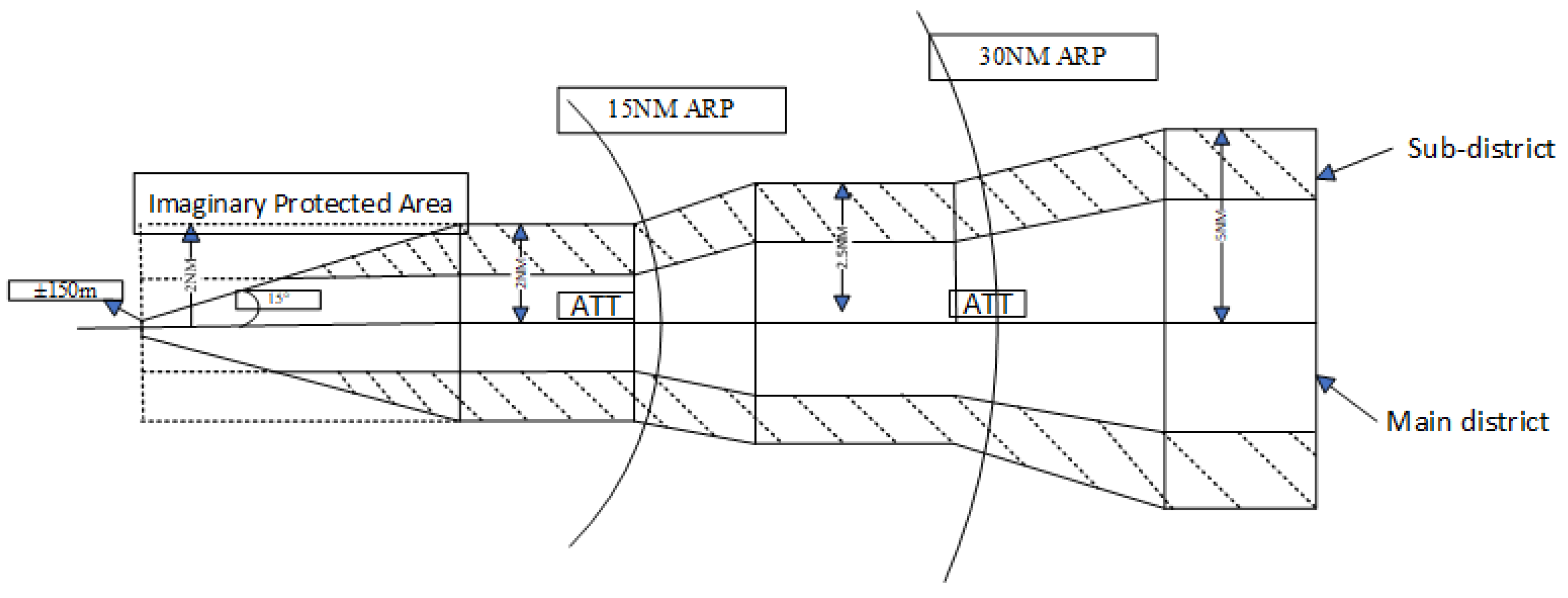
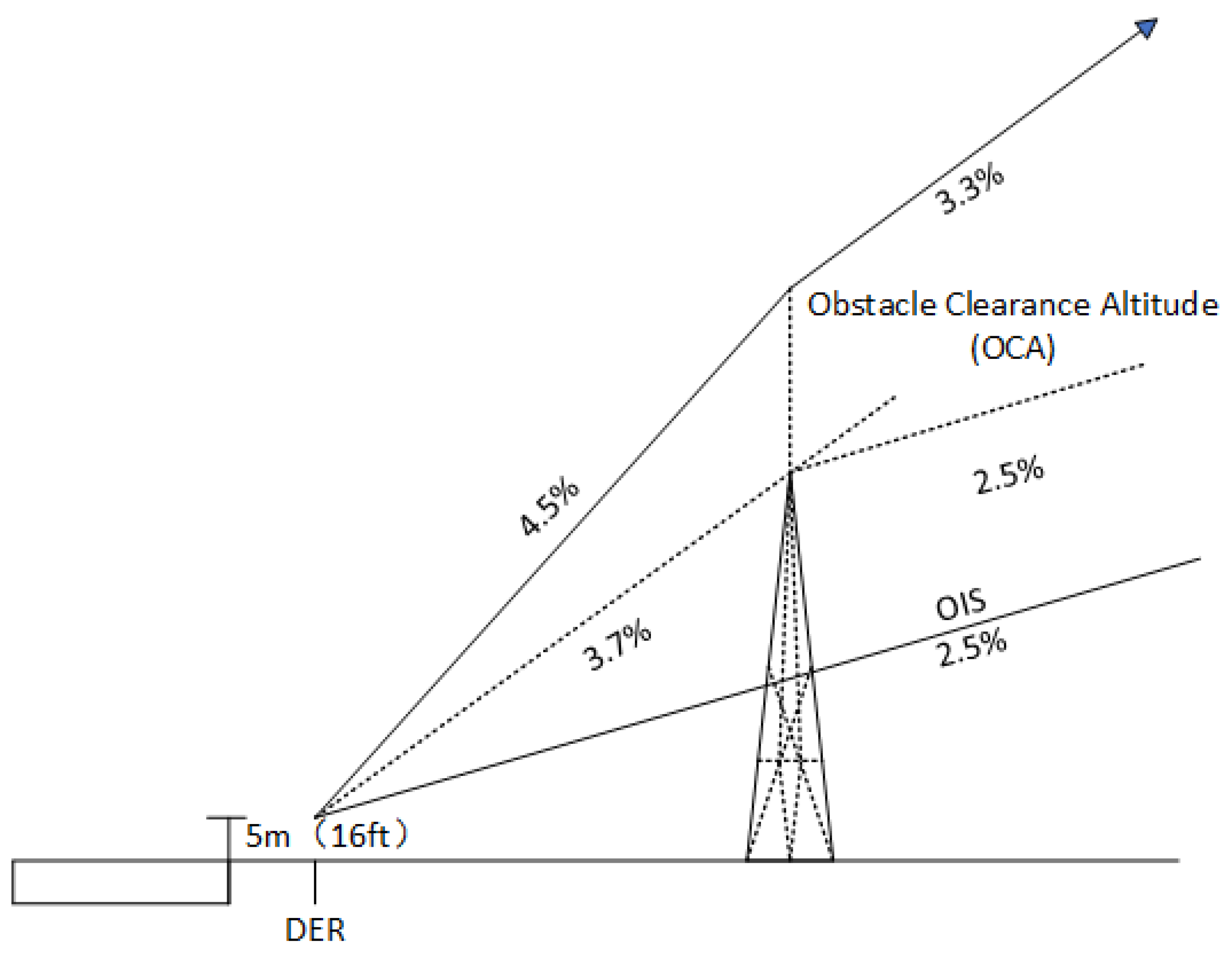
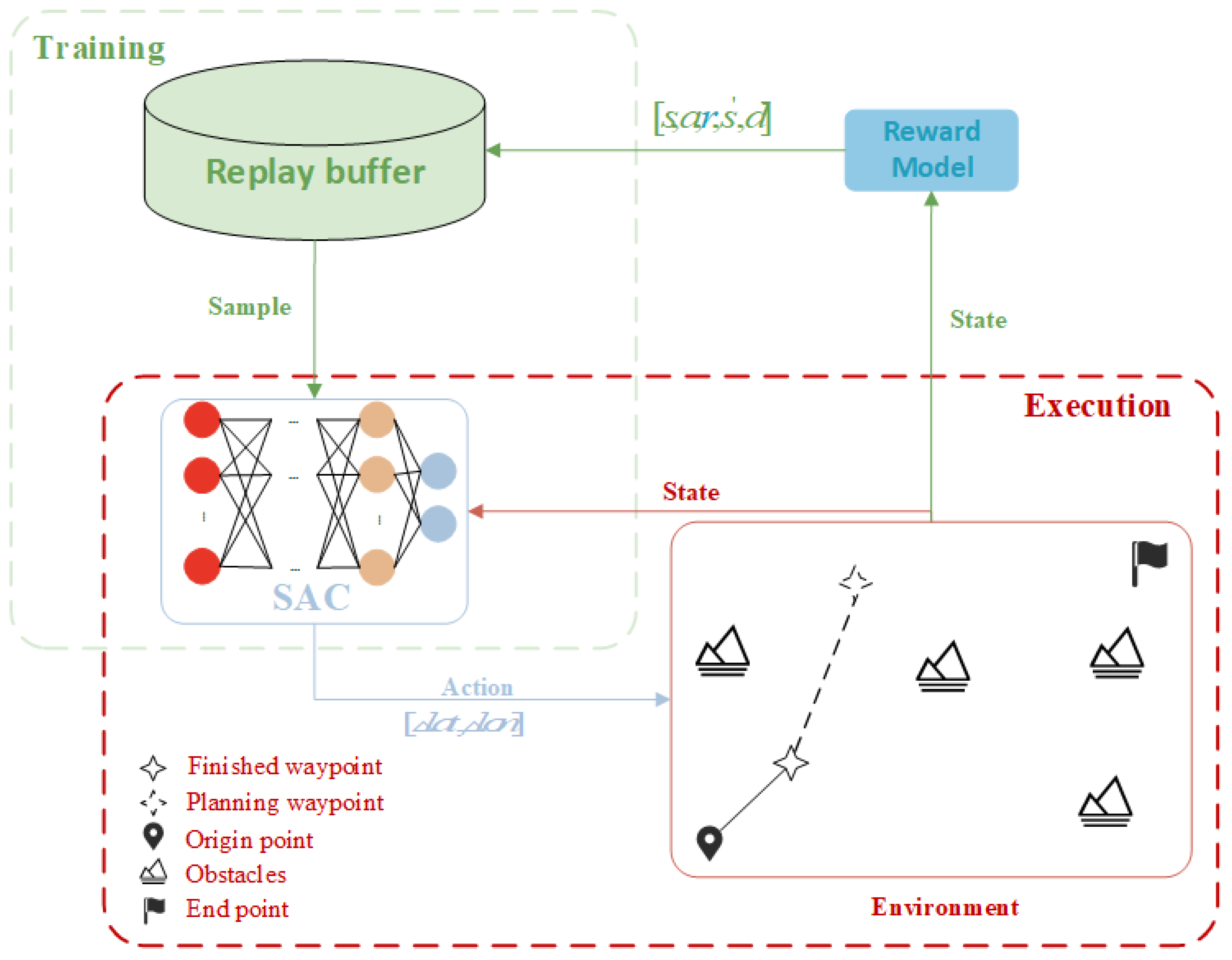
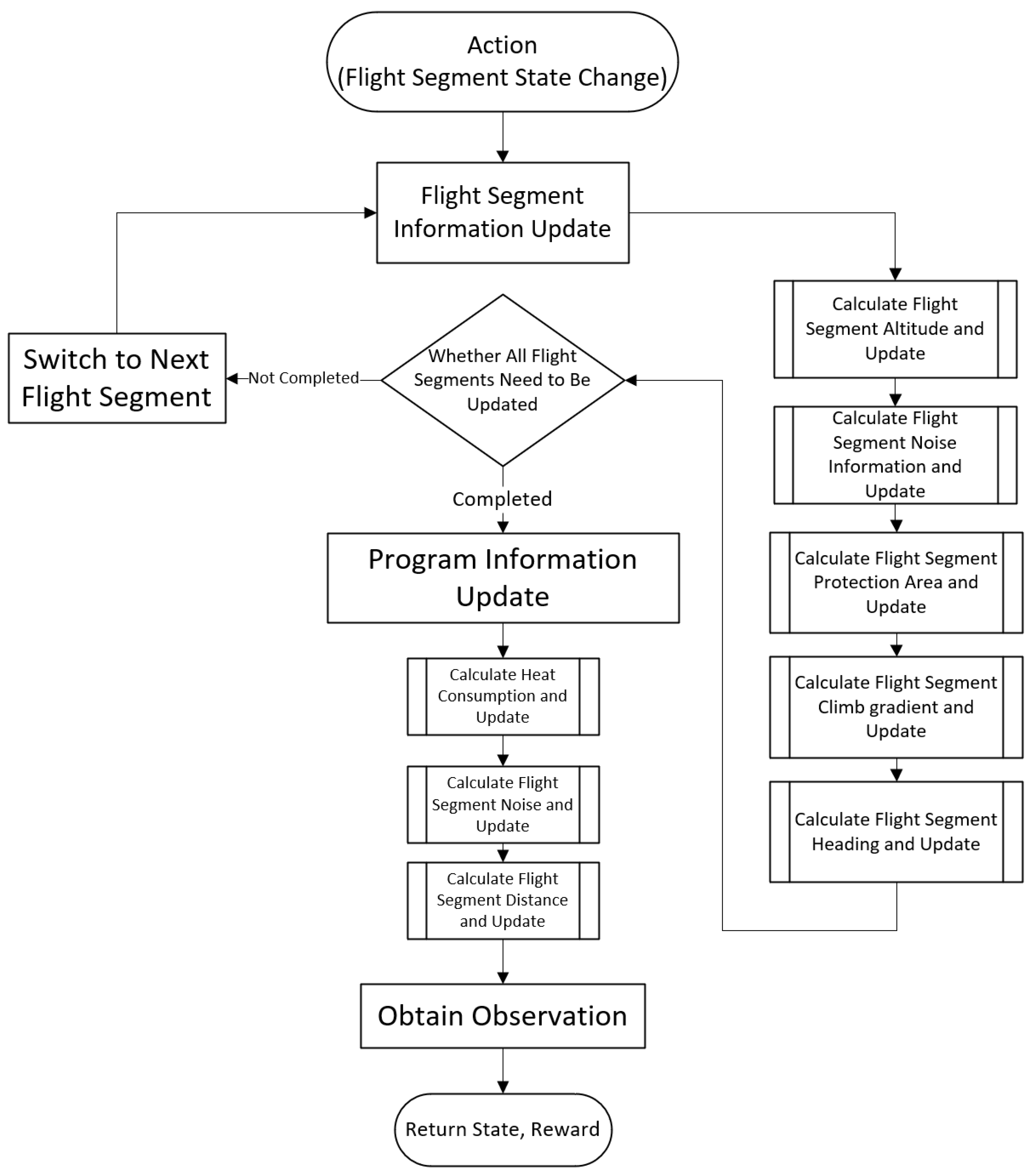
4.2.1. Reward Engineering
In this section, a reward engineering approach is employed to define the reward function. Three key adjustments were made to the reward function, focusing on four crucial aspects of flight procedure design: safety, economy, simplicity, and environmental sustainability.
Reward Function 1:
The objective is to optimize the flight procedure design by balancing multiple objectives: safety, economy, simplicity, and noise reduction. The mathematical expression for the reward function is as follows (Equation (
