AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generation at the Ground Segment as Broad Context



Abstract
1. Introduction
- (i)
- a single-date multi-spectral (MS) image, radiometrically corrected for atmospheric, adjacency and topographic effects,
- (ii)
- stacked with its data-derived scene classification map (SCM), whose general-purpose, user- and application-independent thematic map legend includes quality layers cloud and cloud–shadow,
- (iii)
- to be systematically generated at the ground segment, automatically (without human–machine interaction) and in near real-time.
- outcome and process requirements specification, including computational complexity estimation,
- information/knowledge representation,
- system design (architecture),
- algorithm, and
- implementation.
- (i)
- “Fully automated”, i.e., no human–machine interaction and no labeled data set for supervised inductive learning-from-data are required by the system to run, which reduces timeliness, which is the time span from EO data acquisition to EO data-derived VAPS generation, as well as costs in manpower (e.g., to collect training data) and computer power (no training time is required).
- (ii)
- Near real-time, e.g., computational complexity increases linearly with image size.
- (iii)
- Robust to changes in input sensory data acquired across space, time and sensors.
- (iv)
- Scalable to changes in MS imaging sensor’s spatial and spectral resolution specifications.
- (v)
- Last but not least, AutoCloud+ must be eligible for use in multi-sensor, multi-temporal and multi-angular EO big data cubes, either radiometrically uncalibrated, such as MS images typically acquired without radiometric Cal metadata files by small satellites [84] or small unmanned aerial vehicles (UAVs) [85], or radiometrically calibrated into TOARF, SURF or surface albedo values in agreement with the GEO-CEOS QA4EO Cal/Val requirements [3].
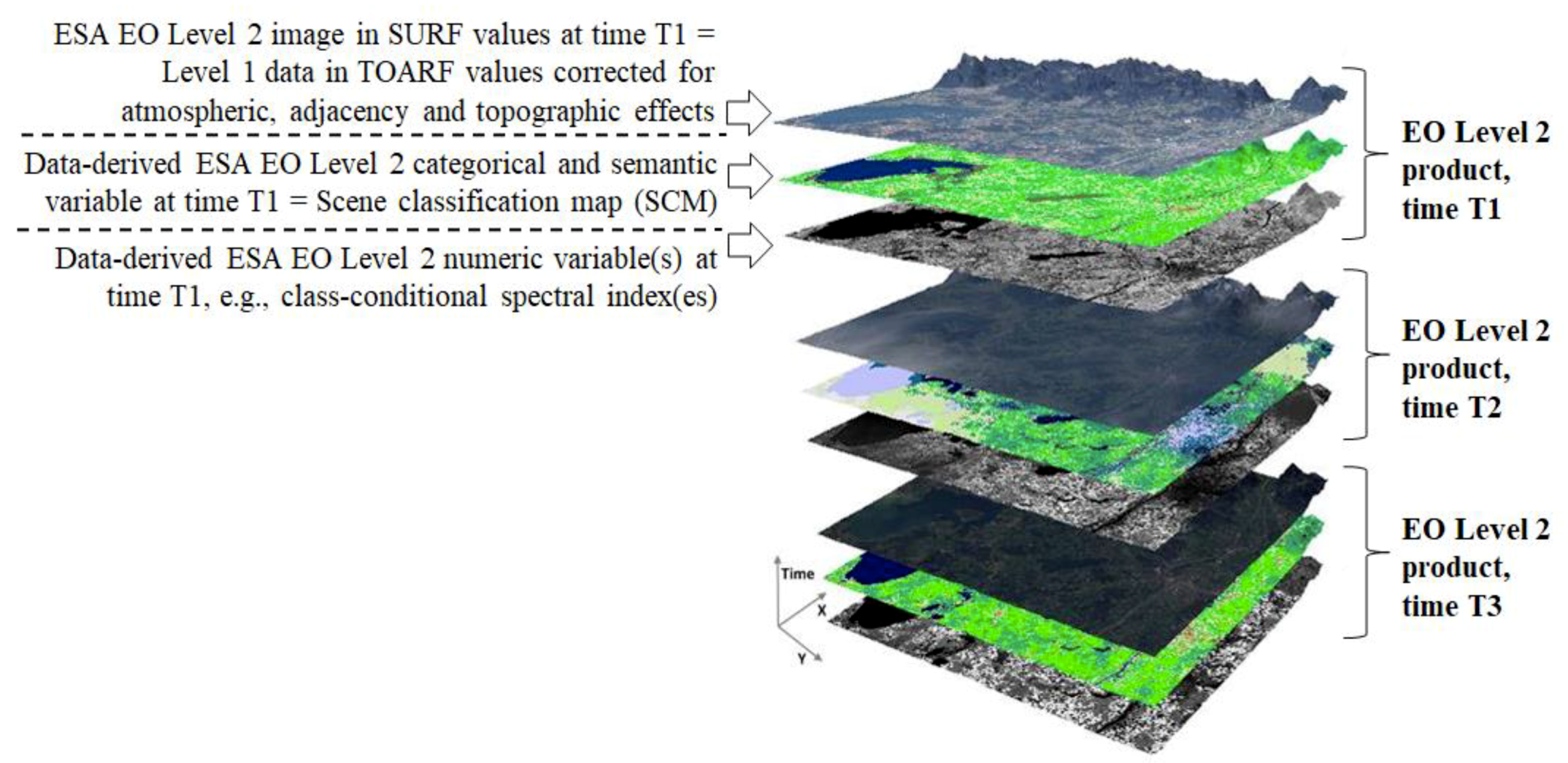
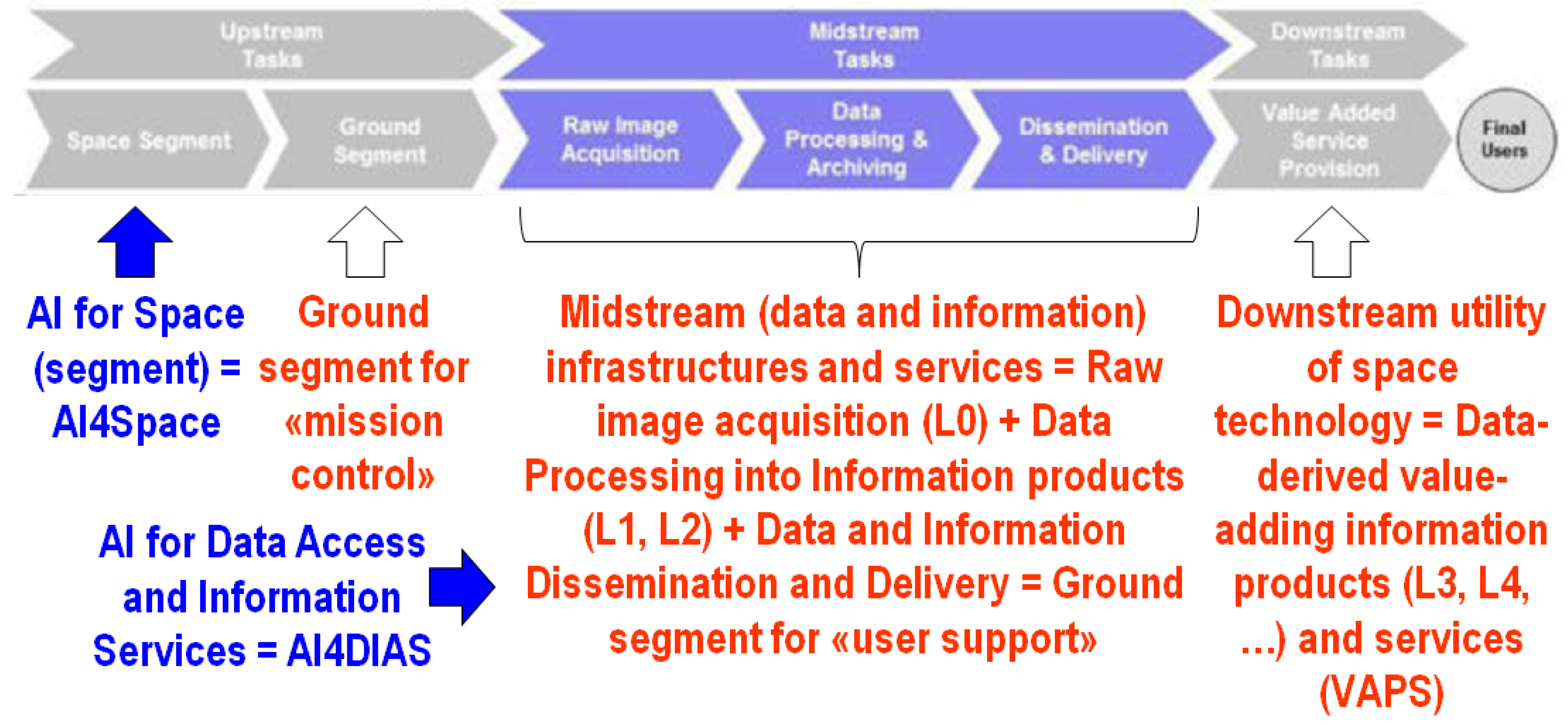
2. Systematic ESA EO Level 2 Information Product Generation as a Broad Context of Cloud/Cloud–Shadow Quality Layers Detection in a Cognitive Science Domain
- (i)
- Degree of automation, inversely related to human–machine interaction, e.g., inversely related to the number of system’s free-parameters to be user-defined based on heuristics.
- (ii)
- Effectiveness, e.g., thematic mapping accuracy.
- (iii)
- Efficiency in computation time and in run-time memory occupation.
- (iv)
- Robustness (vice versa, sensitivity) to changes in input data.
- (v)
- Robustness to changes in input parameters to be user-defined.
- (vi)
- Scalability to changes in user requirements and in sensor specifications.
- (vii)
- Timeliness from data acquisition to information product generation.
- (viii)
- Costs in manpower and computer power.
- (ix)
- Value, e.g., semantic value of output products, economic value of output services, etc.
