
Semiparametric Estimation of a Corporate Bond Rating Model

Abstract
1. Introduction
2. Data and Variable Construction
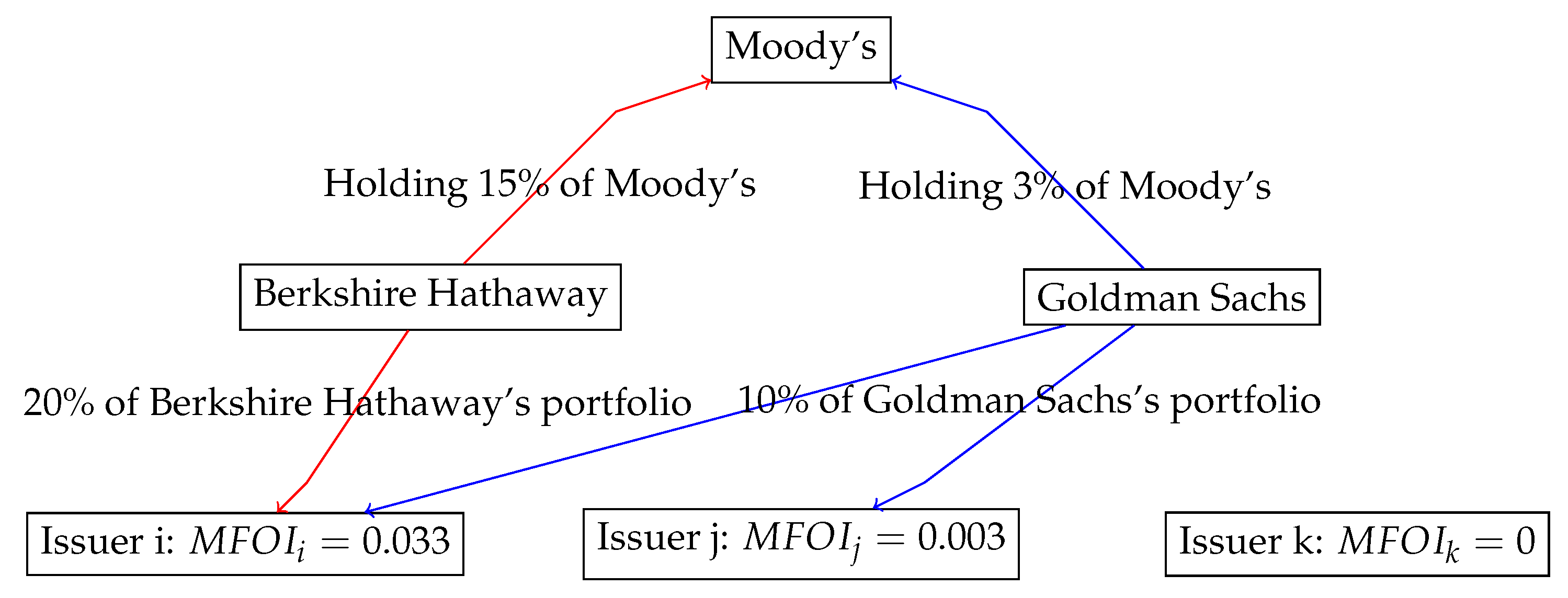
Measuring Conflicts of Interest
3. Empirical Model
3.1. Model and Motivation for the Estimator
3.2. Estimation Strategy
4. Results
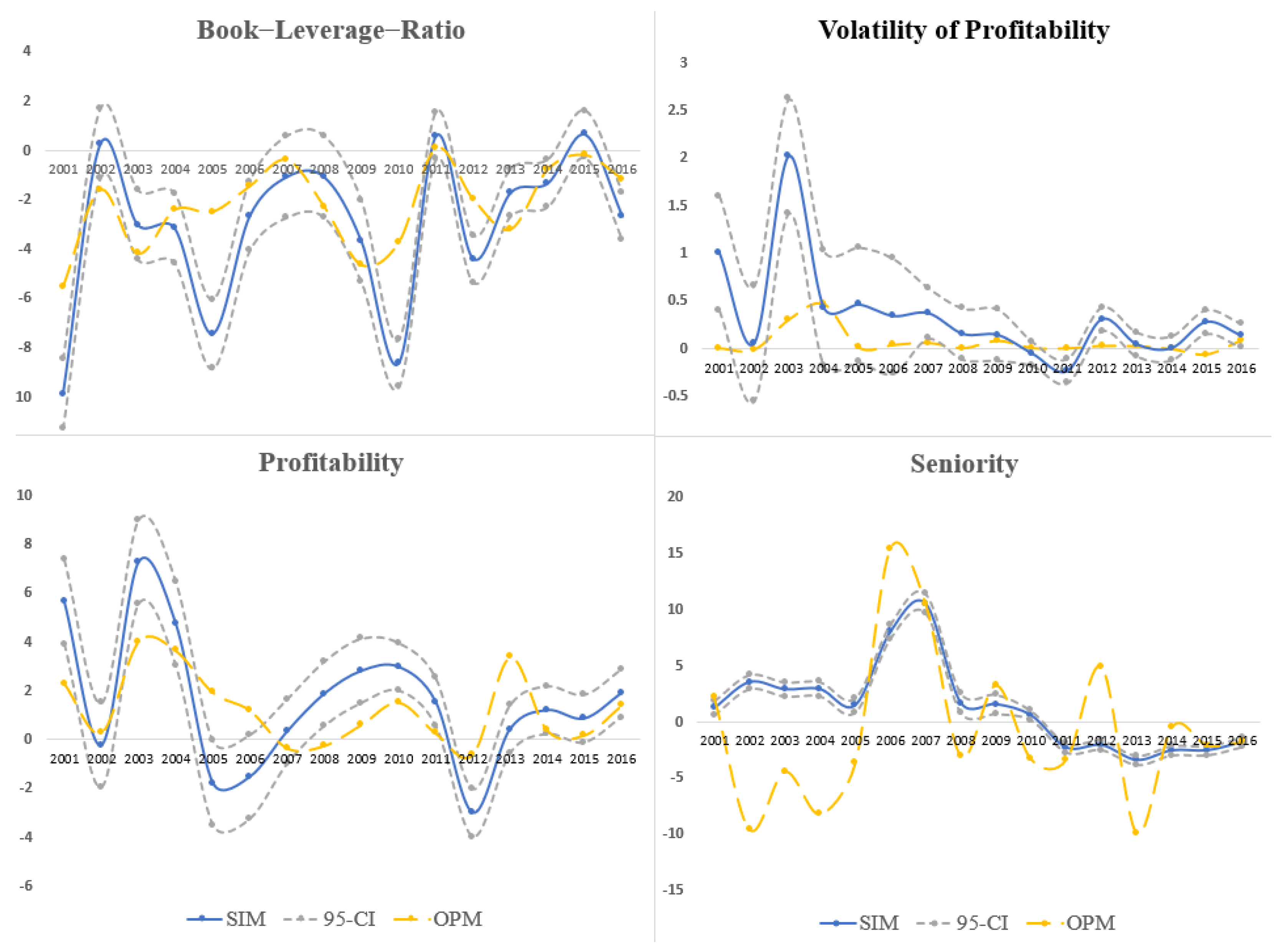
4.1. Simulation Evidence
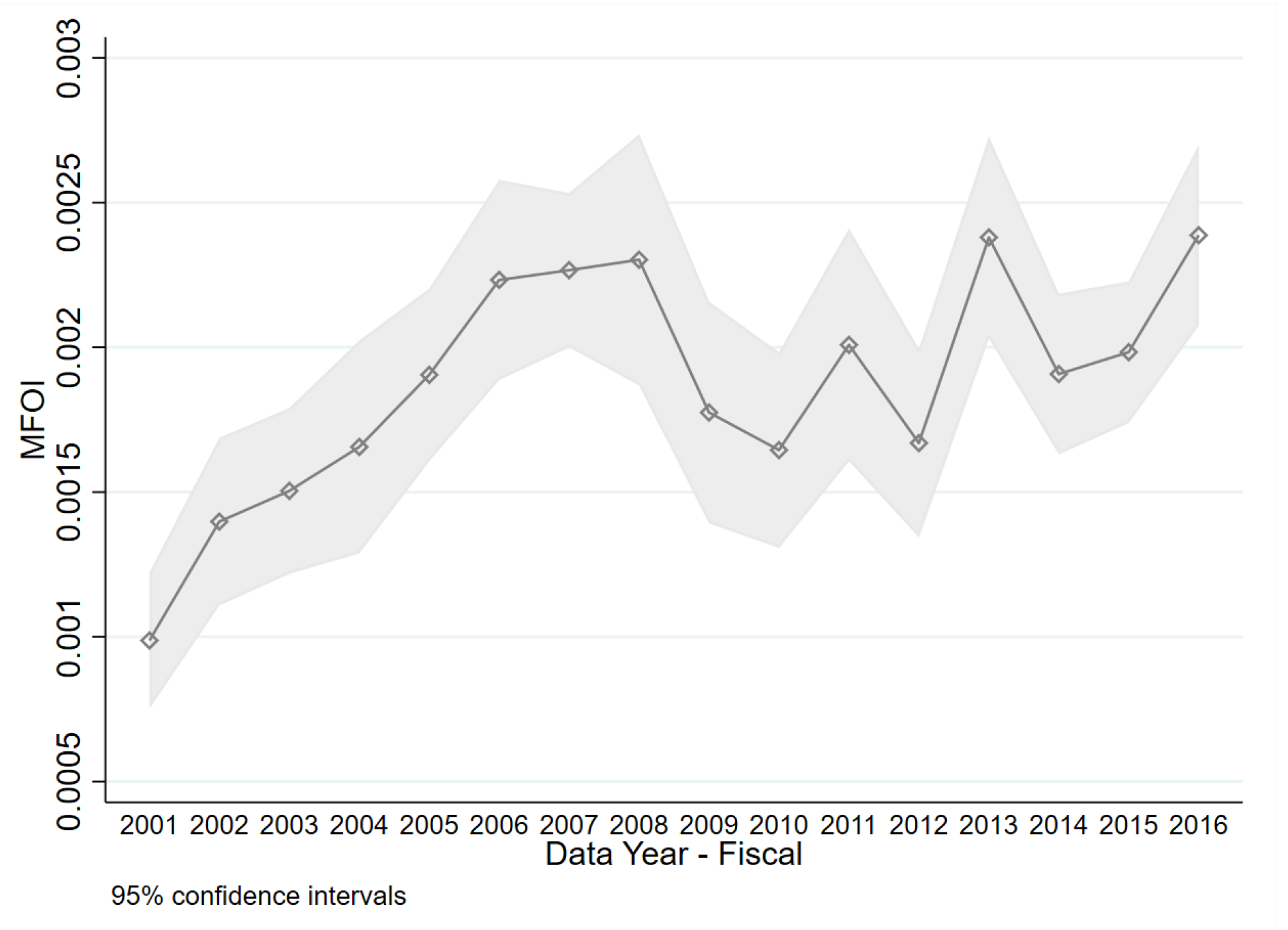
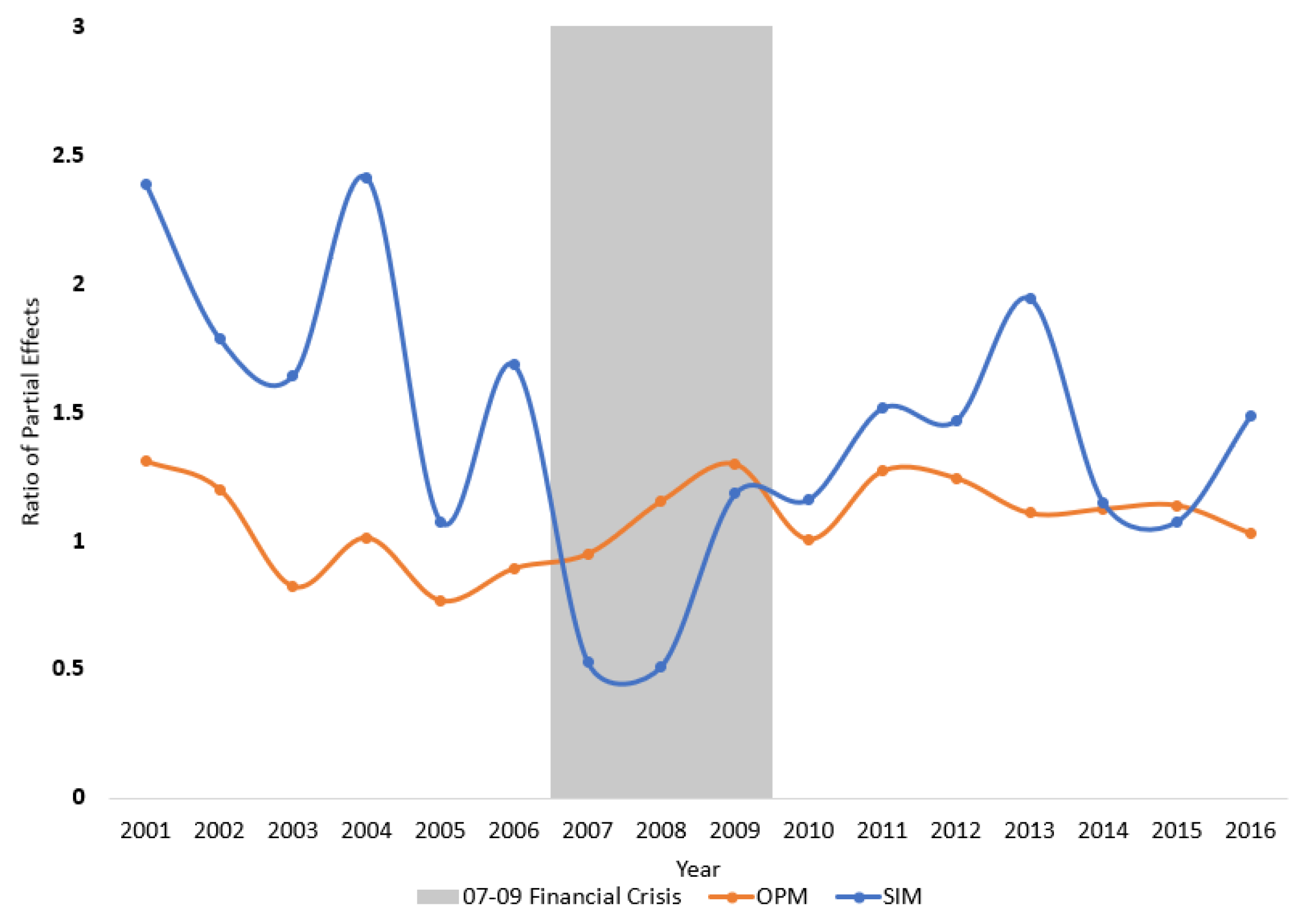
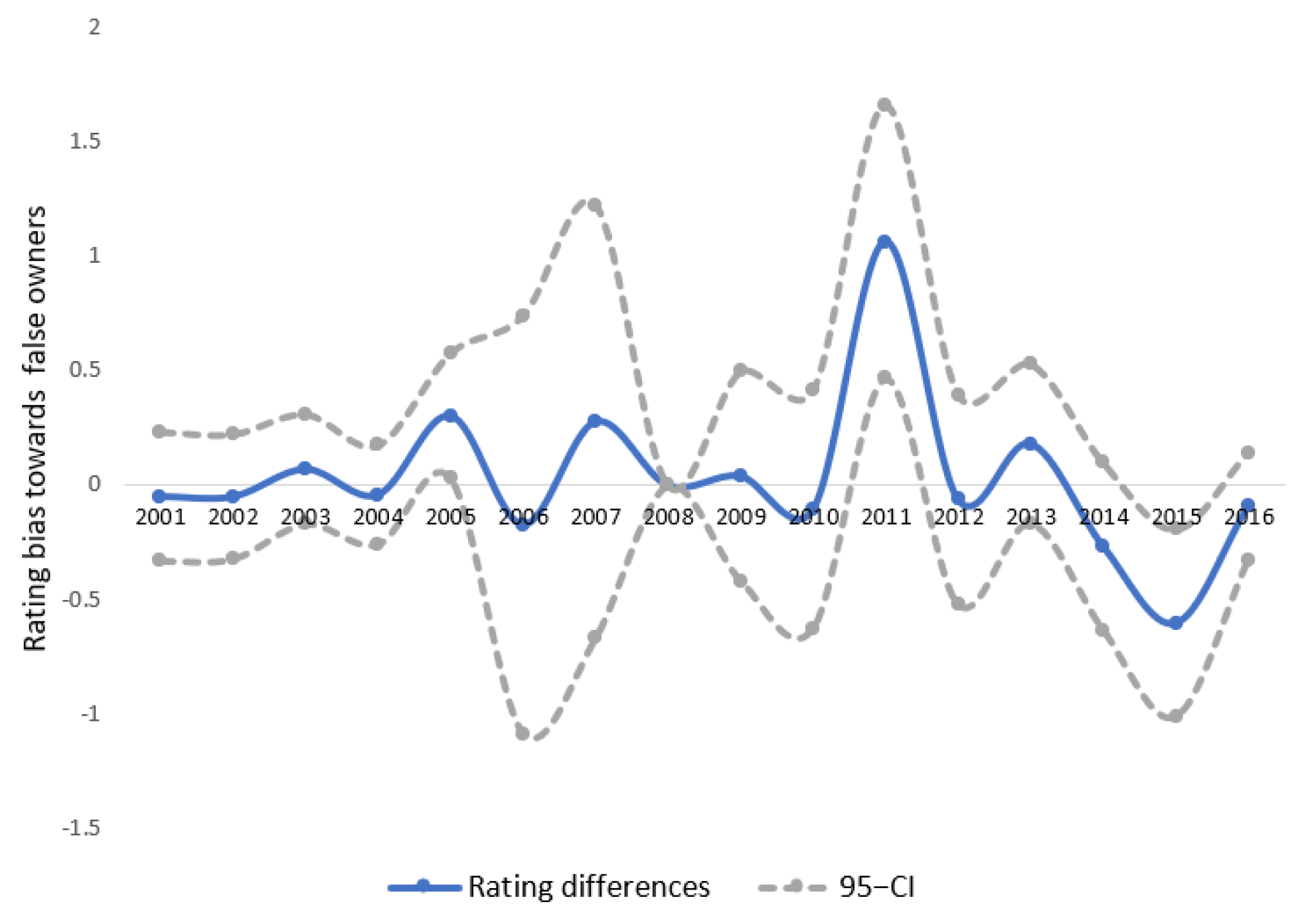
4.2. Empirical Illustration: Estimating Moody’s Rating Bias from 2001–2016
4.3. A Placebo Test for Rating Bias
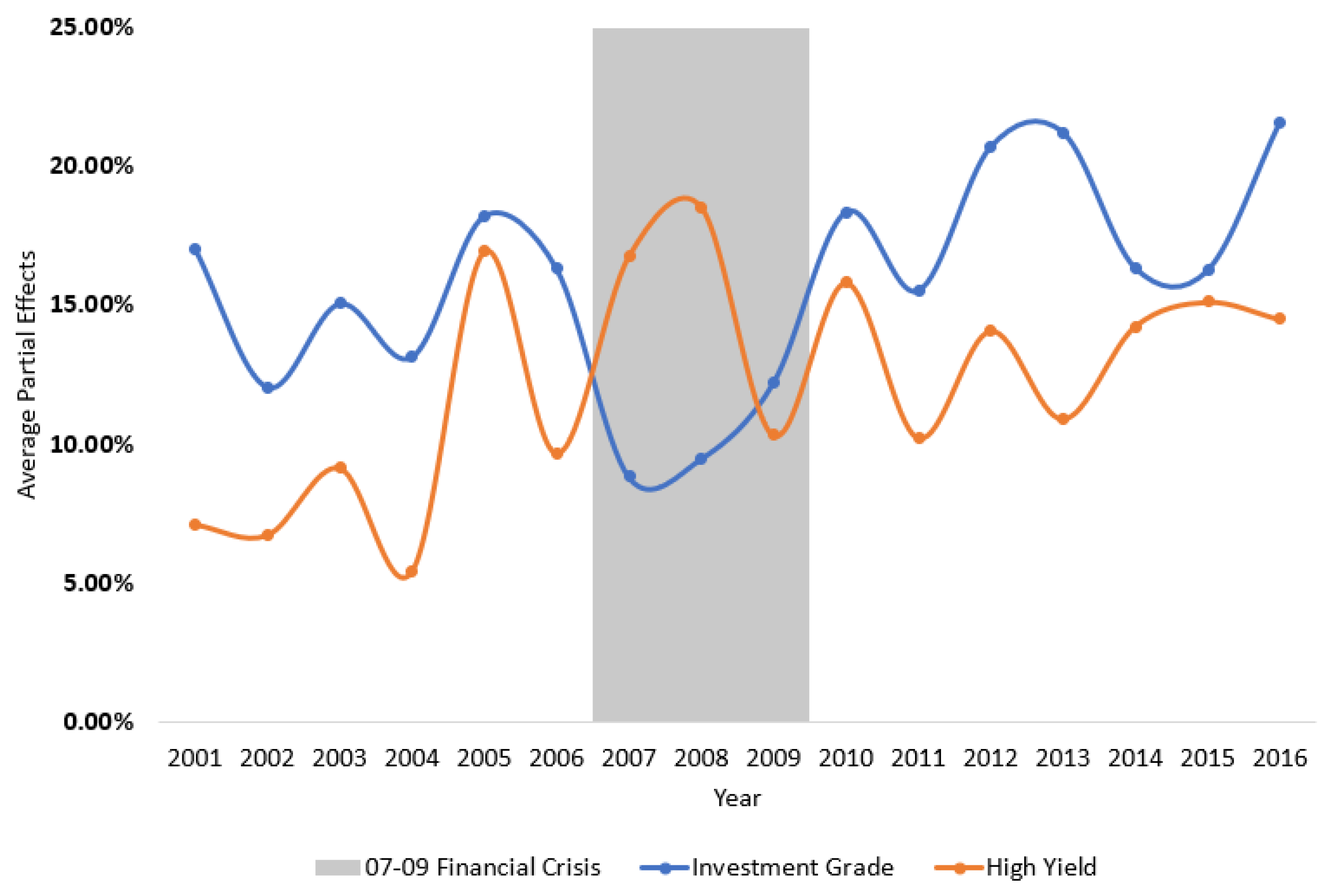
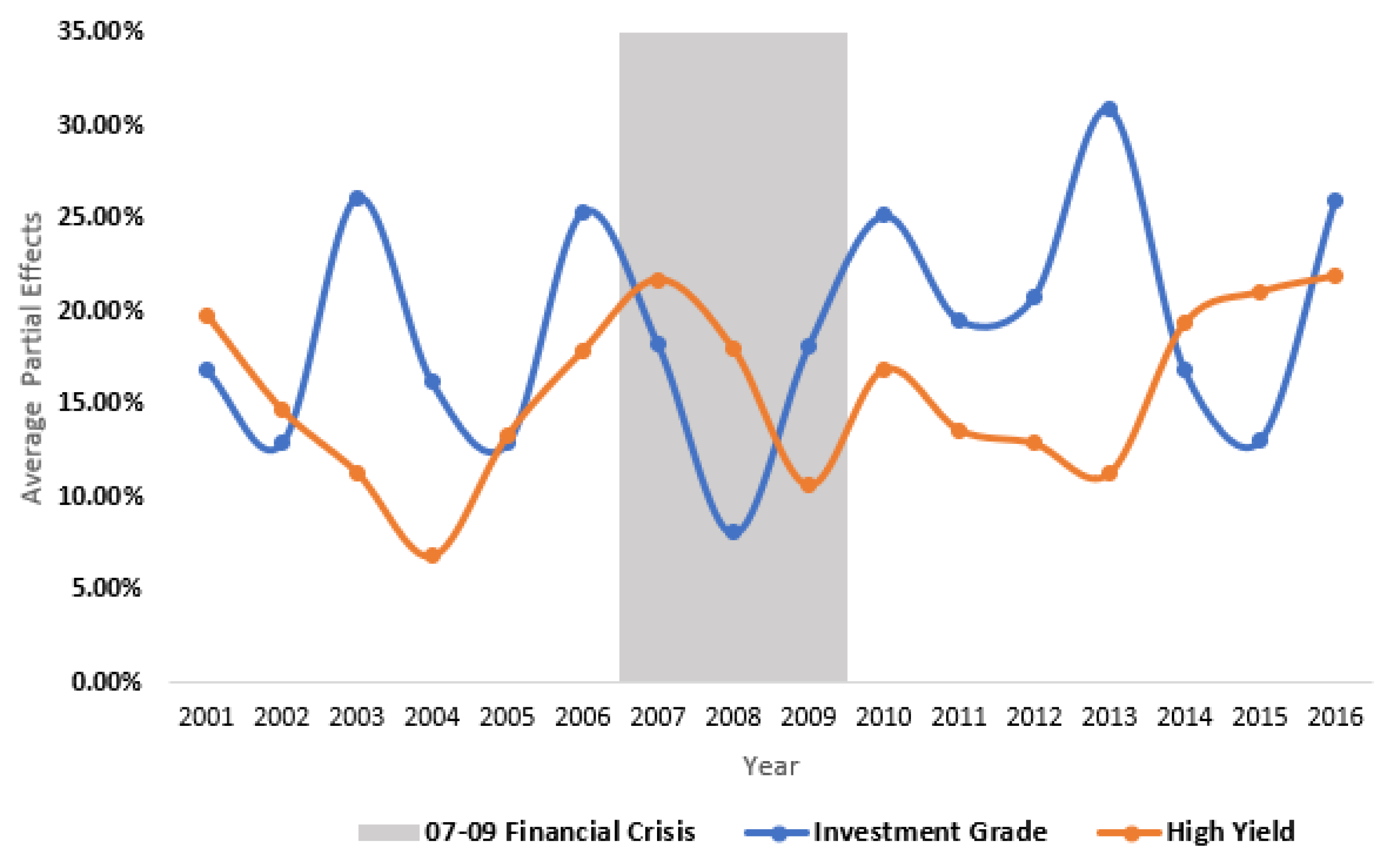
4.4. Bias in Issuer Ratings
5. Conclusions
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CRA | Credit Rating Agency |
| MFOI | Moody-Firm-Ownership-Index, defined in Equation (1) |
| OPM | Ordered-Probit Model |
| SIM-M | Semiparametric multiple-index model with kernel (this paper) |
| SIM-1 | Semiparametric single-index model (Klein and Sherman 2002) |
Appendix A. Definitions and Assumptions
Appendix B. Asymptotic Theorems
| 1. | For theoretical studies on the issuer-paid model and rating shopping, see Bolton et al. (2012); Sangiorgi et al. (2009); Skreta and Veldkamp (2009) and some empirical evidence (He et al. 2015; Jiang et al. 2012; Mathis et al. 2009). |
| 2. | Extensive literature addresses semiparametric models and the estimation of semiparametric single index models, including Härdle and Stoker (1989); Horowitz and Härdle (1996); Ichimura (1993); Klein and Spady (1993); Manski (1985); Powell et al. (1989). See Stewart (2005), Lewbel (2000), and Klein and Sherman (2002) for applications of a single-index model in the context of an ordered-response model. |
| 3. | Alternatively, one may also use the sieves method to estimate the rating probability. Such methods are more convenient when some prior information and constraints, such as monotonicity, additivity, and nonnegativity, needs to be incorporated in the conditional probabilities (Chen 2007). For instance, Coppejans (2007) estimates an ordered model with a quadratic-spline under the restriction that the distribution functions across all categories are the same. Such a constraint, however, is not appropriate in the current application because Moody’s rating standard can vary with categories. |
