1. Introduction
In recent years, due to congestion, air pollution, climate change, energy scarcity, and physical inactivity, an increasing importance has been attributed to sustainable transport modes, and in particular to cycling. Municipalities have drawn attention to these issues and started to implement different strategies to encourage a greater usage of bicycles on urban streets and to reduce car trips. Many cities have decided to invest in the construction of quality bikeways with the intention to incentivize people to cycle even medium (and long) distances on a daily basis.
Several studies have found positive correlations between bike facilities and levels of bicycling. Dill and Carr [
1] have analyzed data from 35 large cities across the U.S., finding that cities with higher levels of bicycle infrastructure were characterized by higher levels of bicycle commuting. Pucher and Buehler found that the key to achieving high levels of cycling in Dutch, Danish, and German cities appears to be the provision of separate cycling facilities [
2].
Many researchers have studied cyclists’ preferences and have estimated route choice models for planning new bicycle infrastructure. Most of these studies were based on stated preference (SP) data and on opinion surveys. Dill and Voros [
3] explored the relationships between levels of cycling and demographics, objective environmental factors, perceptions of the environment, and attitudes based on the results from a random phone survey of adults in the Portland, Oregon. Stinson and Bhat [
4], proposed empirical models to evaluate the importance of factors (such as travel time and pavement quality) affecting commuter bicyclists’ route choices. Winters et al. [
5] evaluated 73 motivators and deterrents of cycling based on a survey (telephone interviews) and a self-administered survey (either via the web or mail) of 1402 current and potential cyclists in metropolitan Vancouver. These studies highlighted the cyclists’ preference for physically separated bike paths and on-road bike lanes separated by markers. The known limitation of SP studies arises from the difference between stated and observed behavior [
6].
In the past, only a few studies were based on revealed preference (RP) data due to the limited availability of this data type. The results of Howard and Burns [
7] show that bicycle commuters in metropolitan Phoenix respond to the provision of bicycle facilities. Nelson and Allen [
8] found that each additional mile of bikeway per 100,000 people is associated with a 0.069% increase in bicycle commuting.
Data on cycling volumes is the result of choices actually made by cyclists in a real outdoor environment and therefore help to support decision making. Such information is necessary to understand what factors influence ridership. Bike flows can be collected with traditional manual or instrumental counts, which have some drawbacks: Traditional manual counts lack spatial detail and temporal coverage [
9,
10]. Instrumental and permanent counting stations do provide continuous data, but cover typically only a small number of road sections [
11].
More recently, the widespread use of smartphones and mobile applications for self-localization and navigation has increased the availability of observed cyclists’ data in the form of time series of GPS points, called GPS traces. This type of data provides detailed information about the origin/destination of trips as well as the chosen routes. Furthermore, GPS traces allow to determine the total deviation (detour) generated for cyclists in terms of extra distances traveled with respect to the shortest possible route. Empirical data on detour rates do exist. Detours have been calculated in different ways, see for example Pritchard et al. [
12] and Griffin and Jiao [
13].
The availability of GPS traces led to the development of new cyclists’ route choice models. Dill collected data on bicycling behavior from 166 regular cyclists (1955 trips) in the Portland, Oregon, using GPS devices [
14]. This study highlighted that a well-connected network of low traffic streets may be more effective than adding bike lanes on major streets with a high volumes of motor vehicle traffic. Menghini et al. estimated the route choice model for bicyclists from a large sample of GPS observations (2498 trips) collected in Zürich, Switzerland [
15]. Their conclusion has been that the trip-length dominates the choices of the Zurich cyclists. Hood et al. analyzed GPS traces from cyclists (366 users and 2777 trips) in San Francisco, USA, and proved a preference for separated bicycle lanes—especially for infrequent cyclists [
16]. Broach et al. estimated the route choice of cyclists (164 users and 1449 trips) in Portland metropolitan area, USA [
17]. Their study confirmed that route length and slopes do have a negative effect on cyclists’ route choice. In addition, they found that high traffic volumes, high turn frequencies, and traffic signals are also repellant road attributes according to the cyclists’ route choice. Zimmermann et al. estimated a link-based bike route choice model from a sample of GPS observations (103 users and 648 trips) in the city of Eugene, Oregon [
18]. Their study confirmed the sensibility of cyclists to distance, traffic volume, slopes, crossings and the presence of bike facilities, distinguishing between average slope above or below 4%, and traffic volume above or below 8000 vehicles per day. More recently, Bernardi et al. analyzed the GPS traces recorded by approximately 280 bicycle users throughout the Netherlands [
19]; the results show a high usage of cycleway links and the preference of the shortest route by frequent cyclists. Casello and Usyukov used GPS data on cyclists’ activities to estimate a generalized-cost function that reflects the cyclists’ evaluation of path alternatives [
20]: their model correctly predicted the revealed path choice for 65% of the examined trips.
