The semantic method proposed is first presented through a system overview in
Section 2.1 that explains it and shows the components of the system. Then
Section 2.2 presents the knowledge representations that drive the detection process. This knowledge describes the three main domains, which are the algorithm, the object and the data domains. Finally,
Section 2.3 explains the overall process of knowledge-driven detection. The knowledge-driven detection process is composed of three steps: the data processing through algorithm management, the classification and the self-learning.
2.1. System Overview
The proposed method is a semantic approach that uses knowledge domains of data, algorithm, objects and acquisition processing to drive the detection process. A knowledge analysis engine that allows for manipulating this knowledge is connected to a processing engine that executes algorithms chosen by the knowledge analysis engine. The reasoning that understands the requirements of each algorithm parameterizes the selected algorithms automatically. This processing works step by step to provide adapted processing at each step. This specific processing depends on the objects sought, the characteristics of the data (e.g., its content, its specific context, its acquisition process) and the results of the executed algorithms. It takes into account algorithms inputs, algorithms prerequisites, algorithms outputs, algorithms parameters and conditional-restrictions of algorithms interdependencies, in order to select algorithms adapted to each step. This strategy makes a detection process very flexible thanks to the full treatment under the regime of semantics. Such processing that selects and parameterizes the adapted algorithms step by step results in the execution of a sequence of algorithms specific to the processed use case. This capability of adaptation finally leads to a robust detection process. Thanks to the defined knowledge that guides the overall process, the detection process can manage unexpected situations through a self-knowledge-based learning step, which proposes a possible continuation.
Several aspects must be taken into account to design such a detection process. First, a global process must drive the entire detection process by using explicit knowledge. Therefore, the whole process requires techniques to formulate and use this knowledge. Next, the global process needs algorithms to perform the processing. It must automatically assess the relevance of each algorithm to the specific detection context to select the most appropriate algorithm to run. The use of algorithms with knowledge requires an understanding of each algorithm’s parameter to relate a parameter value to the value of an object or data characteristic. Then the overall process must use the relationship between the algorithm parameters and the characteristics of the objects or data to configure the algorithms. Moreover, the dynamic adaptation of the detection process requires the automatic execution of algorithms and the transformation of algorithmic results into a field of knowledge. To enrich the knowledge base, the automatic execution of algorithms and the updating of knowledge by interpreting algorithmic results require a technical and conceptual connection between the semantic paradigm and the algorithmic paradigm. Finally, conclusions must be drawn from the results obtained. These conclusions should not only serve to identify elements but should also guide the detection process to increase its effectiveness. Indeed, an analysis of these conclusions must be carried out to draw lessons from the experience from which these conclusions were drawn.
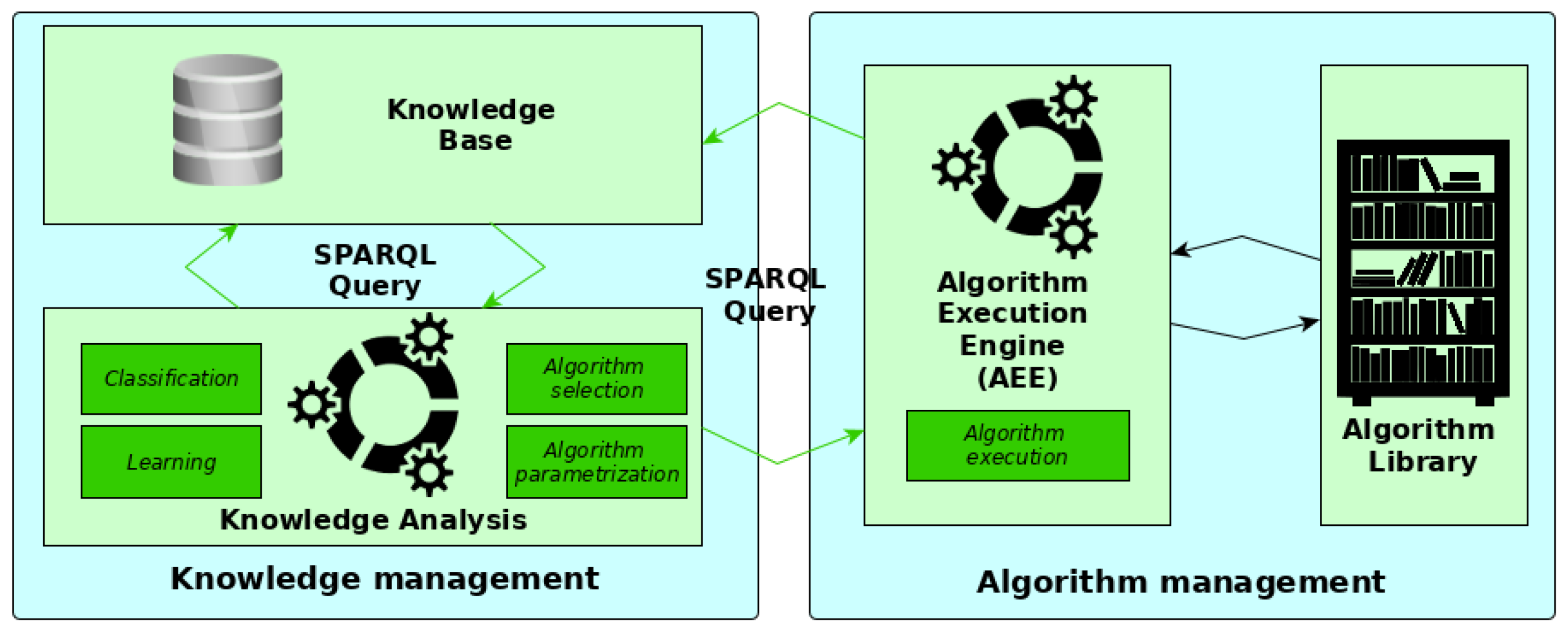
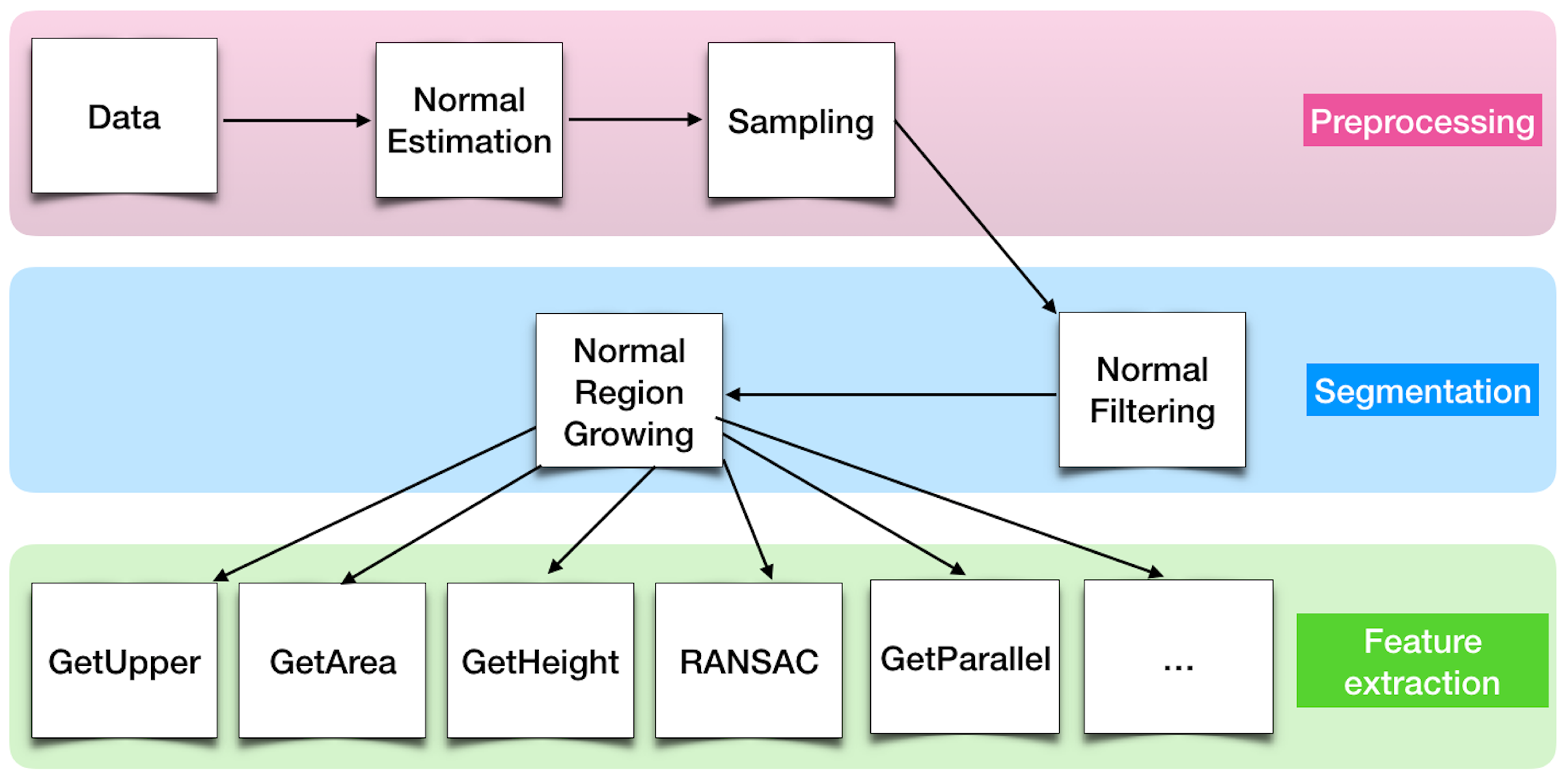
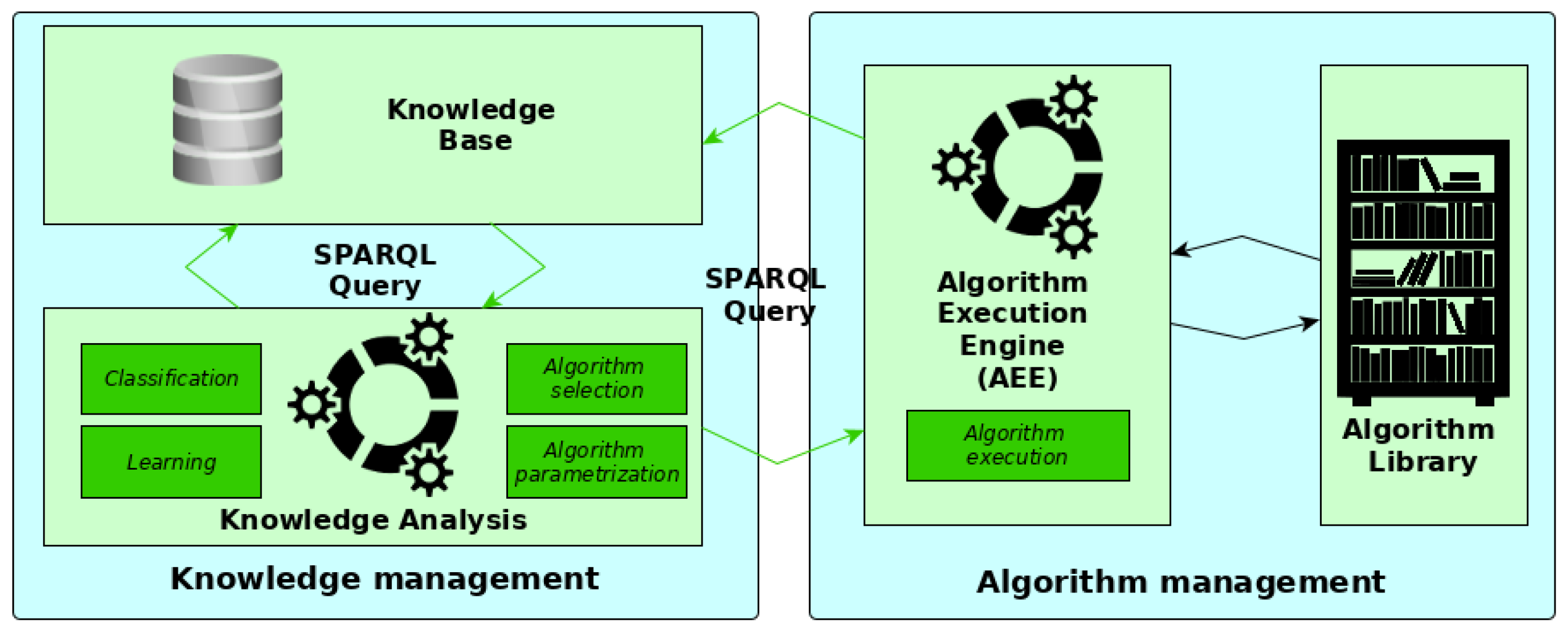
Figure 1 shows the main components of the presented system that addresses these requirements.
The proposed system is composed of algorithm libraries containing a multitude of algorithms that allow covering the processing of different 3D data. Each of these algorithms has a detailed description modeled in the knowledge base stored in a triplestore.
This knowledge is used and managed through a knowledge analysis engine (KAE), which aims at guiding the entire object detection process and adapting it to the data provided and the objects sought. This adaptation of the detection process begins with the selection of the most relevant algorithms, among all the algorithms available in the algorithm libraries. The estimation of this relevance depends on the characteristics of the objects sought and the data used. The selected algorithms are then automatically configured by KAE according to their execution context. In addition to the characteristics of the objects sought and the data used, the context of algorithm execution depends on the results obtained upstream from the execution of other algorithms. After the full parameterization of an algorithm, the KAE converts the algorithm information into SPARQL queries [
40] using a SPARQL-function (similarly to the approach in Reference [
41]) to call the execution of the algorithms.
An algorithm execution engine (AEE) uses information in the received SPARQL query to execute the algorithm related to this query. It then interprets the result to be returned through the SPARQL query to enrich the knowledge base. This enrichment then allows the KAE to reason on the new information to draw conclusions and identify objects through classification.
This step is followed by an analysis of the results to learn dynamically from the experience of achieved results. This learning then allows for specifically improving knowledge about objects and data, depending on the specific application context.
2.2. Knowledge Modeling
Knowledge is structured and modeled to guide the process of data understanding. This knowledge is defined as a knowledge base through the semantic standard OWL2 [
42] which is an improvement on the semantic standard OWL [
43].
