Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS


Abstract
1. Introduction
2. Background
2.1. Metadata
2.2. Interoperability, Data Catalogs, Geoinformation Systems, and THREDDS
3. Related Work
3.1. Metadata Models
3.2. Geospatial Metadata Standardization, Interoperability, and Cataloging
3.3. Web Harvesting and Crawling
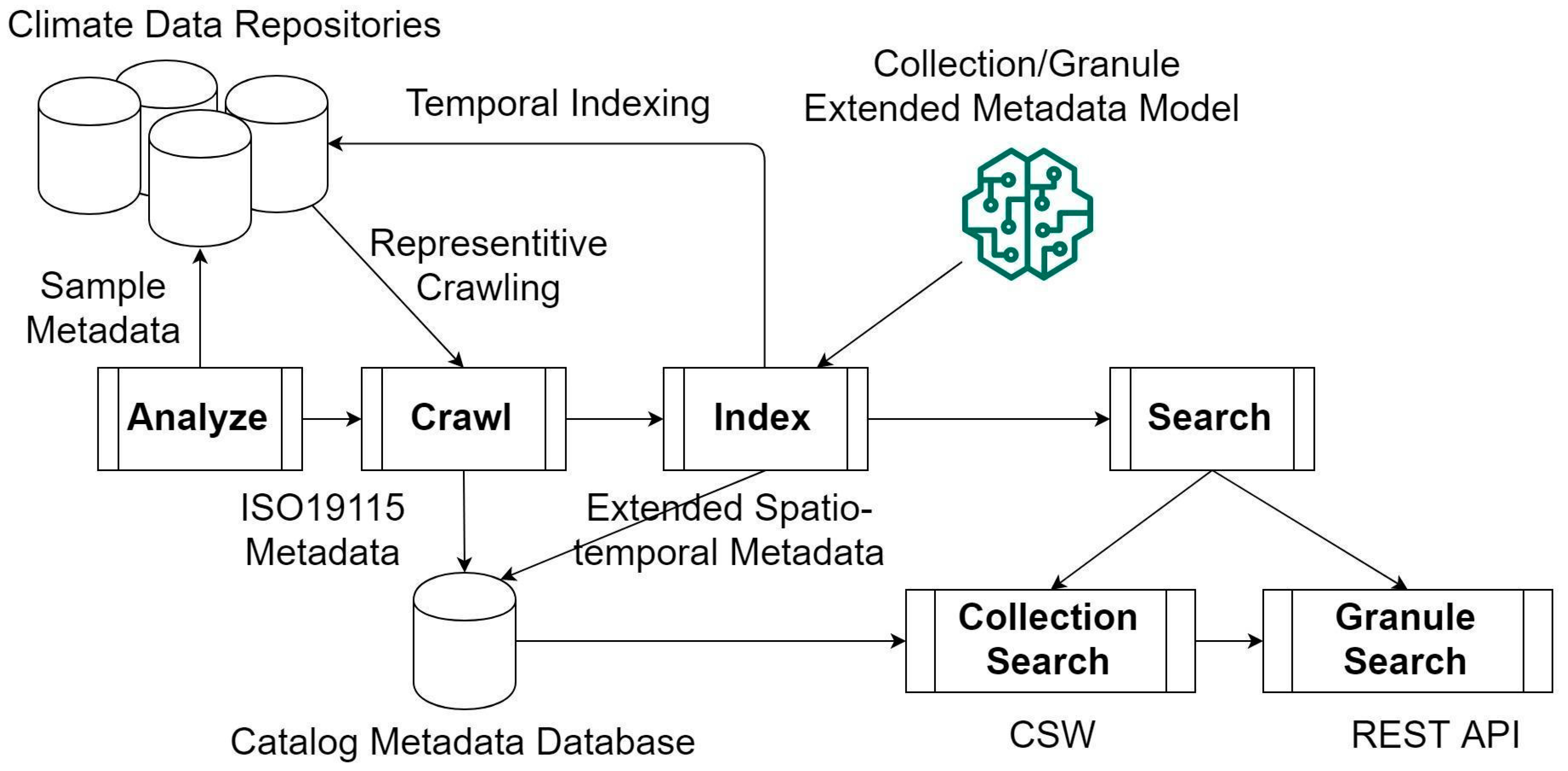
4. Materials and Methods
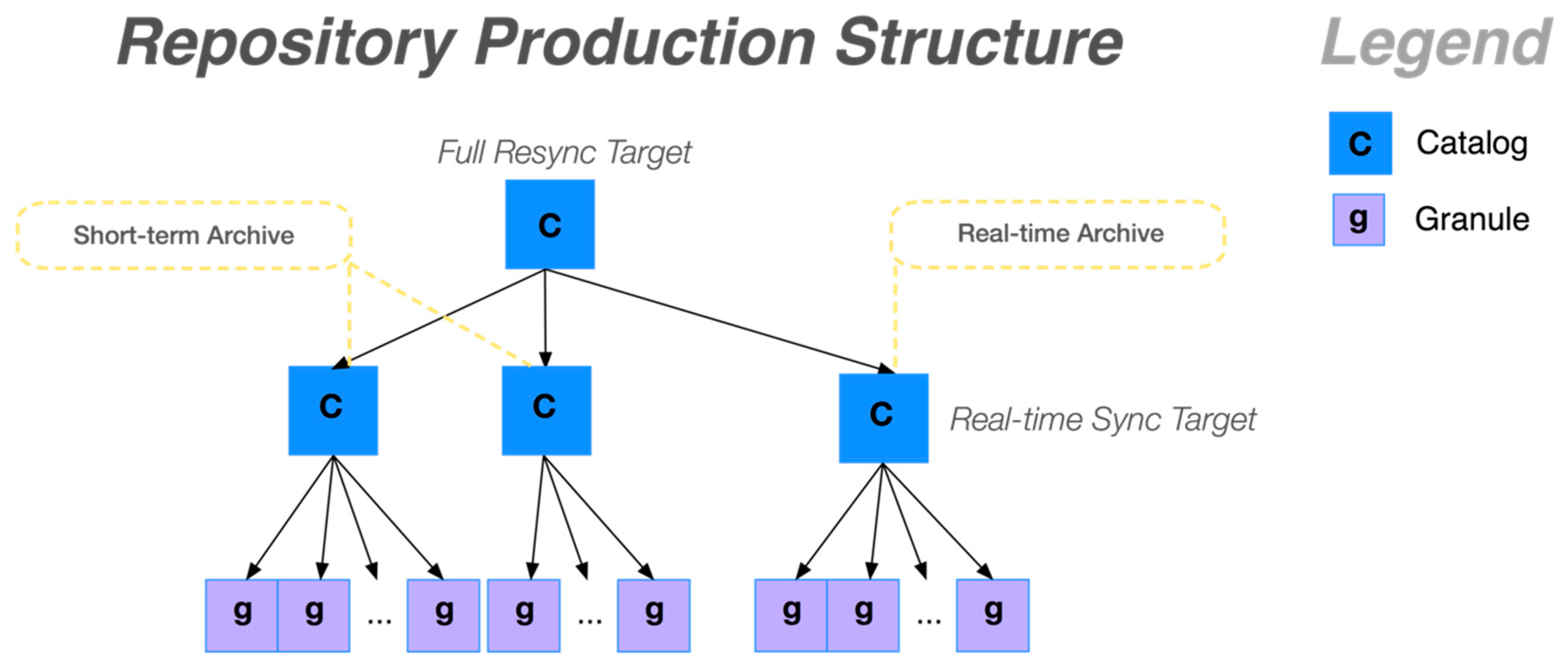
4.1. Metadata Repository Selection
4.2. Repository Analysis
- Pure archival directories: These folders only contain old collections and granules and will never be updated or deleted.
