
Preschoolers Mark Focus Types Through Multimodal Prominence: Further Evidence for the Precursor Role of Gestures


Abstract
:1. Introduction
1.1. Focus Types: A Definition
1.2. The Prosodic and Gestural Marking of Focus Types in Adult Speech
1.3. The Prosodic Marking of Focus Types in Child Speech
1.4. The Gestural Marking of Focus Types in Child Speech
1.5. The Present Study
- Do three- to five-year-old children vary prosodic prominence to distinguish between information, contrastive, and corrective focus?
- Do three- to five-year-old children employ manual and non-manual (head, eyebrow, torso, and legs) gestures in terms of presence to distinguish between information, contrastive, and corrective focus?
- Do three- to five-year-old children vary gestural prominence to distinguish between information, contrastive, and corrective focus?
- Do gestural abilities to distinguish information, contrastive, and corrective focus emerge prior to prosodic abilities during the developmental period from three to five?
2. Materials and Methods
2.1. Participants
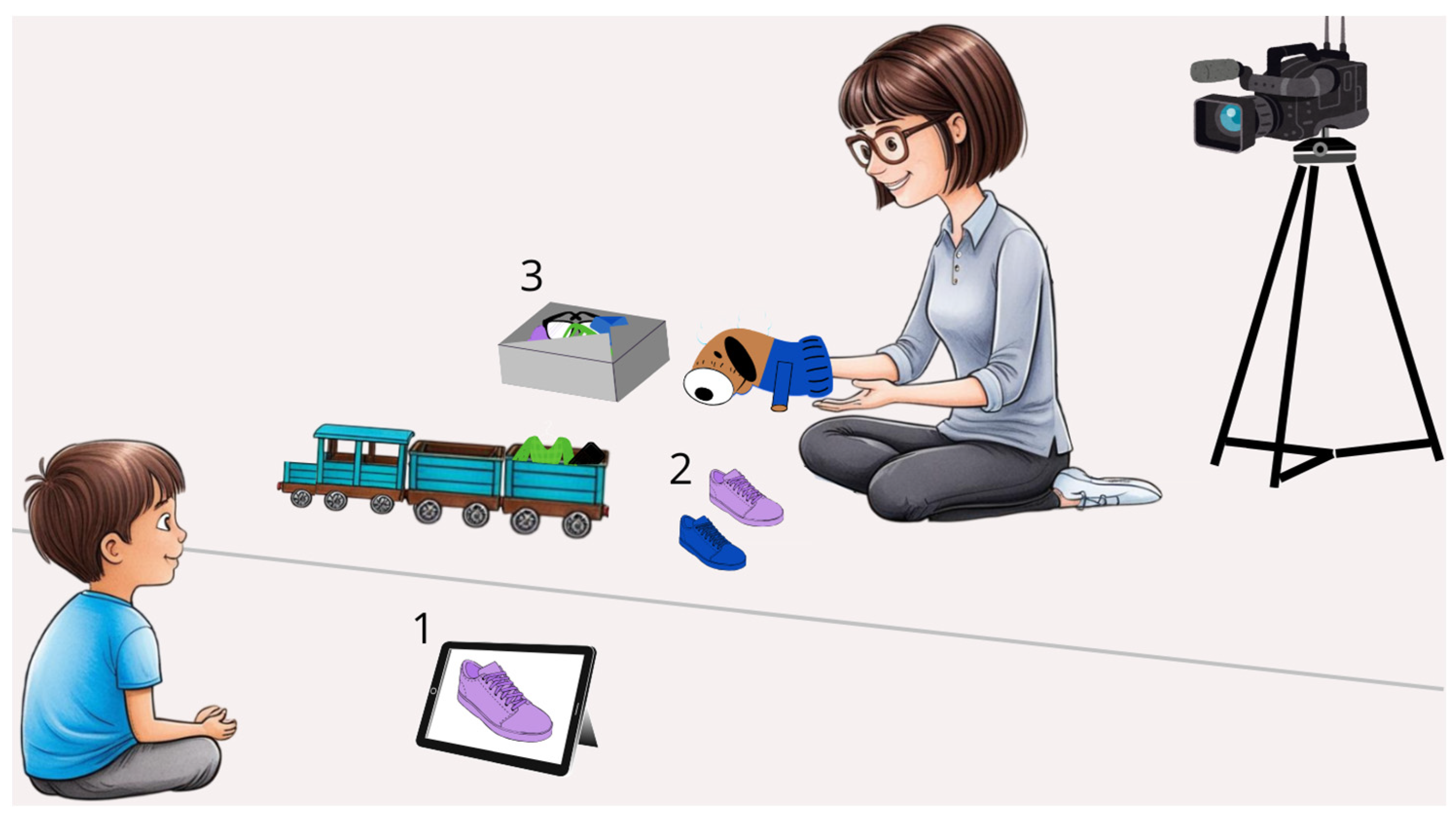
2.2. The Train Task: Creation and Piloting Process
2.3. Materials and Experimental Conditions
2.4. Procedure
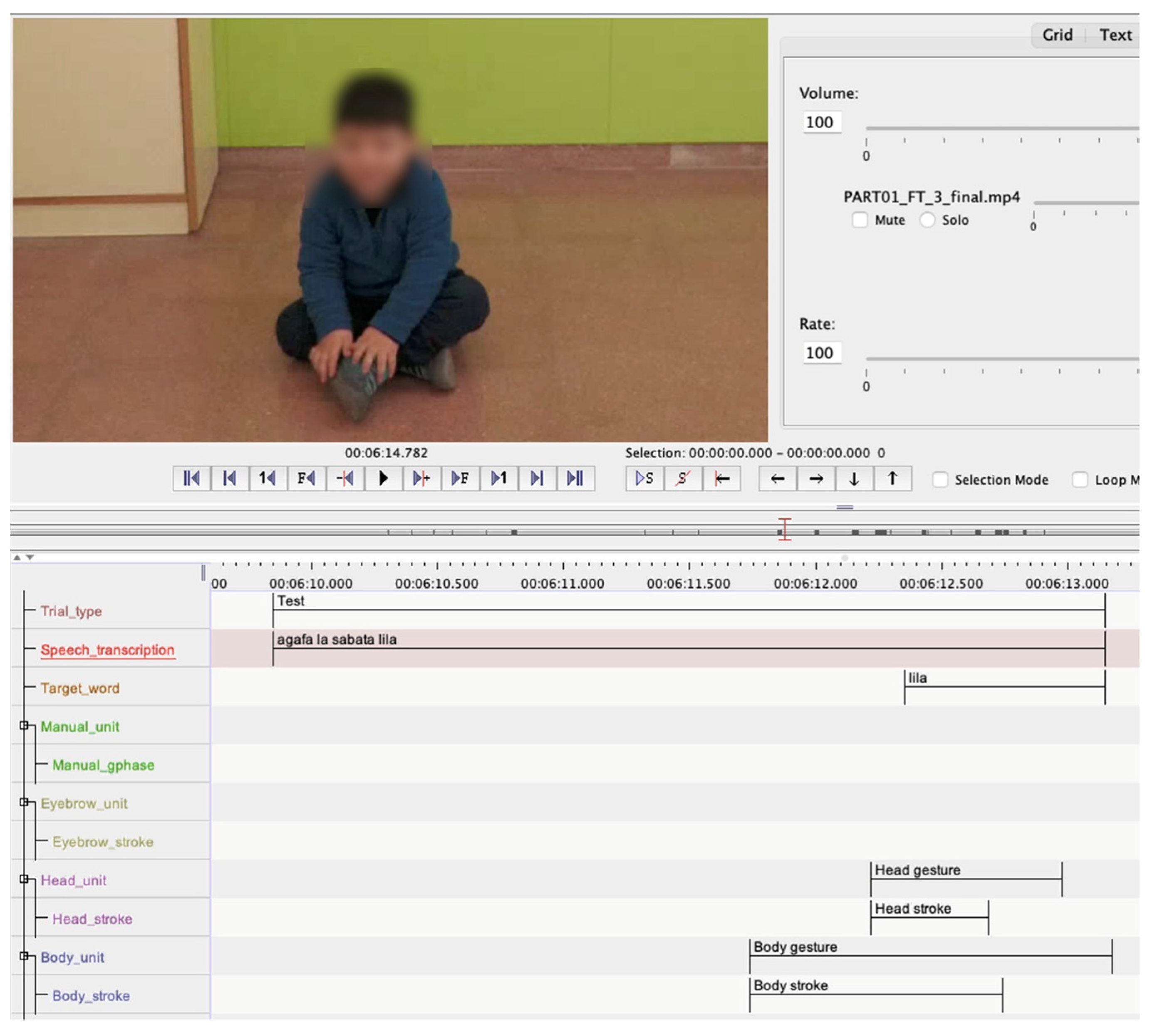
2.5. Data Coding
2.5.1. Prosodic Prominence
2.5.2. Gesture Presence
2.5.3. Gestural Prominence
2.5.4. Reliability
2.6. Data Preparation and Statistical Analysis
3. Results
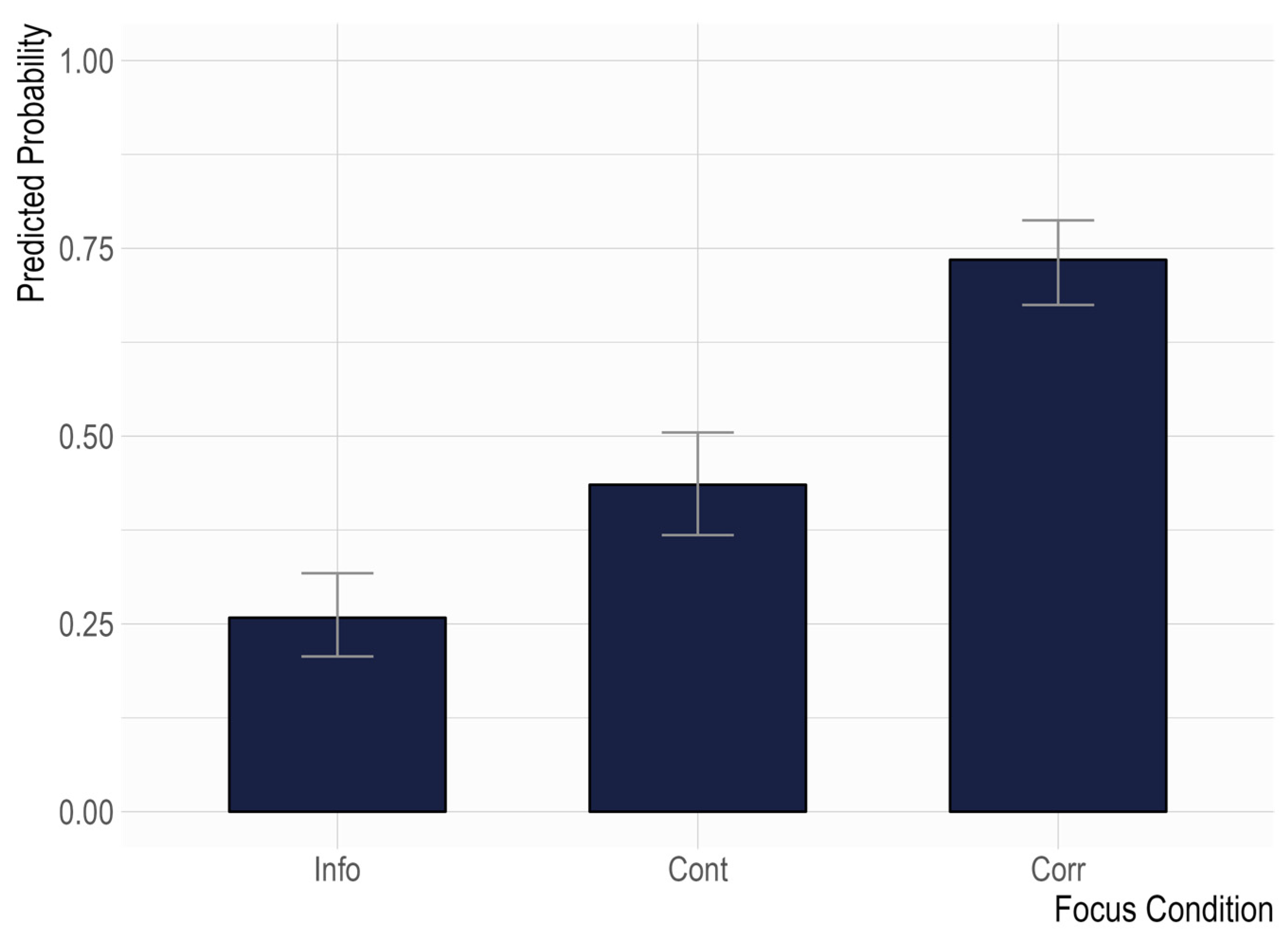
3.1. The Use of Prosodic Prominence in Distinguishing Focus Types Across Age Groups
3.2. The Use of Gestures in Distinguishing Focus Types Across Age Groups
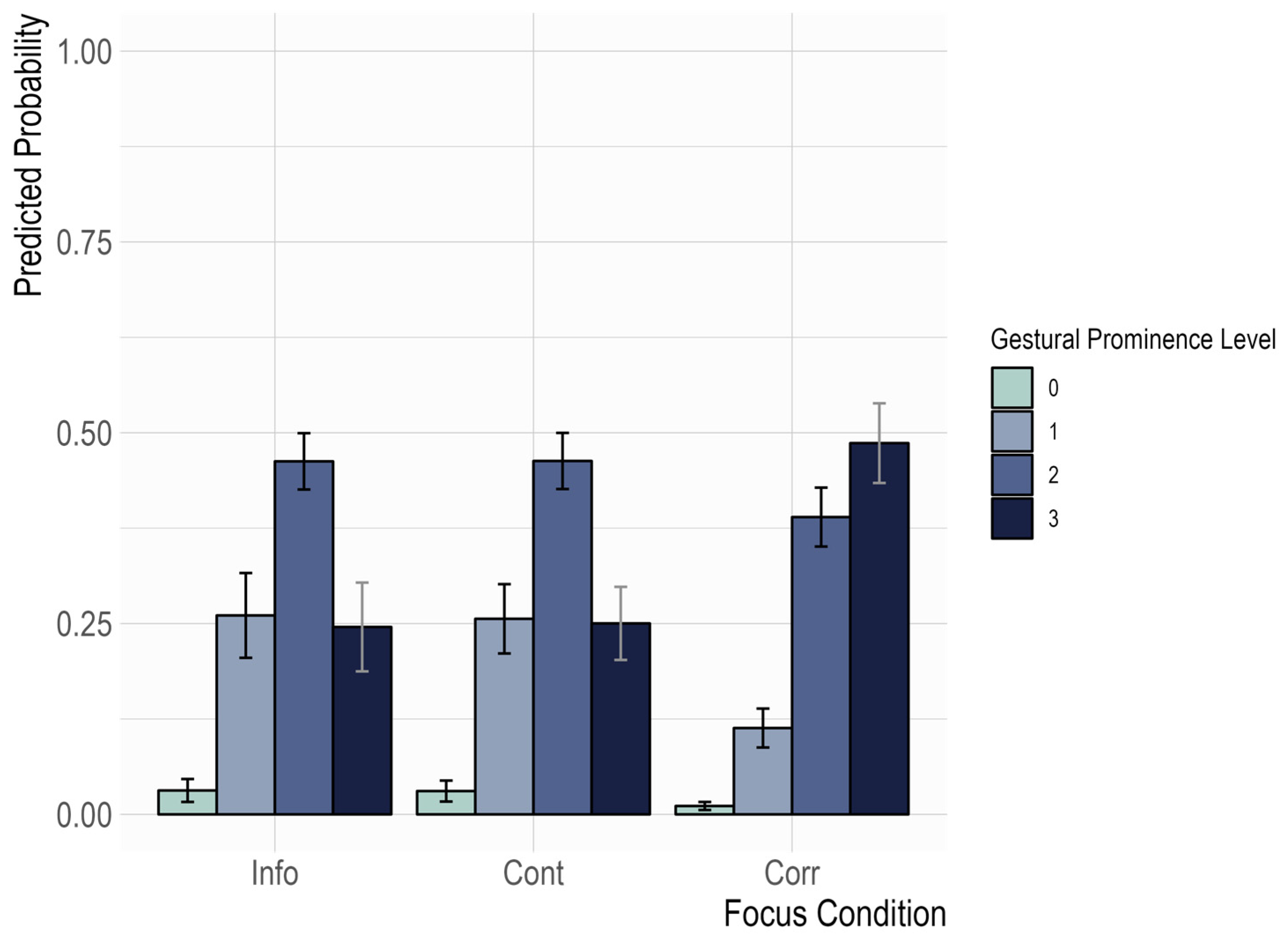
3.3. The Use of Gestural Prominence in Distinguishing Focus Types Across Age Groups
