Smartphone-Based Pedestrian’s Avoidance Behavior Recognition towards Opportunistic Road Anomaly Detection †



Abstract
:1. Introduction
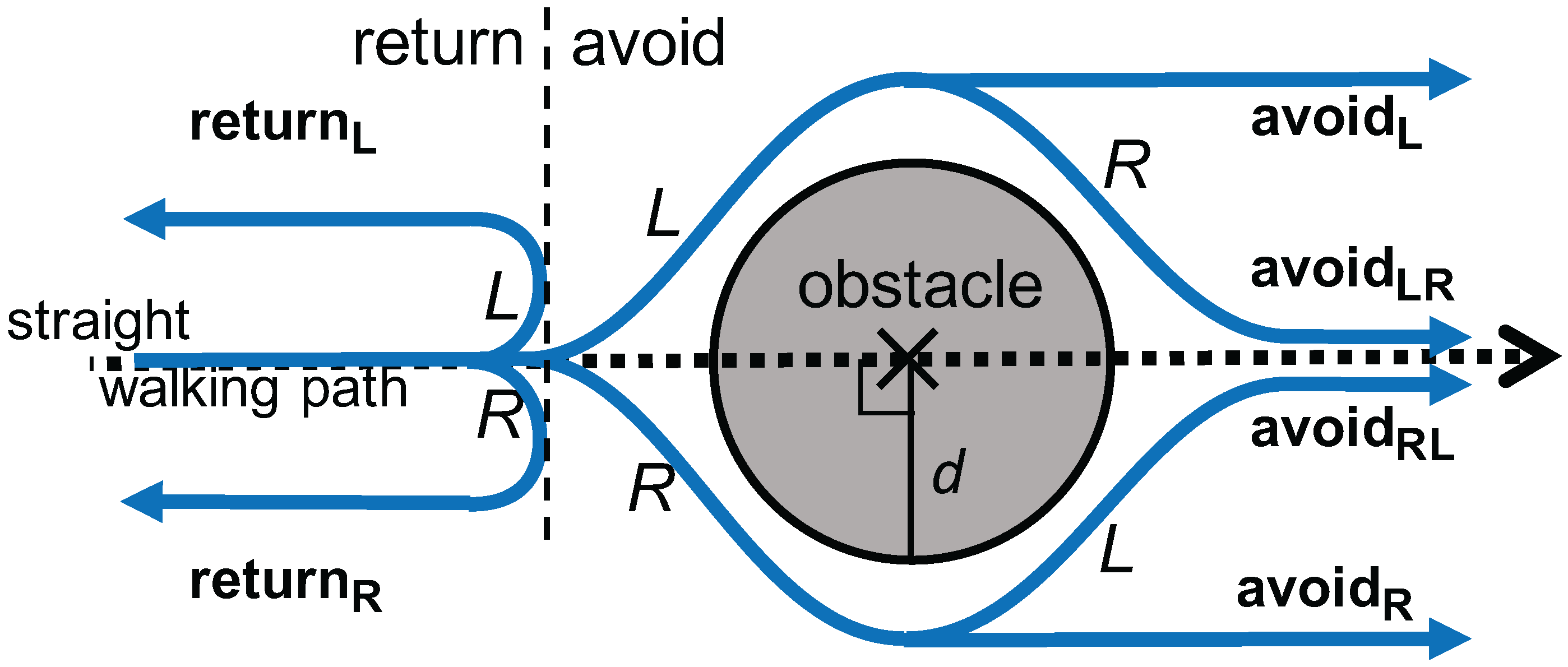
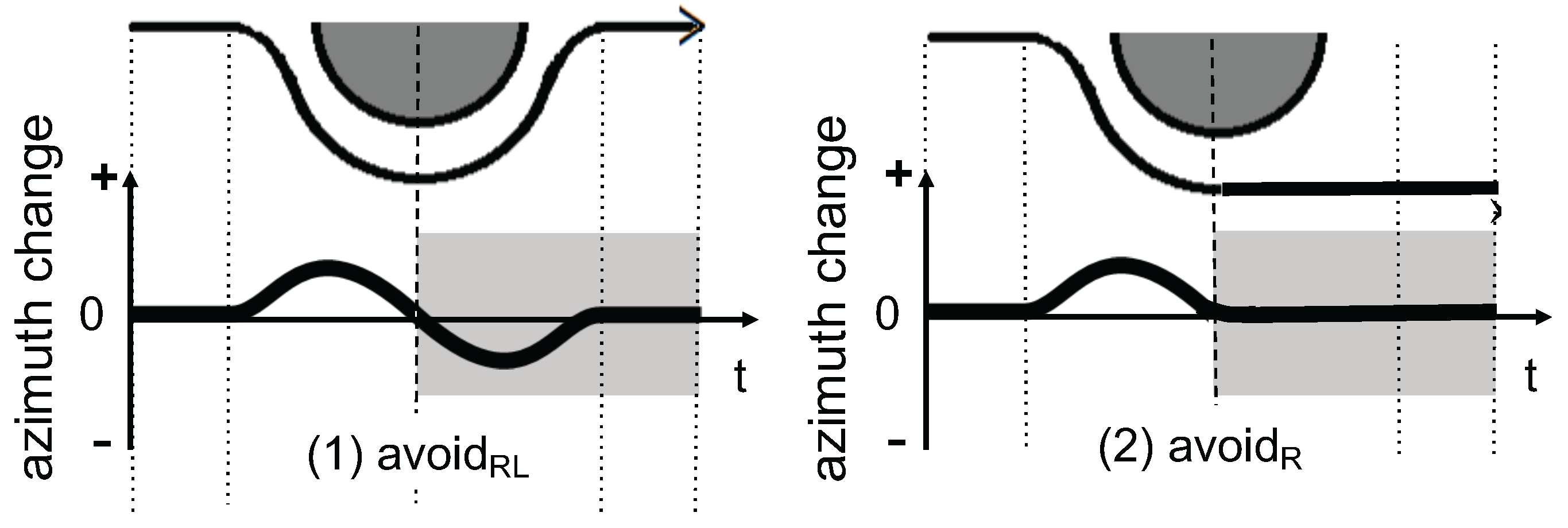
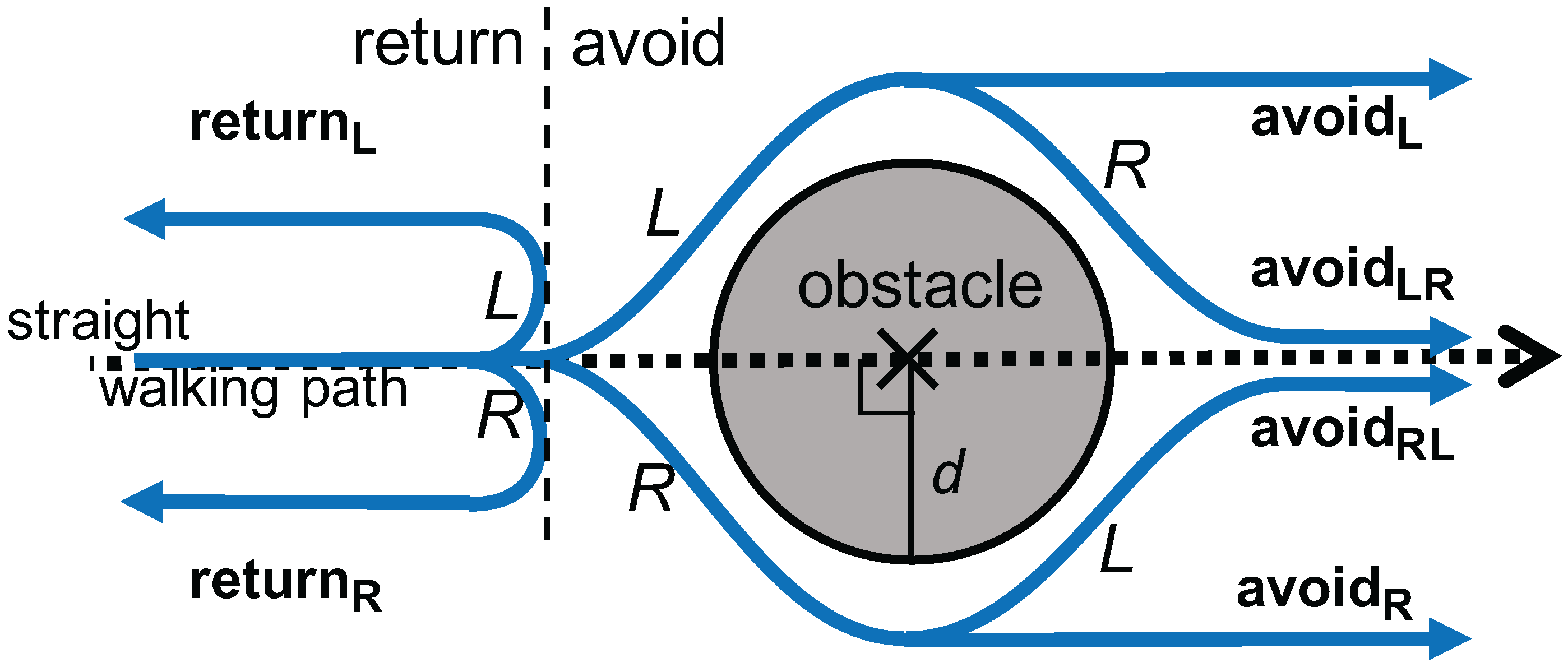
- A smartphone-based road anomaly detection system is presented, in which obstacle avoidance behaviors are categorized into three classes. The three classes include: (1) returning to the same line in the vicinity of avoiding an obstacle; (2) going straight after avoiding an obstacle; and (3) reversing his/her course; which may indicate the impact of the obstacle on pedestrians. The three classes may indicate the severity of obstacles, which would be helpful for an administrative entity to plan a repair schedule.
