Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It?




Abstract
1. Introduction
- We perform a trend-driven analysis by conducting Kmeans time-series clustering using fine-grained home dwell time records from SafeGraph.
- We assess the statistical significance of sixteen selected demographic/socioeconomic variables among categorized groups derived from the time-series clustering. Those variables cover economic status, race and ethnicity, age and household type, education, and transportation.
- We discuss the potential demographic/socioeconomic variables that lead to the disparity in home dwell time during the COVID-19 pandemic, how they reflect the long-standing health inequity in the U.S., and what can be suggested for better policy-making.
2. Datasets
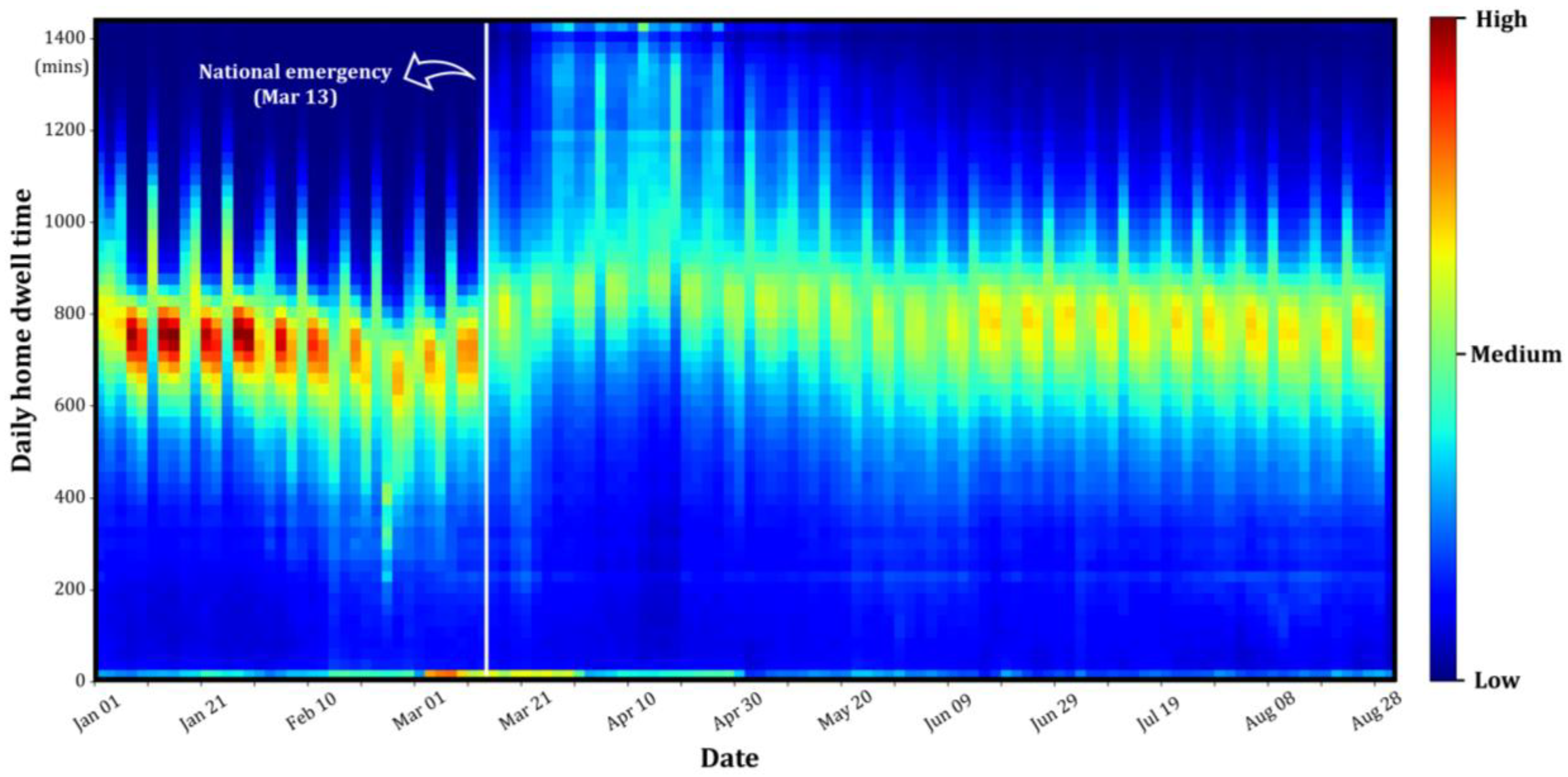
2.1. Home Dwell Time
2.2. Demographic/Socioeconomic Variables
3. Methods
3.1. Preprocessing
3.2. Time-Series Clustering
3.3. Analytical Approaches
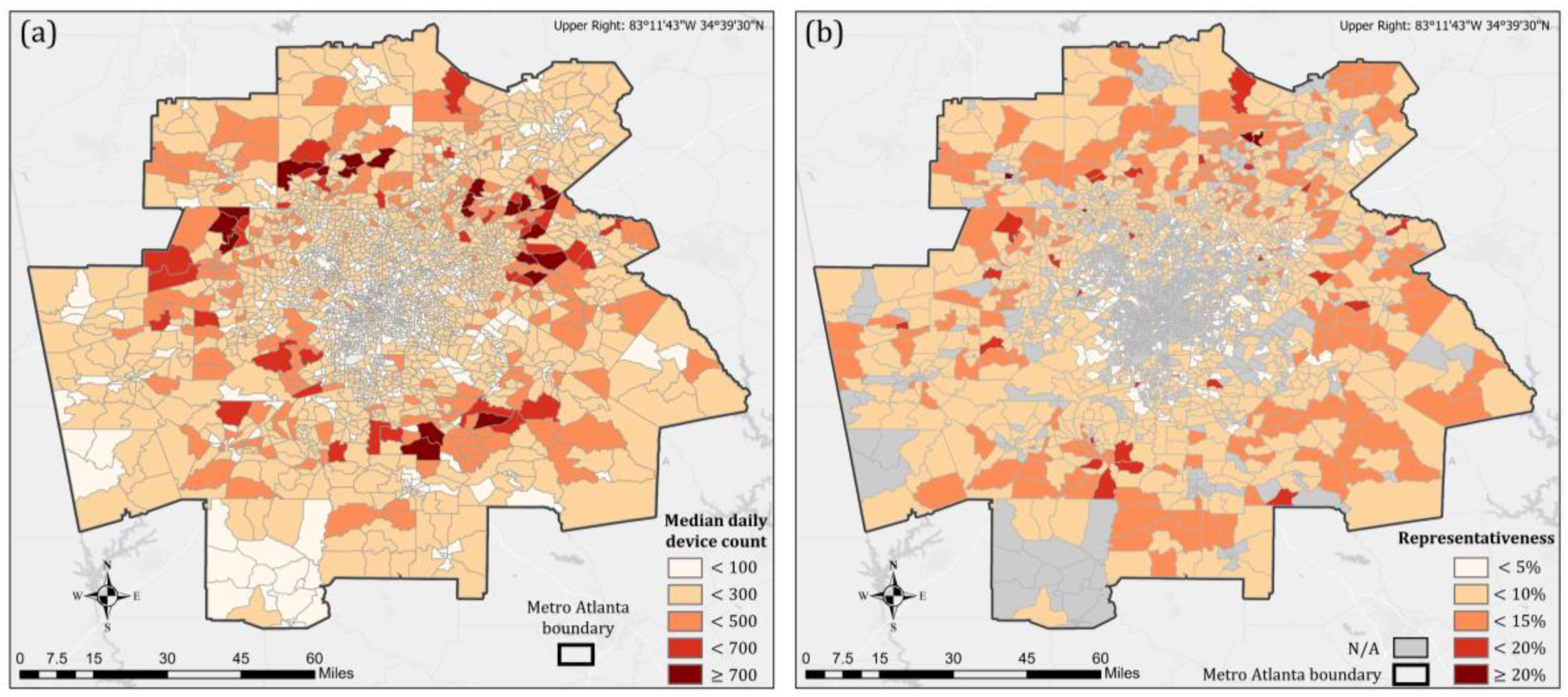
4. Profile of the Study Area
5. Results
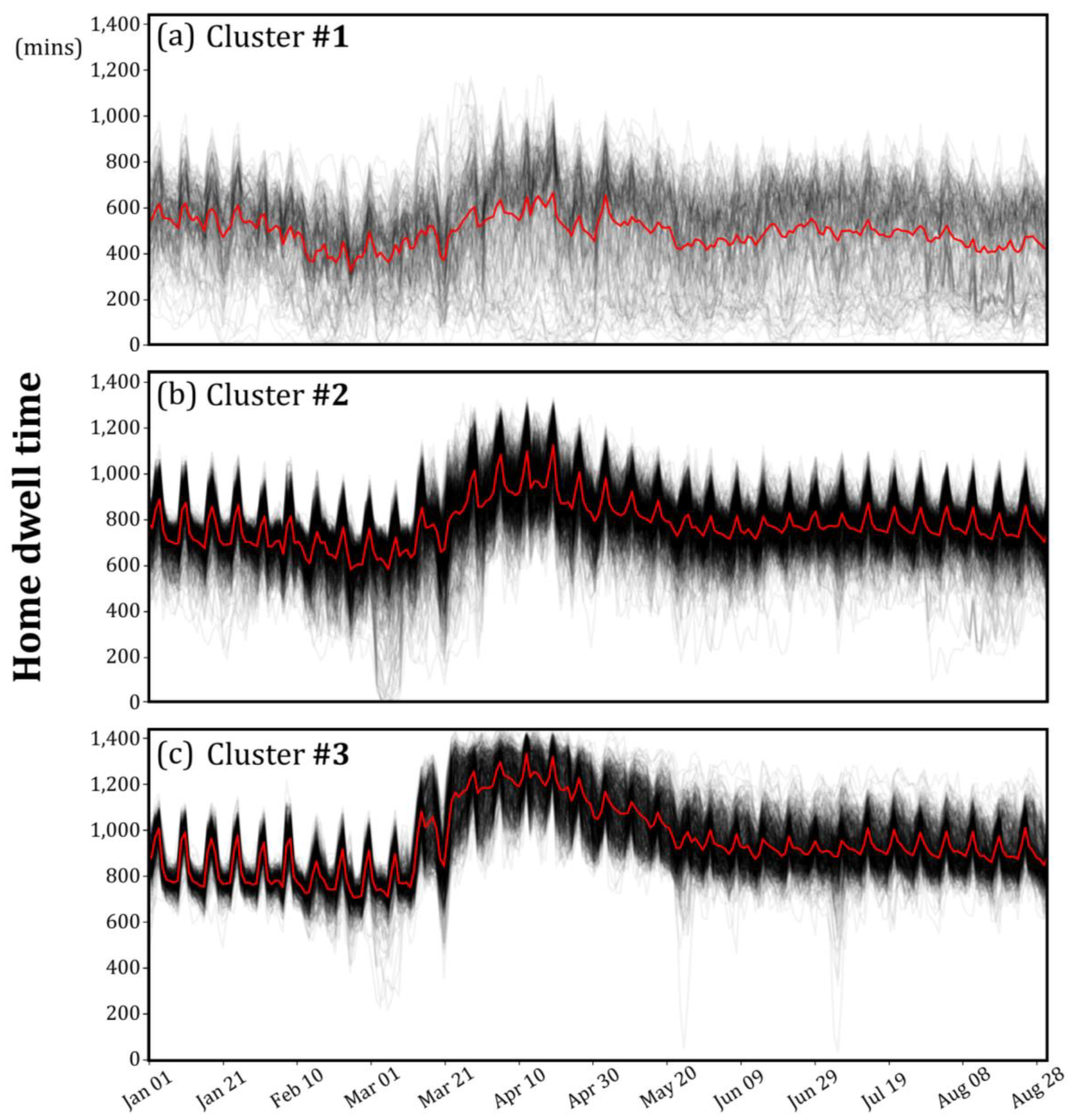