4. Discussion
4.1. Prosodic Prominence Across Focus Types and Age Groups
4.2. Gesture Presence Across Focus Types and Age Groups
4.3. Gestural Prominence in Relation to Focus Types and Age Groups
4.4. Timing of Acquisition of Prosodic and Gesture Cues in Marking Focus Types
4.5. Limitations and Further Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Structure | Example | Focus Condition | N | Percent |
|---|---|---|---|---|
| Complex NP | (Agafa) [la]Determiner [sabata]Noun [lila]Adjective | Total | 748 | 37.57% |
| Information | 247 | |||
| Contrastive | 347 | |||
| Corrective | 154 | |||
| Simple NP | (Agafa) [la]Determiner [gorra]Noun or (Agafa) [aquella]Pronoun | Total | 421 | 21.15% |
| Information | 309 | |||
| Contrastive | 101 | |||
| Corrective | 11 | |||
| AP | (Agafa) [la]Determiner [lila]Noun | Total | 754 | 37.87% |
| Information | 98 | |||
| Contrastive | 296 | |||
| Corrective | 360 | |||
| Repeated focused words | (Agafa) [aquesta,]Pronoun [la]Determiner [sabata]Noun [lila]Adjective or (Agafa) [la]Determiner [lila,]Adjective, [la]Determiner [lila]Adjective | Total | 58 | 2.91% |
| Information | 5 | |||
| Contrastive | 16 | |||
| Corrective | 37 | |||
| No speech | deictic gesture | Total | 10 | 0.5% |
| Information | 1 | |||
| Contrastive | 3 | |||
| Corrective | 6 |
| Articulators | N | Percent |
|---|---|---|
| Hand | 287 | 29.99 |
| Hand and head | 53 | 5.96 |
| Hand and eyebrow | 17 | 1.78 |
| Hand and torso | 24 | 2.51 |
| Hand, head, and eyebrow | 18 | 1.88 |
| Hand, head, and torso | 8 | 0.84 |
| Hand, eyebrow, and torso | 1 | 0.10 |
| Hand, eyebrow, and legs | 2 | 0.21 |
| Hand, eyebrow, torso, legs | 1 | 0.10 |
| Hand, head, eyebrow, and torso | 4 | 0.42 |
| Hand, head, eyebrow, torso, and legs | 1 | 0.10 |
