_Zhu.png)
Space Manipulator Collision Avoidance Using a Deep Reinforcement Learning Control



Abstract
:1. Introduction
2. Background
Deep Deterministic Policy Gradient
3. Kinematics and Dynamics
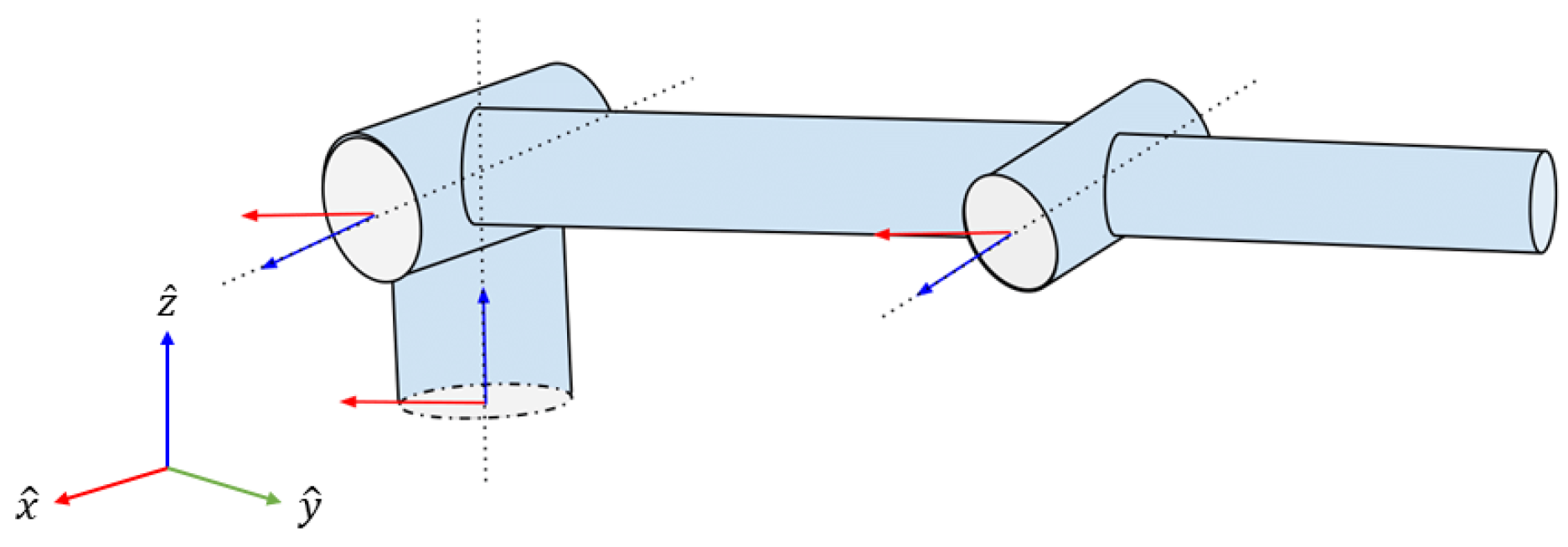
3.1. Kinematics
3.2. Dynamics
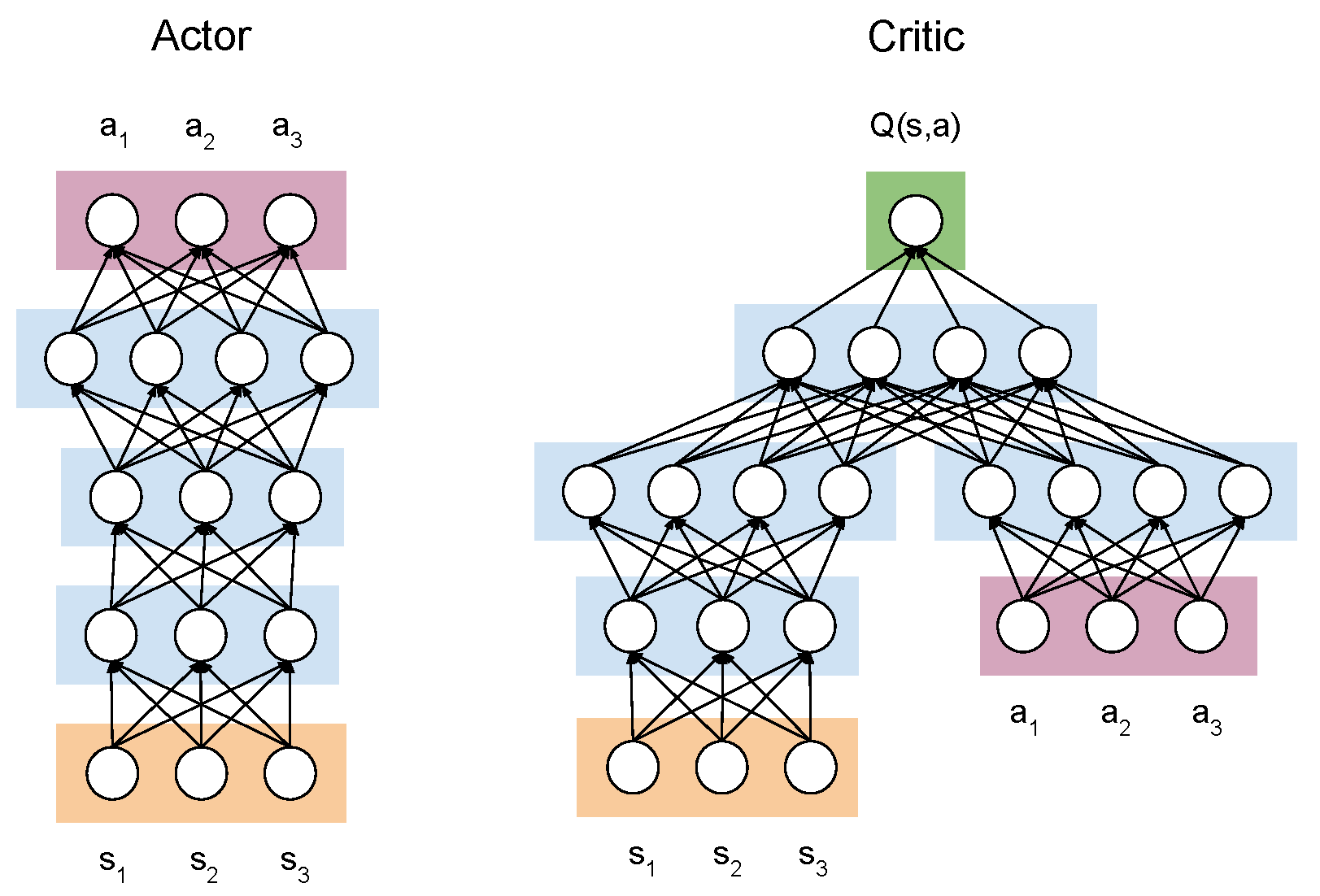
4. Deep Reinforcement Learning Model
4.1. Deep Deterministic Policy Gradient
4.2. Environment
States and Actions
4.3. Reward Function
4.3.1. Free-Flying Base
4.3.2. Free-Floating Base
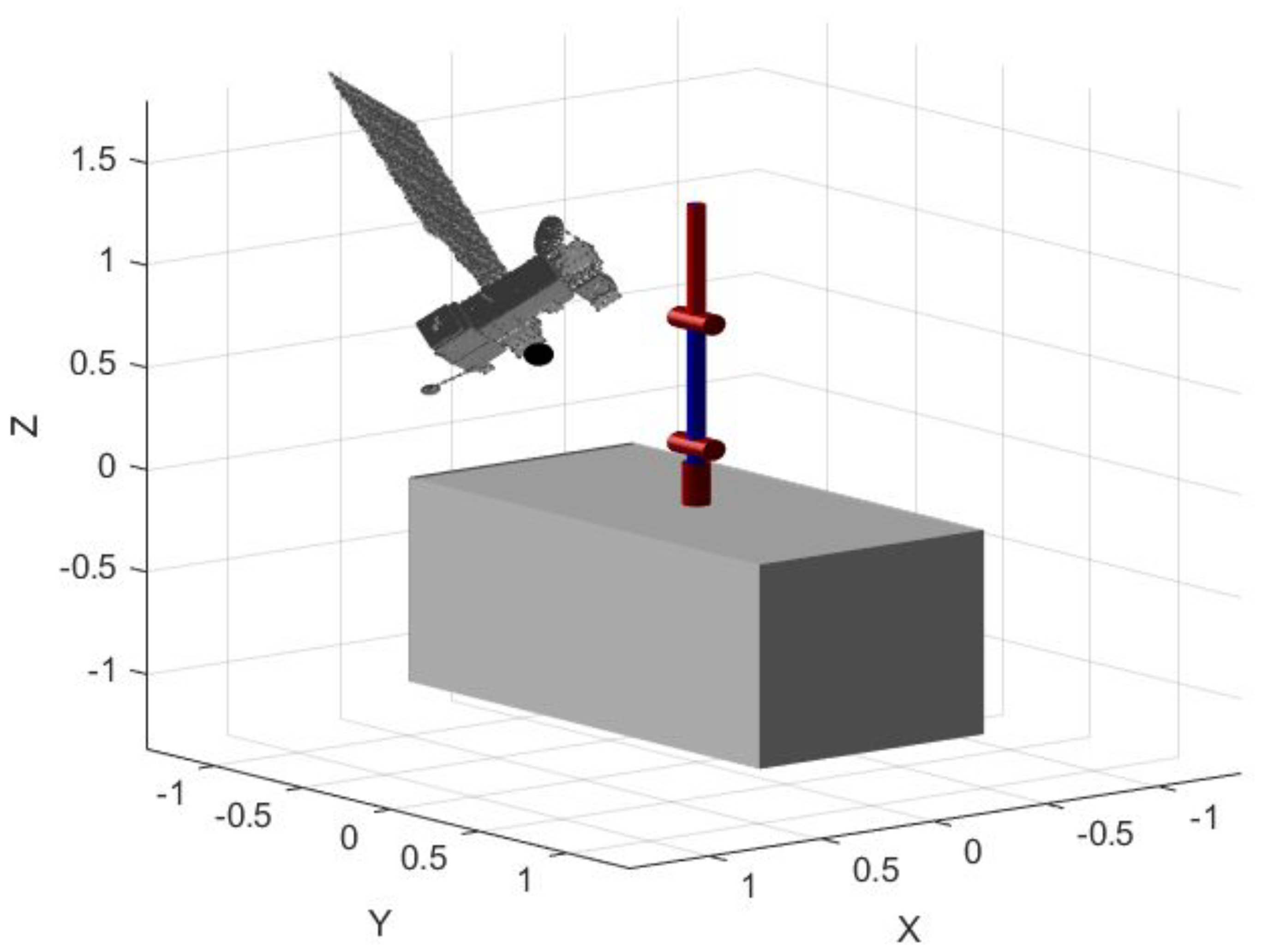
5. Simulation Parameters for Training and Testing
- Cooperative target, free-flying base spacecraft and manipulator
- Cooperative target, free-floating base spacecraft and manipulator
- Non-cooperative target, free-flying base spacecraft and manipulator
- Non-cooperative target, free-floating base spacecraft and manipulator
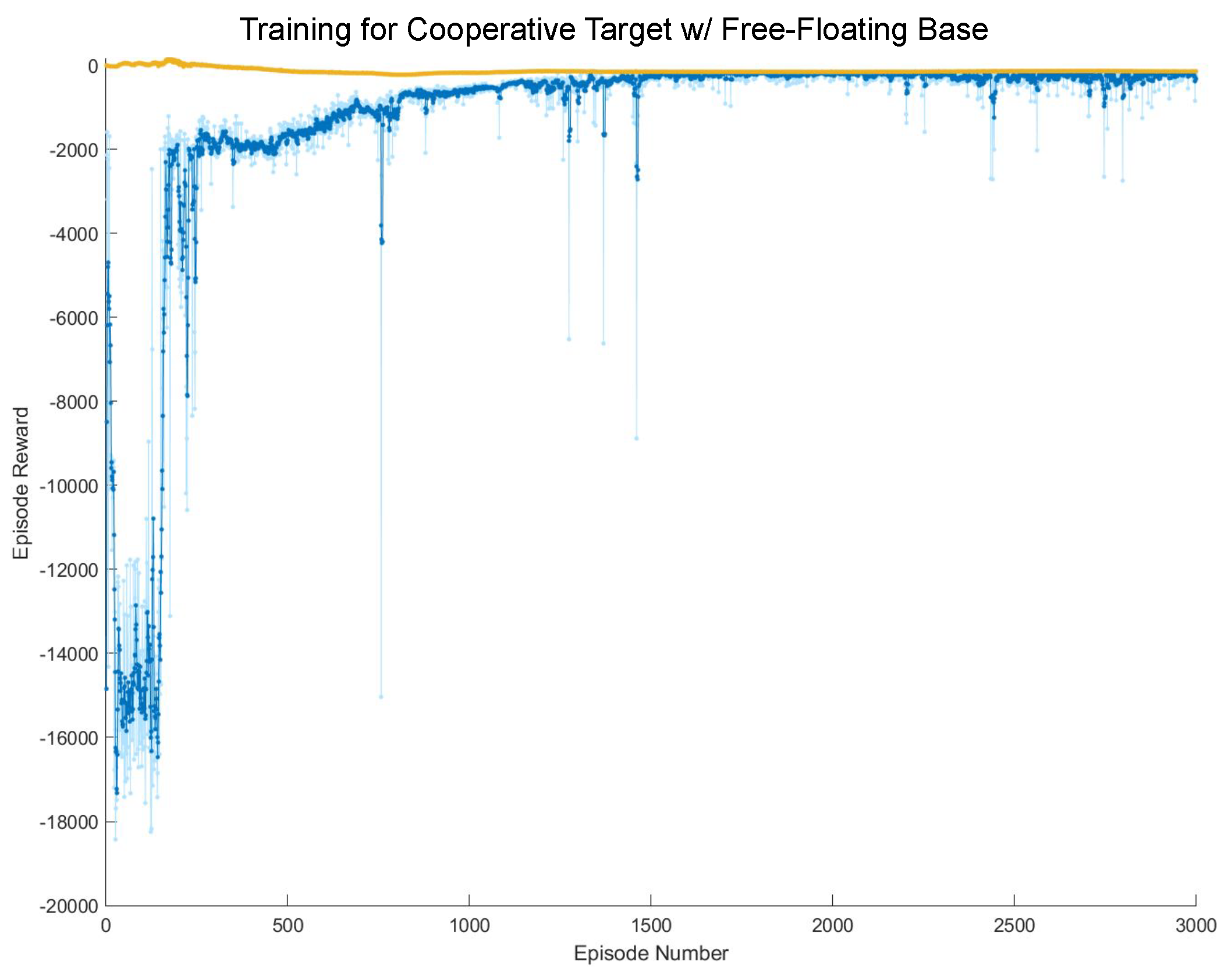
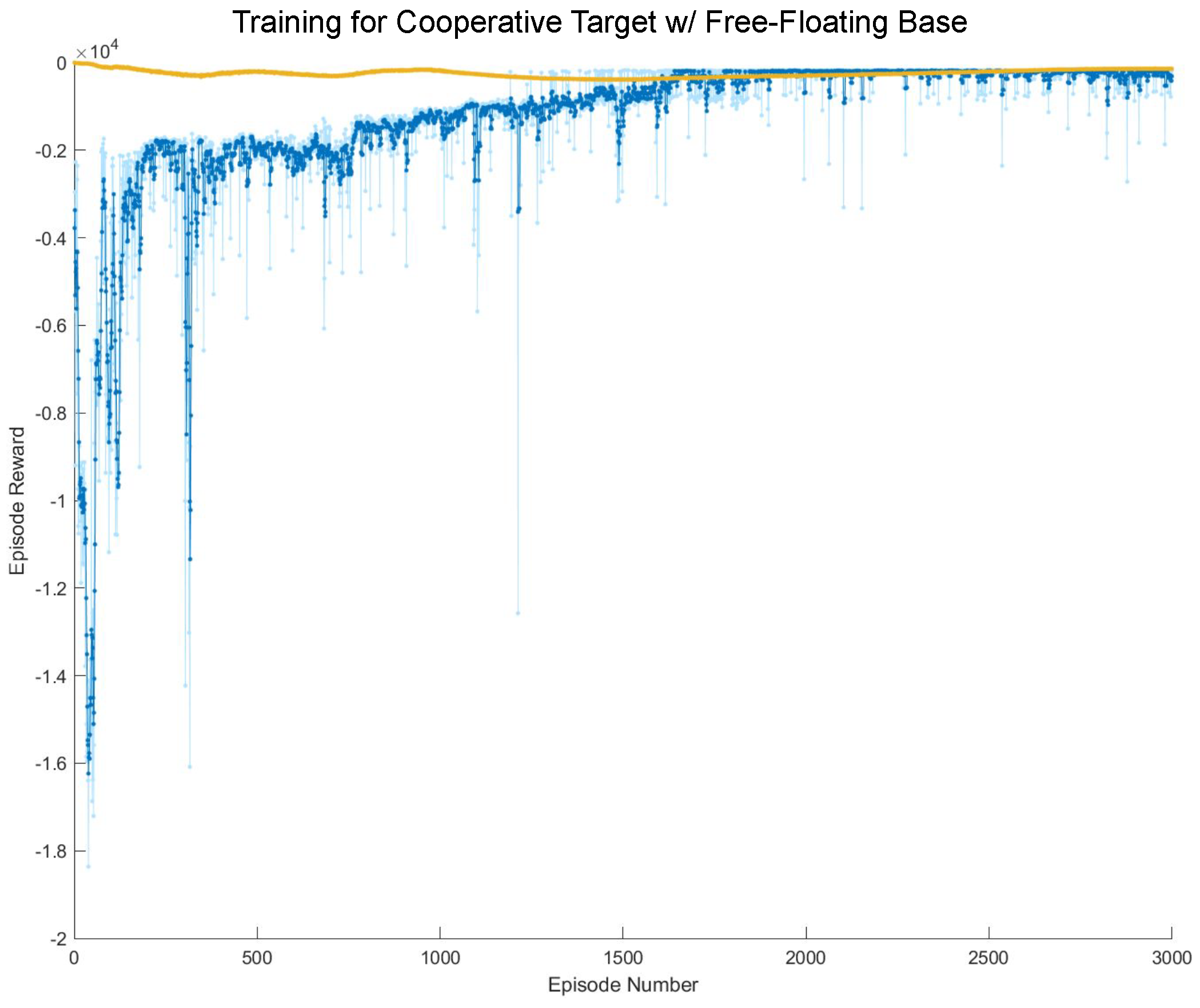
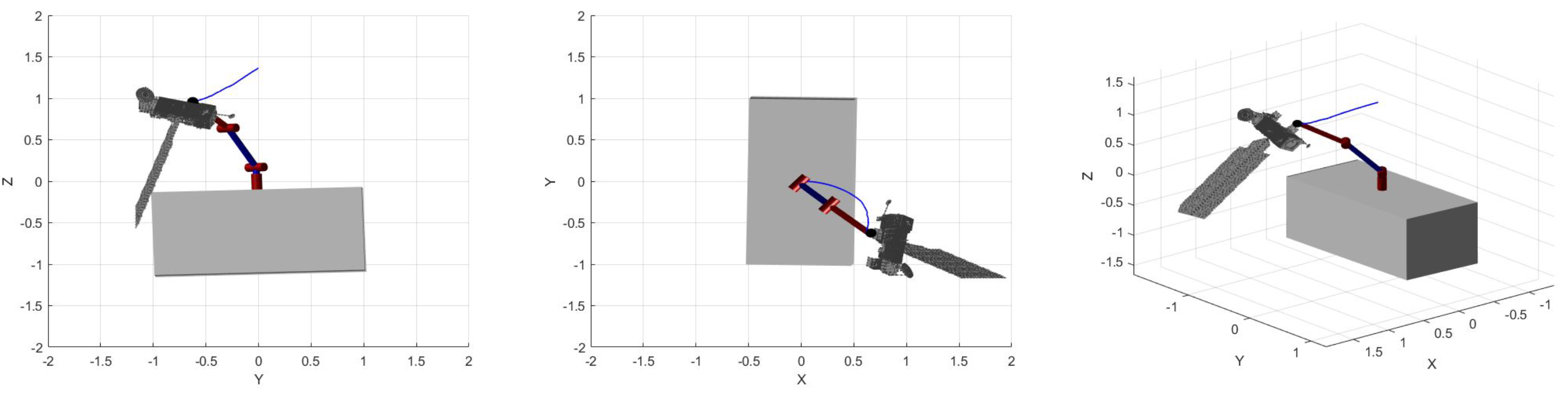
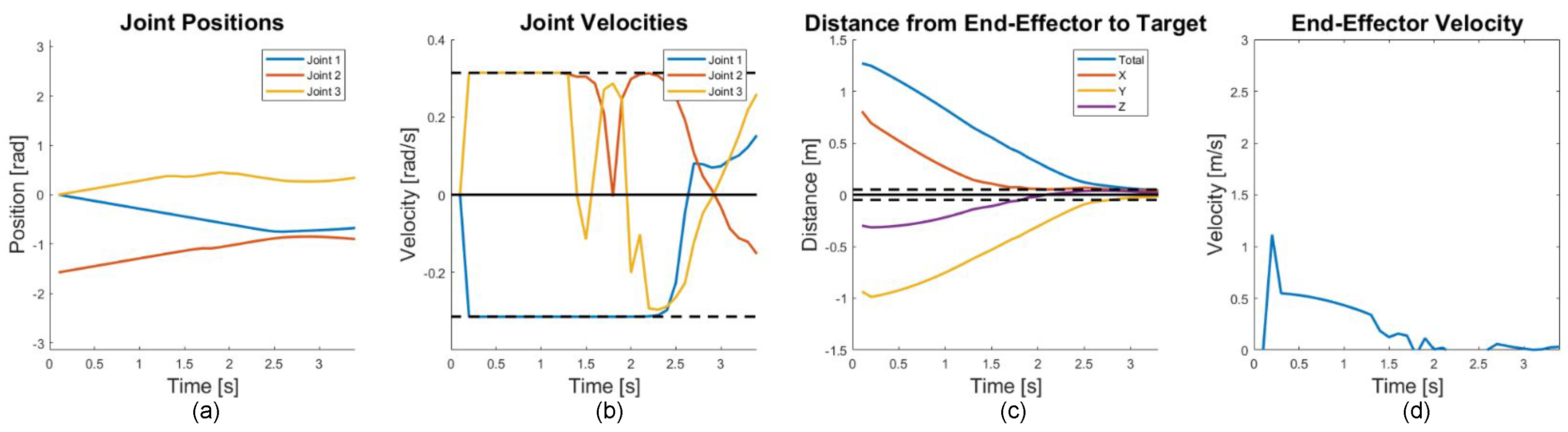
6. Results and Discussion