- Mixed archival directories: Some of the sub-folders contain archive material, some contain live, streaming near real-time data granules and collections.
- Daily archival directories: Folders that contain streaming data for a given day; when the day passes, this directory becomes an archive folder and does not need to be mirrored again. When daily archives expire, all the data resources for that day are deleted together.
4.3. Crawling
4.4. Indexing
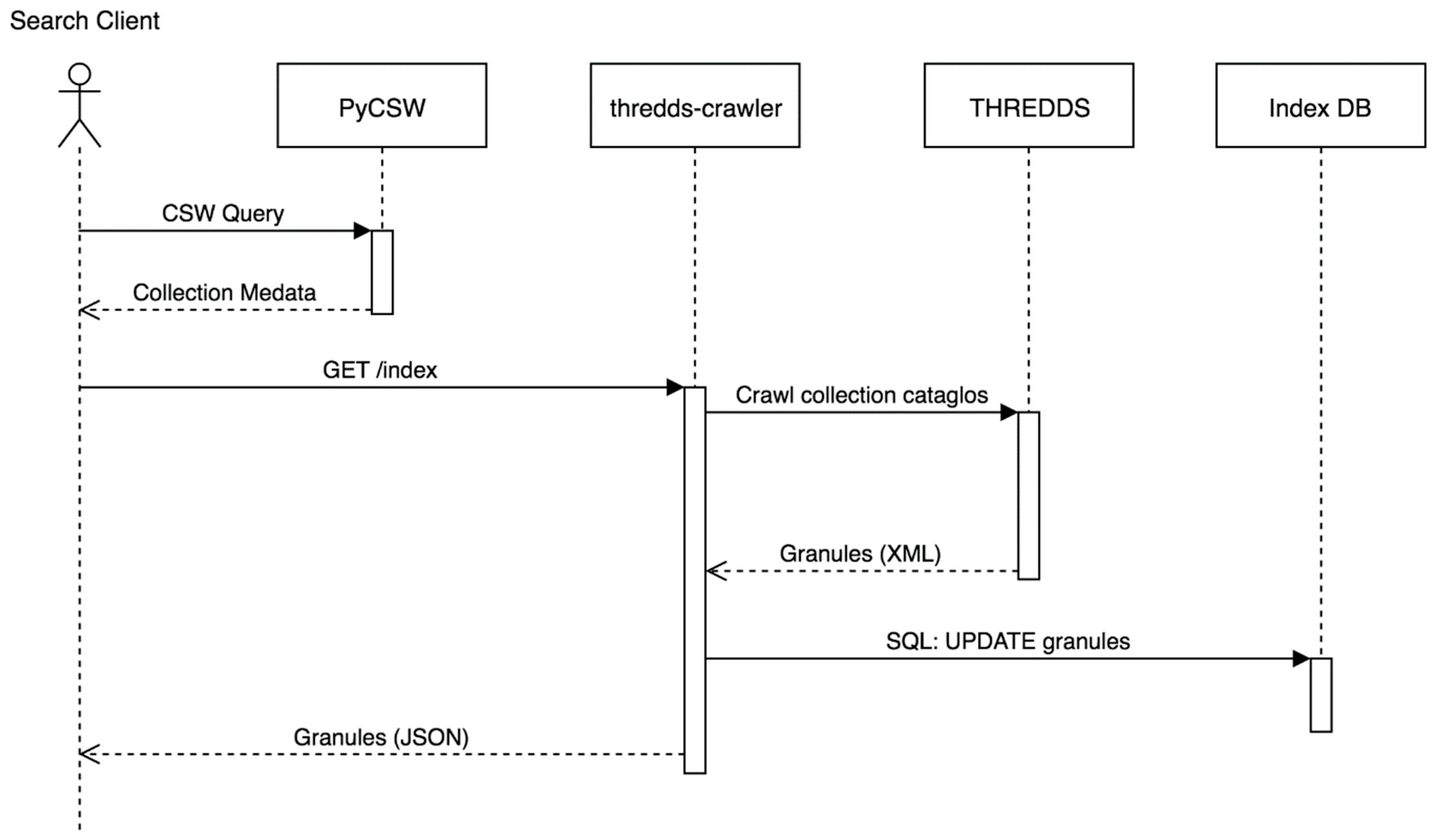
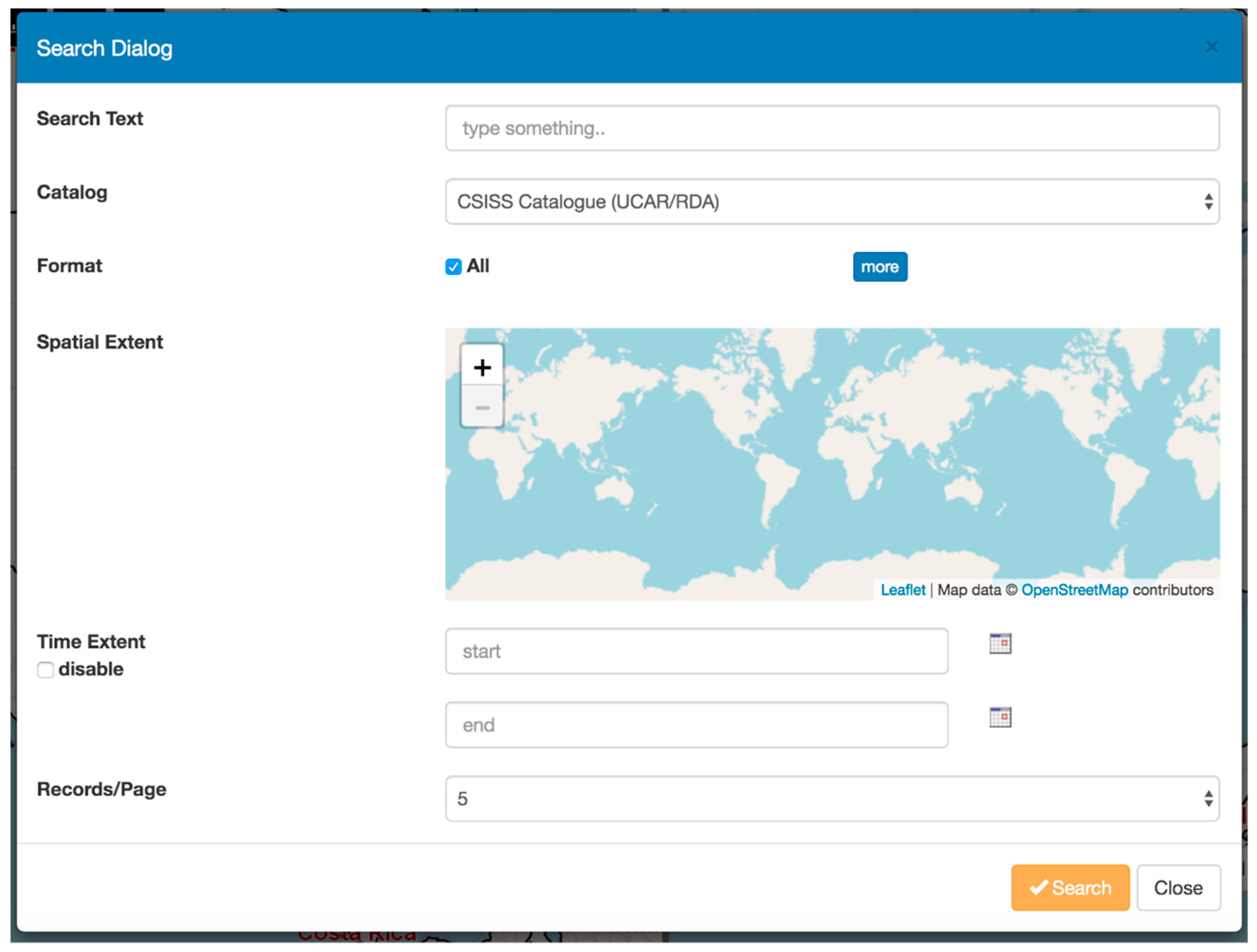
4.5. Two-Step Search Process
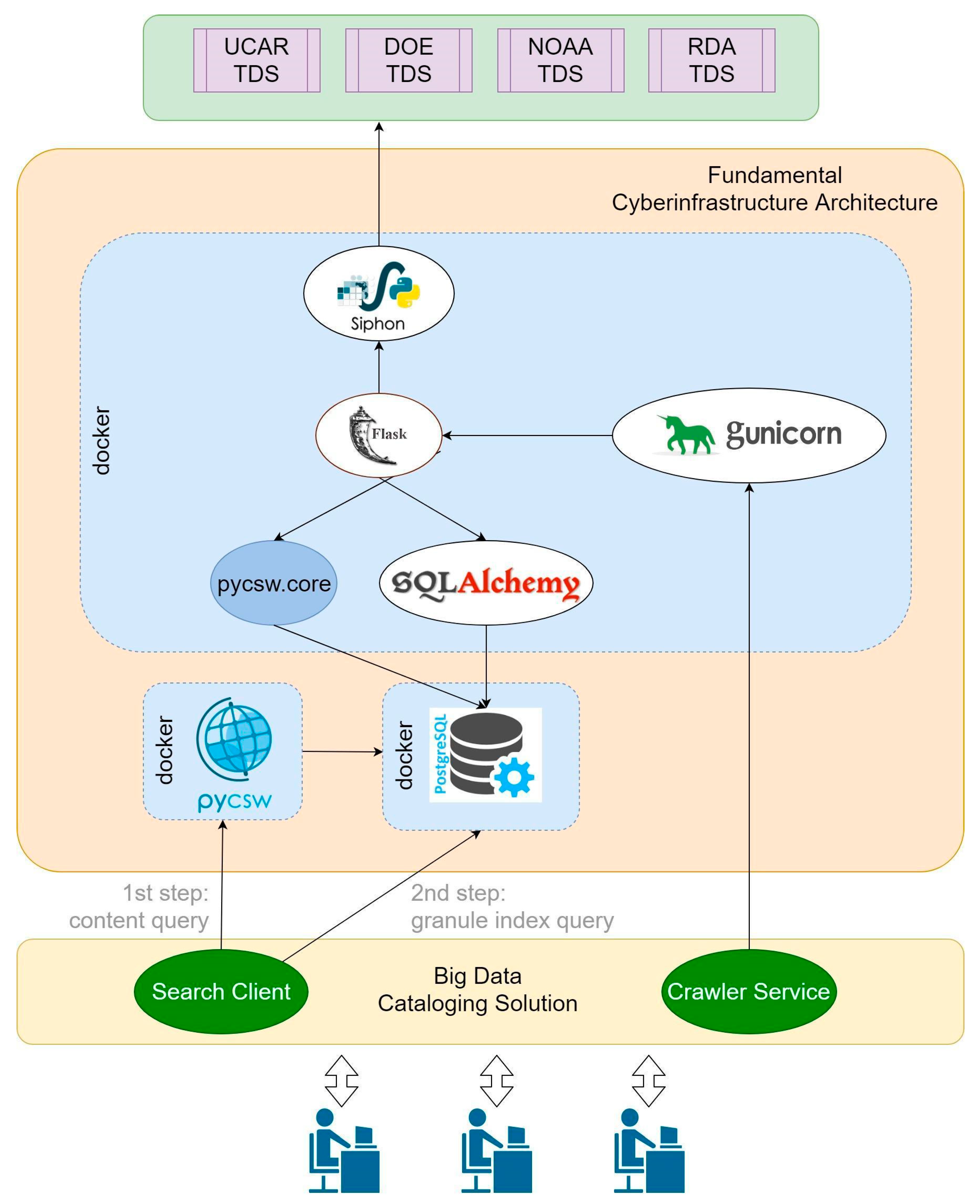
5. Implementation
5.1. Crawler Service Implementation
5.2. Search System Implementation
6. Experiment and Results
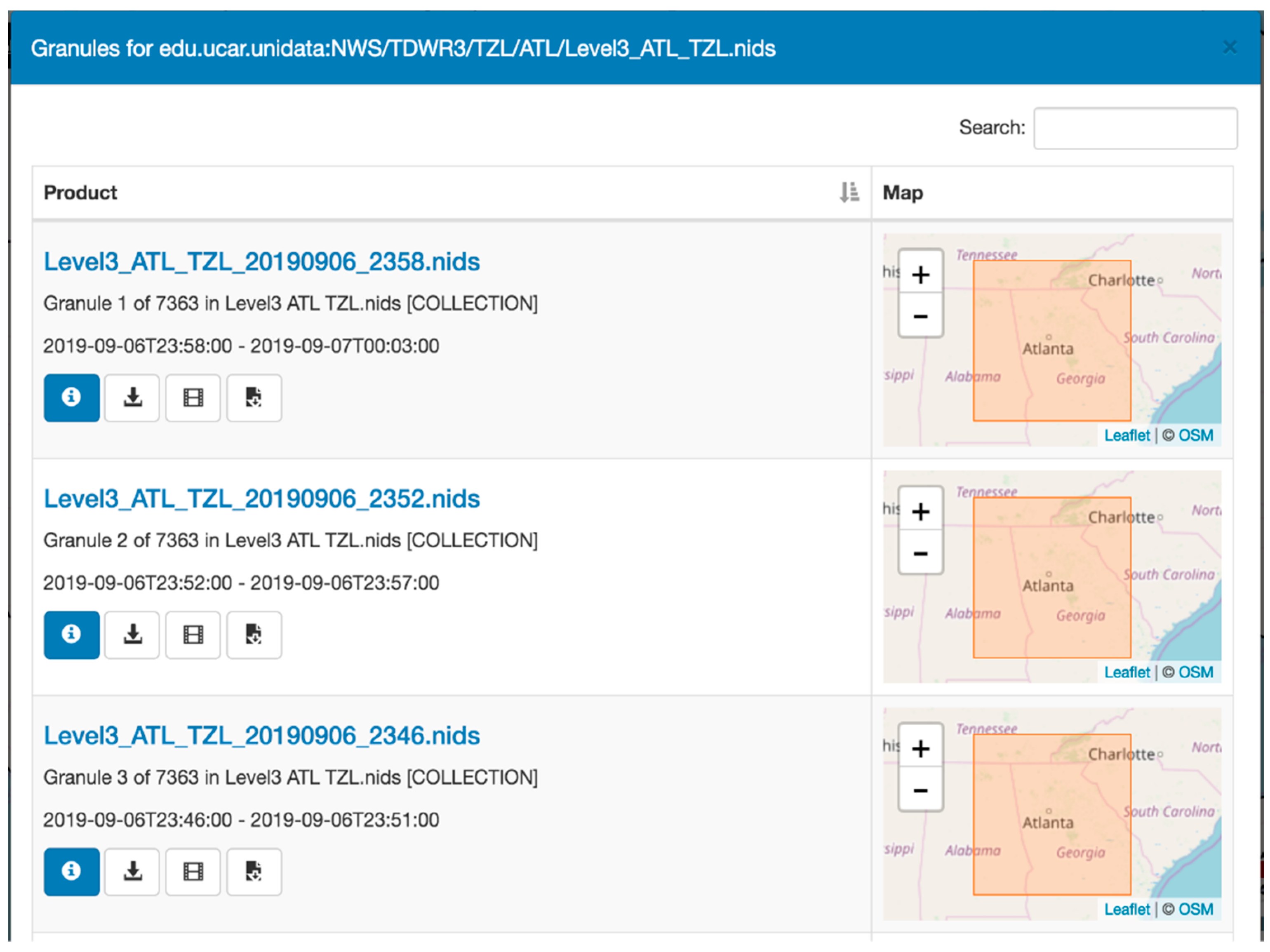
6.1. Searching the NEXRAD Dataset
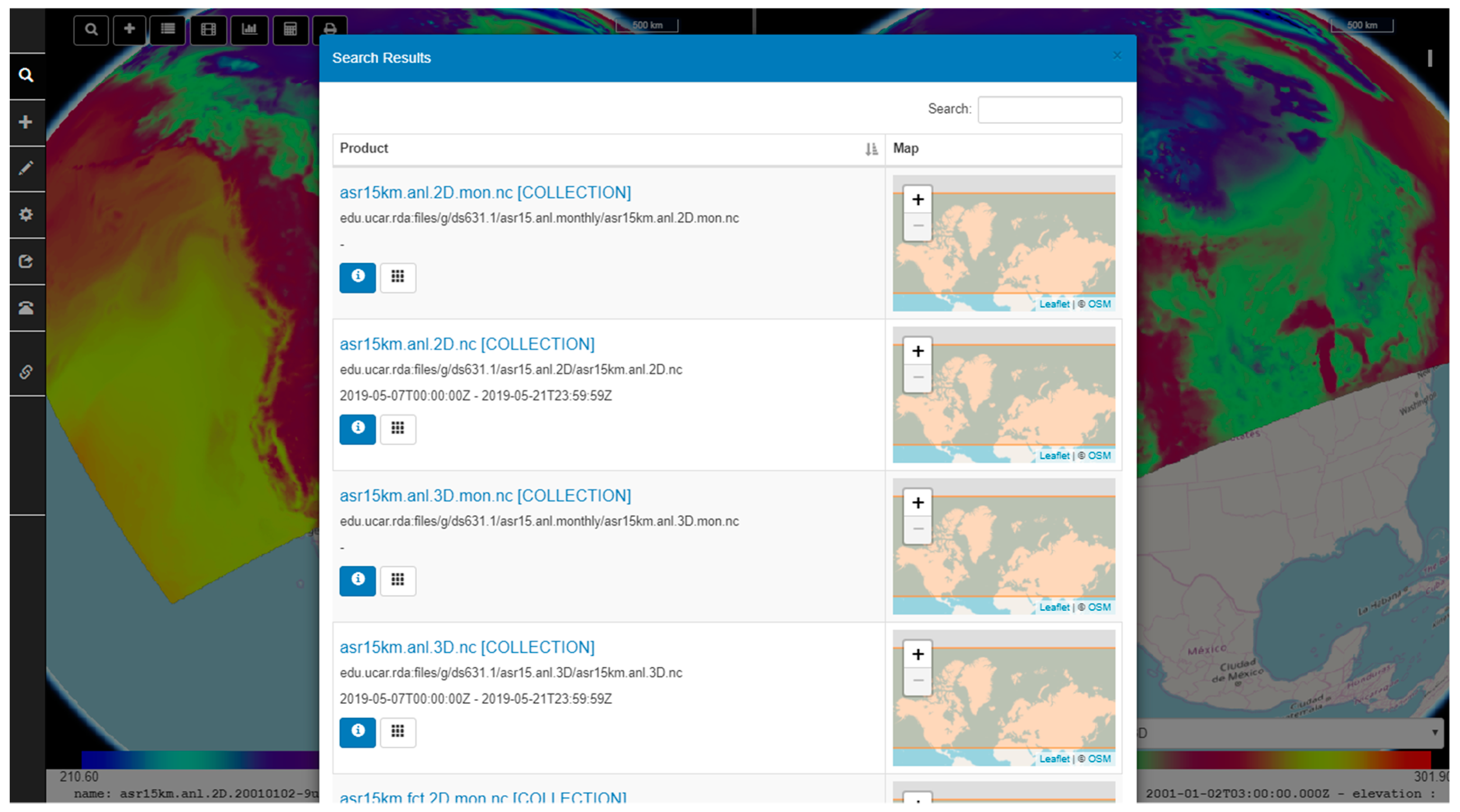
6.2. Searching UCAR RDA (Research Data Archive) TDS Repository
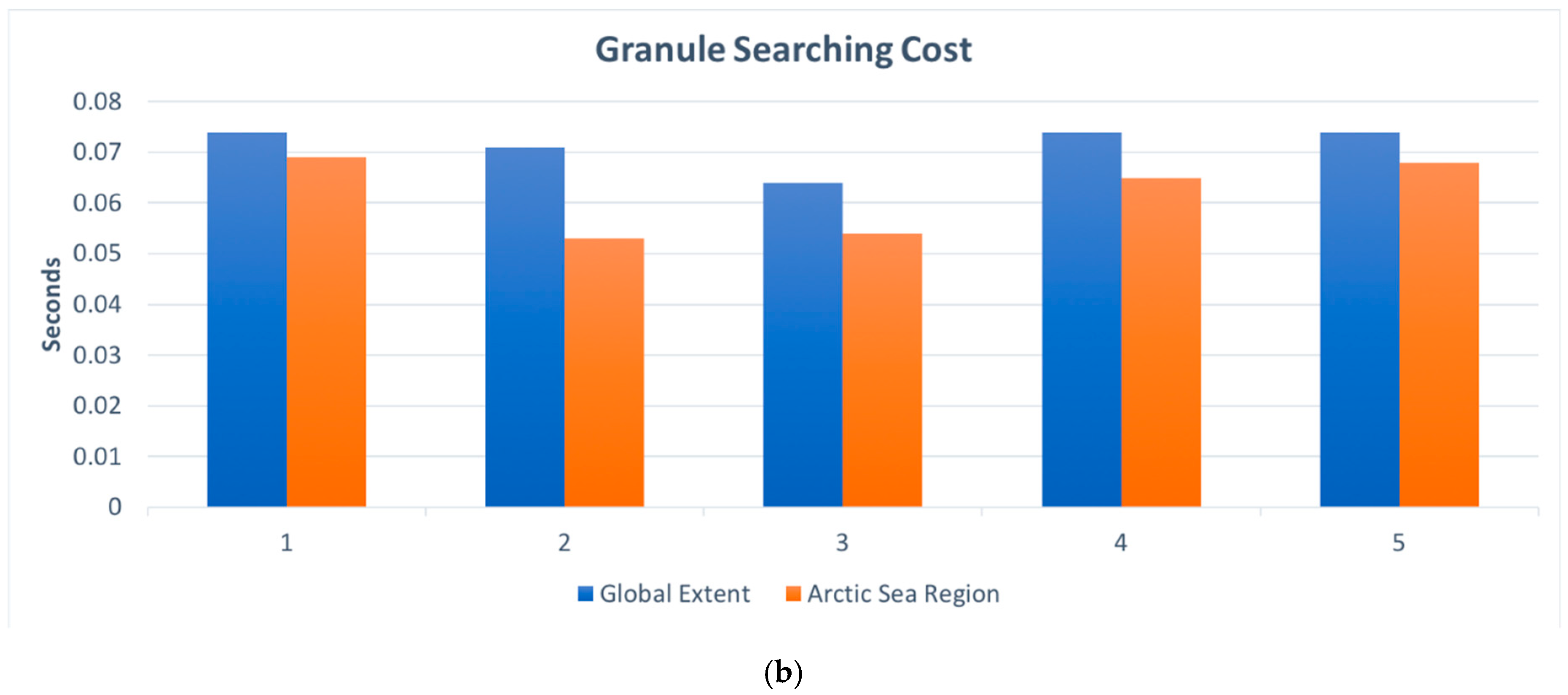
6.3. Performance Evaluation
7. Discussion
7.1. Can the Proposed Solution Address the Volume Challenge?
7.2. Can the Proposed Solution Address the Velocity Challenge?
7.3. Can the Proposed Solution Reduce Metadata Crawling Redundancy?
7.4. What Are the Benefits and Drawbacks of the Proposed Solution Compared to Other Big Data Searching Strategies?
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wright, D.J.; Wang, S. The emergence of spatial cyberinfrastructure. Proc. Natl. Acad. Sci. USA 2011, 108, 5488–5491. [Google Scholar] [CrossRef] [PubMed]
- CyberinfrastruCture Vision for 21st Century DisCoVery; National Science Foundation Cyberinfrastructure Council: Arlington, VA, USA, 2007.
- Yang, C.; Goodchild, M.; Gahegan, M. Geospatial Cyberinfrastructure: Past, present and future. Comput. Environ. Urban Syst. 2010, 34, 264–277. [Google Scholar] [CrossRef]
- Yue, P.; Gong, J.; Di, L.; Yuan, J.; Sun, L.; Sun, Z.; Wang, Q. GeoPW: Laying Blocks for the Geospatial Processing Web. Trans. GIS 2010, 14, 755–772. [Google Scholar] [CrossRef]
- Di, L. Geospatial Sensor Web and Self-adaptive Earth Predictive Systems (SEPS). In Proceedings of the Earth Science Technology Office (ESTO)/Advanced Information System Technology (AIST) Sensor Web Principal Investigator (PI) Meeting, San Diego, CA, USA, 13 February 2007. [Google Scholar]
- Zhao, P.; Yu, G.; Di, L. Geospatial Web Services. In Emerging Spatial Information Systems and Applications, 1st ed.; IGI Global: Hershey, PA, USA, 2006; pp. 1–35. [Google Scholar]
- Shukla, J.; Palmer, T.N.; Hagedorn, R.; Hoskins, B.; Kinter, J.; Marotzke, J.; Miller, M.; Slingo, J.; Shukla, J.; Palmer, T.N.; et al. Toward a New Generation of World Climate Research and Computing Facilities. Bull. Am. Meteorol. Soc. 2010, 91, 1407–1412. [Google Scholar] [CrossRef]
