New Reliability Studies of Data-Driven Aircraft Trajectory Prediction



Abstract
1. Introduction
2. Related Works on Trajectory-Based Operations
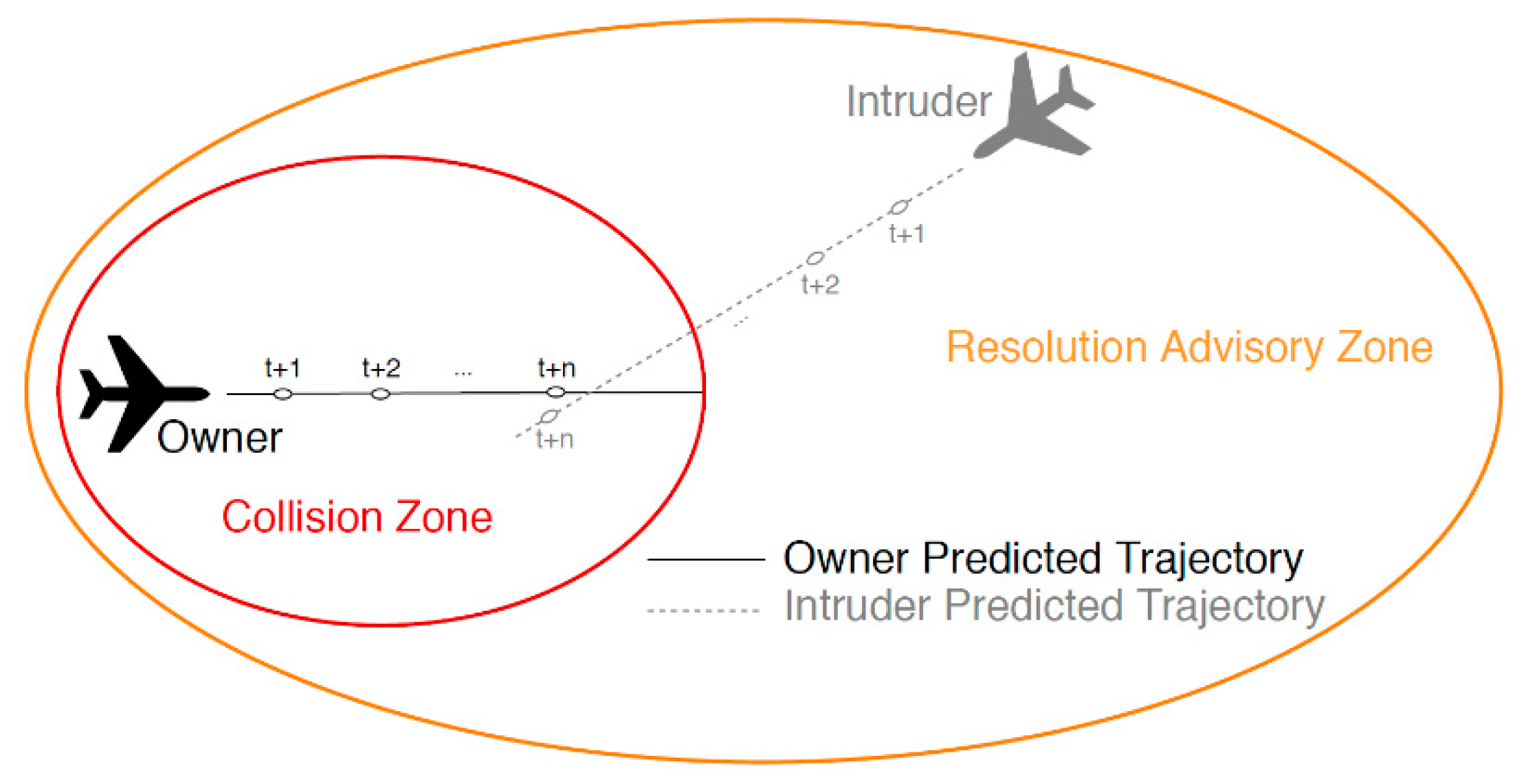
2.1. Collision Avoidance
2.2. Data-Driven Trajectory Prediction
3. Building Data-Driven Predictors
3.1. Logistic Regression (LR)
3.2. Support Vector Regression (SVR)
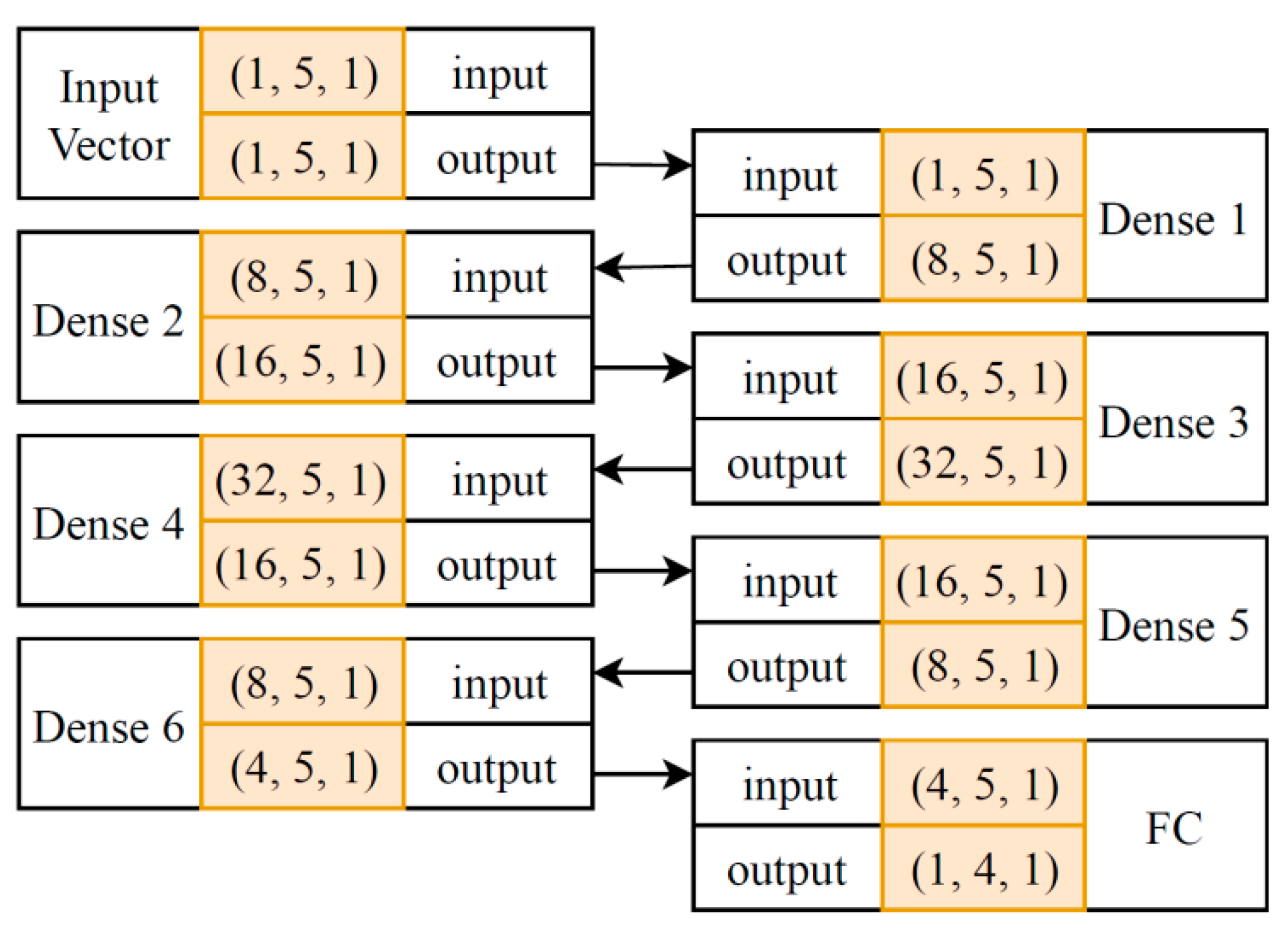
3.3. Deep Neural Network (DNN)
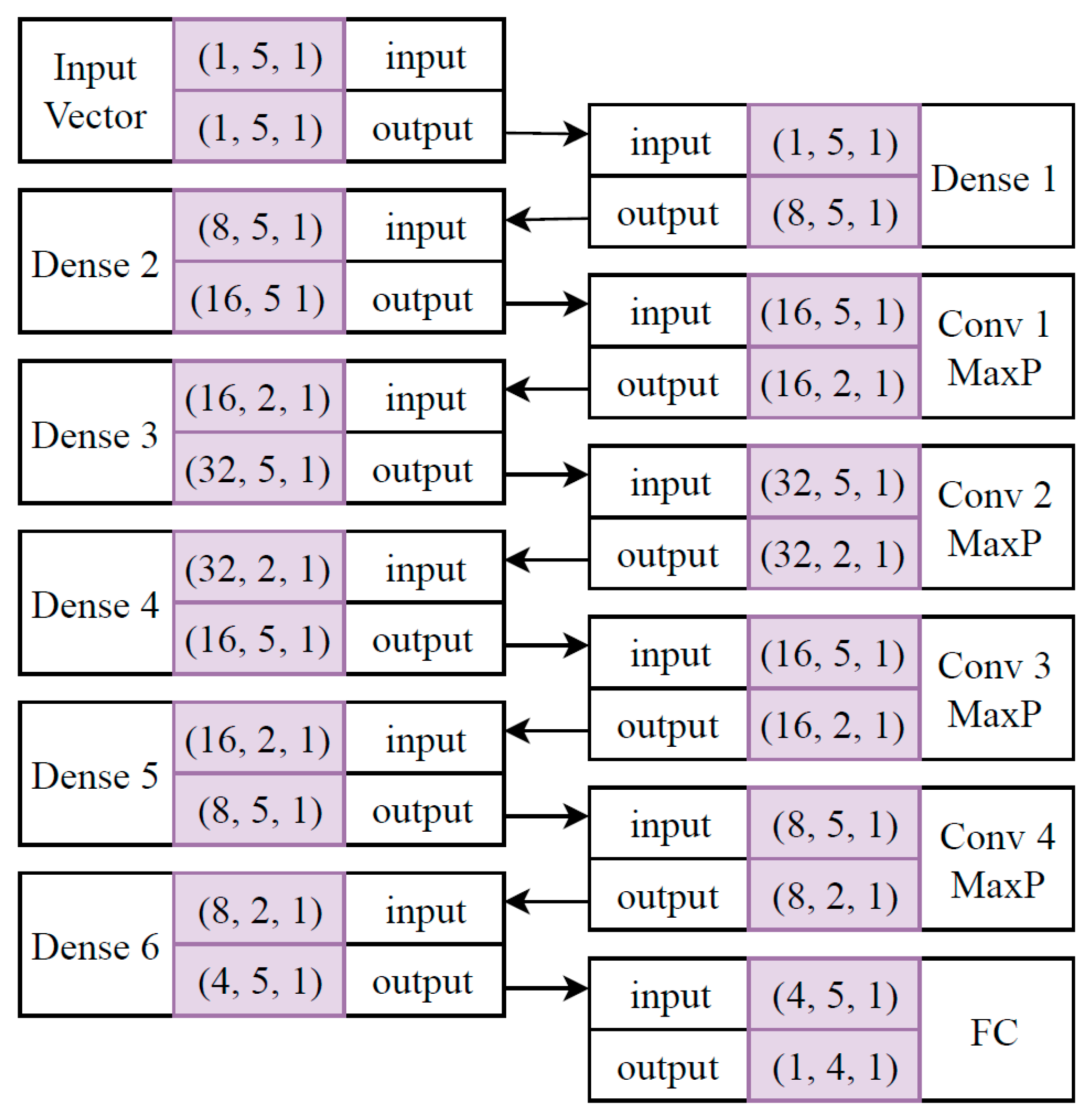
3.4. Convolutional Neural Network (CNN)
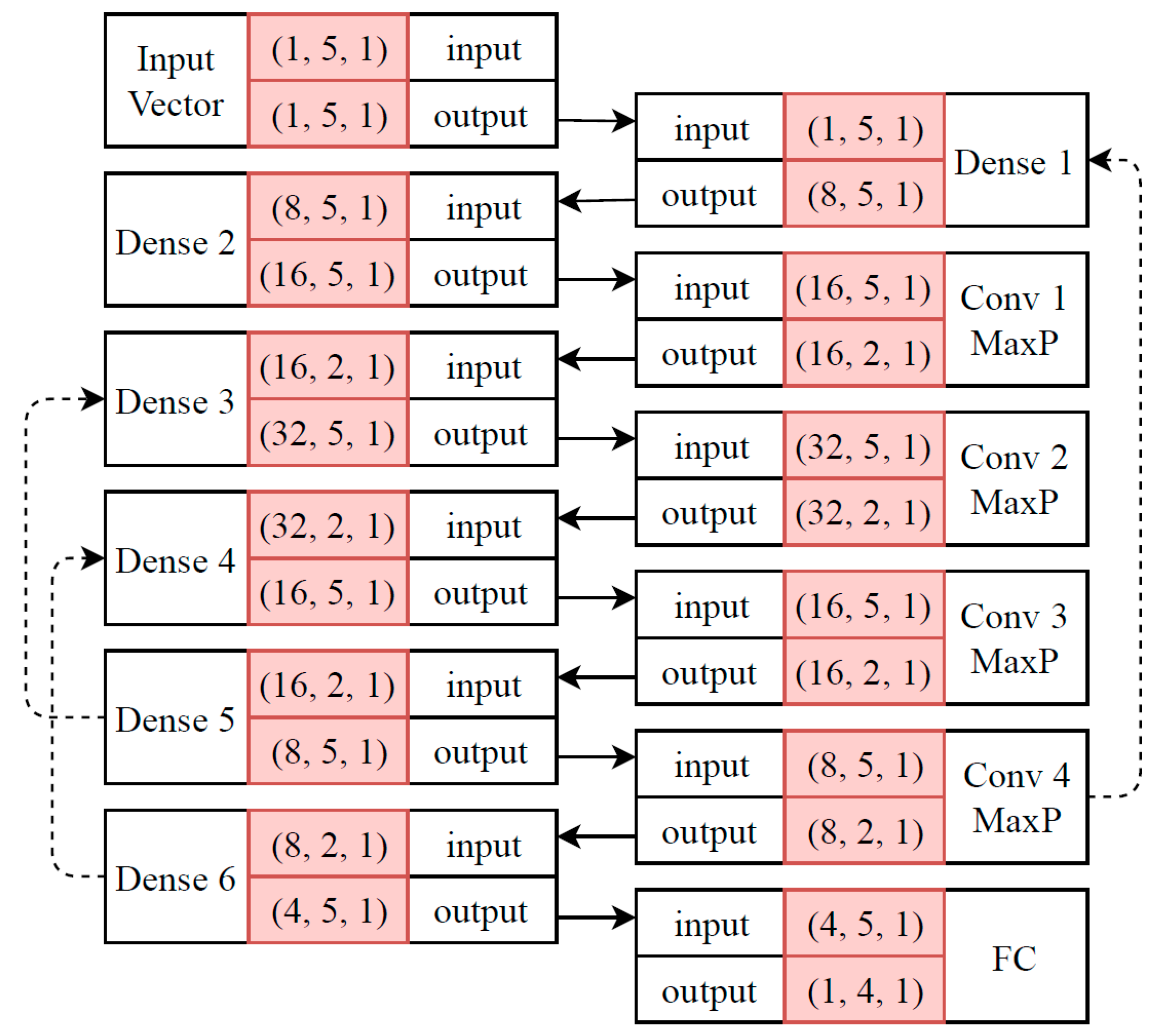
3.5. Recurrent CNN (RNN)
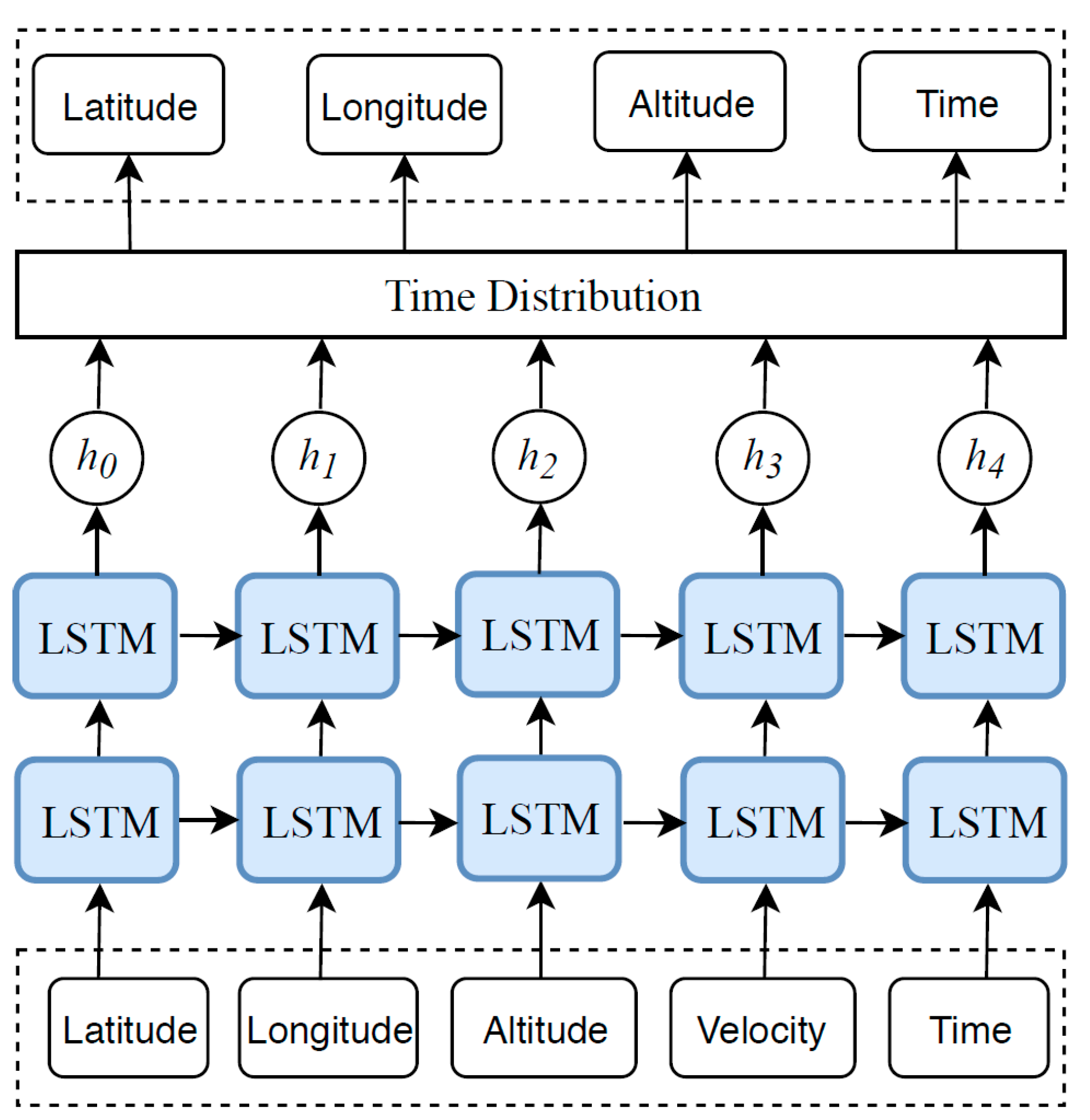
3.6. Long Short-Term Memory (LSTM)
4. Numerical Results
4.1. Dataset
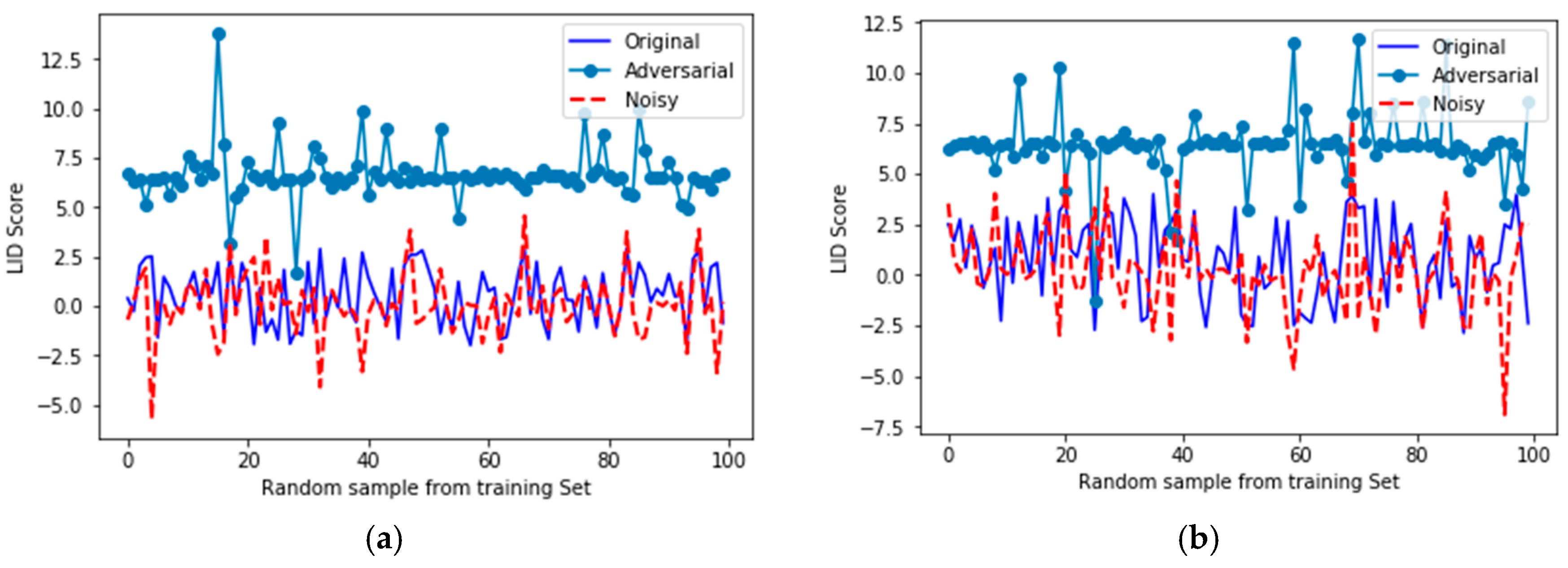
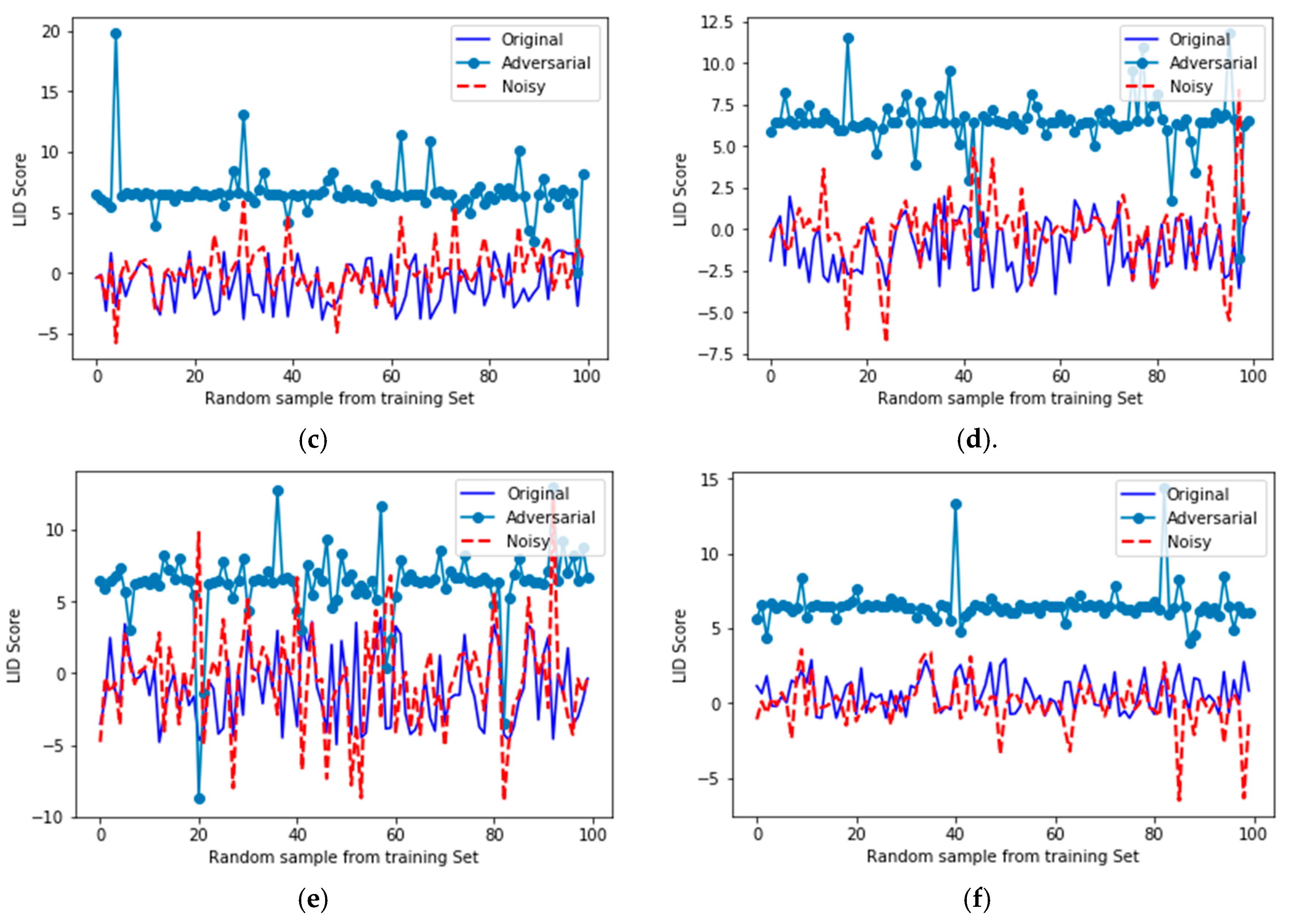
4.2. Measuring the Resiliency of Models
4.3. Adversarial Retraining
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Adesina, D.; Adagunodo, O.; Dong, X.; Qian, L. Aircraft Location Prediction using Deep Learning. In Proceedings of the 2019 IEEE Military Communications Conference (MILCOM 2019), Norfolk, VA, USA, 12–14 November 2019; pp. 127–132. [Google Scholar]
- Murrieta-Mendoza, A.; Romain, C.; Botez, R.M. Commercial aircraft lateral flight reference trajectory optimization. IFAC-PapersOnLine 2016, 49, 1–6. [Google Scholar] [CrossRef]
- Murrieta-Mendoza, A.; Botez, R. Aircraft Vertical Route Optimization Deterministic Algorithm for a Flight Management System; 0148-7191; SAE Technical Paper: Warrendale, PA, USA, 2015. [Google Scholar]
- Murrieta-Mendoza, A.; Botez, R.M. Methodology for vertical-navigation flight-trajectory cost calculation using a performance database. J. Aerosp. Inf. Syst. 2015, 12, 519–532. [Google Scholar] [CrossRef]
