Fused Transparent Visualization of Point Cloud Data and Background Photographic Image for Tangible Cultural Heritage Assets


Abstract
:1. Introduction
2. Fused Transparent Visualization of Point Cloud Data and Background Photographic Image
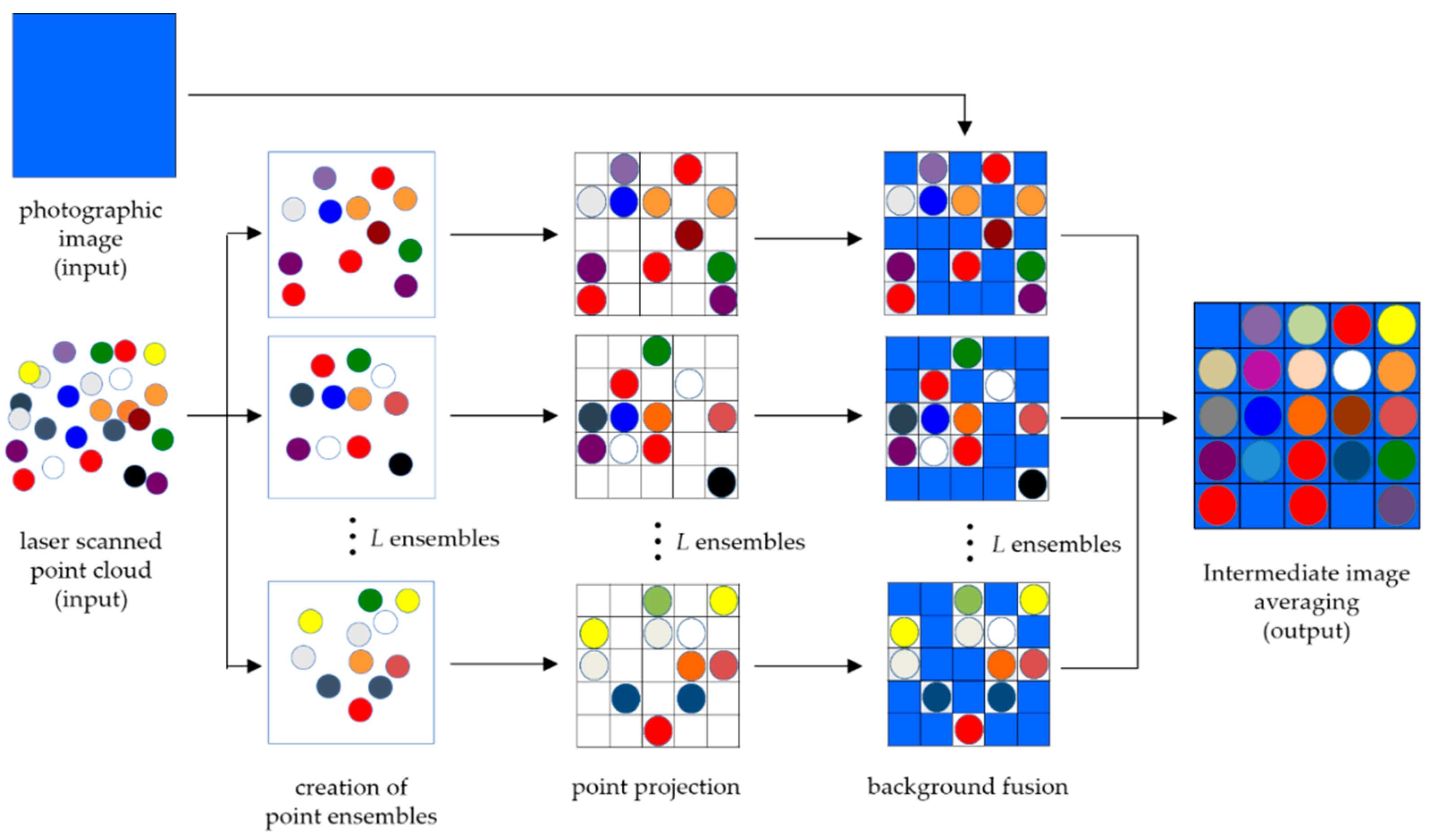
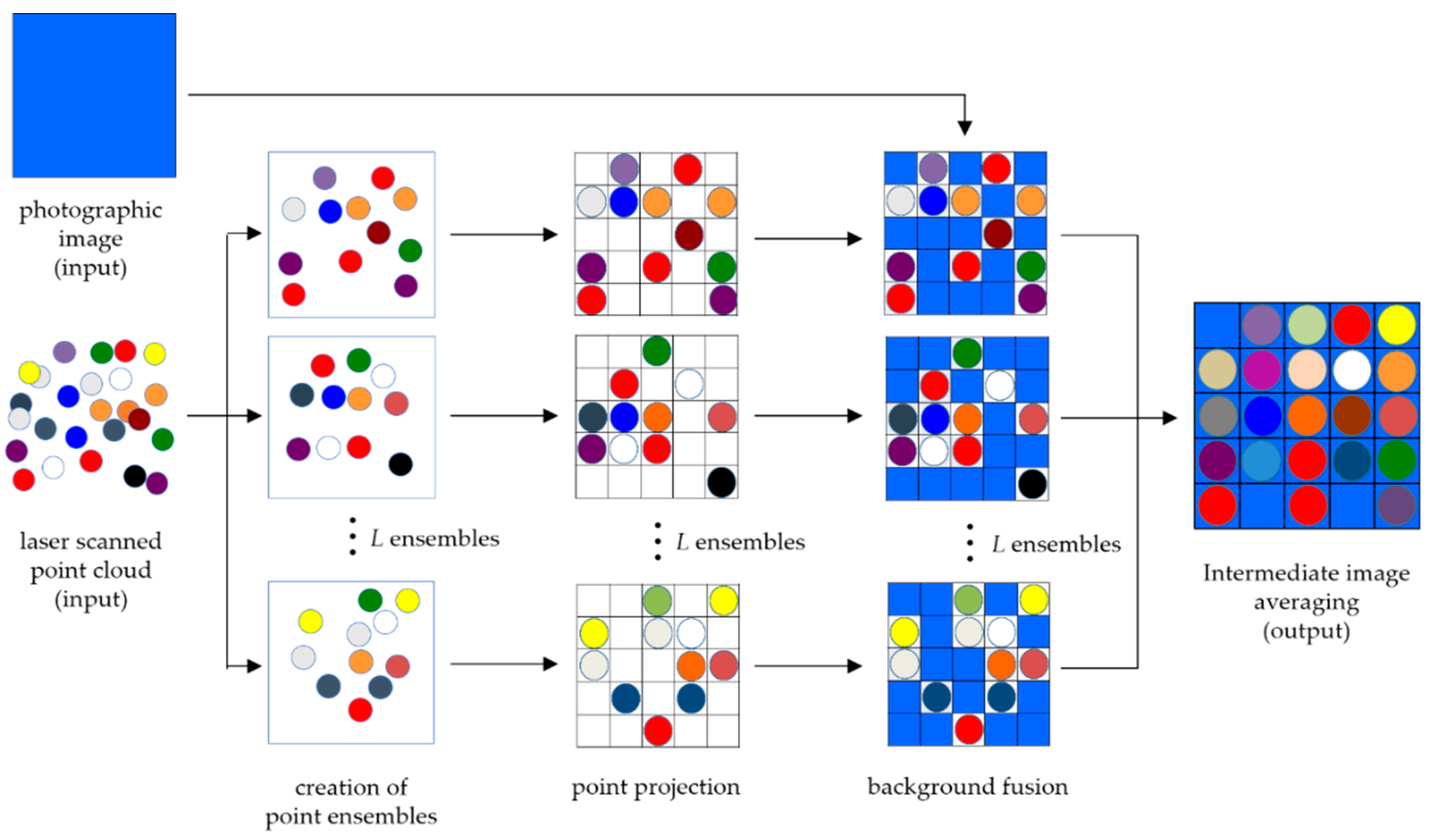
2.1. Fused Transparent Visualization Procedure
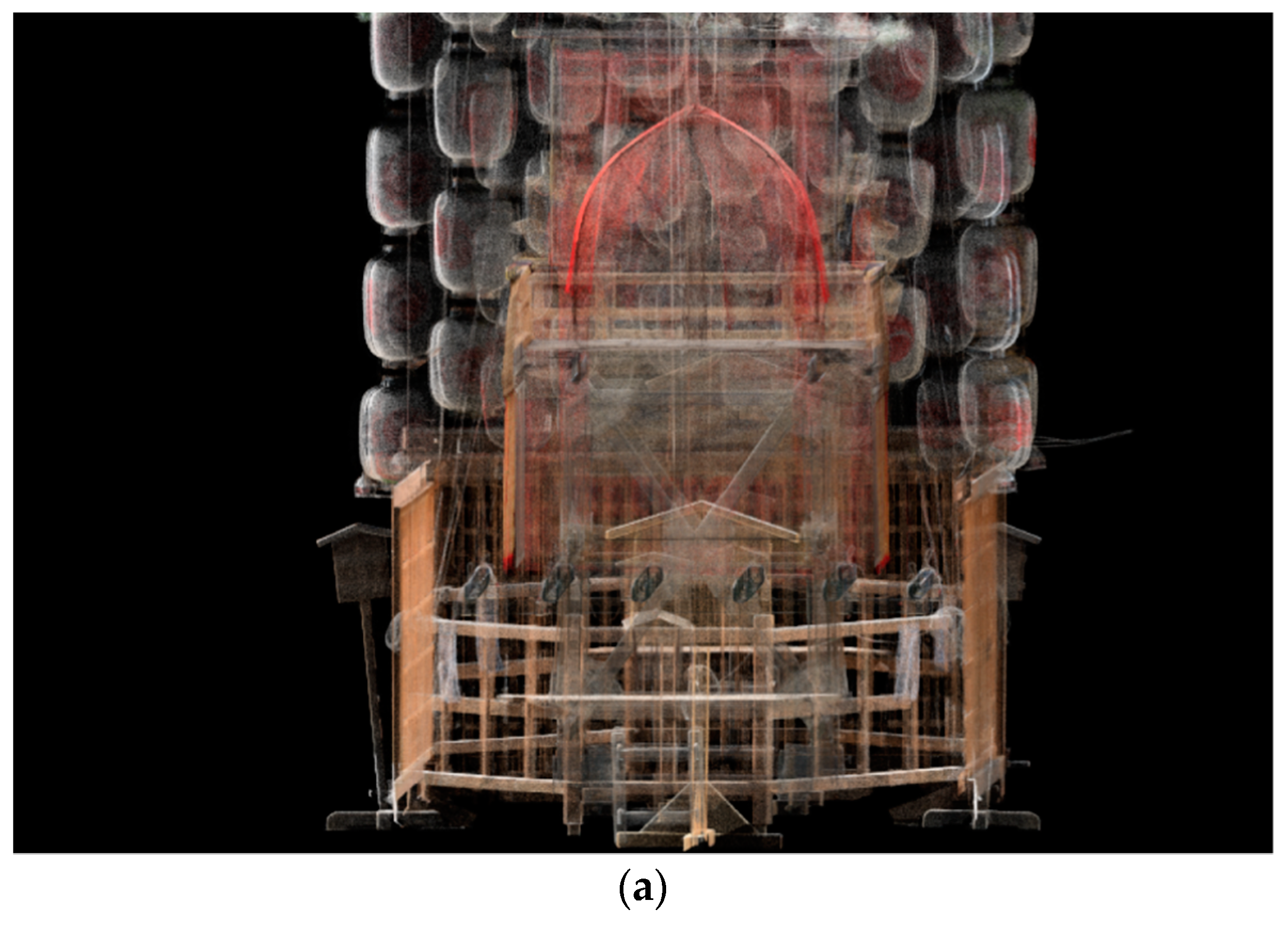
2.2. Application to a Laser-Scanned Point Cloud
3. Visibility Enhancement for Fused Transparent Visualization
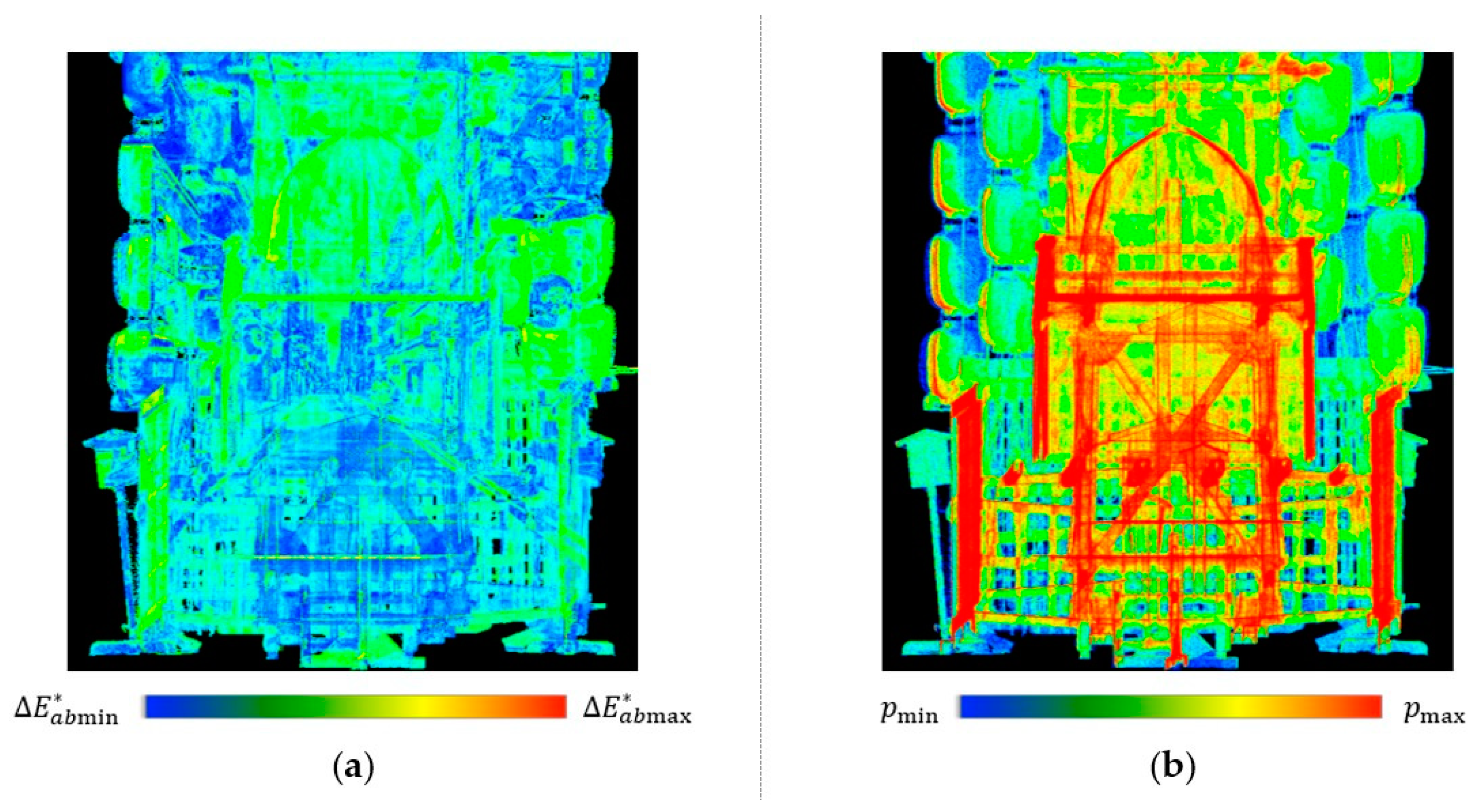
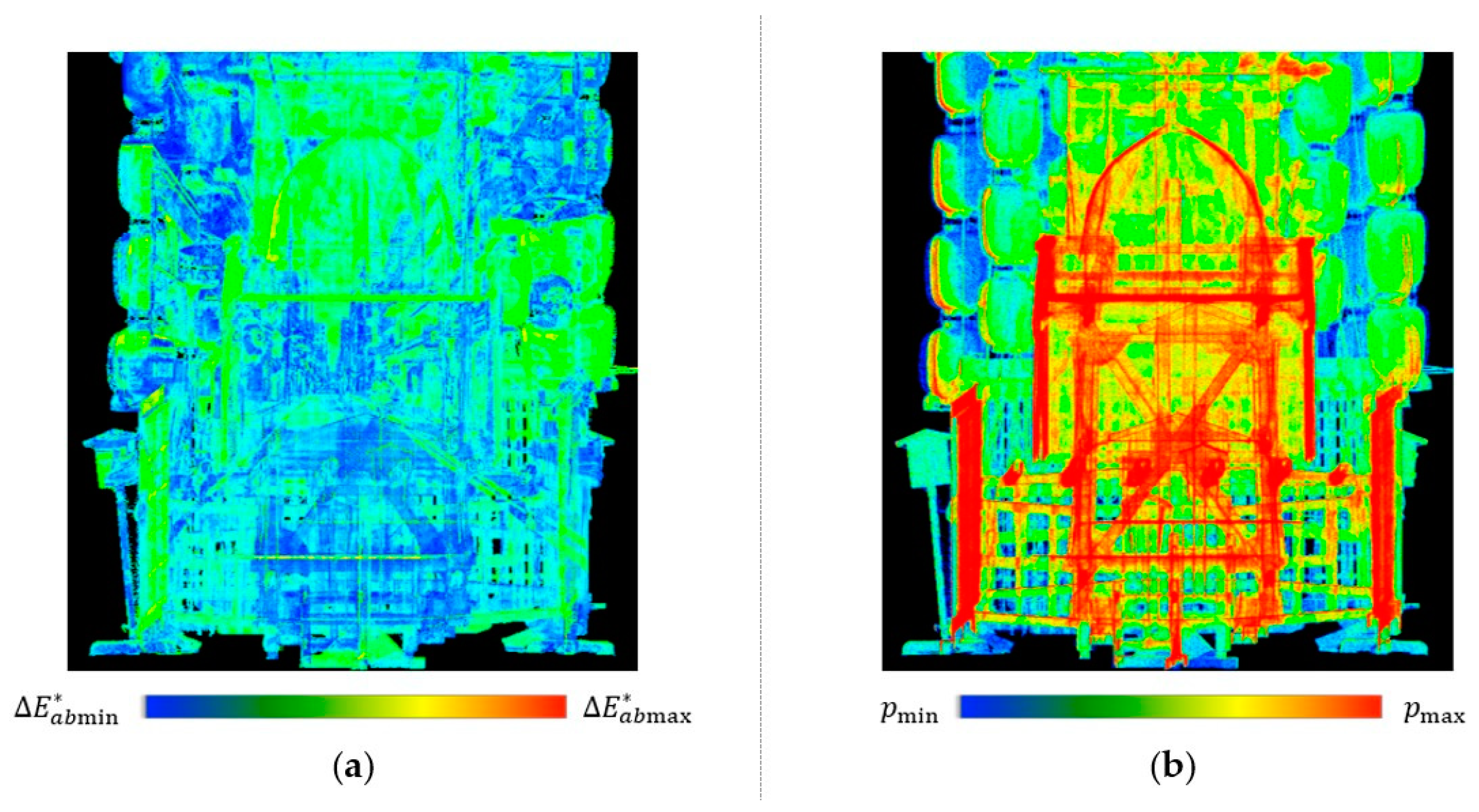
3.1. Causes of the Problem
3.2. Lightness Adjustment
3.3. Color Enhancement
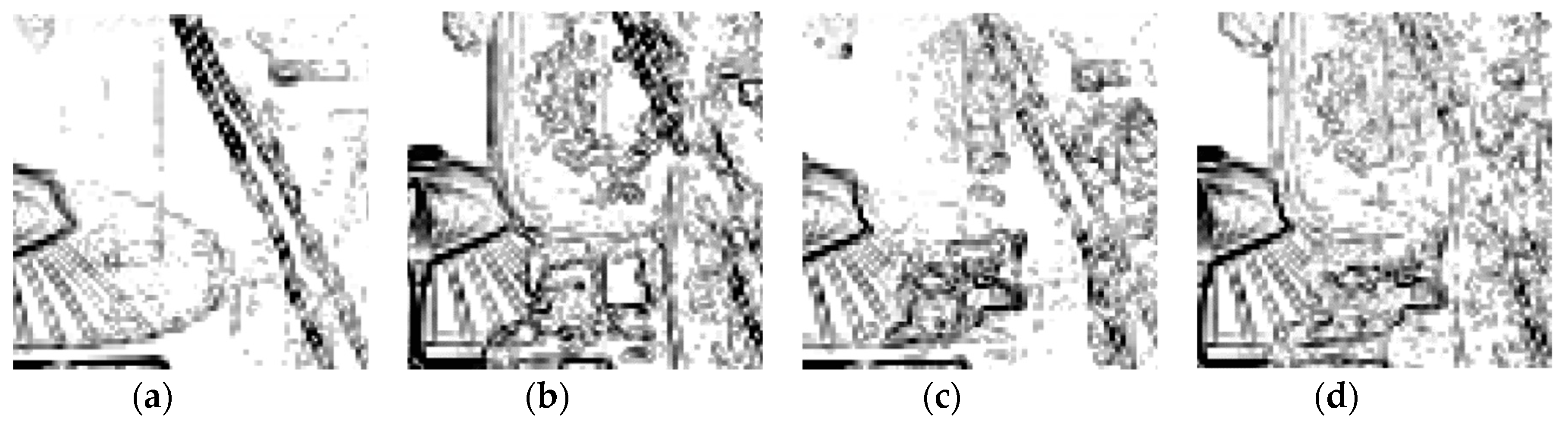
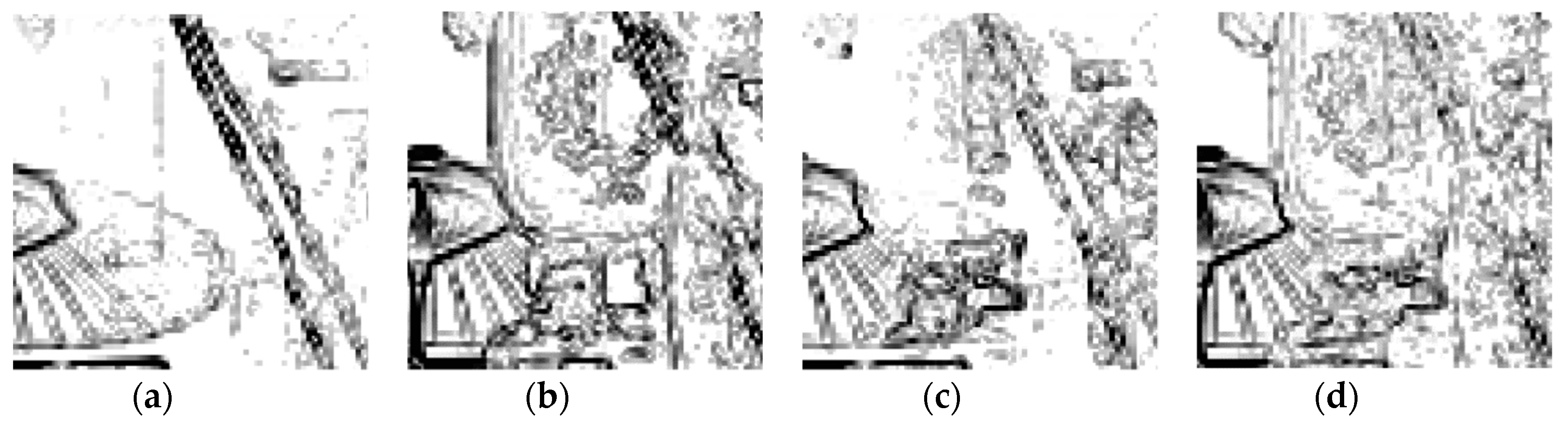
4. Experimental Results and Evaluations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


References
- Zorich, D.M. A Survey of Digital Cultural Heritage Initiatives and Their Sustainability Concerns; Council on Library and Information Resources: Washington, DC, USA, 2003. [Google Scholar]