| Head | 224 | 23.41 |
| Head and eyebrow | 1 | 0.10 |
| Head and torso | 86 | 8.99 |
| Head and legs | 4 | 0.42 |
| Head, eyebrow, and torso | 5 | 0.52 |
| Head, eyebrow, and legs | 1 | 0.10 |
| Head, torso and legs | 3 | 0.31 |
| Eyebrow | 23 | 2.40 |
| Torso | 143 | 14.94 |
| Torso and eyebrow | 10 | 1.04 |
| Torso and legs | 6 | 0.63 |
| Legs | 22 | 2.30 |
| 1 | The materials used in the Train Task are available at https://osf.io/7nqke/ (accessed on 22 April 2025). |
| 2 | Only one instance in the final analyzed database involved left dislocation of the focused word. |
| 3 | The materials used to train the raters for the annotation of prosodic prominence, gesture presence, and gestural prominence are available at https://osf.io/k384c/ (accessed on 22 April 2025). |
References
- Adli, A. (2011). A heuristic mathematical approach for modeling constraint cumulativity: Contrastive focus in Spanish and Catalan. The Linguistic Review, 28(2), 111–173. [Google Scholar] [CrossRef]
- Anderson, N. J., Graham, S. A., Prime, H., Jenkins, J. M., & Madigan, S. (2021). Linking quality and quantity of parental linguistic input to child language skills: A meta-analysis. Child Development, 92, 484–501. [Google Scholar] [CrossRef]
- Arnhold, A., Chen, A., & Järvikivi, J. (2016). Acquiring complex focus-marking: Finnish 4- to 5-year-olds use prosody and word order in interaction. Frontiers in Psychology, 7, 1886. [Google Scholar] [CrossRef] [PubMed]
- Astruc, L., Payne, E., Post, B., Vanrell, M. D. M., & Prieto, P. (2013). Tonal targets in early child English, Spanish, and Catalan. Language and Speech, 56(2), 229–253. [Google Scholar] [CrossRef]
