Integrating GEOBIA, Machine Learning, and Volunteered Geographic Information to Map Vegetation over Rooftops


Abstract

1. Introduction
1.1. Background
1.2. Types of Urban Vegetation Maps
1.3. Classification Algorithms
2. Data and Methods
2.1. Study Area
2.2. Datasets
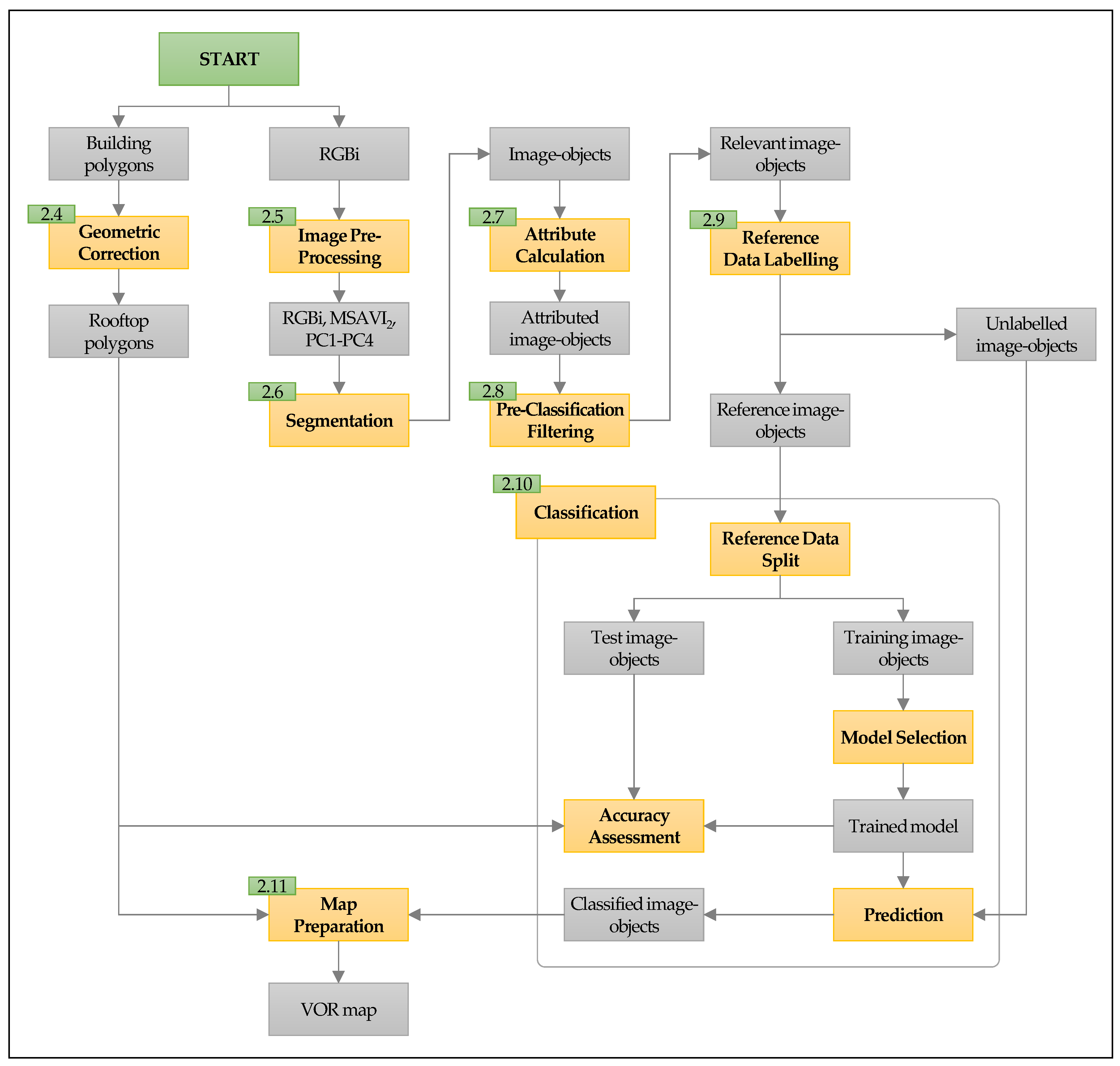
2.3. Overview of Methodology
2.4. Geometric Correction to Generate Rooftop Polygons
2.5. Image Pre-Processing
2.6. Segmentation
2.7. Attribute Calculation
2.8. Pre-Classification Filtering
2.9. Sampling and Response Design
2.10. Classification and Accuracy Assessment
2.11. Map Preparation
3. Results
3.1. Segmentation, Pre-Classification Filtering, and Reference Data Selection
3.2. Model Selection, Classification Accuracy, and Hypothesis Testing
3.2.1. Model Selection
3.2.2. Detailed and Simplified Class Accuracies
3.2.3. Over-Rooftop and Full-Scene Accuracies
3.2.4. Hypothesis Testing
3.2.5. VOR Qualitative Assessment
4. Discussion
4.1. Accuracy Assessment
4.2. Feature Selection and Pre-Classification Filtering
4.3. Fuzzy Vegetation and Heterogeneous Classes
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DAS | Digital Aerial Survey |
| DN | Digital Number |
| DT | Decision Tree |
| GEOBIA | Geographic Object-Based Image Analysis |
| kNN | k-Nearest Neighbour |
| LiDAR | Light Detection and Ranging |
| LULC | Land-Use and Land-Cover |
| MSAVI | Modified Soil-Adjusted Vegetation Index |
| MSS | Multispectral Scanner |
| NDVI | Normalized Difference Vegetation Index |
| NIR | Near-Infrared |
| OSM | OpenStreetMap |
| PC | Principal Component |
| RBF | Radial Basis Function |
| RGB | Red, Green, and Blue |
| RGBi | Red, Green, Blue, and near-infrared |
| SAVI | Soil-Adjusted Vegetation Index |
| SVM | Support Vector Machine |
| TIR | Thermal Infrared |
| VGI | Volunteered Geographic Information |
| VHR | Very High Resolution |
| VOR | Vegetation Over Rooftops |
References
- Roy, S.; Byrne, J.; Pickering, C. A systematic quantitative review of urban tree benefits, costs, and assessment methods across cities in different climatic zones. Urban For. Urban Green. 2012, 11, 351–363. [Google Scholar] [CrossRef]
- Nowak, D.J.; Crane, D.E.; Stevens, J.C. Air pollution removal by urban trees and shrubs in the United States. Urban For. Urban Green. 2006, 4, 115–123. [Google Scholar] [CrossRef]
- Armson, D.; Ennos, A.R.; Stringer, P. The effect of tree shade and grass on surface and globe temperatures in an urban area. Urban For. Urban Green. 2012, 11, 245–255. [Google Scholar] [CrossRef]
- Livesley, S.J.; Baudinette, B.; Glover, D. Rainfall interception and stem flow by eucalypt street trees–The impacts of canopy density and bark type. Urban For. Urban Green. 2014, 13, 192–197. [Google Scholar] [CrossRef]