- Parry, R. Digital heritage and the rise of theory in museum computing. Mus. Manag. Curatorship 2005, 20, 333–348. [Google Scholar] [CrossRef]
- Hachimura, K.; Li, L.; Choi, W.; Fukumori, T.; Nishiura, T.; Yano, K. Generating virtual yamahoko parade of the gion festival. In New Developments in Digital Archives; Hacihmura, K., Tanaka, H.T., Eds.; Nakanishiya Publishing: Kyoto, Japan, 2012; pp. 259–279. [Google Scholar]
- Yano, K.; Nakaya, T.; Isoda, Y. (Eds.) Virtual Kyoto: Exploring the Past Present and Future of Kyoto; Nakanishiya Publishing: Kyoto, Japan, 2007; pp. 1–161. [Google Scholar]
- Magnenat-Thalmann, N.; Foni, N.; Papagiannakis, G.; Cadi-Yazli, N. Real time animation and illumination in ancient roman sites. Int. J. Virtual Real. 2007, 6, 11–24. [Google Scholar]
- Hachimura, K. Digital archiving of dance by using motion capture technology. In New Directions in Digital Humanities for Japanese Arts and Cultures; Kawashima, A., Akama, R., Yano, K., Hachimura, K., Inaba, M., Eds.; Nakanishiya Publishing: Kyoto, Japan, 2008; pp. 167–182. [Google Scholar]