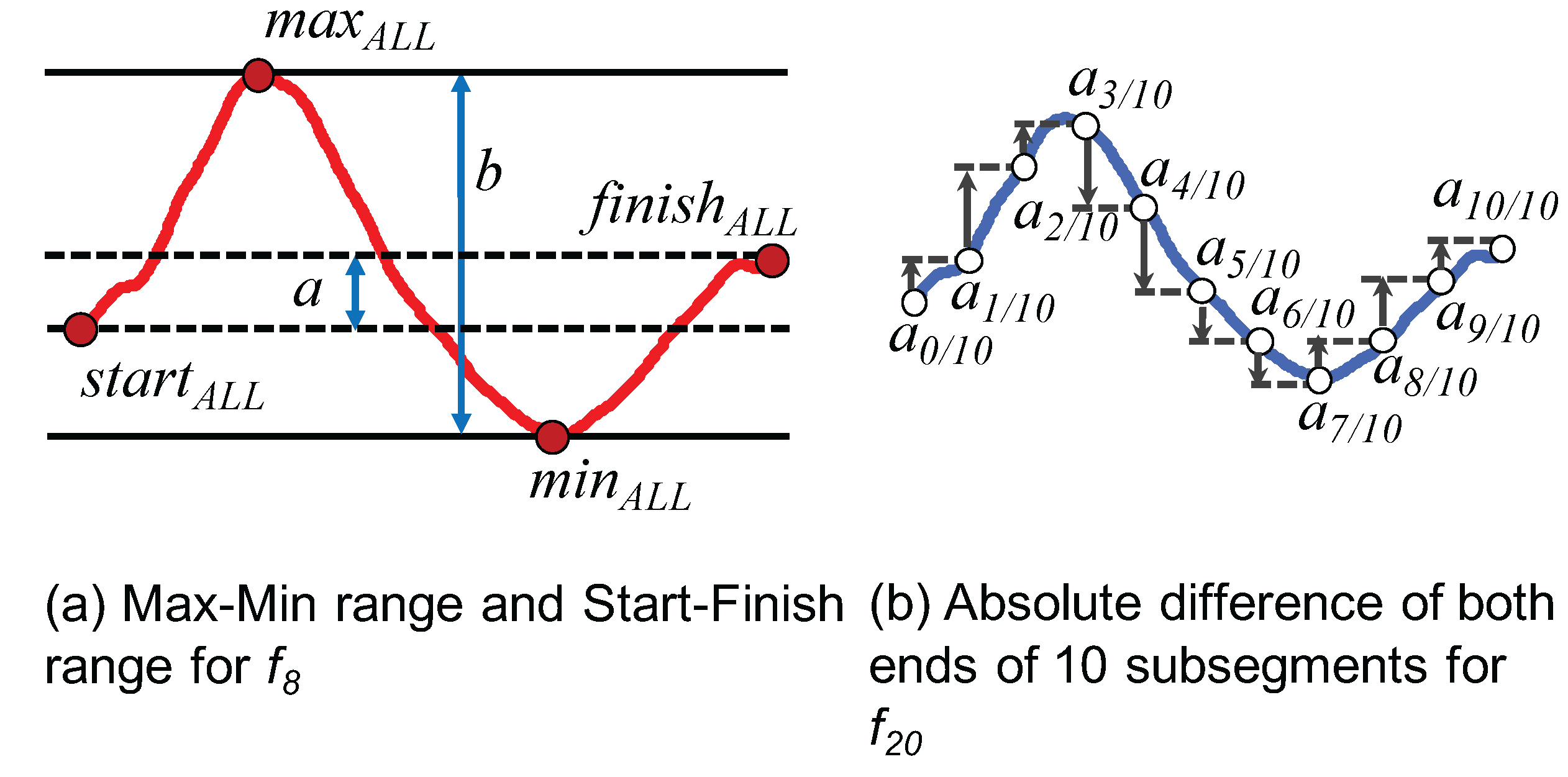
- Twenty nine classification features are defined based on the characteristics of the azimuth change of each class. The relevance of the features is evaluated.
- We extensively analyze the effects of various factors on the recognition performance. This includes the individuals who provide data for training classifiers and the position of sensors (i.e., smartphones) on their bodies, as well as the size of target obstacles.
2. Related Work
3. Avoidance Behavior Recognition
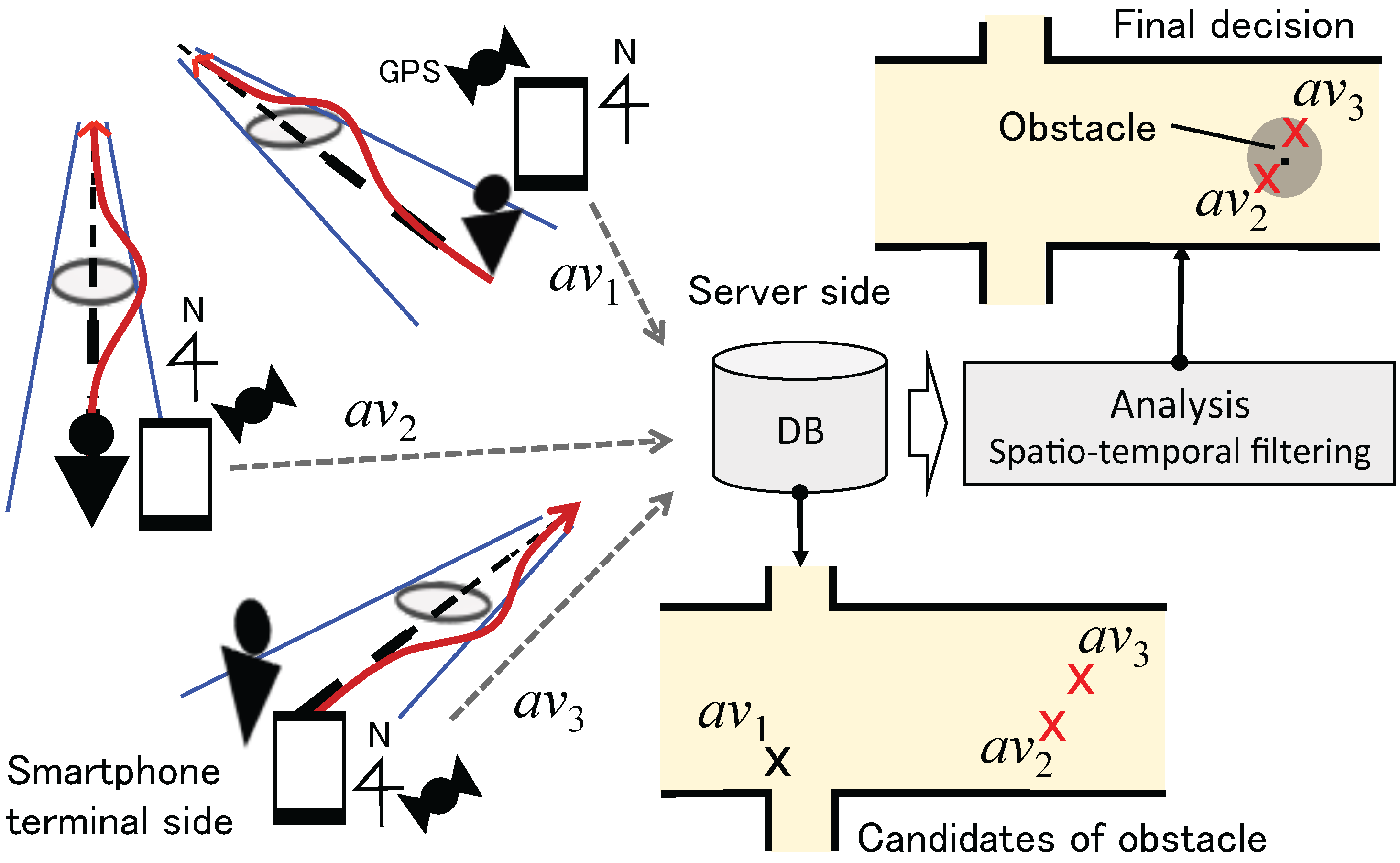
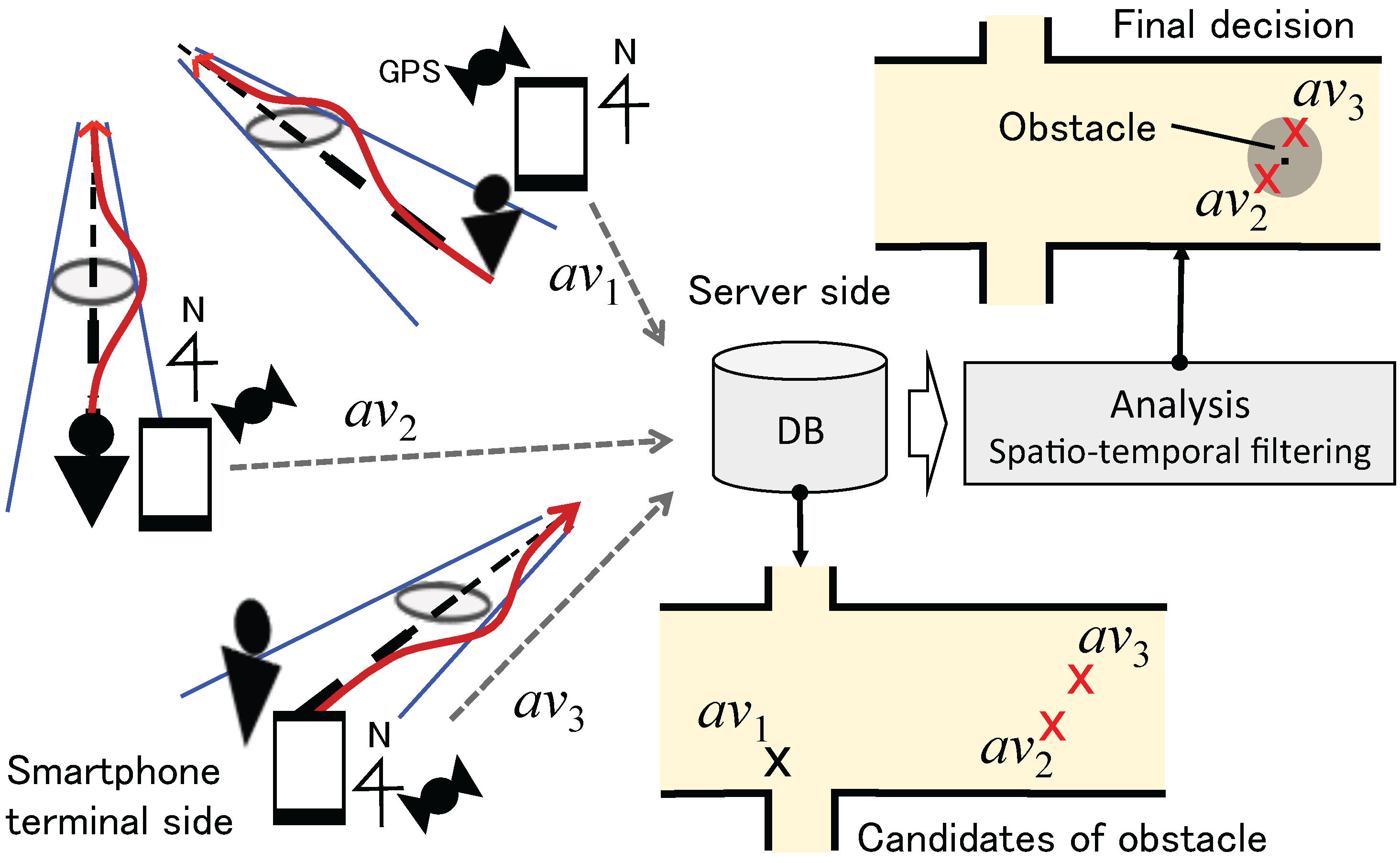
3.1. System Overview
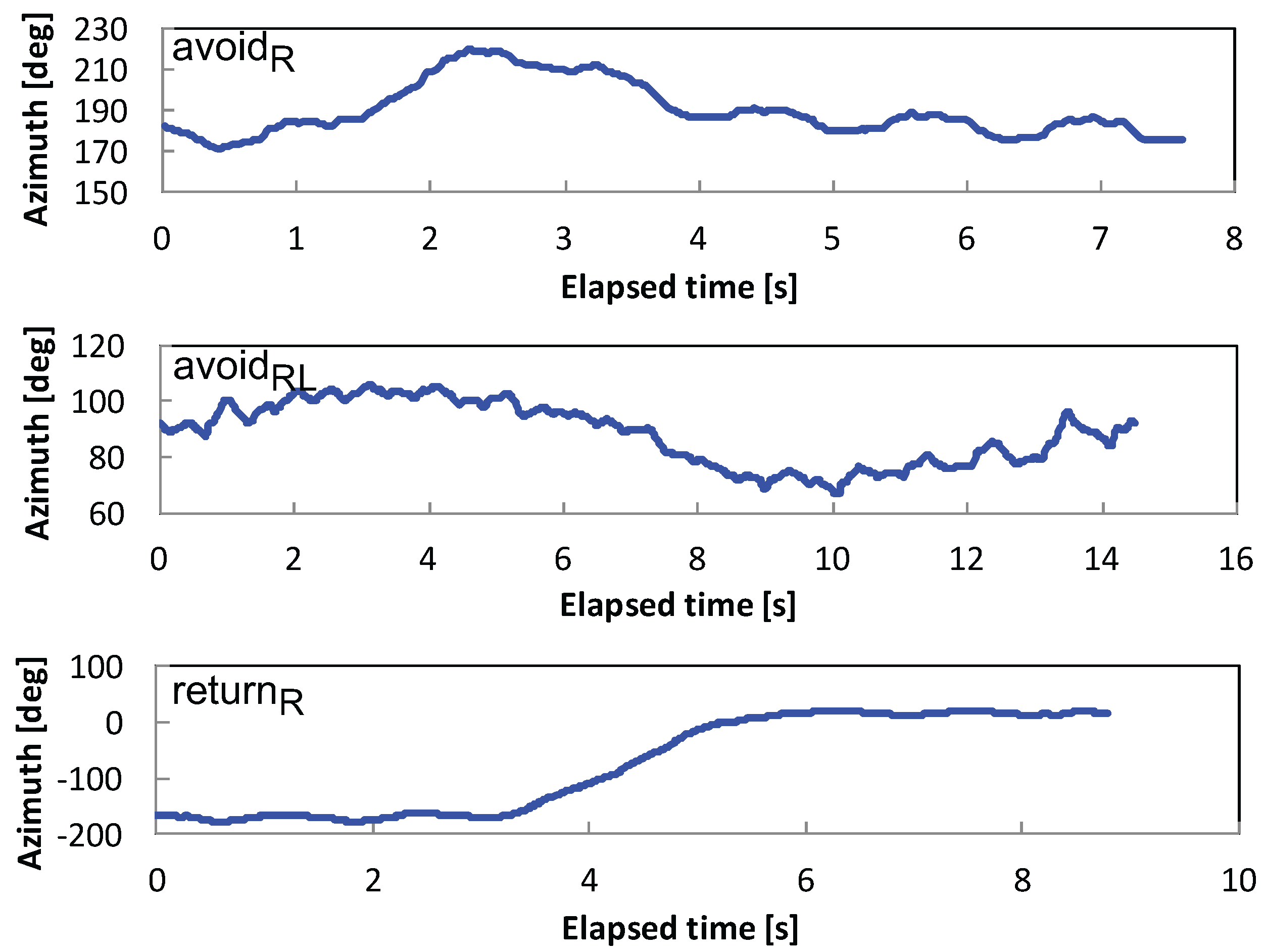
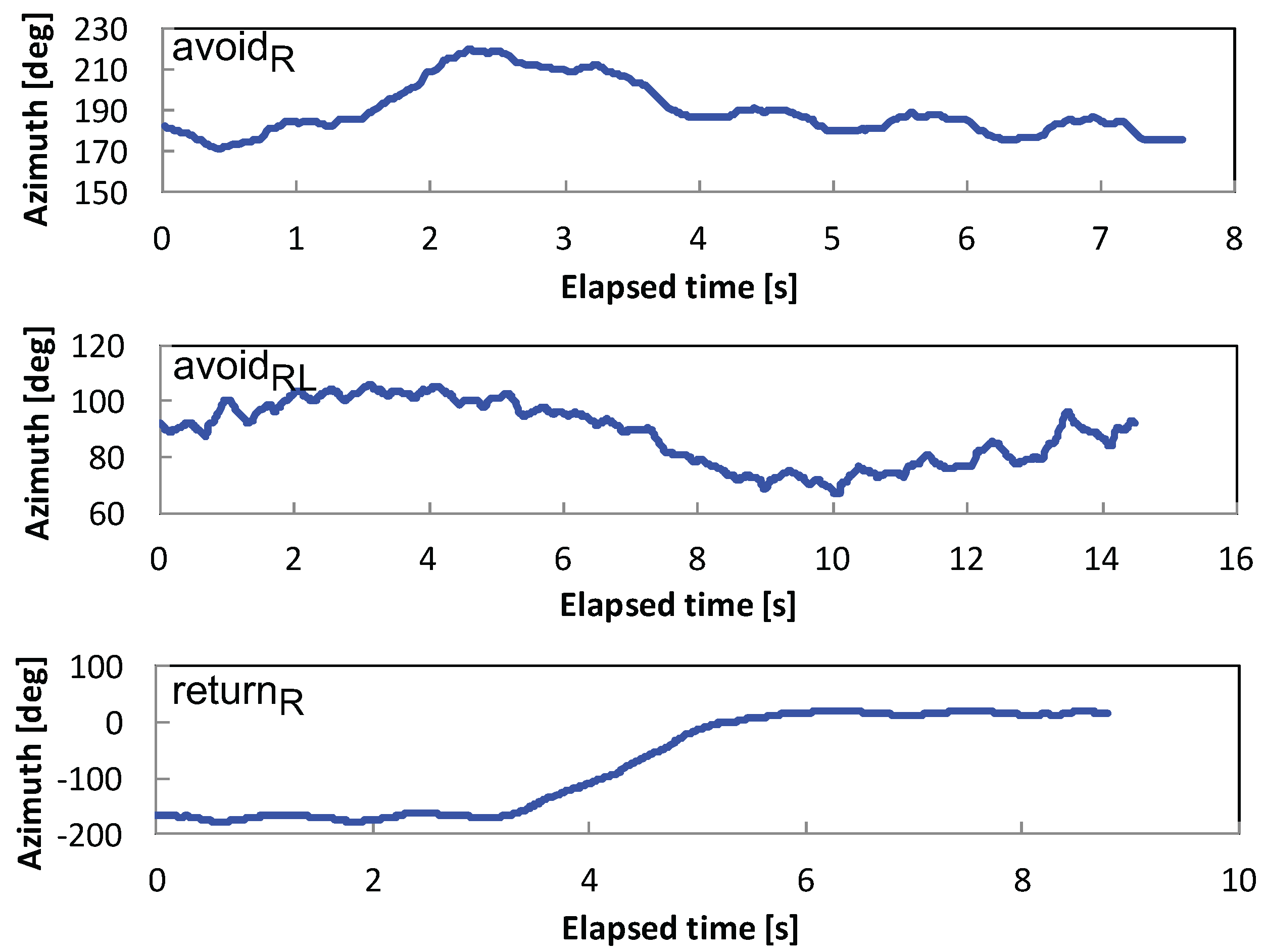
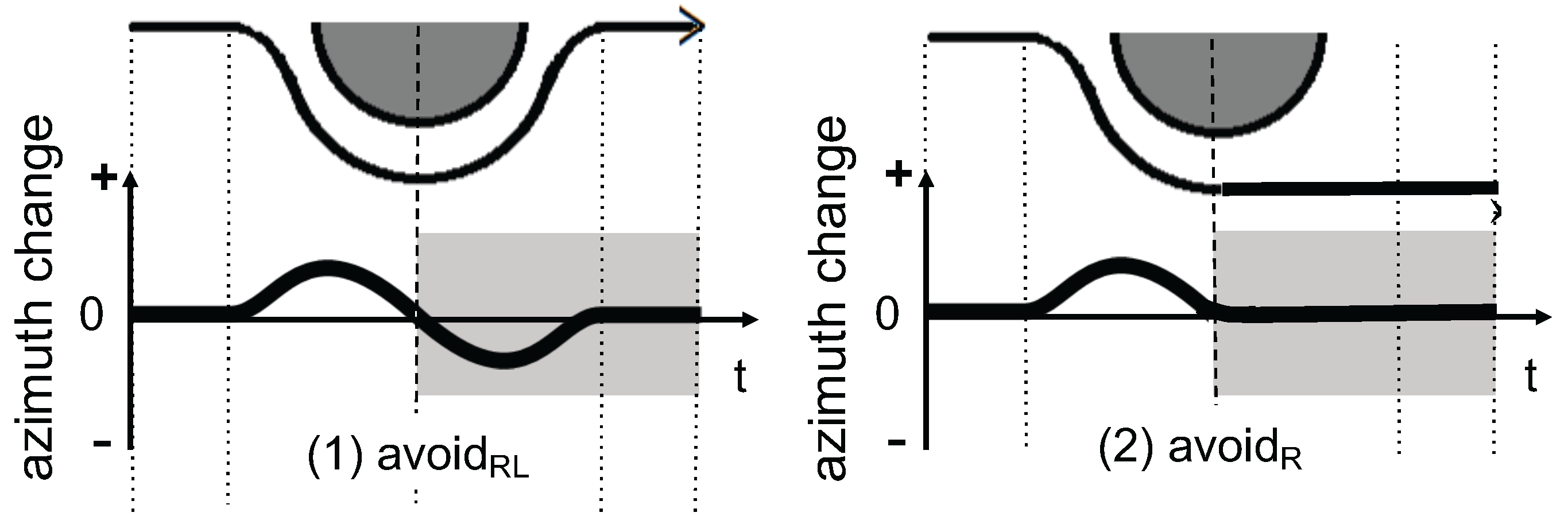
3.2. Avoidance Behavior Modeling