- Song, X.P.; Tan, P.Y.; Edwards, P.; Richards, D. The economic benefits and costs of trees in urban forest stewardship: A systematic review. Urban For. Urban Green. 2018, 29, 162–170. [Google Scholar] [CrossRef]
- Nyberg, R.; Johansson, M. Indicators of road network vulnerability to storm-felled trees. Nat. Hazards 2013, 69, 185–199. [Google Scholar] [CrossRef]
- Jacbos, B.; Mikhailovich, N.; Delaney, C. Benchmarking Australia’s Urban Tree Canopy: An i-Tree Assessment; Final Report; University of Technology Sydney: Sydney, Australia, 2014. [Google Scholar]
- Ordóñez, C.; Duinker, P.N. Assessing the vulnerability of urban forests to climate change. Environ. Rev. 2014, 22, 311–321. [Google Scholar] [CrossRef]
- Brandt, L.; Lewis, A.D.; Fahey, R.; Scott, L.; Darling, L.; Swanston, C. A framework for adapting urban forests to climate change. Environ. Sci. Policy 2016, 66, 393–402. [Google Scholar] [CrossRef]
- Gill, S.E.; Handley, J.F.; Ennos, A.R.; Pauleit, S. Adapting cities for climate change: The role of the green infrastructure. Built. Environ. 2007, 33, 115–133. [Google Scholar] [CrossRef]
- Fogl, M.; Moudrý, V. Influence of vegetation canopies on solar potential in urban environments. Appl. Geogr. 2016, 66, 73–80. [Google Scholar] [CrossRef]
- Hemachandran, B. Developing HEAT Scores with h-Res Thermal Imagery to Support Urban Energy Efficiency. Master’s Thesis, University of Calgary, Calgary, AB, Canada, 2013, unpublished. [Google Scholar]
- Zhao, Q.; Myint, S.W.; Wentz, E.A.; Fan, C. Rooftop surface temperature analysis in an urban residential environment. Remote Sens. 2015, 7, 12135–12159. [Google Scholar] [CrossRef]
- Hay, G.J.; Kyle, C.; Hemachandran, B.; Chen, G.; Rahman, M.M.; Fung, T.S.; Arvai, J.L. Geospatial technologies to improve urban energy efficiency. Remote Sens. 2011, 3, 1380–1405. [Google Scholar] [CrossRef]
- Nichol, J. An emissivity modulation method for spatial enhancement of thermal satellite images in urban heat island analysis. Photogramm. Eng. Remote Sens. 2009, 75, 547–556. [Google Scholar] [CrossRef]
- The City of Calgary. 2014 September Snow Storm & Tree Debris Clean up. Available online: http://www.calgary.ca/CSPS/Parks/Documents/History/Conserving-Calgarys-Historic-Streets-Plan.pdf (accessed on 10 November 2018). (Archived by WebCite® at http://www.webcitation.org/73qB7uKFG).
- Pu, R.; Landry, S. A comparative analysis of high spatial resolution IKONOS and WorldView-2 imagery for mapping urban tree species. Remote Sens. Environ. 2012, 124, 516–533. [Google Scholar] [CrossRef]
