
Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification



Abstract
:1. Introduction
- (1)
- We propose a new method, the adaptive density optimization method, for vehicle GPS trajectory optimization based on the density clustering method and the spatial distribution of tracking points. Outliers mixed in the raw data are removed automatically using adaptive density optimization method.
- (2)
- We explore a novel way to infer lane-level information from low-precision spatiotemporal vehicle GPS trajectories (MLIT).
- (3)
- We detect turn rules of each lane by tracking vehicle trajectories in relation to the rate of reckless driving.
2. Related Work
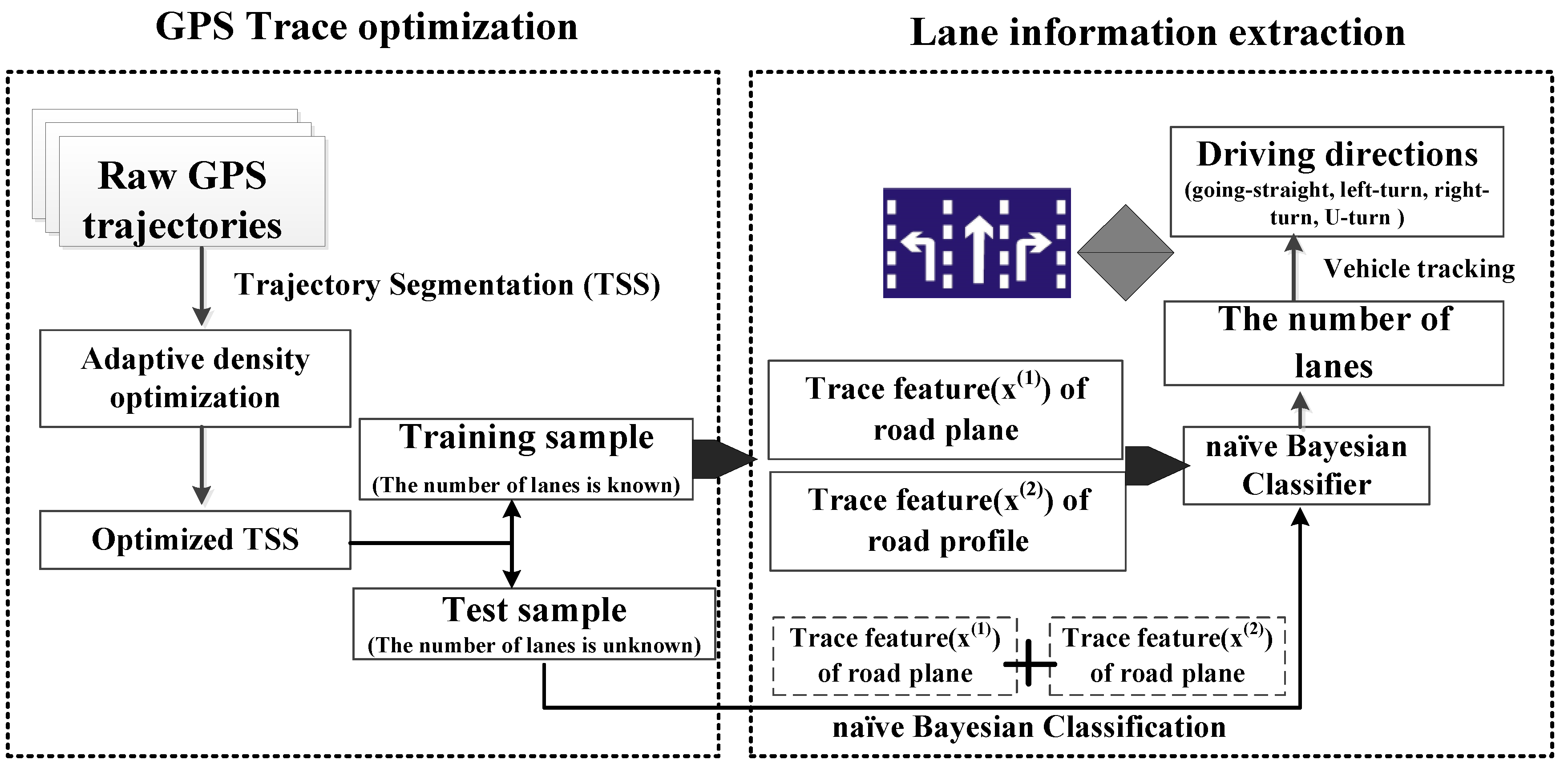
3. Lane-Level Road Network Information Extraction from Vehicle GPS Trajectories
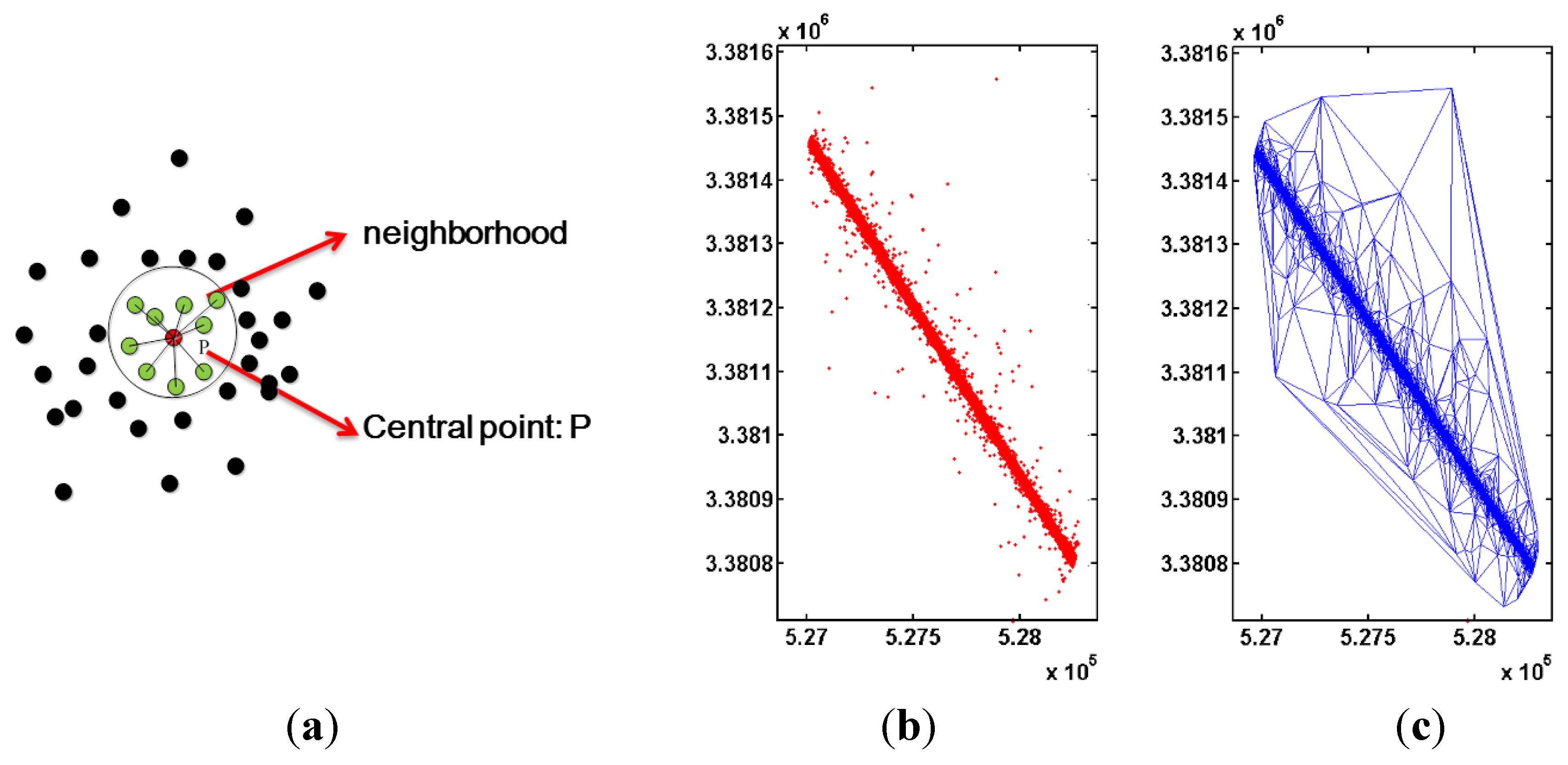
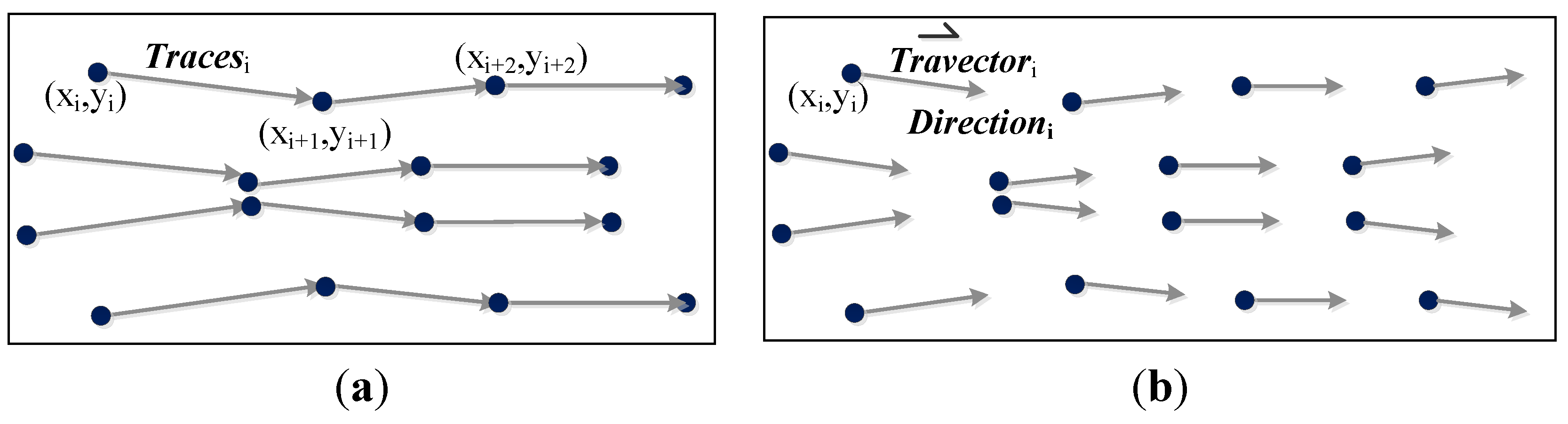
3.1. Vehicle GPS Trajectory Optimization
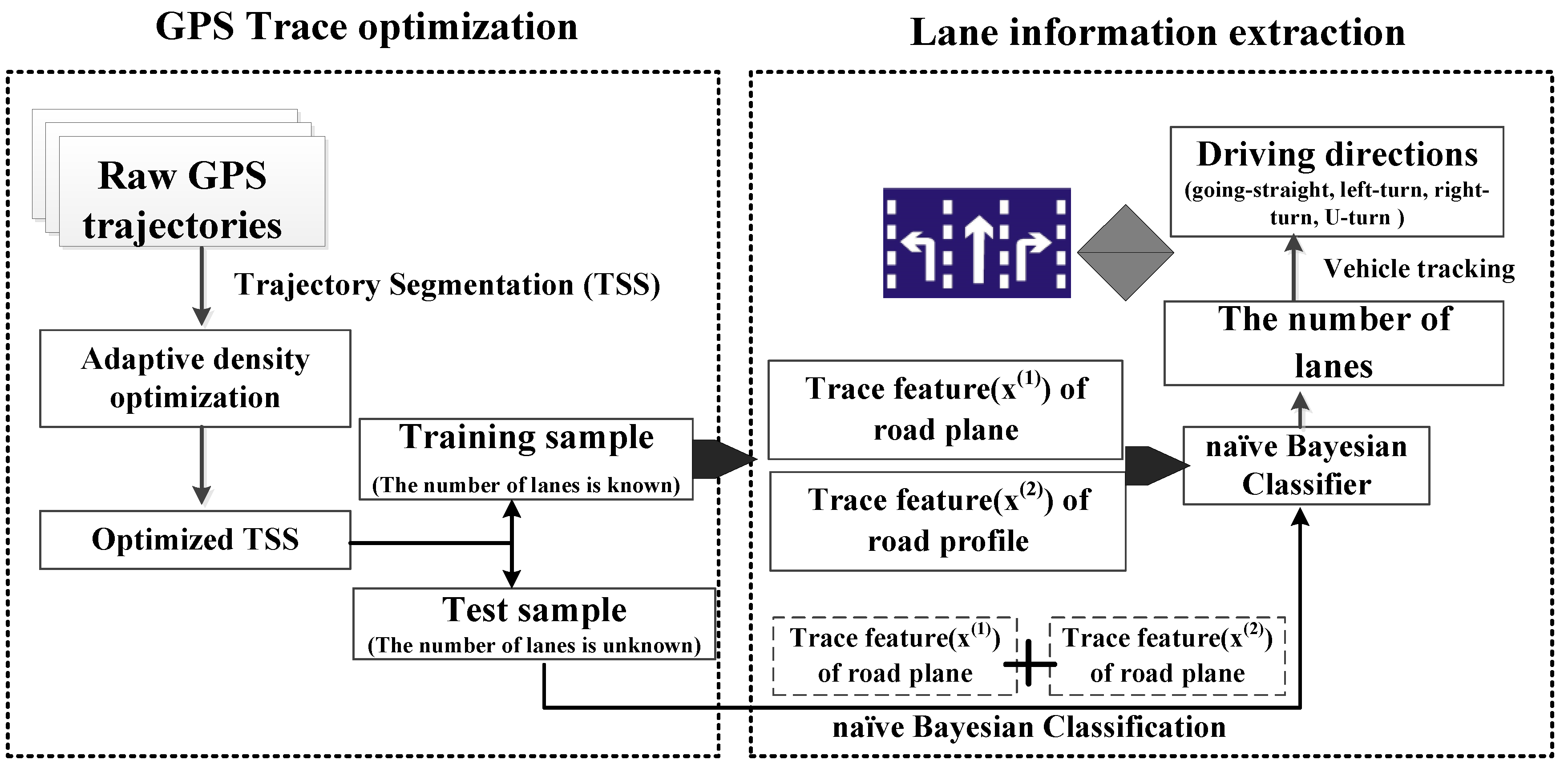
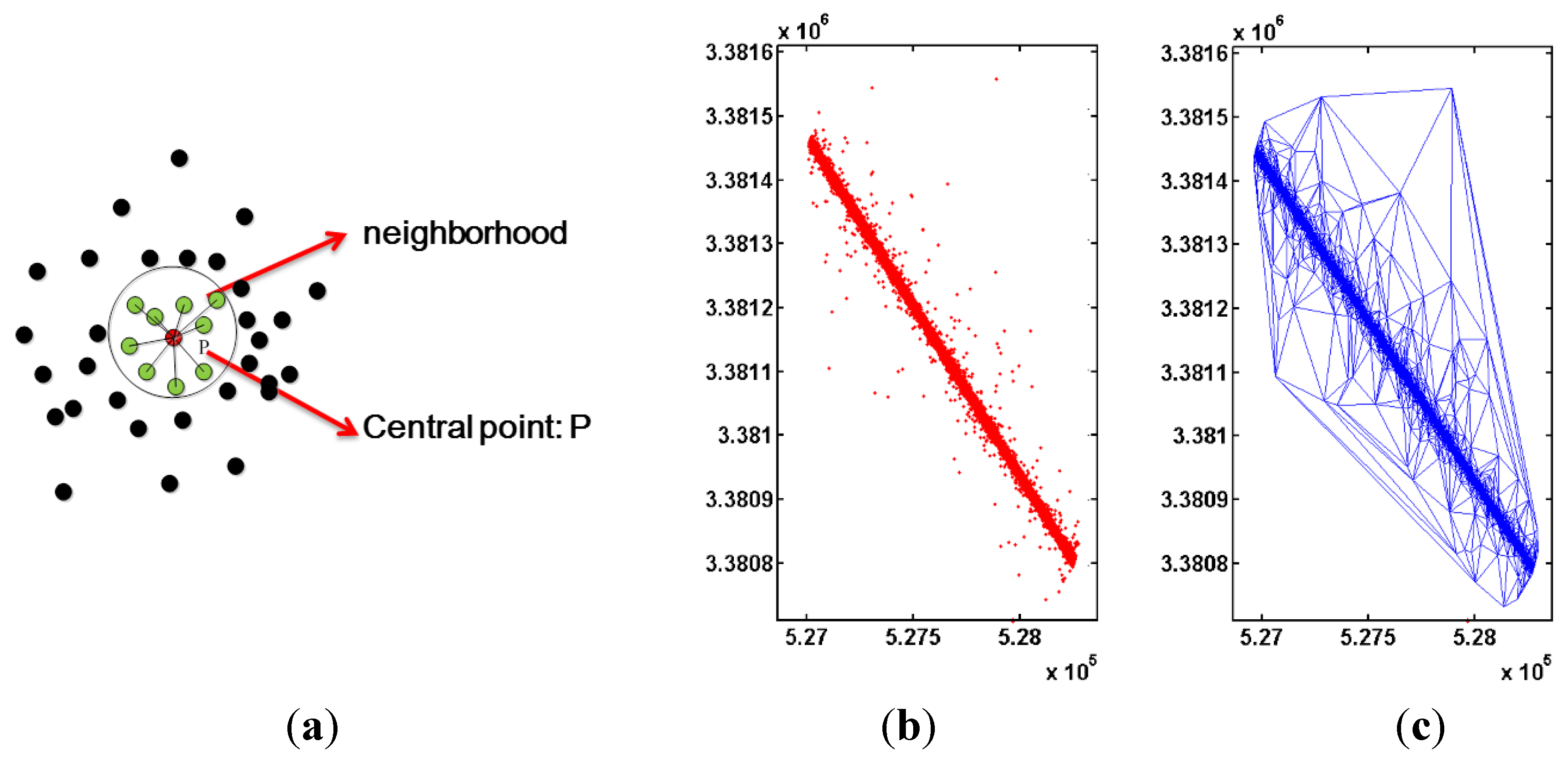
3.1.1. Adaptive Density Optimization Method
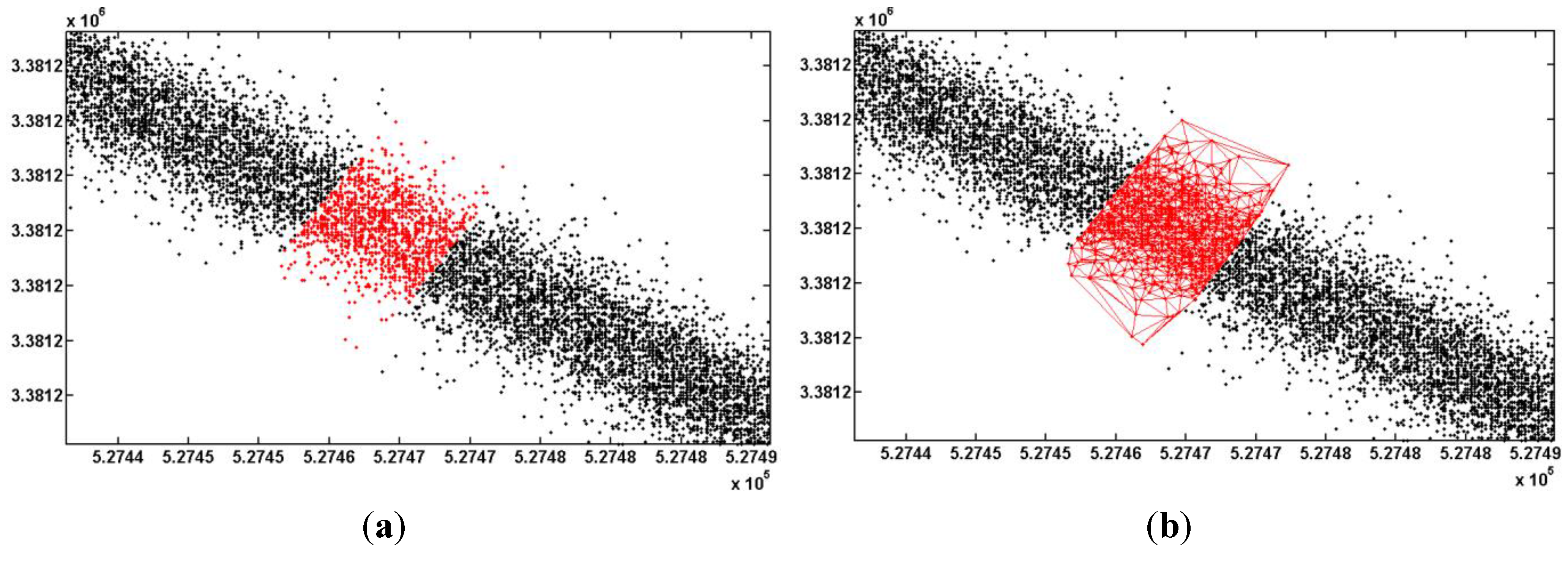
3.1.2. Optimization
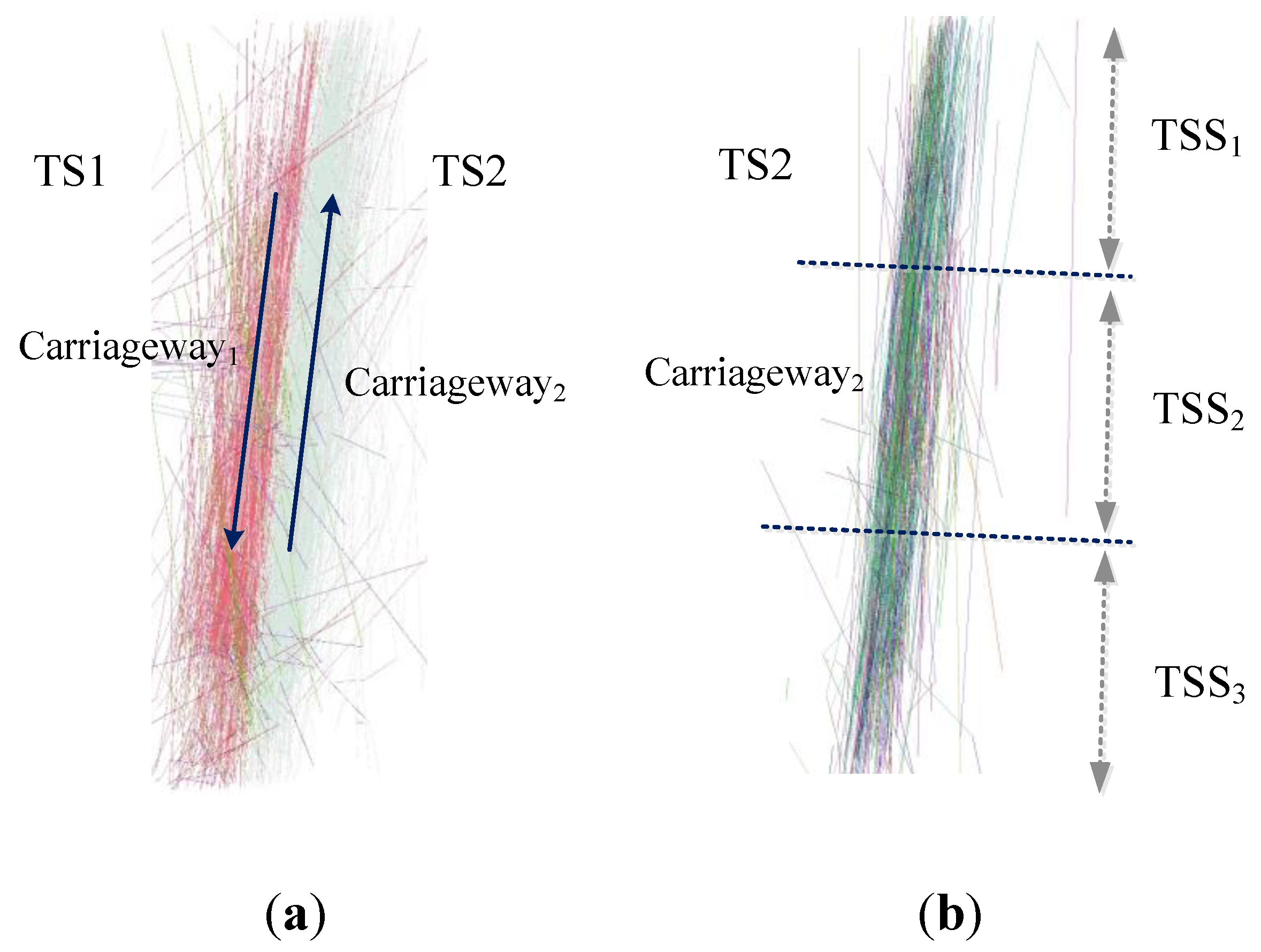
3.2. Lane Number Extraction Based on Naïve Bayesian Classification
3.2.1. The Basic Method
3.2.2. Naïve Bayesian Classifier
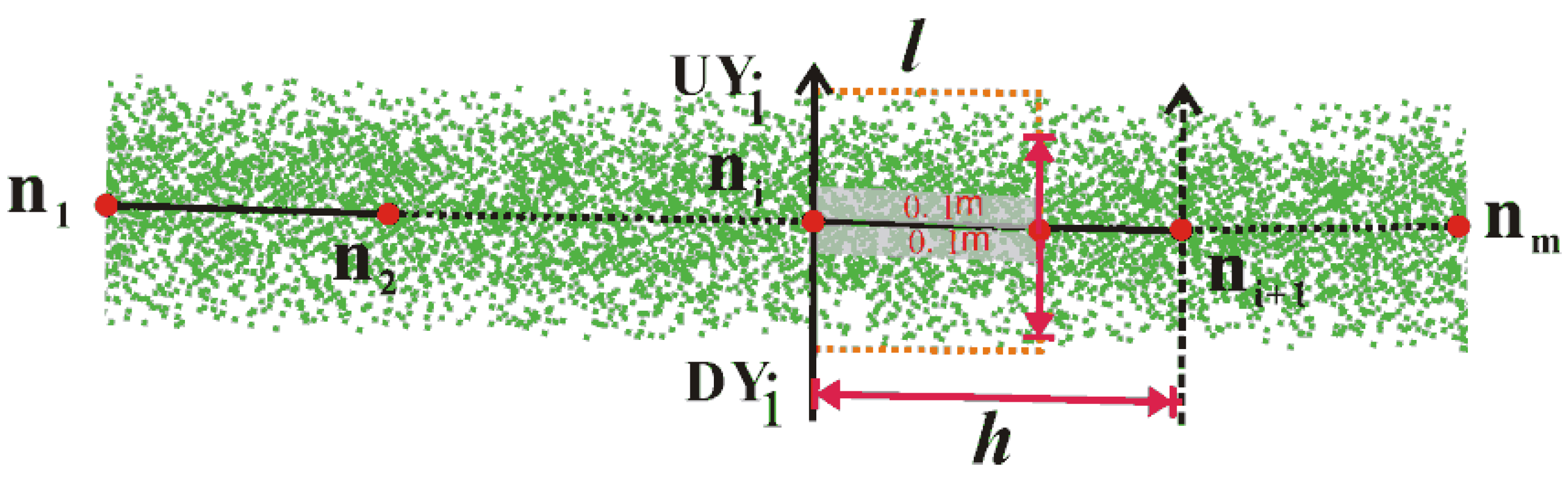
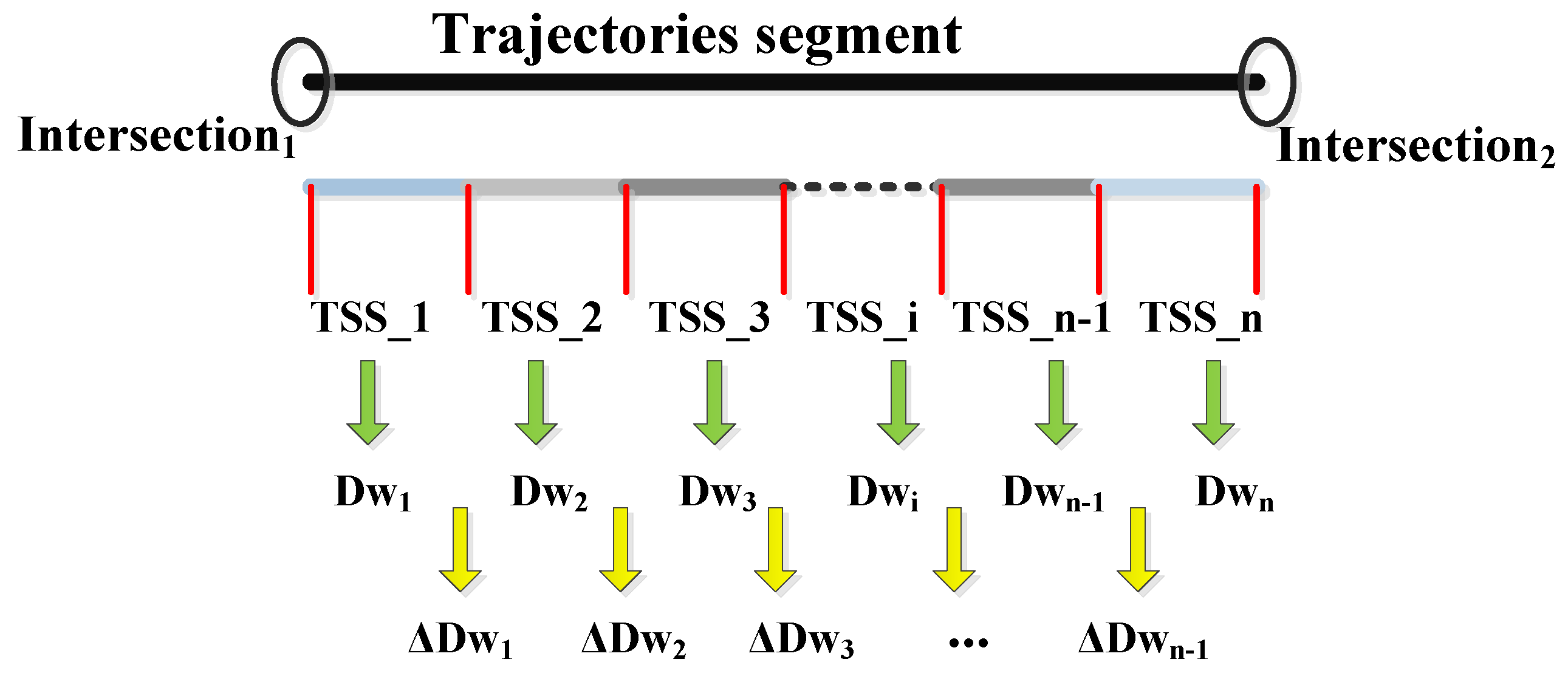