- Remondino, F.; Barazzetti, L.; Nex, F.; Scaioni, M.; Sarazzi, D. UAV photogrammetry for mapping and 3D modeling current status and future perspectives. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 38, C22. [Google Scholar] [CrossRef]
- Masuda, H.; He, J. TIN generation and point-cloud compression for vehicle-based mobile mapping systems. Adv. Eng Inform. 2015, 29, 841–850. [Google Scholar] [CrossRef]
- Guidi, G.; Frischer, B.; Simone, M.D.; Cioci, A.; Spinetti, A.; Carosso, L.; Micoli, L.L.; Russo, M.; Grasso, T. Virtualizing Ancient Rome: 3D acquisition and Modeling of a Large Plaster-of-Paris Model of Imperial Rome. In Proceedings of SPIE 5665; SPIE: Bellingham, WA, USA, 2005; Volume Videometrics VIII; pp. 119–133. [Google Scholar]
- Ikeuchi, K.; Oishi, T.; Takamatsu, J.; Sagawa, R.; Nakazawa, A.; Kurazume, R.; Nishino, K.; Kamakura, M.; Okamoto, Y. The great Buddha project: Digitally archiving, restoring and analyzing cultural heritage objects. Int. J. Comput. Vis. 2007, 75, 189–208. [Google Scholar] [CrossRef]
