1. Introduction
With the development of intelligent information technology, advanced guidance laws play a crucial role in accurate interception missions. Furthermore, when confronting different types of maneuvering evaders, it is crucial for the pursuer to rapidly perceive the environment and generate a favorable, accurate, and effective guidance strategy. Therefore, intelligent guidance laws for intercepting maneuvering evaders have attracted the attention of many scholars.
Traditional guidance laws include proportional navigation guidance (PNG) [
1], augmented proportional navigation guidance (APNG) [
2], optimal guidance laws (OGLs) [
3], and sliding mode control (SMC) guidance laws [
4]. However, those methods are not intelligent and need many manual settings. Additionally, the evader is treated as a stationary object. As is well known, intercepting maneuvering evaders involves a game process known as the classical pursuit–evasion game. For solving the interception problem of maneuvering evaders, differential game (DG) theory shows its advantages, where the interception problem is transformed into finding the saddle point of Nash equilibrium. In [
5], an intelligent guidance algorithm was proposed for effectively intercepting the maneuverable target by virtue of DG concepts. The engagement kinematics, in addition to the direct intercept condition, were developed with 2D engagement. In [
6], linear quadratic differential game (LQDG) guidance laws were proposed for solving the two-pursuit versus single-evader problem. The interception strategy was derived from the Nash equilibrium strategy set of the game. Similarly, in [
7], differential game guidance laws were proposed for a linear system. However, obtaining an analytic solution becomes nearly impossible as the system grows more complex.
To address the nonlinear problem, adaptive dynamic programming (ADP) techniques provide powerful tools to solve nonlinear DG problems. Value iteration and policy iteration are employed to solve differential game guidance laws (DGGLs). In [
8], a data-driven value iteration (VI) algorithm was proposed to solve the adaptive continuous-time linear optimal output regulation, and the author designed an online value iteration algorithm to learn the feedback control gain. In [
9], an online policy iteration algorithm was proposed to achieve infinite-horizon optimal design for nonlinear two-player zero-sum games. However, insufficient iterations within a fixed sampling time may lead to system instability. To address this problem, in [
10], the author proposed a time-based neuro-dynamic programming (NDP) algorithm, where the previous history of system states and cost function approximations were considered to solve the iteration problem. In [
11], three neural network approximators were designed to learn the cost function, and an online NDP algorithm was proposed to solve the two-player zero-sum game problem in a continuous-time (CT) system. However, these guidance laws are not autonomous intelligent strategies, indicating that guidance systems lack the attributes of intelligent decision-making systems.
With the development of ADP techniques, reinforcement learning (RL) is gaining more attention as an effective method for obtaining autonomous intelligent guidance strategies. In [
12], reinforcement learning was applied to solve the differential game problem, and the minimax point was found using discrete iteration. In [
13], the researchers investigated the use of reinforcement learning techniques, based on the Q-learning algorithm, to implement interception strategies. Moreover, in [
14], based on Q-learning and the fuzzy inference system, a fuzzy logic controller was proposed for solving pursuit–evasion differential games. The proposed method could solve the maneuverability of the evader when it is unknown. In [
15], Jun Jet Tai’s work on reinforcement learning algorithms demonstrates that PyFlyt enables the configuration of arbitrary UAV types, such as dog fighting in the open-source PyFlyt software (PyFlyt 4.0.0). However, these reinforcement learning algorithms were implemented by discretizing the continuous action domain, potentially leading to exponential growth in calculations. To address this problem, deep reinforcement learning (DRL), with its advantage in solving the continuous control problem, was considered. In [
16], modified multiagent reinforcement learning was proposed to achieve the underwater target hunting task under the constraints of energetic flows and acoustic propagation delay. In [
17], deep deterministic policy gradient (DDPG) techniques were applied in guidance applications, and an intelligent impact time guidance law with the field-of-view was proposed. The guidance gain was obtained by the DDPG framework, which maximizes the expected total reward. In [
18], for solving the hypersonic pursuit–evasion game, an intelligent maneuver strategy was proposed based on the TD3 algorithm and a deep neural network; the proposed algorithm could explore potential maneuver manners. Similar work is discussed in reference [
19]. Although these DRL guidance laws can solve the interception problem by maximizing the expected reward, the evader is regarded as part of the environment without intelligent decision. Furthermore, there exist almost no papers that study the differential game guidance law (DGGL) for solving the interception problem in a continuous domain by DRL.
This paper innovatively combines DRL technology with DG theory to solve the DDGL design in the continuous domain. An intelligent differential game guidance law (IDGGL) algorithm is proposed. The main contributions of this paper are emphasized as follows.
1. Unlike traditional guidance laws, the advantages of the proposed IDGGL are saving cost efforts and avoiding tedious manual settings. The guidance model is obtained directly from environmental interaction learning through reinforcement learning. It is an intelligent guidance strategy, which can save more simulation time.
2. The problem of differential game interception is transformed into a Markov game. In general guidance algorithms based on deep reinforcement learning, the evader’s strategy is not considered. Unlike traditional DRL algorithms, our method formulates the guidance problem as a differential game, which allows for more sophisticated strategies in adversarial scenarios. The proposed IDGGL algorithm aims to determine the minimax saddle point rather than maximize the return. In this way, the evader is traded as an intelligent agent. This is the first application for DRL to solve the differential game interception problem.
3. Unlike numerous research works on guidance algorithms based on deep reinforcement learning, in our paper, a complex reward function is considered; on the one hand, the designed reward function aligns better with practical applications; on the other hand, it makes the training process faster and the trained model more accurate. A reasonable reward function is designed, which emphasizes not only the terminal interception distance but also the energy consumption and interception distance in the interception process. Additionally, replay buffer stores, “soft” target networks, and normalization techniques are adopted to make the training process more efficient. Additionally, for practical application, the action space with an added noise process is considered.
The structure of this paper is organized as follows. In
Section 2, the pursuit–evasion game problem and the core concepts and principles of RL are presented. The framework of the zero-sum differential Markov game and the proposed IDGGL are presented in
Section 3. In
Section 4, numerical experiments are carried out to evaluate the performance of the proposed IDGGL strategy.
Section 5 presents some conclusions.
2. Problem Statement and Preliminaries
First, we present the formulation of the pursuit–evasion game. In this engagement, the pursuer tries to intercept the evader, while the evader tries to escape from the pursuer. Then, the core concepts and principles of RL are introduced.
