
Guided Classification System for Conceptual Overlapping Classes in OpenStreetMap



Abstract
:1. Introduction
2. Related Work
2.1. VGI Quality Assessment
2.2. VGI Quality Enhancement: Approaches and Methods
2.3. Human-Centered Data Classification
3. Beyond Data Classification in VGI Projects: The Case of OpenStreetMap
3.1. Classification by Tags (key = value)
3.2. Subjective Classification
- Incomplete classification: the limited local knowledge of a participant or the unclear perceived observation from the provided satellite images impacts the classification granularity. In a pilot study on the OSM data set of Germany (May 2015), we found 225,933 entities related to water body classes. Only 20% of these entities have finer classes like lake, waste water, etc. We detected about 10,520,418 unclassified building entities, which have a coarser classification as building while other entities of building are classified into finer classes like residential, industrial, etc.
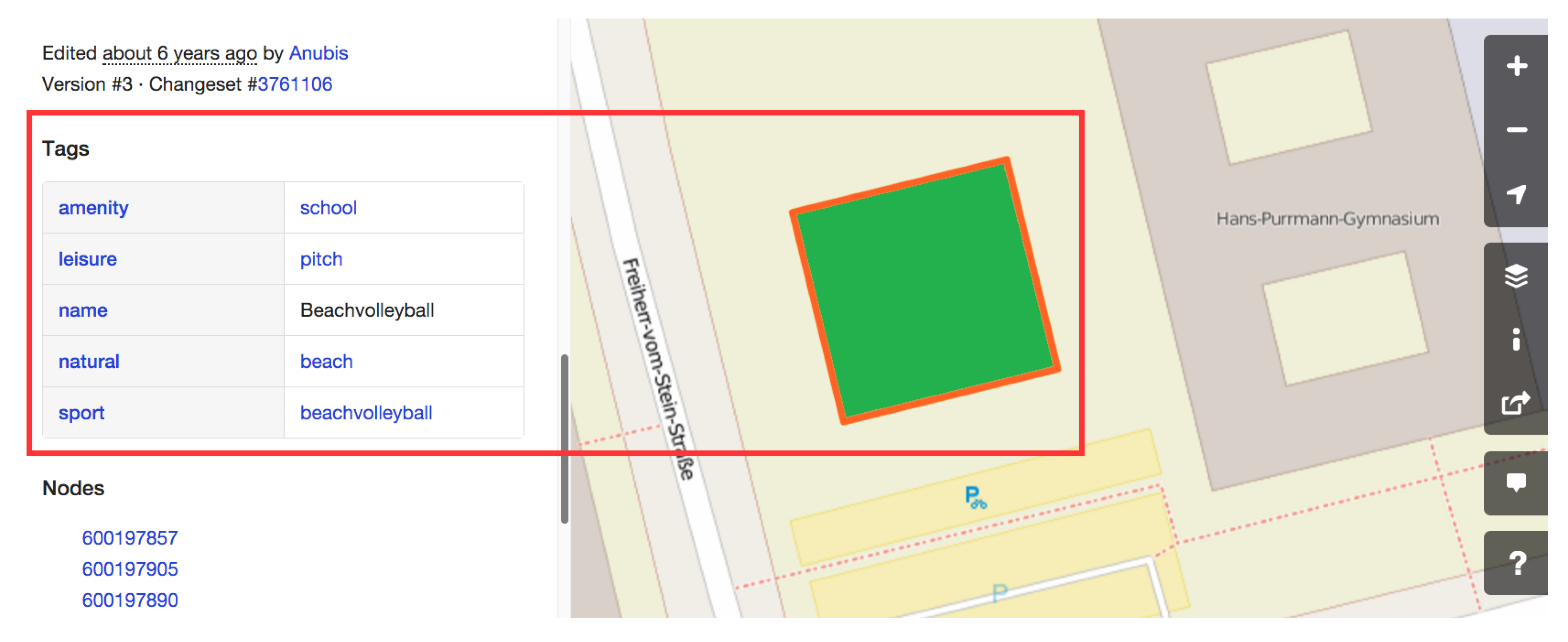
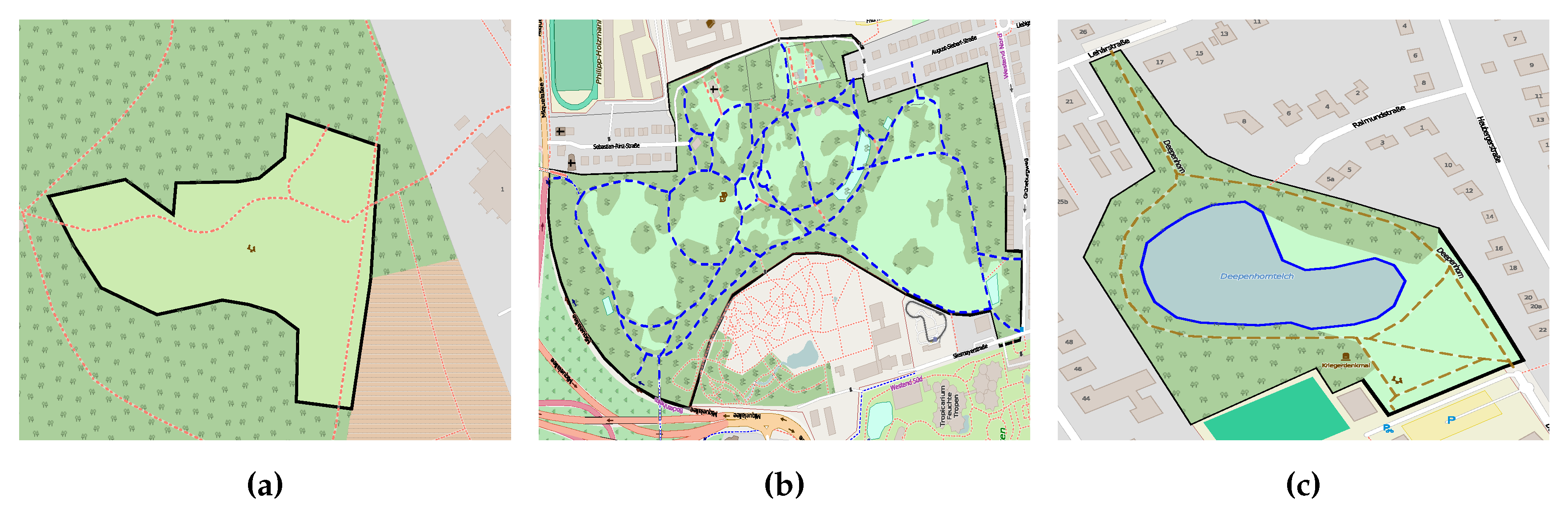
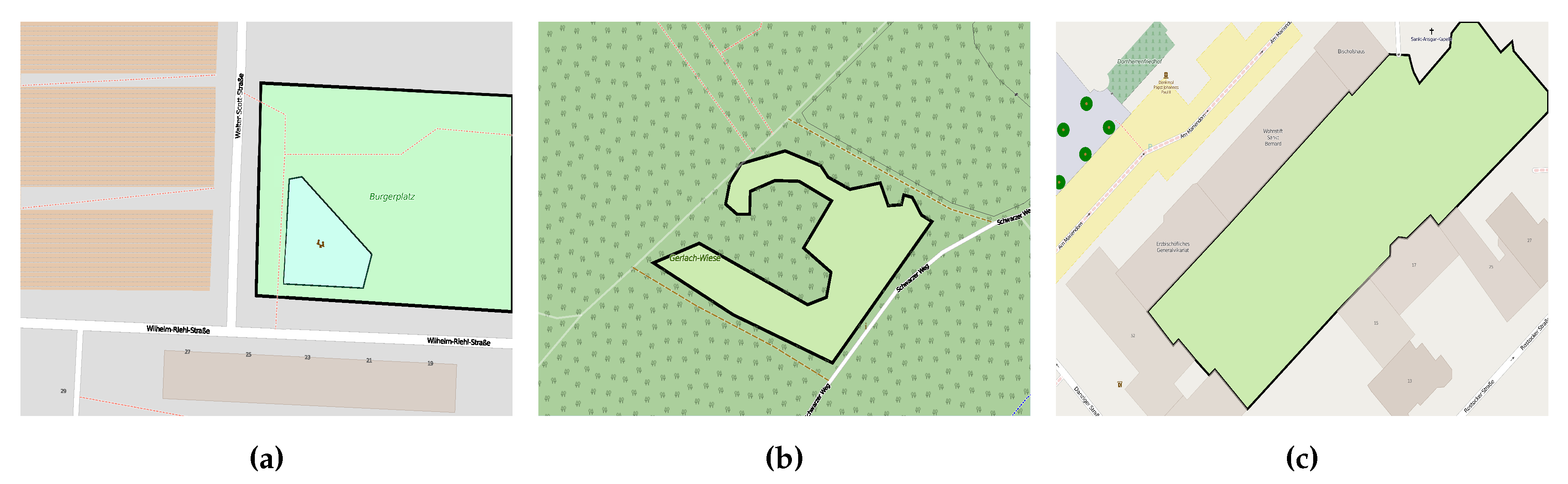
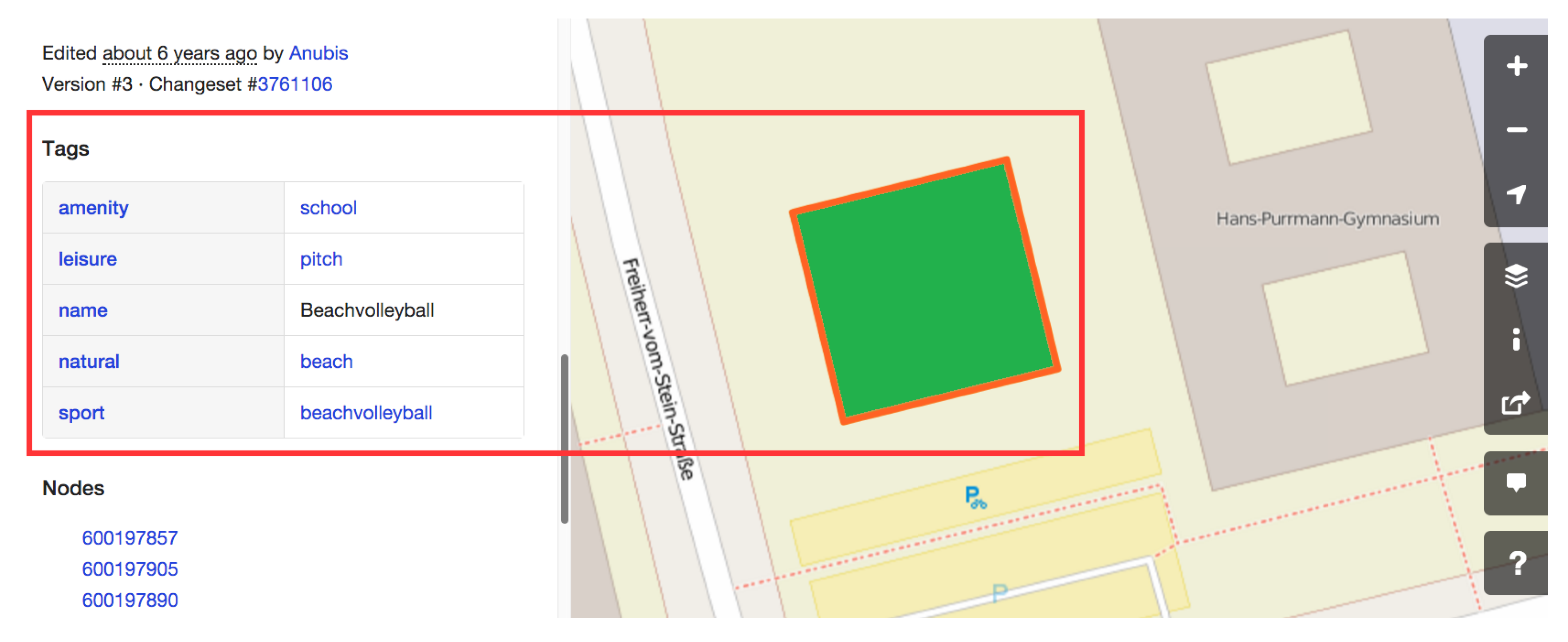
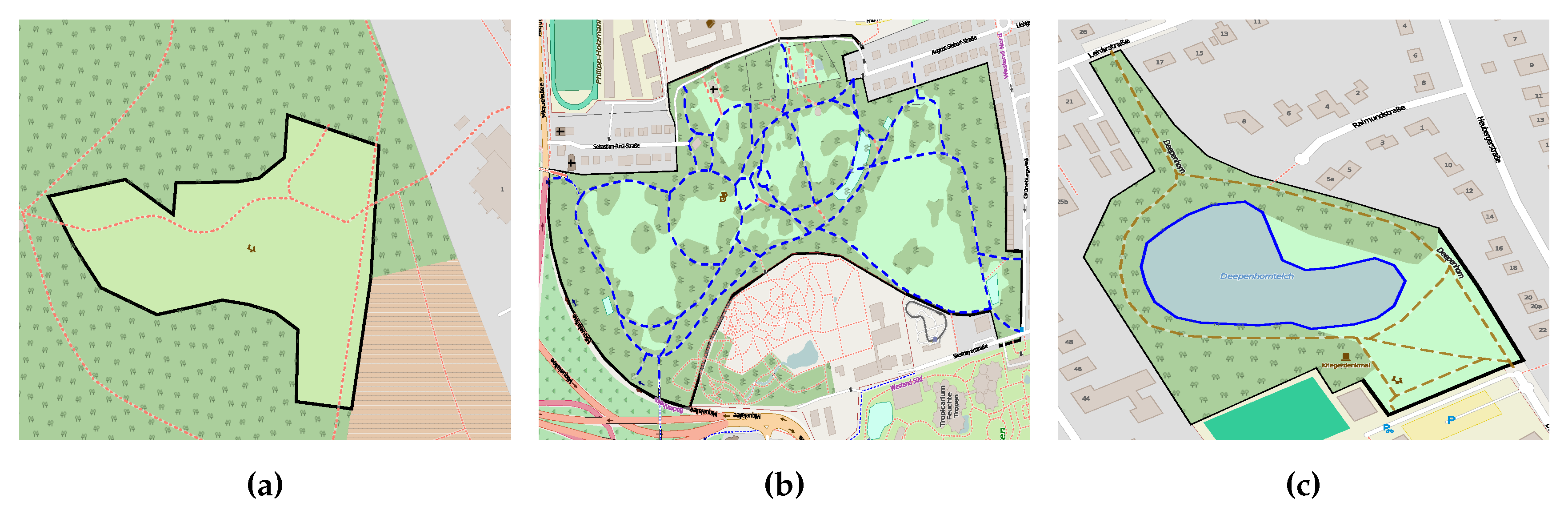
- Inconsistent classification: when participants interpret a given feature differently, they assign it to conflicting classes or an ambiguous class. During our investigations, we found out that some entities are assigned to conflicting classes; some entities are classified as meadow (i.e., grass land) and wetland (i.e., water body). Figure 1 illustrates a clear example of the classification inconsistency, when the given entity is classified by the pitch, school, and beach classes.
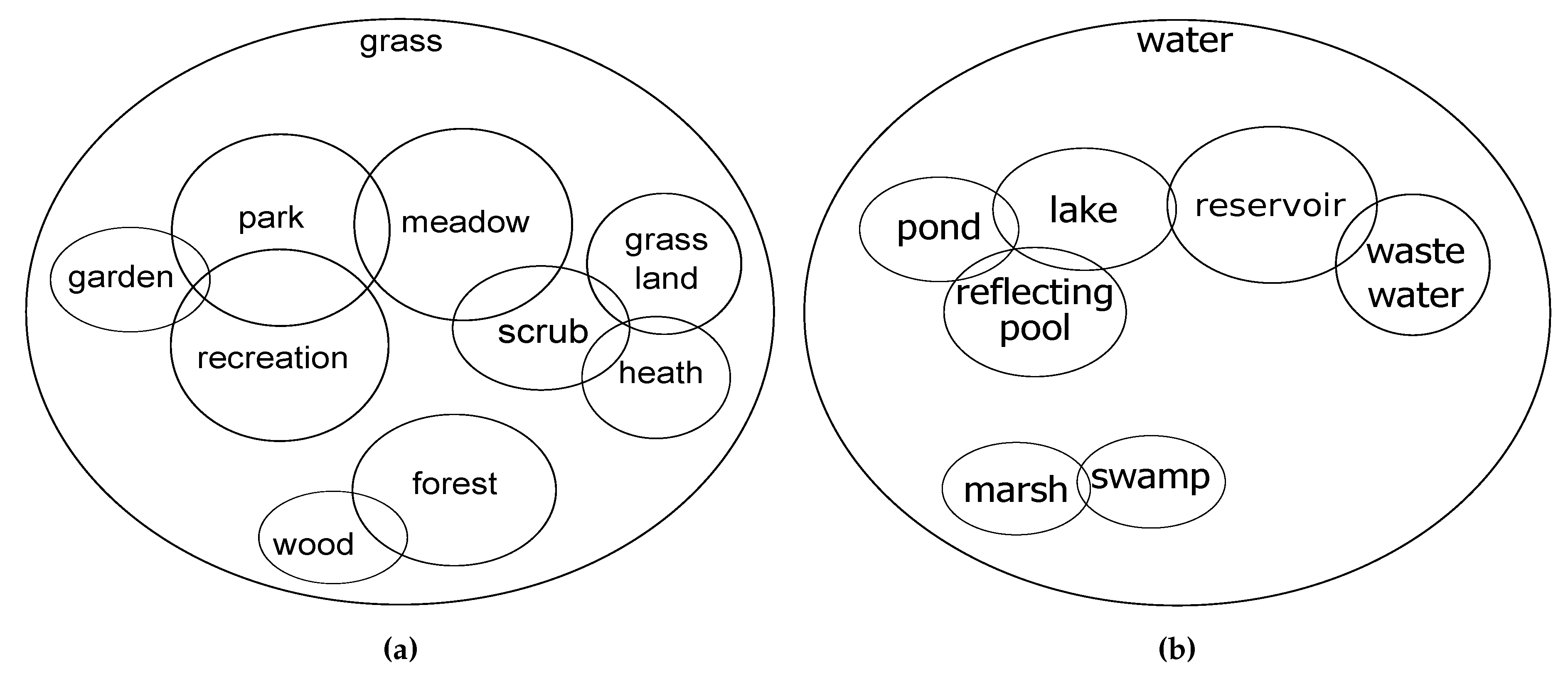
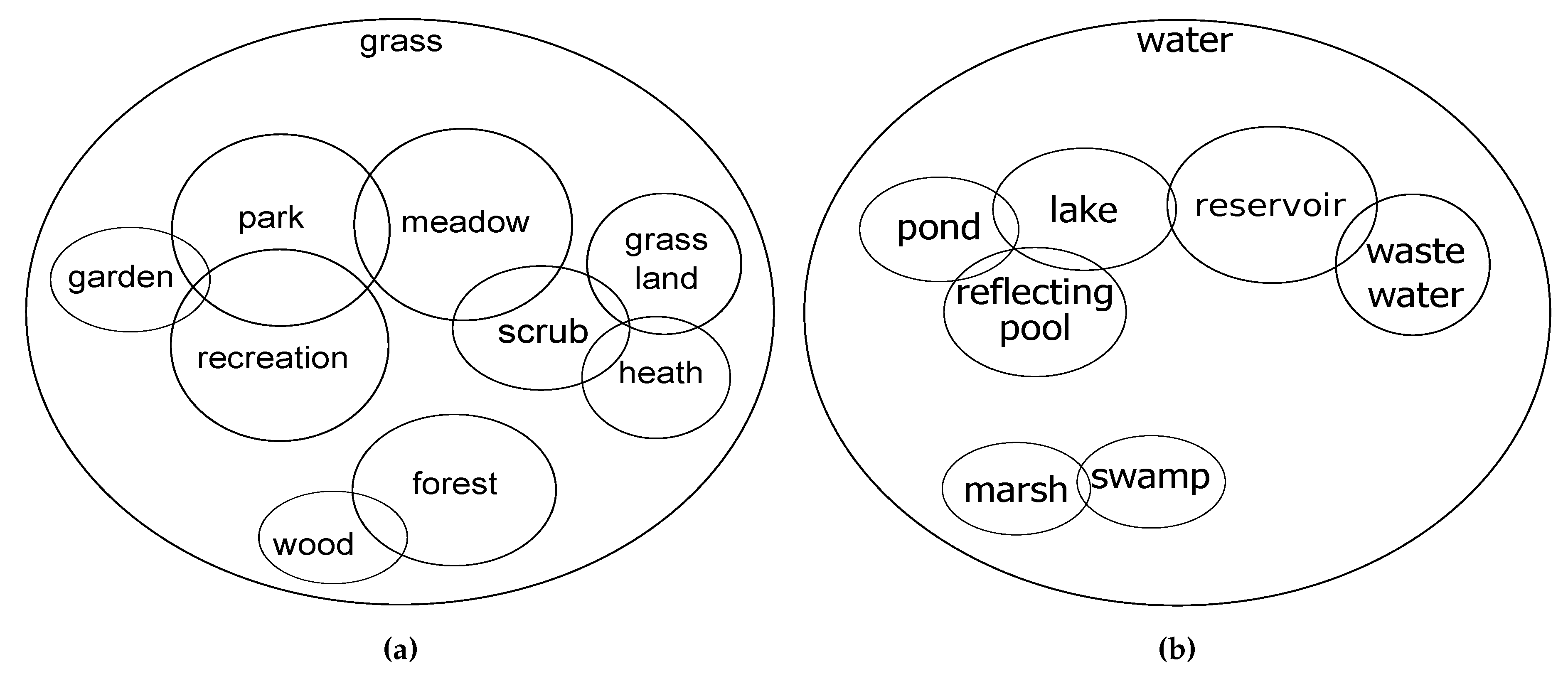
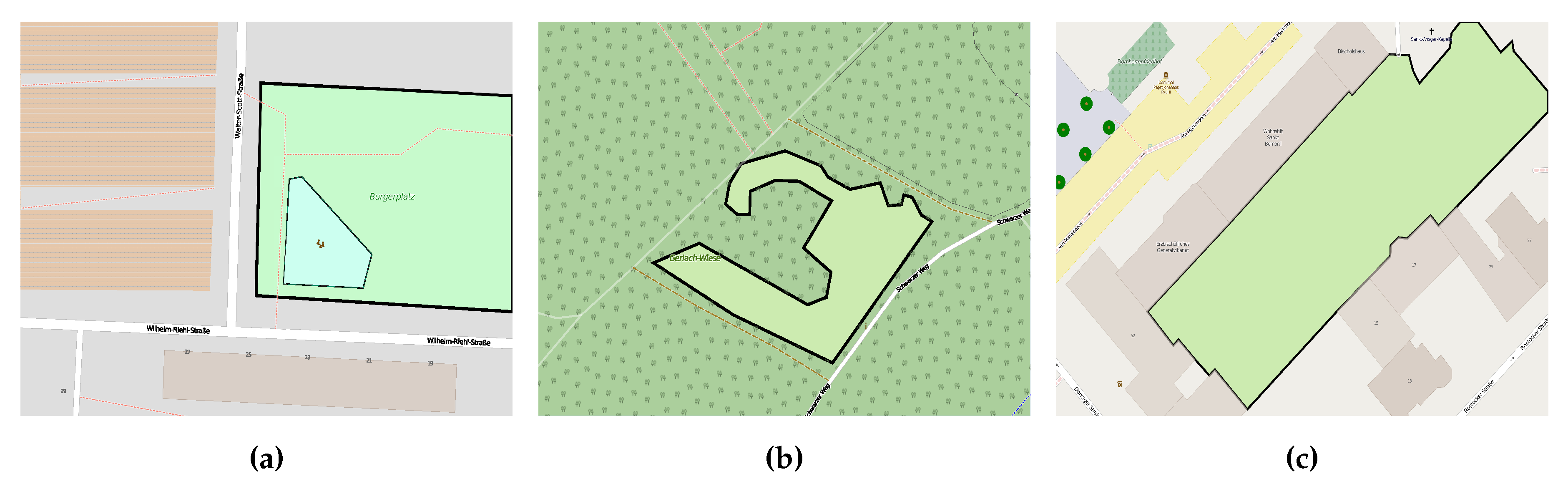
3.3. Conceptual Overlapping Classes
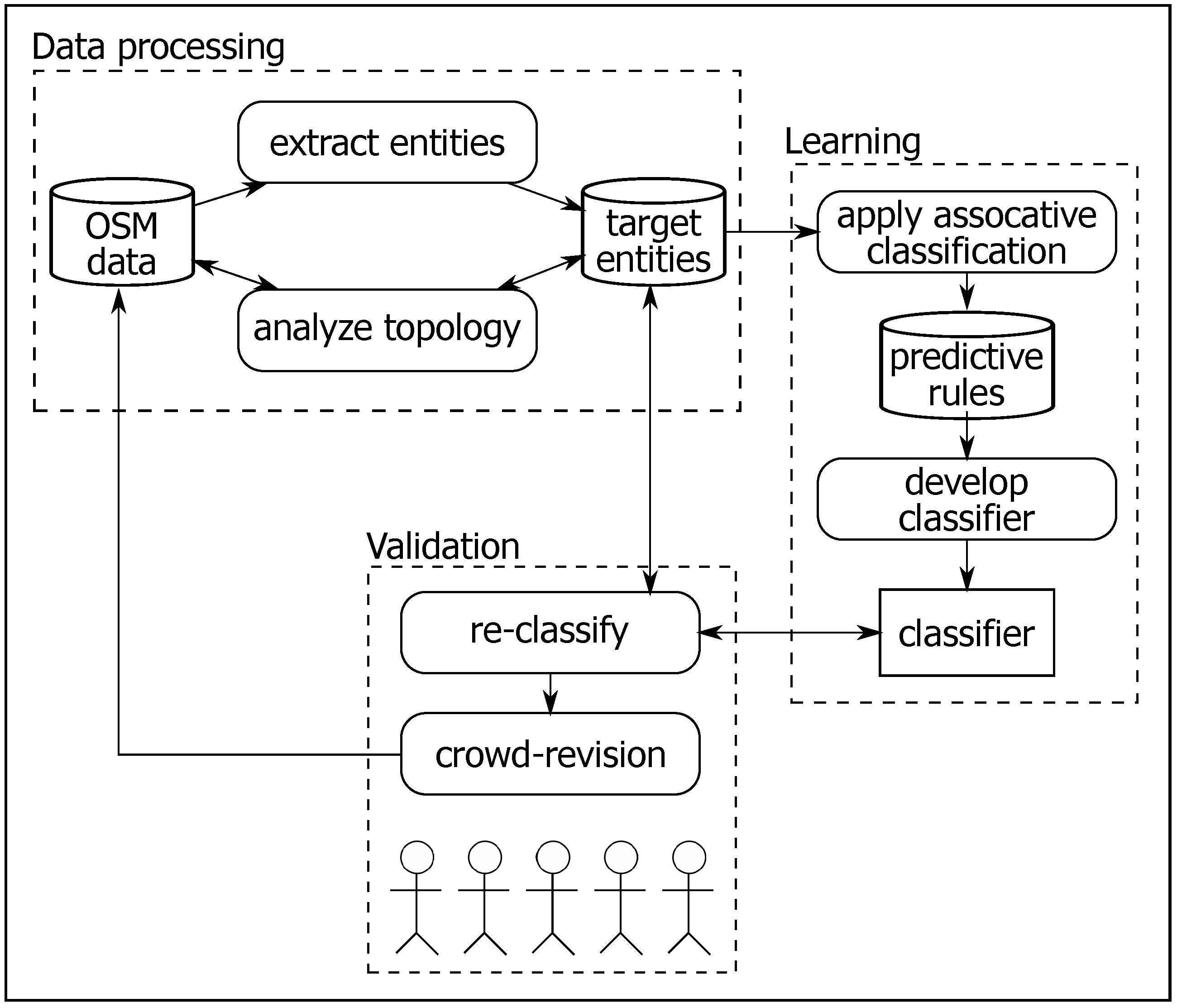