22)):
The safety component is defined as follows (Equation (
23)):
where
represent state parameters, and
indicates the state variable.
to
contribute positively, while
and
contribute negatively.
The simplicity component is defined as follows (Equation (
24)):
The economic component is represented as (Equation (
25)):
where
is the total length of the flight procedure, and
is the distance from the starting point to the endpoint of the linear flight path.
In the previous definition (Equation (
15)),
is clearly defined.
The noise reward component is expressed as (Equation (
26)):
where
N (Equation (
27)) is calculated based on the environmental model in the Problem Formulation section, ensuring that the reward function remains consistent throughout the noise reward.
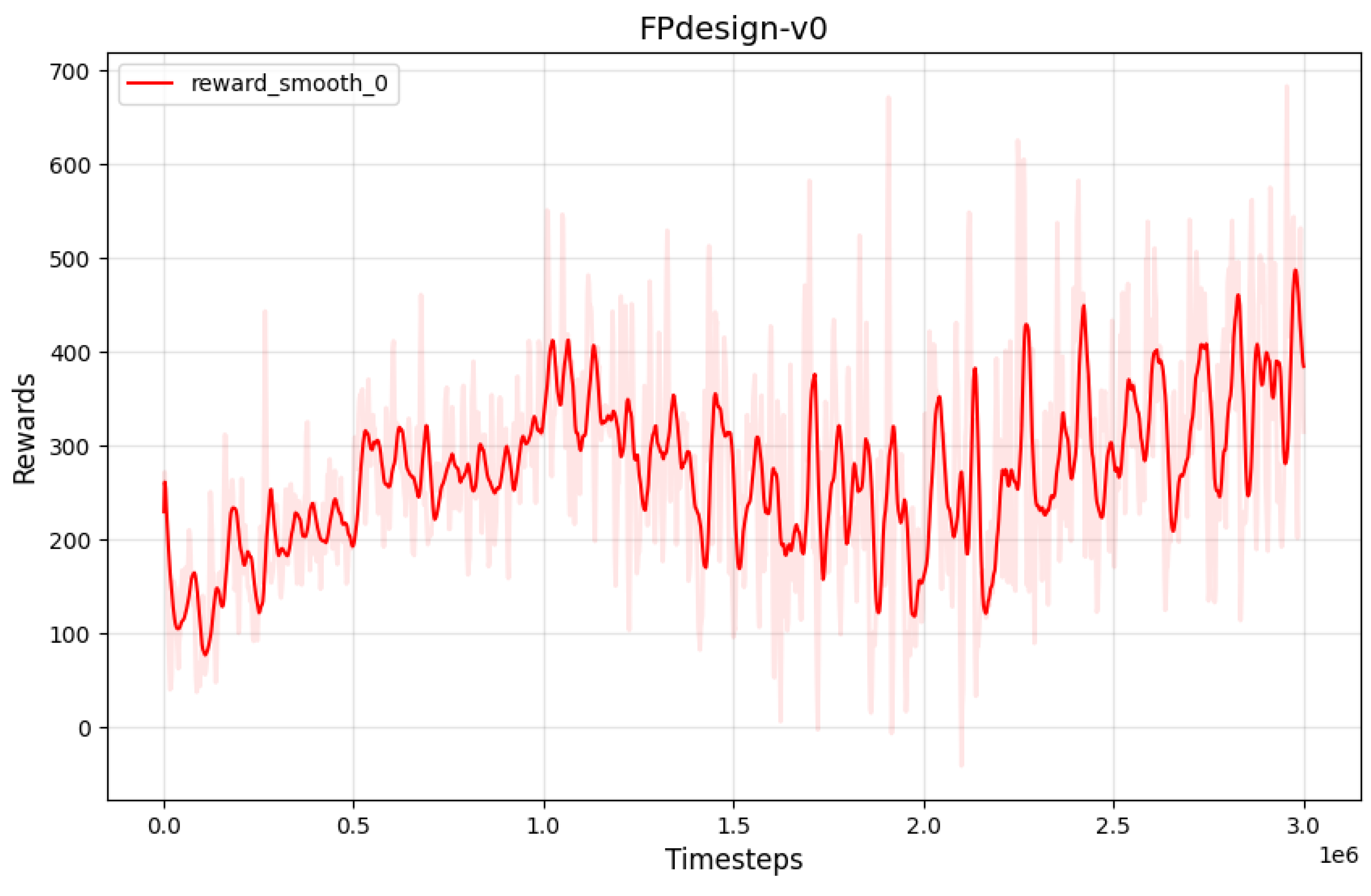
Based on the reward count obtained from the reward curve, as illustrated in
Figure 7, it can be observed that the reward function exhibits continuous variation. Furthermore, it has been trained over
iterations, indicating that the configuration of the reward function is not capable of fully meeting the task requirements.