One of the main problems with GPS data is its representativeness, because data collection is usually provided on a volunteer basis, which is not necessarily representative for the entire population [
21]. This type of problem has been highlighted by Jestico et al. [
22], who used data provided by strava.com to quantify how well crowdsourced fitness app data represent ridership through a comparison with manual cycling counts in Victoria, British Columbia. Another problem is the level of detail of the network: in many cases, the success of identifying the correct network links from GPS points is limited if the bike network model is not sufficiently detailed [
23,
24].
This paper explains how to estimate the city-wide bicycle flows and how to identify weak points of the road network in terms of bicycle friendliness. Both methods are data driven, explicit and do not require the calibration of sophisticated models. Nevertheless, a route choice model is also calibrated explaining the reasons for deviations at certain road links.
The paper is organized as follows.
Section 2 describes the study area and the features of the bike network.
Section 3 depicts the bicycle flows obtained by traditional (manual and instrumental) counting methods and by GPS data collected by smartphone application.
Section 3 identifies a correlation between cycling counts and GPS data and describes the bicycle flow reconstruction method. In
Section 4, a deviation analysis is carried out and a Logit model is calibrated in order to shed more light on the reasons for the decision of individuals to accept deviations by assessing the route characteristics of chosen routes and shortest routes.
Section 5 discusses the results of the analysis. Concluding remarks and future research directions are presented in
Section 6.
4. Deviation Analysis
The deviation analysis aims to identify the network links which are the most avoided by all cyclists who registered GPS traces. The analysis starts with the following basic assumption: given the choice of two routes with identical properties (same safety, pavement, environment, etc.), cyclists would always choose the shortest one. If this is true, the cyclist would only accept a longer route if it offered better properties (safer, quieter, etc.). From a different perspective, if certain road links are avoided by deviating on alternative links, then the avoided links are supposed to possess fewer attractive characteristics with respect to the alternative, even though these characteristics may be good in the absolute sense. In an ideal bicycle network, no cyclists should feel constrained to take a longer route due to some repellant characteristics of the shortest route, or due to the better characteristics of longer routes. The most “avoided links” of the city’s road network are therefore identified with the km of deviation caused to cyclists. The total deviation metric for each road link i is calculated in the following way:
Figure 9 shows links 1, 2 and 3 which are not chosen, despite they are part of the shortest route (solid line); whereas, links 4, 5 and 6 are part of the chosen route (dashed line). In case of the non-overlapping section between node A and B shown in
Figure 9, the chosen route
is constituted by links 4, 5 and 6, while the shortest route section
contains links 1, 2 and 3. The partial deviation
of links in
equals to
L
4 + L
5 + L
6 − (L
1 + L
2 + L
3). The total deviation metric for the central part of Bologna network is shown in
Figure 10.
The highest total deviation metric can been seen on the main radial roads from and into the city center. As seen in
Figure 10, these are also roads with high bicycle flows. This means that many cyclists actually do use these radial roads but also many try to avoid them. Note that there are also roads in the city center with high bicycle flows, but generating almost no deviations. For a discussion of these findings, see
Section 5.
On average, the chosen route parts are 20% longer with respect to the shortest route parts. Analyzing the road attributes of the chosen part and the shortest part of all non-overlapping sections of all trips, the causes for the deviations become clearer—see the first three columns of
Table 1. As expected, cyclists accept deviations in order to travel on roads with: (1) a high share of reserved bikeways, (2) a high share of low priority roads (roads with one lane per direction and speed limits of 30 km/h), (3) a low intersection density, and (4) a low share of mixed access, such as lanes with bike/bus access or lanes where bikes and pedestrians are allowed. This last result confirms the findings of the research carried out by Bernardi et al. [
39], in which the authors quantified the effects and frequencies of disturbances on bicycle facilities, particularly from pedestrians and buses.
