
Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Navigation



Abstract
1. Introduction
Related Works
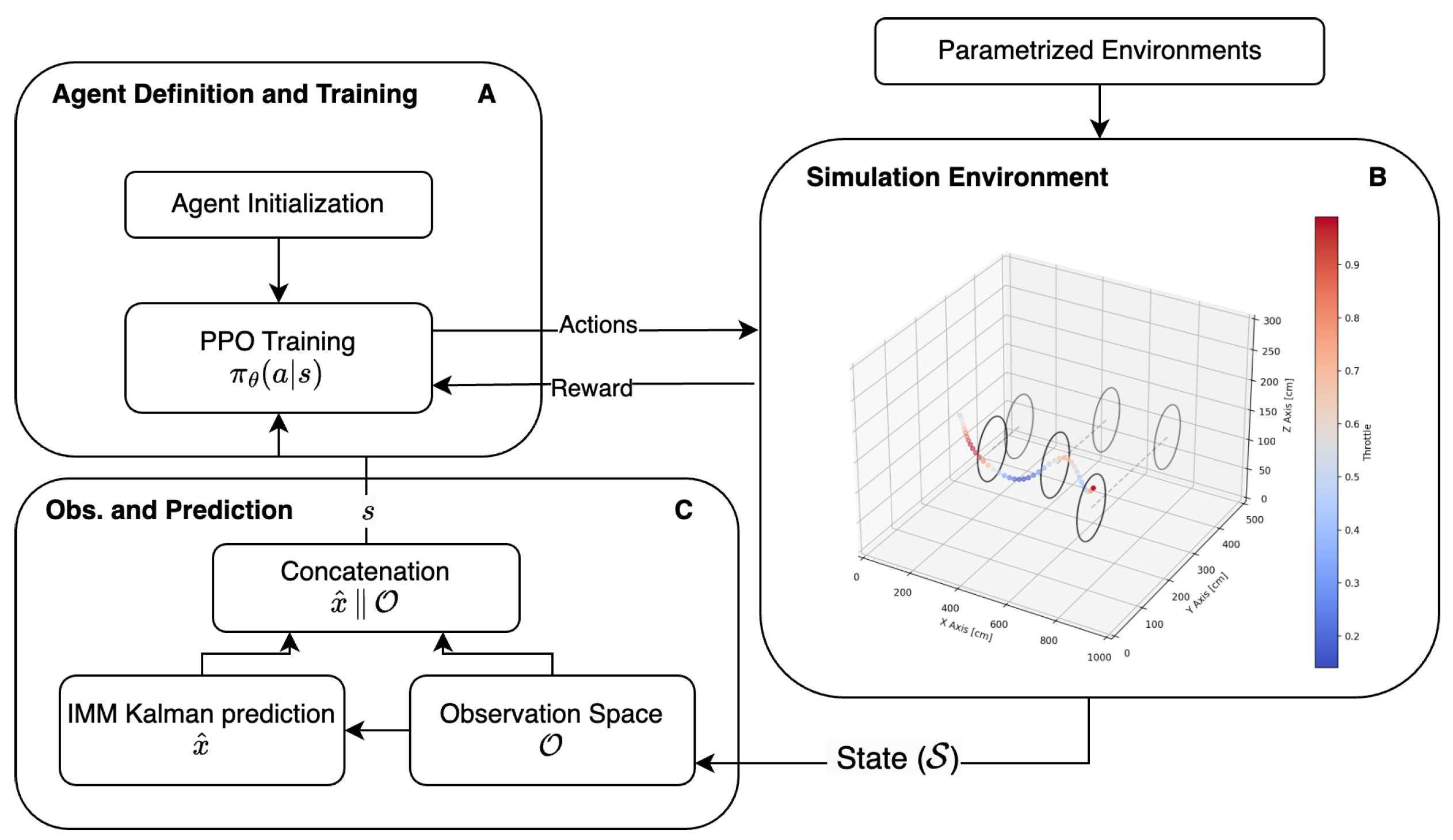
2. Methodology
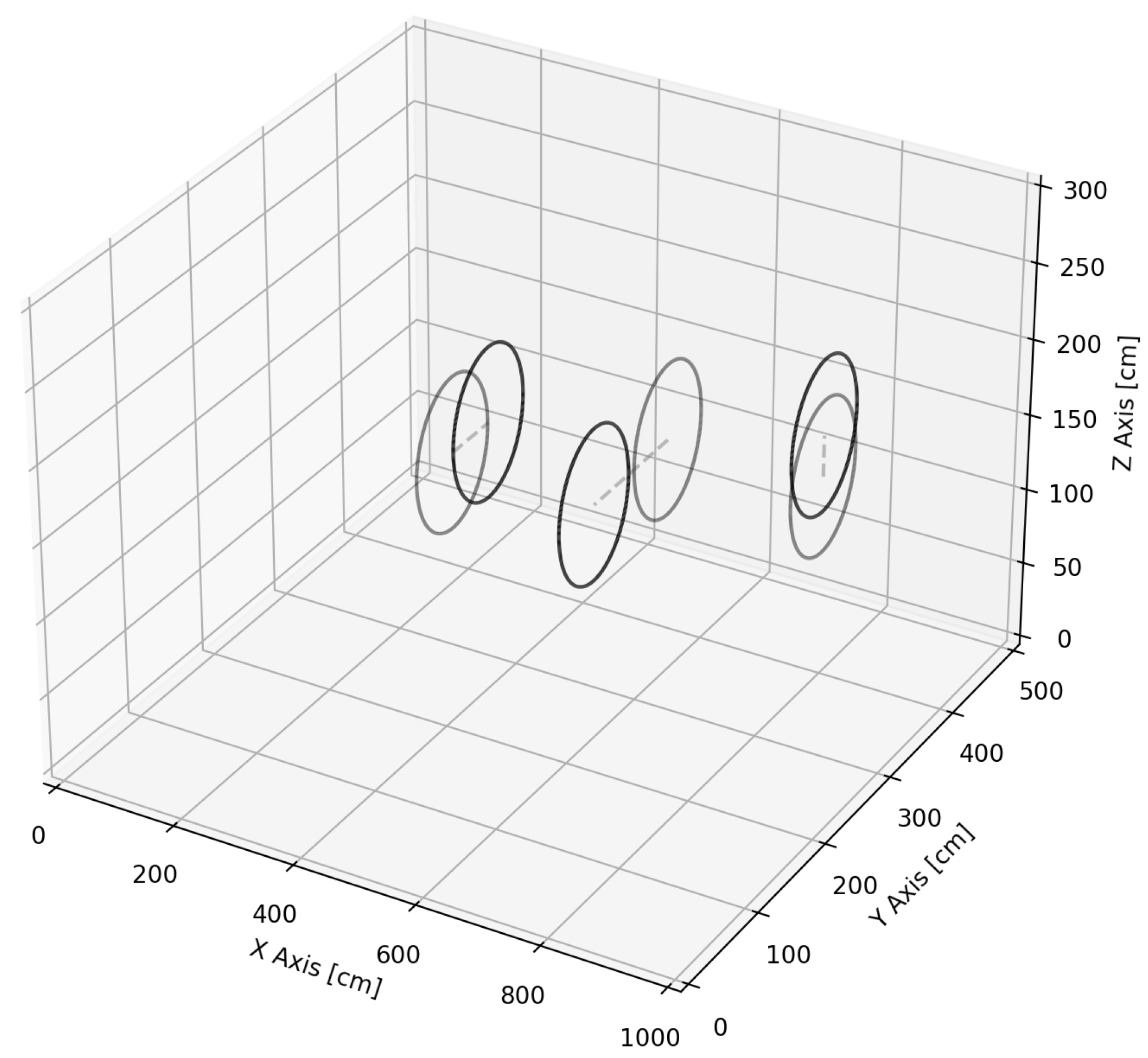
2.1. Simulation Environment
- v represents the resulting velocity vector of the drone in ;
- is the action vector sampled from the action space A;
- ⊙ denotes the element-wise multiplication (Hadamard product);
- is the vector of maximum translational speeds for each axis;
- for , where and in a identify the direction of movement along the respective axes, with indicating movement in the positive direction of the axis and indicating movement in the negative direction.
| Algorithm 1 Overview of the Algorithm that Operates the Environment |
|
2.2. Proximal Policy Optimization (PPO)
2.3. Reward Function
- is the reward for passing through an active gate.
- is the reward for moving towards the nearest gate in the forward direction.
- is awarded upon completing the course, i.e., passing all gates.
- is the penalty for colliding with obstacles.
- is the time penalty applied at each time step, scaled by , the count of gates passed plus one.
- indicates whether an active gate was passed (1 if true, 0 otherwise).
- M is the condition for forward movement reward (1 if the movement vector aligns with the gate vector and the distance to the center of the gate is appropriate, 0 otherwise).
- T indicates whether the agent has collided (1 if true, 0 otherwise).
- C indicates whether all gates have been passed (1 if true, 0 otherwise).
2.4. IMM Kalman and Representation of the Enriched Observation Space
- Agent Pose: The coordinates and orientation of the agent for self-localization.
