This section illustrates the experimental study carried out, along with the results obtained. In this paper, we implemented the proposed approach on OSM data of India for classifying the contributors.
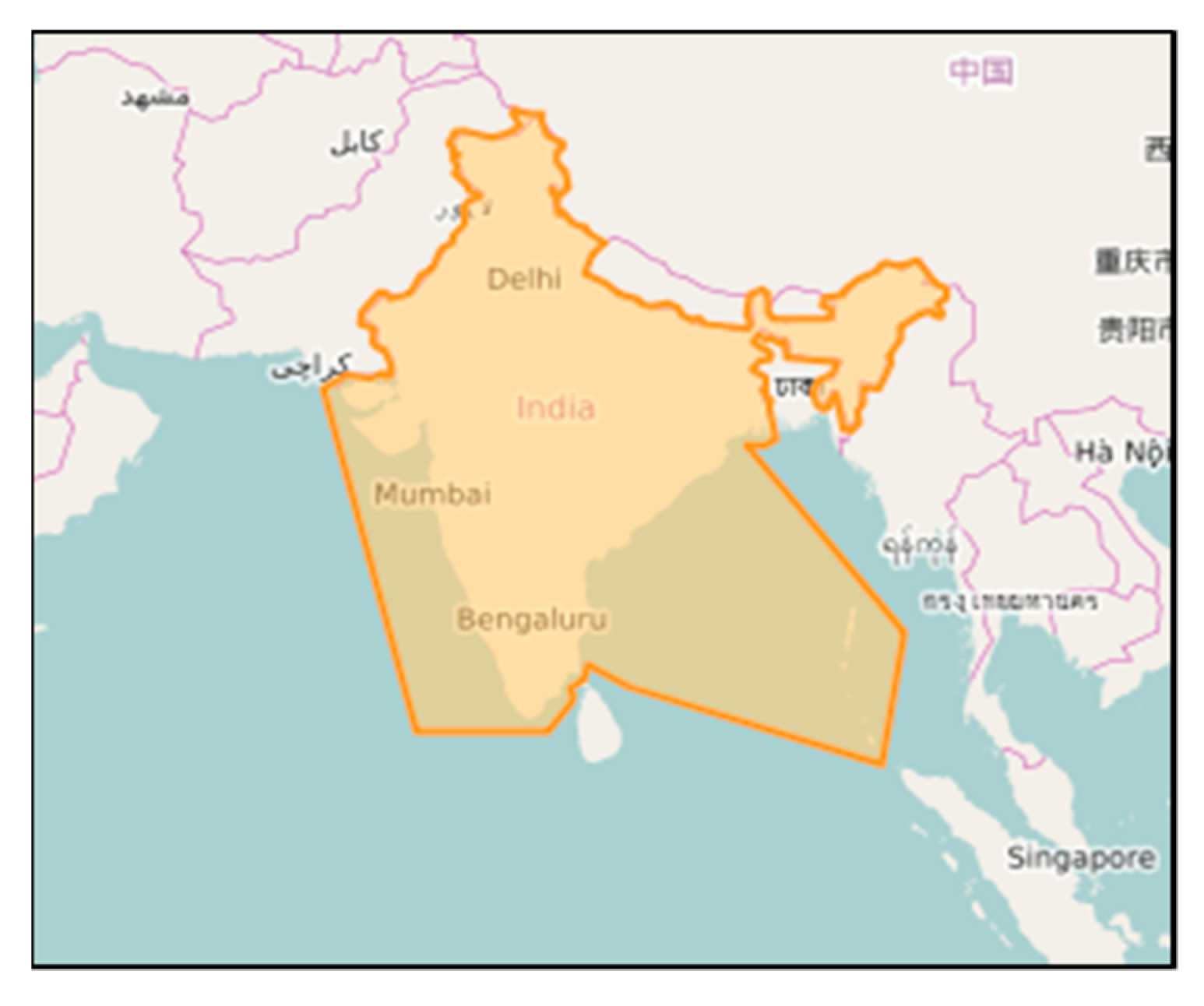
Figure 2 shows the boundary extent of the study region under consideration. We could build our own OSM data history for a specific region of interest using the osmium tool (
https://github.com/osmcode/osmium-tool). This tool took two input files: the OSM full history dump that contained the entire history of the OSM data sized 56 GB in pbf format (
http://planet.openstreetmap.org/planet/full-history/, accessed on 15 July 2019) and a JSON configuration file that described the bounding co-ordinates’ extent, output directory path, and output file format. The other two main methods for extracting OSM data are (1) defining a specific area to download the contained XML information from the OSM website using various tools, or (2) downloading freely available data in different formats through the Geofabrik website. This research adopted the latter. The OSM history dump for India contained the entire history of Indian OSM data (
https://osm-internal.download.geofabrik.de/asia/india, accessed on 15 July 2019), sized 7 GB in pbf format. The history file contained numerous features describing users, elements, changesets, and modifications. The file included all versions of nodes, ways, and relations that ever existed, including deleted objects and changesets. The history file of India represented data on nearly 27,550 users. The history data represented anonymous edits with no user ID and no username, with a value of 0 for the user ID entity in the pbf file. In our experimentation, we discarded the anonymous edits to make the user analysis more transparent and accurate. At this point, we had a .pbf file for the study region containing every OSM element version through time.