- Sherretz, L.A.; Fulker, D.W. Unidata: Enabling Universities to Acquire and Analyze Scientific Data. Bull. Am. Meteorol. Soc. 1988, 69, 373–376. [Google Scholar] [CrossRef]
- Schnase, J.L.; Duffy, D.Q.; Tamkin, G.S.; Nadeau, D.; Thompson, J.H.; Grieg, C.M.; McInerney, M.A.; Webster, W.P. MERRA Analytic Services: Meeting the Big Data challenges of climate science through cloud-enabled Climate Analytics-as-a-Service. Comput. Environ. Urban Syst. 2017, 61, 198–211. [Google Scholar] [CrossRef]
- Khan, M.A.; Uddin, M.F.; Gupta, N. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- Habermann, T. Metadata Life Cycles, Use Cases and Hierarchies. Geosciences 2018, 8, 179. [Google Scholar] [CrossRef]
- Greenberg, J. Metadata and the World Wide Web. Encycl. Libr. Inf. Sci. 2003, 3, 1876–1888. [Google Scholar]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Bernard, L.; Mäs, S.; Müller, M.; Henzen, C.; Brauner, J. Scientific geodata infrastructures: Challenges, approaches and directions. Int. J. Digit. Earth 2014, 7, 613–633. [Google Scholar] [CrossRef]
- Domenico, B.; Caron, J.; Davis, E.; Kambic, R.; Nativi, S. Thematic Real-Time Environmental Distributed Data Services (THREDDS): Incorporating Interactive Analysis Tools into NSDL; Multimedia Research Group, University of Southampton: Southampton, UK, 1997; Volume 2. [Google Scholar]
- John Caron, U.; Davis, E. UNIDATA’s THREDDS data server. In Proceedings of the 22nd International Conference on Interactive Information Processing Systems for Meteorology, Oceanography, and Hydrology, Atlanta, GA, USA, 27 January–3 February 2006. [Google Scholar]
- Sun, Z.; Di, L.; Hao, H.; Wu, X.; Tong, D.Q.; Zhang, C.; Virgei, C.; Fang, H.; Yu, E.; Tan, X.; et al. CyberConnector: A service-oriented system for automatically tailoring multisource Earth observation data to feed Earth science models. Earth Sci. Inform. 2018, 11, 1–17. [Google Scholar] [CrossRef]
- Di, L.; Sun, Z.; Yu, E.; Song, J.; Tong, D.; Huang, H.; Wu, X.; Domenico, B. Coupling of Earth science models and earth observations through OGC interoperability specifications. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3602–3605. [Google Scholar]
- Di, L.; Sun, Z.; Zhang, C. Facilitating the Easy Use of Earth Observation Data in Earth system Models through CyberConnector. In Proceedings of the AGU Fall Meeting, New Orleans, LA, USA, 11–15 December 2017. Abstract #IN21D-0072. [Google Scholar]
- Sun, Z.; Di, L. CyberConnector COVALI: Enabling inter-comparison and validation of Earth science models. In Proceedings of the AGU Fall Meeting, Washington, DC, USA, 10–14 December 2018. Abstract #IN23B-0780. [Google Scholar]
- Schellnhuber, H.J. ‘Earth system’ analysis and the second Copernican revolution. Nature 1999, 402, C19–C23. [Google Scholar] [CrossRef]
