Performance Evaluation of GIS-Based Artificial Intelligence Approaches for Landslide Susceptibility Modeling and Spatial Patterns Analysis



Abstract
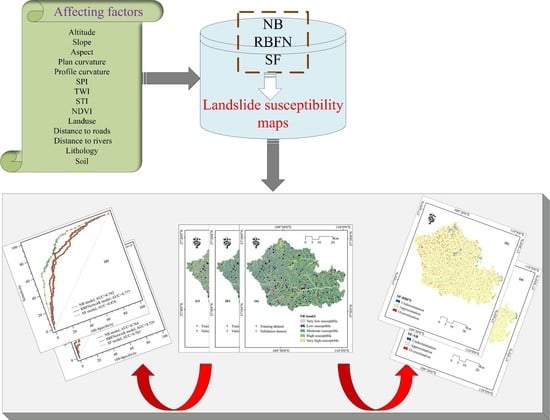
1. Introduction
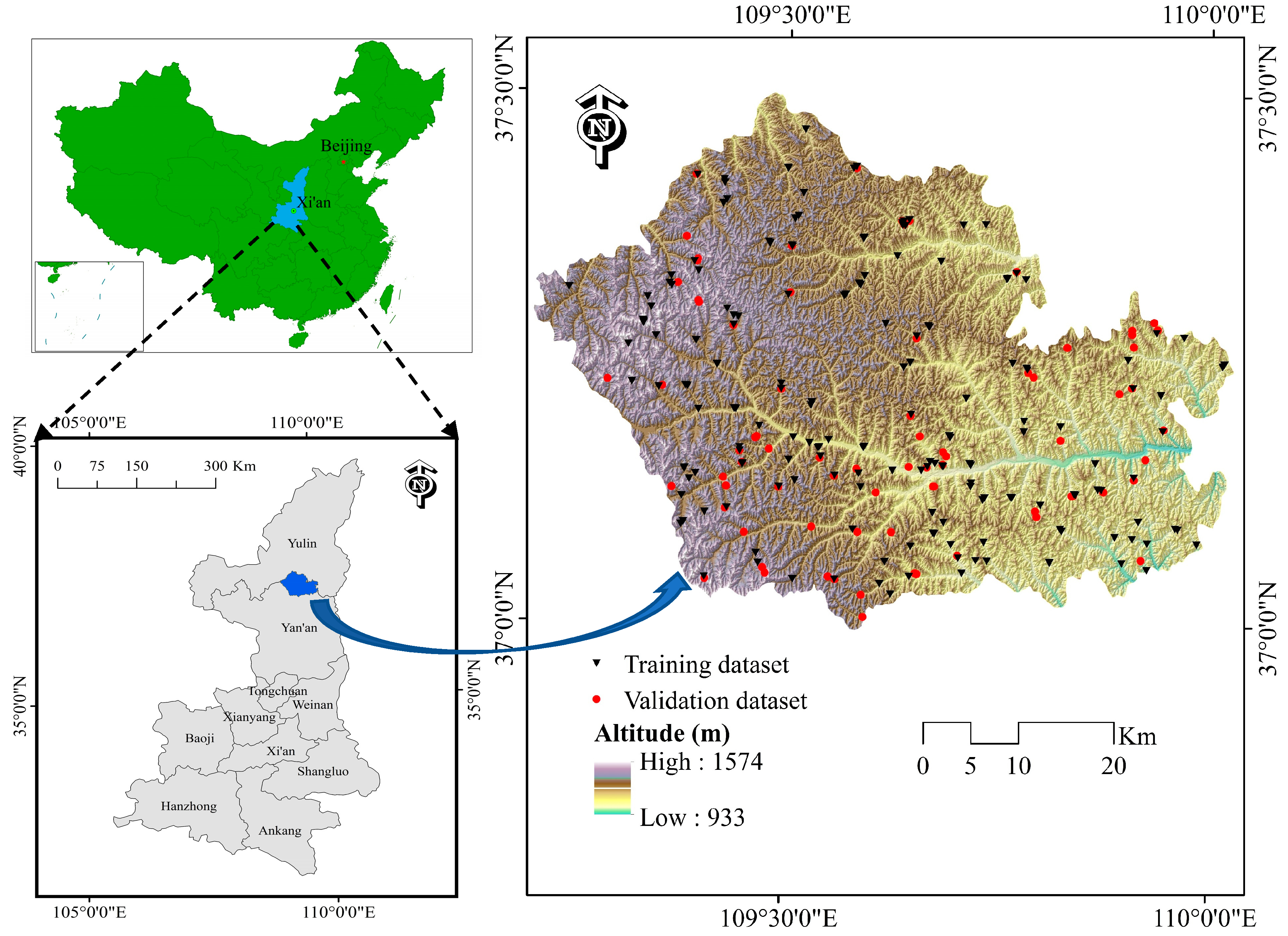
2. Geological and Geomorphological Setting
3. Materials and Methods
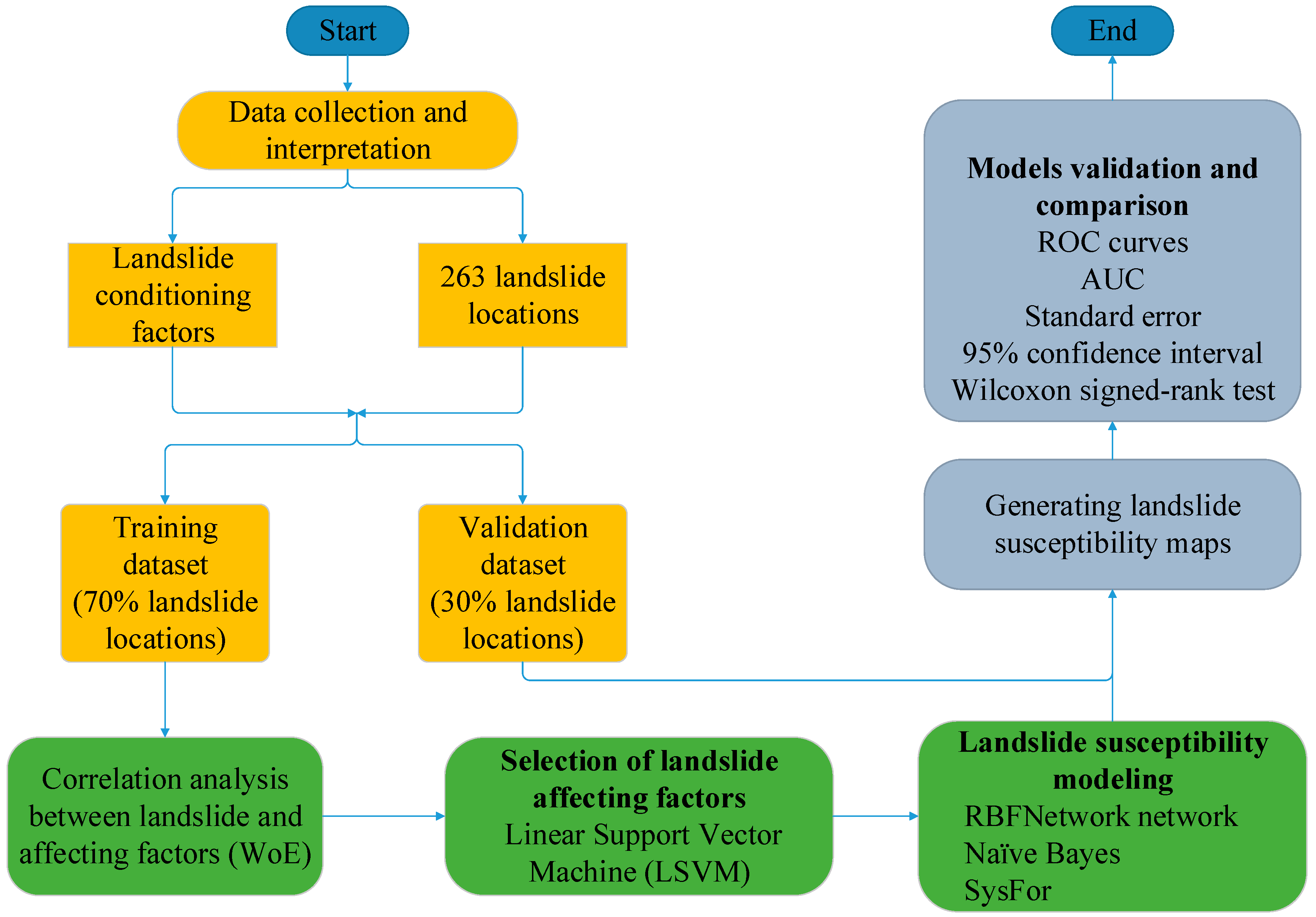
3.1. Methodology
3.2. Preparation of Training and Validation Datasets
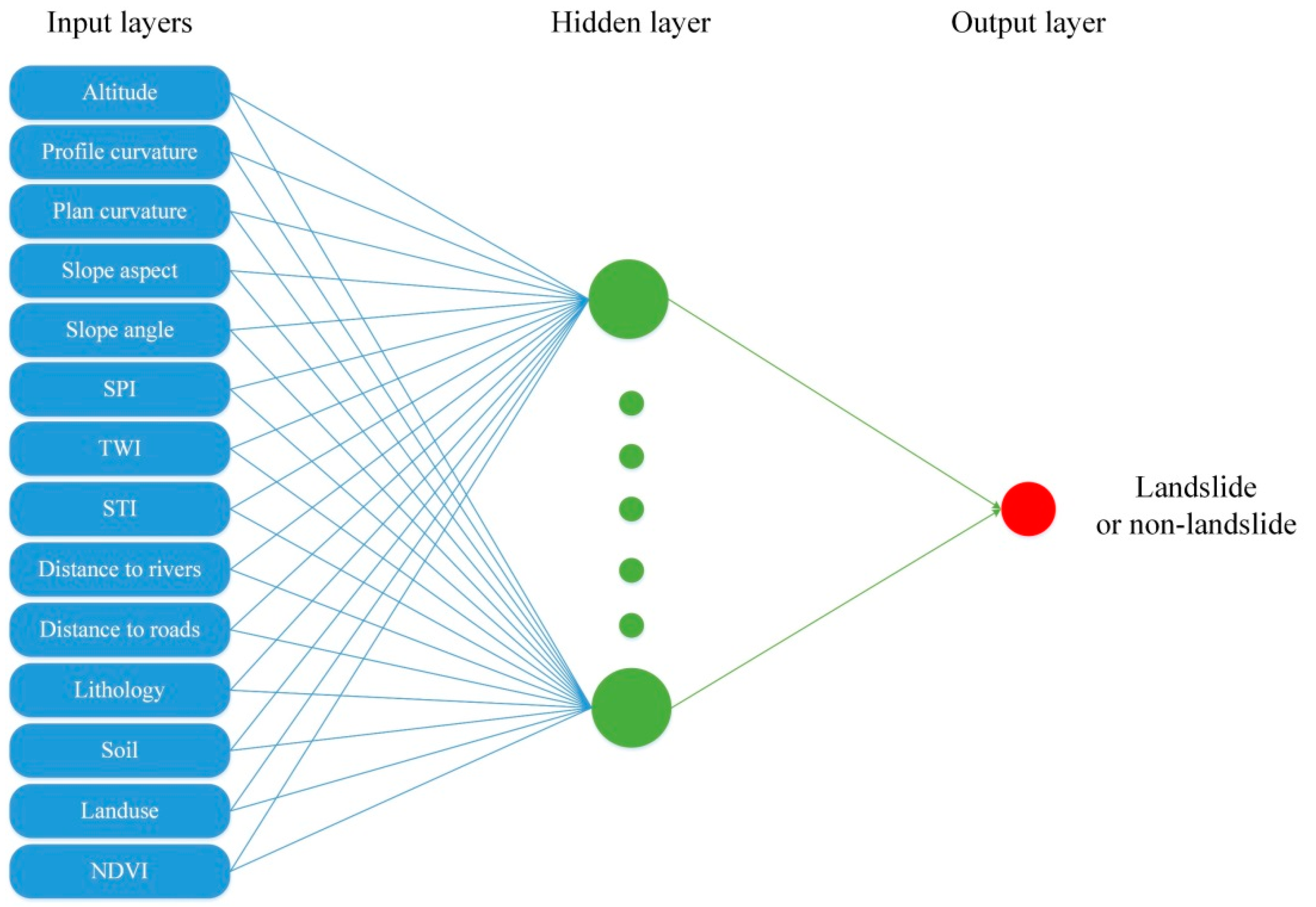
3.3. Landslide Affecting Factors
3.4. Weights of Evidence
3.5. Naïve Bayes
3.6. Radial Basis Function Network
3.7. SysFor
3.8. Support Vector Machine
4. Results and Analysis
4.1. Correlation Analysis of Affecting Factors
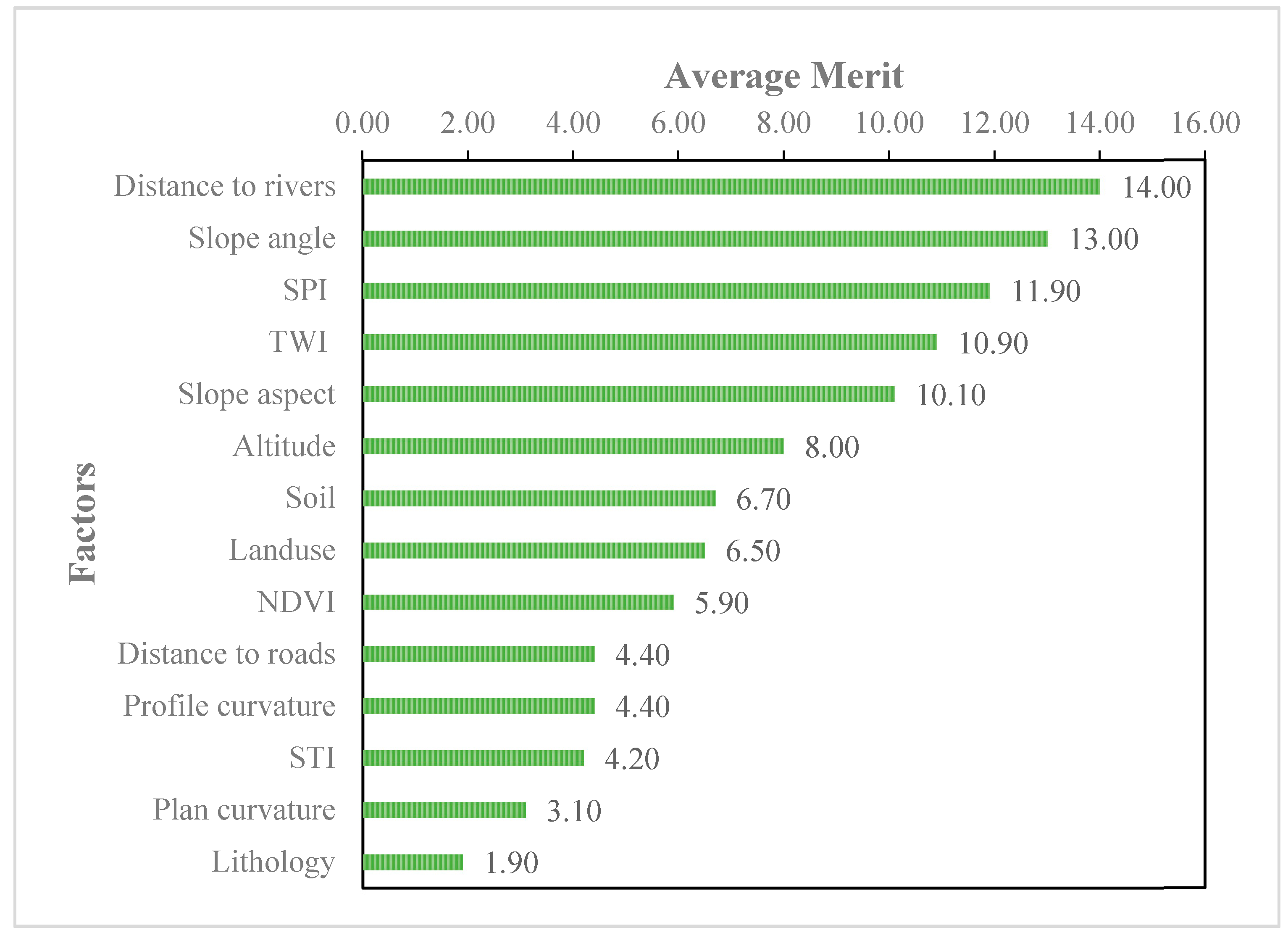
4.2. Selection of Landslide-Affecting Factors
4.3. Constructing Landslide Susceptibility Maps
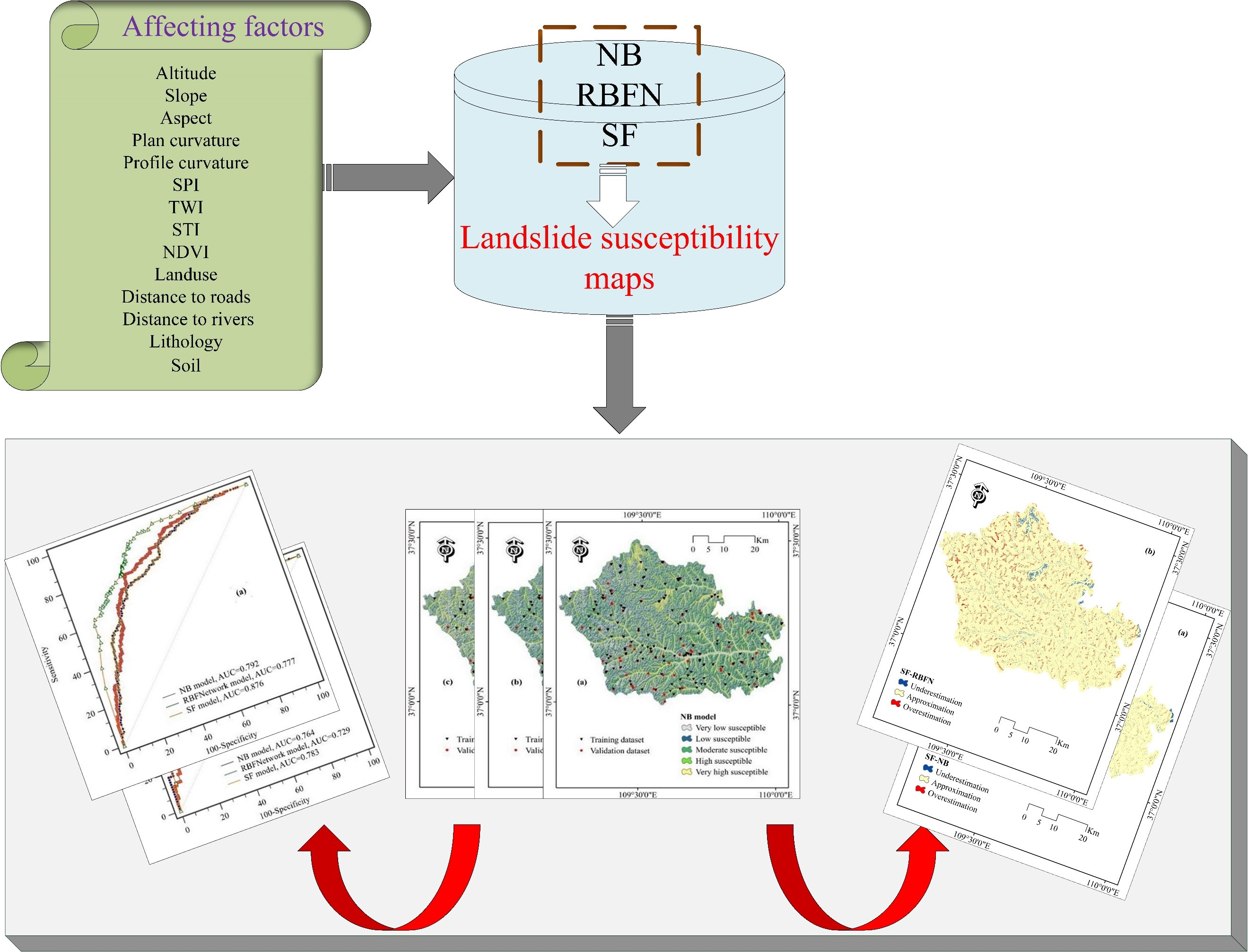
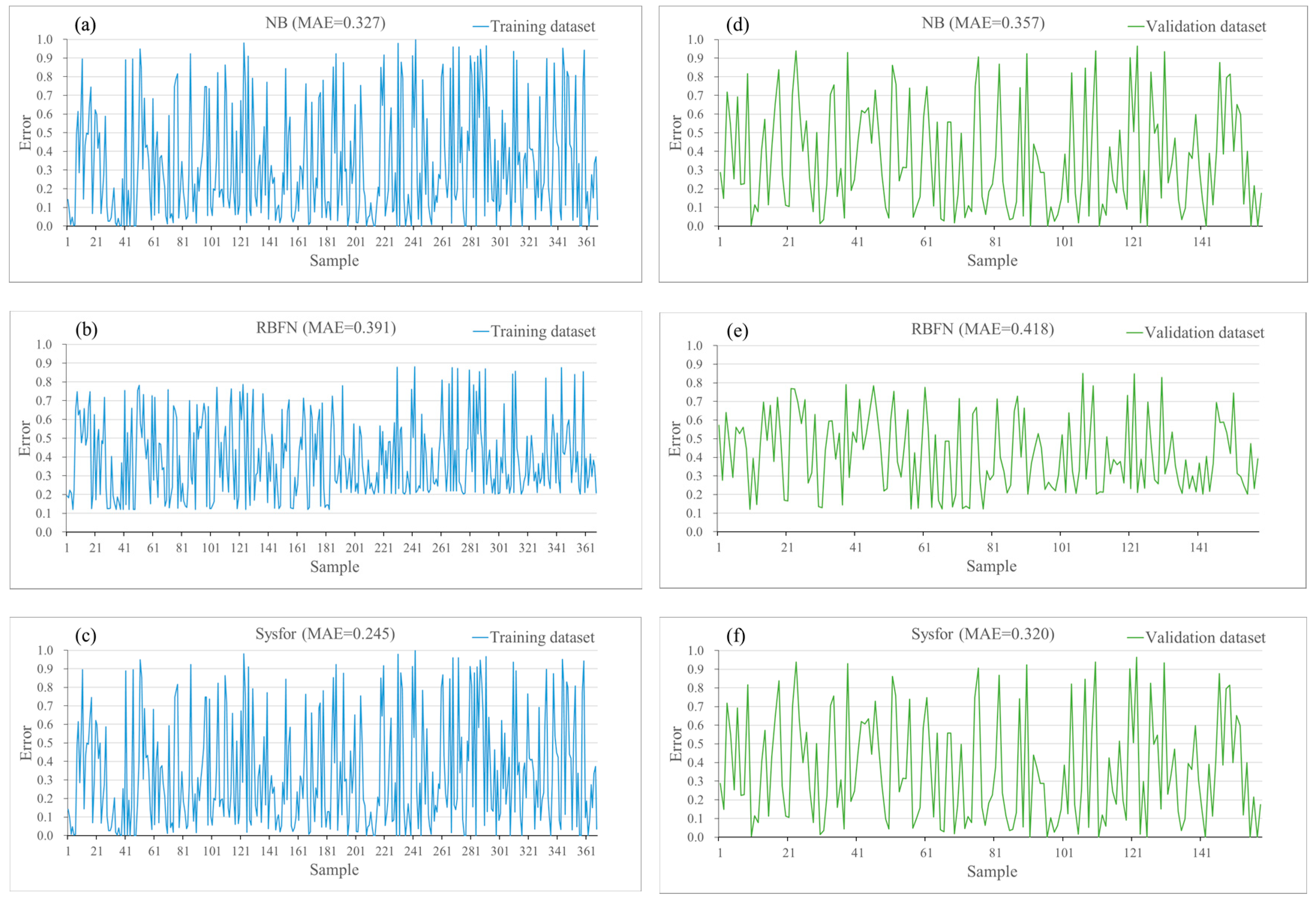
4.4. Models Validation and Comparison
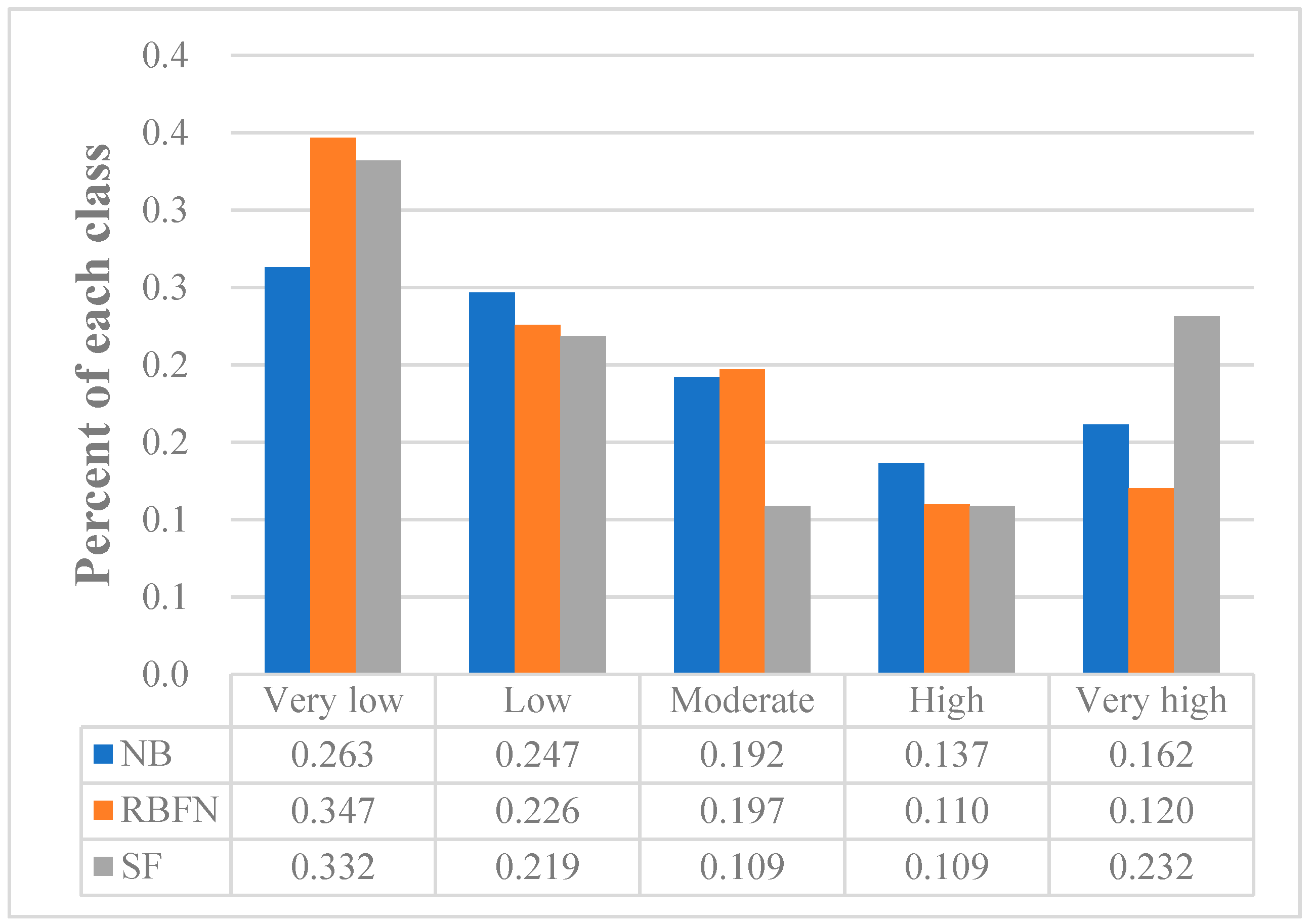
4.5. Comparison of Landslide Susceptibility Maps
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Van Westen, C.; Van Asch, T.W.; Soeters, R. Landslide hazard and risk zonation—why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Pradhan, B. Landslide susceptibility mapping of a catchment area using frequency ratio, fuzzy logic and multivariate logistic regression approaches. J. Indian Soc. Remote Sens. 2010, 38, 301–320. [Google Scholar] [CrossRef]
- Wang, G.; Lei, X.; Chen, W.; Shahabi, H.; Shirzadi, A. Hybrid Computational Intelligence Methods for Landslide Susceptibility Mapping. Symmetry 2020, 12, 325. [Google Scholar] [CrossRef]
- Wan, S. A spatial decision support system for extracting the core factors and thresholds for landslide susceptibility map. Eng. Geol. 2009, 108, 237–251. [Google Scholar] [CrossRef]
- Akgün, A.; Bulut, F. GIS-based landslide susceptibility for Arsin-Yomra (Trabzon, North Turkey) region. Environ. Geol. 2007, 51, 1377–1387. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.-H.; Kim, I.-S. Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: Case study of Youngin, Korea. Landslides 2007, 4, 327–338. [Google Scholar] [CrossRef]
- Akgun, A. A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: A case study at zmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Nefeslioglu, H.A.; Gokceoglu, C.; Sonmez, H. An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng. Geol. 2008, 97, 171–191. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, W. Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation. Remote Sens. 2020, 12, 2180. [Google Scholar] [CrossRef]