3.1. Feature Selection and Metadata Summarization
For ease of access and experimentation, the raw data in the given OSM history underwent a feature selection process to extract useful attributes that constitute OSM metadata to describe the data. The selection of relevant features supports efficient model construction for the user proficiency prediction from OSM history. The features in OSM history were grouped into three categories. The attributes representing element description formed element-based metadata, attributes reflecting more information on changeset formed changeset-based metadata, and attributes describing behavioral patterns formed user-based metadata. In this research, we implemented aggregation operations on these metadata to gather relevant features to know how each user contributed through time, as well as the production of changesets, modification patterns, contribution intensity, and element representations. Some of the aggregation operations are listed below.
The OSM lifespan of the user could be evaluated using the first contribution date and last contribution date of the user.
The extraction date and first contribution date provided the number of inscription days.
The changeset duration (in minutes) could be evaluated using the first date (starting) and last date (ending) of the changeset.
The mean of the changeset duration could be associated with the changeset quantity for each user related to user-based metadata attributes. It provided information on how many changesets the user produced in their lifespan, along with its mean duration.
The user contribution for each element could be grouped and counted. It reflected the reliability of the user in their contribution and their interest with unique elements.
OSM element versioning was determined using the first date and last date of the changeset modification. The maximum and minimum values of the versions were calculated to identify whether the current OSM element was up to date, and whether it was corrected or autocorrected, to describe the contribution intensity of users.
All modifications by the user were grouped and counted for each element type (node, way, and relation) to identify total modifications improved, deleted, updated, corrected, and autocorrected to complete user element representation.
The aggregation operations were user-defined based on the requirement of the research problem addressed. The three metadata categories were built up using these aggregation operations. Among the three metadata categories available, the
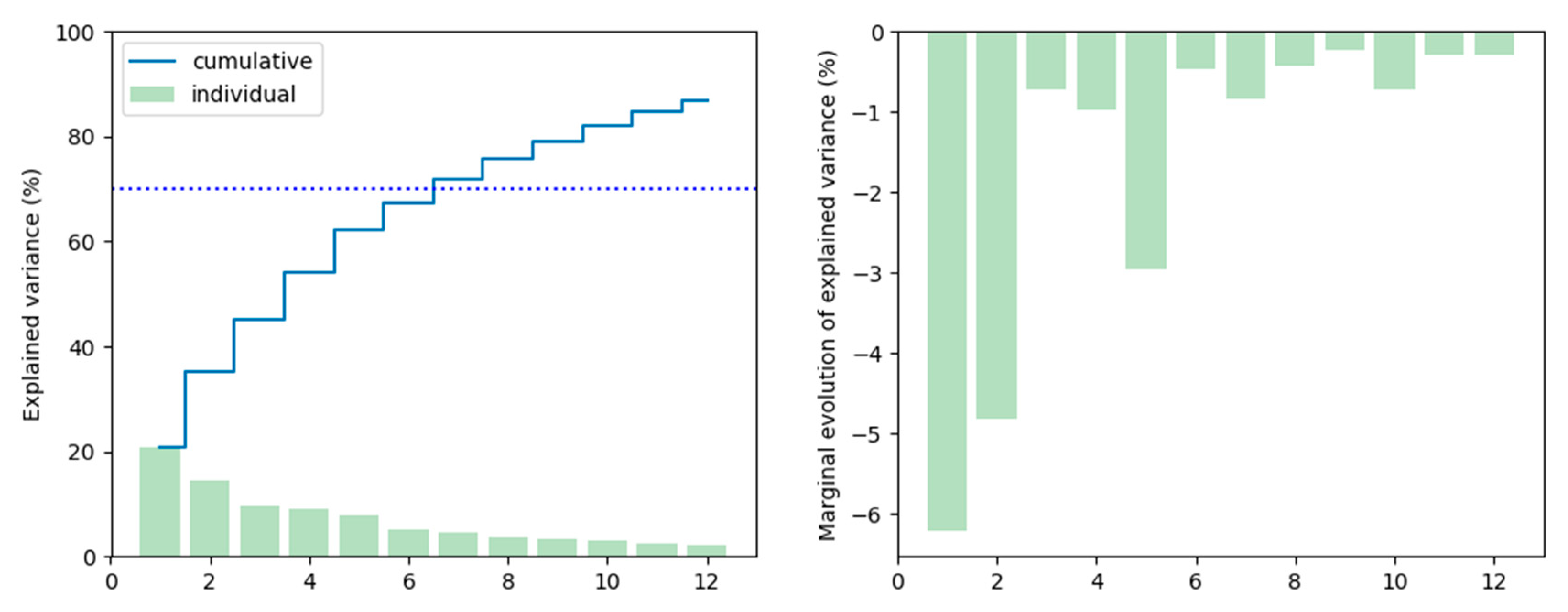
user-based metadata provided more information for user classification and clustering. This phase of exploratory data analysis highly required metadata summarization using PCA. Metadata summarization is a process of identifying and encapsulating useful patterns from given metadata to direct the analytics by emphasizing the connections and variances within the attributes. To choose the number of components for PCA, we followed the rule of thumb, hereby the explained variance proportion was at least 70%. As a result, we selected seven PCA components (
Figure 3).
