Abstract
Information on the distribution and dynamics of dwellings and their inhabitants is essential to support decision-making in various fields such as energy provision, land use planning, risk assessment and disaster management. However, as various different of approaches to estimate the current distribution of population and dwellings exists, further evidence on past dynamics is needed for a better understanding of urban processes. This article therefore addresses the question of whether and how accurately historical distributions of dwellings and inhabitants can be reconstructed with commonly available geodata from national mapping and cadastral agencies. For this purpose, an approach for the automatic derivation of such information is presented. The data basis is constituted by a current digital landscape model and a 3D building model combined with historical land use information automatically extracted from historical topographic maps. For this purpose, methods of image processing, machine learning, change detection and dasymetric mapping are applied. The results for a study area in Germany show that it is possible to automatically derive decadal historical patterns of population and dwellings from 1950 to 2011 at the level of a 100 m grid with slight underestimations and acceptable standard deviations. By a differentiated analysis we were able to quantify the errors for different urban structure types.
1. Introduction
The spatial distribution of dwelling units and population is highly relevant for addressing general questions of resource management and spatial planning [1,2,3]. Currently, high-resolution population distributions are especially gaining importance for risk assessment and disaster management with regard to technical or natural hazards [4]. Also for research on energy consumption and demand modelling, detailed information on building stocks and inhabitants are becoming important [5,6]. Beyond the demand for current spatial distributions, also those of the past are of relevance. As these allow information on the dynamics to be obtained, pathways open for analysing long term changes in land use and settlement structures retrospectively [7]. This information is of interest to analyse causes and trajectories of land use policies but also to model the distribution of building ages within the current urban fabrics [8]. Crols et al. [3] also highlight the relevance of deducing historical information for validating urban dynamic models, such as in the field of urban and regional economics [9].
Given these needs for historical geographic information, constraints arise when it comes to data sources. For most countries, national census data provide figures on population and housing with full coverage and homogeneity in equal temporal intervals. However, the main drawbacks of these data are the low spatial resolution and the rather long (usually decadal) update cycles. Furthermore, demographic and socio-economic statistical data are often aggregated on large spatial units for example, at the ward, municipal, or state level according to privacy or administrative concerns [10]. A further challenge, particularly in multi-temporal analysis, is the limited comparability over time due to changing administrative units [3]. Whereas on a local level, some major cities own a wide range of socio-economic data at the city block level, the data are very heterogeneous with respect to the data structure and quality. Also, these data are often not available in smaller towns and rural settlements, leaving only an incomplete spatial coverage. Hence, in many countries, official data remain limited, which prevents a fine-grained analysis of settlement development.
To overcome these limitations, research groups in remote sensing and cartography/GIScience have been working on the development of methods for mapping populations for years [11]. Thus, techniques of dasymetric mapping (sometimes disaggregation) were established, which allow census data to be transformed to “finer map units” by means of ancillary data. Eicher and Brewer [12] and Maantay, Morocco and Herrmann [13] give a good overview of different dasymetric methods, allowing for a disaggregation through methods such as areal weighted transformation. Further, ancillary land-use or land-cover data are used to link population to effectively occupied areas [14,15]. This land use information is derived through multispectral satellite imagery [12,14,16,17,18]. In the work of Gallego et al. [19] a 100 m population density grid for Europe has been estimated using CORINE Land Cover data. Even higher resolution at the urban block, plot or even building level is obtained using cadastral data [13] and digital topographic maps at a scale of 1:50,000 [20] or 1:25,000 [21]. Zoraghein & Leyk [22] deal with various interpolation methods for a refined dasymetric mapping in order to generate temporally consistent population compositions.
Digital building footprint data play a special role in the endeavour to further develop these modelling approaches, as residential population strongly relates to the function, the size and the height of buildings [23]. They obtained best results using a volumetric method instead of an areametric method which considers the number of building floors. Ural, Hussain and Shan [24] later modified the approach by introducing a weighting scheme for different housing types such as “houses” and “apartments.” Meinel, Hecht and Herold [21] differentiate between eight residential building types and apply empirically determined average dwelling and population densities but also non-residential uses within buildings are integrated to provide for more accurate estimations [23,25,26]. Such models also open a way for multi-temporal estimations of populations as information on buildings and functions allows respective changes in population distributions to be estimated during the day and night time [27,28] or different seasons due to tourism [29]. Analyses of long-term dynamics in populations mostly rely on remote sensing data [30]. However, for the United States address point locations and address information from the private Zillow Transaction and Assessment Database (ZTRAX) have recently been used for characterizing settlement activities at a very fine spatial and temporal resolution [31]. On this basis, it was possible to generate settlement layers for the United States over 200 years with a spatial resolution of 250 m.
In this paper, urban morphologies, which are derived from topographic data and historical maps, are a starting point to further develop the long-term applicability of building-based models. Herold [32] proposes an approach to automatically extract building information from historical maps. As topographic maps were periodically compiled, dynamics in urban morphologies can be derived. Hence, combining this approach of map extraction with information on buildings offers a promising way to generate large-scale population and dwelling estimations for long time periods. We thereby increase the spatial and temporal extent of building-based methodologies for dasymetric mapping. Here, we thus aim at the following research questions: How can historical data and dynamics on the population and the number of dwellings be derived by analysing multi-temporal urban morphologies through the combined processing of geographic vector data, statistical data and historical topographic raster maps? What accuracies can be achieved with automatic derivation?
To answer these questions, we first present a methodological framework (Section 2) for the automated derivation of this information, based solely on conventional data available in European and other developed countries. We then present the study area and the data used to test our approach (Section 3). The estimation results will be presented in Section 4 and critically discussed in Section 5 with particular focus on possible sources of error. The article ends with a conclusion (Section 6).
2. Methodological Framework
This section describes the proposed framework for mapping the dynamics of population and dwellings by means of a spatiotemporal analysis of the urban morphology. Data sources and methods as well as the associated processing steps will be presented in detail.
2.1. Data Sources
This study proposes a methodology which makes use of topographic data and maps to derive the urban morphology. These data are used in order to estimate the historical distribution of dwellings and inhabitants. First, the question of appropriate data sources needs to be clarified. For the description of the current built environment (urban morphology), several data sources can be used but differ in spatial resolution, data quality, data availability and data costs. A very popular data source in earth observation of fast-growing cities is remote sensing data such as aerial imagery, very high-resolution (VHR) satellite imagery or airborne light detection and ranging (LiDAR) data. Nowadays, digital spatial vector data products and services from National Mapping and Cadastral Agencies (NMCAs) offer a variety of products (e.g., cadastral data, digital landscape models, 3D city models, topographic maps) that describe the urban morphology at a very detailed level. Furthermore, volunteered geographic information (VGI) platforms, such as OpenStreetMap, have recently become increasingly important for urban morphology analysis.