- Klose, M.; Gruber, D.; Damm, B.; Gerold, G. Spatial databases and GIS as tools for regional landslide susceptibility modeling. Z. Geomorphol. 2014, 58, 1–36. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide susceptibility assessment in vietnam using support vector machines, decision tree, and Naive Bayes Models. Math. Probl. Eng. 2012, 2012. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, W. GIS-Based Evaluation of Landslide Susceptibility Models Using Certainty Factors and Functional Trees-Based Ensemble Techniques. Appl. Sci. 2020, 10, 16. [Google Scholar] [CrossRef]
- Wang, G.; Chen, X.; Chen, W. Spatial Prediction of Landslide Susceptibility Based on GIS and Discriminant Functions. ISPRS Int. J. Geo-Inf. 2020, 9, 144. [Google Scholar] [CrossRef]
- Nsengiyumva, J.B.; Luo, G.; Amanambu, A.C.; Mind’je, R.; Habiyaremye, G.; Karamage, F.; Ochege, F.U.; Mupenzi, C. Comparing probabilistic and statistical methods in landslide susceptibility modeling in Rwanda/Centre-Eastern Africa. Sci. Total Environ. 2019, 659, 1457–1472. [Google Scholar] [CrossRef]
- Mondal, S.; Mandal, S. Data-driven evidential belief function (EBF) model in exploring landslide susceptibility zones for the Darjeeling Himalaya, India. Geocarto Int. 2020, 35, 818–856. [Google Scholar] [CrossRef]
- Althuwaynee, O.F.; Pradhan, B.; Lee, S. Application of an evidential belief function model in landslide susceptibility mapping. Comput. Geosci. 2012, 44, 120–135. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, F.; Chen, H.; Wu, Y.; Li, T.; Li, W.; Wang, Q.; Liu, P. GIS-based landslide susceptibility analysis using frequency ratio and evidential belief function models. Environ. Earth Sci. 2016, 75, 948. [Google Scholar] [CrossRef]
- Ramesh, V.; Anbazhagan, S. Landslide susceptibility mapping along Kolli hills Ghat road section (India) using frequency ratio, relative effect and fuzzy logic models. Environ. Earth Sci. 2015, 73, 8009–8021. [Google Scholar] [CrossRef]
- Rasyid, A.R.; Bhandary, N.P.; Yatabe, R. Performance of frequency ratio and logistic regression model in creating GIS based landslides susceptibility map at Lompobattang Mountain, Indonesia. Geoenviron. Disasters 2016, 3, 19. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.; Chen, W.; Ahmad, B.B. Landslide susceptibility mapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y. GIS-based evaluation of landslide susceptibility using hybrid computational intelligence models. CATENA 2020, 195, 104777. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Bui, D.T. A novel hybrid intelligent model of support vector machines and the MultiBoost ensemble for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 2865–2886. [Google Scholar] [CrossRef]
- Ada, M.; San, B.T. Comparison of machine-learning techniques for landslide susceptibility mapping using two-level random sampling (2LRS) in Alakir catchment area, Antalya, Turkey. Nat. Hazards 2018, 90, 237–263. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef]
