3.1. Stimuli
Studies analysing the durational patterns of contrastive gemination in Italian often use minimal pairs (e.g.,
pala ‘shovel’—
palla ‘ball’) and compare the duration of the target consonant; such minimal pairs exist in large numbers in Italian and allow researchers to control for many possible confounds, given that the phonological context of the target phoneme is exactly the same within each pair. However, this is obviously not applicable for inherently long consonants: as previously stated, no minimal pairs exist for these consonants, meaning that we can never compare short vs. long counterparts within the same phonological context. For this reason, some studies have contrasted the durations of these consonants with comparable contrastive geminates with the closest articulatory characteristics (e.g., /l/ for /ʎ/, cf.
Celata & Kaeppeli, 2003). We chose to contrast the duration of target consonants in the word-internal intervocalic position (e.g.,
ozono, ‘ozone’), where they are said to be phonetically long, with counterparts in the word-internal post-consonantal position (
enzima, ‘enzyme’), where they are said to be short.
We prepared a list of 150 stimuli with /ts/, /dz/, /ʃ/, /ɲ/ and /ʎ/ (
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5), in which we controlled for the position (post-consonantal, intervocalic) and stress condition (pre-stressed, post-stressed, unstressed) of the target consonant. It must be noted that the unstressed condition consists of stimuli with two or more unstressed syllables at the beginning, with the target consonant between the first and the second syllable. These words may be said to contain a secondary stress on the first syllable, meaning that the target consonant would be in a condition closer to pre-stressed than real unstressed. However, the existence and nature of secondary stress in Italian is debated (for different views, cf.
Bertinetto, 1976;
Vogel & Scalise, 1982;
Marotta, 1999;
Krämer, 2009). Here, we simply used the label ‘unstressed’ to refer to target consonants occurring between two syllables that do not carry primary lexical stress.