- Active Gate Pose: The position and orientation of the tracked gate, which the agent aims to navigate through.
- Nearest Gate Distance: The spatial distance between the agent and the nearest gate, guiding the agent towards its goal.
- Average Agent Speed: Reflects the agent’s movement speed, crucial for planning and trajectory estimation.
- Gate Velocity: Important for anticipating the motion of dynamic gates or targets.
- Mixing Process: At the beginning of each time step, the state estimate and covariance from the previous step are mixed across the models based on the model probabilities, preparing a set of initial conditions for each filter.
- Model-Specific Filtering: A Kalman filter prediction and update cycle is executed using the mixed initial conditions for each model. This results in updated state estimates and covariances for each model.
- Model Probability Update: The likelihood of each observation given the model-specific predictions is calculated; it is then used to update the probabilities of each model being the correct representation of the system dynamics.
- Combination: Finally, all models’ state estimates and covariances are combined based on the updated model probabilities to produce the overall state estimate and covariance.
- represents the probability of transitioning from model at time step k to model at time step .
- Common choices for the diagonal elements ( and ) are values close to 1 (e.g., 0.9 or 0.95) to promote filter stability and persistence.
- The off-diagonal elements ( and ) represent the probability of switching to the other model. These values can be tuned based on the target’s expected frequency of maneuvers.