- He, Q.; Shahabi, H.; Shirzadi, A.; Li, S.; Chen, W.; Wang, N.; Chai, H.; Bian, H.; Ma, J.; Chen, Y.; et al. Landslide spatial modelling using novel bivariate statistical based naïve bayes, rbf classifier, and rbf network machine learning algorithms. Sci. Total Environ. 2019, 663, 1–15. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S.; Jung, H.; Lee, S. Landslide susceptibility mapping using random forest and boosted tree models in Pyeong-Chang, Korea. Geocarto Int. 2018, 33, 1000–1015. [Google Scholar] [CrossRef]
- Paudel, U.; Oguchi, T.; Hayakawa, Y.S. Multi-Resolution Landslide Susceptibility Analysis Using a DEM and Random Forest. Int. J. Geosci. 2016, 07, 726–743. [Google Scholar] [CrossRef]
- Hong, H.; Miao, Y.; Liu, J.; Zhu, A. Exploring the effects of the design and quantity of absence data on the performance of random forest-based landslide susceptibility mapping. Catena 2019, 176, 45–64. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Bui, D.T.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment. Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Roodposhti, M.S.; Blaschke, T.; Aryal, J. Comparing GIS-based support vector machine kernel functions for landslide susceptibility mapping. Arab. J. Geosci. 2017, 10, 122. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]
- Truong, X.L.; Mitamura, M.; Kono, Y.; Raghavan, V.; Yonezawa, G.; Truong, X.Q.; Do, T.H.; Tien Bui, D.; Lee, S. Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree. Appl. Sci. 2018, 8, 1046. [Google Scholar] [CrossRef]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Mrker, M.; Rotigliano, E. Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: Application to the 2009 storm event in Messina (Sicily, southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar] [CrossRef]
- Song, Y.; Niu, R.; Xu, S.; Ye, R.; Peng, L.; Guo, T.; Li, S.; Chen, T. Landslide Susceptibility Mapping Based on Weighted Gradient Boosting Decision Tree in Wanzhou Section of the Three Gorges Reservoir Area (China). ISPRS Int. J. Geo-Inf. 2018, 8, 4. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.T.; Zhang, T.; Zhang, L.; Chai, H.; et al. Landslide Susceptibility Modeling Based on GIS and Novel Bagging-Based Kernel Logistic Regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W. Landslide Susceptibility Evaluation Using Hybrid Integration of Evidential Belief Function and Machine Learning Techniques. Water 2019, 12, 113. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rossi, M. Landslide susceptibility modeling in a landslide prone area in Mazandarn Province, north of Iran: A comparison between GLM, GAM, MARS, and M-AHP methods. Theor. Appl. Climatol. 2017, 130, 609–633. [Google Scholar] [CrossRef]