- Aureli, T., Spinelli, M., Fasolo, M., Garito, M. C., Perucchini, P., & D’Odorico, L. (2017). The pointing–vocal coupling progression in the first half of the second year of life. Infancy, 22(6), 801–818. [Google Scholar] [CrossRef]
- Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. [Google Scholar] [CrossRef]
- Bavelas, J. B. (2022). Face-to-face dialogue: Theory, research, and applications. Oxford University Press. [Google Scholar]
- Beaupoil-Hourdel, P. (2022). Embodying language complexity: Co-speech gestures between age 3 and 4. In A. Morgenstern, & S. Goldin-Meadow (Eds.), Gesture in language: Development across the lifespan (pp. 380–442). De Gruyter Mouton. [Google Scholar] [CrossRef]
- Beaupoil-Hourdel, P., Morgenstern, A., & Boutet, D. (2016). A child’s multimodal negations from 1 to 4: The interplay between modalities. In P. Larrivée, & C. Lee (Eds.), Negation and polarity: Experimental perspectives (Vol. 1, pp. 95–123). Springer International Publishing. [Google Scholar] [CrossRef]
- Benazzo, S., & Morgenstern, A. (2014). A bilingual child’s multimodal path into negation. Gesture, 14(2), 171–202. [Google Scholar] [CrossRef]
- Boersma, P., & Weenink, D. (2022). Praat: Doing phonetics by computer (Version 6.2.06) [Computer Software]. Available online: https://www.praat.org (accessed on 22 April 2025).
- Brown, L., & Prieto, P. (2021). Gesture and prosody in multimodal communication. In M. Haugh, D. Z. Kádár, & M. Terkourafi (Eds.), The cambridge handbook of sociopragmatics (pp. 430–453). Cambridge University Press. [Google Scholar] [CrossRef]
- Campisi, E., & Özyürek, A. (2013). Iconicity as a communicative strategy: Recipient design in multimodal demonstrations for adults and children. Journal of Pragmatics, 47(1), 14–27. [Google Scholar] [CrossRef]
