Extracting Building Areas from Photogrammetric DSM and DOM by Automatically Selecting Training Samples from Historical DLG Data


Abstract
1. Introduction
2. Methods
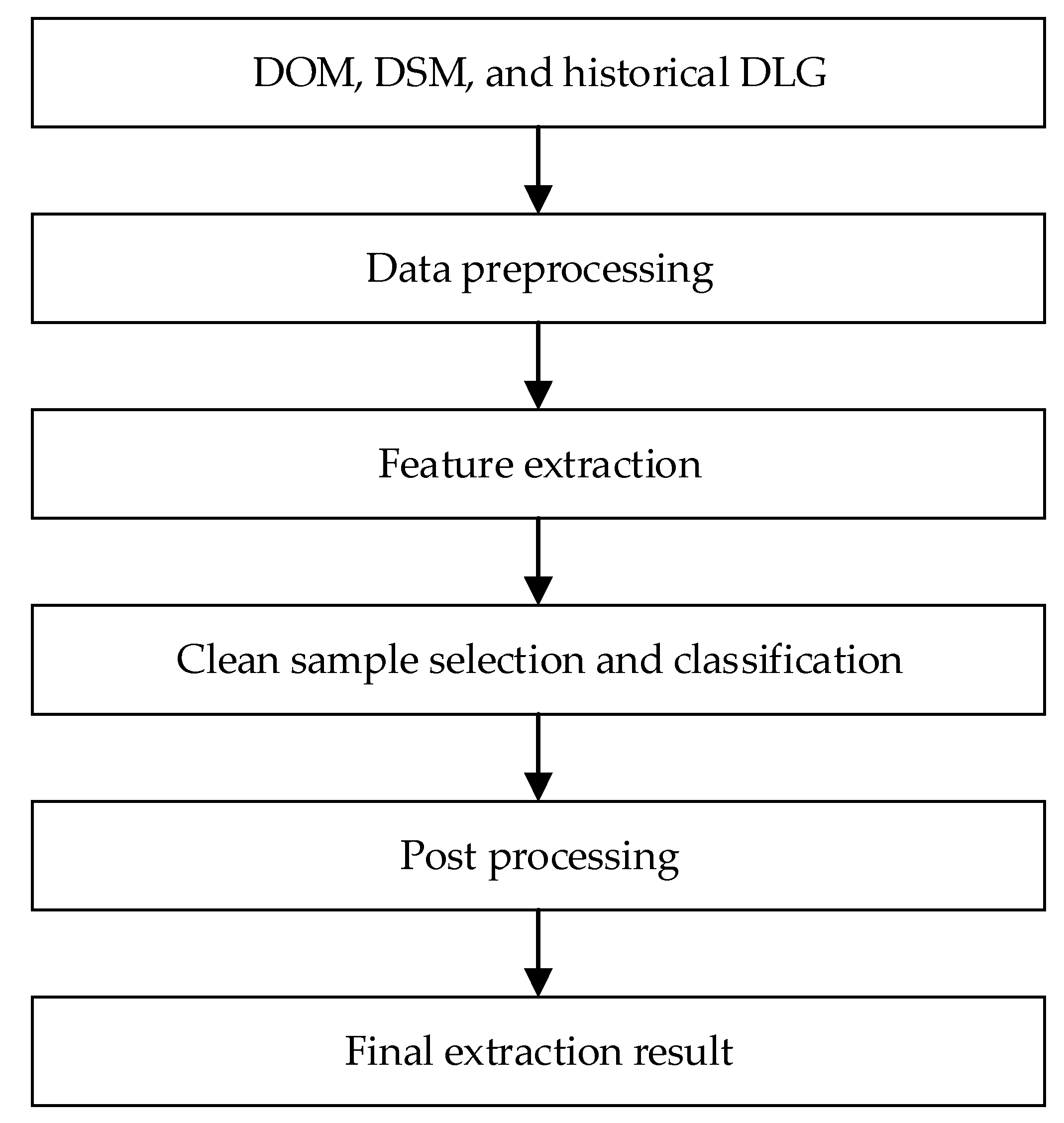
2.1. Overview the Method
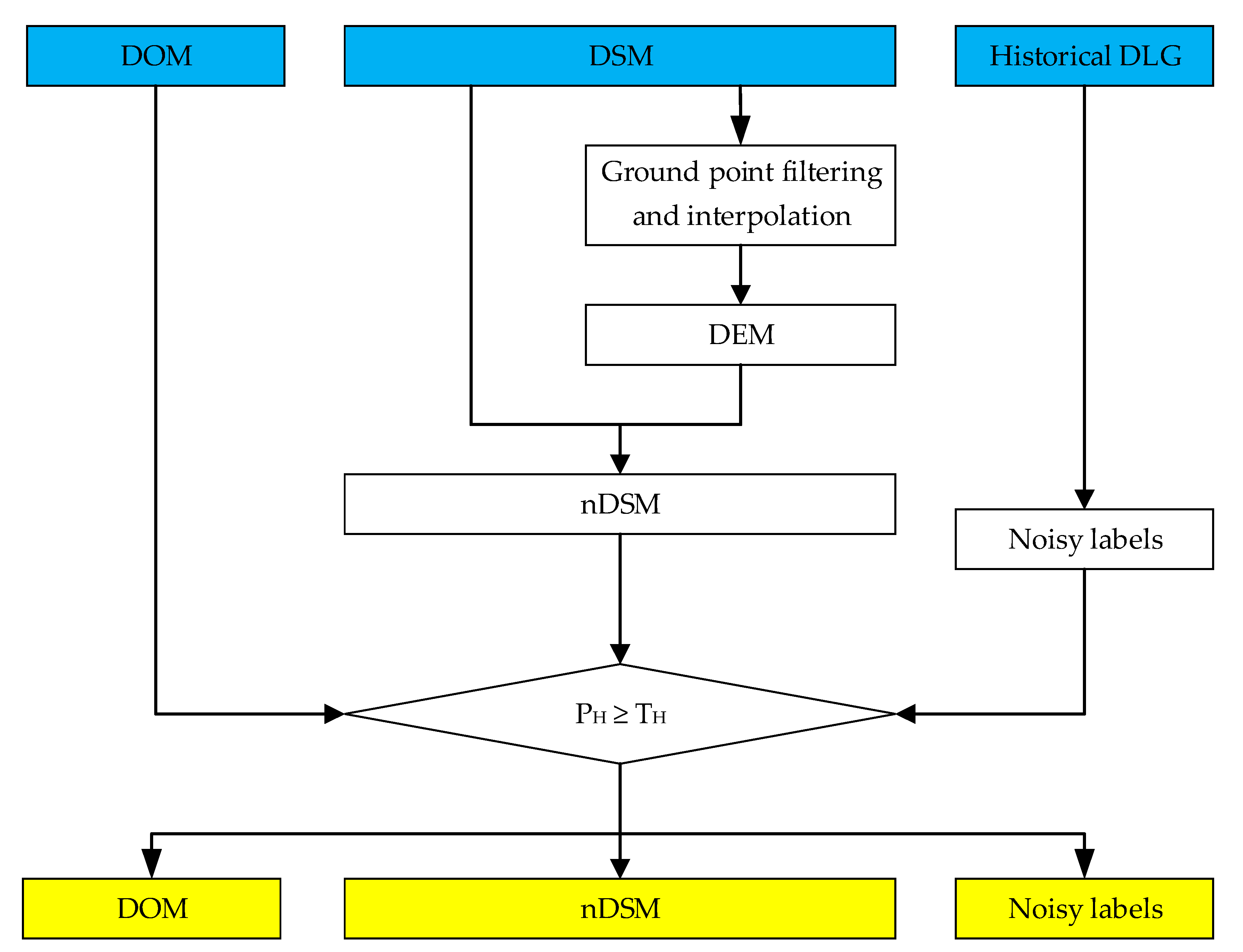
2.2. Data Preprocessing
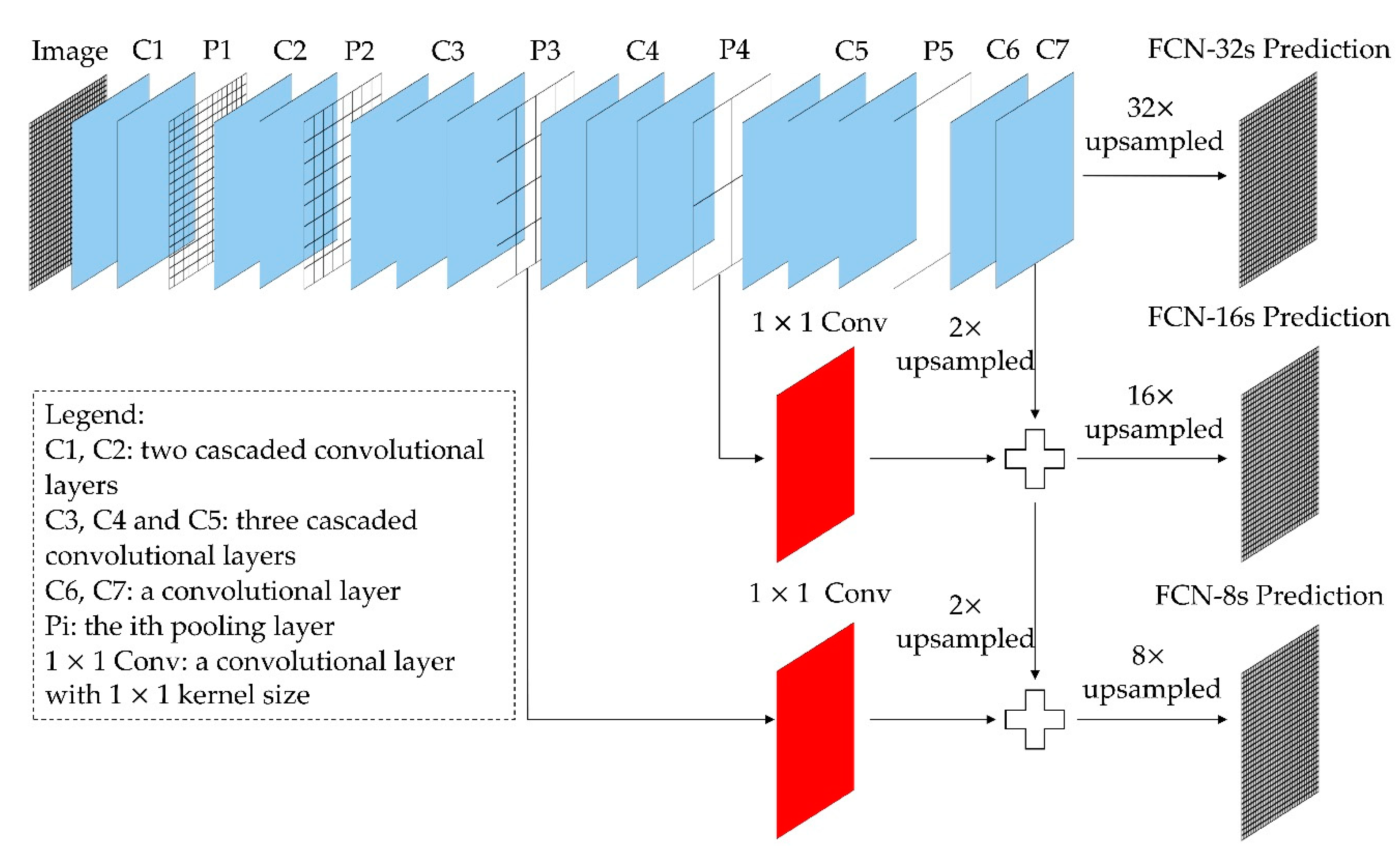
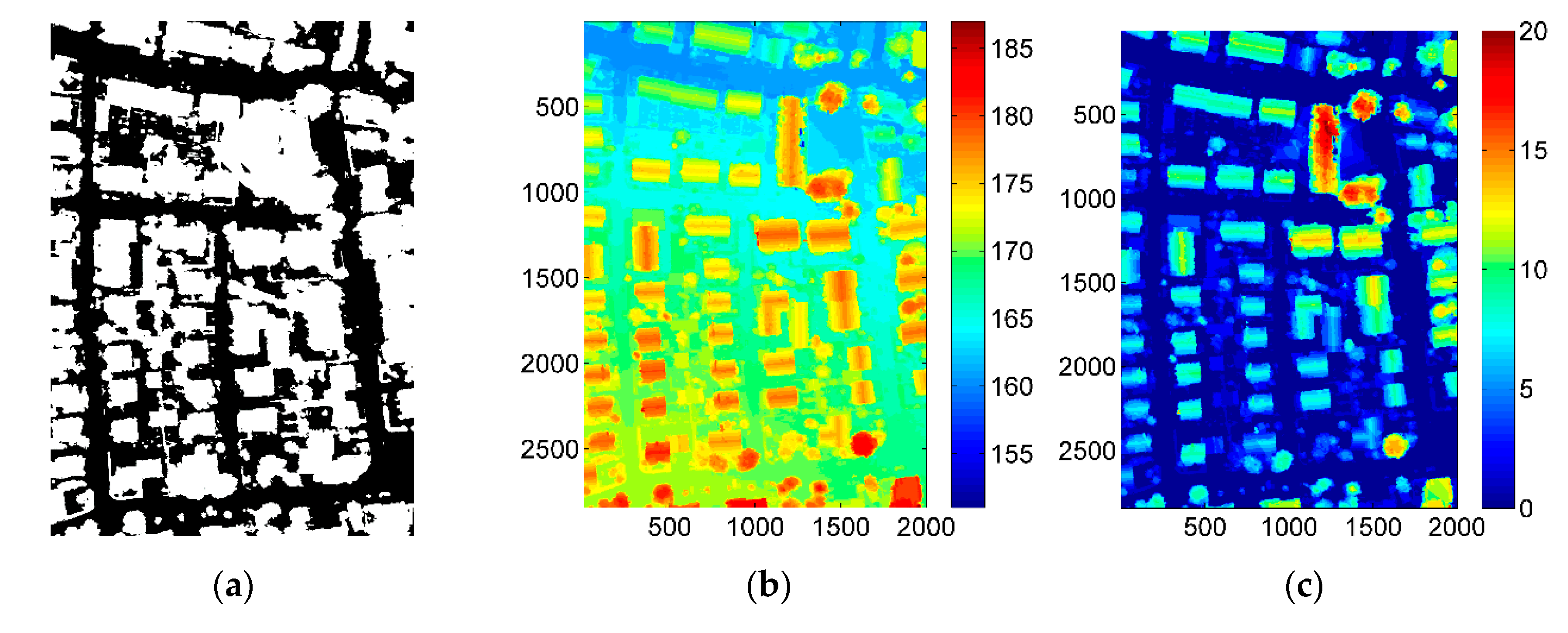
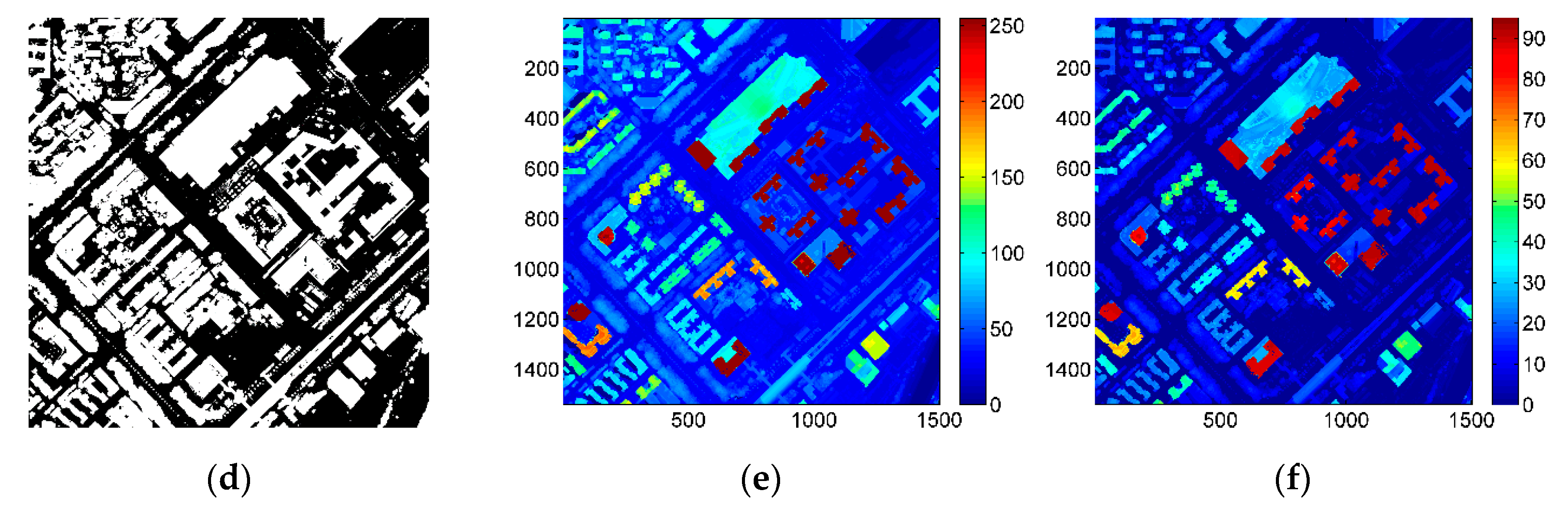
2.3. Feature Extraction
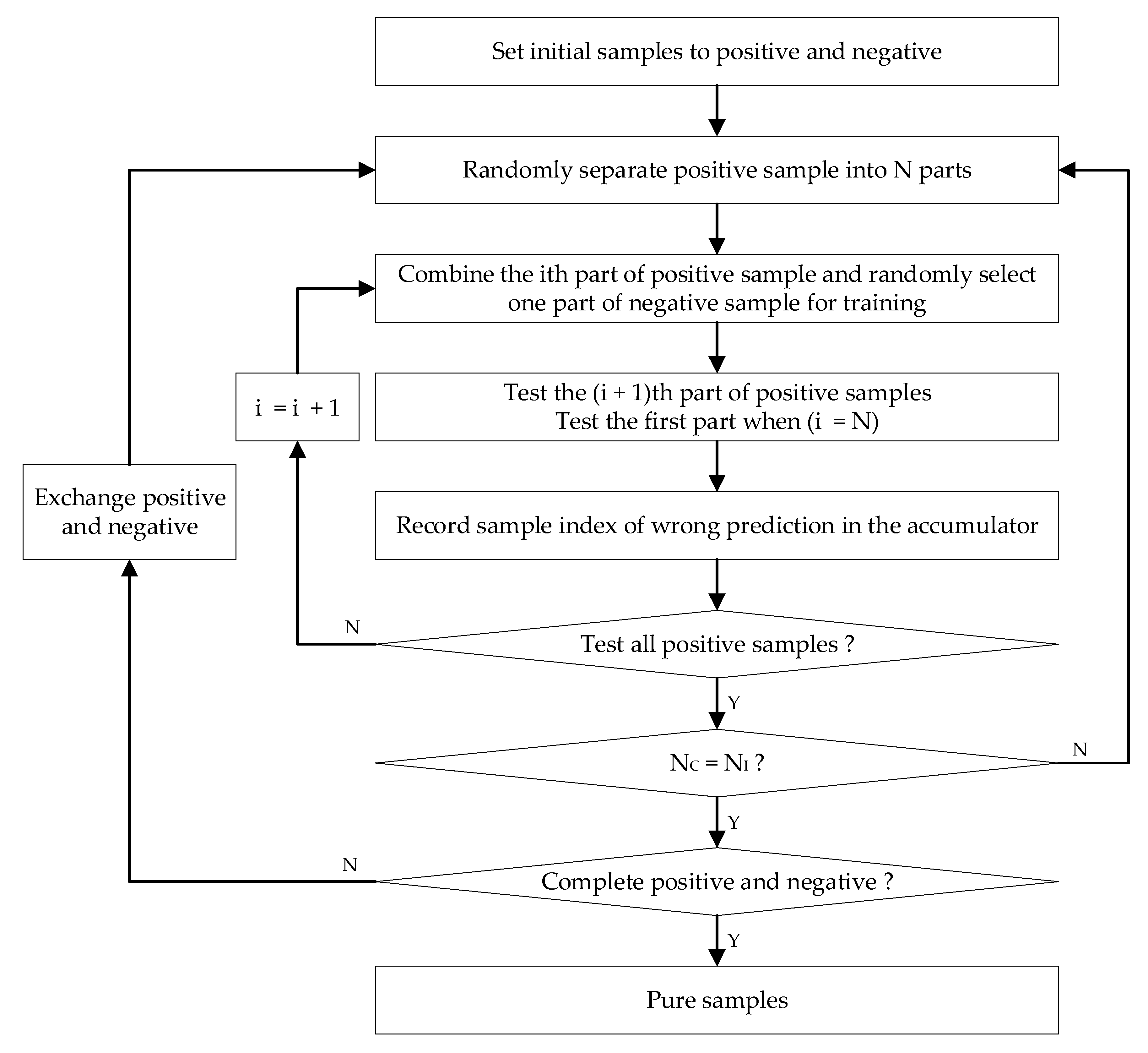
2.4. Clean Sample Selection and Classification
2.5. Post Processing
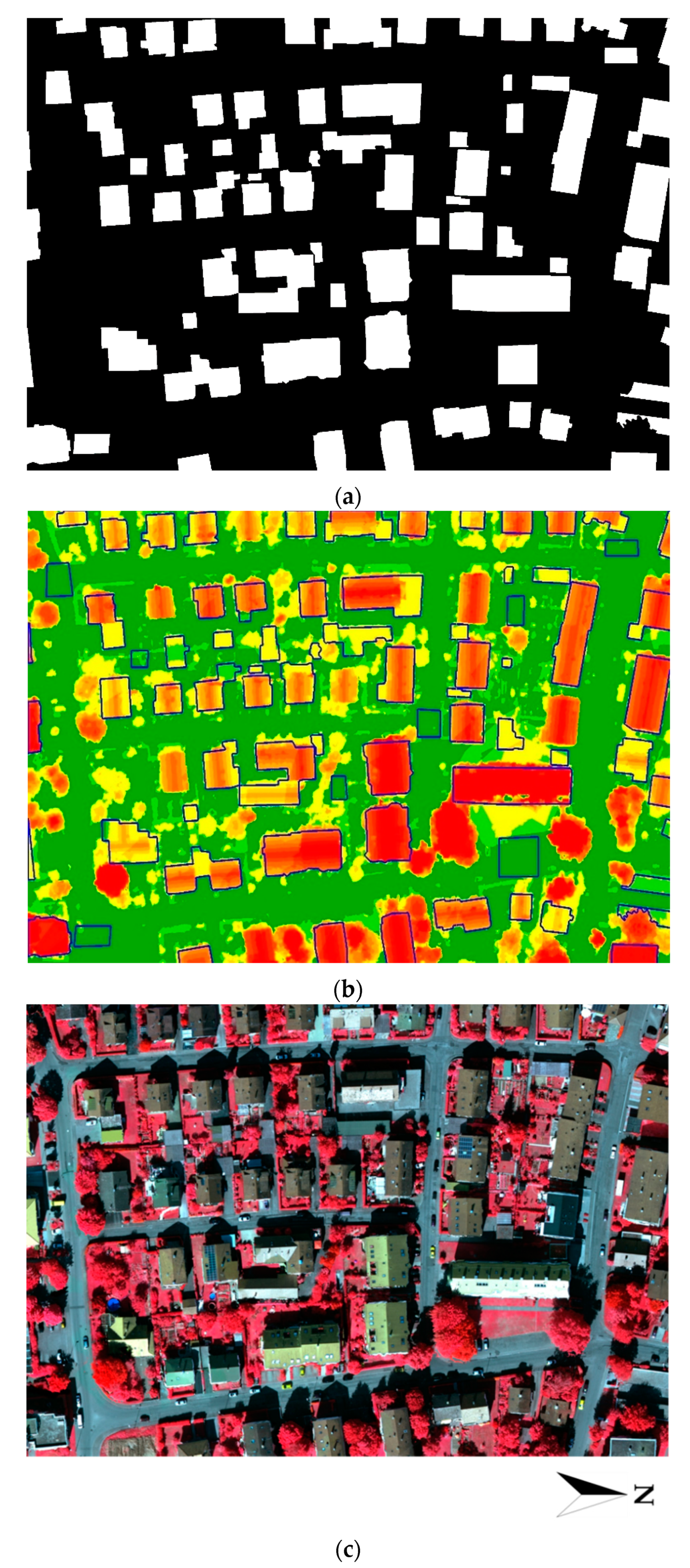
3. Data Sets and Evaluation Criteria
3.1. Data Sets Description