2.1. The Formulation of the Pursuit–Evasion Game
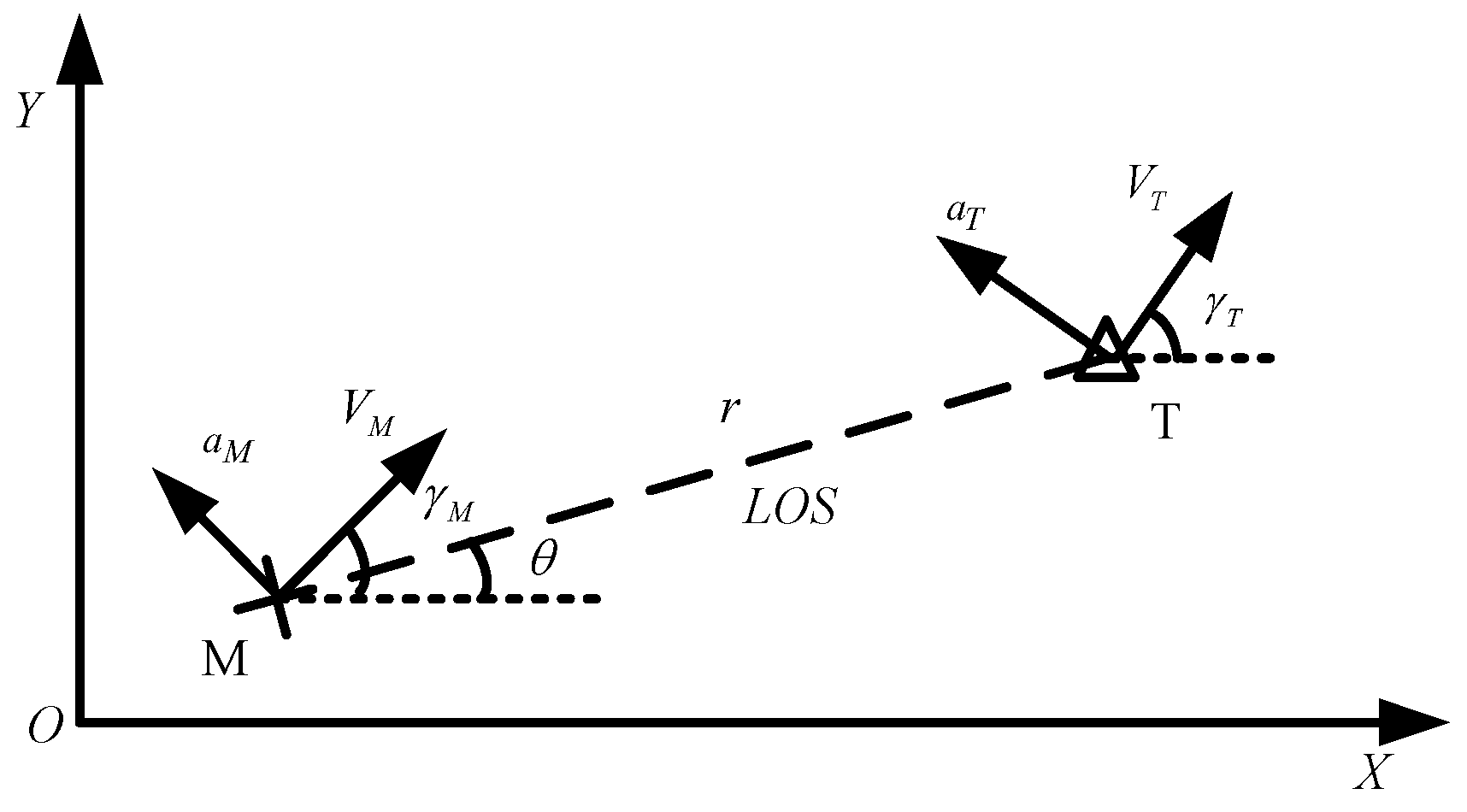
In this subsection, the engagement scenario in a plane is considered in
Figure 1. The
X-Y plane denotes the Cartesian reference frame. The variables
represent the velocity and the lateral acceleration of the pursuer and the evader, respectively. The variables
denote the flight path angles of the pursuer and the evader, respectively.
are the control inputs of the two players. We define the pursuer–evader relative distance and the line of sight (LOS) angle as
rd and
θ.
In the terminal guidance stage, the interception time is very short; without loss of generality, the speeds of all agents are a constant speed. Thus, the interception curve appears to be a straight line. Then, the nonlinear kinematics of the pursuit–evasion game can be formulated as follows:
where
represents the closing velocity, and
donates the angular rate of the LOS.
In order to successfully intercept the evader, the concept of zero miss distance is used [
5]. It can be defined as
It can be found that when the angular rate of the LOS approaches 0, the pursuer can intercept the evader. In general, there always exist external disturbances. Therefore,
are chosen as the states of the system [
20]; by deriving Equation (2), accurate nonlinear dynamic equations can be obtained
where
,
,
, and
and
are external disturbances. Generally, in practical applications, controllers are always affected by external disturbances, and considering the influence of external disturbances can make the training model more suitable for practical applications.
Traditionally, it is difficult to obtain the pursuer control command when the system has external disturbances. In this paper, the accurate nonlinear dynamics system is not required; we adopt the DRL technique to learn the interception strategy.
The first-order dynamics of the pursuer can be expressed as follows:
where
and
are the position and the lateral acceleration of the pursuer, respectively.
is a constant.
The first-order dynamics of the evader can be expressed as follows:
where
and
are the position and the lateral acceleration of the evader, respectively.
is a constant.
In the RL simulation, we utilized Equations (5)~(12) to achieve the motion of the pursuer and the evader. External disturbances were considered in the action space.
2.2. RL Framework
The basic principle of RL is that an agent interacts with the environment and learns a control policy, which can be described as a Markov Decision Process (MDP). The MDP consists of five elements , where denotes a set of states, is a set of actions, represents the state transition probabilities, is the reward function, and denotes the optimal discount rate. In the MDP, at each timestep t, the agent interacts with the environment, receives a state , takes an action , and obtains a reward . Then, a trajectory is generated.
The goal in RL of the agent is to learn a control policy
, which describes states to a transition probability over the action. In general, the control policy
can be learned by maximizing the return function, which is the sum of the future reward:
The state-value function
and action-value function
are used in many RL algorithms for obtaining the control policy
[
19]:
where
is the policy expected function. For the convenience of writing,
is written as
E in the following section.
For solving the continuous control problem, DRL shows its advantages. The basic idea of DRL involves adopting neural networks (NNs) to approximate the action-value function and state-value function. Typical algorithms in this domain include deep deterministic policy gradient (DDPG) and TD3. The main idea of these algorithms is that the state-value function and action-value function are parameterized by NNs. In this paper, we consider that the pursuer is continuously controlled.