- Carignan, C., Esteve-Gibert, N., Lœvenbruck, H., Dohen, M., & D’Imperio, M. (2024). Co-speech head nods are used to enhance prosodic prominence at different levels of narrow focus in French. The Journal of the Acoustical Society of America, 156(3), 1720–1733. [Google Scholar] [CrossRef]
- Chen, A. (2011). The developmental path to phonological focus-marking in Dutch. In S. Frota, G. Elordieta, & P. Prieto (Eds.), Prosodic categories: Production, perception and comprehension (pp. 93–109). Springer. [Google Scholar] [CrossRef]
- Chen, A. (2015). Children’ use of intonation in reference and the role of input. In L. Serratrice, & S. E. M. Allen (Eds.), The acquisition of reference (pp. 83–104). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Chen, A. (2018). Get the focus right across languages: Acquisition of prosodic focus-marking in production. In P. Prieto, & N. Esteve-Gibert (Eds.), The development of prosody in first language acquisition (pp. 295–314). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Chen, A., & Höhle, B. (2018). Four- to five-year-olds’ use of word order and prosody in focus marking in Dutch. Linguistics Vanguard, 4(1), 20160101. [Google Scholar] [CrossRef]
- Chouinard, M. M., & Clark, E. V. (2003). Adult reformulations of child errors as negative evidence. Journal of Child Language, 30(3), 637–669. [Google Scholar] [CrossRef]
- Christensen, R. H. B. (2023). Ordinal-regression models for ordinal data (R Package Version 2023.12.4). Available online: https://CRAN.R-project.org/package=ordinal (accessed on 22 April 2025).
- Chung, H.-Y. (2012). Two types of focus in Castilian Spanish [Doctoral dissertation, The University of Texas at Austin]. Repository University of Texas Libraries. Available online: http://hdl.handle.net/2152/19471 (accessed on 22 April 2025).
