
Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information


Abstract
1. Introduction
- It introduces a novel node importance evaluation method based on ITG for single-layer networks, expanding the methods available for assessing node importance in such networks.
- A node importance identification method in MHAN through aggregating multi-source information is proposed. Enhancing the protection of key nodes and preventing key node collapses provide a reference for improving aviation network resilience.
- A cascading failure model of MHAN is developed, which fully considers the super-capacity operation of the aviation network, thus enhancing the applicability of cascading failure studies to real-world aviation networks. It guides the structural optimization and invulnerability improvement of aviation networks.
- The node influence index defined based on the cascading failure model provides a new method and idea for identifying important nodes in multi-layer networks.
2. Literature Review
2.1. Key Nodes Identification
- (1)
- Network structure: The network structure includes the single-layer network (SLN), multi-layer network (MMN), and interdependent multi-layer network (IMN). It should be noted that the SLN does not have intra-layer nodes or layers.
- (2)
- Method: In the process of identifying key nodes, it is generally necessary to calculate the intra-layer node importance (INI), the layer importance (LI), and the final node importance (NI) based on certain methods. These methods include classical algorithms or optimizing classical algorithms (CAs), the comprehensive evaluation method (CEM), results fusion (RF), and the aggregation of multi-source information (AMS). Among them, RF focuses on combining processing results from different sources using, for example, weighted summation or weighted averaging, and AMS focuses on the use of algorithms to integrate data or features from multiple sources of information [3].
- (3)
- Symbol descriptions: Checkmarks (√) mean that the network structure is used in the study. N/A means that the network does not have the corresponding structure. Circles (o) mean that it is not considered in this study.
2.2. Cascading Failure
- (1)
- Network structure: The network structure includes SLN and IMN.
- (2)
- Load redistribution: The load redistribution encompasses the redistribution strategies of loads for both overloaded and failed nodes. Typically, these strategies involve distributing loads based on one of the following criteria: the number of neighboring nodes (NNs), the load proportion of neighboring nodes (LPN), or the real-time residual capacity of neighboring nodes (RRCN).
- (3)
- Symbol descriptions: Checkmarks (√) mean that the study uses the network structure. Bold checkmarks (✔) and squares (☐) mean that the study does and does not consider the element, respectively.
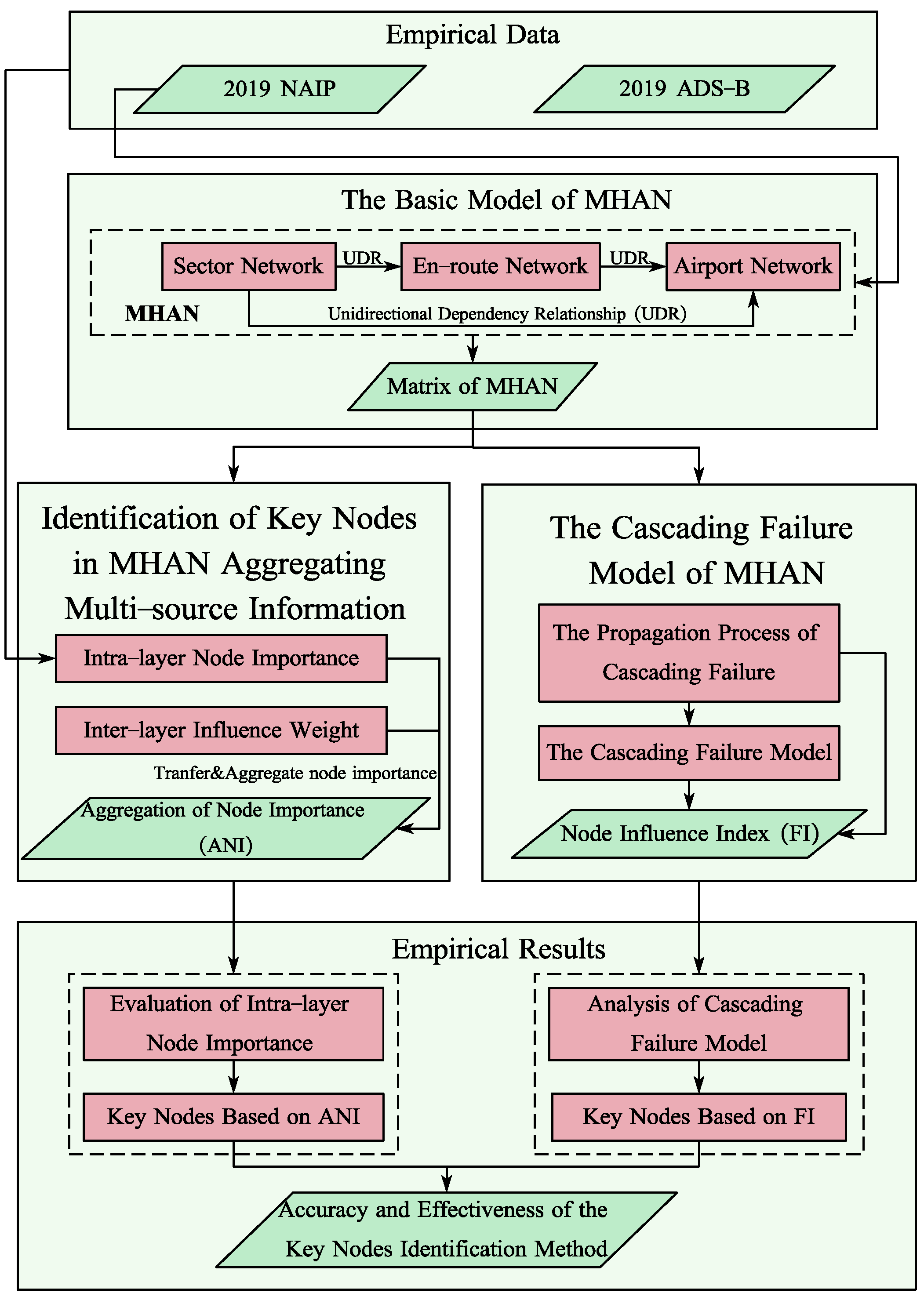
3. Methodological Framework
4. The Basic Model of Multi-Layer Heterogeneous Aviation Network
4.1. Construction Description and Assumptions
- Nodes. In this MHAN framework, airports are represented as nodes in the AN, while the EN employs ground navigation facilities like omnidirectional beacon stations, distance-finding stations, or non-directional beacon stations as nodes. Additionally, the SN merges high sectors into corresponding low sectors, disregarding temporarily open sectors, with sectors serving as nodes. Thus, the MHAN comprises three distinct types of heterogeneous nodes.