- Calvin, K.; Bond-Lamberty, B. Integrated human-earth system modeling—State of the science and future directions. Environ. Res. Lett. 2018, 13, 063006. [Google Scholar] [CrossRef]
- Hurrell, J.W.; Holland, M.M.; Gent, P.R.; Ghan, S.; Kay, J.E.; Kushner, P.J.; Lamarque, J.-F.; Large, W.G.; Lawrence, D.; Lindsay, K.; et al. The Community Earth system Model: A Framework for Collaborative Research. Bull. Am. Meteorol. Soc. 2013, 94, 1339–1360. [Google Scholar] [CrossRef]
- Reid, W.V.; Bréchignac, C.; Tseh Lee, Y. Earth system research priorities. Science 2009, 325, 245. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Lovelock, J. Gaia: The living Earth. Nature 2003, 426, 769–770. [Google Scholar] [CrossRef]
- Holm, P.; Goodsite, M.E.; Cloetingh, S.; Agnoletti, M.; Moldan, B.; Lang, D.J.; Leemans, R.; Moeller, J.O.; Buendía, M.P.; Pohl, W.; et al. Collaboration between the natural, social and human sciences in Global Change Research. Environ. Sci. Policy 2013, 28, 25–35. [Google Scholar] [CrossRef]
- Burnett, K.; Ng, K.B.; Park, S. A comparison of the two traditions of metadata development. J. Am. Soc. Inf. Sci. 1999, 50, 1209–1217. [Google Scholar] [CrossRef]
- Di, L.; Moe, K.L.; Yu, G. Metadata requirements analysis for the emerging Sensor Web. Int. J. Digit. Earth 2009, 2, 3–17. [Google Scholar] [CrossRef]
- Di, L.; Schlesinger, B.M.; Kobler, B.U.S. Federal Geographic Data Committee (FGDC) Content Standard for Digital Geospatial Metadata; Federal Geographic Data Committee: Reston, VA, USA, 2000.
- Yue, P.; Gong, J.; Di, L. Augmenting geospatial data provenance through metadata tracking in geospatial service chaining. Comput. Geosci. 2010, 36, 270–281. [Google Scholar] [CrossRef]
- Di, L.; Kobler, B. NASA Standards for Earth Remote Sensing Data. Int. Arch. Photogramm. Remote Sens. 2000, 33, 147–155. [Google Scholar]
- Yue, P.; Sun, Z.; Gong, J.; Di, L.; Lu, X. A provenance framework for Web geoprocessing workflows. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 3811–3814. [Google Scholar]
- Sun, Z.; Yue, P.; Di, L. GeoPWTManager: A task-oriented web geoprocessing system. Comput. Geosci. 2012, 47, 34–45. [Google Scholar] [CrossRef]
- Sun, Z.; Yue, P.; Lu, X.; Zhai, X.; Hu, L. A Task Ontology Driven Approach for Live Geoprocessing in a Service-Oriented Environment. Trans. GIS 2012, 16, 867–884. [Google Scholar] [CrossRef]
- Sun, Z.; Peng, C.; Deng, M.; Chen, A.; Yue, P.; Fang, H.; Di, L. Automation of Customized and Near-Real-Time Vegetation Condition Index Generation Through Cyberinfrastructure-Based Geoprocessing Workflows. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4512–4522. [Google Scholar] [CrossRef]