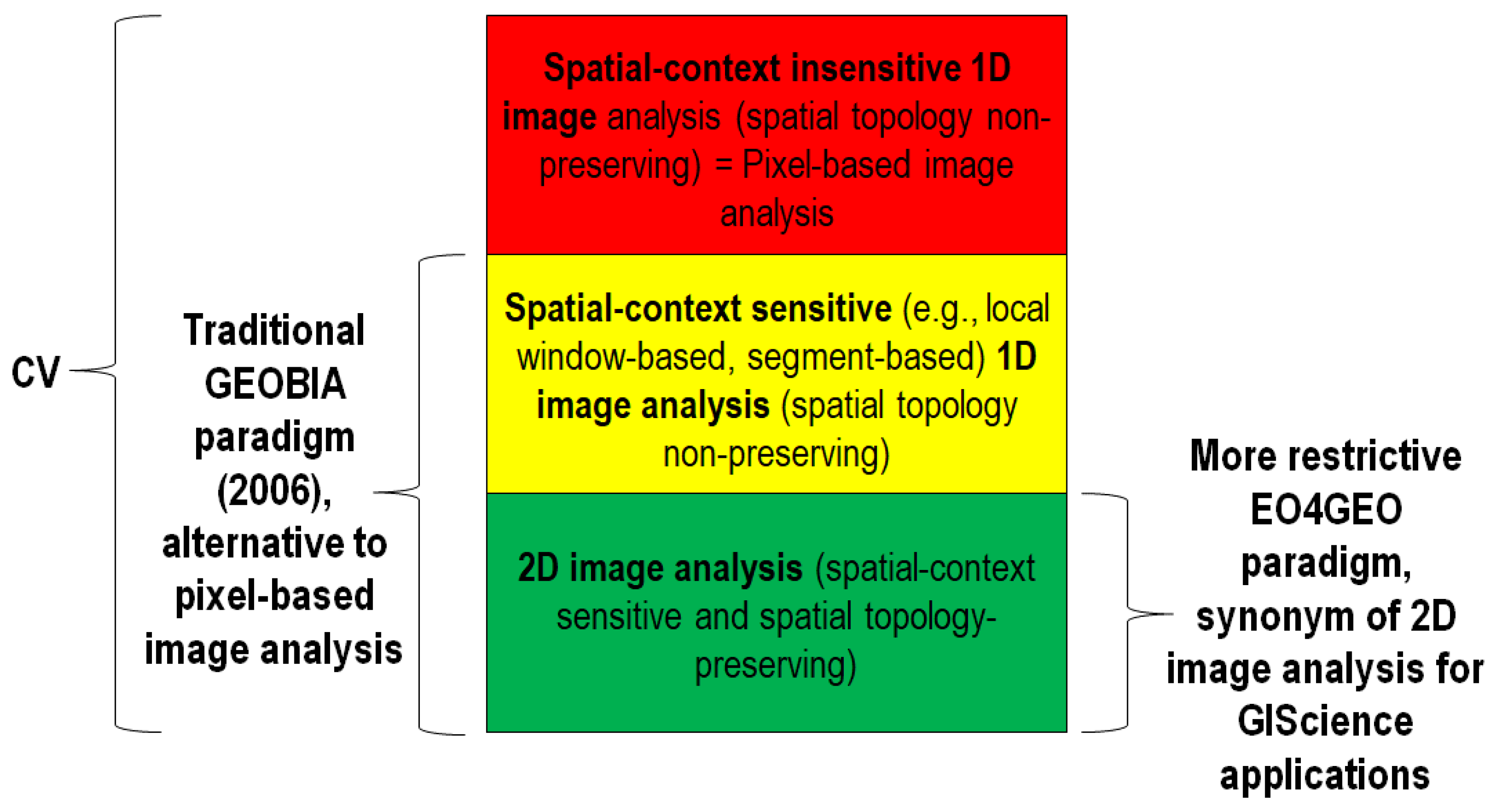
If a chromatic CV ⊃ EO-IU system does not down-scale seamlessly to achromatic image analysis, then it tends to ignore the paramount spatial information in favor of subordinate (secondary) spatial context-insensitive color information, such as MS signatures typically investigated in traditional pixel-based single-date or multi-temporal EO-IU algorithms. In other words, a necessary and sufficient condition for a CV ⊃ EO-IU system to fully exploit primary spatial topological information (e.g., adjacency, inclusion, etc.) and spatial non-topological information (e.g., spatial distance, angle distance) components, in addition to secondary colorimetric information, is to perform nearly as well when input with either panchromatic or color imagery.[13]
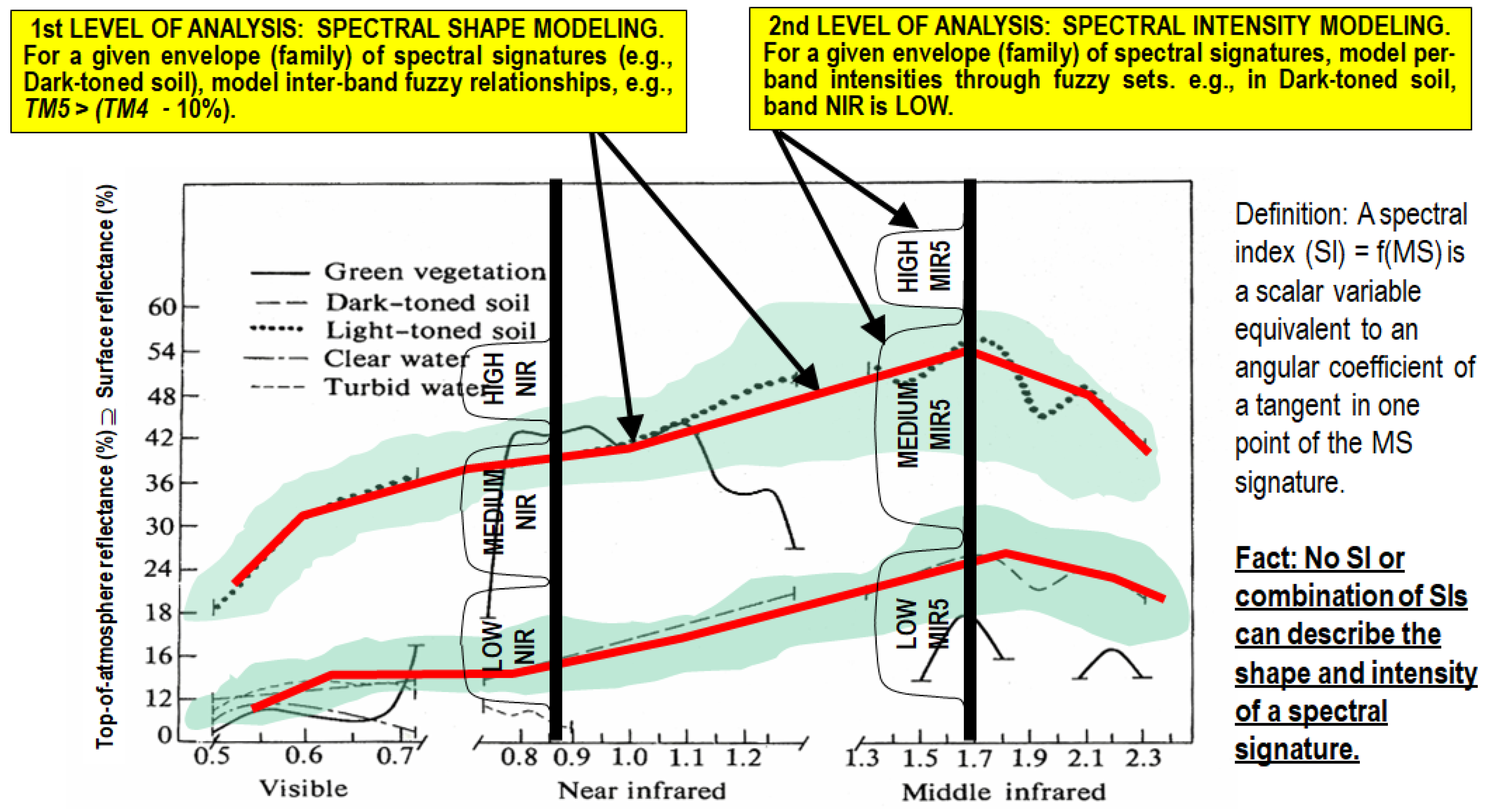
- Well-known in statistics, the principle of statistic stratification states that “stratification will always achieve greater precision provided that the strata have been chosen so that members of the same stratum are as similar as possible in respect of the characteristic of interest” [152].
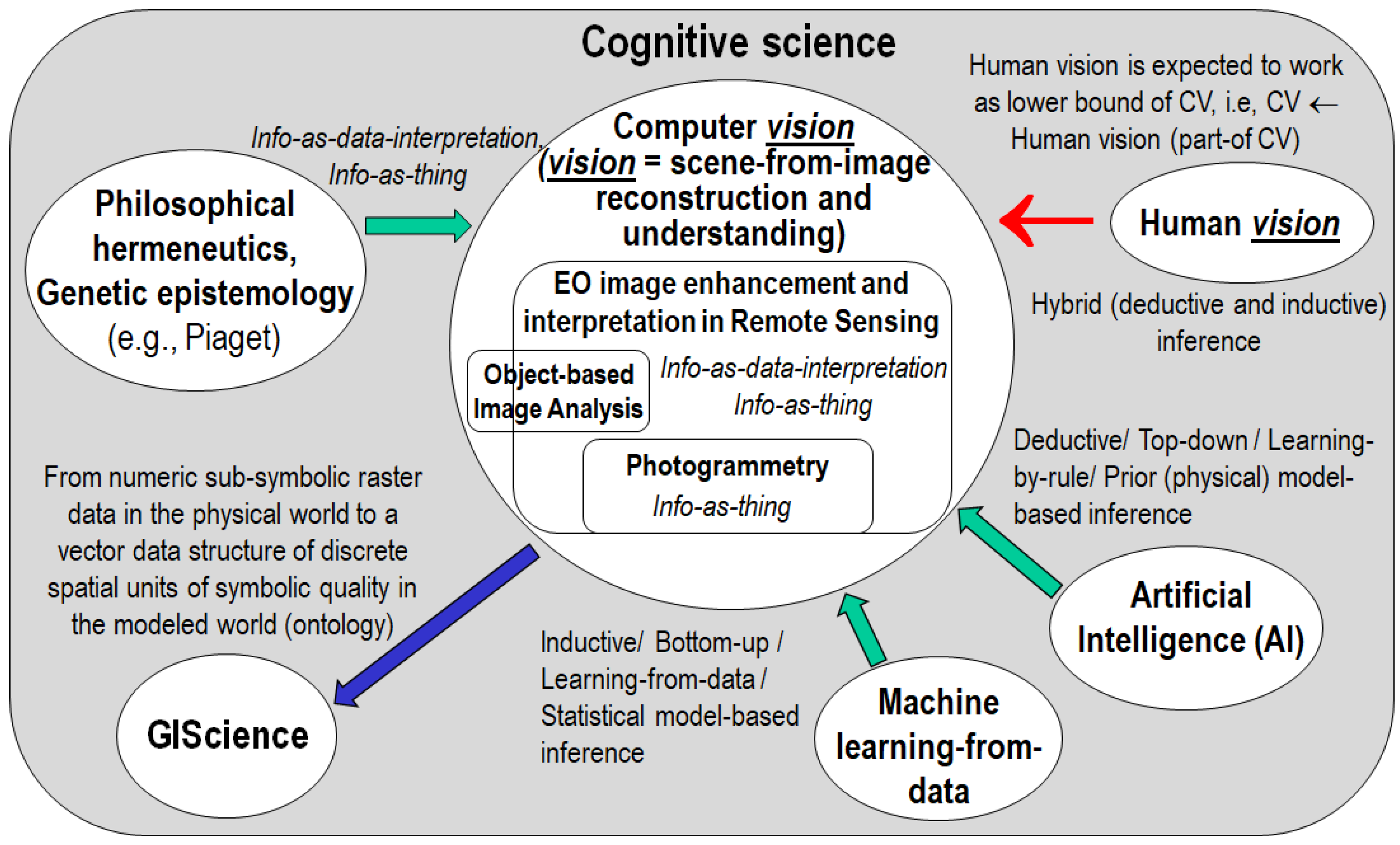
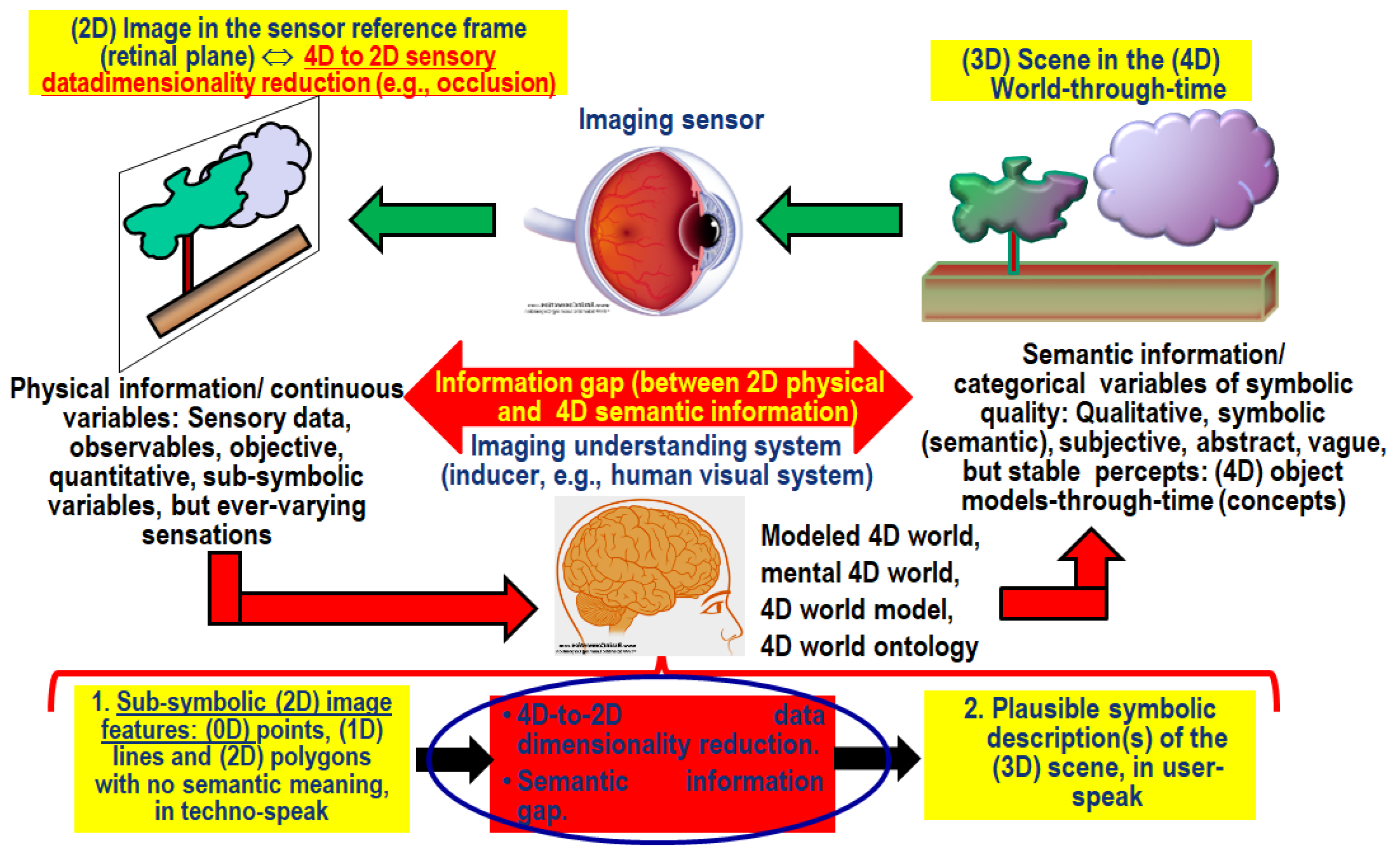
- A Bayesian approach to CV, where driven-without-knowledge (unconditional) data analytics is replaced by driven-by-(prior) knowledge (class-conditional, masked) data analytics [76,122,153,154]. In the words of Quinlan: “one of David Marr’s key is the notion of constraints. The idea that the human visual system embodies constraints that reflect properties of the world is foundational. Indeed, this general view seemed (to me) to provide a sensible way of thinking about Bayesian approaches to vision. Accordingly, Bayesian priors are Marr’s constraints. The priors/constraints have been incorporated into the human visual system over the course of its evolutionary history (according to the “levels of understanding of an information processing system” manifesto proposed by Marr and extended by Tomaso Poggio in 2012)” [153,154]. In agreement with a Bayesian approach to CV, our working hypothesis, shown in Figure 4, postulates that CV includes a computational model of human vision [13,76,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104], i.e., ‘Human vision → CV’. In practice, a CV system is constrained to comply with human visual perception. This CV requirement agrees with common sense, although it is largely oversighted in the RS and CV literature. In the words of Marcus: “there is no need for machines to literally replicate the human mind, which is, after all, deeply error prone, and far from perfect. But there remain many areas, from natural language understanding to commonsense reasoning, in which humans still retain a clear advantage. Learning the mechanisms underlying those human strengths could lead to advances in AI, even if the goal is not, and should not be, an exact replica of human brain. For many people, learning from humans means neuroscience; in my view, that may be premature. We do not yet know enough about neuroscience to literally reverse engineer the brain, per se, and may not for several decades, possibly until AI itself gets better. AI can help us to decipher the brain, rather than the other way around. Either way, in the meantime, it should certainly be possible to use techniques and insights drawn from cognitive and developmental psychology, now, in order to build more robust and comprehensive AI, building models that are motivated not just by mathematics but also by clues from the strengths of human psychology” [30]. According to Iqbal and Aggarwal: “frequently, no claim is made about the pertinence or adequacy of the digital models as embodied by computer algorithms to the proper model of human visual perception... This enigmatic situation arises because research and development in computer vision is often considered quite separate from research into the functioning of human vision. A fact that is generally ignored, is that biological vision is currently the only measure of the incompleteness of the current stage of computer vision, and illustrates that the problem is still open to solution” [155]. For example, according to Pessoa, “if we require