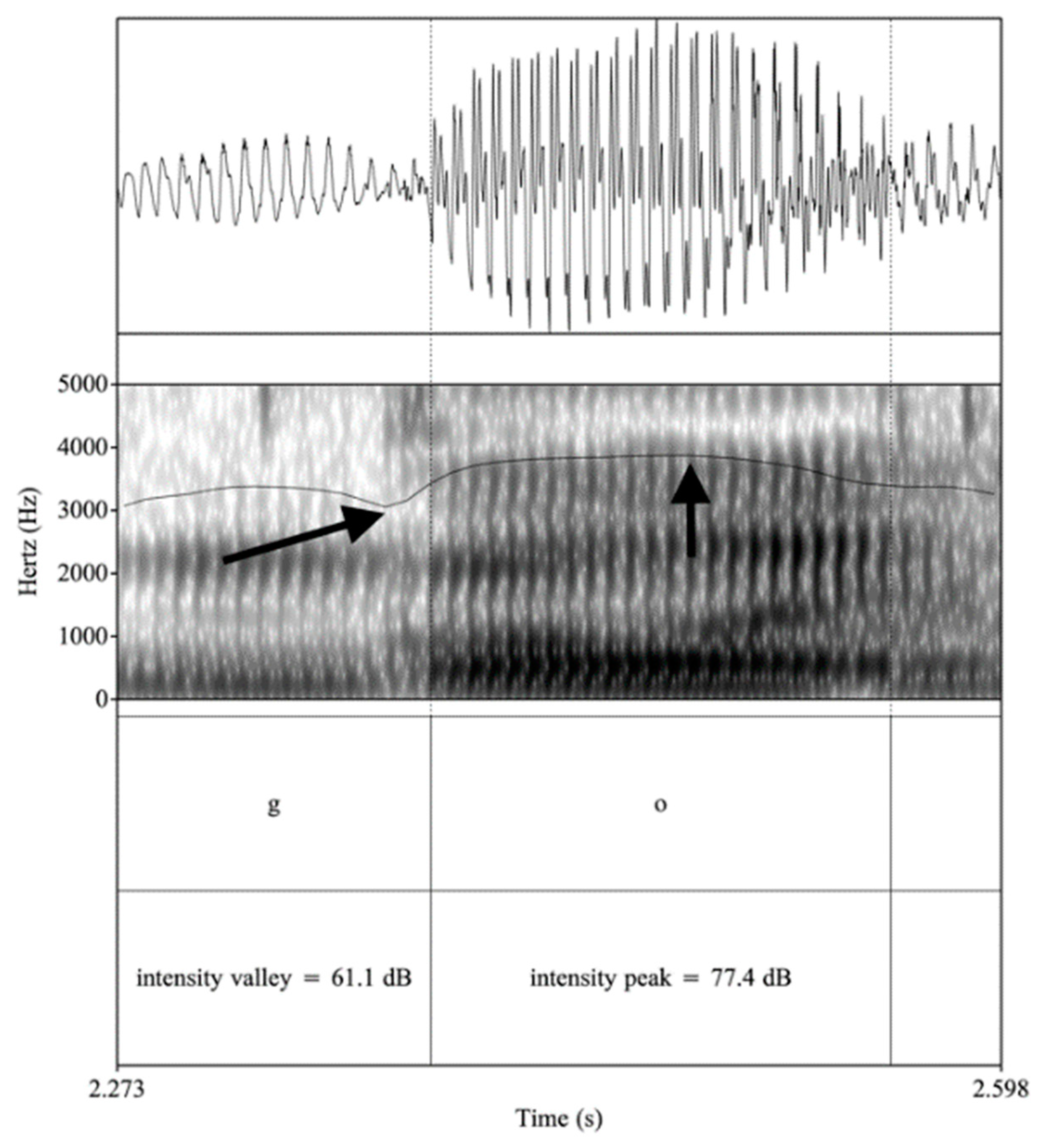
4.1.2. Voiced Consonants
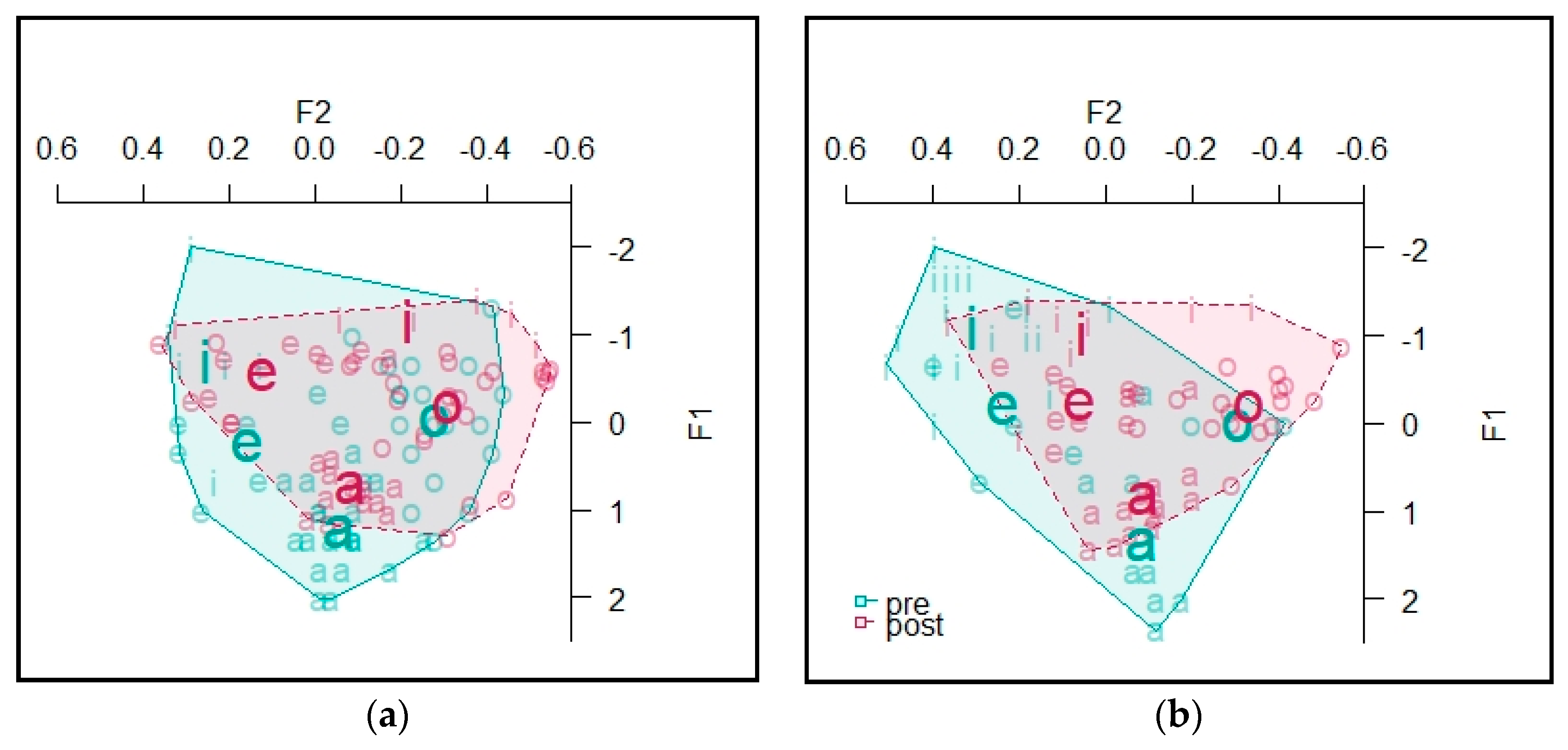
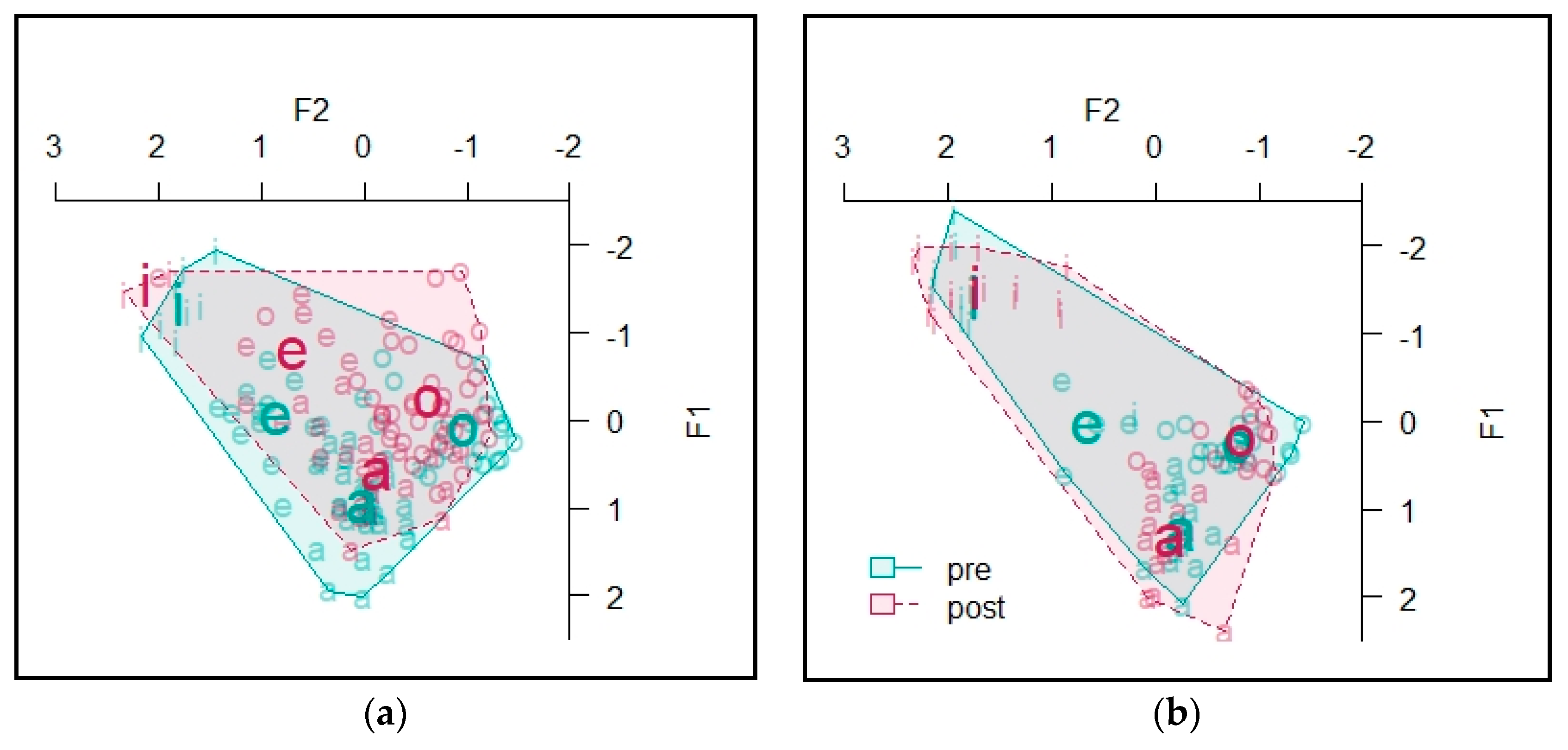
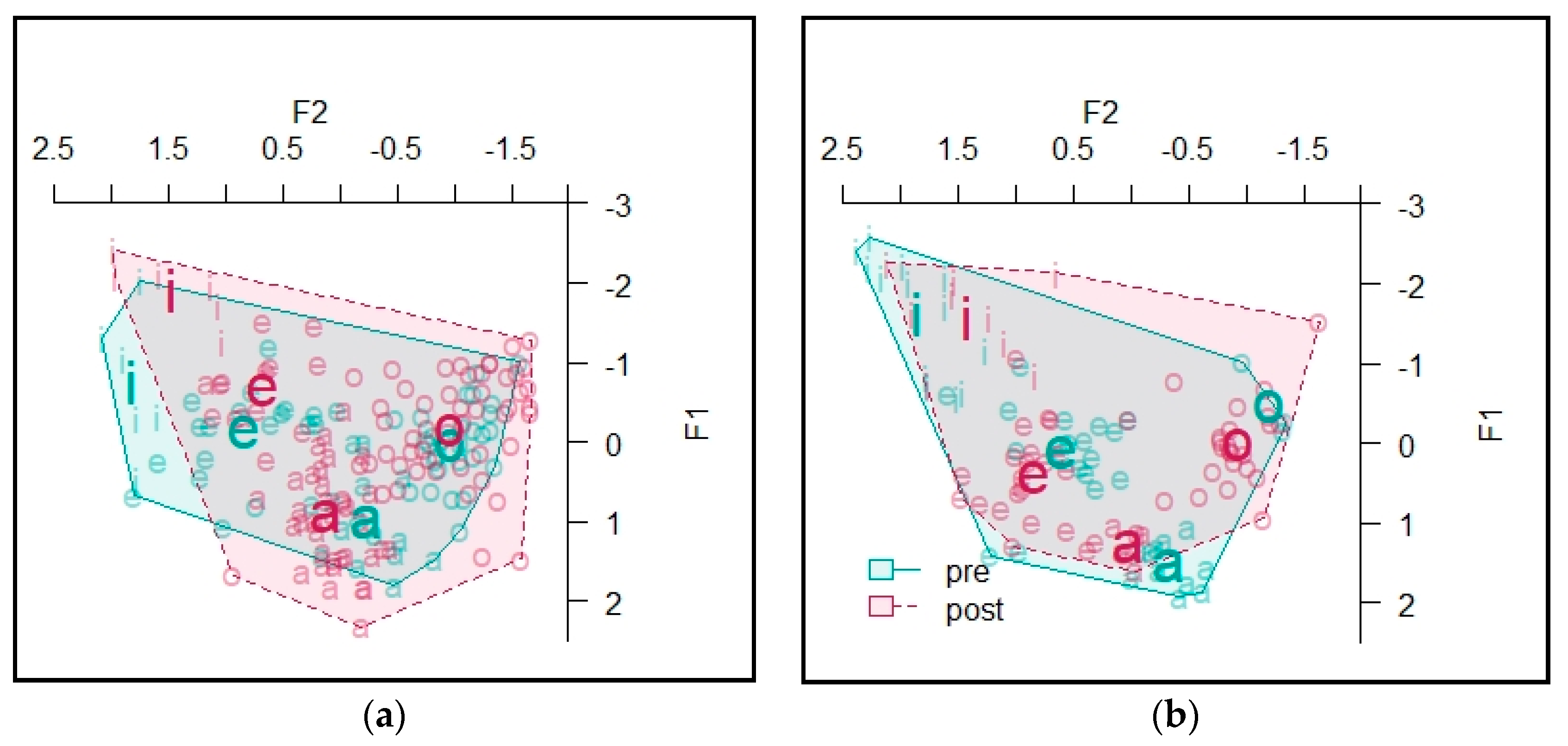
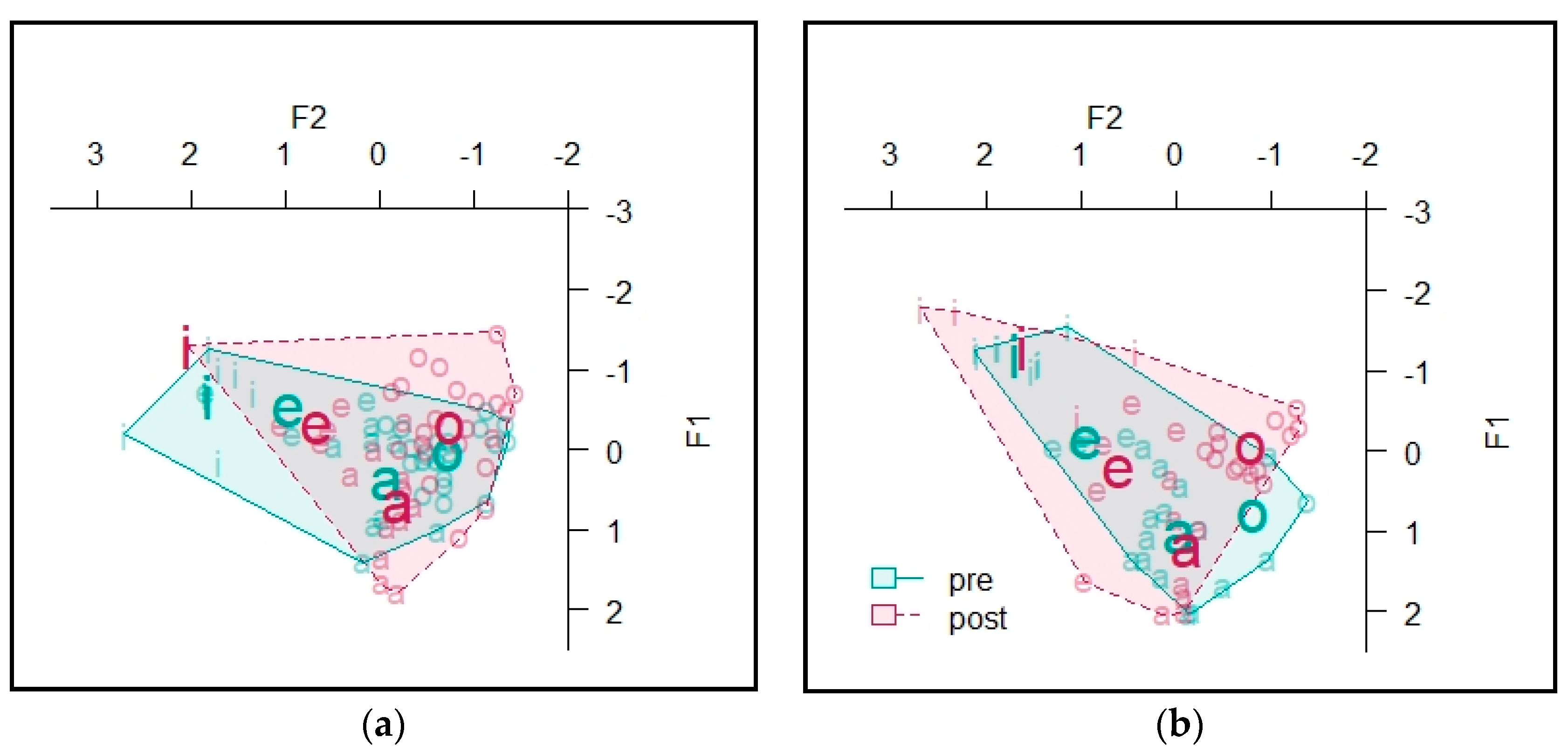
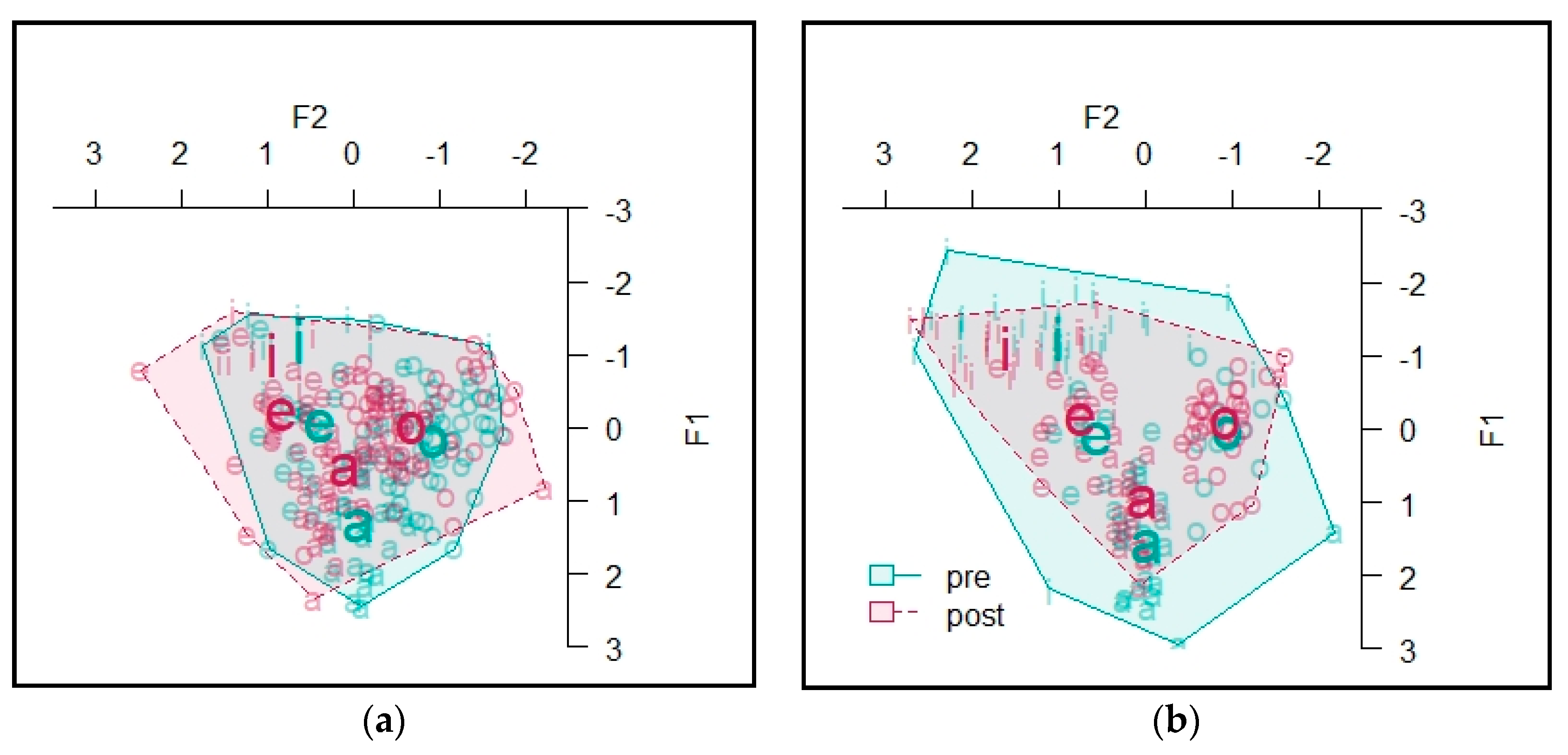
4.2. Vowels
4.2.1. Informant A
4.2.2. Informant B
4.2.3. Informant C
4.2.4. Informant D
4.2.5. Informant E
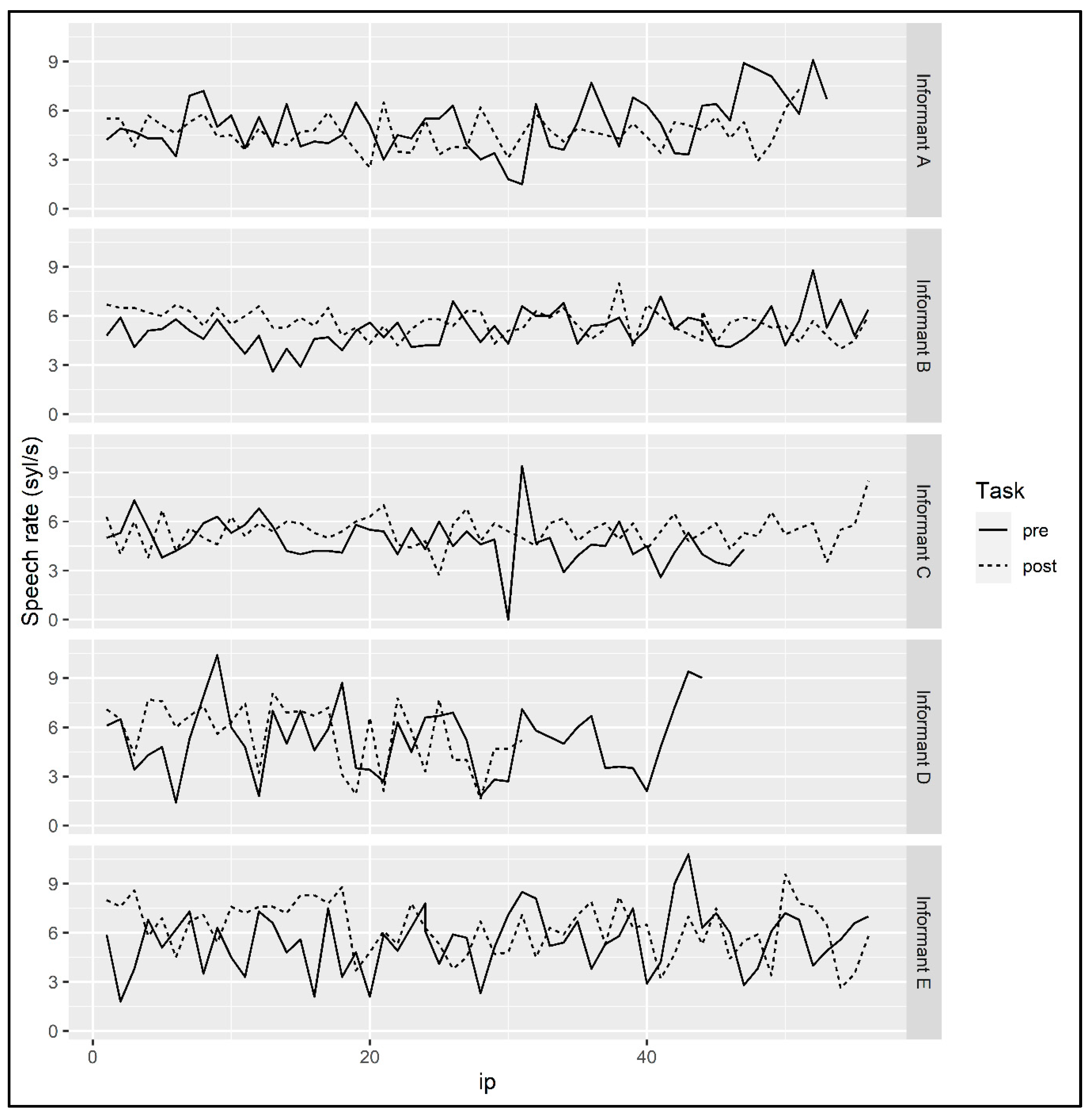
4.3. Speech Rate
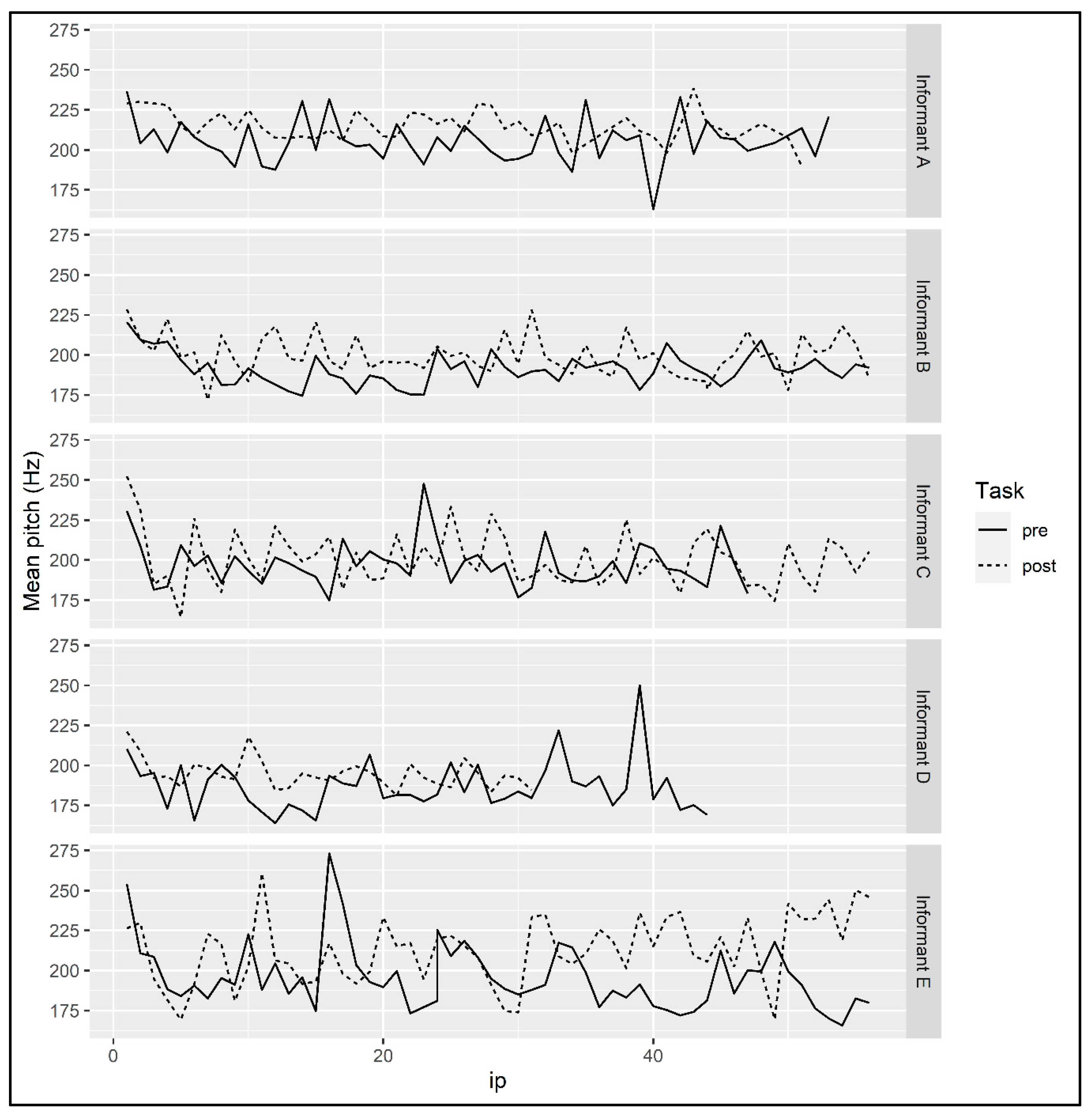
4.4. Mean Pitch
4.5. Pitch range
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| /p/ | /k/ | /b/ | /d/ | |
|---|---|---|---|---|
| Beginning | 12 | 21 | 6 | 17 |
| End | 7 | 28 | 8 | 18 |
| Unstressed | Stressed | |
|---|---|---|
| Beginning | 51 | 32 |
| End | 57 | 47 |
| [a] | [e] | [i] | [o] | |
|---|---|---|---|---|
| Beginning | 27 | 12 | 23 | 21 |
| End | 28 | 21 | 14 | 41 |
Appendix B
| /p/ | /k/ | /b/ | /d/ | |
|---|---|---|---|---|
| Beginning | 17 | 22 | 22 | 17 |
| End | 15 | 31 | 15 | 27 |
| Unstressed | Stressed | |
|---|---|---|
| Beginning | 72 | 45 |
| End | 74 | 46 |