- Tigges, J.; Lakes, T.; Hostert, P. Urban vegetation classification: Benefits of multitemporal RapidEye satellite data. Remote Sens. Environ. 2013, 136, 66–75. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009; ISBN 978-1-4200-5512-2. [Google Scholar]
- Myeong, S.; Nowak, D.J.; Hopkins, P.F.; Brock, R.H. Urban cover mapping using digital, high-spatial resolution aerial imagery. Urban Ecosyst. 2001, 5, 243–256. [Google Scholar] [CrossRef]
- Mathieu, R.; Aryal, J.; Chong, A.K. Object-based classification of IKONOS imagery for mapping large-scale vegetation communities in urban areas. Sensors 2007, 7, 2860–2880. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; Vailshery, L.; Jaganmohan, M.; Nagendra, H. Mapping urban tree species using very high resolution satellite imagery: Comparing pixel-based and object-based approaches. ISPRS Int. J. Geo-Inf. 2013, 2, 220–236. [Google Scholar] [CrossRef]
- Nielsen, A.B.; Östberg, J.; Delshammar, T. Review of urban tree inventory methods used to collect data at single-tree level. Arboric. Urban For. 2014, 40, 96–111. [Google Scholar]
- Blaschke, T.; Hay, G.J.; Weng, Q.; Resch, B. Collective sensing: Integrating geospatial technologies to understand urban systems—An overview. Remote Sens. 2011, 3, 1743–1776. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective; Always Learning; Pearson Education: London, UK, 2016; ISBN 9780134058160. [Google Scholar]
- Abdulkarim, B.; Kamberov, R.; Hay, G.J. Supporting urban energy efficiency with volunteered roof information and the Google Maps API. Remote Sens. 2014, 6, 9691–9711. [Google Scholar] [CrossRef]
- Zhang, X.; Feng, X.; Jiang, H. Object-oriented method for urban vegetation mapping using IKONOS imagery. Int. J. Remote Sens. 2010, 31, 177–196. [Google Scholar] [CrossRef]
- Yang, T.L. Mapping vegetation in an urban area with stratified classification and multiple endmember spectral mixture analysis. Remote Sens. Environ. 2013, 133, 251–264. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Liu, H.; Liao, W.; Zhang, L. Semantic classification of urban trees using very high resolution satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1413–1424. [Google Scholar] [CrossRef]
- Jensen, J.R.; Im, J.; Hardin, P.; Jensen, R.R. Image Classification. In The SAGE Handbook of Remote Sensing; SAGE Publications, Ltd.: London, UK, 2009; pp. 269–281. ISBN 9780857021052. [Google Scholar]
- Moskal, L.M.; Styers, D.M.; Halabisky, M. Monitoring urban tree cover using object-based image analysis and public domain remotely sensed data. Remote Sens. 2011, 3, 2243–2262. [Google Scholar] [CrossRef]