- Borrelli, L.; Ciurleo, M.; Gullà, G. Shallow landslide susceptibility assessment in granitic rocks using GIS-based statistical methods: The contribution of the weathering grade map. Landslides 2018, 15, 1127–1142. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Mezaal, M.R.; Pradhan, B. An improved algorithm for identifying shallow and deep-seated landslides in dense tropical forest from airborne laser scanning data. Catena 2018, 167, 147–159. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Naghibi, S.A. Prioritization of landslide conditioning factors and its spatial modeling in Shangnan County, China using GIS-based data mining algorithms. Bull. Eng. Geol. Environ. 2018, 77, 611–629. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Selecting optimal conditioning factors in shallow translational landslide susceptibility mapping using genetic algorithm. Eng. Geol. 2015, 192, 101–112. [Google Scholar] [CrossRef]
- Mahalingam, R.; Olsen, M.J.; O’Banion, M.S. Evaluation of landslide susceptibility mapping techniques using lidar-derived conditioning factors (Oregon case study). Geomat. Nat. Hazards Risk 2016, 7, 1884–1907. [Google Scholar] [CrossRef]
- Cevik, E.; Topal, T. GIS-based landslide susceptibility mapping for a problematic segment of the natural gas pipeline, Hendek (Turkey). Environ. Geol. 2003, 44, 949–962. [Google Scholar] [CrossRef]
- Yalcin, A.; Bulut, F. Landslide susceptibility mapping using GIS and digital photogrammetric techniques: A case study from Ardesen (NE-Turkey). Nat. Hazards 2007, 41, 201–226. [Google Scholar] [CrossRef]
- Lee, S. Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int. J. Remote Sens. 2005, 26, 1477–1491. [Google Scholar] [CrossRef]
- Galli, M.; Ardizzone, F.; Cardinali, M.; Guzzetti, F.; Reichenbach, P. Comparing landslide inventory maps. Geomorphology 2008, 94, 268–289. [Google Scholar] [CrossRef]
- Yalcin, A. GIS-based landslide susceptibility mapping using analytical hierarchy process and bivariate statistics in Ardesen (Turkey): Comparisons of results and confirmations. Catena 2008, 72, 1–12. [Google Scholar] [CrossRef]
- Costanzo, D.; Rotigliano, E.; Irigaray, C.; Jiménez-Perálvarez, J.; Chacón, J. Factor Selection Procedures in a Google Earth TM Aided Landslide Susceptibility Model: Application to the Beiro River Basin (Spain). In Landslide Science and Practice; Springer: Berlin/Heidelberg, Germany, 2013; pp. 541–550. [Google Scholar]