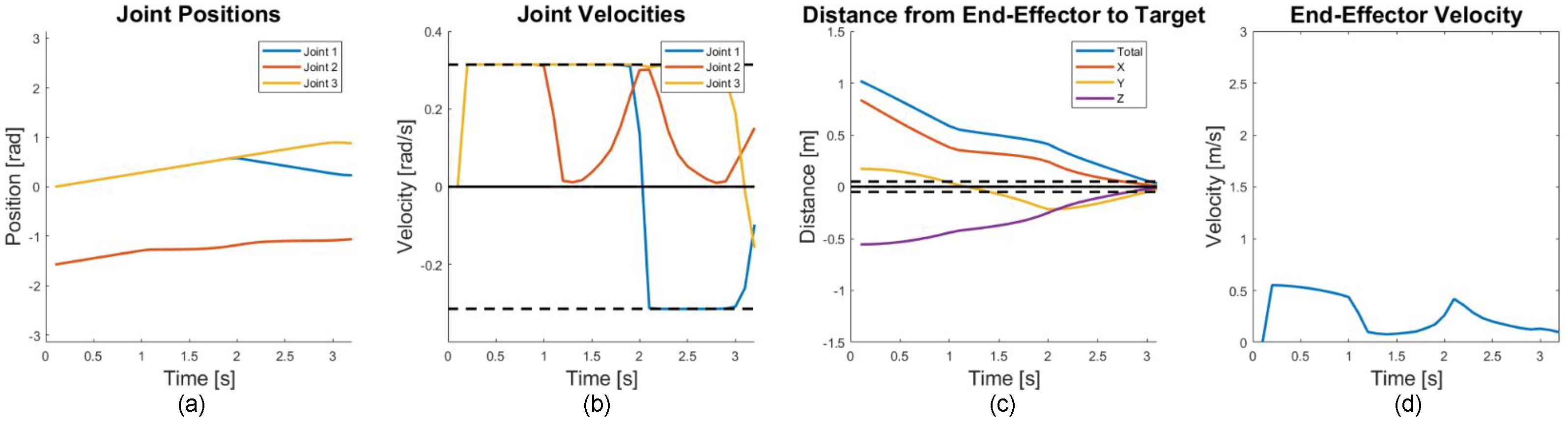
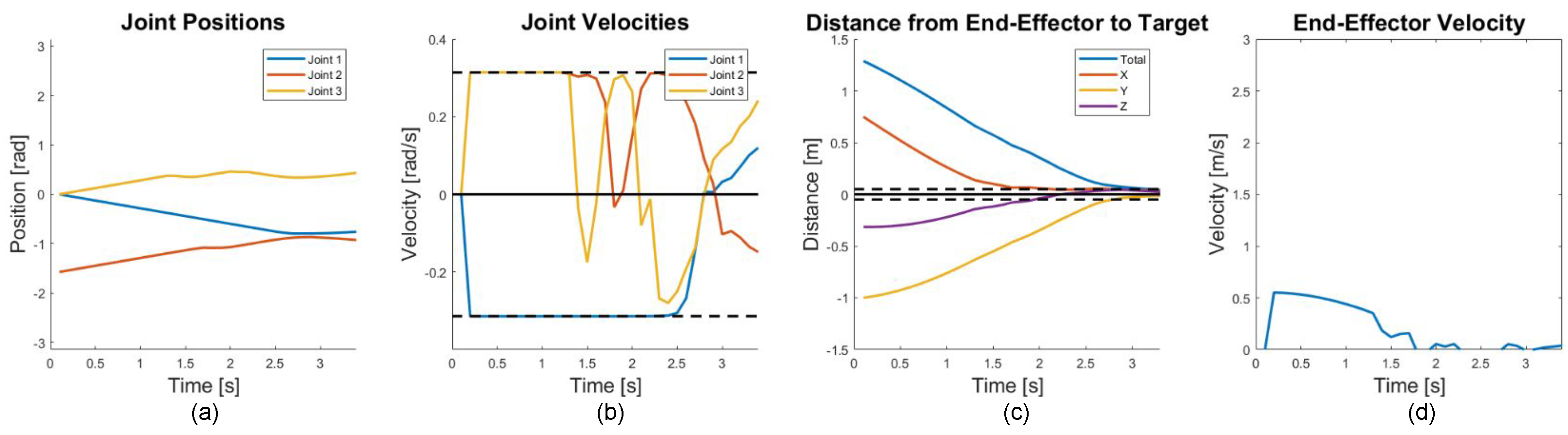
6.1. Cooperative Target
6.2. Non-Cooperative Target
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ellery, A. Tutorial review on space manipulators for space debris mitigation. Robotics 2019, 8, 34. [Google Scholar] [CrossRef]
- Miller, D.; Magilton, E. On-Orbit Satellite Servicing Standards Are a Necessity for the Private Space Industry. Air Space Law 2018, 31, 4. [Google Scholar]
- Flores-Abad, A.; Ma, O.; Pham, K.; Ulrich, S. A review of space robotics technologies for on-orbit servicing. Prog. Aerosp. Sci. 2014, 68, 1–26. [Google Scholar]
- Rybus, T. Obstacle avoidance in space robotics: Review of major challenges and proposed solutions. Prog. Aerosp. Sci. 2018, 101, 31–48. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, X.Y.; Chen, P.; Cai, G. Hybrid control scheme for grasping a non-cooperative tumbling satellite. IEEE Access 2020, 8, 54963–54978. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, S.; Zheng, X.; Ma, W.; Xie, X.; Liu, L. Reinforcement learning with prior policy guidance for motion planning of dual-arm free-floating space robot. Aerosp. Sci. Technol. 2023, 136, 108098. [Google Scholar] [CrossRef]