In our approach, we have decided to use official spatial data from NMCAs for the following reasons. NMCAs offer nationwide well-structured spatial vector data where relevant objects such as buildings, roads and land use information are explicitly modelled. In remote sensing data, these objects are depicted implicitly (in different data scenes with varying acquisition conditions) and additional resources for image interpretation are necessary to extract the relevant objects and structure them explicitly in a database. A further disadvantage of remote sensing data is significantly higher data costs particularly for large areas under investigation. OpenStreetMap is a good option for cities but data quality is currently not sufficient for analysing the urban morphology for larger regions due to incomplete building footprints in rural areas [33].
The workflow of our approach requires the following spatial data:
- Topographic raster maps (historical data): The maps should be at a scale of 1: 25,000 or larger and should contain the building footprints cartographically represented as solid, hatched or coloured areal symbols.
- Land use data (current data): A polygon data set for the seamless description of land use at the urban block level. This data set can usually be derived from digital landscape models from NMCAs at a scale of 1:10,000 to 1:25,000.
- Building model (current data): 2D building footprints or 3D building model in Level of Detail 1 (LoD1).
Furthermore, official statistical data on the number of inhabitants, the number of dwellings and the average household size at the municipal level are required to generate the parameters for the modelling. An additional building sample is required to obtain locally valid building type-specific assumptions on the story height (in m) and the dwelling unit size (in m2). For this purpose, the number of stories, the number of dwelling units as well as the building type are collected. If no local sample data are available, standard parameters from the urban planning literature can also be used.
2.2. General Workflow
The workflow and processing steps of our methodology are depicted in Figure 1. The individual steps are described in more detail in the next subsections. Required input data are a digital landscape model and a building model of the current time (t0) as well as topographic maps of n historical time points (t-1, …, t-n) for which the spatial population and dwelling distribution is estimated.
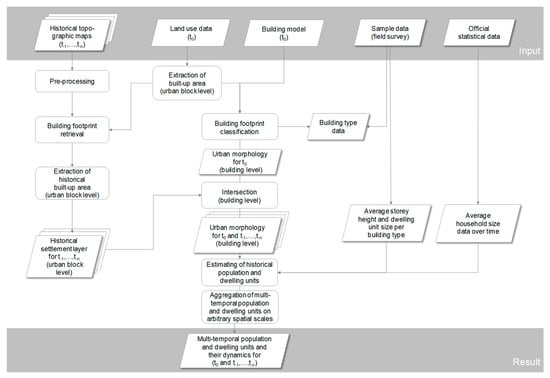
Figure 1.
Methodological framework and processing steps.
2.3. Pre-Processing of the Topographic Maps
The pre-processing consists of the following steps: (a) scanning of analogue topographic maps for digital processing, (b) geo-referencing of the digital raster maps, (c) transformation, (d) extraction of the black layer through binarization and finally (e) mosaicking of the images.
In the first scanning process (a) the analogue map is converted into a digital image. Here, a scan density of 508 dpi (50 μm spacing) is used. This value has been proven to be sufficient for the automatic interpretation of digitized topographic maps [34,35]. After the topographic maps are scanned and georeferenced at a scale of 1:25,000, a pixel corresponds to an area of 1.25 by 1.25 m in nature.
With regard to the automated building extraction, not only the spatial but also the spectral resolution is crucial. The scanned colour maps are stored as 24-bit RGB colour images. In the following, the georeferencing process (b) assigns real-world coordinates to each pixel of the scanned raster map. Usually this is done manually by means of Ground Control Points (GCPs). Herold et al. [36] have introduced a procedure for an automatic georeferencing of topographic maps for the operational acquisition of spatiotemporal data on urban growth. This procedure can be part of the whole workflow, especially if a large number of map sheets need to be processed. Subsequently, all maps were harmonized in a geodetic transformation process (c). As a common reference system we used the projected Cartesian coordinate system DHDN/3 degrees Gauss-Krueger zone 3 (EPSG code 31467). In the binarization process (d) the black layer is extracted from the raster images, where all map elements shown in black are represented in a binary raster (1: black, 0: rest). Here we applied an unsupervised classification approach (Iso Cluster Unsupervised Classification with 12 classes). The classes reflect–according to the map key–the various color-coded map objects such as black objects (e.g., buildings, street outlines), green objects (e.g., vegetation), blue objects (e.g., water bodies) and so on. In preparation for the building footprint retrieval, the individual raster maps were then merged into one raster file for each time step. After this mosaicking step (e), a raster data set was available for each of the years 1950, 1960, 1970, 1980, 1990 and 2000.
2.4. Building Footprint Retrieval
The raster data sets contain the required map information in implicit form. That is, in order to make use of the historical information such as building footprints, the data need to be transformed. The transformation is achieved by employing a region-oriented segmentation approach. Region-oriented segmentation is defined as the spatial partitioning of an image into sets of regions that meet a defined homogeneity criterion. For the data set at hand, we used the object morphologies as homogeneity criteria. To address the shape (and size) of the image objects, methods of mathematical morphology are applied. The basic morphological operators which are used in this work can be conceptualized as non-linear image filters [32]. The most important filters are, according to [37], opening and closing, which are sequences of the basic operators erosion and dilation. In order to separate compact objects (building footprints) from linear and less compact objects (such as street lines), we employed a sequence of these morphological operations with the following parameters: a circle and an opening radius of 3 pixels (3.75 m in nature) are used as a structuring element (SE). The size of the SE depends on the resolution and needs to be adjusted according to the map image resolution (here 508 dpi). The SE depends further on the quality of the map scan and the segmentation process. Hence, the size of the SE cannot be determined solely deductively. The optimal SE size needs to be empirically adapted for other map scales, resolutions and scan qualities. In a second step, all other information with similar morphological characteristics as buildings, such as certain letters or map symbols, need to be detected and removed from the building data by means of an appropriate pattern recognition algorithm, which should be designed to be adaptable to the map layout. An adaptable pattern recognition approach for the maps at a scale of 1:25,000 used herein is described in Meinel et al. [21]. Subsequently, the built-up area from the current land use data set is used to mask the settlement area as a region-of-interest (ROI). The result is the extracted building layer (Figure 2). This procedure reduces both the computational load and the misclassification of non-building objects (false positives). A detailed and more generalized description of this complete auxiliary process of building footprint retrieval from maps can be found in References [21,32].