- Tan, X.; Di, L.; Deng, M.; Huang, F.; Ye, X.; Sha, Z.; Sun, Z.; Gong, W.; Shao, Y.; Huang, C. Agent-as-a-service-based geospatial service aggregation in the cloud: A case study of flood response. Environ. Model. Softw. 2016, 84, 210–225. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Zhang, C.; Fang, H.; Yu, E.; Lin, L.; Tang, J.; Tan, X.; Liu, Z.; Jiang, L.; et al. Building robust geospatial web services for agricultural information extraction and sharing. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–4. [Google Scholar]
- Tan, X.; Di, L.; Deng, M.; Chen, A.; Sun, Z.; Huang, C.; Shao, Y.; Ye, X. Agent-and Cloud-Supported Geospatial Service Aggregation for Flood Response. ISPRS Ann Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 13–18. [Google Scholar] [CrossRef]
- Jiang, L.; Sun, Z.; Qi, Q.; Zhang, A. Spatial Correlation between Traffic and Air Pollution in Beijing. Prof. Geogr. 2019, 71, 654–667. [Google Scholar] [CrossRef]
- Liang, L.; Geng, D.; Huang, T.; Di, L.; Lin, L.; Sun, Z. VCI-based Analysis of Spatio-temporal Variations of Spring Drought in China from 1981 to 2015. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Stanbul, Turkey, 16–19 July 2019; pp. 1–6. [Google Scholar]
- Zhong, S.; Di, L.; Sun, Z.; Xu, Z.; Guo, L. Investigating the Long-Term Spatial and Temporal Characteristics of Vegetative Drought in the Contiguous United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 836–848. [Google Scholar] [CrossRef]
- Zhong, S.; Xu, Z.; Sun, Z.; Yu, E.; Guo, L.; Di, L. Global vegetative drought trend and variability analysis from long-term remotely sensed data. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–6. [Google Scholar]
- Bai, Y.; Di, L. Providing access to satellite imagery through OGC catalog service interfaces in support of the Global Earth Observation System of Systems. Comput. Geosci. 2011, 37, 435–443. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, N. Use of service middleware based on ECHO with CSW for discovery and registry of MODIS data. Geo-Spat. Inf. Sci. 2010, 13, 191–200. [Google Scholar] [CrossRef]
- Bai, Y.; Di, L.; Wei, Y. A taxonomy of geospatial services for global service discovery and interoperability. Comput. Geosci. 2009, 35, 783–790. [Google Scholar] [CrossRef]
- Chen, N.; Di, L.; Yu, G.; Gong, J.; Wei, Y. Use of ebRIM-based CSW with sensor observation services for registry and discovery of remote-sensing observations. Comput. Geosci. 2009, 35, 360–372. [Google Scholar] [CrossRef]
- Di, L.; Yu, G.; Shao, Y.; Bai, Y.; Deng, M.; McDonald, K.R. Persistent WCS and CSW services of GOES data for GEOSS. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 1699–1702. [Google Scholar]
- Hu, C.; Di, L.; Yang, W. The research of interoperability in spatial catalogue service between CSW and THREDDS. In Proceedings of the 2009 17th International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August 2009; pp. 1–5. [Google Scholar]
