
Effects of Language Ontology on Transatlantic Automatic Speech Understanding Research Collaboration in the Air Traffic Management Domain


 ,
,  ,
,
Abstract
1. Introduction
1.1. Broad Context of the Study
1.2. Structure of the Paper
1.3. Background
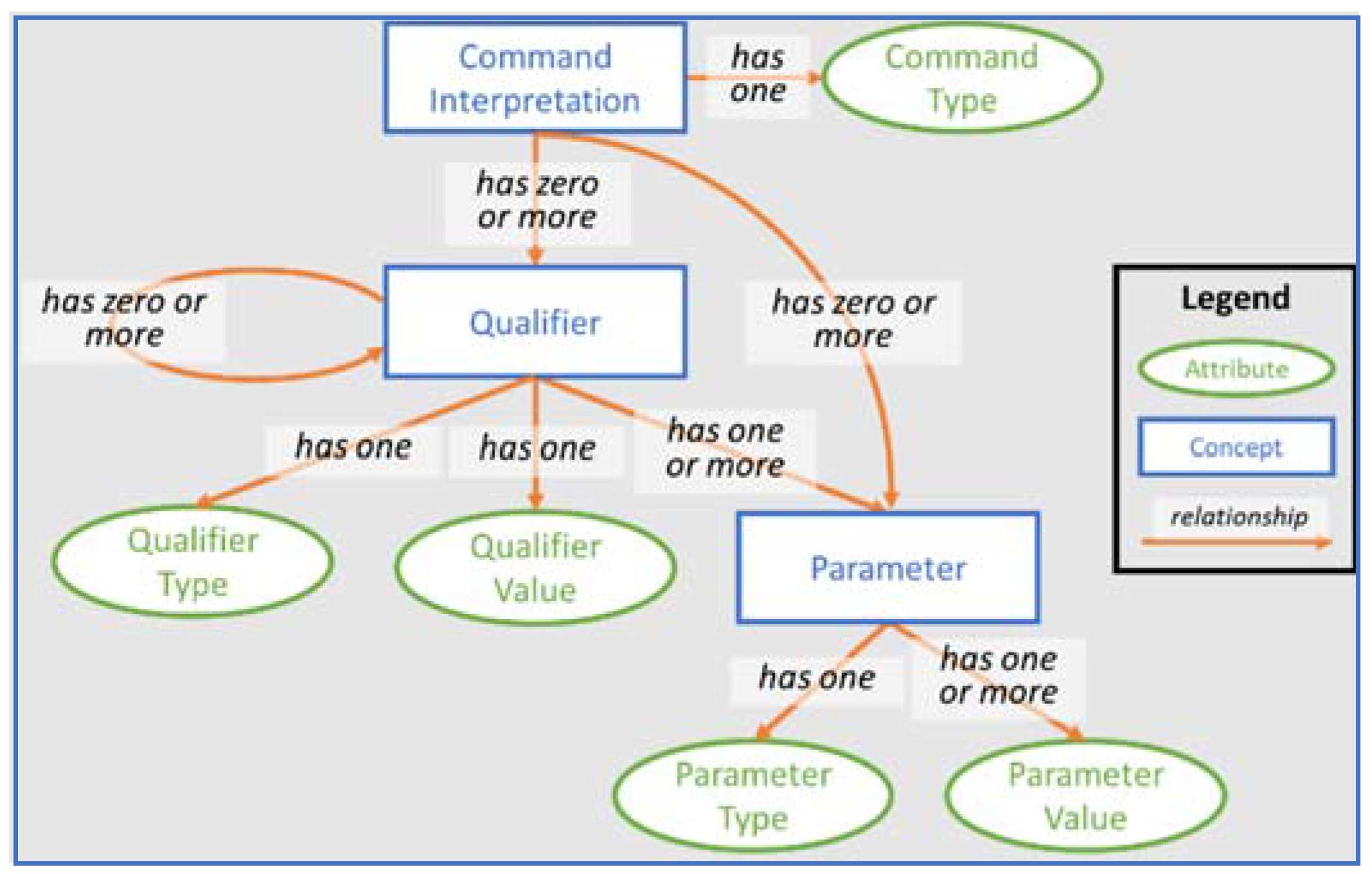
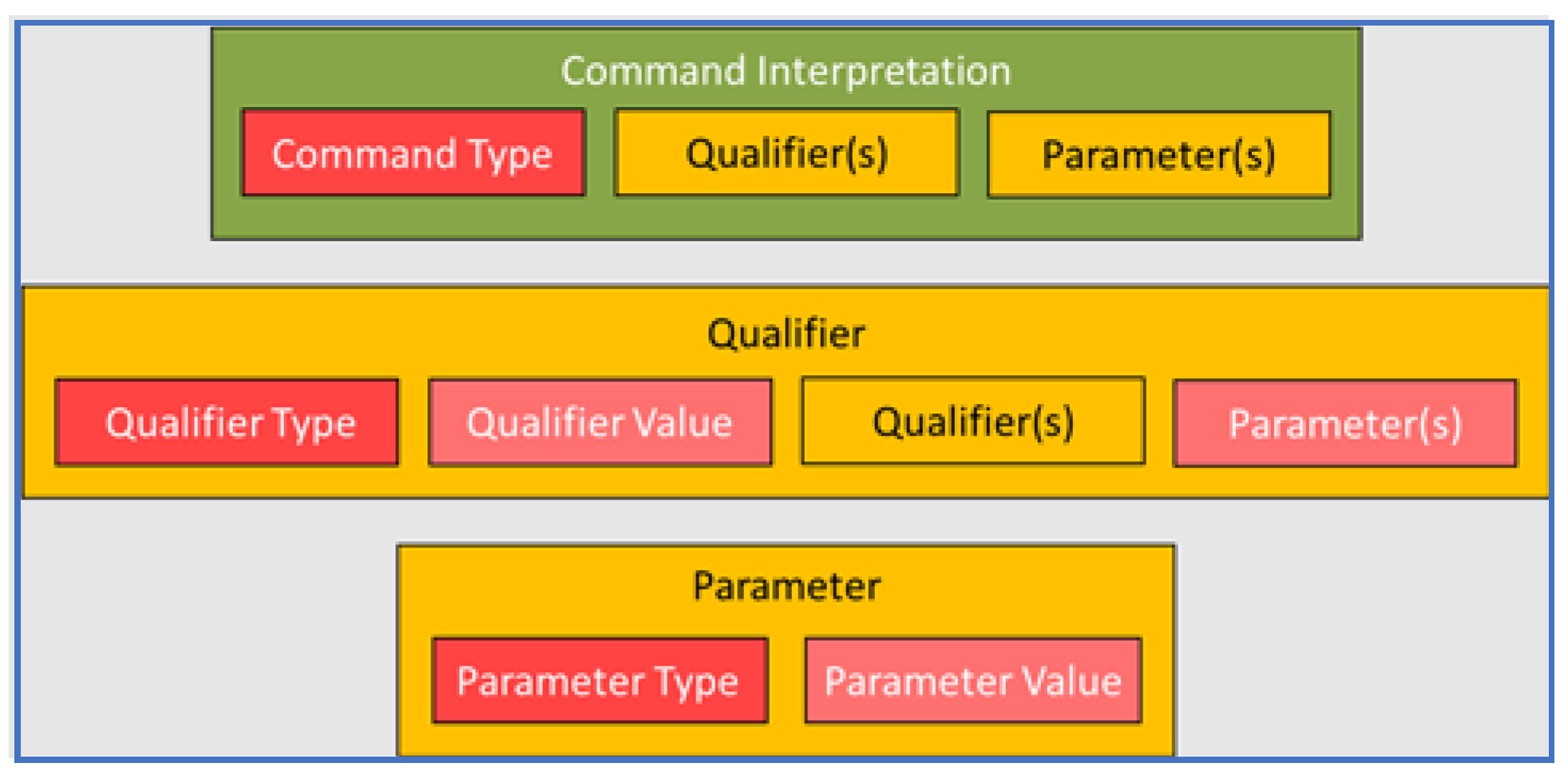
1.4. What We Mean by Ontology
2. A Comparison of Two ATC Ontologies
2.1. Lexical Level
- Identical words with different spellings (e.g., juliett versus juliet).
- How initialisms are handled (e.g., ILS versus i l s).
- Words with similar meaning and different pronunciations and spelling (e.g., nine versus niner).
- Words absent from one ontology or the other (e.g., the word altimeter does not occur in European ATC communications and the corresponding ICAO term QNH is absent from US ATC communications) [28].
- Whether speech disfluencies and coarticulation are captured at the word level (e.g., cleartalan versus cleared to land).
- Words not represented in the US English language (e.g., the German word wiederhoeren for a farewell).
2.2. Semantic Level
- How callsigns are represented.
- The extent of and representation of inferred and implied information in the semantic representations.