3. Deep Reinforcement Learning Formulation of Differential Games
In this section, the pursuit–evasion game problem is considered as a zero-sum differential game. By combining Markov games and DRL, the IDGGL is proposed. Our emphasis is on two agents interacting with the environment and learning the Nash equilibrium strategy.
3.1. The Framework of the Zero-Sum Differential Markov Game
In the traditional Markov Decision Process (MDP), an agent interacts with the environment and maximizes the reward. Based on the MDP, the zero-sum differential Markov game is described by a tuple , where denotes the set of states. denotes the pursuer’s action space. represents the evader’s action space. is the set of observations. is the state transition probability denotes the reward function of the agents. The reward function describes the rewards that the pursuer acquires based on the actions of the evader. represents the discount rate. In this paper, ; only the relative distance and LOS are observable during the process.
The behavior of the player is determined by a policy
, which maps each state to an optimal action
The evader’s actions can affect the optimal policy. The control strategy of the evader can be obtained through an observer. Thus, a rational pursuer knows the evader’s entire policy. Considering the impact of the evader’s strategies can make the learning model more suitable for practical applications. It is important to note that the policy may be stochastic, reflecting the stochastic nature of actions chosen by the evader and the environment. The goal of DRL is to learn a policy for two agents, who interact with a stochastic environment while finding the saddle point of the return function. The sum of the discounted future reward is defined as the return function, as follows:
where
represents the discount factor.
is the designed reward function, which is presented in
Section 3.3.
The expected total return is defined as the value function as follows:
In the zero-sum differential Markov game, the pursuer tries to maximize the value function, while the evader has the contrary purpose that minimizes the value function.
According to the Bellman equation, the recursive relationship of the differential game value function yields
Unlikely traditional DRL, the zero-sum differential Markov game includes the evader’s strategy; the optimal policy of two agents is implemented by solving the following optimal value function
where
is the optimal control variable of the pursuer and the evader. In the Markov game, the pursuer obtains the optimal control policy when the evader chooses the optimal control. In this paper, the pursuer learns the optimal interception policy when the evader chooses the optimal escape strategy. Thus,
represents the control variables of two players in the game process.
In the DRL pursuit–evasion game, the pursuer will definitely learn the optimal control policy. In other words, the DRL algorithm will converge to the optimal value function ; the convergence of the DRL algorithm is given.
Theorem 1. Under the framework of the zero-sum differential Markov game, the update rule of the value function is given as followswhere
is the step-size and satisfies
. Then, the DRL algorithm will converge to the optimal value function
, which corresponds to the optimal control policy. Proof. First, we define the maximum error function as
where
is the
n-th step value function.
Then, Equation (19) can be rewritten as
where
represents the Bellman operator.
Similarly,
can be written as
Subtracting Equation (21) from Equation (22) and combining Equation (23), we have
Therefore, it can be concluded that the maximum
is
times
. Let
represent the initial maximum error between
and
. Then, upon the
k-th iteration, the cumulative error can be obtained
□
Due to the fact that , it can be concluded that . Therefore, when we have . Thus, the DRL algorithm will converge to the optimal value function . In other words, when the pursuer learns the optimal policy, the closed-loop system of the pursuit–evasion game is stable.
Directly optimizing the value function or action-value function can obtain the optimal policy. However, this approach requires accurate model information. In practical applications, implementing such methods with model uncertainties can be challenging. Fortunately, model-free RL algorithms relax this requirement and find the optimal policy. One method to find the optimal policy is iteratively evaluating the value function, which is approximated by NNs. A well-known algorithm for this approach is the Q-learning algorithm. However, iterative approaches are typically limited to discrete action spaces. Another method involves policy gradient algorithms, which learn a deterministic function. In this approach, the action-value function is updated by the gradient direction of the value function with respect to the action. A well-known algorithm in this category is the DDPG algorithm [
21], which can be applied in the continuous action domain. Thanks to this property, our proposed algorithm may solve the zero-sum differential game problem based on the framework of DDPG. The implementation is explained in the next section.
3.2. The Proposed Algorithm
For solving the zero-sum differential Markov game problem, an actor–critic NN framework is adopted based on the DDPG algorithm. In the zero-sum differential Markov game, our aim is to find the saddle point, which corresponds to learning the Nash equilibrium. The action-value function
describes the return of the pursuer acquiring the maximum reward while the evader obtains the minimum reward. This function is approximated using the NN
and parameterized by
. The action-value function, commonly utilized in many RL algorithms, describes the expected return after taking actions
in state
.
According to the Bellman equation, the recursive relationship of the action-value function yields
The action-value function is parameterized by
; based on the temporal difference (TD) error, the loss function can be defined as follows:
where
By minimizing the loss function, the parameter
is updated by using the gradient descent algorithm:
where
is the learning rate of the critic network.
The inner expectation can be avoided by taking a deterministic policy. Thereafter, Equation (27) becomes the following:
From Equation (31), it can be seen that the policy function depends only on the environment, which means
can be learned by using off-policy and transitions. Thus, the critic NN maps states to a specific action, which is parameterized by
. The update rule is to the expected return function
with respect to the actor parameters:
where
represents the partial derivative of parameter
.
For the player, we expect maximizing the policy function. Therefore, the parameter
is updated by using the policy gradient:
where
is the learning rate of the actor network.
Remark 1. In most optimization algorithms, samples are typically assumed to be independent and uniformly distributed. However, this assumption no longer holds when the samples are obtained from exploring sequentially in an environment. To address this problem, we adopt an experience replay buffer, as inspired by the DDPG algorithm. The finite replay buffer stores finite-sized transitions, denoted as, which are sampled from the environment according to the sample policy. The actor and critic network can be updated by sampling a minibatch from the buffer. By using the experience replay buffer, the algorithm is an off-policy and benefits from learning across a set of uncorrelated transitions, rather than online. Additionally, minibatches are set in the learning process.
Remark 2. Directly implementing the actor–critic NN can lead to instability, particularly in environments where the update of the critic network may diverge. To address this issue, a modification similar to the one used in the DDPG algorithm is employed, which involves using “soft” target updates. We create two copy target networks for calculating target values. The weights of target networks are updated by the following iteration:where
is a constant, with
. In general, a smaller
(e.g., 0.001) ensures stable and gradual updates, reducing the risk of oscillations and divergence. The two target networks of Equations (36) and (37) are copied from the actor–critic network, The initialization of the two target networks is random seed. In DRL, the target network helps stabilize training by providing consistent target values for Q-network updates, reducing oscillations and divergence in the learning process. Similarly, the soft target network stabilizes training in DDPG by gradually updating the target network parameters with a small fraction of the main network’s parameters, reducing volatility and improving learning stability. The two target networks of Equations (36) and (37) are copied from the actor–critic network; the initialization of the two target networks is random seed.
