
Copula–Based vMEM Specifications versus Alternatives: The Case of Trading Activity


Abstract
:1. Introduction
2. A Copula Approach to Multiplicative Error Models
3. Maximum Likelihood Inference
3.1. Parameters in the Conditional Mean
3.2. Parameters in the pdf of the Error Term
- Normal copula: , ;
- Student-T copula: , , .
3.2.1. Expectation Targeting
3.2.2. Concentrated Log-Likelihood
3.3. Asymptotic Variance-Covariance Matrix
4. Alternative Specifications of the Distribution of Errors
4.1. Multivariate Gamma
4.2. Multivariate Lognormal
4.3. Semiparametric
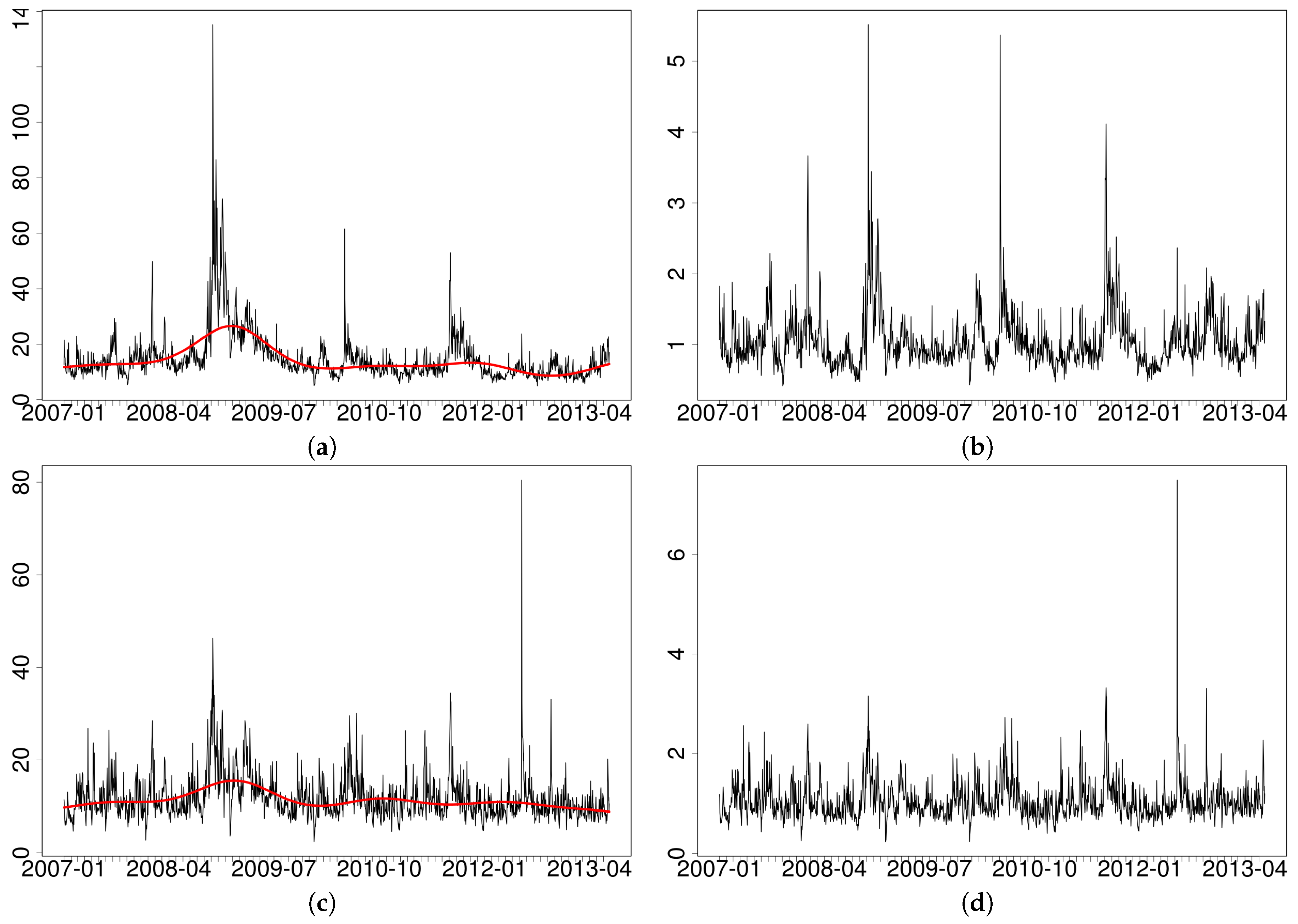
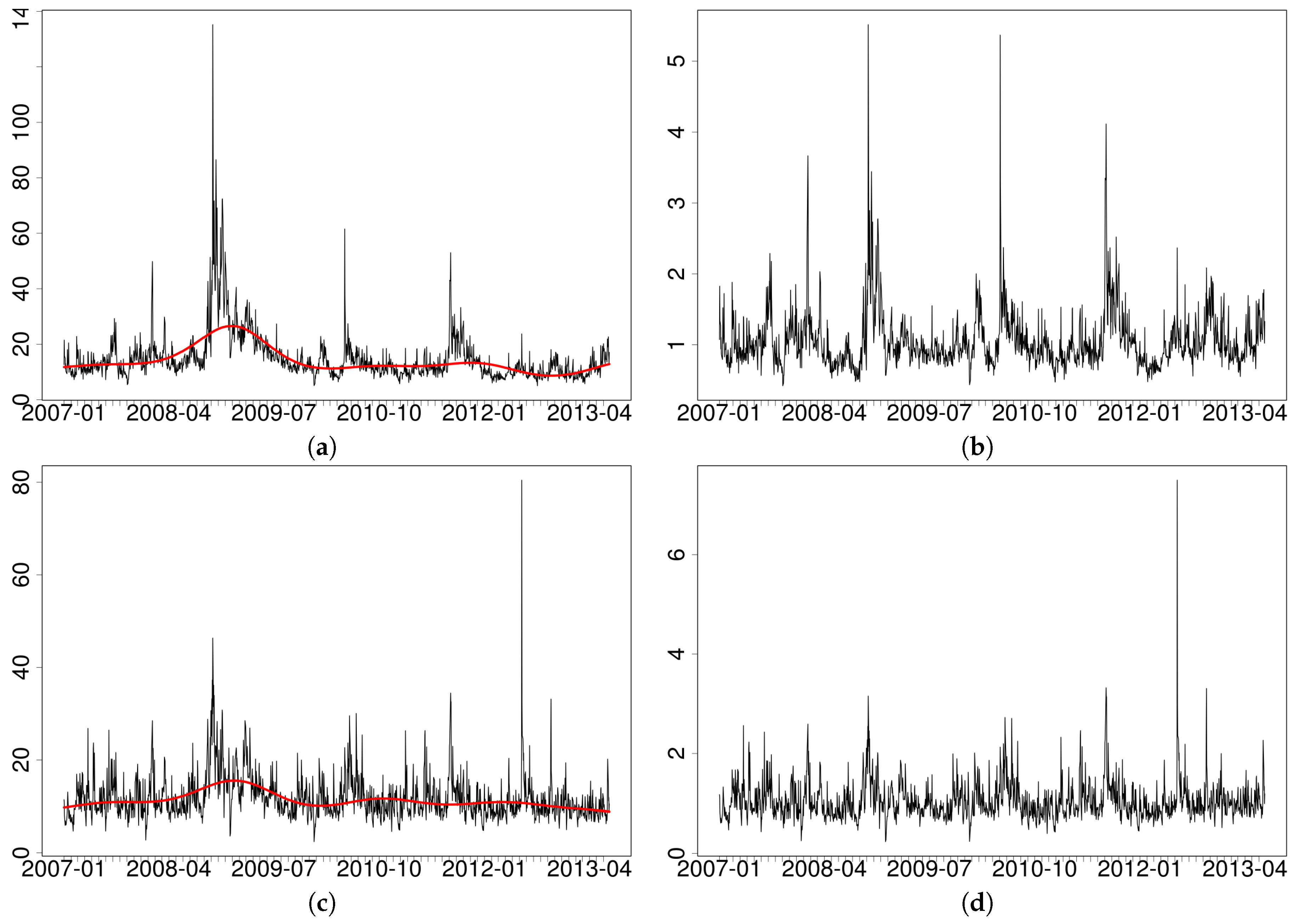
5. Trading Activity and Volatility within a vMEM
- we take the log of the original series;
- we fit on each log-series a spline based regression with additive errors, using time t (a progressive counter from the first to the last observation in the sample) as an independent variable;5
- the residuals of the previous regression are then exponentiated to get the adjusted series.