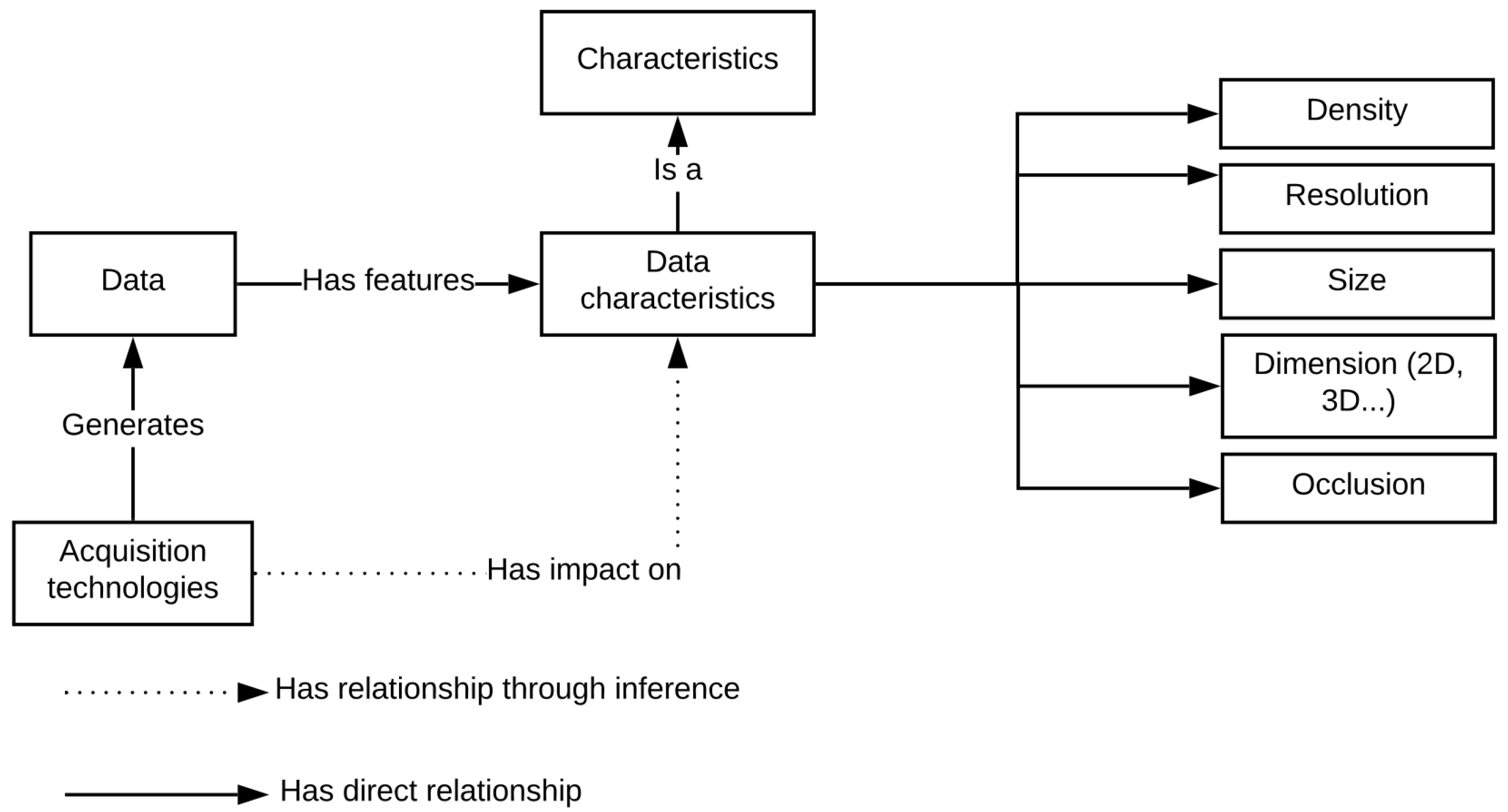
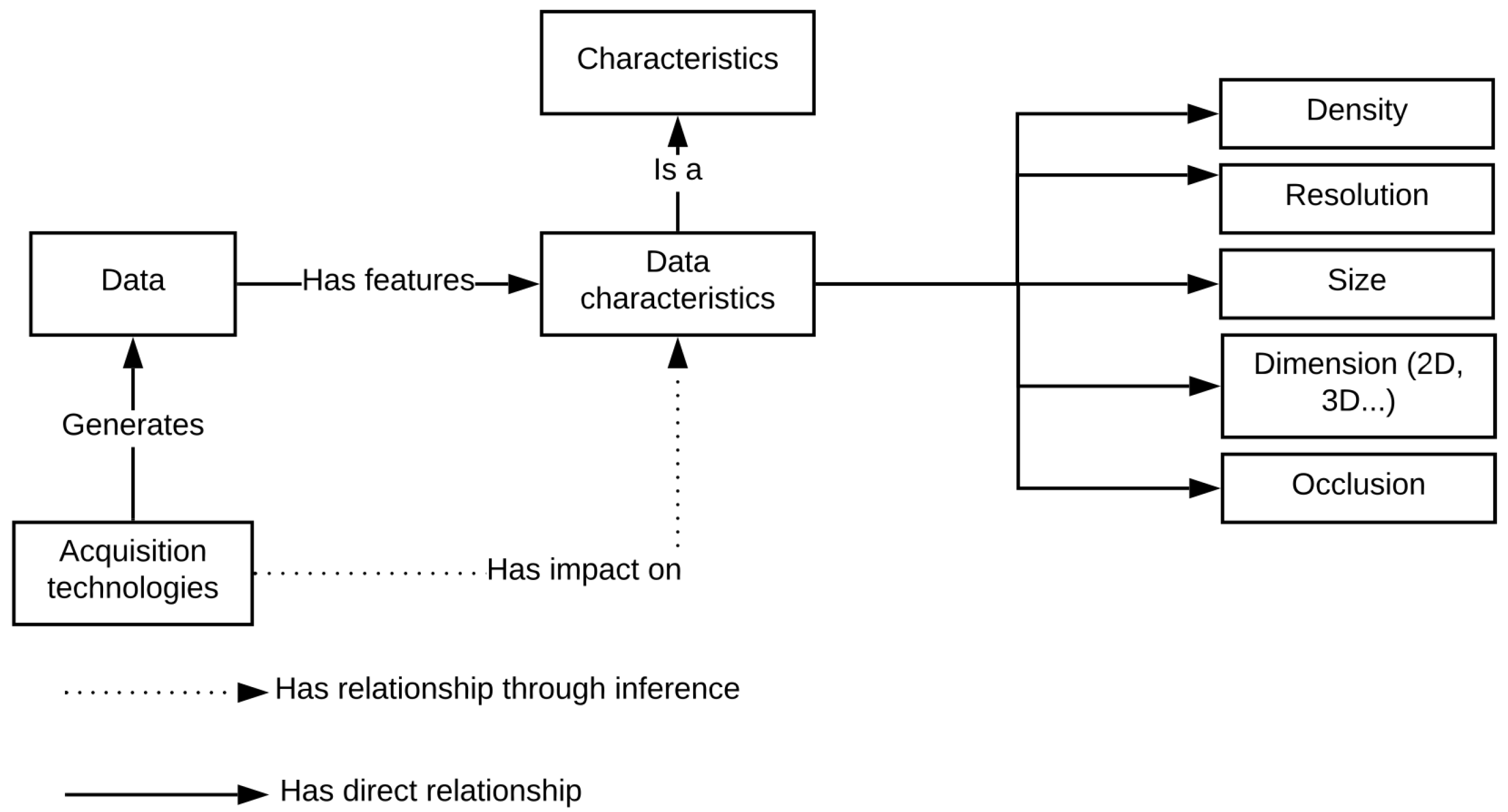
Figure 2 shows the organization of knowledge.
Reference [
44] presents the requirement of the knowledge modeling for the design of the object detection process. It is necessary to detect the geometric characteristics of the objects (e.g., shape, surface) and their topologic relationships (e.g., distance between objects, connection, perpendicular) in order to identify the objects that constitute the data. The detection of these characteristics requires the use of algorithms. Algorithms are designed to identify geometries (e.g., plane, line, sphere, segments, orientation). They provide new data (e.g., sampled data, filtered data) or new data characteristics (e.g., segments, density).
Let us consider an algorithm designed to detect planes (such as RANSAC or the Hough transformation) as an example. This algorithm generates segments (data parts) from data where each segment represents a plane. Thus it allows the detection of different objects with a planar geometry (e.g., wall, ceiling, floor, table, door). The behavior of algorithms depends mainly on the characteristics of the data (e.g., size, density), which depend on the acquisition process. However, the acquisition process is influenced on the one hand by the scene containing the objects to digitize (for example, any object may occlude another) and on the other hand, by various external factors (for example, light intensity and color, calibration of the measuring instrument, indoor or outdoor environment). Moreover, knowledge is organized hierarchically (i.e., one element can be a subset of another). For example, a vertical wall is a kind of wall that is a kind of object.
2.2.1. Data Knowledge
As shown in
Figure 2, data is a representation of a scene, obtained through acquisition. This acquisition process, more precisely the instruments and the methods used for the acquisition, influences the data characteristics. In addition, elements influencing the acquisition process itself, such as external factors and the acquired scene, transitively impact the data characteristics. The data characteristics such as density, noise, resolution, dimension, size and occlusion comprise the specificity of each data.
Figure 3 shows the generic semantic description and the relation between any data and its acquisition process.
The specificity of the data has an impact on the process of understanding the data content. That is why the characteristics of data must be considered to guide the process of understanding. The semantic representation of the relationship between data and its acquisition process allows for inferring data characteristics from the information of the acquisition process. Thus, information about the acquisition process indirectly guides the process of detection through the data characteristics. Let us take a striking example in an outdoor scene acquired by the Lidar laser scanner. This example is illustrated in
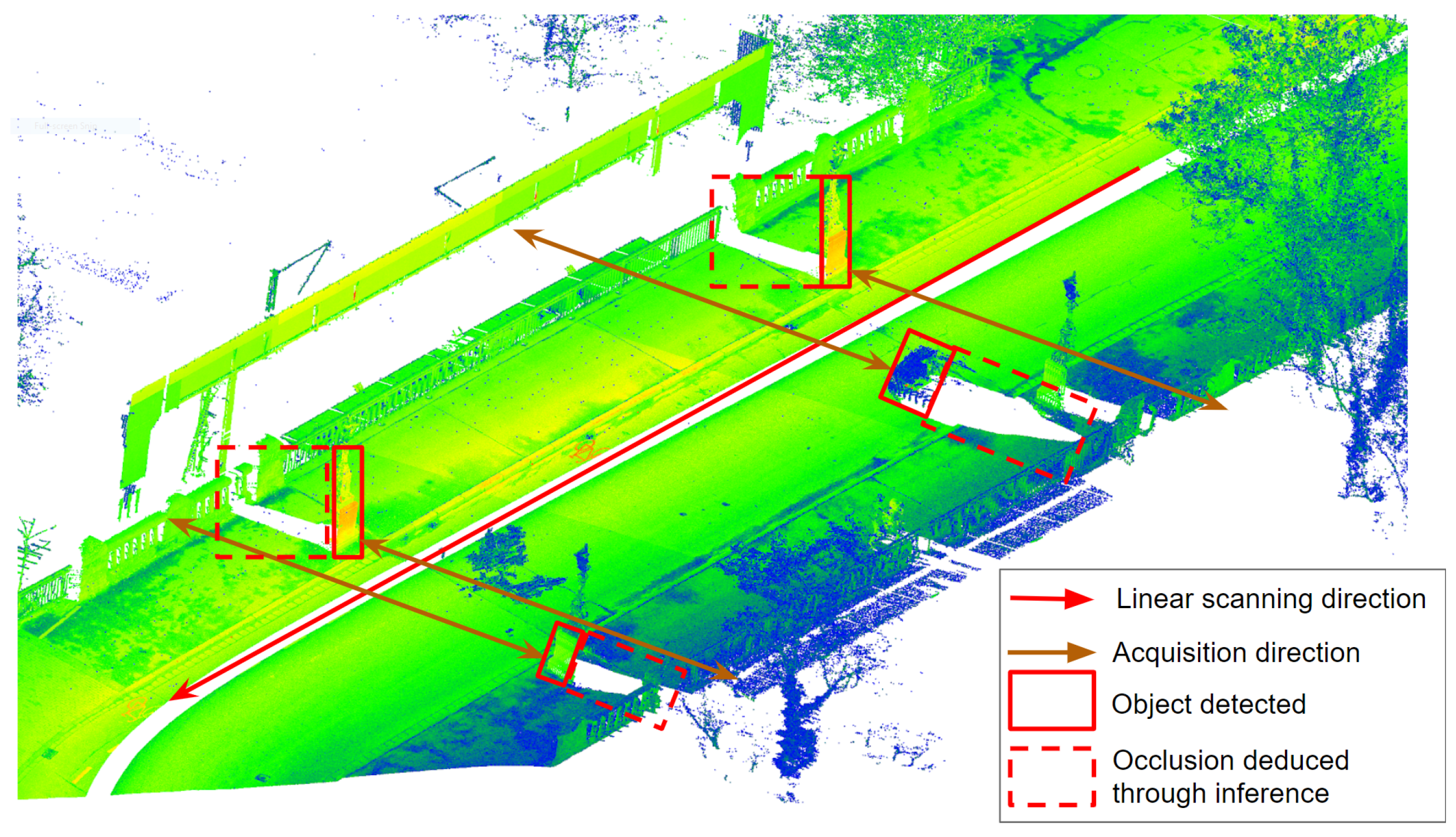
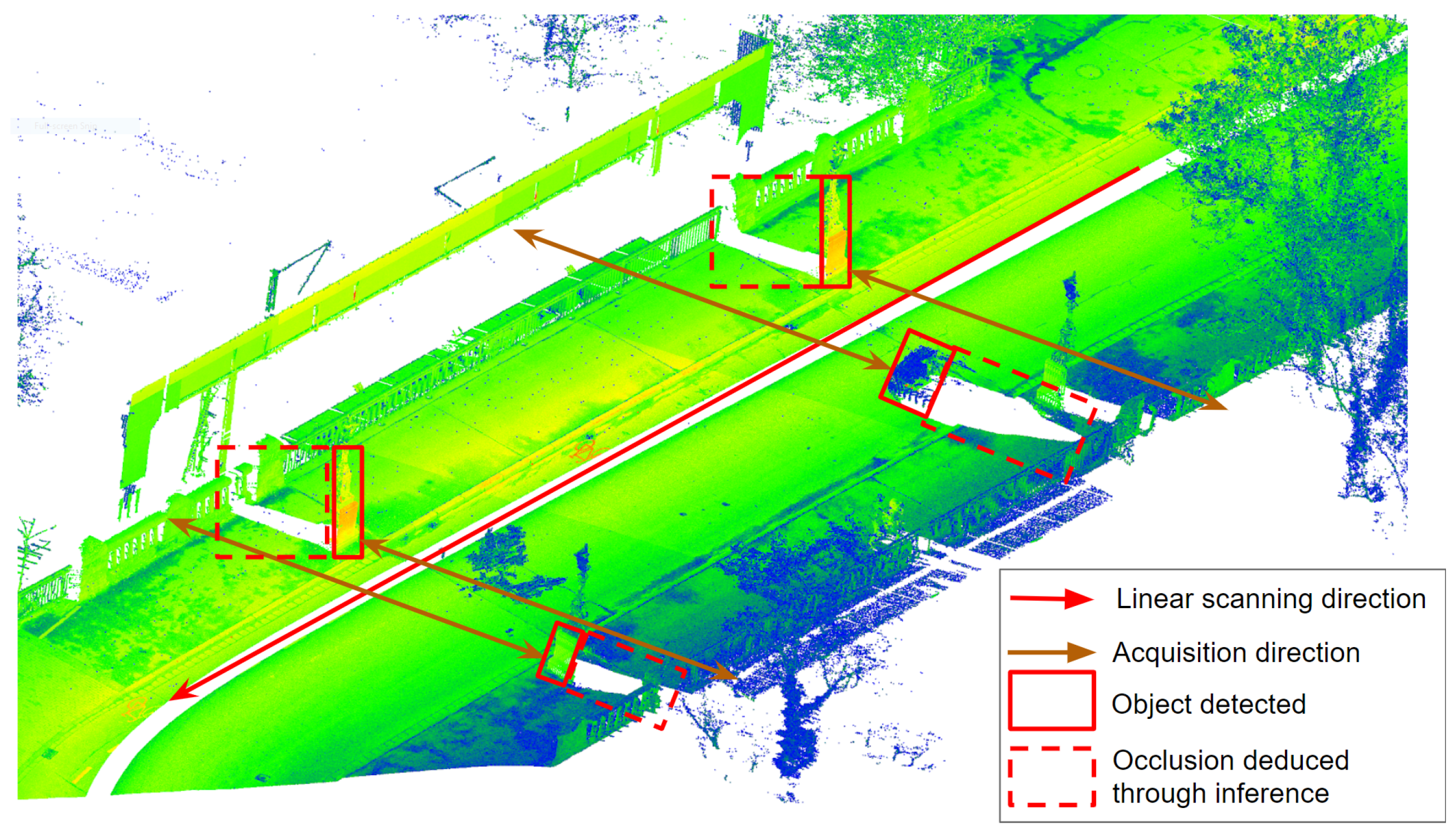
Figure 4.