| 4. | Macro variables are not included because the model will be estimated separately for each year. |
| 5. | Moody’s was founded as a private company in 1900, acquired by Dun&Bradstreet (D&B) in 1962, and remained one of its divisions until 4 October 2000, when it was spun off and listed on the NYSE. The S&P has been a fully owned division of McGraw-Hill, a publicly traded company, since 1966. Going public makes CRAs more vulnerable to conflicts of interest. For example, Kedia et al. (2017) found that Moody’s assigned favorable ratings toward issuers that Moody’s shareholders have invested in. |
| 6. | From 2001 to 2010, Moody’s had two shareholders, Berkshire Hathaway and Davis Selected Advisors, which collectively own about 23.5% of Moody’s. |
| 7. | The numerical rating matches the seven ordinal rating categories: , and (from the highest credit quality to the lowest). |
| 8. | The vector is assumed to be exogenous throughout. Intuitively, and as one might have expected, some information contained in S, e.g., the manager’s ability, may also drive institutional investors’ investment decisions, implying that is endogenous. The problem of endogeneity can be handled, for example, using the control function approach proposed by Blundell and Powell (2004) provided with a valid exclusion restriction. |
| 9. | Specifically, the rating probability in an ordered-probit model is
|
| 10. | Since the functional form of in (6) is not specified, conditioning on the original index and a linear transformation of them deliver the same amount information on ratings. Therefore, without some normalization, the limiting log-likelihood function cannot be uniquely maximized at the true parameters, which is necessary for identification. |
| 11. | More specifically, u is generated from a distribution, standardized to have a mean of zero and unit variance. , and is a standardized . |