- Walker, J.S.; Briggs, J.M. An object-oriented approach to urban forest mapping in Phoenix. Photogramm. Eng. Remote Sens. 2007, 73, 577–583. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Zhang, K.; Hu, B. Individual urban tree species classification using very high spatial resolution airborne multi-spectral imagery using longitudinal profiles. Remote Sens. 2012, 4, 1741–1757. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV remote sensing for urban vegetation mapping using random forest and texture analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef]
- Iovan, C.; Boldo, D.; Cord, M. Detection, characterization, and modeling vegetation in urban areas from high-resolution aerial imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 206–213. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J. A support vector regression approach to estimate forest biophysical parameters at the object level using airborne LiDAR transects and QuickBird data. Photogramm. Eng. Remote Sens. 2011, 77, 733–741. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Welch, R. Spatial resolution requirements for urban studies. Int. J. Remote Sens. 1982, 3, 139–146. [Google Scholar] [CrossRef]
- Jensen, J.; Cowen, D. Remote sensing of urban/suburban infrastructure and socio-economic attributes. Photogramm. Eng. Remote Sens. 1999, 65, 611–622. [Google Scholar]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–89. ISBN 978-3-540-77058-9. [Google Scholar]
- Ke, Y.; Quackenbush, L.J. A review of methods for automatic individual tree-crown detection and delineation from passive remote sensing. Int. J. Remote Sens. 2011, 32, 4725–4747. [Google Scholar] [CrossRef]
- Zhen, Z.; Quackenbush, L.J.; Zhang, L. Trends in automatic individual tree crown detection and delineation—Evolution of LiDAR data. Remote Sens. 2016, 8, 333. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- The City of Calgary. Conserving Calgary’s Historic Streets: A Conservation Plan for 27 of Calgary’s Historic Streetscapes. Available online: http://www.calgary.ca/CSPS/Parks/Documents/History/Conserving-Calgarys-Historic-Streets-Plan.pdf (accessed on 13 September 2018).
- The City of Calgary. Urban Forest Management. Available online: https://maps.calgary.ca/TreeSchedule/ (accessed on 13 September 2018).
- The City of Calgary. History of Annexation. Available online: http://www.calgary.ca/PDA/pd/Documents/pdf/history-of-annexation.pdf (accessed on 13 September 2018).
- The City of Calgary. Digital Aerial Survey. Available online: http://www.calgary.ca/CS/IIS/Pages/Mapping-products/Digital-Aerial-Survey.aspx (accessed on 13 September 2018). (Archived by WebCite® at http://www.webcitation.org/71yZ8TSDM).
