Bangkok CCTV Image through a Road Environment Extraction System Using Multi-Label Convolutional Neural Network Classification

 , ,
, ,
Abstract
1. Introduction
- We extract a combination of road environment situations, such as rain, no rain, daylight, darkness, crowded traffic, non-crowded traffic, wet roads, and dry roads, by using a multi-label convolutional neural network with existing CCTV images—eliminating the need for new sensors designed specifically for such tasks, reducing costs—and detect multiple events at the same time.
- The developed network has only a few convolutional layers, with the addition of dropout and batch normalization layers. The network performed well on our multi-label dataset in terms of performance and efficiency. We compared it to other models, such as VGG and ResNet, which provide high performance, but require a high amount of computational time for processing.
- Finally, we propose an application framework to test our model, and we expect that it can be implemented in many different locations, including developing countries, which have a large number of CCTV images but lack specific sensors. To our knowledge, no other framework has been proposed that uses CCTV images to extract the road environment with a multi-label classification technique.
2. Related Works
2.1. CCTV and Road Environment Applications
2.2. Multi-Label Classification
3. Materials and Methods
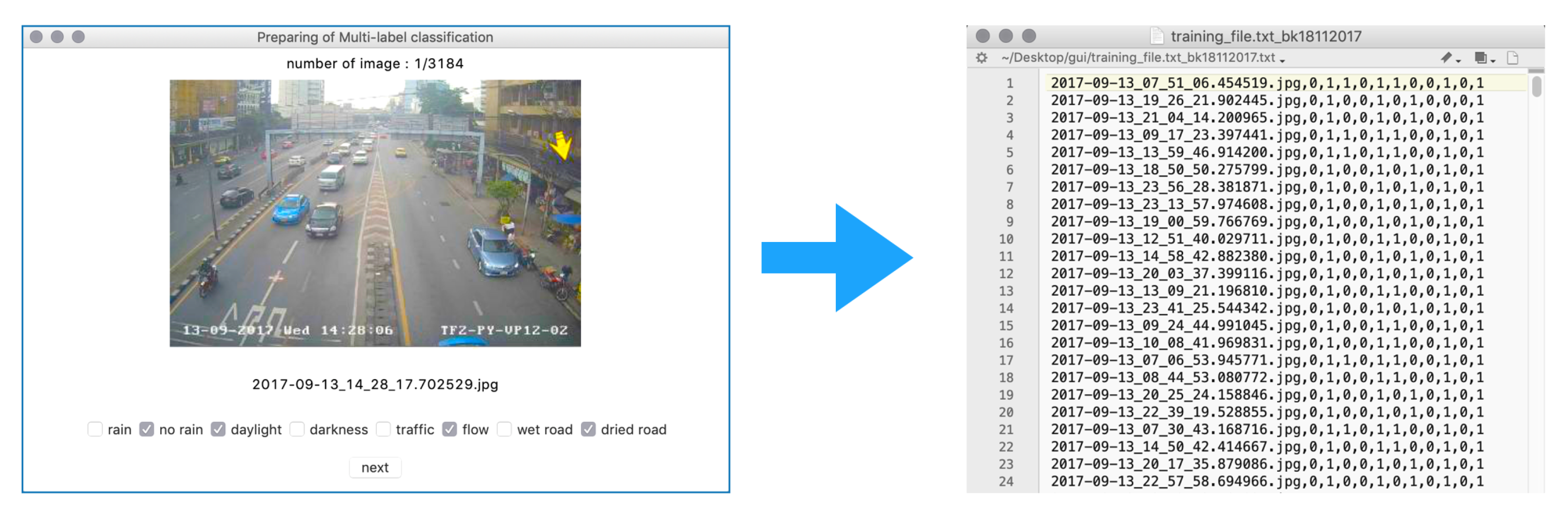
3.1. Dataset
3.2. Model
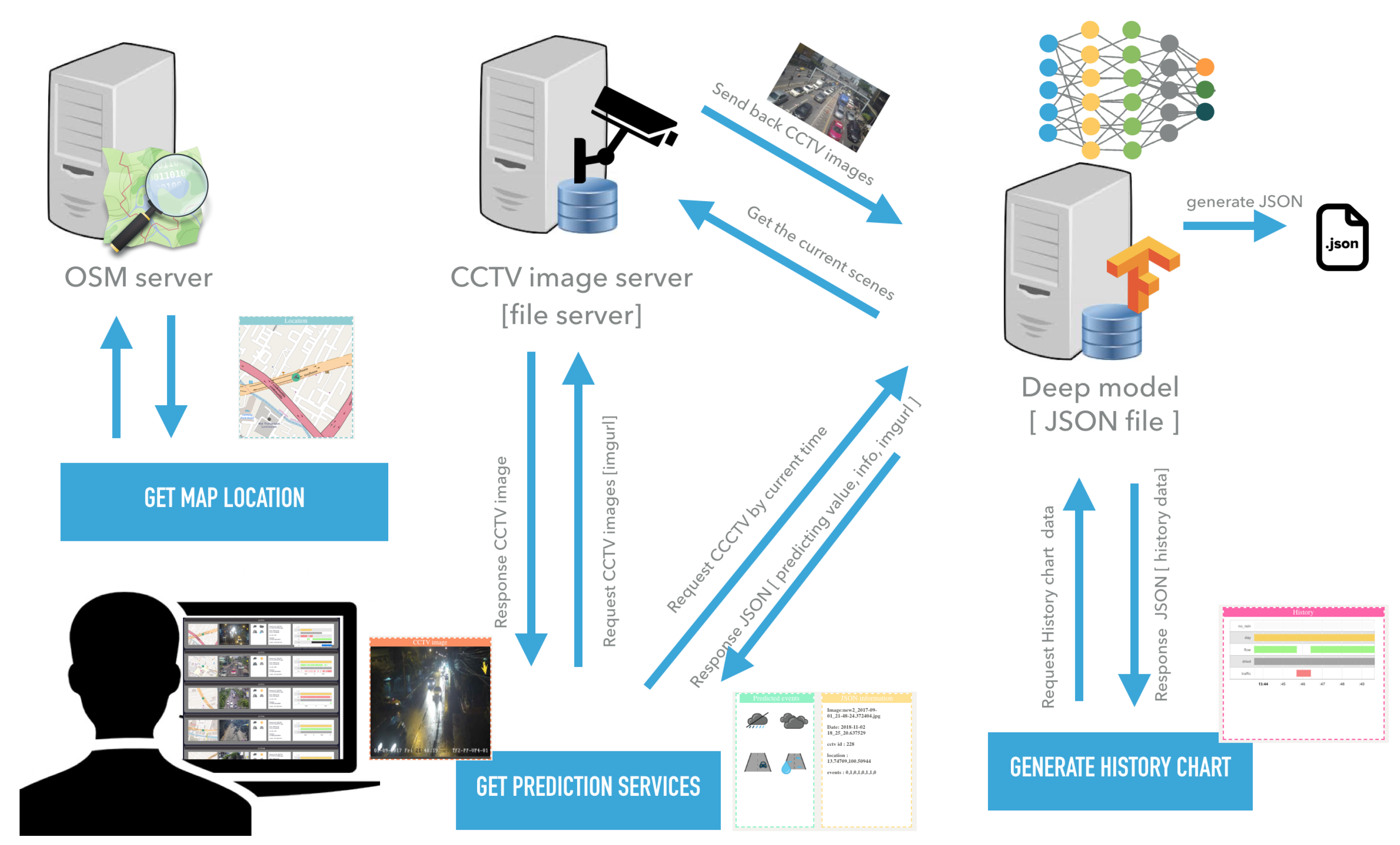
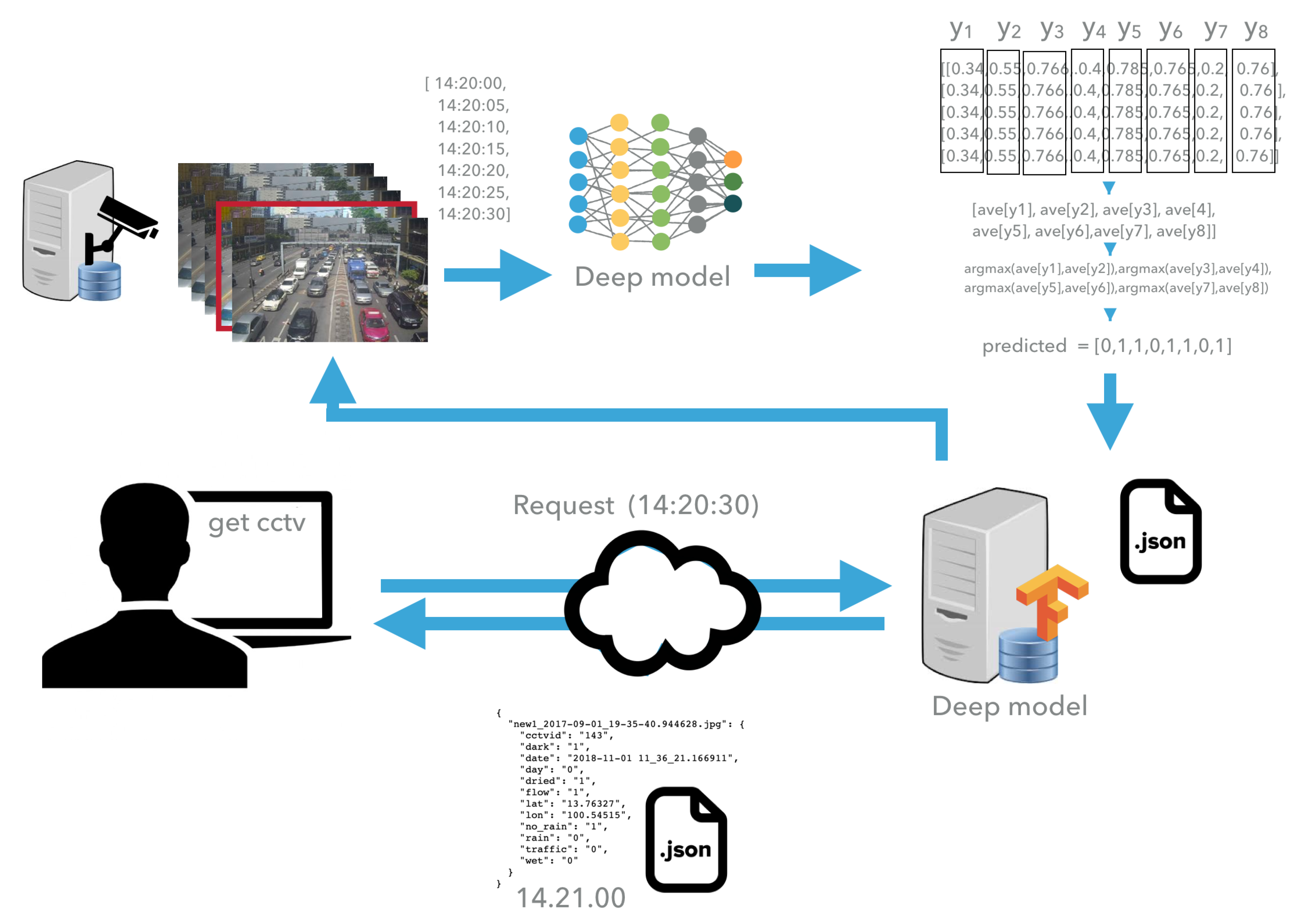
3.3. System Architecture
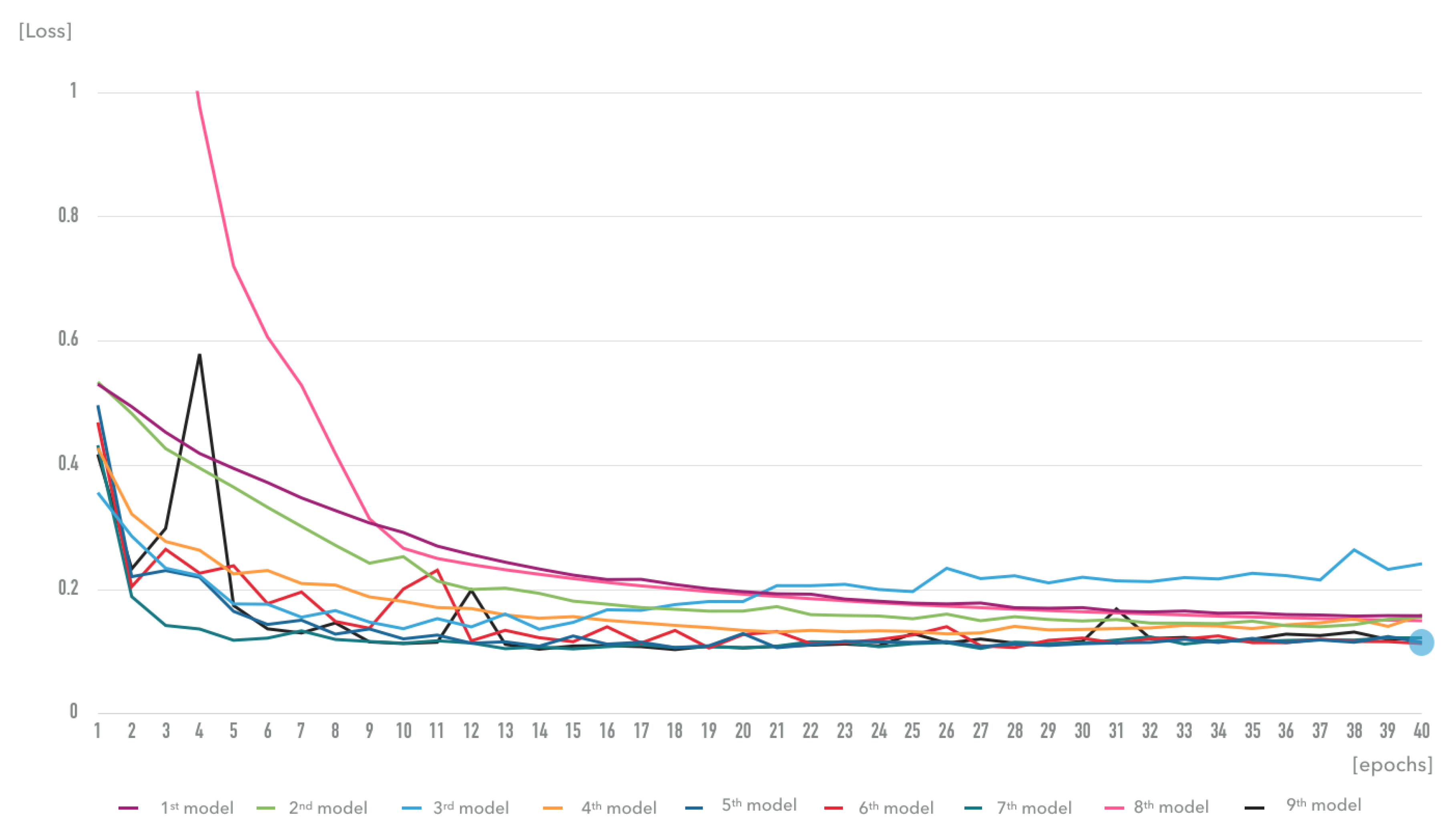
4. Results and Discussion
4.1. Evaluation Metrics
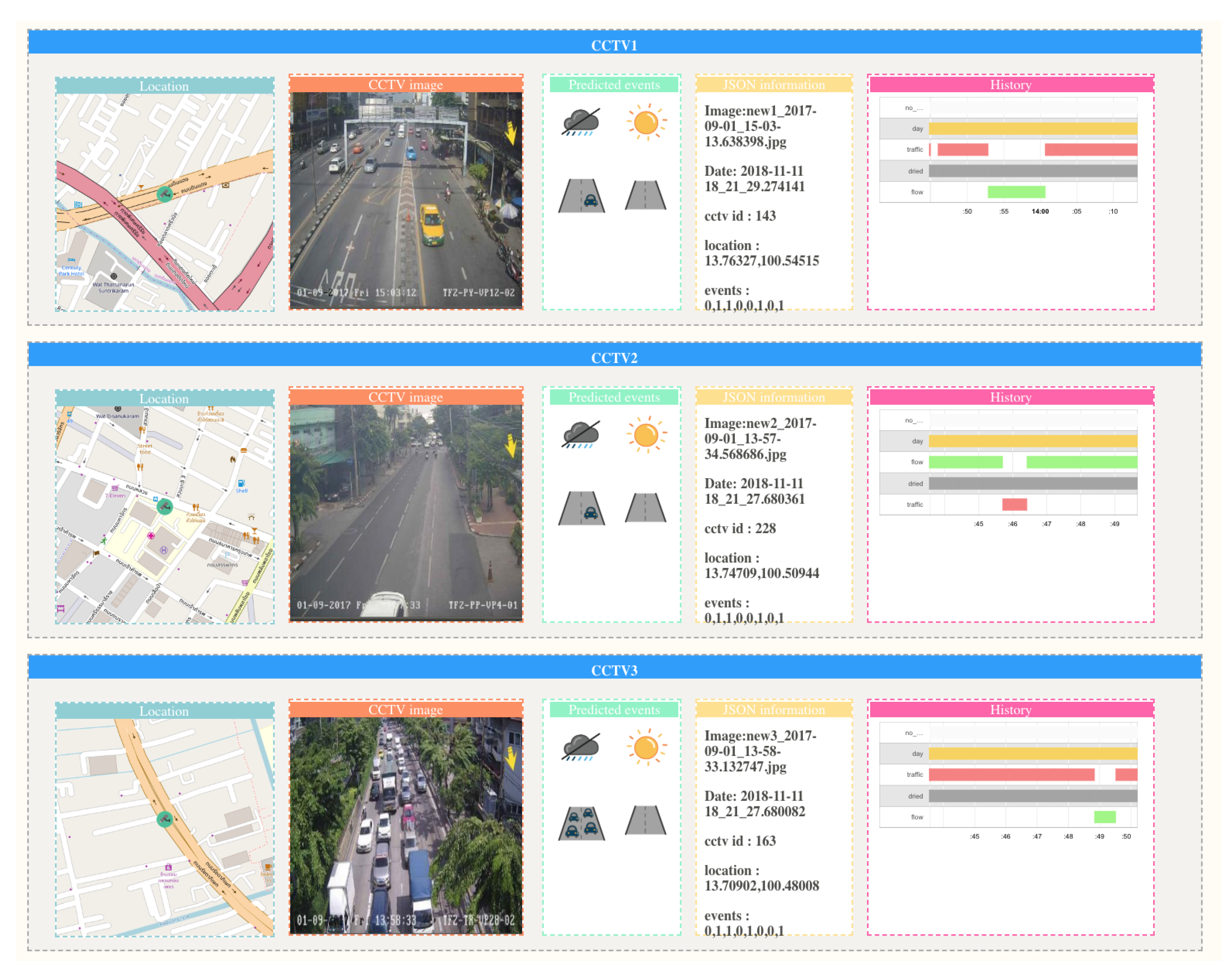
4.2. Road Environment Extraction System
5. Conclusions and Outlooks
6. Software and Hardware to Be Used
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | Average precision |