| 12. | Confidence Intervals were constructed based on the asymptotic results derived in Appendix B. |
| 13. | The partial effects for MFOI in the ordered-response model are,
The Average Partial Effect, or APE, is computed by evaluating the partial effect for each bond i and averaging the computed effects,
The above calculation can be performed for any category. That is, even for a C-rated bond, one can compute the change in the probability of this bond being rated into AAA. To make the presentation concise and practically relevant, I only report the APE for the category that is one-notch better than the current rating grade. That is, I interpret the APE as the probabilistic change of obtaining a better rating grade if the issuer’s share-ownership relationship with Moody’s strengthens by . |
| 14. | This implies that the CRA will be “punished” once a highly rated investment results in default. See Bolton et al. (2012) for a discussion. |
| 15. | The suggested trimming rule is indeed ad-hoc because the selected threshold may be bad for other DGP. The asymptotic theorems developed later abstracts away from the trimming issue. It is possible to develop a data-dependent optimal trimming rule similar to Ma and Wang (2019), which is left for future work. |
| 16. |
References
- Abrevaya, Jason, Yu-Chin Hsu, and Robert Lieli. 2015. Estimating conditional average treatment effects. Journal of Business & Economic Statistics 33: 485–505. [Google Scholar]
- Ahn, Hyungtaik, Hidehiko Ichimura, James L. Powell, and Paul A. Ruud. 2017. Simple estimators for invertible index models. Journal of Business & Economic Statistics 36: 1–10. [Google Scholar]
- Amemiya, Takeshi. 1981. Qualitative response models: A survey. Journal of Economic Literature 19: 1483–536. [Google Scholar]
- Baghai, Ramin P., Henri Servaes, and Ane Tamayo. 2014. Have rating agencies become more conservative? Implications for capital structure and debt pricing. The Journal of Finance 69: 1961–2005. [Google Scholar] [CrossRef]