- Dylla, K.; Frischer, B.; Mueller, P.; Ulmer, A.; Haegler, S. Rome Reborn 2.0: A case study of virtual city reconstruction using procedural modeling techniques. In Proceedings of CAA 2009; Archaeopress: Oxford, UK, 2009; pp. 62–66. [Google Scholar]
- Remondino, F.; Girardi, S.; Rizzi, A.; Gonzo, L. 3D modeling of complex and detailed cultural heritage using multi-resolution data. ACM J. Comput. Cult. Herit. 2009, 2, 2. [Google Scholar] [CrossRef]
- Koller, D.; Frischer, B.; Humpherys, G. Research challenges for digital archives of 3d cultural heritage models. ACM J. Comput. Cult. Herit. 2009, 2, 7. [Google Scholar] [CrossRef]
- Kersten, T.P.; Keller, F.; Saenger, J.; Schiewe, J. Automated Generation of an Historic 4D City Model of Hamburg and Its Visualisation with the GE Engine. In Proceedings of Progress in Cultural Heritage Preservation (Lecture Notes in Computer Science 7616); Springer: Berlin, Germany, 2012; pp. 55–65. [Google Scholar]
- Kobbelt, L.; Botsch, M. A survey of point-based techniques in computer graphics. Comput. Graph. 2004, 28, 801–814. [Google Scholar] [CrossRef]
- Gross, M.; Pfister, H. (Eds.) Point-Based Graphics; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Discher, S.; Richter, S.; Dollner, J. A Scalable WebGL-based Approach for Visualizing Massive 3D Point Clouds using Semantics-Dependent Rendering Techniques. In Proceedings of Web3D’18; ACM: New York, NY, USA, 2018; p. 19. [Google Scholar]
- Discher, S.; Masopust, L.; Schulz, S.; Richter, R.; Dollner, J. A point based and image-based multi-pass rendering technique for visualizing massive 3D point clouds in VR environments. J. WSCG 2018, 26, 76–84. [Google Scholar] [CrossRef]
- Thiel, F.; Discher, S.; Richter, R.; Dollner, J. Interaction and locomotion techniques for the exploration of massive 3D point clouds in VR environments. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42. [Google Scholar] [CrossRef]