The statistics of the road link attributes of the overlapping sections of each trip (i.e., all links where the chosen and shortest routes coincide) are presented in the last column of
Table 1. It becomes evident that the values of the mixed road access share, the reserved bikeway share and the intersection density are in between the values of the shortest route (column 1) and the chosen route (column 2) of the non-overlapping sections. One could conclude that cyclists tend to deviate if road attribute values are below/above those of the overlapping sections. An exception is the low priority road share, where the overlapping sections show values even below that of the shortest route.
In order to shed more light on the decision of individuals to accept deviations, a Logit model is calibrated, where the user has the choice between two alternatives of non-overlapping route segments (as illustrated in
Figure 9), where one of the alternatives is the shortest route. The systematic utility function
of alternative
i is defined as:
where
is the distance of the route segment,
is the share of exclusive bikeway, and
is the share of low priority roads as percentage of the respective distance. The set of observations has been prepared as follows. In a first subset, the route sections have been considered, where the chosen route is different from the shortest route. In a second subset, route sections have been identified, where the shortest route completely coincides with the chosen route. In this case, a longer route alternative (that has not been chosen by the cyclist) has been generated as follows: the second shortest route that connects the extremities of the shortest route section is determined such that the second shortest route section does not overlap with the shortest route section. This is similar to the method applied by Marchal et al. [
36]. In this way, a route alternative is generated that is the closest possible to the chosen (and shortest) route alternative. In order to avoid a bias towards longer or shorter distances, the size of the first and second observation subset are kept equal.
The calibration resuls of a total of 4678 observations is shown in
Table 2. The attributes chosen are all significant and R
2 = 0.160. The small parameter values result in Odds ratios close to one, which is reasonable considering that attribute values are in the order of 10
−2–10
−3. Other attributes like the node density or the share of mixed bikeway access have turned out not to be significant when included in this model. The signs of the model parameters are reasonable—see also the discussion in
Section 6. The calibration has been repeated with GPS traces in Bologna from the ECC of the year 2015. The result of this calibration shows parameter values within the standard error bounds of the result from ECC of the year 2016 shown in
Table 2.
One can use Equation (2) to estimate the deviation necessary to equilibrate the systematic utilities of both route alternatives. Setting
, and resolving for the deviation yields in