- Bai, Y.; Di, L.; Chen, A.; Liu, Y.; Wei, Y. Towards a Geospatial Catalogue Federation Service. Photogramm. Eng. Remote Sens. 2007, 73, 699–708. [Google Scholar] [CrossRef]
- Spéry, L.; Claramunt, C.; Libourel, T. A Spatio-Temporal Model for the Manipulation of Lineage Metadata. Geoinformatica 2001, 5, 51–70. [Google Scholar] [CrossRef]
- She, J.; Feng, X.; Liu, B.; Xiao, P.; Wang, P. Conceptual Data Modeling on the Evolution of the Spatiotemporal Object; Chen, J., Pu, Y., Eds.; International Society for Optics and Photonics: The Hague, The Netherlands, 2007; Volume 6753, p. 67530H. [Google Scholar]
- Simmhan, Y.L.; Plale, B.; Gannon, D. A survey of data provenance in e-science. ACM SIGMOD Rec. 2005, 34, 31–36. [Google Scholar] [CrossRef]
- Sun, Z.; Yue, P.; Hu, L.; Gong, J.; Zhang, L.; Lu, X. GeoPWProv: Interleaving Map and Faceted Metadata for Provenance Visualization and Navigation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5131–5136. [Google Scholar]
- Di, L.; Shao, Y.; Kang, L. Implementation of Geospatial Data Provenance in a Web Service Workflow Environment with ISO 19115 and ISO 19115-2 Lineage Model. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5082–5089. [Google Scholar]
- West, L.A.; Hess, T.J. Metadata as a knowledge management tool: Supporting intelligent agent and end user access to spatial data. Decis. Support Syst. 2002, 32, 247–264. [Google Scholar] [CrossRef]
- Nogueras, J.; Zarazaga, F.J.; Muro, R.P. Interoperability between metadata standards. In Geographic Information Metadata for Spatial Data Infrastructures; Springer: Berlin/Heidelberg, Germany, 2005; pp. 89–127. [Google Scholar]
- Zhao, P. Geospatial Web Services: Advances in Information Interoperability: Advances in Information Interoperability; IGI Global: Hershey, PA, USA, 2010. [Google Scholar]
- Haslhofer, B.; Klas, W. A survey of techniques for achieving metadata interoperability. ACM Comput. Surv. 2010, 42, 7. [Google Scholar] [CrossRef]
- Wei, Y.; Di, L.; Zhao, B.; Liao, G.; Chen, A. Transformation of HDF-EOS metadata from the ECS model to ISO 19115-based XML. Comput. Geosci. 2007, 33, 238–247. [Google Scholar] [CrossRef]
- Di, L. The development of remote-sensing related standards at FGDC, OGC, and ISO TC 211. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2003), Toulouse, France, 21–25 July 2003; Volume 1, pp. 643–647. [Google Scholar]
- Di, L. Distributed geospatial information services-architectures, standards, and research issues. Int Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 35 Pt 2. [Google Scholar]
- ISO. ISO 19115: Geographic Information—Metadata; ISO: Geneva, Switzerland, 2013. [Google Scholar]