- Holtkamp, D.J.; Goshtasby, A.A. Precision registration and mosaicking of multicamera images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3446–3455. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A modified adjusted vegetation index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Kauth, R.J.; Thomas, G.S. The tasselled cap—A graphic description of the spectral-temporal development of agricultural crops as seen by Landsat. In Proceedings of the Symposium on Machine Processing of Remotely Sensed Data, West Lafayette, IN, USA, 29 June–1 July 1976; pp. 41–51. [Google Scholar]
- Crist, E.P.; Cicone, R.C. A physically-based transformation of thematic mapper data—The TM tasseled cap. IEEE Trans. Geosci. Remote Sens 1984, GE-22, 256–263. [Google Scholar] [CrossRef]
- Harris Geospatial Solutions Inc. Segmentation Algorithms Background. Available online: http://www.harrisgeospatial.com/docs/BackgroundSegmentationAlgorithm.html (accessed on 13 September 2018). (Archived by WebCite® at http://www.webcitation.org/71yX3GhvP).
- Harris Geospatial Solutions Inc. Merge Algorithms Background. Available online: http://www.harrisgeospatial.com/docs/BackgroundMergeAlgorithms.html (accessed on 13 September 2018). (Archived by WebCite® at http://www.webcitation.org/71yXkbNa0).
- Smith, G.M.; Morton, R.D. Real world objects in GEOBIA through the exploitation of existing digital cartography and image segmentation. Photogramm. Eng. Remote Sens. 2010, 76, 163–171. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 99, 1–15. [Google Scholar] [CrossRef]
- Harris Geospatial Solutions Inc. List of Attributes. Available online: http://www.harrisgeospatial.com/docs/AttributeList.html (accessed on 13 September 2018). (Archived by WebCite® at http://www.webcitation.org/71yXmokmR).
- Harris Geospatial Solutions Inc. Texture Metrics Background. Available online: http://www.harrisgeospatial.com/docs/backgroundtexturemetrics.html (accessed on 13 September 2018). (Archived by WebCite® at http://www.webcitation.org/71yXqA6AW).
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors. 2018, 18, 18. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Vapnik, V.N.; Chapelle, O. Bounds on error expectation for support vector machines. Neural Comput. 2000, 12, 2013–2036. [Google Scholar] [CrossRef] [PubMed]
- Keerthi, S.S.; Lin, C.-J. Asymptotic behaviors of support vector machines with gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei, Taiwan, 2003–2016; Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 13 September 2018).
- Salk, C.; Fritz, S.; See, L.; Dresel, C.; McCallum, I. An exploration of some pitfalls of thematic map assessment using the new map tools resource. Remote Sens. 2018, 10, 376. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Agresti, A.; Min, Y. Effects and non-effects of paired identical observations in comparing proportions with binary matched-pairs data. Stat. Med. 2004, 23, 65–75. [Google Scholar] [CrossRef] [PubMed]
- Radoux, J.; Bogaert, P. Good practices for object-based accuracy assessment. Remote Sens. 2017, 9, 646. [Google Scholar] [CrossRef]