Reward Function 2:
The optimization objectives of the flight procedure have been further adjusted. Compared to the first version, the design has eliminated the economic objective and focuses on three aspects: safety, simplicity, and noise. Additionally, the safety reward has been normalized, while the normalization setting for the simplicity reward has been removed. The mathematical expression of the reward function is Equation (
28):
The safety reward in the updated version is expressed as follows (Equation (
29)):
where
represent positive safety factors (such as safety zone distances), and
represent negative risk factors (such as proximity to obstacles). The original version of the equation was
. In the revised version, a normalization factor of 4 has been introduced to refine the safety components, enabling a more nuanced evaluation of the reward based on minor variations in the parameters.
The simplicity reward is defined as Equation (
30), where
can be found in Equation (
15).
The noise reward is expressed as Equation (
26), which remains unchanged from the previous version.
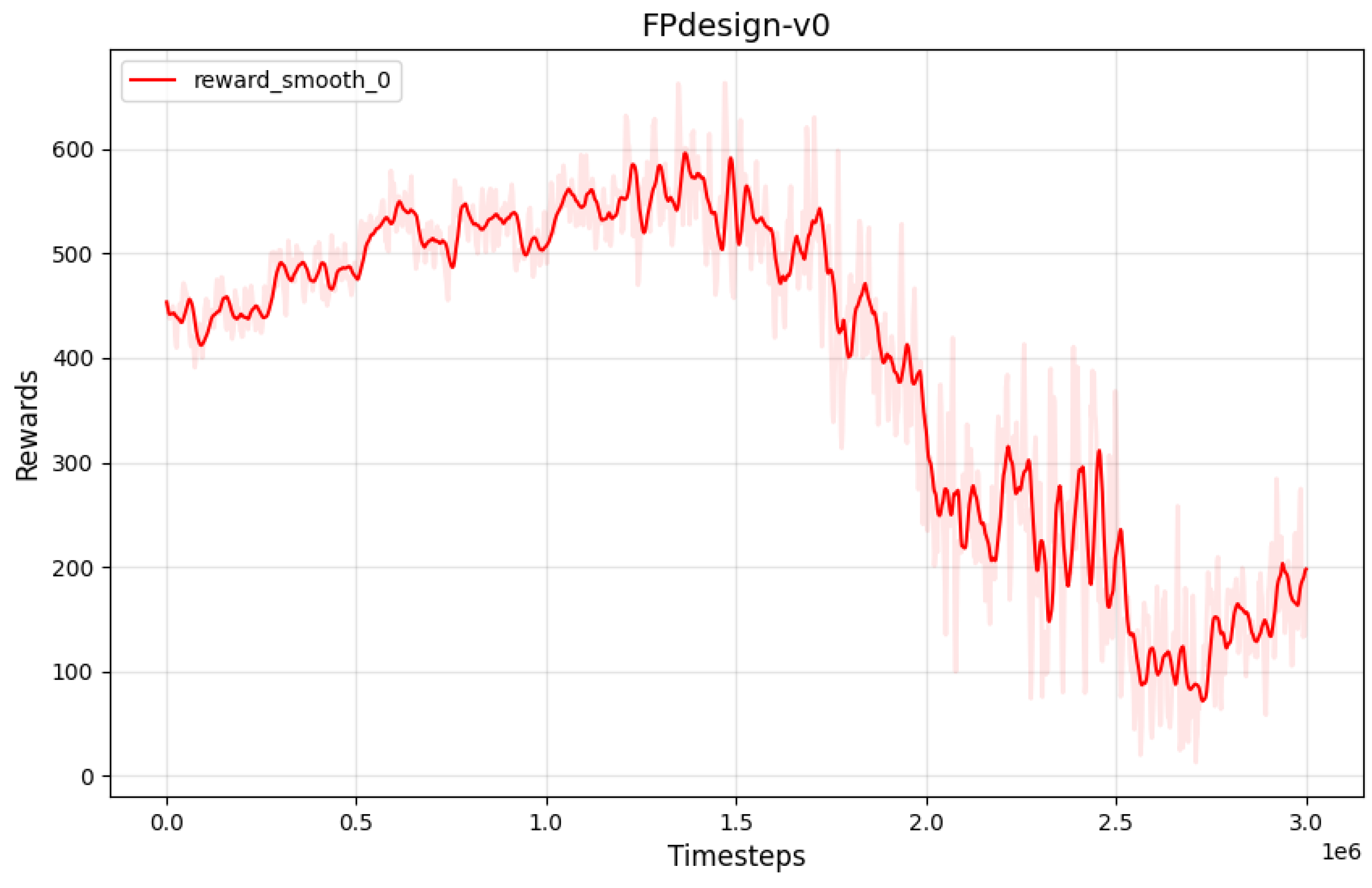
The reward function curve is illustrated in
Figure 8. It can be observed that the initial high reward indicates that the strategy is well adapted to the environment, while the mid-stage descent may be related to conflicts among multiple objectives. The late-stage stabilization at a lower level suggests that the strategy has converged, but the desired performance has not been fully achieved.