- Becker, Bo, and Todd Milbourn. 2011. How did increased competition affect credit ratings? Journal of Financial Economics 101: 493–514. [Google Scholar] [CrossRef]
- Blundell, Richard W., and James L. Powell. 2004. Endogeneity in semiparametric binary response models. The Review of Economic Studies 71: 655–79. [Google Scholar] [CrossRef]
- Bolton, Patrick, Xavier Freixas, and Joel Shapiro. 2012. The credit ratings game. The Journal of Finance 67: 85–111. [Google Scholar] [CrossRef]
- Chen, Xiaohong. 2007. Large sample sieve estimation of semi-nonparametric models. In Handbook of Econometrics. Amsterdam: Elsevier BV, vol. 6, pp. 5549–632. [Google Scholar]
- Coppejans, Mark. 2007. On efficient estimation of the ordered response model. Journal of Econometrics 137: 577–614. [Google Scholar] [CrossRef]
- Donkers, Bas, and Marcia Schafgans. 2008. Specification and estimation of semiparametric multiple-index models. Econometric Theory 24: 1584–606. [Google Scholar] [CrossRef]
- Griffin, John M., and Dragon Yongjun Tang. 2012. Did subjectivity play a role in cdo credit ratings? The Journal of Finance 67: 1293–328. [Google Scholar] [CrossRef]
- Härdle, Wolfgang, and Thomas M. Stoker. 1989. Investigating smooth multiple regression by the method of average derivatives. Journal of the American Statistical Association 84: 986–95. [Google Scholar] [CrossRef]
- He, Jie, Jun Qian, and Philip E. Strahan. 2015. Does the market understand rating shopping? predicting mbs losses with initial yields. The Review of Financial Studies 29: 457–85. [Google Scholar] [CrossRef]
- Horowitz, Joel L. 1998. Semiparametric Methods in Econometrics: Lecture Notes in Statistics. New York: Springer Science & Business Media, vol. 131. [Google Scholar]
- Horowitz, Joel L., and Wolfgang Härdle. 1996. Direct semiparametric estimation of single-index models with discrete covariates. Journal of the American Statistical Association 91: 1632–40. [Google Scholar] [CrossRef]
- Ichimura, Hidehiko. 1993. Semiparametric least squares (sls) and weighted sls estimation of single-index models. Journal of Econometrics 58: 71–120. [Google Scholar] [CrossRef]