| [a] | [e] | [i] | [o] | |
|---|---|---|---|---|
| Beginning | 44 | 18 | 16 | 39 |
| End | 36 | 10 | 19 | 55 |
Appendix C
| /p/ | /t/ | /k/ | /b/ | /d/ | |
| Beginning | 20 | 2 | 34 | 3 | 9 |
| End | 11 | 9 | 51 | 15 | 20 |
| Unstressed | Stressed | |
| Beginning | 69 | 45 |
| End | 108 | 61 |
| [a] | [e] | [i] | [o] | |
| Beginning | 26 | 36 | 19 | 33 |
| End | 43 | 35 | 16 | 75 |
Appendix D
| /p/ | /t/ | /k/ | /d/ | |
|---|---|---|---|---|
| Beginning | 10 | 3 | 18 | 8 |
| End | 6 | 6 | 18 | 13 |
| Unstressed | Stressed | |
|---|---|---|
| Beginning | 39 | 28 |
| End | 38 | 30 |
| [a] | [e] | [i] | [o] | |
|---|---|---|---|---|
| Beginning | 23 | 7 | 16 | 21 |
| End | 20 | 9 | 5 | 34 |
Appendix E
| /p/ | /t/ | /k/ | /b/ | /d/ | /g/ | |
|---|---|---|---|---|---|---|
| Beginning | 18 | 14 | 54 | 20 | 23 | 23 |
| End | 28 | 18 | 69 | 18 | 37 | 19 |
| Unstressed | Stressed | |
|---|---|---|
| Beginning | 109 | 78 |
| End | 120 | 94 |
| [a] | [e] | [i] | [o] | |
|---|---|---|---|---|
| Beginning | 48 | 31 | 45 | 63 |
| End | 59 | 37 | 34 | 84 |
