
Using Large Language Models for Aerospace Code Generation: Methods, Benchmarks, and Potential Values

Abstract
1. Introduction
- Thoroughly summarized large LLM-based code-generation methods and explored their potential aerospace applications, aiming to offer insights for tackling aerospace challenges.
- Introduction of the first repository-level benchmark for on-board device code generation, featuring 825 samples from 5 real-world projects to accurately assess LLM capabilities.
- Conducted extensive evaluations of 10 state-of-the-art LLMs on the benchmark, clearly revealing their performance disparities in on-board device code generation, guiding LLM selection and improvement in aerospace.
2. Background
2.1. Large Language Model for Code Generation
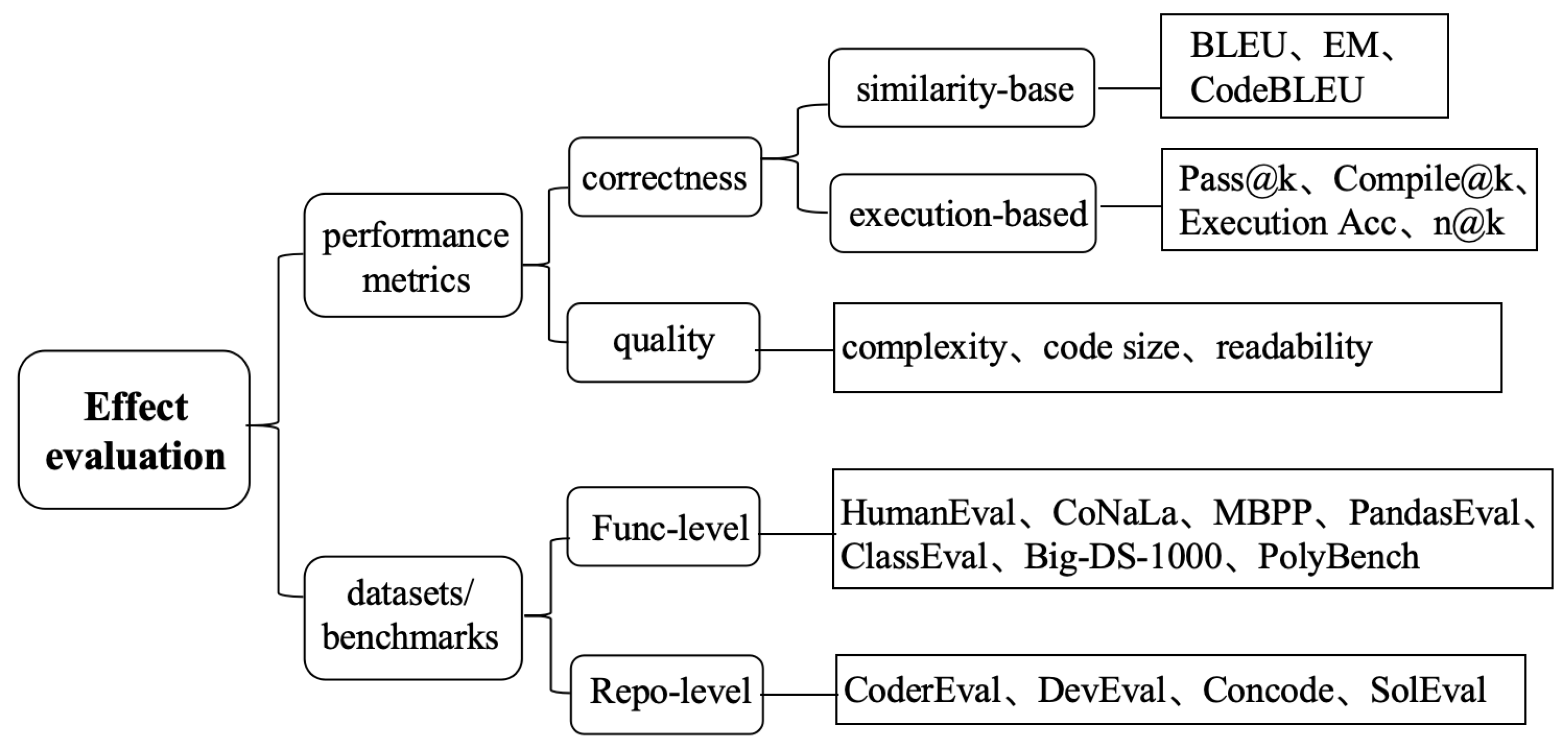
2.2. Evaluation Metrics and Benchmarks for Code Generation
- Function-level benchmarks. These benchmarks contain human-written problems or requirements and require LLMs to generate independent code snippets.