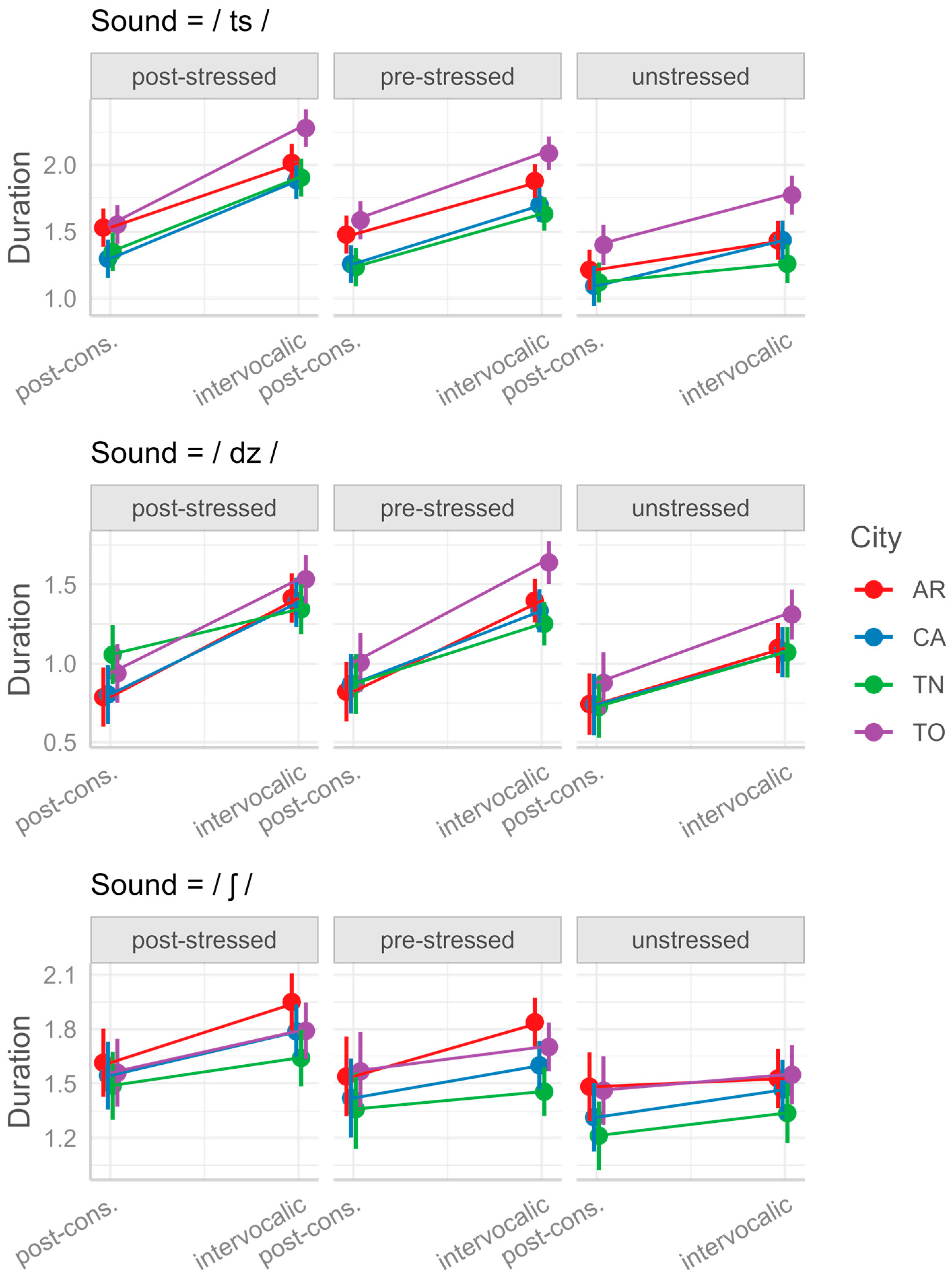
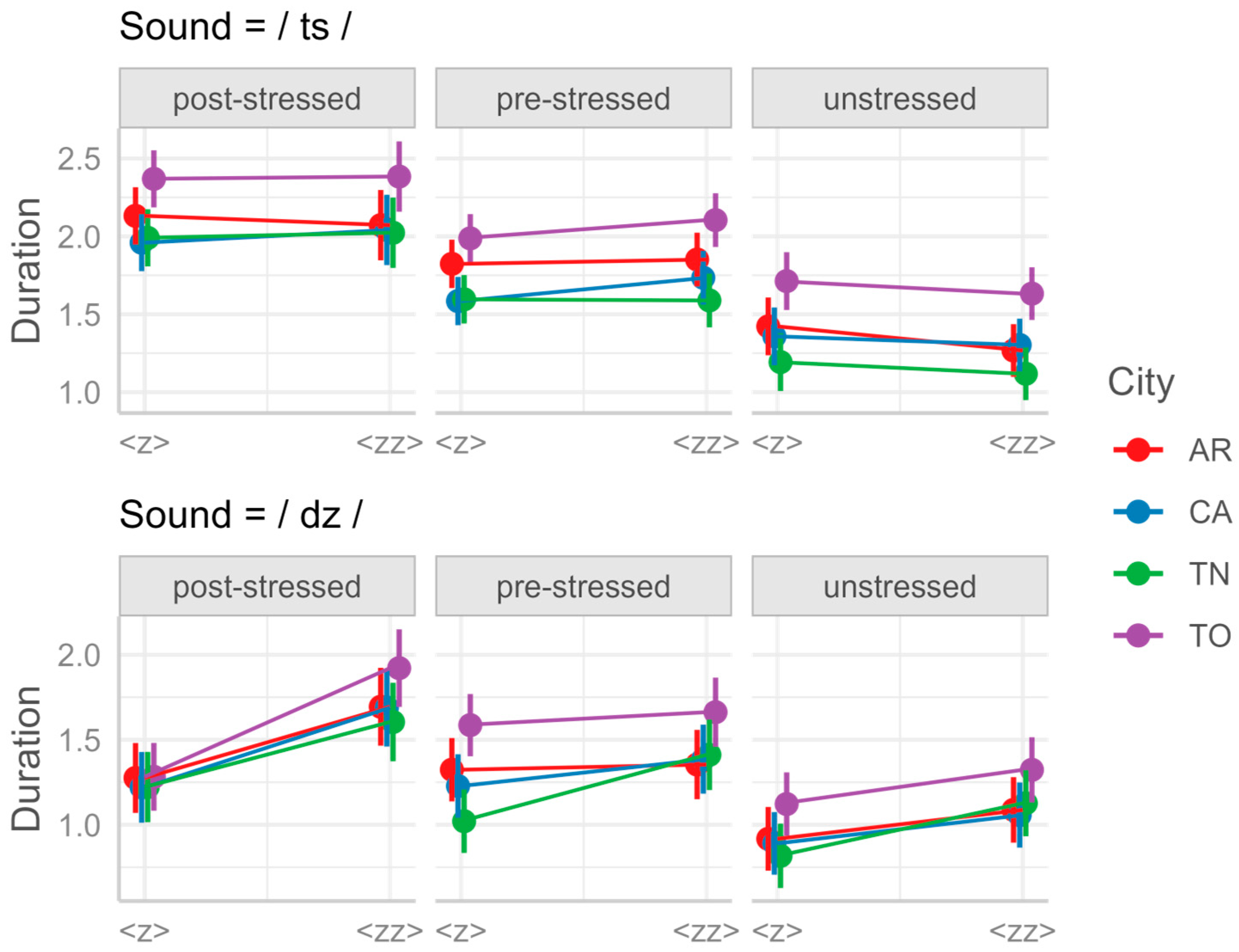
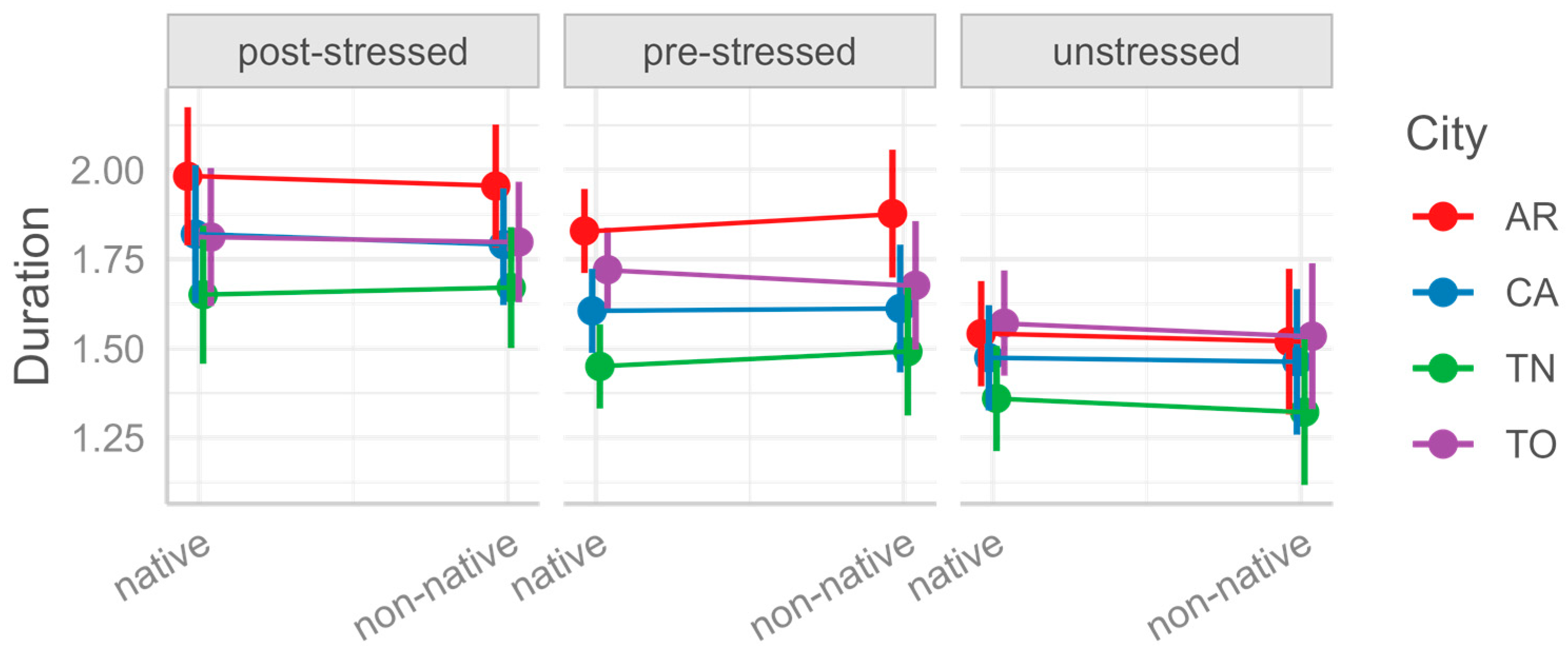
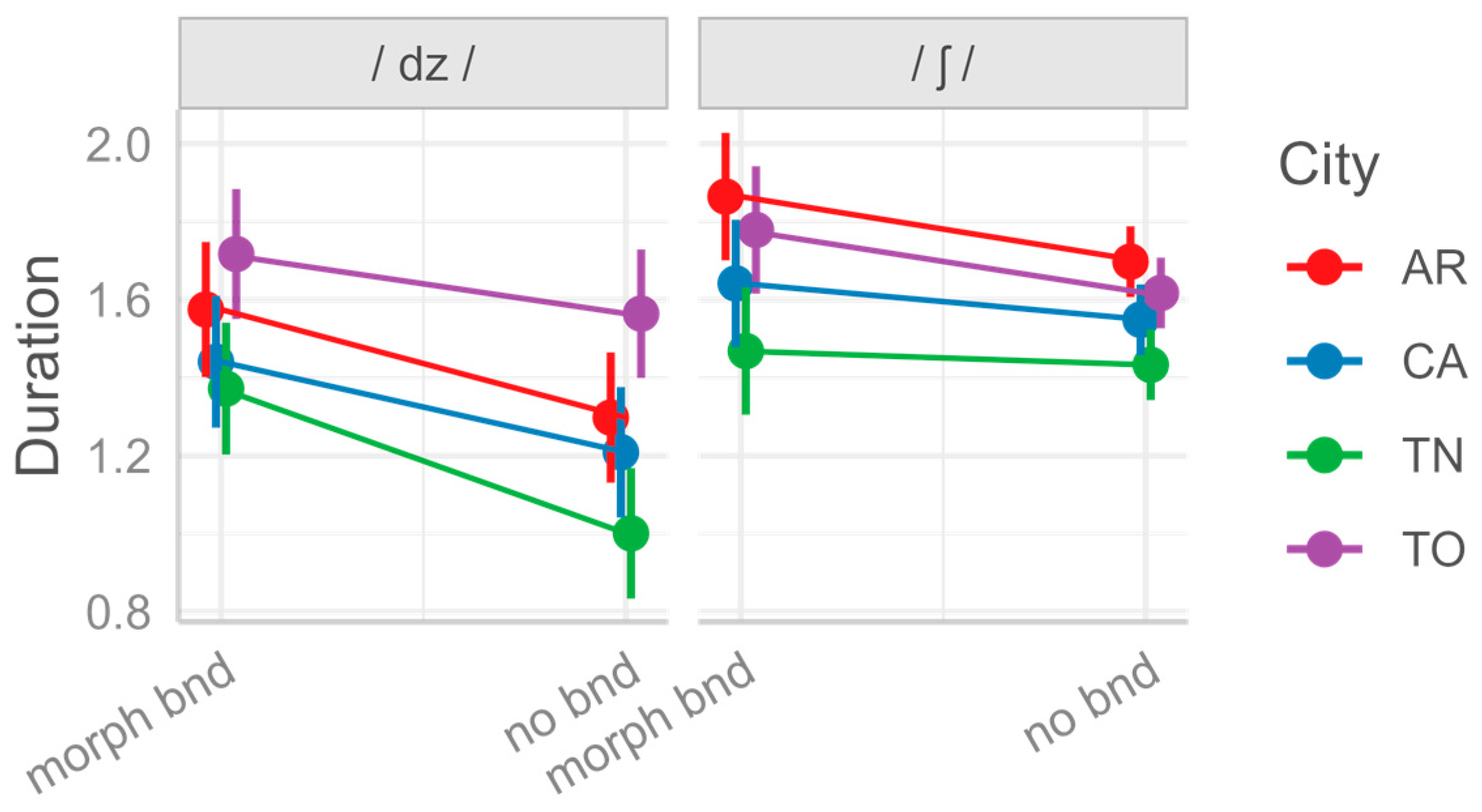
Apart from the stress and position, for some of our consonants we controlled for other factors too. For /ts/ and /dz/, we controlled for spelling (single vs. double letter in the intervocalic position, e.g., sazi ‘satiated’ vs. mazzi ‘bunches’); for /ʃ/, we controlled for native vs. foreign status/spelling (e.g., nasce ‘he/she is born’ vs. fashion); and for /dz/ and /ʃ/, we controlled for the presence vs. absence of a morphological boundary before the target consonant (e.g., coscienza ‘conscience’ vs. retroscena ‘backstage’).