4. Rule-Guided Classification Approach
- (1)
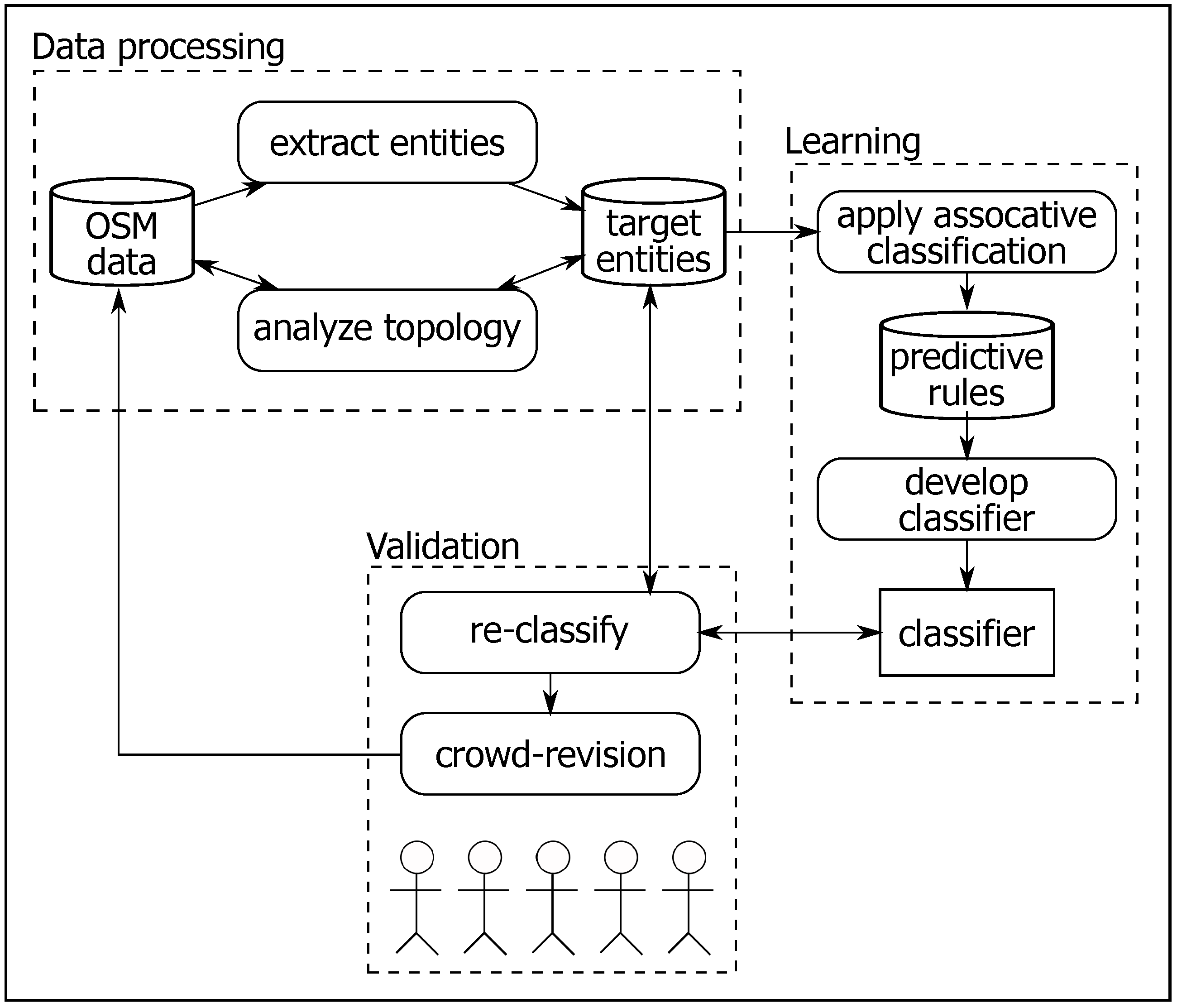
- Data processing:From the OSM data set of Germany, we extracted the entities of target classes. The entities are extracted from the most densely populated cities to ensure data of high quality. We are concerned with the areal entities. Thus, to understand the qualitative characteristics of the classes, we topologically checked each individual entity. We developed an automatic algorithm using the 9-Intersection Model (9IM) to perform the investigation [63]. This investigation aims to find out the common topological relations between pairs of entities; these relations are potentially useful to distinguish between similar classes. For example, find the relation between pairs of entity (, ), when represents the target feature (e.g., park entity) and is another kind of nearby feature to (e.g., playground, water bodies, etc.).