The PCA algorithm took the number of components (seven) as the input parameter. After the implementation of PCA on the
user-based metadata, the information about each user was summarized within the seven user-defined PCA components. These summarization results revealed hidden information that needed further interpretation. The PCA correlation circle in
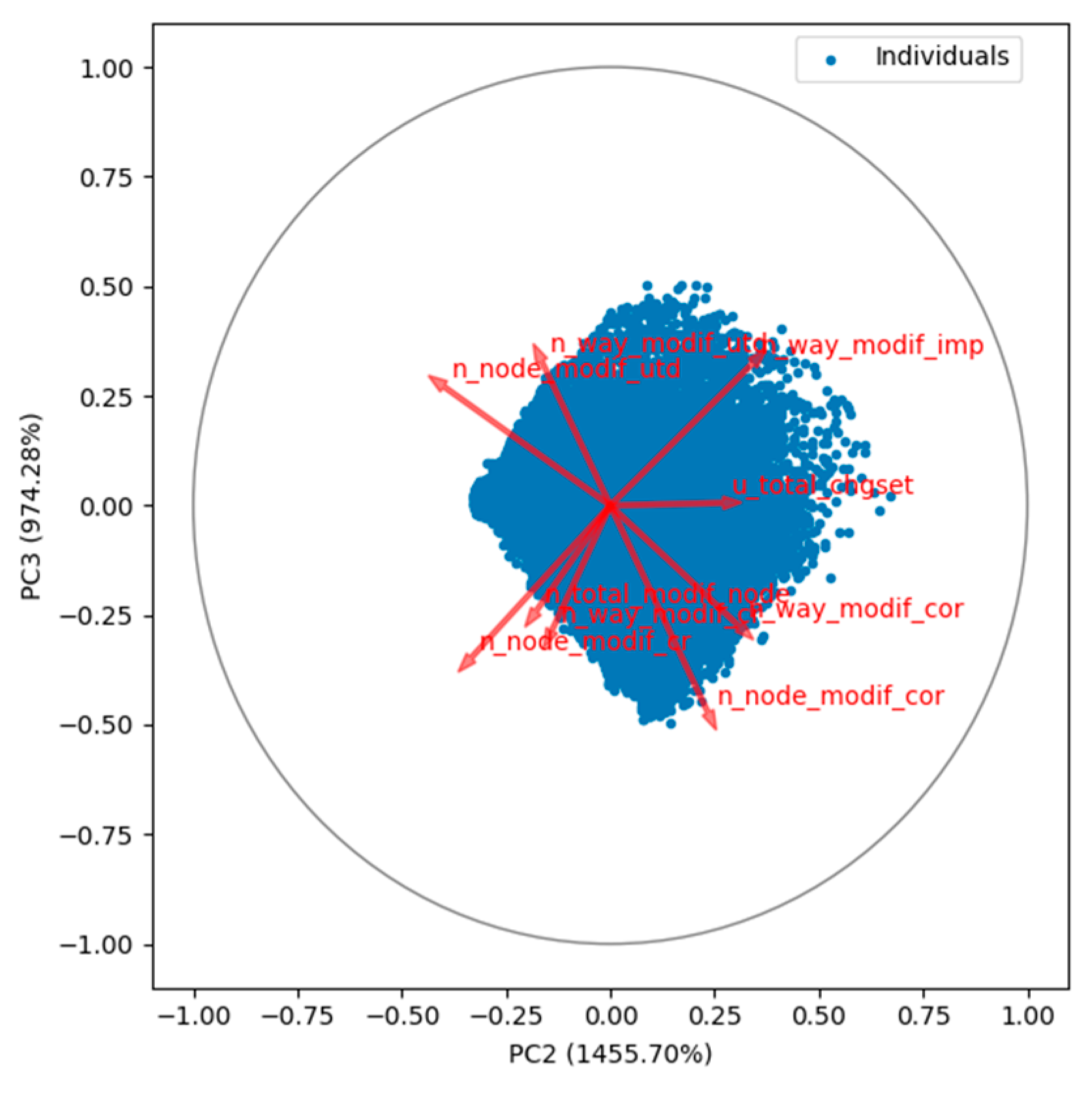
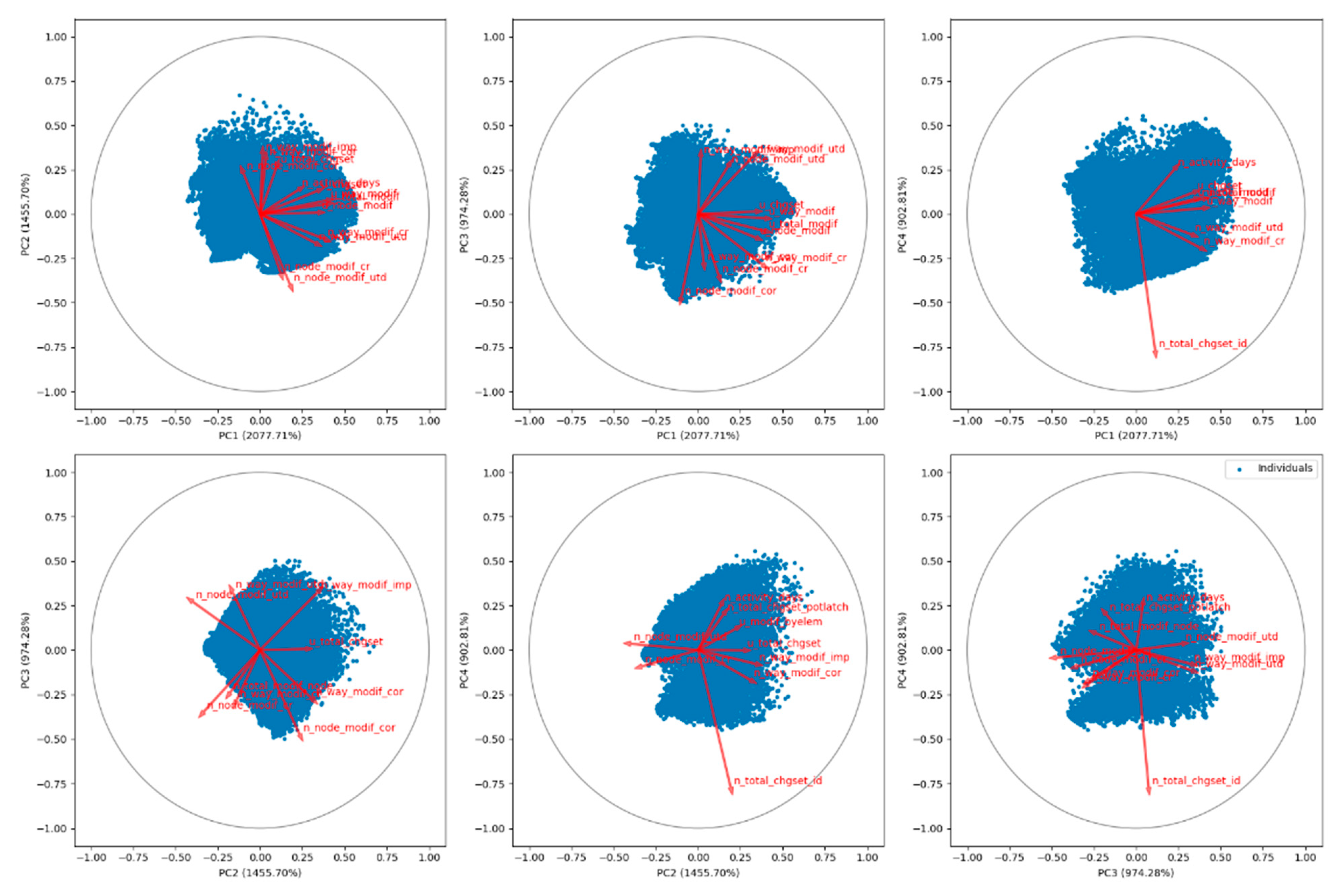
Figure 4 (
Figure A1,
Appendix D) represents the attributes in a two-dimensional circle with the most explained variance plotted on the horizontal axes and the second most explanatory attributes placed on the vertical axes. Here, if two lines were in the same direction, the attributes were highly