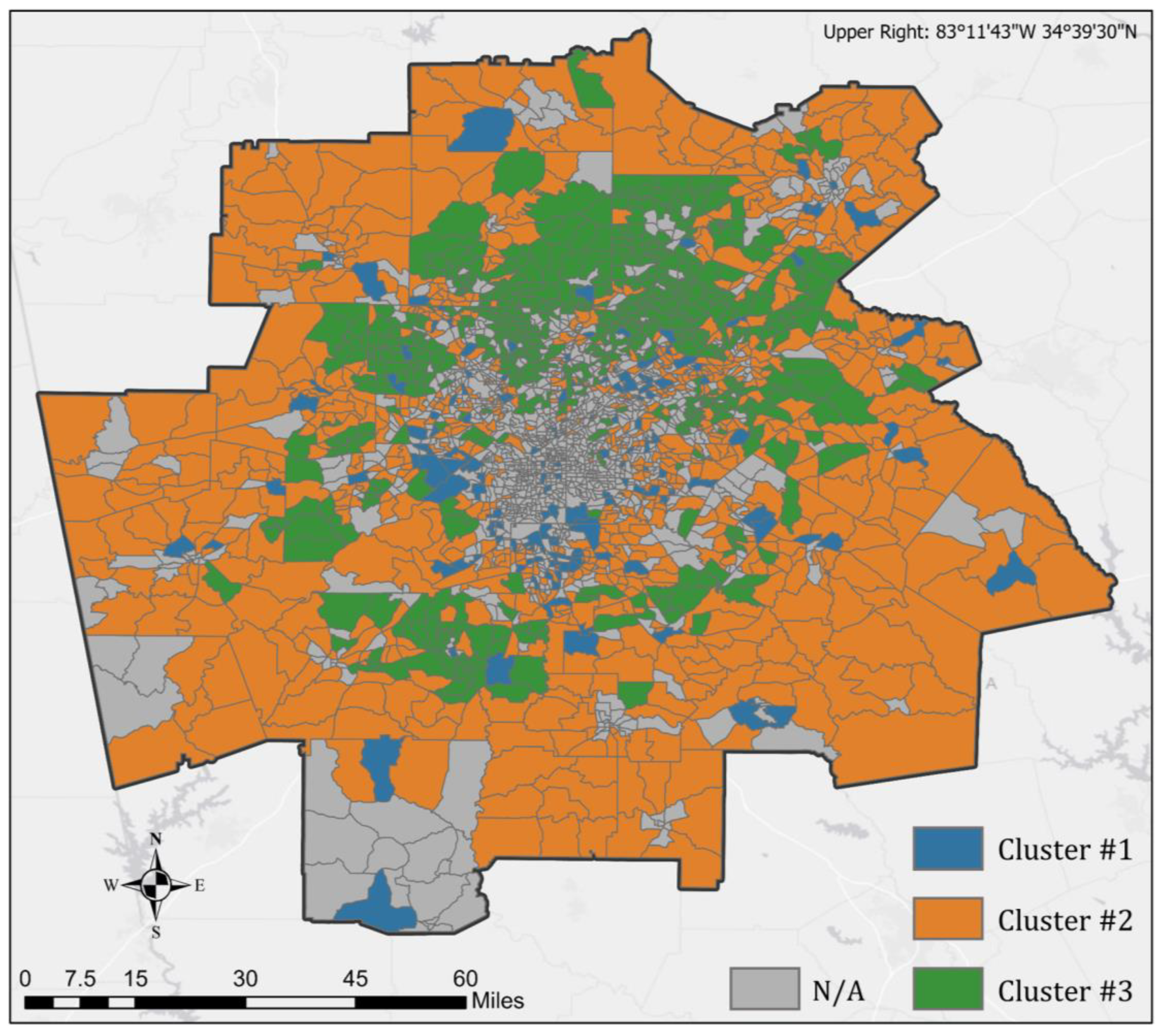
5.1. Identified CBG Clusters and Their Spatial Distribution
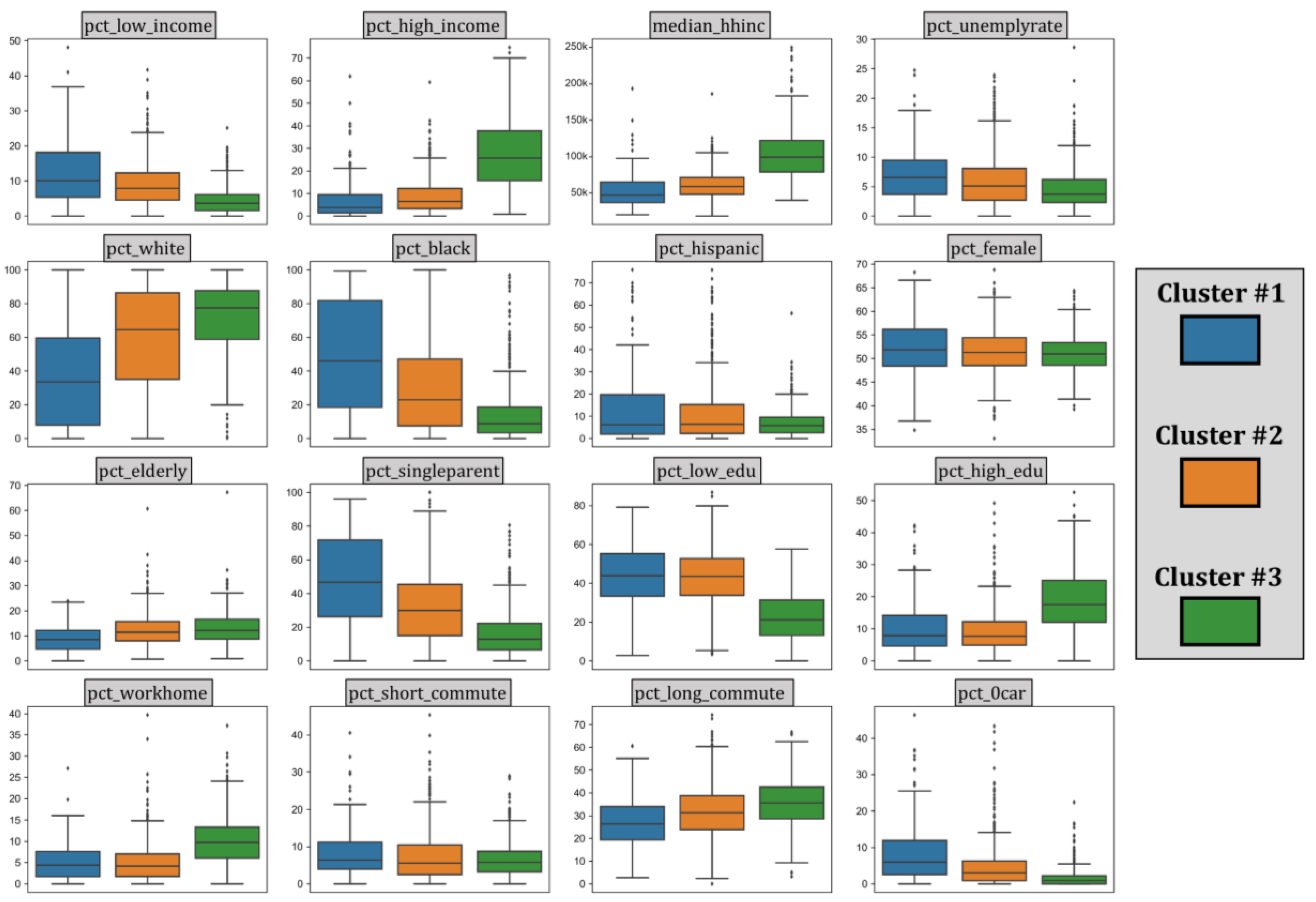
5.2. Demographic/Socioeconomic Variables in Three Identified Clusters
5.3. ANOVA and Tukey’s Test for Clustered CBGs
6. Discussion
6.1. What Do We Learn?
6.2. Limitations and Future Directions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GEOID 1 | County Name |
|---|---|
| 13,171 | Lamar County |
| 13,063 | Clayton County |
| 13,089 | DeKalb County |
| 13,227 | Pickens County |
| 13,045 | Carroll County |