This example shows an acquisition process by horizontal scanning (see brown arrows in
Figure 4) along a linear path (illustrated by the red arrow in
Figure 4). Such acquisition process using a Lidar laser scanner as an acquisition instrument systematically produces a local loss of information caused by objects that occlude parts of the scene. The loss of information often translates into an over-segmentation (the same object segmented into several parts) and detection failure during the process of data understanding.
However, a reasoning mechanism can anticipate and compensate for this loss of local information. In this example, the reasoning allows for inferring the location of possibly occluded areas (highlighted by the red dotted rectangle in
Figure 4) from the position of the measuring instrument and the detection of an object (illustrated by the red rectangle in
Figure 4) in the alignment of the horizontal scan. Thus, reasoning on information about the acquisition process (acquisition method, measuring instrument, the content of the acquired scene) allows for anticipating and locating the occluded areas. The identification of occluded areas provides information that improves the detection process. For example, it allows for gathering each part of an object which was separated due to some occlusions into the same object. It also provides essential information that influences the selection of algorithms through relations between algorithm requirement and the characteristics of the data.
2.2.2. Object Knowledge
The understanding of data requires a description of the objects contained in the acquired scene to facilitate the object searching and thus the data content understanding. This object description is semantically represented inside the knowledge base. The description of object characteristics aims at guiding the strategy of object detection. Indeed, the simpler the object shape is, the simpler its detection strategy can be. On the contrary, objects with complex shapes require more elaborate detection strategies.
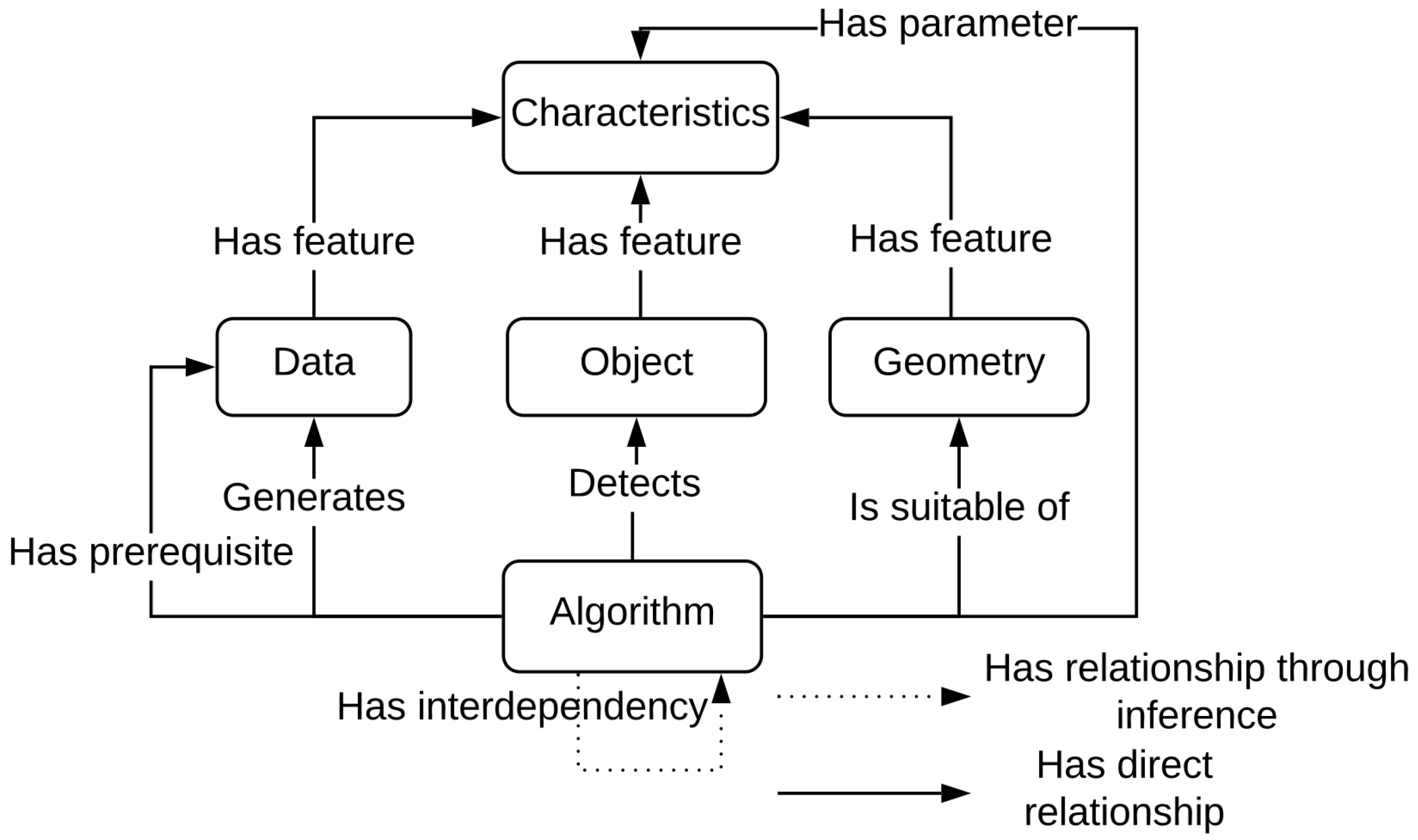
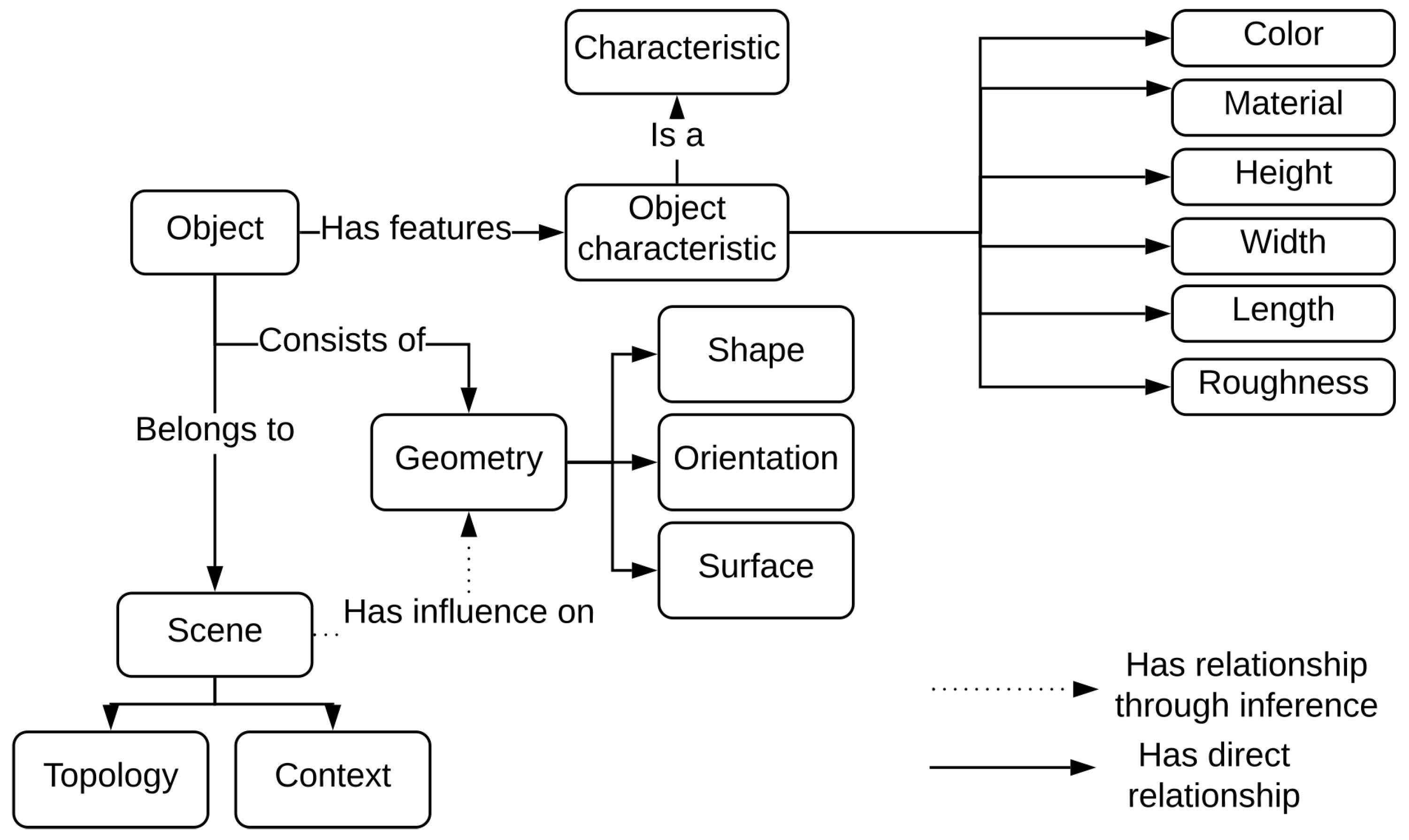
Three main parts compose the semantic description of objects: object characteristics, its geometry and the scene that it belongs to. They aim at facilitating the adaptation of detection strategies.
Figure 5 illustrates the generic semantic description of an object.
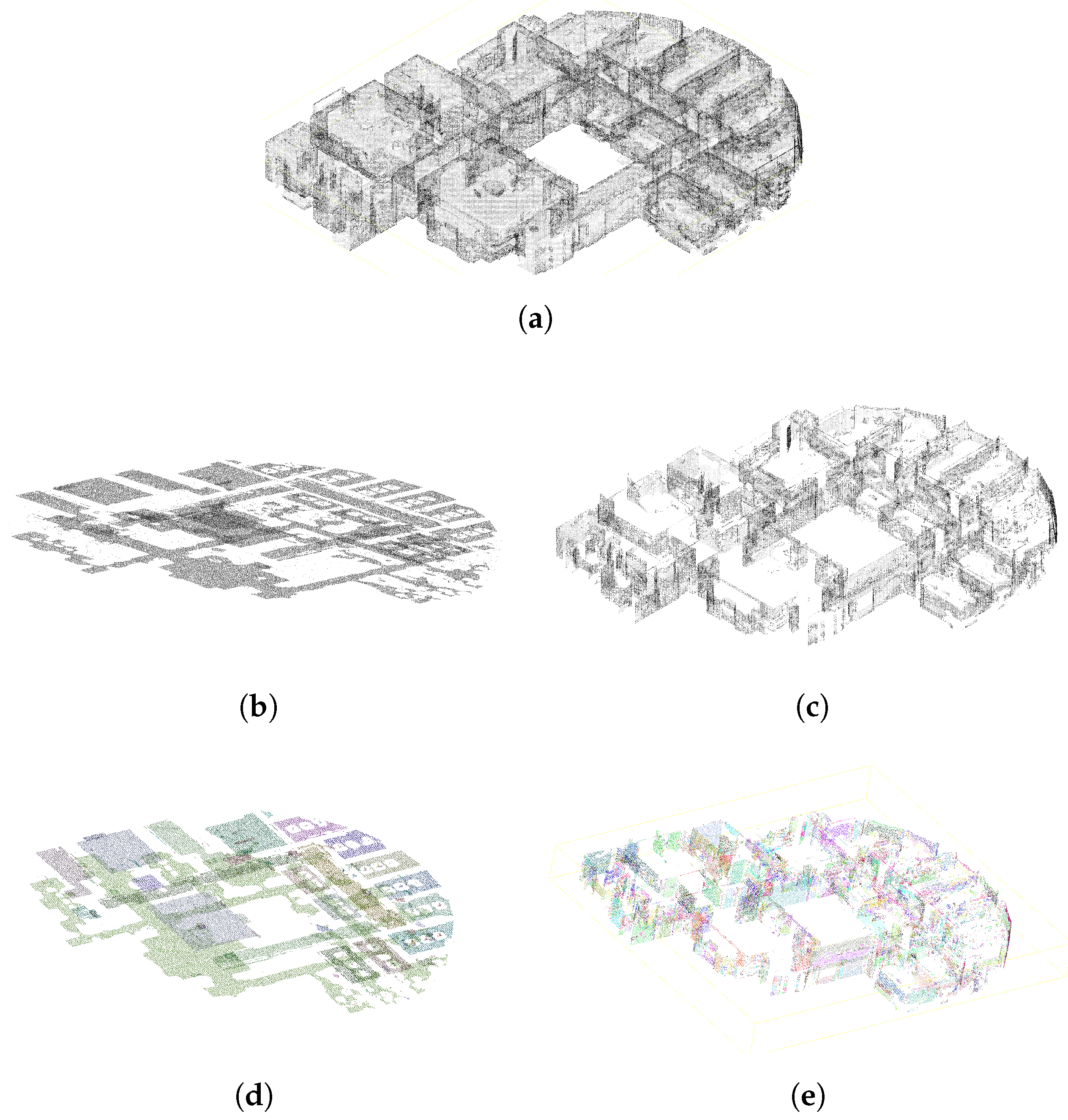
Characteristics are the first part of the object description. These characteristics are specific to each object and influence the process of acquisition (e.g., size, color, material). Let us take as an example the acquisition of an indoor scene with a transparent glass table.
Figure 6 shows such scene acquired with laser scanner technologies by the company NavVis (NavVis:
https://www.navvis.com/).
The glass tray of the table presented in this figure has an insufficient density of points to allow the detection of the table. On the contrary, the acquisition of a matt object such as chairs in
Figure 6 provides a proper density of points that facilitates its detection.
The Equation (
1) shows a formal logical rule that compares the characteristics (
) of the object (
) with the acquisition technologies (
) to automatically infer the density variation in a data (
). Moreover, an object represented with a low density means that several segments represent it after the data segmentation. The knowledge base contains a class called SegmentsSet, defined as composed of several similar segments (having similar characteristics). Therefore, if an object is represented with a low density, then it is a set of segments.