- Wu, Y.H.; Yu, Z.C.; Li, C.Y.; He, M.J.; Hua, B.; Chen, Z.M. Reinforcement learning in dual-arm trajectory planning for a free-floating space robot. Aerosp. Sci. Technol. 2020, 98, 105657. [Google Scholar] [CrossRef]
- Li, Y.; Hao, X.; She, Y.; Li, S.; Yu, M. Constrained motion planning of free-float dual-arm space manipulator via deep reinforcement learning. Aerosp. Sci. Technol. 2021, 109, 106446. [Google Scholar] [CrossRef]
- Li, Y.; Li, D.; Zhu, W.; Sun, J.; Zhang, X.; Li, S. Constrained motion planning of 7-DOF space manipulator via deep reinforcement learning combined with artificial potential field. Aerospace 2022, 9, 163. [Google Scholar] [CrossRef]
- Papadopoulos, E.; Dubowsky, S. On the nature of control algorithms for free-floating space manipulators. IEEE Trans. Robot. Autom. 1991, 7, 750–758. [Google Scholar] [CrossRef]
- Huang, P.; Xu, Y.; Liang, B. Dynamic balance control of multi-arm free-floating space robots. Int. J. Adv. Robot. Syst. 2005, 2, 13. [Google Scholar] [CrossRef]
- Rybus, T.; Seweryn, K.; Sasiadek, J.Z. Control system for free-floating space manipulator based on nonlinear model predictive control (NMPC). J. Intell. Robot. Syst. 2017, 85, 491–509. [Google Scholar] [CrossRef]
- Wang, M.; Luo, J.; Fang, J.; Yuan, J. Optimal trajectory planning of free-floating space manipulator using differential evolution algorithm. Adv. Space Res. 2018, 61, 1525–1536. [Google Scholar] [CrossRef]
- Wang, X.; Luo, X.; Han, B.; Chen, Y.; Liang, G.; Zheng, K. Collision-free path planning method for robots based on an improved rapidly-exploring random tree algorithm. Appl. Sci. 2020, 10, 1381. [Google Scholar] [CrossRef]
- Nishida, S.; Yoshikawa, T. Space debris capture by a joint compliance controlled robot. In Proceedings of the Proceedings 2003 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM 2003), Kobe, Japan, 20–24 July 2003; Volume 1, pp. 496–502. [Google Scholar]