- Repository-level benchmarks. These benchmarks require LLMs to generate new programs according to the requirements and context within the current codebase. Compared with code snippet-level benchmarks, codebase-level benchmarks are more challenging and closer to real-world software development scenarios.
3. Benchmark-RepoSpace
3.1. Overview
3.2. Benchmark Construction
3.2.1. Project Selection
3.2.2. Function Parsing
3.2.3. Manual Annotation
3.2.4. Contextual Parsing
- Source file retrieval and parsing to obtain definition lists (types, functions, variables, constants)
- Static analysis to identify external calls and extract their signatures
4. Experimental Setup
4.1. Research Questions
4.2. Metrics
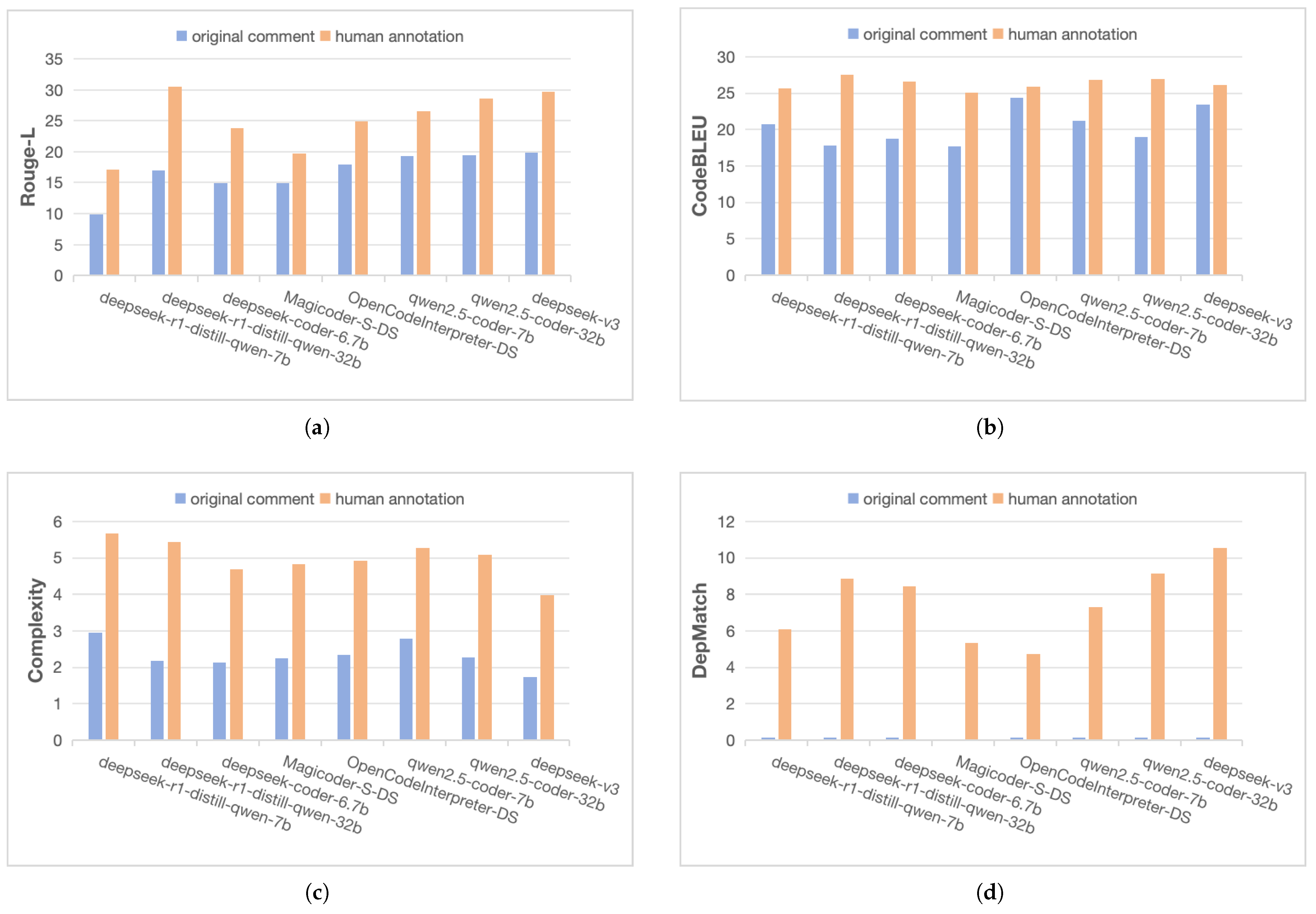
- For functional correctness verification, we adopted the static evaluation methods Rouge-L and CodeBLEU based on similarity.
- For code quality assessment, we use the measured complexity.
- Innovatively, we propose the DepMatch metric to statically analyze the call accuracy of mission-critical libraries in generated code.
4.3. Implementation Details
5. Result
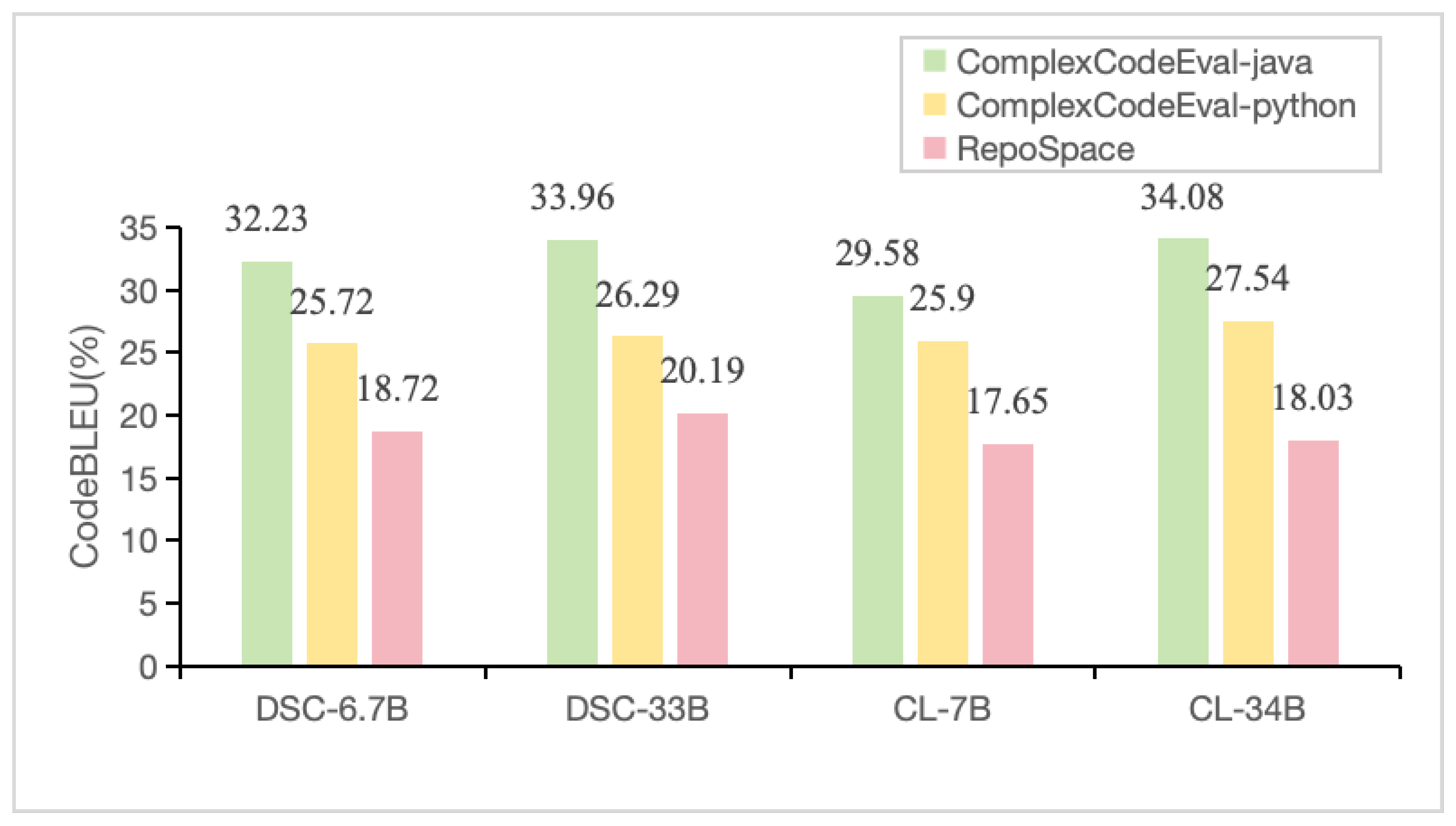
5.1. RQ1—What Is the Impact of Domain Differences on LLMs Code Generation?
5.2. RQ2—How Do Different LLMs Perform in Generating Non-Standalone Functions?
5.3. RQ3—How Do Different Prompting Templates Affect the Effectiveness of These Models?
- “Detailed/Brief” refers to whether a detailed description of the task is provided. For example, the first pink instruction in Figure 6 is “detailed” because it provides specific information about the input format. In contrast, the “brief” description of the second pink directive provides only the basic requirements.
- Single step/Step by step refers to whether additional instructions are added before the prediction. For example, the first blue instruction prompt (i.e., “Step by Step”) further specifies the model-generating code based on the above example, while the second blue instruction prompt (i.e., “Single Step”) does not contain this information.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, M.; Gu, B.; Guo, X.; Dong, X.; Wang, Z.; Chen, R. Aerospace embedded software dependability guarantee technology and application. Sci. Sin. (Technol.) 2015, 45, 198–203. [Google Scholar]
- Yang, M.; Gu, B.; Duan, Z.; Jin, Z.; Zhan, N.; Dong, Y.; Tian, C.; Li, G.; Dong, X.; Li, X. Intelligent program synthesis framework and key scientific problems for embedded software. Chin. Space Sci. Technol. 2022, 42, 1–7. [Google Scholar] [CrossRef]