| BMA | Bangkok Metropolitan Administration |
| BN | Batch normalization |
| CCTV | Closed circuit television |
| CNNs | Convolutional neural networks |
| GPU | Graphics processing unit |
| JSON | JavaScript Object Notation |
| MAP | Mean average precision |
| OSM | Open Street Map |
| ReLU | Rectified linear unit |
| SGD | Stochastic gradient decent |
| SVM | Support vector machine |
References
- Goodwin, L.C. Weather Impacts on Arterial Traffic Flow; Mitretek Systems Inc.: Falls Church, VA, USA, 2002. [Google Scholar]
- Haug, A.; Grosanic, S. Usage of road weather sensors for automatic traffic control on motorways. Transp. Res. Procedia 2016, 15, 537–547. [Google Scholar] [CrossRef]
- Trimek, J. Public confidence in CCTV and Fear of Crime in Bangkok, Thailand. Int. J. Crim. Justice Sci. 2016, 11, 17. [Google Scholar]
- Nemade, B. Automatic traffic surveillance using video tracking. Procedia Comput. Sci. 2016, 79, 402–409. [Google Scholar] [CrossRef]
- Mogelmose, A.; Trivedi, M.M.; Moeslund, T.B. Vision-Based Traffic Sign Detection and Analysis for Intelligent Driver Assistance Systems: Perspectives and Survey. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1484–1497. [Google Scholar] [CrossRef]
- Lee, J.; Hong, B.; Shin, Y.; Jang, Y.J. Extraction of weather information on road using CCTV video. In Proceedings of the 2016 International Conference on Big Data and Smart Computing (BigComp), Hong Kong, China, 18–20 January 2016. [Google Scholar]
- Fu, D.; Zhou, B.; Hu, J. Improving SVM based multi-label classification by using label relationship. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Duplex metric learning for image set classification. IEEE Trans. Image Process. 2018, 27, 281–292. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv, 2018; arXiv:1804.02767. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Gao, D.; Liu, Y.; Han, J. Multi-scale and Discriminative Part Detectors Based Features for Multi-label Image Classification. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Memon, I.; Chen, L.; Majid, A.; Lv, M.; Hussain, I.; Chen, G. Travel recommendation using geo-tagged photos in social media for tourist. Wirel. Pers. Commun. 2015, 80, 1347–1362. [Google Scholar] [CrossRef]
- Memon, M.H.; Li, J.P.; Memon, I.; Arain, Q.A. GEO matching regions: Multiple regions of interests using content based image retrieval based on relative locations. Multimed. Tools Appl. 2017, 76, 15377–15411. [Google Scholar] [CrossRef]
- Grega, M.; Matiolański, A.; Guzik, P.; Leszczuk, M. Automated detection of firearms and knives in a CCTV image. Sensors 2016, 16, 47. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.-Y.; Hauptmann, A. Mosift: Recognizing Human Actions in Surveillance Videos. Available online: http://www.cs.cmu.edu/~mychen/publication/ChenMoSIFTCMU09.pdf (accessed on 30 January 2019).