correlated; orthogonal lines represented unrelated attributes, and lines that were opposite in direction represented negatively related attributes.
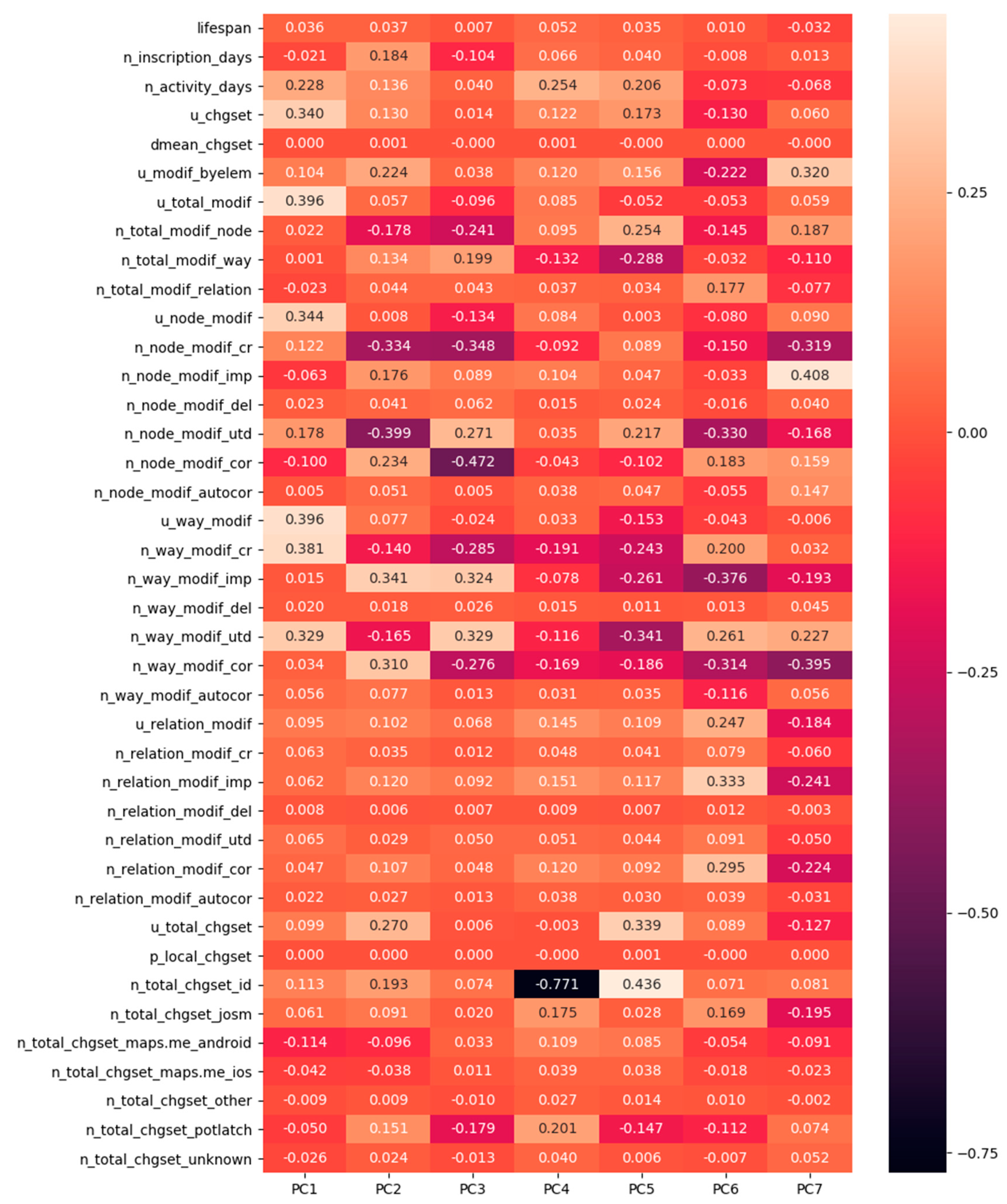
For a better interpretation of results, we plotted them on a heatmap (
Figure 5). The user’s contribution hidden on metadata attributes was represented within the range −1 (high negative contribution) to +1 (high positive contribution). Each feature (
Figure 5) had unique variance values for each principal component. These values determined the combination of features that described the principal components. This observation helped us to draw conclusions about the characteristics perceived in each principal component (
Appendix D,
Table A2, and
Table A3).