that a CV system should be able to predict perceptual effects, such as the well-known Mach bands illusion where bright and dark bands are seen at ramp edges, then the number of published vision models becomes surprisingly small” [156], see Figure 9. In the words of Serre, “there is growing consensus that optical illusions are not a bug but a feature. I think they are a feature. They may represent edge cases for our visual system, but our vision is so powerful in day-to-day life and in recognizing objects" [97,98]. For example, to account for contextual optical illusions, Serre introduced innovative feedback connections between neurons within a layer [97,98], whereas typical DCNNs [34,35,36,37,38] feature feedforward connections exclusively. In the CV and RS common practice, constraint ‘Human vision → CV’ is a viable alternative to heuristics typically adopted to constrain inherently ill-posed inductive learning-from-data algorithms, where a priori knowledge is typically encoded by design based on empirical criteria [30,33,64]. For example, designed and trained end-to-end for either object detection [36], semantic segmentation [37] or instance segmentation [38], state-of-the-art DCNNs [34] encode a priori knowledge by design, where architectural metaparameters must be user-defined based on heuristics. In inductive DCNNs trained end-to-end, number of layers, number of filters per layer, spatial filter size, inter-filter spatial stride, local filter size for spatial pooling, spatial pooling filter stride, etc., are typically user-defined based on empirical trial-and-error strategies. As a result, inductive DCNNs work as heuristic black boxes [30,64], whose opacity contradicts the well-known engineering principles of modularity, regularity and hierarchy typical of scalable systems [39]. In general, inductive learning-from-data algorithms are inherently semi-automatic (requiring system’s free-parameters to be user-defined based on heuristics, including architectural metaparameters) and site-specific (data-dependent) [2]. "No Free Lunch” theorems have shown that inductive learning-from-data algorithms cannot be universally good [40,41].
3. Related Works in Cloud and Cloud–Shadow Quality Layers Detection
- The single-date multi-sensor FMask open source algorithm [58], originally developed for single-date 30 m resolution 7-band (from visible blue, B, to thermal InfraRed, TIR) Landsat-5/7/8 MS imagery, which includes a thermal band as key input data requirement. FMask was recently extended to 10 m/20 m resolution Sentinel-2 MS imagery [59], featuring no thermal band, and to Landsat image time-series (multiTemporal Mask, TMask) [60]. The potential relevance of FMask is augmented by considering that CFmask, an Fmask program version transcoded into the C programming language for increased efficiency, is adopted for cloud, cloud–shadow and snow/ice classification by the LEDAPS and LaSRC algorithms for atmospheric correction in the U.S. Landsat ARD product [139,140,141,142,143]. Unfortunately, CFMask is affected by known artifacts [63]. Moreover, in a recent comparison of cloud and cloud–shadow detectors, those implemented in LEDAPS scored low among alternative solutions [62].
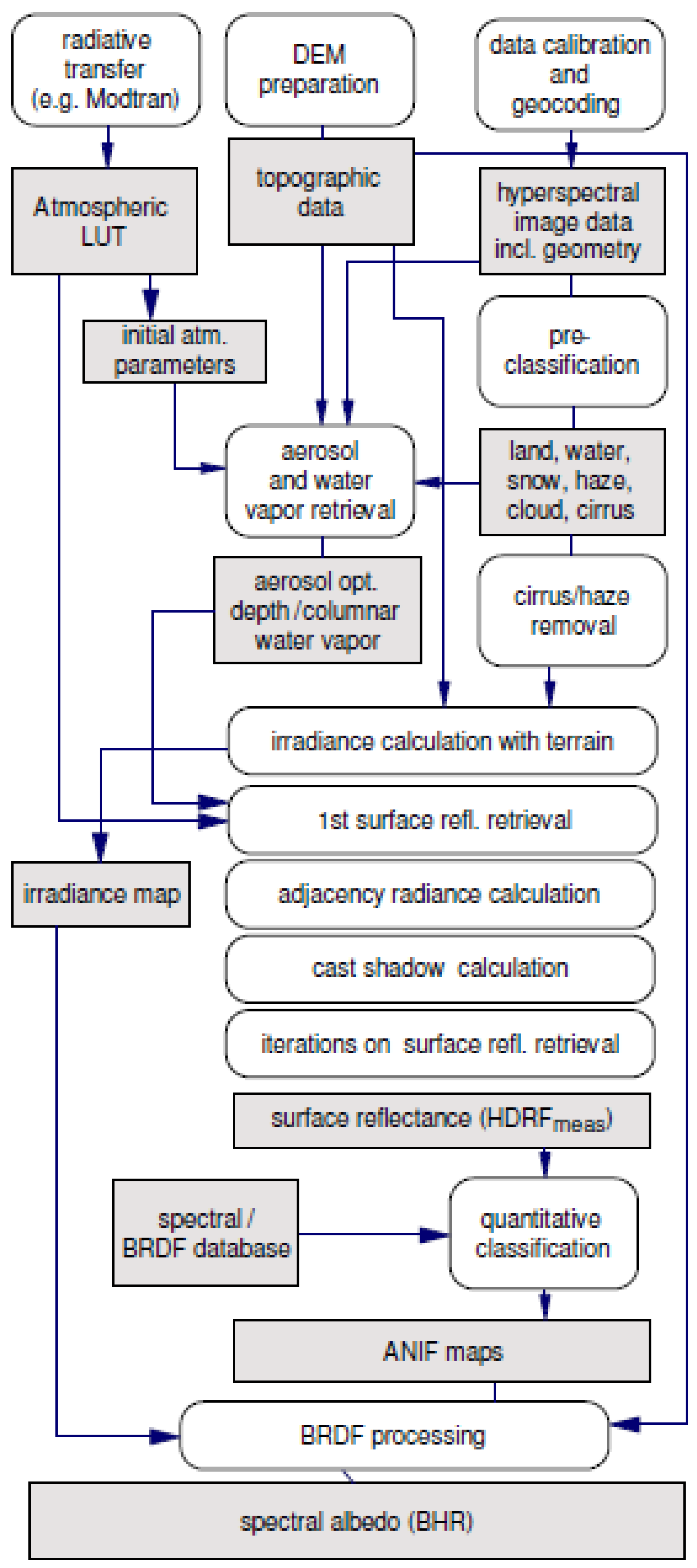
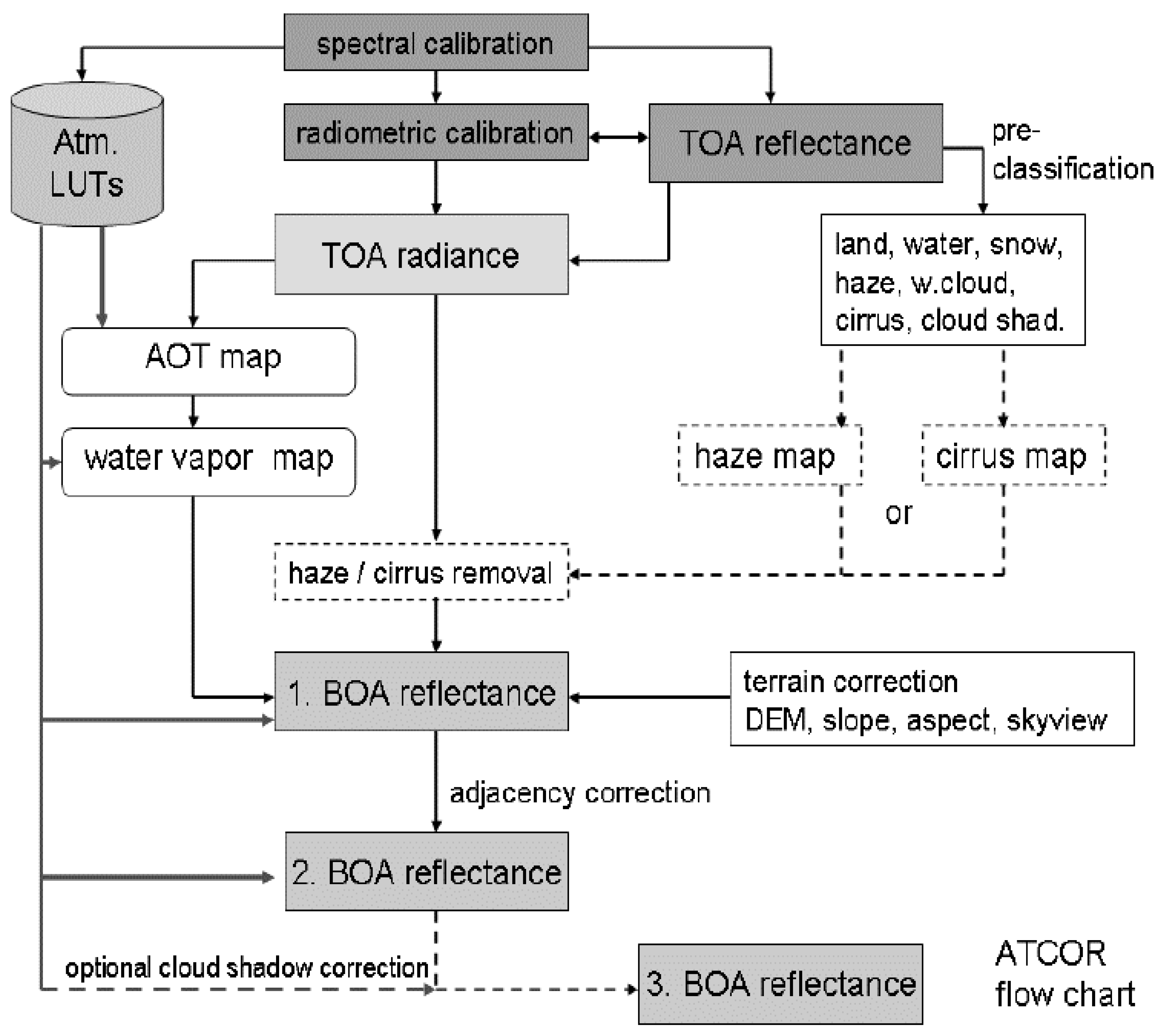
- The single-date single-sensor ESA Sen2Cor prototype processor, capable of automated atmospheric, adjacency and topographic effect correction and SCM product generation, including cloud and cloud–shadow detection (refer to the SCM legend shown in Table 1), whose input is an ESA EO Level 1 image, radiometrically calibrated into TOARF values, originally acquired at Level 0 (in dimensionless DNs provided with no radiometric unit of measure) by the ESA Sentinel-2 Multi-Spectral Instrument (MSI) exclusively. The ESA Sen2Cor prototype processor is distributed free-of-cost by ESA to be run on the user side [11,12]. Hence, it does not satisfy the ESA EO Level 2 product requirements specification proposed in Section 1. ESA Sen2Cor incorporates capabilities of the ATCOR commercial software toolbox [71,72,73], see Figure 11. ESA Sen2Cor is affected by known artifacts [44,47,61], which may be inherited at least in part from ATCOR.
