Optimized Spatiotemporal Data Scheduling Based on Maximum Flow for Multilevel Visualization Tasks

Abstract
:1. Introduction
- Defined a multilevel visualization task and its data preference and designed framework of spatiotemporal data scheduling according to the structure of spatiotemporal data storage and scheduling in a cloud environment.
- Mapping the network topology of data resource scheduling to the maximum flow model and constructed a maximum flow scheduling model of spatiotemporal data can clearly quantify the ability of multisource and multigranular spatiotemporal data services.
- Designed two task-driven dynamic adjustment methods of maximum flow model parameters: cache node and storage node capacity allocation. This method can control the multitype spatiotemporal data flow size while maintaining the optimization of global data flow, and flexibly adapt to the needs of tasks under limited hardware resources in the cloud environment.
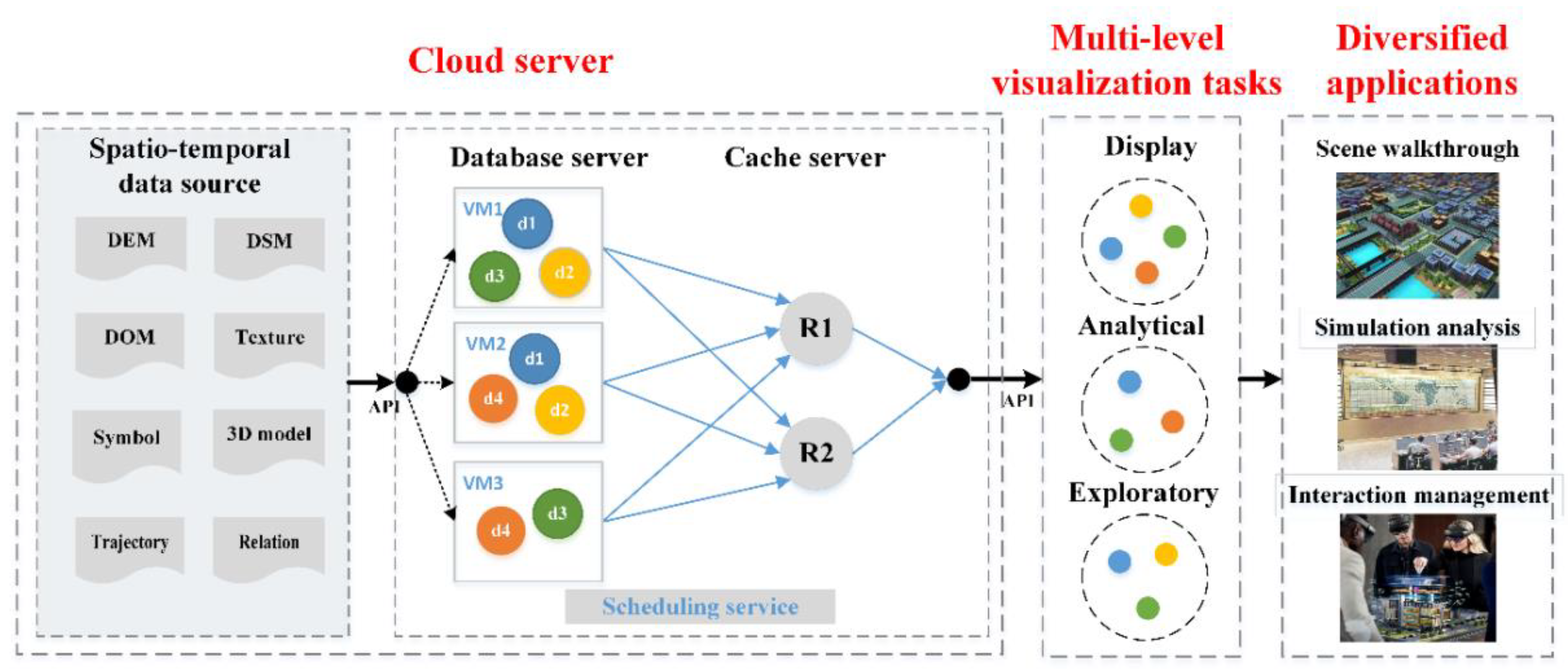
2. Spatiotemporal Data Scheduling Framework for Multilevel Visualization Tasks
2.1. Multilevel Visualization Tasks and Data Preferences
2.2. Spatiotemporal Data Scheduling Framework
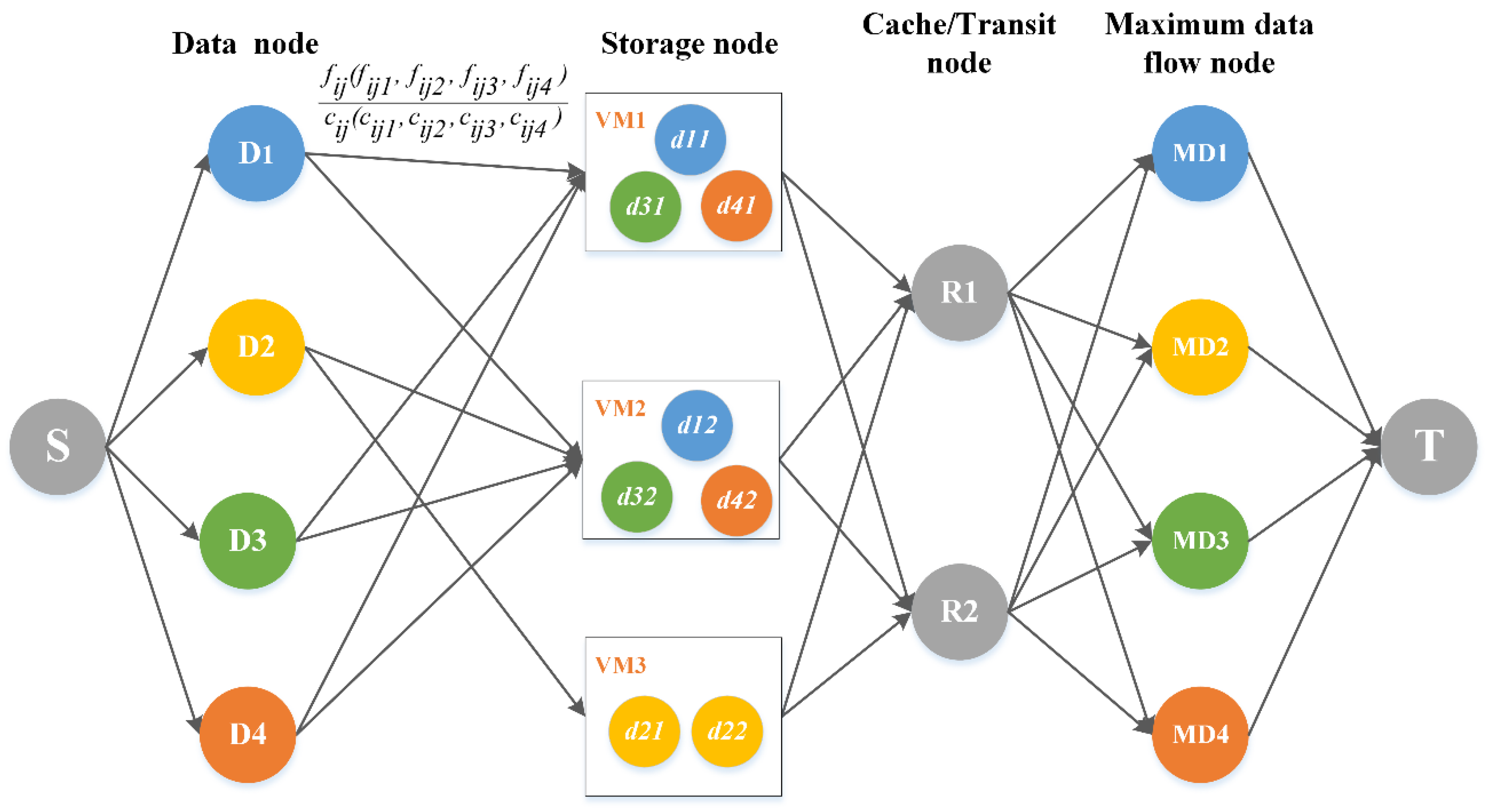
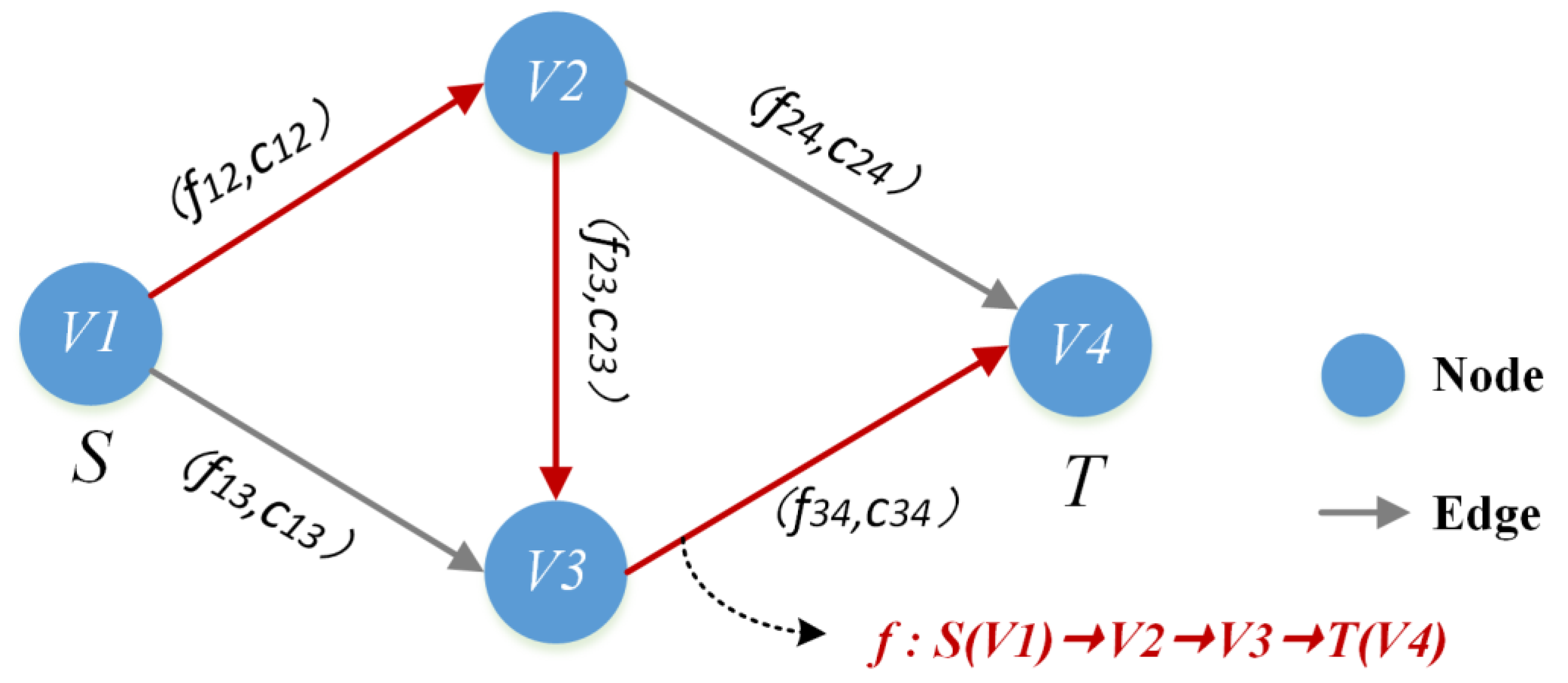
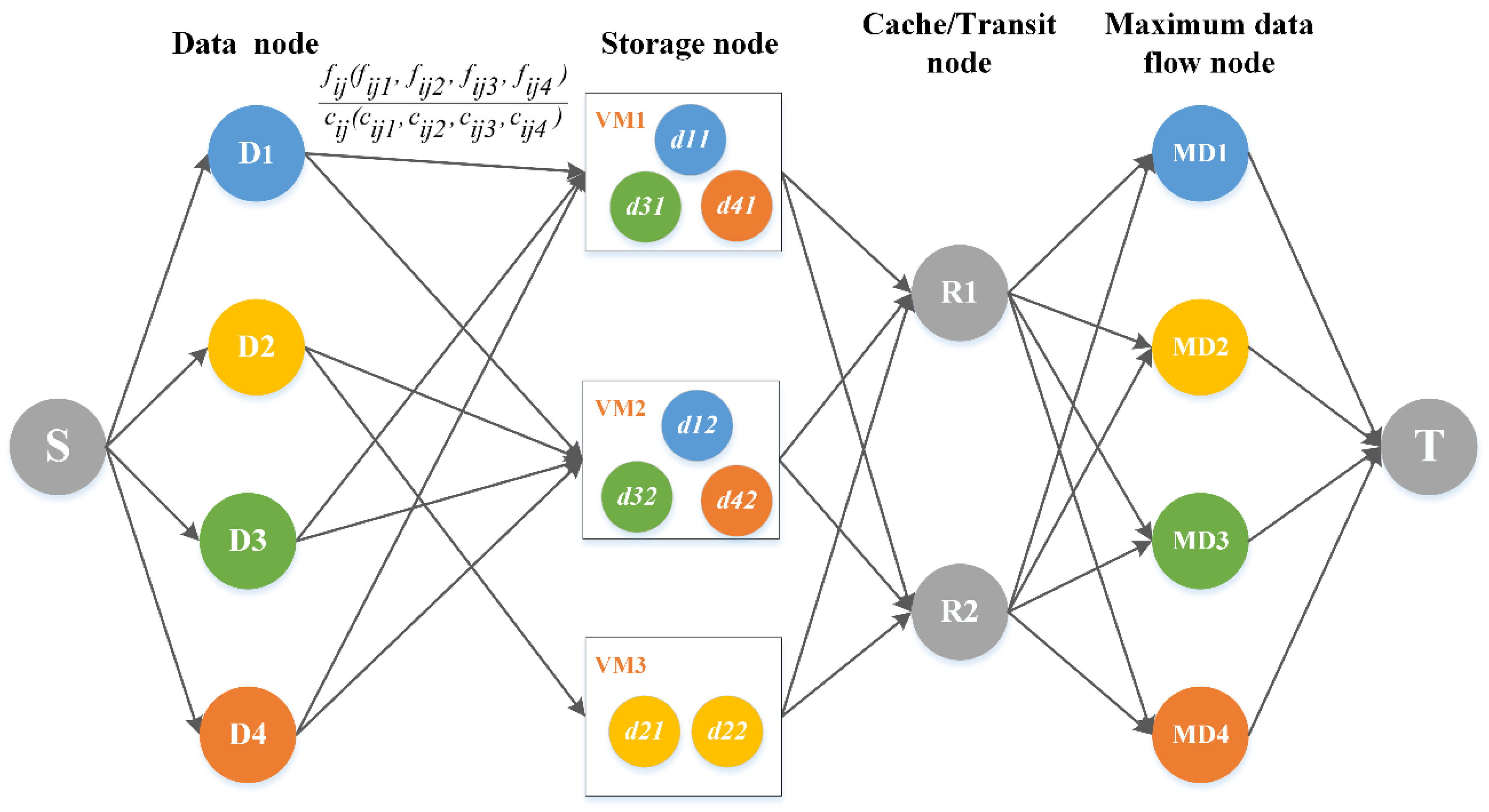
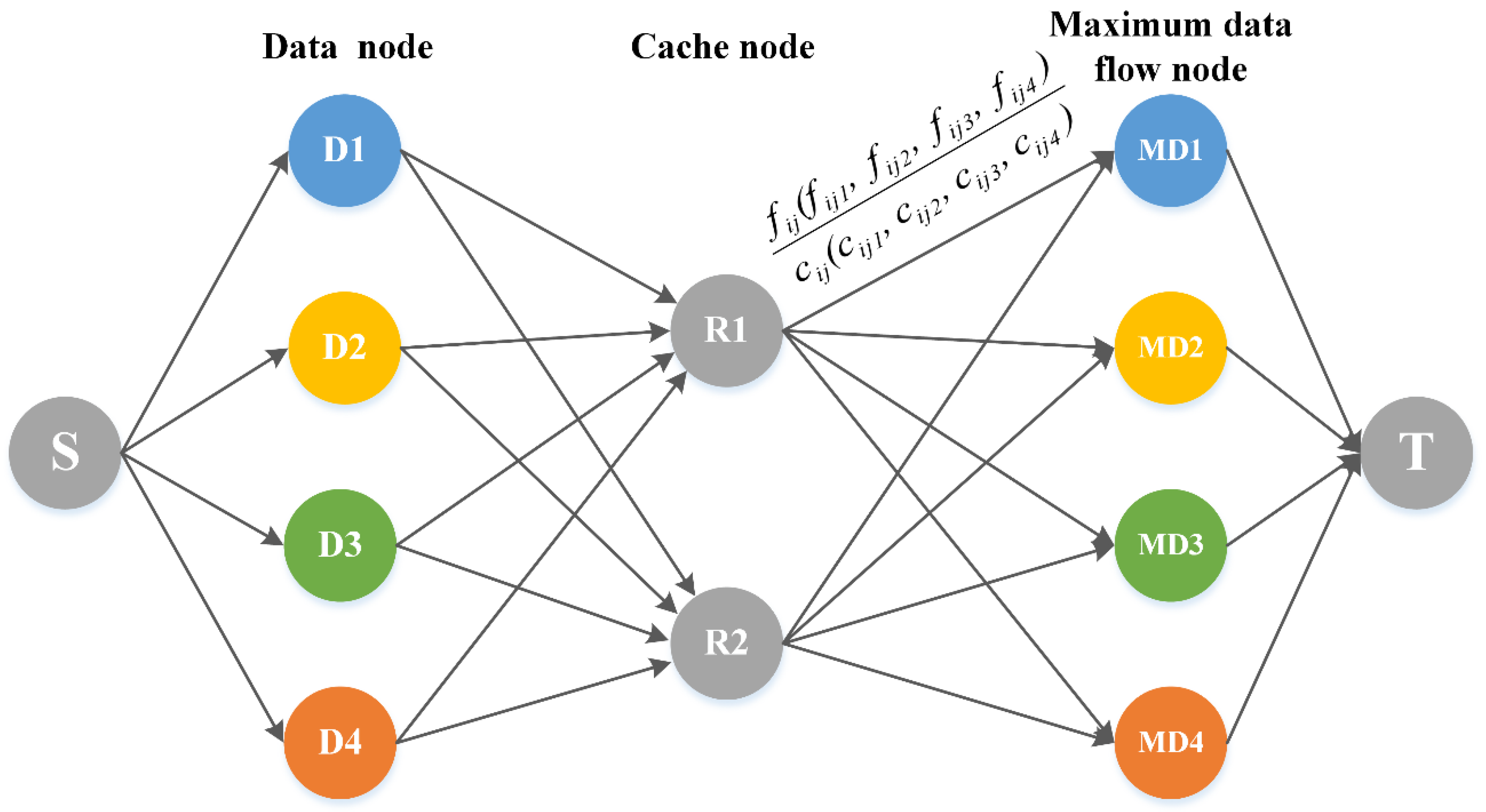
3. Spatiotemporal Data Scheduling Model Based on Maximum Flow
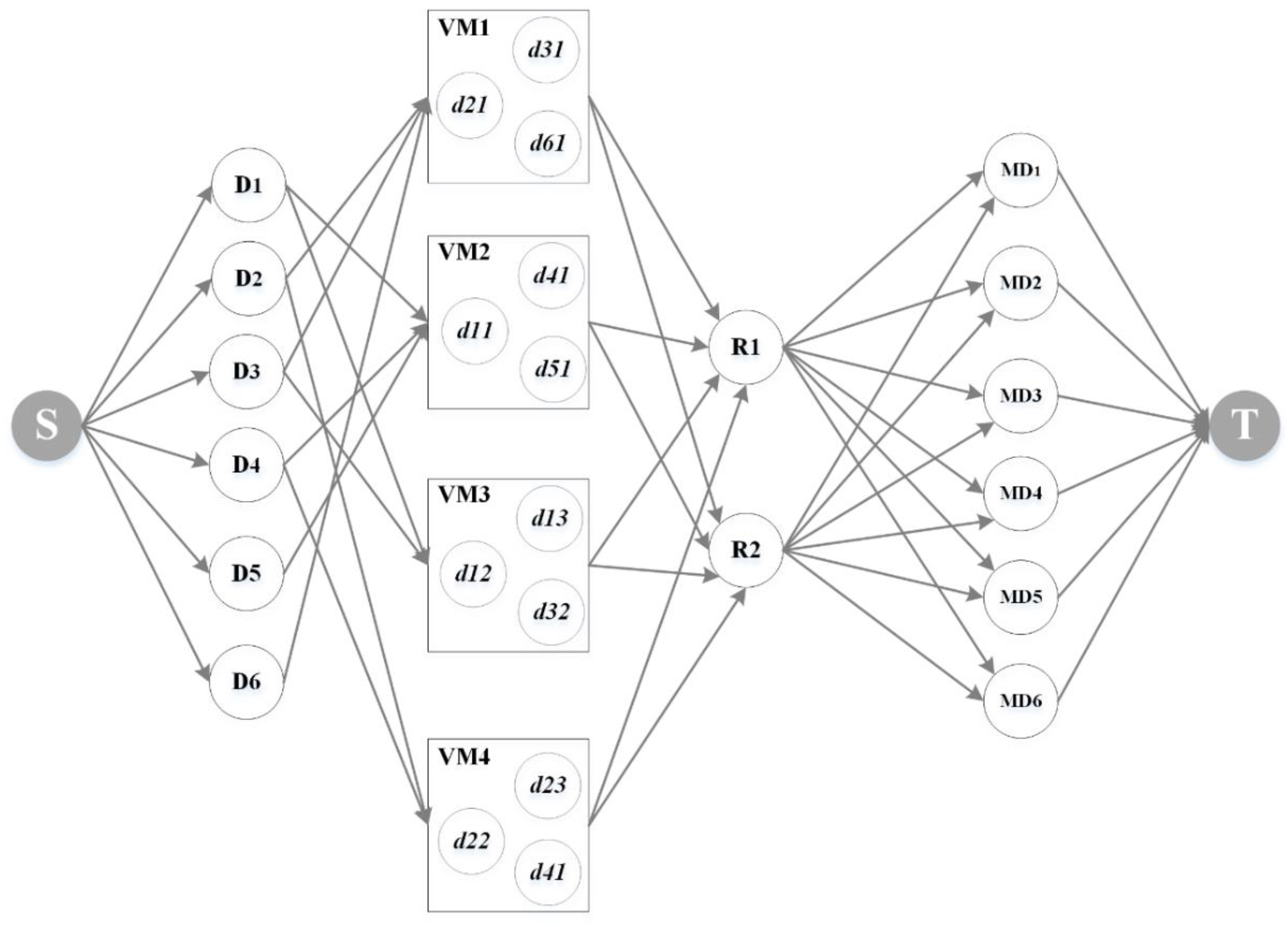
3.1. Construction of Maximum Flow Model for Spatiotemporal Data Scheduling
3.2. Initialization Configuration of Node and Edge Capacity