- Colletta, J.-M., Guidetti, M., Capirci, O., Cristilli, C., Demir, O. E., KuneneNicolas, R. N., & Levine, S. (2014). Effects of age and language on cospeech gesture production: An investigation of French, American, and Italian children’s narratives. Journal of Child Language, 42(1), 122–145. [Google Scholar] [CrossRef] [PubMed]
- Cruschina, S., & Mayol, L. (2022). The realization of information focus in Catalan. Languages, 7(4), 310. [Google Scholar] [CrossRef]
- Debreslioska, S., & Gullberg, M. (2019). Discourse reference is bimodal: How information status in speech interacts with presence and viewpoint of gestures. Discourse Process, 56, 41–60. [Google Scholar] [CrossRef]
- Destruel, E., Lalande, L., & Chen, A. (2024). The development of prosodic focus marking in French. Frontiers in Psychology, 15, 1360308. [Google Scholar] [CrossRef]
- Dodane, C., & Massini-Cagliari, G. (2010). La prosodie dans l’acquisition de la négation: Étude de cas d’une enfant monolingue francaise. ALFA Revista de Lingüística, 54(2), 335–360. [Google Scholar]
- Dufter, A., & Gabriel, C. (2016). 14. Information structure, prosody, and word order. In S. Fischer, & C. Gabriel (Eds.), Manual of grammatical interfaces in Romance (pp. 419–456). De Gruyter. [Google Scholar] [CrossRef]
- Esteve-Gibert, N., Lœvenbruck, H., Dohen, M., & D’Imperio, M. (2022). Pre-schoolers use head gestures rather than prosodic cues to highlight important information in speech. Developmental Science, 25(1), e13154. [Google Scholar] [CrossRef]
- Face, T. L., & D’Imperio, M. (2005). Reconsidering a focal typology: Evidence from Spanish and Italian. Rivista di Linguistica, 17(2), 271–289. [Google Scholar]
- Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. [Google Scholar] [CrossRef]
- Frota, S. (2002). The prosody of focus: A case-study with cross-linguistic implications. Proceedings of Speech Prosody, 2002, 319–322. [Google Scholar] [CrossRef]
- Galati, A., & Brennan, S. E. (2013). Speakers adapt gestures to addressees’ knowledge: Implications for models of co-speech gesture. Language, Cognition and Neuroscience, 29(4), 435–451. [Google Scholar] [CrossRef]
- Gamer, M., Lemon, J., Fellows, I., & Singh, P. (2019). irr: Various coefficients of interrater reliability and agreement (R Package Version 0.84.1). Available online: https://CRAN.R-project.org/package=irr (accessed on 22 April 2025).
- Ganzeboom, H. B. G., De Graaf, P. M., & Treiman, D. J. (1992). A standard international socio-economic index of occupational status. Social Science Research, 21(1), 1–56. [Google Scholar] [CrossRef]
- Goldin-Meadow, S. (2015). Gesture as a window onto communicative abilities: Implications for diagnosis and intervention. Perspectives on Language Learning and Education, 22(2), 50–60. [Google Scholar] [CrossRef] [PubMed]
- Grice, M., & Kügler, F. (2021). Prosodic prominence—A cross-linguistic perspective. Language and Speech, 64(2), 253–260. [Google Scholar] [CrossRef]
- Grünloh, T., Lieven, E., & Tomasello, M. (2015). Young children’s intonational marking of new, given and contrastive referents. Language Learning and Development, 11(2), 95–127. [Google Scholar] [CrossRef]
- Gwet, K. L. (2022). irrCAC: Computing chance-corrected agreement coefficients (CAC) (R Package Version 1.0). Available online: https://cran.r-project.org/web/packages/irrCAC/index.html (accessed on 22 April 2025).
- Holler, J., & Stevens, R. (2007). The effect of common ground on how speakers use gesture and speech to represent size information. Journal of Language and Social Psychology, 26(1), 4–27. [Google Scholar] [CrossRef]
- Hornby, P. A., & Hass, W. A. (1970). Use of contrastive stress by preschool children. Journal of Speech and Hearing Research, 13, 359–99. [Google Scholar] [CrossRef]
- Hostetter, A., Alibali, M., & Schrager, S. (2011). Chapter 5. If you don’t already know, I’m certainly not going to show you! Motivation to communicate affects gesture production. In G. Stam, & M. Ishino (Eds.), Integrating gestures: The interdisciplinary nature of gesture (pp. 61–74). John Benjamins. [Google Scholar] [CrossRef]
- Hübscher, I., Garufi, M., & Prieto, P. (2019a). The development of polite stance in preschoolers: How prosody, gesture, and body cues pave the way. Journal of Child Language, 46(5), 825–862. [Google Scholar] [CrossRef]
- Hübscher, I., & Prieto, P. (2019). Gestural and prosodic development act as sister systems and jointly pave the way for children’s sociopragmatic development. Frontiers in Psychology, 10, 1259. [Google Scholar] [CrossRef]
- Hübscher, I., Vincze, L., & Prieto, P. (2019b). Children’s signaling of their uncertain knowledge state: Prosody, face, and body cues come first. Language Learning and Development, 15(4), 366–389. [Google Scholar] [CrossRef]
- Ito, K. (2014). Children’s pragmatic use of prosodic prominence. In D. Mathews (Ed.), Pragmatic development in first language acquisition (pp. 199–218). John Benjamins. [Google Scholar] [CrossRef]
- Ito, K. (2018). Gradual development of focus prosody and affect prosody comprehension. In P. Prieto, & N. Esteve-Gibert (Eds.), The development of prosody in first language acquisition (pp. 247–270). John Benjamins Publishing Company. [Google Scholar] [CrossRef]