- Stehman, S. V Statistical rigor and practical utility in thematic map accuracy assessment. ISPRS J. Photogramm. Remote Sens. 2001, 67, 727–734. [Google Scholar]
- Cai, L.; Shi, W.; Miao, Z.; Hao, M. Accuracy assessment measures for object extraction from remote sensing images. Remote Sens. 2018, 10, 303. [Google Scholar] [CrossRef]
- Marceau, D.J.; Howarth, P.J.; Dubois, J.M.; Gratton, D.J. Evaluation of the grey-level co-occurrence matrix method for land-cover classification using SPOT imagery. IEEE Trans. Geosci. Remote Sens. 1990, 28, 513–519. [Google Scholar] [CrossRef]
- Hay, G.J.; Niemann, K.O.; McLean, G.F. An object-specific image-texture analysis of H-resolution forest imagery. Remote Sens. Environ. 1996, 55, 108–122. [Google Scholar] [CrossRef]
- Berard, G.M.; Cloutis, E.A.; Mann, P. Leaf reflectance and transmission properties (350–2500 nm): Implications for vegetation indices. J. Near Infrared Spectrosc. 2017, 25, 138–144. [Google Scholar] [CrossRef]
- Ardila, J.P.; Bijker, W.; Tolpekin, V.A.; Stein, A. Quantification of crown changes and change uncertainty of trees in an urban environment. ISPRS J. Photogramm. Remote Sens. 2012, 74, 41–55. [Google Scholar] [CrossRef]
- Shorter, N.; Kasparis, T. Automatic vegetation identification and building detection from a single nadir aerial image. Remote Sens. 2009, 1, 731–757. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Variance | Band Contributions (Factor Loadings) | ||||
|---|---|---|---|---|---|---|
| Total | Cumulative | Red | Green | Blue | NIR | |
| PC1 | 82.9% | 82.9% | 32% | 27% | 30% | 10% |
| PC2 | 16.0% | 98.9% | 0% | 2% | 12% | 86% |
| PC3 | 0.9% | 99.8% | 61% | 2% | 34% | 3% |
| PC4 | 0.2% | 100.0% | 6% | 69% | 24% | 1% |
| Attribute | Type 1 | Description/Equation 3,4 | |
|---|---|---|---|
| Mean | Spectral | Mean of values | |
| Maximum | Spectral | Maximum of values | |
| Minimum | Spectral | Minimum of values | |
| Standard deviation | Spectral | Standard deviation of values | |
| Range | Texture 2 | Average of kernel range values | |
| Mean | Texture 2 | Average of kernel mean values | |
| Variance | Texture 2 | Average of kernel variance values | |
| Entropy | Texture 2 | Average of kernel entropy values, where | |
| (2) | |||
| Area | Spatial | Total area within object less area within any holes | |
| Length | Spatial | Length of object perimeter and perimeters of any holes | |
| Compactness | Spatial | (3) | |
| Convexity | Spatial | (4) | |
| Solidity | Spatial | (5) | |
| Roundness | Spatial | (6) | |
| Form factor | Spatial | (7) | |
| Elongation | Spatial | (8) | |
| Rectangular fit | Spatial | (9) | |
| Main direction | Spatial | Angle subtended by major axis and x-axis (degrees) | |
| Major length | Spatial | Major axis length for an oriented bounding box | |
| Minor length | Spatial | Minor axis length for an oriented bounding box | |
| Holes | Spatial | Number of holes | |
| Hole solid ratio | Spatial | (10) | |
| Detailed Classes | Simplified Classes |
|---|---|
| (V.1) Healthy vegetation | (V) Vegetation |
| (V.2) Senescing vegetation | |
| (V.3) Shadowed vegetation | |