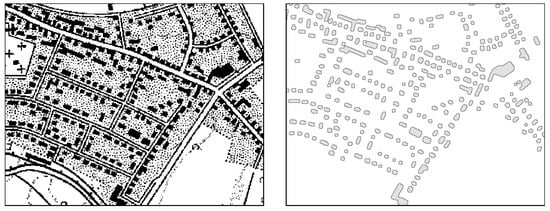
Figure 2.
Original binarized map images (left, black–foreground, white–background) and the retrieved building footprints (TK25 © LVermGeo 2014).
2.5. Derivation of Building Age
This processing step serves to determine the period of construction for each building. This can only be determined at the level of the urban blocks due to the spatial positional discrepancies of the extracted buildings from different time periods. The following steps were necessary for performing the time series analysis:
- Calculating the built-up coverage: For each urban block and time slice, the built-up coverage (proportion of building area in the block area) is calculated based on a spatial intersection of the extracted building footprints from the topographic maps and the urban block geometry taken from the ATKIS® Basic DLM. The calculated built-up coverages over time form the basis for determining the time of first construction of an urban block. The block-based calculation avoids building-by-building comparisons over time, which may be impossible due to the varying map quality, layout and positional inaccuracies across the time series.
- Determination of a threshold value: For distinguishing between built-up and not built-up at a specific time, a threshold value needs to be applied. The optimal threshold value was determined by performing a Receiver Operating Characteristic (ROC) analysis on given reference data. The reference data include a map of built-up areas for the year 1970. Together with the calculated built-up coverages, they were input data for the ROC analysis. Thus, an optimum threshold value of 0.025 was determined, that is, only from a built-up coverage of 2.5% is an area regarded as built-up (with a sensitivity of 0.948 and a specificity of 0.785).
- Historical settlement layer: In this step, the urban blocks of all time slices are classified according to built-up and not built-up by applying the threshold value to the built-up coverage values. Subsequently, the time of first construction is determined on the basis of the development pattern. The result is the historical settlement layer.
- Historical urban morphology at the building level: In a final step, the buildings are intersected with the historical settlement layer at the urban block level and the age data are attached to the building layer (see Figure 3).
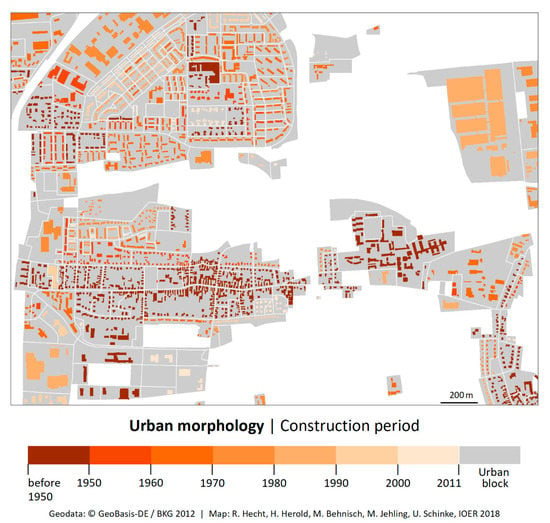 Figure 3. Period of construction derived by intersecting the historical settlement layer at the block level and the building footprints representing historical urban morphologies.
Figure 3. Period of construction derived by intersecting the historical settlement layer at the block level and the building footprints representing historical urban morphologies.
2.6. Classification of Building Footprints
In this processing step, the building footprints are classified according to a set of predefined building types. For this purpose, we apply the building classification approach with a supervised learning strategy introduced by Hecht et al. [38]. In this strategy, a classifier is trained on the basis of a given set of training samples (buildings with class labels and object features) using a machine learning technique. The Random Forest (RF) algorithm by Breiman [39] is used as a machine learning algorithm that constructs a large number of decision trees, each tree being trained with a random bootstrap sample of the training data. By comparing RF with 15 other algorithms, this ensemble-based classifier has been proven to be the best method for building classification in terms of accuracy and efficiency [40]. The object features required for the classification are geometrical, topological, semantic and statistical measures. These have been calculated using digital image processing techniques and spatial analysis on the basis of the building geometry as well as urban block geometry taken from a digital landscape model. Before the classification approach was applied, small polygons <10 m2 were first removed from the data set. Utilizing the automatic building classification approach, buildings are differentiated into 11 different building types. A distinction is made between multi-family houses (MFH), single-family houses (SFH), rural houses (RH) and non-residential houses, which are further subdivided (see Figure 4). Observations in the RF that are not part of the bootstrap sample can be used as out-of-bag (OOB) observations to estimate the prediction error. The estimated OOB error in the study area was 7.7% (corresponding to a total accuracy of 92.3%), which is comparable with the findings in Reference [38].
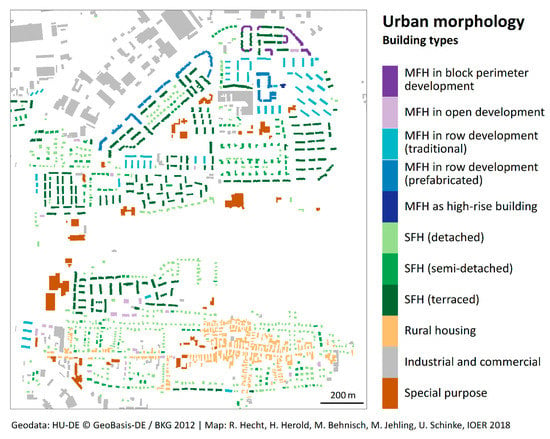
Figure 4.
Result of the automatic building classification process for a subset of the study area.