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
- AI: Artificial general Intelligence
- AI4DIAS: Artificial Intelligence for Data and Information Access Services (at the ground segment)
- AI4Space: Artificial Intelligence for Space (segment)
- ARD: Analysis Ready Data (format)
- ATCOR: Atmospheric/Topographic Correction commercial sofwtare product
- AVHRR: Advanced Very High Resolution Radiometer
- BC: Basic Color
- BIVRFTAB: Bivariate Frequency Table
- Cal: Calibration
- Cal/Val: Calibration and Validation
- CBIR: Content-Based Image Retrieval
- CEOS: Committee on Earth Observation Satellites
- CESBIO: Centre d’Etudes Spatiales de la Biosphère
- CFMask: C (programming language version of) Function of Mask
- CLC: CORINE Land Cover (taxonomy)
- CNES: Centre national d’études spatiales
- CNN: Convolutional Neural Network
- CORINE: Coordination of Information on the Environment
- CV: Computer Vision
- DCNN: Deep Convolutional Neural Network
- DEM: Digital Elevation Model
- DIAS: Data and Information Access Services
- DLR: Deutsches Zentrum für Luft- und Raumfahrt (German Aerospace Center)
- DN: Digital Number
- DP: Dichotomous Phase (in the FAO LCCS taxonomy)
- DRIP: Data-Rich, Information-Poor (syndrome)
- EO: Earth Observation
- EO-IU: EO Image Understanding
- EO-IU4SQ: EO Image Understanding for Semantic Querying
- ESA: European Space Agency
- FAO: Food and Agriculture Organization
- FIEOS: Future Intelligent EO imaging Satellites
- FMask: Function of Mask
- GEO: Intergovernmental Group on Earth Observations
- GEOSS: Global EO System of Systems
- GIGO: Garbage In, Garbage Out principle of error propagation
- GIS: Geographic Information System
- GIScience: Geographic Information Science
- GUI: Graphic User Interface
- IGBP: International Global Biosphere Programme
- IoU: Intersection over Union
- IU: Image Understanding
- LAI: Leaf Area Index
- LC: Land Cover
- LCC: Land Cover Change
- LCCS: Land Cover Classification System (taxonomy)
- LCLU: Land Cover Land Use
- LEDAPS: Landsat Ecosystem Disturbance Adaptive Processing System
- MAACS: Multisensor Atmospheric Correction and Cloud Screening
- MAJA: Multisensor Atmospheric Correction and Cloud Screening (MACCS)-Atmospheric/Topographic Correction (ATCOR) Joint Algorithm
- mDMI: Minimally Dependent and Maximally Informative (set of quality indicators)
- MHP: Modular Hierarchical Phase (in the FAO LCCS taxonomy)
- MIR: Medium InfraRed
- MODIS: Moderate Resolution Imaging Spectroradiometer
- MS: Multi-Spectral
- MSI: (Sentinel-2) Multi-Spectral Instrument
- NASA: National Aeronautics and Space Administration
- NIR: Near InfraRed
- NLCD: National Land Cover Data
- NOAA: National Oceanic and Atmospheric Administration
- NP: Non-deterministic Polynomial
- OBIA: Object-Based Image Analysis
- OGC: Open Geospatial Consortium
- OP: Outcome (product) and Process
- OP-Q2I: Outcome and Process Quantitative Quality Index
- QA4EO: Quality Accuracy Framework for Earth Observation
- Q2I: Quantitative Quality Indicator
- RGB: monitor-typical Red-Green-Blue data cube
- RMSE: Root Mean Square Error
- RS: Remote Sensing
- RTD: Research and Technological Development
- SCBIR: Semantic Content-Based Image Retrieval
- SCM: Scene Classification Map
- SEIKD: Semantics-Enabled Information/Knowledge Discovery
- Sen2Cor: Sentinel 2 (atmospheric, topographic and adjacency) Correction Prototype Processor
- SIAM™: Satellite Image Automatic Mapper™
- STRATCOR: Stratified Topographic Correction
- SURF: Surface Reflectance
- TIR: Thermal InfraRed
- TM (superscript): (non-registered) Trademark
- TMask: Temporal Function of Mask
- TOA: Top-Of-Atmosphere
- TOARD: TOA Radiance
- TOARF: TOA Reflectance
- UAV: Unmanned Aerial Vehicle
- UML: Unified Modeling Language
- USGS: US Geological Survey
- Val: Validation
- VAPS: Value-Adding information Products and Services
- VQ: Vector Quantization
- WGCV: Working Group on Calibration and Validation
References
- Schaepman-Strub, G.; Schaepman, M.E.; Painter, T.H.; Dangel, S.; Martonchik, J.V. Reflectance quantities in optical remote sensing—Definitions and case studies. Remote Sens. Environ. 2006, 103, 27–42. [Google Scholar] [CrossRef]
- Liang, S. Quantitative Remote Sensing of Land Surfaces; John Wiley and Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Group on Earth Observation/Committee on Earth Observation Satellites (GEO-CEOS). A Quality Assurance Framework for Earth Observation, Version 4.0. 2010. Available online: http://qa4eo.org/docs/QA4EO_Principles_v4.0.pdf (accessed on 17 November 2018).
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Group on Earth Observation (GEO). The Global Earth Observation System of Systems (GEOSS) 10-Year Implementation Plan. 2005. Available online: http://www.earthobservations.org/docs/10-Year%20Implementation%20Plan.pdf (accessed on 19 January 2012).
- Ghosh, D.; Kaabouch, N. A Survey on Remote Sensing Scene Classification Algorithms. WSEAS Trans. Signal Proc. 2014, 10, 504–519. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S. Object based image analysis for automated information extraction-a synthesis. In Proceedings of the Measuring the Earth II ASPRS Fall Conference, San Antonio, CA, USA, 6–10 November 2006; pp. 6–10. [Google Scholar]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis–towards a new paradigm. ISPRS J. Photogram. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- European Space Agency (ESA). Sentinel-2 User Handbook, Standard Document; ESA: Paris, France, 2015. [Google Scholar]
- Deutsches Zentrum für Luft-und Raumfahrt e.V. (DLR); VEGA Technologies. Sentinel-2 MSI–Level 2A Products Algorithm Theoretical Basis Document; Document S2PAD-ATBD-0001; European Space Agency: Paris, France, 2011. [Google Scholar]
- Baraldi, A. Pre-Processing, Classification and Semantic Querying of Large-Scale Earth Observation Spaceborne/Airborne/Terrestrial Image Databases: Process and Product Innovations. Ph.D. Thesis, Agricultural and Food Sciences, Department of Agricultural Sciences, University of Naples “Federico II”, Naples, Italy, 2017. Available online: https://www.researchgate.net/publication/317333100_Pre-processing_classification_and_semantic_querying_of_large-scale_Earth_observation_spaceborneairborneterrestrial_image_databases_Process_and_product_innovations (accessed on 30 January 2018).
- Baraldi, A.; Humber, M.L.; Tiede, D.; Lang, S. GEO-CEOS stage 4 validation of the Satellite Image Automatic Mapper lightweight computer program for ESA Earth observation Level 2 product generation—Part 1: Theory. Cogent Geosci. 2018, 1467357. [Google Scholar] [CrossRef] [PubMed]
- Baraldi, A.; Humber, M.L.; Tiede, D.; Lang, S. GEO-CEOS stage 4 validation of the Satellite Image Automatic Mapper lightweight computer program for ESA Earth observation Level 2 product generation—Part 2: Validation. Cogent Geosci. 2018, 1467254. [Google Scholar] [CrossRef] [PubMed]
- Di Gregorio, A.; Jansen, L. Land Cover Classification System (LCCS): Classification Concepts and User Manual; FAO Corporate Document Repository; FAO: Rome, Italy, 2000; Available online: http://www.fao.org/DOCREP/003/X0596E/X0596e00.htm (accessed on 10 February 2012).
- Swain, P.H.; Davis, S.M. Remote Sensing: The Quantitative Approach; McGraw-Hill: New York, NY, USA, 1978. [Google Scholar]
- Capurro, R.; Hjørland, B. The concept of information. Annu. Rev. Inf. Sci. Technol. 2003, 37, 343–411. [Google Scholar] [CrossRef]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis and Machine Vision; Chapman & Hall: London, UK, 1994. [Google Scholar]
- Fonseca, F.; Egenhofer, M.; Agouris, P.; Camara, G. Using ontologies for integrated geographic information systems. Trans. GIS 2002, 6, 231–257. [Google Scholar] [CrossRef]
- Growe, S. Knowledge-based interpretation of multisensor and multitemporal remote sensing images. Int. Arch. Photogramm. Remote Sens. 1999, 32, 71. [Google Scholar]
- Laurini, R.; Thompson, D. Fundamentals of Spatial Information Systems; Academic Press: London, UK, 1992. [Google Scholar]
- Matsuyama, T.; Hwang, V.S. SIGMA–A Knowledge-Based Aerial Image Understanding System; Plenum Press: New York, NY, USA, 1990. [Google Scholar]
- Sowa, J. Knowledge Representation: Logical, Philosophical, and Computational Foundations; Brooks Cole Publishing Co.: Pacific Grove, CA, USA, 2000. [Google Scholar]
- Ahlqvist, O. Using uncertain conceptual spaces to translate between land cover categories. Int. J. Geogr. Inf. Sci. 2005, 19, 831–857. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide–Addendum 2000; Technical Report No. 40; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Lillesand, T.; Kiefer, R. Remote Sensing and Image Interpretation; John Wiley & Sons: New York, NY, USA, 1979. [Google Scholar]
- Belward, A. (Ed.) The IGBP-DIS Global 1 Km Land Cover Data Set “DISCover”: Proposal and Implementation Plans; IGBP-DIS Working Paper 13; International Geosphere Biosphere Programme, European Commission Joint Research Center, ISPRA: Varese, Italy, 1996. [Google Scholar]
- Dumitru, C.O.; Cui, S.; Schwarz, G.; Datcu, M. Information content of very-high-resolution SAR images: Semantics, geospatial context, and ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1635–1650. [Google Scholar] [CrossRef]
- Marcus, G. Deep Learning: A Critical Appraisal. arXiv, 2018; arXiv:1801.00631. Available online: https://arxiv.org/ftp/arxiv/papers/1801/1801.00631.pdf (accessed on 16 January 2018).