- Hakima, H.; Bazzocchi, M.C. CubeSat with Dual Robotic Manipulators for Debris Mitigation and Remediation. In Proceedings of the 5th IAA Conference on University Satellite Missions and CubeSat Workshop, Rome, Italy, 28–31 January 2003. [Google Scholar]
- Liu, Y.Q.; Yu, Z.W.; Liu, X.F.; Cai, G.P. Active detumbling technology for high dynamic non-cooperative space targets. Multibody Syst. Dyn. 2019, 47, 21–41. [Google Scholar] [CrossRef]
- Lahr, G.J.; Soares, J.V.; Garcia, H.B.; Siqueira, A.A.; Caurin, G.A. Understanding the implementation of impedance control in industrial robots. In Proceedings of the 2016 XIII Latin American Robotics Symposium and IV Brazilian Robotics Symposium (LARS/SBR), Recife, Brazil, 8–12 October 2016; pp. 269–274. [Google Scholar]
- Gang, C.; Yuqi, W.; Yifan, W.; Liang, J.; Zhang, L.; Guangtang, P. Detumbling strategy based on friction control of dual-arm space robot for capturing tumbling target. Chin. J. Aeronaut. 2020, 33, 1093–1106. [Google Scholar]
- Flores-Abad, A.; Terán, M.A.G.; Ponce, I.U.; Nandayapa, M. Compliant Force Sensor-Less Capture of an Object in Orbit. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 497–505. [Google Scholar] [CrossRef]