References
- Abercrombie, David. 1967. Elements of General Phonetics. Edinburgh: Edinburgh University Press. [Google Scholar]
- Adank, Patti, Roel Smits, and Roeland van Hout. 2004. A comparison of vowel normalization procedures for language variation research. The Journal of the Acoustical Society of America 116: 3099–107. [Google Scholar] [CrossRef]
- Alvord, Scott. 2009. Disambiguating declarative and interrogative meaning with intonation in Miami Cuban Spanish. Southwest Journal of Linguistics 28: 21–66. [Google Scholar]
- Alvord, Scott. 2010. Variation in Miami Cuban Spanish interrogative intonation. Hispania 93: 235–55. [Google Scholar]
- Alvord, Scott, and Brandon Rogers. 2014. Miami-Cuban Spanish vowels in contact. Sociolinguistic Studies 8: 139–70. [Google Scholar] [CrossRef]
- Amengual, Mark. 2012. Interlingual influence in bilingual speech: Cognate status effect in a continuum of bilingualism. Bilingualism: Language and Cognition 15: 517–30. [Google Scholar] [CrossRef]
- Amengual, Mark. 2019. Type of early bilingualism and its effect on the acoustic realization of allophonic variants: Early sequential and simultaneous bilinguals. International Journal of Bilingualism 23: 954–70. [Google Scholar]
- Au, Terry Kit-Fong, Janet Oh, Leah Knightly, Sun-Ah Jun, and Laura Romo. 2008. Salvaging a childhood language. Journal of Memory and Language 58: 998–1011. [Google Scholar] [CrossRef]
- Avelino, Heriberto. 2018. Mexico City Spanish. Journal of the International Phonetic Association 48: 223–30. [Google Scholar] [CrossRef]
- Benmamoun, Elabbas, Silvina Montrul, and Maria Polinsky. 2013. Heritage languages and their speakers: Opportunities and challenges for linguistics. Theoretical Linguistics 39: 129–81. [Google Scholar] [CrossRef]
- Berman, Ruth. 2004. Between emergence and mastery: The long developmental route of language acquisition. In Language Development across Childhood and Adolescence. Edited by Ruth Berman. Amsterdam: John Benjamins, pp. 9–34. [Google Scholar]
- Boersma, Paul, and David Weenink. 2020. Praat: Doing phonetics by computer. Available online: www.praat.org (accessed on 6 June 2020).
