1. Introduction
The Marco Polo argali (
Ovis ammon polii) is a subspecies of argali (
Ovis ammon), and is considered the longest-horned species of wild sheep. Named after the explorer Marco Polo and first described scientifically in 1841 by Edward Blyth, Marco Polo argali occurs in the Tajikistan Pamir Mountains [
1], as well as in limited regions in China, Afghanistan, Pakistan, and Kyrgyzstan [
2]. Due to the sheep’s impressive horn, foreign hunters are willing to pay large amounts of money for a hunt [
3]. In fact, in a report by Luschekina [
4] covering the years 1967 to 1989, a total of $20 million was paid by wealthy trophy hunters. Recent studies on the status of the argali population have shown a decline in numbers [
5,
6] caused by trophy hunting and subsistence poaching [
7].
O. ammon has been categorized in several lists, such as the Appendix II of CITES and the 2000 IUCN Red List, as vulnerable or threatened species. O. Aknazarov, Pamir Biological Institute Director, said that the total number of Marco Polo sheep in the Tajik Pamirs may only be between 3000 to 5000 animals. Valdez
et al. [
2], however, counted a total of 8649, 8392, and 7663 sheep in a four-year successive surveys from 2009 to 2012. Argalis usually inhabit the rolling hills that lack tall vegetation to visually scan for predators [
8]. They also prefer rugged mountainous landscapes for escape cover and relies on speed for evading predators [
