1. Introduction
We know very little about the demonstrative system in American Sign Language (ASL), or any other signed language for that matter. Demonstratives serve to ground nominal expressions within the context in which they are uttered (
Langacker 2008), and hence play an important role in coordinating attention within discourse. According to
Hoffmeister (
1978), who completed a longitudinal study of two deaf children of deaf parents acquiring ASL, the demonstrative function is carried by pointing signs.
Baker-Shenk and Cokely (
1980), by contrast, list four variants of the sign glossed THAT in their description of demonstratives in ASL. More recently, several groups of investigators have examined pointing signs in signed languages more closely, and even compared them to co-speech pointing by hearing speakers (
Coppola and Senghas 2010;
Cormier et al. 2013;
Fenlon et al. 2019;
Meier and Lillo-Martin 2013;
Perniss and Özyürek 2015). These investigators find that pointing in both signed and spoken languages is very common, and is often used to direct attention, specify referents, locations and directions, and to indicate verb arguments. However, none of the studies on pointing in signed languages have focused on the demonstrative function of pointing signs, and in some cases, have purposely excluded pointing signs that fulfilled a demonstrative function. Hence, while there is extensive description and analysis of pointing signs, and particularly of the use of points as personal pronouns in ASL, the literature on demonstratives in ASL and other signed languages is strikingly sparse.
Traditionally, pointing signs have been treated as holistic symbolic units with little attention to underlying cognitive structures implicated in their recruitment for linguistic function. Wilcox and colleagues have recently introduced an innovative approach to understanding pointing signs by analyzing them as pointing constructions within a Cognitive Grammar framework (