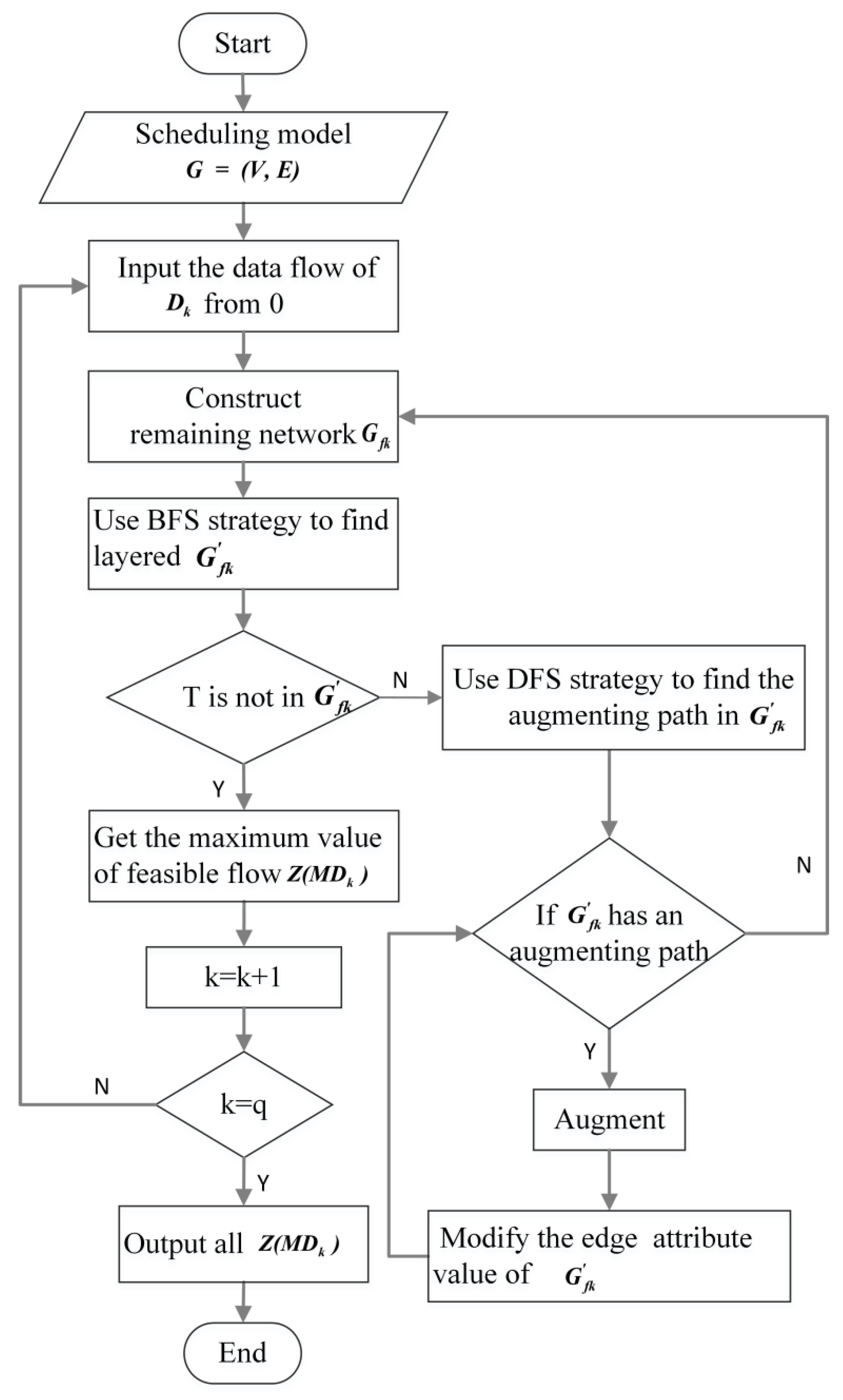
3.3. Maximum Flow Algorithm
- Inputting the data flow of from 0 in the model ;
- Construct the remaining network of the model and use the BFS strategy to find the layered residual network of the scheduling model; if the sink node is not in , go to (6);
- Use the DFS strategy to find the augmenting path. If has an augmenting path from source node S to sink node T, go to (4); if not, go to (5);
- According to the found augmenting path and the augmenting value, augment and modify the directed edge attribute of the layered residual network , then go to (3);
- has no augmenting path available; go to (2);
- The resulting feasible flow is the maximum flow of ;
- To start increasing the flow of , repeat steps (2) through (6) until k = q.