- Katz, J., & Selkirk, E. (2011). Contrastive focus vs. discourse-new: Evidence from phonetic prominence in English. Language, 87(4), 771–816. [Google Scholar] [CrossRef]
- Kendon, A. (2004). Gesture: Visible action as utterance. Cambridge University Press. [Google Scholar]
- Kim, S., Paulus, M., Sodian, B., & Proust, J. (2016). Young children’s sensitivity to their own ignorance in informing others. PLoS ONE, 11(3), e0152595. [Google Scholar] [CrossRef] [PubMed]
- Krifka, M. (2008). Basic notions of information structure. Acta Linguistica Hungarica, 55(3–4), 243–276. [Google Scholar] [CrossRef]
- Kügler, F., & Calhoun, S. (2021). Prosodic encoding of information structure. In C. Gussenhoven, & A. Chen (Eds.), The oxford handbook of language prosody (pp. 453–467). Oxford University Press. [Google Scholar]
- Kügler, F., & Gollrad, A. (2015). Production and perception of contrast: The case of the rise-fall contour in German. Frontiers in Psychology, 6, 1254. [Google Scholar] [CrossRef]
- Kügler, F., Smolibocki, B., Arnold, D., Baumann, S., Braun, B., Grice, M., Jannedy, S., Michalsky, J., Niebuhr, O., & Peters, J. (2015). DIMA: Annotation guidelines for German intonation. In The Scottish Consortium for ICPhS 2015 (Ed.), Proceedings of the 18th International Congress of Phonetic Sciences. IPA Public Archive. [Google Scholar]
- MacWhinney, B., & Bates, E. (1978). Sentential devices for conveying givenness and newness: A cross-cultural developmental study. Journal of Verbal Learning and Verbal Behavior, 17(5), 539–558. [Google Scholar] [CrossRef]
- Marian, V., Blumenfeld, H. K., & Kaushanskaya, M. (2007). The language experience and proficiency questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech Language and Hearing Research, 50(4), 940–967, Translation by Puig-Mayenco & Tubau (2016), Universitat Autònoma de Barcelona. [Google Scholar] [CrossRef] [PubMed]
- Mayol, L. (2007). Right-dislocation in Catalan: Its discourse function and counterparts in English. Languages in Contrast, 7(2), 203–20. [Google Scholar] [CrossRef]
- Morgenstern, A., Blondel, M., Beaupoil-Hourdel, P., Benazzo, S., Boutet, D., Kochan, A., & Limousin, F. (2018). The blossoming of negation in gesture, sign and oral productions. In M. Hickman, E. Veneziano, & H. Jisa (Eds.), Sources of variation in first language acquisition: Languages, contexts, and learners (pp. 339–364). John Benjamins. [Google Scholar] [CrossRef]
- Murillo, E., & Capilla, A. (2016). Properties of vocalization- and gesture-combinations in the transition to first words. Journal of Child Language, 43(4), 890–913. [Google Scholar] [CrossRef]
- Peppé, S., & McCann, J. (2003). Assessing intonation and prosody in children with atypical language development: The PEPS–C test and the revised version. Clinical Linguistics & Phonetics, 17, 345–354. [Google Scholar]
- Prieto, P. (2014). The intonational phonology of Catalan. In S.-A. Jun (Ed.), Prosodic typology II (1st ed., pp. 43–80). Oxford University Press. [Google Scholar] [CrossRef]
- Pronina, M., Prieto, P., Bischetti, L., & Bambini, V. (2023). Expressive pragmatics and prosody in young preschoolers are more closely related to structural language than to mentalizing. Language Learning and Development, 19(3), 323–344. [Google Scholar] [CrossRef]
- R Core Team. (2024). R: A language and environment for statistical computing [Computer software]. R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 22 April 2025).
- Repp, S. (2010). Defining ‘contrast’ as an information-structural notion in grammar. Lingua, 120(6), 1333–1345. [Google Scholar] [CrossRef]
- Repp, S. (2016). Contrast: Dissecting an elusive information-structural notion and its role in Grammar. In C. Féry, & S. Ishihara (Eds.), The Oxford handbook of information structure (1st ed., pp. 270–289). Oxford University Press. [Google Scholar] [CrossRef]
- Rohrer, P. L. (2022). A temporal and pragmatic analysis of gesture-speech association: A corpus-based approach using the novel MultiModal MultiDimensional (M3D) labeling system [Doctoral dissertation, Nantes Université-Universitat Pompeu Fabra]. E-Reopositori UPF. Available online: http://hdl.handle.net/10803/687534 (accessed on 22 April 2025).
- Rohrer, P. L., Florit-Pons, J., Vilà-Giménez, I., & Prieto, P. (2022). Children use non-referential gestures in narrative speech to mark discourse elements which update common ground. Frontiers in Psychology, 12, 661339. [Google Scholar] [CrossRef] [PubMed]
- Rohrer, P. L., Tütüncübasi, U., Vilà-Giménez, I., Florit-Pons, J., Esteve-Gibert, N., Ren-Mitchell, A., Shattuck-Hufnagel, S., & Prieto, P. (2023). The MultiModal MultiDimensional (M3D) labeling system. Available online: https://doi.org/10.17605/osf.io/ankdx (accessed on 22 April 2025).
- Sánchez-Ramón, P., Gregori, A., Kugler, F., & Prieto, P. (2024, September 6). La prominència prosòdica va lligada a la prominència gestual? El marcatge multimodal del focus en català [Conference presentation]. Workshop de la prosòdia del català, Palma de Mallorca, Spain. [Google Scholar]
- Sánchez-Ramón, P., Gregori, A., Kugler, F., & Prieto, P. (in preparation). The multimodal marking of focus types in Catalan and German.