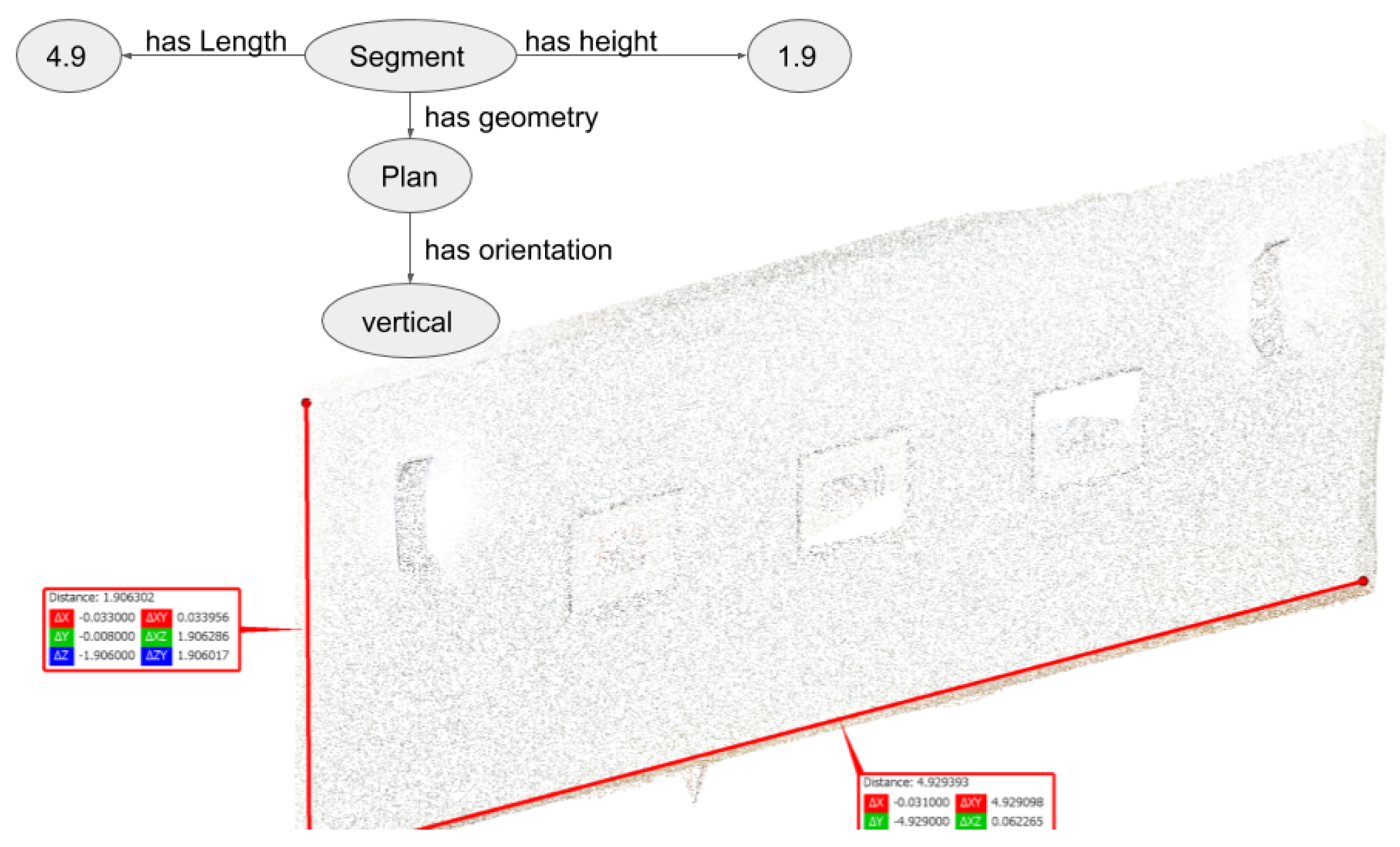
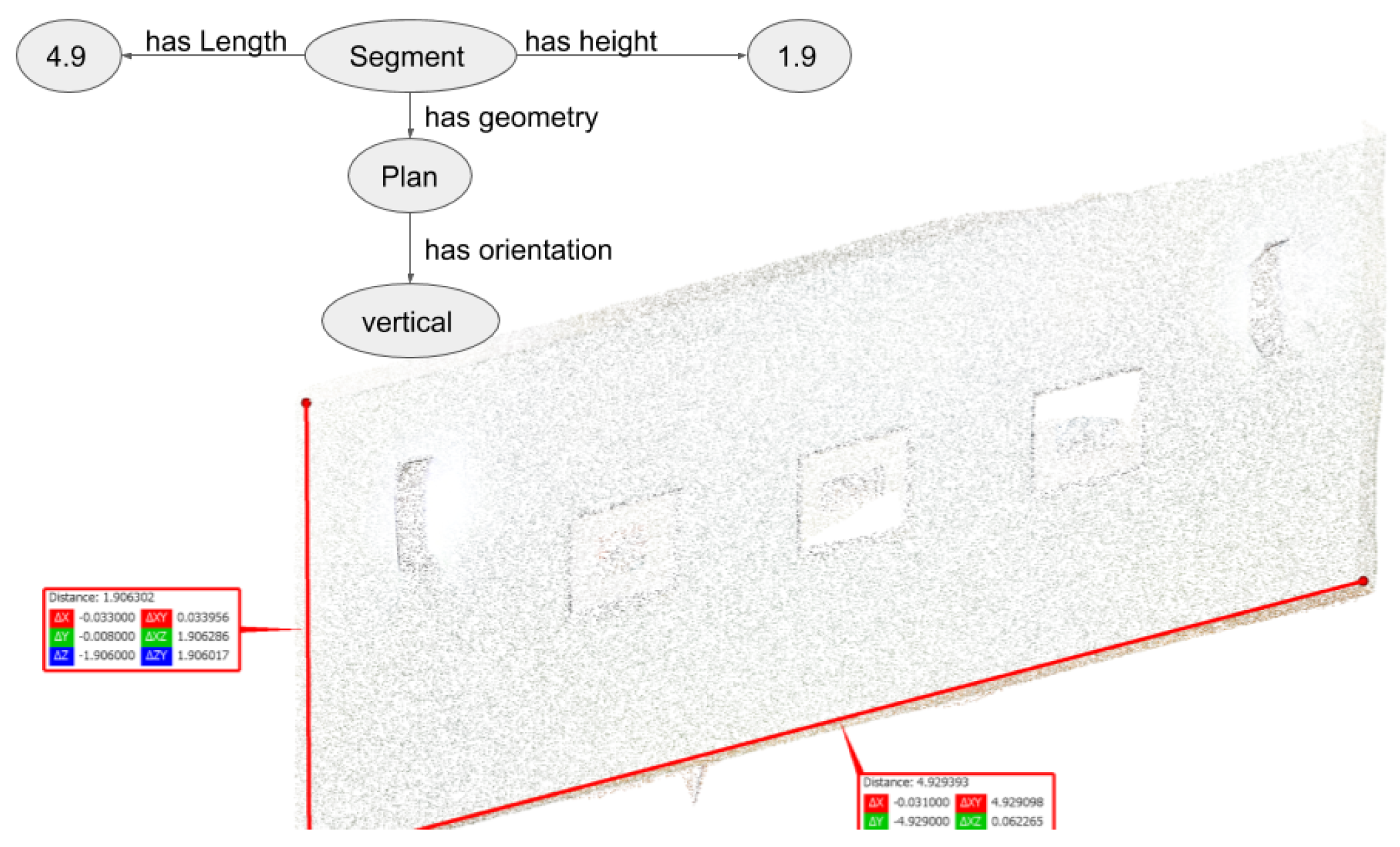
The geometries representing the objects constitute the second part of the object description. A shape (e.g., rectangular, triangular, cubic, cylindrical, spherical, free), an orientation (e.g., vertical, horizontal, oblique) and a surface (e.g., regular, irregular, planar, linear) are the components of the geometry definition. Moreover, an object can be defined as a compound of several objects.
Let us continue with the example of the table to illustrate the geometry part of its semantic description. A table is composed of one tray. A tray is a horizontal plane. This description guides the selection of algorithms to identify objects. The object identification comes from the detection of geometries that belongs to its description. However, the geometries of an object may not be sufficient to differentiate objects (cf. the same geometrical definition of ceiling and floor presented in
Table 1 of the
Section 3.2) or to detect objects whose points’ density does not allow the detection of the geometry (e.g., the glass table in
Figure 6). That is why the object description requires a third description part, which is the scene description.
The scene description is composed of two aspects: the topological links between objects (e.g., parallel, perpendicular, in contact, on, inside, next to, above, below, surrounding) and the context in which they are found (e.g., outside, inside, street, modern building, archaeological excavation).
Topological links facilitate the object detection by providing further information to classify it or by deducing the position of an object through the detection of another. Let us take as an example the topological relationship between a table and chairs in the use case presented in
Figure 6. A table is described as surrounded by chairs. The property surround of an object by a set of objects is further defined through a relationship between their shapes. As shown in Equation (
2), the definition of the surround property applied to this case of tables say that “a table (
) is surrounded by a set of chairs (
)” is equivalent to says that “the shape (
) of the table (
) overlaps the shape (
) built from the set of chairs (
)”.
Thus in the context illustrated in
Figure 6, this topological information can be used to infer the position of the table and facilitate its detection. The context of the scene can influence the geometry and other characteristics of an object. That is why linking the semantic object description to a scene context supports the detection process to search the geometry adapted to the context.
Let us take as an example two different geometries of tables. The first geometry of a table defined as a working table is associated with a scene context of working rooms. It corresponds to the context shows in
Figure 6. The working table is described as a table composed of a specific tray that has a rectangular shape. The second geometry of a table defined as round table is associated with a context of lounge rooms. The round table is described as a table composed of a specific tray that has a circular shape. Both these specific descriptions of table respect the general semantic description of a table presented in
Section 2.2.2.
Figure 7 illustrates this difference of geometry linked to a specific context.
Thanks to such definitions of these two specific tables, the system can adapt the detection process according to the table definition corresponding to the scene represented in the data processed.
2.2.3. Algorithm
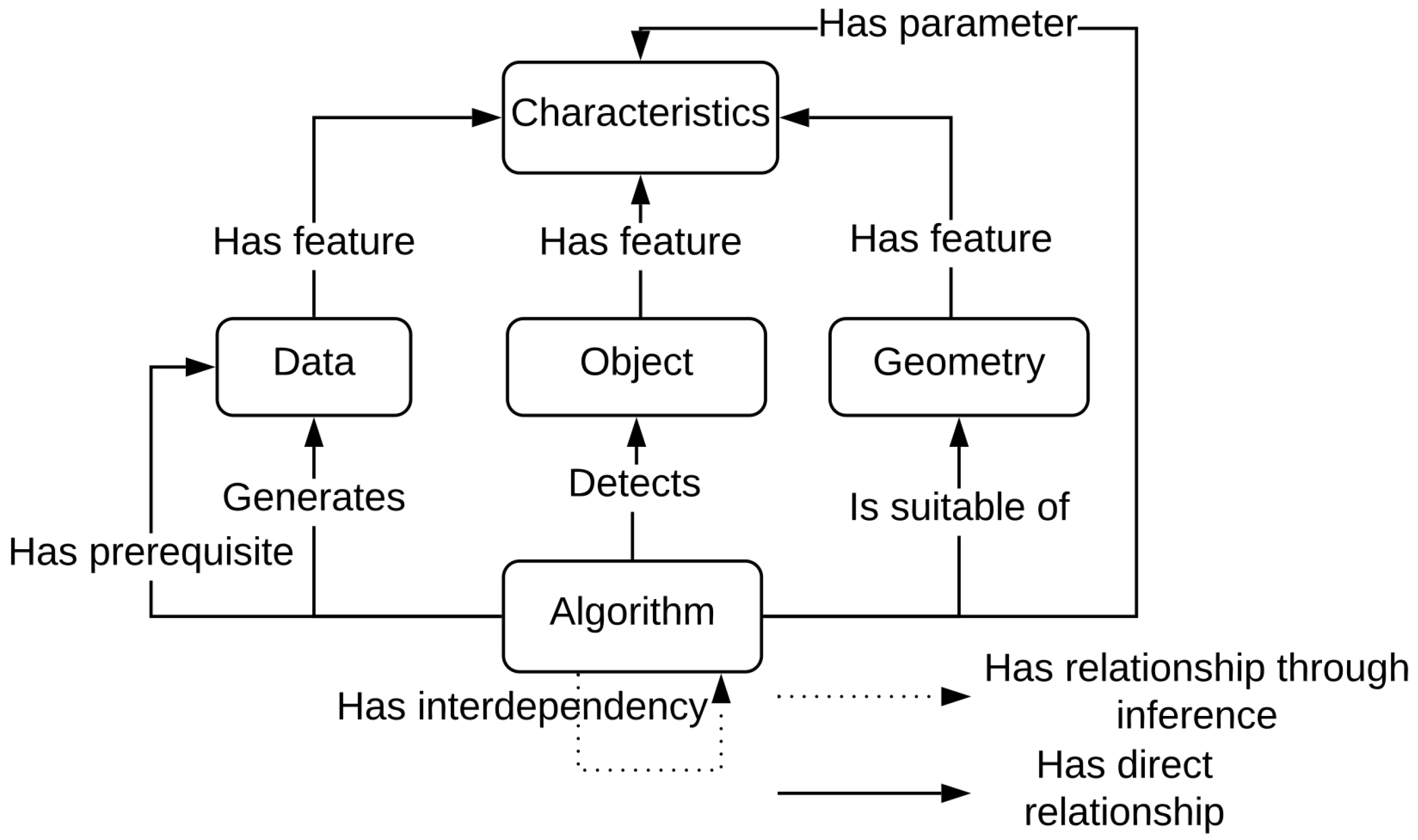
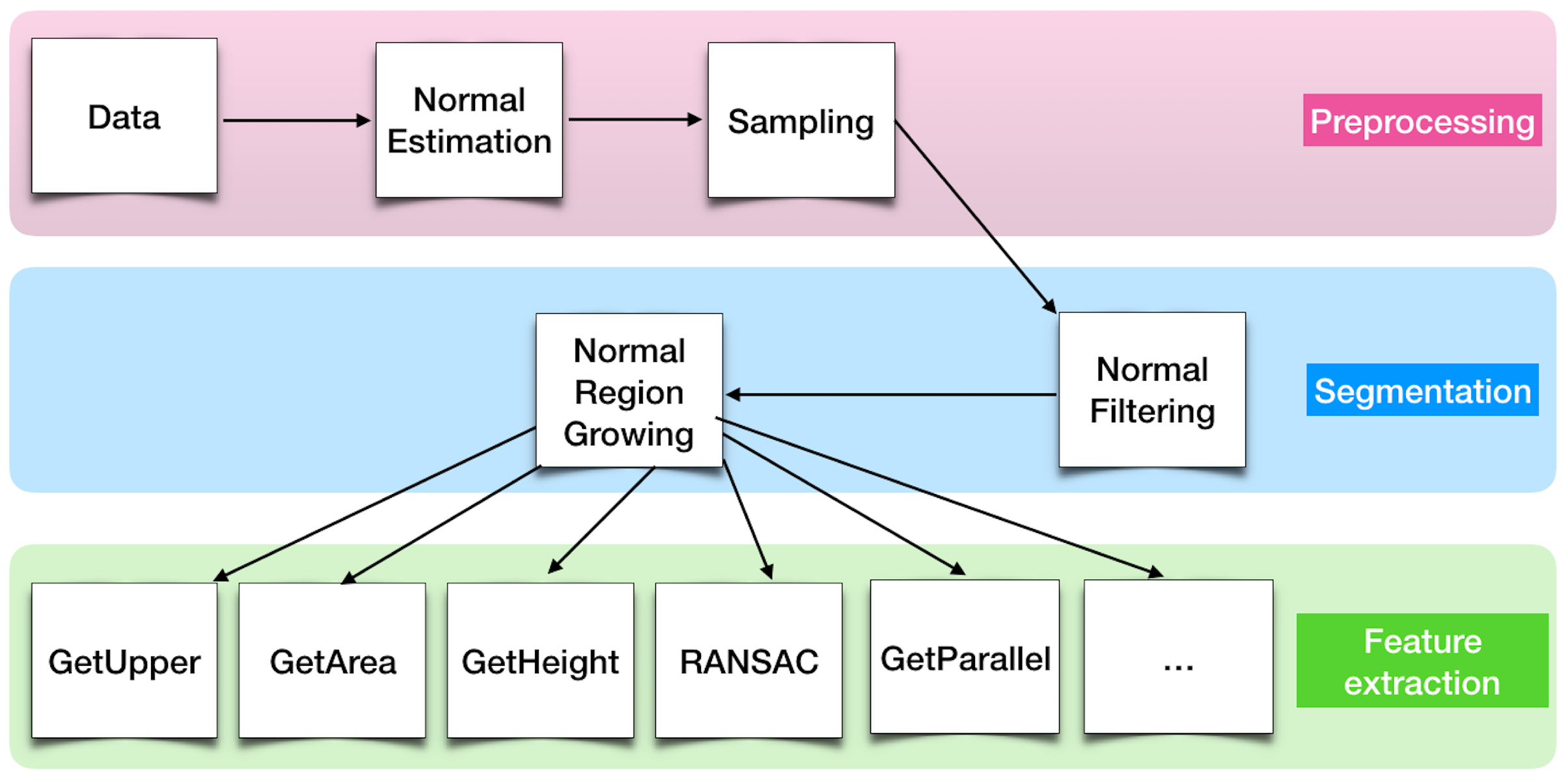
Algorithms are the components that perform the process of object detection. They aim at providing data or data characteristics that give information contributing to detecting geometries and objects contained in the data. Therefore the semantic description of an algorithm defines an algorithm as generating data, detecting objects and being adapted to geometries. This generic semantic description of any algorithm is presented in
Figure 8.