- Dancila, B.D.; Beulze, B.; Botez, R.M. Geometrical vertical trajectory optimization–comparative performance evaluation of phase versus phase and altitude-dependent preferred gradient selection. IFAC-PapersOnLine 2016, 49, 17–22. [Google Scholar] [CrossRef]
- Patrón, R.S.F.; Botez, R.M. Flight trajectory optimization through genetic algorithms for lateral and vertical integrated navigation. J. Aerosp. Inf. Syst. 2015, 12, 533–544. [Google Scholar] [CrossRef]
- Murrieta-Mendoza, A.; Ruiz, H.; Kessaci, S.; Botez, R.M. 3D reference trajectory optimization using particle swarm optimization. In Proceedings of the 17th AIAA Aviation Technology, Integration, and Operations Conference, Denver, CO, USA, 5–9 June 2017; p. 3435. [Google Scholar]
- Murrieta-Mendoza, A.; Hamy, A.; Botez, R.M. Four-and three-dimensional aircraft reference trajectory optimization inspired by ant colony optimization. J. Aerosp. Inf. Syst. 2017, 14, 597–616. [Google Scholar] [CrossRef]
- Murrieta-Mendoza, A.; Botez, R.M.; Bunel, A. Four-dimensional aircraft en route optimization algorithm using the artificial bee colony. J. Aerosp. Inf. Syst. 2018, 15, 307–334. [Google Scholar] [CrossRef]
- Murrieta-Mendoza, A.; Ternisien, L.; Beuze, B.; Botez, R.M. Aircraft vertical route optimization by beam search and initial search space reduction. J. Aerosp. Inf. Syst. 2018, 15, 157–171. [Google Scholar] [CrossRef]
- Ruby, M.; Botez, R.M. Trajectory optimization for vertical navigation using the harmony search algorithm. IFAC-PapersOnLine 2016, 49, 11–16. [Google Scholar] [CrossRef]
- Nolan, M. Fundamentals of Air Traffic Control; Cengage Learning: Boston, MA, USA, 2010. [Google Scholar]