- Moore, I.D.; Grayson, R.; Ladson, A. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Beven, K.; Kirkby, M.; Schofield, N.; Tagg, A. Testing a physically-based flood forecasting model (TOPMODEL) for three UK catchments. J. Hydrol. 1984, 69, 119–143. [Google Scholar] [CrossRef]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Pourghasemi, H.; Moradi, H.; Aghda, S.F. Landslide susceptibility mapping by binary logistic regression, analytical hierarchy process, and statistical index models and assessment of their performances. Nat. Hazards 2013, 69, 749–779. [Google Scholar] [CrossRef]
- Liu, J.; Mason, P.; Clerici, N.; Chen, S.; Davis, A.; Miao, F.; Deng, H.; Liang, L. Landslide hazard assessment in the Three Gorges area of the Yangtze river using ASTER imagery: Zigui–Badong. Geomorphology 2004, 61, 171–187. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Panahi, M.; Shahabi, H.; Wang, Y.; Shirzadi, A.; Pirasteh, S.; Alesheikh, A.A.; Khosravi, K.; Panahi, S. Spatial prediction of landslide susceptibility using gis-based data mining techniques of anfis with whale optimization algorithm (woa) and grey wolf optimizer (gwo). Appl. Sci. 2019, 9, 3755. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 34, 1177–1201. [Google Scholar] [CrossRef]
- Regmi, N.R.; Giardino, J.R.; Vitek, J.D. Modeling susceptibility to landslides using the weight of evidence approach: Western Colorado, USA. Geomorphology 2010, 115, 172–187. [Google Scholar] [CrossRef]
- Ozdemir, A.; Altural, T. A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J. Asian Earth Sci. 2013, 64, 180–197. [Google Scholar] [CrossRef]
- Bhargavi, P.; Jyothi, S. Applying naive bayes data mining technique for classification of agricultural land soils. Int. J. Comput. Sci. Netw. Secur. 2009, 9, 117–122. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Pham, B.T.; Khosravi, K.; Prakash, I. Application and comparison of decision tree-based machine learning methods in landside susceptibility assessment at Pauri Garhwal Area, Uttarakhand, India. Environ. Process. 2017, 4, 711–730. [Google Scholar] [CrossRef]
- Powell, M.J. The theory of radial basis function approximation in 1990. Adv. Numer. Anal. 1992, 105–210. [Google Scholar]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royal Signals and Radar Establishment Malvern (United Kingdom): Malvern, UK, 1988. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; pp. 281–297. [Google Scholar]
- Rumellhart, D. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–362. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1994. [Google Scholar]
- Islam, Z.; Giggins, H. Knowledge discovery through SysFor: A systematically developed forest of multiple decision trees. In Proceedings of the Ninth Australasian Data Mining Conference-Volume 121, Ballarat, Australia, 1–2 December 2011; pp. 195–204. [Google Scholar]
- Al-Saggaf, Y.; Islam, M.Z. Data mining and privacy of social network sites’ users: Implications of the data mining problem. Sci. Eng. Ethics 2015, 21, 941–966. [Google Scholar] [CrossRef]