Wilcox and Occhino 2016;
Martínez and Wilcox 2019). We adopt the analytic tools of these linguists to expand on past investigations of pointing signs in ASL, and to evaluate the phonological and semantic variation of pointing signs used as demonstratives.
According to
Wilcox and Occhino (
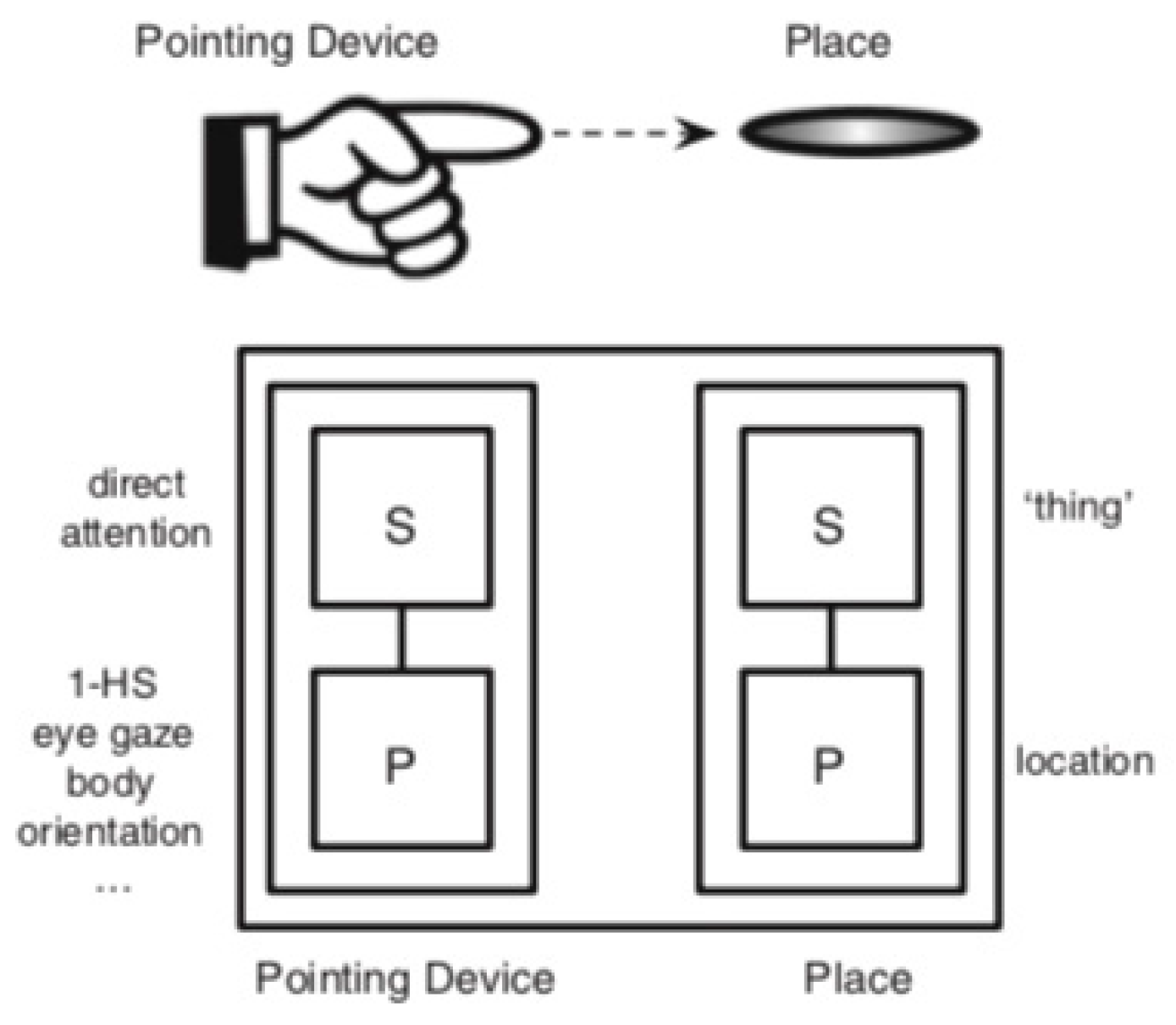
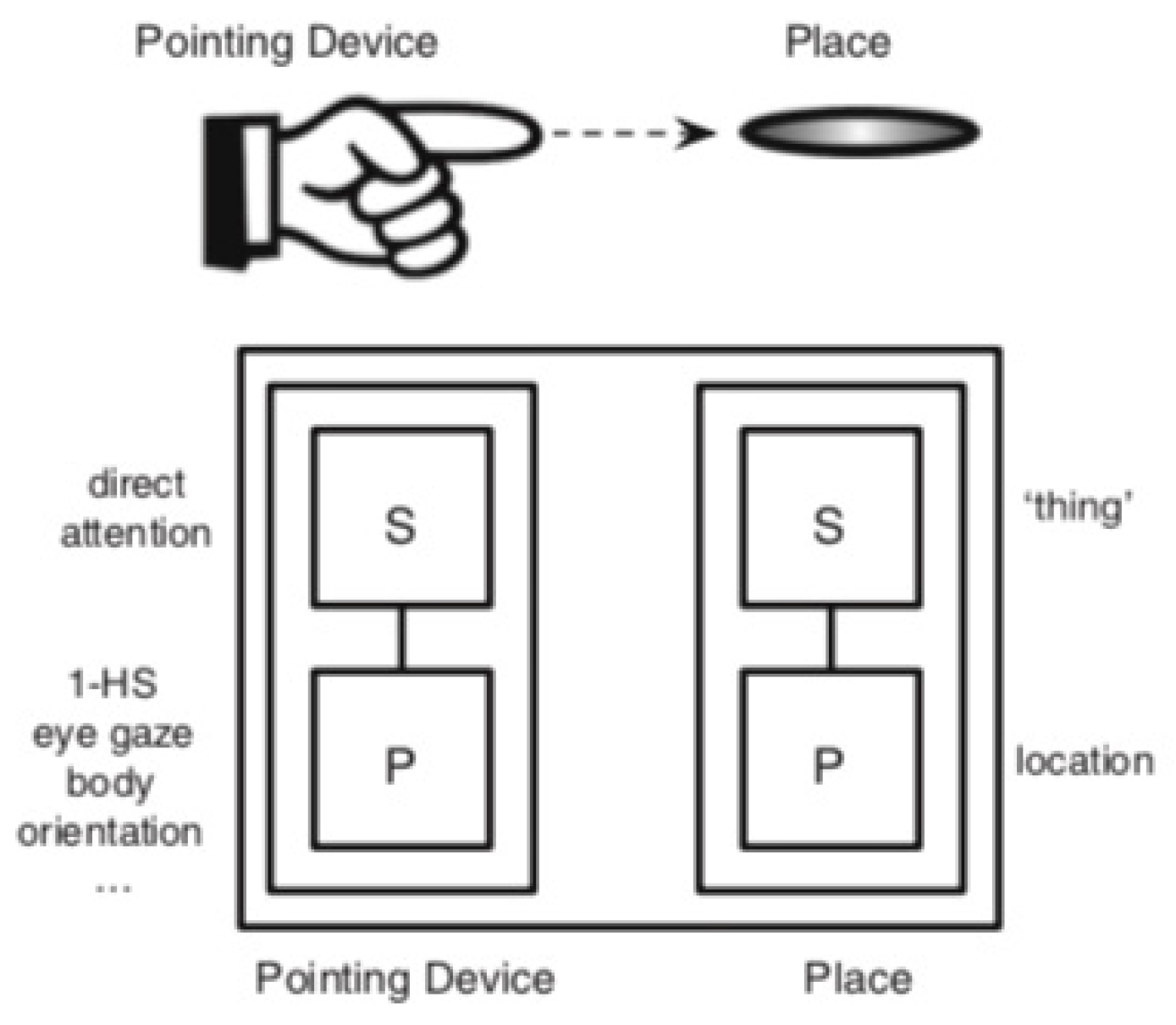
2016, p. 379), “Pointing signs are composite symbolic constructions consisting of two component symbolic structures.” The first symbolic structure is the
Pointing Device. As a symbolic structure, the Pointing Device has both a phonological and a semantic pole. The phonological pole consists of an articulator identifying a direction, typically an outstretched index finger (see
Figure 1), but potentially taking many other forms including an upraised chin, pouting lips, and even raised eyebrows. The semantic pole of the Pointing Device is to direct attention. Notably, the Pointing Device directs attention to another symbolic structure, which
Wilcox and Occhino (
2016, p. 378) call
Place. Place, like the Pointing Device, consists of a phonological pole, a location in space, as well as a semantic pole, which they propose is a schematic category of ‘thing’, which becomes instantiated within a specific discourse context as the referent associated with a location in space. This technical jargon allows investigators to distinguish physical spaces in the discourse context of two signers from their symbolic functions in communication.
Figure 2, from
Wilcox and Occhino (
2016, p. 380), depicts the relationship between the Pointing Device and Place in a Cognitive Grammar architecture.