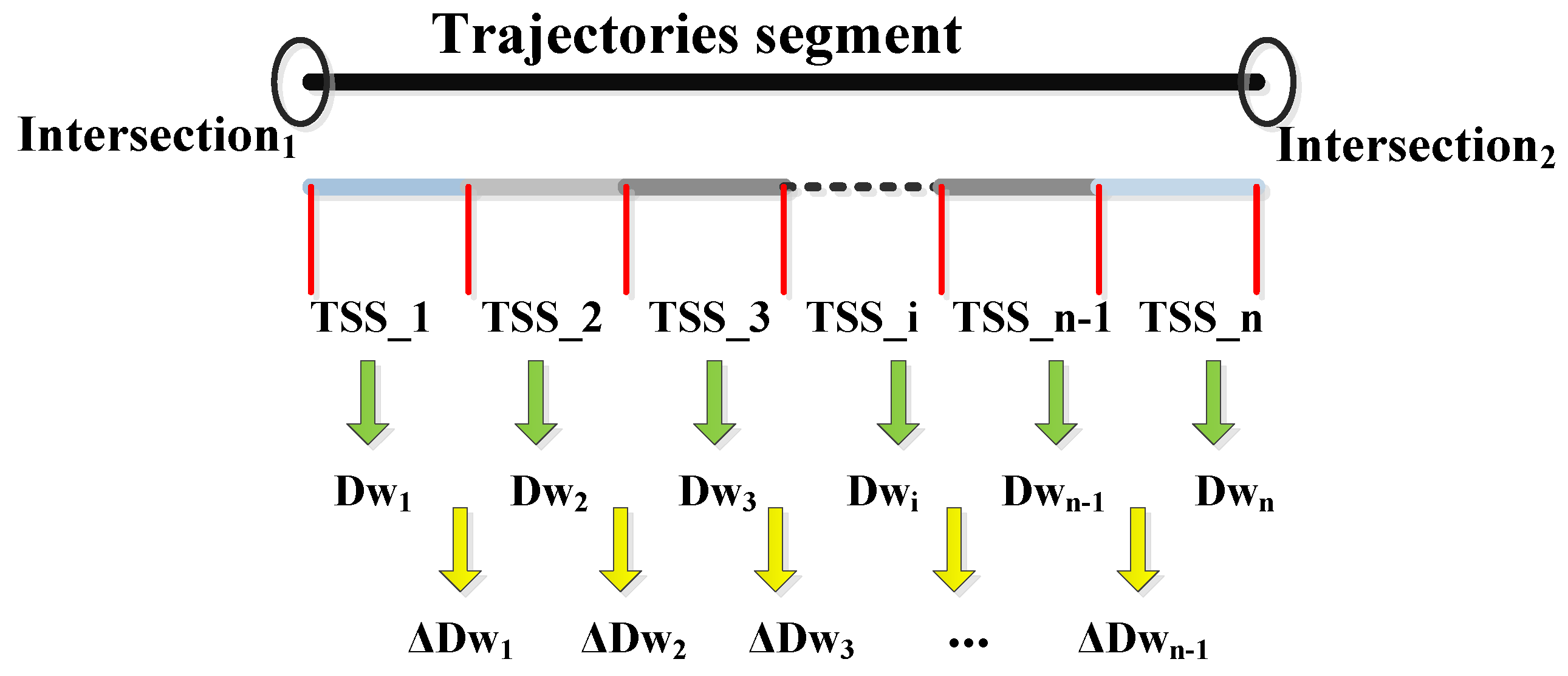
| /*Initialization*/ |
| Coordinate origin: n1; |
| horizontal axis: the direction of the current TSS; |
| longitudinal axis: UYi = 0; DYi = 0; |
| Sliding window: length = l; width = w; proportion = 0; |
| /*Assignment*/ |
| for each TSSi, do |
| repeat |
| Moving the sliding window along the positive direction and negative direction of the longitudinal axis and accumulating the Proportion (Proportion = current points number in sliding window/all points in the current TSS) |
| until proportion = 100% |
| set Dwi = ∑ (maximum |UYj| + | maximum |DYj|)/(h/l); j = 1,2,…, (h/l). |
| set Coordinate origin changed to ni+1; UYi+1 = 0;DYi+1 = 0; i = 1,2,…,m. |