In the process of algorithm selection, the relevance of an algorithm to detect objects is estimated according to the semantic description of each algorithm. This relevance is defined through a link “is suitable” between algorithms and the geometries of the objects.
Algorithms can also have data prerequisites and can produce data characteristics. Therefore, some algorithms satisfy the prerequisites of other algorithms by producing data characteristics required by others. The inference process automatically creates such relationship (shown by the dotted arrow in
Figure 8) that makes these algorithms interdependent. Let us take the example of the segmentation algorithm by normal; this algorithm requires a point cloud with a normal estimated for each point. The algorithm of normal estimation estimates the normal of each point and thus produces a point cloud with estimated normals. Therefore the normal estimation algorithm satisfies the prerequisite of the normal segmentation algorithm. That is why the inference process deduces the interdependency relationship between normal estimation and normal segmentation algorithms that allows them to be combined during the detection process. Some algorithms also require parameters, whose value influences the algorithm result. The role of a parameter is generally to configure mathematical functions or to define a threshold. That is why parameters are mainly primitive values like integers or doubles. The choice of these values by experts depends on the characteristics of data and objects. That is why the choice of parameter values in this methodology is defined through an equation, whose computation depends on elements from object and data descriptions. These elements can be characteristics or geometries of an object but also data characteristics, including factors related to the acquisition process that impact the data. For example, the radius parameter of the normal region growing is computed through an equation that depends on the data resolution.
2.3. Knowledge-Driven Object Detection
The detection of objects and geometries in the data is entirely knowledge-driven to provide knowledge that is then analyzed in a learning phase to generate new and more accurate knowledge about the application case, thus improving the effectiveness of detection.
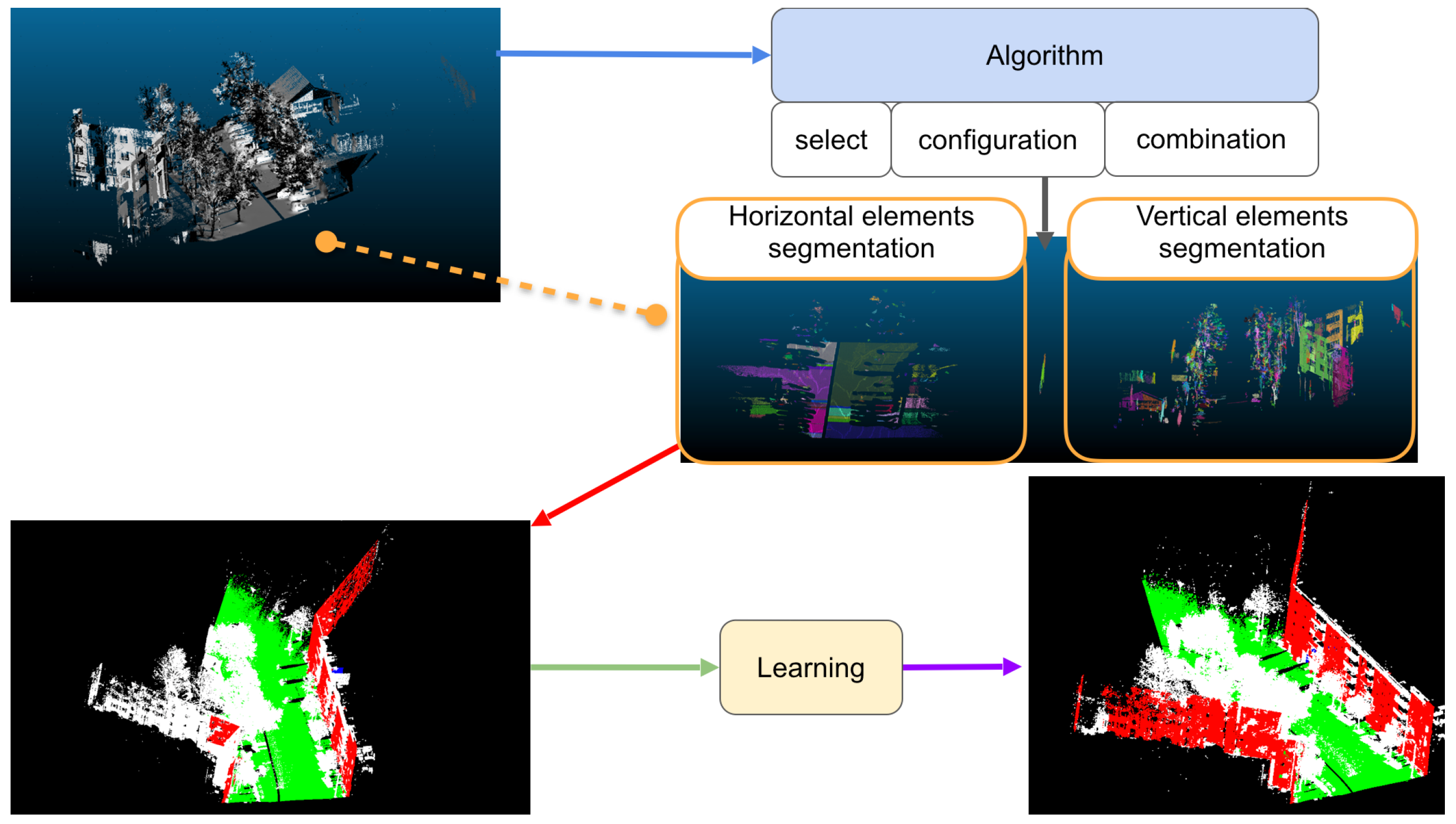
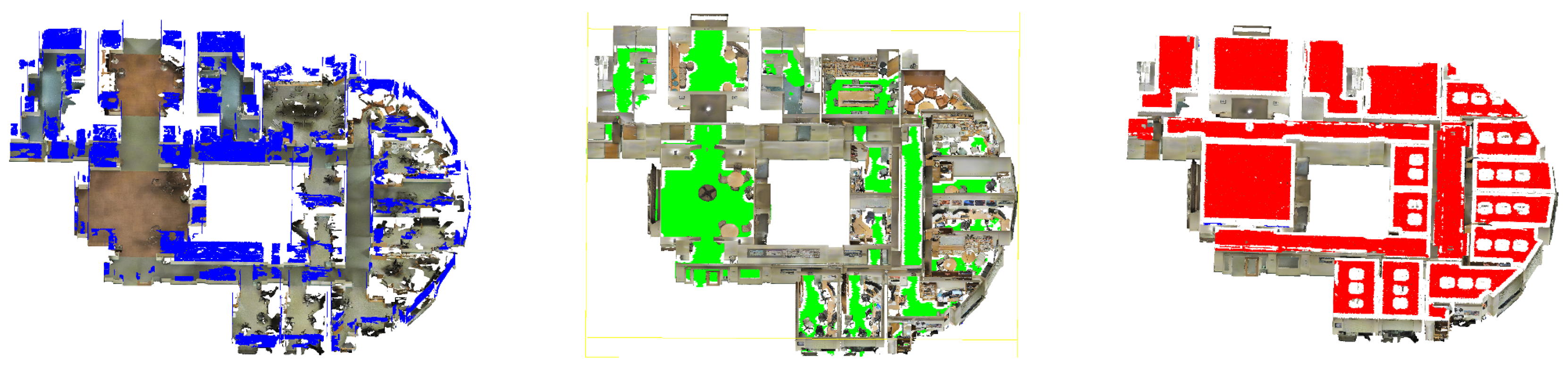
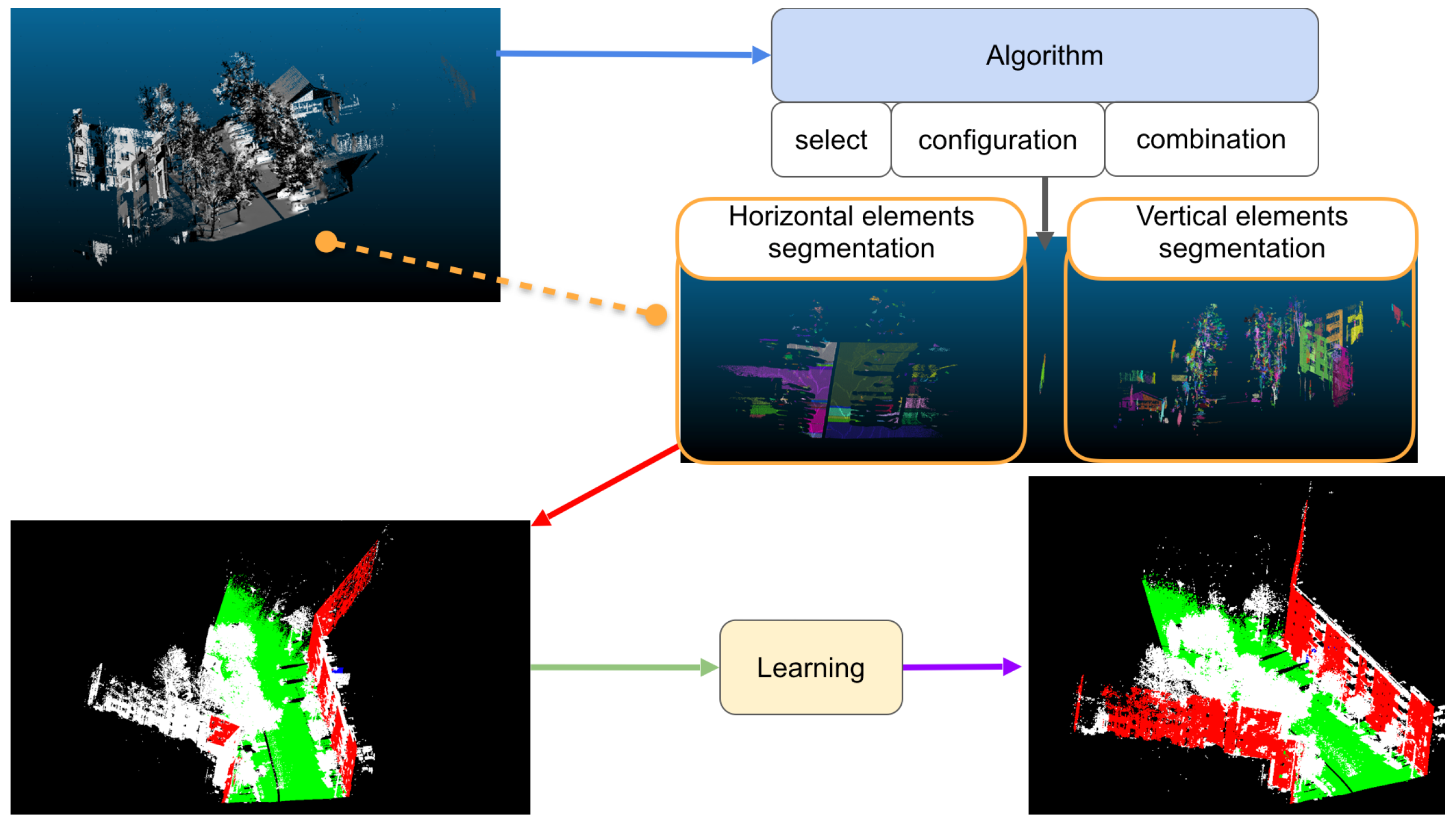
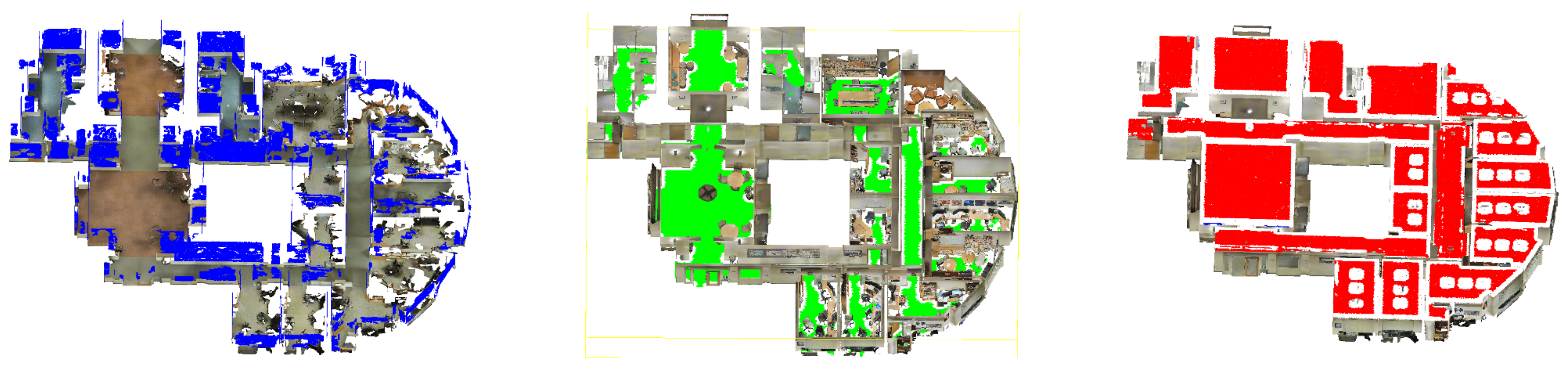
Figure 9 shows an overview of a facade detection process in an urban point cloud.