2.7. Calculation of the Number of Dwellings and Inhabitants
The derivation of the dwelling units and inhabitants at the level of individual buildings is based on various model assumptions. The assumptions have been made based on numbers from the literature and our own empiric analysis and, if possible, made for each building type. The following assumptions are required for the processing:
- Mean story height (sh)
- Conversion factor (cf)
- Dwelling unit size (dz)
- Household size (hh)
The first relevant parameter is based on an assumption about the mean story height (sh) per building type in order to estimate the number of stories for each building (sn). This is necessary because the number of stories is usually not given in 3D building models. If the height of the building is also unknown (e.g., in the case of 2D building footprints), assumptions can be made about the typical number of stories, taking into account the type of building and the settlement structure [21]. By multiplying the number of stories by the area of the building footprint, the total floor area (fa) in m2 can be calculated. In order to derive the actual living space (ls) in m², the fa value is reduced by applying a conversion factor (cf), since not the entire floor area of a building is usable for living (e.g., stairways etc.). The urban planning literature in Germany proposes a reduction of the area by a factor of 0.8 [41]. Once the living space has been calculated, the number of dwelling units can be calculated considering average dwelling unit sizes for each building type. An estimation of the number of inhabitants can be made with the help of an assumption about the average household size (hh). Statistical data on average household sizes are provided by the statistical offices at the municipal level and also exist for historical time periods. Values for mean story heights and the mean dwelling sizes can only be derived indirectly from official statistics and literature. Since these can be very different regionally, we propose working with an empirical sample in the study area.
2.8. Aggregation
As a result of the previous step (Section 2.6), the current or historical figures on the population and number of apartments at the building level are available for each time period. In a next and final step, the figures can be aggregated to any spatial level and the dynamics can be calculated by measuring the change in the total and relative values.
3. Study Area and Data Sets
3.1. Study Area
As a test bed we have chosen a study area “Landau” in Southwest Germany which is characterized by a hilly landscape with vineyards of the Upper Rhine Plain and the Palatinate Forest (see Figure 5). The area comprises 107 municipalities of smaller urban centres and predominantly rural areas with a total population of approx. 280,000 inhabitants. Landau in der Pfalz, a medium-sized town with currently 46,292 inhabitants (Federal Statistical Office of Rhineland-Palatinate, 2017) is centrally located. The study area consists of more than 140,000 buildings which are taken into account in the processing. The small-scale administrative structure of the region allows for good access to historic data on population for model validation.
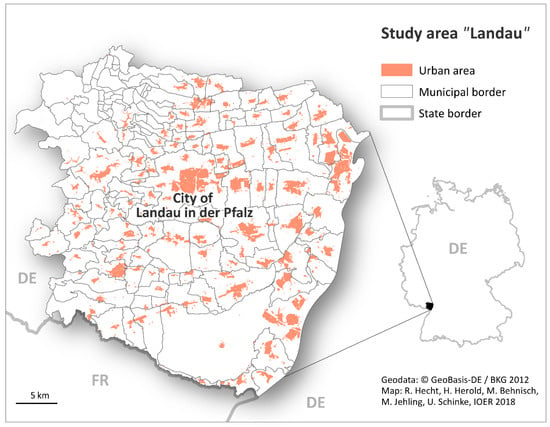
Figure 5.
Administrative structure and urban area of the study area “Landau” and location in Germany.
3.2. Data Sets
As input data, we use official data that are commonly available in European countries and in most other developed countries. For this study we acquire and use the following data:
- Building data: 3D building model in LoD1 from the year 2012
- Land use data: Digital Landscape Model of the German Authoritative Topographic-Cartographic Information System (ATKIS base DLM) from the year 2012
- Topographic raster maps: German topographic maps (TK 25) at a scale of 1:25,000 from the years 1950, 1960, 1970, 1980, 1990 and 2000.
A 3D building model in LoD1 provided by the Federal State Office for Surveying and Geo Information Rhineland-Palatinate (Landesamt für Vermessung und Geobasis information, LVermGeo), is used as the building model. It contains all building footprints from the real estate cadastre, which are enriched with additional height information using LiDAR. The land use data is taken from the ATKIS Base-DLM, the Digital Landscape Model of the Authoritative Topographic Cartographic Information System (ATKIS) in Germany with a scale of 1:10,000–1:25,000. It contains land use information and the street network and differentiates between the four land use classes for built-up areas: residential area, industrial/commercial area, mixed-use area and specific functional area [42]. The urban block geometry can be extracted from the ATKIS Base-DLM by selecting the object group ‘2100’ (built-up area) which is used as input for the building footprint classification process. It further serves as a spatial unit for calculating building coverage ratios for the multi-temporal analysis. Topographic maps serve as a source for the reconstruction of historical morphology. For the study area, map sheets of the German topographic maps (TK 25) at a scale of 1:25,000 from the years 1950, 1960, 1970, 1980, 1990 and 2000 were acquired by the LVermGeo. Figure A1 in the Appendix A shows the individual maps, in which urban development is clearly visible, on the example of an eastern section of the city of Landau.
For the parametrization and validation of the model we use the following data:
- Field survey data: Data set of 603 buildings with information on the average story height and average size of dwelling units per building type. This data was used to parameterize the model.
- Grid cell based statistical census data: Population and number of dwelling units at the level of 100 m grid cells based on the INSPIRE Geographical Grid System. The data are taken from Zensus2011.de, which is provided by the Federal Statistical Office (Destatis). These data are used for the validation of the estimates of the historical population and dwelling units.
- Official statistics at the municipal level: Current and historical statistical data on population and household size obtained from the Federal Statistical Office of Rhineland-Palatinate. These data are used for the validation of the historical estimates.
Table 1 shows the assumptions and values for different building types that are required for the derivation of the population and dwellings (cf. Section 2.7). The average household size (hh) of all types of residential buildings can be taken from the official statistics of Rhineland-Palatinate. This parameter expresses the relationship between the number of dwellings and the number of inhabitants. The parameters for the story height (sh) and dwelling unit size (dz) are derived using an empirical sample in the study area. As a conversion factor we use the value of 0.8 for all building types with the exception of rural buildings. Our own empirical survey has shown that a factor of 0.34 is necessary for rural buildings, as they have a particularly high proportion of floor areas not used for residential purposes.

Table 1.
Building-typical assumptions for the calculation of dwelling units and inhabitants.
4. Results
In this section, the results of applying the methodological framework developed in Section 2 to the test bed “Landau” using available data sets are presented. First, the results of the automatically derived historical population and dwellings as well as their dynamics are presented (Section 4.1). The derived figures are then validated by comparison with official census data on the number of inhabitants and housing in 2011 at the level of 100 m grid cells (Section 4.2). Finally, the accuracy of the population dynamics is validated at the municipal level (Section 4.3).
4.1. Historical Population and Dwellings and Dynamics
First, we take a look at the derived quantities of population and dwellings for the test bed “Landau.” A growth in the map series is clearly visible (see Figure 6 and Figure A2 in the Appendix A). If one considers the differences between 1950 and 2011, it becomes clear that settlement expansions took place over the entire area under investigation. However, it is also visible that settlement with higher densities took place around the City of Landau (see Figure 7). The effect of considering the urban morphology (through different types of residential buildings) in the process of calculating the population is particularly noticeable here.