5.1. Modeling Results
5.2. Forecasting
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Expectation Targeting
Appendix A.1. Framework
Appendix A.2. Auxiliary results
Appendix A.3. The Asymptotic Distribution of the Sample Mean
References
- Andersen, Torben G. 1996. Return Volatility and Trading Volume: An Information Flow Interpretation of Stochastic Volatility. The Journal of Finance 51: 169–204. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Peter F. Christoffersen, and Francis X. Diebold. 2006. Volatility and Correlation Forecasting. In Handbook of Economic Forecasting. Edited by Graham Elliott, Clive W.J. Granger and Allan Timmermann. New York: North Holland, pp. 777–878. [Google Scholar]
- Barndorff-Nielsen, Ole E., Peter Reinhard Hansen, Asger Lunde, and Neil Shephard. 2009. Realised kernels in Practice: trades and quotes. Econometrics Journal 12: 1–32. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., Peter Reinhard Hansen, Asger Lunde, and Neil Shephard. 2011. Multivariate realised kernels: Consistent positive semi-definite estimators of the covariation of equity prices with noise and non-synchronous trading. Journal of Econometrics 162: 149–69. [Google Scholar] [CrossRef]
- Bodnar, Taras, and Nikolaus Hautsch. 2016. Dynamic conditional correlation multiplicative error processes. Journal of Empirical Finance 36: 41–67. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Bouyé, Eric, Valdo Durrleman, Ashkan Nikeghbali, Gaël Riboulet, and Thierry Roncalli. 2000. Copulas for Finance: A Reading Guide and Some Applications. Technical Report. Credit Lyonnais, Paris: Groupe de Recherche Opérationelle. [Google Scholar]
- Brownlees, Christian T., and Giampiero M. Gallo. 2006. Financial Econometric Analysis at Ultra–High Frequency: Data Handling Concerns. Computational Statistics and Data Analysis 51: 2232–45. [Google Scholar] [CrossRef]
- Brownlees, Christian T., and Giampiero M. Gallo. 2010. Comparison of Volatility Measures: A Risk Management Perspective. Journal of Financial Econometrics 8: 29–56. [Google Scholar] [CrossRef]
- Cerrato, Mario, John Crosby, Minjoo Kim, and Yang Zhao. 2015. Modeling Dependence Structure and Forecasting Market Risk with Dynamic Asymmetric Copula. Technical Report. Glasgow, Scotland: Adam Smith Business School, University of Glasgow. [Google Scholar]
- Cherubini, Umberto, Elisa Luciano, and Walter Vecchiato. 2004. Copula Methods in Finance. New York: Wiley. [Google Scholar]
- Chou, Ray Yeutien. 2005. Forecasting Financial Volatilities with Extreme Values: The Conditional Autoregressive Range (CARR) Model. Journal of Money, Credit and Banking 37: 561–82. [Google Scholar] [CrossRef]
- Cipollini, Fabrizio, and Giampiero M. Gallo. 2010. Automated variable selection in vector multiplicative error models. Computational Statistics & Data Analysis 54: 2470–86. [Google Scholar] [CrossRef]
- Cipollini, Fabrizio, Robert F. Engle, and Giampiero M. Gallo. 2013. Semiparametric Vector MEM. Journal of Applied Econometrics 28: 1067–86. [Google Scholar] [CrossRef]
- De Luca, Giovanni, and Giampiero M. Gallo. 2009. Time-varying Mixing Weights in Mixture Autoregressive Conditional Duration Models. Econometric Reviews 28: 102–20. [Google Scholar] [CrossRef]
- Demarta, Stefano, and Alexander J. McNeil. 2005. The t Copula and Related Copulas. International Statistical Review 73: 111–29. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing Predictive Accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar] [CrossRef]
- Embrechts, Paul, Alexander McNeil, and Daniel Straumann. 2002. Correlation and dependence in risk management: properties and pitfalls. In Risk Management: Value at Risk and Beyond. Edited by M. A. H. Dempster. Cambridge: Cambridge University Press, pp. 176–223. [Google Scholar]
- Engle, Robert F. 2002. New Frontiers for ARCH Models. Journal of Applied Econometrics 17: 425–46. [Google Scholar] [CrossRef]