- Zhang, W.; Wu, Q.M.J.; Yin, H.B. Moving vehicles detection based on adaptive motion histogram. Digit. Signal Process. 2010, 20, 793–805. [Google Scholar] [CrossRef]
- Kurdi, H.A. Survey on Traffic Control using Closed Circuit Television (CCTV). In Proceedings of the International Conference on Digital Information Processing, E-Business and Cloud Computing (DIPECC), Society of Digital Information and Wireless Communication, Dubai, UAE, 23–25 October 2013. [Google Scholar]
- Swathy, M.; Nirmala, P.S.; Geethu, P.C. Survey on Vehicle Detection and Tracking Techniques in Video Surveillance. Int. J. Comput. Appl. 2017, 160, 22–25. [Google Scholar]
- Ganesh, R.B.; Appavu, S. An Intelligent Video Surveillance Framework with Big Data Management for Indian Road Traffic System. Int. J. Comput. Appl. 2015, 123, 12–19. [Google Scholar]
- Choi, Y.; Choe, H.G.; Choi, J.Y.; Kim, K.T.; Kim, J.B.; Kim, N.I. Automatic Sea Fog Detection and Estimation of Visibility Distance on CCTV. J. Coast. Res. 2018, 85, 881–885. [Google Scholar] [CrossRef]
- Maxwell, A.; Li, R.; Yang, B.; Weng, H.; Ou, A.; Hong, H.; Zhou, Z.; Gong, P.; Zhang, C. Deep learning architectures for multi-label classification of intelligent health risk prediction. BMC Bioinform. 2017, 18, 523. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H.; Shen, C. Multi-label learning based deep transfer neural network for facial attribute classification. Pattern Recogn. 2018, 80, 225–240. [Google Scholar] [CrossRef]
- Herrera, F.; Charte, F.; Rivera, A.J.; del Jesus, M.J. Multilabel classification. In Multilabel Classification; Springer: Cham, Switzerland, 2016; pp. 17–31. [Google Scholar]
- Sorower, M.S. A literature Survey on Algorithms for Multi-Label Learning; Oregon State University: Corvallis, OR, USA, 2010; Volume 18. [Google Scholar]
- Katakis, I.; Tsoumakas, G.; Vlahavas, I. Multilabel text classification for automated tag suggestion. In Proceedings of the ECML/PKDD 2008 Discovery Challenge, Antwerp, Belgium, 15–19 September 2008. [Google Scholar]
- Available online: https://github.com/chairathAIT/multi-label-assign (accessed on 30 January 2019).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Park, S.; Kwak, N. Analysis on the dropout effect in convolutional neural networks. In Computer Vision— ACCV 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Available online: https://www.youtube.com/watch?v=i0FoXhCus4U (accessed on 30 January 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
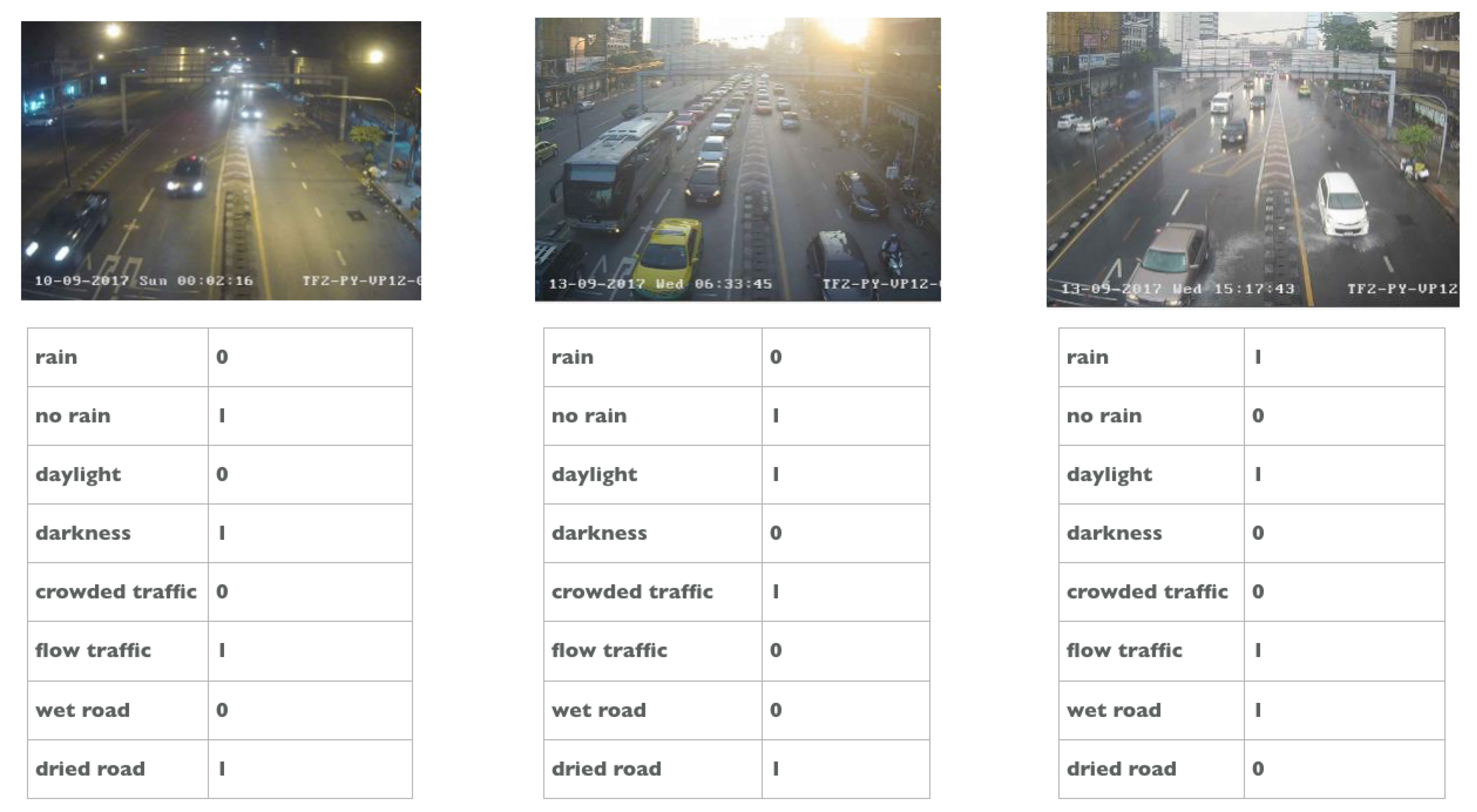