| Algorithm 2 IMM Kalman Filter Integration for Gate Position Prediction |
|
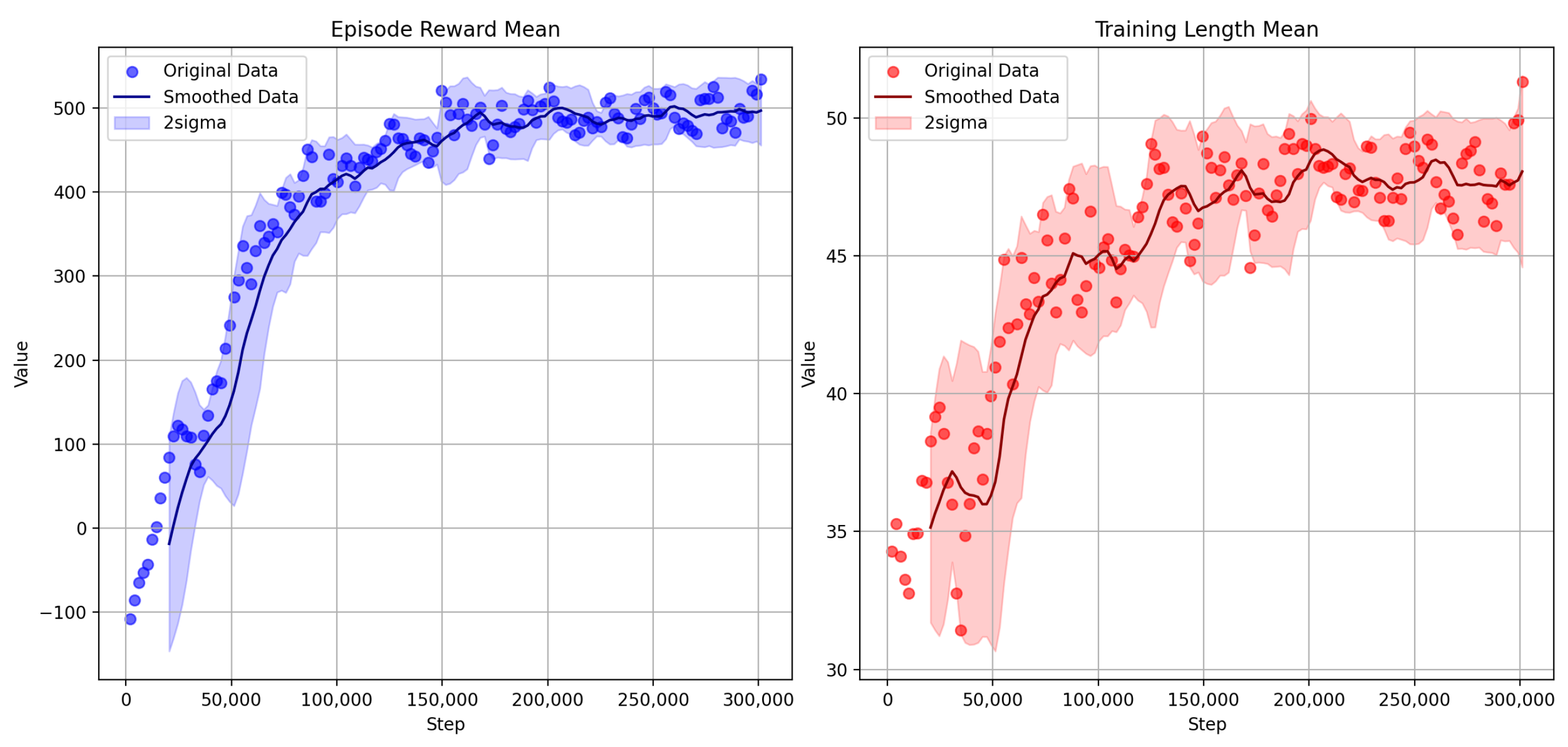
3. Experiments and Results
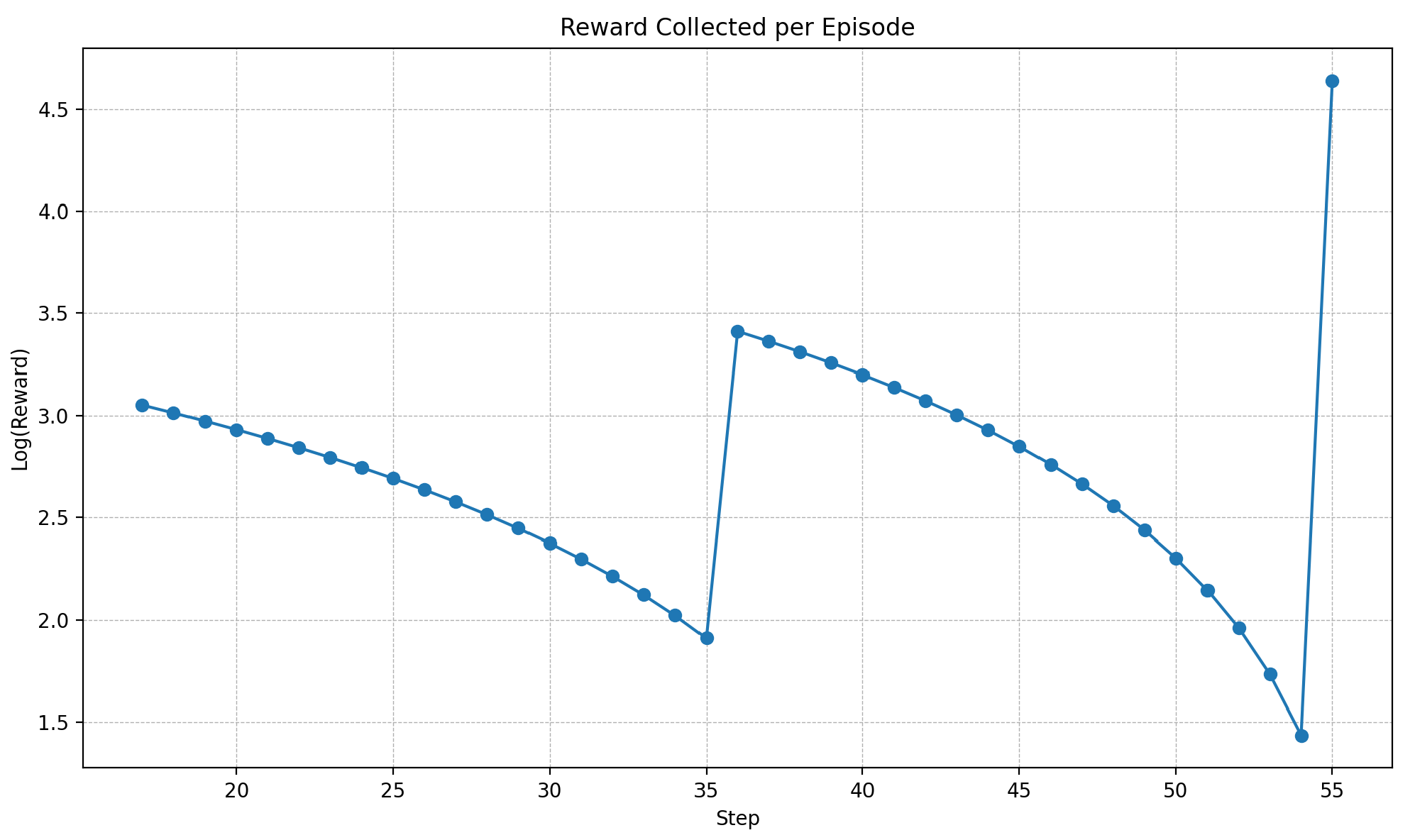
- Cumulative Reward: This metric measures the agent’s performance in its assigned task, where superior scores indicate optimized actions towards fulfilling the objective. This metric was beneficial during the tuning phase of the PPO algorithm when comparing two different parametrizations of the same model. It cannot be used to categorize the performances across episodes.where:
- represents the total cumulative reward obtained by the agent throughout an episode.