3.2. Assessment Criteria
3.3. Parameters Setting
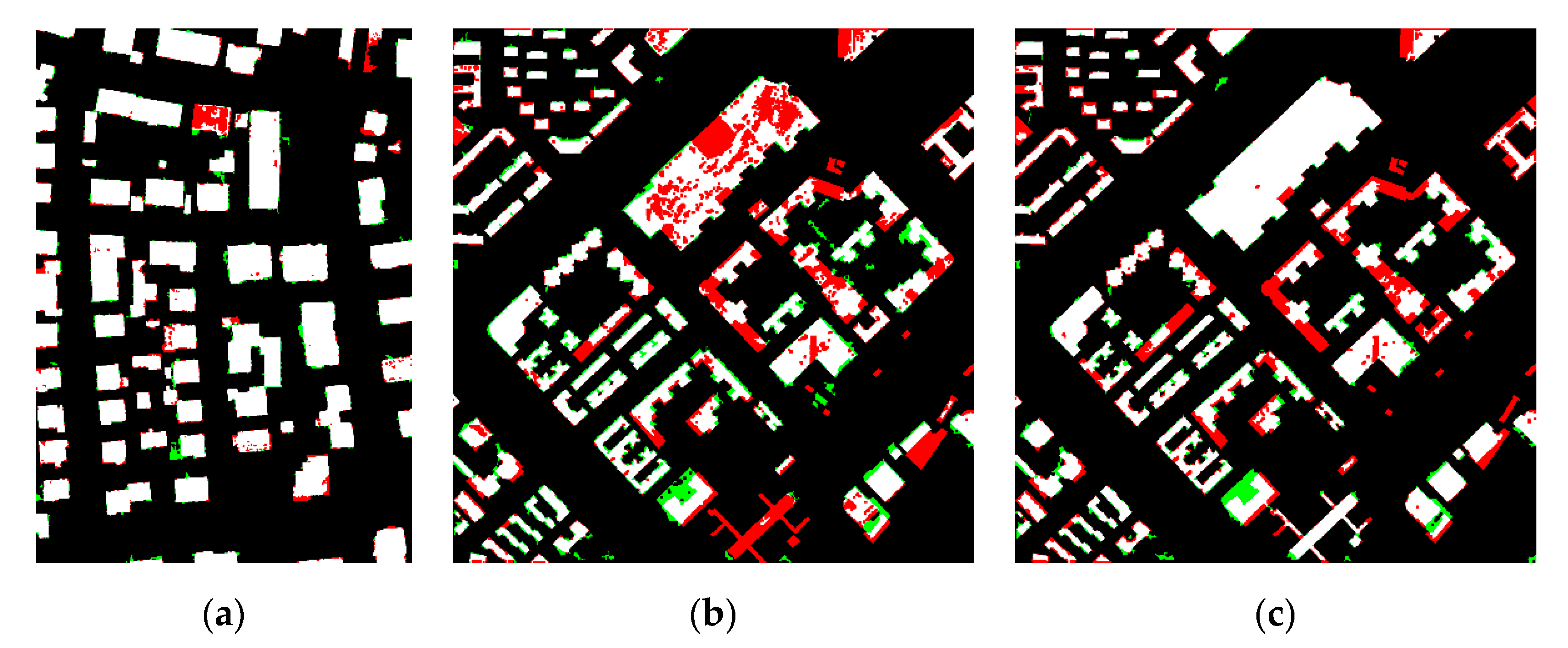
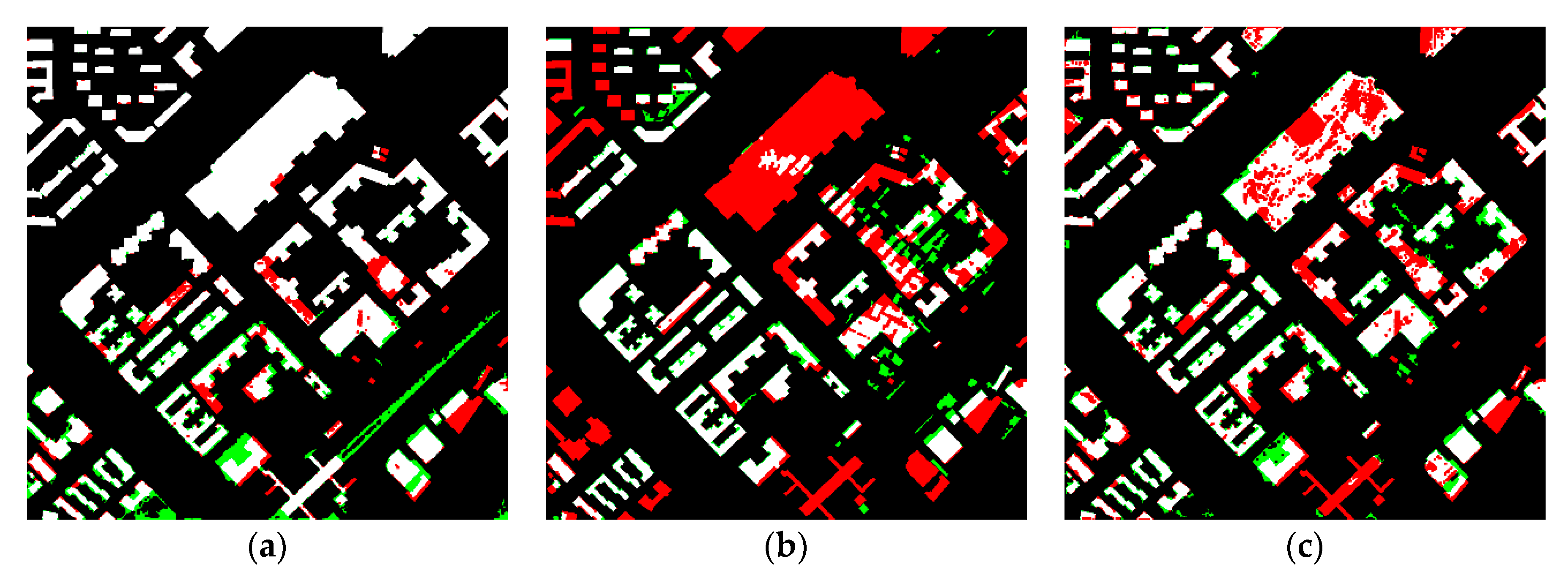
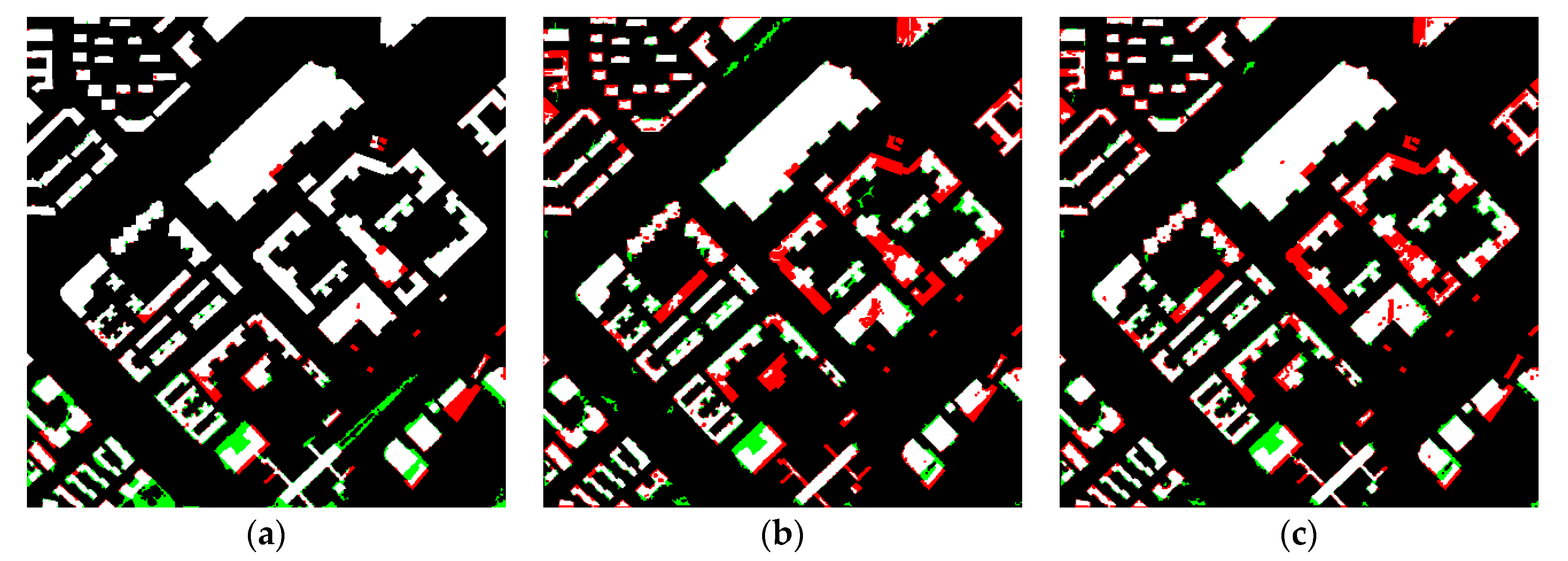
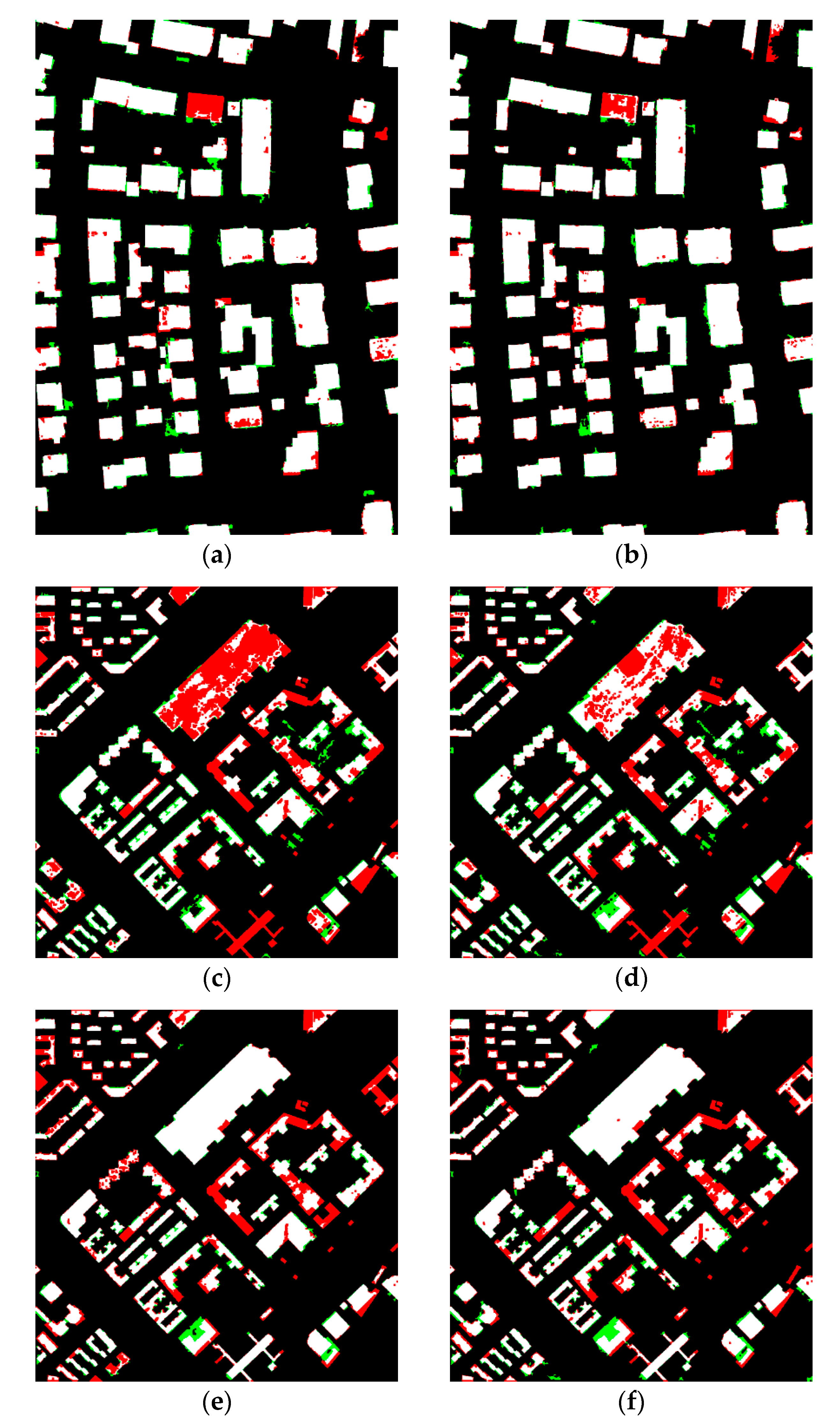
4. Results and Discussion
4.1. Results
4.2. Discussion
4.2.1. Label Selection
4.2.2. Feature Selection
4.2.3. Feature Dimension Reduction
4.2.4. Limitation of Proposed Method
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Du, S.; Zhang, Y.; Zou, Z.; Hua, S.; He, X.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogram. Remote Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Vu, T.; Fumio, Y.; Masashi, M. Multi-scale solution for building extraction from LiDAR and image data. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 281–289. [Google Scholar] [CrossRef]
- Parape, C.; Premachandra, C.; Tamura, M. Optimization of structure elements for morphological hit-or-miss transform for building extraction from VHR imagery in natural hazard areas. Int. J. Mach. Learn Cybern. 2015, 6, 641–650. [Google Scholar] [CrossRef]
- Liasis, G.; Stavrou, S. Building extraction in satellite images using active contour and color features. Int. J. Remote Sens. 2016, 37, 1127–1153. [Google Scholar] [CrossRef]
- Mayer, G.; Neto, J. Verification of color vegetation indices for automated crop imaging applications. Comput. Electron. Age 2008, 63, 282–293. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogram. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Gevaert, C.; Persello, C.; Elberink, S.; Vosselman, G.; Sliuzas, R. Context-based filtering of noisy labels for automatic basemap updating from UAV data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 11, 2731–2741. [Google Scholar] [CrossRef]
- Guo, Z.; Du, S. Mining parameters information for building extraction and change detection with very high-resolution imagery and GIS data. GISci. Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Wan, T.; Lu, H.; Lu, Q.; Luo, N. Classification of high-resolution remote-sensing image using openstreetmap information. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2305–2309. [Google Scholar] [CrossRef]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE T. Neur. Net. Lear. 2013, 25, 845–869. [Google Scholar]
- Maas, A.; Rottensteiner, F.; Heipke, C. A label noise tolerant random forest for the classification of remote sensing data based on outdated maps for training. Comput. Vis. Image Und. 2019, 188, 102782. [Google Scholar] [CrossRef]
- Jin, X.; Davis, C. Automated building extraction from high-resolution satellite imagery in urban areas using structural, contextual, and spectral information. EURASIP J. Adv. Sig. Pr. 2005, 14, 745309. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust rooftop extraction from visible band images using higher order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Sun, X.; Lin, X.; Shen, S.; Hu, Z. High-resolution remote sensing data classification over urban areas using random forest ensemble and fully connected conditional random field. ISPRS Int. J. Geo-inf. 2017, 6, 245. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Schuegraf, P.; Bittner, K. Automatic Building Footprint Extraction from Multi-Resolution Remote Sensing Images Using a Hybrid FCN. ISPRS Int. J. Geo-Inf. 2019, 8, 191. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogram. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Fraser, C. Automatic segmentation of raw LiDAR data for extraction of building roofs. Remote Sens. 2014, 6, 3716–3751. [Google Scholar] [CrossRef]
- Zarea, A.; Mohammadzadeh, A. A novel building and tree detection method from LiDAR data and aerial images. IEEE J. Sel. Top. Appl. Earth Observ. Remote. Sens. 2015, 9, 1864–1875. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Software CloudCompare. Available online: www.cloudcompare.org (accessed on 19 December 2019).