3.3. Avoidance Behavior Recognition
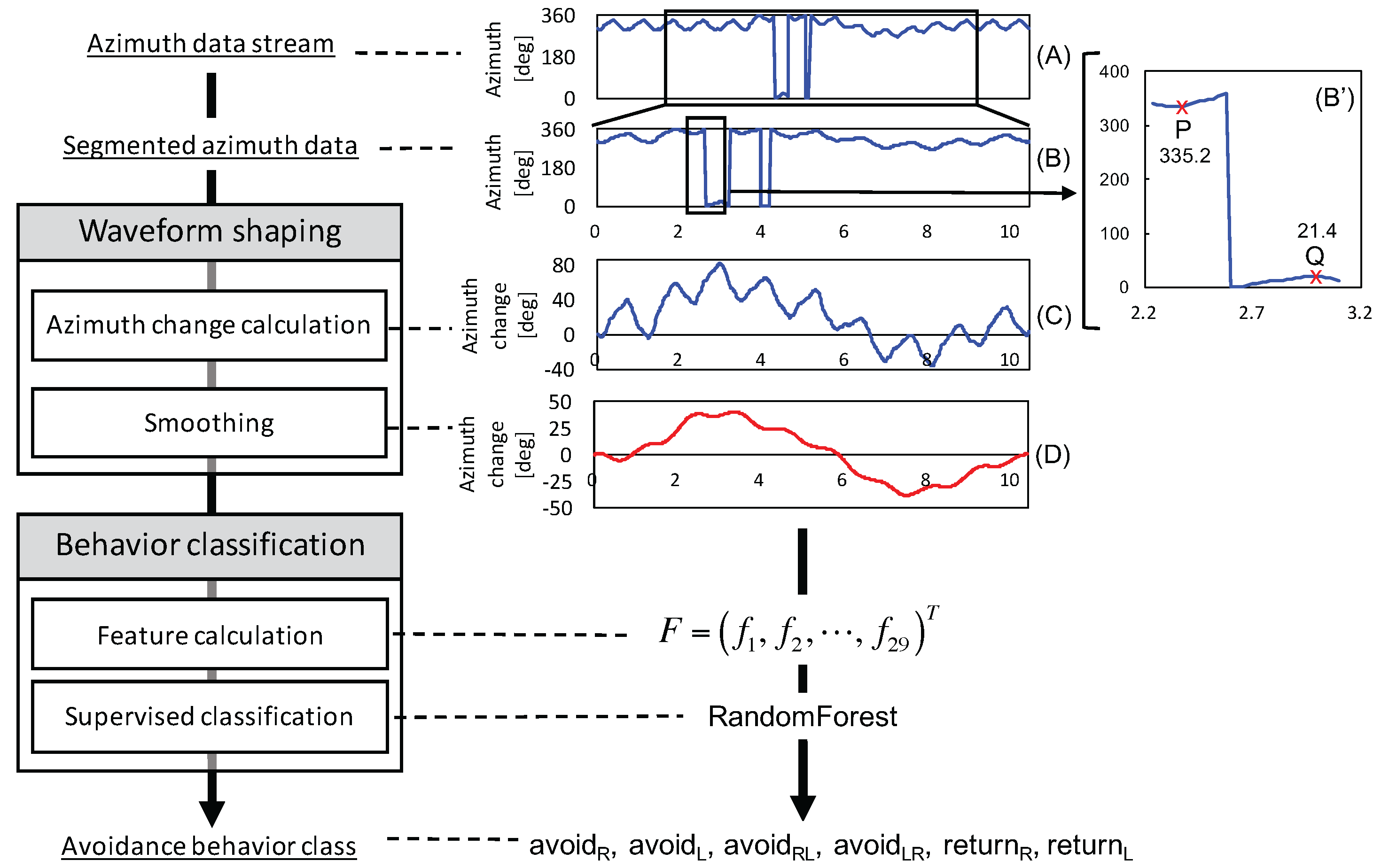
3.3.1. Waveform Shaping
| Algorithm 1 Calculate Azimuth Change Relative to the First Value in a Segment. |
|
3.3.2. Behavior Classification
4. Offline Experiment
4.1. Dataset
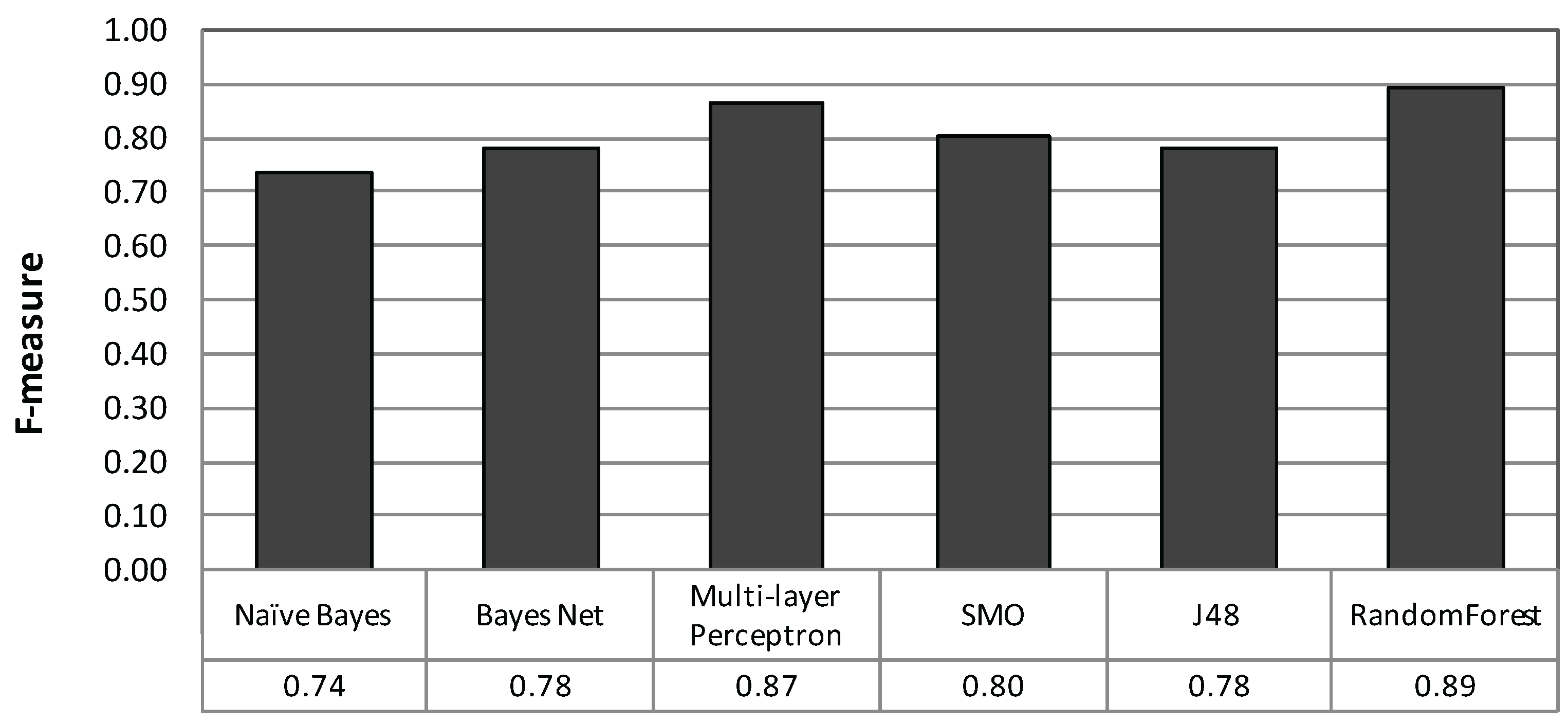
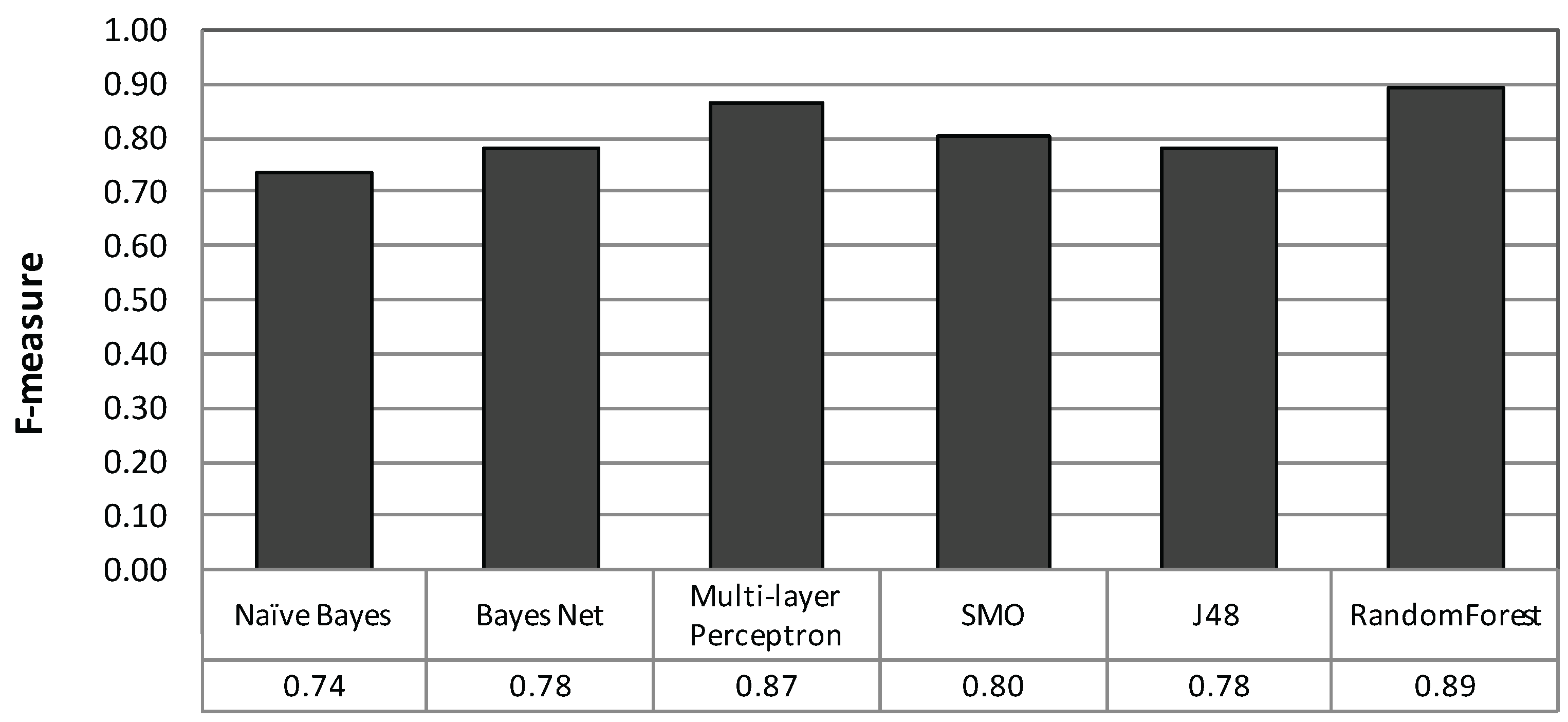
4.2. Basic Classification Performance
4.2.1. Method
4.2.2. Result and Analysis
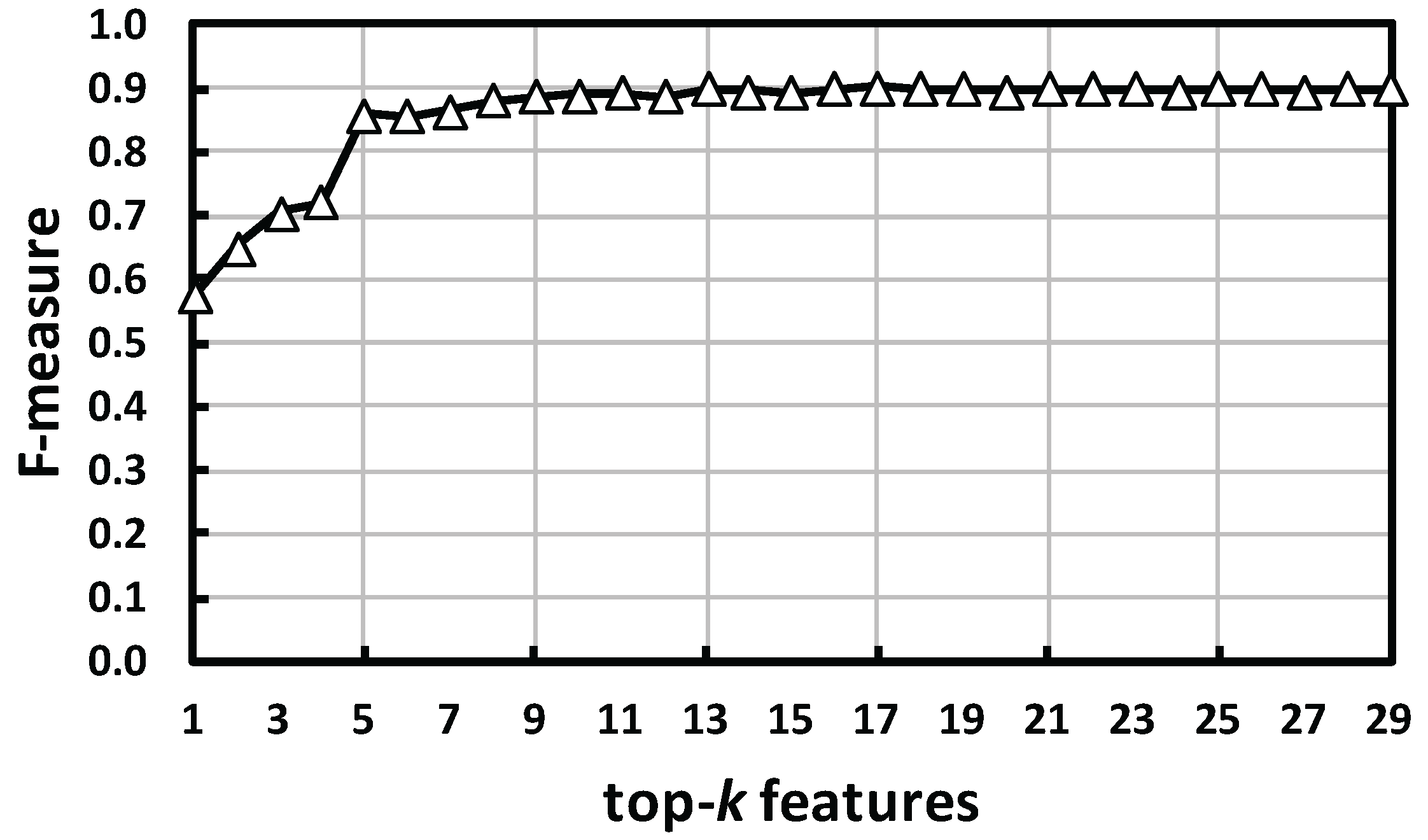
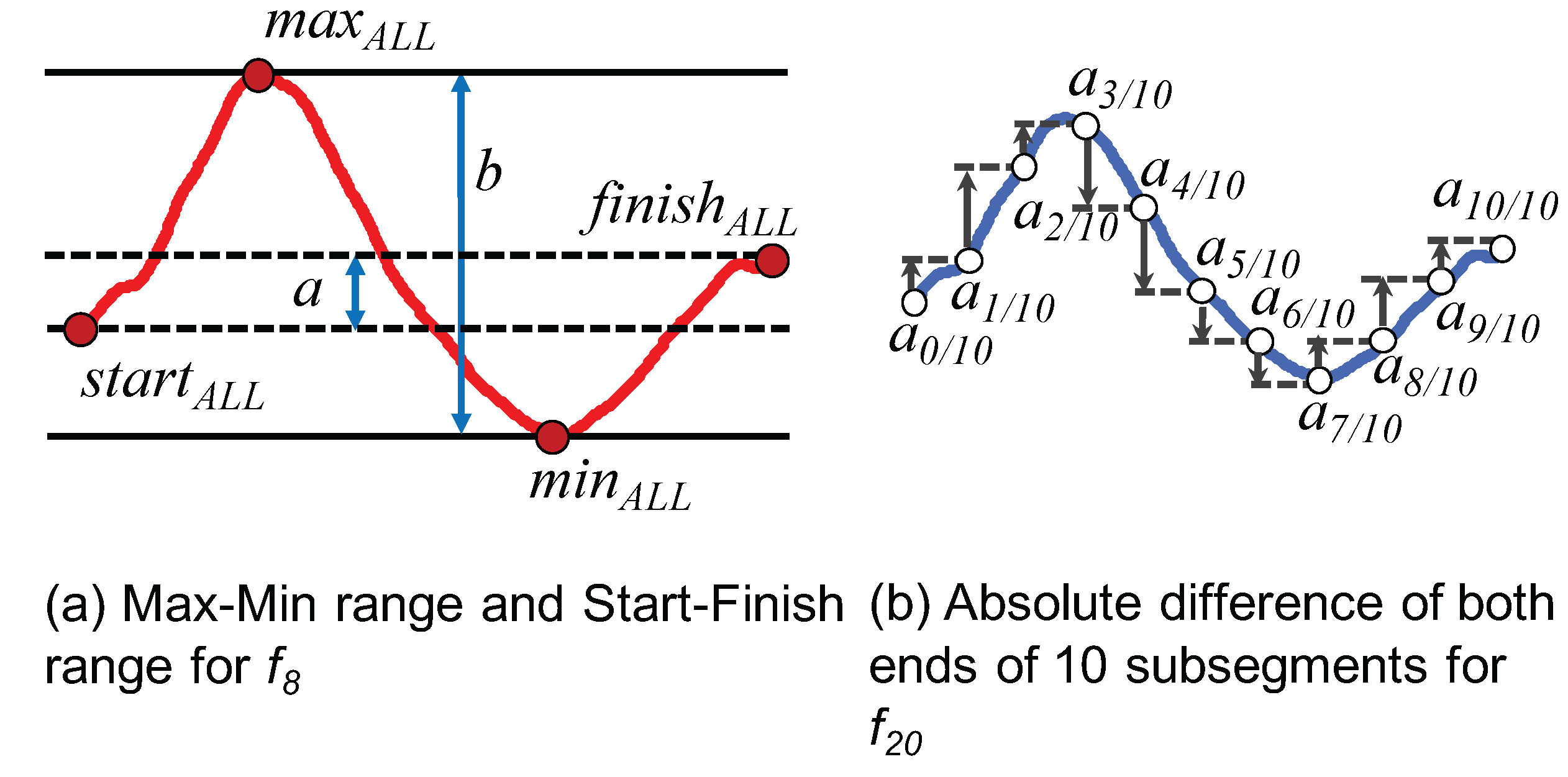
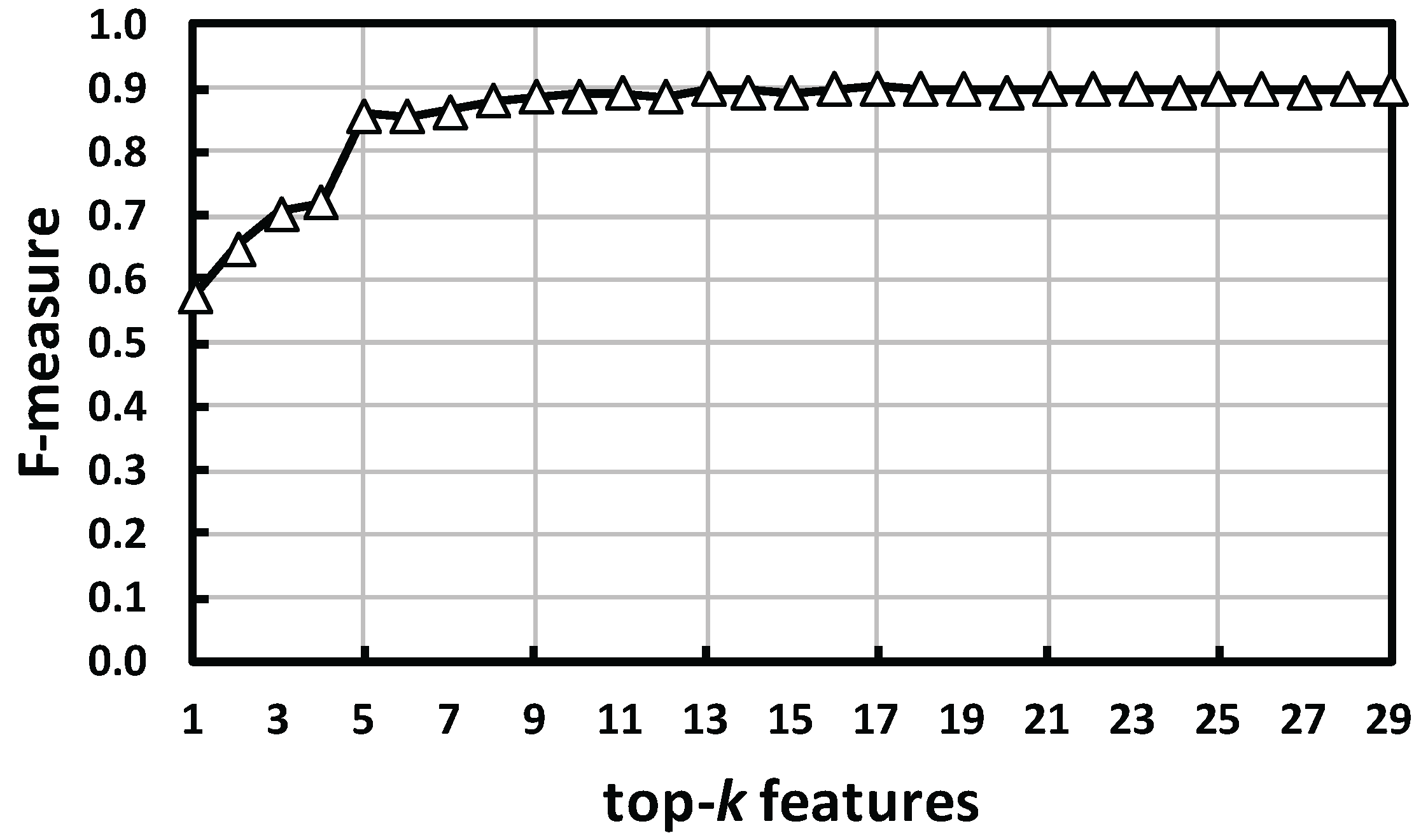
4.3. Feature Relevance
4.3.1. Method
4.3.2. Result and Analysis
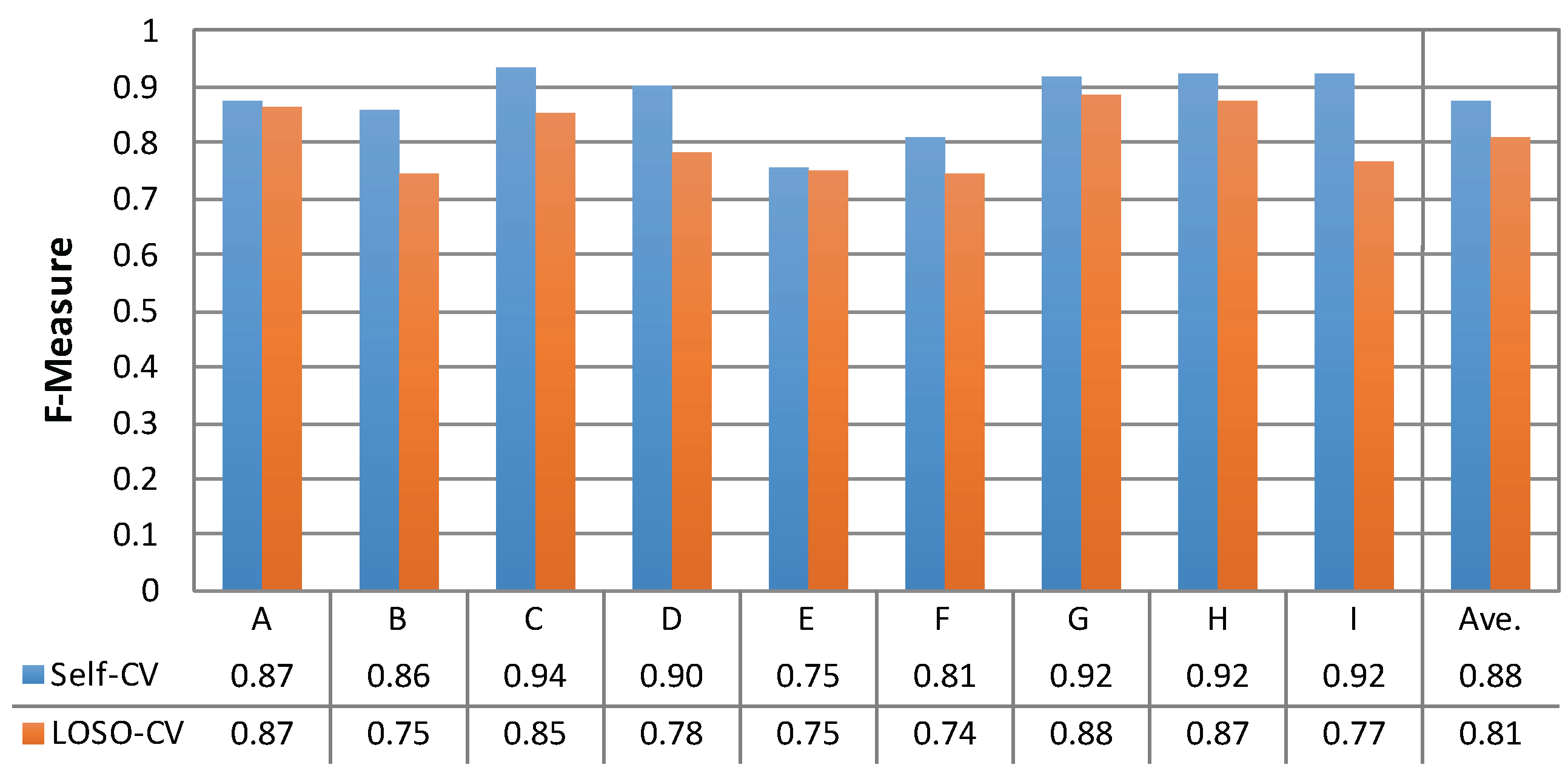
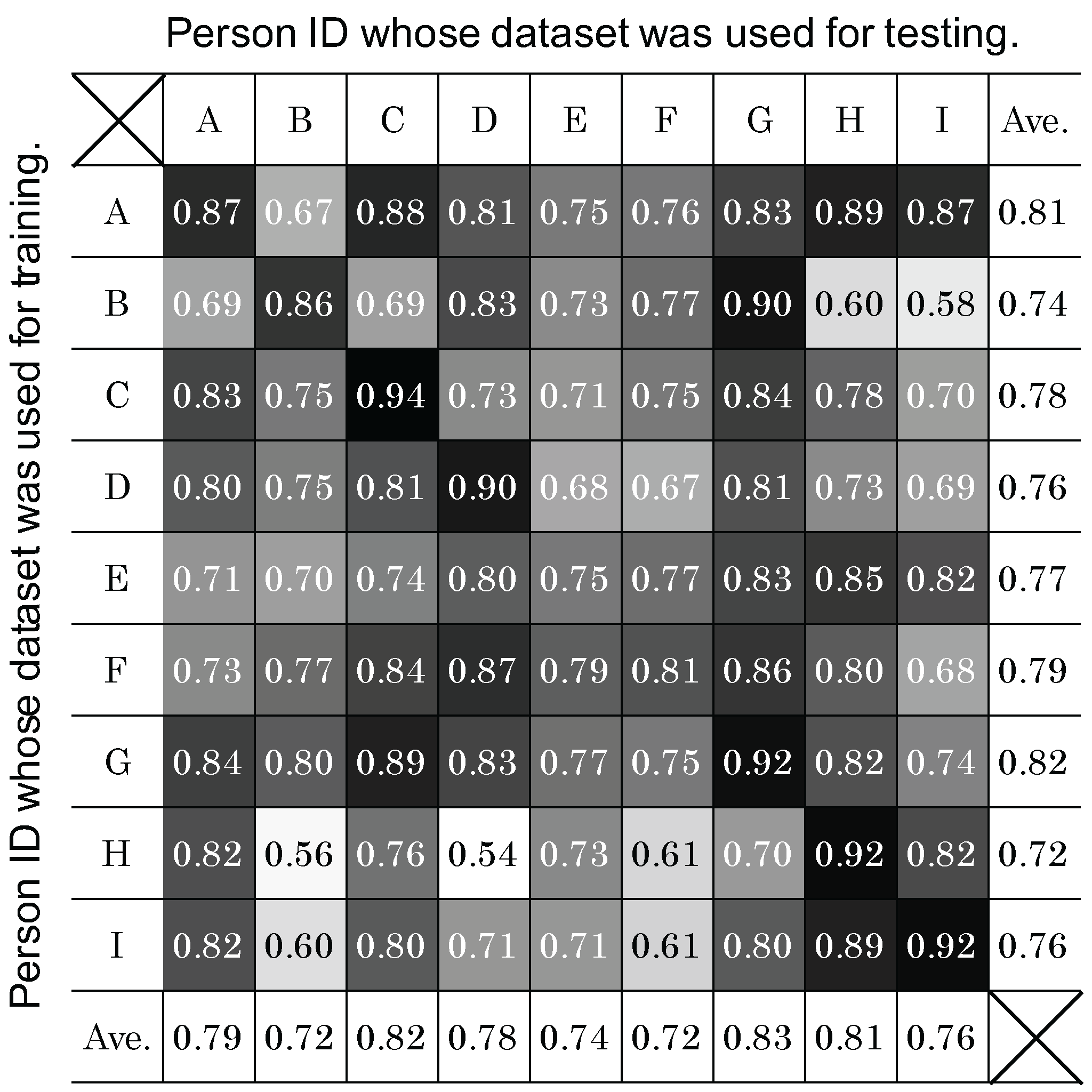
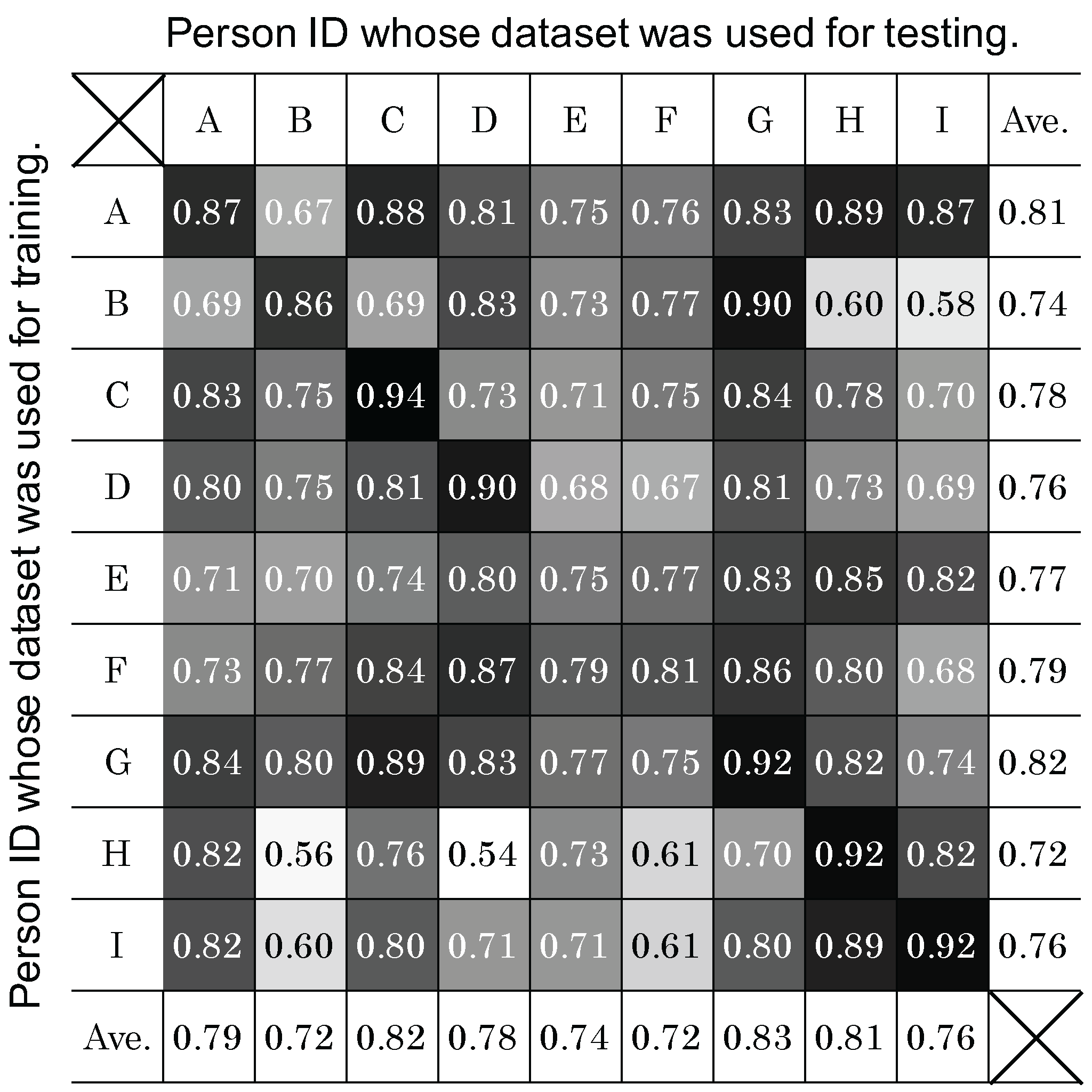
4.4. Person Dependency
4.4.1. Method