- Serrat, E., Aguilar-Mediavilla, E., Sanz-Torrent, M., Andreu, L., Amadó, A., Badia, I., & Serra, M. (2022). Inventaris del desenvolupament d’habilitats comunicatives MacArthur-Bates en català. Universitat Oberta de Catalunya. [Google Scholar]
- Snow, D. (1998). Children’s imitations of intonation contours: Are rising tones more difficult than falling tone? Journal of Speech, Language, and Hearing Research, 41, 576–587. [Google Scholar] [CrossRef]
- Stalnaker, R. (2002). Common ground. Linguistics and Philosophy, 25(5/6), 701–721. Available online: http://www.jstor.org/stable/25001871 (accessed on 22 April 2025). [CrossRef]
- The Language Archive. (2023). ELAN (Version 6.7) [Computer software]. Max Plank Institute for Psycholinguistics. Available online: https://archive.mpi.nl/tla/elan (accessed on 22 April 2025).
- Thorson, J. C., & Morgan, J. L. (2021). Prosodic realizations of new, given, and corrective referents in the spontaneous speech of toddlers. Journal of Child Language, 48(3), 541–568. [Google Scholar] [CrossRef] [PubMed]
- Umbach, C. (2004). On the notion of contrast in information structure and discourse structure. Journal of Semantics, 21(2), 155–175. [Google Scholar] [CrossRef]
- Vallduví, E. (1994). Detachment in Catalan and information packaging. Journal of Pragmatics, 22, 573–601. [Google Scholar] [CrossRef]
- Vander Klok, J., Goad, H., & Wagner, M. (2018). Prosodic focus in English vs. French: A scope account. Glossa: A Journal of General Linguistics, 3(1), 71. [Google Scholar] [CrossRef]
- Vanrell, M. D. M., & Fernández Soriano, O. (2013). Variation at the interfaces in ibero-romance. Catalan and spanish prosody and word order. Catalan Journal of Linguistics, 12, 253. [Google Scholar] [CrossRef]
- Vanrell, M. D. M., Stella, A., Fivela, B. G., & Prieto, P. (2013). Prosodic manifestations of the effort code in Catalan, Italian and Spanish contrastive focus. Journal of the International Phonetic Association, 43(2), 195–220. [Google Scholar] [CrossRef]
- Wagner, P., Malisz, Z., & Kopp, S. (2014). Gesture and speech in interaction: An overview. Speech Communication, 57, 209–232. [Google Scholar]
- Wells, B., Peppé, S., & Goulandris, N. (2004). Intonation development from five to thirteen. Journal of Child Language, 31(4), 749–778. [Google Scholar] [CrossRef] [PubMed]
- Wiig, E. H., Secord, W. A., & Semel, E. (2009). Clinical evaluation of language fundamentals—Preschool Spanish (CELF 2). Pearson. [Google Scholar]
- Wonnacott, E., & Watson, D. G. (2008). Acoustic emphasis in four year olds. Cognition, 107(3), 1093–1101. [Google Scholar] [CrossRef] [PubMed]



| N | Sex | Age Range (Years; Months) | Average Age (Years; Months) | |
|---|---|---|---|---|
| Total | 116 | 54 girls | 3; 3–6; 3 | 4; 10 |
| Three-year-olds | 34 | 14 girls | 3; 3–4; 0 | 3; 8 |
| Four-year-olds | 36 | 19 girls | 4; 1–5; 0 | 4; 8 |
| Five-year-olds | 46 | 21 girls | 5; 1–6; 3 | 5; 10 |
| Focus Condition | Expected Production | Example Stimuli |
|---|---|---|
| Information | (Agafa) el [llibre negre]Focus Lit. trans. 1: (Pick up) the [book black]Focus Trans. 2: (Pick up) the black book |  |
| Contrastive | (Agafa) la sabata [lila]Focus Lit. trans.: (Pick up) the shoe [purple]Focus Trans.: (Pick up) the purple shoe |  |
| Corrective | No, (agafa) la sabata [lila]Focus Lit. trans.: No, (pick up) the shoe [purple]Focus Trans.: No, (pick up) the purple shoe |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coego, S.; Esteve-Gibert, N.; Prieto, P. Preschoolers Mark Focus Types Through Multimodal Prominence: Further Evidence for the Precursor Role of Gestures. Languages 2025, 10, 92. https://doi.org/10.3390/languages10050092
Coego S, Esteve-Gibert N, Prieto P. Preschoolers Mark Focus Types Through Multimodal Prominence: Further Evidence for the Precursor Role of Gestures. Languages. 2025; 10(5):92. https://doi.org/10.3390/languages10050092
Chicago/Turabian StyleCoego, Sara, Núria Esteve-Gibert, and Pilar Prieto. 2025. "Preschoolers Mark Focus Types Through Multimodal Prominence: Further Evidence for the Precursor Role of Gestures" Languages 10, no. 5: 92. https://doi.org/10.3390/languages10050092
APA StyleCoego, S., Esteve-Gibert, N., & Prieto, P. (2025). Preschoolers Mark Focus Types Through Multimodal Prominence: Further Evidence for the Precursor Role of Gestures. Languages, 10(5), 92. https://doi.org/10.3390/languages10050092