We were not able to fully control for (i) word length across conditions, (ii) lexical frequency, (iii) surrounding vowels, or (iv) grammatical category. However, in order to account for potential effects of word length on segmental durations, we included the number of syllables as a control variable in our models. Similarly, in order to control for potential effects of word frequency, we included the frequency of our stimuli extracted from the
itTenTen corpus (
Jakubíček et al., 2013) as a control variable in our models. Another limitation of the dataset is that many words prime each other (e.g.,
conscio—inconscio, sazio—saziato). However, the order of presentation of stimuli was randomised for every participant, so that some speakers pronounced
sazio before
saziato, and others pronounced them in the opposite order. Although this was no guarantee of control, it was an attempt to (at least partially) counterbalance this priming effect.
We included three target words in each experimental condition. Initially, we had included further stimuli in the word-initial position (zebra), taking care to avoid contexts where RF may apply. However, such stimuli were problematic because (i) the word-initial position was missing for some consonants; (ii) the selection of /ts/ and /dz/ in the word-initial position varies across varieties, making it difficult to select stimuli that would work for all speakers; (iii) an impressionistic evaluation revealed that some speakers had produced RF in this position. For these reasons, stimuli with target consonants in the word-initial position were discarded from the analysis presented in this paper and may possibly be the object of a future study on RF. The exclusion of stimuli with target consonants in the word-initial position left us with 135 words for the analysis.
Table 1 and
Table 3 show the stimuli analysed for /ts/ and /dz/. We have to make a note concerning /dz/ stimuli in the post-stressed intervocalic position spelled with singleton <z>: all of them are foreign names (
Gaza, Mozart) or loanwords (
kamikaze). This could not be avoided, since no native Italian word contains /dz/ in this condition. Their (partially) foreign status may imply a certain amount of variability in how Italian speakers pronounce these words. However,
Canepari (
2009) only reported geminate pronunciations (as non-marked) for these words in Italian. Realisations that were different from the target (in this case, a voiced alveolar affricate) were discarded from the analysis.
The stimuli recorded for /
ʃ/ are shown in
Table 3. For this consonant, we were not able to separate the foreign
status and foreign
spelling of target words; this is because the sound /
ʃ/ is systematically spelled <sc> in native Italian words and <sh> or <ch> in loanwords. Additionally, we have to make a note about
bolscevico (‘Bolshevik’): this word has two possible stress patterns ([bolʃeˈviko], [bolˈʃɛviko], according to
Canepari, 2009). It had been included in the dataset because no alternative could be found in the pre-stressed post-consonantal position, and in the hope that a conspicuous number of participants would pronounce [bolˈʃɛviko]. Unfortunately, only 4 out of 40 participants pronounced it as hoped, and therefore this word was discarded from the analysis.
The stimuli recorded for /
ʎ/ are shown in
Table 4. Unfortunately, the analysis of this consonant was limited because we ran into issues finding suitable stimuli filling all experimental conditions. Stimuli with post-consonantal /
ʎ/ are only available with a word-internal morphemic boundary, more specifically when the clitic
gli (‘to him’) is added to an infinitive verb form. In the post-stressed position, we recorded stimuli in both the post-consonantal and intervocalic positions, all with a morphemic boundary and therefore comparable. In the pre-stressed position, we recorded stimuli without a morphemic boundary, but no post-consonantal counterparts existed to compare them with. In the unstressed position, we recorded stimuli with /
ʎ/ in the intervocalic position with a morphemic boundary but failed to record post-consonantal counterparts.
The stimuli recorded for /
ɲ/ are shown in
Table 5. Like for /
ʎ/, the analysis of this consonant is limited because words with post-consonantal /
ɲ/ in the unstressed position do not exist in Italian. Furthermore, post-consonantal /
ɲ/ in the pre-stressed and post-stressed positions is exclusively found in toponyms of northern Italy. We recognise that this may constitute a potential bias, given that northern speakers may be more familiar with these place names, as well as with the /r
ɲ/ cluster, which is virtually non-existent in central and southern Italy.
3.2. Format
For each stimulus, we created a short sentence (from 5 to 10 words) containing the target word in the final nuclear position (e.g., Verranno processati per resistenza alla polizia ‘They will be tried for resisting the police’, L’isola fu divisa in quattro per evitare screzi ‘The island was divided into four to avoid disagreements’). No distractors were added, to avoid making the recording procedure too long and tiresome for participants. We reasoned that, since we had five different target consonants, and since target words were presented within sentences, participants were not likely to detect a pattern in the test or spot the goal of our study.