which is the difference in distance, depending on the difference in exclusive bikeway share and the difference in low priority road share. The deviation
obtained from Equation (3) ensures a path choice probability of 50%.
5. Discussion
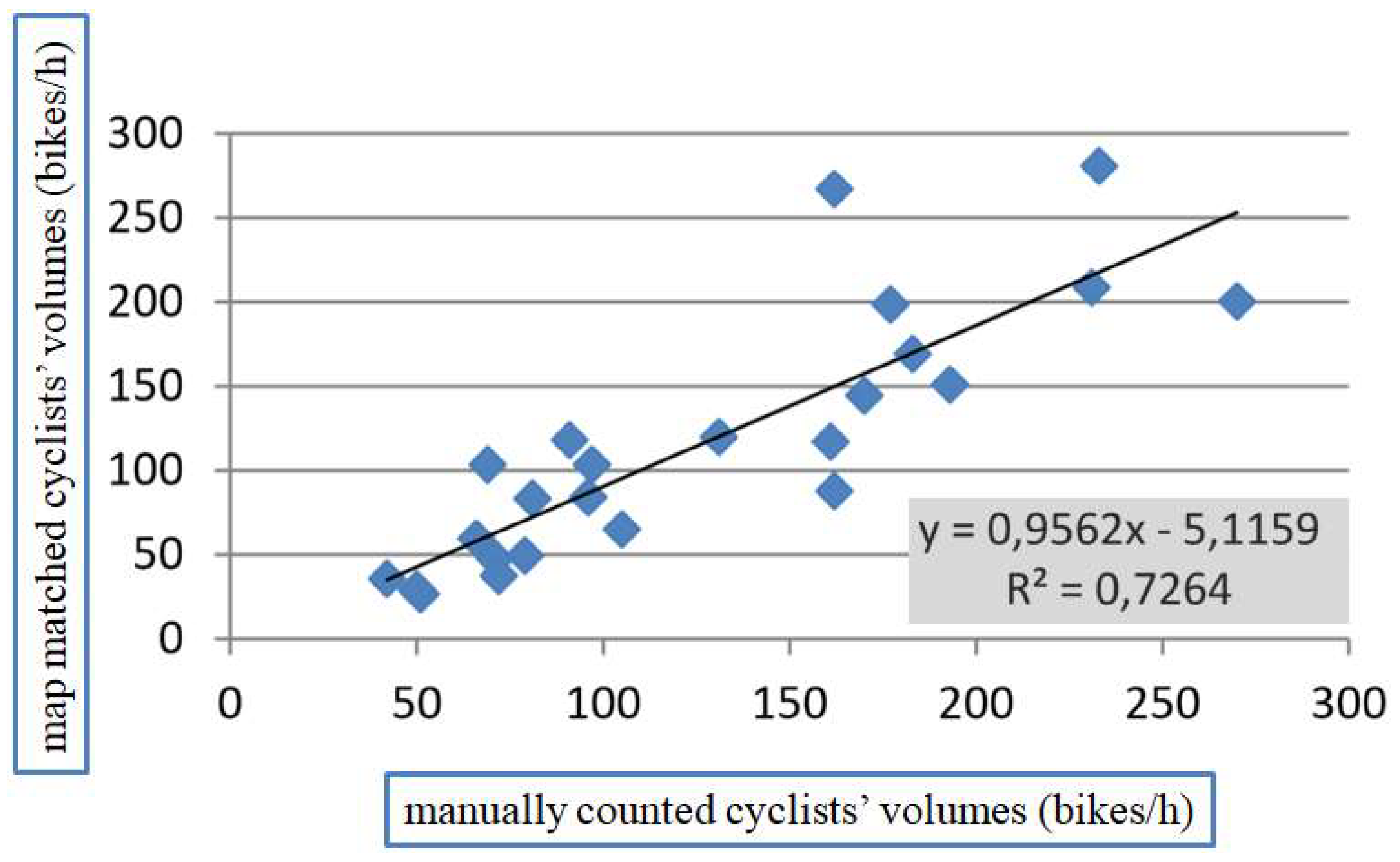
Regarding the estimation of all bicycle flows on the network, the high agreement of flows from GPS traces and manual/instrumental counts (R
2 = 0.73) is significantly better than the results obtained by previous studies, e.g., Jestico et al. [
22] obtained an R
2 of 0.4 for the a.m. peak period. The reason for this difference is likely due to the more detailed network model of Bologna, representing better the cyclists’ freedom to move on all possible links in both directions. Based on this correlation, one crowdsourced cyclist corresponds in average to 59 cyclists counted with traditional methods, which is consistent with previous findings in [
22].
Although crowdsourced cyclists represent a small portion of all cyclists, the flows obtained from the map matched GPS data are consistent with the observed flows on the main sections of the Bologna cycle network. Only a few outliers emerge, most likely due to two potential error sources: (1) the days of data sampling of the two methods do not entirely overlap because the GPS records have been registered during the whole month of May, while the traffic counts have been conducted only for two weeks of the same month; (2) the sampling hours do not exactly overlap either, because the GPS traces are selected by their begin time while the traditional methods count the cyclists actually passing by the road-section during the analyzed time interval.
The applied deviation metric from
Section 4 quantifies the total deviations of cyclists generated by single road links, but the metric itself does not identify the reasons for the deviations. However, it becomes evident that those radial roads with high bike flows and high deviations in
Figure 10 are characterized by an absence of reserved bike lanes, a high level of bus traffic, often on reserved bus lanes, and a high density of intersections. In contrast, those roads where bicycle flows are high but deviations are low, are characterized by low motorized traffic volumes, a high share of bike lanes and the absence of major bus routes.
Nevertheless, the total deviation metric depends on the presence of alternative routes with respect to the shortest route and their respective road attributes: in case there are no feasible route alternatives to avoid a certain link, then the total deviation metric of the respective link is zero, even though the attributes may be unfavourable. In case the shortest route has favourable link attributes but the alternative has even more favourable link attributes, then the total deviation metric is high despite the good conditions on the shortest route. The former case is the most severe as criticalities of unfavourable roads for cyclists without route alternatives remain undiscovered by the deviation analysis.