- (2)
- Learning:The target of the learning phase is developing a classifier able to potentially distinguish between similar classes. We apply an associative classification [64] data mining mechanism to perform the learning task. This mining approach utilizes the association rule to construct the classification system [64]. First, we extract a set of predictive rules that describe each class, and then these rules were ranked and organized into the classifier. During the classification process, a given entity is matched against the entire extracted set of rules. The matched rules are ranked in descending order based on their confidence measures. Due to the overlapping problem (see Section 3), the developed classifier is configured to give the two most appropriate classes instead of picking out a single class.
- (3)
- Validation:Due to the nature of VGI, the proposed approach exploits crowdsourcing to validate the classification. The entities are re-classified using the developed classifier. Afterwards, they are presented to the public again for the purpose of revising the recommended classes. The validation phase has multiple functionalities: (a) enhance/ensure the target entities’ classification by crowdsourcing revision; (b) understand the public conception of target classes; and (c) find out the response of participants to the provided recommendations.
5. Grass&Green: Customized Quality Assurance Application
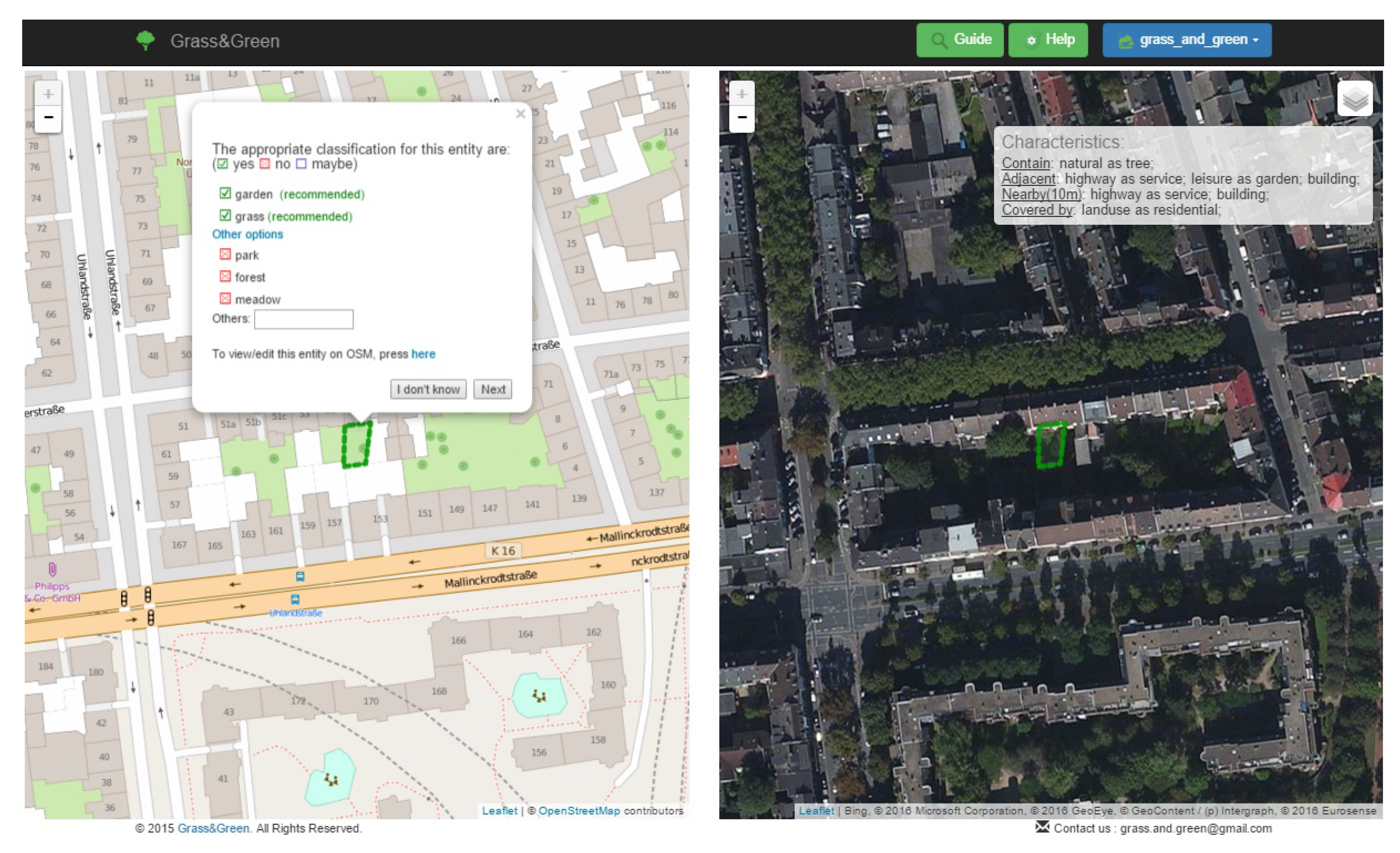
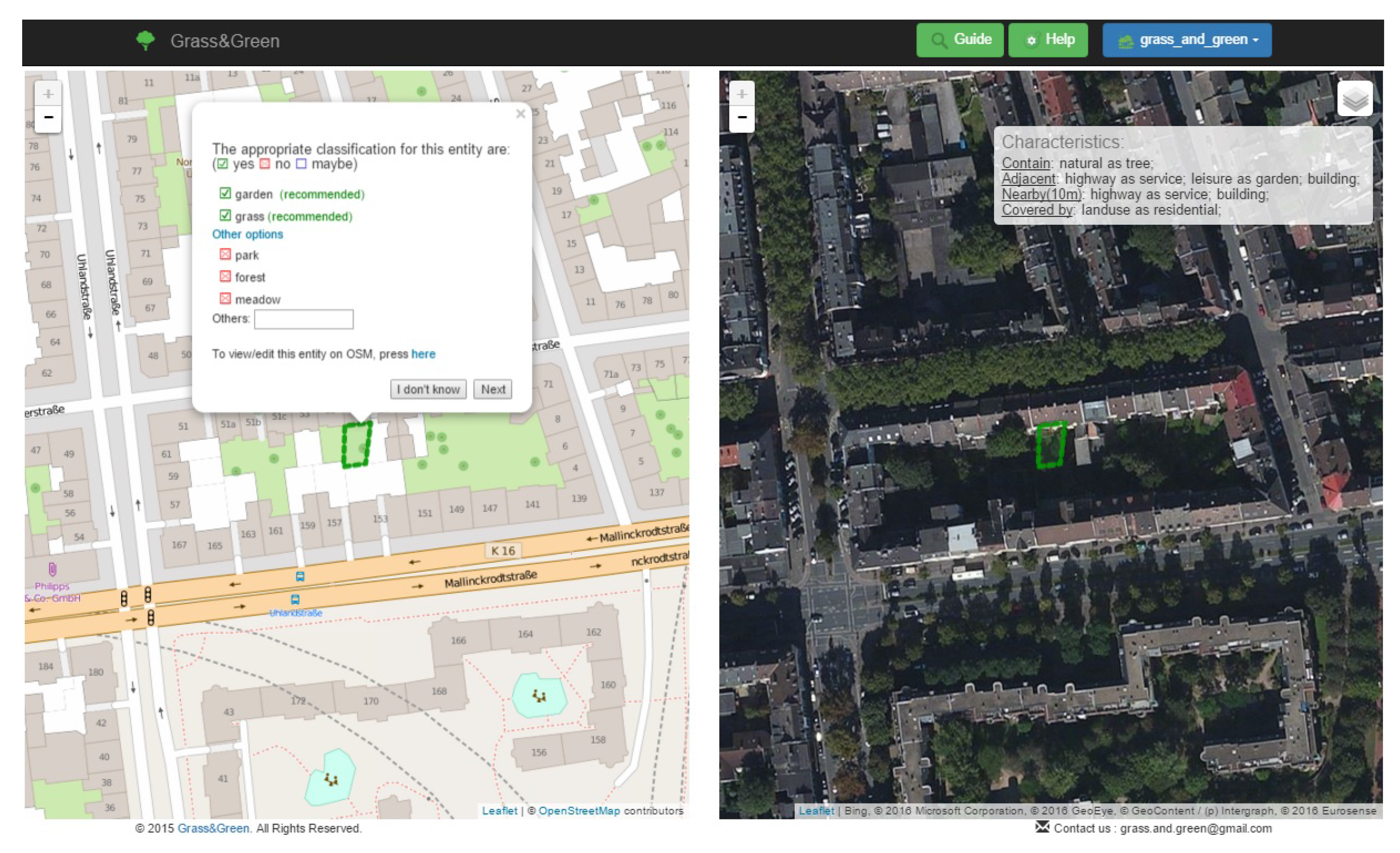
5.1. Application Description
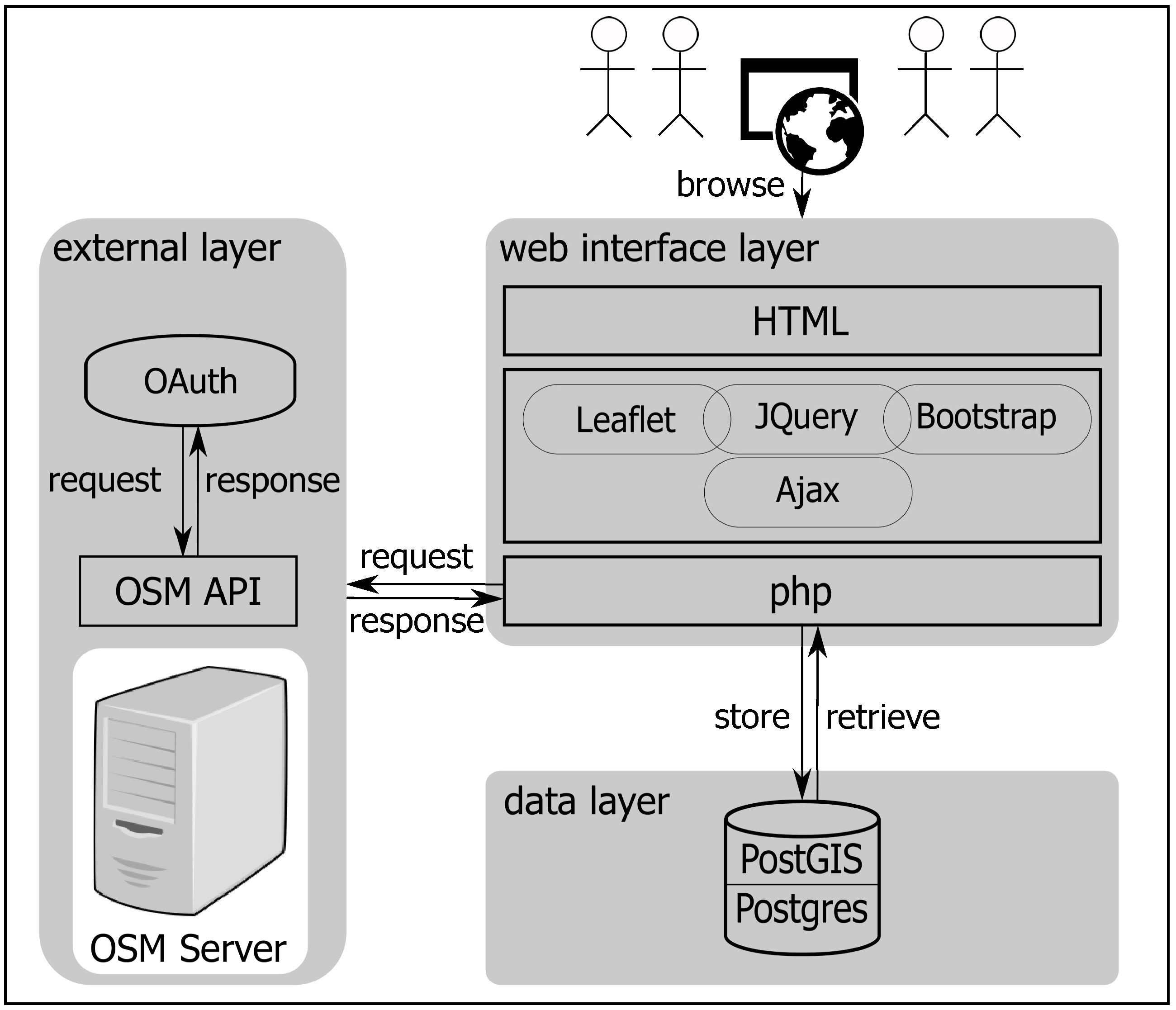
5.2. Application Architecture
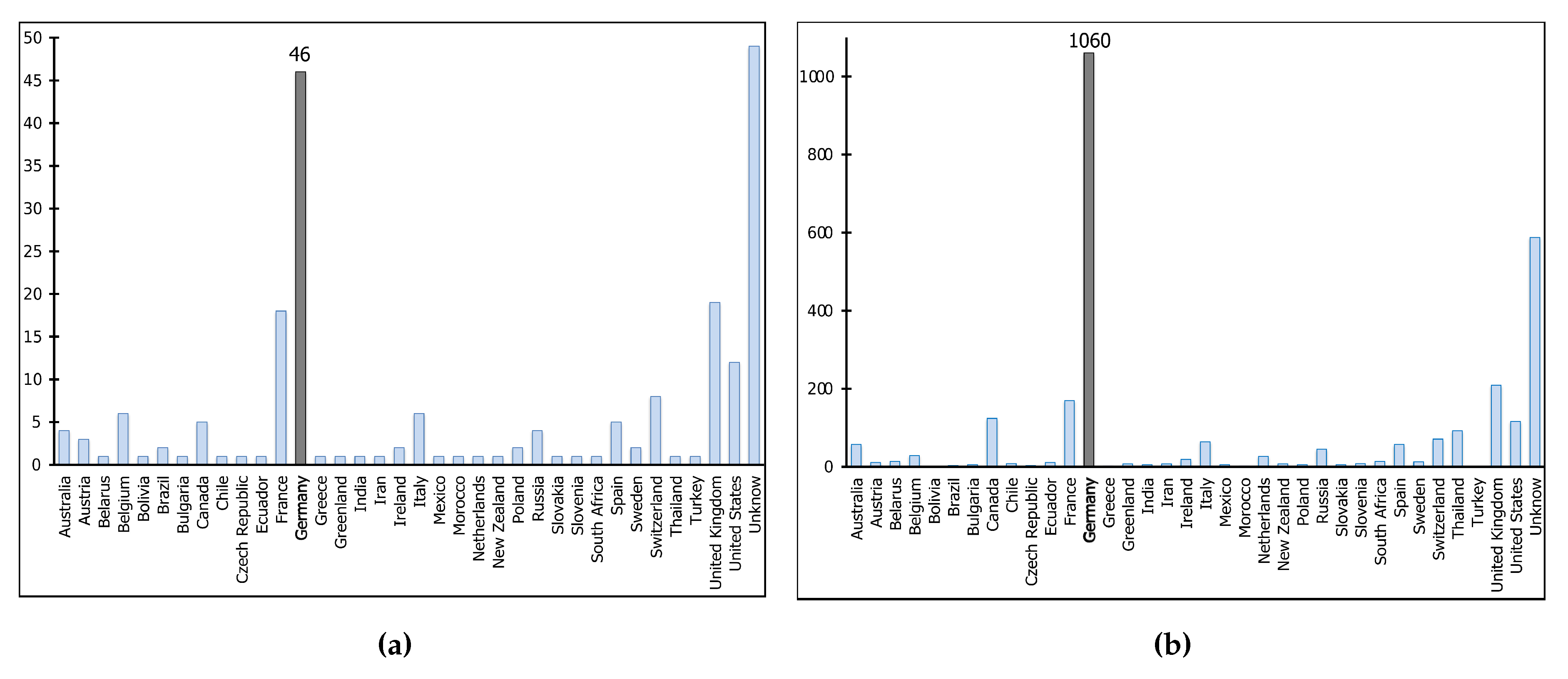
5.3. Announcement Methods and Target Participants
- OSM diaries:We announced the launch and the objectives of the application locally to the OSM mappers through the project diaries (https://www.openstreetmap.org/user/grass_and_green/diary). The OSM diaries are public to every one.
- Social Media:We developed two pages for the project: one on Twitter (https://twitter.com/grass_and_green) and the other on Facebook (https://www.facebook.com/grassANDgreen/) to use the power of social media to attract public participants. We infrequently sent news of the application and thanked the participants on the project pages.