- Bhattacharya, A.; Culler, D.E.; Ortiz, J.; Hong, D.; Whitehouse, K.; Culler, D. Enabling Portable Building Applications through Automated Metadata Transformation; University of California at Berkeley: Berkeley, CA, USA, 2014. [Google Scholar]
- Nogueras-Iso, J.; Zarazaga-Soria, F.J.J.; Be´jarbe´jar, R.; Lvarez, P.J.A.; Muro-Medrano, P.R.R.; Béjar, R.; Álvarez, P.J.; Muro-Medrano, P.R.R. OGC Catalog Services: A key element for the development of Spatial Data Infrastructures. Comput. Geosci. 2005, 31, 199–209. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Gaigalas, J. SUIS: Simplify the use of geospatial web services in environmental modelling. Environ. Model. Softw. 2019, 119, 228–241. [Google Scholar] [CrossRef]
- Singh, G.; Bharathi, S.; Chervenak, A.; Deelman, E.; Kesselman, C.; Manohar, M.; Patil, S.; Pearlman, L. A Metadata Catalog Service for Data Intensive Applications. In Proceedings of the 2003 ACM/IEEE Conference on Supercomputing, Phoenix, AZ, USA, 15–21 November 2003. [Google Scholar]
- Tan, X.; Di, L.; Deng, M.; Fu, J.; Shao, G.; Gao, M.; Sun, Z.; Ye, X.; Sha, Z.; Jin, B. Building an Elastic Parallel OGC Web Processing Service on a Cloud-Based Cluster: A Case Study of Remote Sensing Data Processing Service. Sustainability 2015, 7, 14245–14258. [Google Scholar] [CrossRef]
- Desai, K.; Devulapalli, V.; Agrawal Asst, S.; Kathiria Asst, P.; Patel Professor, A. Web Crawler: Review of Different Types of Web Crawler, Its Issues, Applications and Research Opportunities. Int. J. Adv. Res. Comput. Sci. 2017, 8, 1199–1202. [Google Scholar]
- Li, W.; Wang, S.; Bhatia, V. PolarHub: A large-scale web crawling engine for OGC service discovery in cyberinfrastructure. Comput Environ Urban Syst. 2016, 59, 195–207. [Google Scholar] [CrossRef]
- Pallickara, S.L.; Pallickara, S.; Zupanski, M.; Sullivan, S. Efficient Metadata Generation to Enable Interactive Data Discovery over Large-scale Scientific Data Collections. In Proceedings of the 2010 IEEE Second International Conference on Cloud Computing Technology and Science, Indianapolis, IN, USA, 30 November–3 December 2010. [Google Scholar]
- Lopez, L.A.; Khalsa, S.J.S.; Duerr, R.; Tayachow, A.; Mingo, E. The BCube Crawler: Web Scale Data and Service Discovery for EarthCube. In Proceedings of the AGU Fall Meeting, San Francisco, CA, USA, 15–19 December 2014. Abstracts IN51C-06. [Google Scholar]
- Khalsa, S.J.S. Data and Metadata Brokering–Theory and Practice from the BCube Project. Data Sci. J. 2017, 16, 1–8. [Google Scholar] [CrossRef]
- Song, J.; Di, L. Near-Real-Time OGC Catalogue Service for Geoscience Big Data. ISPRS Int. J. Geo-Inf. 2017, 6, 337. [Google Scholar] [CrossRef]
- Unidata THREDDs Client Catalog Spec 1.0.7. Available online: https://www.unidata.ucar.edu/software/tds/current/catalog/InvCatalogSpec.html (accessed on 26 August 2019).