- Land Change Science; Gutman, G., Janetos, A.C., Justice, C.O., Moran, E.F., Mustard, J.F., Rindfuss, R.R., Skole, D., Turner, B.L., Cochrane, M.A., Eds.; Kluwer: Dordrecht, The Netherlands, 2004. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Clarendon: Oxford, UK, 1995. [Google Scholar]
- Cherkassky, V.; Mulier, F. Learning from Data: Concepts, Theory, and Methods; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Vedaldi, A. Deep filter banks for texture recognition, description, and segmentation. Int. J. Comput. Vis. 2014. [Google Scholar] [CrossRef] [PubMed]
- Bartoš, M. Cloud and Shadow Detection in Satellite Imagery. Master’s Thesis, Computer Vision and Image Processing, Faculty of Electrical Engineering, Department of Cybernetics, Czech Technical University, Prague, Czech Republic, 2017. [Google Scholar]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- He, K.; Gkioxari, G.; Dol’ar, P.; Girshick, R. Mask R-CNN. arXiv, 2018; arXiv:1703.06870v3. [Google Scholar] [CrossRef] [PubMed]
- Lipson, H. Principles of modularity, regularity, and hierarchy for scalable systems. J. Biol. Phys. Chem. 2007, 7, 125–128. [Google Scholar] [CrossRef]
- Wolpert, D.H. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Zhaoxiang, Z.; Iwasaki, A.; Guodong, X.; Jianing, S. Small Satellite Cloud Detection Based on Deep Learning and Image Compression. Preprints 2018. Available online: https://www.preprints.org/manuscript/201802.0103/v1 (accessed on 7 August 2018).
- Baraldi, A. Automatic Spatial Context-Sensitive Cloud/Cloud-Shadow Detection in Multi-Source Multi-Spectral Earth Observation Images–AutoCloud+, Invitation to tender ESA/AO/1-8373/15/I-NB–VAE: Next Generation EObased Information Services. arXiv, 2015; arXiv:1701.04256. Available online: https://arxiv.org/ftp/arxiv/papers/1701/1701.04256.pdf (accessed on 8 January 2017).
- Gascon, F.; Bouzinac, C.; Thépaut, O.; Jung, M.; Francesconi, B.; Louis, J.; Lonjou, V.; Lafrance, B.; Massera, S.; Gaudel-Vacaresse, A.; et al. Copernicus Sentinel-2A Calibration and Products Validation Status. Remote Sens. 2017, 9, 584. [Google Scholar] [CrossRef]
- Goodwin, N.R.; Collett, L.J.; Denham, R.J.; Flood, N.; Tindall, D. Cloud and cloud-shadow screening across Queensland, Australia: An automated method for Landsat TM/ETM+ time series. Remote Sens. Environ. 2013, 134, 50–65. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Desjardins, C.; Auer, S.; Richter, R. MAJA Algorithm Theoretical Basis Document. 2017. Available online: https://zenodo.org/record/1209633#.W2ffFNIzZaQ (accessed on 17 November 2018).
- Hagolle, O.; Rouquié, B.; Desjardins, C.; Makarau, A.; Main-knorn, M.; Rochais, G.; Pug, B. Recent Advances in Cloud Detection and Atmospheric Correction Applied to Time Series of High Resolution Images. RAQRS, 19 September 2017. Available online: https://www.researchgate.net/profile/Olivier_Hagolle2/publication/320402521_Recent_advances_in_cloud_detection_and_atmospheric_correction_applied_to_time_series_of_high_resolution_images/links/59eeee074585154350e83669/Recent-advances-in-cloud-detection-and-atmospheric-correction-applied-to-time-series-of-high-resolution-images.pdf (accessed on 8 August 2018).
- Hagolle, O.; Huc, M.; Pascual, D.V.; Dedieu, G. A multi-temporal method for cloud detection, applied to FORMOSAT-2, VENμS, LANDSAT and SENTINEL-2 images. Remote Sens. Environ. 2010, 114, 1747–1755. [Google Scholar] [CrossRef]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-use methods for the detection of clouds, cirrus, snow, shadow, water and clear sky pixels in Sentinel-2 MSI images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef]
- Huang, C.; Thomas, N.; Goward, S.N.; Masek, J.G.; Zhu, Z.; Townshend, J.R.G.; Vogelmann, J.E. Automated masking of cloud and cloud shadow for forest change analysis using Landsat images. Int. J. Remote Sens. 2010, 31, 5449–5464. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ Automated Cloud-Cover Assessment (ACCA) Algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P. The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Khlopenkov, K.V.; Trishchenko, A.P. SPARC: New cloud, snow, and cloud shadow detection scheme for historical 1-km AVHHR data over Canada. J. Atmos. Ocean. Technol. 2007, 24, 322–343. [Google Scholar] [CrossRef]
- le Hégarat-Mascle, S.; André, C. Reduced false alarm automatic detection of clouds and shadows on SPOT images using simultaneous estimation. Proc. SPIE 2010, 1, 1–12. [Google Scholar]
- Lück, W.; van Niekerk, A. Evaluation of a rule-based compositing technique for Landsat-5 TM and Landsat-7 ETM+ images. Int. J. Appl. Earth Obs. Geoinf. 2016, 47, 1–14. [Google Scholar] [CrossRef]
- Luo, Y.; Trishchenko, A.P.; Khlopenkov, K.V. Developing clear-sky, cloud and cloud-shadow mask for producing clear-sky composites at 250-meter spatial resolution for the seven MODIS land bands over Canada and North America. Remote Sens. Environ. 2008, 112, 4167–4185. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud-shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud-shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Louis, J.; Hagolle, O.; Müller-Wilm, U.; Alonso, K. The Sen2Cor and MAJA cloud masks and classification products. In Proceedings of the 2nd Sentinel-2 Validation Team Meeting, ESA-ESRIN, Frascati, Rome, Italy, 29–31 January 2018. [Google Scholar]
- Foga, S.; Scaramuzza, P.; Guo, S.; Zhu, Z.; Dilley, R., Jr.; Beckmann, T.; Schmidt, G.; Dwyer, J.; Hughes, M.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- U.S. Geological Survey (USGS). U.S. Landsat Analysis Ready Data (ARD) Artifacts. 2018. Available online: https://landsat.usgs.gov/us-landsat-ard-artifacts (accessed on 15 July 2018).
- Bupe, C. Is Deep Learning Fundamentally Flawed and Hitting a Wall? Was Gary Marcus Correct in Pointing out Deep Learning’s Flaws? Quora 2018. Available online: https://www.quora.com/Is-Deep-Learning-fundamentally-flawed-and-hitting-a-wall-Was-Gary-Marcus-correct-in-pointing-out-Deep-Learnings-flaws (accessed on 7 August 2018).
- Pearl, J. Causality: Models, Reasoning and Inference; Cambridge University Press: New York, NY, USA, 2009. [Google Scholar]
- Mazzuccato, M.; Robinson, D. Market Creation and the European Space Agency. European Space Agency (ESA) Report. 2017. Available online: https://marianamazzucato.com/wp-content/uploads/2016/11/Mazzucato_Robinson_Market_creation_and_ESA.pdf (accessed on 17 November 2018).
- Baraldi, A. Impact of radiometric calibration and specifications of spaceborne optical imaging sensors on the development of operational automatic remote sensing image understanding systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 104–134. [Google Scholar] [CrossRef]
- Pacifici, F. Atmospheric Compensation in Satellite Imagery. U.S. Patent 9396528B2, 19 July 2016. [Google Scholar]
- Pacifici, F.; Longbotham, N.; Emery, W.J. The Importance of Physical Quantities for the Analysis of Multitemporal and Multiangular Optical Very High Spatial Resolution Images. IEEE Trans. Geosci. Remote Sens. 2014. [Google Scholar] [CrossRef]
- Baraldi, A.; Tiede, D. AutoCloud+, a “universal” single-date multi-sensor physical and statistical model-based spatial context-sensitive cloud/cloud-shadow detector in multi-spectral Earth observation imagery. In Proceedings of the GEOBIA 2018, Montpellier, France, 18–22 June 2018. [Google Scholar]
- Richter, R.; Schläpfer, D. Atmospheric/Topographic Correction for Satellite Imagery–ATCOR-2/3 User Guide. Version 8.2 BETA. 2012. Available online: http://www.dlr.de/eoc/Portaldata/60/Resources/dokumente/5_tech_mod/atcor3_manual_2012.pdf (accessed on 12 April 2013).
- Richter, R.; Schläpfer, D. Atmospheric/Topographic Correction for Airborne Imagery–ATCOR-4 User Guide, Version 6.2 BETA. 2012. Available online: http://www.dlr.de/eoc/Portaldata/60/Resources/dokumente/5_tech_mod/atcor4_manual_2012.pdf (accessed on 12 April 2013).
- Dorigo, W.; Richter, R.; Baret, F.; Bamler, R.; Wagner, W. Enhanced automated canopy characterization from hyperspectral data by a novel two step radiative transfer model inversion approach. Remote Sens. 2009, 1, 1139–1170. [Google Scholar] [CrossRef]
- Schläpfer, D.; Richter, R.; Hueni, A. Recent developments in operational atmospheric and radiometric correction of hyperspectral imagery. In Proceedings of the 6th EARSeL SIG IS Workshop, Tel Aviv, Israel, 16–19 March 2009; Available online: http://www.earsel6th.tau.ac.il/~earsel6/CD/PDF/earsel-PROCEEDINGS/3054%20Schl%20pfer.pdf (accessed on 14 July 2012).
- Bertero, M.; Poggio, T.; Torre, V. Ill-posed problems in early vision. Proc. IEEE 1988, 76, 869–889. [Google Scholar] [CrossRef]
- Marr, D. Vision; Freeman and C: New York, NY, USA, 1982. [Google Scholar]
- Serra, R.; Zanarini, G. Complex Systems and Cognitive Processes; Springer-Verlag: Berlin, Germany, 1990. [Google Scholar]
- Parisi, D. La Scienza Cognitive tra Intelligenza Artificiale e vita Artificiale, in Neurosceinze e Scienze dell’Artificiale: Dal Neurone all’Intelligenza; Patron Editore: Bologna, Italy, 1991. [Google Scholar]
- Miller, G.A. The cognitive revolution: A historical perspective. Trends Cogn. Sci. 2003, 7, 141–144. [Google Scholar] [CrossRef]
- Varela, F.J.; Thompson, E.; Rosch, E. The Embodied Mind: Cognitive Science and Human Experience; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Capra, F.; Luisi, P.L. The Systems View of Life: A Unifying Vision; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Baraldi, A.; Boschetti, L. Operational automatic remote sensing image understanding systems: Beyond Geographic Object-Based and Object-Oriented Image Analysis (GEOBIA/GEOOIA)—Part 1: Introduction. Remote Sens. 2012, 4, 2694–2735. [Google Scholar] [CrossRef]
- Baraldi, A.; Boschetti, L. Operational automatic remote sensing image understanding systems: Beyond Geographic Object-Based and Object-Oriented Image Analysis (GEOBIA/GEOOIA)—Part 2: Novel system architecture, information/knowledge representation, algorithm design and implementation. Remote Sens. 2012, 4, 2768–2817. [Google Scholar] [CrossRef]
- Satellite Applications Catapult, Small Is the New Big–Nano/Micro-Satellite Missions for Earth Observation and Remote Sensing. White Paper. 2018. Available online: https://sa.catapult.org.uk/wp-content/uploads/2016/03/Small-is-the-new-Big.pdf (accessed on 17 November 2018).
- Small Drones Market by Type (Fixed-Wing, Rotary-Wing, Hybrid/Transitional), Application, MTOW (<5 kg, 5–25 kg, 25–150 kg), Payload (Camera, CBRN Sensors, Electronic Intelligence Payload, Radar), Power Source, and Region–Global Forecast to 2025. Available online: https://www.researchandmarkets.com/research/lkh233/small_drones?w=12 (accessed on 17 November 2018).
- Fowler, M. UML Distilled, 3rd ed.; Addison-Wesley: Boston, MA, USA, 2003. [Google Scholar]
- Tsotsos, J.K. Analyzing vision at the complexity level. Behav. Brain Sci. 1990, 13, 423–469. [Google Scholar] [CrossRef]
- DiCarlo, J. The Science of Natural Intelligence: Reverse Engineering Primate Visual Perception. Keynote. CVPR17 Conference. 2017. Available online: https://www.youtube.com/watch?v=ilbbVkIhMgo (accessed on 5 January 2018).