- Al-Saggaf, Y.; Nielsen, S. Self-disclosure on Facebook among female users and its relationship to feelings of loneliness. Comput. Hum. Behav. 2014, 36, 460–468. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Mladenić, D.; Brank, J.; Grobelnik, M.; Milic-Frayling, N. Feature selection using linear classifier weights: Interaction with classification models. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 234–241. [Google Scholar]
- Gruber, S.; Haeberli, W. Permafrost in steep bedrock slopes and its temperature©\related destabilization following climate change. J. Geophys. Res. Earth Surf. 2007, 112. [Google Scholar] [CrossRef]
- Aghdam, I.N.; Varzandeh, M.H.M.; Pradhan, B. Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ. Earth Sci. 2016, 75, 1–20. [Google Scholar] [CrossRef]
- Chauhan, S.; Sharma, M.; Arora, M.K. Landslide susceptibility zonation of the Chamoli region, Garhwal Himalayas, using logistic regression model. Landslides 2010, 7, 411–423. [Google Scholar] [CrossRef]
- Prandini, L.; Guidiini, G.; Bottura, J.; Pan ano, W.; Santos, A. Behavior of the vegetation in slope stability: A critical review. Bull. Int. Assoc. Eng. Geol.-Bull. l’Assoc. Int. 1977, 16, 51–55. [Google Scholar] [CrossRef]
- Chung, C.-J.F.; Fabbri, A.G. Validation of spatial prediction models for landslide hazard mapping. Nat. Hazards 2003, 30, 451–472. [Google Scholar] [CrossRef]
- Hosseinalizadeh, M.; Kariminejad, N.; Chen, W.; Pourghasemi, H.R.; Alinejad, M.; Mohammadian Behbahani, A.; Tiefenbacher, J.P. Gully headcut susceptibility modeling using functional trees, naïve Bayes tree, and random forest models. Geoderma 2019, 342, 1–11. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Wang, X.; Ahmad, B.B. Evaluating the usage of tree-based ensemble methods in groundwater spring potential mapping. J. Hydrol. 2020, 583, 124602. [Google Scholar] [CrossRef]
- Xiao, T.; Segoni, S.; Chen, L.; Yin, K.; Casagli, N. A step beyond landslide susceptibility maps: A simple method to investigate and explain the different outcomes obtained by different approaches. Landslides 2019, 1–14. [Google Scholar] [CrossRef]
- Guo, C.; Qin, Y.; Ma, D.; Xia, Y.; Chen, Y.; Si, Q.; Lu, L. Ionic composition, geological signature and environmental impacts of coalbed methane produced water in China. Energy Sources Part A Recovery Util. Environ. Eff. 2019, 1–15. [Google Scholar] [CrossRef]
- Abedini, M.; Tulabi, S. Assessing LNRF, FR, and AHP models in landslide susceptibility mapping index: A comparative study of Nojian watershed in Lorestan province, Iran. Environ. Earth Sci. 2018, 77, 405. [Google Scholar] [CrossRef]