9].
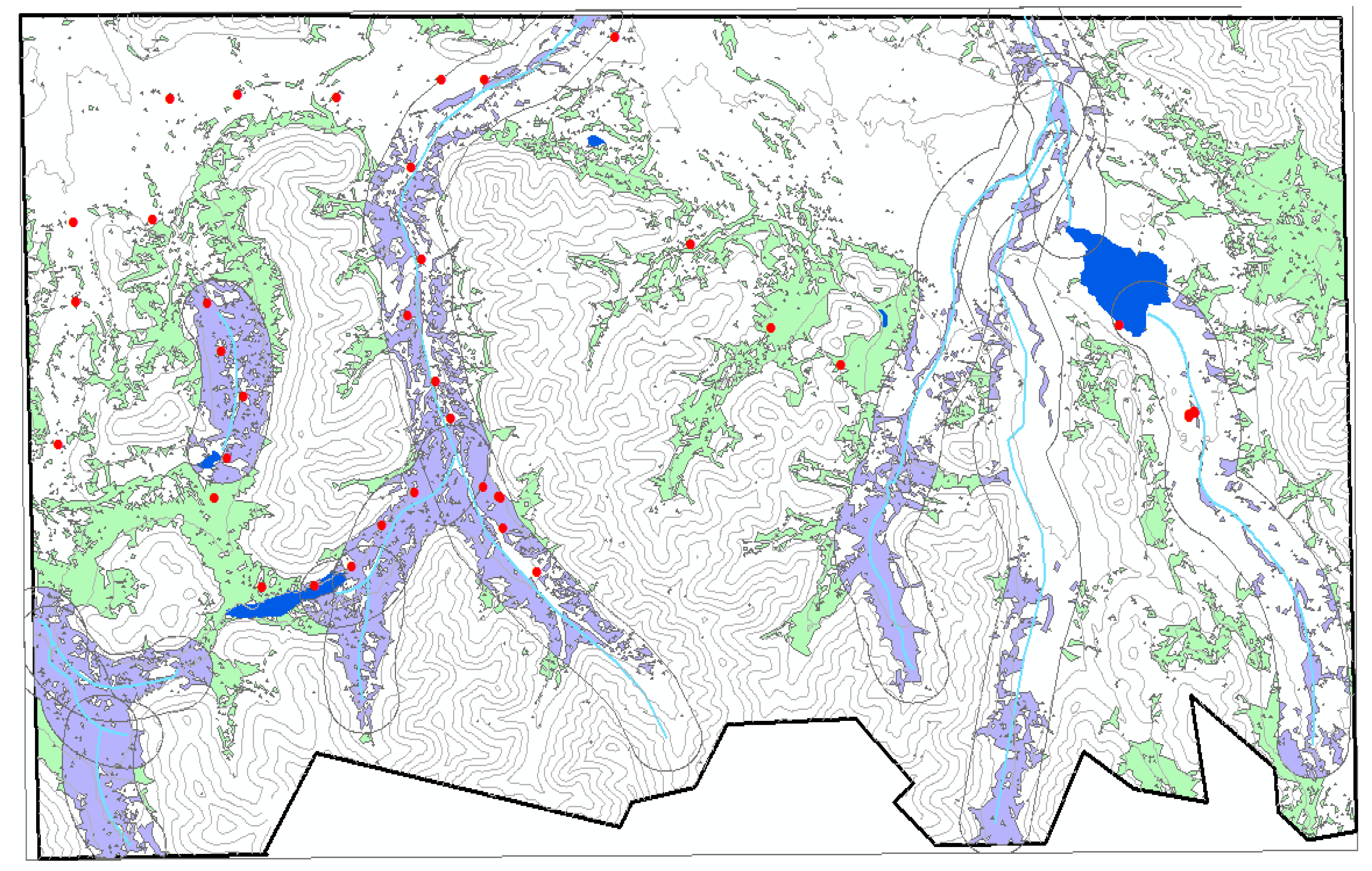
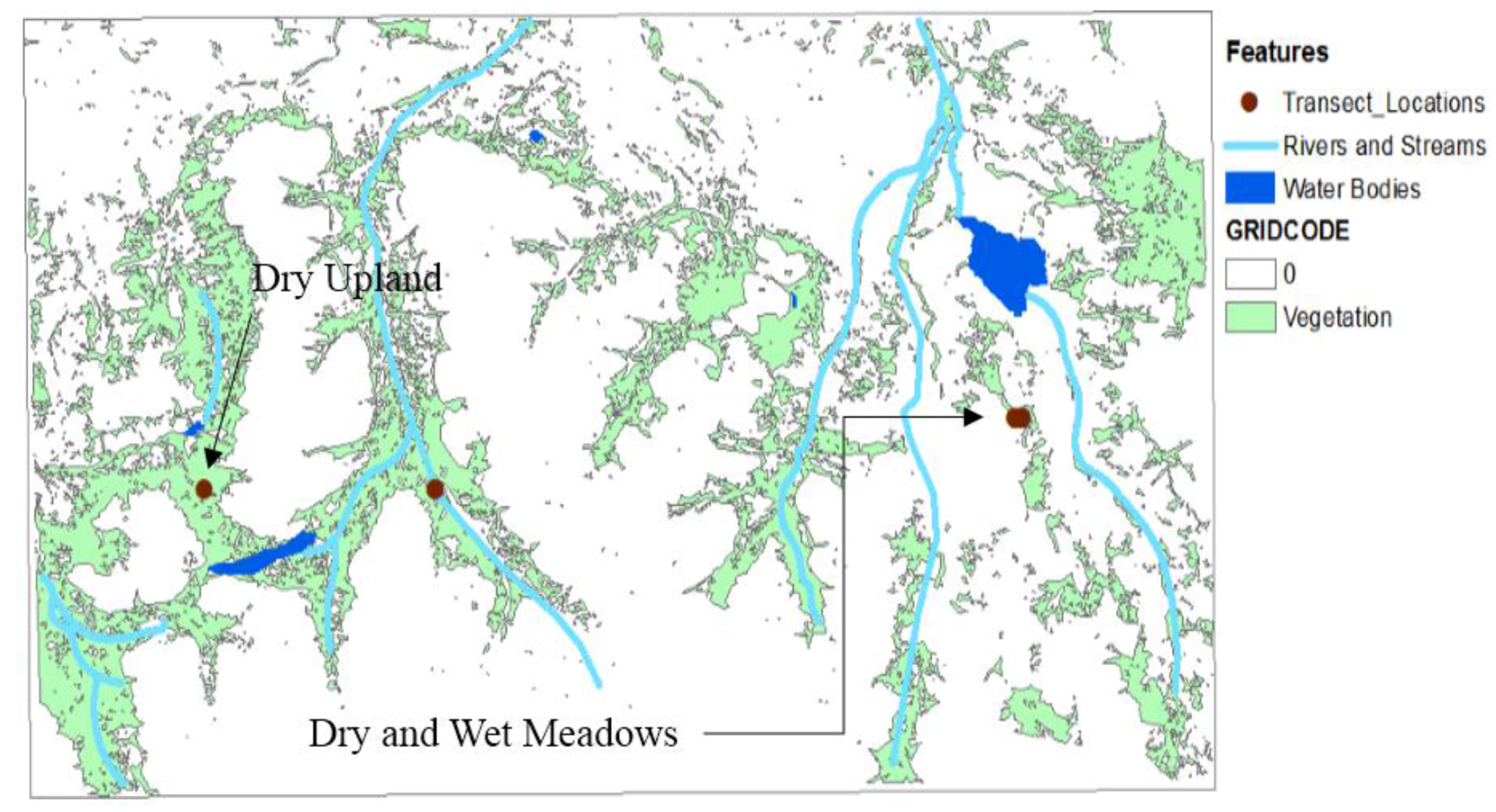
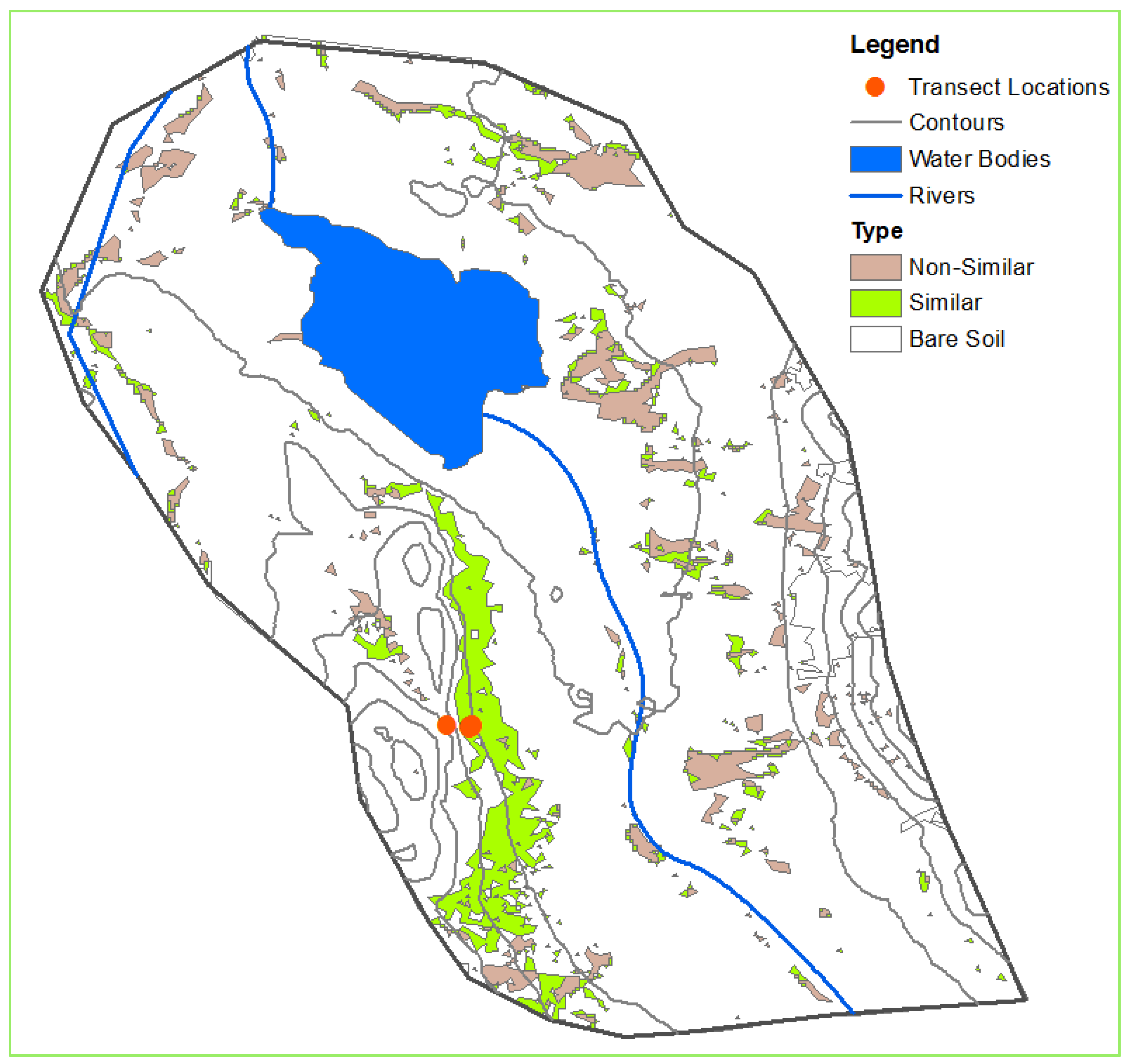
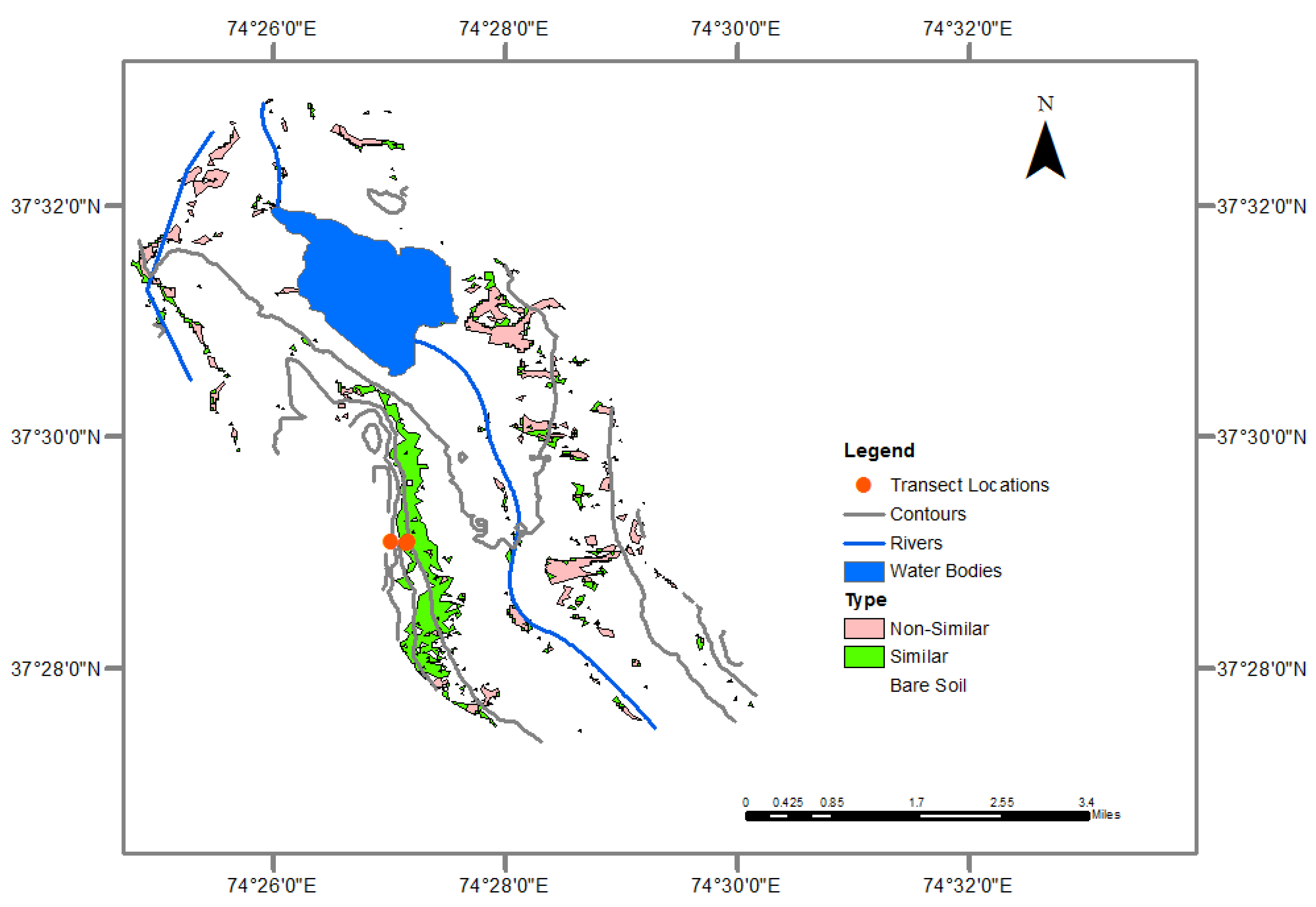
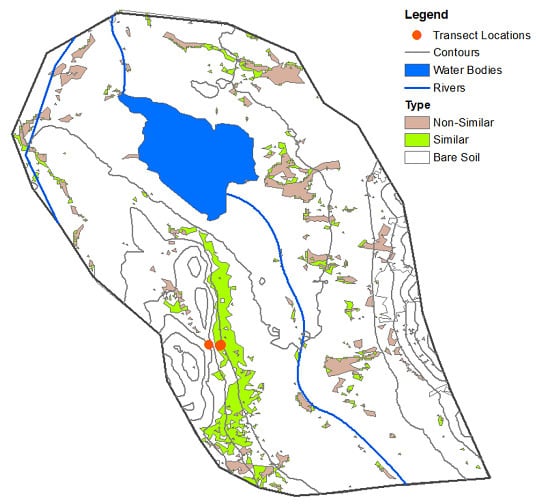
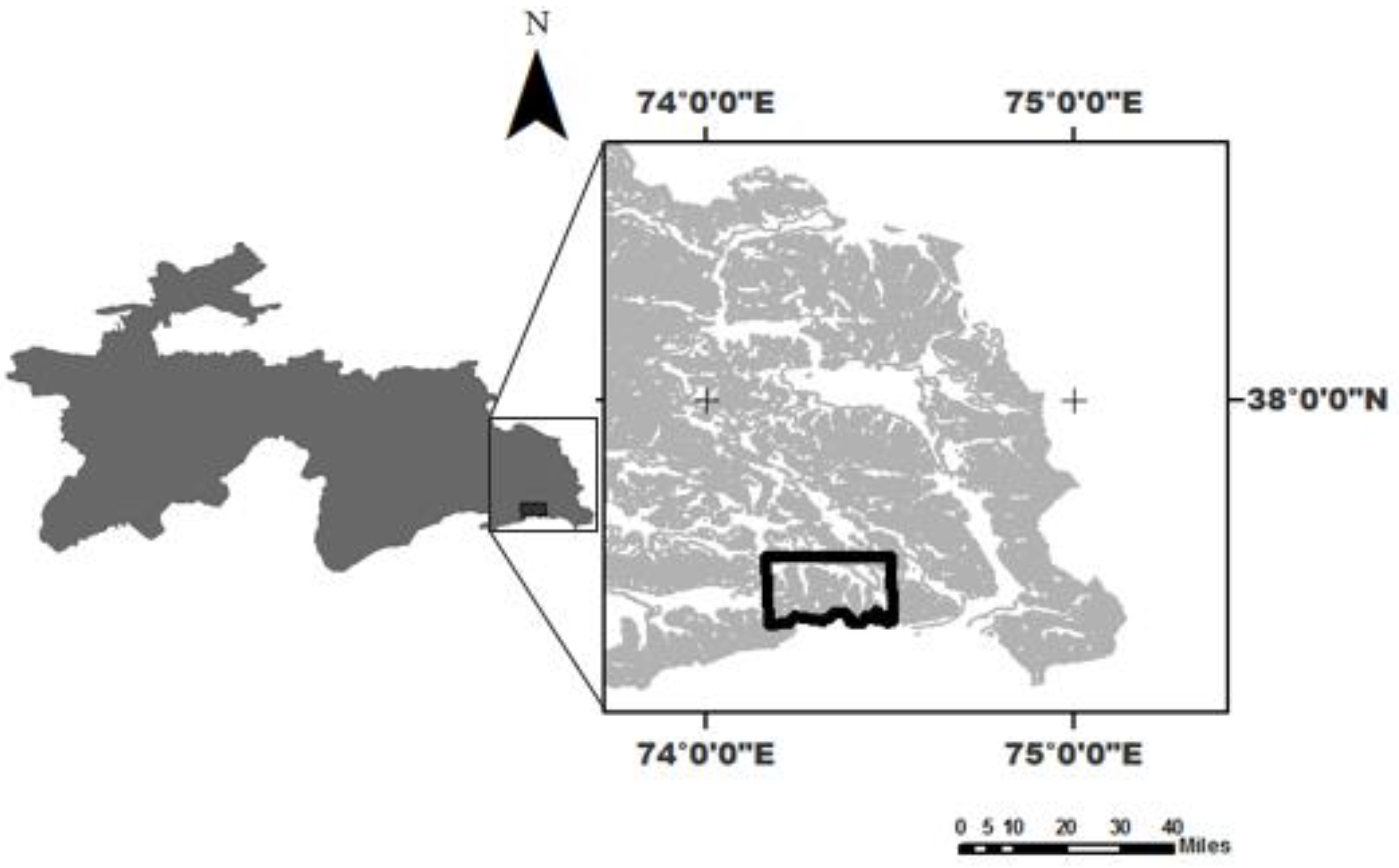
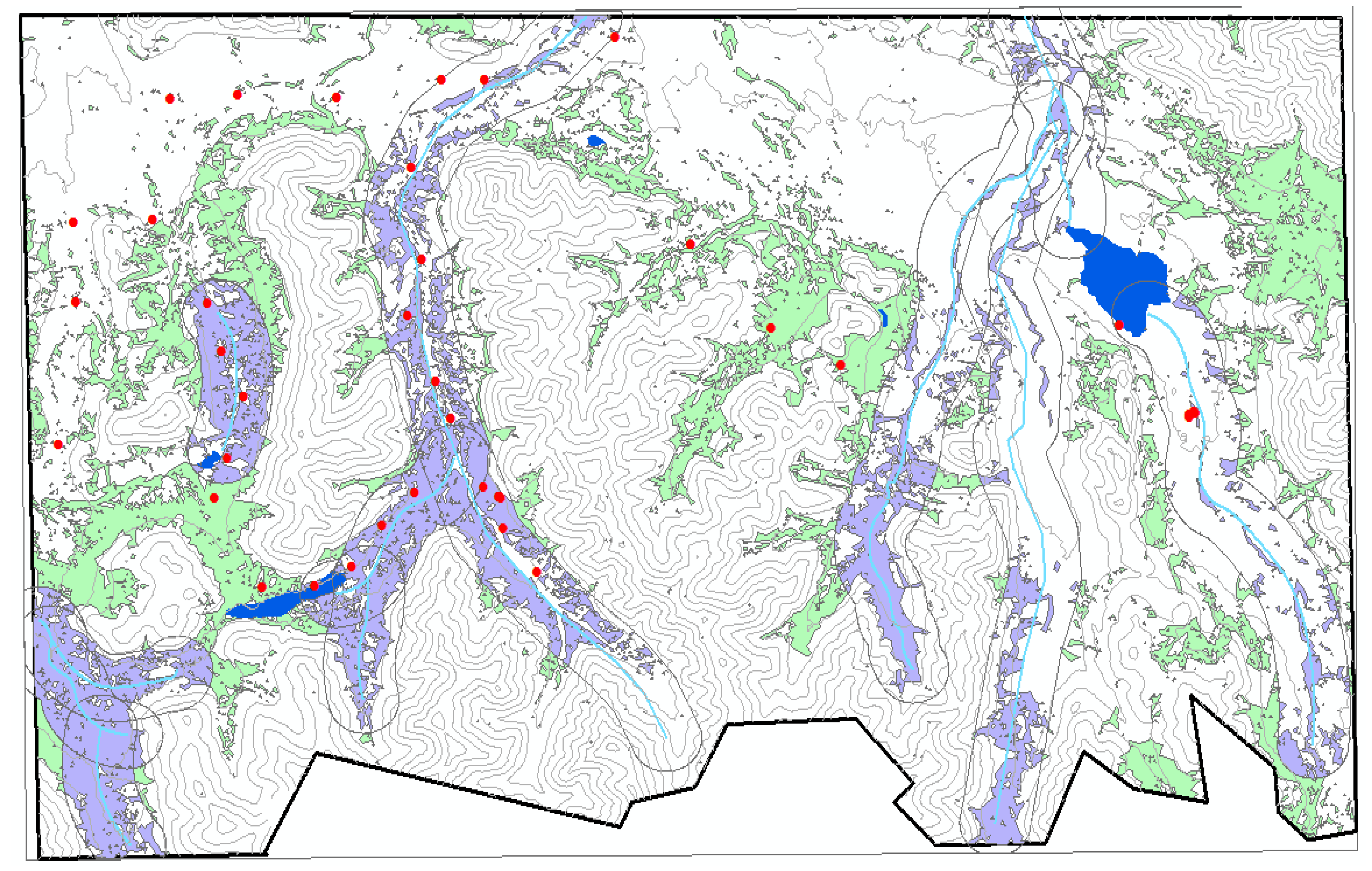
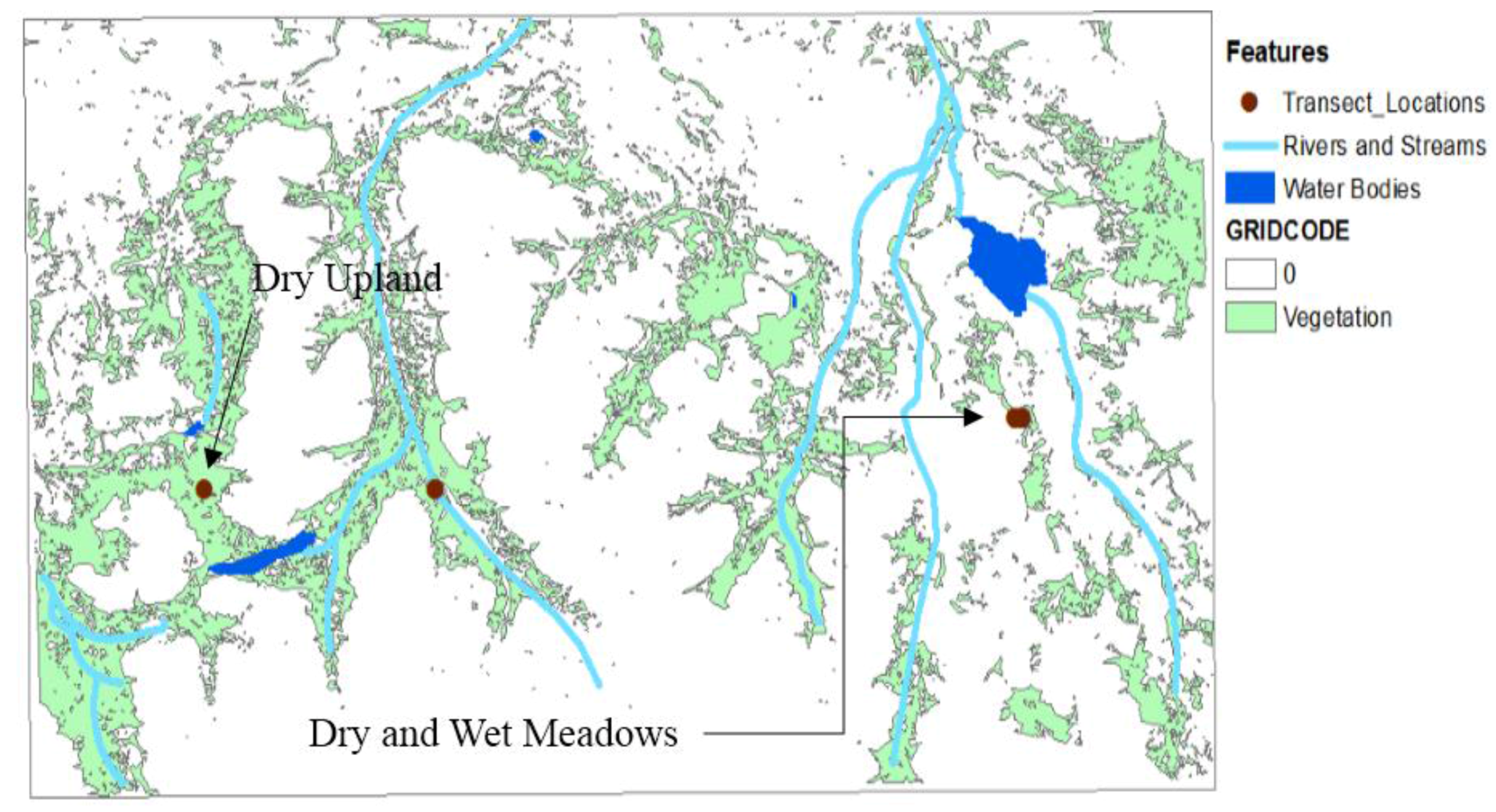
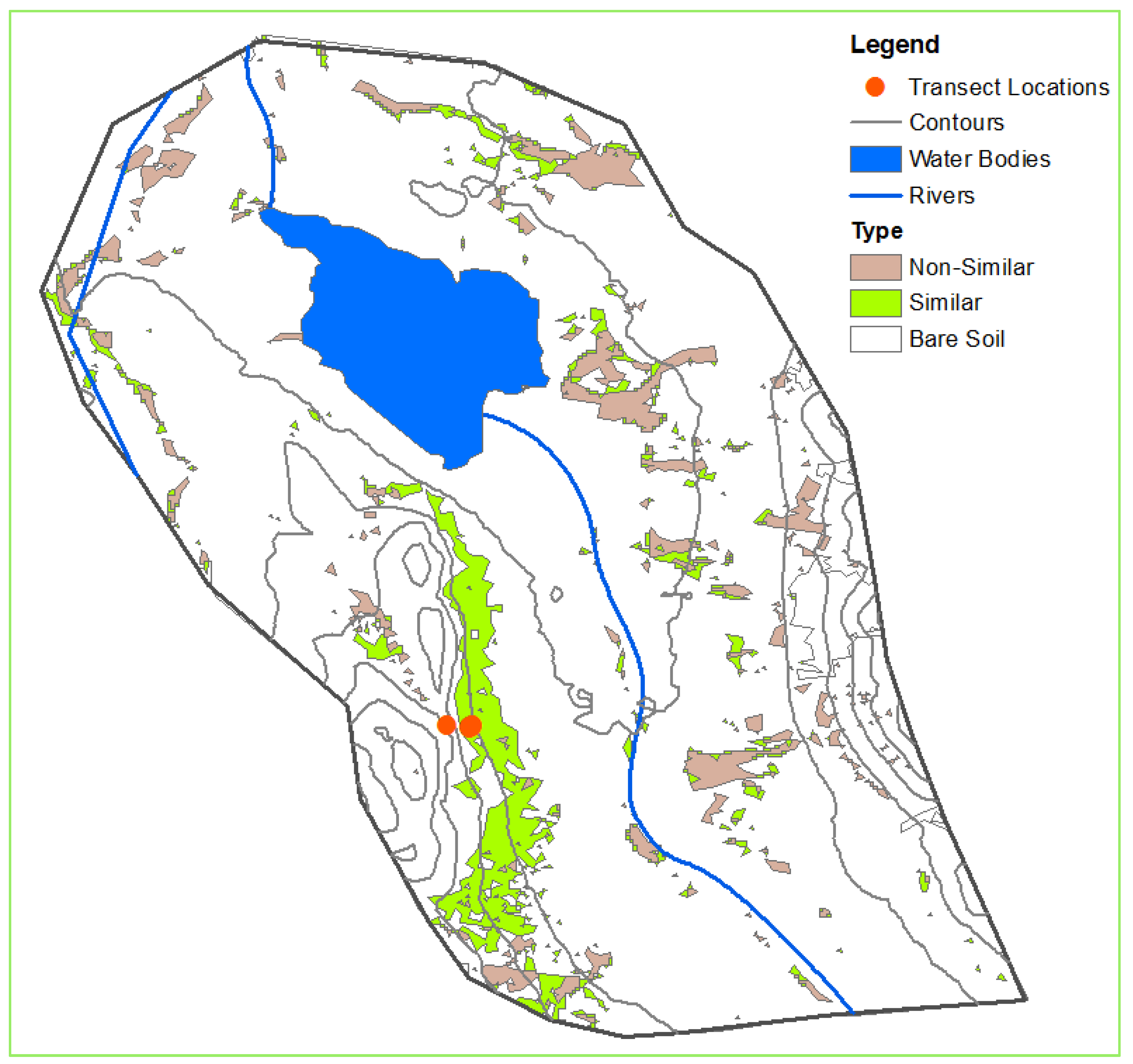
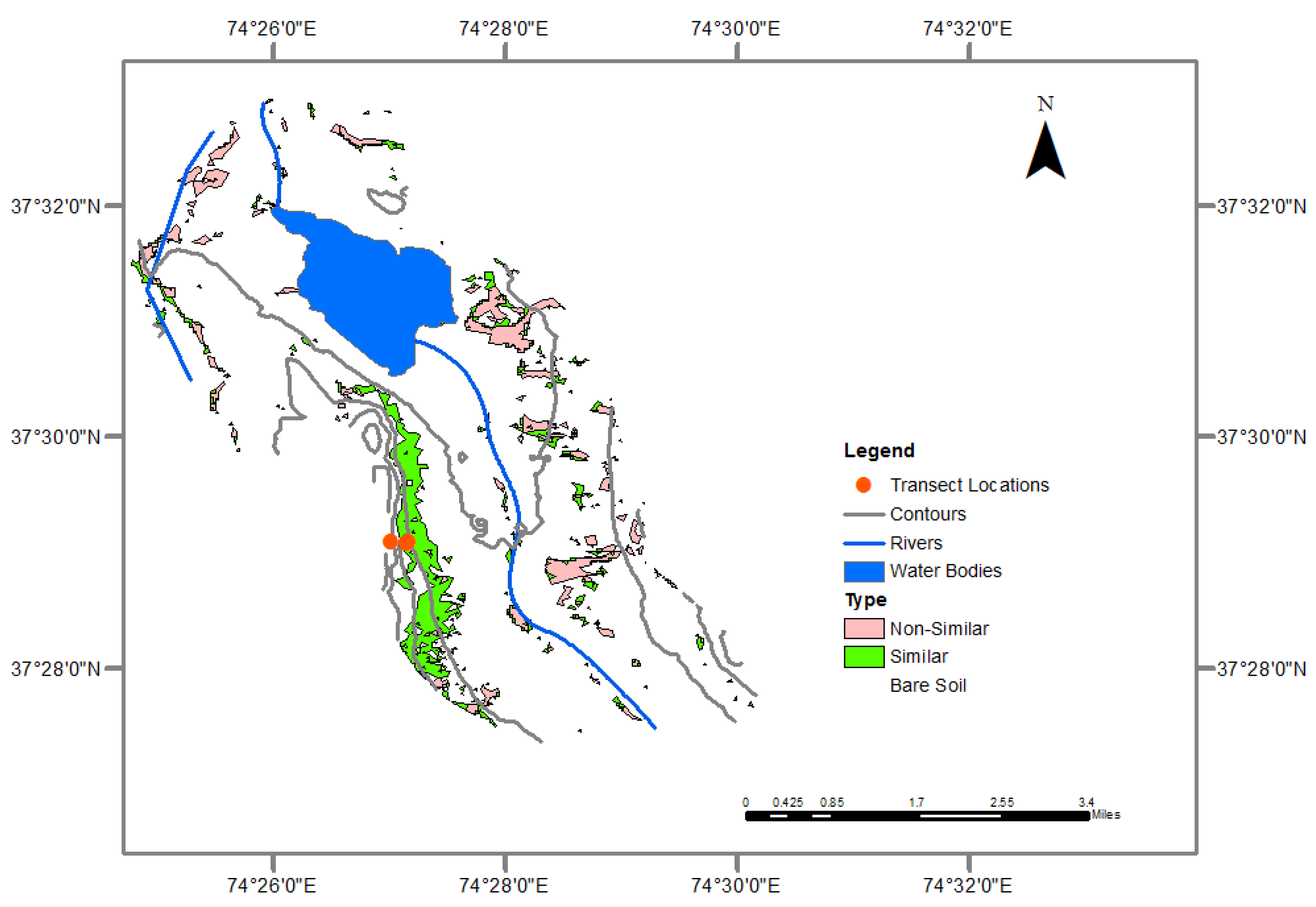
In this report, we described a small portion of our study area in the southeastern Tajik Pamirs that contained the two available datasets—one dataset listed the occupancy locations of wild sheep, and the second dataset detailed transect surveys that showed surface characteristics of possible sheep habitat. Using remote sensing techniques and geographic information systems (GIS), descriptions of the sheep habitat were presented in GIS layers. We generated individual layers to obtain information on argali patterns and habitat suitability and to make the dataset available online to the rest of the research community.
3. Data and Methodology
Systematic description of data processing steps is presented here:
(1) Preprocessing of the Landsat image to enhance the quality of the data and to remove noise caused by internal and external conditions and eliminate other undesirable characteristics produced by the sensor.