- t is the time step within the episode, ranging from 1 to T.
- T denotes the terminal time step of the episode at which the episode ends.
- is the reward received at time step t, reflecting the immediate benefit of the action taken by the agent at that step.
- Average Reward per Action: Measures the quality of decisions, with higher values indicating superior decision making, leading to higher rewards for each action.
- Success Rate: Represents the ratio of episodes where the agent accomplishes its objective, indicating the reliability of a model trained. This metric is also used to analyze the test environments.
- High average reward and high success rate indicate optimal algorithm performance.
- Low average reward but high success rate suggest frequent goal accomplishment with room for proficiency improvement.
- High average reward but low success rate implies proficient actions but less frequent goal accomplishment.
- Low average reward and low success rate indicate subpar algorithm performance.
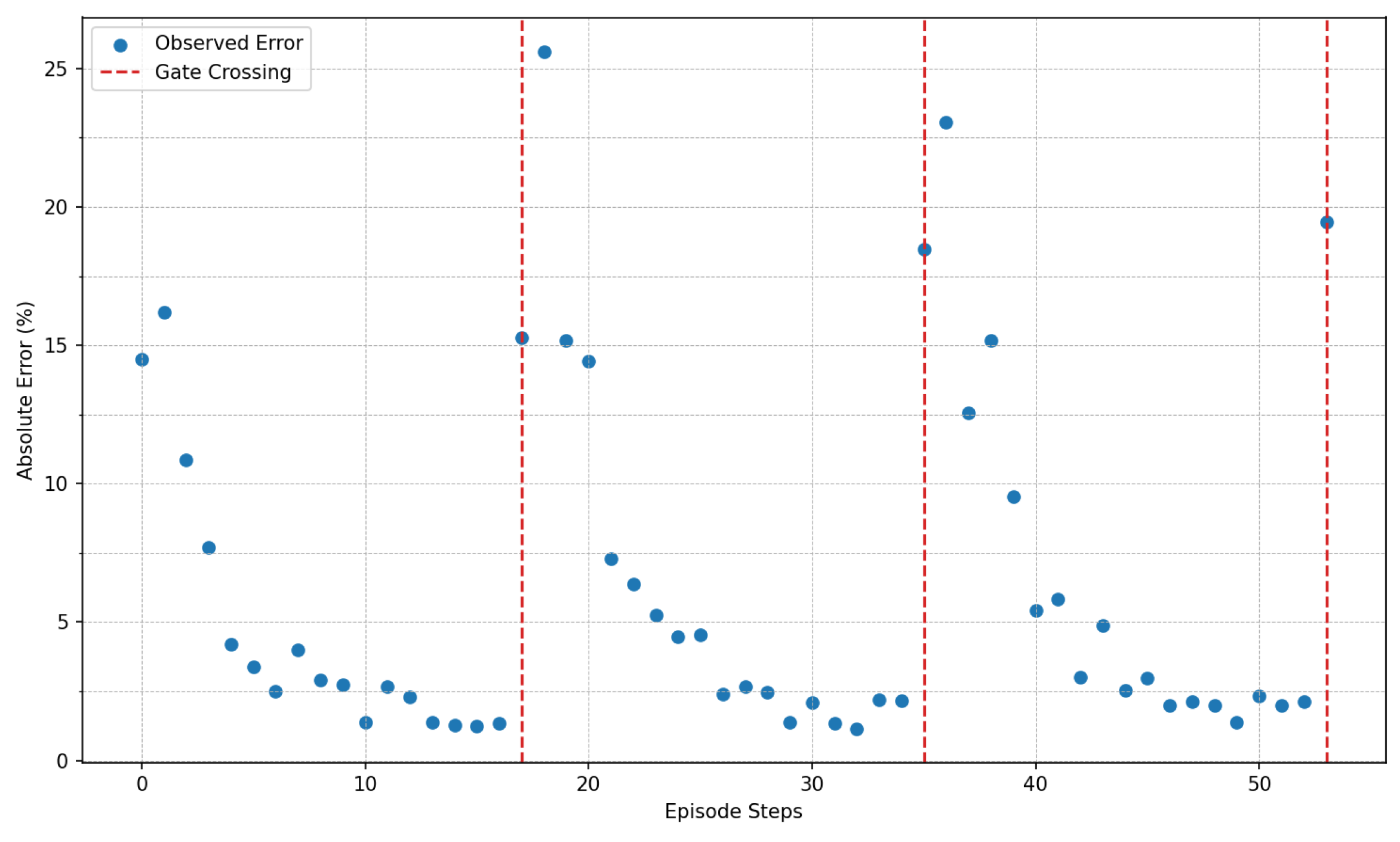
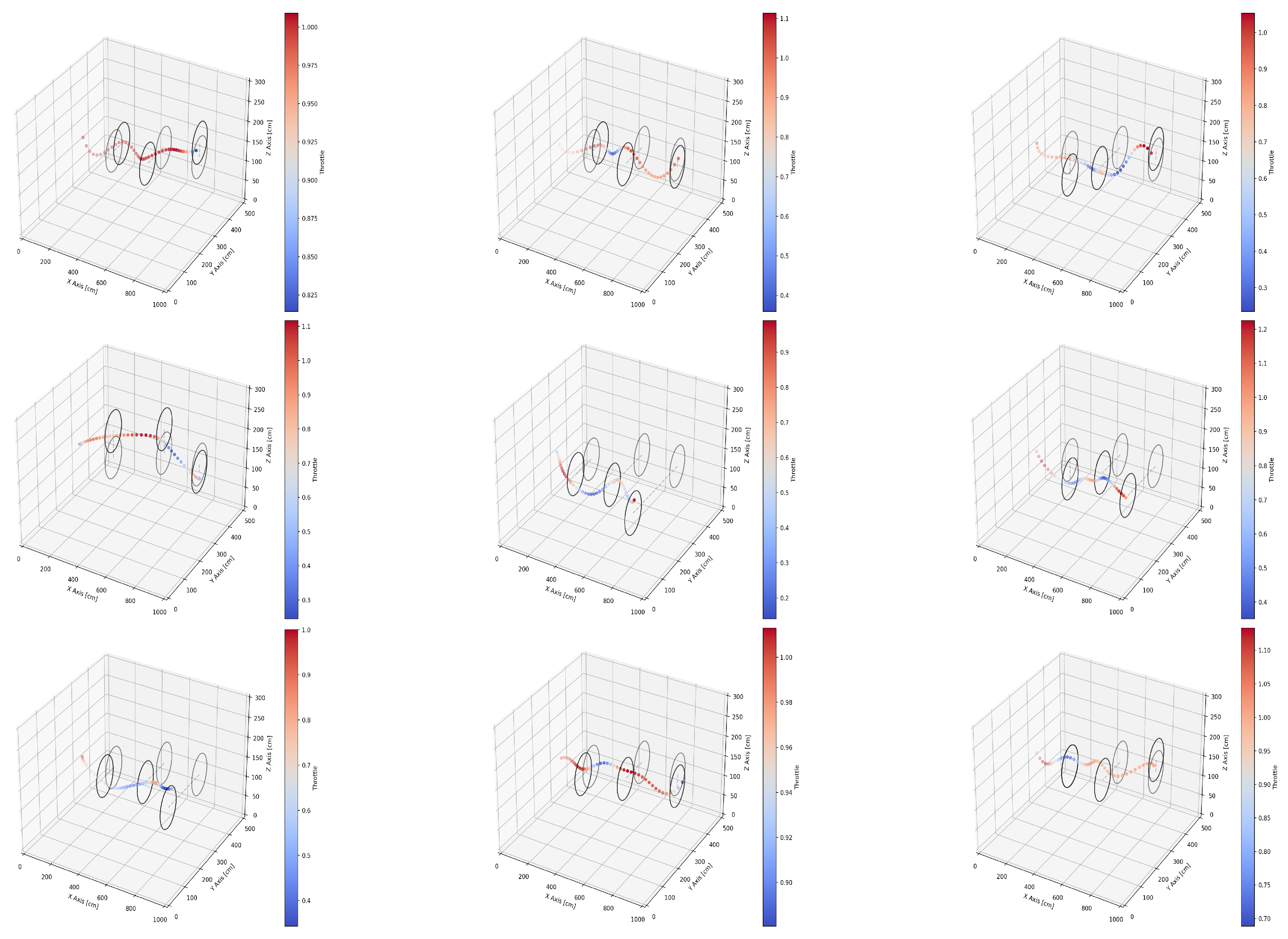
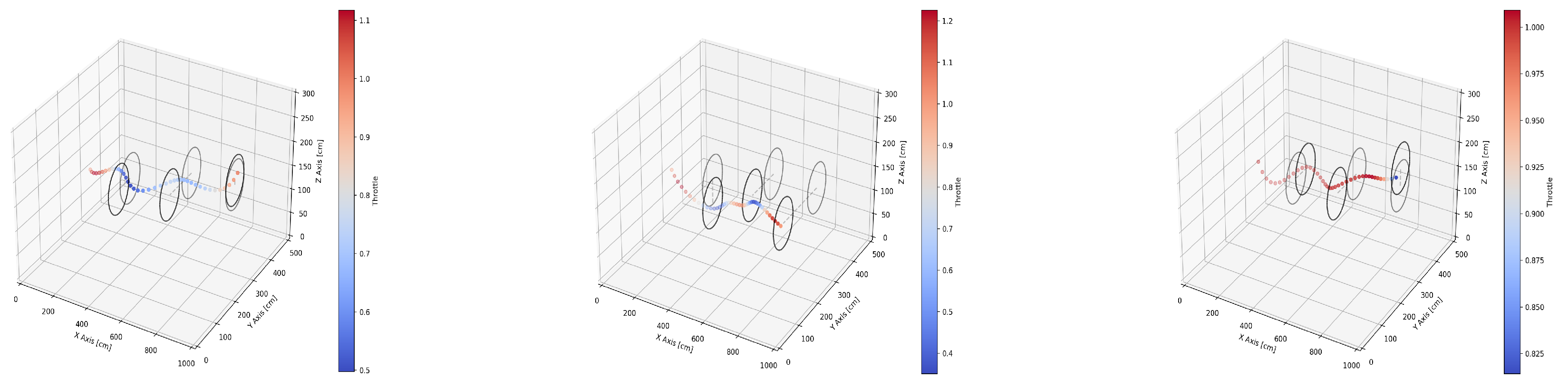
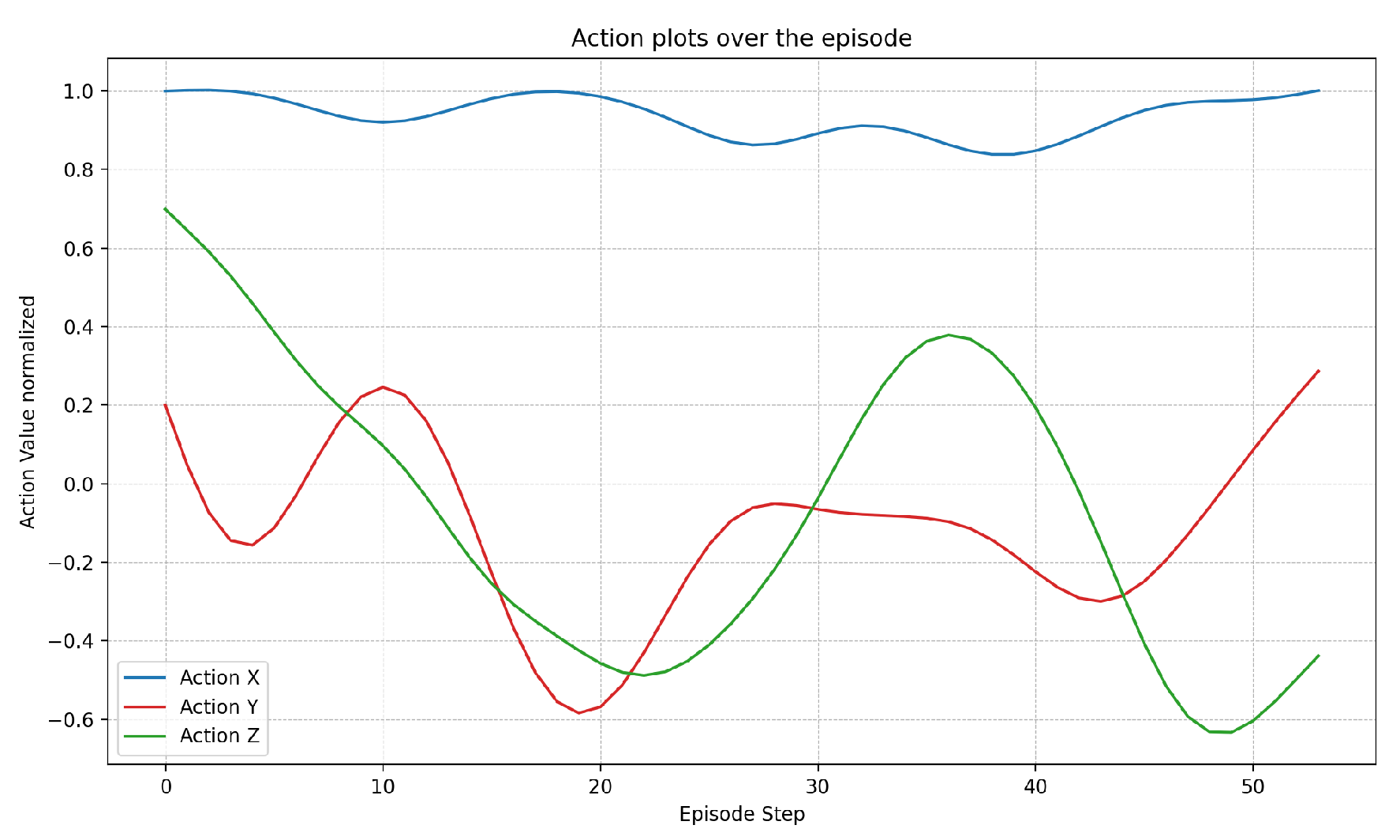
3.1. Flying through Dynamic Gates
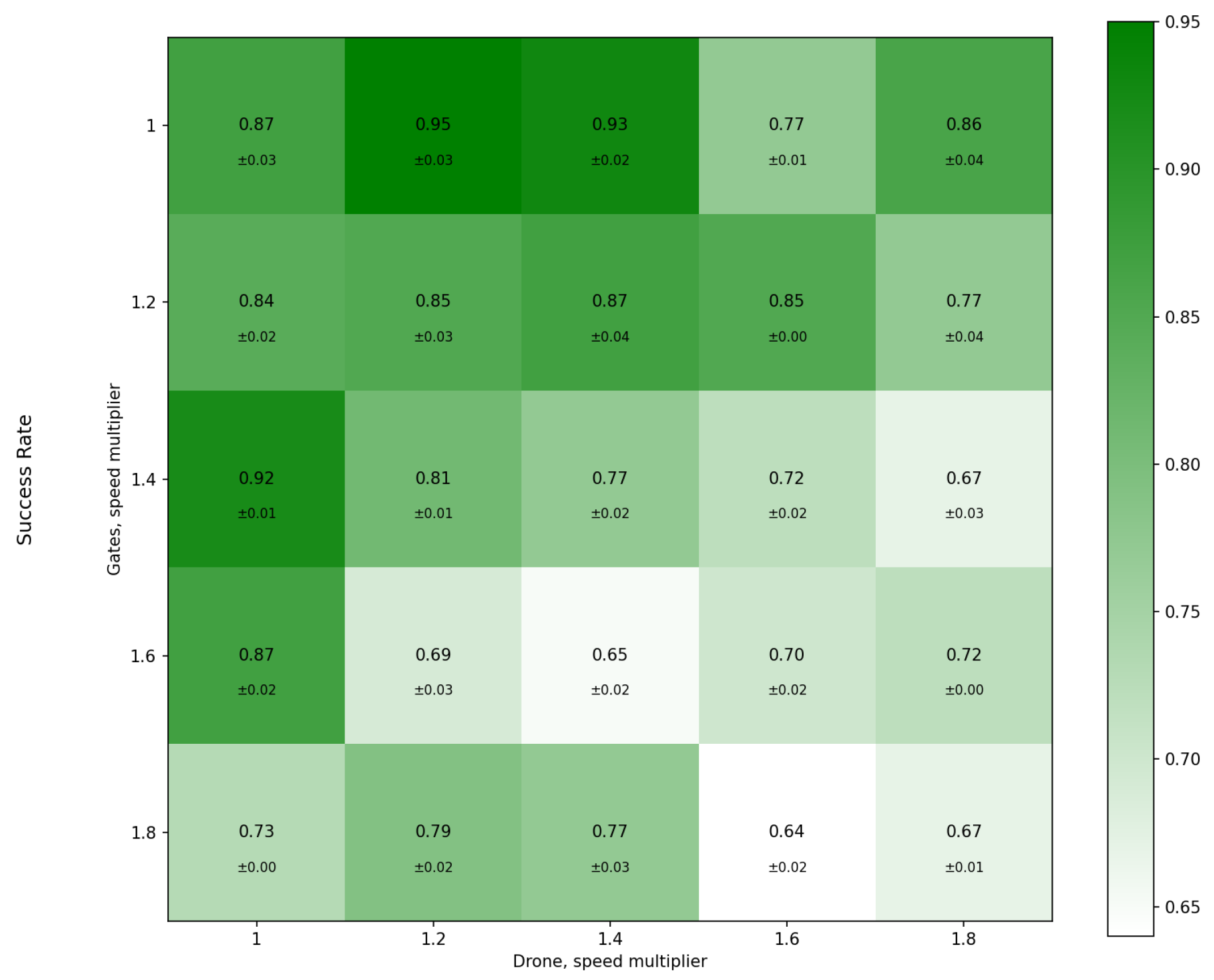
3.2. Effect of the Drone and Gate Speed
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Otto, A.A.; Agatz, N.; Campbell, J.J.; Golden, B.B.; Pesch, E.E. Optimization Approaches for Civil Applications of Unmanned Aerial Vehicles (UAVs) or Aerial Drones. Networks 2018, 72, 411–458. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Glasius, R.; Komoda, A.; Gielen, S.C. Neural Network Dynamics for Path Planning and Obstacle Avoidance. Neural Netw. 1995, 8, 125–133. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Neumann, G.; Peters, J. A Survey on Policy Search for Robotics. Found. Trends® Robot. 2013, 2, 1–142. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Kakade, S.M. A Natural Policy Gradient. Adv. Neural Inf. Process. Syst. 2001, 14, 1531–1538. [Google Scholar]