- Demir, G. Landslide susceptibility mapping by using statistical analysis in the North Anatolian Fault Zone (NAFZ) on the northern part of Suşehri Town, Turkey. Nat. Hazards 2018, 92, 133–154. [Google Scholar] [CrossRef]
- Lin, W.-T.; Lin, C.-Y.; Chou, W.-C. Assessment of vegetation recovery and soil erosion at landslides caused by a catastrophic earthquake: A case study in Central Taiwan. Ecol. Eng. 2006, 28, 79–89. [Google Scholar] [CrossRef]
- Gonzalez-Ollauri, A.; Mickovski, S.B. Hydrological effect of vegetation against rainfall-induced landslides. J. Hydrol. 2017, 549, 374–387. [Google Scholar] [CrossRef]
- Hadmoko, D.S.; Lavigne, F.; Samodra, G. Application of a semiquantitative and GIS-based statistical model to landslide susceptibility zonation in Kayangan Catchment, Java, Indonesia. Nat. Hazards 2017, 87, 437–468. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, T.; Wu, S.; Tang, H.; Liang, C. Dynamics characteristic of red clay in a deep-seated landslide, Northwest China: An experiment study. Eng. Geol. 2018, 239, 254–268. [Google Scholar] [CrossRef]
- Pham, B.T. A Novel Classifier Based on Composite Hyper-cubes on Iterated Random Projections for Assessment of Landslide Susceptibility. J. Geol. Soc. India 2018, 91, 355–362. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pourghasemi, H.R.; Indra, P.; Dholakia, M. Landslide susceptibility assesssment in the Uttarakhand area (India) using GIS: A comparison study of prediction capability of na ve bayes, multilayer perceptron neural networks, and functional trees methods. Theor. Appl. Climatol. 2017, 128, 255–273. [Google Scholar] [CrossRef]
- Bibri, S.E. Data science for urban sustainability: Data mining and data-analytic thinking in the next wave of city analytics. In Smart Sustainable Cities of the Future; Springer: Berlin/Heidelberg, Germany, 2018; pp. 189–246. [Google Scholar]
- Chen, W.; Fan, L.; Li, C.; Pham, B.T. Spatial prediction of landslides using hybrid integration of artificial intelligence algorithms with frequency ratio and index of entropy in nanzheng county, china. Appl. Sci. 2020, 10, 29. [Google Scholar] [CrossRef]
- Chen, W.; Yan, X.; Zhao, Z.; Hong, H.; Bui, D.T.; Pradhan, B. Spatial prediction of landslide susceptibility using data mining-based kernel logistic regression, naive Bayes and RBFNetwork models for the Long County area (China). Bull. Eng. Geol. Environ. 2019, 78, 247–266. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Pradhan, B.; Sameen, M.I. Landslide susceptibility modeling: Optimization and factor effect analysis. In Laser Scanning Applications in Landslide Assessment; Springer: Berlin/Heidelberg, Germany, 2017; pp. 115–132. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Lithology | Geologic Ages |
|---|---|---|
| A | Sandy gravel, loess-like silt | Quaternary |