- Ichimura, Hidehiko, and Lung-Fei Lee. 1991. Semiparametric least squares estimation of multiple index models: Single equation estimation. In Nonparametric and Semiparametric Methods in Econometrics and Statistics. Paper presented at Fifth International Symposium in Economic Theory and Econometrics, Cambridge, UK, July 26; pp. 3–49. [Google Scholar]
- Jiang, John Xuefeng, Mary Harris Stanford, and Yuan Xie. 2012. Does it matter who pays for bond ratings? Historical evidence. Journal of Financial Economics 105: 607–21. [Google Scholar] [CrossRef]
- Kedia, Simi, Shivaram Rajgopal, and Xing Zhou. 2016. Large shareholders and credit ratings. Journal of Financial Economics 124: 632–53. [Google Scholar] [CrossRef]
- Klein, Roger, and Chan Shen. 2010. Bias corrections in testing and estimating semiparametric, single index models. Econometric Theory 26: 1683–718. [Google Scholar] [CrossRef]
- Klein, Roger W., and Robert P. Sherman. 2002. Shift restrictions and semiparametric estimation in ordered response models. Econometrica 70: 663–91. [Google Scholar] [CrossRef]
- Klein, Roger W., and Richard H. Spady. 1993. An efficient semiparametric estimator for binary response models. Econometrica: Journal of the Econometric Society 61: 387–421. [Google Scholar] [CrossRef]
- Lewbel, Arthur. 2000. Semiparametric qualitative response model estimation with unknown heteroscedasticity or instrumental variables. Journal of Econometrics 97: 145–77. [Google Scholar] [CrossRef]
- Ma, Xinwei, and Jingshen Wang. 2019. Robust inference using inverse probability weighting. Journal of the American Statistical Association 115: 1–10. [Google Scholar] [CrossRef]
- Manski, Charles F. 1985. Semiparametric analysis of discrete response: Asymptotic properties of the maximum score estimator. Journal of Econometrics 27: 313–33. [Google Scholar] [CrossRef]
- Mathis, Jerome, James McAndrews, and Jean-Charles Rochet. 2009. Rating the raters: Are reputation concerns powerful enough to discipline rating agencies? Journal of Monetary Economics 56: 657–74. [Google Scholar] [CrossRef]