Participants were asked to complete a read-aloud task with the list of sentences, visually presented on a computer screen via
SpeechRecorder (
Draxler & Jänsch, 2004). To avoid experimental issues due to the order of presentation and to limit the impact of fatigue on task performance, the stimuli were presented in random order. All participants gave informed consent for the analysis of their recordings and did not receive any type of compensation. They were recorded in the university premises by the authors, either in a sound-proof booth or in a silent room (depending on availability), with professional equipment. The reading task took approximately 15 min. All recordings were of sufficient audio quality for performing acoustic measurements of duration.
After recording the target sentences, participants completed a questionnaire providing information about their sociolinguistic background. At the end of the questionnaire, we also included three questions to gain some information about their awareness of pronunciation patterns. Participants were provided three word pairs and had to inform us whether they pronounced them differently or in the same way: pesca ‘peach’—pesca ‘fishing’, razza ‘race’—razza ‘ray’ and vizi ‘vices’—vizzi ‘withered’. The only pair of relevance for our study was vizi—vizzi, testing whether participants thought that the single letter <z> vs. double letter <zz> indicated a length distinction. The other two pairs served solely as distractors and featured items with highly marked variations that are easily recognised by naïve speakers: the /e/–/ɛ/ (found in the first word pair) contrast is neutralised in many regional varieties, while the /ts/–/dz/ distinction (found in the second word pair) carries minimal functional load and is strongly influenced by regional variation.
3.3. Participants
We recorded 10 participants in each of 4 survey points in Italy (total = 40 participants). The survey points were the cities of Arezzo (AR, Tuscany), Cagliari (CA, Sardinia), Trento (TN, Trentino-Alto Adige) and Turin (TO, Piedmont). By no means are these four survey points supposed to fully represent the considerable amount of regional variation found in Italian varieties. However, they do reflect some of the major geographic and dialectal areas of the peninsula, and those which are claimed to differ in terms of gemination: central varieties (AR, close to Standard Italian), north-western varieties (TO), north-eastern varieties (TN) and Sardinian (CA).
An anonymous reviewer pointed out the transitional nature of Trento between Lombard and Venetian and the presence of bilingualism in its province. However, scholars classify Trento within Venetian varieties, with linguistic trends favouring Venetian in urban areas (
Zamboni, 1977;
Cortelazzo, 1983;
Bonfaldini, 1983), and bilingualism is limited to specific communities (e.g., Ladin in Fassa Valley, Cimbrian in Luserna, see
Dell’Aquila et al., 2022) beyond the city of Trento. Moreover, none of our participants reported using minority languages. Another reviewer noted that the Arezzo variety may be peripheral within the Tuscan area. However, it has to be noted that Tuscan sociolinguistic situation is rather peculiar and is presently affected by koineization. More local features that are not widely shared are losing ground, while pan-Tuscan elements that are less attributable to precise territorial divisions tend to be consolidated. In this respect, the Florentine variety is far from being a prestigious model because of its features that are perceived as highly vernacular. The levelling of the dialect has led to the disappearance of local phenomena even in peripheral areas, such as Arezzo (
Giannelli, 2000;
Calamai, 2017;
Binazzi, 2019). Finally, the regional variety spoken in the city of Arezzo is still clearly classified as a central variety, and patterns with dialects south of the Massa–Senigallia line with respect to gemination.
All participants were native speakers of the regional varieties considered, were born and raised in the region where they were recorded by parents who were also born in the target region (except 2 speakers in TO and 3 speakers in AR, who had one parent born in another region—we inspected data for these speakers, and they did not seem to behave as outliers within their respective groups). All participants were young adults, recruited among university students (mean age = 23.73, range: 20 to 36); 25 of them identified as women, 15 as men. Many of them claimed that they spoke Italian with a regional accent (7 in TN, 8 in TO, 9 in AR, 10 in CA), and many also claimed that they spoke or understood the local dialect (9 in AR, 9 in CA, 9 in TO, 5 in TN). The average self-declared frequency with which participants claimed to use the local dialect from 1 (never) to 5 (all the time) was 2.6 in AR, 2.5 in CA, 2.2 in TO and 1.5 in TN. All participants but one claimed that they spoke English, and most participants also claimed to speak one or more other languages: French (n = 23), Spanish (n = 14), German (n = 13), Russian (n = 5), Mandarin (n = 3), Japanese (n = 1), Portuguese (n = 1). Participants’ responses to the three linguistic awareness questions (see
Section 3.2) are illustrated in
Figure 1. Most participants claimed that they pronounced
vizi and
vizzi in the same way, although northern speakers were slightly less likely to claim that. In total, 12 speakers claimed to make a difference between
vizi and
vizzi, of which 2 were in AR, 3 in CA, 3 in TO and 4 in TN.