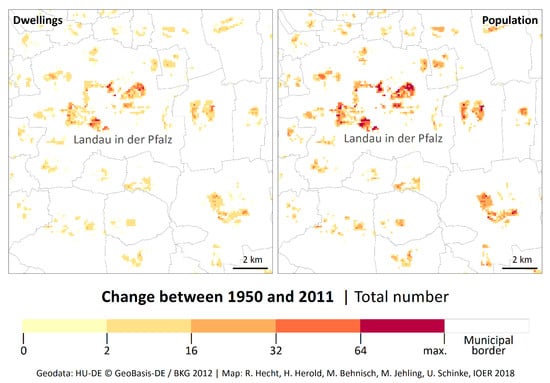
Figure 6.
Automatically processed dynamics in dwellings (left) and population (right) at the level of 100 m grid cells for the central part of the study area.
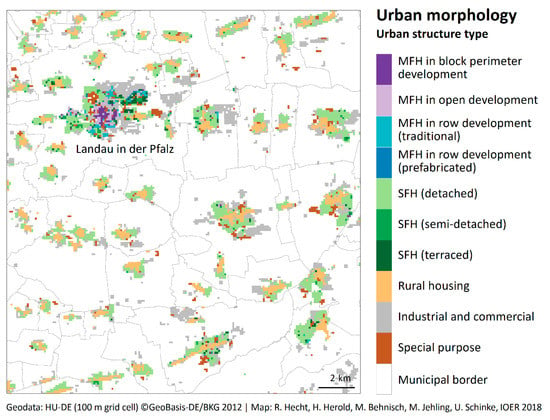
Figure 7.
Derived urban structure type at the level of 100 m grid cells.
4.2. Cell-Based Validation of the Current State Using Census Data 2011
The results of the derived numbers for population and dwelling units are validated at the level of grid cells with a spacing of 100 m. As reference grid data we used the official census data of the year 2011. The derived grid values compared to the reference and their differences are shown in Figure A3 in the Appendix A. Figure 8 contains two histograms showing the absolute error for population and dwelling units. Table 2 gives an overview of statistical parameters for both absolute estimation errors. In summary, we underestimate the total population and the dwellings. The range of the estimation error for the population is between −346 and +244. The median is −5 and the standard deviation is 17.43. The range of the estimation error for the dwelling units is between −98 and +118. The median is −2 and the standard deviation is 8.32.
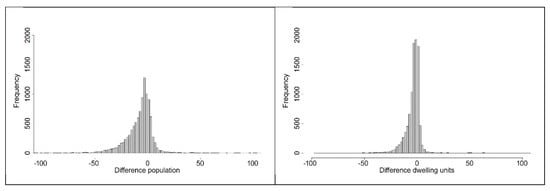
Figure 8.
Histogram of the absolute error for population and dwelling units in the year 2011. The error is measured as the difference between estimated values and reference values.
Table 2.
Absolute error of the results at the study area level from calculating the difference between estimated values and reference values.
For an in-depth understanding of both estimation results, we consider the error differentiated by urban structure types (cf. Table 2 and Table 3). For this purpose, we reduce the building types to the classes shown in Figure 7. It becomes clear that the different urban structure types have different densities and errors. The highest density is found in multi-family housing in block perimeter development, followed by multi-family housing in row development. It is obvious that we overestimate both the population (diff = 11.8%) and the dwelling units (diff = 23.3%) in multi-family houses in block perimeter development. We underestimate both the population (diff = −17.5%) and the dwelling units (diff = −20.5%) in multi-family housing in open structure. We achieve satisfactory estimation results for the population (diff = −3.1%) and dwelling units (diff = 2.1) in multi-family housing in row development.
Table 3.
Absolute error (dwelling units) of the results for different structural building types.
4.3. Validation of the Population Dynamics
The results are also validated with regard to population dynamics from 1950 onwards. The official statistics provide reference values at the municipal level. Due to changes in administrative boundaries, the statistics were aggregated manually to match current municipal extents. Based on this timeline, the estimated dynamics from 1950 to 2010 are validated. Table 4 indicates the validation statistics for the study areas. The relative median and mean error increase from later to earlier time steps. The standard deviation is characterized by low values which, however, become higher the older the observed time is. This also applies to the inter-quartile range (IQR). Figure 9 highlights the validation results for the years and gives a more detailed view of the deviation regarding outliers.
Table 4.
Relative error (%) of the results for all municipalities (n = 107).
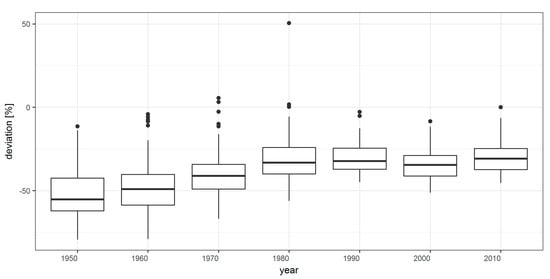
Figure 9.
Distribution of relative errors for time steps.
In order to assess the mean and median relative errors in older time steps, a further validation is required. Figure 10 addresses the validation of the results through the comparison of the logarithms of the absolute estimated and reference numbers of inhabitants. The results underline once again the observed underestimation of the population at the community level. It is also shown that the error increases with the size of the municipality. The increase of deviation towards older time steps also becomes visible in the absolute error.
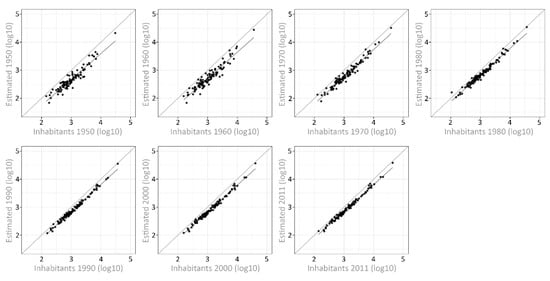
Figure 10.
Scatter plot showing the estimated and reference values of the number of inhabitants. The light grey line represents the optimal result.
5. Discussion
In this study, it is shown that the analysis of multi-temporal data on urban morphology allows for the automated derivation of historical dynamics of population and dwellings at a very detailed spatial level. This was realized by a combined processing of official geodata of the national mapping and cadastral authorities, particularly a Digital Landscape Model and a 3D building model, historical topographic maps from different time periods as well as official statistical data. Since the approach is highly automated and works with commonly available geodata, it is particularly well suited for large-scale applications, such as at the national level, or for application in other countries. In the following, the approach and the results are critically discussed with regard to limitations (Section 5.1) and transferability (Section 5.2).