Demonstratives serve to (1) indicate the location of a referent relative to the deictic center, and (2) coordinate interlocutors’ joint attentional focus (
Diessel 2006). This functional division emphasizes the
spatial and
social dimensions of demonstrative use (e.g.,
Lyons 1977;
Diessel 1999). Based on Wilcox and colleagues’ analysis of pointing constructions, we propose that these functions are related forms of nominal grounding. Specifically, whether spatial or social, demonstratives direct attention to ground nominal reference within a discourse context.
The goal of the present study was to elicit ASL demonstratives in a naturalistic task to provide additional insight into the form and function of demonstratives in ASL. Given our limited understanding of demonstratives, we selected a task that would elicit unrehearsed utterances from signers, while also allowing us to determine whether responses varied along dimensions that have previously been found to impact demonstrative selection. In virtually all spoken languages, demonstrative systems distinguish between at least two spatial locations; a
proximal demonstrative is used to identify referents near the speaker, and a
distal demonstrative is used to identify referents far from the speaker (
Anderson and Keenan 1985), but no such claims have been made for any signed languages. Second, speakers modify their demonstrative choice relative to social dimensions of an ongoing interaction, yet we do not yet know whether signers also take the attentional status of the interlocutor into account when producing demonstratives. For this initial study, we asked the following research questions:
- (1)
What signs function as demonstratives in ASL?
- (2)
Do signers generate unique signed forms when identifying referents in proximal vs. distal locations?