After the detailed inspection of attributes variances within each principal component (PC), we briefly described the seven components as follows:
PC-1, principal component 1 (PC 1), had higher values for the following features: updated changesets, updated total modifications, updated node modifications, updated way modifications, number of way modifications created, and number of way modifications up to date. Furthermore, it had lower values for the following features: inscription days, the number of node modifications corrected, and the number of node modifications improved.
PC1 had a high concentration of node and way modifications with fewer improvements, deletions and corrections. It had a high degree of way_modifications_up to date. It had a relatively higher value for lifespan with more changesets. PC1 characterized experienced, skillful, and versatile users.
PC-2 had high values for inscription days. PC2 was strongly correlated with way and node modifications; it contained contributions by old users (inscription days), who were not productive since their inscription. Potlatch was the most used editor. PC2 provided synonymously high corrected and autocorrected contributions.
PC-3 had a negative value for inscription days. It consisted of contributions by recent users (inscription). It contained equal contributions to up to date and deleted modifications; it produced a relatively high number of way and relation modifications. PC3 represented quite active users in recent times (most used editor-android, ios).
PC-4 had a high value for the number of activity days. It corresponded to long-term users with more activity days. The editors included a wide variety right from Potlatch and Josm to Android and IOS. PC4 was impacted by relation modifications representing very productive active users and foreign users (local_changeset).
PC-5 had a high user changeset value. Changeset contributions impacted it; often, contributions were autocorrected. PC5 signaled a local, inexperienced, recent user, who was very productive in terms of elements and node modifications.
PC-6 had a marginal value for lifespan and negative values for inscription days and activity days. Relation modifications impacted it; subsequently, other users frequently corrected their modifications. PC6 was a sign of specialization to complex structures and foreign users.