| 13,297 | Walton County |
| 13,013 | Barrow County |
| 13,223 | Paulding County |
| 13,199 | Meriwether County |
| 13,113 | Fayette County |
| 13,143 | Haralson County |
| 13,015 | Bartow County |
| 13,139 | Hall County |
| 13,077 | Coweta County |
| 13,159 | Jasper County |
| 13,151 | Henry County |
| 13,085 | Dawson County |
| 13,097 | Douglas County |
| 13,211 | Morgan County |
| 13,135 | Gwinnett County |
| 13,231 | Pike County |
| 13,247 | Rockdale County |
| 13,121 | Fulton County |
| 13,149 | Heard County |
| 13,067 | Cobb County |
| 13,057 | Cherokee County |
| 13,217 | Newton County |
| 13,255 | Spalding County |
| 13,035 | Butts County |
| 13,117 | Forsyth County |
References
- WHO Coronavirus Disease (COVID-19)—Events as They Happen. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/events-as-they-happen (accessed on 7 September 2020).
- WHO Coronavirus Disease (COVID-19)—Weekly Epidemiological Update. Available online: https://www.who.int/docs/default-source/coronaviruse/situation-reports/20200907-weekly-epi-update-4.pdf?sfvrsn=f5f607ee_2 (accessed on 7 September 2020).