Reward Function 3:
The third version of the reward function represents a significant improvement and expansion over the second version, aiming to optimize the performance of the flight procedure more comprehensively while enhancing adaptability to complex environmental constraints. The second version of the reward function primarily focused on three aspects: safety, simplicity, and noise control. In this version, the simplicity reward was calculated based on the turning angle, without differentiating between angle and distance simplicity, and it lacked a clear penalty for boundary violations. The third version refines the simplicity objectives by explicitly separating them into angle simplicity and distance simplicity, optimizing both turning angles and segment distances. This refinement significantly enhances the specificity and interpretability of the rewards. The reward function and the definitions of its variables (including their value ranges) are summarized in Equation (
31) and
Table 5, respectively:
The safety reward
is derived from Equation (
32), where
takes values between 0 and 1. The previous four states are related to flight disturbance information, with no reward values for obstacles.
and
represent the changes in the pitch and roll angles of the flight segment. If there are deviations in the pitch and roll angles, a penalty is applied.
The angle simplicity reward
is determined by the three angles affected by the current selected flight path, denoted as
. A turn angle is considered part of a straight departure procedure if it is less than 120 degrees, thus the setting state value must be less than 0.66 to obtain the angle simplicity reward. The calculation method is given by Equation (
33), and the formula for the angle simplicity reward is expressed as:
The distance simplicity reward
is primarily determined by
,
, and
. When the boundary flag
is set to 1, the total value of the reward function is directly set to 0, representing the maximum negative reward. When the boundary flag
is 0, and the calculated value of
is positive, the value for
is computed as twice the value of
. Empirically, this encourages the strategy to explore within a limited distance. Additionally, when the state value
(representing the total procedure length) is less than 0.3, an additional reward based on
is added, as shown in Equation (
35):
The environmental reward
is derived from the negative reward of noise. It remains an empirical formula, calculated by dividing the total noise