PC-7 had low and negative values for inscription days, lifespan, and activity days. It indicated novice users and learners with fewer activity days. It had limited contributions to way and node modifications, which were probably equal to the rate of node and way deletions.
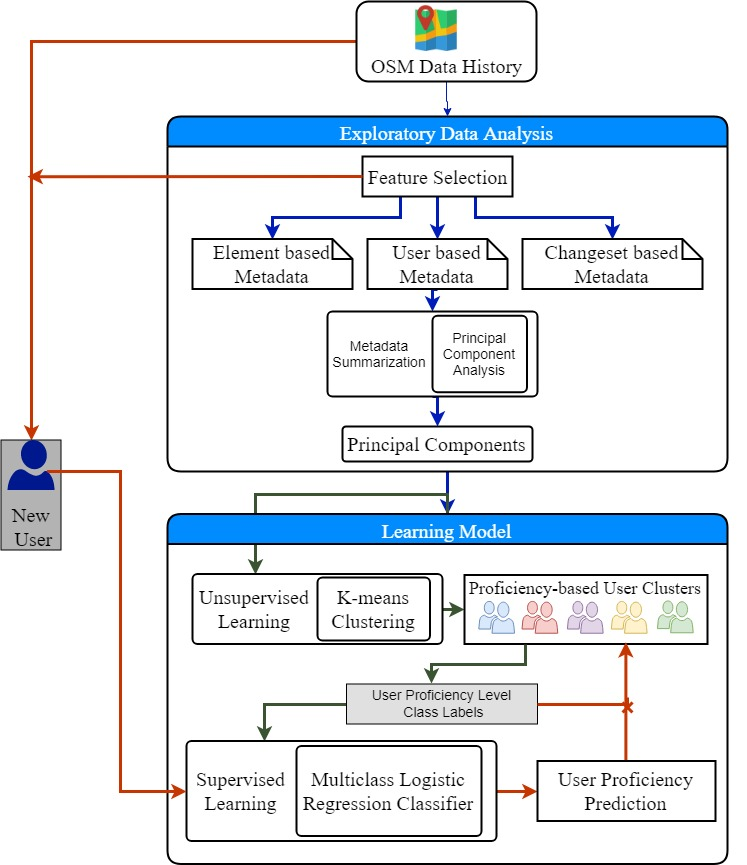
3.2. Unsupervised Learning for User Clustering
In the previous section, the results of PCA described the user contribution pattern through the features available in the user-based metadata. Hence, each component constituted specific characteristics depicting the contribution trend. With the use of these components, we learned the contribution characteristics of an individual user. Grouping similar users without any prior labeling of user groups took place through unsupervised clustering. As discussed in
Section 2.2.2, we implemented the K-means clustering algorithm on the OSM history dataset to cluster users based on the
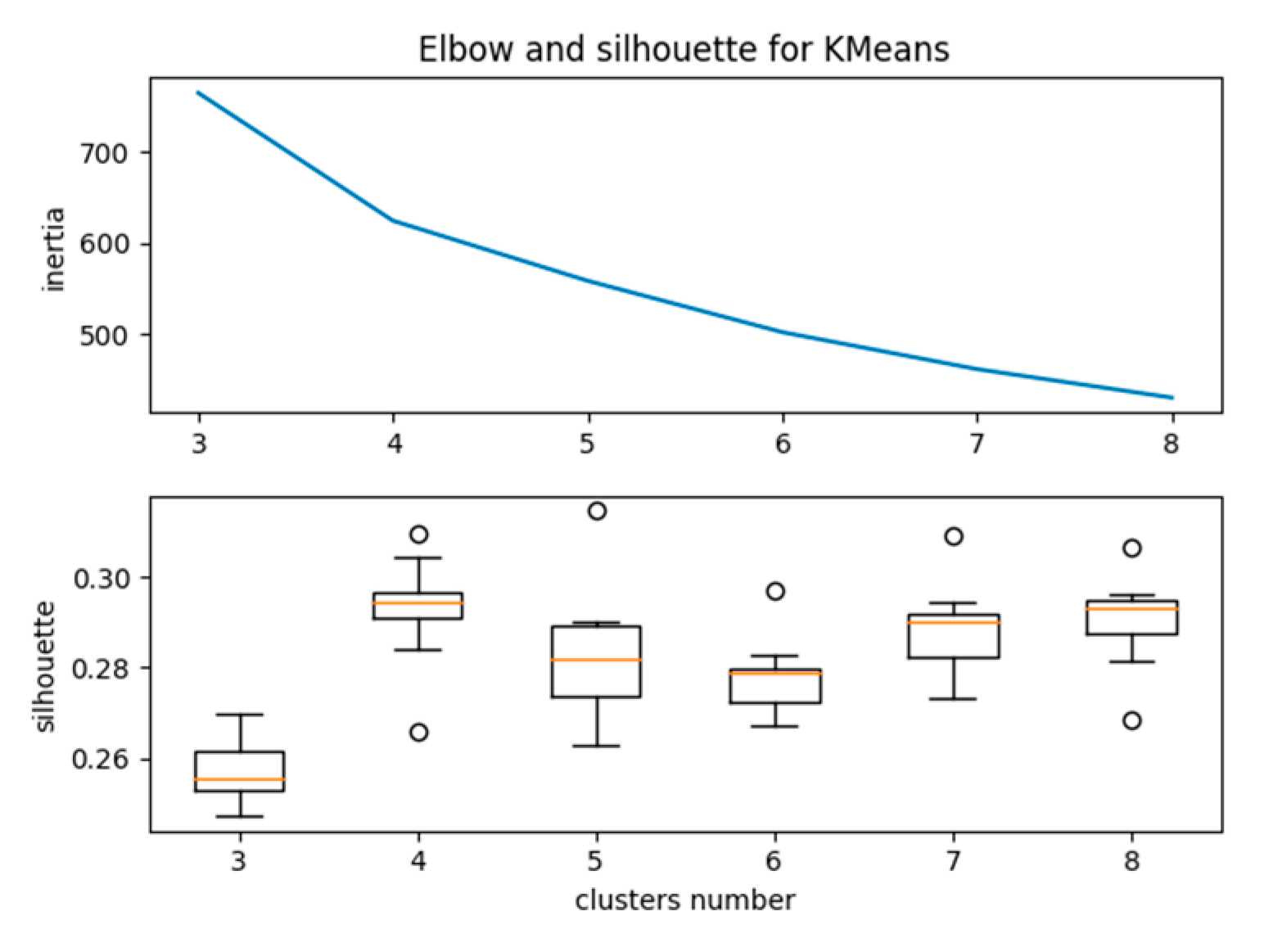
user-based metadata. The input parameter for K-means clustering was the number of clusters of the data. The elbow and silhouette methods are ideal methods for determining the optimized number of clusters. In the elbow method, for a range of values of k, we calculated the sum of squared errors for each value of k. Our goal was to achieve a minimum value for “k” with a low sum of squared errors so as to achieve robust clustering for the dataset. As shown in
Figure 6, when we plotted the sum of squared errors on a line chart, we could realize the line as an arm, and the “elbow” on the arm was the best value of k.
Similarly, the silhouette value is a measure of how similar a user is to his cluster compared to other clusters. In
Figure 6, for each value of k, the average silhouette is plotted, and the location of the maximum indicates the appropriate number of clusters. As per
Figure 6, the optimum number of clusters for our study was five. After implementing the K-means clustering with five as the user-defined number of clusters, the user clusters in the OSM user contribution history were listed out, as shown in
Table 1.