- The level of detail represented for advisory-type transmissions (e.g., traffic advisories, pilot call-in status information).
- Which less-common ATCo instructions have defined representations.
- How ambiguous ATCo instructions are represented.
2.3. Examples of Ontology Representations from ATC Communications
2.4. Quantifying the Differences
- Separation and combination of words/letters
- ○
- ”ILS” vs. “i l s” (23 times)
- ○
- “southwest”, etc., vs. “south west”, etc. (19 times)
- Different spellings
- ○
- “nine” vs. “niner” (9 times)
- ○
- “juliett” vs. “juliet” (6 times)
- ○
- “OK” vs. “okay” (4 times)
- Special sounds and their notation
- ○
- “[unk]” vs. no transcription (7 times)
- ○
- “[hes]” vs. “uh” (7 times)
3. Impact of Ontology on Collaboration
3.1. Data Sharing
3.1.1. Text Data
3.1.2. Semantic Annotations
3.2. Reusing Models and Algorithms
3.2.1. Automatic Speech Recognition Models
3.2.2. Semantic Parsing Algorithms
3.3. Sharing and Reusing Applications
3.3.1. Examples of Application Specific Ontologies
3.3.2. Closed Runway Operation Detection (CROD)
3.3.3. Wrong Surface Operations Detection (WSOD)
3.3.4. Approach Clearance Usage Analysis (ACUA)
3.3.5. Prefilling Radar Labels for Vienna Approach (PRLA)