- Edges. The MHAN comprises both intra-layer and inter-layer edges. Intra-layer edges are defined as follows: within the AN, edges form between any two airports if there are flights between them; within the EN, edges represent the routes between ground navigation facilities; within the SN, edges correspond to the handover relationships of inter-sector flights. Inter-layer edges are delineated as follows: based on air traffic management rules [49], inter-layer edges between AN and EN represent the connections between airport nodes and corresponding en-route nodes, indicating the connection relationship of aircraft entering en-routes from airports or landing at airports from en-routes. The inter-layer edge between the AN and SN represents the connection between airport nodes and corresponding sector nodes, depicting control sectors’ authority over aircraft takeoff and landing at the respective airports. Lastly, the inter-layer edge between the EN and SN denotes the links between nodes of en-route points and corresponding sector nodes, illustrating the sectors’ management of traffic flow along en-routes. Consequently, the MHAN encompasses six types of heterogeneous edges.
- The MHAN is directed. During aircraft operation, aircraft can take off or land from airports, pass en-route points, and enter or exit sectors. Therefore, it is assumed that the AN, EN, and SN are all undirected. However, there exists a unidirectional dependency relationship [16] between the networks: the airport node facilitates flight takeoff and landing under the normal operation of the corresponding en-route node and sector node, and the en-route node executes flight transportation functions when the associated sector node operates effectively. Hence, the inter-layer edges are directed. Consequently, the MHAN is an intra-layer undirected inter-layer directed network.
4.2. The Construction of Multi-Layer Heterogeneous Aviation Network
5. Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information
5.1. Evaluation of Intra-Layer Node Importance
5.1.1. The Index System for Evaluating Intra-Layer Node Importance
- 1.
- Network Structural Characteristics (NSC)
- 2.
- Network Vulnerability (NV)
- 3.
- Traffic Flow Characteristics (TFC)
5.1.2. Evaluation of Intra-Layer Node Importance Based on Improved TOPSIS-Grey Relational Analysis
| Algorithm 1. Evaluation of intra-layer node importance based on ITG |
| ; |
| 1. do |
| 2. ; |
| 3. ; |
| 4. ; |
| 5. ; |
| 6. by |
| ; |
| 7. do |
| 8. by |
| is |
| ; |
| 9. do |
| 10. by |
| ; |
| 11. end for |
| 12. ; |
| 13. ; |
| 14. ; |
| 15. end for |
| 16. end for |
| 17. |
5.1.3. Evaluation Criterion of Intra-Layer Node Importance
- (1)
- The Monotonicity Index
- (2)
- SIR Model
- (3)
- Kendall’s Tau Coefficient
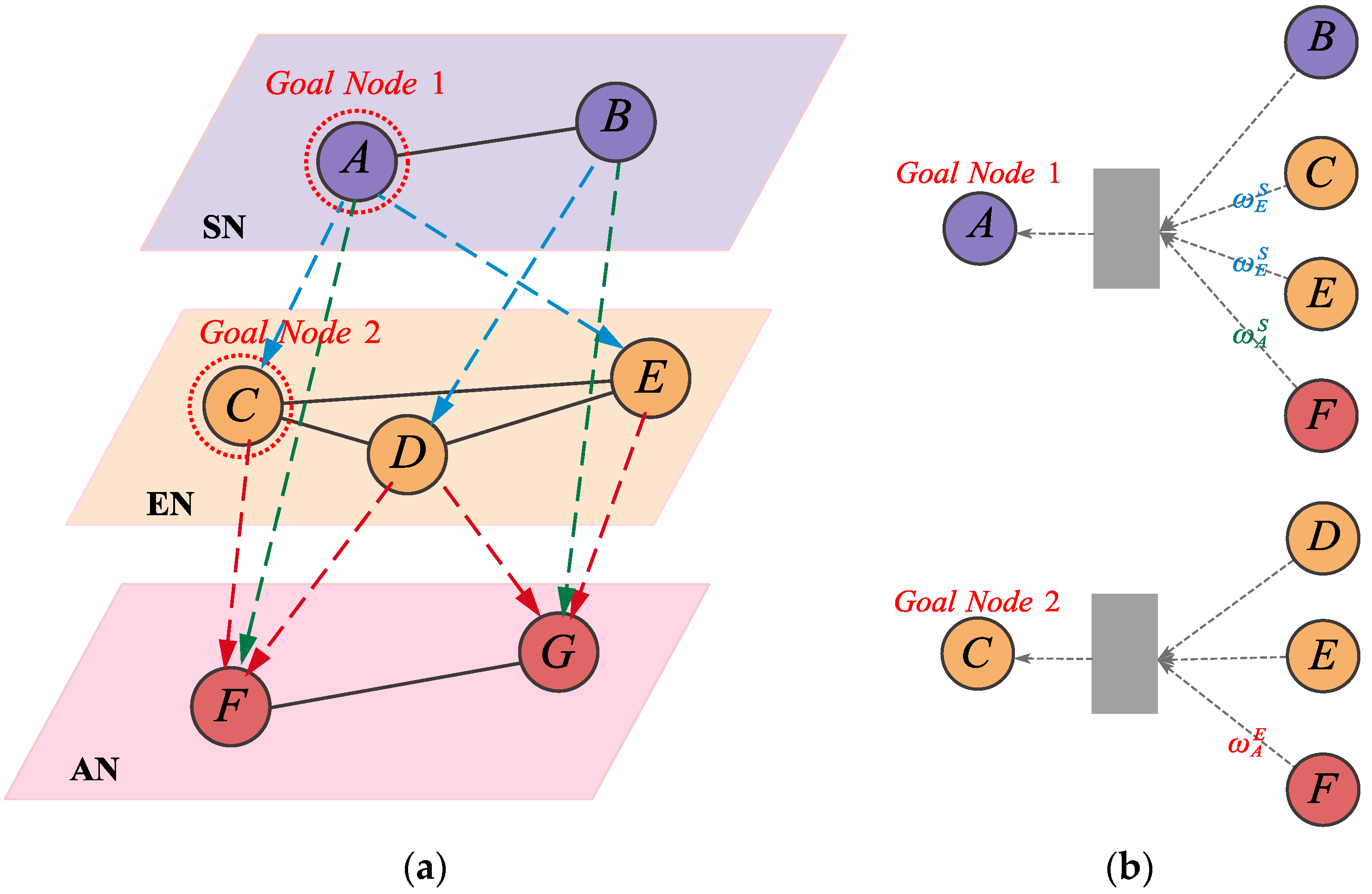
5.2. Quantification of Inter-Layer Influence Weight
5.3. Calculation of Node Importance through Aggregating Multi-Source Information
| Algorithm 2. Calculation of ANI |
| ; |
| the adjacency matrix of MHAN |
| 1. do |
| 2. do |
| 3. using Algorithm 1; 4. end for |
| 5. end for |
| 6. do |
| 7. using Equation (23); |
| 8. end for |
| 9. do |
| 10. do |
| 11. using Equation (24); |
| 12. end for |
| 13. end for |
| 14. |
6. The Cascading Failure Model of Multi-Layer Heterogeneous Aviation Network
6.1. The Propagation Process of Cascading Failure in Multi-Layer Heterogeneous Aviation Network
- Airport Node Failure
- En-route Node Failure
- Sector Node Failure
- Initial normal operation phase. Initialize the load and capacity of each node in MHAN, where the load of each node does not exceed its capacity and air traffic operates normally.