- Engle, Robert F., and Giampiero M. Gallo. 2006. A Multiple Indicators Model for Volatility Using Intra-Daily Data. Journal of Econometrics 131: 3–27. [Google Scholar] [CrossRef]
- Engle, Robert F., and Jeffrey R. Russell. 1998. Autoregressive Conditional Duration: A New Model for Irregularly Spaced Transaction Data. Econometrica 66: 1127–62. [Google Scholar] [CrossRef]
- Engle, Robert F., and Joe Mezrich. 1995. Grappling with GARCH. Risk 8: 112–17. [Google Scholar]
- Engle, Robert F., and Jose Gonzalo Rangel. 2008. The Spline-GARCH Model for Low Frequency Volatility and Its Global Macroeconomic Causes. Review of Financial Studies 21: 1187–222. [Google Scholar] [CrossRef]
- Frahm, Gabriel, Markus Junker, and Alexander Szimayer. 2003. Elliptical Copulas: Applicability and Limitations. Statistics & Probability Letters 63: 275–86. [Google Scholar] [CrossRef]
- Francq, Christian, Lajos Horvath, and Jean-Michel Zakoïan. 2011. Merits and drawbacks of variance targeting in GARCH models. Journal of Financial Econometrics 9: 619–56. [Google Scholar] [CrossRef]
- Gallo, Giampiero M., and Edoardo Otranto. 2015. Forecasting realized volatility with changing average levels. International Journal of Forecasting 31: 620–34. [Google Scholar] [CrossRef]
- Hamilton, James Douglas. 1994. Time Series Analysis. Princeton: Princeton University Press. [Google Scholar]
- Hautsch, Nikolaus. 2008. Capturing common components in high-frequency financial time series: A multivariate stochastic multiplicative error model. Journal of Economic Dynamics and Control 32: 3978–4015. [Google Scholar] [CrossRef]
- Hautsch, Nikolaus, Peter Malec, and Melanie Schienle. 2013. Capturing the Zero: A New Class of Zero-Augmented Distributions and Multiplicative Error Processes. Journal of Financial Econometrics 12: 89–121. [Google Scholar] [CrossRef]
- Horváth, Lajos, Piotr Kokoszka, and Ricardas Zitikis. 2006. Sample and Implied Volatility in GARCH Models. Journal of Financial Econometrics 4: 617–35. [Google Scholar] [CrossRef]
- Joe, Harry. 1997. Multivariate Models and Dependence Concepts. London: Chapman & Hall. [Google Scholar]
- Johnson, Norman L., Samuel Kotz, and Narayanaswamy Balakrishnan. 2000. Continuous Multivariate Distributions. New York: John Wiley & Sons, vol. 1. [Google Scholar]
- Kostadinov, Krassimir. 2005. Non-parametric Estimation of Elliptical Copulae with Application to Credit Risk. Technical Report. Munich, Germany: Munich University of Technology. [Google Scholar]
- Kristensen, Dennis, and Oliver Linton. 2004. Consistent Standard Errors for Target Variance Approach to GARCH Estimation. Econometric Theory 20: 990–93. [Google Scholar] [CrossRef]
- Lindskog, Filip, Alexander McNeil, and Uwe Schmock. 2003. Kendall’s tau for elliptical distributions. In Credit Risk: Measurement, Evaluation and Management. Edited by Georg Bol, Gholamreza Nakhaeizadeh, Svetlozar T. Rachev, Thomas Ridder and Karl-Heinz Vollmer. Heidelberg: Physica-Verlag. [Google Scholar]
- Manganelli, Simone. 2005. Duration, Volume and Volatility Impact of Trades. Journal of Financial Markets 8: 377–99. [Google Scholar] [CrossRef]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2005. Quantitative Risk Management: Concepts, Techniques, and Tools. Princeton: Princeton University Press. [Google Scholar]
- Nelsen, Roger B. 1999. An introduction to Copulas. Lecture Notes in Statistics. New York: Springer. [Google Scholar]
- Newey, Whitney K., and Daniel McFadden. 1994. Large sample estimation and hypothesis testing. In Handbook of Econometrics. Edited by Robert Engle and Dan McFadden. New York: Elsevier, vol. 4, chapter 36. pp. 2111–45. [Google Scholar]
- Nocedal, Jorge, and Stephen J. Wright. 2006. Numerical Optimization. Springer Series in Operations Research and Financial Engineering; Berlin: Springer. [Google Scholar]
- Noss, Joseph. 2007. The Econometrics of Optimal Execution in an Order-Driven Market. Master’s dissertation, Nuffield College, Oxford University, Oxford, UK. [Google Scholar]