| end for |
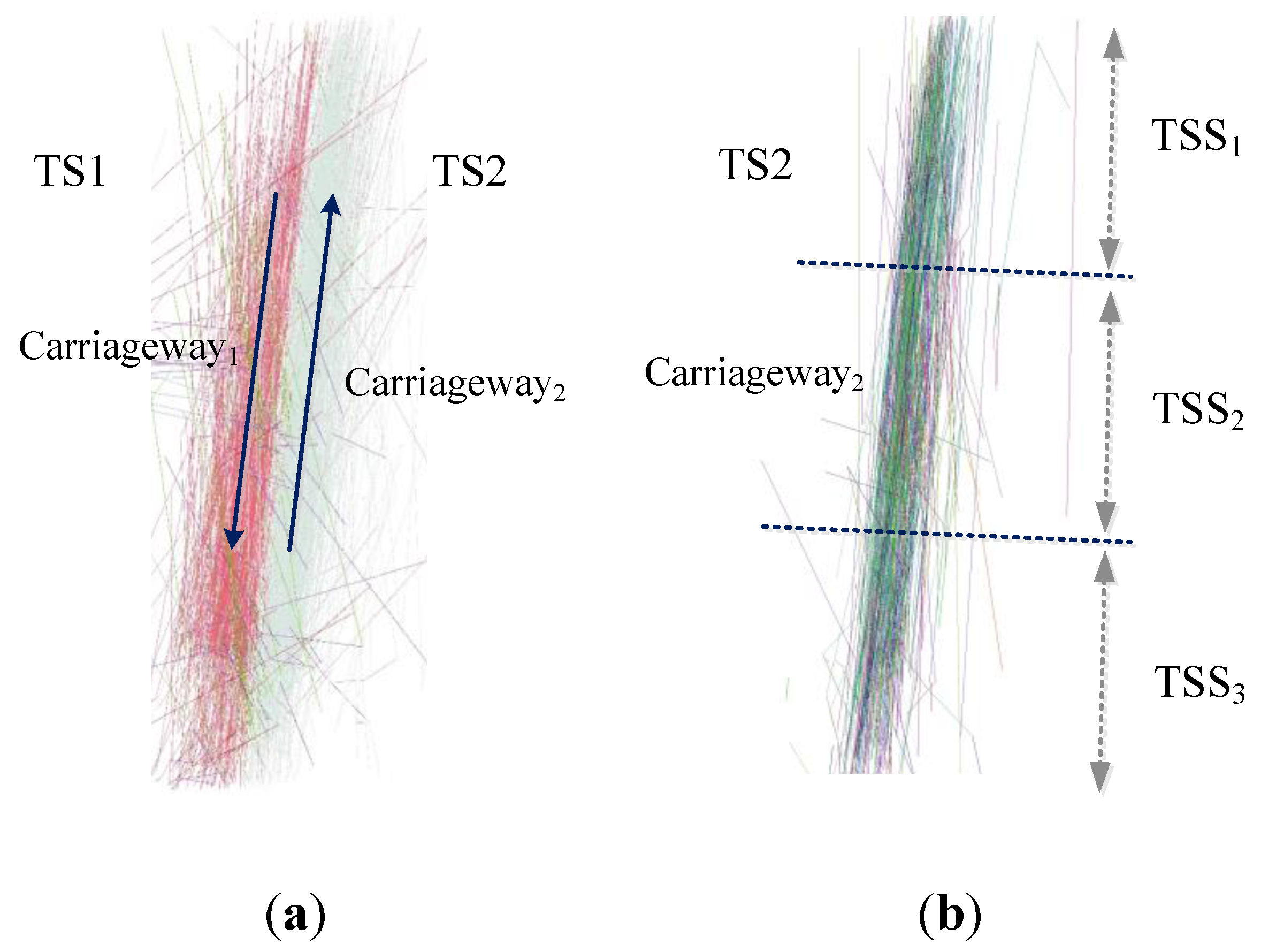
3.3. The Detection of Turn Rules of Each Lane

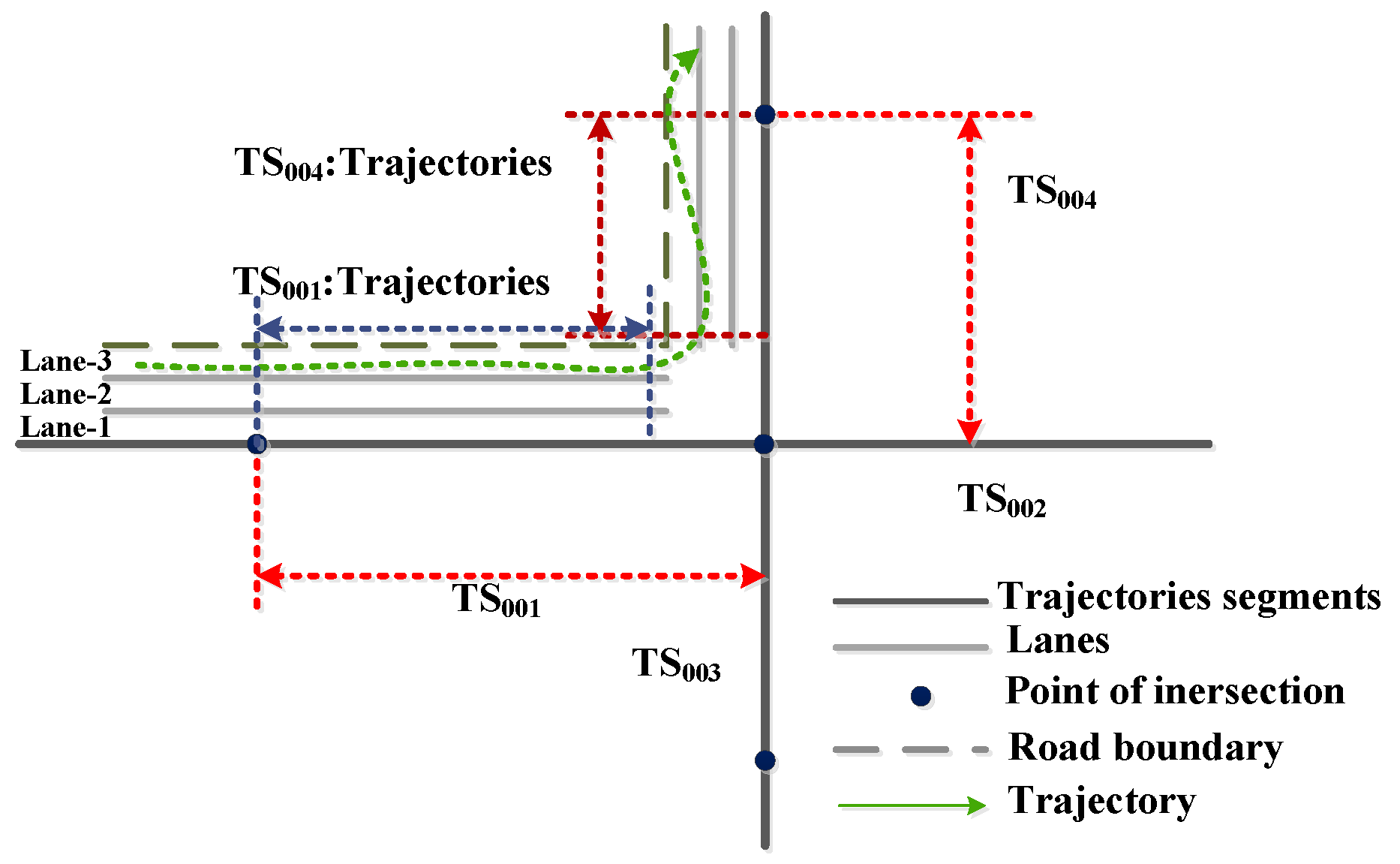
4. Experiments and Results
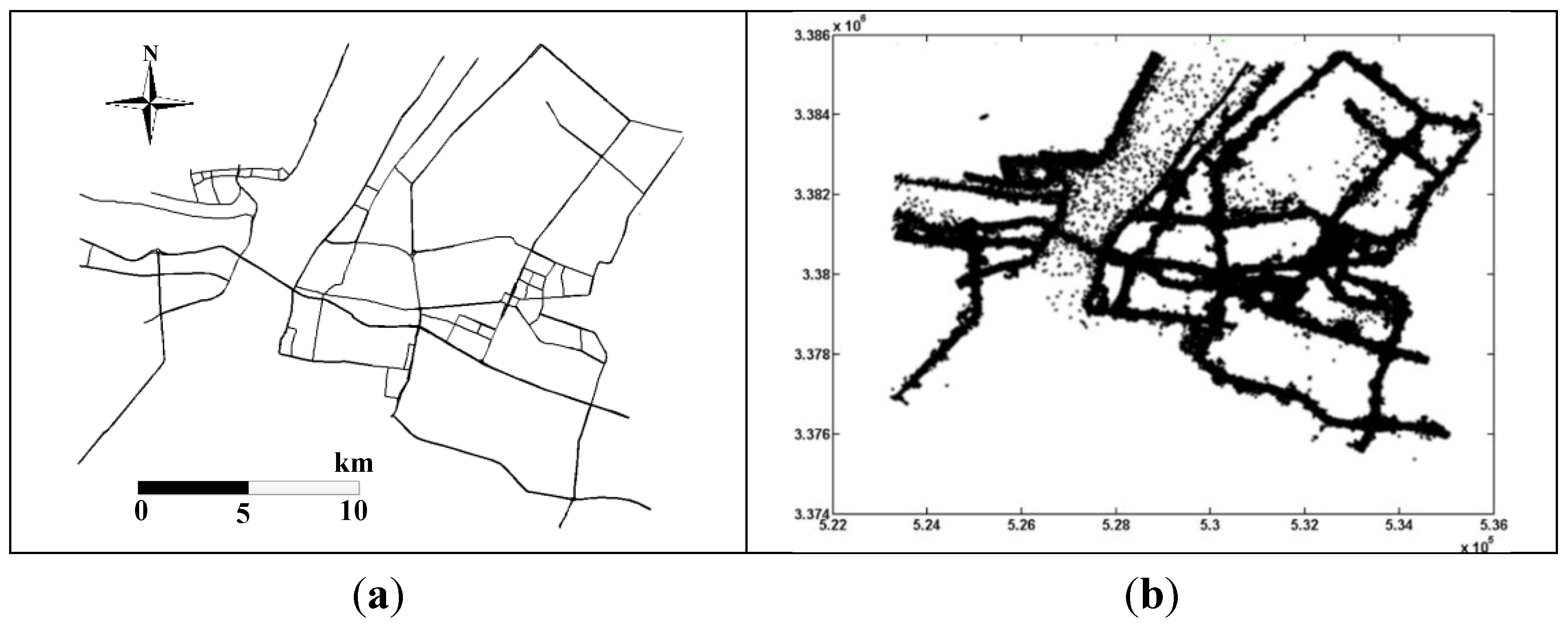
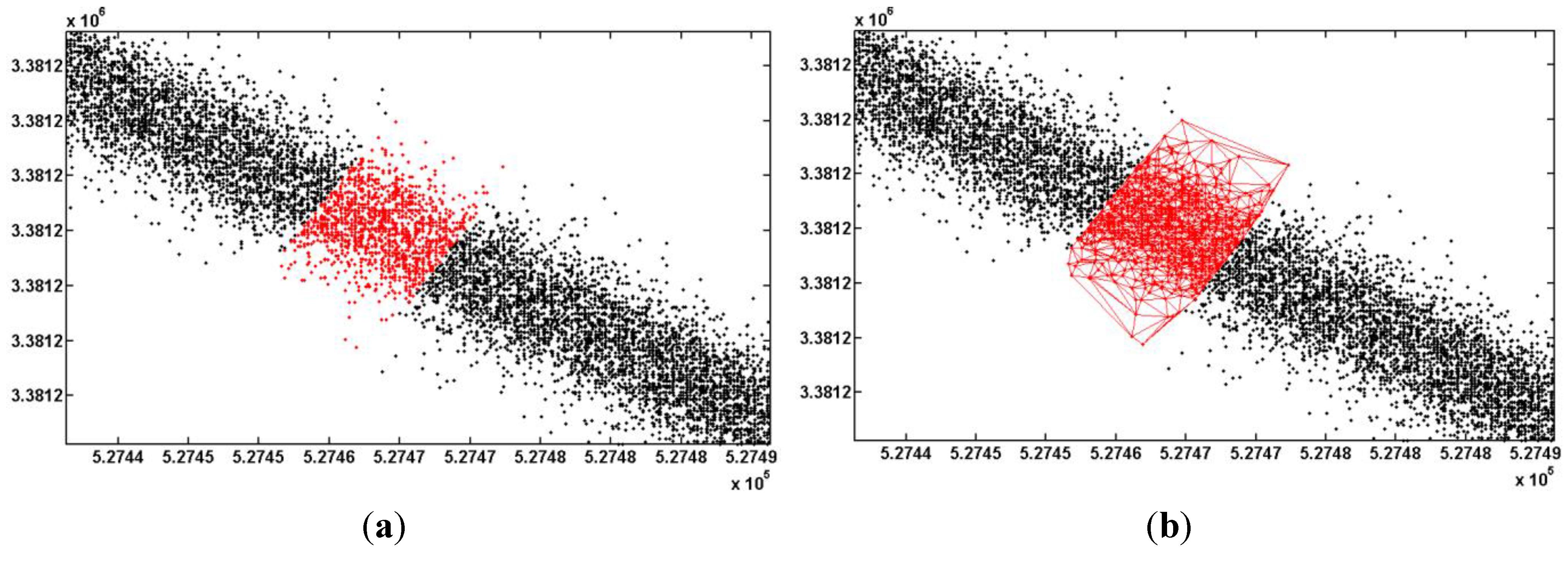
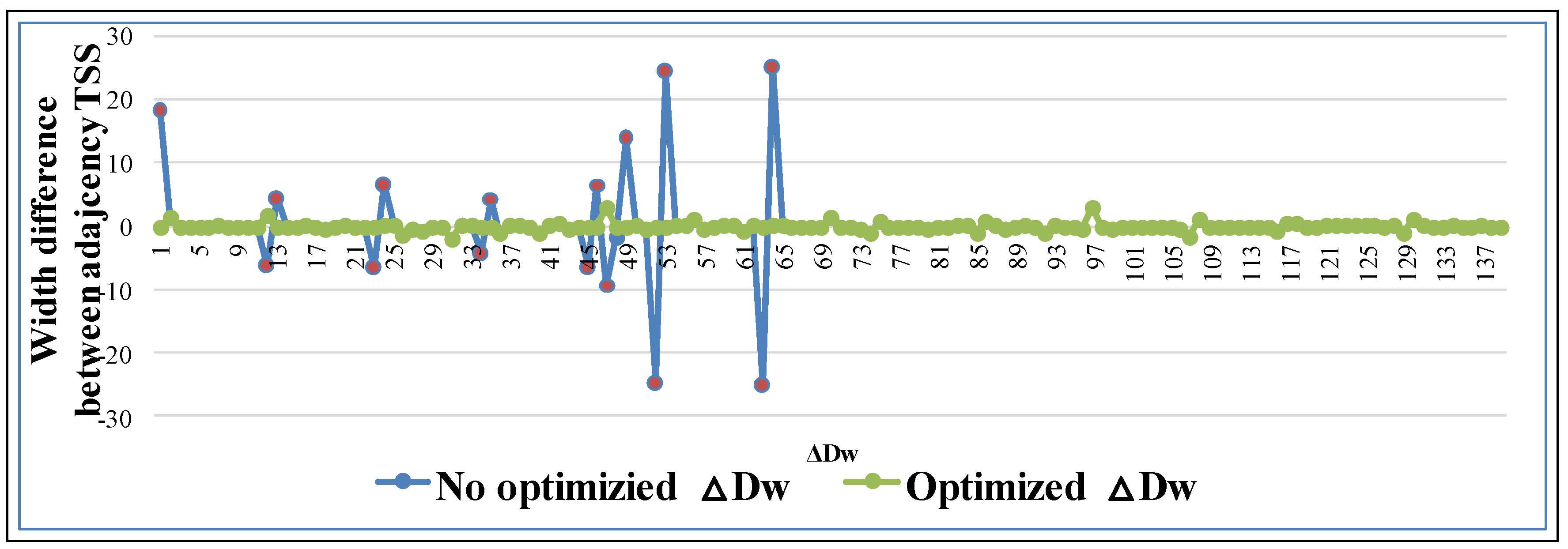
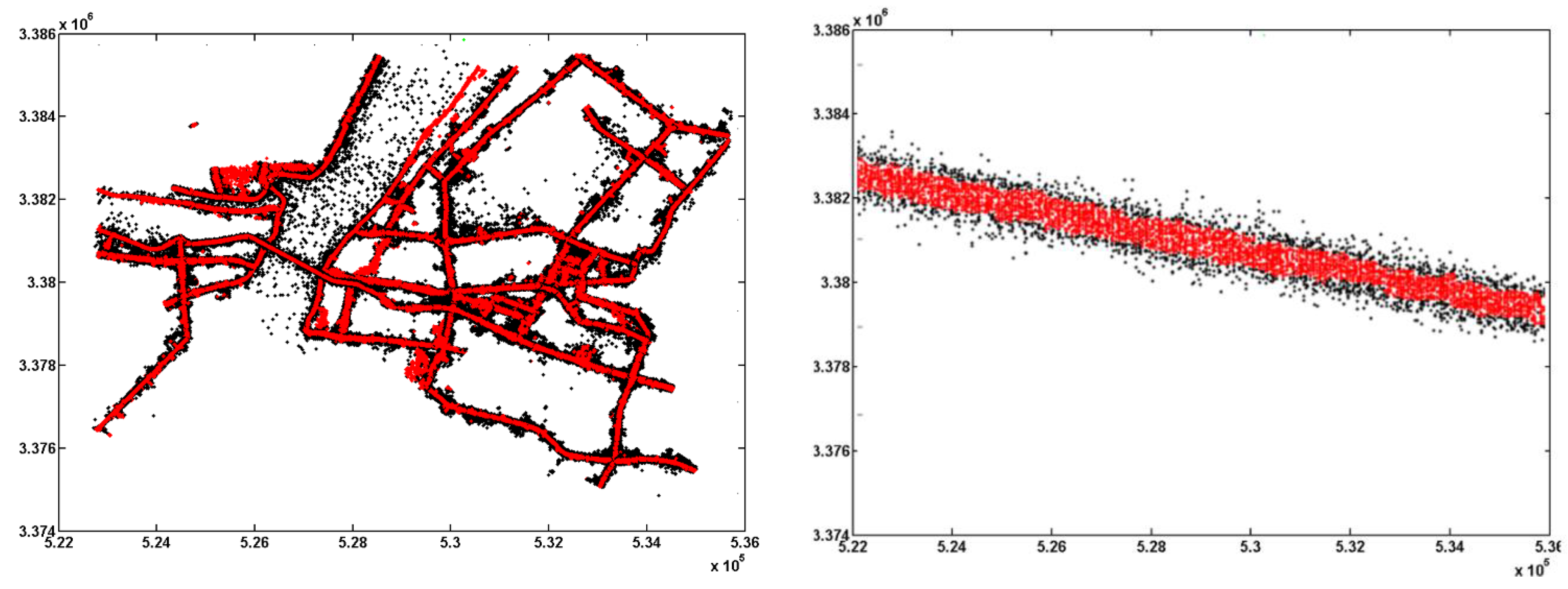
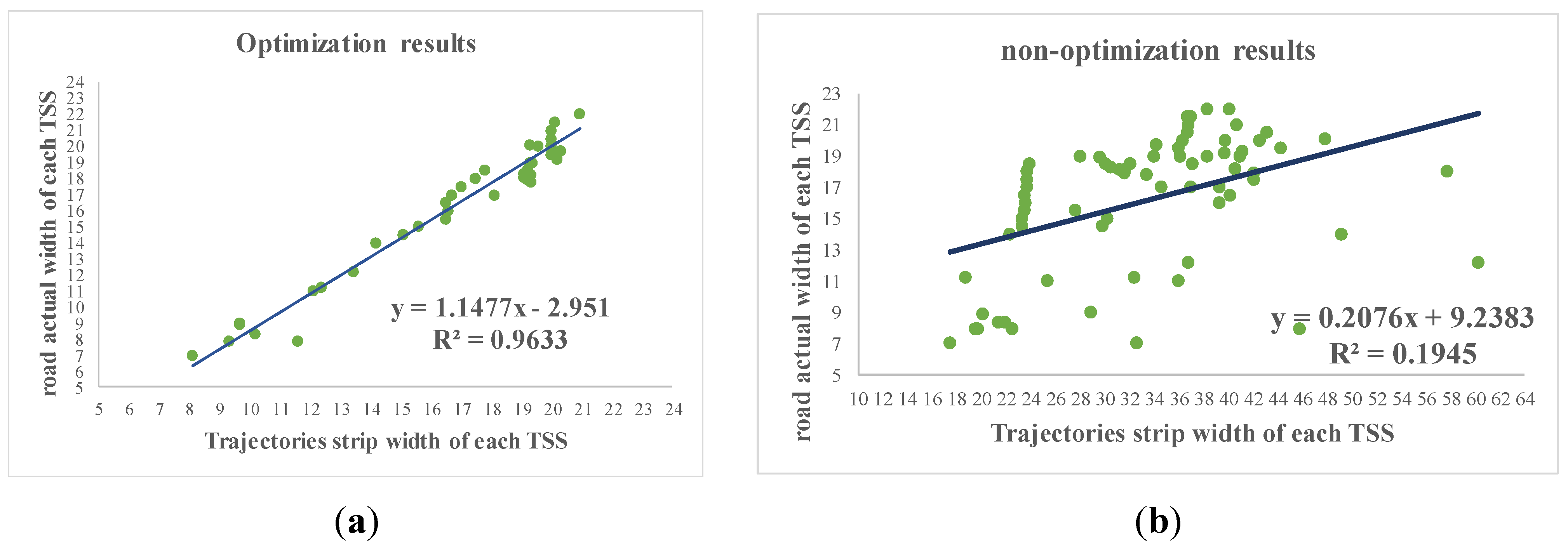
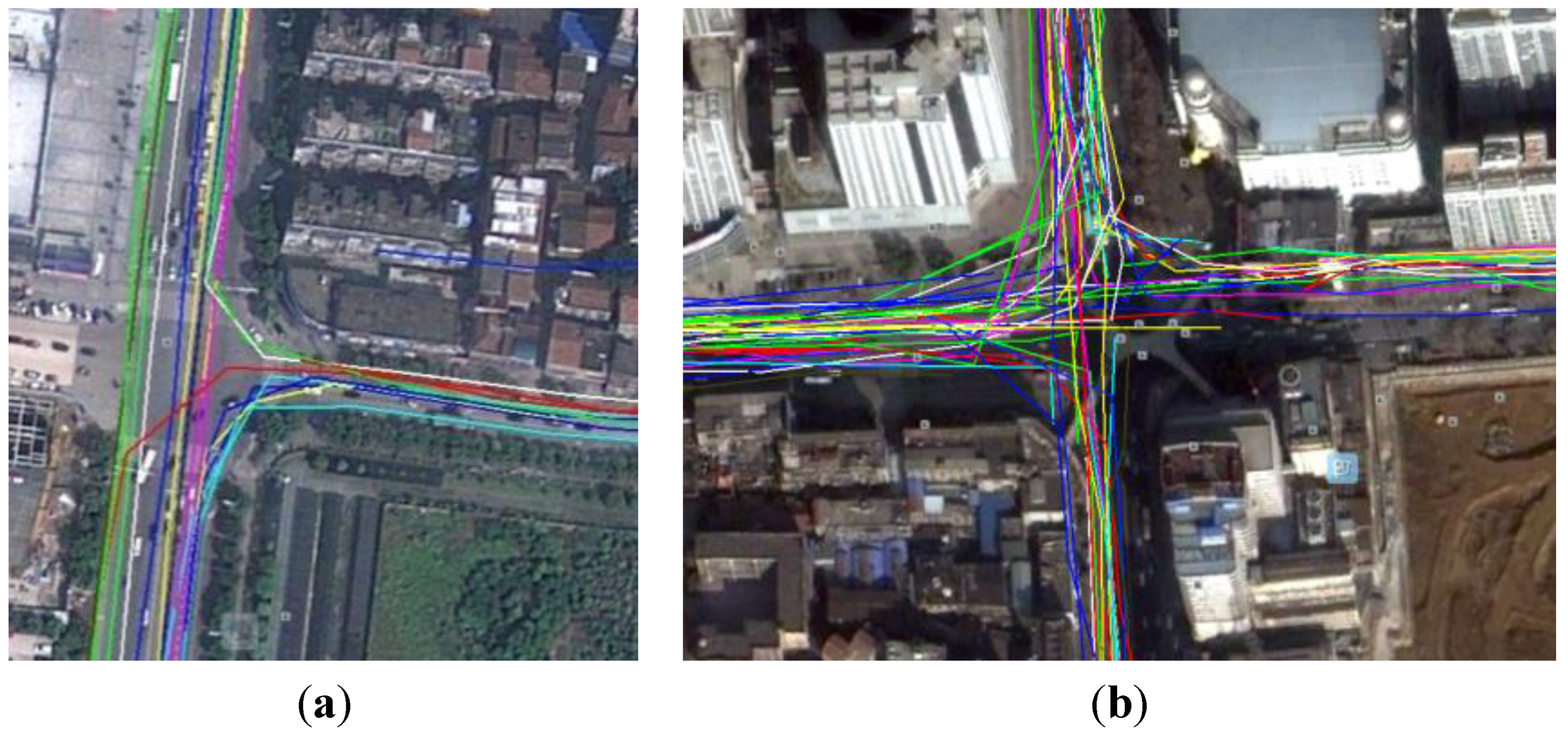
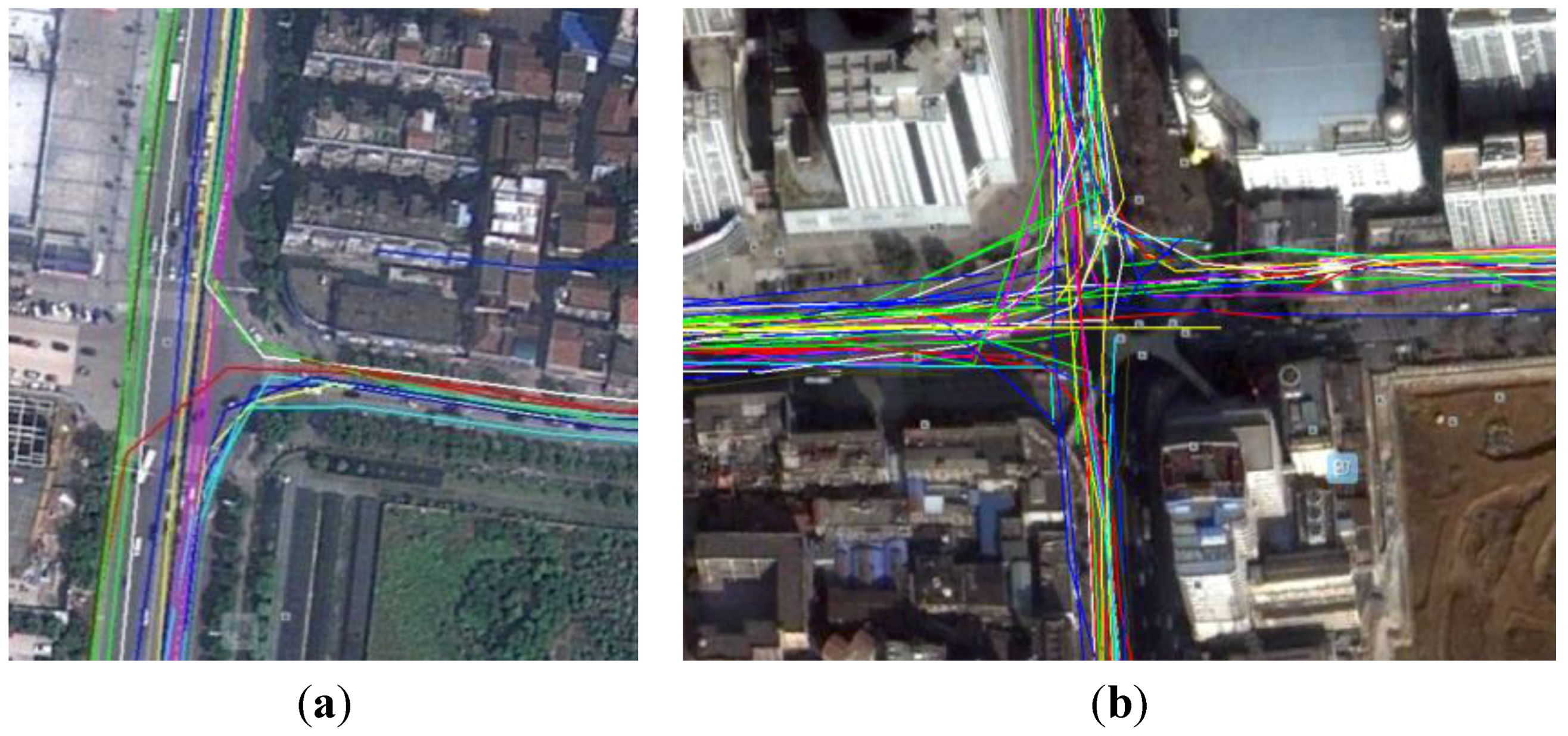
4.1. Trajectory Optimization
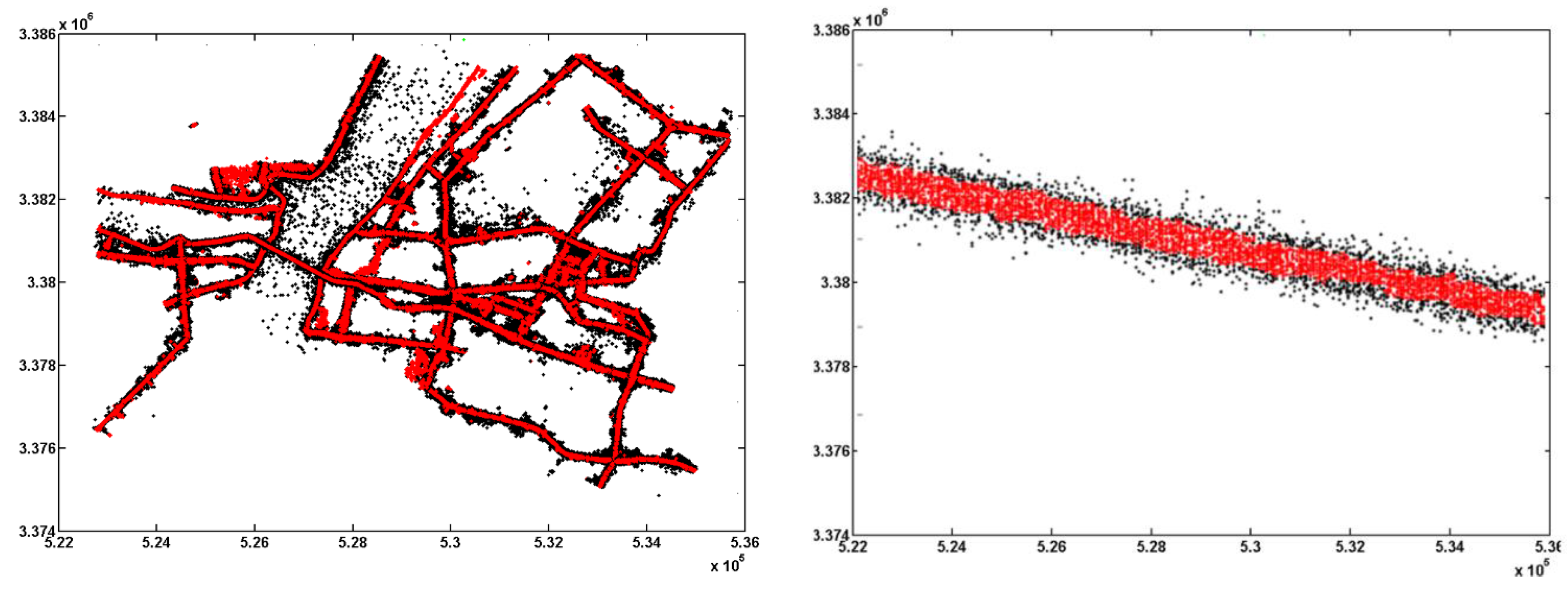

4.2. The Construction of Naïve Bayesian Classifier
4.3. Lane Information Extraction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Sample (ID) | Trace Feature: x(1)/m | Trace Feature: x(2) | Category Label Set: y |