- Node failure phase under attack. When a node within MHAN is subjected to a random or deliberate attack, it immediately fails, triggering the redistribution of its load to neighboring nodes within the same layer. This redistribution follows a predefined load redistribution strategy.
- Cascade failure propagation phase. Firstly, assess whether the neighbor nodes of other layers connected to the failure nodes are restricted by them. If restricted, these neighboring nodes fail, and the load is allocated to the neighbor nodes of the same layer according to the redistribution strategy. Secondly, after the load of the failed nodes is allocated to the neighbor nodes, some of them have loads exceeding the maximum capacity permissible range and fail, and the load is redistributed to their neighbor nodes in the same layer. Additionally, nodes that do not exceed their maximum capacity permissible range but operate in an overload condition will redistribute excess load to the remaining neighbor nodes of the same layer. The above two steps are cycled sequentially to store the propagation process of cascade failure.
- Termination phase of failure. The cascading failure process concludes when no new nodes fail in MHAN and all nodes stabilize.
6.2. The Cascading Failure Model of Multi-Layer Heterogeneous Aviation Network
6.2.1. Initial Load
6.2.2. Critical Capacity
6.2.3. Overload Coefficient and Failure Probability
6.2.4. Load Redistribution Strategy
6.3. Node Influence Index
6.3.1. The Network Failure Scale
6.3.2. The Average Load Change in Neighboring Nodes
6.3.3. Node Influence Index
7. Empirical Results: Case Study of the Aviation Network in Western China
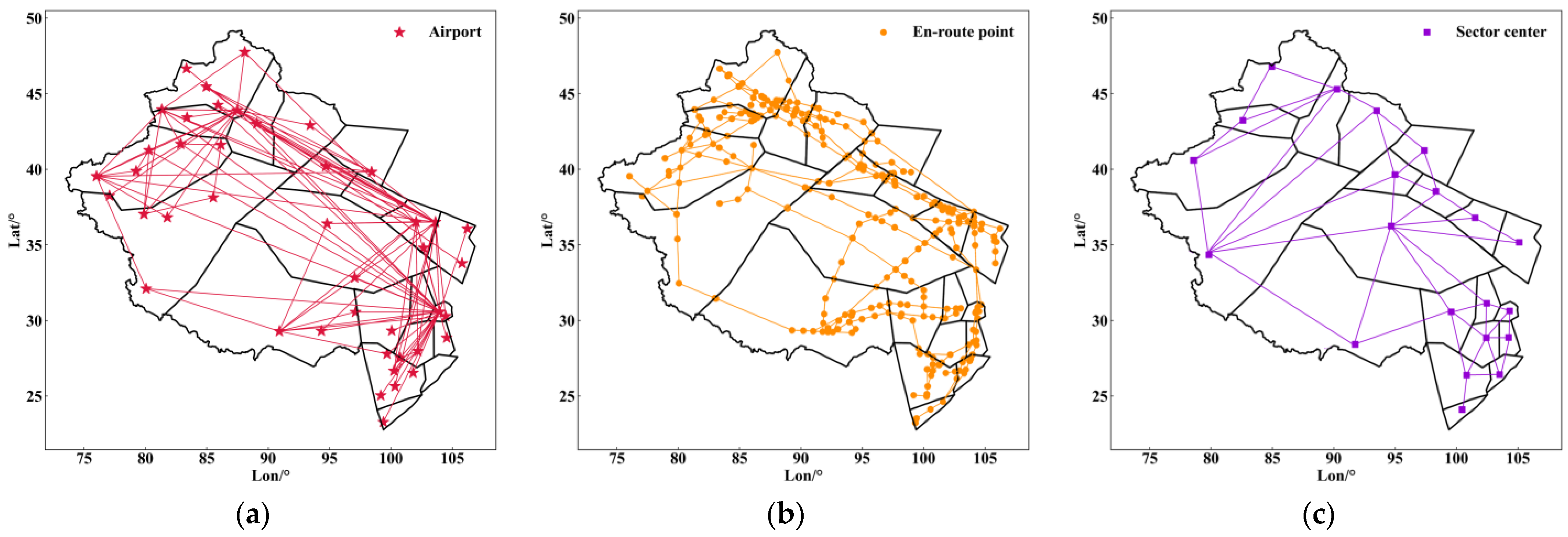
7.1. Multi-Layer Heterogeneous Aviation Network in Western China
7.2. Evaluation of Intra-Layer Node Importance
7.2.1. Calculation of Evaluation Index Weight
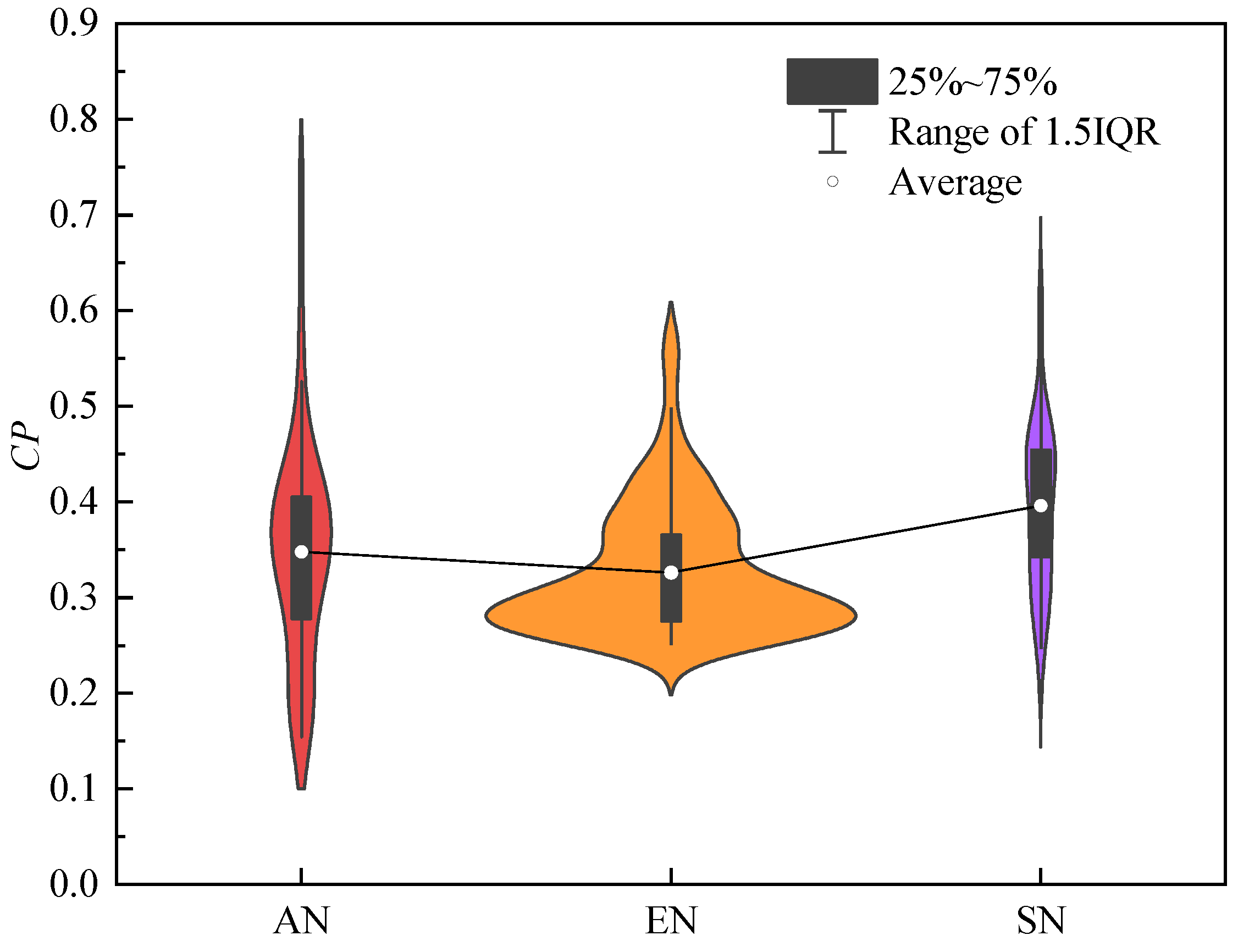