- Yung, K.L.; Tang, Y.M.; Ip, W.H.; Kuo, W.T. A systematic review of product design for space instrument innovation, reliability, and manufacturing. Machines 2021, 9, 244. [Google Scholar] [CrossRef]
- Chen, X.; Gao, F.; Han, X.; Weihua, M. Large model code generation technology and its potential applications to aerospace. Aerosp. Control 2025, 43, 8–16. [Google Scholar]
- Alnusair, A.; Zhao, T.; Yan, G. Rule-based detection of design patterns in program code. Int. J. Softw. Tools Technol. Transf. 2014, 16, 315–334. [Google Scholar] [CrossRef]
- Shen, S.; Zhu, X.; Dong, Y.; Guo, Q.; Zhen, Y.; Li, G. Incorporating domain knowledge through task augmentation for front-end JavaScript code generation. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 1533–1543. [Google Scholar]
- Fried, D.; Aghajanyan, A.; Lin, J.; Wang, S.; Wallace, E.; Shi, F.; Zhong, R.; Yih, W.T.; Zettlemoyer, L.; Lewis, M. Incoder: A generative model for code infilling and synthesis. arXiv 2022, arXiv:2204.05999. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Roziere, B.; Gehring, J.; Gloeckle, F.; Sootla, S.; Gat, I.; Tan, X.E.; Adi, Y.; Liu, J.; Sauvestre, R.; Remez, T.; et al. Code llama: Open foundation models for code. arXiv 2023, arXiv:2308.12950. [Google Scholar]
- Zhu, Q.; Guo, D.; Shao, Z.; Yang, D.; Wang, P.; Xu, R.; Wu, Y.; Li, Y.; Gao, H.; Ma, S.; et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv 2024, arXiv:2406.11931. [Google Scholar]
- Zhang, Z.; Wang, Y.; Wang, C.; Chen, J.; Zheng, Z. Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation. arXiv 2024, arXiv:2409.20550. [Google Scholar]
- Park, D.H.; Kim, S.D. XML rule based source code generator for UML CASE tool. In Proceedings of the Eighth Asia-Pacific Software Engineering Conference, Macao, China, 4–7 December 2001; pp. 53–60. [Google Scholar]
- Koziolek, H.; Burger, A.; Platenius-Mohr, M.; Rückert, J.; Abukwaik, H.; Jetley, R.; P, A.P. Rule-based code generation in industrial automation: Four large-scale case studies applying the cayenne method. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Software Engineering in Practice, Seoul, Republic of Korea, 5–11 October 2020; pp. 152–161. [Google Scholar]
- Jugel, U.; Preußner, A. A case study on API generation. In Proceedings of the System Analysis and Modeling: About Models: 6th International Workshop, SAM 2010, Oslo, Norway, 4–5 October 2010; Revised Selected Papers 6; pp. 156–172. [Google Scholar]