- Others:Mailing lists and paper-based flyers are also utilized to target other researchers and students as well.
6. Results
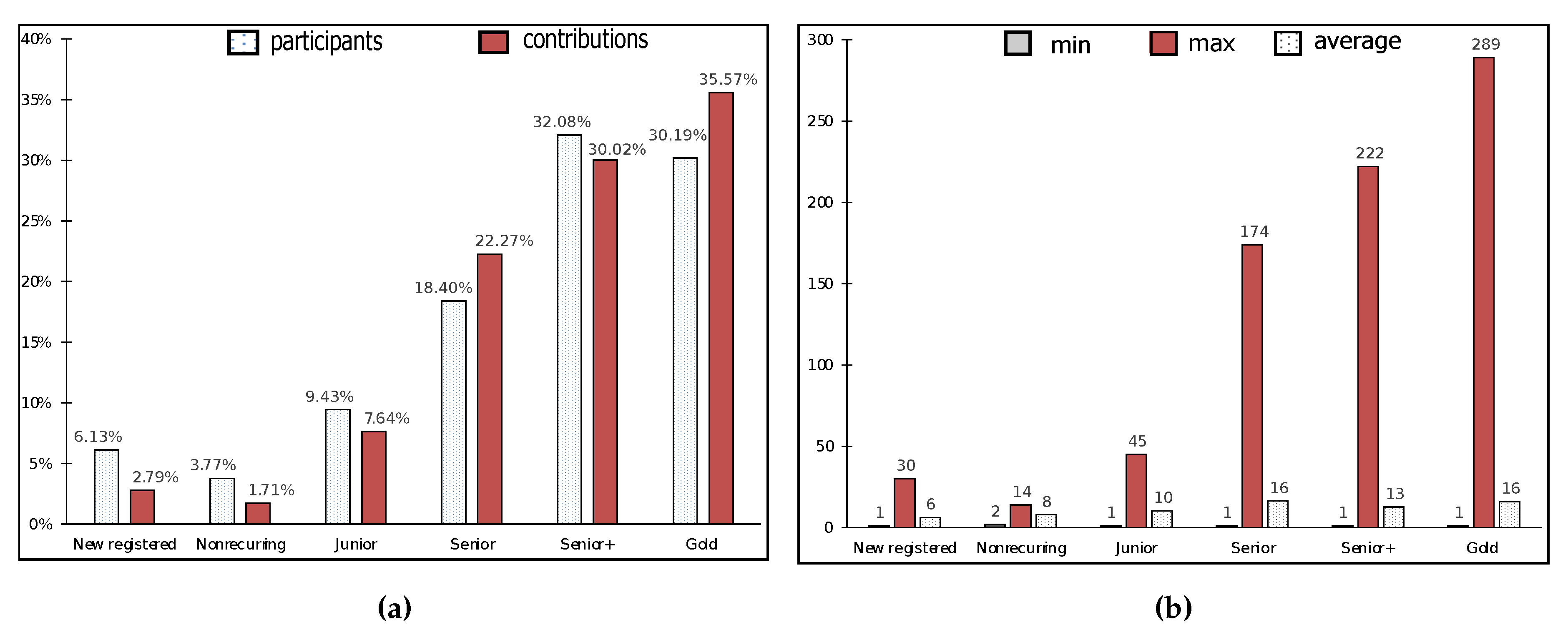
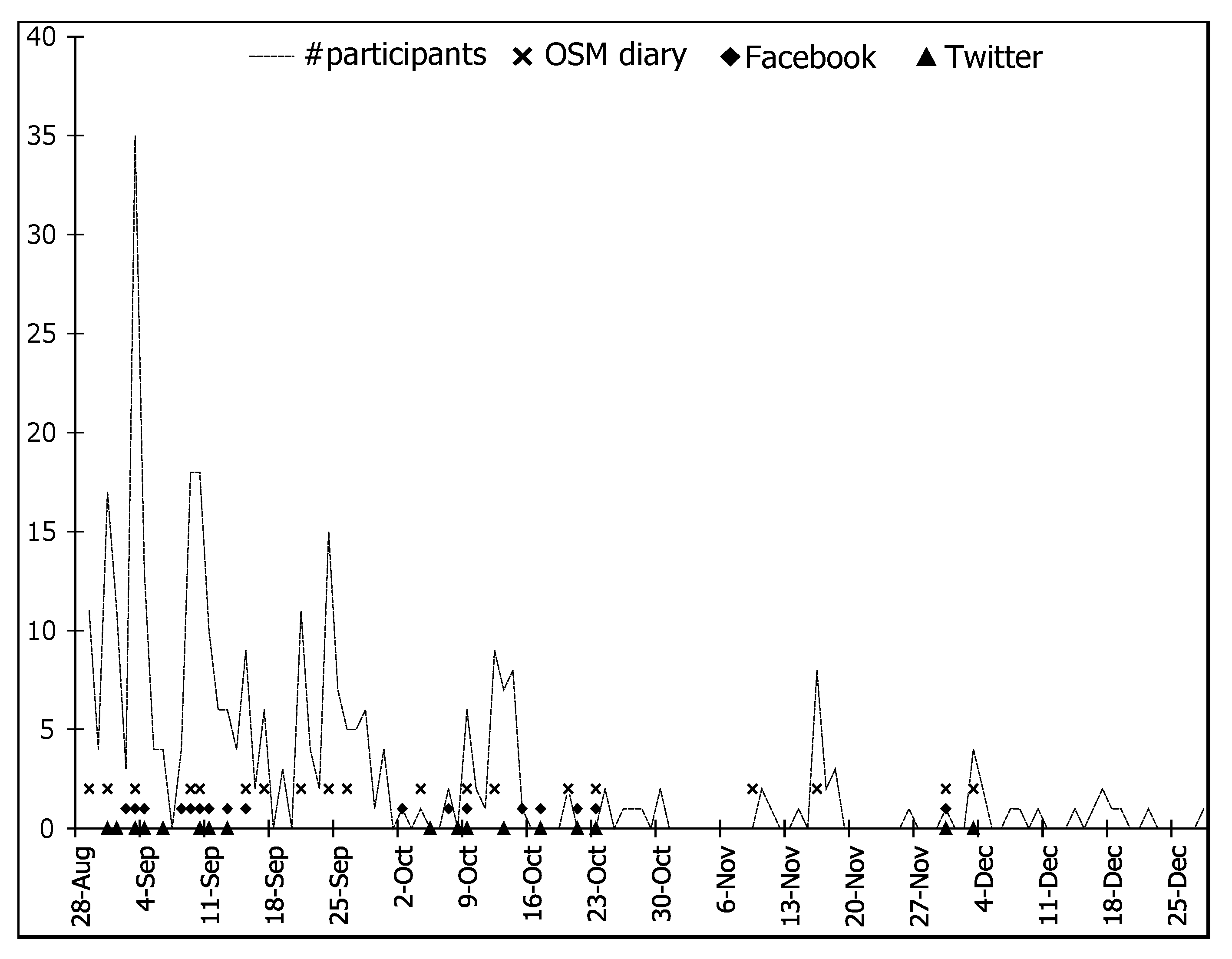
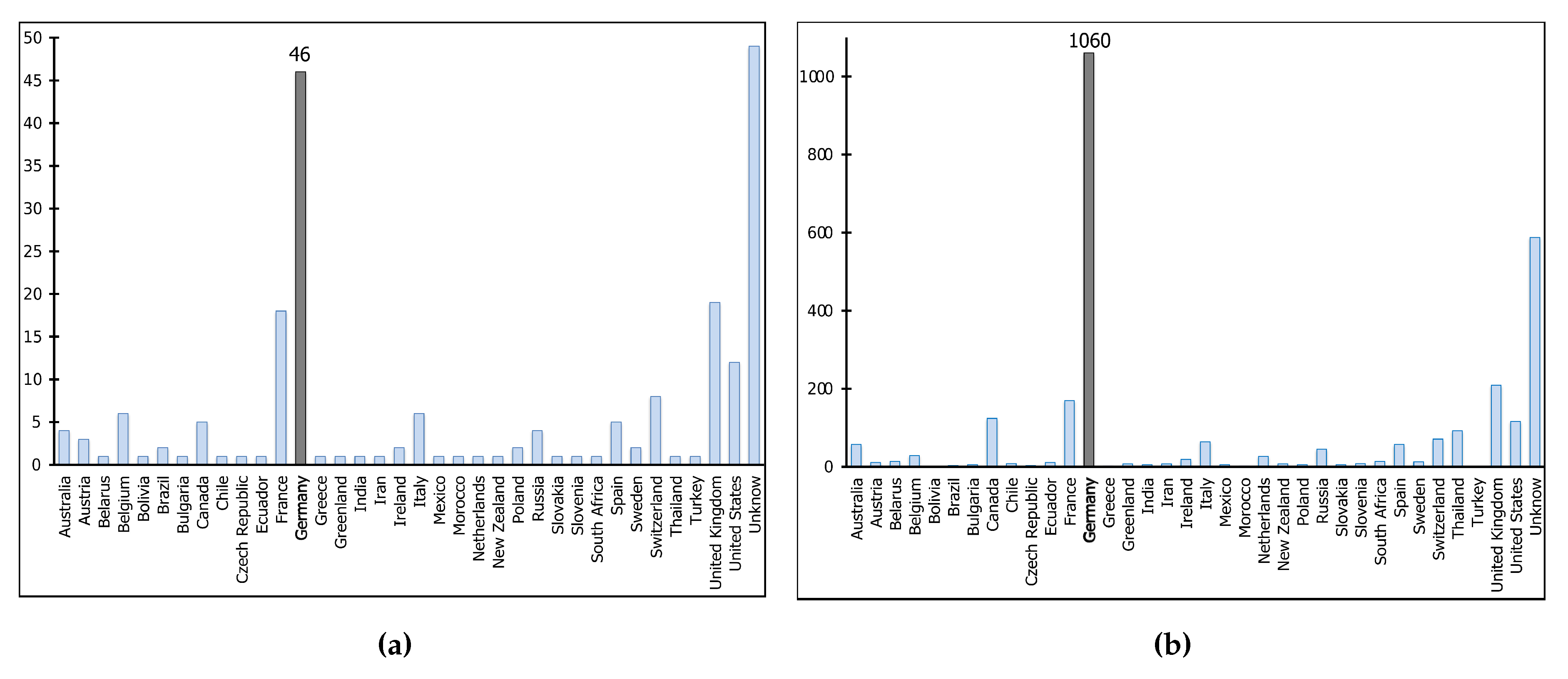
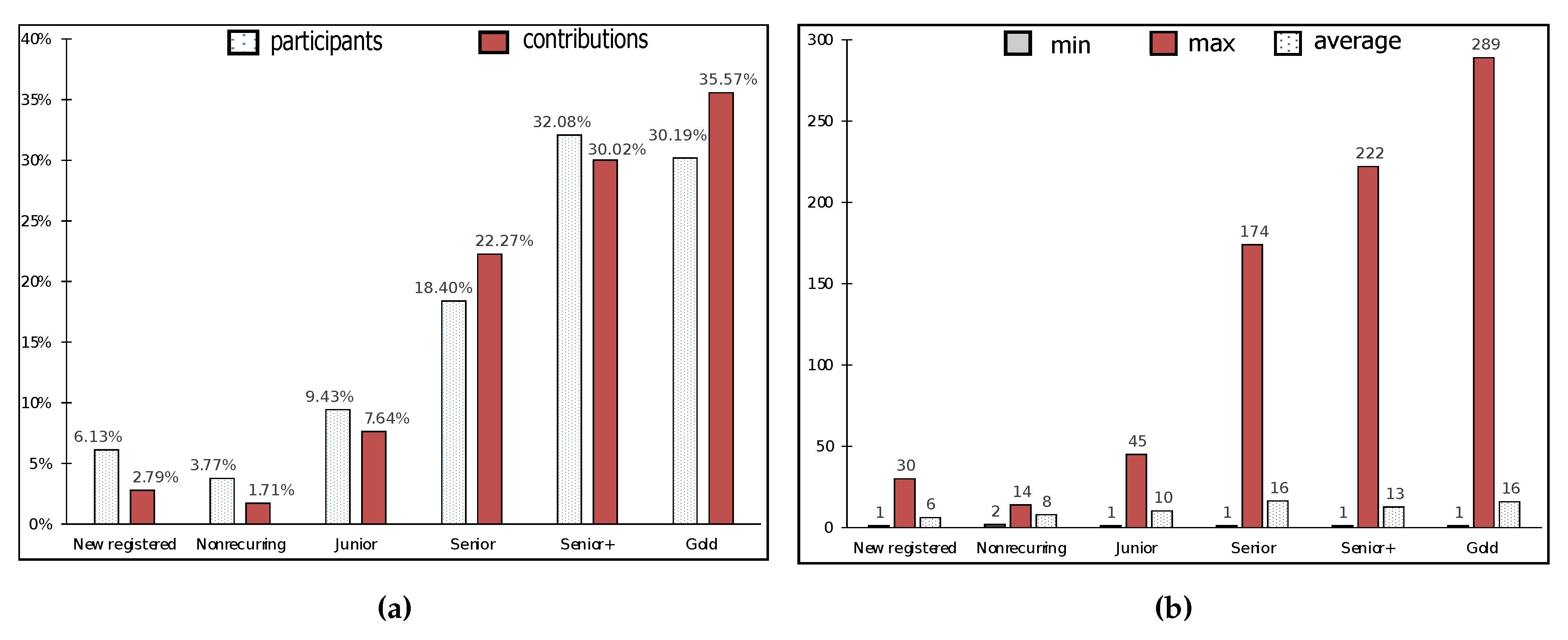
6.1. Participant and Contribution Patterns
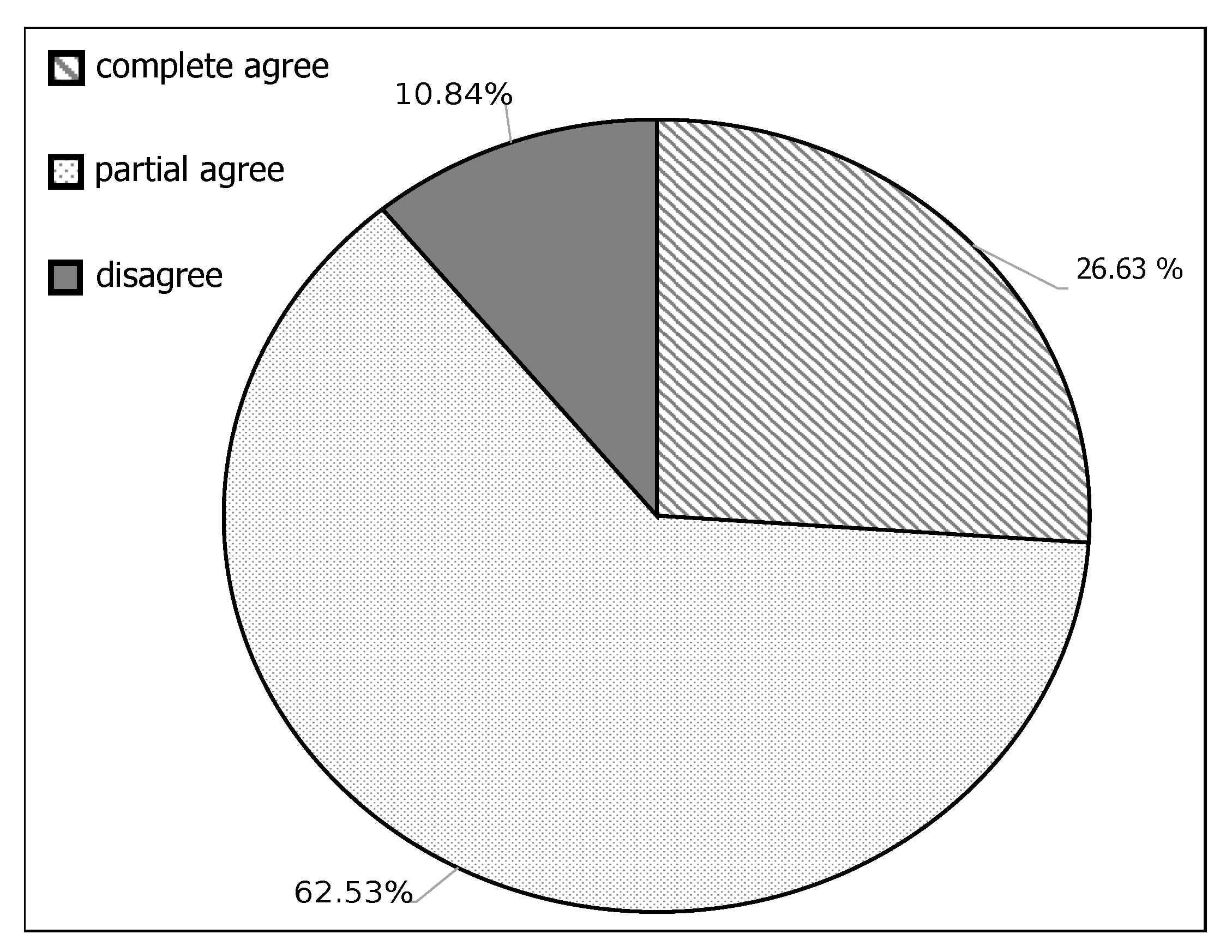
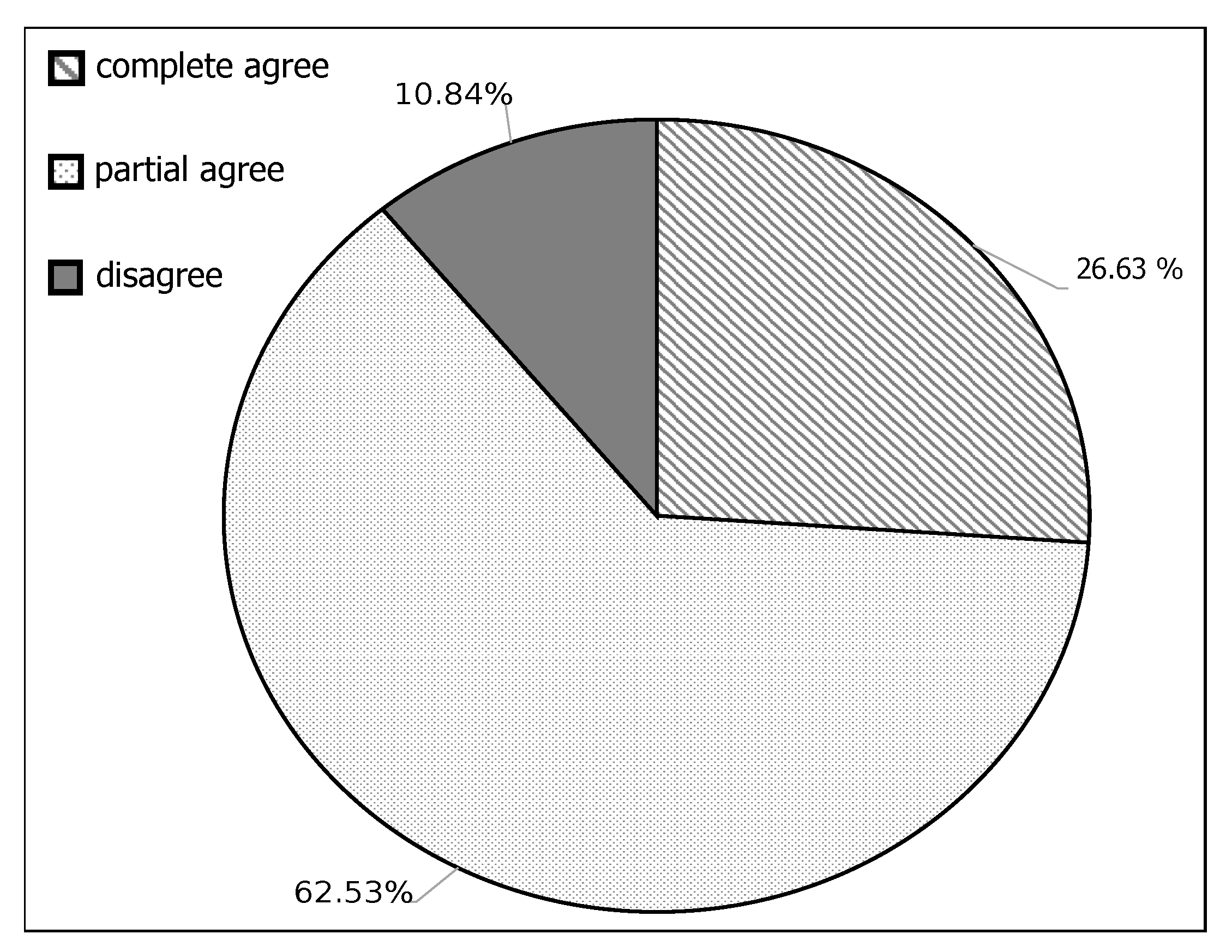
6.2. Participant Responses
- Complete agreement: when a participant agrees with both of the recommended classes and marks them with the “yes” option.
- Partial agreement: when a participant agrees with only one of the recommended classes and marks the other with a “no” or “maybe” option.
- Disagreement: when a participant does not agree with any of the recommended classes and marks them both with a “no” or “maybe” option.
6.3. Enhanced Data Classification Quality
6.4. Participant Feedback
7. Discussion
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Gouveia, C.; Fonseca, A. New approaches to environmental monitoring: The use of ICT to explore volunteered geographic information. GeoJournal 2008, 72, 185–197. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P. Can Volunteered Geographic Information be a participant in eEnvironment and SDI? In Environmental Software Systems. Frameworks of eEnvironment; Springer: Berlin, Germany, 2011; pp. 115–122. [Google Scholar]
- Roche, S.; Propeck-Zimmermann, E.; Mericskay, B. GeoWeb and crisis management: Issues and perspectives of volunteered geographic information. GeoJournal 2013, 78, 21–40. [Google Scholar] [CrossRef]
- Zook, M.; Graham, M.; Shelton, T.; Gorman, S. Volunteered Geographic Information and crowdsourcing disaster relief: A case study of the Haitian earthquake. World Med. Health Policy 2010, 2, 7–33. [Google Scholar] [CrossRef]
- Foth, M.; Bajracharya, B.; Brown, R.; Hearn, G. The second life of urban planning? Using NeoGeography tools for community engagement. J. Locat. Based Serv. 2009, 3, 97–117. [Google Scholar] [CrossRef]
- Mooney, P.; Sun, H.; Yan, L. VGI as a dynamically updated data source in location-based services in urban environments. In Proceedings of the 2nd International Workshop in Ubiquitous Crowdsourcing: UbiCrowd’11, Beijing, China, 17–21 September 2011.