7.2.2. Evaluation Results of Intra-Layer Node Importance
7.2.3. Evaluation Results Validity Analysis of Intra-Layer Node Importance
7.3. Calculation of Node Importance in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information
7.4. The Cascade Failure of Multi-Layer Heterogeneous Aviation Network
7.4.1. Analysis of Cascading Failure in Multi-Layer Heterogeneous Aviation Network under Different Attack Modes
7.4.2. The Correlation between Network Failure Scale and Parameters of Cascade Failure Model
7.5. Node Importance Verification Analysis Based on Node Influence Index
8. Conclusions
- For each layer network of MHAN, network structural characteristics emerge as the most crucial indices. Moreover, the intra-layer node importance evaluation method based on the improved TOPSIS-grey Relational Analysis demonstrates superior capability in distinguishing the intra-layer node importance, yielding more accurate assessment outcomes.
- When the intra-layer importance of a node is large, it may not necessarily be a key node in the overall MHAN; the more critical nodes in MHAN are sector nodes and pivotal en-route nodes situated at hubs.
- As the cascading failure model is influenced by the overload coefficient , initial load adjustment coefficient , and capacity limit , variations in these parameters directly impact the failure scale of MHAN. As increases, there is a notable decrease in the network’s failure scale; when and are fixed, a higher results in a larger cascading failure scale. With increasing within a certain range, the failure scale of MHAN significantly decreases. Thus, judiciously setting these parameters can effectively govern the extent of cascading failures in MHAN.
- Based on the node influence index, it is verified that the key node identification method of MHAN by aggregating multi-source information proposed in this paper is accurate and effective.