- Kolovos, D.S.; García-Domínguez, A.; Rose, L.M.; Paige, R.F. Eugenia: Towards disciplined and automated development of GMF-based graphical model editors. Softw. Syst. Model. 2017, 16, 229–255. [Google Scholar] [CrossRef]
- Märtin, L.; Schatalov, M.; Hagner, M.; Goltz, U.; Maibaum, O. A methodology for model-based development and automated verification of software for aerospace systems. In Proceedings of the 2013 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2013; pp. 1–19. [Google Scholar]
- Deshmukh, M.; Weps, B.; Isidro, P.; Gerndt, A. Model driven language framework to automate command and data handling code generation. In Proceedings of the 2015 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015; pp. 1–9. [Google Scholar]
- Sutskever, I. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Sun, Z.; Zhu, Q.; Mou, L.; Xiong, Y.; Li, G.; Zhang, L. A grammar-based structural cnn decoder for code generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7055–7062. [Google Scholar]
- Svyatkovskiy, A.; Deng, S.K.; Fu, S.; Sundaresan, N. Intellicode compose: Code generation using transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; pp. 1433–1443. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Ni, C.; Yin, X.; Yang, K.; Zhao, D.; Xing, Z.; Xia, X. Distinguishing look-alike innocent and vulnerable code by subtle semantic representation learning and explanation. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, San Francisco, CA, USA, 3–9 December 2023; pp. 1611–1622. [Google Scholar]
- Yin, X.; Ni, C.; Wang, S. Multitask-based evaluation of open-source llm on software vulnerability. IEEE Trans. Softw. Eng. 2024, 50, 3071–3087. [Google Scholar] [CrossRef]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified pre-training for program understanding and generation. arXiv 2021, arXiv:2103.06333. [Google Scholar]
- Wang, Y.; Le, H.; Gotmare, A.D.; Bui, N.D.; Li, J.; Hoi, S.C. Codet5+: Open code large language models for code understanding and generation. arXiv 2023, arXiv:2305.07922. [Google Scholar]
- Luo, Z.; Xu, C.; Zhao, P.; Sun, Q.; Geng, X.; Hu, W.; Tao, C.; Ma, J.; Lin, Q.; Jiang, D. Wizardcoder: Empowering code large language models with evol-instruct. arXiv 2023, arXiv:2306.08568. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Liu, H.; Tam, D.; Muqeeth, M.; Mohta, J.; Huang, T.; Bansal, M.; Raffel, C.A. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1950–1965. [Google Scholar]