4. Task-Driven Maximum Flow Allocation Method for Spatiotemporal Data
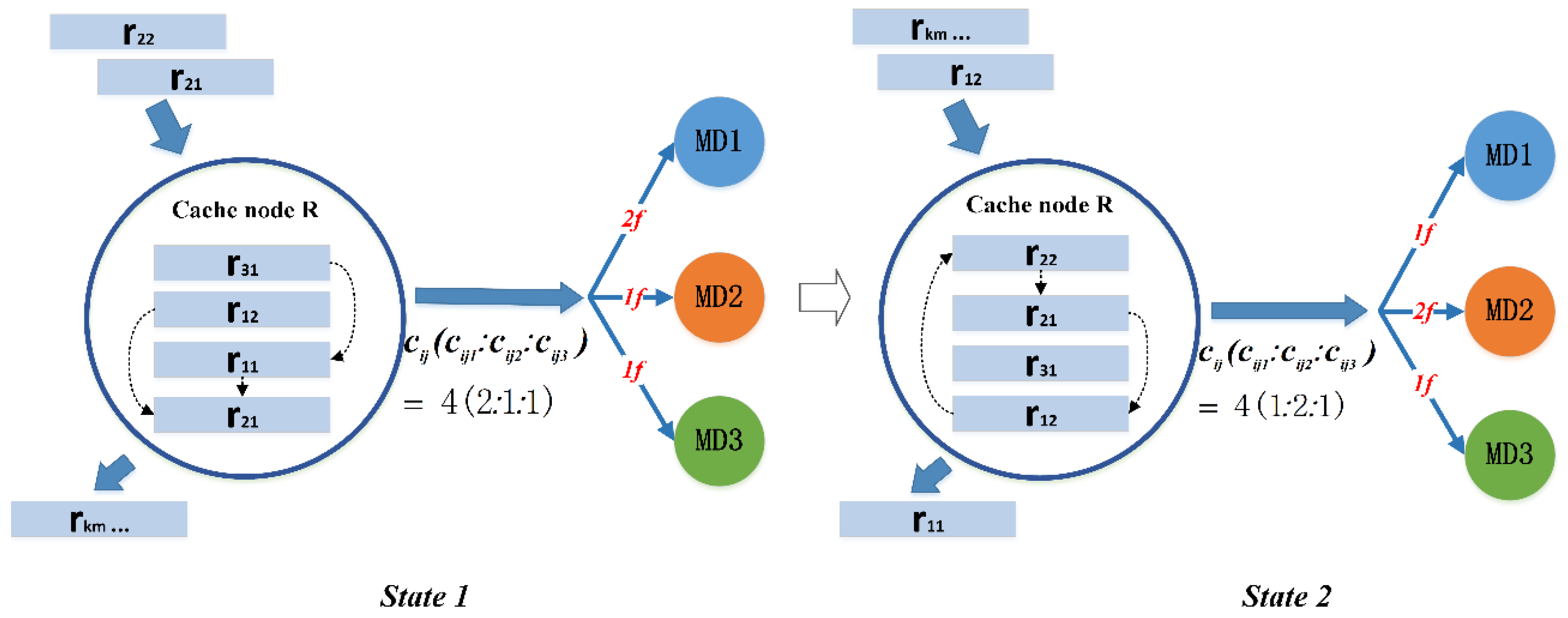
4.1. Capacity Allocation of Cache Node
4.2. Capacity Allocation of Storage Node
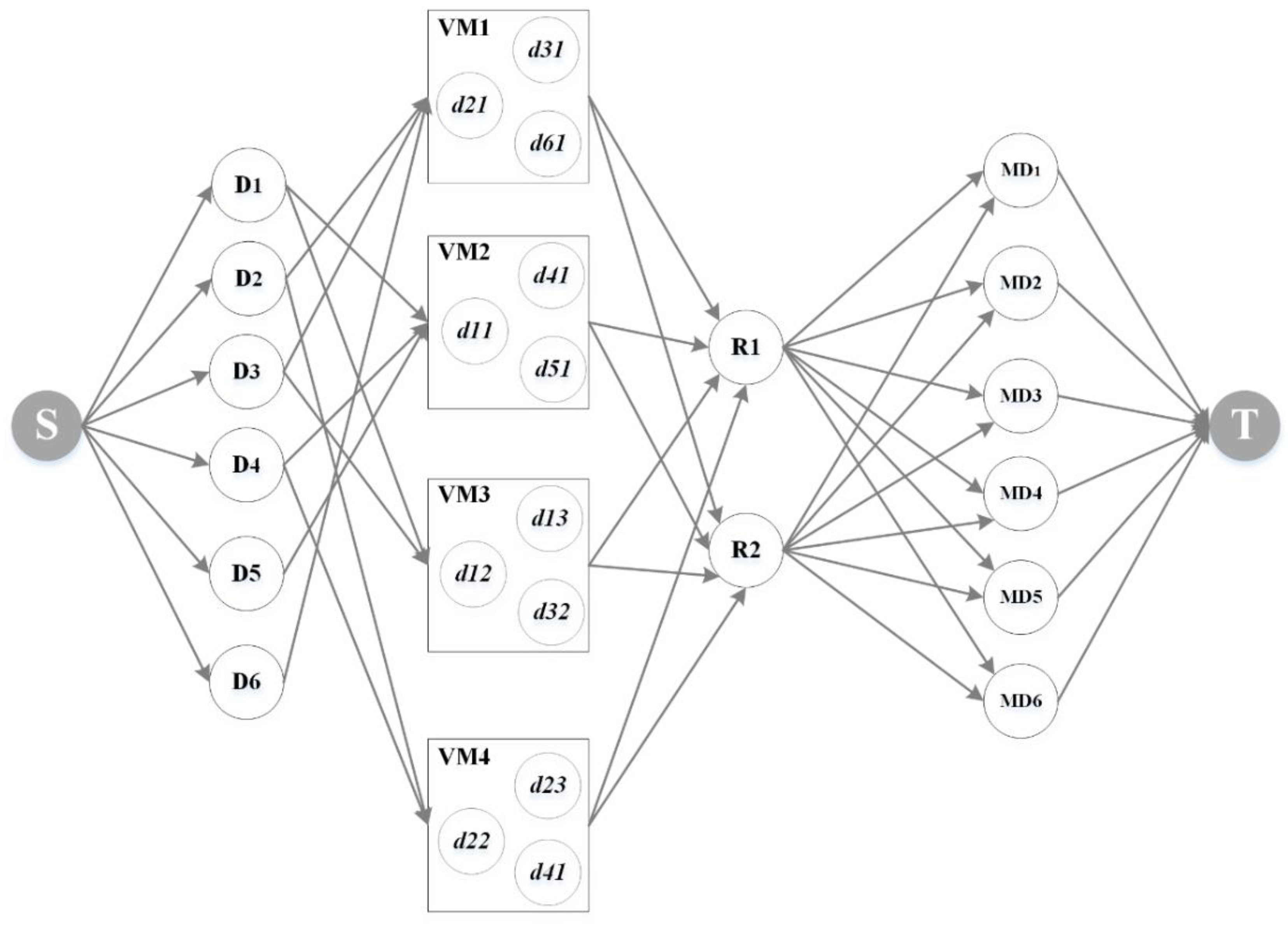
5. Experimental Analysis
5.1. Experimental Environment and Data
5.2. Experimental Results and Analysis
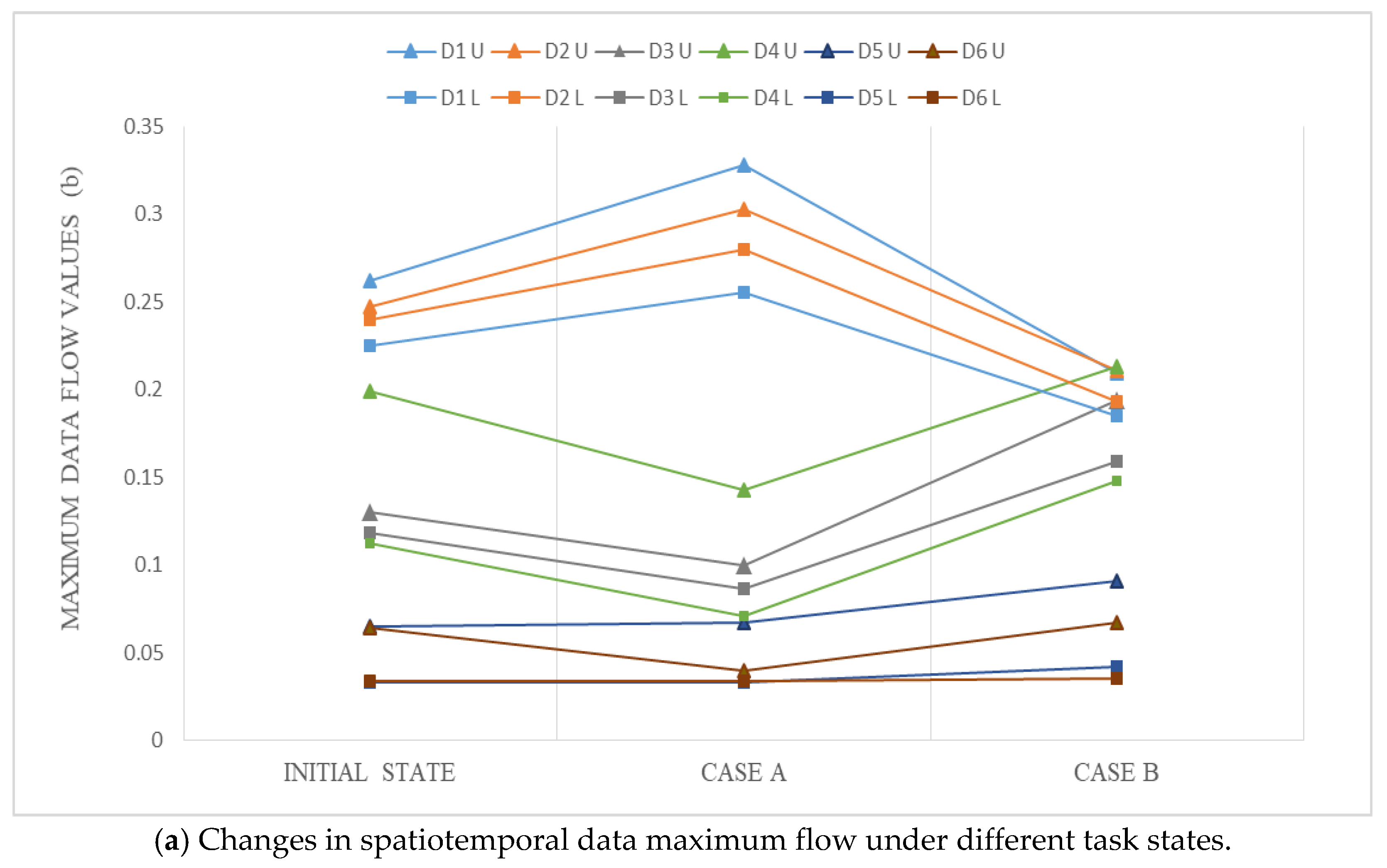
5.2.1. Data Maximum Flow Calculation of the Initial State
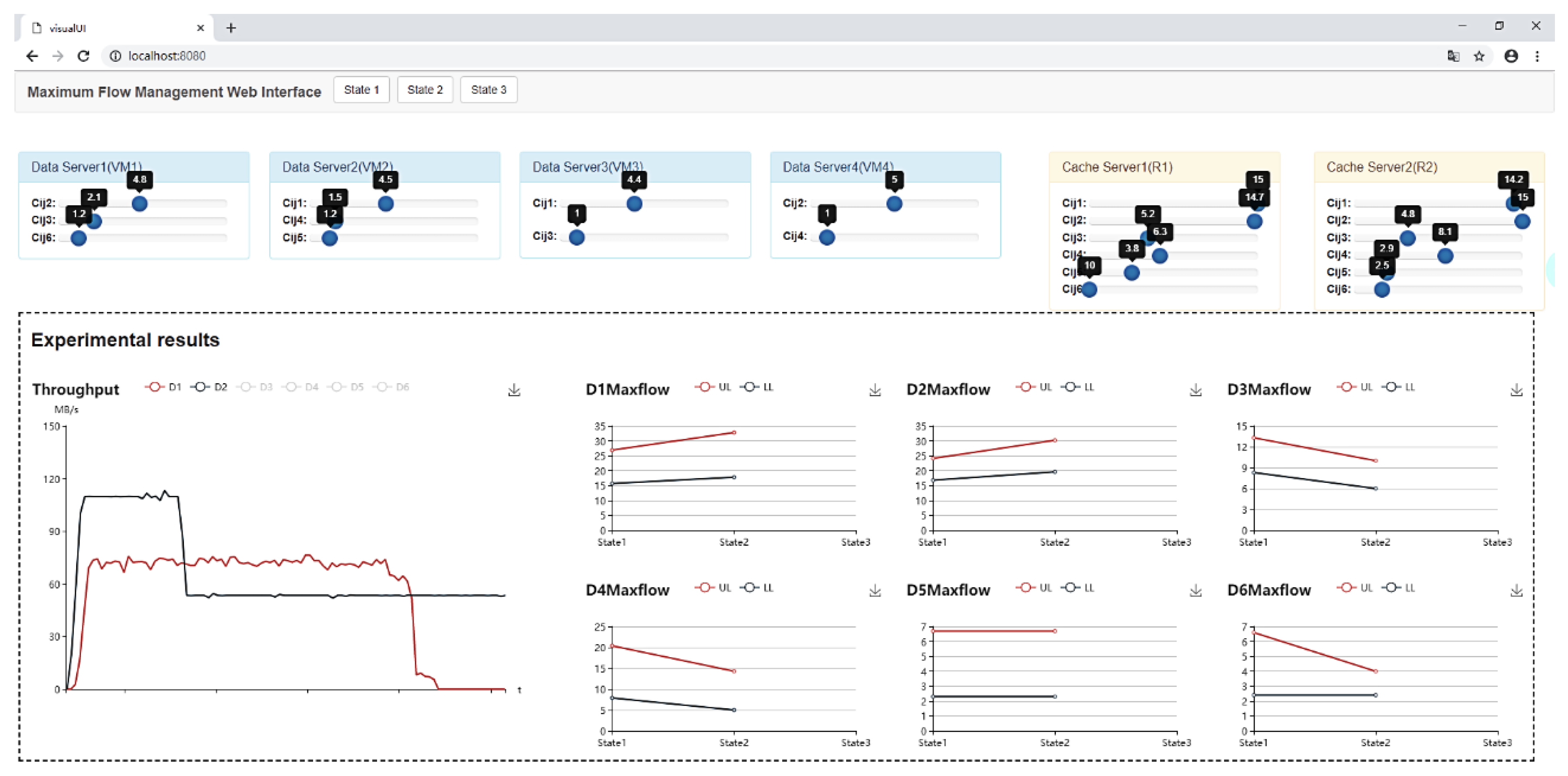
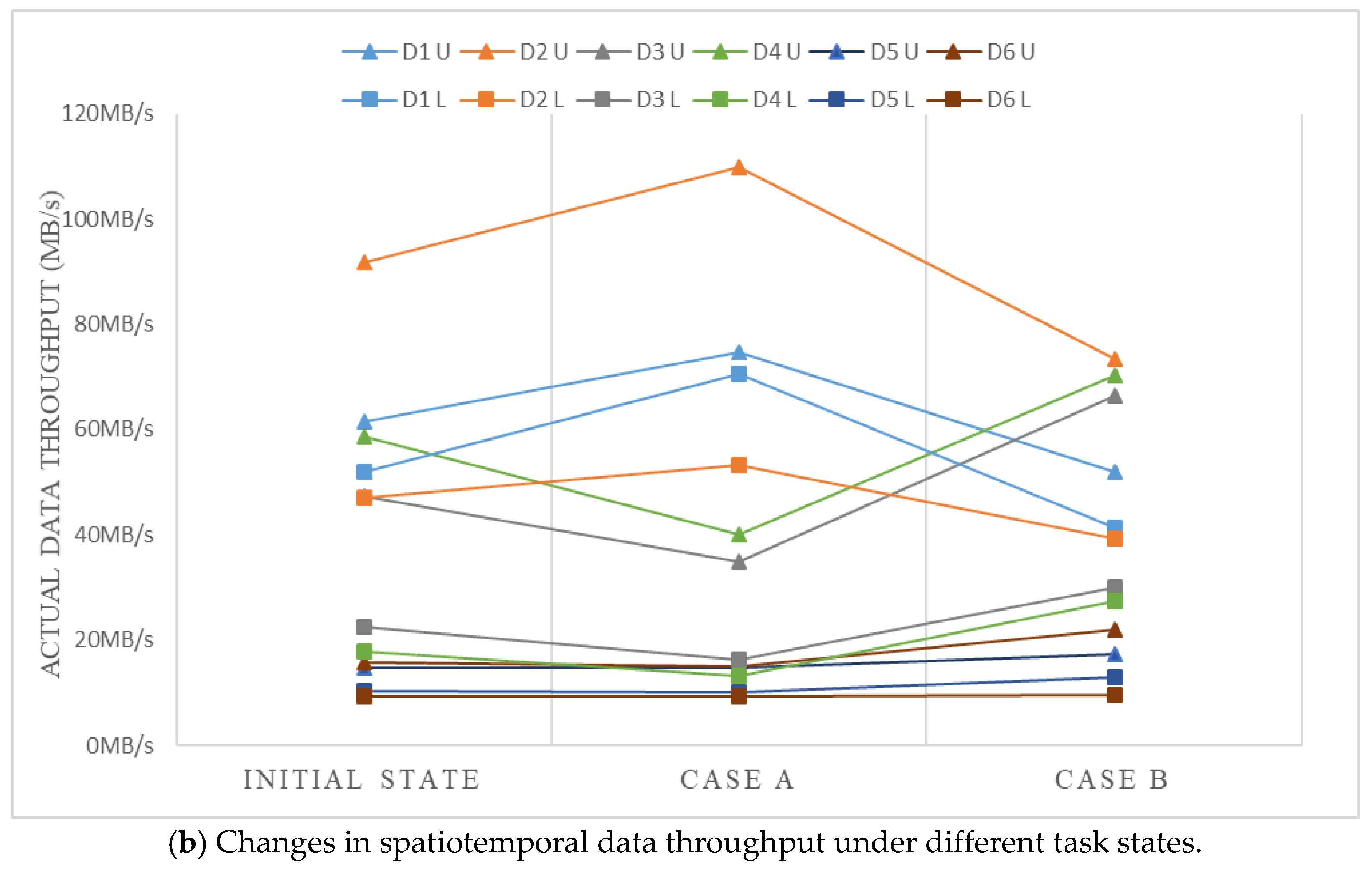
5.2.2. MFS Model Adjustment
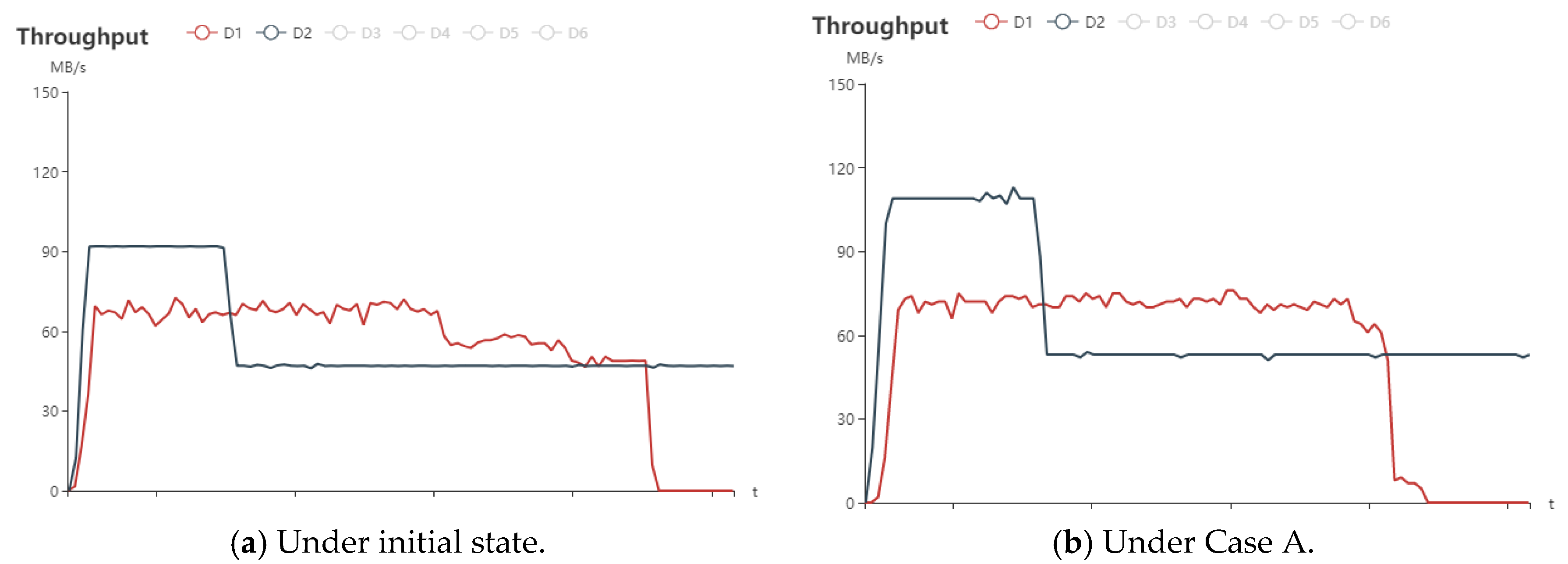
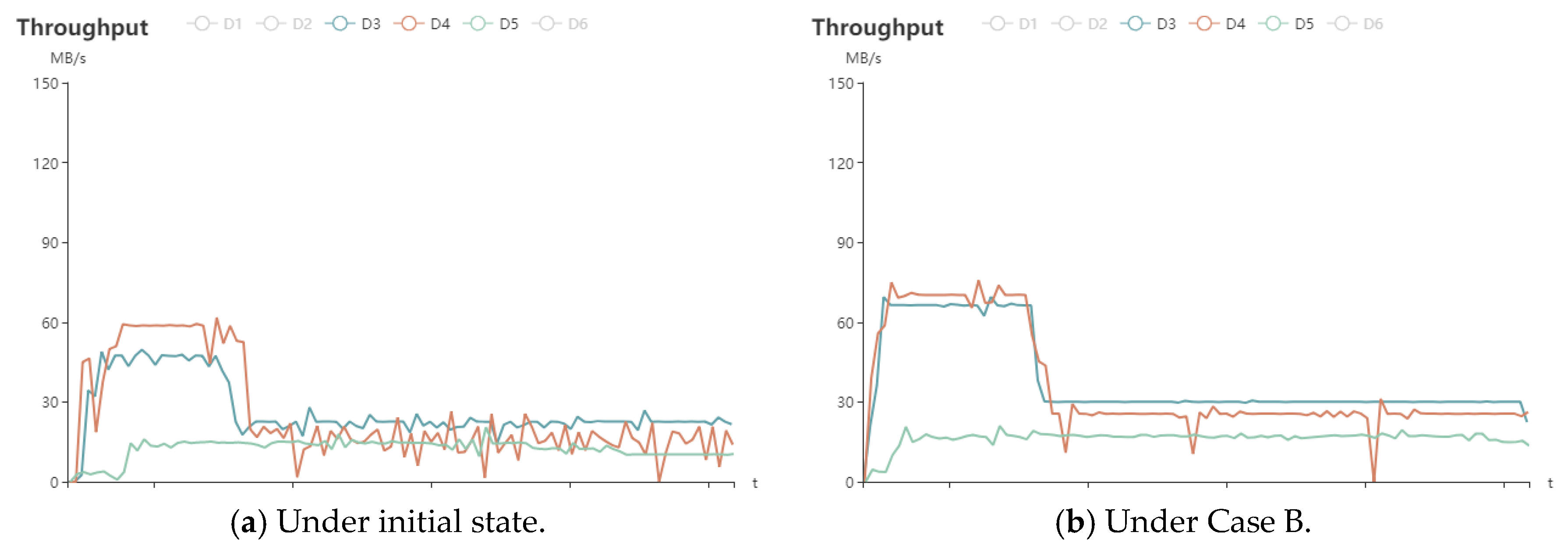
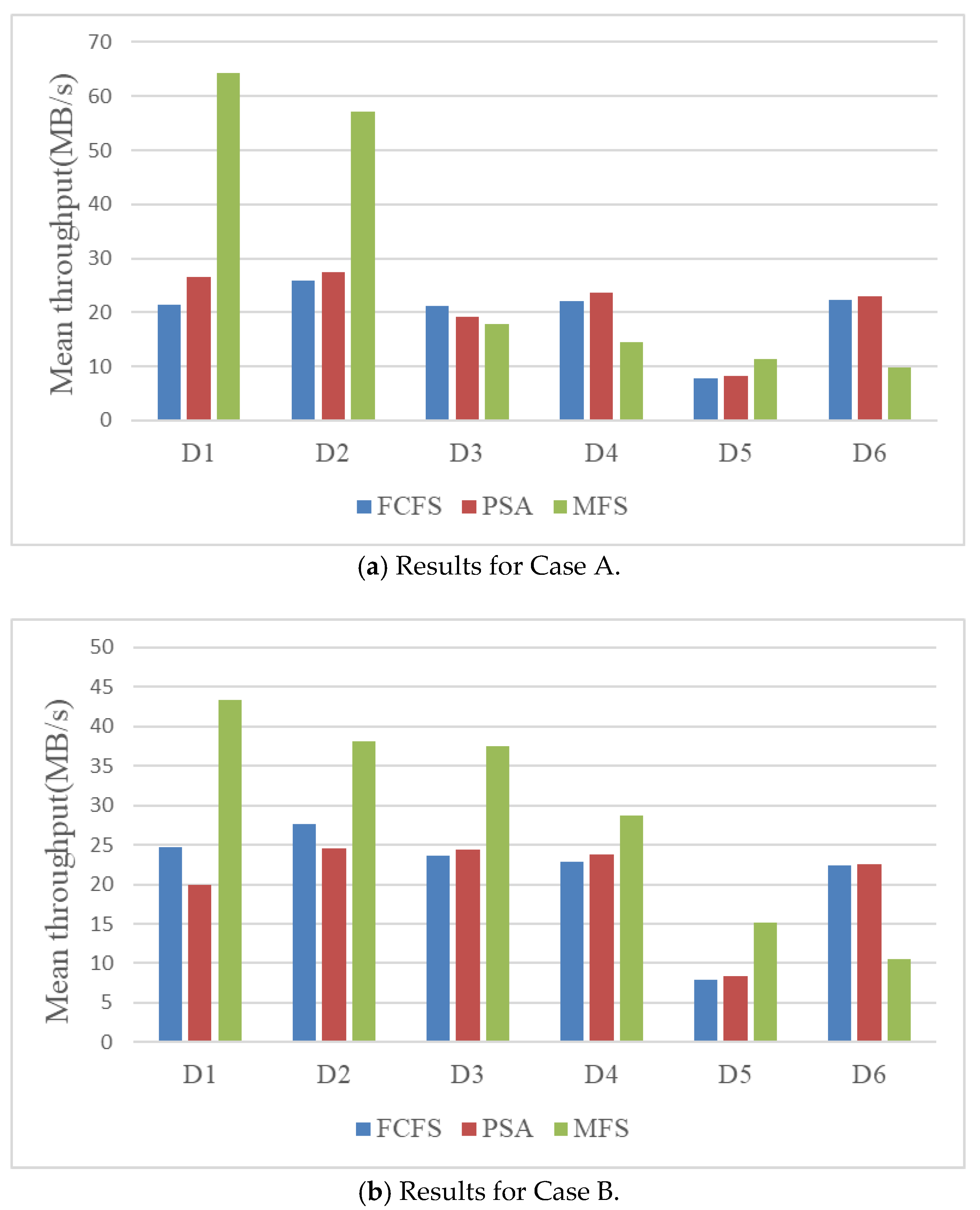
5.2.3. Mean Throughput Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, M.; Zhu, J.; Zhu, Q.; Qi, H.; Yin, L.; Zhang, X.; Feng, B.; He, H.; Yang, W.; Chen, L. Optimization of simulation and visualization analysis of dam-failure flood disaster for diverse computing systems. Int. J. Geogr. Inf. Sci. 2017, 31, 1891–1906. [Google Scholar] [CrossRef]
- Wu, C.; Zhu, Q.; Zhang, Y.; Du, Z.; Ye, X.; Qin, H.; Zhou, Y. A NOSQL–SQL hybrid organization and management approach for real-time geospatial data: A case study of public security video surveillance. ISPRS Int. J. Geo-Inf. 2017, 6, 21. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Zhang, H.; Hu, Y.; Guo, X.; Zhu, Z.; Jia, J.; Zhu, H. Cesium Based Lightweight WebBIM Technology for Smart City Visualization Management. In Proceedings of the International Conference on Inforatmion Technology in Geo-Engineering, Guimarães, Portugal, 29 September–2 October 2019; pp. 84–95. [Google Scholar]
- Gröger, G.; Plümer, L. CityGML–Interoperable semantic 3D city models. ISPRS J. Photogramm. Remote Sens. 2012, 71, 12–33. [Google Scholar] [CrossRef]
- Biljecki, F.; Ledoux, H.; Stoter, J. Improving the consistency of multi-LOD CityGML datasets by removing redundancy. In 3D Geoinformation Science; Springer: Cham, Switzerland, 2015; pp. 1–17. [Google Scholar]
- Trubka, R.; Glackin, S.; Lade, O.; Pettit, C. A web-based 3D visualisation and assessment system for urban precinct scenario modelling. ISPRS J. Photogramm. Remote Sens. 2016, 117, 175–186. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, Q.; Liu, G.; Zheng, W.; Li, Z.; Du, Z. GeoScope: Full 3D geospatial information system case study. Geo-Spat. Inf. Sci. 2011, 14, 150. [Google Scholar] [CrossRef]
- Zhai, W.; Chi, Z.; Fang, F.; Lv, C. Research on Spatial Data Organization for Large Scale Scene. Comput. Eng. 2003, 20. [Google Scholar]
- Wang, W.; Lv, Z.; Li, X.; Xu, W.; Zhang, B.; Zhu, Y.; Yan, Y. Spatial query based virtual reality GIS analysis platform. Neurocomputing 2018, 274, 88–98. [Google Scholar] [CrossRef]
- Tan, Q.; Liu, Q.; Sun, Z. Research and Application of Beijing Earthquake Disaster Prevention System Based on GIS. In Proceedings of the 2018 IEEE International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 18–20 August 2018; pp. 275–279. [Google Scholar]