- Gardner, R.W.; Genin, D.; McDowell, R.; Rouff, C.; Saksena, A.; Schmidt, A. Probabilistic model checking of the next-generation airborne collision avoidance system. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Kochenderfer, M.J.; Holland, J.E.; Chryssanthacopoulos, J.P. Next-Generation Airborne Collision Avoidance System; Massachusetts Institute of Technology-Lincoln Laboratory: Lexington, MA, USA, 2012. [Google Scholar]
- Jin, W.; Li, Y.; Xu, H.; Wang, Y.; Tang, J. Adversarial Attacks and Defenses on Graphs: A Review and Empirical Study. arXiv 2020, arXiv:2003.00653. [Google Scholar]
- Federal Aviation Administration. Introduction to TCAS II; Version 7.1; Federal Aviation Administration: Washington, DC, USA, 2011.
- Kuchar, J.K.; Yang, L.C. A review of conflict detection and resolution modeling methods. IEEE Trans. Intell. Transp. Syst. 2000, 1, 179–189. [Google Scholar] [CrossRef]
- Ceruti, A.; Bombardi, T.; Piancastell, L. Visual Flight Rules Pilots into Instrumental Meteorological Conditions: A Proposal for a Mobile Application to Increase In-flight Survivability. Int. Rev. Aerosp. Eng. (IREASE) 2016, 9, 4610–4616. [Google Scholar] [CrossRef]
- Saggiani, G.; Persiani, F.; Ceruti, A.; Tortora, P.; Troiani, E.; Giuletti, F.; Amici, S.; Buongiorno, M.; Distefano, G.; Bentini, G. A UAV system for observing volcanoes and natural hazards. AGUFM 2007, 2007, GC11B-05. [Google Scholar]
- Yu, Z.; Zhang, Y.; Jiang, B.; Su, C.-Y.; Fu, J.; Jin, Y.; Chai, T. Decentralized fractional-order backstepping fault-tolerant control of multi-UAVs against actuator faults and wind effects. Aerosp. Sci. Technol. 2020, 104, 105939. [Google Scholar] [CrossRef]
- Yu, Z.-Q.; Liu, Z.-X.; Zhang, Y.-M.; Qu, Y.-H.; Su, C.-Y. Decentralized fault-tolerant cooperative control of multiple UAVs with prescribed attitude synchronization tracking performance under directed communication topology. Front. Inf. Technol. Electron. Eng. 2019, 20, 685–700. [Google Scholar] [CrossRef]