Data processing is performed using algorithms (illustrated by the blue arrow in
Figure 9). These algorithms must be selected, configured and combined (shown under the blue box in
Figure 9) according to the application case (e.g., acquisition context, objects sought) and the prerequisites of each algorithm (e.g., low noise, high density, estimated normal).
Let us take the example of a facade defined as a planar surface perpendicular to the ground with a height of at least 12 m. The detection of this facade requires algorithms for plane detection, size estimation and topological link assessment (e.g., parallel, perpendicular). These algorithms may have prerequisites such as normal estimation or whether the data is small in size or not noisy. Thus other algorithms such as normal estimation, denoising and, sampling algorithms must be combined in a sequence to satisfy the needs of some selected algorithms in some cases.
The results provided by each executed algorithm are analyzed and correlated with each other (shown by orange frames in
Figure 9) to identify objects and geometries in the data (shown by the red arrow in
Figure 9). In this case, the analysis and correlation of algorithm results allow identifying ground (in green) and some facades (in red). The management of algorithms and the interpretation of results are entirely driven by reasoning. This reasoning is based on the knowledge presented in
Section 2.2.
However, it is not possible to formulate the knowledge in such a way as to describe all possible cases. In the case illustrated in
Figure 9, parts of the facades are not detected because the information on these parts (height less than 12 m, not connected to the ground) differs from the knowledge of the facades (height greater than 12 m and perpendicular to the ground). The discrepancy between the information collected and the knowledge at the preliminary stage may be due to multiple factors (e.g., sensitivity of the acquisition instrument, acquisition condition, insufficient light, objects too far away). Consequently, the knowledge needs to be adjusted according to the application case and the information computed.
Knowledge adaptation requires understanding how objects are represented in the data to anticipate possible variations and to compensate for the discrepancy between the information obtained and the knowledge. Understanding the representation of objects and geometries (“learning” frame in
Figure 9), requires analyzing the objects and geometry detected to formulate hypotheses on the characteristics, allowing them to be better identified.
In the case presented by
Figure 9, the analysis of the detected facades allows the inference that facades can have a height between 10 and 13 m and that they may not be connected to the ground, which has discontinuities (areas without ground). This new knowledge is integrated into prior knowledge and allows the behavior of the detection process to be changed. The detection strategy becomes specialized for the application case, which leads to better results (shown by the purple arrow in
Figure 9).
2.3.1. Algorithm Management
The management of algorithms is carried out through reasoning on global knowledge as explained in Reference [
45].
This reasoning aims firstly at automatically selecting the algorithms the most adapted to the processed use case. Next, it configures the selected algorithms according to the description of data and objects corresponding to the use case. Finally, it executes configured algorithms and retrieves their result to integrate them into the knowledge base.
The selection of the most adapted algorithms is applied through three steps. The first step consists of selecting algorithms that allow the detection of either objects or characteristics of objects present in the processed data and modeled into the knowledge base. The second step is to add algorithms which capable of working on the processed data to the previous selection. In the third step, algorithms producing data or characteristics that satisfy prerequisites of the previously selected algorithm are added to the set of selected algorithms,. The set of selected algorithms resulting from these three steps is analyzed to filter only algorithms whose prerequisites are satisfied. This set of selected algorithms with prerequisites satisfied is then configurated and executed. The configuration of each algorithm is done by first setting its inputs, then adjusting its parameters.
Data is assigned as an input of an algorithm if and only if it has all the characteristics defined as a prerequisite by the algorithm. For example, a color segmentation algorithm requires that the data be colored, so only data with the characteristic of being “colored” will be assigned as input to the algorithm.
The parameters of the algorithms determine their behavior. The parameter values of each algorithm are calculated using equations defined in the semantic description of the algorithm. These equations match characteristics of the objects or geometries for which algorithms are preferable with the characteristics of the data that the algorithms take as input. Thus the parameter values of each algorithm are adapted to the data and the objects or geometries sought.
Then the configured algorithms are executed through the SPARQL function call. Semantic values (e.g., xsd:string, xsd:double, xsd:int) are converted to algorithmic values (e.g., string, double, int) and the algorithm is instantiated, configured and executed dynamically. The results of the algorithms are then converted into the semantic paradigm and incorporated into existing knowledge.
For example, an estimated normals segmentation algorithm produces as knowledge segments whose orientation is homogeneous. The homogeneity threshold of the segments is defined according to the parameters of the algorithm. It is thus adapted to the characteristics of the data (e.g., density, resolution) and the characteristics of the objects (e.g., volume, size, roughness).
2.3.2. Classification
The result of executed algorithms provides further information about the data and its content that support the detection of objects and geometries. Their adding to the knowledge base enriches it, allowing further reasoning and information deduction to pursue the detection process.
The semantic descriptions of objects allow for identifying the class of a segment. The reasoning compares the segment characteristics to each object description (characteristics, geometry and scene) to identify the object descriptions that correspond to the segment characteristics.
The classification process uses the characteristics and geometries of the object description first. The description of characteristics and geometries of an object is translated into a logical rule, used to classify segments.
Let us pursue the example of the class called “Table.” This table class is composed of a horizontal plane. It also has characteristics, which are an area greater than 0.5 m and a height between 30 m and 70 m. The following description in Listing 1 corresponds to the “Table” definition in the Manchester syntax:
2 (Object or SegmentsSet)
3 and (isComposedOf exactly 1
4 (Plane and (hasOrientation only Horizontal))
5 and (hasArea exactly 1 xsd:double [> 0.5])
6 and (hasHeight exactly 1 xsd:double [> 30, < 70]))
Listing 1: Example of Table modeling in the Manchester syntax.
The following logical rule is the translation result of the above “Table” description:
All segments satisfying the rule above are identified as a table. However, although the geometries and characteristics of object description can be adapted to different contexts (as explained in
Section 2.2.2), they are not always sufficient to detect objects as shown by the use case of
Figure 6.
Indeed, in this use case, the glass material of the table produces a representation with a low density of points inside the data. During the detection process, this low density produces an over-segmentation of tables. It means a table is represented by several segments, rather than a single segment. Thus, during the step of classification by geometry and characteristics, such over-segmentation of tables leads to only two segments representing a part of a table satisfying the Equation (
3). Therefore, only two segments are classified as a table (on a total of eight tables) and these segments do not adequately represent a table. This use case shows that the detection of an object represented by a low density of points in the data and whose detection process only takes into account its geometry and characteristics obtains a low and inaccurate result of the detection. That is why this methodology also uses topological relationships to improve the classification.
The topology-based classification uses the topological relationship between segments to classify them. Similar to the previous classification, the topological descriptions of objects are translated into a logical rule. Thus a segment is classified into an object class if and only if the segment satisfies all the topological relationships of a given object class. Let us pursue the example of the topological relationship of a “Table.” The definition of the “surround” property results in the creation of the logic rule shown by the Equation (
4).
Thanks to the identification of segments that are surrounded by chairs, the process can create segment sets composed of segments that have some characteristics of a table (e.g., horizontal plane, height between 30 cm and 70 cm, surrounded by the same chair set). Then sets that satisfy the Equation (
3) are classified as a table.
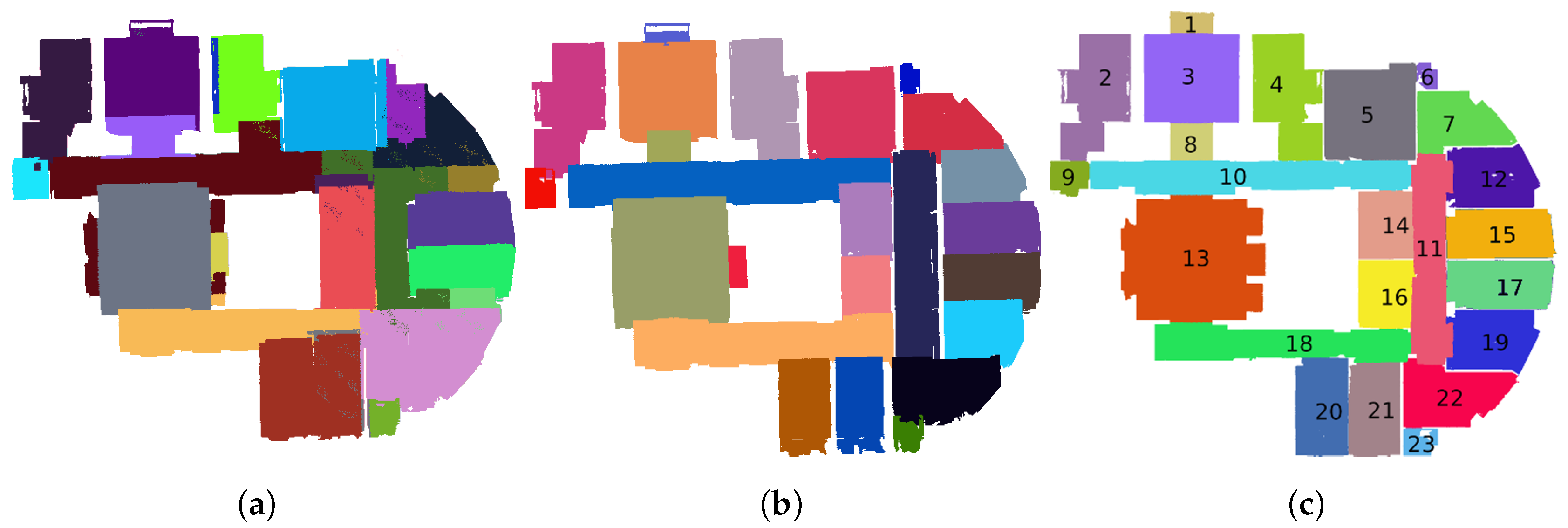
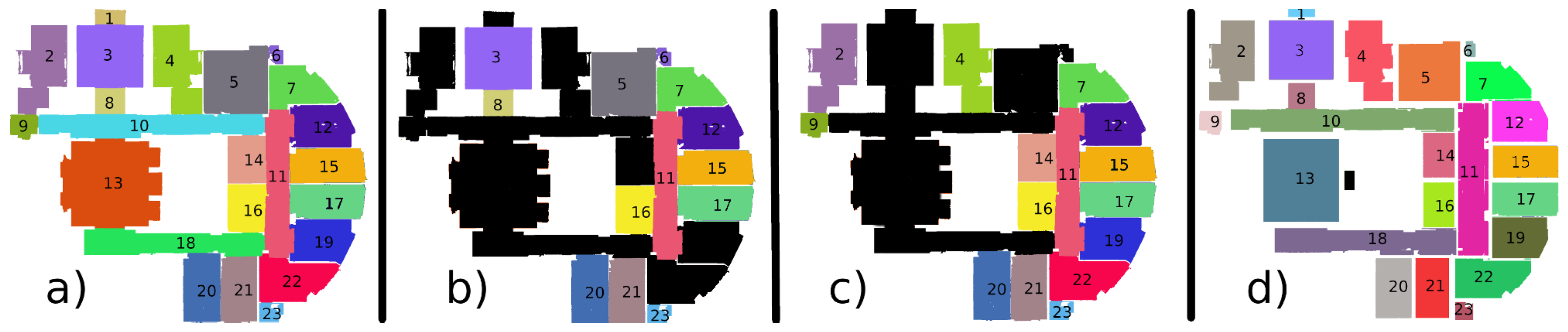
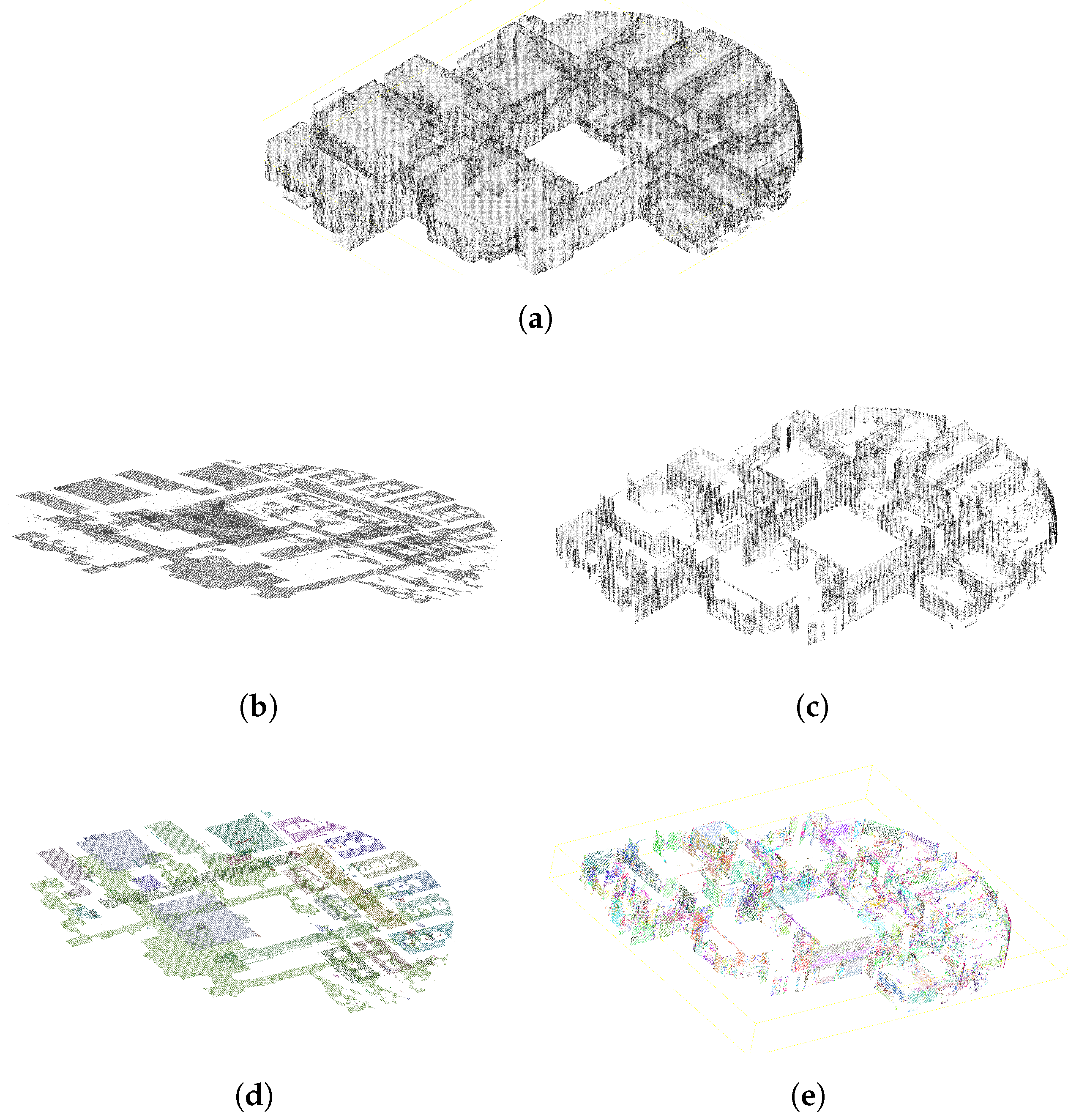
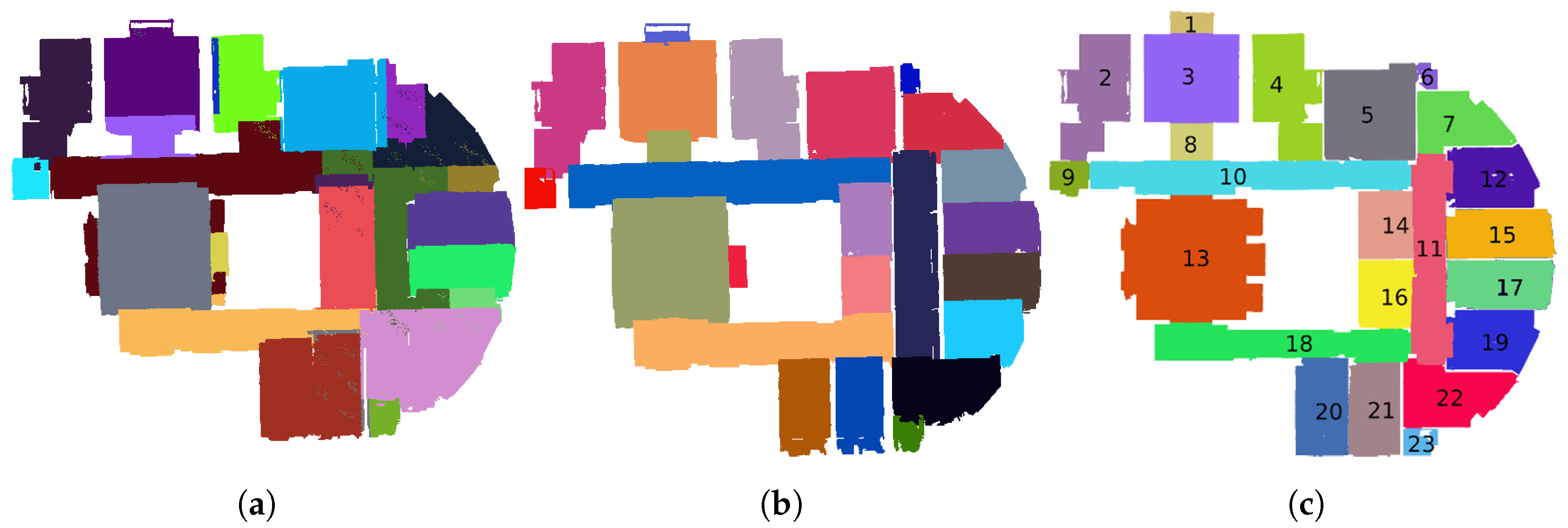
Figure 10 shows steps to detect tables thanks to the topological relationship between a table and chairs. First the process detects chairs. The result of the chair detection is shown in
Figure 10a. Secondly, an algorithm creates an energy minimalization graph gathering chairs into sets, as illustrated in
Figure 10b. Finally, the detection process searches segments that overlap the chair graphs to classify these segments as tables. The result of this classification is presented in
Figure 10c.