- du Buf, H.; Rodrigues, J. Image morphology: From perception to rendering. In IMAGE–Computational Visualistics and Picture Morphology; The University of Algarve: Faro, Portugal, 2007. [Google Scholar]
- Kosslyn, S.M. Image and Brain; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 411–426. [Google Scholar] [CrossRef] [PubMed]
- Sylvester, J.; Reggia, J. Engineering neural systems for high-level problem solving. Neural Netw. 2016, 79, 37–52. [Google Scholar] [CrossRef] [PubMed]
- Vecera, S.; Farah, M. Is visual image segmentation a bottom-up or an interactive process? Percept. Psychophys. 1997, 59, 1280–1296. [Google Scholar] [CrossRef] [PubMed]
- Burt, P.; Adelson, E. The laplacian pyramid as a compact image code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Jain, A.; Healey, G. A multiscale representation including opponent color features for texture recognition. IEEE Trans. Image Process. 1998, 7, 124–128. [Google Scholar] [CrossRef] [PubMed]
- Slotnick, S.D.; Thompson, W.L.; Kosslyn, S.M. Visual mental imagery induces retinotopically organized activation of early visual areas. Cereb. Cortex 2005, 15, 1570–1583. [Google Scholar] [CrossRef] [PubMed]
- Mély, D.; Linsley, D.; Serre, T. Complementary surrounds explain diverse contextual phenomena across visual modalities. Psychol. Rev. 20 September 2018. [Google Scholar]
- Teaching Computers to See Optical Illusions. Available online: https://neurosciencenews.com/optical-illusions-neural-network-ai-9901/ (accessed on 1 October 2018).
- Mason, C.; Kandel, E.R. Central Visual Pathways. In Principles of Neural Science; Kandel, E., Schwartz, J., Eds.; Appleton and Lange: Norwalk, CT, USA, 1991; pp. 420–439. [Google Scholar]
- Gouras, P. Color Vision. In Principles of Neural Science; Kandel, E., Schwartz, J., Eds.; Appleton and Lange: Norwalk, CT, USA, 1991; pp. 467–479. [Google Scholar]
- Kandel, E.R. Perception of Motion, Depth and Form. In Principles of Neural Science; Kandel, E., Schwartz, J., Eds.; Appleton and Lange: Norwalk, CT, USA; 1991; pp. 441–466. [Google Scholar]
- Wilson, H.R.; Bergen, J.R. A four mechanism model for threshold spatial vision. Vis. Res. 1979, 19, 19–32. [Google Scholar] [CrossRef]
- Hubel, D.; Wiesel, T. Receptive fields of single neurons in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Wiesel, T.N.; Hubel, D.H. Spatial and chromatic interactions in the lateral geniculate body of the rhesus monkey. J. Neurophys. 1966, 29, 1115–1156. [Google Scholar] [CrossRef] [PubMed]
- Couclelis, H. What GIScience is NOT: Three theses. In Invited speaker. In Proceedings of the GIScience ’12 International Conference, Columbus, OH, USA, 18–21 September 2012. [Google Scholar]
- Moore’s Law. Available online: https://en.wikipedia.org/wiki/Moore%27s_law (accessed on 1 October 2018).
- Baraldi, A.; Gironda, M.; Simonetti, D. Operational two-stage stratified topographic correction of spaceborne multi-spectral imagery employing an automatic spectral rule-based decision-tree preliminary classifier. IEEE Trans. Geosci. Remote Sens. 2010, 48, 112–146. [Google Scholar] [CrossRef]
- Piaget, J. Genetic Epistemology; Columbia University Press: New York, NY, USA, 1970. [Google Scholar]
- National Aeronautics and Space Administration (NASA). Data Processing Levels. 2016. Available online: https://science.nasa.gov/earth-science/earth-science-data/data-processing-levels-for-eosdis-data-products (accessed on 20 December 2016).
- Baraldi, A.; Tiede, D.; Sudmanns, M.; Belgiu, M.; Lang, S. Automated near real-time Earth observation Level 2 product generation for semantic querying. In Proceedings of the GEOBIA 2016, University of Twente Faculty of Geo-Information and Earth Observation (ITC), Enschede, The Netherlands, 14–16 September 2016. [Google Scholar]
- Baraldi, A.; Tiede, D.; Sudmanns, M.; Lang, S. Systematic ESA EO Level 2 product generation as pre-condition to semantic content-based image retrieval and information/knowledge discovery in EO image databases. In Proceedings of the BiDS’17 2017 Conference on Big Data from Space, Toulouse, France, 28–30 March 2017. [Google Scholar]
- Tiede, D.; Baraldi, A.; Sudmanns, M.; Belgiu, M.; Lang, S. Architecture and prototypical implementation of a semantic querying system for big earth observation image bases. Eur. J. Remote Sens. 2017, 50, 452–463. [Google Scholar] [CrossRef] [PubMed]
- Augustin, H.; Sudmanns, M.; Tiede, D.; Baraldi, A. A semantic Earth observation data cube for monitoring environmental changes during the Syrian conflict. In Proceedings of the AGIT 2018, Salzburg, Austria, 3–6 July 2018; pp. 214–227. [Google Scholar] [CrossRef]
- Sudmanns, M.; Tiede, D.; Lang, S.; Baraldi, A. Semantic and syntactic interoperability in online processing of big Earth observation data. Int. J. Digit. Earth 2018, 11, 95–112. [Google Scholar] [CrossRef] [PubMed]
- Smeulders, A.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Frintrop, S. Computational visual attention. In Computer Analysis of Human Behavior, Advances in Pattern Recognition; Salah, A.A., Gevers, T., Eds.; Springer: Berlin, Germany, 2011. [Google Scholar]
- Hadamard, J. Sur les problemes aux derivees partielles et leur signification physique. Princet. Univ. Bull. 1902, 13, 49–52. [Google Scholar]
- Baraldi, A.; Boschetti, L.; Humber, M. Probability sampling protocol for thematic and spatial quality assessments of classification maps generated from spaceborne/airborne very high resolution images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 701–760. [Google Scholar] [CrossRef]
- Shepherd, J.D.; Dymond, J.R. BRDF correction of vegetation in AVHRR imagery. Remote Sens. Environ. 2000, 74, 397–408. [Google Scholar] [CrossRef]
- Danaher, T. An empirical BRDF correction for landsat TM and ETM+ imagery. In Proceedings of the 11th Australia Remote Sensing Photogrammetry Conference, Brisbane, Adelaide, Australia, 21–25 August 2002; pp. 2654–2657. [Google Scholar]
- Wu, A.; Li, Z.; Cihlar, J. Effects of land cover type and greenness on advanced very high resolution radiometer bidirectional reflectances: Analysis and removal. J. Geophys. Res. 1995, 100, 9179–9192. [Google Scholar] [CrossRef]
- Ghahramani, Z. Bayesian nonparametrics and the probabilistic approach to modelling. Philos. Trans. R. Soc. 2011, 1–27. [Google Scholar] [CrossRef]
- Wikipedia. Bayesian Inference. 2017. Available online: https://en.wikipedia.org/wiki/Bayesian_inference. (accessed on 14 March 2017).
- Duke University. Patient Safety—Quality Improvement. Measurement: Process and Outcome Indicators. Duke Center for Instructional Technology. 2016. Available online: http://patientsafetyed.duhs.duke.edu/module_a/measurement/measurement.html (accessed on 18 September 2016).
- Boschetti, L.; Flasse, S.P.; Brivio, P.A. Analysis of the conflict between omission and commission in low spatial resolution dichotomic thematic products: The Pareto boundary. Remote Sens. Environ. 2004, 91, 280–292. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Systems and Science, 2nd ed.; Wile: New York, NY, USA, 2005. [Google Scholar]
- Baraldi, A.; Lang, S.; Tiede, D.; Blaschke, T. Earth observation big data analytics in operating mode for GIScience applications–The (GE)OBIA acronym(s) reconsidered. In Proceedings of the GEOBIA 2018, Montpellier, France, 18–22 June 2018. [Google Scholar]
- Lang, S.; Baraldi, A.; Tiede, D.; Hay, G.; Blaschke, T. Towards a (GE)OBIA 2.0 manifesto–Achievements and open challenges in information & knowledge extraction from big Earth data. In Proceedings of the GEOBIA 2018, Montpellier, France, 18–22 June 2018. [Google Scholar]
- Castelletti, D.; Pasolli, L.; Bruzzone, L.; Notarnicola, C.; Demir, B. A novel hybrid method for the correction of the theoretical model inversion in bio/geophysical parameter estimation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4764–4774. [Google Scholar] [CrossRef]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic spectral rule-based preliminary classification of radiometrically calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye and DMC/SPOT-1/-2 imagery—Part I: System design and implementation. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1299–1325. [Google Scholar] [CrossRef]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic spectral rule-based preliminary classification of radiometrically calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye and DMC/SPOT-1/-2 imagery—Part II: Classification accuracy assessment. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1326–1354. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Yuan, M.; Cova, T.J. Towards a general theory of geographic representation in GIS. Int. J. Geogr. Inf. Sci. 2007, 21, 239–260. [Google Scholar] [CrossRef]
- Bernus, P.; Noran, O. Data Rich–But Information Poor. In Collaboration in a Data-Rich World; Camarinha-Matos, L., Afsarmanesh, H., Fornasiero, R., Eds.; PRO-VE 2017; IFIP Advances in Information and Communication Technology; Springer: Berlin, Germany, 2017; Volume 506, pp. 206–214. [Google Scholar]
- European Union. Copernicus Observer—The Upcoming Copernicus Data and Information Access Services (DIAS). 26 May 2017. Available online: http://copernicus.eu/news/upcoming-copernicus-data-and-information-access-services-dias (accessed on 15 July 2018).
- European Union. The DIAS: User-Friendly Access to Copernicus Data and Information. June 2018. Available online: http://copernicus.eu/sites/default/files/Data_Access/Data_Access_PDF/Copernicus_DIAS_Factsheet_June2018.pd (accessed on 15 July 2018).
- Committee on Earth Observation Satellites (CEOS). CEOS Analysis Ready Data–CEOS Analysis Ready Data for Land (CARD4L) Products. 2018. Available online: http://www.ceos.org/ard/ (accessed on 4 May 2018).
- U.S. Geological Survey (USGS). U.S. Landsat Analysis Ready Data (ARD). Available online: https://landsat.usgs.gov/ard (accessed on 15 July 2018).
- U.S. Geological Survey (USGS). U.S. Landsat Analysis Ready Data (ARD) Data Format Control Book (DFCB) Version 4.0. January 2018. Available online: https://landsat.usgs.gov/sites/default/files/documents/LSDS-1873_US_Landsat_ARD_DFCB.pdf (accessed on 15 July 2018).
- Dwyer, J.; Roy, D.; Sauer, B.; Jenkerson, C.; Zhang, H.; Lymburner, L. Analysis Ready Data: Enabling Analysis of the Landsat Archive. Remote Sens. 2018, 10, 1363. [Google Scholar]
- National Aeronautics and Space Administration (NASA). Harmonized Landsat/Sentinel-2 (HLS) Project. 2018. Available online: https://hls.gsfc.nasa.gov (accessed on 20 August 2018).
- Helder, D.; Markham, B.; Morfitt, R.; Storey, J.; Barsi, J.; Gascon, F.; Clerc, S.; LaFrance, B.; Masek, J.; Roy, D.; et al. Observations and recommendations for the calibration of Landsat 8 OLI and Sentinel 2MSI for improved data interoperability. Remote Sens. 2018, 10, 1340. [Google Scholar] [CrossRef]
- Zhou, G. Architecture of Future Intelligent Earth Observing Satellites (FIEOS) in 2010 and Beyond; Technical Report; National Aeronautics and Space Administration Institute of Advanced Concepts (NASA-NIAC): Washington, DC, USA, 2001.
- GISCafe News. Earth-i Led Consortium Secures Grant from UK Space Agency. 19 July 2018. Available online: https://www10.giscafe.com/nbc/articles/view_article.php?section=CorpNews&articleid=1600936 (accessed on 15 July 2018).
- Vermote, E.; Saleous, N. LEDAPS Surface Reflectance Product Description–Version 2.0; Dept Geography and NASA/GSFC Code 614.5; University of Maryland: College Park, MD, USA, 2007. [Google Scholar]
- Riaño, D.; Chuvieco, E.; Salas, J.; Aguado, I. Assessment of different topographic corrections in Landsat TM data for mapping vegetation types. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1056–1061. [Google Scholar] [CrossRef]
- Leprieur, C.; Durand, J.M.; Peyron, J.L. Influence of topography on forest reflectance using Landsat Thematic Mapper and digital terrain data. Photogramm. Eng. Remote Sens. 1988, 54, 491–496. [Google Scholar]
- Thomson, A.G.; Jones, C. Effects of topography on radiance from upland vegetation in North Wales. Int. J. Remote Sens. 1990, 11, 829–840. [Google Scholar] [CrossRef]
- Bishop, M.P.; Colby, J.D. Anisotropic reflectance correction of SPOT-3 HRV imagery. Int. J. Remote Sens. 2002, 23, 2125–2131. [Google Scholar] [CrossRef]
- Bishop, M.P.; Shroder, J.F.; Colby, J.D. Remote sensing and geomorphometry for studying relief production in high mountains. Geomorphology 2003, 55, 345–361. [Google Scholar] [CrossRef]
- Hunt, N.; Tyrrell, S. Stratified Sampling. Coventry University, 2012. Available online: http://www.coventry.ac.uk/ec/~nhunt/meths/strati.html (accessed on 3 January 2012).