- Peters, J.; Muelling, K.; Altun, Y. Relative Entropy Policy Search. In Proceedings of the Twenty-Fourth National Conference on Artificial Intelligence (AAAI), Physically Grounded AI Track, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Bry, A.; Roy, N. Rapidly-Exploring Random Belief Trees for Motion Planning Under Uncertainty. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning Agile and Dynamic Motor Skills for Legged Robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef]
- Song, Y.; Lin, H.; Kaufmann, E.; Duerr, P.; Scaramuzza, D. Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Stulp, F.; Sigaud, O. Path Integral Policy Improvement with Covariance Matrix Adaptation. In Proceedings of the 29th International Conference on Machine Learning (ICML), Edinburgh, Scotland, 26 June–1 July 2012. [Google Scholar]
- Sun, Y.; Wierstra, D.; Schaul, T.; Schmidhuber, J. Efficient Natural Evolution Strategies. In Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation, Montreal, MN, Canada, 8–12 July 2009; pp. 539–546. [Google Scholar]
- Sehnke, F.; Osendorfer, C.; Rückstieß, T.; Graves, A.; Peters, J.; Schmidhuber, J. Policy Gradients with Parameter-Based Exploration for Control. In Proceedings of the International Conference on Artificial Neural Networks, Prague, Czech Republic, 3–6 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 387–396. [Google Scholar]
- Schaal, S. Dynamic Movement Primitives—A Framework for Motor Control in Humans and Humanoid Robotics. In Adaptive Motion of Animals and Machines; Springer: Berlin/Heidelberg, Germany, 2006; pp. 261–280. [Google Scholar]