- Powell, James L., James H. Stock, and Thomas M. Stoker. 1989. Semiparametric estimation of index coefficients. Econometrica: Journal of the Econometric Society 57: 1403–430. [Google Scholar] [CrossRef]
- Sangiorgi, Francesco, Jonathan Sokobin, and Chester Spatt. 2009. Credit-Rating Shopping, Selection and the Equilibrium Structure of Ratings. Technical Report, Working Paper. Pittsburgh: Stockholm School of Economics, Carnegie Mellon University. [Google Scholar]
- Shen, Chan, and Roger Klein. 2019. Recursive Differencing for Estimating Semiparametric Models. Available online: https://economics.rutgers.edu/downloads-hidden-menu/faculty-cv-s/1824-shen-and-klein-2019/file (accessed on 1 December 2019).
- Silverman, Bernhard W. 1982. Algorithm as 176: Kernel density estimation using the fast fourier transform. Journal of the Royal Statistical Society Series C (Applied Statistics) 31: 93–99. [Google Scholar] [CrossRef]
- Skreta, Vasiliki, and Laura Veldkamp. 2009. Ratings shopping and asset complexity: A theory of ratings inflation. Journal of Monetary Economics 56: 678–95. [Google Scholar] [CrossRef]
- Stewart, Mark B. 2005. A comparison of semiparametric estimators for the ordered response model. Computational Statistics & Data Analysis 49: 555–73. [Google Scholar]
- Strobl, Günter, and Han Xia. 2012. The Issuer-Pays Rating Model and Ratings Inflation: Evidence from Corporate Credit Ratings. Unpublished Working Paper. Available online: http://efa2011.efa-online.org/fisher.osu.edu/blogs/efa2011/files/APE_8_2.pdf (accessed on 1 December 2019).
- White, Lawrence J. 2002. The credit rating industry: An industrial organization analysis. In Ratings, Rating Agencies and the Global Financial System. Berlin: Springer, pp. 41–63. [Google Scholar]
- Xia, Yingcun. 2008. A multiple-index model and dimension reduction. Journal of the American Statistical Association 103: 1631–40. [Google Scholar] [CrossRef]
- Xia, Yingcun, Howell Tong, W. K. Li, and Li-Xing Zhu. 2002. An adaptive estimation of dimension reduction space. Journal of the Royal Statistical Society Series B Statistical Methodology 64: 363–410. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Investment Grade | High-Yield | |||