4.4.2. Result and Analysis
4.5. Effect of Sensor Storing Position
4.5.1. Method
4.5.2. Result and Analysis
4.6. Robustness to Unknown Obstacle Size
4.6.1. Method
4.6.2. Result and Analysis
5. Conclusions
- A 10-fold CV showed an average classification performance with an F-measure of 0.89 for six avoidance behaviors.
- The recognition system could handle the obstacle sizes of 0.2 to 1.5 m. Untrained sizes of obstacle avoidance were also recognized with an F-measure of 0.94.
- A user-independent classifier classified six avoidance behaviors with an F-measure of 0.81. The possibility of improving a user-independent classification by choosing classifiers trained by compatible persons was shown.
- Features resulting from (1) splitting a segment into the first half and the second half and (2) considering the monotonicity of change effectively recognized avoidance behaviors.
- The performance slightly depends on the sensor (smartphone) storing position on the body. Selecting a classifier for a particular position improves the performance. To reduce the cost of data collection, only the data from “hand” and “trousers back pocket” need be collected.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- City of Chiba. Chiba-Repo Field Trial: Review Report. 2013. Available online: http://www.city.chiba.jp/shimin/shimin/kohokocho/documents/chibarepo-hyoukasho.pdf (accessed on 30 September 2016).
- mySociety Limited. FixMyStreet. Available online: http://fixmystreet.org (accessed on 30 September 2016).