- Seemann, P.; Palma, G.; Dellepiane, M.; Cignoni, P.; Goesele, M. Soft Transparency for Point Cloud Rendering. In Proceedings of Eurographics Symposium on Rendering: Experimental Ideas Implementations; ACM: New York, NY, USA, 2018; pp. 95–106. [Google Scholar]
- Tanaka, S.; Hasegawa, K.; Okamoto, N.; Umegaki, R.; Wang, S.; Uemura, M.; Okamoto, A.; Koyamada, K. See-Through Imaging of Laser-scanned 3D Cultural Heritage Objects based on Stochastic Rendering of Large-Scale Point Clouds. In Proceedings of ISPRS Annals Photogrammetry Remote Sensing and Spatial Information Sciences; Copernicus Publications: Göttingen, Germany, 2016; pp. 73–80. [Google Scholar]
- Hasegawa, K.; Li, L.; Okamoto, N.; Yanai, S.; Yamaguchi, H.; Okamoto, A.; Tanaka, S. Application of stochastic point-based rendering to laser-scanned point clouds of various cultural heritage objects. Int. J. Autom. Technol. 2018, 12, 348–355. [Google Scholar] [CrossRef]
- Tanaka, S.; Nakagawa, M. Path Design for Ground-based Panoramic Image Acquisition. In Proceedings of ACRS 2015; AARS: Tokyo, Japan, 2015; p. 118634. [Google Scholar]