- Boomershine, Amanda. 2013. The perception of English vowels by monolingual, bilingual, and heritage speakers of Spanish and English. In Selected Proceedings of the 15th Hispanic Linguistics Symposium. Edited by Chad Howe, Sarah E. Blackwell and Margaret Lubbers Quesada. Somerville: Cascadilla Proceedings Project, pp. 103–18. [Google Scholar]
- Bosker, Hans, Anne-France Pinget, Hugo Quené, Ted Sanders, and Nivja H. de Jong. 2012. What makes speech sound fluent? The contributions of pauses, speed and repairs. Language Testing 30: 159–75. [Google Scholar] [CrossRef]
- Bowles, Melissa, and Silvina Montrul. 2014. Heritage Spanish speakers in university language courses: A decade of difference. ADFL Bulletin 43: 112–22. [Google Scholar]
- Bradlow, Ann. 1995. A comparative acoustic study of English and Spanish vowels. Journal of the Acoustical Society of America 97: 1916–24. [Google Scholar] [CrossRef] [PubMed]
- Bullock, Barbara. 2009. Prosody in contact in French: A case study from a heritage variety in the USA. International Journal of Bilingualism 13: 165–94. [Google Scholar] [CrossRef]
- Carrasco, Patricio, José Ignacio Hualde, and Miquel Simonet. 2012. Dialect differences in Spanish voiced obstruent allophony: Costa Rican versus Iberian Spanish. Phonetica 69: 149–79. [Google Scholar] [CrossRef] [PubMed]
- Carreira, María, and Olga Kagan. 2018. Heritage language education: A proposal for the next 50 years. Foreign Language Annals 51: 152–68. [Google Scholar] [CrossRef]
- Chang, Charles B. forthcoming. Phonetics and phonology. In The Cambridge Handbook of Heritage Languages and Linguistics. Edited by Silvina Montrul and Maria Polinsky. Cambridge: Cambridge University Press.
- Chládková, Katerina, Paola Escudero, and Paul Boersma. 2011. Context-Specific Acoustic Differences between Peruvian and Iberian Spanish Vowels. Journal of the Acoustical Society of America 130: 416–28. [Google Scholar] [CrossRef]
- Cho, Taehong, and Peter Ladefoged. 1999. Variation and universals in VOT: Evidence from 18 languages. Journal of Phonetics 27: 207–29. [Google Scholar] [CrossRef]
- Colantoni, Laura, and Irina Marinescu. 2010. The scope of stop weakening in Argentine Spanish. In Selected Proceedings of the 4th Conference on Laboratory Approaches to Spanish Phonology. Edited by Marta Ortega-Llebaria. Somerville, MA: Cascadilla Proceedings Project, pp. 100–14. [Google Scholar]
- Colantoni, Laura, Alejandro Cuza, and Natalia Mazzaro. 2016. Task related effects in the prosody of Spanish heritage speakers. In Intonational Grammar in Ibero-Romance: Approaches across Linguistic Subfields. Edited by Meghan Armstrong, Nicholas Henriksen and Maria del Mar Vanrell. Amsterdam: John Benjamin, pp. 3–24. [Google Scholar]
- Cole, Jennifer, José Ignacio Hualde, Caroline L. Smith, Christopher Eager, Timothy Mahrt, and Ricardo Napoleão de Souza. 2019. Sound, structure and meaning: The bases of prominence ratings in English, French and Spanish. Journal of Phonetics 75: 113–47. [Google Scholar] [CrossRef]
- De-la-Mota, Carme, Pedro Martín Butragueño, and Pilar Prieto. 2010. Mexican Spanish intonation. In Transcription of Intonation of the Spanish Language. Edited by Pilar Prieto and Paolo Roseano. Munich: Lincom, pp. 319–50. [Google Scholar]
- Delattre, Pierre. 1969. An acoustic and articulatory study of vowel reduction in four languages. IRAL 7: 294–325. [Google Scholar] [CrossRef]
- Eddington, David. 2011. What are the contextual variations of /b d g/ in colloquial Spanish? Probus 23: 1–19. [Google Scholar] [CrossRef]
- Estebas-Vilaplana, Eva. 2009. Teach Yourself English Pronunciation. A Coruña: Netbiblio. [Google Scholar]
- Estebas-Vilaplana, Eva. 2014. The evaluation of intonation: Pitch range differences in Spanish and English. In Evaluation in Context. Edited by Geoff Thompson and Laura Alba Juez. Amsterdam: John Benjamins, pp. 179–94. [Google Scholar]
- Elias, Vanessa, Sean McKinnon, and Ángel Milla-Muñoz. 2017. The effects of code-switching and lexical stress on vowel quality and duration of heritage speakers of Spanish. Language 4: 29. [Google Scholar]
- Face, Timothy. 2003. Intonation in Spanish declaratives: Differences between lab and spontaneous speech. Catalan Journal of Linguistics 2: 115–31. [Google Scholar] [CrossRef]
- Flege, James Emil. 1992. Speech learning in a second language. In Phonological Development: Models, Research, Implications. Edited by Charles A. Ferguson, Lise Menn and Carol Stoel-Gammon. Timonium: York Press, pp. 565–604. [Google Scholar]
- Flege, James Emil. 1995. Second-language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by William Strange. Timonium: York Press, pp. 229–73. [Google Scholar]
- George, Angela, and Anne Hoffman-González. 2019. Dialect and identity: US heritage language learners of Spanish abroad. Study Abroad Research in Second Language Acquisition and International Education 4: 252–79. [Google Scholar] [CrossRef]
- Gil Fernández, Juana. 2007. Fonética para Profesores de Español: de la Teoría a la Práctica. Madrid: Arco/Libros. [Google Scholar]
- Gussenhoven, Carlos. 2002. Intonation and interpretation: Phonetics and phonology. In Proceedings of Speech Prosody 2002. Edited by Bernard Bel and Isabelle Marlien. Aix-en-Provence: Aix-en-Provence Laboratoire Parole et Langage, pp. 47–57. [Google Scholar]
- Hermegnies, Bernard, and Dolors Poch-Olivé. 1992. A study of style-induced vowel variability: Laboratory versus spontaneous speech in Spanish. Speech Communication 11: 429–37. [Google Scholar] [CrossRef]
- Hirschberg, Julia, and Barbara Grosz. 1992. Intonational features of local and global discourse structure. In Proceedings of the Workshop on Speech and Natural Language. Edited by the ACM International Conference on Human Language Technology Research. Morristown: Association for Computational Linguistics, pp. 441–46. [Google Scholar]
- Hualde, José Ignacio. 2005. The Sounds of Spanish. Cambridge: Cambridge University Press. [Google Scholar]
- Hualde, José Ignacio, and Pilar Prieto. 2015. Intonational variation in Spanish: European and American varieties. In Intonation in Romance. Edited by Sónia Frota and Pilar Prieto. Oxford: Oxford University Press, pp. 350–91. [Google Scholar]
- Kehoe, Margaret, and Conxita Lleó. 2017. Vowel reduction in German-Spanish bilinguals. In Romance-Germanic Bilingual Phonology. Edited by Mehmet Yavas, Margaret Kehoe and Walcir Cardoso. Sheffield: Equinox, pp. 14–37. [Google Scholar]
- Kim, Ji-Young. 2011. L1-L2 phonetic interference in the production of Spanish heritage speakers in the US. The Korean Journal of Hispanic Studies 4: 1–28. [Google Scholar]