- Ceruti, A.; Curatolo, S.; Bevilacqua, A.; Marzocca, P. Image Processing Based Air Vehicles Classification for UAV Sense and Avoid Systems; SAE Technical Paper: Warrendale, PA, USA, 2015; ISSN 0148-7191. [Google Scholar]
- Julian, K.D.; Kochenderfer, M.J.; Owen, M.P. Deep neural network compression for aircraft collision avoidance systems. J. Guid. Control Dyn. 2019, 42, 598–608. [Google Scholar] [CrossRef]
- Guo, L.; YU, X.; Zhang, X.; Zhang, Y. Safety control system technologies for UAVs: Review and prospect. Sci. Sin. Inf. 2020, 50, 184–194. [Google Scholar] [CrossRef]
- Benavides, J.V.; Kaneshige, J.; Sharma, S.; Panda, R.; Steglinski, M. Implementation of a trajectory prediction function for trajectory based operations. In Proceedings of the AIAA Atmospheric Flight Mechanics Conference, Minneapolis, MI, USA, 13–16 August 2012; p. 2198. [Google Scholar]
- Sahawneh, L.R.; Beard, R.W. A probabilistic framework for unmanned aircraft systems collision detection and risk estimation. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 242–247. [Google Scholar]
- Jilkov, V.P.; Ledet, J.H.; Li, X.R. Multiple model method for aircraft conflict detection and resolution in intent and weather uncertainty. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 1004–1020. [Google Scholar] [CrossRef]
- Pereida, K.; Schoellig, A.P. Adaptive model predictive control for high-accuracy trajectory tracking in changing conditions. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7831–7837. [Google Scholar]
- Wang, M.; Luo, J.; Walter, U. A non-linear model predictive controller with obstacle avoidance for a space robot. Adv. Space Res. 2016, 57, 1737–1746. [Google Scholar] [CrossRef]