- Paraschos, A.; Daniel, C.; Peters, J.R.; Neumann, G. Probabilistic Movement Primitives. In Advances in Neural Information Processing Systems; NeurIPS Proceedings; Curran Associates, Inc.: Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2616–2624. [Google Scholar]
- Williams, B.; Toussaint, M.; Storkey, A.J. Modelling Motion Primitives and Their Timing in Biologically Executed Movements. In Advances in Neural Information Processing Systems; NeurIPS Proceedings; Curran Associates, Inc.: Vancouver, BC, Canada, 3–6 December 2007; pp. 1609–1616. [Google Scholar]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical Movement Primitives: Learning Attractor Models for Motor Behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef] [PubMed]
- Peters, J.; Schaal, S. Reinforcement Learning of Motor Skills with Policy Gradients. Neural Netw. 2008, 21, 682–697. [Google Scholar] [CrossRef]
- Kober, J.; Peters, J.R. Policy Search for Motor Primitives in Robotics. In Advances in Neural Information Processing Systems; NeurIPS Proceedings; Curran Associates, Inc. (Jun 2009): Vancouver, BC, Canada, 8–10 December 2008; pp. 849–856. [Google Scholar]
- Kober, J.; Oztop, E.; Peters, J. Reinforcement Learning to Adjust Robot Movements to New Situations. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019, arXiv:1509.02971. [Google Scholar]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to Fly by Crashing. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3948–3955. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Saeedi, S.; Thibault, C.; Trentini, M.; Li, H. 3D Mapping for Autonomous Quadrotor Aircraft. Unmanned Syst. 2017, 5, 181–196. [Google Scholar] [CrossRef]
- Rupprecht, C.; Laina, I.; DiPietro, R.S.; Baust, M. Learning in an Uncertain World: Representing Ambiguity through Multiple Hypotheses. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3611–3620. [Google Scholar]