- Le, T.T.; Andreadakis, Z.; Kumar, A.; Roman, R.G.; Tollefsen, S.; Saville, M.; Mayhew, S. The COVID-19 vaccine development landscape. Nat. Rev. Drug. Discov. 2020, 19, 305–306. [Google Scholar] [CrossRef] [PubMed]
- Weill, J.A.; Stigler, M.; Deschenes, O.; Springborn, M.R. Social distancing responses to COVID-19 emergency declarations strongly differentiated by income. Proc. Natl. Acad. Sci. USA 2020, 117, 19658–19660. [Google Scholar] [CrossRef]
- Kraemer, M.U.; Yang, C.H.; Gutierrez, B.; Wu, C.H.; Klein, B.; Pigott, D.M.; Du Plessis, L.; Faria, N.R.; Li, R.; Hanage, W.P.; et al. The effect of human mobility and control measures on the COVID-19 epidemic in China. Science 2020, 368, 493–497. [Google Scholar] [CrossRef] [PubMed]
- Shim, E.; Tariq, A.; Choi, W.; Lee, Y.; Chowell, G. Transmission potential and severity of COVID-19 in South Korea. Int. J. Infect. Dis. 2020, 93, 339–344. [Google Scholar] [CrossRef] [PubMed]
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Stoecklin, S.B.; Rolland, P.; Silue, Y.; Mailles, A.; Campese, C.; Simondon, A.; Mechain, M.; Meurice, L.; Nguyen, M.; Bassi, C.; et al. First cases of coronavirus disease 2019 (COVID-19) in France: Surveillance, investigations and control measures. Eurosurveillance 2020, 25, 2000094. [Google Scholar]
- Baek, C.; McCrory, P.B.; Messer, T.; Mui, P. Unemployment effects of stay-at-home orders: Evidence from high frequency claims data. Inst. Res. Labor Employ. Work. Pap. 2020, 1–72. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Jiang, Y.; Ye, X.; Deng, C.; Zhang, J.; Li, X. The characteristics of multi-source mobility datasets and how they reveal the luxury nature of social distancing in the U.S. during the COVID-19 pandemic. medRxiv 2020. [Google Scholar] [CrossRef]
- Almagro, M.; Orane-Hutchinson, A. The Determinants of the Differential Exposure to COVID-19 in New York City and Their Evolution Over Time. Covid Econ. Vetted Real-Time Pap. 2020, 103293. [Google Scholar] [CrossRef]
- Bonaccorsi, G.; Pierri, F.; Cinelli, M.; Flori, A.; Galeazzi, A.; Porcelli, F.; Schmidt, A.L.; Valensise, C.M.; Scala, A.; Quattrociocchi, W.; et al. Economic and social consequences of human mobility restrictions under COVID-19. Proc. Natl. Acad. Sci. USA 2020, 117, 15530–15535. [Google Scholar] [CrossRef]
- Chiou, L.; Tucker, C. Social distancing, internet access and inequality (No. w26982). Natl. Bur. Econ. Res. 2020. [Google Scholar] [CrossRef]
- Barnett-Howell, Z.; Mobarak, A.M. The Benefits and Costs of Social Distancing in Rich and Poor Countries. arXiv 2020, arXiv:2004.04867. [Google Scholar]
- Urban Residents in States Hit Hard by COVID-19 Most Likely to See It as a Threat to Daily Life. Available online: https://www.pewresearch.org/fact-tank/2020/03/20/urban-residents-in-states-hit-hard-by-covid-19-most-likely-to-see-it-as-a-threat-to-daily-life/ (accessed on 13 September 2020).
- Lou, J.; Shen, X.; Niemeier, D. Are stay-at-home orders more difficult to follow for low-income groups? J. Transp. Geogr. 2020, 89, 102894. [Google Scholar] [CrossRef]
- SafeGraph-Social Distancing Metrics. Available online: https://docs.safegraph.com/docs/social-distancing-metrics (accessed on 14 September 2020).
- Proclamation on Declaring a National Emergency Concerning the Novel Coronavirus Disease (COVID-19) Outbreak. Available online: https://www.whitehouse.gov/presidential-actions/proclamation-declaring-national-emergency-concerning-novel-coronavirus-disease-covid-19-outbreak/ (accessed on 7 September 2020).
- American Community Survey Information Guide. Available online: https://www.census.gov/content/dam/Census/programs-surveys/acs/about/ACS_Information_Guide.pdf (accessed on 15 September 2020).
- When to Use 1-Year, 3-Year, or 5-Year Estimates. Available online: https://www.census.gov/programs-surveys/acs/guidance/estimates.html (accessed on 15 September 2020).