3.3.6. Electronic Flight Strip in Multiple Remote Tower Environment (MRT)
3.3.7. Integration of ASRU with A-SMGCS for Apron Control at Frankfurt and Simulation Pilots in Lab Environment (SMGCS and SPA)
3.3.8. Workload Prediction for London Terminal Area (WLP)
3.3.9. Integration of ASRU and CPDLC (CPDLC)
3.3.10. Pilot Weather Reports (PWR)
3.3.11. Use of Visual Separation (VFR)
3.3.12. Simulation Pilots in Enroute Domain Controller Training (SPET)
3.3.13. Readback Error Detection for Enroute Controllers (RB-E)
3.3.14. Readback Error Detection for Tower Controllers (RB-T)
3.4. Application-Specific Metrics
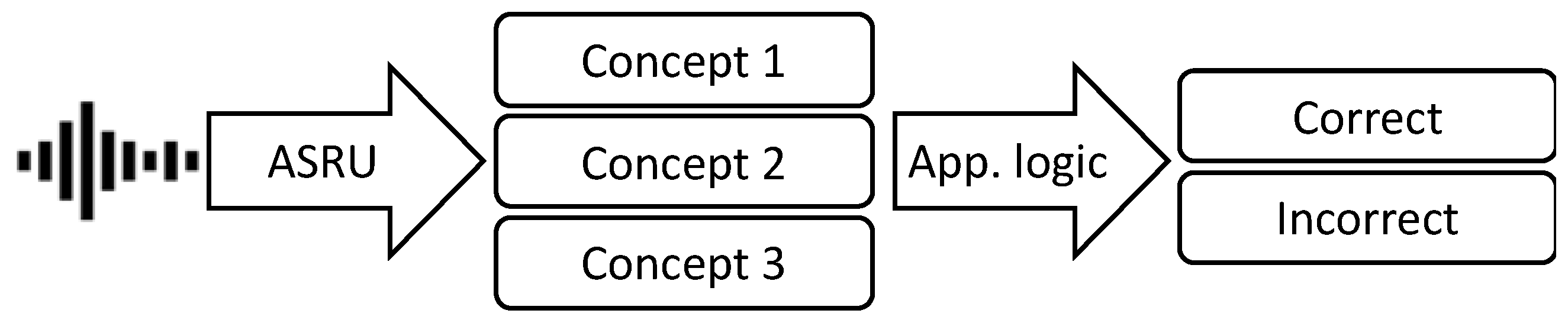
4. Quantitative Analyses with Applied Ontologies
4.1. Application-Specific Metrics for a Workload Assessment in the Lab Environment
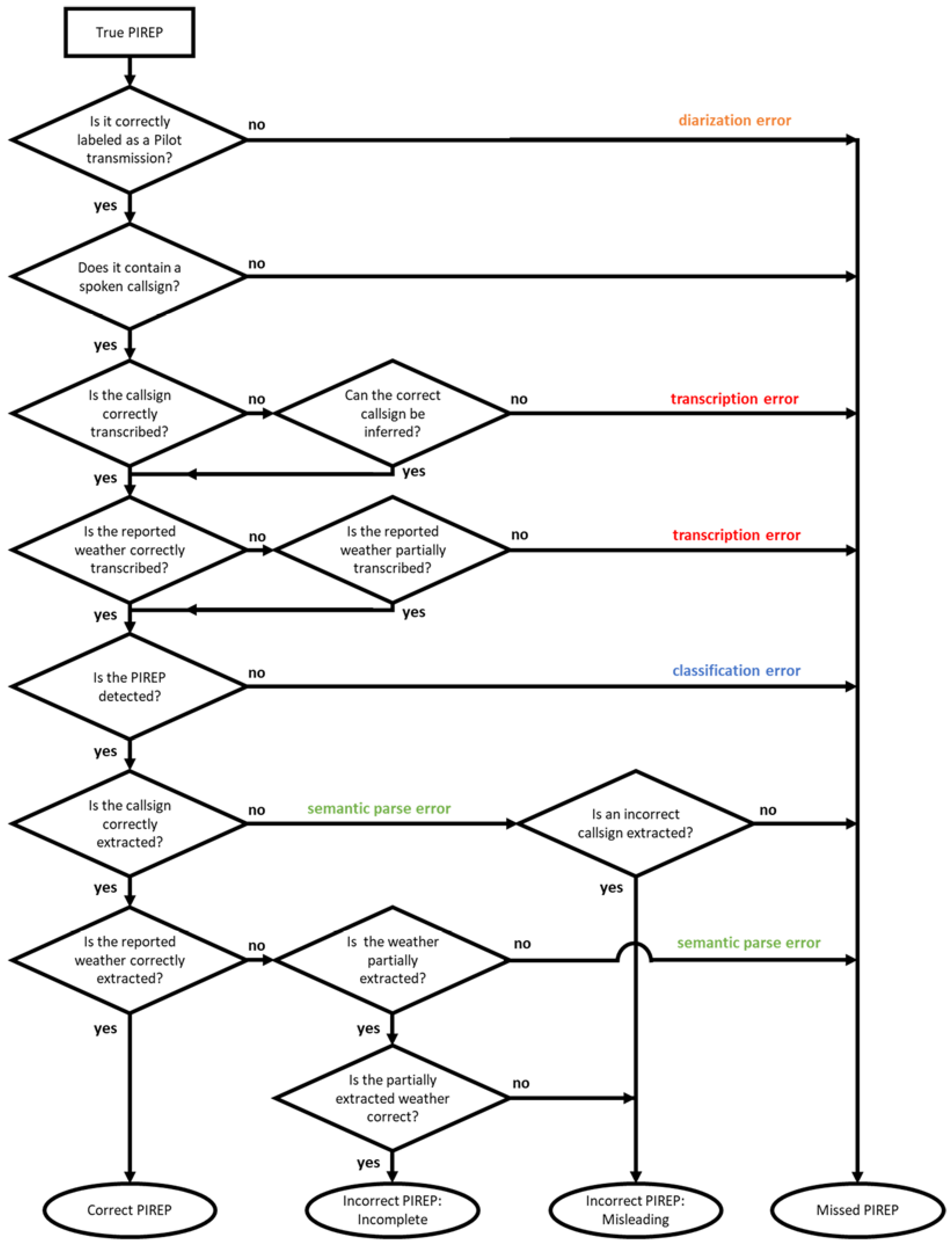
4.2. Application-Specific Metrics for a Post-Operations Pilot Report Analysis
- The number of correctly detected and accurately formatted pilot reports (PIREPs), i.e., correct PIREPs.
- The number of correctly detected but incorrectly formatted PIREPs (incorrect PIREPs because they are incomplete, misleading, or both).
- The number of PIREPs not detected or not mapped to a formatted PIREP (missed PIREPs).