- Goldman, J.; Shilton, K.; Burke, J.; Estrin, D.; Hansen, M.; Ramanathan, N.; Reddy, S.; Samanta, V.; Srivastava, M.; West, R. Participatory Sensing: A Citizen-Powered Approach to Illuminating the Patterns that Shape Our World; Foresight and Governance Project, White Paper; Woodrow Wilson International Center for Scholars: Washington, DC, USA, 2009. [Google Scholar]
- Lane, N.D.; Miluzzo, E.; Lu, H.; Peebles, D.; Choudhury, T.; Campbell, A.T. A survey of mobile phone sensing. IEEE Commun. Mag. 2010, 48, 140–150. [Google Scholar] [CrossRef]
- Carrera, F.; Guerin, S.; Thorp, J.B. By the people, for the people: The crowdsourcing of “STREETBUMP”: An automatic pothole mapping app. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-4/W1, 19–23. [Google Scholar] [CrossRef]
- Chen, D.; Cho, K.T.; Han, S.; Jin, Z.; Shin, K.G. Invisible Sensing of Vehicle Steering with Smartphones. In Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys ’15), Florence, Italy, 18–22 May 2015; pp. 1–13.
- Eriksson, J.; Girod, L.; Hull, B.; Newton, R.; Madden, S.; Balakrishnan, H. The Pothole Patrol: Using a Mobile Sensor Network for Road Surface Monitoring. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services (MobiSys ’08), Breckenridge, CO, USA, 17–20 June 2008; pp. 29–39.
- Kaneda, S.; Asada, S.; Yamamoto, A.; Kawachi, Y.; Tabata, Y. A Hazard Detection Method for Bicycles by Using Probe Bicycle. In Proceedings of the IEEE 38th International Computer Software and Applications Conference Workshops (COMPSACW), Västerås, Sweden, 21–25 July 2014; pp. 547–551.