| (N.4) Light grey rooftops | (N) Non-vegetation |
| (N.5) Dark grey rooftops | |
| (N.6) Red and brown rooftops | |
| (N.7) Concrete | |
| (N.8) Other impervious bright | |
| (N.9) Other impervious dark |
| Tags for Representing Roads | Tags Representing Areas Absent of Rooftops/VOR | ||||
|---|---|---|---|---|---|
| Key | Value | Key | Value | Key | Value |
| highway = | motorway | leisure = | park | natural = | wood |
| motorway_link | golf_course | water | |||
| secondary | sports_centre | scrub | |||
| secondary_link | pitch | landuse = | retail | ||
| tertiary | shop = | mall | recreation_ground | ||
| tertiary_link | amenity = | parking | industrial | ||
| service | school | military | |||
| residential | clinic | cemetery | |||
| unclassified 1 | waterway = | riverbank | brownfield | ||
| Detailed Class Label | Total No. of Reference Objects (# Pixels) | No. of Training Objects (# Pixels) | No. of Test Objects (# Pixels) | No. of Over-Rooftop Test Objects (# Pixels) |
|---|---|---|---|---|
| (V.1) Healthy vegetation | 557 (43,709) | 278 (20,737) | 279 (22,972) | 43 (3819) |
| (V.2) Senescing vegetation | 237 (23,327) | 119 (12,212) | 118 (11,115) | 14 (1500) |
| (V.3) Shadowed vegetation | 97 (8451) | 49 (4516) | 48 (3935) | 7 (762) |
| (N.4) Light grey rooftops | 54 (15,213) | 27 (6794) | 27 (8419) | 15 (5063) |
| (N.5) Dark grey rooftops | 51 (21,031) | 26 (9768) | 25 (11,263) | 13 (6705) |
| (N.6) Red and brown rooftops | 25 (3384) | 12 (1417) | 13 (1967) | 5 (1067) |
| (N.7) Concrete | 121 (7943) | 60 (4110) | 61 (3833) | 11 (811) |
| (N.8) Other impervious bright | 128 (16,277) | 64 (8433) | 64 (7844) | 8 (1077) |
| (N.9) Other impervious dark | 74 (5713) | 37 (2935) | 37 (2778) | 6 (619) |
| Total | 1344 (145,048) | 672 (74,126) | 672 (70,922) | 122 (21,423) |
| M86—Detailed: | Reference Class Labels—Full-Scene | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Predicted Class Labels | V.1 | V.2 | V.3 | N.4 | N.5 | N.6 | N.7 | N.8 | N.9 |
| (V.1) Healthy vegetation | 232 | 33 | 4 | 0 | 1 | 0 | 1 | 1 | 7 |
| (V.2) Senescing vegetation | 26 | 82 | 0 | 0 | 0 | 0 | 0 | 5 | 5 |
| (V.3) Shadowed vegetation | 7 | 0 | 41 | 0 | 0 | 0 | 0 | 0 | 0 |
| (N.4) Light grey rooftops | 0 | 0 | 0 | 12 | 1 | 0 | 8 | 5 | 1 |
| (N.5) Dark grey rooftops | 1 | 2 | 0 | 0 | 12 | 1 | 1 | 1 | 7 |
| (N.6) Red and brown rooftops | 2 | 2 | 0 | 0 | 2 | 4 | 1 | 1 | 1 |
| (N.7) Concrete | 4 | 5 | 0 | 1 | 4 | 0 | 30 | 15 | 2 |
| (N.8) Other impervious bright | 7 | 5 | 0 | 9 | 0 | 4 | 6 | 30 | 3 |
| (N.9) Other impervious dark | 6 | 5 | 2 | 0 | 4 | 3 | 2 | 2 | 13 |
| Producer’s Accuracy | 81% | 61% | 87% | 55% | 50% | 33% | 61% | 50% | 33% |
| Producer’s Accuracy Variance | 4% | 7% | 9% | 18% | 17% | 24% | 12% | 11% | 13% |
| User’s Accuracy | 83% | 69% | 85% | 44% | 48% | 31% | 49% | 47% | 35% |
| User’s Accuracy Variance | 4% | 8% | 10% | 19% | 20% | 26% | 13% | 12% | 16% |
| Overall Accuracy | 67.9% | ||||||||
| Overall Accuracy Variance | 3.3% | ||||||||
| M9—Detailed: | Reference Class Labels—Full-Scene | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Predicted Class Labels | V.1 | V.2 | V.3 | N.4 | N.5 | N.6 | N.7 | N.8 | N.9 |