- Compared with the key node identification method by aggregating multi-source information, the key node identification method based on node influence relies heavily on accurate modeling of the network structure and failure propagation process and is limited to specific types of networks or specific failure propagation assumptions, which restricts its generalization ability. The key node identification method through aggregating multi-source information is comprehensive and robust, and it is suitable for various types of networks and application scenarios.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full Name |
| MHAN | Multi-layer Heterogeneous Aviation Network |
| SLN | Single-layer Network |
| MMN | Multi-dimensional Multi-layer Network |
| IMN | Interdependent Multi-layer Network |
| INI | Intra-layer Node Importance |
| LI | Layer Importance |
| NI | Node Importance |
| CA | Classical Algorithms or Optimizing Classical Algorithms |
| CEM | Comprehensive Evaluation Method |
| RF | Results Fusion |
| AMS | Aggregation of Multi-source Information |
| NN | Number of Neighboring Nodes |
| LPN | Load Proportion of Neighboring Nodes |
| RRCN | Real-time Residual Capacity of Neighboring Nodes |
| ITG | Improved TOPSIS-grey Relational Analysis |
| AN | Airport Network |
| EN | En-route Network |
| SN | Sector Network |
| NSC | Network Structural Characteristics |
| NV | Network Vulnerability |
| TFC | Traffic Flow Characteristics |
| ANI | Node Importance through Aggregating Multi-source Information |
| DC | Degree Centrality |
| BC | Betweenness Centrality |
| CC | Clustering Coefficient |
| IK | Improved K-shell |
| DE | Network Efficiency Decrease Rate |
| NE | Network Efficiency |
| DN | Network Connectivity Coefficient Decrease Rate |
| NCC | Network Connectivity Coefficient |
| HAF | Hourly Average Flow |
| PHF | Peak Hour Flow |
| S | Susceptible |
| I | Infected |
| R | Removed |
| CT | Classical TOPSIS |
| Parameter | Implication |
| Set of nodes and edges in MHAN | |
| Set of all nodes in MHAN | |
| Set of all edges in MHAN | |
| Nodes of type m, | |
| Number of node types | |
| N | Total number of nodes in MHAN |
| Edges of type l, | |
| Number of edge types | |
| The k-th intra-layer network | |
| / | Number of nodes in or |
| Adjacency matrix of , | |
| A | Set of intra-layer adjacency matrices |
| The directed inter-layer network of layer k and layer h | |
| Set of directed edges of | |
| Adjacency matrix of , | |
| B | Set of inter-layer adjacency matrices |
| The matrix of MHAN | |
| DC of node | |
| Edge between and | |
| the BC of node | |
| Number of shortest paths between any two nodes and | |
| Number of shortest paths passing through node between any two nodes and | |
| CC of node | |
| Total number of neighboring nodes of | |
| Actual number of edges existing among the neighboring nodes of | |
| Node information entropy of | |
| Node importance of based on DC | |
| Set of same-layer neighboring nodes of | |
| Length of the shortest path between and | |
| Network efficiency decrease rate corresponding to node | |
| New NE after removing node and its edges | |
| Number of connected components of | |
| Number of nodes in the i-th connected component | |
| Average shortest path of the i-th connected component | |
| Number of shortest paths in the i-th connected component | |
| Length of the shortest path between and in the i-th connected component | |
| Network connectivity coefficient decrease rate corresponding to node | |
| New NCC after removing node and its edges | |
| Hourly average flow of | |
| Number of statistical slots | |
| Number of flights during slot t | |
| Peak hour flow of | |
| Evaluation index vector of , | |
| Intra-layer importance of | |
| Initial decision matrix of , | |
| Standardized initial decision matrix of | |
| Weight vector of , | |
| Weighted decision matrix of , | |
| Positive ideal solution of | |
| Negative ideal solution of | |
| , | Weighted Mahalanobis distance of |
| Covariance matrix of | |
| Diagonal matrix of , | |
| , | Grey correlation coefficients of |
| Resolution-function ratio | |
| , | Grey correlation degree of |
| , | Proximity of |
| , | Preference coefficients of position and shape, respectively |
| Inter-layer influence weight between the h-th layer and the k-th layer networks in MHAN | |
| G | Gravitational constant |
| Set of cross-layer neighbor nodes of node | |
| , , | Inter-layer influence weights between EN and AN, SN and AN, SN and EN, respectively |
| Initial load of node | |
| Degree of | |
| Initial load adjustment coefficient | |
| Critical capacity of node | |
| Capacity limit | |
| Limit capacity coefficient | |
| Failure probability of the node | |
| Actual load of node at time step s | |
| Overload coefficient | |
| Additional load allocated from the failed node to its neighboring node | |
| S | Total number of time steps from the initial state to the end of the cascading failure |
| Allocation ratio from the overloaded node to its neighboring node | |
| Excess load allocated from the overloaded node to node | |
| Network failure scale of node | |
| Number of failed nodes in MHAN | |
| Number of failed edges in MHAN | |
| M | Number of edges in MHAN |
| Average load change in neighboring nodes of node | |
| Number of same-layer neighboring nodes of node | |
| Load of node after the cascade failure concludes | |