4.3. European Word-Level Challenges and Statistics
4.4. US Word-Level Statistics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Command Types in European and MITRE Ontology

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MITRE | European | Example/Explanation |
|---|---|---|
| Climb | CLIMB | climb to flight level three two zero |
| Descend | DESCEND | descend to flight level one four zero |
| Tries always to derive, whether CLIMB or DESCEND | ALTITUDE | if no descend or climb keyword is provided/recognized in transmission |
| StopAltitude | STOP_ALTITUDE/ STOP_CLIMB/ STOP_DESCEND | stop descent at flight level one zero zero |
| Maintain | MAINTAIN ALTITUDE/ PRESENT_ALTITUDE | maintain flight level one eight zero; maintain present level |
| Cancel | NO_ALTI_RESTRICTIONS | No altitude constraints at all. |
| MITRE | European | Example/Explanation |
|---|---|---|
| IncreaseSpeed | INCREASE/INCREASE_BY | increase to zero point eight four mach |
| ReduceSpeed | REDUCE/REDUCE_BY | reduce speed to two two zero knots |
| Tries always to derive, whether REDUCE or INCREASE. | SPEED | if no reduce or increase keyword is provided/recognized in transmission |
| RESUME_NORMAL_SPEED | Still the published speed constraints are relevant. | |
| Cancel SpeedRestriction | NO_SPEED_RESTRICTIONS | The speed restriction is removed |
| DoNotExceed | OR_LESS used as qualifier | Speed limit |
| Maintain | MAINTAIN SPEED/PRESENT_SPEED | maintain present speed |
| SpeedChange | SPEED, INCREASE, REDUCE used in Europe | |
| REDUCE_FINAL_APPROACH_SPEED | reduce final approach speed | |
| REDUCE_MIN_APPROACH_SPEED | reduce minimum approach speed | |
| REDUCE_MIN_CLEAN_SPEED | reduce minimum clean speed | |
| HIGH_SPEED_APPROVED | speed is yours |
| MITRE | European | Example/Explanation |
|---|---|---|
| Climb (At) | RATE_OF_CLIMB | climb with two thousand feet per minute (or greater)/ climb at three thousand feet per minute |
| Descend (At) | RATE_OF_DESCENT | descend with two thousand five hundred feet per minute |
| Maintain | maintain three thousand in the climb/ maintain three thousand five feet per minute in the climb | |
| VERTICAL_RATE | if no climb or descent keyword is provided/recognized in transmission | |
| EXPEDITE_PASSING | expedite passing flight level three four zero |
| MITRE | European | Example/Explanation |
|---|---|---|
| TurnLeft, TurnRight | HEADING/TURN/TURN_BY (Qualifier LEFT/RIGHT) | turn left heading two seven zero; turn right by one zero degrees |
| Turn | TURN/TURN_BY (Qualifier LEFT/RIGHT) | turn right by one zero degrees |
| TURN (without a value) Qualifier LEFT/RIGHT) | turn right | |
| Fly | HEADING (Qualifier none) | fly heading three six zero (no keyword left/right recognized) |
| Maintain | CONTINUE_PRESENT_HEADING/MAINTAIN HEADING | continue present heading |
| MAGNETIC_TRACK | magnetic track one one five |
| MITRE | European | Example/Explanation |
|---|---|---|
| Direct | DIRECT_TO/DIRECT Approach_Leg/LatLong | direct to delta lima four five five/ direct final runway three four direct six zero north zero one five west |
| Resume | NAVIGATION_OWN | own navigation |
| Cleared | CLEARED TO | cleared to london heathrow |
| Circle | ORBIT (Qualifier LEFT/RIGHT) | make orbits to the left |
| MITRE | European | Example/Explanation |
|---|---|---|
| Cleared (STAR/SID/Approach) | CLEARED/CLEARED VIA/MISS_APP_PROC | cleared via sorok one november |
| Intercept (Approach/ApproachType) | INTERCEPT_LOCALIZER | intercept localizer for runway |
| INTERCEPT_GLIDEPATH | intercept glidepath | |
| JOIN_TRAFFIC_CIRCUIT | right traffic circuit for runway three four | |
| Join | TRANSITION | join nerdu four november transition |
| Resume | NAVIGATION_OWN | resume navigation |
| Continue | CONTINUE_APPROACH | continue approach runway zero one |
| Cleared | CLEARED Approach_Type | cleared Rnav approacch zero nine center |
| Cancel (Approach/ SpeedRestriction/ AltitudeRestriction) | CANCEL Approach_Type | cancel approach for runway zero five |
| Climb (Via) | climb via the capital one departure | |
| Descend (Via) | descend via the cavalier four arrival | |
| GO_AROUND | go around |
References
- Chen, S.; Kopald, H.; Chong, R.S.; Wei, Y.-J.; Levonian, Z. Readback error detection using automatic speech recognition. In Proceedings of the 12th USA/Europe Air Traffic Management Research and Development Seminar (ATM2017), Seattle, WA, USA, 26–30 June 2017. [Google Scholar]
- Helmke, H.; Ondřej, K.; Shetty, S.; Arilíusson, H.; Simiganosch, T.S.; Kleinert, M.; Ohneiser, O.; Ehr, H.; Zuluaga, J.P. Readback error detection by automatic speech recognition and understanding: Results of HAAWAII project for Isavia’s enroute airspace. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Kleinert, M.; Chen, S.; Kopald, H.D.; Tarakan, R.M. Transatlantic Approaches for Automatic Speech Understanding in Air Traffic Management. In Proceedings of the Submitted to 15th USA/Europe Air Traffic Management Research and Development Seminar (ATM2023), Savannah, GA, USA, 5–9 June 2023. [Google Scholar]
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Tarakan, R.; Baldwin, K.; Rozen, N. An automated simulation pilot capability to support advanced air traffic controller training. In Proceedings of the 26th Congress of ICAS and 8th AIAA ATIO, Anchorage, AK, USA, 14–19 September 2008. [Google Scholar]
- Schultheis, S. Integrating advanced technology into air traffic controller training. In Proceedings of the 14th AIAA Aviation Technology, Integration, and Operations Conference, Atlanta, GA, USA, 16–20 June 2014. [Google Scholar]
- Updegrove, J.A.; Jafer, S. Optimization of Air Traffic Control Training at the Federal Aviation Administration Academy. Aerospace 2017, 4, 50. [Google Scholar] [CrossRef]
- Federal Aviation Administration. 2012 National Aviation Research Plan; Federal Aviation Administration: Washington, DC, USA, 2012.