- Okimoto, Tatsuyoshi. 2008. New Evidence of Asymmetric Dependence Structures in International Equity Markets. The Journal of Financial and Quantitative Analysis 43: 787–815. [Google Scholar] [CrossRef]
- Patton, Andrew J. 2006. Modelling asymmetric exchange rate dependence. International Economic Review 47: 527–56. [Google Scholar] [CrossRef]
- Patton, Andrew J. 2013. Copula Methods for Forecasting Multivariate Time Series. In Handbook of Economic Forecasting. Edited by Graham Elliott and Allan Timmermann. New York: Elsevier, vol. 2, Part B. pp. 899–960. [Google Scholar]
- Powell, Michael J.D. 2006. The NEWUOA software for unconstrained optimization without derivatives. In Large-Scale Nonlinear Optimization. Edited by Gianni D. Pillo and Massimo Roma. New York: Springer Verlag, pp. 255–97. [Google Scholar]
- Schmidt, Rafael. 2002. Tail dependence for elliptically contoured distributions. Mathematical Methods of Operations Research 55: 301–27. [Google Scholar] [CrossRef]
- Song, Peter Xue-Kun. 2000. Multivariate Dispersion Models Generated From Gaussian Copula. Scandinavian Journal of Statistics 27: 305–20. [Google Scholar] [CrossRef]
| 1 | In some applications, especially involving returns, their elliptical symmetry may constitute a limit (cf., for example, Patton (2006), Okimoto (2008), Cerrato et al. (2015) and reference therein). Copulas in the Archimedean family (Clayton, Gumbel, Joe-Clayton, etc.) offer a way to bypass such a limitation but suffer from other drawbacks and, in any case, seem to be less relevant for the variables of interest for a vMEM (here, different indicators of trading activity). They will not be pursued in what follows. |
| 2 | This is equivalent to variance targeting in a GARCH context (Engle and Mezrich 1995), where the constant term of the conditional variance model is assumed to be a function of the sample unconditional variance and of the other parameters. In this context, other than a preference for the term expectation targeting since we are modeling a conditional mean, the main argument stays unchanged. |
| 3 | Even when is a matrix, the value of has to satisfy the cubic equation:
|
| 4 | |
| 5 | Alternative methods, such as a moving average of fixed length (centered or uncentered), can be used but in practice they deliver very similar results and will not be discussed in detail here. The spline regression is estimated with the gam() function in the R package mgcv by using default settings. |
| 6 | All models are estimated using Expectation Targeting (Section 3.2.1). The Normal copula based specifications are estimated resorting to the concentrated log-likelihood approach (Section 3.2.2). We omit estimates of the constant term . |
| 7 | The estimated degrees of freedom are (s.e. ) and (s.e. ), respectively, in the A-T and AB-T formulations. We also tried full ML estimation of the AB-N specification getting a value of the log-likelihood equal to , very close to the concentrated log-likelihood approach (Section 3.2.2) used in Table 3. |
| 8 | The stark improvement in the likelihood functions, coming from the explicit consideration of the correlation structure, does not guarantee similar gains in the forecasting ability of the same variables. This is similar to what happens in modeling returns, when the likelihood function of ARMA models is improved by superimposing a GARCH structure on the conditional variances: no substantive change in the fit of the conditional mean and no better predictive ability. |
| 9 | No attempt at pruning the structure of the model following the automated procedure suggested in Cipollini and Gallo (2010) was performed. |
| 10 | Calculations with our routines written in R were performed on an Intel i7-5500U 2.4Ghz processor. We did not perform an extensive comparison of estimation times and we did not optimize performance by removing tracing of intermediate results. Moreover, the copula-based and the alternative specifications are optimized resorting to different algorithms: the first ones, more cumbersome to optimize, are estimated toward a combination of NEWUOA (Powell 2006) and Newton-Raphson; for the second ones we used a dogleg algorithm (Nocedal and Wright 2006, ch. 4). |