| Class | Definition |
|---|---|
| Rain | There are droplets or rain streaks, or the image is blurry due to heavy rain. |
| Non-rain | There are no components of rain in the image. |
| Daylight | Sunlight is evident during the day, normally from 7:00–17:00. |
| Darkness | There is darkness because it is night or because of a lack of sunlight during the day. |
| Crowded traffic | An image is equally divided into four parts. If there are groups of cars in all four parts, we define the image as showing crowded traffic. |
| Flow traffic | If there are no cars in any of the four areas, the scene is considered to show flow traffic. |
| Wet road | The road appears to have water on the surface. |
| Dry road | The road does not appear to have water on the surface. |
| Input Size | Optimizer | Learning Rate | Batch Size | Epochs | Loss Function |
|---|---|---|---|---|---|
| 224 × 224 | Stochastic gradient descent (SGD) | 0.0001 | 12 | 40 | Binary cross-entropy |
| No. | Third | Fourth | Fifth | Sixth | Seventh | Ninth |
|---|---|---|---|---|---|---|
| 1 | Conv 32 | Conv 32 | Conv 32 | Conv 32 | Conv 32 | Conv 32 |
| 2 | ReLU | ReLU | ReLU | ReLU | ReLU | ReLU |
| 3 | Conv 32 | Conv 32 | - | - | - | - |
| 4 | ReLU | ReLU | - | - | - | - |
| 5 | Max pooling | Max pooling | Max pooling | Max pooling | Max pooling | Max pooling |
| 6 | - | Dropout(0.25) | Dropout(0.25) | Dropout(0.25) | - | Dropout(0.25) |
| 7 | Conv 64 | Conv 64 | Conv 64 | Conv 64 | Conv 64 | Conv 64 |
| 8 | ReLU | ReLU | ReLU | ReLU | ReLU | ReLU |
| 9 | Conv 64 | Conv 64 | Conv 64 | - | Conv 64 | Conv 64 |
| 10 | ReLU | ReLU | ReLU | - | ReLU | ReLU |
| 11 | Max pooling | Max pooling | Max pooling | Max pooling | Max pooling | Max pooling |
| 12 | - | Dropout(0.25) | Dropout(0.25) | Dropout(0.25) | Dropout(0.25) | Dropout(0.25) |
| 13 | Flatten | Flatten | Flatten | Flatten | Flatten | Flatten |
| 14 | Dense 512 | Dense 512 | Dense 512 | Dense 512 | Dense 512 | Dense 512 |
| 15 | - | - | BN | BN | BN | BN |
| 16 | ReLU | ReLU | ReLU | ReLU | ReLU | ReLU |
| 17 | - | Dropout(0.5) | Dropout(0.5) | Dropout(0.5) | Dropout(0.5) | Dropout(0.5) |
| 18 | Dense 8 | Dense 8 | Dense 8 | Dense 8 | Dense 8 | Dense 4 |
| 19 | Sigmoid | Sigmoid | Sigmoid | Sigmoid | Sigmoid | Sigmoid |
| 15 layers | 18 layers | 17 layers | 15 layers | 16 layers | 17 layers |
| Model | Rain | No-Rain | Daylight | Nighttime | Crowded | Flow | Wet | Dried | MAP |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.920 | 0.972 | 0.969 | 0.956 | 0.843 | 0.888 | 0.916 | 0.974 | 0.930 |