The 30-m spatial resolution Landsat 7 Enhanced Thematic Mapper Plus (ETM+) image from July 2012 was used for the analysis to coincide with the date of the fieldwork. The level-1 terrain-corrected product (L1T) Landsat time-series data were obtained from the U.S. Geological Survey Earth Resources Observation and Science (USGS EROS) resource archive (
http://eros.usgs.gov/). The month of July is within the period identified to be the vegetation response peak [
14]; the time of year when the development stage of the vegetation produces the highest spectral signals. Using ERDAS Imagine [
15], we normalized the image by converting the measured digital number (DN) values to top of atmosphere (TOA) reflectance units [
16].
(2) Screening of cloud patches, cloud shadows, and snow were performed to ensure that the image was devoid of obstructions that may result in false classification of the vegetation cover.
We did visual and/or spectral examinations of the image to assess for cloud presence and shadow contaminations, delineated them and then masked out from the analysis. Most of the contaminations were found south of the Landsat scene. Since our study area was located near the center of the scene, we managed to avoid 95% of the cloud cover and snow. Thus, clouds, shadows, and snow cover were not major constraints in the image processing. For the snow mask, we created the Normalized Difference Snow Index (NDSI) [
17] image to distinguish snow from other surrounding features. A threshold was applied to the NDSI to filter the non-snow features that may have been misclassified as snow by examining reflectance at other wavelengths. Further, we did extensive manual deleting of isolated snow artifacts especially in transition areas between snow and non-snow features located on steep slopes.
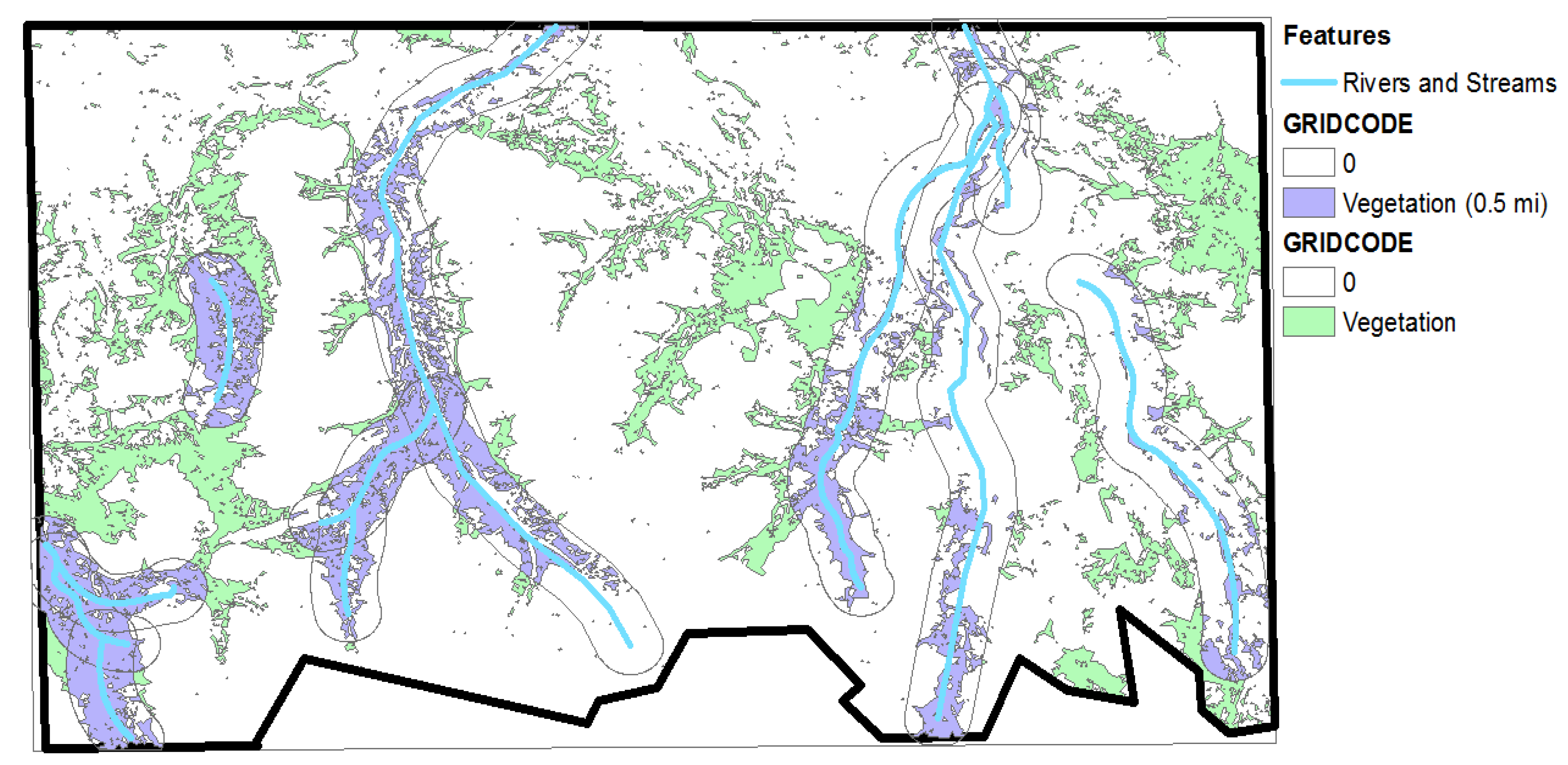
(3) The integration of the variables such as digital elevation model (DEM), Normalized Difference Vegetation Index (NDVI), Principal Component Analysis (PCA), Modified Soil-adjusted Vegetation Index (MSAVI), and texture features into the object-based image classification analysis.
Instead of the pixel-based method, we utilized the object-based image analysis (OBIA) for our image classification, guaranteeing a much higher classification accuracy [
18,
19,
20,
21]. OBIA is appropriate to capture the landscape patterns and derive the dynamics of neighboring objects.