- Kim, Ji-Young. 2019. Heritage speakers’ use of prosodic strategies in focus marking in Spanish. International Journal of Bilingualism 23: 986–1004. [Google Scholar] [CrossRef]
- Knightly, Leah, Sun-Ah Jun, Janet Oh, and Terry Kit-fong Au. 2003. Production benefits of childhood overhearing. Journal of the Acoustical Society of America 114: 465–74. [Google Scholar] [CrossRef] [PubMed]
- Kupisch, Tanja, and Jason Rothman. 2018. Terminology matters! Why difference is not incompleteness and how early child bilinguals are heritage speakers. International Journal of Bilingualism 22: 564–82. [Google Scholar] [CrossRef]
- Labov, William. 1972. Language in the Inner City: Studies in the Black English Vernacular. Philadelphia: University of Pennsylvania Press. [Google Scholar]
- Ladd, D. Robert. 2008. Intonational Phonology, 2nd ed. Cambridge: Cambridge University Press. [Google Scholar]
- Lehiste, Ilse. 1982. Some phonetic characteristics of discourse. Studia Linguistica 36: 117–30. [Google Scholar] [CrossRef]
- Lipski, John. 1994. Latin American Spanish. London: Longman. [Google Scholar]
- Lisker, Leigh, and Arthur Abramson. 1964. A Cross-language study of voicing in initial stops: Acoustical measurements. Word 20: 384–422. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur Abramson. 1967. Some effects of context on voice onset time in English stops. Language and Speech 10: 1–28. [Google Scholar] [CrossRef]
- Lleó, Conxita. 2018. Bilingual children’s prosodic development. The Development of Prosody in First Language Acquisition 23: 317. [Google Scholar]
- Lleó, Conxita, and Martin Rakow. 2005. Markedness effects in the acquisition of voiced stop spirantization by Spanish-German bilinguals. In Proceedings of the 4th International Symposium on Bilingualism. Edited by James Cohen, Kara T. McAlister, Kellie Rolstad and Jeff MacSwan. Cascadilla: Cascadilla Press, pp. 1353–71. [Google Scholar]
- Lobanov, Boris. 1971. Classification of Russian vowels spoken by different speakers. Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Lowry, Orla. 2002. The stylistic variation of nuclear patterns in Belfast English. Journal of the International Phonetic Association 32: 33–42. [Google Scholar] [CrossRef]
- Marín Gálvez, Rafael. 1994–95. La duración vocálica en español. ELUA Estudios de Lingüística 10: 213–26. [Google Scholar]
- Martínez Celdrán, Eugenio. 1984. Fonética: con Especial Referencia a la Lengua Castellana. Barcelona: Teide. [Google Scholar]
- Martínez Celdrán, Eugenio. 1995. En torno a las vocales del español: análisis y reconocimiento. Estudios de Fonética Experimental 7: 195–218. [Google Scholar]
- Mascaró, Joan. 1984. Continuant spreading in Basque, Catalan, and Spanish. In Language Sound Structure. Edited by Mark Aronoff and Richard T. Oehrle. Cambridge: MIT Press, pp. 287–98. [Google Scholar]
- Montrul, Silvina. 2016. The Acquisition of Heritage Languages. Cambridge: Cambridge University Press. [Google Scholar]
- Navarro, Tomás. 1918. Manual de Pronunciación Española. Madrid: CSIC. [Google Scholar]
- Oh, Janet, and Terry Kit-fong Au. 2005. Learning Spanish as a heritage language: The role of sociocultural background variables. Language, Culture and Curriculum 18: 229–41. [Google Scholar] [CrossRef]
- Oliveira, Miguel. 2000. Prosodic Features in Spontaneous Narratives. Ph.D. dissertation, Simon Fraser University, Vancouver, BC, Canada. [Google Scholar]
- Parra, Maria-Luisa, Marta Llorente Bravo, and Maria Polinsky. 2018. De bueno a muy bueno: How Pedagogical Intervention Boosts Language Proficiency in Advanced Heritage Learners. Heritage Language Journal 15: 203–241. [Google Scholar] [CrossRef]
- Pascual y Cabo, Diego, and Jason Rothman. 2012. The (il)logical problem of heritage speaker bilingualism and incomplete acquisition. Applied Linguistics 33: 1–7. [Google Scholar]
- Pavlenko, Aneta. 2006. Narrative competence in a second language. In Educating for Advanced Foreign Language Capacities. Edited by Heidi Byrnes, Heather Weger and Katherine Sprang. Washington: Georgetown University Press, pp. 105–17. [Google Scholar]
- Pierrehumbert, Janet, and Julia Hirschberg. 1990. The meaning of intonational contours in the interpretation of discourse. In Intentions in Communication. Edited by Philip R. Cohen, Jerry Morgan and Martha E. Pollack. Cambridge, MA: MIT Press, pp. 271–311. [Google Scholar]
- Pike, Kenneth. 1945. The Intonation of American English. Ann Arbor: University of Michigan Press. [Google Scholar]
- Polinsky, Maria. 2008. Heritage language narratives. In Heritage Language Education: A New Field Emerging. Edited by Donna Brinton, Olga Kagan and Susan Bauckus. New York: Routledge, pp. 149–64. [Google Scholar]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press. [Google Scholar]
- Polinsky, Maria, and Olga Kagan. 2007. Heritage languages: In the ‘wild’ and in the classroom. Linguistics and Language Compass 1: 368–95. [Google Scholar] [CrossRef]
- Potowski, Kim, Jill Jegerski, and Kara Morgan-Short. 2009. The effects of instruction on linguistic development in Spanish heritage language speakers. Language Learning 59: 537–79. [Google Scholar] [CrossRef]
- Queen, Robin. 2006. Phrase-final intonation in narratives told by Turkish-German bilinguals. International Journal of Bilingualism 10: 153–78. [Google Scholar] [CrossRef]
- Rao, Rajiv. 2010. Final lengthening and pause duration in three dialects of Spanish. In Selected Proceedings of the 4th Conference on Laboratory Approaches to Spanish Phonology. Edited by Marta Ortega-Llebaria. Somerville, MA: Cascadilla Proceedings Project, pp. 69–82. [Google Scholar]
- Rao, Rajiv. 2014. On the status of the phoneme /b/ in heritage speakers of Spanish. Sintagma 26: 37–54. [Google Scholar]
- Rao, Rajiv. 2015. Manifestations of /bdg/ in heritage speakers of Spanish. Heritage Language Journal 12: 48–74. [Google Scholar]
- Rao, Rajiv. 2016. On the nuclear intonational phonology of heritage speakers of Spanish. In Advances in Spanish as a Heritage Language. Edited by Diego Pascual y Cabo. Amsterdam: John Benjamins, pp. 51–80. [Google Scholar]
- Rao, Rajiv. 2019. The phonological system of adult heritage speakers of Spanish in the United States. In The Routledge Handbook of Spanish Phonology. Edited by Sonia Colina and Fernando Martínez-Gil. New York/London: Routledge, pp. 439–52. [Google Scholar]
- Rao, Rajiv, ed. 2020. Spanish Phonetics and Phonology in Contact: Studies from Africa, the Americas, and Spain. Amsterdam: John Benjamins. [Google Scholar]
- Rao, Rajiv, and Mark Amengual. In press. La fonética y fonología del español como lengua de herencia. In Aproximaciones al Español como Lengua de Herencia. Edited by Diego Pascual y Cabo and Julio Torres. New York and London: Routledge.