- Liu, X.F.; Cai, G.P.; Wang, M.M.; Chen, W.J. Contact control for grasping a non-cooperative satellite by a space robot. Multibody Syst. Dyn. 2020, 50, 119–141. [Google Scholar] [CrossRef]
- Sangiovanni, B.; Rendiniello, A.; Incremona, G.P.; Ferrara, A.; Piastra, M. Deep reinforcement learning for collision avoidance of robotic manipulators. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 2063–2068. [Google Scholar]
- Satheeshbabu, S.; Uppalapati, N.K.; Fu, T.; Krishnan, G. Continuous control of a soft continuum arm using deep reinforcement learning. In Proceedings of the 2020 3rd IEEE International Conference on Soft Robotics (RoboSoft), New Haven, CT, USA, 15 May–15 July 2020; pp. 497–503. [Google Scholar]
- Rahimpour, Z.; Verbič, G.; Chapman, A.C. Actor-critic learning for optimal building energy management with phase change materials. Electr. Power Syst. Res. 2020, 188, 106543. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Wang, Y.; Sun, J.; He, H.; Sun, C. Deterministic policy gradient with integral compensator for robust quadrotor control. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 50, 3713–3725. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Guoqing, M.; li, L.; Zhenglin, Y.; Guohua, C.; Yanbin, Z. Movement Characteristics Analysis and Dynamic Simulation of Collaborative Measuring Robot. In Proceedings of the IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2017; Volume 187, p. 012043. [Google Scholar]
- Khalil, W. Dynamic modeling of robots using recursive newton-euler techniques. In Proceedings of the ICINCO2010, Madeira, Portugal, 15–18 June 2010. [Google Scholar]
- Zi, B.; Duan, B.; Du, J.; Bao, H. Dynamic modeling and active control of a cable-suspended parallel robot. Mechatronics 2008, 18, 1–12. [Google Scholar] [CrossRef]
- Zong, L.; Emami, M.R.; Luo, J. Reactionless control of free-floating space manipulators. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 1490–1503. [Google Scholar] [CrossRef]
- MATLAB Reinforcement Learning Toolbox; The MathWorks: Natick, MA, USA, 2022.