| 2 | 0.885 | 0.992 | 0.977 | 0.955 | 0.879 | 0.847 | 0.893 | 0.989 | 0.927 |
| 3 | 0.909 | 0.982 | 0.981 | 0.938 | 0.797 | 0.899 | 0.942 | 0.980 | 0.928 |
| 4 | 0.892 | 0.987 | 0.985 | 0.959 | 0.813 | 0.924 | 0.935 | 0.980 | 0.934 |
| 5 | 0.942 | 0.986 | 0.984 | 0.967 | 0.839 | 0.935 | 0.966 | 0.989 | 0.951 |
| 6 | 0.940 | 0.987 | 0.993 | 0.940 | 0.831 | 0.921 | 0.977 | 0.982 | 0.946 |
| 7 | 0.949 | 0.989 | 0.990 | 0.947 | 0.823 | 0.931 | 0.970 | 0.986 | 0.948 |
| 8 | 0.925 | 0.976 | 0.967 | 0.966 | 0.831 | 0.909 | 0.959 | 0.938 | 0.938 |
| 9 | 0.945 | 0.971 | 0.986 | 0.951 | 0.834 | 0.921 | 0.963 | 0.972 | 0.942 |
| Model | Exact Match | Hamming Loss | MAP | Training Time (minutes) | Prediction Time (seconds) |
|---|---|---|---|---|---|
| 1 | 0.763 | 0.05 | 0.93 | 00:31 | 00:00:22 |
| 2 | 0.760 | 0.060 | 0.927 | 00:38 | 00:00:25 |
| 3 | 0.775 | 0.055 | 0.928 | 00:28 | 00:00:09 |
| 4 | 0.792 | 0.051 | 0.942 | 00:29 | 00:00:10 |
| 5 | 0.84 | 0.039 | 0.951 | 00:23 | 00:00:09 |
| 6 | 0.831 | 0.042 | 0.946 | 00:23 | 00:00:09 |
| 7 | 0.832 | 0.043 | 0.948 | 00:23 | 00:00:09 |
| 8 | 0.776 | 0.053 | 0.938 | 00:55 | 00:00:33 |
| 9 | 0.84 | 0.045 | 0.942 | 00:24 | 00:00:09 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sirirattanapol, C.; NAGAI, M.; Witayangkurn, A.; Pravinvongvuth, S.; Ekpanyapong, M. Bangkok CCTV Image through a Road Environment Extraction System Using Multi-Label Convolutional Neural Network Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 128. https://doi.org/10.3390/ijgi8030128
Sirirattanapol C, NAGAI M, Witayangkurn A, Pravinvongvuth S, Ekpanyapong M. Bangkok CCTV Image through a Road Environment Extraction System Using Multi-Label Convolutional Neural Network Classification. ISPRS International Journal of Geo-Information. 2019; 8(3):128. https://doi.org/10.3390/ijgi8030128
Chicago/Turabian StyleSirirattanapol, Chairath, Masahiko NAGAI, Apichon Witayangkurn, Surachet Pravinvongvuth, and Mongkol Ekpanyapong. 2019. "Bangkok CCTV Image through a Road Environment Extraction System Using Multi-Label Convolutional Neural Network Classification" ISPRS International Journal of Geo-Information 8, no. 3: 128. https://doi.org/10.3390/ijgi8030128
APA StyleSirirattanapol, C., NAGAI, M., Witayangkurn, A., Pravinvongvuth, S., & Ekpanyapong, M. (2019). Bangkok CCTV Image through a Road Environment Extraction System Using Multi-Label Convolutional Neural Network Classification. ISPRS International Journal of Geo-Information, 8(3), 128. https://doi.org/10.3390/ijgi8030128