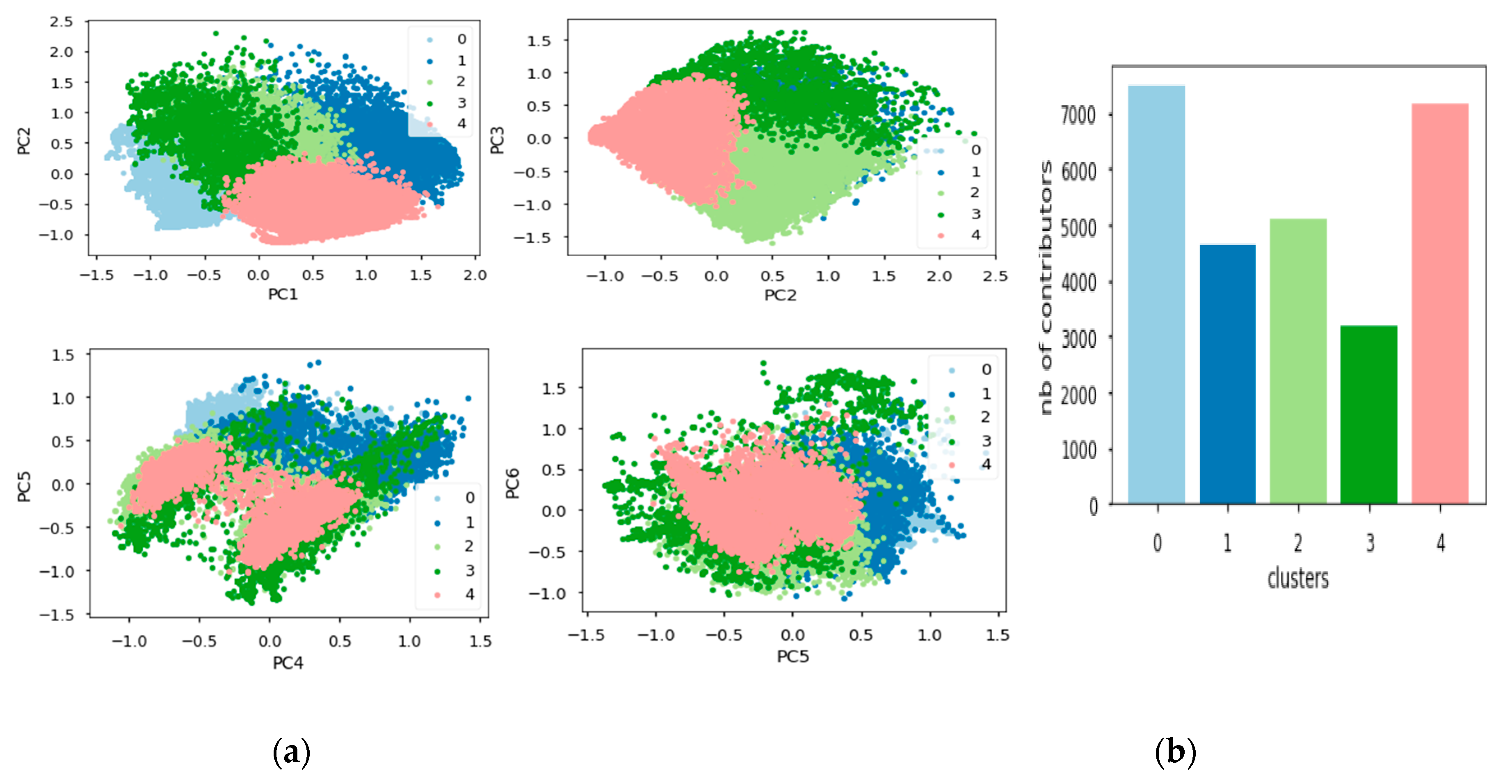
Each cluster had unique values for all principal components, representing users with comparable contribution patterns. From
Table 1, for cluster “0” (C0) the value for PC5 was high; cluster “1” (C1) and cluster “4” (C4) both had high values for PC1, yet, when observing the other PC values, C1 had the second highest value for PC2, whereas C4 had the second highest value for PC7. Cluster “2” (C2) had high values for PC2; cluster “3” (C3) had a high value for PC3. None of the clusters exhibited high values for PC4 and PC6, which means that there existed no long-term very productive active users and no users specialized with complex structures for the study region. Based on these values, the clusters that represented the proficiency level of users were C0 (locally unexperienced contributors), C1 (key contributors), C2 (old one-time contributors), C3 (recent contributors), and C4 (fairly productive contributors) (
Table 2).
Figure 7 depicts the uneven distribution of the contributors within the India OSM history data. The clusters C0 and C4 had the maximum number of users, while C3 had the minimum number of users.
To conclude, based on the Indian OSM History data, there were 17% of users revealing a higher level of proficiency to provide continuous valid contributions in OSM. The data provided by these users were characterized to exhibit better credibility, as knowing the way that users contributed gave information about their ability to do so properly. Also, similar to PCA, individual users could be analyzed even after K-means clustering (
Table 3).