- Quinlan, P. Marr’s Vision 30 years on: From a personal point of view. Perception 2012, 41, 1009–1012. [Google Scholar] [CrossRef] [PubMed]
- Poggio, T. The Levels of Understanding Framework; Technical Report, MIT-CSAIL-TR-2012-014, CBCL-308; Computer Science and Artificial Intelligence Laboratory: Cambridge, MA, USA, 31 May 2012. [Google Scholar]
- Iqbal, Q.; Aggarwal, J.K. Image retrieval via isotropic and anisotropic mappings. In Proceedings of the IAPR Workshop Pattern Recognition Information Systems, Setubal, Portugal, 2–4 July 2001; pp. 34–49. [Google Scholar]
- Pessoa, L. Mach Bands: How Many Models are Possible? Recent Experimental Findings and Modeling Attempts. Vision Res. 1996, 36, 3205–3227. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation. In Angewandte Geographische Informationsverarbeitung XII; Strobl, J., Ed.; Herbert Wichmann Verlag: Berlin, Germany, 2000; Volume 58, pp. 12–23. [Google Scholar]
- Espindola, G.M.; Camara, G.; Reis, I.A.; Bins, L.S.; Monteiro, A.M. Parameter selection for region-growing image segmentation algorithms using spatial autocorrelation. Int. J. Remote Sens. 2006, 27, 3035–3040. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- U.S. Geological Survey (USGS). Landsat Surface Reflectance Code (LaSRC) v1.2.0. 2018. Available online: https://github.com/USGS-EROS/espa-surface-reflectance/tree/lasrc_v1.2.0/ (accessed on 15 July 2018).
- Baraldi, A.; Humber, M. Quality assessment of pre-classification maps generated from spaceborne/airborne multi-spectral images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification software products: Part 1–Theory. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1307–1329. [Google Scholar] [CrossRef]
- Baraldi, A.; Humber, M.; Boschetti, L. Quality assessment of pre-classification maps generated from spaceborne/airborne multi-spectral images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification software products: Part 2–Experimental results. Remote Sens. 2013, 5, 5209–5264. [Google Scholar] [CrossRef]
- Planet Labs. Planet Surface Reflectance Product. 2018. Available online: https://assets.planet.com/marketing/PDF/Planet_Surface_Reflectance_Technical_White_Paper.pdf (accessed on 11 July 2018).
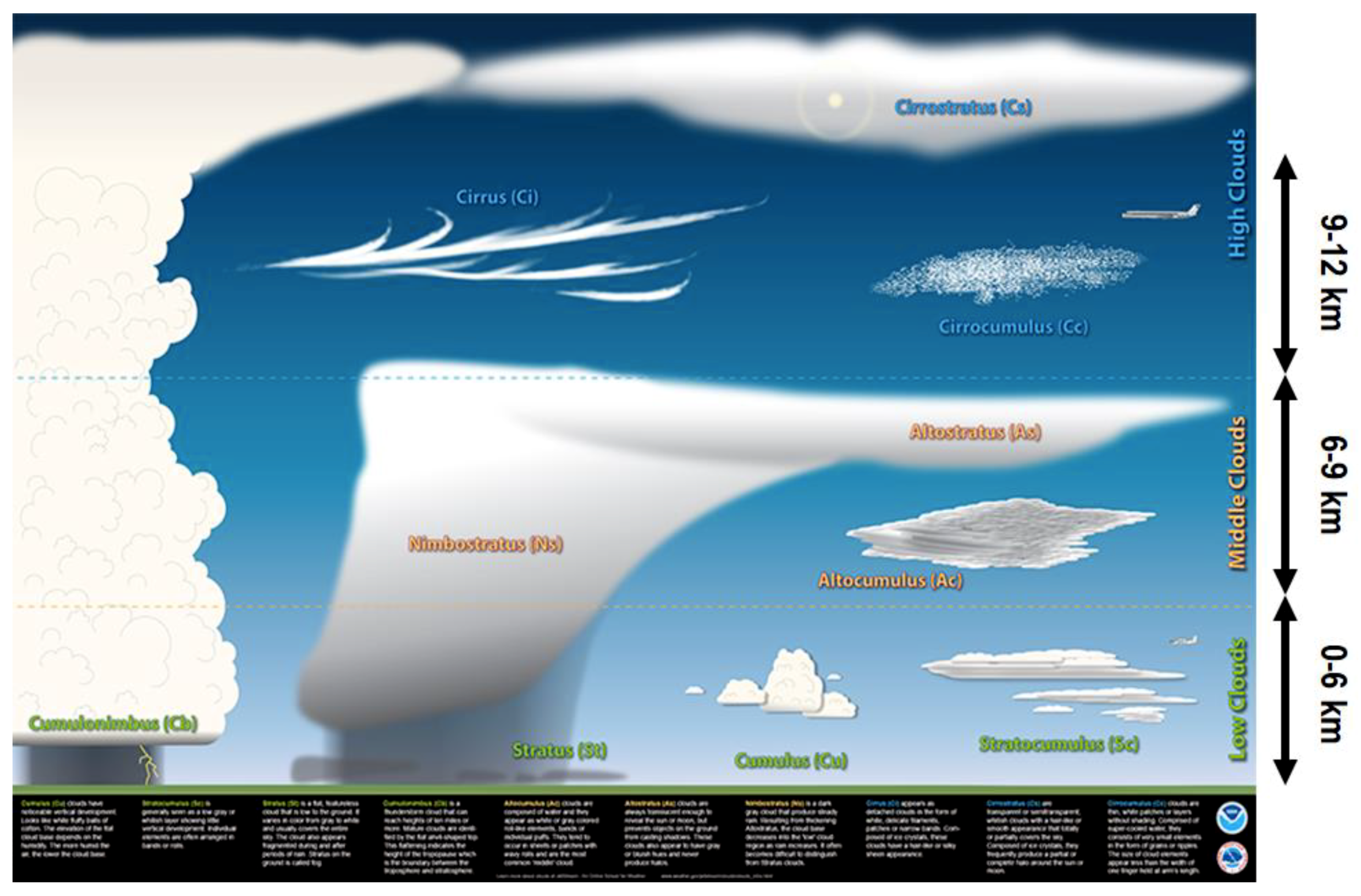
- National Oceanic and Atmospheric Administration (NOAA), National Weather Service. Ten Basic Clouds. Available online: https://www.weather.gov/jetstream/basicten (accessed on 14 November 2018).
- Etzioni, O. What Shortcomings Do You See with Deep Learning? 2017. Available online: https://www.quora.com/What-shortcomings-do-you-see-with-deep-learning (accessed on 8 January 2018).
- Axios. Artificial Intelligence Pioneer, Geoffrey Hinton, Says We Need to Start Over. 15 September 2017. Available online: https://www.axios.com/artificial-intelligence-pioneer-says-we-need-to-start-over-1513305524-f619efbd-9db0-4947-a9b2-7a4c310a28fe.html (accessed on 8 January 2018).
- Meer, P. Are we making real progress in computer vision today? Image Vis. Comput. 2012, 30, 472–473. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. arXiv, 2014; arXiv:1412.1897. Available online: https://arxiv.org/pdf/1412.1897.pdf (accessed on 8 January 2018).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv, 2013; arXiv:1312.6199. Available online: https://arxiv.org/pdf/1312.6199.pdf (accessed on 8 January 2018).
- Martinetz, T.; Berkovich, G.; Schulten, K. Topology representing networks. Neural Netw. 1994, 7, 507–522. [Google Scholar] [CrossRef]
- Berlin, B.; Kay, P. Basic Color Terms: Their Universality and Evolution; University of California: Berkeley, CA, USA, 1969. [Google Scholar]
- Griffin, L.D. Optimality of the basic color categories for classification. J. R. Soc. Interface 2006, 3, 71–85. [Google Scholar] [CrossRef] [PubMed]
- Chavez, P. An improved dark-object subtraction technique for atmospheric scattering correction of multispectral data. Remote Sens. Environ. 1988, 24, 459–479. [Google Scholar] [CrossRef]
- Baraldi, A.; Puzzolo, V.; Blonda, P.; Bruzzone, L.; Tarantino, C. Automatic spectral rule-based preliminary mapping of calibrated Landsat TM and ETM+ images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2563–2586. [Google Scholar] [CrossRef]
- Adams, J.B.; Donald, E.S.; Kapos, V.; Almeida Filho, R.; Roberts, D.A.; Smith, M.O.; Gillespie, A.R. Classification of multispectral images based on fractions of endmembers: Application to land-cover change in the Brazilian Amazon. Remote Sens. Environ. 1995, 52, 137–154. [Google Scholar] [CrossRef]
- Kuzera, K.; Pontius, R.G., Jr. Importance of matrix construction for multiple-resolution categorical map comparison. GISci. Remote Sens. 2008, 45, 249–274. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Connors, J. Expanding the conceptual, mathematical and practical methods for map comparison. In Proceedings of the 7th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, Lisbon, Portugal, 5–7 July 2006; Caetano, M., Painho, M., Eds.; Instituto Geográfico Português: Lisboa; Portugal, 2006; pp. 64–79. [Google Scholar]
- Stehman, S.V.; Czaplewski, R.L. Design and analysis for thematic map accuracy assessment: Fundamental principles. Remote Sens. Environ. 1998, 64, 331–344. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data; Lewis Publishers: Boca Raton, FL, USA, 1999. [Google Scholar]
- Lunetta, R.; Elvidge, D. Remote Sensing Change Detection: Environmental Monitoring Methods and Applications; Taylor & Francis: London, UK, 1999. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Classification |
|---|---|
| 0 | NO_DATA |
| 1 | SATURATED_OR_DEFECTIVE |
| 2 | DARK_AREA_PIXELS |
| 3 | CLOUD_SHADOWS |
| 4 | VEGETATION |
| 5 | BARE_SOILS |
| 6 | WATER |
| 7 | CLOUD_LOW_PROBABILITY |
| 8 | CLOUD_MEDIUM_PROBABILITY |
| 9 | CLOUD_HIGH_PROBABILITY |
| 10 | THIN_CIRRUS |
| 11 | SNOW |
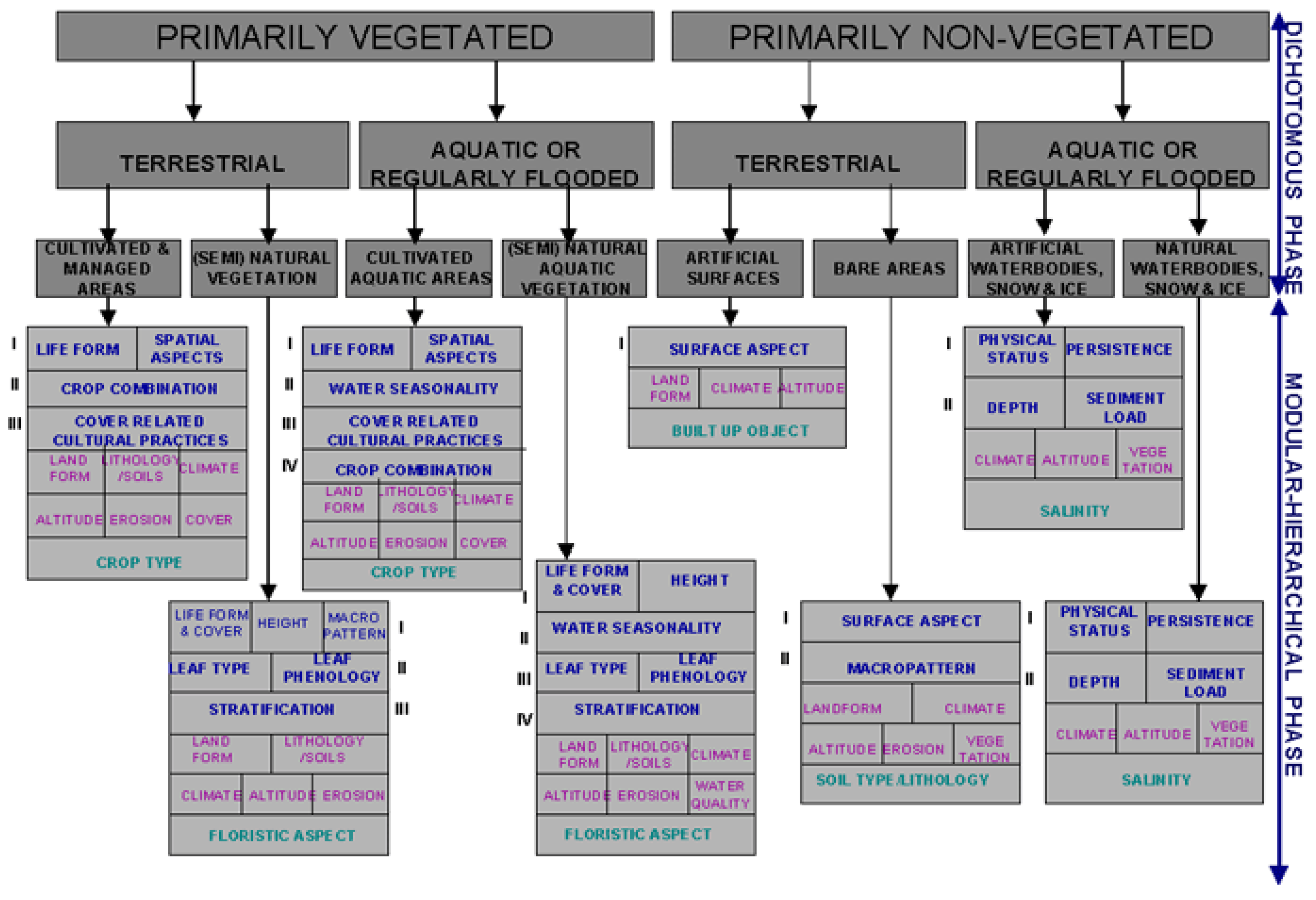
| Original FAO LCCS-DP Identifier | Label | “Augmented” FAO LCCS-DP taxonomy, class name | Pseudocolor |
|---|---|---|---|
| A11 | 1 | Cultivated and Managed Terrestrial (non-aquatic) Vegetated Areas | |
| A12 | 2 | Natural and Semi-Natural Terrestrial Vegetation | |
| A23 | 3 | Cultivated Aquatic or Regularly Flooded Vegetated Areas | |
| A24 | 4 | Natural and Semi-Natural Aquatic or Regularly Flooded Vegetation | |
| B35 | 5 | Artificial Surfaces and Associated Areas | |
| B36 | 6 | Bare Areas | |
| B47 | 7 | Artificial Waterbodies, Snow and Ice | |
| B48 | 8 | Natural Waterbodies, Snow and Ice | |
| 9 | Quality layer: Cloud | ||
| 10 | Quality layer: Cloud–shadow | ||
| 11 | Others (e.g., unknowns, no data, etc.) |
| Label | ATCOR-2/3/4 Spectral pre-Classification, Land Cover (LC) Class Definition | Order of Detection |
|---|---|---|
| 0 | Background | |
| 1 | Cloud shadow | 5 |