- Morency, C.; Paez, A.; Roorda, M.J.; Mercado, R.; Farber, S. Distance traveled in three canadian cities: Spatial analysis from the perspective of vulnerable population segments. J. Transp. Geogr. 2011, 19, 39–50. [Google Scholar] [CrossRef]
- Farber, S.; Páez, A.; Mercado, R.G.; Roorda, M.; Morency, C. A time-use investigation of shopping participation in three Canadian cities: Is there evidence of social exclusion? Transportation 2011, 38, 17–44. [Google Scholar] [CrossRef]
- Farber, S.; Páez, A. My car, my friends, and me: A preliminary analysis of automobility and social activity participation. J. Transp. Geogr. 2009, 17, 216–225. [Google Scholar] [CrossRef]
- Páez, A.; Gertes Mercado, R.; Farber, S.; Morency, C.; Roorda, M. Relative accessibility deprivation indicators for urban settings: Definitions and application to food deserts in Montreal. Urban Stud. 2010, 47, 1415–1438. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Jiang, Y.; Li, X.; Porter, D. Twitter, human mobility, and COVID-19. arXiv 2020, arXiv:2007.01100. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Pham, D.T.; Dimov, S.S.; Nguyen, C.D. Selection of K in K-means clustering. Proc. Inst. Mech. Eng. C 2005, 219, 103–119. [Google Scholar] [CrossRef]
- St, L.; Wold, S. Analysis of variance (ANOVA). Chemom. Intell. Lab. Syst. 1989, 6, 259–272. [Google Scholar]
- Abdi, H.; Williams, L.J. Tukey’s honestly significant difference (HSD) test. In Encyclopedia of Research Design; Salkind, N.J., Ed.; SAGE Publication, Inc.: Thousand Oaks, CA, USA, 2010; Volume 3, pp. 1–5. [Google Scholar]
- Metropolitan and Micropolitan Statistical Areas Population Totals and Components of Change: 2010–2019. Available online: https://www.census.gov/data/tables/time-series/demo/popest/2010s-total-metro-and-micro-statistical-areas.html (accessed on 20 September 2020).
- Bobo, L.; Johnson, J.; Oliver, M.; Farley, R.; Bluestone, B.; Browne, I.; Danziger, S.; Green, G.; Holzer, H.; Krysan, M.; et al. Multi-City Study of Urban Inequality, 1992–1994 [Atlanta, Boston, Detroit, and Los Angeles]; Inter-University Consortium for Political and Social Research: Ann Arbor, MI, USA, 2020. [Google Scholar]
- Wyczalkowski, C.K.; Welch, T.; Pasha, O. Inequities of Transit Access: The Case of Atlanta, GA. J. Comp. Urban Law Policy 2020, 4, 654–681. [Google Scholar]
- Bullard, R.D.; Johnson, G.S.; Torres, A.O. Sprawl Atlanta: Social Equity Dimensions of Uneven Growth and Development; Clark Atlanta University, The Environmental Justice Resource Center: Atlanta, GA, USA, 1999. [Google Scholar]
- Keating, L. Atlanta: Race, Class, and Urban Expansion; Temple University Press: Philadelphia, PA, USA, 2001; pp. 7–40. [Google Scholar]
- Press Releases, Governor Brian P. Kemp—Office of the Governor. Available online: https://gov.georgia.gov/press-releases?field_press_release_type_target_id=All&page=17 (accessed on 20 September 2020).
- Where States Reopened and Cases Spiked after the U.S. Shutdown, The Washington Post. Available online: https://www.washingtonpost.com/graphics/2020/national/states-reopening-coronavirus-map/ (accessed on 20 September 2020).