Remark 3. A major challenge in the learning process in continuous action spaces is exploration. The environment initializes random states, and the agent explores the environment by choosing probability action spaces. To address this issue, a random noise sample from a noise process is added in our exploration policy . The action space can be rewritten as For the convenience of training, we assume that the noise of the agent and all agents has the same distribution [
22]. The noise satisfies the following:
where
is the mean of the noise,
represents the exploration variance of the noise, and
is the mean attraction constant.
denotes the sampling time.
The pseudocode of the proposed algorithm for solving the zero-sum differential Markov game is as follows (Algorithm 1):
| Algorithm 1. Pursuer interception strategy based on DDPG |
| 1. Randomly initialize the actor and critic networks with weights and # Initialize actor–critic network |
| 2. Initialize the target networks with weights and # Initialize target network |
| 3. Initialize the experience buffer # Initialize experience buffer |
| 4. for episode , Max Episode do # learning process |
| 5. Initialize random noise to the action for exploration # Initialize action noise |
| 6. Initialize the initial state of the pursuer and the evader # Initialize environmental status |
| 7. Obtain initial observation state # Initialize observation status |
| 8. for do # Action chosen |
| 9. select action based on current state and current policy |
| 10. observe the evader selecting action based on current state and current policy |
| 11. Execute the action and the evader execute the action , then observe and the new state |
| 12. Store the transition in the experience buffer |
| 13. sample a random minibatch of N transitions from |
| 14. Calculate: # Calculate actor–critic network |
15. Calculate the TD error and update the critic network using gradient descent:
# Update critic network |
16. update the actor network using policy gradient:
# Update actor network |
17. Update the target network:
# Update target network |
| 18. if the task is accomplished then |
| 19. Terminate the current episode |
| 20. end if |
| 21. end for |
| 22. end for # End learning |
3.3. The IDGGL Design Based on the Proposed Algorithm
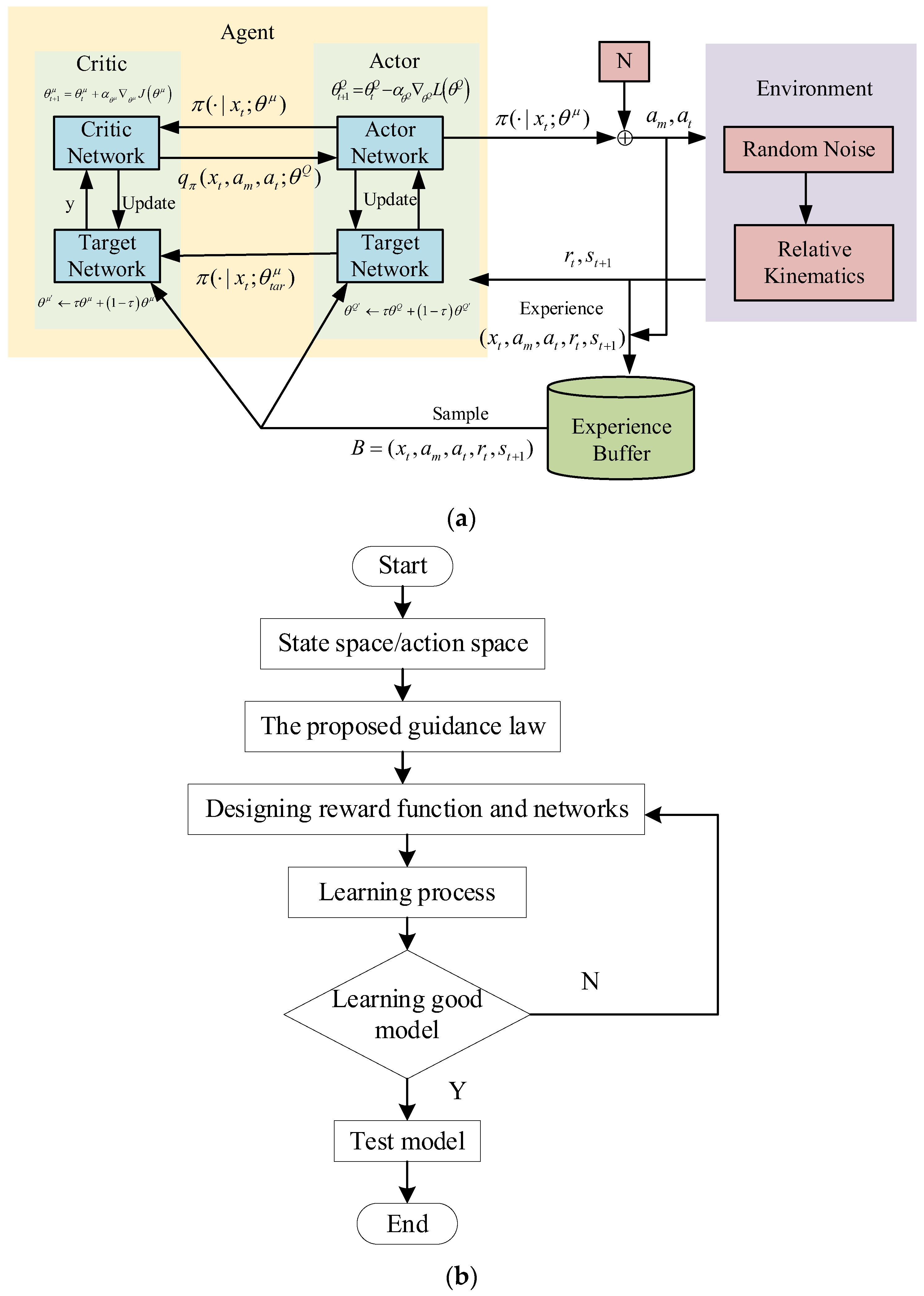
Based on the above section, we formulate the zero-sum differential Markov game problem in the DRL framework. The proposed IDGGL strategy can be learned by using the proposed algorithm. The basic structure of the system and algorithm flowchart are illustrated in
Figure 2, which describes the specific implementation process. Next, the pursuit–evasion environment, states, action spaces, and the reward function are presented. Importantly, the reward function design is one of the key points.
- A.