N, updated by the procedure, by 10,000, as shown in Equation (
36):
where
N is calculated as shown in Equation (
27), based on the environmental model detailed in the Problem Formulation section.
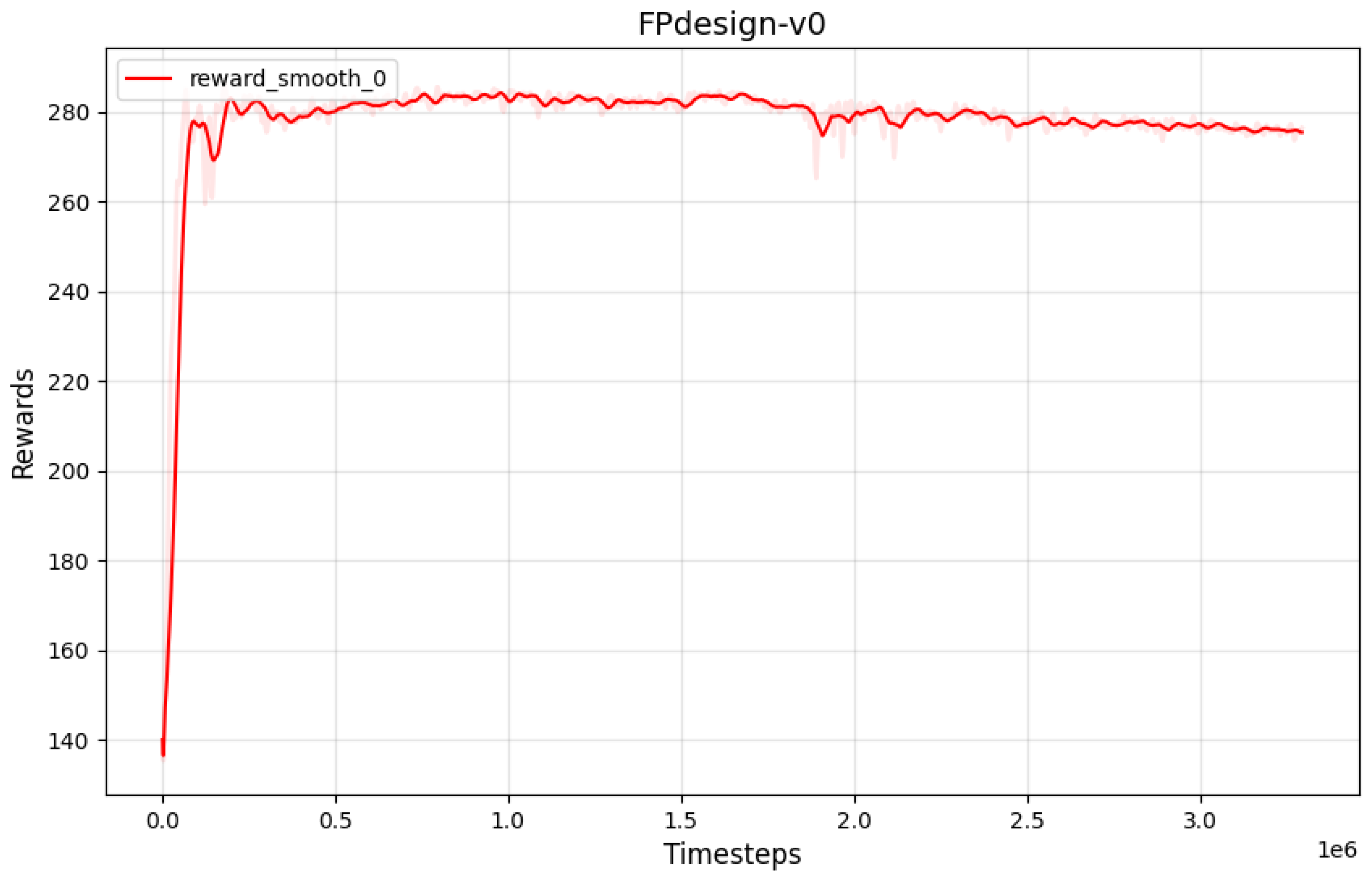
The reward function curve is shown below. As seen from
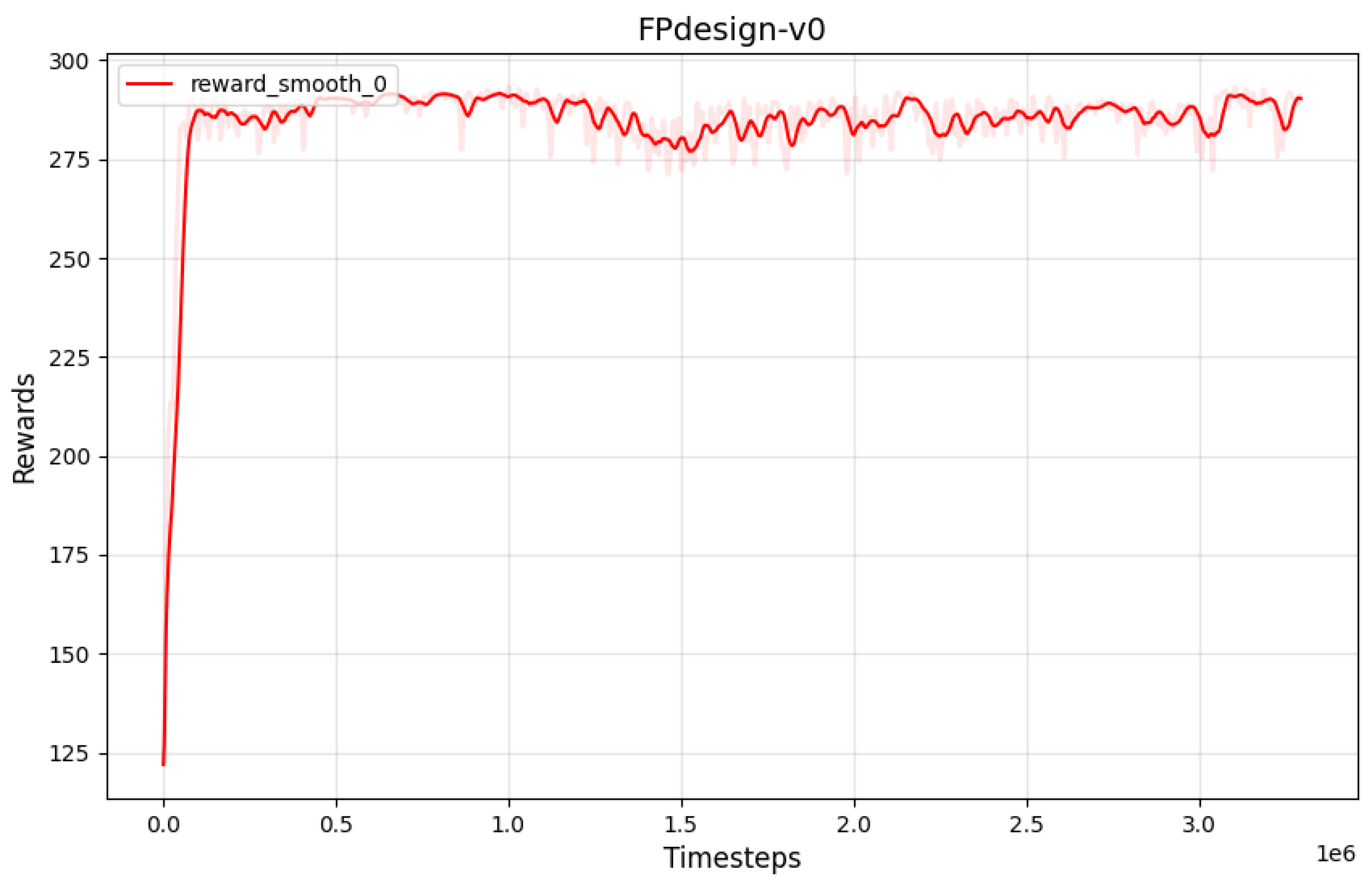
Figure 9, the curve converges around 50,000 iterations. The reward curve demonstrates an overall upward trend with oscillations close to a peak value, indicating that the model has learned an effective strategy. The algorithm and environmental adjustments can be considered complete.
The results of the three reward functions:
The models trained with the three aforementioned reward functions were each used to sample 50 independent trajectories, and the proportion of fully safe flight procedures among these 50 trajectories was statistically analyzed. Subsequently, the fully safe flight procedures were subjected to flight simulation tests using the BlueSky simulation platform, where the average fuel consumption and flight time were recorded. The experimental results are presented in
Table 6. In BlueSky, the aircraft type employed was the A320, with a speed setting of 200 kt, which falls within the permissible departure procedure speed range for Category C aircraft.
BlueSky is an open-source air traffic management simulation platform that provides a flexible and extensible environment, supporting the integration of OpenAP and BADA aerodynamic data packages for flight simulation validation. The platform offers statistical functionalities for fuel consumption and flight time [
36].
Table 6 demonstrates that reward function 3, which was carefully designed, achieves the best performance, with a safe procedure ratio of 46%, an average fuel consumption of 150.3 kg, and an average flight time of 523 seconds. The proportion of safe procedures is significantly higher than those obtained with the other two reward functions. This improvement is attributed to the stable state achieved by the model trained with reward function 3 during the later training phase, as illustrated in
Figure 9. In contrast, the models trained with reward functions 1 and 2 did not converge, resulting in unstable outputs and lower safe procedure ratios. Additionally, it was observed that even with the model using reward function 3, approximately half of the sampled flight procedures failed to meet safety standards, highlighting a direction for future improvement.