- Haklay, M.; Weber, P. OpenStreetMap: User-generated street maps. IEEE Pervasive Computing 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Savelyev, A.; Xu, S.; Janowicz, K.; Mülligann, C.; Thatcher, J.; Luo, W. Volunteered geographic services: Developing a linked data driven location-based service. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Spatial Semantics and Ontologies, Chicago, IL, USA, 1 November 2011; pp. 25–31.
- Elwood, S.; Goodchild, M.F.; Sui, D.Z. Researching Volunteered Geographic Information: Spatial data, geographic research, and new social practice. Ann. Assoc. Am. Geogr. 2012, 102, 571–590. [Google Scholar] [CrossRef]
- Ali, A.L.; Schmid, F. Data quality assurance for Volunteered Geographic Information. In Geographic Information Science; Springer: Vienna, Austria, 2014; pp. 126–141. [Google Scholar]
- Devillers, R.; Stein, A.; Bédard, Y.; Chrisman, N.; Fisher, P.; Shi, W. Thirty years of research on spatial data quality: achievements, failures, and opportunities. Trans. GIS 2010, 14, 387–400. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of Volunteered Geographic Information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Goodchild, M.F. Assertion and authority: The science of user-generated geographic content. In Proceedings of the Colloquium for Andrew U. Frank’s 60th Birthday, Vienna, Italy, 30 June–1 July 2008.
- Guptill, S.C.; Morrison, J.L. Elements of Spatial Data Quality; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Ali, A.L.; Schmid, F.; Falomir, Z.; Freksa, C. Towards rule-guided classification for Volunteered Geographic Information. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 211–217. [Google Scholar] [CrossRef]
- Ali, A.L.; Falomir, Z.; Schmid, F.; Freksa, C. Rule-guided human classification of Volunteered Geographic Information. ISPRS J. Photogramm and Remote Sens. 2016, in press. [Google Scholar]
- OSM Users’ diaries. Available online: https://www.openstreetmap.org/diary (accessed on 24 May 2016).
- OSMstats. Available online: http://osmstats.neis-one.org/ (accessed on 24 May 2016).
- stensen, O.M.; Smits, P.C. ISO/TC211: Standardisation of geographic information and geo-informatics. In Proceedings of the 2002 IEEE International Geoscience and Remote Sensing Symposium, IGARSS’02, Toronto, ON, Canada, 24–28 June 2002; Volume 1, pp. 261–263.