State Spaces
In the pursuit–evasion game scenario, the relative kinematic models of the pursuer and the evader are considered as state spaces, which can be designed as follows:
The relative distance and the rate of the relative distance can directly reflect the success or failure of interception. The active radar seeker can provide information on the relative distance and LOS. Traditional control techniques like PNG assume that the LOS rate is known. By referring to the principle of PNG, the LOS and LOS rate are chosen as state spaces, which reflect the angle information and can ensure that the pursuer approaches the evader as parallel as possible. Thus, all states can be calculated and fully characterize the engagement states.
- B.
Action Spaces
In the zero-sum differential Markov game, we consider two action spaces in the continuous space, which are the normal accelerations of the pursuer and the evader
.
where
and
denote the limit coefficients of the acceleration. It can be seen that the accelerations of the two agents are limited to a certain range, which is beneficial for the control command.
- C.
Reward Function
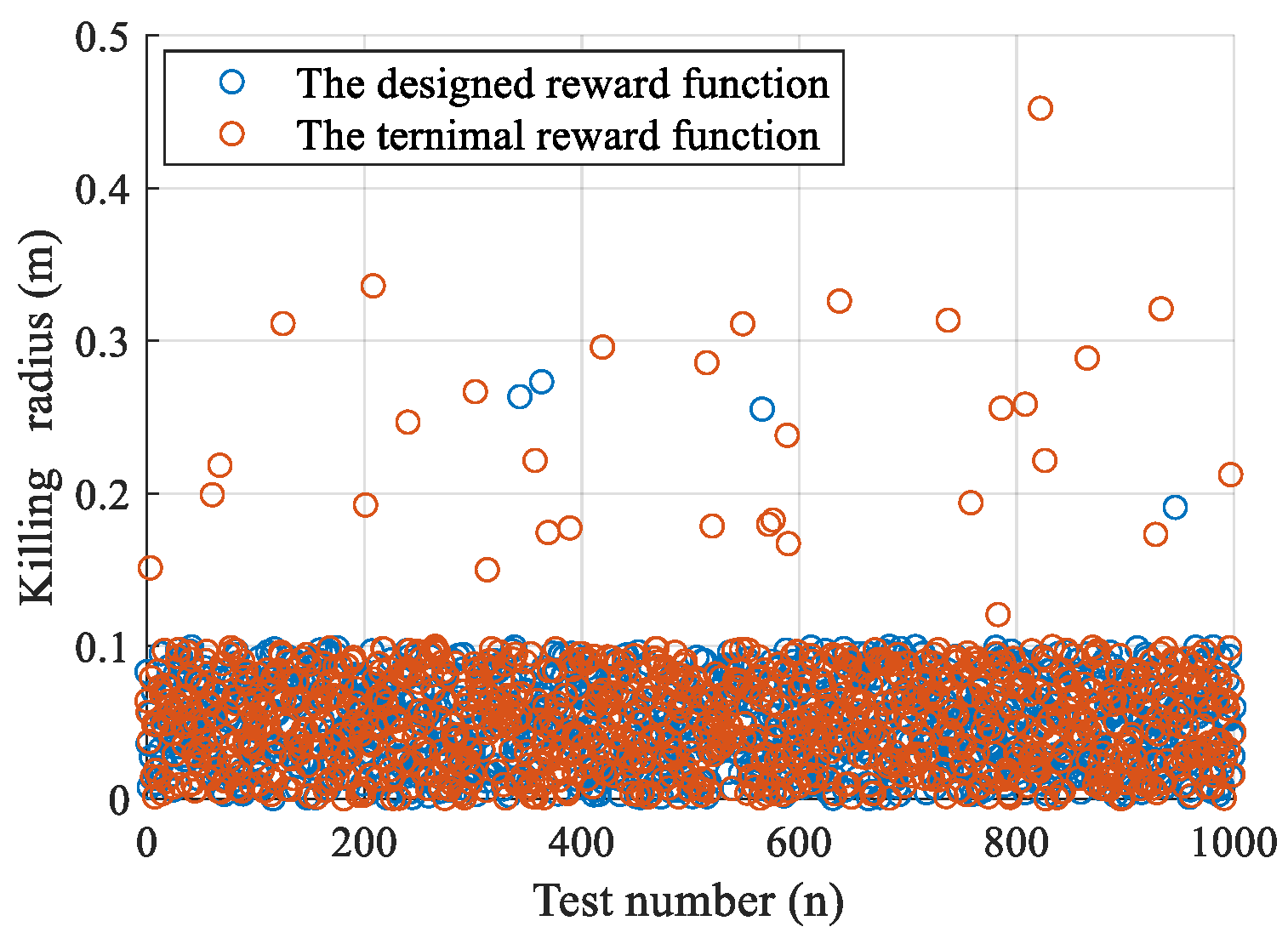
In order to successfully intercept the evader, a reasonable reward function not only affects the learning speed and feasibility but also reflects the interception efficiency of the pursuer. Therefore, a proper reward function design is crucial for learning the optimal interception guidance law. According to the pursuit–evasion information, the reward function is designed as follows.
(1) The terminal reward
. This term reflects whether the pursuer successfully intercepts the evader or not. This function is designed as
where
represents the distance of successful interception. In most cases,
is also the interception radius, which is set as
0.1 m.
is the interception reward.
(2) The relative distance reward
. This term means that the pursuer tried to intercept the evader. The closer the pursuer is to the evader, the higher the reward that will be obtained. This function is designed as
where
is the initial relative distance between the pursuer and the evader;
is a constant weight.
(3) The control effect reward
. This term takes into account the overload of the pursuer and encourages the pursuer to intercept the evader within the minimum energy consumption. This function is designed as
where
is the limited overload of the pursuer;
is a constant weight.
(4) The LOS reward
. This term refers to proportional navigation guidance (PNG), which ensures that the pursuer intercepts the evader as close as possible in parallel. This term also ensures that the evader is maintained within the pursuer’s LOS. The function is designed as
where
is the initial LOS,
denotes the initial rate of the LOS, and
and
are constant weights.
In summary, the total designed reward function is
where
is the reward function in Equation (16).
is the terminal reward.
is the process reward.