- Dai, L.; Cao, Q.; Xia, Y.; Gao, Y. Distributed MPC for formation of multi-agent systems with collision avoidance and obstacle avoidance. J. Frankl. Inst. 2017, 354, 2068–2085. [Google Scholar] [CrossRef]
- Foo, J.L.; Knutzon, J.; Kalivarapu, V.; Oliver, J.; Winer, E. Path planning of unmanned aerial vehicles using B-splines and particle swarm optimization. J. Aerosp. Comput. Inf. Commun. 2009, 6, 271–290. [Google Scholar] [CrossRef]
- Cobano, J.A.; Conde, R.; Alejo, D.; Ollero, A. Path planning based on genetic algorithms and the monte-carlo method to avoid aerial vehicle collisions under uncertainties. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 4429–4434. [Google Scholar]
- Duan, H.; Luo, Q.; Shi, Y.; Ma, G. hybrid particle swarm optimization and genetic algorithm for multi-UAV formation reconfiguration. IEEE Comput. Intell. Mag. 2013, 8, 16–27. [Google Scholar] [CrossRef]
- Barratt, S.T.; Kochenderfer, M.J.; Boyd, S.P. Learning probabilistic trajectory models of aircraft in terminal airspace from position data. IEEE Trans. Intell. Transp. Syst. 2018, 20, 3536–3545. [Google Scholar] [CrossRef]
- Andersson, O.; Wzorek, M.; Doherty, P. Deep learning quadcopter control via risk-aware active learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3812–3818. [Google Scholar]
- Pham, D.-T.; Tran, N.P.; Alam, S.; Duong, V.; Delahaye, D. A machine learning approach for conflict resolution in dense traffic scenarios with uncertainties. In Proceedings of the Thirteenth USA/Europe Air Traffic Management Research and Development Seminar (ATM2019), Vienna, Austria, 17–21 June 2019; pp. 1–12. [Google Scholar]
- Wang, X.; Sun, T.; Yang, R.; Li, C.; Luo, B.; Tang, J. Quality-aware dual-modal saliency detection via deep reinforcement learning. Signal Process. Image Commun. 2019, 75, 158–167. [Google Scholar] [CrossRef]