- (3)
How do signers modify their demonstrative signs when joint focus of attention is disrupted?
2. Method
2.1. Participants
Ten deaf adult fluent signers of ASL participated in the experiment. All participants gave their informed consent for inclusion before they participated in the study. Consenting procedures were conducted in accordance with 45 CFR Part 46 of the U.S. Department of Health and Human Services (HHS). In this preliminary analysis, we report the results from 4 participants (3 female, 1 male) whose ages ranged from 36–43. All the participants were bilingual in ASL and English, and considered ASL to be their dominant language. Participants completed the Bilingual Language Profile (
Birdsong et al. 2012). Self-evaluation for ASL fluency on a scale of 0 to 6 was on average 5.8 for signing ASL, and 5.8 for understanding ASL. Self-evaluation for English fluency was 5.3 for reading, and 5.3 for writing.
2.2. Materials and Procedure
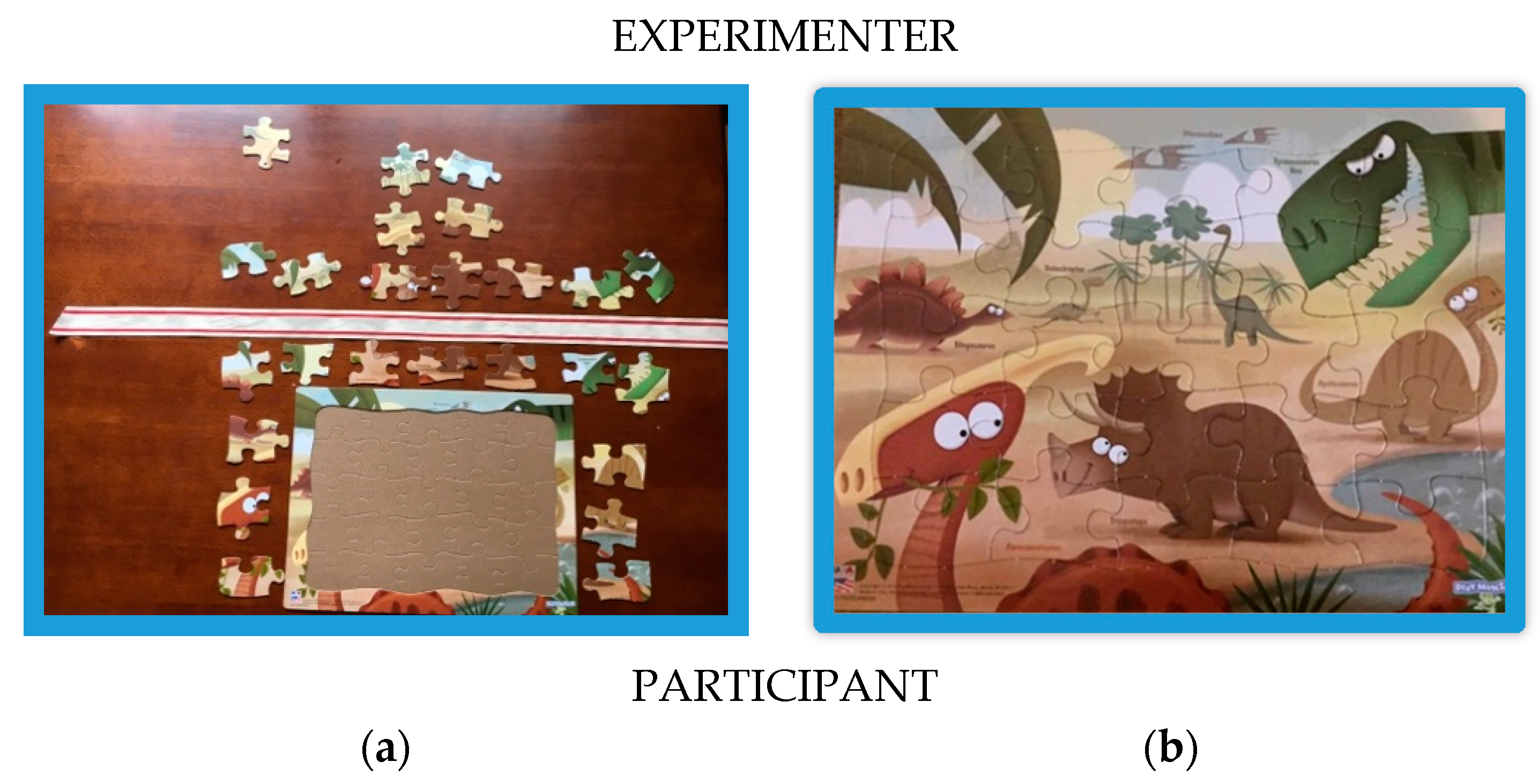
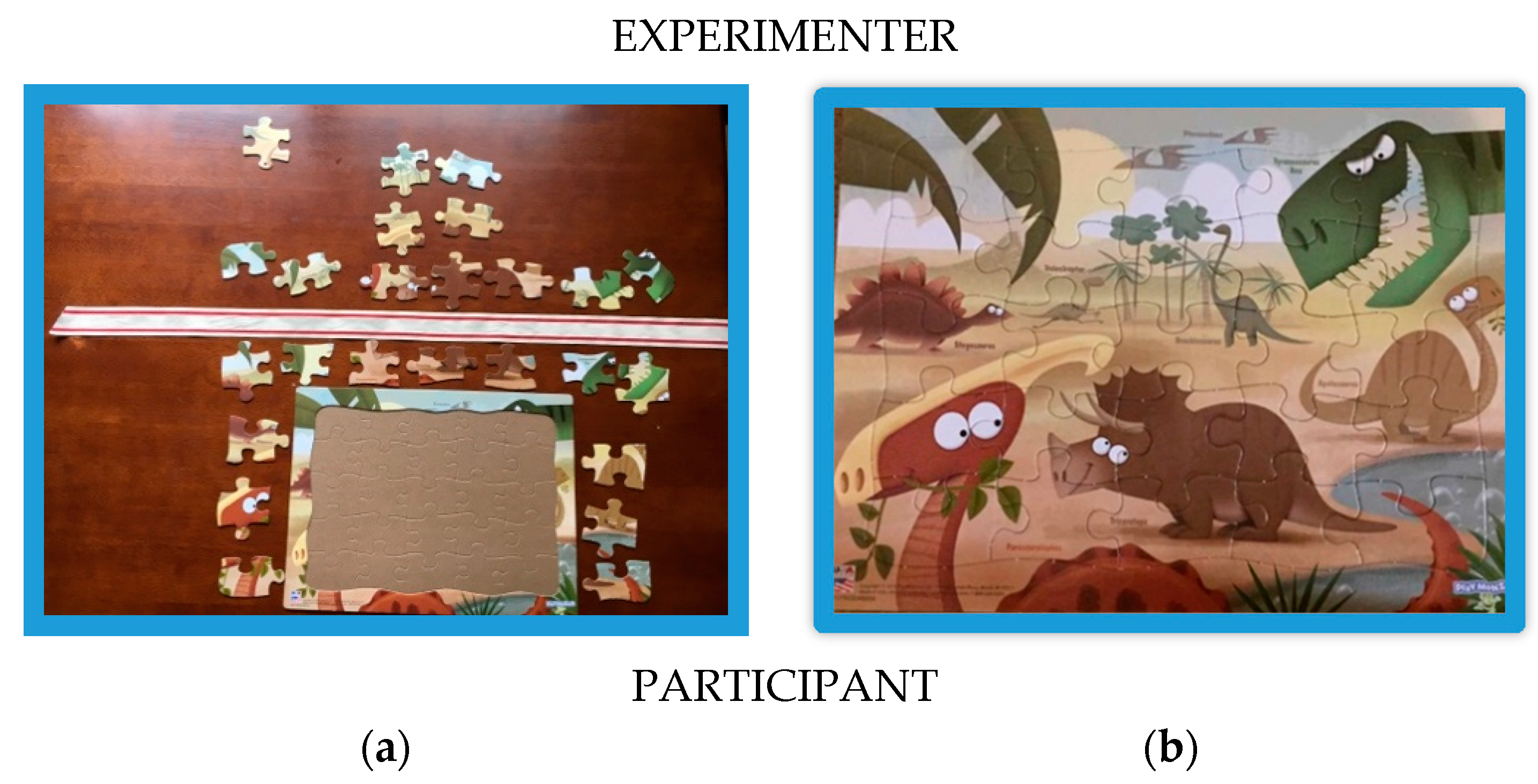
The participant was seated at a card table across from the experimenter. A 25-piece bordered puzzle with a picture of several dinosaurs was positioned on the table in front of the participant (see
Figure 3a). A band divided the participant and the puzzle board from the experimenter’s side of the table. 13 puzzle pieces were placed on the participant’s side of the barrier (the proximal region) and 12 were placed on the experimenter’s side (the distal region). The experimenter explained that the task was to put the puzzle together following two rules. First, the participant was not allowed to touch the pieces, and second, the participant was not permitted to reach across the barrier. The participant was not instructed to use any particular form of language.