- Richter, C.; Bry, A.; Roy, N. Polynomial Trajectory Planning for Aggressive Quadrotor Flight in Dense Indoor Environments. In Proceedings of the International Symposium on Robotics Research (ISRR), Venice, Italy, 22–29 October 2013. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR. pp. 1928–1937. [Google Scholar]
- Blom, H.A.P. An efficient filter for abruptly changing systems. In Proceedings of the 23rd IEEE Conference on Decision and Control, Las Vegas, NV, USA, 12–14 December 1984; Volume 2, pp. 656–658. [Google Scholar]
- Bar-Shalom, Y.; Li, X.R. Multitarget-Multisensor Tracking: Principles and Techniques; YBS Publishing: Storrs, CT, USA, 1995. [Google Scholar]
- Mazor, E.; Averbuch, A.; Bar-Shalom, Y.; Dayan, J. Interacting Multiple Model Methods in Target Tracking: A Survey. IEEE Trans. Aerosp. Electron. Syst. 1998, 34, 103–123. [Google Scholar] [CrossRef]
- Li, X.R.; Jilkov, V.P. Survey of maneuvering target tracking. Part I: Dynamic models. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1333–1364. [Google Scholar]
- Li, X.R.; Jilkov, V.P. Survey of maneuvering target tracking. Part V: Multiple-model methods. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1255–1321. [Google Scholar]
- Bugallo, M.F.; Xu, S.; Djurić, P.M. Performance Comparison of EKF and Particle Filtering Methods for Maneuvering Targets. Digit. Signal Process. 2007, 17, 774–786. [Google Scholar] [CrossRef]
- Wan, M.; Li, P.; Li, T. Tracking Maneuvering Target with Angle-Only Measurements Using IMM Algorithm Based on CKF. In Proceedings of the 2010 International Conference on Communications and Mobile Computing, Shenzhen, China, 12–14 April 2010. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Maximum x Dimension [m] | 10.0 |
| Maximum y Dimension [m] | 5.0 |
| Maximum z Dimension [m] | 3.0 |