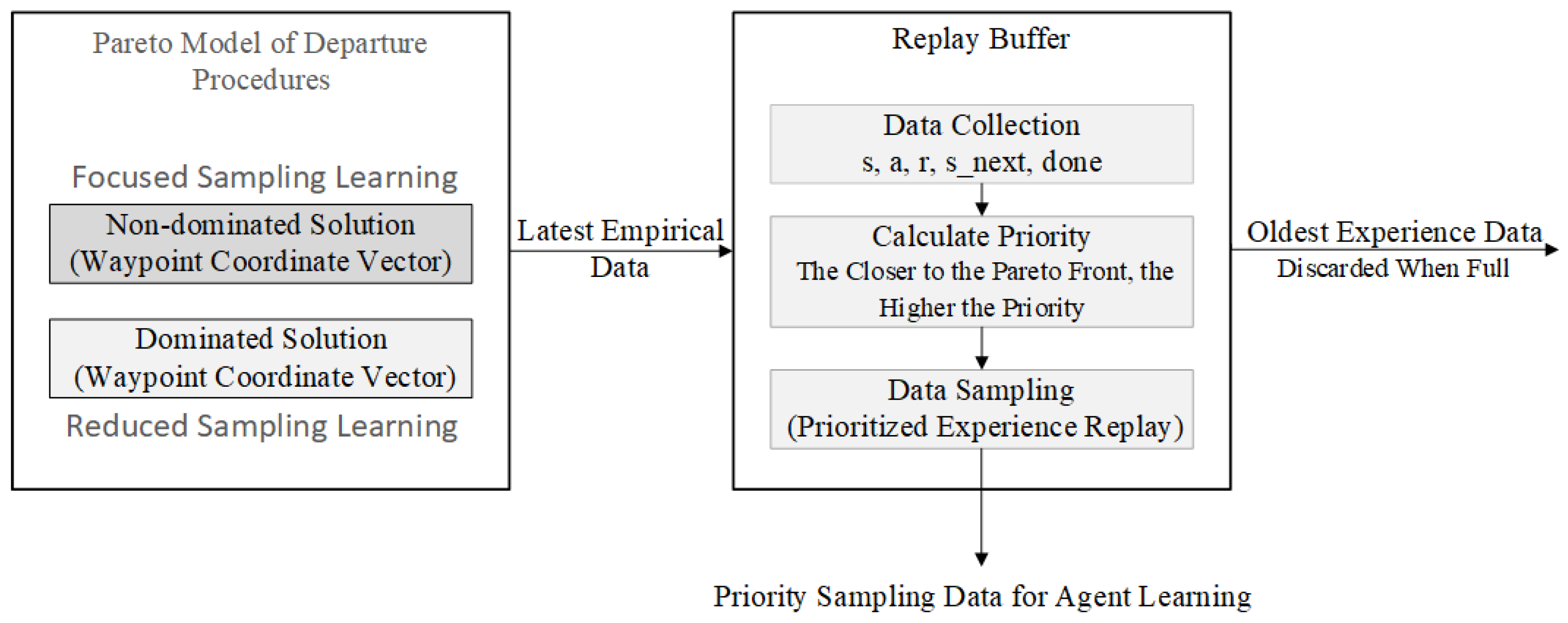
4.2.2. Pareto-Based Replay Buffer Sampling
The experiment includes two comparison groups: one group applies the soft actor–critic (SAC) algorithm with an unmodified sampling mechanism, while the other employs an improved replay buffer within the SAC algorithm [
37]. The convergence curve of the original SAC reward is shown in
Figure 9, while the reward curve of SAC with the improved replay buffer and dynamic learning rate adjustment is shown in
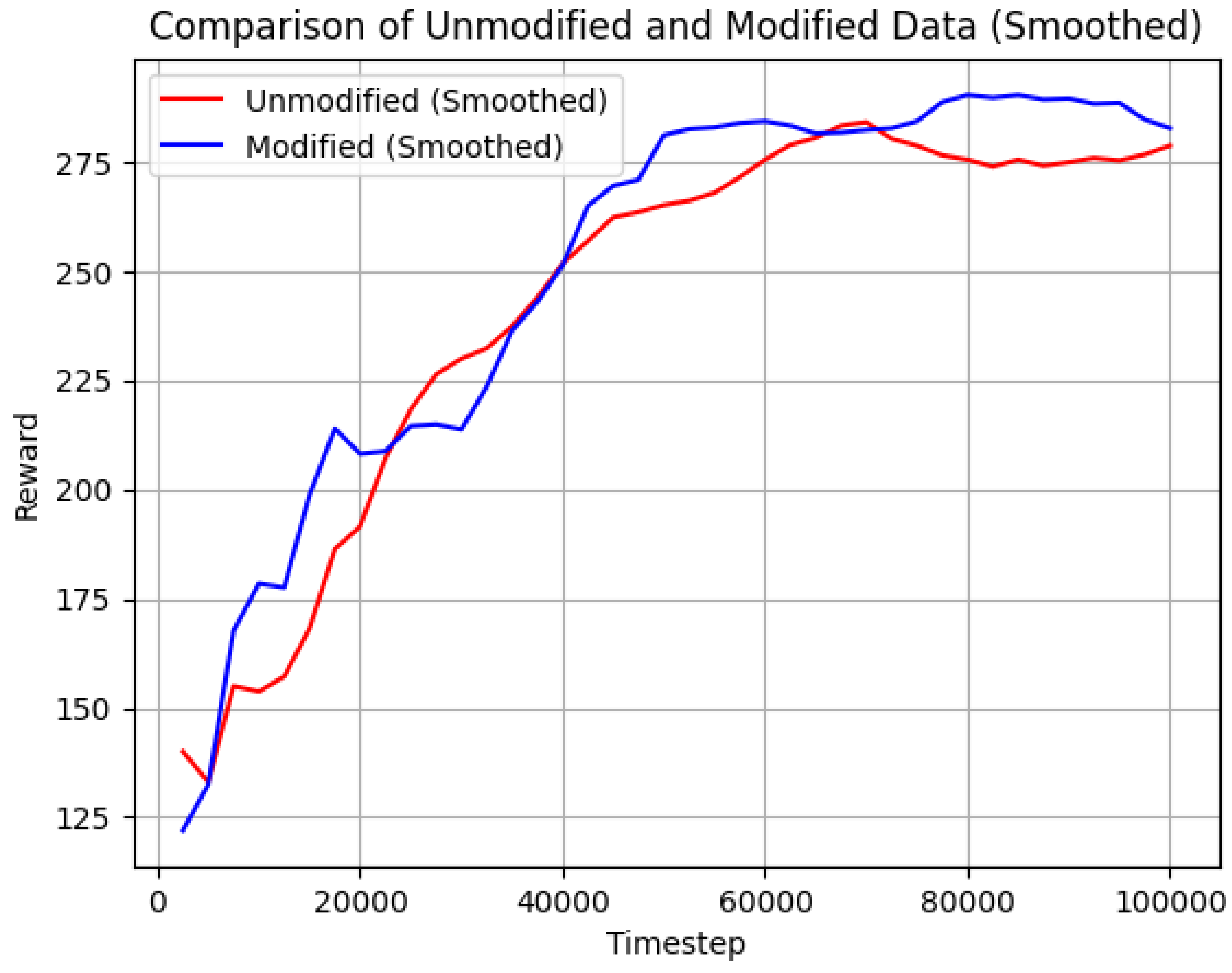
Figure 10. The reward curve of the improved SAC converges in a significantly shorter number of time steps and does not exhibit the slight decline in peak values observed in the later stages of training with the original SAC algorithm. Furthermore, dynamic learning rate adjustment helps maintain the variance of the reward curve within a reasonable range.