- Rao, Rajiv, and Emily Kuder. 2016. Research on heritage Spanish phonetics and phonology: Pedagogical and curricular implications. Journal of New Approaches in Educational Research 5: 99–106. [Google Scholar] [CrossRef]
- Rao, Rajiv, and Rebecca Ronquest. 2015. The heritage Spanish phonetic/phonological system: Looking back and moving forward. Studies in Hispanic and Lusophone Linguistics 8: 403–14. [Google Scholar] [CrossRef]
- Ready, Carol. 2020. Mexican heritage Spanish speakers’ vowel production in cognate and non-cognate words. Hispanic Studies Review 4: 155–85. [Google Scholar]
- Robles-Puente, Sergio. 2014. Prosody in Contact: Spanish in Los Angeles. Ph.D. dissertation, University of Southern California, Los Angeles, CA, USA. [Google Scholar]
- Ronquest, Rebecca. 2012. An Acoustic Analysis of Heritage Spanish Vowels. Ph.D. dissertation, Indiana University, Bloomington, IN, USA. [Google Scholar]
- Ronquest, Rebecca. 2013. A acoustic examination of unstressed vowel reduction in heritage Spanish. In Selected Proceedings of the 15th Hispanic Linguistics Symposium. Edited by Chad Howe, Sarah Blackwell and Margaret Lubbers Quesada. Somerville: Cascadilla Proceedings Project, pp. 151–71. [Google Scholar]
- Ronquest, Rebecca. 2016. Stylistic variation in heritage Spanish vowel production. Heritage Language Journal 13: 275–97. [Google Scholar] [CrossRef]
- Ronquest, Rebecca. 2018. Vowels. In The Cambridge Handbook of Spanish Linguistics. Edited by Kimberly L. Geeslin. Cambridge: Cambridge University Press, pp. 145–64. [Google Scholar]
- Ronquest, Rebecca, and Rajiv Rao. 2018. Heritage Spanish phonetics and phonology. In The Routledge Handbook on Spanish as a Heritage Language. Edited by Kim Potowski. New York and London: Routledge, pp. 164–77. [Google Scholar]
- Rosner, Burton, Luis E. López-Bascuas, José E. García-Albea, and Richard P. Fahey. 2000. Voice-onset Times for Castilian Spanish initial stops. Journal of Phonetics 28: 217–224. [Google Scholar] [CrossRef]
- Ruiz Moreno, Mario. 2020. Phonetic Production in Early and Late German-Spanish Bilinguals. Ph.D. dissertation, University of Hamburg, Hamburg, Germany. [Google Scholar]
- Selting, Margret. 1994. Emphatic speech style- with special focus on the prosodic signalling of heightened emotive involvement in conversation. Journal of Pragmatics 22: 375–408. [Google Scholar] [CrossRef]
- Shea, Christine. 2019. Dominance, proficiency, and Spanish heritage speakers’ production of English and Spanish vowels. Studies in Second Language Acquisition 41: 123–49. [Google Scholar] [CrossRef]
- Silva-Corvalán, Carmen. 1994. Language Contact and Change: Spanish in Los Angeles. Oxford: Oxford University Press. [Google Scholar]
- Solon, Megan, Nyssa Knarvik, and Josh DeClerck. 2019. On comparison groups in heritage phonetics/phonology research: The case of bilingual Spanish vowels. Hispanic Studies Review 4: 165–92. [Google Scholar]
- Stangen, Ilse, Tanja Kupisch, Anna Lia Proietti Ergün, and Marina Zielke. 2015. Foreign accent in heritage speakers of Turkish in Germany. In Transfer Effects in Multilingual Language Development. Edited by Hagen Peukert. Amsterdam: John Benjamins, pp. 87–108. [Google Scholar]
- Swerts, Marc. 1997. Prosodic features at discourse boundaries of different strength. Journal of the Acoustical Society of America 101: 514–21. [Google Scholar] [CrossRef] [PubMed]
- Theodore, Rachel, Joanne Miller, and David DeSteno. 2009. Individual talker differences in voice-onset-time: Contextual influences. Journal of the Acoustical Society of America 125: 3974–82. [Google Scholar] [CrossRef]
- Torres, Julio, Diego Pascual y Cabo, and Michael Beusterein. 2018. What’s next? Heritage language learners shape new paths in Spanish teaching. Hispania 100: 271–76. [Google Scholar] [CrossRef]
- Wennerstrom, Ann. 2001. Intonation and evaluation in oral narratives. Journal of Pragmatics 33: 1183–1206. [Google Scholar] [CrossRef]
- Willis, Erik. 2005. An initial examination of Southwest Spanish vowels. Southwest Journal of Linguistics 24: 185–99. [Google Scholar]
- Yao, Yao. 2009. Understanding VOT Variation in Spontaneous Speech. UC Berkeley Phonology Lab Annual Report. Available online: http://linguistics.berkeley.edu/phonlab/documents/2009/Yao_VOT_variation.pdf (accessed on 12 October 2018).
- Yu, Vickie Y., Luc F. De Nil, and Elizabeth W. Pang. 2015. Effects of age, sex and syllable number on voice onset time: Evidence from children’s voiceless aspirated stops. Language and Speech 58: 152–67. [Google Scholar] [CrossRef]
- Zárate-Sández. 2015. Perception and Production of Intonation among English-Spanish Bilingual Speakers at Different Proficiency Levels. Ph.D. dissertation, Georgetown University, Washington DC, USA. [Google Scholar]
| 1 | |
| 2 | Since the current study deals with the geographic and social context of the US, we focus on studies carried out in the US in this section. Examples of studies on the segmental phonology of HSs of Spanish coming from Europe include Kehoe and Lleó (2017), Lleó (2018) and Lleó and Rakow (2005). |
| 3 | All informants other than informant D were born, raised, and went to school in the location indicated in this column. In the case of informant D, she lived in Chile until age 6, when she moved to Massachusetts, where she subsequently did all of her schooling. |
| 4 | This informant acquired Portuguese and Spanish at home before beginning school, where she began learning English. As an adult, she is trilingual, but prefers English and Spanish over Portuguese. |
| 5 | An author of this paper and two individuals trained by this author jointly conducted the acoustic analysis. The author supervised the entire process to ensure accuracy and reliability. |
| 6 | While some highly controlled studies have focused on potential effects of adjacent consonants on the acoustic measures of vowels (e.g., Chládková et al. 2011), we attempted to but ultimately decided against coding for this variable due to the more unscripted, uncontrollable nature of our data; that is, token imbalances would not have allowed for reliable statistical measures. |
| 7 |














| Sound Class | Main Findings/Effects | Key References |
|---|---|---|
| Vowels | Vowel reduction in both HS and late immigrant bilinguals, asymmetrical vowel space; speech style, dominance, proficiency, code-switching, cognates | Alvord and Rogers (2014); Elias et al. (2017); Ready (2020); Ronquest (2012, 2013, 2016); Shea (2019); Solon et al. (2019); Willis (2005) |
| VOT in voiceless stops | HSs < L2 learners; type of childhood experience, cognates | (Amengual (2012); Au et al. (2008); Kim (2011; VOT in voiced stops as well); Knightly et al. (2003) |