- Baldwin, K. Air Traffic Controller Training Performance Assessment and Feedback: Data Collection and Processing; The MITRE Corporation: McLean, VA, USA, 2021. [Google Scholar]
- Schäfer, D. Context-Sensitive Speech Recognition in the Air Traffic Control Simulation. Ph.D. Thesis, University of Armed Forces, Munich, Germany, 2001. [Google Scholar]
- Ciupka, S. Siris big sister captures DFS (original German title: Siris große Schwester erobert die DFS. Transmission 2012, 1, 14–15. [Google Scholar]
- Cordero, J.M.; Rodriguez, N.; de Pablo, J.M.; Dorado, M. Automated speech recognition in controller communications applied to workload measurement. In Proceedings of the 3rd SESAR Innovation Days, Stockholm, Sweden, 26–28 November 2013. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing ATM efficiency with assistant-based speech recognition. In Proceedings of the 12th USA/Europe Air Traffic Management Research and Development Seminar (ATM2017), Seattle, WA, USA, 26–30 June 2017. [Google Scholar]
- Subramanian, S.V.; Kostiuk, P.F.; Katz, G. Custom IBM Watson speech-to-text model for anomaly detection using ATC-pilot voice communication. In Proceedings of the 2018 Aviation Technology, Integration, and Operations Conference, Atlanta, GA, USA, 25–29 June 2018. [Google Scholar]
- Kopald, H.; Chen, S. Design and evaluation of the closed runway operation prevention device. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Chicago, IL, USA, 27–31 October 2014. [Google Scholar]
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A real-time ATC safety monitoring framework using a deep learning approach. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4572–4581. [Google Scholar] [CrossRef]
- Lowry, M.; Pressburger, T.; Dahl, D.A.; Dalal, M. Towards autonomous piloting: Communicating with air traffic control. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019. [Google Scholar]
- Chen, S.; Kopald, H.; Tarakan, R.; Anand, G.; Meyer, K. Characterizing national airspace system operations using automated voice data processing. In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar (ATM2019), Vienna, Austria, 17–21 June 2019. [Google Scholar]
- Chen, S.; Kopald, H.; Avjian, B.; Fronzak, M. Automatic pilot report extraction from radio communications. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022. [Google Scholar]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.F.; Ohneiser, O.; Vink, N.; Cerna, A.; Hartikainen, P.; Josefsson, B.; Langr, D.; et al. Ontology for transcription of ATC speech commands of SESAR 2020 solution PJ.16-04. In Proceedings of the IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018. [Google Scholar]
- Bundesministerium für Bildung und Forschung, “KI-in der Praxis,” Bundesministerium für Bildung und Forschung. Available online: https://www.softwaresysteme.pt-dlr.de/de/ki-in-der-praxis.php (accessed on 13 April 2023).
- Deutsches Zentrum für Luft und Raumfahrt e.V. (DLR). Virtual/Augmented Reality Applications for Tower (SESAR Solution PJ.05-W2-97.1). Available online: https://www.remote-tower.eu/wp/project-pj05-w2/solution-97-1/ (accessed on 13 April 2023).
- SESAR Joint Undertaking. Industrial Research Project: Digital Technologies for Tower. SESAR 3 Joint Undertaking. Available online: https://www.sesarju.eu/projects/DTT (accessed on 13 April 2023).
- European Commission. PJ.10 W2 Separation Management and Controller Tools. [Online]. Available online: https://cordis.europa.eu/programme/id/H2020_SESAR-IR-VLD-WAVE2-10-2019/de (accessed on 13 April 2023).
- Deutsches Zentrum für Luft- und Raumfahrt e.V. (DLR). HAAWAII: Highly Automated Air Traffic Controller Workstations with Artificial Intelligence Integration. Available online: https://www.haawaii.de/wp/ (accessed on 13 April 2023).
- Federal Aviation Administration. JO 7110.65Z—Air Traffic Control; Federal Aviation Administration: Washington, DC, USA, 2021.
- Foley, J.D.; Van Dam, A. Fundamentals of Interactive Computer Graphics, 1st ed.; Addison-Wesley Publishing Company: Reading, MA, USA, 1982. [Google Scholar]
- International Civil Aviation Organization. Procedures for Air Navigation Services (PANS)—Air Traffic Management (Doc 4444); International Civil Aviation Organization: Montreal, QC, Canada, 2016. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet Physics—Doklady; American Institute of Physics: College Park, ML, USA, 1965; Volume 10, pp. 707–710. [Google Scholar]
- Harfmann, J. D5.4 Human Performance Metrics Evaluation. Publicly available Deliverable of SESAR-2 funded HAAWAII Project, 2022-08-05, version 01.00.00. 2022. Available online: https://www.haawaii.de/wp/dissemination/references/ (accessed on 13 April 2023).