| Node influence index of | |
| Average degree | |
| Average shortest path length | |
| Clustering coefficient | |
| Transmission rate threshold in the SIR model | |
| Transmission rate | |
| Monotonicity index | |
| Intra-layer node importance ranking vector of the k-th layer network | |
| Number of nodes with the same intra-layer importance | |
| Recovery rate | |
| Spreading capability ranking vector of the k-th layer network | |
| Second-order neighbor average degree | |
| Kendall’s Tau coefficient | |
| Combination sequence based on and , | |
| Number of concordant pairs in | |
| Number of discordant pairs in |
References
- Wang, X.; Pan, W.; Zhao, M. Analysis of both robustness and congestion of aeronautical interdependent network. China Saf. Sci. J. 2018, 28, 110–115. [Google Scholar]
- Xu, Z.; Zeng, W.; Chu, X.; Cao, P. Multi-aircraft trajectory collaborative prediction based on social long short-term memory network. Aerospace 2021, 8, 115. [Google Scholar] [CrossRef]
- Wan, L.; Zhang, M.; Li, X.; Sun, L.; Wang, X.; Liu, K. Identification of important nodes in multilayer heterogeneous networks incorporating multirelational information. IEEE Trans. Comput. Soc. Syst. 2022, 9, 1715–1724. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Huang, G. Efficiency and robustness of weighted air transport networks. Transp. Res. Part E Logist. Transp. Rev. 2019, 122, 14–26. [Google Scholar] [CrossRef]
- Wang, H.; Ma, L.; Xu, P. Research on identification method of key aircraft based on temporal network. J. Beijing Univ. Aeronaut. Astronaut. 2023, 5, 1–17. [Google Scholar]
- Li, J.; Wen, X.; Wu, M.; Liu, F.; Li, S. Identification of key nodes and vital edges in aviation network based on minimum connected dominating set. Phys. A Stat. Mech. Its Appl. 2020, 541, 123340. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, J.; Wang, J.; Zhu, P. An optimization method for critical node identification in aviation network. Front. Phys. 2022, 10, 944136. [Google Scholar] [CrossRef]
- Tian, W.; Fang, Q.; Zhou, X.; Song, J. Research on identification method of key nodes in en-route network. J. Southwest Jiaotong Univ. 2022, 7, 1–10. [Google Scholar]
- Zhang, Z.; Qu, C. Node importance analysis of airport network considering gravitational correlation. J. Saf. Environ. 2022, 22, 3269–3279. [Google Scholar]
- Motter, A.E.; Lai, Y.C. Cascade-based attacks on complex networks. Phys. Rev. E 2002, 66, 065102. [Google Scholar] [CrossRef]
- Fan, C.; Wang, B.; Tian, J. Cascading failure model in aviation network considering overload condition and failure probability. J. Comput. Appl. 2022, 42, 502–509. [Google Scholar]
- Tian, W.; Zhou, X.; Fang, Q.; Song, J. Vulnerability analysis of en-route network based on cascading failure. J. Southwest Jiaotong Univ. 2023, 11, 1–17. [Google Scholar]
- Kong, J.; Lu, J.; Liang, H. Air traffic control sector network resilience evaluation based on cascading failures model. J. Saf. Environ. 2023, 23, 3978–3984. [Google Scholar]
- Zhang, C.; Zhang, F.; Wang, Y.; Wu, H. Method to analyse the robustness of aviation communication network based on complex networks. Syst. Eng. Electron. 2015, 37, 180–184. [Google Scholar]
- Chen, S. Research on Resilience of Air Transportation Interdependent Network. Master Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2019. [Google Scholar]
- Wang, X.; Pan, W.; Zhao, M. Vulnerability of air traffic interdependent network. Acta Aeronaut. Astronaut. Sin. 2018, 39, 275–284. [Google Scholar]
- Wang, X.; Wei, Y.; He, M. Air traffic CPS structural characteristics and resilience evaluation. J. Beijing Univ. Aeronaut. Astronaut. 2022, 50, 1–16. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Tang, X.; Wang, J.; Zhong, J.; Pan, Y. Predicting essential proteins based on weighted degree centrality. IEEE/ACM Trans. Comput. Biol. Bioinform. 2013, 11, 407–418. [Google Scholar] [CrossRef] [PubMed]
- Prountzos, D.; Pingali, K. Betweenness centrality: Algorithms and implementations. In Proceedings of the 18th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Shenzhen, China, 23–27 February 2013; pp. 35–46. [Google Scholar]
- Li, P.; Ren, Y.; Xi, Y. An importance measure of actors (set) within a network. Syst. Eng. 2004, 4, 13–20. [Google Scholar]
- Cheng, G.; Lu, Y.; Zhang, M.; Huang, J. Node importance evaluation and network vulnerability analysis on complex network. J. Natl. Univ. Def. Technol. 2017, 39, 120–127. [Google Scholar]
- Bian, T.; Hu, J.; Deng, Y. Identifying influential nodes in complex networks based on AHP. Phys. A Stat. Mech. Its Appl. 2017, 479, 422–436. [Google Scholar] [CrossRef]
- Yang, S.; Jiang, Y.; Tong, T.; Yan, Y.; Gan, G. A method of evaluating importance of nodes in complex network based on Tsallis entropy. Acta Phys. Sin. 2021, 70, 273–284. [Google Scholar] [CrossRef]
- Buldyrev, S.V.; Parshani, R.; Paul, G.; Stanley, H.E.; Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 2010, 464, 1025–1028. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, T.; Narayanam, R. Cross-layer betweenness centrality in multiplex networks with applications. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 397–408. [Google Scholar]
- Maulana, A.; Emmerich, M.T. Towards many-objective optimization of eigenvector centrality in multiplex networks. In Proceedings of the 2017 4th International Conference on Control, Decision and Information Technologies (CoDIT), Barcelona, Spain, 5–7 April 2017; pp. 0729–0734. [Google Scholar]