5.1. Limitations
The methodology and the selected data are characterized by certain limitations. The small-scale validation at the 100 m grid level shows a mean of −7.8 and a standard deviation of 17.4 for the derived population for 2011. The dwellings can obviously be derived with smaller uncertainties than the population (mean of −3.2 and standard deviation of 8.3). In its current state, the methodology is appropriate for studying regional rather than small-scale processes at the level of individual buildings. The validation of the historical population at the municipal level shows a smaller standard deviation due to the larger aggregation units. The standard deviation, however, becomes larger the further one goes into the past. This systematic increase opens up the possibility of linear correction.
The errors have various reasons, which are mostly data-related. One reason is the limited semantic detail of the 3D building model. Mixed use is not taken into account in our model, since a building is either residential or non-residential. As a result, in central locations the number of dwellings and the population are overestimated. This is in accordance with the positive error for multi-family housing in block perimeter development, which is predominant in these areas. Therefore, it would be appropriate to take into account the fractional building use, where the proportion of the residential use or the absolute residential floor space within a building is known [25,26]. However, the question remains where to get this information for the past, if even current cadastral data do not contain this information.
Further sources of error result from the quality of the topographic maps. In our approach, the building age is estimated at the block level because the positional accuracy of the extracted buildings is not sufficient for change detection at building level. Hence, demolition and infill development processes within an urban block have not been considered yet. To achieve this, a more enhanced building matching approach should be implemented [43].
A further limitation results from the use of assumptions based on a sample and official statistics. The quality of the estimate depends on the quality and availability of the input parameters. Household size is only estimated through applying a regional mean value for each time step without considering different household types or further socio-demographic parameters. For example, usually newly developed areas with single-family housing attract mostly young family households with children. The fact that household types are not taken into account obviously leads to a strong underestimation of these areas. This implies that also areas with a high concentration of an aged population can be identified, where above-average floor space per inhabitant leads to an overestimation by our model. In the future, however, the approach could be extended by including demographic data such as age structure and gender. Depending on the availability of data, time series of demographic estimates could then be derived using an aerial interpolation coupled with dasymetric refinement [22].
Finally, the approach is limited to an estimation of the residential population. It is thus equivalent to a model of the night-time population. The daytime population density reflects where people commute to and spend their waking hours. It plays an important role in urban and regional planning of transport and utilities and thus long-term dynamics would be of interest. There are already approaches to model daytime population [27,28]. An integration into the framework developed would require further historical data, which are not available. However, a simplified model could be tested that considers assumptions about the number of workplaces for non-residential buildings or land uses. Here, retrieving data on the historical usage of non-residential buildings remains a further challenge.
5.2. Transferability
The transferability of the approach solely depends on the availability of the input data used in the workflow. While current land use data sets, census data and even building models are widely available, the historical estimation depends on topographic map data, which may restrict the temporal resolution in certain regions of the world. In many, in particular European countries, however, periodically updated cartographic records do exist for many centuries. Digital libraries and national mapping increasingly make these historical map collections accessible. Depending on the map layout and design, the methods for building retrieval (Section 2.4) have to be adapted. Schinke et al. [44] provide an overview of European map layouts with a focus on the mapping of the urban structure. If no official geodata is available, OpenStreetMap could be used as an alternative data source for current land use and building footprints. However, it should be verified in advance whether the data quality is adequate for the study area [33].
Furthermore, our approach depends on building-typical assumptions for the calculation of dwelling units and inhabitants. Here, it is very helpful to find efficient ways to integrate local knowledge about the average story height, conversion factor, dwelling unit size and household size.
5.3. Field of Applications
The developed approach offers potential for a broad field of application in various disciplines. For policy making, the approach allows for substituting missing census data. Beyond that, our approach can also help to improve the capabilities of spatial microsimulation approaches for small area estimations of socio-economic data [45]. Thus, offering new opportunities in population science. By applying a linear correction and further interpolation, approaches to quantitative historical demography could be further developed with regard to automation [7]. Also, through the ability to develop long time series, sufficient time steps for calibration and validation of population modelling and simulation approaches [3] can be retrieved. Further, research on settlement structures and changes, for example, urban sprawl and suburbanization can be addressed through identifying path-dependencies and effects of related policies. A comprehensive understanding of the past evolution of population, buildings and dwellings is therefore an essential condition for formulating comprehensive and reliable long-term visions and management strategies [46,47]. Finally, the approach offers a contribution to preserving historical knowledge of urban structure. If the approach could be improved so that changes can be quantified at the building level, it could provide an important source for investigating evolution and mortality from building stock [48] and to derive rules for procedural modelling of cities [49].
6. Conclusions
With regard to the first research question on how long-term dynamics of population and dwellings can be automatically mapped, we propose a methodological framework by analysing multi-temporal urban morphologies. The urban morphology is described in high spatial resolution by the derivation of building types from a 3D building model and a digital landscape model. Furthermore, the history of urban morphology is reconstructed through the analysis of historical topographic maps at the scale of 1:25,000. Using dasymetric mapping techniques, the number of dwellings and the population can be estimated by the disaggregation of official census data at the municipal level to the residential floor spaces. By applying the procedure to a study area in Southwest Germany, we were able to test the applicability of the approach by using existing geodata. For the study area, decadal historical population and dwelling numbers were derived for the period from 1950 to 2011 and the dynamics calculated and visualized. With reference to the second research question on accuracy, the error was quantified by comparing the results with official data at both the 100 m grid level (current dwellings and population) and the municipal level (historical population). The results show that population and dwellings are underestimated for certain urban structure types and that the underestimation increases as one goes further into the past. For the population (2011) we observed a relative error of −29.7% compared to reference data. For older time steps, the error becomes larger and increases to 51.2% for the year 1950. Further research should therefore be carried out to develop an appropriate method for error correction. Since the deviation increases systemically, the possibility of a linear correction arises. Regarding the variance, geographic differences should be analysed. Here the relationship between household characteristics and building structure and age should also be addressed.
Author Contributions
R.H. and H.H. conceived and designed the study. H.H. and M.J. are responsible for data collection and harmonization. All authors analysed the data. M.B. and M.J. did the subsequent statistical analysis. The manuscript was written in collaboration.
Funding
This research received no external funding.