- ISO/TC211. Available online: http://www.isotc211.org/ (accessed on 24 May 2016).
- Haklay, M. How good is Volunteered Geographic Information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Ludwig, I.; Voss, A.; Krause-Traudes, M. A comparison of the street networks of Navteq and OSM in Germany. In Advancing Geoinformation Science for a Changing World; Springer: Berlin, Gernany, 2011; pp. 65–84. [Google Scholar]
- Arsanjani, J.J.; Mooney, P.; Zipf, A.; Schauss, A. Quality assessment of the contributed land use information from OpenStreetMap versus authoritative datasets. In OpenStreetMap in GIScience; Springer: Berlin, Germany, 2015; pp. 37–58. [Google Scholar]
- Dorn, H.; Törnros, T.; Zipf, A. Quality evaluation of VGI using authoritative data—A comparison with land use data in southern Germany. ISPRS Int. J. Geo-Inf. 2015, 4, 1657–1671. [Google Scholar] [CrossRef]
- Vaz, E.; Jokar Arsanjani, J. Crowdsourced mapping of land use in urban dense environments: An assessment of Toronto. Can. Geogr. 2015. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Metzger, M.J. The credibility of Volunteered Geographic Information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Bishr, M.; Kuhn, W. Geospatial information bottom-up: A matter of trust and semantics. In The European Information Society; Springer: Berlin, Germany, 2007; pp. 365–387. [Google Scholar]
- Neis, P.; Zipf, A. Analyzing the contributor activity of a Volunteered Geographic Information project: The case of OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012, 1, 146–165. [Google Scholar] [CrossRef]
- Neis, P.; Zielstra, D.; Zipf, A. The street network evolution of crowdsourced maps: OpenStreetMap in Germany 2007–2011. Future Internet 2011, 4, 1–21. [Google Scholar] [CrossRef]
- Keßler, C.; de Groot, R.T.A. Trust as a proxy measure for the quality of Volunteered Geographic Information in the case of OpenStreetMap. In Geographic Information Science at the Heart of Europe; Springer: Berlin, Germany, 2013; pp. 21–37. [Google Scholar]
- Keßler, C.; Trame, J.; Kauppinen, T. Tracking editing processes in Volunteered Geographic Information: The case of OpenStreetMap. In Proceedings of Workshop on Identifying Objects, Processes and Events in Spatio-Temporally Distributed Data (IOPE 2011), Belfast, ME, USA, 12–16 September 2016.