| Agent Spawn Area [m] (x, y, z) 1 | (2.0, 5.0, 3.0) |
| End Episode Area [m] (x, y, z) 2 | (9.5, 5.0, 3.0) |
| Parameter | Description | Value |
|---|---|---|
| learning_rate | Learning rate, can be a function | |
| n_steps | Steps per environment per update | 2048 |
| batch_size | Minibatch size | 64 |
| n_epochs | Epochs when optimizing loss | 10 |
| gamma | Discount factor | 0.99 |
| gae_lambda | Trade-off bias/variance in GAE | 0.95 |
| clip_range | Clipping parameter, can be a function | 0.2 |
| normalize_advantage | Normalize advantage or not | True |
| ent_coef | Entropy coefficient | 0.0 |
| vf_coef | Value function coefficient | 0.5 |
| max_grad_norm | Max gradient norm for clipping | 0.5 |
| use_sde | Use state-dependent exploration | False |
| sde_sample_freq | Sample frequency for gSDE noise matrix | −1 |
| stats_window_size | Window size for rollout logging | 100 |
| Parameter | Value |
|---|---|
| Agent’s Max Translation Speed [x, y, z] (cm/s) | [15.0, 10.0, 10.0] |
| Gates Speed (cm/s) | 3.0 |
| Success Rate (%) | |
| Average Reward per Action |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marino, F.; Guglieri, G. Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Navigation. Aerospace 2024, 11, 395. https://doi.org/10.3390/aerospace11050395
Marino F, Guglieri G. Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Navigation. Aerospace. 2024; 11(5):395. https://doi.org/10.3390/aerospace11050395
Chicago/Turabian StyleMarino, Francesco, and Giorgio Guglieri. 2024. "Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Navigation" Aerospace 11, no. 5: 395. https://doi.org/10.3390/aerospace11050395
APA StyleMarino, F., & Guglieri, G. (2024). Beyond Static Obstacles: Integrating Kalman Filter with Reinforcement Learning for Drone Navigation. Aerospace, 11(5), 395. https://doi.org/10.3390/aerospace11050395