The experimenter asked the participant a sequence of questions to elicit the selection of puzzle pieces for placement in the puzzle. Joint attention was manipulated by asking two types of questions. For
Find It questions (n = 25), the experimenter described what the piece looked like, e.g., “GREEN DINOSAUR HIS EYE WHICH?” ‘Which piece has the green dinosaur’s eye?’ The second question type was
Misunderstanding questions (n = 10): after the participant identified a piece as a response to a
Find It question, the experimenter explicitly ignored the participant’s choice and selected a different piece, pointing at it and using non-manuals appropriate to a Yes/No question, ‘This one?’ These
Misunderstanding questions were designed to create a context in which the experimenter was no longer jointly focused on the same puzzle piece as the participant, thereby prompting responses in which the participant corrected the experimenter and clarified the intended puzzle piece. Other responses that were not scripted but arose naturally throughout the task were also included in the analysis if the participant produced a demonstrative referring to a puzzle piece. The task ended when the puzzle was completed (see
Figure 3b). The entire session was videotaped.
2.3. Coding
Coders transcribed all participant responses using an in-house glossing annotation system in Excel. A unique entry was created for every indicating sign that identified one or more puzzle pieces, including points with any handshape (e.g., IX, IX_B, IX_2), the sign THAT, and classifier constructions (e.g., CL:G_Place_puzzle_piece_in_puzzle). For each sign that identified a puzzle piece, coders specified the gesture type (point, THAT or other), the joints involved in the articulation, movement trajectory, the handshape, any hand-internal movements, and the orientation of the handshape, as well as the direction of the participant’s gaze. Non-manual signals were also coded, including: eyebrows, squinting, cheek raising, mouth, chin, shoulder raise, and head tilt. An online coding manual was stored with the video data so that coders could refer to it at any time. After completing coding of half of one participant’s video, the coding was checked by the first two authors for consistency, and any necessary changes were discussed with the coders.
A total of 183 responses to the experimenter’s questions including 258 demonstratives (some responses included multiple demonstratives) were produced by participants. In total, 175 responses (96%) included a demonstrative. Each demonstrative (n = 258) was further categorized according to:
- (1)
The target location of the puzzle piece denoted by the participant’s demonstrative: proximal (n = 110), distal (n = 124), or both (n = 24).
- (2)
Interaction type: Find It questions (n = 213), Misunderstanding questions (n = 45). Participant responses that were not direct responses to the puzzle script were categorized according to the preceding trial type, Find It or Misunderstanding. For example, one participant responded to a Find It question by clarifying, “No touching, right? That one.” But when the experimenter said, “No, no touching the puzzle pieces,” the participant expanded on their previous utterance, “That one on the other side of the purple line.” Both responses were included in the Find It condition.
3. Results
We first attempted to determine the range of forms that participants used to express demonstrative function. Ninety-five percent of all demonstratives were pointing signs. However, these pointing signs exhibited variation in form. For example, 70% of pointing signs used a canonical extended index finger and 88% included an extended index finger with some modification to the remaining fingers (G-handshape, E-handshape with an extended index, extension of pinky and/or thumb, etc.). The most common movement trajectory was a straight movement (81%), with some pointing signs using a larger arc movement (19%). The majority of pointing signs were produced with the palm oriented downward (74%), but the palm was also oriented inward (22%) and even upward (3%).