By comparing the convergence curves of the reward functions for both algorithms, as illustrated in
Figure 11, it is observed that the convergence speeds are comparable. However, the reward curve obtained from the improved algorithm reaches peak values closer to the theoretically optimal strategy during convergence. While this method results in an increase in the variance of the reward curve, the dynamic learning rate adjustment strategy effectively keeps it within an acceptable range.
Through experimental evaluation, the average score of the improved SAC reward shows a 4% increase compared to the original SAC reward, as illustrated in
Table 7 below. Moreover, the optimization speed of the improved method is 28.6% faster than the original approach, as shown in
Figure 12.
From the visualization results in
Figure 13, it can be observed that the improved SAC algorithm demonstrates more significant effects in terms of optimization speed and results. This indicates the effectiveness of scalarizing the reward function in multi-objective optimization and demonstrates the efficacy of the Pareto-optimal prioritized experience replay sampling strategy in enhancing algorithm performance.
Furthermore, we conducted 50 independent samplings using the SAC algorithm with the improved sampling strategy and calculated the proportion of absolutely safe flight procedures. These procedures were then subjected to flight simulation tests using the BlueSky simulation platform, where the average fuel consumption and flight time were recorded. The experimental results are presented in
Table 8. The improved SAC algorithm demonstrates significant enhancements in the safety procedure ratio, average fuel consumption, and average flight time. Specifically, the safety procedure ratio increased from 46% to 56%, the average fuel consumption decreased from 150.3 kg to 137.2 kg, and the average flight time was reduced from 523 s to 500 s. These findings indicate that the improved SAC algorithm exhibits superior performance in multi-objective optimization.
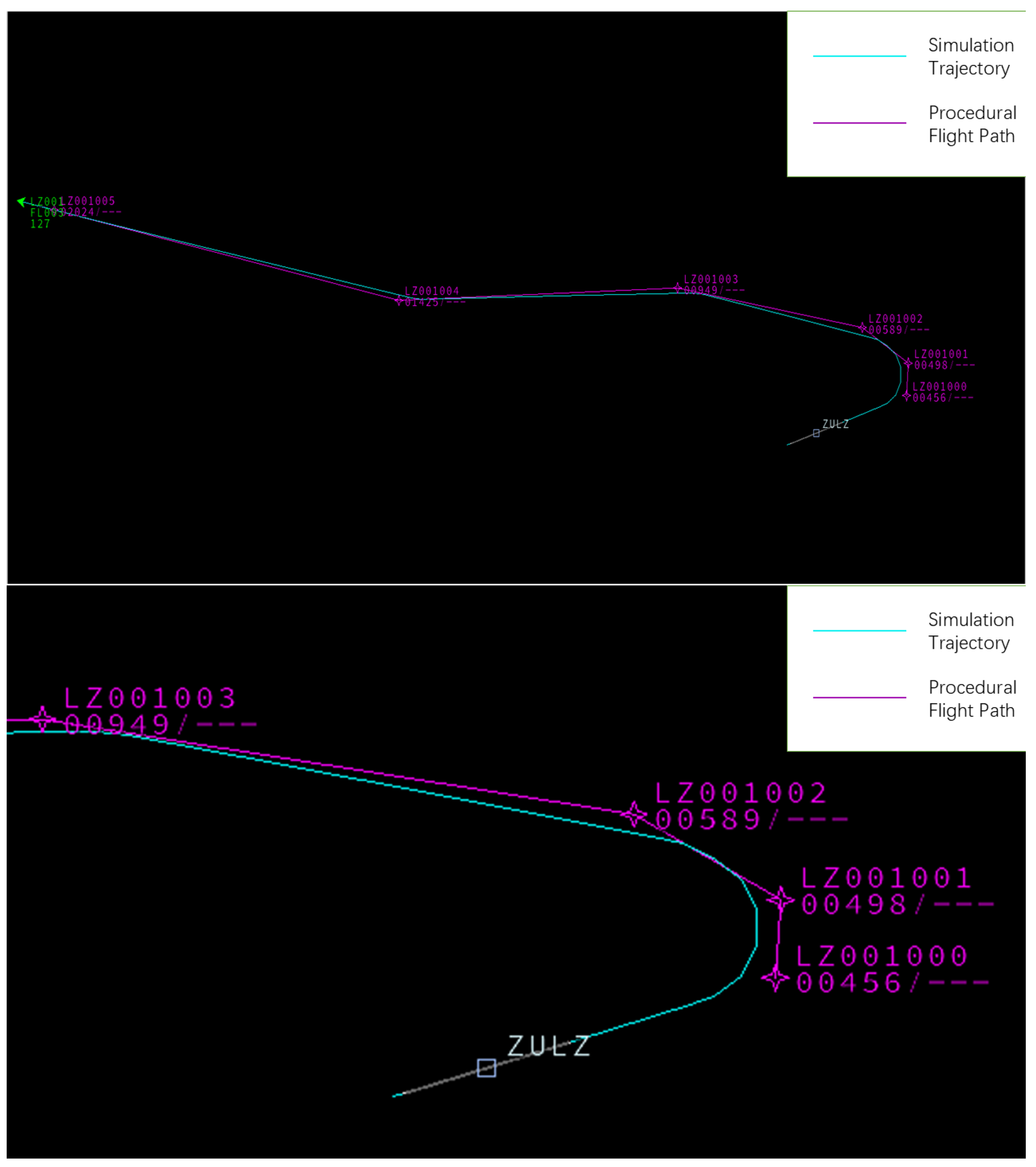
The visualization results of the improved SAC algorithm in BlueSky are presented in
Figure 13, with a detailed comparison shown in
Figure 14. The figures demonstrate that the procedures designed by the proposed method can be accurately executed by the flight simulator, highlighting the practical value of the approach presented in this study.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}