- Li, X.; Lv, Z.; Hu, J.; Zhang, B.; Shi, L.; Feng, S. XEarth: A 3D GIS Platform for managing massive city information. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Shenzhen, China, 12–14 June 2015; pp. 1–6. [Google Scholar]
- Gao, P.; Liu, Z.; Xie, M.; Tian, K. The development of and prospects for private cloud GIS in China. Asian J. Geoinformatics 2015, 14. [Google Scholar]
- Zhao, S.; Sun, X.; Chen, J.; Duan, Z.; Zhang, Y.; Zhang, Y. Relational granulation method based on quotient space theory for maximum flow problem. Inf. Sci. 2018, 507, 472–484. [Google Scholar] [CrossRef]
- Song, W.; Jin, B.; Li, S.; Wei, X.; Li, D.; Hu, F. Building spatiotemporal cloud platform for supporting GIS application. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 55. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.; Tan, E.C.; Chan, K. 3D Terrain visualization for Web GIS. Map Asia 2003, 13–15. [Google Scholar]
- Su, T.; Cao, Z.; Lv, Z.; Liu, C.; Li, X. Multi-dimensional visualization of large-scale marine hydrological environmental data. Adv. Eng. Softw. 2016, 95, 7–15. [Google Scholar] [CrossRef]
- Kang, H.-K.; Li, K.-J. A standard indoor spatial data model—OGC IndoorGML and implementation approaches. ISPRS Int. J. Geo-Inf. 2017, 6, 116. [Google Scholar] [CrossRef]
- Ferreira, N.; Poco, J.; Vo, H.T.; Freire, J.; Silva, C.T. Visual exploration of big spatio-temporal urban data: A study of new york city taxi trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef]
- Gaillard, J.; Peytavie, A.; Gesquiére, G. Visualisation and personalisation of multi-representations city models. Int. J. Digit. Earth 2020, 13, 627–644. [Google Scholar] [CrossRef]
- Jaillot, V.; Servigne, S.; Gesquière, G. Delivering time-evolving 3D city models for web visualization. Int. J. Geogr. Inf. Sci. 2020, 1–23. [Google Scholar] [CrossRef]
- Cozzi, P. Introducing 3D tiles. Cesium Blog 2015, 10. [Google Scholar]
- Chen, Y.; Shooraj, E.; Rajabifard, A.; Sabri, S. From IFC to 3D tiles: An integrated open-source solution for visualising BIMs on cesium. ISPRS Int. J. Geo-Inf. 2018, 7, 393. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zhou, Y.; Zhang, Y. A Multi-Level Cache Framework for Remote Resource Access in Transparent Computing. IEEE Netw. 2018, 32, 140–145. [Google Scholar] [CrossRef]
- Jin, B.; Song, W.; Zhao, K.; Wei, X.; Hu, F.; Jiang, Y. A high performance, spatiotemporal statistical analysis system based on a Spatiotemporal Cloud Platform. ISPRS Int. J. Geo-Inf. 2017, 6, 165. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.; Chong, Y.; Xu, Z.; Tan, X. An enhanced active caching strategy for data-intensive computations in distributed GIS. J. Supercomput. 2017, 73, 4324–4346. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Wang, X.; Shi, X. A Replacement Strategy for A Distributed Caching System Based on The Spatiotemporal Access Pattern of Geospatial Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 133–137. [Google Scholar] [CrossRef] [Green Version]