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Adv. Neural Inf. Process. Syst. 2023, 36, 10088–10115. [Google Scholar]
- Li, J.; Li, G.; Li, Y.; Jin, Z. Structured chain-of-thought prompting for code generation. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–23. [Google Scholar] [CrossRef]
- Schäfer, M.; Nadi, S.; Eghbali, A.; Tip, F. An empirical evaluation of using large language models for automated unit test generation. IEEE Trans. Softw. Eng. 2023, 50, 85–105. [Google Scholar] [CrossRef]
- Jiang, X.; Dong, Y.; Wang, L.; Fang, Z.; Shang, Q.; Li, G.; Jin, Z.; Jiao, W. Self-planning code generation with large language models. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–30. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Li, G.; Jin, Z.; Hao, Y.; Hu, X. Skcoder: A sketch-based approach for automatic code generation. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; pp. 2124–2135. [Google Scholar]
- Zhang, X.; Zhou, Y.; Yang, G.; Chen, T. Syntax-aware retrieval augmented code generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 1291–1302. [Google Scholar]
- Zhang, K.; Zhang, H.; Li, G.; Li, J.; Li, Z.; Jin, Z. Toolcoder: Teach code generation models to use api search tools. arXiv 2023, arXiv:2305.04032. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Ren, S.; Guo, D.; Lu, S.; Zhou, L.; Liu, S.; Tang, D.; Sundaresan, N.; Zhou, M.; Blanco, A.; Ma, S. Codebleu: A method for automatic evaluation of code synthesis. arXiv 2020, arXiv:2009.10297. [Google Scholar]
- Zeng, Z.; Wang, Y.; Xie, R.; Ye, W.; Zhang, S. Coderujb: An executable and unified java benchmark for practical programming scenarios. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, Vienna, Austria, 16–20 September 2024; pp. 124–136. [Google Scholar]
- Yu, H.; Shen, B.; Ran, D.; Zhang, J.; Zhang, Q.; Ma, Y.; Liang, G.; Li, Y.; Wang, Q.; Xie, T. Codereval: A benchmark of pragmatic code generation with generative pre-trained models. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–12. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-level code generation with alphacode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; An, G.; Yoo, S. Iterative refactoring of real-world open-source programs with large language models. In Proceedings of the International Symposium on Search Based Software Engineering, Porto de Galinhas, Brazil, 15 July 2024; pp. 49–55. [Google Scholar]