- Rahmede, C.; Iacovacci, J.; Arenas, A.; Bianconi, G. Centralities of nodes and influences of layers in large multiplex networks. J. Complex Netw. 2018, 6, 733–752. [Google Scholar] [CrossRef]
- Ding, C.; Li, K. Centrality ranking in multiplex networks using topologically biased random walks. Neurocomputing 2018, 312, 263–275. [Google Scholar] [CrossRef]
- Luo, H.; Yan, G.; Zhang, M.; Bao, J.; Li, J.; Liu, T.; Yang, B.; Wei, J. Research on node importance fused multi-information for multi-relational social networks. J. Comput. Res. Dev. 2020, 57, 954–970. [Google Scholar]
- Feng, F.; Cai, M.; Jia, J. Key node identification of China railway express transportation network based on multi-layer complex network. J. Transp. Syst. Eng. Inf. Technol. 2022, 22, 191–200. [Google Scholar]
- Zhou, X.; Bouyer, A.; Maleki, M.; Mohammadi, M.; Arasteh, B. Identifying top influential spreaders based on the influence weight of layers in multiplex networks. Chaos Solitons Fractals 2023, 173, 113769. [Google Scholar] [CrossRef]
- Lv, L.; Hu, P.; Zheng, Z.; Bardou, D.; Zhang, T.; Wu, H.; Niu, S.; Yu, G. A community-based centrality measure for identifying key nodes in multilayer networks. IEEE Trans. Comput. Soc. Syst. 2023, 2, 2448–2463. [Google Scholar] [CrossRef]
- Wang, D.; Wang, H.; Zou, X. Identifying key nodes in multilayer networks based on tensor decomposition. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Novoa-del-Toro, E.M.; Mezura-Montes, E.; Vignes, M.; Térézol, M.; Magdinier, F.; Tichit, L.; Baudot, A. A multi-objective genetic algorithm to find active modules in multiplex biological networks. PLoS Comput. Biol. 2021, 17, e1009263. [Google Scholar] [CrossRef]
- Wu, Y.; Ding, Y.; Wang, J.; Wang, X. Determination of the key ccRCC-related molecules from monolayer network to three-layer network. Cancer Genet. 2021, 256, 40–47. [Google Scholar] [CrossRef]
- Fan, L. Research and Application of Key Node Identification and Reliability of Multi-layer Complex Network. Master Thesis, Xidian University, Xi’an, China, 2022. [Google Scholar]
- Wang, X.; Xu, J. Cascading failures in coupled map lattices. Phys. Rev. E 2004, 70, 056113. [Google Scholar] [CrossRef]
- Dorogovtsev, S.N.; Mendes, J.F.F.; Samukhin, A.N. Giant strongly connected component of directed networks. Phys. Rev. E 2001, 64, 025101. [Google Scholar] [CrossRef]
- Li, C.; Li, W.; Cao, C.; Wang, Y. Robustness analysis of interdependent networks for cascading failure. J. Syst. Simul. 2019, 31, 538–548. [Google Scholar]
- Li, S.; Yang, H.; Song, B. Study on co-evolution of underload failure and overload cascading failure in multi-layer supply chain network. Comput. Sci. 2021, 48, 351–358. [Google Scholar]
- Li, Y.; Wang, B.; Wang, H.; Ma, F.; Zhang, J.; Ma, H.; Zhang, Y.; Mohamed, M.A. Importance assessment of communication equipment in cyber-physical coupled distribution networks based on dynamic node failure mechanism. Front. Energy Res. 2022, 10, 911985. [Google Scholar] [CrossRef]
- Wang, Q.; Zhu, Z.; Chen, H.; Sun, J.; Guan, W.; RIVERA-DURóN, R.R. Node resistance characteristic of heterogeneous multi-layer transportation networks under cascading failure based on coupled map lattice. China J. Highw. Transp. 2022, 35, 263–274. [Google Scholar]
- Zhang, J.; Huang, J.; Zhang, Z. Analysis of the effect of node attack method on cascading failures in multi-layer directed networks. Chaos Solitons Fractals 2023, 168, 113156. [Google Scholar] [CrossRef]
- Jia, C.; Li, M.; Liu, R. Percolation and cascading dynamics on multilayer complex networks. J. Univ. Electron. Sci. Technol. China 2022, 51, 148–160. [Google Scholar]
- CCAR-93-R5; Civil Aviation Air Traffic Management Rules. Ministry of Transport of the People’s Republic of China: Beijing, China, 2017.
- Kenett, D.Y.; Perc, M.; Boccaletti, S. Networks of networks–an introduction. Chaos Solitons Fractals 2015, 80, 1–6. [Google Scholar] [CrossRef]
- Wang, M.; Li, W.; Guo, Y.; Peng, X.; Li, Y. Identifying influential spreaders in complex networks based on improved k-shell method. Phys. A Stat. Mech. Its Appl. 2020, 554, 124229. [Google Scholar] [CrossRef]
- Wu, J.; Tan, Y. Study on measure of complex network invulnerability. J. Syst. Eng. 2005, 20, 128–131. [Google Scholar]
- Zheng, M.; Yang, J. Construction method evaluation of roadbed underpass high-speed railway bridge based on AHP-CRITIC method and TOPSIS method. J. Saf. Environ. 2023, 23, 2563–2571. [Google Scholar]
- Zeng, A.; Zhang, C. Ranking spreaders by decomposing complex networks. Phys. Lett. A 2013, 377, 1031–1035. [Google Scholar] [CrossRef]
- Pastor-Satorras, R.; Vespignani, A. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 2001, 86, 3200. [Google Scholar] [CrossRef]
- Knight, W.R. A computer method for calculating Kendall’s tau with ungrouped data. J. Am. Stat. Assoc. 1966, 61, 436–439. [Google Scholar] [CrossRef]
- Ma, L.; Ma, C.; Zhang, H.; Wang, B. Identifying influential spreaders in complex networks based on gravity formula. Phys. A Stat. Mech. Its Appl. 2016, 451, 205–212. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y.; Liu, G.; Wang, L. Evaluation method of importance for nodes in complex networks based on importance contribution. Complex Syst. Complex. Sci. 2014, 11, 26–32+49. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Network Structure | Method | ||||