- Ma, T.; Hao, Y.; Shen, W.; Tian, Y.; Al-Rodhaan, M. An improved web cache replacement algorithm based on weighting and cost. IEEE Access 2018, 6, 27010–27017. [Google Scholar] [CrossRef]
- Olanrewaju, R.F.; Baba, A.; Khan, B.U.I.; Yaacob, M.; Azman, A.W.; Mir, M.S. A study on performance evaluation of conventional cache replacement algorithms: A review. In Proceedings of the 2016 Fourth International Conference on Parallel, Distributed and Grid Computing (PDGC), Himachal Pradesh, India, 22–24 December 2016; pp. 550–556. [Google Scholar]
- Li, R.; Feng, W.; Wu, H.; Huang, Q. A replication strategy for a distributed high-speed caching system based on spatiotemporal access patterns of geospatial data. Comput. Environ. Urban Syst. 2017, 61, 163–171. [Google Scholar] [CrossRef]
- Ghribi, C.; Hadji, M.; Zeghlache, D. Energy efficient vm scheduling for cloud data centers: Exact allocation and migration algorithms. In Proceedings of the 2013 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, Delft, The Netherlands, 13–16 May 2013; pp. 671–678. [Google Scholar]
- Jin, J.; Luo, J.; Song, A.; Dong, F.; Xiong, R. Bar: An efficient data locality driven task scheduling algorithm for cloud computing. In Proceedings of the 2011 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Newport Beach, CA, USA, 23–26 May 2011; pp. 295–304. [Google Scholar]
- Bhat, M.A.; Shah, R.M.; Ahmad, B. Cloud Computing: A solution to Geographical Information Systems (GIS). Int. J. Comput. Sci. Eng. 2011, 3, 594–600. [Google Scholar]
- Calciu, I.; Sen, S.; Balakrishnan, M.; Aguilera, M.K. How to implement any concurrent data structure for modern servers. Acm Sigops Oper. Syst. Rev. 2017, 51, 24–32. [Google Scholar] [CrossRef]
- Kharouf, R.A.A.; Alzoubaidi, A.R.; Jweihan, M. An integrated architectural framework for geoprocessing in cloud environment. Spat. Inf. Res. 2017, 25, 89–97. [Google Scholar] [CrossRef]
- Pignone, M.; Cogliano, R.; Moschillo, R. The development of a cloud-GIS platform for the management and sharing of geographic data during the Central Italy seismic sequence. Ann. Geophys. 2017, 59. [Google Scholar]
- Yuan, D.; Yang, Y.; Liu, X.; Chen, J. A data placement strategy in scientific cloud workflows. Future Gener. Comput. Syst. 2010, 26, 1200–1214. [Google Scholar] [CrossRef]
- Ziani, A.; Medouri, A. Use of cloud computing technologies for geographic information systems. In Proceedings of the International Conference on Advanced Information Technology, Services and Systems, Tangier, Morocco, 14–15 April 2017; pp. 315–323. [Google Scholar]
- Zhan, Z.-H.; Liu, X.-F.; Gong, Y.-J.; Zhang, J.; Chung, H.S.-H.; Li, Y. Cloud computing resource scheduling and a survey of its evolutionary approaches. ACM Comput. Surv. 2015, 47, 63. [Google Scholar] [CrossRef] [Green Version]
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. Cloud container technologies: A state-of-the-art review. IEEE Trans. Cloud Comput. 2017. [Google Scholar] [CrossRef]