The calibration of a binominal logit model allows to determine the choice probability, given the attributes of two non-overlapping route alternatives. The attributes distance, share of exclusive bikeways and share of low-priority roads have been found to be significant. The negative sign of and the positive sign of are expected as a longer distance is a disincentive and the presence of a an exclusive bikeway is an incentive for cyclists. The negative sign of related to the share of low-priority roads seems to contradict the previous analyses where the average route on deviations contains a lower share of low priority roads with respect to routes where shortest and chosen routes overlap. One explanation could be the way the alternative routes are generated: probably the second shortest route between two points does use minor roads which cyclists would typically avoid, or cyclists are simply not aware of such alternatives. The determination of road priorities is a heuristic algorithm derived from OSM attributes such as speed limits, number of lanes and access restrictions. It is possible that some types of low priority roads are in reality not attractive to cyclists. A possibility to avoid such problems would be to consider only alternative routes used by at least one cyclist instead of using the adopted route generation method. Another solution would be to specify a model which quantifies the probability to accept a route by considering only the link attributes of the chosen routes, enhanced by a dummy variable indicating whether the chosen route is also the shortest route. Such a model would definitively avoid the problem of alternative route generation. However, modelling errors could be introduced by ignoring all attributes of alternative routes.
The result from Equation (3) relates the differences in road attributes between two alternative routes with the distance that would compensate those differences. The meaning of this result shall be explained by a simple numerical example: assuming two route alternatives, one with a 100% exclusive bikeway and the other without any bikeway, and both alternatives are without priority roads. In such a case, the first alternative could be 3.2 km longer than the second while still attracting 50% of the cyclists.
6. Conclusions
In this research, the cyclists’ flows obtained by traditional counting methods have been compared with GPS traces from smartphones at the same locations and during the same time period.
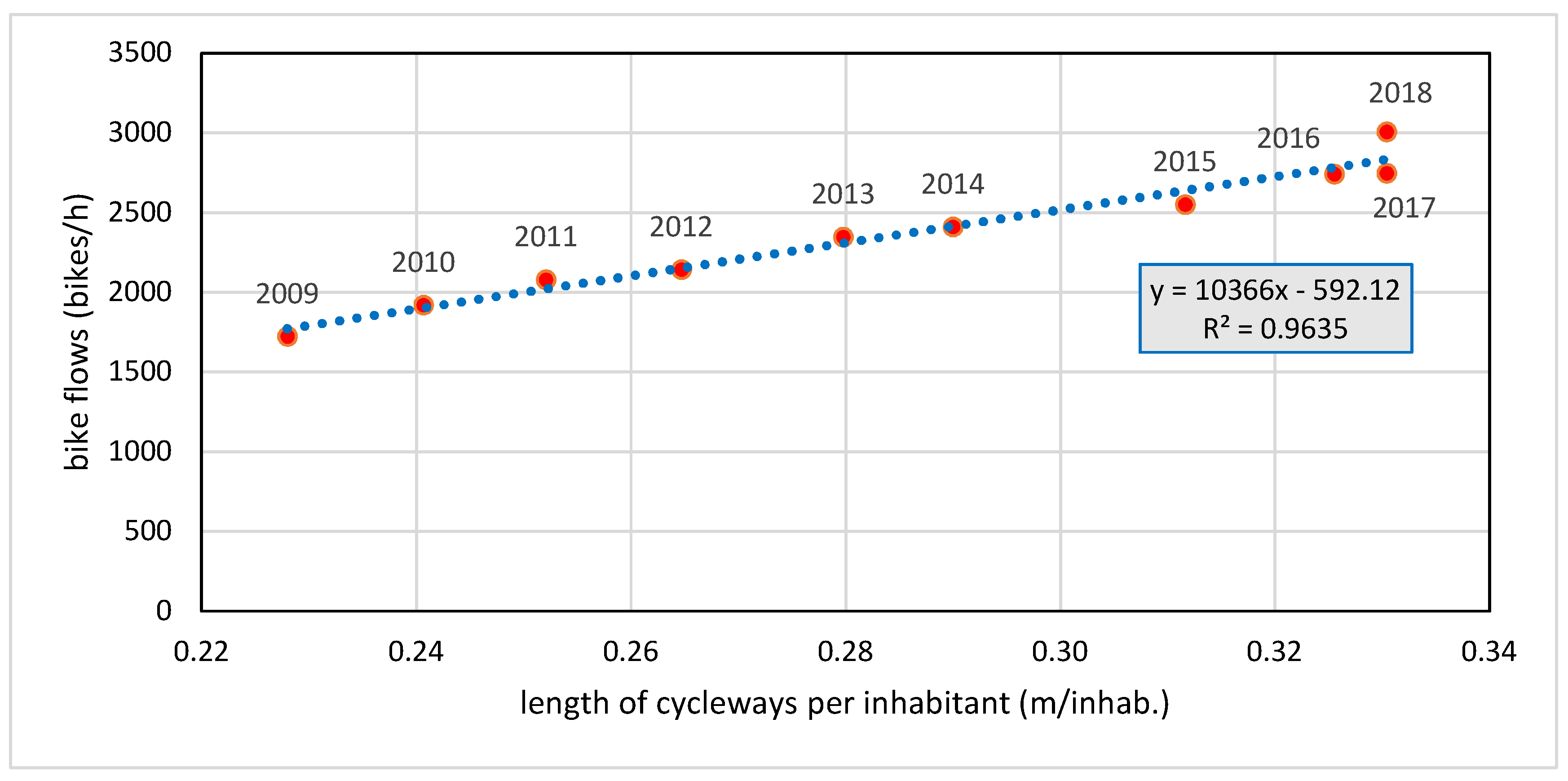
Although crowdsourced cyclists represent often a small portion of all cyclists, they do represent well the ridership of Bologna in terms of cyclists’ volumes and gender distribution. This result emerges clearly by comparing traditional counting method with GPS traces, confirming their representativeness of the population. The correlation between cycling counts and GPS data collected by smartphones has been relatively high, with an R2 value of 0.73. This correlation is significantly higher than