- Cummins, C.; Seeker, V.; Grubisic, D.; Elhoushi, M.; Liang, Y.; Roziere, B.; Gehring, J.; Gloeckle, F.; Hazelwood, K.; Synnaeve, G.; et al. Large language models for compiler optimization. arXiv 2023, arXiv:2309.07062. [Google Scholar]
- Li, Z.; He, Y.; He, L.; Wang, J.; Shi, T.; Lei, B.; Li, Y.; Chen, Q. FALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system. arXiv 2024, arXiv:2410.21349. [Google Scholar]
- Puri, R.; Kung, D.S.; Janssen, G.; Zhang, W.; Domeniconi, G.; Zolotov, V.; Dolby, J.; Chen, J.; Choudhury, M.; Decker, L.; et al. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv 2021, arXiv:2105.12655. [Google Scholar]
- Pan, Y.; Shao, X.; Lyu, C. Measuring code efficiency optimization capabilities with ACEOB. J. Syst. Softw. 2025, 219, 112250. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.D.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Lai, Y.; Li, C.; Wang, Y.; Zhang, T.; Zhong, R.; Zettlemoyer, L.; Yih, W.T.; Fried, D.; Wang, S.; Yu, T. DS-1000: A natural and reliable benchmark for data science code generation. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 18319–18345. [Google Scholar]
- Li, J.; Li, G.; Zhao, Y.; Li, Y.; Liu, H.; Zhu, H.; Wang, L.; Liu, K.; Fang, Z.; Wang, L.; et al. Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories. arXiv 2024, arXiv:2405.19856. [Google Scholar]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Adv. Neural Inf. Process. Syst. 2023, 36, 21558–21572. [Google Scholar]
- Jiang, J.; Li, Z.; Qin, H.; Jiang, M.; Luo, X.; Wu, X.; Wang, H.; Tang, Y.; Qian, C.; Chen, T. Unearthing Gas-Wasting Code Smells in Smart Contracts with Large Language Models. IEEE Trans. Softw. Eng. 2024, 51, 879–903. [Google Scholar] [CrossRef]
- Zhou, Y.; Muresanu, A.I.; Han, Z.; Paster, K.; Pitis, S.; Chan, H.; Ba, J. Large language models are human-level prompt engineers. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Liao, D.; Pan, S.; Sun, X.; Ren, X.; Huang, Q.; Xing, Z.; Jin, H.; Li, Q. A 3-CodGen: A Repository-Level Code Generation Framework for Code Reuse with Local-Aware, Global-Aware, and Third-Party-Library-Aware. IEEE Trans. Softw. Eng. 2024, 50, 3369–3384. [Google Scholar] [CrossRef]
- Khan, M.A.M.; Bari, M.S.; Do, X.L.; Wang, W.; Parvez, M.R.; Joty, S. xcodeeval: A large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval. arXiv 2023, arXiv:2303.03004. [Google Scholar]