- Xavier, M.G.; Neves, M.V.; Rossi, F.D.; Ferreto, T.C.; Lange, T.; De Rose, C.A. Performance evaluation of container-based virtualization for high performance computing environments. In Proceedings of the 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Belfast, UK, 27 February–1 March 2013; pp. 233–240. [Google Scholar]
- Ramkumar, K.; Gunasekaran, G. Preserving security using crisscross AES and FCFS scheduling in cloud computing. Int. J. Adv. Intell. Paradig. 2019, 12, 77–85. [Google Scholar] [CrossRef] [Green Version]
- Arslan, S.; Topcuoglu, H.R.; Kandemir, M.T.; Tosun, O.; Computing, D. Scheduling opportunities for asymmetrically reliable caches. J. Parallel Distrib. Comput. 2019, 126, 134–151. [Google Scholar] [CrossRef]
- Lee, Z.; Ying, W.; Wen, Z. A dynamic priority scheduling algorithm on service request scheduling in cloud computing. In Proceedings of the International Conference on Electronic & Mechanical Engineering & Information Technology, Shenyang, China, 7 September 2012; pp. 4665–4669. [Google Scholar]
- Meng, L.; Reichenbacher, T. Map-based mobile services. In Map-based Mobile Services: Theories, Methods and Implementations; Meng, L., Reichenbacher, T., Zipf, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–10. [Google Scholar] [CrossRef]
- Peters, S.; Jahnke, M.; Murphy, C.E.; Meng, L.; Abdul-Rahman, A. Cartographic Enrichment of 3D City Models—State of the Art and Research Perspectives; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Mingwei, L.; Qing, Z.; Jun, Z.; Bin, F.; Yun, L.; Junxiao, Z.; Xiao, F.; Pengcheng, Z.; Weijun, Y.; Xinwen, X. The multi-level visualization task model for multi-modal spatio-temporal data. Acta Geod. Cartogr. Sin. 2018, 47, 1098. [Google Scholar]
- Qing, Z.; Xiao, F.U. The review of visual analysis methods of multi-modal spatio-temporal big data. Acta Geod. Cartogr. Sin. 2017, 46, 1672. [Google Scholar]
- Goldberg, A.V.; Tarjan, R.E. Efficient maximum flow algorithms. Commun. Acm 2014, 57, 82–89. [Google Scholar] [CrossRef]
- Everitt, T.; Hutter, M. Analytical results on the BFS vs. DFS algorithm selection problem. Part I: Tree search. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Canberra, Australia, 29 November–2 December 2020; pp. 15–165. [Google Scholar]
- Goldfarb, D.; Grigoriadis, M.D. A computational comparison of the dinic and network simplex methods for maximum flow. Ann. Oper. Res. 1988, 13, 81–123. [Google Scholar] [CrossRef]
- Nirmala, H.; Girijamma, H.A. Fuzzy Priority Scheduling Algorithm for Multiprocessor Systems. In Proceedings of the 2017 International Conference on Recent Advances in Electronics and Communication Technology (ICRAECT), Bangalore, India, 16–17 March 2017. [Google Scholar]
- Zhu, Q.; Feng, B.; Li, M.; Chen, M.; Xu, Z.; Xie, X.; Zhang, Y.; Liu, M.; Huang, Z.; Feng, Y. An efficient sparse graph index method for dynamic and associated data. Acta Geodaetica et Cartographica Sinica 2020, 49, 681–691. [Google Scholar]