|---|---|---|---|
| 1 | 7.9–12.2 | 2 | 2 |
| 2 | 7.9–12.2 | 3 | 2 |
| … | … | … | … |
| 2,780 | 7.9–12.2 | 2 | 2 |
| 2,781 | 10.2–19.8 | 3 | 3 |
| 2,782 | 10.2–19.8 | 3 | 3 |
| … | … | … | … |
| 4,980 | 10.2–19.8 | 4 | 3 |
| 4,981 | 13.2–20.8 | 4 | 4 |
| 4,982 | 13.2–20.8 | 4 | 4 |
| … | … | … | … |
| 6,870 | 13.2–20.8 | 3 | 4 |
| 6,871 | 17.6–25.8 | 4 | 5 |
| 6,872 | 17.6–25.8 | 5 | 5 |
| … | … | … | … |
| 7,650 | 17.6–25.8 | 5 | 5 |
| TS | TSS | x(1)/m | x(2) | The Number of Lanes (Detections) | The Number of Lanes (True Value) | Driving Direction (Detections) | Driving Direction (True Value) |
|---|---|---|---|---|---|---|---|
| TS001 | TSS001 | 10.1 | 2 | 2 | 2 |  | |
| TSS002 | 9.9 | 2 | 2 | 2 | | | |
| … | … | … | … | … | … | … | |
| TS002 | TSS001 | 14.1 | 4 | 4 | 3 |  | |
| TSS002 | 14.2 | 4 | 4 | 3 | | | |
| … | … | … | … | … | … | … | |
| TSS016 | 15.4 | 3 | 3 | 3 | | | |
| … | … | … | … | … | … | … | |
| TS003 | TSS001 | 19.2 | 4 | 4 | 4 | | |
| TSS002 | 20.3 | 4 | 4 | 4 | | | |
| TSS003 | 20.3 | 3 | 3 | 4 | | | |
| … | … | … | … | … | … | … | |
| TSS042 | 20.3 | 5 | 5 | 3 | | |
indicates that vehicle drivers go straight, and multi-headed arrows show that vehicle drivers can travel in straight direction or turn left at an intersection, as shown in Table 2. At the same time, the accuracy of turn rules of lane detection depends largely on the results of the number of lanes. In Table 2, the turn rules from lanes in the test samples also get a misclassification because of an incorrect estimate of the number of lanes.4.4. Quantitative Evaluation
4.4.1. Quantitative Evaluation for Number of Lane Identification
4.4.2. Quantitative Evaluation for Turn Rules Detection
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gonzalez, J.P.; Ozguner, U. Lane detection using histogram-based segmentation and decision trees. In Proceedings of 2000 IEEE Intelligent Transportation Systems, Dearborn, MI, USA, 1–3 October 2000.