Acknowledgments
All mentioned official spatial base data were at the disposal of the IOER for the purposes of research. The authors would like to thank the Federal Agency for Cartography and Geodesy (Bundesamt für Kartographie und Geodäsie, BKG) and the Federal State Office for Surveying and Geo Information Rhineland-Palatinate (Landesamt für Vermessung und Geobasisinformation, LVermGeo) for the provision of this data. We gratefully acknowledge the European Fund of Regional Development (INTERREG IV) and the Wissenschaftsoffensive Oberrhein, which partly funded this research. Finally, we would like to thank Ulrike Schinke for her valuable support in improving the maps in the revised manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A

Figure A1.
Topographic maps of six different points in time as a basis for the analysis. The map shows a north-eastern part of the City of Landau (Data source: TK25 © LVermGeo 2014).
Figure A1.
Topographic maps of six different points in time as a basis for the analysis. The map shows a north-eastern part of the City of Landau (Data source: TK25 © LVermGeo 2014).


Figure A2.
Historic dwellings and population for 1950, 1980 and 2011 at the level of 100 m grid cells.
Figure A2.
Historic dwellings and population for 1950, 1980 and 2011 at the level of 100 m grid cells.


Figure A3.
Derived dwelling units and population in comparison to the reference values and the calculated difference at the level of 100 m grid cells.
Figure A3.
Derived dwelling units and population in comparison to the reference values and the calculated difference at the level of 100 m grid cells.

References
- Ahola, T.; Virrantaus, K.; Krisp, J.M.; Hunter, G.J. A spatio-temporal population model to support risk assessment and damage analysis for decision-making. Int. J. Geogr. Inf. Sci. 2007, 21, 935–953. [Google Scholar] [CrossRef]
- Cockx, K.; Canters, F. Incorporating spatial non-stationarity to improve dasymetric mapping of population. Appl. Geogr. 2015, 63, 220–230. [Google Scholar] [CrossRef]
- Crols, T.; Vanderhaegen, S.; Canters, F.; Engelen, G.; Poelmans, L.; Uljee, I.; White, R. Downdating high-resolution population density maps using sealed surface cover time series. Landsc. Urban Plan. 2017, 160, 96–106. [Google Scholar] [CrossRef]
- Renner, K.; Schneiderbauer, S.; Pruß, F.; Kofler, C.; Martin, D.; Cockings, S. Spatio-temporal population modelling as improved exposure information for risk assessments tested in the Autonomous Province of Bolzano. Int. J. Disaster Risk Reduct. 2018, 27, 470–479. [Google Scholar] [CrossRef]
- Evans, S.; Liddiard, R.; Steadman, P. 3DStock: A new kind of three-dimensional model of the building stock of England and Wales, for use in energy analysis. Environ. Plan. B 2017, 44, 227–255. [Google Scholar] [CrossRef]
- Beck, A.; Long, G.; Boyd, D.S.; Rosser, J.F.; Morley, J.; Duffield, R.; Sanderson, M.; Robinson, D. Automated classification metrics for energy modelling of residential buildings in the UK with open algorithms. Environ. Plan. B 2018. [Google Scholar] [CrossRef]
- Ekamper, P. Using cadastral maps in historical demographic research: Some examples from the Netherlands. Hist. Fam. 2010, 15, 1–12. [Google Scholar] [CrossRef]
- Jehling, M.; Hecht, R.; Herold, H. Assessing urban containment policies within a suburban context—An approach to enable a regional perspective. Land Use Policy 2018, 77, 846–858. [Google Scholar] [CrossRef]
- Pan, H.; Deal, B.; Chen, Y.; Hewings, G. A Reassessment of urban structure and land-use patterns: Distance to CBD or network-based?—Evidence from Chicago. Reg. Sci. Urban Econ. 2018, 70, 215–228. [Google Scholar] [CrossRef]
- Alahmadi, M.; Atkinson, P.; Martin, D. Estimating the spatial distribution of the population of Riyadh, Saudi Arabia using remotely sensed built land cover and height data. Comput. Environ. Urban Syst. 2013, 41, 167–176. [Google Scholar] [CrossRef]
- Wu, S.; Qiu, X.; Wang, L. Population Estimation Methods in GIS and Remote Sensing: A Review. GISci. Remote Sens. 2005, 42, 80–96. [Google Scholar] [CrossRef]
- Eicher, C.L.; Brewer, C.A. Dasymetric Mapping and Areal Interpolation: Implementation and Evaluation. Cartogr. Geogr. Inf. Sci. 2001, 28, 125–138. [Google Scholar] [CrossRef]
- Maantay, J.A.; Maroko, A.R.; Herrmann, C. Mapping Population Distribution in the Urban Environment: The Cadastral-based Expert Dasymetric System (CEDS). Cartogr. Geogr. Inf. Sci. 2007, 34, 77–102. [Google Scholar] [CrossRef]
- Langford, M.; Unwin, D.J. Generating and mapping population density surfaces within a geographical information system. Cartogr. J. 1994, 31, 21–26. [Google Scholar] [CrossRef]
- Fisher, P.F.; Langford, M. Modelling the Errors in Areal Interpolation between Zonal Systems by Monte Carlo Simulation. Environ. Plan. A 1995, 27, 211–224. [Google Scholar] [CrossRef]
- Holt, J.B.; Lo, C.P.; Hodler, T.W. Dasymetric Estimation of Population Density and Areal Interpolation of Census Data. Cartogr. Geogr. Inf. Sci. 2004, 31, 103–121. [Google Scholar] [CrossRef]
- Mennis, J. Generating Surface Models of Population Using Dasymetric Mapping. Prof. Geogr. 2003, 55, 31–42. [Google Scholar]
- Tatem, A.J.; Noor, A.M.; von Hagen, C.; Di Gregorio, A.; Hay, S.I. High Resolution Population Maps for Low Income Nations: Combining Land Cover and Census in East Africa. PLoS ONE 2007, 2, e1298. [Google Scholar] [CrossRef] [PubMed]
- Gallego, F.J. A population density grid of the European Union. Popul. Environ. 2010, 31, 460–473. [Google Scholar] [CrossRef]
- Langford, M.; Higgs, G.; Radcliffe, J.; White, S. Urban population distribution models and service accessibility estimation. Comput. Environ. Urban Syst. 2008, 32, 66–80. [Google Scholar] [CrossRef]