- Wang, Y.; He, C.; Liu, X.; Liao, M. A hierarchical fully convolutional network integrated with sparse and low-rank subspace representations for PolSAR imagery classification. Remote Sens. 2018, 10, 342. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Chaib, S.; Gu, Y.; Yao, H. An informative feature selection method based on sparse PCA for VHR scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 13, 147–151. [Google Scholar] [CrossRef]
- Rutzinger, M.; Rottensteiner, F.; Pfeifer, N. A comparison of evaluation techniques for building extraction from airborne laser scanning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2009, 2, 11–20. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sets | Pixel-Based (%) | Object-Based (%) | |||||
|---|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | ||
| Area1 | DLG_M | 93.22 | 96.52 | 90.19 | 97.33 | 94.81 | 92.41 |
| Area2 | DLG2008 | 70.05 | 87.07 | 63.45 | 87.91 | 87.91 | 78.43 |
| DLG2014 | 77.52 | 92.33 | 72.83 | 86.81 | 92.94 | 81.44 | |
| Strategy | Pixel-Based (%) | Object-Based (%) | ||||
|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | |
| (1) | 98.45 | 99.53 | 97.99 | 100.00 | 98.68 | 98.68 |
| (2) | 89.53 | 99.76 | 89.34 | 89.33 | 98.53 | 88.16 |
| (3) | 93.22 | 96.52 | 90.19 | 97.33 | 94.81 | 92.41 |
| Strategy | Pixel-Based (%) | Object-Based (%) | ||||
|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | |
| (1) | 89.77 | 89.10 | 80.89 | 90.10 | 92.13 | 83.67 |
| (2) | 47.52 | 82.44 | 43.15 | 47.25 | 50.00 | 32.09 |
| (3) | 70.05 | 87.07 | 63.45 | 87.91 | 87.91 | 78.43 |
| Strategy | Pixel-Based (%) | Object-Based (%) | ||||
|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | |
| (1) | 93.17 | 92.15 | 86.32 | 93.41 | 91.40 | 85.86 |
| (2) | 73.33 | 97.61 | 72.03 | 64.84 | 83.10 | 57.28 |
| (3) | 77.52 | 92.33 | 72.83 | 86.81 | 92.94 | 81.44 |
| Date Sets | Strategy | Pixel-Based (%) | Object-Based (%) | ||||
|---|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | ||
| Area1 DLG_M | (1) | 80.24 | 67.99 | 58.24 | 96.00 | 55.45 | 50.70 |
| (2) | 80.30 | 77.75 | 65.29 | 90.66 | 62.39 | 58.62 | |
| (3) | 94.11 | 92.73 | 87.65 | 98.67 | 83.15 | 82.22 | |
| (4) | 93.22 | 96.52 | 90.19 | 97.33 | 94.81 | 92.41 | |
| Area2 DLG2008 | (1) | 81.23 | 63.34 | 55.25 | 87.91 | 48.19 | 45.20 |
| (2) | 68.12 | 84.42 | 60.51 | 81.32 | 83.15 | 69.81 | |
| (3) | 82.41 | 71.48 | 62.02 | 94.51 | 63.70 | 61.43 | |
| (4) | 70.05 | 87.07 | 63.45 | 87.91 | 87.91 | 78.43 | |
| Area2 DLG2014 | (1) | 78.01 | 64.92 | 54.88 | 85.71 | 47.56 | 44.07 |
| (2) | 75.56 | 90.81 | 70.19 | 85.71 | 86.67 | 75.73 | |
| (3) | 88.04 | 73.34 | 66.70 | 96.70 | 65.19 | 63.77 | |
| (4) | 77.52 | 92.33 | 72.83 | 86.81 | 92.94 | 81.44 | |
| Data Sets | Strategy | Pixel-Based (%) | Object-Based (%) | ||||
|---|---|---|---|---|---|---|---|
| Completeness | Correctness | Quality | Completeness | Correctness | Quality | ||
| Area1 DLG_M | (1) | 92.65 | 94.92 | 88.28 | 97.33 | 93.59 | 91.25 |
| (2) | 93.22 | 96.52 | 90.19 | 97.33 | 94.81 | 92.41 | |
| Area2 DLG2008 | (1) | 60.01 | 86.47 | 54.86 | 84.62 | 90.59 | 77.78 |
| (2) | 70.05 | 87.07 | 63.45 | 87.91 | 87.91 | 78.43 | |
| Area2 DLG2014 | (1) | 74.80 | 94.20 | 71.51 | 85.71 | 95.12 | 82.11 |
| (2) | 77.52 | 92.33 | 72.83 | 86.81 | 92.94 | 81.44 | |
| Data Sets | Strategy | Dimensions | Selecting (s) | Training (s) |
|---|---|---|---|---|
| Area1 DLG_M | (1) | 7 | 1792.94 | 76.98 |
| (2) | 12 | 3228.36 | 254.82 | |
| (3) | 256 | 10,335.00 | 1008.17 | |
| (4) | 19 | 3897.31 | 351.32 | |
| Area2 DLG2008 | (1) | 7 | 524.42 | 22.35 |
| (2) | 12 | 886.76 | 25.97 | |
| (3) | 256 | 4197.98 | 330.40 | |
| (4) | 19 | 1052.79 | 55.70 | |
| Area2 DLG2014 | (1) | 7 | 514.98 | 29.91 |
| (2) | 12 | 900.47 | 30.42 | |
| (3) | 256 | 4866.32 | 508.12 | |
| (4) | 19 | 1078.41 | 66.66 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, Y.; Nie, K.; Li, X.; Wang, W. Extracting Building Areas from Photogrammetric DSM and DOM by Automatically Selecting Training Samples from Historical DLG Data. ISPRS Int. J. Geo-Inf. 2020, 9, 18. https://doi.org/10.3390/ijgi9010018
Chen S, Zhang Y, Nie K, Li X, Wang W. Extracting Building Areas from Photogrammetric DSM and DOM by Automatically Selecting Training Samples from Historical DLG Data. ISPRS International Journal of Geo-Information. 2020; 9(1):18. https://doi.org/10.3390/ijgi9010018
Chicago/Turabian StyleChen, Siyang, Yunsheng Zhang, Ke Nie, Xiaoming Li, and Weixi Wang. 2020. "Extracting Building Areas from Photogrammetric DSM and DOM by Automatically Selecting Training Samples from Historical DLG Data" ISPRS International Journal of Geo-Information 9, no. 1: 18. https://doi.org/10.3390/ijgi9010018
APA StyleChen, S., Zhang, Y., Nie, K., Li, X., & Wang, W. (2020). Extracting Building Areas from Photogrammetric DSM and DOM by Automatically Selecting Training Samples from Historical DLG Data. ISPRS International Journal of Geo-Information, 9(1), 18. https://doi.org/10.3390/ijgi9010018