- Wang, Y.; Teoh, E.K.; Shen, D. Lane detection using B-snake. In Proceedings of 1999 International Conference on Information Intelligence and Systems, Bethesda, MD, USA, 3 October 1999.
- Hillel, A.B.; Lerner, R.; Levi, D.; Raz, G. Recent progress in road and lane detection: A survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Kammel, S.; Pitzer, B. Lidar-based lane marker detection and mapping. In Proceedings of Intelligent Vehicles Symposium, Eindhoven, the Netherlands, 4–6 June 2008.
- Thuy, M.; León, F. Lane detection and tracking based on Lidar data. Metrol. Meas. Syst. 2010, 17, 311–321. [Google Scholar] [CrossRef]
- Yang, B.S.; Dong, Z.; Zhao, G.; Dai, W.X. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Phothogr. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krumm, J. Probabilistic modeling of traffic lanes from GPS traces. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010.
- Yeh, A.G.O.; Zhong, T.; Yue, Y. Hierarchical polygonization for generating and updating lane-based road network information for navigation from road markings. Int. J. Geogr. Inf. Sci. 2015, 29, 1509–1533. [Google Scholar] [CrossRef]
- Liu, X.T.; Ban, Y.F. Uncovering spatio-temporal cluster patterns using massive floating car data. ISPRS Int. J. Geo-Inf. 2013, 2, 371–384. [Google Scholar] [CrossRef]
- Sainio, J.; Westerholm, J.; Oksanen, J. Generating heat maps of popular routes online from massive mobile sports tracking application data in milliseconds while respecting privacy. ISPRS Int. J. Geo-Inf. 2015, 4, 1813–1826. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of 18th International World Wide Web Conference, Madrid, Spain, 20–24 April 2009.
- Giannotti, F.; Nanni, M.; Pinelli, F.; Pedreschi, D. Trajectory pattern mining. In Proceedings of 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007.
- Yin, P.; Ye, M.; Lee, W.C.; Li, Z. Mining GPS data for trajectory recommendation. In Advances in Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2014; pp. 50–61. [Google Scholar]
- Tang, L.L; Chang, X.M.; Li, Q.Q. Public travel route optimization based on ant colony optimization algorithm and taxi GPS data. China J. Highw. Transp. 2011, 24, 89–95. [Google Scholar]
- Wang, J.; Rui, X.; Song, X.; Tan, X. A novel approach for generating routable road maps from vehicle GPS trajectories. Int. J. Geogr. Inf. Sci. 2014, 29, 69–91. [Google Scholar] [CrossRef]
- Tang, L.L.; Huang, F.Z.H.; Zhang, X.Y.; Li, Q.Q. Road Network change detection based on floating car data. J. Netw. 2012, 7, 1063–1070. [Google Scholar] [CrossRef]
- Zhou, B.D.; Li, Q.Q.; Mao, Q.Z.H.; Tu, W.; Zhang, X.; Chen, L. ALIMC: Activity landmark-based indoor mapping via crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2774–2785. [Google Scholar] [CrossRef]
- De Fabritiis, C.; Ragona, R.; Valenti, G. Traffic estimation and prediction based on real time floating car data. In Proceedings of 11th International IEEE Conference on Intelligent Transportation Systems (ITSC), Beijing, China, 12–15 October 2008.
- Sun, D.; Zhang, C.; Zhang, L.; Chen, F.; Peng, Z.R. Urban travel behavior analyses and route prediction based on floating car data. Trans. Lett. Int. J. Trans. Res. 2014, 6, 118–125. [Google Scholar] [CrossRef]
- Lee, W.C.; Krumm, J. Trajectory preprocessing. In Computing with Spatial Trajectories; Zheng, Y., Zhou, X., Eds.; Springer: New York, NY, USA, 2011; pp. 3–33. [Google Scholar]
- Brakatsoulas, S.; Pfoser, D.; Salas, R.; Wenk, C. On map-matching vehicle tracking data. In Proceedings of 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005.
- Haklay, M.; Weber, P. OpenStreetMap: User-generated street maps. IEEE Perv. Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Yanagisawa, Y.; Akahani, J.; Satoh, T. Shape-based similarity query for trajectory of mobile objects. In Proceedings of 4th International Conference on Mobile Data Management, Melbourne, Australia, 21–24 January 2003.
- Bruntrup, R.; Edelkamp, S.; Jabbar, S. Incremental map generation with GPS traces. In Proceedings of the 2005 IEEE Intelligent Transportation Systems, Vienna, Austria, 13–15 September 2005.
- Li, J.; Qin, Q.; Xie, C.; Zhao, Y.; Li, J.; Qin, Q. Integrated use of spatial and semantic relationships for extracting road networks from floating car data. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 238–247. [Google Scholar] [CrossRef]
- Liu, C.H.Y.; Xiong, L.; Hu, X.Y.; Shan, J. A progressive buffering method for road map update using OpenStreetMap data. ISPRS Int. J. Geo-Inf. 2015, 4, 1246–1264. [Google Scholar] [CrossRef]
- Li, Q.Q.; Tang, L.L.; Zuo, X.Q.; Li, H.W. Transect-based three dimensional road modeling and visualization. Geo-Spat. Inf. Sci. 2004, 7, 14–17. [Google Scholar]
- Pollak, K.; Peled, A.; Hakkert, S. Geo-based statistical models for vulnerability prediction of highway network segments. ISPRS Int. J. Geo-Inf. 2014, 3, 619–637. [Google Scholar] [CrossRef]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schroedl, S. Constrained k-means clustering with background knowledge. In Proceedings of 18th International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June–1 July 2001.
- Edelkamp, S.; Schrödl, S. Route planning and map inference with global positioning trajectories. Comput. Sci. Perspect. 2003, 2598, 128–151. [Google Scholar]
- Uduwaragoda, A.; Perera, A.S.; Dias, S.A.D. Generating lane level road data from vehicle trajectories using kernel density estimation. In Proceedings of the 16th International IEEE Annual Conference on Intelligent Transportation Systems (ITSC), Hague, the Netherlands, 6–9 October 2013.
- Han, J.; Kamber, M. Mining stream, time-series, and sequence data. In Data mining: Concepts and techniques; Asma, S., Ed.; Elsevier: USA, 2011; pp. 467–531. [Google Scholar]
- Shekhar, S.; Evans, M.R.; Kang, J.M.; Pradeep, M. Identifying patterns in spatial information: A survey of methods. WIREs Data Min. Knowl. Discov. 2011, 1, 193–214. [Google Scholar] [CrossRef]
- Liu, Q.; Tang, J.; Deng, M.; Shi, Y. An iterative detection and removal method for detecting spatial clusters of different densities. Trans. in GIS 2015, 19, 82–106. [Google Scholar] [CrossRef]
- Lee, J.G.; Han, J. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, L.; Yang, X.; Kan, Z.; Li, Q. Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification. ISPRS Int. J. Geo-Inf. 2015, 4, 2660-2680. https://doi.org/10.3390/ijgi4042660
Tang L, Yang X, Kan Z, Li Q. Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification. ISPRS International Journal of Geo-Information. 2015; 4(4):2660-2680. https://doi.org/10.3390/ijgi4042660
Chicago/Turabian StyleTang, Luliang, Xue Yang, Zihan Kan, and Qingquan Li. 2015. "Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification" ISPRS International Journal of Geo-Information 4, no. 4: 2660-2680. https://doi.org/10.3390/ijgi4042660
APA StyleTang, L., Yang, X., Kan, Z., & Li, Q. (2015). Lane-Level Road Information Mining from Vehicle GPS Trajectories Based on Naïve Bayesian Classification. ISPRS International Journal of Geo-Information, 4(4), 2660-2680. https://doi.org/10.3390/ijgi4042660