|---|---|---|---|---|
| Mean | Std.Dev. | Mean | Std.Dev. | |
| Firm Characteristics | ||||
| log(asset) | 10.88 | 1.92 | 8.26 | 1.45 |
| book_lev | 0.33 | 0.18 | 0.44 | 0.20 |
| convDe_asset | 0.01 | 0.03 | 0.03 | 0.07 |
| rent_asset | 0.01 | 0.01 | 0.02 | 0.03 |
| cash_asset | 0.11 | 0.12 | 0.08 | 0.09 |
| debt_ebitda | 4.95 | 11.16 | 4.45 | 20.76 |
| ebitda_int | 14.45 | 31.30 | 4.82 | 5.91 |
| profit | 0.31 | 0.28 | 0.03 | 8.38 |
| PPE_asset | 0.23 | 0.26 | 0.37 | 0.28 |
| CAPEX_asset | 0.03 | 0.04 | 0.07 | 0.10 |
| profit_vol | 0.06 | 1.84 | −0.92 | 41.74 |
| Bond Characteristics | ||||
| log(issuing amount) | 12.69 | 1.69 | 12.66 | 0.73 |
| seniority | 0.93 | 0.26 | 0.69 | 0.46 |
| security | 0.01 | 0.06 | 0.09 | 0.00 |
| Small Bandwidth | Large Bandwidth | |||||||
|---|---|---|---|---|---|---|---|---|
| Trimming | TRUE | Mean | SD | RMSE | Mean | SD | RMSE | |
| 0.9 | SIM-1 | 2 | 2.569 | 0.452 | 0.776 | 2.608 | 0.460 | 0.830 |
| SIM-M | 2 | 2.026 | 0.551 | 0.552 | 1.987 | 0.481 | 0.481 | |
| OP | 2 | 2.634 | 0.593 | 0.995 | 2.669 | 0.621 | 1.070 | |
| 0.95 | SIM-1 | 2 | 2.551 | 0.434 | 0.738 | 2.602 | 0.445 | 0.808 |
| SIM-M | 2 | 2.003 | 0.535 | 0.535 | 1.985 | 0.453 | 0.453 | |
| OP | 2 | 2.620 | 0.599 | 0.983 | 2.622 | 0.565 | 0.953 | |
| 0.99 | SIM-1 | 2 | 2.539 | 0.423 | 0.714 | 2.591 | 0.450 | 0.800 |
| SIM-M | 2 | 1.964 | 0.476 | 0.477 | 1.963 | 0.431 | 0.433 | |
| OP | 2 | 2.607 | 0.615 | 0.983 | 2.607 | 0.547 | 0.916 | |
| Investment Grade (IG) | High Yield (HY) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Year | Aaa | Aa | A | Baa | Ba | B | C | Total | % of IG |
| 2001 | 10 | 45 | 162 | 214 | 111 | 94 | 11 | 647 | 66.62% |
| 2002 | 1 | 78 | 142 | 212 | 71 | 105 | 7 | 616 | 70.29% |
| 2003 | 9 | 112 | 149 | 210 | 123 | 168 | 30 | 801 | 59.93% |
| 2004 | 3 | 81 | 91 | 174 | 89 | 155 | 18 | 611 | 57.12% |
| 2005 | 6 | 118 | 106 | 150 | 86 | 88 | 15 | 569 | 66.78% |
| 2006 | 3 | 164 | 161 | 189 | 58 | 65 | 22 | 662 | 78.10% |
| 2007 | 8 | 238 | 326 | 151 | 48 | 69 | 13 | 853 | 84.76% |
| 2008 | 2 | 110 | 151 | 139 | 29 | 11 | 4 | 446 | 90.13% |