- Ayhan, S.; Samet, H. Aircraft trajectory prediction made easy with predictive analytics. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 21–30. [Google Scholar]
- Liu, Y.; Hansen, M. Predicting aircraft trajectories: A deep generative convolutional recurrent neural networks approach. arXiv 2018, arXiv:1812.11670. [Google Scholar]
- Wu, H.; Chen, Z.; Sun, W.; Zheng, B.; Wang, W. Modeling Trajectories with Recurrent Neural Networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3083–3090. [Google Scholar]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 1–26 July 2018; pp. 1672–1678. [Google Scholar]
- Guan, X.; Lv, R.; Sun, L.; Liu, Y. A study of 4D trajectory prediction based on machine deep learning. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 24–27. [Google Scholar]
- Ter Braak, C.J.; Looman, C.W. Weighted averaging, logistic regression and the Gaussian response model. Vegetatio 1986, 65, 3–11. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic Regression. In Reading and Understanding Multivariate Statistics; Grimm, L.G., Yarnold, P.R., Eds.; American Psychological Association: Washington, DC, USA, 1995; pp. 217–244. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Allison, P.D. Logistic Regression Using SAS: Theory and Application; SAS institute: Cary, NC, USA, 2012. [Google Scholar]
- Chen, D.-R.; Wu, Q.; Ying, Y.; Zhou, D.-X. Support vector machine soft margin classifiers: Error analysis. J. Mach. Learn. Res. 2004, 5, 1143–1175. [Google Scholar]
- Rocha, M.; Cortez, P.; Neves, J. Evolution of neural networks for classification and regression. Neurocomputing 2007, 70, 2809–2816. [Google Scholar] [CrossRef]