| Lexical Representation | eurowings 1 3 9 alpha cleared I L S approach oh 8 right auf wiedersehen | |
| MITRE Ontology Word-Level | eurowings uh one three niner alfa cleared i l s approach oh eight right auf wiedersehen | |
| European Ontology Word-Level | euro wings [hes] one three nine alfa cleared ILS approach [spk] O eight right [NE German] auf wiedersehen [/NE] | |
| Controller Transmission | november three mike victor cleared I L S runway two one approach | |
| SLUS | Callsign: {N, 3MV, GA}, Cleared: {21, ILS} | |
| SLEU | N123MV (CLEARED ILS) 21 | |
| Callsign and Unit Inference | fedex five eighty two heavy maintain four thousand three hundred | |
| SLUS | Callsign: {FDX, 582, H, Commercial}, Maintain: {Feet, 4300} | |
| SLEU | FDX482 (MAINTAIN ALTITUDE) 4300 none | |
| Transmission with Multiple Commands | good day american seven twenty six descend three thousand feet turn right heading three four zero | |
| SLUS | Callsign: {AAL, 726, Commercial}, Courtesy, Descend: {3000, Feet}, TurnRight: {340, Heading} | |
| SLEU | AAL726 GREETING, AAL726 DESCEND 3000 ft, AAL726 HEADING 340 RIGHT | |
| Transmissions without Callsign | fly zero four zero cleared I L S approach | |
| SLUS | Fly: {040, Heading}, Cleared: {ILS} | |
| SLEU | NO_CALLSIGN HEADING 040 none, NO_CALLSIGN (CLEARED ILS) none | |
| lufthansa one two charlie go ahead | ||
| SLUS | Callsign: {DLH, 12C, Commercial} | |
| SLEU | DLH12C NO_CONCEPT | |
| Transmissions with more than one Callsign | lufthansa six alfa charlie descend one eight zero break break speed bird six nine one turn right heading zero nine five cleared I L S runway three four right | |
| SLUS | Callsign: {DLH, 6AC, Commercial}, Descend: {180, FL}, Callsign: {BAW, 691, Commercial}, TurnRight: {95, Heading} Cleared: {34R, ILS} | |
| SLEU | DLH6AC DESCEND 180 none, BAW691 HEADING 095 RIGHT, BAW691 (CLEARED ILS) 34R | |
| stand by first speed bird sixty nine thirteen turn right by ten degrees | ||
| SLUS | Callsign: {BAW, 6913, Commercial}, TurnRight: {10, Degrees} | |
| SLEU | NO_CALLSIGN CALL_YOU_BACK, BAW6913 TURN_BY 10 RIGHT | |
| Altitude with Limiting Condition | maintain four thousand feet until established | |
| SLUS | Maintain: {4000, Feet} | |
| SLEU | (MAINTAIN ALTITUDE) 4000 ft (UNTIL ESTABLISHED) | |
| Instructions with Position-Based Conditions | at dart two you are cleared I L S runway two one left | |
| SLUS | Cleared: {21L, ILS} | |
| SLEU | NO_CALLSIGN (CLEARED ILS) 21L (WHEN PASSING DART2) | |
| leaving baggins descend and maintain one four thousand feet | ||
| SLUS | Descend: {14,000, Feet} | |
| SLEU | NO_CALLSIGN DESCEND 14,000 ft (WHEN PASSING BGGNS) | |
| Instructions with Advisories | maintain two fifty knots for traffic | |
| SLUS | Maintain: {250, Knots, for traffic} | |
| SLEU | NO_CALLSIGN (MAINTAIN SPEED) 250 kt, NO_CALLSIGN (INFORMATION TRAFFIC) none | |
| traffic twelve o’clock two miles same direction and let’s see the helicopter | ||
| SLUS | Traffic: {Distance: 2, OClock: 12, TrafficType: helicopter} | |
| SLEU | NO_CALLSIGN (INFORMATION TRAFFIC) | |
| caution wake turbulence one zero miles in trail of a heavy boeing seven eighty seven we’ll be going into this [unk] | ||
| SLUS | Wake: () | |
| SLEU | (CAUTION WAKE_TURBULENCE) | |
| Pilot Transmission as Readback | descend flight level one seven zero silver speed | |
| SLUS | Descend: {170, FL} | |
| SLEU | NO_CALLSIGN PILOT DESCEND 170 FL | |
| Pilot Transmission as Report | speed bird two one alfa flight level two one two descend flight level one seven zero inbound dexon | |
| SLUS | Callsign: {BAW, 21A, Commercial} Descend: {170, FL} | |
| SLEU | BAW21A PILOT REP ALTITUDE 212 FL BAW21A PILOT REP DESCEND 170 FL BAW21A PILOT REP DIRECT_TO DEXON none | |
| Correction of Instruction | speed bird one one descend level six correction altitude six thousand feet | |
| SLUS | Callsign: {BAW, 11, Commercial}, Descend: {6000, Feet}, | |
| SLEU | BAW11 CORRECTION BAW11 DESCEND 6000 ft | |
| speed bird one one descend level six correction six thousand feet disregard turn left heading three two five degrees | ||
| SLUS | Callsign: {BAW, 11, Commercial} Descend: {6000, Feet} TurnLeft: {325, Heading} | |
| SLEU | BAW11 DISREGARD BAW11 HEADING 325 LEFT | |
| Type of Semantic Comparison | Overlap of Concepts |
|---|---|
| Concept present in both ontologies before adaptation | 82% |
| Corresponding concept after small adjustments | 95% |
| Achievable match with existing model structures | 100% |
| Ground Truth Transcript | Automatically Transcribed Text | |
|---|---|---|
| Example 1 | good day american seven twenty six descend three thousand feet turn right heading three four zero | good day american seven twenty six descend four thousand feet turn right heading three zero |
| Example 2 | cleared ILS three four | cleared i l s three five |
| Name | Definition |
|---|---|
| True Positive (TP) | TP is the total number of True Positives: The concept is present and correctly and fully (including all subcomponents) detected |