- Mohan, P.; Padmanabhan, V.N.; Ramjee, R. Nericell: Rich Monitoring of Road and Traffic Conditions Using Mobile Smartphones. In Proceedings of the 6th ACM Conference on Embedded Network Sensor Systems (SenSys ’08), Raleigh, NC, USA, 4–7 November 2008; pp. 323–336.
- Ishikawa, T.; Fujinami, K. Pedestrian’s Avoidance Behavior Recognition for Road Anomaly Detection in the City. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing and ACM International Symposium on Wearable Computers (UbiComp/ISWC ’15), Osaka, Japan, 7–11 September 2015; pp. 201–204.
- Bhoraskar, R.; Vankadhara, N.; Raman, B.; Kulkarni, P. Wolverine: Traffic and road condition estimation using smartphone sensors. In Proceedings of the IEEE Fourth International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 3–7 January 2012; pp. 1–6.
- Kamimura, T.; Kitani, T.; Kovacs, D.L. Automatic classification of motorcycle motion sensing data. In Proceedings of the IEEE International Conference on Consumer Electronics—Taiwan (ICCE-TW), Taipei, Taiwan, 26–28 May 2014; pp. 145–146.
- Seraj, F.; van der Zwaag, B.J.; Dilo, A.; Luarasi, T.; Havinga, P.J.M. RoADS: A road pavement monitoring system for anomaly detection using smart phones. In Proceedings of the 1st International Workshop on Machine Learning for Urban Sensor Data, SenseML 2014, Nancy, France, 15 September 2014; pp. 1–16.
- Thepvilojanapong, N.; Sugo, K.; Namiki, Y.; Tobe, Y. Recognizing bicycling states with HMM based on accelerometer and magnetometer data. In Proceedings of the SICE Annual Conference (SICE), Tokyo, Japan, 13–18 September 2011; pp. 831–832.
- Iwasaki, J.; Yamamoto, A.; Kaneda, S. Road information-sharing system for bicycle users using smartphones. In Proceedings of the IEEE 4th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 27–30 October 2015; pp. 674–678.
- Jain, S.; Borgiattino, C.; Ren, Y.; Gruteser, M.; Chen, Y.; Chiasserini, C.F. LookUp: Enabling Pedestrian Safety Services via Shoe Sensing. In Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services (MobiSys ’15), Florence, Italy, 18–22 May 2015; pp. 257–271.
- Alessandroni, G.; Klopfenstein, L.C.; Delpriori, S.; Dromedari, M.; Luchetti, G.; Paolini, B.D.; Seraghiti, A.; Lattanzi, E.; Freschi, V.; Carini, A.; et al. SmartRoadSense: Collaborative Road Surface Condition Monitoring. In Proceedings of the 8th International Conference on Mobile Ubiquitous Computing, Systems, Servies and Technologies, Rome, Italy, 24–28 August 2014; pp. 210–215.
- Tatebe, K.; Nakajima, H. Avoidance behavior against a stationary obstacle under single walking: A study on pedestrian behavior of avoiding obstacles (I). J. Archit. Plan. Environ. Eng. 1990, 418, 51–57. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Hu, J.; Brown, M.K.; Turin, W. HMM based online handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 1039–1045. [Google Scholar]
- Wilson, A.D.; Bobick, A.F. Parametric Hidden Markov Models for gesture recognition. IEEE trans. Pattern Anal. Mach. Intell. 1999, 21, 884–900. [Google Scholar] [CrossRef]
- Liu, J.; Zhonga, L.; Wickramasuriyab, J.; Vasudevanb, V. uWave: Accelerometer-based personalized gesture recognition, its applications. Pervasive Mob. Comput. 2009, 5, 657–675. [Google Scholar] [CrossRef]
- Rajko, S.; Qian, G.; Ingalls, T.; James, J. Real-time gesture recognition with minimal training requirements and on-line learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Machine Learning Group at University of Waikato. Weka 3—Data Mining with Open Source Machine Learning Software in Java. Available online: http://www.cs.waikato.ac.nz/ml/weka/ (accessed on 30 September 2016).
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2011. [Google Scholar]
- Fujinami, K.; Kouchi, S. Recognizing a Mobile Phone’s Storing Position as a Context of a Device and a User. In Proceedings of the 9th International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous), Beijing, China, 12–14 December 2012; pp. 76–88.
- Ichikawa, F.; Chipchase, J.; Grignani, R. Where’s The Phone? A Study of Mobile Phone Location in Public Spaces. In Proceedings of the 2nd International Conference on Mobile Technology, Applications and Systems, Guangzhou, China, 15–17 November 2005; pp. 1–8.
- Ben Abdesslem, F.; Phillips, A.; Henderson, T. Less is More: Energy-efficient Mobile Sensing with Senseless. In Proceedings of the 1st ACM Workshop on Networking, Systems, and Applications for Mobile Handhelds (MobiHeld ’09), Barcelona, Spain, 16–21 August 2009; pp. 61–62.
- Rana, R.K.; Chou, C.T.; Kanhere, S.S.; Bulusu, N.; Hu, W. Ear-phone: An End-to-end Participatory Urban Noise Mapping System. In Proceedings of the 9th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN ’10), Stockholm, Sweden, 12–15 April 2010; pp. 105–116.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| sum of absolute difference of | |||
| both ends of 10 subsegments | |||
| Types of avoidance | , , |
| Size of obstacles (d) | 0.2, 0.5, 0.7, 1.0, 1.5 m |
| Storing positions | hand (texting), trousers front pocket, trousers back pocket, chest pocket |
| Subjects | 7 males and 2 females in their 20s |
| Number of trials | 6 times per condition |
| Terminal | Samsung, Galaxy Nexus |
| Android version | Android 4.2.1 |
| Sensor type | Sensor.TYPE_ORIENTATION |
| Sampling rate | 10 Hz |
| Type | Segments | Person | Segments | Size | Segments |
|---|---|---|---|---|---|
| 865 | A | 540 | 0.2 | 844 | |
| 866 | B | 262 | 0.5 | 486 | |
| 865 | C | 508 | 0.7 | 838 | |
| 866 | D | 528 | 1.0 | 480 | |
| 215 | E | 288 | 1.5 | 814 | |
| 215 | F | 336 | Stored | Segments | |
| G | 358 | hand | 952 | ||
| H | 538 | trousers front pocket | 966 | ||
| I | 534 | trousers back pocket | 968 | ||
| chest pocket | 1006 |
| Classifier | Parameter |
|---|---|
| Naive Bayes | N/A |
| Bayesian network | -Q K2 “-P 1 -S BAYES” -E SimpleEstimator “-A 0.5” |
| MLP | -L 0.3 -M 0.2 -N 500 -V 0 -E 20 -H a |
| SMO | -C 1.0 -P 1.0E-12 -K “PolyKernel -E 1.0 -C 250007” |
| J48 | -C 0.25 -M 2 |
| Random forest | -I 100 -K 0 |
| Label\Recognition | (1) | (2) | (3) | (4) | (5) | (6) |
|---|---|---|---|---|---|---|
| (1) | 182 | 19 | 7 | 7 | 0 | 0 |
| (2) | 25 | 179 | 6 | 6 | 0 | 0 |
| (3) | 7 | 6 | 183 | 19 | 0 | 0 |
| (4) | 7 | 6 | 24 | 179 | 0 | 0 |
| (5) | 0 | 0 | 0 | 0 | 215 | 0 |
| (6) | 0 | 0 | 0 | 0 | 0 | 215 |
| Class | Recall | Precision | F-Measure |
|---|---|---|---|
| 0.85 | 0.83 | 0.84 | |
| 0.83 | 0.85 | 0.84 | |
| 0.85 | 0.83 | 0.84 | |
| 0.83 | 0.85 | 0.84 | |
| 1.00 | 1.00 | 1.00 | |
| 1.00 | 1.00 | 1.00 | |
| Average | 0.89 | 0.89 | 0.89 |
| Trained with\Test with | (1) | (2) | (3) | (4) | Average |
|---|---|---|---|---|---|
| (1) Hand (texting) | 0.86 | 0.82 | 0.82 | 0.91 | 0.86 |
| (2) Trousers front pocket | 0.85 | 0.85 | 0.86 | 0.89 | 0.86 |
| (3) Trousers back pocket | 0.83 | 0.85 | 0.88 | 0.88 | 0.86 |
| (4) Chest pocket | 0.86 | 0.83 | 0.80 | 0.91 | 0.85 |
| Average | 0.85 | 0.84 | 0.84 | 0.90 | – |
| Approach | Average |
|---|---|
| (0) Tuned classifier for each position | 0.87 |
| (1) Single classifier with the dataset from all positions | 0.89 |
| (2) Sharing classifiers with some positions | 0.88 |
| Class | Average | ||||||
|---|---|---|---|---|---|---|---|
| F-measure | 0.93 | 0.91 | 0.92 | 0.91 | 1.00 | 1.00 | 0.94 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishikawa, T.; Fujinami, K. Smartphone-Based Pedestrian’s Avoidance Behavior Recognition towards Opportunistic Road Anomaly Detection. ISPRS Int. J. Geo-Inf. 2016, 5, 182. https://doi.org/10.3390/ijgi5100182
Ishikawa T, Fujinami K. Smartphone-Based Pedestrian’s Avoidance Behavior Recognition towards Opportunistic Road Anomaly Detection. ISPRS International Journal of Geo-Information. 2016; 5(10):182. https://doi.org/10.3390/ijgi5100182
Chicago/Turabian StyleIshikawa, Tsuyoshi, and Kaori Fujinami. 2016. "Smartphone-Based Pedestrian’s Avoidance Behavior Recognition towards Opportunistic Road Anomaly Detection" ISPRS International Journal of Geo-Information 5, no. 10: 182. https://doi.org/10.3390/ijgi5100182
APA StyleIshikawa, T., & Fujinami, K. (2016). Smartphone-Based Pedestrian’s Avoidance Behavior Recognition towards Opportunistic Road Anomaly Detection. ISPRS International Journal of Geo-Information, 5(10), 182. https://doi.org/10.3390/ijgi5100182