- Meinel, G.; Hecht, R.; Herold, H. Analyzing building stock using topographic maps and GIS. Build. Res. Inf. 2009, 37, 468–482. [Google Scholar] [CrossRef]
- Zoraghein, H.; Leyk, S. Data-enriched interpolation for temporally consistent population compositions. GISci. Remote Sens. 2018, 32. [Google Scholar] [CrossRef]
- Lwin, K.; Murayama, Y. A GIS Approach to Estimation of Building Population for Micro-spatial Analysis. Trans. GIS 2009, 13, 401–414. [Google Scholar] [CrossRef]
- Ural, S.; Hussain, E.; Shan, J. Building population mapping with aerial imagery and GIS data. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 841–852. [Google Scholar] [CrossRef]
- Kunze, C.; Hecht, R. Semantic enrichment of building data with volunteered geographic information to improve mappings of dwelling units and population. Comput. Environ. Urban Syst. 2015, 53, 4–18. [Google Scholar] [CrossRef]
- Biljecki, F.; Arroyo Ohori, K.; Ledoux, H.; Peters, R.; Stoter, J. Population Estimation Using a 3D City Model: A Multi-Scale Country-Wide Study in the Netherlands. PLoS ONE 2016, 11, e0156808. [Google Scholar] [CrossRef] [PubMed]
- Bhaduri, B.; Bright, E.; Coleman, P.; Urban, M.L. LandScan USA: A high-resolution geospatial and temporal modeling approach for population distribution and dynamics. GeoJournal 2007, 69, 103–117. [Google Scholar] [CrossRef]
- Greger, K. Spatio-Temporal Building Population Estimation for Highly Urbanized Areas Using GIS: Spatio-Temporal Building Population Estimation. Trans. GIS 2015, 19, 129–150. [Google Scholar] [CrossRef]
- Batista e Silva, F.; Marín Herrera, M.A.; Rosina, K.; Ribeiro Barranco, R.; Freire, S.; Schiavina, M. Analysing spatiotemporal patterns of tourism in Europe at high-resolution with conventional and big data sources. Tour. Manag. 2018, 68, 101–115. [Google Scholar] [CrossRef]
- Morton, T.A.; Yuan, F. Analysis of population dynamics using satellite remote sensing and US census data. Geocarto Int. 2009, 24, 143–163. [Google Scholar] [CrossRef]
- Leyk, S.; Uhl, J.H. HISDAC-US, historical settlement data compilation for the conterminous United States over 200 years. Sci. Data 2018, 5, 180175. [Google Scholar] [CrossRef] [PubMed]
- Herold, H. Geoinformation from the Past; Springer: Wiesbaden, Germany, 2018; ISBN 978-3-65-820569-0. [Google Scholar]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring Completeness of Building Footprints in OpenStreetMap over Space and Time. ISPRS Int. J. Geo-Inf. 2013, 2, 1066–1091. [Google Scholar] [CrossRef]
- Deseilligny, M.P.; Mariani, R.; Labiche, J.; Mullot, R. Topographic maps automatic interpretation: Some proposed strategies. In Graphics Recognition Algorithms and Systems; Lecture Notes in Computer Science; Tombre, K., Chhabra, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1389, pp. 175–193. ISBN 978-3-54-064381-4. [Google Scholar]
- Illert, A. Automatic Digitization of Large Scale Maps. In Proceedings of the Auto-Carto 10, London, UK, 25–28 March 1991; pp. 113–122. [Google Scholar]
- Herold, H.; Roehm, P.; Hecht, R. Georeferenced Maps as a Source for High Resolution Urban Growth Analyses. In Proceedings of the 25th ICA International Cartographic Conference, Paris, France, 3–8 July 2011; pp. 1–5. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson/Prentice Hall: Upper Saddle River, NJ, USA, 2008; ISBN 978-0-13-168728-8. [Google Scholar]
- Hecht, R.; Meinel, G.; Buchroithner, M. Automatic identification of building types based on topographic databases—A comparison of different data sources. Int. J. Cartogr. 2015, 1, 18–31. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hecht, R. Automatische Klassifizierung von Gebäudegrundrissen: Ein Beitrag zur Kleinräumigen Beschreibung der Siedlungsstruktur; Rhombos-Verl.: Berlin, Germany, 2014; Volume 63, ISBN 978-3-94-410163-7. [Google Scholar]
- Korda, M. (Ed.) Städtebau; Vieweg+Teubner Verlag: Wiesbaden, Germany, 1999; ISBN 978-3-32-296807-4. [Google Scholar]
- GeoBasis-DE. Digital Base Landscape Model; Documentation from 20.09.2011; Federal Agency for Cartography and Geodesy: Frankfurt, Germany, 2011; Available online: http://www.geodatenzentrum.de/docpdf/basis-dlm_eng.pdf (accessed on 12 December 2018).
- Zhang, X.; Ai, T.; Stoter, J.; Zhao, X. Data matching of building polygons at multiple map scales improved by contextual information and relaxation. ISPRS J. Photogramm. Remote Sens. 2014, 92, 147–163. [Google Scholar] [CrossRef]
- Schinke, U.; Herold, H.; Meinel, G.; Prechtel, N. Analysis of European Topographic Maps for Automatic Acquisition of Urban Land Use Information. In Proceedings of the 26th ICA International Cartographic Conference, Dresden, Germany, 25–30 August 2013. [Google Scholar]
- Whitworth, A.; Carter, E.; Ballas, D.; Moon, G. Estimating uncertainty in spatial microsimulation approaches to small area estimation: A new approach to solving an old problem. Comput. Environ. Urban Syst. 2017, 63, 50–57. [Google Scholar] [CrossRef]
- Hassler, U.; Kohler, N. The ideal of resilient systems and questions of continuity. Build. Res. Inf. 2014, 42, 158–167. [Google Scholar] [CrossRef]
- Hudson, P. Urban Characterisation; Expanding Applications for, and New Approaches to Building Attribute Data Capture. Hist. Environ. Policy Pract. 2018, 9, 306–327. [Google Scholar] [CrossRef]
- Aksözen, M.; Hassler, U.; Kohler, N. Reconstitution of the dynamics of an urban building stock. Build. Res. Inf. 2017, 45, 239–258. [Google Scholar] [CrossRef]
- Roumpani, F.; Hudson, P.; Hudson-Smith, A. The Use of Historical Data in Rule-Based Modelling for Scenarios to Improve Resilience within the Building Stock. Hist. Environ. Policy Pract. 2018, 9, 328–345. [Google Scholar] [CrossRef]










© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).