Baker-Shenk and Cokely (
1980) describe four variations of the sign THAT as comprising the demonstratives in ASL. Participants identified a puzzle piece with the sign THAT only 12 times, and all instances of THAT were accompanied in the same utterance by pointing signs that also functioned as demonstratives. Six of the uses including THAT were co-articulated sequentially with a point in a phonologically reduced manner suggesting a single construction, possibly a result of contact with the English expression, “That one,” (cf.
Baker-Shenk and Cokely 1980).
Figure 4 shows sample variations in demonstrative form, including co-articulation of THAT with a point.
Our second analysis addressed whether participants distinguished proximal and distal referents on the basis of different demonstrative forms. We first evaluated whether the sign THAT was used more frequently for distal or proximal referents. We found that half of the tokens were produced in reference to proximal referents and half in reference to distal referents. Subsequently, we hypothesized that distal demonstratives might be produced with an extended finger rather than a G-handshape, and an arc trajectory rather than a straight trajectory.
Table 1 shows that neither handshape nor trajectory of pointing signs aligned categorically with proximity. Although participants were more likely to use an extended index than any other handshape for distal referents (79%), this was true for proximal referents as well (59%). Pointing sign trajectory also did not distinguish proximal and distal referents. Participants were more likely to produce an arc trajectory for distal referents (23%) than proximal referents (14%), but the majority of pointing signs were produced with a straight trajectory regardless of the proximity of the referent.
Our final analysis evaluated whether participants modified their demonstratives in response to the question types that were designed to establish (
Find It) or disrupt (
Misunderstanding) joint attention. We evaluated the non-manual features of the demonstratives to determine whether specific non-manual features occurred more frequently with demonstratives in response to one question type or the other. Further, we included proximity in this analysis to determine whether facial expressions signaled proximity in addition to or instead of joint attention. We hypothesized that participants would be more likely to produce eye gaze directed at the experimenter instead of at the puzzle piece on
Misunderstanding Trials. As can be seen in
Table 2, this prediction was only partially supported by the data. Note that we eliminated 5 trials on which participants’ eye gaze was directed to a location on the puzzle board (all in response to
Find It questions), and 18 trials on which participants shifted their eye gaze between the puzzle piece and the experimenter during the trial. For the remaining trials, participants looked at the experimenter twice as often on
Misunderstanding trials (15%) than on
Find It trials (7%) for proximal referents, but they never looked at the experimenter (0%) on distal
Misunderstanding trials even though they sometimes did (6%) for distal
Find It trials. This pattern of results demonstrates that signers deploy eye gaze in a strategic manner in misunderstanding contexts, but proximity also influences the location of eye gaze. This may reflect a differential usefulness of eye gaze as a Pointing Device for proximal vs. distal locations. We return to this question in the discussion.
In addition to eye gaze, we discovered that a constellation of non-manual features was more likely to accompany demonstratives on
Misunderstanding trials than
Find It trials, and on distal trials than on proximal trials. Specifically, participants produced a combination of shoulder raising, head tilt, eye squinting, and cheek raising that we will call
Facial Compression. Facial compression appears to signal directive force and specificity of the demonstrative. As can be seen in
Table 3, facial compression was produced on half or more of the
Misunderstanding trials. Regardless of proximity, facial compression adds directive force in an attempt to establish joint attention following misunderstanding. Facial compression is also twice as likely to be produced with distal than with proximal demonstratives when there is no disruption to joint attention. Note that pointing signs become increasingly generic with distance. We propose that facial compression signals that the signer is not using a distal pointing sign to identify a generic location, but rather a specific distal location.