- Unidata THREDDS Support [THREDDS #BIA-775104]: Unidata THREDDs Metadata Structure and Volume. Juozasgaigalas@gmail.com. Gmail. Available online: https://mail.google.com/mail/u/0/#search/Unidata+THREDDs+metadata+structure+and+volume/FMfcgxvwzcCgSZmpPZsQFqdjLlCkPNfm (accessed on 26 August 2019).
- Ansari, S.; Del Greco, S.; Kearns, E.; Brown, O.; Wilkins, S.; Ramamurthy, M.; Weber, J.; May, R.; Sundwall, J.; Layton, J.; et al. Unlocking the Potential of NEXRAD Data through NOAA’s Big Data Partnership. Bull. Am. Meteorol. Soc. 2018, 99, 189–204. [Google Scholar] [CrossRef]
- Theodoridis, Y.; Sellis, T.; Papadopoulos, A.N.; Manolopoulos, Y. Specifications for Efficient Indexing in Spatiotemporal Databases. In Proceedings of the Tenth International Conference on Scientific and Statistical Database Management, Capri, Italy, 3 July 1998. [Google Scholar]
- Zhang, C.; Di, L.; Sun, Z.; Lin, L.; Yu, E.G.; Gaigalas, J. Exploring cloud-based Web Processing Service: A case study on the implementation of CMAQ as a Service. Environ. Model. Softw. 2019, 113, 29–41. [Google Scholar] [CrossRef]
- Aronson, E.; Ferrini, V.; Gomez, B. Geoscience 2020: Cyberinfrastructure to Reveal the Past, Comprehend the Present, and Envision the Future; National Science Foundation: Alexandria, VA, USA, 2015.
- Heiss, W.H.; McGrew, D.L.; Sirmans, D. Nexrad: Next generation weather radar (WSR-88D). Microw. J. 1990, 33, 79–89. [Google Scholar]
- Bromwich, D.H.; Wilson, A.B.; Bai, L.; Liu, Z.; Barlage, M.; Shih, C.-F.; Maldonado, S.; Hines, K.M.; Wang, S.-H.; Woollen, J.; et al. The Arctic System Reanalysis, Version 2. Bull. Am. Meteorol. Soc. 2018, 99, 805–828. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catalog | Sub-Catalogs/Granules | Estimated Catalogs Size | New Granule Production | Granularity | Regularity |
|---|---|---|---|---|---|
| NCEP Forecast | 5300/5300 | 500 MB | 6 h | Coarse | Regular |
| Observations | 8/186 | 20 MB | Irregular | Coarse | Irregular |
| Satellite | 1500/71,000 | 150 MB | 10 min | Fine | Regular |
| Radar | 25,000/7 million | 25 GB | 5–10 min (irregular) | Very fine | Irregular |
| Data Type | Example TDS Catalog Path |
|---|---|
| RADAR | Radar Data › NEXRAD Level III Radar › PTA › YUX › 20190830 › Level3_YUX_PTA_20190830_1713.nids |
| Model | Forecast Model Data › GEFS Members › Analysis › GEFS_Global_1p0deg_Ensemble_ana_20190731_0000.grib2 › GEFS_Global_1p0deg_Ensemble_ana_20190731_0000.grib2 |
| Satellite | Satellite Data › GOES West Products › CloudAndMoistureImagery › Mesoscale-2 › Channel16 › 20190831 › OR_ABI-L2-CMIPM2-M6C16_G17_s20192430003570_e20192430003570_c20192430003570.nc |
| Data Type | Example TDS Dataset Identifier |
|---|---|
| RADAR | NWS/NEXRAD3/PTA/YUX/20190830/Level3_YUX_PTA_20190830_1713.nids |
| Model | grib/NCEP/GEFS/Global_1p0deg_Ensemble/members-analysis/GEFS_Global_1p0deg_Ensemble_ana_20190731_0000.grib2 |
| Satellite | goes-west-products/CloudAndMoistureImagery/Mesoscale-2/Channel16/20190831/OR_ABI-L2-CMIPM2-M6C16_G17_s20192430003570_e20192430003570_c20192430003570.nc |
| Data Type | Calculated Example Dataset Collection Identifier |
|---|---|
| RADAR | edu.ucar.unidata:NWS/NEXRAD3/PTA/YUX/Level3_YUX_PTA.nids |
| Model | edu.ucar.unidata:grib/NCEP/GEFS/Global_1p0deg_Ensemble/members-analysis/GEFS_Global_1p0deg_Ensemble_ana.grib2 |
| Satellite | edu.ucar.unidata:goes-west-products/CloudAndMoistureImagery/Mesoscale-2/Channel16/OR_ABI-L2-CMIPM2-M6C16_G17.nc |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaigalas, J.; Di, L.; Sun, Z. Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS. ISPRS Int. J. Geo-Inf. 2019, 8, 494. https://doi.org/10.3390/ijgi8110494
Gaigalas J, Di L, Sun Z. Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS. ISPRS International Journal of Geo-Information. 2019; 8(11):494. https://doi.org/10.3390/ijgi8110494
Chicago/Turabian StyleGaigalas, Juozas, Liping Di, and Ziheng Sun. 2019. "Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS" ISPRS International Journal of Geo-Information 8, no. 11: 494. https://doi.org/10.3390/ijgi8110494
APA StyleGaigalas, J., Di, L., & Sun, Z. (2019). Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS. ISPRS International Journal of Geo-Information, 8(11), 494. https://doi.org/10.3390/ijgi8110494