This application case shows the role of topological links in locating objects when the acquisition conditions are not optimal. Moreover, it also illustrates that the study of the topological relationships allows for identifying objects that are composed of several objects.
Let us take another example in a completely different use case to illustrate the role of topological relationship in the management of occlusions due to the acquisition process.
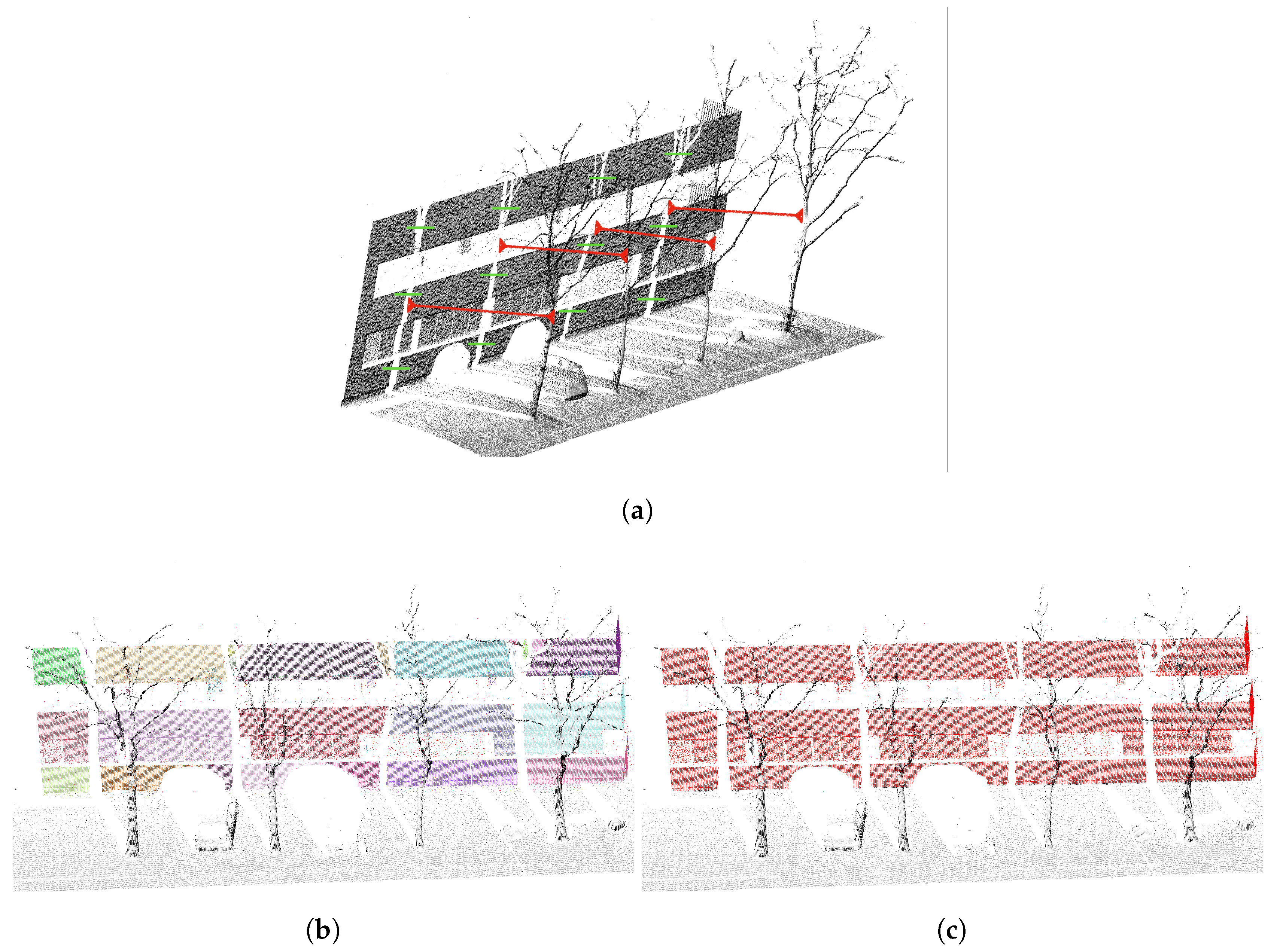
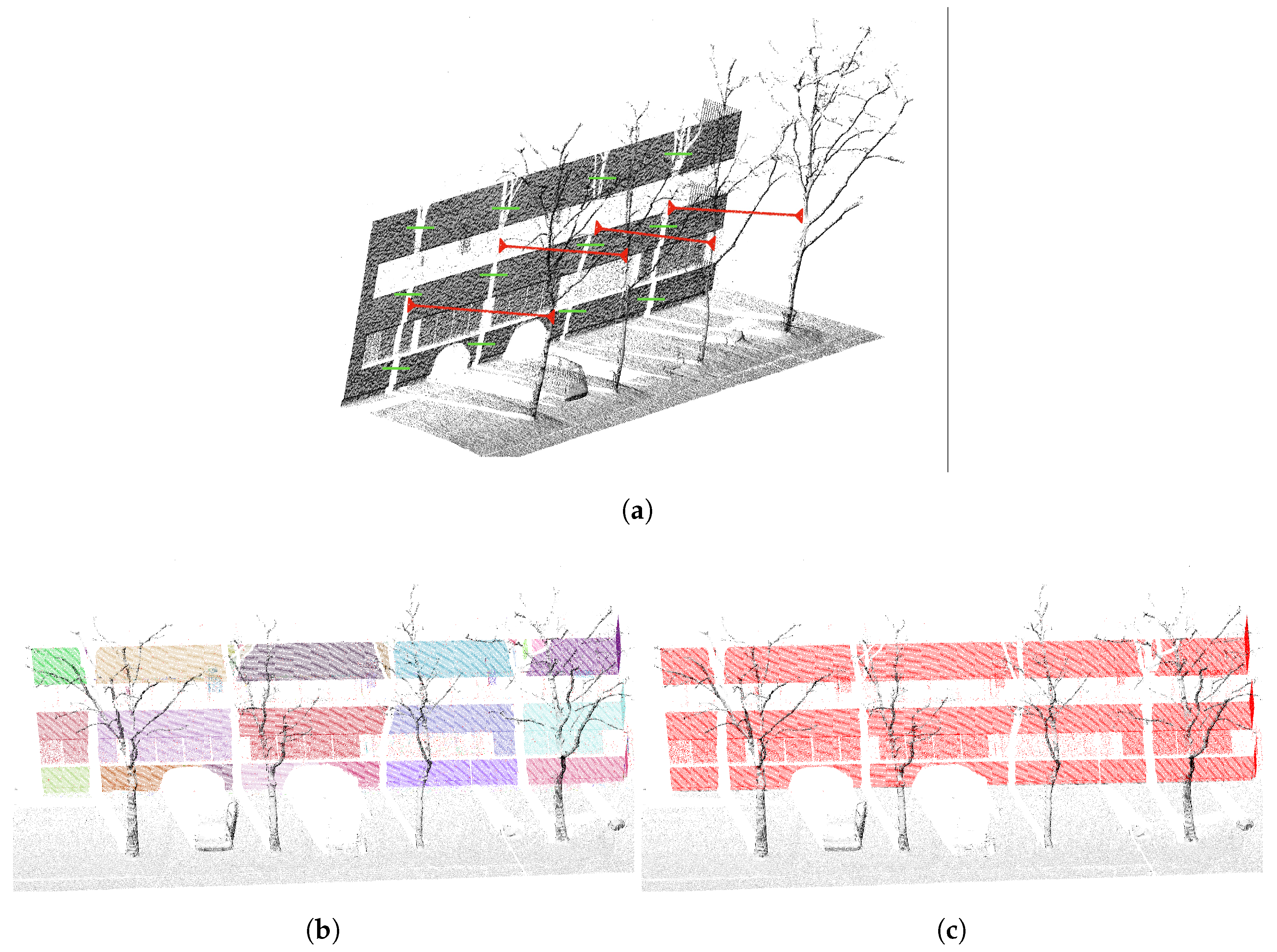
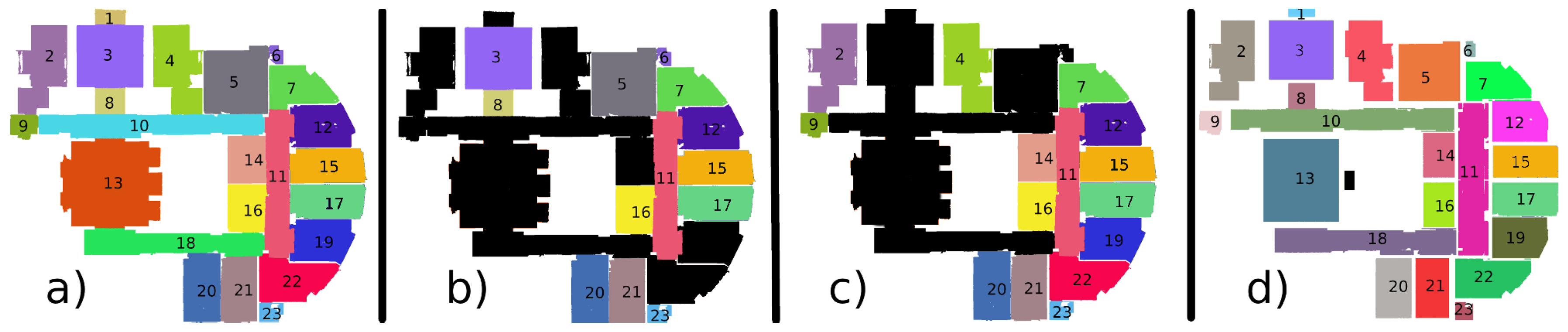
Figure 11a shows a use case of wall detection, where occlusions during the acquisition process lead to dividing the same wall into several segments, identified as independent walls by the first steps of the detection process (as shown in
Figure 11b).
In this use case, the occlusions are generated by trees. Thanks to knowledge about the acquisition process and the detection of trees, the system is able to predict the presence of occlusions (illustrated in red in
Figure 11a). The information about occlusions is inferred into the knowledge base, by creating a topological “occlusion” relationship (illustrated in green in
Figure 11a) between elements separated by an occlusion. Thus by specifying in the knowledge base that two walls having the same geometry and having a relationship of connection or occlusion are a single wall, it allows the gathering of several walls into a single wall (as shown in
Figure 11c).
Despite the definition and classification according to geometries, characteristics and topologies of objects, some objects still not detected due to, on the one hand, a difference between the representation inside the data and the semantic description of the object and on the other hand, insufficient description of topological relationships. That is why this methodology is also composed of a self-learning step based on knowledge.
2.3.3. Self-Knowledge-Based Learning
Self-knowledge-based learning aims at improving the detection process through new knowledge generation or compensation of any deviation between the semantic description of an object and its representation inside the data. This learning uses the experience gained from the first detection process to generate or adapt to global knowledge. This experience corresponds to new knowledge coming from the study of the results obtained in each application case. This new knowledge specific to each application case provides information to guide the detection process more precisely than the general knowledge previously used. This knowledge that is more adapted to the application case improves the detection process by selecting and configuring more adapted algorithms and by refining the classification through object definitions more specific to the processed use case.