4. Discussion
ASL signers rely primarily on pointing signs for demonstrative function in the context of a task in which individuals are selecting referents in a field of possible referents. We found two of the four demonstrative forms using the sign glossed THAT identified by
Baker-Shenk and Cokely (
1980), but these forms were much less likely to be produced than a pointing sign. One question for future investigation is whether the discourse context constrained the selection of demonstratives, or whether pointing signs tend to outnumber other possible forms that function as demonstratives in ASL. Given the ubiquity of pointing signs in all signed languages, we anticipate that pointing signs are frequently used as demonstratives across many discourse contexts.
Spoken languages typically have at least two demonstrative forms that are used to distinguish proximal (e.g.,
this) and distal (e.g.,
that) referents (
Diessel 1999). The acquisition literature documents a tendency for proximal demonstratives to be acquired earlier, used more frequently, and used in a more consistent manner (
Clark and Sengul 1978). These findings in the literature prompted us to investigate whether participants would use specific forms or modulate their demonstratives to identify whether or not the referent of the demonstrative was proximal or distal. We were able to rule out the possibility that the sign THAT is used primarily with distal referents. There also were no modulations to pointing signs that categorically distinguished proximal and distal referents. For example, although an extended index finger and an arc trajectory were more commonly used for distal referents than for proximal referents, both features of pointing signs occurred for both categories of space. A similar lack of categorical usage of demonstratives in spoken languages has been interpreted as evidence that speakers are not selecting demonstratives solely on the basis of actual physical space, but on their
construal of space (
Enfield 2003;
Peeters and Özyürek 2016;
Shin and Morford forthcoming). Speakers’ construals are manifestations of the
social as well as the
physical dimensions of the discourse context.
In ASL, this interplay of social and physical dimensions can be found in the use of non-manual marking, which plays an essential role in modifying demonstrative meaning. We found that eye gaze was predicted on the basis of both factors together. Signers increased eye gaze to the experimenter following a misunderstanding, but only when the locus of the referent was proximal to the signer. Imagine sitting across from someone who is showing you an object close to their hand. If they look down at the object they are specifying, their eyelids will obstruct your view of their gaze direction. By contrast, if they are pointing to something that is far away from themselves, their point will be fairly indistinct, but their eye gaze can add a supplemental cue to the locus of the referent. This explanation could account for the differential use of eye gaze to clarify the locus of a referent following a misunderstanding. When the locus of the referent was distal, participants used their eye gaze as an additional cue to the locus of the referent. But when the referent was proximal, they increased their (already rare) eye gaze to the experimenter to check whether she was following their pointing sign. These results demonstrate the importance of distinguishing the Pointing Device from Place in pointing constructions (
Wilcox and Occhino 2016). Traditional accounts of pointing investigate only the direction of the extended index finger, but a cognitive grammar approach considers all pointing devices that are articulated in the pointing construction, and the semantics associated with the place indicated by each pointing device. Signers are strategic in managing the use of different Pointing Devices to direct attention, and to assess the success of their communicative bids. Future research on demonstratives in signed languages must include an analysis of eye gaze in addition to manual Pointing Devices.
A second non-manual feature that we found to be essential in describing the Place of demonstrative pointing constructions was the use of
facial compression. Points decrease in specificity as the distance between the Pointing Device and the Place increases (
Cooperrider 2016). However, signers are able to modify the specificity of a Pointing Device by adding facial compression. This configuration of non-manuals including shoulder raising, head tilt, squinting, and cheek raising is an iconic demonstration of the need to narrow the scope of the cone of reference extending from a Pointing Device. Further, facial compression functions intersubjectively to convey to an addressee that the signer has a specific locus in mind when joint attention has been disrupted. As with eye gaze, the use of facial compression provides another demonstration of the fact that language users construe the discourse on the basis of both physical and social dimensions.
In closing, this study provides preliminary results that demonstratives in signed languages may rely heavily on a single device, the pointing construction. However, this construction can be modulated along many dimensions to achieve referent selection and tracking with the addressee. As in spoken languages, demonstratives in ASL are not used in a categorical manner to distinguish proximal and distal referents. Signers are sensitive to both spatial and social dimensions of the discourse context in demonstrative selection in ASL.





{kind=link}
{kind=link}
{kind=link}
{kind=link}