- D’Antonio, F.; Fogliaroni, P.; Kauppinen, T. VGI edit history reveals data trustworthiness and user reputation. In Proceedings of the 17th AGILE Conference on Geographic Information Science, Connecting a Digital Europe through Location and Place, Castellon, Spain, 3–6 June 2014.
- Neis, P.; Zielstra, D.; Zipf, A. Comparison of Volunteered Geographic Information data contributions and community development for selected world regions. Future Internet 2013, 5, 282–300. [Google Scholar] [CrossRef]
- Ballatore, A.; Zipf, A. A conceptual quality framework for Volunteered Geographic Information. In Proceedings of the 12th International Conference on Spatial Information Theory COSIT 2015, Santa Fe, NM, USA, 12–16 October 2015; pp. 89–107.
- Barron, C.; Neis, P.; Zipf, A. A comprehensive framework for intrinsic OpenStreetMap quality analysis. Trans. GIS 2014, 18, 877–895. [Google Scholar] [CrossRef]
- Hecht, B.; Stephens, M. A tale of cities: Urban biases in Volunteered Geographic Information. In Proceeding of the 8th International Conference on Weblogs and Social Media (ICWSM), Oxford, UK, 27–29 May 2014.
- Quattrone, G.; Mashhadi, A.; Capra, L. Mind the map: the impact of culture and economic affluence on crowd-mapping behaviours. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; pp. 934–944.
- Schmid, F.; Kutz, O.; Frommberger, L.; Kauppinen, T.; Cai, C. Intuitive and natural interfaces for geospatial data classification. In Proceedings of Workshop on Place-Related Knowledge Acquisition Research (P-KAR), Kloster Seeon, Germany, 31 August 2012.
- Schmid, F.; Frommberger, L.; Cai, C.; Dylla, F. Lowering the barrier: How the What-You-See-Is-What-You-Map paradigm enables people to contribute volunteered geographic information. In Proceedings of the 4th Annual Symposium on Computing for Development, Cape Town, South Africa, 6–7 December 2013; pp. 8–18.
- Pourabdollah, A.; Morley, J.; Feldman, S.; Jackson, M. Towards an authoritative OpenStreetMap: Conflating OSM and OS OpenData national maps’ road network. ISPRS Int. J. Geo-Inf. 2013, 2, 704–728. [Google Scholar] [CrossRef]
- Vandecasteele, A.; Devillers, R. Improving Volunteered Geographic Data quality using semantic similarity measurements. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 1, 143–148. [Google Scholar] [CrossRef]
- Ali, A.L.; Schmid, F.; Al-Salman, R.; Kauppinen, T. Ambiguity and plausibility: Managing classification quality in Volunteered Geographic Information. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 143–152.
- Yanenko, O.; Schlieder, C. Game principles for enhancing the quality of user-generated data collections. In Proceedings of the AGILE, Workshop Geogames Geoplay, Castellon, Spain, 3–6 June 2014; pp. 1–5.
- Karagiannakis, N.; Giannopoulos, G.; Skoutas, D.; Athanasiou, S. OSMRec tool for automatic recommendation of categories on spatial entities in OpenStreetMap. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 337–338.
- OSMRecPlugin. Available online: https://github.com/GeoKnow/OSMRec (accessed on 24 May 2016).
- OSM Inspector. Available online: http://tools.geofabrik.de/osmi/ (accessed on 24 May 2016).
- Keep Right. Available online: http://keepright.ipax.at/ (accessed on 24 May 2016).
- Map Roulette. Available online: http://maproulette.org/ (accessed on 24 May 2016).
- Map Dust. Available online: http://www.mapdust.com/ (accessed on 24 May 2016).
- NOVAM. Available online: http://b3e.net/novam/ (accessed on 24 May 2016).
- Fisher, P.F. Models of uncertainty in spatial data. Geograph. Inf. Syst. 1999, 1, 191–205. [Google Scholar]
- Sparks, K.; Klippel, A.; Wallgrün, J.O.; Mark, D. Citizen science land cover classification based on ground and aerial imagery. In Spatial Information Theory; Springer: Berlin, Germany, 2015; pp. 289–305. [Google Scholar]
- Klippel, A.; Sparks, K.; Wallgrün, J.O. Pitfalls and potentials of crowd science: A meta-analysis of contextual influences. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 325–331. [Google Scholar] [CrossRef]
- Foody, G.; See, L.; Fritz, S.; Van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.; Comber, A. Accurate attribute mapping from volunteered geographic information: issues of volunteer quantity and quality. Cartogr. J. 2014, 52, 1–9. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; See, L.; Schepaschenko, D.; Van der Velde, M.; Kraxner, F.; Obersteiner, M. Geo-Wiki: An online platform for improving global land cover. Environ. Model. Softw. 2012, 31, 110–123. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P. The annotation process in OpenStreetMap. Trans. GIS 2012, 16, 561–579. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M.; Wilson, D.C. Geographic knowledge extraction and semantic similarity in OpenStreetMap. Knowl. Inf. Syst. 2013, 37, 61–81. [Google Scholar] [CrossRef]
- Baglatzi, A.; Kokla, M.; Kavouras, M. Semantifying OpenStreetMap. In Proceedings of the 5th International Terra Cognita Workshop, Boston, MA, USA, 12 November 2012; pp. 39–50.
- Comber, A.J.; Fisher, P.; Harvey, F.; Gahegan, M.; Wadsworth, R. Using metadata to link uncertainty and data quality assessments. In Proceedings of the 12th International Symposium on Spatial Data Handling, Vienna, Austria, 12–14 July 2006; pp. 279–292.
- Grira, J.; Bédard, Y.; Roche, S. Spatial data uncertainty in the VGI world: Going from consumer to producer. Geomatica 2010, 64, 61–72. [Google Scholar]
- Egenhofer, M.J.; Al-Taha, K.K. Reasoning about Gradual Changes of Topological Relationships. In Proceedings of International Conference GIS—From Space to Territory: Theories and Methods of Spatio-Temporal Reasoning, Pisa, Italy, 21–23 September 1992; pp. 196–219.
- Thabtah, F. A review of associative classification mining. Knowl. Eng. Rev. 2007, 22, 37–65. [Google Scholar] [CrossRef]
- Ubuntu Server. Available online: http://www.ubuntu.com/server (accessed on 24 May 2016).
- OpenScienceMap. Available online: http://www.opensciencemap.org/ (accessed on 24 May 2016).
- Wordnet. Available online: https://wordnet.princeton.edu/ (accessed on 24 May 2016).
- Leaflet. Available online: http://leafletjs.com/ (accessed on 1 June 2016).
- Bootstrap. Available online: http://getbootstrap.com/ (accessed on 1 June 2016).
- JQuery. Available online: https://jquery.com/ (accessed on 1 June 2016).
- OAuth. Available online: http://oauth.net/ (accessed on 1 June 2016).
- Crone, G.R. Maps and Their Makers: An Introduction to the History of Cartography; Hutchinson’s University Library: London, UK, 1966. [Google Scholar]
- Goodchild, M.F.; Gopal, S. The Accuracy of Spatial Databases; CRC Press: Boca Raton, FL, USA, 1989. [Google Scholar]
- Goodchild, M.F. Data Models and Data Quality: Problems and Prospects. Available online: http://www.geog.ucsb.edu/ good/papers/192.pdf (accessed on 1 June 2016).
- Thatcher, J. From Volunteered Geographic Information to Volunteered Geographic Services. In Crowdsourcing Geographic Knowledge; Springer: Berlin, Germany, 2013; pp. 161–173. [Google Scholar]
- Parker, C.J.; May, A.; Mitchell, V.; Burrows, A. Capturing volunteered information for inclusive service design: potential benefits and challenges. Des. J. 2013, 16, 197–218. [Google Scholar] [CrossRef]
- Frank, A.U. Spatial ontology: A geographical information point of view. In Spatial and Temporal Reasoning; Springer: Berlin, Germany, 1997; pp. 135–153. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OSM Tag | Class | OSM Tag | Class |
|---|---|---|---|
| landuse = grass or landcover = grass | grass | natural = wood or wood = yes | wood |
| leisure = park | park | natural = water | water |
| leisure = garden | garden | natural = water water = lake | lake |
| landuse = recreation ground | recreation | natural = water water = pond | pond |
| landuse = meadow | meadow | natural = water water = reflecting_pool | reflecting pool |
| natural = scrub | scrub | natural = water water = reservoir | reservoir |
| natural = grassland | grassland | natural = water water = wastewater | waste water |
| natural = heath | heath | natural = wetland wetland = swamp | swamp |
| landuse = forest | forest | natural = wetland wetland = marsh | marsh |
| Entities/Class Before Validation | Participants’ Response | Previous Class in Recommendation | Previous Class Not in Recommendation | Acceptance Percentage |
|---|---|---|---|---|
| 412 entities (garden) | yes/maybe | 261 | 11 | 75.9% |
| no | 88 | 52 | ||
| 1,136 entities (grass) | yes/maybe | 942 | 24 | 89.2% |
| no | 98 | 72 | ||
| 731 entities (park) | yes/maybe | 426 | 41 | 85.2% |
| no | 67 | 197 | ||
| Total 2279 entities | 85.5% |
| Classes | In Recommended Classes | Participants Response | |
|---|---|---|---|
| yes/maybe | no | ||
| forest | 748 | 184 | 564 |
| garden | 753 | 443 | 310 |
| grass | 1,970 | 1,605 | 365 |
| park | 747 | 542 | 205 |
| meadow | 340 | 106 | 234 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.L.; Sirilertworakul, N.; Zipf, A.; Mobasheri, A. Guided Classification System for Conceptual Overlapping Classes in OpenStreetMap. ISPRS Int. J. Geo-Inf. 2016, 5, 87. https://doi.org/10.3390/ijgi5060087
Ali AL, Sirilertworakul N, Zipf A, Mobasheri A. Guided Classification System for Conceptual Overlapping Classes in OpenStreetMap. ISPRS International Journal of Geo-Information. 2016; 5(6):87. https://doi.org/10.3390/ijgi5060087
Chicago/Turabian StyleAli, Ahmed Loai, Nuttha Sirilertworakul, Alexander Zipf, and Amin Mobasheri. 2016. "Guided Classification System for Conceptual Overlapping Classes in OpenStreetMap" ISPRS International Journal of Geo-Information 5, no. 6: 87. https://doi.org/10.3390/ijgi5060087
APA StyleAli, A. L., Sirilertworakul, N., Zipf, A., & Mobasheri, A. (2016). Guided Classification System for Conceptual Overlapping Classes in OpenStreetMap. ISPRS International Journal of Geo-Information, 5(6), 87. https://doi.org/10.3390/ijgi5060087