- Porter, T.; Duff, T. Compositing digital images. Comput. Graph. 1984, 18, 253–259. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lightness Adjustment | Color Enhancement | Fused Transparent Visualization |
|---|---|---|
| 0.09 | 2.38 | 3.19 |
| SPBR | Proposed Fused Transparent Visualization | Proposed Method with Lightness Adjustment | Proposed Method with Color Enhancement | Proposed Method with Lightness Adjustment and Color Enhancement | |
|---|---|---|---|---|---|
| Transparent visualization | Yes | Yes | Yes | Yes | Yes |
| Fused visualization | No | Yes | Yes | Yes | Yes |
| Visibility in regions with similar object-background colors (e.g., counters of the lanterns) | Poor | Poor | Good | Poor | Good |
| Visibility in regions with few projected points (e.g., patterns of the lanterns) | Poor | Poor | Poor | Good | Good |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Hasegawa, K.; Nii, I.; Tanaka, S. Fused Transparent Visualization of Point Cloud Data and Background Photographic Image for Tangible Cultural Heritage Assets. ISPRS Int. J. Geo-Inf. 2019, 8, 343. https://doi.org/10.3390/ijgi8080343
Li L, Hasegawa K, Nii I, Tanaka S. Fused Transparent Visualization of Point Cloud Data and Background Photographic Image for Tangible Cultural Heritage Assets. ISPRS International Journal of Geo-Information. 2019; 8(8):343. https://doi.org/10.3390/ijgi8080343
Chicago/Turabian StyleLi, Liang, Kyoko Hasegawa, Itaru Nii, and Satoshi Tanaka. 2019. "Fused Transparent Visualization of Point Cloud Data and Background Photographic Image for Tangible Cultural Heritage Assets" ISPRS International Journal of Geo-Information 8, no. 8: 343. https://doi.org/10.3390/ijgi8080343
APA StyleLi, L., Hasegawa, K., Nii, I., & Tanaka, S. (2019). Fused Transparent Visualization of Point Cloud Data and Background Photographic Image for Tangible Cultural Heritage Assets. ISPRS International Journal of Geo-Information, 8(8), 343. https://doi.org/10.3390/ijgi8080343