| (V.1) Healthy vegetation | 243 | 21 | 3 | 0 | 0 | 0 | 6 | 0 | 6 |
| (V.2) Senescing vegetation | 27 | 82 | 0 | 0 | 0 | 0 | 2 | 3 | 4 |
| (V.3) Shadowed vegetation | 3 | 0 | 45 | 0 | 0 | 0 | 0 | 0 | 0 |
| (N.4) Light grey rooftops | 1 | 0 | 0 | 12 | 0 | 0 | 6 | 7 | 1 |
| (N.5) Dark grey rooftops | 4 | 0 | 0 | 0 | 10 | 0 | 1 | 3 | 7 |
| (N.6) Red and brown rooftops | 1 | 1 | 0 | 0 | 0 | 4 | 0 | 6 | 1 |
| (N.7) Concrete | 5 | 4 | 0 | 4 | 3 | 0 | 29 | 15 | 1 |
| (N.8) Other impervious bright | 4 | 11 | 0 | 11 | 1 | 2 | 6 | 28 | 1 |
| (N.9) Other impervious dark | 11 | 2 | 1 | 0 | 4 | 2 | 2 | 3 | 12 |
| Producer’s Accuracy | 81% | 68% | 92% | 44% | 56% | 50% | 56% | 43% | 36% |
| Producer’s Accuracy Variance | 4% | 7% | 7% | 16% | 21% | 32% | 12% | 10% | 14% |
| User’s Accuracy | 87% | 69% | 94% | 44% | 40% | 31% | 48% | 44% | 32% |
| User’s Accuracy Variance | 4% | 8% | 7% | 19% | 20% | 26% | 13% | 12% | 15% |
| Overall Accuracy | 69.2% | ||||||||
| Overall Accuracy Variance | 3.1% | ||||||||
| M86—Simplified: | Reference Class Labels | |||
|---|---|---|---|---|
| Full-Scene | Over Rooftops Only | |||
| Predicted Class Labels | V | N | V | N |
| (V) Vegetation | 425 | 20 | 57 | 7 |
| (N) Non-vegetation | 41 | 186 | 3 | 55 |
| Producer’s Accuracy | 91% | 90% | 95% | 89% |
| Producer’s Accuracy Variance | 2% | 4% | 5% | 7% |
| User’s Accuracy | 96% | 82% | 89% | 95% |
| User’s Accuracy Variance | 2% | 5% | 8% | 6% |
| Overall Accuracy | 90.9% | 91.8% | ||
| Overall Accuracy Variance | 2.1% | 4.9% | ||
| M9—Simplified: | Reference Class Labels | |||
|---|---|---|---|---|
| Full-Scene | Over Rooftops Only | |||
| Predicted Class Labels | V | N | V | N |
| (V) Vegetation | 424 | 21 | 57 | 7 |
| (N) Non-vegetation | 45 | 182 | 7 | 51 |
| Producer’s Accuracy | 90% | 90% | 89% | 88% |
| Producer’s Accuracy Variance | 2% | 4% | 7% | 8% |
| User’s Accuracy | 95% | 80% | 89% | 88% |
| User’s Accuracy Variance | 2% | 5% | 8% | 8% |
| Overall Accuracy | 90.2% | 88.5% | ||
| Overall Accuracy Variance | 2.2% | 5.7% | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Griffith, D.C.; Hay, G.J. Integrating GEOBIA, Machine Learning, and Volunteered Geographic Information to Map Vegetation over Rooftops. ISPRS Int. J. Geo-Inf. 2018, 7, 462. https://doi.org/10.3390/ijgi7120462
Griffith DC, Hay GJ. Integrating GEOBIA, Machine Learning, and Volunteered Geographic Information to Map Vegetation over Rooftops. ISPRS International Journal of Geo-Information. 2018; 7(12):462. https://doi.org/10.3390/ijgi7120462
Chicago/Turabian StyleGriffith, David C., and Geoffrey J. Hay. 2018. "Integrating GEOBIA, Machine Learning, and Volunteered Geographic Information to Map Vegetation over Rooftops" ISPRS International Journal of Geo-Information 7, no. 12: 462. https://doi.org/10.3390/ijgi7120462
APA StyleGriffith, D. C., & Hay, G. J. (2018). Integrating GEOBIA, Machine Learning, and Volunteered Geographic Information to Map Vegetation over Rooftops. ISPRS International Journal of Geo-Information, 7(12), 462. https://doi.org/10.3390/ijgi7120462