- Feng, J.; Liu, J.; Gao, C.; Chong, C.Y.; Wang, C.; Gao, S.; Xia, X. Complexcodeeval: A benchmark for evaluating large code models on more complex code. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024; pp. 1895–1906. [Google Scholar]
- Gu, X.; Chen, M.; Lin, Y.; Hu, Y.; Zhang, H.; Wan, C.; Wei, Z.; Xu, Y.; Wang, J. On the effectiveness of large language models in domain-specific code generation. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–22. [Google Scholar] [CrossRef]
- Li, J.; Zhao, Y.; Li, Y.; Li, G.; Jin, Z. Acecoder: An effective prompting technique specialized in code generation. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–26. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description | Potential Applications | References |
|---|---|---|---|
| Pre-train | Trains the model through a large corpus of unlabeled code to enable understanding of the structure and semantics of a programming language. | Suitable for generating basic spacecraft embedded software modules (such as data acquisition and communication protocol analysis), providing initial implementations of algorithms for orbit optimization, mission scheduling, and attitude control, as well as generating general analytical tool code for telemetry data, image processing, and scientific calculations. | [24,25] |
| Fine-tuning | Optimizes the predictive training model through a supervised learning framework to enable it to execute specific task instructions. | Provides strong support for scenarios with high complexity and high precision requirements, such as generating control algorithm codes for specific spacecraft types. The model is effectively enhanced for space-specific missions and can more accurately respond to complex requirements in the field. | [26,27,28,29,30] |
| Prompt engineering | Guides the model to generate code by optimizing prompt words without additional training. | Can be used for prototype code development, quickly generating task scripts or algorithm prototypes, and validating new task concepts or techniques. Additionally, in real-time mission generation, it can dynamically create flight control logic or data processing programs to meet current needs, making it especially suitable for aerospace scenarios with changing requirements. | [31,32,33] |