- Ord, J.K.; Getis, A. Local spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Karaye, I.M.; Horney, J.A. The impact of social vulnerability on COVID-19 in the US: An analysis of spatially varying relationships. Am. J. Prev. Med. 2020, 59, 317–325. [Google Scholar] [CrossRef] [PubMed]
- Holtgrave, D.R.; Barranco, M.A.; Tesoriero, J.M.; Blog, D.S.; Rosenberg, E.S. Assessing racial and ethnic disparities using a COVID-19 outcomes continuum for New York State. Ann. Epidemiol. 2020, 48, 9–14. [Google Scholar] [CrossRef] [PubMed]
- Laurencin, C.T.; McClinton, A. The COVID-19 pandemic: A call to action to identify and address racial and ethnic disparities. J. Racial Ethn. Health Disparities 2020, 7, 398–402. [Google Scholar] [CrossRef]
- Bianchi, S.M. The changing demographic and socioeconomic characteristics of single parent families. J. Marriage Fam. 1994, 20, 71–97. [Google Scholar] [CrossRef]
- Nguyen, V.K.; Peschard, K. Anthropology, inequality, and disease: A review. Annu. Rev. Anthropol. 2003, 32, 447–474. [Google Scholar] [CrossRef]
- Muennig, P.; Franks, P.; Jia, H.; Lubetkin, E.; Gold, M.R. The income-associated burden of disease in the United States. Soc. Sci. Med. 2005, 61, 2018–2026. [Google Scholar] [CrossRef]
- Mechanic, D. Disadvantage, inequality, and social policy. Health Aff. 2002, 21, 48–59. [Google Scholar] [CrossRef] [PubMed]
- Kodinariya, T.M.; Makwana, P.R. Review on determining number of Cluster in K-Means Clustering. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2013, 1, 90–95. [Google Scholar]
- Lletı, R.; Ortiz, M.C.; Sarabia, L.A.; Sánchez, M.S. Selecting variables for k-means cluster analysis by using a genetic algorithm that optimises the silhouettes. Anal. Chim. Acta. 2004, 515, 87–100. [Google Scholar] [CrossRef]
- Böhning, D. Multinomial logistic regression algorithm. Ann. Inst. Stat. Math. 1992, 44, 197–200. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Nasri, A.; Zhang, L. Impact of metropolitan-level built environment on travel behavior. Transp. Res. Rec. 2012, 2323, 75–79. [Google Scholar] [CrossRef]
- Zhang, L.; Hong, J.; Nasri, A.; Shen, Q. How built environment affects travel behavior: A comparative analysis of the connections between land use and vehicle miles traveled in US cities. J. Transp. Land Use 2012, 5, 40–52. [Google Scholar] [CrossRef]







| Variable Notations | Descriptions |
|---|---|
| Economic status | |
| pct_low_income | percent of household income less than $15,000 |
| pct_high_income | percent of household income greater than $150,000 |
| median_hhinc | median household income |
| pct_unemployrate | unemployment rate |
| Race and ethnicity | |
| pct_white | percent of White |
| pct_black | percent of Black |
| pct_hispanic | percent of Hispanic |
| Gender, age and household type | |
| pct_female | percent of female |
| pct_elderly | percent of age 65 or older |
| pct_singleparent | percent of single-parent families among parenting families having children under 18 |
| Education | |
| pct_low_edu | percent of education equal or less than highschool |
| pct_grad_edu | percent of education of master, professional, or doctoral degrees |
| Transportation | |
| pct_workhome | percent of work from home |
| pct_short_commute | percent of commuters with 10 min or shorter trips |
| pct_long_commute | percent of commuters with 40 min or longer trips |
| pct_0car | percent of 0 car households |
| Variable Notations | F Statistics | Sig. (p-Value) |
|---|---|---|
| Economic status | ||
| pct_low_income | 151.71 | <0.001 * |
| pct_high_income | 516.20 | <0.001 * |
| median_hhinc | 507.33 | <0.001 * |
| pct_unemployrate | 32.94 | <0.001 * |
| Race and ethnicity | ||
| pct_white | 108.15 | <0.001 * |
| pct_black | 137.81 | <0.001 * |
| pct_hispanic | 30.34 | <0.001 * |
| Gender, age, and household type | ||
| pct_female | 4.98 | 0.017 |
| pct_elderly | 22.40 | <0.001 * |
| pct_singleparent | 177.58 | <0.001 * |
| Education | ||
| pct_low_edu | 366.83 | <0.001 * |
| pct_grad_edu | 261.75 | <0.001 * |
| Transportation | ||
| pct_workhome | 193.02 | <0.001 * |
| pct_short_commute | 4.56 | 0.022 |
| pct_long_commute | 36.19 | <0.001 * |
| pct_0car | 131.14 | <0.001 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Li, Z.; Lu, J.; Wang, S.; Wei, H.; Chen, B. Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It? ISPRS Int. J. Geo-Inf. 2020, 9, 675. https://doi.org/10.3390/ijgi9110675
Huang X, Li Z, Lu J, Wang S, Wei H, Chen B. Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It? ISPRS International Journal of Geo-Information. 2020; 9(11):675. https://doi.org/10.3390/ijgi9110675
Chicago/Turabian StyleHuang, Xiao, Zhenlong Li, Junyu Lu, Sicheng Wang, Hanxue Wei, and Baixu Chen. 2020. "Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It?" ISPRS International Journal of Geo-Information 9, no. 11: 675. https://doi.org/10.3390/ijgi9110675
APA StyleHuang, X., Li, Z., Lu, J., Wang, S., Wei, H., & Chen, B. (2020). Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It? ISPRS International Journal of Geo-Information, 9(11), 675. https://doi.org/10.3390/ijgi9110675