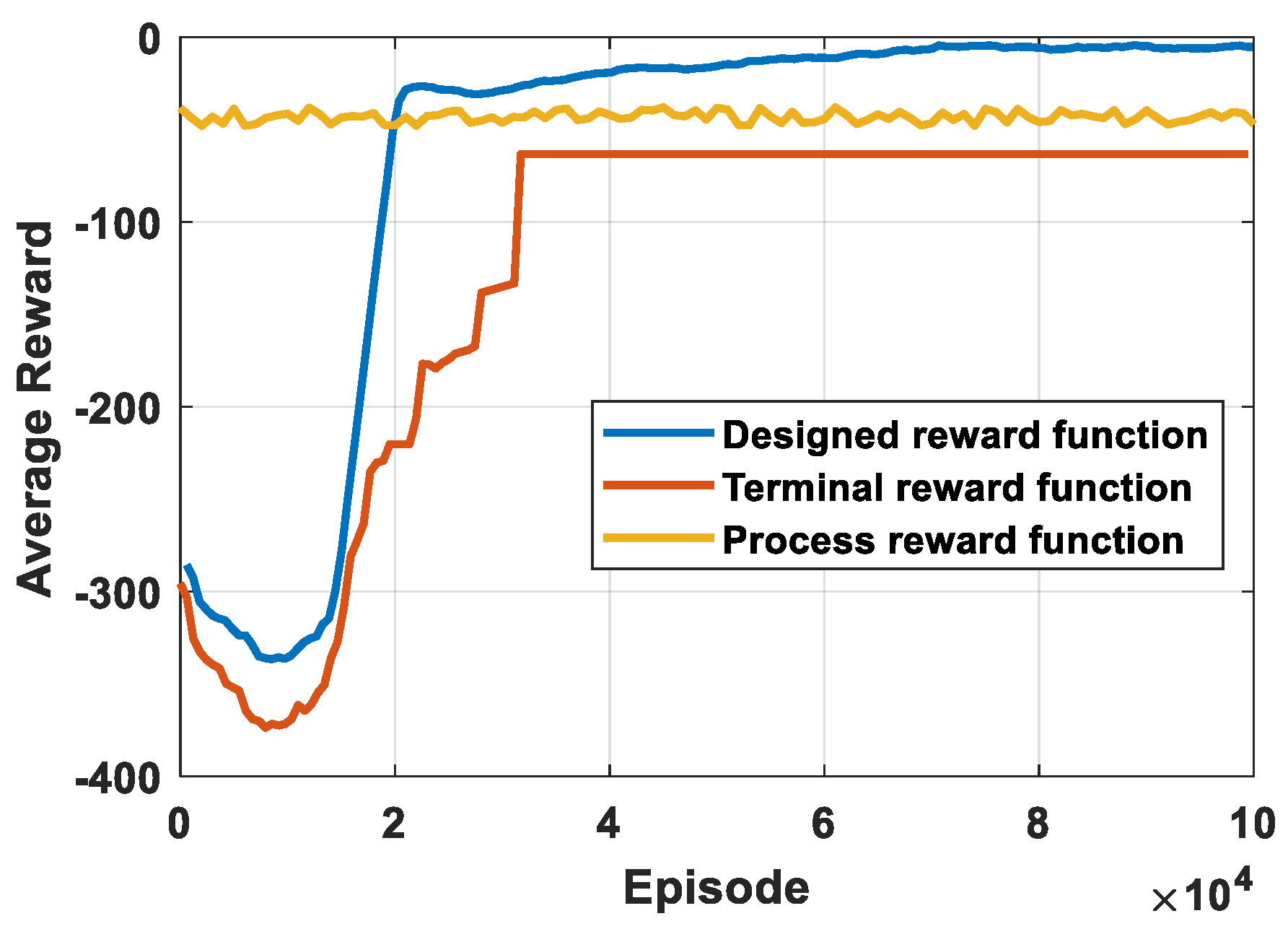
The proposed reward function is a comprehensive function, which consists of interception accuracy, energy consumption, and interception distance.
Remark 4. Since the process of DRL is stochastic in nature, the selected parameters of the reward function are not quantitative. In this paper, based on a lot of training results, the parameters of the reward function are selected as shown in Table 1. In order to improve the training efficiency, the normalized tips are adopted in the training process. The normalized states and actions are defined as follows:
where
represents the initial value of the variable
, and
stands for the maximum acceleration of two agents.
- D.
Neural Network Structure and Hyperparameter Setting
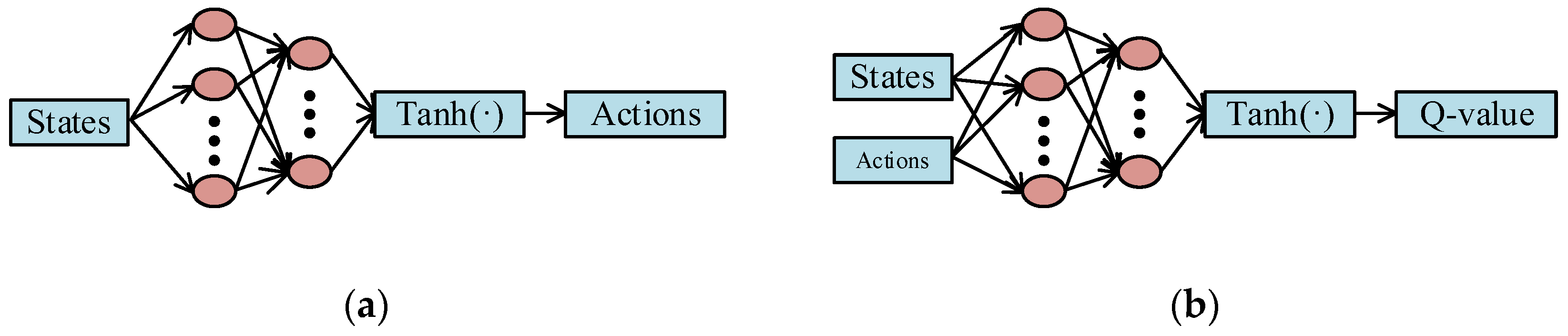
Inspired by the DDPG algorithm, the actor–critic NN is shown in
Figure 3. Both networks have a similar structure, which is composed of four-layer fully connected neural networks. The input layer of the actor network (
Figure 3a) is states; the output layer of the actor network is actions. The input layer of the critic network (
Figure 3b) is states and actions; the output layer of the critic network is Q-value. Two hidden layers are considered, which are activated by the Relu function. The numbers of two hidden layers are set as 128 and 64, respectively. The ReLU function is defined as follows:
The output layer is activated by the Tanh function, which can be expressed as
From Equation (48), it can be seen that the output layer is limited in (−1,1). Therefore, the problem of action saturation can be avoided.
The details of the input layer, hidden layers, and output layer are shown in
Table 2. All hyperparameters are listed in
Table 3.