| Retrieval augmented | Provides powerful technical support for space missions by combining external retrieval capabilities with precise knowledge enhancements. | Can generate code templates similar to previous tasks by retrieving historical task documents or technical databases, and also generate code compatible with existing systems or tools, thereby improving development efficiency and consistency. | [34,35,36] |
| Type | Name | Size |
|---|---|---|
| Code LLM | Qwen2.5-Coder | 7 B/32 B |
| DeepSeek-Coder | 6.7 B/33 B | |
| Magicoder-S-DS | 6.7 B | |
| OpenCodeInterpreter-DS | 6.7 B | |
| CodeLlama | 7 B/34 B | |
| General LLM | DeepSeek-R1-Distill-Qwen | 7 B/32 B |
| DeepSeek-V3 | 671 B (API) |
| LLMs | Size | Rouge-L | CodeBLEU | Complexity | DepMatch |
|---|---|---|---|---|---|
| 6.7B-7B | |||||
| Qwen2.5-Coder | 7B | 29.86 | 30.46 | 5.81 | 29.15 |
| DeepSeek-Coder | 6.7B | 26.63 | 32.18 | 5.21 | 30.32 |
| Magicoder-S-DS | 6.7B | 24.55 | 31.50 | 5.52 | 27.76 |
| OpenCodeInterpreter-DS | 6.7B | 29.55 | 30.16 | 5.41 | 28.09 |
| CodeLlama | 7B | 27.25 | 31.76 | 5.58 | 27.72 |
| DeepSeek-R1-Distill-Qwen | 7B | 23.12 | 28.15 | 6.18 | 29.79 |
| 32 B-671B | |||||
| CodeLlama | 34B | 32.61 | 33.25 | 5.79 | 27.65 |
| Qwen2.5-Coder | 32B | 32.63 | 33.48 | 5.59 | 29.31 |
| DeepSeek-Coder | 33B | 33.68 | 33.94 | 5.83 | 31.19 |
| DeepSeek-R1-Distill-Qwen | 32B | 35.71 | 32.18 | 6.02 | 29.51 |
| DeepSeek-V3 | 671B (API) | 36.75 | 34.58 | 4.51 | 32.34 |
| Det. | Ts. | Rouge-L | CodeBLEU |
|---|---|---|---|
| 25.63 | 31.38 | ||
| ✓ | 25.12 | 31.76 | |
| ✓ | 23.42 | 29.91 | |
| ✓ | ✓ | 26.63 | 32.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, R.; Zhang, L.; Lyu, M.; Lyu, L.; Xue, C. Using Large Language Models for Aerospace Code Generation: Methods, Benchmarks, and Potential Values. Aerospace 2025, 12, 498. https://doi.org/10.3390/aerospace12060498
He R, Zhang L, Lyu M, Lyu L, Xue C. Using Large Language Models for Aerospace Code Generation: Methods, Benchmarks, and Potential Values. Aerospace. 2025; 12(6):498. https://doi.org/10.3390/aerospace12060498
Chicago/Turabian StyleHe, Rui, Liang Zhang, Mengyao Lyu, Liangqing Lyu, and Changbin Xue. 2025. "Using Large Language Models for Aerospace Code Generation: Methods, Benchmarks, and Potential Values" Aerospace 12, no. 6: 498. https://doi.org/10.3390/aerospace12060498
APA StyleHe, R., Zhang, L., Lyu, M., Lyu, L., & Xue, C. (2025). Using Large Language Models for Aerospace Code Generation: Methods, Benchmarks, and Potential Values. Aerospace, 12(6), 498. https://doi.org/10.3390/aerospace12060498