- MATLAB Deep Learning Toolbox; The MathWorks: Natick, MA, USA, 2022.
- Chu, C.; Takahashi, K.; Hashimoto, M. Comparison of Deep Reinforcement Learning Algorithms in a Robot Manipulator Control Application. In Proceedings of the 2020 International Symposium on Computer, Consumer and Control (IS3C), Taichung City, Taiwan, 13–16 November 2020; pp. 284–287. [Google Scholar]
- Malagon, M.; Ceberio, J. Evolving Neural Networks in Reinforcement Learning by means of UMDAc. arXiv 2019, arXiv:1904.10932. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lane, K. NASA 3D Resources: Aqua; NASA: Washington, DC, USA, 2010. [Google Scholar]
- Gilbert, E.G.; Johnson, D.W.; Keerthi, S.S. A fast procedure for computing the distance between complex objects in three-dimensional space. IEEE J. Robot. Autom. 1988, 4, 193–203. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kinematics | (rad) | a (m) | d (m) | (rad) |
|---|---|---|---|---|
| Joint 1 | 0 | 0.1273 | ||
| Joint 2 | 0.612 | 0 | 0 | |
| Joint 3 | 0.5723 | 0 | 0 |
| Dynamics | Mass (kg) | Center of Mass (m) |
|---|---|---|
| Link 1 | 7.10 | (0.021, 0.000, 0.027) |
| Link 2 | 12.7 | (0.380, 0.000, 0.158) |
| Link 3 | 4.27 | (0.240, 0.000, 0.068) |
| Parameter | Value |
|---|---|
| Step Size | 0.1 |
| Max Steps per Episode | 200 |
| Actor Learn Rate | 0.001 |
| Critic Learn Rate | 0.001 |
| Batch Size | 32 |
| Experience Buffer | 100,000 |
| Condition | Value |
|---|---|
| Base Spacecraft Length (m) | 1 |
| Base Spacecraft Width (m) | 2 |
| Base Spacecraft Depth (m) | 1 |
| Base Spacecraft Mass (kg) | 1000 |
| Manipulator Joint Positions, (rad) | (0, , 0) |
| Manipulator Joint Velocities, (rad/s) | (0, 0, 0) |
| Reward Weight, | −10 |
| Reward Weight, | 100 |
| Reward Weight, | 0.1 |
| Parameter | Cooperative | Non-Cooperative |
|---|---|---|
| Target Satellite Center of Mass (m) | (0.75, 0, 0.5) | (0.85, −1, 0.85) |
| Grasping Location (m) | (0.84, 0.17, 0.81) | (0.75, −1, 1.05) |
| Attitude (deg) | (−60, 140, 180) | (0, 0, 0) |
| Velocity (m/s) | (0, 0, 0) | (0, 0.1, 0) |
| Angular Velocity (deg/s) | (0, 0, 0) | (0.5, 1, 0) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blaise, J.; Bazzocchi, M.C.F. Space Manipulator Collision Avoidance Using a Deep Reinforcement Learning Control. Aerospace 2023, 10, 778. https://doi.org/10.3390/aerospace10090778
Blaise J, Bazzocchi MCF. Space Manipulator Collision Avoidance Using a Deep Reinforcement Learning Control. Aerospace. 2023; 10(9):778. https://doi.org/10.3390/aerospace10090778
Chicago/Turabian StyleBlaise, James, and Michael C. F. Bazzocchi. 2023. "Space Manipulator Collision Avoidance Using a Deep Reinforcement Learning Control" Aerospace 10, no. 9: 778. https://doi.org/10.3390/aerospace10090778
APA StyleBlaise, J., & Bazzocchi, M. C. F. (2023). Space Manipulator Collision Avoidance Using a Deep Reinforcement Learning Control. Aerospace, 10(9), 778. https://doi.org/10.3390/aerospace10090778