| Lenition in voiced stops | Acoustic evidence of weakening away from stop realization > L2 learners; use and exposure as children/adults, type of bilingual, word position, syllable stress, task type | Amengual (2019); Au et al. (2008); Knightly et al. (2003); Rao (2014, 2015) |
| Informant | Year at University | Birth Place[3] | Parents’ Origin | Acquisition of Spanish | Acquisition of English | Home Language (Childhood and Current) | Schooling in Spanish |
|---|---|---|---|---|---|---|---|
| A | 2nd | Los Angeles | Mexico | Birth | Age 5 | Spanish/ English | Bilingual Kinder-2nd grade |
| B | 1st | Los Angeles | Argentina (father)/ Brazil (mother)[4] | Birth | Age 5 | Spanish with father | None |
| C | 1st | Los Angeles | El Salvador | Birth | Birth (older siblings) | Spanish/ English | None |
| D | 3rd | Santiago, Chile | Chile | Birth | Age 6 (when moved to US) | Spanish | None |
| E | 3rd | Cathedral City, CA | Mexico | Birth | Age 5 | Spanish | None |
| [a] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning
of course | Mean | 1.23 | −0.06 | 1.35 | −0.09 | |
| SD | 0.48 | 0.08 | 0.91 | 0.06 | ||
| End of course | Mean | 0.72 | −0.09 | 0.83 | −0.10 | |
| SD | 0.4 | 0.07 | 0.56 | 0.08 | ||
| [e] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.25 | 0.16 | −0.19 | 0.233 | |
| SD | 0.46 | 0.15 | 0.81 | 0.12 | ||
| End of course | Mean | −0.56 | 0.12 | −0.25 | 0.06 | |
| SD | 0.33 | 0.16 | 0.32 | 0.10 | ||
| [i] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.72 | 0.25 | −1.11 | 0.31 | |
| SD | 0.86 | 0.08 | 0.54 | 0.14 | ||
| End of course | Mean | −1.18 | −0.22 | −0.44 | 0.08 | |
| SD | 0.17 | 0.31 | 1.84 | 0.22 | ||
| [o] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.04 | −0.282 | 0.01 | −0.31 | |
| SD | 0.71 | 0.10 | - | 0.15 | ||
| End of course | Mean | −0.19 | 0.31 | −0.21 | −0.34 | |
| SD | 0.61 | 0.18 | 0.37 | 0.12 | ||
| [a] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.97 | 0.00 | 1.27 | −0.24 | |
| SD | 0.46 | 0.27 | 0.44 | 0.15 | ||
| End of course | Mean | 0.58 | −0.13 | 1.33 | −0.16 | |
| SD | 0.46 | 0.40 | 0.52 | 0.27 | ||
| [e] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.05 | 0.85 | 0.04 | 0.63 | |
| SD | 0.41 | 0.38 | 0.44 | 0.30 | ||
| End of course | Mean | −0.78 | 0.68 | n/a | n/a | |
| SD | 0.67 | 0.62 | n/a | n/a | ||
| [i] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −1.35 | 1.78 | −1.44 | 1.73 | |
| SD | 0.37 | 0.22 | 0.68 | 0.64 | ||
| End of course | Mean | −2.15 | 2.37 | −1.54 | 1.71 | |
| SD | 1.15 | 0.848 | 028 | 0.49 | ||
| [o] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.09 | −0.97 | 0.27 | −0.80 | |
| SD | 0.39 | 0.42 | 0.18 | 0.34 | ||
| End of course | Mean | −0.22 | −0.56 | 0.19 | −0.85 | |
| SD | 0.56 | 0.65 | 0.32 | 0.35 | ||
| [a] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.97 | −0.24 | 1.52 | −0.33 | |
| SD | 0.55 | 0.29 | 0.28 | 0.22 | ||
| End of course | Mean | 0.90 | 0.10 | 1.27 | 0.01 | |
| SD | 0.70 | 0.33 | 0.22 | 0.09 | ||
| [e] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.16 | 0.82 | 0.09 | 0.59 | |
| SD | 0.52 | 0.50 | 0.60 | 0.43 | ||
| End of course | Mean | −0.69 | 0.66 | 0.39 | 0.83 | |
| SD | 0.52 | 0.31 | 0.60 | 0.34 | ||
| [i] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.77 | 1.81 | −1.64 | 1.85 | |
| SD | 0.88 | 0.16 | 0.74 | 0.36 | ||
| End of course | Mean | −1.92 | 1.46 | −1.60 | 1.41 | |
| SD | 0.36 | 0.41 | 0.55 | 0.50 | ||
| [o] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.02 | −0.97 | −0.49 | −1.21 | |
| SD | 0.50 | 0.40 | 0.47 | 0.21 | ||
| End of course | Mean | −0.19 | −0.98 | −0.01 | −0.93 | |
| SD | 0.69 | 0.54 | 0.54 | 0.29 | ||
| [a] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.41 | −0.07 | 1.05 | −0.03 | |
| SD | 0.64 | 0.39 | 0.69 | 0.47 | ||
| End of course | Mean | 0.47 | −0.16 | 1.58 | −0.15 | |
| SD | 1.01 | 0.38 | 1.00 | 0.53 | ||
| [e] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.65 | 1.30 | −0.13 | 0.95 | |
| SD | 0.36 | 0.96 | 0.07 | 0.33 | ||
| End of course | Mean | −0.30 | 0.65 | −0.12 | 0.65 | |
| SD | 0.19 | 0.28 | 1.17 | 0.37 | ||
| [i] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.69 | 1.83 | −1.22 | 1.71 | |
| SD | 0.46 | 0.41 | 0.17 | 0.35 | ||
| End of course | Mean | −1.30 | 2.05 | −1.30 | 1.62 | |
| SD | - | - | 0.63 | 1.07 | ||
| [o] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.05 | −0.72 | 0.79 | −0.81 | |
| SD | 0.35 | 0.39 | 0.25 | 0.81 | ||
| End of course | Mean | −0.30 | −0.75 | −0.07 | −0.80 | |
| SD | 0.63 | 0.40 | 0.29 | 0.36 | ||
| [a] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 1.32 | −0.07 | 1.58 | −0.03 | |
| SD | 0.63 | 0.30 | 0.65 | 0.52 | ||
| End of course | Mean | 0.55 | 0.08 | 0.96 | 0.02 | |
| SD | 0.77 | 0.52 | 0.72 | 0.43 | ||
| [e] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −0.04 | 0.39 | 0.10 | 0.56 | |
| SD | 0.70 | 0.61 | 0.43 | 0.39 | ||
| End of course | Mean | −0.21 | 0.84 | −0.16 | 0.74 | |
| SD | 0.61 | 0.67 | 0.59 | 0.47 | ||
| [i] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | −1.12 | 0.27 | −1.25 | 1.01 | |
| SD | 0.40 | 1.46 | 0.73 | 0.90 | ||
| End of course | Mean | −1.01 | 0.94 | −1.13 | 1.60 | |
| SD | 0.39 | 0.57 | 0.34 | 0.67 | ||
| [o] | Unstressed | Stressed | ||||
| F1 | F2 | F1 | F2 | |||
| Beginning of course | Mean | 0.16 | −0.94 | −0.03 | −0.80 | |
| SD | 0.64 | 0.42 | 0.67 | 0.67 | ||
| End of course | Mean | −0.06 | −0.59 | −0.10 | −0.84 | |
| SD | 0.64 | 0.79 | 0.53 | 0.62 | ||
| Suprasegmental | Consonants | Vowels | ||||
|---|---|---|---|---|---|---|
| Mean pitch | Pitch Range | Speech Rate | Voiceless | Voiced | ||
| Informant A | ✓ | ✓ | ( ) | ✓ | ✓ | |
| Informant B | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Informant C | ✓ | ✓ | ✓ | |||
| Informant D | ✓ | ✓ | ✓ | ( ) | ✓ | |
| Informant E | ✓ | ✓ | ✓ | ✓ | ✓ | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, R.; Fuchs, Z.; Polinsky, M.; Parra, M.L. The Sound Pattern of Heritage Spanish: An Exploratory Study on the Effects of a Classroom Experience. Languages 2020, 5, 72. https://doi.org/10.3390/languages5040072
Rao R, Fuchs Z, Polinsky M, Parra ML. The Sound Pattern of Heritage Spanish: An Exploratory Study on the Effects of a Classroom Experience. Languages. 2020; 5(4):72. https://doi.org/10.3390/languages5040072
Chicago/Turabian StyleRao, Rajiv, Zuzanna Fuchs, Maria Polinsky, and María Luisa Parra. 2020. "The Sound Pattern of Heritage Spanish: An Exploratory Study on the Effects of a Classroom Experience" Languages 5, no. 4: 72. https://doi.org/10.3390/languages5040072
APA StyleRao, R., Fuchs, Z., Polinsky, M., & Parra, M. L. (2020). The Sound Pattern of Heritage Spanish: An Exploratory Study on the Effects of a Classroom Experience. Languages, 5(4), 72. https://doi.org/10.3390/languages5040072