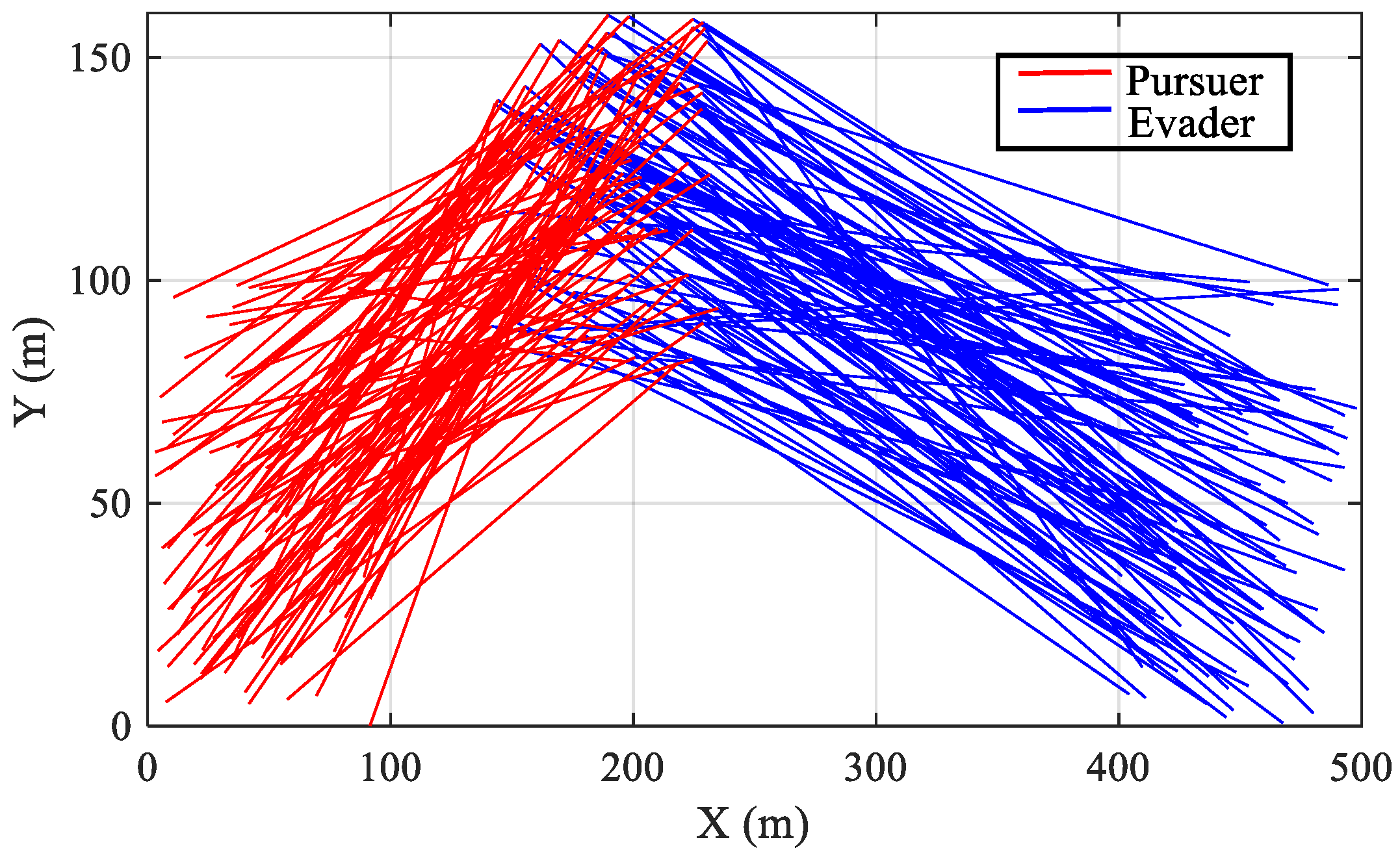
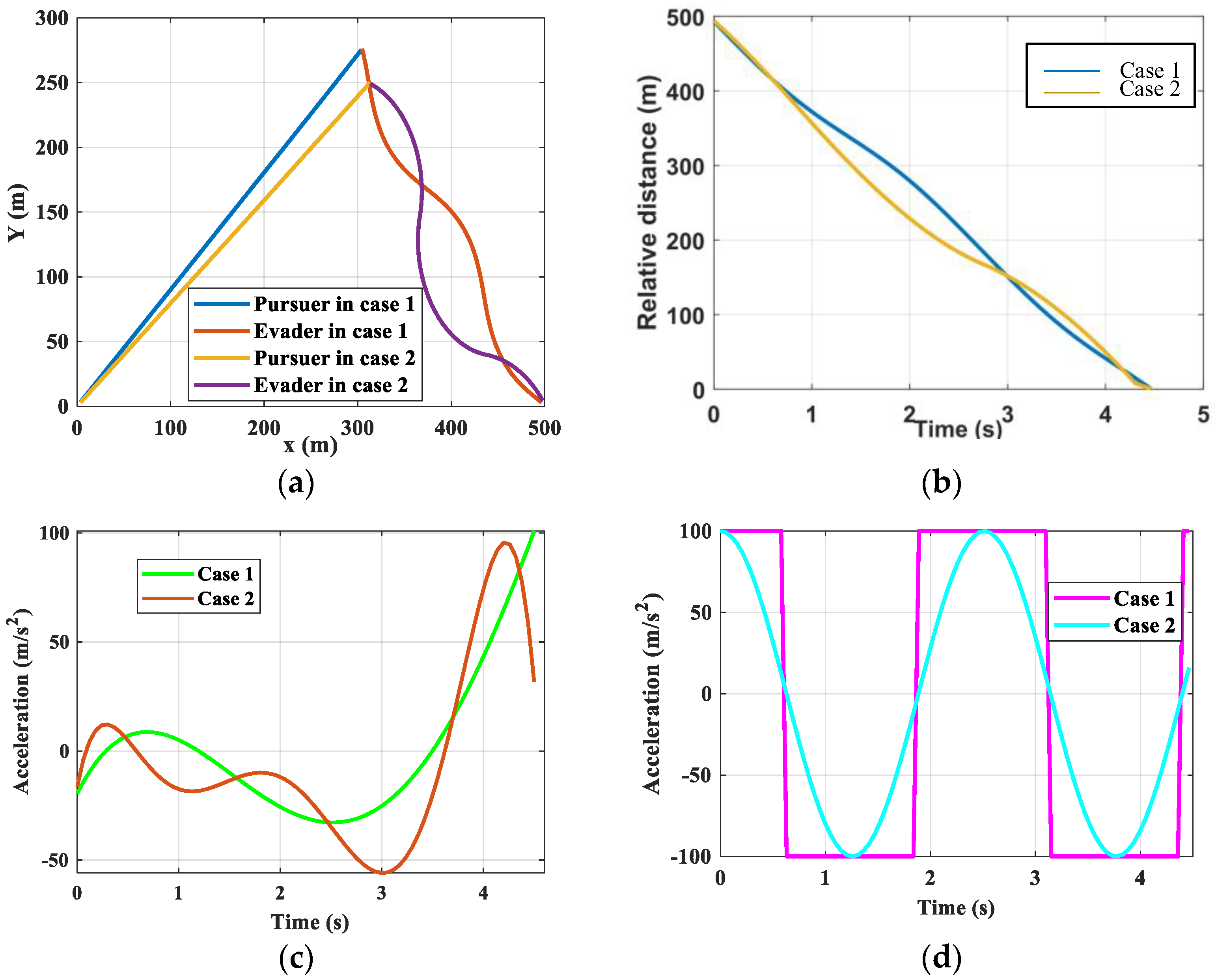
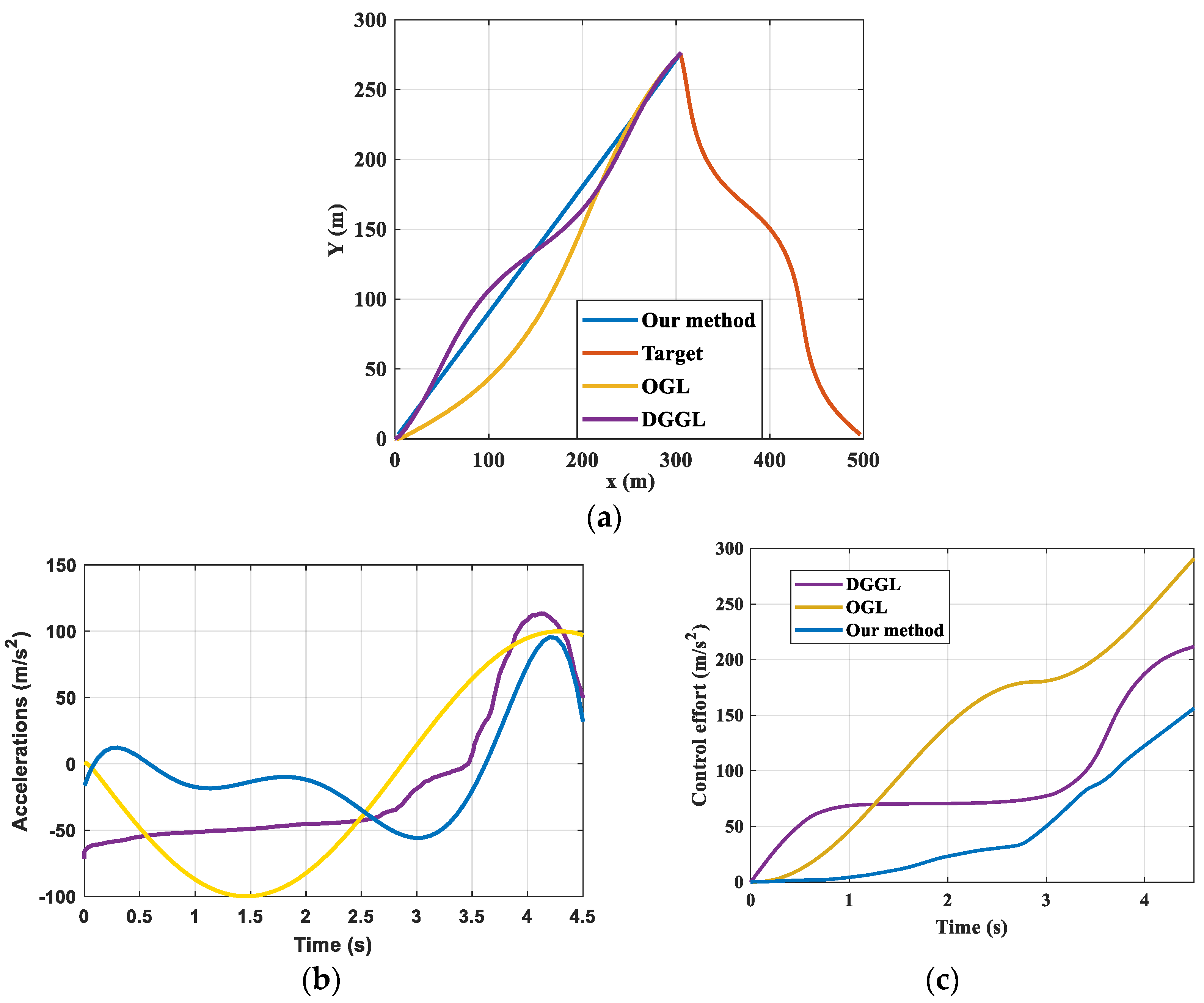
5. Conclusions
This paper proposes an intelligent differential game guidance law based on DRL. First, the interception problem is converted into finding the Nash equilibrium strategy. We proposed an algorithm for obtaining the optimal IDGGL strategy. Subsequently, a reasonable reward function, which includes the interception accuracy, the energy consumption, and the interception distance, is designed for the engagement. The simulation results demonstrate that the proposed IDGGL algorithm exhibits superior performance in terms of acceleration response, control efforts, and quick computation. Moreover, compared with traditional guidance laws, the IDGGL algorithm can confront the complex game environment and avoid tedious manual setting. Additionally, compared to other reinforcement learning guidance laws, the proposed IDGGL algorithm takes into account the effect of the evader. Importantly, by designing a more reasonable reward function, the proposed IDGGL algorithm has good performance in intercepting different maneuvering evaders. The intercepting accuracy is up to 99.2%. All in all, simulation experiments demonstrate the efficiency of the proposed IDGGL. However, the limitations and challenges of the proposed approach include the following: the escape strategies of the evader, real-time processing constraints, the impact of obstacles, complex scenarios. By using a state observer, employing advanced hardware, and using optimizing algorithms, the specific limitations can be solved. In the terminal guidance phase, when the pursuer and the evader reach a certain height, the proposed intelligent differential game guidance law can be used in practical applications. For implementing the proposed method in real-world systems, some modifications should be considered, which include adjustments for environmental variability, integration with existing systems, and considerations for robustness and reliability. For example, when the pursuer and evader are in a 2D scenario and the environmental state is known, the algorithm proposed can completely achieve the interception of the evader. In future work, more complex scenarios should be considered, such as changes in heading angle and the interceptor’s altitude, which would enhance the robustness and applicability of our guidance laws. Additionally, the impact of external disturbances should be considered, such as winds, which lead to the development of more resilient guidance laws capable of operating under various environmental conditions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}