| False Positive (FP) | FP is the total number of False Positives: The concept is incorrectly detected, i.e., either the concept is not present at all or one or more of its subcomponents are incorrect |
| True Negative (TN) | TN is the total number of True Negatives: The concept is correctly not detected |
| False Negative (FN) | FN is the total number of False Negatives: A concept is not detected when it should have been |
| Total (TA) | TA is the total number of annotated transcripts, i.e., the number of gold transcripts |
| Name | Definition |
|---|---|
| Recall | |
| Precision | |
| Accuracy | |
| F1-Score | |
| Fα-Score | |
| Command Recognition Rate (RcR) | |
| Command Recognition Error Rate (CRER) | |
| Command Rejection Rate (RjR) |
| Ground Truth Semantics | Translated Semantics |
|---|---|
| AAL726 GREETING, AAL726 DESCEND 3000 ft, AAL726 HEADING 340 RIGHT | AAL726 GREETING, AAL726 DESCEND, AAL726 HEADING 340 RIGHT |
| Name | Definition | Example |
|---|---|---|
| Recall | 2/(2 + 0) | 100% |
| Precision | 2/(2 + 1) | 66% |
| Accuracy | (2 + 0)/(2 + 0 + 1 + 0) | 66% |
| F1-Score | 50% | |
| Command Recognition Rate (RcR) | (2 + 0)/3 | 66% |
| Command Recognition Error Rate (CRER) | 1/3 | 33% |
| Command Rejection Rate (RjR) | 0/3 | 0% |
| Applications 1 | CROD | WSOD | ACUA | PRLA | MRT | SMGCS | WLP | CPDLC | PWR | VFR | SPA | SPET | RB-E | RB-T |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Command-Type Categories | Closed Runway Operation Detection | Wrong Surface Operations Detection | Approach Clearance Usage Analysis | Prefilling Radar Labels—Approach | Multiple Remote Tower Operations | Integration with A-SMGCS—Apron | Workload Prediction in London TMA | Integration with CPDLC | Pilot Weather Reports | Use of Visual Separation | Simulation Pilot—Apron | Simulation Pilot—Enroute Training | Readback Error Detection—Enroute | Readback Error Detection—Tower |
| Acknowledgement | X | X | ||||||||||||
| Airspace Usage Clearance | X | X | ||||||||||||
| Altimeter/QNH Advisory | X | X | X | X | ||||||||||
| Altitude Change | X | X | X | X | X | X | ||||||||
| Vertical Speed Instruction | X | X | X | X | X | |||||||||
| Attention All Aircraft | X | |||||||||||||
| Callsign | X | X | X | X | X | X | X | X | X | X | X | X | X | |
| Cancel Clearance | X | |||||||||||||
| Correction/Disregard | X | X | X | X | X | X | X | |||||||
| Courtesy | X | |||||||||||||
| Future Clearance Advisory | X | X | ||||||||||||
| Heading | X | X | X | X | X | |||||||||
| Holding | X | X | X | X | X | X | ||||||||
| Information (Wind, Traffic) | X | X | X | |||||||||||
| Maintain Visual Separation | X | |||||||||||||
| Pilot Report | X | X | ||||||||||||
| Procedure Clearance | X | X | X | X | X | |||||||||
| Radar Advisory | X | X | ||||||||||||
| Radio Transfer | X | X | X | X | X | X | X | X | ||||||
| Reporting Instruction | X | X | X | X | X | X | X | |||||||
| Routing Clearance | X | X | X | X | X | |||||||||
| Runway Use Clearance | X | X | X | X | X | X | X | |||||||
| Speed Clearance | X | X | X | X | ||||||||||
| Squawk | X | X | X | |||||||||||
| Taxi/Ground Clearance | X | X | X | |||||||||||
| Traffic Advisory | X | X | X | |||||||||||
| Verify/Confirm | X | X | X | X |
| WER | Total | TP | FP | FN | TN | RcR | RER | RjR | Prc | Rec | Acc | F-1 | F-2 | F-0.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0% | 17,096 | 16,933 | 71 | 94 | 11 | 99.1% | 0.4% | 0.5% | 99.6% | 99.4% | 99.0% | 99.5% | 99.5% | 99.6% |
| 3.1% | 17,096 | 15,869 | 368 | 920 | 10 | 92.9% | 2.2% | 5.4% | 97.7% | 94.5% | 92.5% | 96.1% | 95.1% | 97.1% |
| Ground Truth | Detection | Encoding | |||
|---|---|---|---|---|---|
| 168 | PIREP | 161 | Correct detection | 79 | Correct final PIREP |
| 34 | Incorrect discard—callsign not spoken | ||||
| 8 | Incorrect discard—callsign not detected | ||||
| 26 | Incorrect final PIREP—missed details | ||||
| 14 | Incorrect final PIREP—incorrect flight | ||||
| 7 | Missed detection | ||||
| 96 | Not PIREP | 79 | Correct rejection | ||
| 17 | False detection | ||||
| Vienna Approach | Frankfurt Apron Control | ||||
|---|---|---|---|---|---|
| Word | # Spoken | Freq | Word | # Spoken | Freq |
| two | 8841 | 7.4% | one | 11,724 | 9.3% |
| one | 8128 | 6.8% | november | 7713 | 6.1% |
| zero | 7576 | 6.4% | five | 7100 | 5.6% |
| four | 5805 | 4.9% | two | 5520 | 4.4% |
| three | 5624 | 4.7% | lufthansa | 4994 | 4.0% |
| eight | 5422 | 4.6% | eight | 4939 | 3.9% |
| austrian | 4979 | 4.2% | lima | 4002 | 3.2% |
| six | 4295 | 3.6% | seven | 3882 | 3.1% |
| seven | 4028 | 3.4% | four | 3769 | 3.0% |
| descend | 3909 | 3.3% | hold | 3513 | 2.8% |
| London TMA | Isavia ANS Enroute Traffic | ||||
|---|---|---|---|---|---|
| Word | # Spoken | Freq | Word | # Spoken | Freq |
| one | 7599 | 7.4% | one | 4371 | 5.9% |
| zero | 6284 | 6.1% | zero | 3849 | 5.2% |
| five | 5191 | 5.0% | three | 3255 | 4.4% |
| two | 5019 | 4.9% | five | 3230 | 4.4% |
| seven | 3702 | 3.6% | seven | 3064 | 4.1% |