The inference of new knowledge (e.g., new relationships between objects) or the updating of knowledge (e.g., modification of object geometries) requires the understanding of the structure of the data. The analysis of classification results and information extracted by algorithms must be smart in order to improve the knowledge base efficiently, and thus the detection process, and not regress them.
That is why this methodology uses a self-knowledge-based learning system that consists of three steps. The first step consists of enriching the knowledge base with new information about the detected objects. The second step analyzes information common to the same class to formulate new hypotheses on the data structure. The third step checks the consistency of the hypothesis on the processed use case, either to integrate the validated hypotheses in the form of knowledge or to reformulate the invalidated hypotheses.
2.3.3.1. Step 1: Knowledge Enrichment
The enrichment of knowledge aims at identifying new geometries, characteristics of objects and topological relationships between objects to add them to the knowledge base as specific knowledge about the use case. This enrichment requires a diversity of algorithms to identify topological relationships, extract characteristics and geometries. Thus the more algorithms there are and the more diverse capacities algorithms provide, the more the knowledge base can be enriched. The enrichment comes through generation of queries that request algorithm execution to add segment characteristics, which are not yet present in their semantic description. Let us continue to the example of table detection (cf.
Figure 6). The application of the methodology without learning step results in the detection of seven tables among eight.
Figure 12 highlights the undetected table in an orange rectangle.
Tables have been identified (in blue in
Figure 12) thanks to their topological relationship with chairs. The undetected table (encompassed in orange in
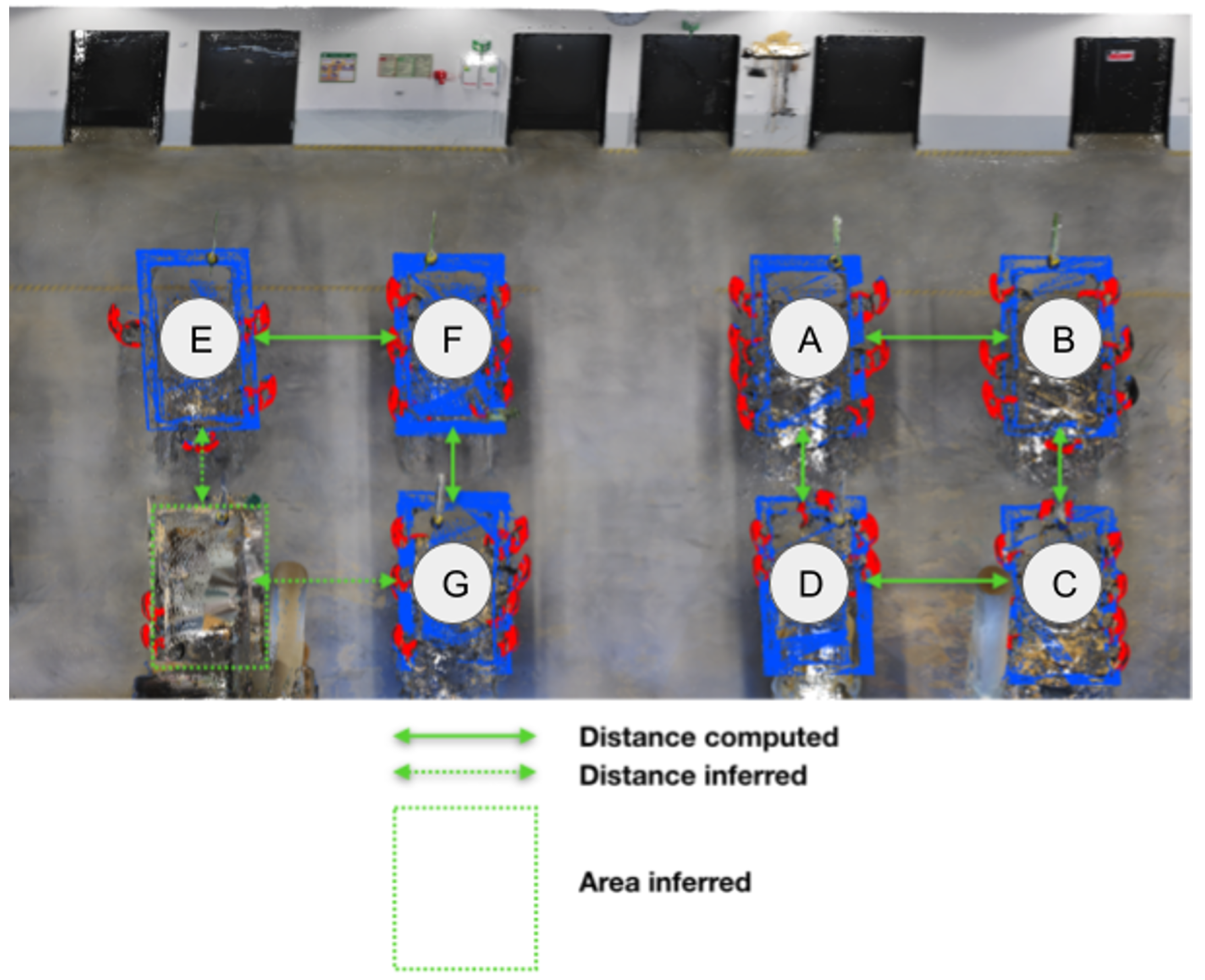
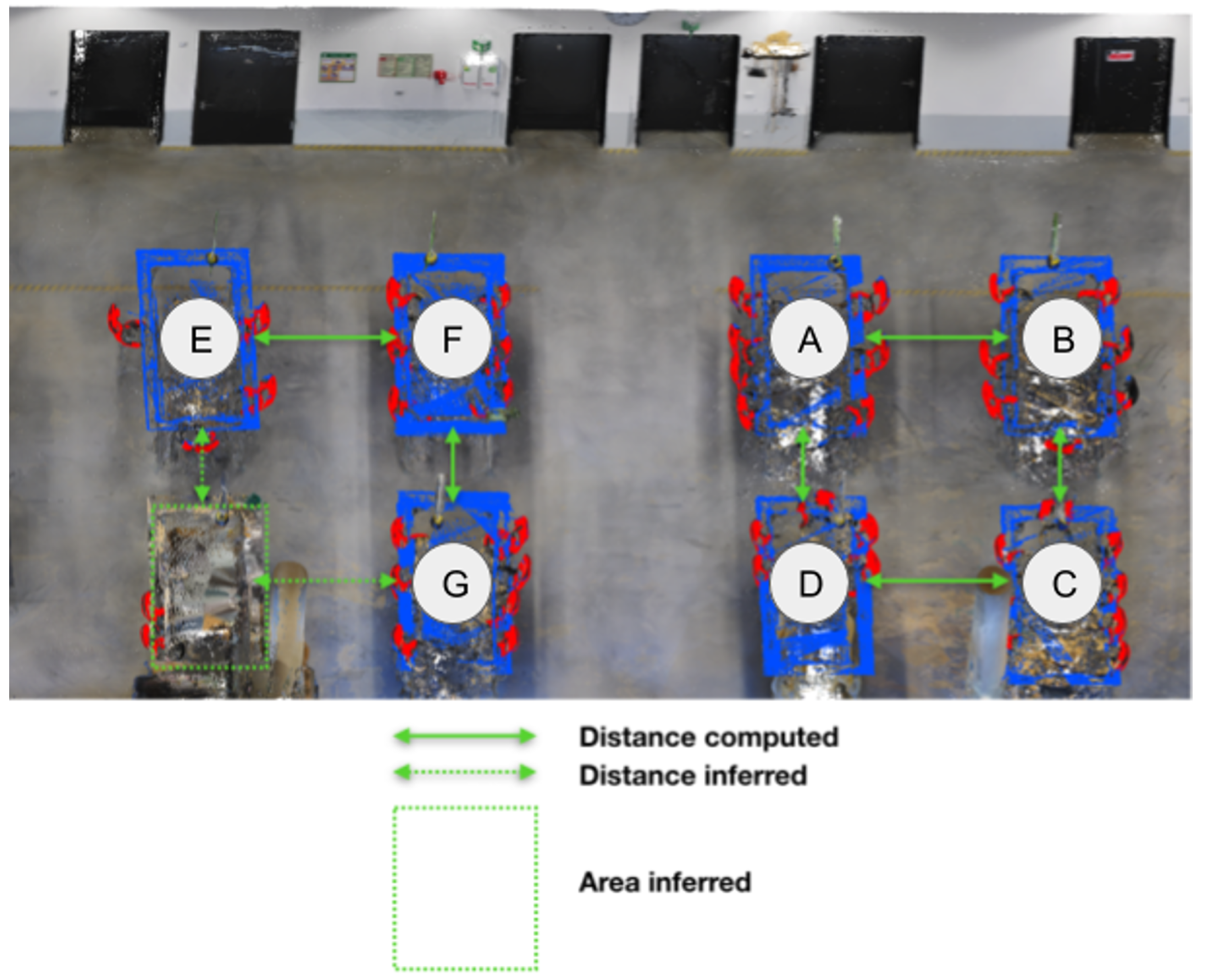
Figure 12) is not surrounded by enough chairs to detect it through its relationship with chairs. Despite this topological relationship between table and chairs, there is no topological relationship described between tables. Therefore, the enrichment of knowledge searches to identify further information characterizing the relations between tables. Thus executed algorithms allow for computed distances between each table and their relationship (e.g., aligned, parallel) from each other but also their dimension (e.g., width, height, length). Then this information of distance and position between tables is added to the knowledge base to be analyzed.
2.3.3.2. Step 2: Hypothesis Formulation
The analysis of characteristics common to segments representing the same object type (e.g., segments or sets of segments representing tables) aims at formulating hypotheses automatically. This formulation of hypothesis identifies and gathers the common points characterizing segments of the same object type and does so for each object type.
Let us take the previous example illustrated by
Figure 12. In this use case, tables are aligned with another table (relation according to orientation north-south in
Figure 13, for example, A is aligned with D) and parallel to other tables (relation according to orientation west-east in
Figure 13, for example, A is parallel to B).
The characteristics estimated from the previous step aims at grouping objects with the same characteristics into subsets of an object type (e.g., “tables aligned with a table,” “tables parallel to a table”). Grouping similar elements into a subset is applied through an aggregation rule using the characteristics that characterize the subset. This rule identifies elements having the characteristics to belong to the subset. Characteristics are divided between numerical (e.g., distance, height) and non-numerical (e.g., parallel, aligned) characteristics. The aggregation rule of groups based on non-numerical characteristics uses a relationship property corresponding to the characteristic.
In the previous example, let us call the group based on the alignment criterion “AlignedWithTable.” The following aggregation rule creates this group:
This rule gathers all segments having a relationship “aligned with” to an object identified as a table, into this group. Similarly, the following aggregation rule (
6) gathers elements parallel to a table into the group called “ParallelToTable.”
The aggregation rules of groups based on numerical characteristics use an interval of values. The value interval aims at providing more flexibility than an average value to assess the integration of an element according to its characteristic value. This value interval is computed through a statistical study of all values representing the characteristic, whose interval is searched. Each studied characteristic does not characterize all elements representing an object type but only a subset of an object type. Likewise, each value interval representing a studied characteristic characterizes only a subset of an object type. That is why it is calculated according to a confidence interval [
46] from a set of value samples. Thus, the interval gives a confidence level. This level corresponds to the percentage of the proportion that the sample represents according to the complete set (e.g., 99%, 75%). The Equation (
7) defines the confidence interval with
the values mean,
the standard deviation,
the number of values and
the confidence coefficient.
Let us pursue the previous example on the proximity criterion between the nearest parallel tables. The group gathered according to this criterion is called “NearParallelTable” and is characterized by a value interval representing the shortest distance between two parallel tables. Thus the shortest distances between parallel tables provide a set of values used to calculate the confidence interval. In this example, the calculated confidence interval is [1.45;1.89]. It means that a segment belongs to this group if it has a distance value with a segment identified as a parallel table between 1.45 m and 1.89 m. Similarly, the height, width and length of tables and the shortest distance between aligned tables are each used as a criterion to apply the same process and create groups of “TableHeight,” “TableWidth,” “TableLength,” “NearAllignedTable,” respectively. These groups are used to formulate a hypothesis on characteristics relevant to characterize the object type in the sense that it improves the detection of objects belonging to this type. Thus all segments belonging to all groups used in the hypothesis are classified as belonging to the object type targeted by the hypothesis. Let us pursue the example of table detection by considering the hypothesis that a table is a segment that belongs to “NearParallelTable,” “NearAllignedTable” “ParallelToTable” and “AlignedWithTable” groups. A logical rule represents the hypothesis. The hypothesis rule corresponding to this example combines four groups and is described by the Equation (
8).
The combination of groups to formulate a hypothesis allows for formulating some complex hypotheses. The more groups are used in a hypothesis; the more specialized the hypothesis is. A too-specific hypothesis has the risk of not finding other segments classified other than the beginning set. Conversely, a too-general hypothesis would not use enough groups to characterize an object type and would be invalidated by creating inconsistency according to the first classification. That is why the improvement of identification requires formulating hypotheses according to a hierarchical order. The hierarchical order consists in the beginning of the formulation of general hypotheses using a single group. Then it consists of adding another group to specify further the hypothesis that was invalid because it was too general.
2.3.3.3. Step 3: Hypothesis Verification
This approach of object detection is driven by knowledge. Thus, the new knowledge produced by the formulation of hypotheses impacts the behavior of the detection process for each considered use case. An impact can be positive by improving the detection process or negative by regressing its quality in the case of an incorrect hypothesis. That is why the hypotheses must be verified to warrant the improvement of the detection process or at least be of equivalent quality.
Such verification requires the measuring of the consequences of the knowledge change or adding on the object detection results. The measurement of consequences is performed by comparing results obtained before and after the integration of the hypothetical knowledge.
A hypothesis is validated if and only if the results obtained after the integration of the hypothetical knowledge do not cause any inconsistency with previously obtained results. Knowledge modeled through constraints and logical rules, and checking the hypothesis validation, is equivalent to checking the consistency of the knowledge base (as explained in the approach in Reference [
47]).
Let us continue with the example used in the
Section 2.3.3.2 and illustrated in
Figure 13. In this example, several groups as “ParallelToTable,” “NearParallelTable” and “TableHeight” are used for hypothesis formulation. By considering the first hypothesis using only “ParallelToTable” and the second hypothesis using “ParallelToTable” combined with “NearParallelTable,” some segments previously classified as a chair are classified as a table after these two hypotheses. As each object type is defined as disjointed from other object types that are not a specification of this type, a segment classified both as a chair and as a table creates an inconsistency inside the knowledge base. Therefore, results obtained by an invalidated hypothesis are removed and a new hypothesis is reformulated.
By following the principle of the group adding to reformulate a more specific hypothesis until finding a consistent result of hypothesis or no more possible hypotheses (cf.
Section 2.3.3.2), the third hypothesis formulated adds the group “TableHeight” to the two previous ones. In this example, the reformulated assumption using the three groups of characteristics allows for the identification of segments belonging to the eighth table that was not previously detected (surrounded in orange in
Figure 12) without inconsistency. The learning process based on the adding of new knowledge specific to the processed use case allows for improving the robustness and the quality of the object detection process, as shown by the result of table detection after learning in
Figure 14.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}