3.4. Data Analysis
All the recordings were transcribed phonemically and forced-aligned with
WebMAUS (
Kisler et al., 2017), then target words were manually checked in
Praat (
Boersma & Weenink, 2023) by the authors. To ensure a homogeneous segmentation check, the authors agreed on a common set of standard criteria based on
Ladefoged (
2003); additionally, each author verified two speakers for each target city in order to balance any potential idiosyncrasies in the segmentation work. Consonants that had been mispronounced (due to slip of the tongue, misplaced stress or any other unexpected mispronunciation) were marked for exclusion during the segmentation check. Then, the target consonant durations were extracted via a
Praat script, normalised and saved in .csv format for statistical analysis.
Durations were normalised to avoid the confounding effect of speech rate differences across participants: normalisation was performed by dividing the target phoneme duration by the average duration of all nuclear segments (i.e., all phonemes contained in the last word of all sentences) produced by a given speaker. In other words, for each speaker, we computed the average duration of all phonemes in the last word of all sentences and used this measure as a reference duration: target phoneme durations were then divided by this by-speaker reference duration to neutralise potential speech rate differences across speakers. Therefore, a normalised value of 1 indicated the average duration of a phoneme in the nuclear position by a given speaker.
The statistical analysis was performed in
R (version 4.3.2,
R Core Team, 2023) via linear mixed-effects models with the
lme4 library (version 1.1.35.1,
Bates et al., 2015). For all models, the dependent variable was consonant duration. In an initial analysis, we built a global model for all our data, evaluating the effects of our primary variables:
Position (post-consonantal vs. intervocalic),
Sound (/ts/, /dz/, /ʃ/, /ɲ/, /ʎ/),
City (AR, CA, TN, TO) and their interactions. Subsequent models evaluated the effects of secondary variables which relate to a subset of the data: for /ts/, /dz/ and /ʃ/, we tested the effect of
Stress (post-stressed, pre-stressed, unstressed; /ɲ/ and /ʎ/ were not included due to missing cases in pre-stressed and unstressed contexts, see
Table 4 and
Table 5); for /ts/ and /dz/, we tested the effect of
Spelling (single vs. double letter, e.g.,
Gaza vs.
gazza); for /ʃ/, we tested the effect of
Foreign Status (native vs. non-native, e.g.,
nasce ‘he/she is born’ vs.
sushi); for /ʃ/ and /dz/, we also tested the effect of the presence vs. absence of a
morphological boundary. We tried to build models that would account for the potential effects of lexical frequency on segmental durations (see
Bybee, 2001), and potential effects due to word length (see
Farnetani & Kori, 1986). With this goal, we included the log-transformed Frequency (extracted from the itTenTen corpus,
Jakubíček et al., 2013) and the
Number of Syllables in the target word. In order to keep the analysis reasonable, we did not involve control variables in interactions.
All models included the random effects of
Speaker (to account for possible idiosyncratic behaviours) and of
Item (to account for possible lexical effects). The structure of the random slopes was kept maximal initially but had to be progressively reduced to avoid convergence issues and singular fit (
Barr et al., 2013). All factors were coded with sum-to-zero contrasts, except
Position, which was contrast-coded with reference level = post-consonantal. P values for fixed effects were obtained from the type 3 Anova table via Satterthwaite’s approximation for the calculation of degrees of freedom as implemented by the
lmerTest library (version 3.1.3,
Kuznetsova et al., 2017). Model predictions were extracted and plotted via the
sjPlot library (version 2.8.15,
Lüdecke, 2023). Post-hoc tests were performed via the
emmeans library (version 1.8.6,
Lenth, 2023) with Tukey adjustment for multiple comparisons.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}