- Feng, B.; Zhu, Q.; Liu, M.; Li, Y.; Zhang, J.; Fu, X.; Zhou, Y.; Li, M.; He, H.; Yang, W. An efficient graph-based spatio-temporal indexing method for task-oriented multi-modal scene data organization. ISPRS Int. J. Geo-Inf. 2018, 7, 371. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Mei, H.; Shen, Y.; Su, S.; Zhang, W.; Wang, J.; Zu, M.; Chen, W. ECharts: A declarative framework for rapid construction of web-based visualization. Vis. Inform. 2018, 2, 136–146. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Visualization Task | Data Type | Data Size (GB) | Number of Containers | |
|---|---|---|---|---|
| Display | DEM | 5.0 | 3 | |
| Building model | 4.3 | 3 | ||
| Analytical | DSM | 3.0 | 2 | |
| Trajectory | 3.1 | 2 | ||
| Relation | 1.6 | 1 | ||
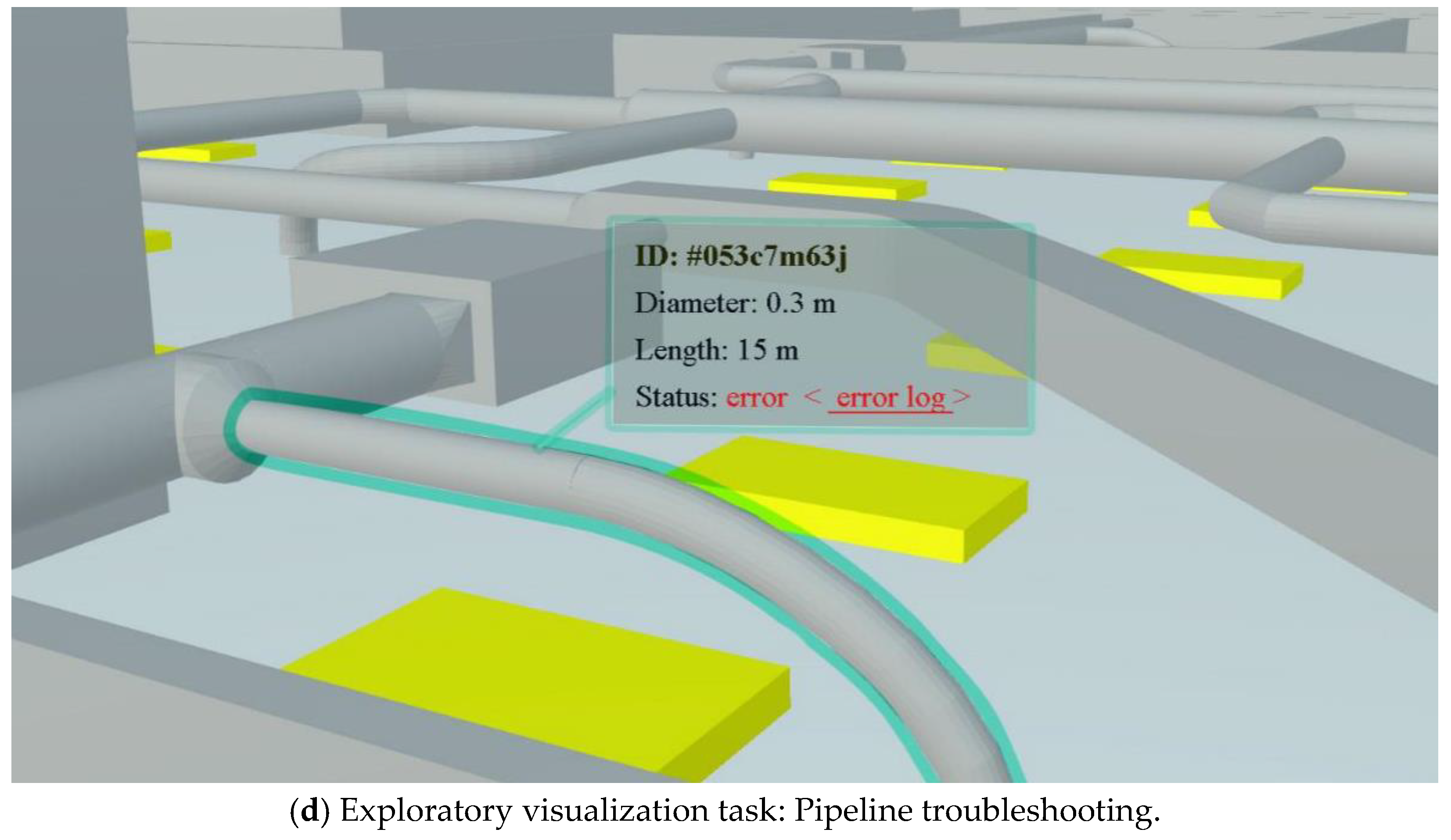
| Exploratory | Pipeline | 1.3 | 1 |
| Node Number | Node Data Size (GB) | Capacity |
|---|---|---|
| (0, 4.3, 3.0, 0, 0, 1.3) | (0, 0.058, 0.041, 0, 0, 0.017)b | |
| (5.0, 0, 0, 3.1, 1.6, 0) | (0.053, 0, 0, 0.034, 0.017, 0)b | |
| (10.0, 0, 3.0, 0, 0, 0) | (0.059, 0, 0.018, 0, 0, 0)b | |
| (0, 8.6, 0, 3.1, 0, 0) | (0, 0.062, 0, 0.023, 0, 0)b | |
| (0.6, 0.5, 0.25, 0.4, 0.15, 0.1) | (0.143, 0.129, 0.057, 0.094, 0.036, 0.026)b | |
| (0.5, 0.5, 0.3, 0.45, 0.125, 0.125) | (0.119, 0.118, 0.073, 0.106, 0.029, 0.039)b |
| 0.225b | 0.262b | |
| 0.240b | 0.247b | |
| 0.118b | 0.130b | |
| 0.112b | 0.199b | |
| 0.033b | 0.065b | |
| 0.034b | 0.064b |
| 0.255b | 0.328b | |
| 0.280b | 0.303b | |
| 0.086b | 0.100b | |
| 0.071b | 0.143b | |
| 0.033b | 0.067b | |
| 0.034b | 0.040b |
| 0.185b | 0.209b | |
| 0.193b | 0.211b | |
| 0.159b | 0.194b | |
| 0.148b | 0.213b | |
| 0.042b | 0.091b | |
| 0.035b | 0.067b |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Chen, M.; Feng, B.; Zhou, Y.; Li, M.; Xu, Z.; Ding, Y.; Liu, M.; Wang, W.; Xie, X. Optimized Spatiotemporal Data Scheduling Based on Maximum Flow for Multilevel Visualization Tasks. ISPRS Int. J. Geo-Inf. 2020, 9, 518. https://doi.org/10.3390/ijgi9090518
Zhu Q, Chen M, Feng B, Zhou Y, Li M, Xu Z, Ding Y, Liu M, Wang W, Xie X. Optimized Spatiotemporal Data Scheduling Based on Maximum Flow for Multilevel Visualization Tasks. ISPRS International Journal of Geo-Information. 2020; 9(9):518. https://doi.org/10.3390/ijgi9090518
Chicago/Turabian StyleZhu, Qing, Meite Chen, Bin Feng, Yan Zhou, Maosu Li, Zhaowen Xu, Yulin Ding, Mingwei Liu, Wei Wang, and Xiao Xie. 2020. "Optimized Spatiotemporal Data Scheduling Based on Maximum Flow for Multilevel Visualization Tasks" ISPRS International Journal of Geo-Information 9, no. 9: 518. https://doi.org/10.3390/ijgi9090518
APA StyleZhu, Q., Chen, M., Feng, B., Zhou, Y., Li, M., Xu, Z., Ding, Y., Liu, M., Wang, W., & Xie, X. (2020). Optimized Spatiotemporal Data Scheduling Based on Maximum Flow for Multilevel Visualization Tasks. ISPRS International Journal of Geo-Information, 9(9), 518. https://doi.org/10.3390/ijgi9090518