| speed | 3677 | 3.6% | two | 2830 | 3.8% |
| three | 3536 | 3.4% | six | 2436 | 3.3% |
| six | 3198 | 3.1% | reykjavik | 2202 | 3.0% |
| four | 3113 | 3.0% | nine | 2057 | 2.8% |
| eight | 2965 | 2.9% | four | 1962 | 2.7% |
| Word | # Spoken | Freq |
|---|---|---|
| one | 31,822 | 7.6% |
| two | 22,210 | 5.3% |
| zero | 19,378 | 4.6% |
| five | 19,266 | 4.6% |
| three | 15,346 | 3.7% |
| eight | 15,085 | 3.6% |
| seven | 14,676 | 3.5% |
| four | 14,649 | 3.5% |
| six | 13,313 | 3.2% |
| nine | 9998 | 2.4% |
| Vienna | Frankfurt | NATS | Isavia | All | |
|---|---|---|---|---|---|
| Number of Words | 118,794 | 125,810 | 102,952 | 73,980 | 421,536 |
| Spoken >4 times | 179 | 291 | 497 | 583 | 931 |
| Words for 95% | 62 | 110 | 205 | 322 | 256 |
| Words for 99% | 112 | 203 | 432 | 754 | 619 |
| Words for 100% | 347 | 520 | 899 | 1375 | 1972 |
| From Corpus Partition of 99,513 Transmissions/1,248,436 Words | |||
|---|---|---|---|
| Unique Words | Cumulative Word Count Percentage | ||
| Spoken >1 time | 4471 | 1st 50 words | 60% |
| Spoken >4 times | 2640 | 1st 100 words | 74% |
| Words for 95% | 542 | 1st 150 words | 81% |
| Words for 99% | 1884 | 1st 500 words | 94% |
| Words for 100% | 7236 | 1st 1000 words | 98% |
| Word | # Spoken | Freq | Additional Information |
|---|---|---|---|
| one | 56,298 | 4.5% | |
| two | 54,376 | 4.4% | |
| three, tree | 45,112 | 3.6% | tree: 167 |
| zero, oh | 43,584 | 3.5% | oh: 3168 |
| five, fife | 32,038 | 2.6% | fife: 1 |
| four | 31,035 | 2.5% | |
| seven | 27,466 | 2.2% | |
| six | 26,410 | 2.1% | |
| eight | 22,324 | 1.8% | |
| nine, niner | 21,901 | 1.8% | niner: 7193 |
| All | 360,544 | 29.0% |
| MITRE | DLR | ||||
|---|---|---|---|---|---|
| Word | Numerical Value | # Spoken | Freq | # Spoken | Freq |
| ten | 10 | 4033 | 0.3% | 270 | 0.1% |
| eleven | 11 | 2788 | 0.2% | 8 | 0.0% |
| twelve | 12 | 3185 | 0.3% | 5 | 0.0% |
| thirteen | 13 | 1810 | 0.1% | 2 | 0.0% |
| fourteen | 14 | 2274 | 0.2% | 4 | 0.0% |
| fifteen | 15 | 2671 | 0.2% | 13 | 0.0% |
| sixteen | 16 | 2224 | 0.2% | 5 | 0.0% |
| seventeen | 17 | 2085 | 0.2% | 3 | 0.0% |
| eighteen | 18 | 2251 | 0.2% | 62 | 0.0% |
| nineteen | 19 | 2404 | 0.2% | 327 | 0.1% |
| twenty | 20 | 17,323 | 1.4% | 972 | 0.2% |
| thirty | 30 | 14,773 | 1.2% | 101 | 0.0% |
| forty | 40 | 11,961 | 1.0% | 45 | 0.0% |
| fifty | 50 | 11,327 | 0.9% | 201 | 0.0% |
| sixty | 60 | 7907 | 0.6% | 286 | 0.1% |
| seventy | 70 | 6882 | 0.6% | 14 | 0.0% |
| eighty | 80 | 7339 | 0.6% | 317 | 0.1% |
| ninety | 90 | 6401 | 0.5% | 21 | 0.0% |
| hundred | 100 | 4726 | 0.4% | 1329 | 0.3% |
| thousand | 1000 | 13,732 | 1.1% | 5019 | 1.2% |
| All | 128,096 | 10.3% | 9004 | 2.1% | |
| Meaning Category | Definition | Examples | # Spoken | Percentage of Corpus Words | Percentage of Vocabulary |
|---|---|---|---|---|---|
| Other | climb, fly, contact, thanks, until | 527,579 | 42.3% | 4.78% | |
| Numeric | Digits, other numbers, number modifiers | zero, ten, hundred, triple, point | 498,066 | 39.9% | 0.51% |
| Callsign Words | Airline names, aircraft types, air service types | United, Cessna, Medevac | 56,265 | 4.5% | 0.90% |
| Phonetic Alphabet | Phonetic alphabet words | Bravo, Charlie, Zulu | 48,077 | 3.9% | 0.39% |
| Place Names | ATC facilities and airport names | Atlanta, Reno | 21,958 | 1.8% | 0.50% |
| Initials | Letters, e.g., “i l s” | V, O, R, J, F, K, D, F | 16,543 | 1.3% | 0.35% |
| Filler Words | Words that fill up space but do not add substance | uh, um | 10,356 | 0.8% | 0.03% |
| Multiple Meanings | Words that can be all or part of airline names, airport names, or general-purpose words | Sky, Midway, Wisconsin | 7084 | 0.6% | 0.12% |
| Waypoint Names | Named fixes and waypoints | SAILZ, KEEEL, HUNTR, KARLA | 706 | 0.1% | 0.04% |
| Total | 1,186,634 | 95.0% | 7.61% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Helmke, H.; Tarakan, R.M.; Ohneiser, O.; Kopald, H.; Kleinert, M. Effects of Language Ontology on Transatlantic Automatic Speech Understanding Research Collaboration in the Air Traffic Management Domain. Aerospace 2023, 10, 526. https://doi.org/10.3390/aerospace10060526
Chen S, Helmke H, Tarakan RM, Ohneiser O, Kopald H, Kleinert M. Effects of Language Ontology on Transatlantic Automatic Speech Understanding Research Collaboration in the Air Traffic Management Domain. Aerospace. 2023; 10(6):526. https://doi.org/10.3390/aerospace10060526
Chicago/Turabian StyleChen, Shuo, Hartmut Helmke, Robert M. Tarakan, Oliver Ohneiser, Hunter Kopald, and Matthias Kleinert. 2023. "Effects of Language Ontology on Transatlantic Automatic Speech Understanding Research Collaboration in the Air Traffic Management Domain" Aerospace 10, no. 6: 526. https://doi.org/10.3390/aerospace10060526
APA StyleChen, S., Helmke, H., Tarakan, R. M., Ohneiser, O., Kopald, H., & Kleinert, M. (2023). Effects of Language Ontology on Transatlantic Automatic Speech Understanding Research Collaboration in the Air Traffic Management Domain. Aerospace, 10(6), 526. https://doi.org/10.3390/aerospace10060526