| 2009 | 3 | 35 | 124 | 211 | 88 | 91 | 11 | 563 | 66.25% |
| 2010 | 7 | 51 | 101 | 172 | 90 | 110 | 26 | 557 | 59.43% |
| 2011 | 10 | 35 | 140 | 201 | 41 | 82 | 14 | 523 | 73.80% |
| 2012 | 3 | 41 | 153 | 261 | 83 | 116 | 25 | 682 | 67.16% |
| 2013 | 12 | 49 | 173 | 311 | 95 | 105 | 31 | 776 | 70.23% |
| 2014 | 8 | 32 | 139 | 303 | 92 | 92 | 20 | 686 | 70.26% |
| 2015 | 20 | 28 | 198 | 370 | 78 | 55 | 7 | 756 | 81.48% |
| 2016 | 26 | 59 | 219 | 357 | 80 | 65 | 3 | 809 | 81.71% |
| Total | 131 | 1276 | 2535 | 3625 | 1262 | 1471 | 257 | 10,557 | |
| Shareholder | T | Mean | Max | Min |
|---|---|---|---|---|
| HARRIS ASSOCIATES L.P. | 21 | 2.42% | 5.02% | 0.00% |
| CHILDREN’S INV MGMT (UK) LLP | 20 | 2.29% | 5.31% | 0.01% |
| SANDS CAPITAL MANAGEMENT, INC. | 28 | 3.01% | 5.59% | 0.40% |
| T. ROWE PRICE ASSOCIATES, INC. | 64 | 1.47% | 5.94% | 0.18% |
| BARCLAYS BANK PLC | 55 | 2.52% | 6.32% | 0.03% |
| GOLDMAN SACHS & COMPANY | 63 | 1.94% | 7.24% | 0.01% |
| VALUEACT CAPITAL MGMT, L.P. | 13 | 5.19% | 7.77% | 0.93% |
| VANGUARD GROUP, INC. | 64 | 3.79% | 7.98% | 1.64% |
| MSDW & COMPANY | 57 | 2.20% | 8.14% | 0.22% |
| DAVIS SELECTED ADVISERS, L.P. | 51 | 5.56% | 8.14% | 0.10% |
| FIDELITY MANAGEMENT & RESEARCH | 64 | 1.99% | 9.08% | 0.00% |
| CAPITAL RESEARCH GBL INVESTORS | 13 | 4.80% | 11.31% | 0.07% |
| CAPITAL WORLD INVESTORS | 35 | 6.07% | 12.60% | 0.66% |
| BERKSHIRE HATHAWAY INC. | 64 | 14.87% | 20.43% | 11.33% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y. Semiparametric Estimation of a Corporate Bond Rating Model. Econometrics 2021, 9, 23. https://doi.org/10.3390/econometrics9020023
Jiang Y. Semiparametric Estimation of a Corporate Bond Rating Model. Econometrics. 2021; 9(2):23. https://doi.org/10.3390/econometrics9020023
Chicago/Turabian StyleJiang, Yixiao. 2021. "Semiparametric Estimation of a Corporate Bond Rating Model" Econometrics 9, no. 2: 23. https://doi.org/10.3390/econometrics9020023
APA StyleJiang, Y. (2021). Semiparametric Estimation of a Corporate Bond Rating Model. Econometrics, 9(2), 23. https://doi.org/10.3390/econometrics9020023