| B | Malan loess, silty clay, sandy cobble | Quaternary |
| C | Lishi loess, silty clay, alluvium | Quaternary |
| D | Loess of Wucheng, silt interbedded with caliche nodule | Quaternary |
| E | Silt mudstone interbedded with calcium structure | Tertiary |
| F | Medium-coarse arkose | Cretaceous |
| G | Muddy limestone, shale siltstone interbedded | Jurassic |
| H | Sandstone, mudstone, argillaceous siltstone | Jurassic |
| I | Sandstone, shale and mudstone interbedded, pebbly sandstone, coal, oil | Jurassic |
| J | Mudstone sandy mudstone conglomerate, coal, oil, oil shale | Jurassic |
| K | Mudstone sandstone siltstone interbedded, coal | Triassic |
| L | Fine sandstone siltstone mudstone interbedded, oil | Triassic |
| Variable | AUC | SE | 95% CI |
|---|---|---|---|
| NB model | 0.792 | 0.0233 | 0.746 to 0.832 |
| RBFNetwork model | 0.777 | 0.0240 | 0.731 to 0.818 |
| SF model | 0.876 | 0.0174 | 0.838 to 0.908 |
| Variable | AUC | SE | 95% CI |
|---|---|---|---|
| NB model | 0.764 | 0.0377 | 0.690 to 0.828 |
| RBFNetwork model | 0.729 | 0.0397 | 0.653 to 0.797 |
| SF model | 0.783 | 0.0360 | 0.710 to 0.844 |
| Pair-Wise Comparison | z-Value | p-Value | Significance |
|---|---|---|---|
| NB vs. RBF Network | 1.081 | 0.280 | No |
| NB vs. SF | 5.677 | 0.000 | Yes |
| RBFNetwork vs. SF | 5.350 | 0.000 | Yes |
| Classification | Comparison Maps | Imbalanced Classes |
|---|---|---|
| Underestimation | SF-NB | Red clay soils |
| SF-RBFN | SPI, 10–20; Red clay soils | |
| Overestimation | SF-NB | Distance to rivers, 0.200 |
| SF-RBFN | Distance to rivers, 0.200 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, X.; Chen, W.; Pham, B.T. Performance Evaluation of GIS-Based Artificial Intelligence Approaches for Landslide Susceptibility Modeling and Spatial Patterns Analysis. ISPRS Int. J. Geo-Inf. 2020, 9, 443. https://doi.org/10.3390/ijgi9070443
Lei X, Chen W, Pham BT. Performance Evaluation of GIS-Based Artificial Intelligence Approaches for Landslide Susceptibility Modeling and Spatial Patterns Analysis. ISPRS International Journal of Geo-Information. 2020; 9(7):443. https://doi.org/10.3390/ijgi9070443
Chicago/Turabian StyleLei, Xinxiang, Wei Chen, and Binh Thai Pham. 2020. "Performance Evaluation of GIS-Based Artificial Intelligence Approaches for Landslide Susceptibility Modeling and Spatial Patterns Analysis" ISPRS International Journal of Geo-Information 9, no. 7: 443. https://doi.org/10.3390/ijgi9070443
APA StyleLei, X., Chen, W., & Pham, B. T. (2020). Performance Evaluation of GIS-Based Artificial Intelligence Approaches for Landslide Susceptibility Modeling and Spatial Patterns Analysis. ISPRS International Journal of Geo-Information, 9(7), 443. https://doi.org/10.3390/ijgi9070443