| 2 | Cirrus—Thin over water | 10 |
| 3 | Cirrus—Medium over water | 11 |
| 4 | Cirrus—Thick over water | 12 |
| 5 | Land (if not 0 to 5 or 6 to 17) | 17 |
| 6 | Saturated (if (DN > 0.9 * DNmax), then saturated) | 1 |
| 7 | Snow/ice | 6 |
| 8 | Cirrus—Thin over land | 7 |
| 9 | Cirrus—Medium over land | 8 |
| 10 | Cirrus—Thick over land | 9 |
| 11 | Haze—Thin/medium over land | 13 |
| 12 | Haze—Thick/medium over land | 14 |
| 13 | Haze—Thin/medium over water | 15 |
| 14 | Haze—Thick/medium over water | 16 |
| 15 | Cloud over land | 3 |
| 16 | Cloud over water | 4 |
| Label | Spectral Categories | Spectral Rule (based on reflectance measured at Landsat TM central wave bands: b1 is located at 0.48 μm, b2 at 0.56 μm, b3 at 0.66 μm, b4 at 0.83 μm, b5 at 1.6 μm, b7 at 2.2 μm) | Pseudocolor |
| 1 | Snow/ice | b4/b3 ≤ 1.3 AND b3 ≥ 0.2 AND b5 ≤ 0.12 | |
| 2 | Cloud | b4 ≥ 0.25 AND 0.85 ≤ b1/b4 ≤ 1.15 AND b4/b5 ≥ 0.9 AND b5 ≥ 0.2 | |
| 3 | Bright bare soil/sand/cloud | b4 ≥ 0.15 AND 1.3 ≤ b4/b3 ≤ 3.0 | |
| 4 | Dark bare soil | b4 ≥ 0.15 AND 1.3 ≤ b4/b3 ≤ 3.0 AND b2 ≤ 0.10 | |
| 5 | Average vegetation | b4/b3 ≥ 3.0 AND (b2/b3 ≥ 0.8 OR b3 ≤ 0.15) AND 0.28 ≤ b4 ≤ 0.45 | |
| 6 | Bright vegetation | b4/b3 ≥ 3.0 AND (b2/b3 ≥ 0.8 OR b3 ≤ 0.15) AND b4 ≥ 0.45 | |
| 7 | Dark vegetation | b4/b3 ≥ 3.0 AND (b2/b3 ≥ 0.8 OR b3 ≤ 0.15) AND b3 ≤ 0.08 AND b4 ≤ 0.28 | |
| 8 | Yellow vegetation | b4/b3 ≥ 2.0 AND b2 ≥_b3 AND b3 ≥ 8.0 AND b4/b5 ≥ 1.5 a | |
| 9 | Mix of vegetation/soil | 2.0 ≤ b4/b3 ≤ 3.0 AND 0.05 ≤ b3 ≤ 0.15 AND b4 ≥ 0.15 | |
| 10 | Asphalt/dark sand | b4/b3 ≤ 1.6 AND 0.05 ≤ b3 ≤ 0.20 AND 0.05 ≤ b4 ≤ 0.20 a AND 0.05 ≤ b5 ≤ 0.25 AND b5/b4 ≥ 0.7 a | |
| 11 | Sand/bare soil/cloud | b4/b3 ≤ 2.0 AND b4 ≥ 0.15 AND b5 ≥ 0.15 a | |
| 12 | Bright sand/bare soil/cloud | b4/b3 ≤ 2.0 AND b4 ≥ 0.15 AND (b4 ≥ 0.25b OR b5 ≥ 0.30 b) | |
| 13 | Dry vegetation/soil | (1.7 ≤ b4/b3 ≤ 2.0 AND b4 ≥ 0.25 c) OR (1.4 ≤ b4/b3 ≤ 2.0 AND b7/b5 ≤ 0.83 c) | |
| 14 | Sparse veg./soil | (1.4 ≤ b4/b3 ≤ 1.7 AND b4 ≥ 0.25 c) OR (1.4 ≤ b4/b3 ≤ 2.0 AND b7/b5 ≤ 0.83 AND b5/b4 ≥ 1.2 c) | |
| 15 | Turbid water | b4 ≤ 0.11 AND b5 ≤ 0.05 a | |
| 16 | Clear water | b4 ≤ 0.02 AND b5 ≤ 0.02 a | |
| 17 | Clear water over sand | b3 ≥ 0.02 AND b3 ≥ b4 + 0.005 AND b5 ≤ 0.02 a | |
| 18 | Shadow | ||
| 19 | Not classified (outliers) |
| Acronyms Digital number (featuring no physical meaning) = DN. Top-of-atmosphere reflectance—TOARF. Surface reflectance—SURF, where TOARF ⊃ SURF, because TOARF ≈ SURF + atmospheric noise + topographic noise. Inductive—I. Deductive—D. Hybrid—Combined I + D = H. 1D Pixel-based (spatial context-insensitive and spatial topology non-preserving) —P. 1D Object-based (spatial context-sensitive, but spatial topology non-preserving) —O. 2D image analysis (spatial context-sensitive and spatial topology-preserving) —2D. Yes: Y. No: N. | Multi-spectral (MS) Sensor(s) | Radiometric calibration | Spatial resolution | Spectral resolution | Single-date (S) or Multi-temporal (MT) | Land cover (LC) class detection, in addition to classes cloud and cloud–shadow, if any | Cloud detection | Cloud–shadow detection | ||||
| Acronyms: TOARF or SURF, refer to cell at top left | Acronyms: Visible Blue, Green, Red = B, G, R. Near InfraRed (IR) = NIR. Medium IR = MIR. Thermal IR = TIR. | Acronyms: I, D or H, refer to cell at top left | Acronyms: P, O or 2D, refer to cell at top left | Acronyms: I, D or H, refer to cell at top left | Acronyms: P, O or 2D, refer to cell at top left | Acronyms: I, D or H, refer to cell at top left | Acronyms: P, O or 2D, refer to cell at top left | Spatial search of cloud–shadow pixels starting from cloud candidates | ||||
| Proposed approach, AutoCloud+ | All MS past, present and future, airborne or spaceborne, whether or not provided with radiometric calibration metadata files | DN or TOARF or SURF or surface albedo | Any | From B, G, R, NIR, MIR to TIR, including Cirrus band (depending on the available spectral channels). | S | H, with LC classes: Water, Shadow, Bare soil, Built-up, Vegetation, Snow, Ice, Fire, Others | P + O + 2D | H | P + O + 2D | H | P + O + 2D | Y |
| Sen2Cor (including all cloud probability classes) | Sentinel-2 MSI | TOARF | 10 m | B, G, R, NIR, MIR to TIR, including Cirrus band. | S | D, with LC classes: Water, Bare soil, Vegetation, Snow | P | D | P | D | P | Y |
| MAJA | Formosat2, LANDSAT 5/7/8, SPOT 4/5, Sentinel 2, VENμS. | TOARF | 5.3 to 30 m | From B, G, R, NIR, MIR to TIR, including Cirrus band (depending on the available spectral channels) | MT | D, with LC classes: Water, Bare soil, Vegetation, Snow | P | D | P | D | P | Y |
| FMask | Landsat-7/8 (with thermal band) and Sentinel-2 (without thermal band) | TOARF | 10 to 30 m | From B, G, R, NIR to MIR, plus TIR when available (in Landsat imagery) | S | D, with LC classes: Clear land, clear water, snow. | P | D | P + contextual to remove isolated pixels | H | P + O, due to segmentation (partitioning) of the cloud layer in the image-domain | Y |
| ATCOR-4 [72] | Airborne, spaceborne | TOARF or SURF or spectral albedo | Any | From B, G, R, NIR to MIR, including Cirrus band (depending on the available spectral channels). No TIR is exploited. | S | D, with LC classes: Water, Land, Haze, Snow/Ice (depending on the available spectral channels) | P | H (D + I, e.g., I = image-wide histogram-based analytics) | P | H | P | N |
| Target classes of individuals (entities in a conceptual model for knowledge representation built upon an ontology language) | |||||
| Class 1, Water body | Class 2, Tulip flower | Class 3, Italian tile roof | |||
| Basic color (BC) names | black | √ | |||
| blue | √ | √ | |||
| brown | √ | √ | √ | ||
| grey | |||||
| green | √ | √ | |||
| orange | √ | ||||
| pink | √ | ||||
| purple | √ | ||||
| red | √ | √ | |||
| white | √ | ||||
| yellow | √ | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baraldi, A.; Tiede, D. AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generation at the Ground Segment as Broad Context. ISPRS Int. J. Geo-Inf. 2018, 7, 457. https://doi.org/10.3390/ijgi7120457
Baraldi A, Tiede D. AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generation at the Ground Segment as Broad Context. ISPRS International Journal of Geo-Information. 2018; 7(12):457. https://doi.org/10.3390/ijgi7120457
Chicago/Turabian StyleBaraldi, Andrea, and Dirk Tiede. 2018. "AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generation at the Ground Segment as Broad Context" ISPRS International Journal of Geo-Information 7, no. 12: 457. https://doi.org/10.3390/ijgi7120457
APA StyleBaraldi, A., & Tiede, D. (2018). AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generation at the Ground Segment as Broad Context. ISPRS International Journal of Geo-Information, 7(12), 457. https://doi.org/10.3390/ijgi7120457