| 11 | One-step ahead predictions at time t for the original series are computed multiplying the corresponding forecast of the adjusted indicator by the value of the low frequency component at . |



{kind=link}
{kind=link}
{kind=link}
| Original | Low Freq. Comp. | Adjusted | ||||
|---|---|---|---|---|---|---|
| 0.646 | 0.778 | 0.800 | 0.847 | 0.609 | 0.743 | |
| 0.890 | 0.780 | 0.932 | ||||
| Conditional Mean (Parameters) | Error Distribution | ||||
|---|---|---|---|---|---|
| I | N | T | S | ||
| D: , , , , diagonal | D-I | ||||
| A: full; , , diagonal | A-I | A-N | A-T | ||
| B: full; , , diagonal | B-N | B-T | |||
| : , full; , diagonal | AB-N | AB-T | AB-LN | AB-S | |
| D-I | A-I | A-N | A-T | B-N | B-T | AB-N | AB-T | AB-LN | AB-S | |
|---|---|---|---|---|---|---|---|---|---|---|
| () | () | () | () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | ||||
| () | () | () | () | () | () | () | ||||
| () | () | () | () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | () | () | () | |
| () | () | () | () | () | () | |||||
| () | () | () | () | () | () | |||||
| 0.2658 | 0.3296 | 0.4558 | 0.4970 | 0.7459 | 0.1705 | 0.2717 | 0.0853 | 0.1550 | ||
| 0.0766 | 0.1153 | 0.1724 | 0.3202 | 0.5098 | 0.0051 | 0.0077 | 0.0001 | 0.0004 | ||
| logLik | 205.53 | 239.75 | 2012.39 | 2086.31 | 1967.02 | 2048.80 | 2045.81 | 2125.12 | 2153.79 | |
| AIC | −375.07 | −4116.61 | −3880.05 | −4041.60 | ||||||
| BIC | −3811.20 | −3961.32 | ||||||||
| LB(12) | 0.0000 | 0.0000 | 0.0001 | 0.0001 | 0.0000 | 0.0000 | 0.0388 | 0.0141 | 0.0450 | 0.0596 |
| LB(22) | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0178 | 0.0109 | 0.0229 | 0.0264 |
| LB(32) | 0.0000 | 0.0000 | 0.0003 | 0.0003 | 0.0000 | 0.0000 | 0.0192 | 0.0132 | 0.0291 | 0.0267 |
| time | 0.342 | 0.753 | 2.628 | 15.044 | 2.485 | 14.707 | 2.714 | 14.859 | 0.155 | 0.132 |
| D-I | A-I | A-N | A-T | B-N | B-T | AB-N | AB-T | AB-LN | AB-S | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.209 | 0.208 | 0.207 | 0.212 | 0.209 | 0.214 | 0.206 | 0.210 | 0.204 | 0.226 | |
| 0.254 | 0.251 | 0.252 | 0.256 | 0.257 | 0.262 | 0.252 | 0.256 | 0.252 | 0.272 | |
| 0.227 | 0.227 | 0.229 | 0.236 | 0.232 | 0.240 | 0.228 | 0.235 | 0.228 | 0.242 |
| A-N | A-T | AB-N | AB-T | AB-LN | AB-S | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.483 | 0.610 | 0.505 | 0.626 | 0.485 | 0.612 | 0.505 | 0.628 | 0.469 | 0.596 | 0.481 | 0.605 | |
| 0.902 | 0.917 | 0.903 | 0.918 | 0.902 | 0.906 | |||||||
| Specification | ||||
|---|---|---|---|---|
| Adjusted | Original | Adjusted | Original | |
| D-I | −2.490 | −2.107 | −2.428 | −2.132 |
| A-I | −1.358 | −1.200 | −1.277 | −1.173 |
| A-N | −0.621 | −0.563 | −0.591 | |
| A-T | −0.449 | −0.422 | −0.431 | |
| B-N | −0.557 | −0.560 | ||
| B-T | −0.479 | −0.389 | −0.490 | |
| AB-N | −0.757 | −0.708 | ||
| AB-LN | 0.868 | 0.720 | 0.980 | 0.742 |
| AB-S | ||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cipollini, F.; Engle, R.F.; Gallo, G.M. Copula–Based vMEM Specifications versus Alternatives: The Case of Trading Activity. Econometrics 2017, 5, 16. https://doi.org/10.3390/econometrics5020016
Cipollini F, Engle RF, Gallo GM. Copula–Based vMEM Specifications versus Alternatives: The Case of Trading Activity. Econometrics. 2017; 5(2):16. https://doi.org/10.3390/econometrics5020016
Chicago/Turabian StyleCipollini, Fabrizio, Robert F. Engle, and Giampiero M. Gallo. 2017. "Copula–Based vMEM Specifications versus Alternatives: The Case of Trading Activity" Econometrics 5, no. 2: 16. https://doi.org/10.3390/econometrics5020016
APA StyleCipollini, F., Engle, R. F., & Gallo, G. M. (2017). Copula–Based vMEM Specifications versus Alternatives: The Case of Trading Activity. Econometrics, 5(2), 16. https://doi.org/10.3390/econometrics5020016