the results obtained by other studies, most likely due to the more detailed representation of the Bologna network, including footpaths in parks and the possibility to cycle one-way roads in both directions. Due to this high correlation, it has been possible to estimate the absolute bicycle flows on all network links by an appropriate scaling of the map-matched flows. The cyclists’ routes are of great value for the planning of cycling infrastructure and the drafting of cycling policies. The proposed method, which combines bicycle counts at a few main road sections with areas covering GPS traces, can readily be applied in other cities in order to reliably estimate the absolute bike flows of an entire urban area.
GPS data have been further used to determine the total deviation metric, which counts the total deviations that a road link causes to cyclists. The total deviation metric is useful to identify weak links of the cycling network, but it does not identify the reason why certain road links are avoided. However, applying the total deviation metric to the Bologna road network, the highest deviation has been seen on trafficked roads without physically protected bike lanes. Also, roads with reserved bus lanes, which are open for bicycles too, showed high deviation rates. Further analyses of chosen and shortest road sections have shown that cyclists are willing to make deviations when the alternative route provides a high share of reserved bikeways, a high share of low-priority lanes, a low intersection density and a low share of roads with mixed traffic (cyclists with buses and pedestrians). Planners should take the deviation metric into considerations for either bike-path construction or bike-network interventions. Obviously, the total deviation metric does not reveal deviations if there are no alternatives to avoid a certain road link. The map-matched traces allowed to calibrate a discrete choice model between two route alternatives, considering distance, share of exclusive bikeway and share of low-priority roads. A longer distance and a higher share of low-priority roads appear to decrease the choice probability, while a higher share of exclusive bikeways does increase the choice probability, as expected. With the same model, it has been possible to quantify the tolerated deviation length in function of the road attributes.
In future works, the representativeness of the results could be improved by statistically weighting the GPS traces according to different person attributes, such as occupation, gender, or age. The route choice model could be enriched by more significant attributes like traffic light density, junctions with left-turns, or junctions with side-roads entering from the right side. In particular, the low-priority road attribute needs to be further refined. The generation of longer route alternatives could be replaced by actually chosen routes and models using only attributes of the chosen routes shall be tested.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}