- Qiu, X.; Zhang, L.; Ren, Y.; Suganthan, P.N.; Amaratunga, G. Ensemble deep learning for regression and time series forecasting. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Ensemble Learning (CIEL), Orlando, FL, USA, 9–12 December 2014; pp. 1–6. [Google Scholar]
- Van Dyk, D.A.; Meng, X.-L. The art of data augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Aqib, M.; Mehmood, R.; Alzahrani, A.; Katib, I.; Albeshri, A.; Altowaijri, S.M. Smarter traffic prediction using big data, in-memory computing, deep learning and GPUs. Sensors 2019, 19, 2206. [Google Scholar] [CrossRef]
- Wiens, T.S.; Dale, B.C.; Boyce, M.S.; Kershaw, G.P. Three way k-fold cross-validation of resource selection functions. Ecol. Model. 2008, 212, 244–255. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv 2018, arXiv:1801.02613. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LR | SVR | DNN | CNN | RNN | LSTM | |
|---|---|---|---|---|---|---|
| 0.0103 | 0.0174 | 0.0139 | 0.0165 | 0.0237 | 0.0142 | |
| 59 | 126 | 207 | 67 | 106 | 92 |
| LR | SVR | DNN | CNN | RNN | LSTM | |
|---|---|---|---|---|---|---|
| Fooling rate | 100 | 100 | 100 | 100 | 100 | 100 |
| Prediction confidence score | 0.784 | 0.843 | 0.732 | 0.879 | 0.910 | 0.881 |
| LR | SVR | DNN | CNN | RNN | LSTM | |
|---|---|---|---|---|---|---|
| LR | 100 | 78.36 | 84.14 | 91.23 | 89.66 | 91.17 |
| SVR | 81.23 | 100 | 84.17 | 95.07 | 84.56 | 89.59 |
| DNN | 90.07 | 89.23 | 100 | 95.81 | 97.33 | 94.46 |
| CNN | 86.75 | 88.71 | 91.63 | 100 | 91.55 | 93.57 |
| RNN | 97.29 | 94.58 | 90.67 | 95.58 | 100 | 98.26 |
| LSTM | 79.16 | 81.92 | 89.99 | 93.52 | 88.37 | 100 |
| Max Iteration | Training Accuracy (%) | Test Accuracy (%) | Penalty | Tolerance | Fitting Intercept | # Jobs | C | |
|---|---|---|---|---|---|---|---|---|
| Without cross-validation | 120 | 86.36 | 84.27 | False | 4 | 0.002 | ||