The users with IDs 3086, 2973, 3744, 30047, and 1399 exhibited a high value for PC2, PC6, PC1, PC2, and PC4, respectively. After the implementation of K-means clustering (
Table 3), the users represented a specific pattern with the PC values, placing them into a particular cluster. The users with IDs 3086 and 30047 exhibited similar patterns of PC values when arranged from higher to lower values of PCs; their orders were PC2, PC 6, PC 1, PC 4, PC 7, PC 5, and PC 3 and PC 6, PC 2, PC 1, PC 4, PC 7, PC 5, and PC 3, respectively. Therefore, they fell into the same cluster C2. Also the users with IDs 2973 and 1399 exhibited similar patterns of PC values when arranged from higher to lower values of PCs; their orders were PC 6, PC 4, PC 5, PC 2, PC 7, PC 3, and PC 1 and PC 4, PC 5, PC 6, PC 2, PC 7, PC 1, and PC 3, respectively. Therefore, they fell within the same cluster C0. The user with ID 3744 exhibited the pattern of cluster C1, which was in the order PC1, PC2, PC4, PC5, PC6, PC7, and PC3.
For a better illustration, we presented the manual observation of the user-based metadata of two distinct users with IDs 3086and 3744 (
Appendix A). We could conclude that user 3744 had better proficiency than user 3086 based on lifespan, activity days, updated changesets, and updated total modifications. User 3086 contributed only once, while user 3744 made more contributions frequently. Thus, user 3086 was identified as an “old one-time contributor”, while user 3744 was a “key contributor”.
3.3. Supervised Learning for User Classification
As a result of unsupervised clustering, the various OSM users’ cluster labels signifying proficiency level were
naive local contributors, key contributors, old one-time contributors, recent contributors, and
fairly productive contributors. Predicting their proficiency level from the evaluation of the contribution pattern in the OSM context helped in the characterization of their contributed data. The unsupervised clustering results could be used to discover user labels that paved the way for supervised learning. As discussed in
Section 2.2.2, we established the classification of users using multiclass logistic regression (MLR). The requirement for classification problems in OSM user evaluation is to train the model to predict qualitative targets of contribution behavior for a particular user. For a better understanding of its need, we assumed a specific scenario where a new user arrives at a new geographic location and contributes certain elements to OSM. Before considering the user’s contributed data as a source for research and analysis, the question of credibility, data quality, and trust remains unanswered. The K-means clustering provided many insights into contribution behavior and user proficiency level. Based on this study, we developed a supervised learning model which was trained using a previous OSM history dataset with class labels.
Before implementing supervised learning, it was necessary to check class balancing. In our dataset, it is clear from
Table 2 that there were impressions on our dataset (India_OSM _History) that were imbalanced. To deal with our imbalanced dataset, we underwent oversampling through synthetic data generation. Our experiments used the synthetic minority oversampling technique (SMOTE). The SMOTE algorithm generates synthetic data of a random set of minority class observations based on feature space similarities from minority samples, rather than data space to shift the bias of classifier learning toward minority classes. This technique can effectively improve the training accuracy of the supervised learning model. Thus, custom-made user-based metadata from OSM history helped to train the MLR learning model. Then, we fed the user metadata with feature values extracted from the OSM history of new users into the trained MLR classifier in the learning process. The classifier automatically classified the data into one of the predetermined contribution behavior labels. To this point, the new user’s proficiency level prediction was complete. To evaluate the performance of the classifier, we ran the MLR model using 2000 sample observations from the custom-made user-based metadata. The classifier was evaluated using a confusion matrix (
Table 4), and metrics such as accuracy, precision, recall, and specificity were calculated (
Table 5).
From the metadata of the given 2000 users in the sample, the learning model classified 1911 users correctly within the five predefined contribution behavior user class labels and misclassified 89 users. The diagonal elements of
Table 4 represent the
true positive (TP) values of the MLR classifier confusion matrix. The
true positives are the total number of users correctly predicted with their actual user class.
True negatives are the total number of users correctly predicted to not be a part of a user class. Similarly,
false positive and false negative values occurred when the actual user classes and the predicted classes contradicted each other. Using these values, we calculated the accuracy, precision, recall, and specificity of the model as follows:
The precision value was the ratio of correctly classified users to the total number of appropriately predicted users. High precision indicates that the user label with a particular user class was classified as such. The
recall value, also called
sensitivity, of the classification model corresponds to the true positive rate of the considered class. The high values for recall indicated that the model correctly recognized the classes. In our model, we had an average recall value of 95.53% (
Table 5), which was slightly lower than the average precision value of 95.56%, which means that the classifier was conservative when classifying the users with an incorrect user class. Also, the average specificity, also known as the true negative rate, was 98.88%, indicating that the MLR model fit the given data well. Also, 95.5% overall accuracy was found to be entirely satisfactory. The values of precision and recall reflected the benefits of balancing the class observations using synthetic data generation. Overall, the results of supervised learning provided a solution to the research hypothesis.
The proposed data-driven model through machine learning methods contributed to the intrinsic quality assessment of VGI. This model is a comprehensive approach that performs analytics over meta-information extracted from OSM history. It does not put forth any quality measures or indicators, as it operates only using the contribution data available in the OSM API. The results of the model demonstrate the various user contribution patterns and user behaviors that help in profiling the user’s proficiency level. The outcome of the methodology is consistent with some discussions in the literature; however, different phenomena may arise when used in other geographic regions where diverse OSM users exist. Overall, the combination of unsupervised and supervised learning provides the potential to reveal all possible combinations of features to explore varied contribution patterns and user behaviors for different use cases.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