|---|---|---|---|---|---|---|
| SLN | MMN | IMN | INI | LI | NI | |
| Tian et al. [8] | √ | N/A | N/A | CEM | ||
| Feng et al. [34] | √ | CEM | o | RF | ||
| Wu et al. [39] | √ | CA | o | CA | ||
| Fan [40] | √ | CA | CA | RF | ||
| Wan et al. [3] | √ | CA | CA | AMS | ||
| This paper | √ | CEM | CA+RF | AMS | ||
| References | Network Structure | Load/ Capacity | Overload Condition | Failure Probability | Load Redistribution | ||
|---|---|---|---|---|---|---|---|
| SLN | IMN | Overload | Failure | ||||
| Kong et al. [13] | √ | ✔ | ☐ | ☐ | ☐ | NN | |
| Chen [15] | √ | ✔ | ✔ | ☐ | ☐ | RRCN | |
| Wang et al. [16] | √ | ✔ | ☐ | ☐ | ☐ | LPN | |
| Wang et al. [17] | √ | ☐ | ☐ | ☐ | ☐ | ☐ | |
| Li et al. [43] | √ | ✔ | ☐ | ☐ | ☐ | LPN | |
| Li et al. [44] | √ | ✔ | ☐ | ☐ | ☐ | LPN | |
| This paper | √ | ✔ | ✔ | ✔ | RRCN | LPN | |
| Network | Nk | Mk | <z> | <d> | <cc> | ||
|---|---|---|---|---|---|---|---|
| AN | 43 | 93 | 4.3256 | 2.2625 | 0.5063 | 0.0963 | 0.13 |
| EN | 265 | 327 | 2.4679 | 13.1761 | 0.0293 | 0.1327 | 0.12 |
| SN | 21 | 42 | 4.0000 | 2.7095 | 0.5833 | 0.1092 | 0.10 |
| Inter-Layer Edge | A-E | A-S | E-S |
|---|---|---|---|
| Number | 5584 | 43 | 277 |
| Network | NSC | NV | TFC | |||||
|---|---|---|---|---|---|---|---|---|
| DC | BC | CC | IK | DE | DN | HAF | PHF | |
| AN | 0.1560 | 0.1344 | 0.1113 | 0.1938 | 0.1540 | 0.0638 | 0.1114 | 0.0753 |
| EN | 0.0886 | 0.1026 | 0.1783 | 0.2183 | 0.0901 | 0.1879 | 0.0845 | 0.0497 |
| SN | 0.1210 | 0.1241 | 0.0884 | 0.2032 | 0.1189 | 0.0642 | 0.1630 | 0.1172 |
| Order | AN | EN | SN | |||
|---|---|---|---|---|---|---|
| Name | CP | Name | CP | Name | CP | |
| 1 | ZUUU | 0.7302 | SADAN | 0.5730 | ZLLLAR04 | 0.5963 |
| 2 | ZWWW | 0.6072 | AKS | 0.5717 | ZWWWAR05 | 0.4780 |
| 3 | ZLLL | 0.5262 | LESVI | 0.5708 | ZUUUAR03 | 0.4674 |
| 4 | ZLXN | 0.4900 | PAMLI | 0.5490 | ZUUUAR11 | 0.4665 |
| 5 | ZWSH | 0.4450 | KANPI | 0.5463 | ZPPPAR06 | 0.4556 |
| 6 | ZULS | 0.4271 | OMBON | 0.5295 | ZUUUAR17 | 0.4547 |
| 7 | ZWTL | 0.4238 | XKC | 0.5243 | ZPXX01 | 0.4520 |
| 8 | ZWYN | 0.4226 | DNC | 0.4986 | ZWWWAR04 | 0.4497 |
| 9 | ZWHZ | 0.4158 | TMS | 0.4890 | ZUUUAR12 | 0.4331 |
| 10 | ZWAK | 0.4123 | JTG | 0.4758 | ZUUUAR08 | 0.4244 |
| 11 | ZWKM | 0.4056 | MAGIV | 0.4752 | ZLXYAR09 | 0.408391 |
| 12 | ZUXC | 0.4011 | JTA | 0.4614 | ZWWWAR06 | 0.387367 |
| 13 | ZUNZ | 0.3983 | HTN | 0.4586 | ZWWWAR02 | 0.365775 |
| 14 | ZPLJ | 0.3922 | BESMI | 0.4578 | ZLXYAR11 | 0.356883 |
| 15 | ZPDL | 0.3821 | UBKER | 0.4482 | ZLLLAR12 | 0.343295 |
| Network | M (DC) | M (BC) | M (CC) | M (IK) | M (CT) | M (ITG) |
|---|---|---|---|---|---|---|
| AN | 0.7121 | 0.4097 | 0.6322 | 0.9368 | 0.9426 | 0.9952 |
| EN | 0.3583 | 0.6803 | 0.7466 | 1 | 0.9913 | 1 |
| SN | 0.6631 | 0.9070 | 0.7761 | 0.9605 | 0.9747 | 0.9990 |
| Network | ||||||
|---|---|---|---|---|---|---|
| AN | 0.7907 | 0.5481 | 0.4751 | 0.8513 | 0.8851 | 0.9579 |
| EN | 0.8870 | 0.6239 | 0.8855 | 0.9569 | 0.9417 | 0.9729 |
| SN | 0.7619 | 0.7319 | 0.4857 | 0.9024 | 0.9136 | 0.9567 |
| A-E | A-S | E-S | |
|---|---|---|---|
| 0.1496 | 0.1394 | 0.1277 |
| Order | Name | Node Type | ANI |
|---|---|---|---|
| 1 | ZWWWAR02 | Sector | 1.7092 |
| 2 | ZWWWAR06 | Sector | 1.6843 |
| 3 | ZLLLAR04 | Sector | 1.5550 |
| 4 | OMBON | En-route | 1.5547 |
| 5 | ZPXX01 | Sector | 1.5133 |
| 6 | URC | En-route | 1.4975 |
| 7 | DNC | En-route | 1.4705 |
| 8 | BESMI | En-route | 1.4414 |
| 9 | VIKUP | En-route | 1.4341 |
| 10 | ZLXYAR09 | Sector | 1.4252 |
| 11 | AKS | En-route | 1.3988 |
| 12 | ZPPPAR06 | En-route | 1.3942 |
| 13 | NIXUK | Sector | 1.3855 |
| 14 | PAMLI | En-route | 1.3739 |
| 15 | XIXAN | En-route | 1.3577 |
| Order | Node Influence | Node Importance | |||
|---|---|---|---|---|---|
| Name | Node Type | FI | Name | Node Type | |
| 1 | ZWWWAR06 | Sector | 0.9074 | ZWWWAR02 | Sector |
| 2 | ZWWWAR02 | Sector | 0.9033 | ZWWWAR06 | Sector |
| 3 | ZLLLAR04 | Sector | 0.9011 | ZLLLAR04 | Sector |
| 4 | OMBON | En-route | 0.8427 | OMBON | En-route |
| 5 | ZPXX01 | Sector | 0.8322 | ZPXX01 | Sector |
| 6 | ZLXYAR09 | Sector | 0.8126 | URC | En-route |
| 7 | URC | En-route | 0.8126 | DNC | En-route |
| 8 | DNC | En-route | 0.8121 | BESMI | En-route |
| 9 | BESMI | En-route | 0.8118 | VIKUP | En-route |
| 10 | VIKUP | En-route | 0.8118 | ZLXYAR09 | Sector |
| 11 | AKS | En-route | 0.8091 | AKS | En-route |
| 12 | ZPPPAR06 | Sector | 0.8091 | ZPPPAR06 | En-route |
| 13 | NIXUK | En-route | 0.7004 | NIXUK | Sector |
| 14 | PAMLI | En-route | 0.6995 | PAMLI | En-route |
| 15 | XIXAN | En-route | 0.6989 | XIXAN | En-route |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Q.; Hu, M.; Yang, L.; Zhao, Z. Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information. Aerospace 2024, 11, 619. https://doi.org/10.3390/aerospace11080619
Gao Q, Hu M, Yang L, Zhao Z. Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information. Aerospace. 2024; 11(8):619. https://doi.org/10.3390/aerospace11080619
Chicago/Turabian StyleGao, Qi, Minghua Hu, Lei Yang, and Zheng Zhao. 2024. "Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information" Aerospace 11, no. 8: 619. https://doi.org/10.3390/aerospace11080619
APA StyleGao, Q., Hu, M., Yang, L., & Zhao, Z. (2024). Identification of Key Nodes in Multi-Layer Heterogeneous Aviation Network through Aggregating Multi-Source Information. Aerospace, 11(8), 619. https://doi.org/10.3390/aerospace11080619