| 5-fold cross-validation | 100 | 91.23 | 87.75 | False | 4 | 0.001 | ||
| 10-fold cross-validation | 95 | 92.13 | 86.49 | True | 8 | 0.003 | ||
| 15-fold cross-validation | 85 | 92.67 | 86.18 | True | 8 | 0.002 |
| LR | SVR | DNN | CNN | RNN | LSTM | |
|---|---|---|---|---|---|---|
| DNN | 78.25 | 86.94 | 100 | 91.25 | 89.36 | 90.71 |
| CNN | 85.13 | 84.58 | 92.47 | 100 | 91.55 | 92.05 |
| RNN | 90.96 | 92.37 | 88.24 | 93.37 | 100 | 91.08 |
| LSTM | 91.45 | 90.33 | 89.69 | 89.99 | 92.28 | 100 |
| c | LR | SVR | DNN | CNN | RNN | LSTM | |
|---|---|---|---|---|---|---|---|
| 0.25 | 86.45 | 77.36 | 80.35 | 81.06 | 78.37 | 79.08 | |
| Fooling rate (%) | 0.50 | 83.25 | 76.28 | 79.47 | 81.69 | 79.84 | 74.41 |
| 0.75 | 84.27 | 75.79 | 80.23 | 81.97 | 80.56 | 73.19 | |
| 0.25 | 66.16 | 56.33 | 61.74 | 57.19 | 59.67 | 61.54 | |
| Regression accuracy (%) | 0.50 | 64.87 | 57.13 | 64.24 | 58.36 | 58.14 | 60.79 |
| 0.75 | 68.97 | 52.87 | 61.58 | 60.76 | 59.42 | 59.45 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hashemi, S.M.; Botez, R.M.; Grigorie, T.L. New Reliability Studies of Data-Driven Aircraft Trajectory Prediction. Aerospace 2020, 7, 145. https://doi.org/10.3390/aerospace7100145
Hashemi SM, Botez RM, Grigorie TL. New Reliability Studies of Data-Driven Aircraft Trajectory Prediction. Aerospace. 2020; 7(10):145. https://doi.org/10.3390/aerospace7100145
Chicago/Turabian StyleHashemi, Seyed Mohammad, Ruxandra Mihaela Botez, and Teodor Lucian Grigorie. 2020. "New Reliability Studies of Data-Driven Aircraft Trajectory Prediction" Aerospace 7, no. 10: 145. https://doi.org/10.3390/aerospace7100145
APA StyleHashemi, S. M., Botez, R. M., & Grigorie, T. L. (2020). New Reliability Studies of Data-Driven Aircraft Trajectory Prediction. Aerospace, 7(10), 145. https://doi.org/10.3390/aerospace7100145