Spectral and topographic variables, namely, NDVI [
22], PCA [
23], MSAVI [
24], and DEM [
25], were integrated with texture features such as homogeneity (HOM), second moment (M2), dissimilarity (DIS), entropy (ENT), and contrast (CON), for the object-based classification. Few studies have noted that the addition of DEM, NDVI, PCA, and MSAVI could help improve image classification results in terms of feature discrimination and accuracy of featured classes (e.g., [
26,
27]). We utilized the DEM from NASA’s Shuttle Radar Topography Mission (SRTM) 90-m digital elevation online dataset
via the USGS website (
http://srtm.usgs.gov/index.php). We rescaled the DEM to the spatial resolution of the spectral variables (30 m). Further, we added the individual Landsat bands 4 and 5 NIR data space to ensure clear separation between vegetation surfaces and soil [
28].
For the texture variables, we took advantage of ENVI software’s textural filters that were based on the co-occurrence measures [
29]. The measures use a matrix to calculate the texture values within the processing window. The matrix gives the instances of occurrences of the relationship between a pixel and its specified neighbor. A number of studies had shown improved land use and land cover (LULC) classification accuracy when using the texture images in OBIA (e.g., [
30,
31]). Stefanov
et al. [
32] and Pesaresi
et al. [
33] used a single band to compute the texture components. In this study, we exhausted every Landsat band and texture feature combination to select the best pairing of band-texture components. A package called FactoMineR was run in the R environment to show opposing vectors, which could designate the best spectral band or bands that will be employed for each particular texture image. Opposing vectors indicate that the components are negatively correlated and considered as best variable candidates for the classification. Once all variables for OBIA were computed, partitioning of the image into segments followed. The result was a segmentation image, where each zone is assigned the computed spectral values of all the pixels that belong to that zone.
Within ENVI’s Feature Extraction module, we applied the k-nearest neighbor (KNN) method to classify the image. We limit the land use classes to only three: vegetation, water, and barren land as our objective was to specifically delineate the summer vegetation cover only. These three classes were not difficult to identify from the Landsat image. For the training data, we relied on the Google Earth engine, the expert knowledge of the area, the spectral signatures of the classes, and the data collected from the field survey in 2012. In addition, reference points from high resolution images of QuickBird (60-cm resolution) and WorldView-2 (50-cm resolution) were tapped to aid in the identification and assigning of classes. As a note, we only used 75% of the points we collected (550 points in total) for training. The remaining 25% was used for classification validation.
We assessed the accuracy of our image classification using overall accuracy (OA), producer’s accuracy (PA), user’s accuracy (UA), and kappa coefficient. We looked at the agreement between the classified image and the reference map; a kappa statistics value of 0.4 means poor agreement, while excellent agreement should have a value of more than 0.85. Any value in between is considered fair to good.
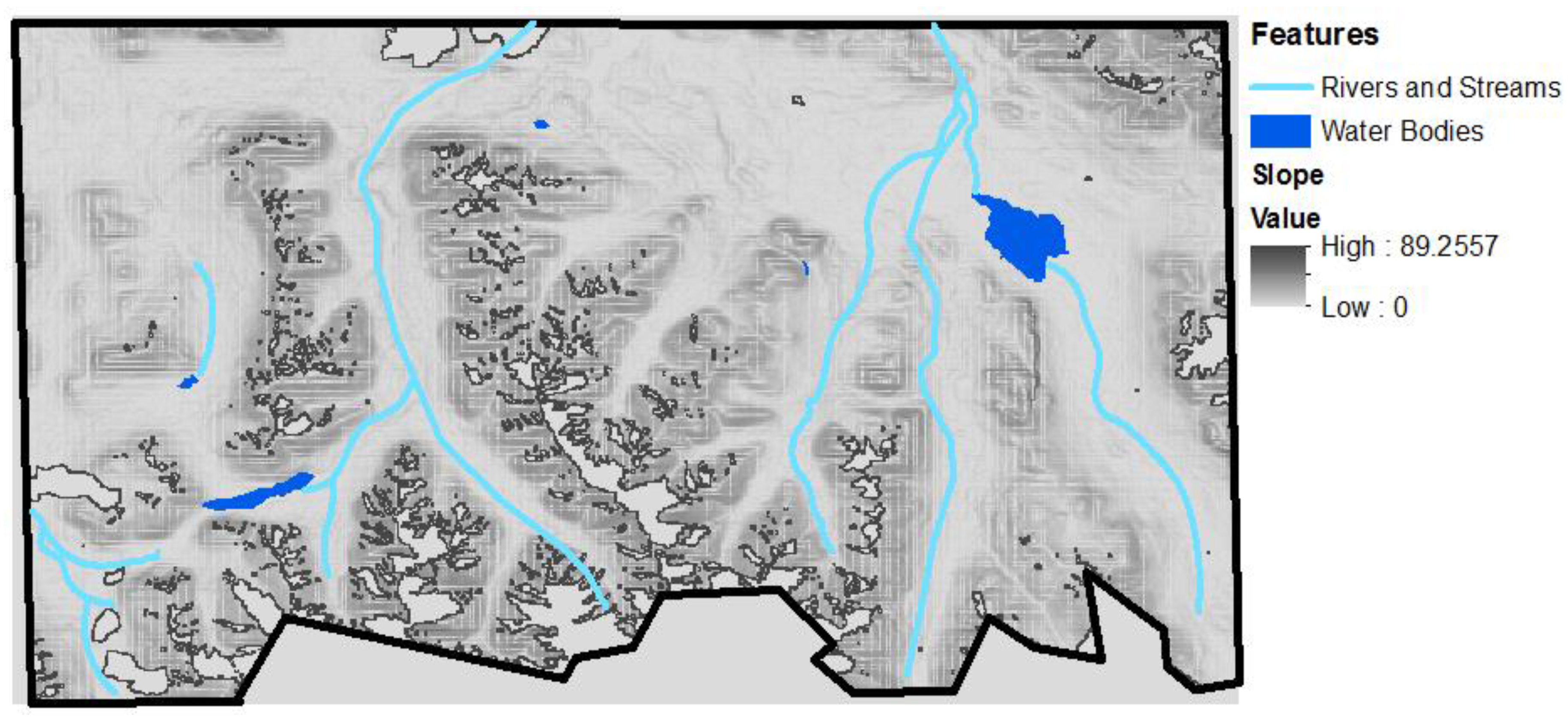
(4) Derivation of secondary raster datasets such as slope, aspect, and river networks.
From the DEM dataset, we derived the slope, aspect, and the TIN, using ArcGIS software.
(5) Overlaying of various vector layers, deriving descriptive statistics using GIS-based analysis, and showing necessary maps.
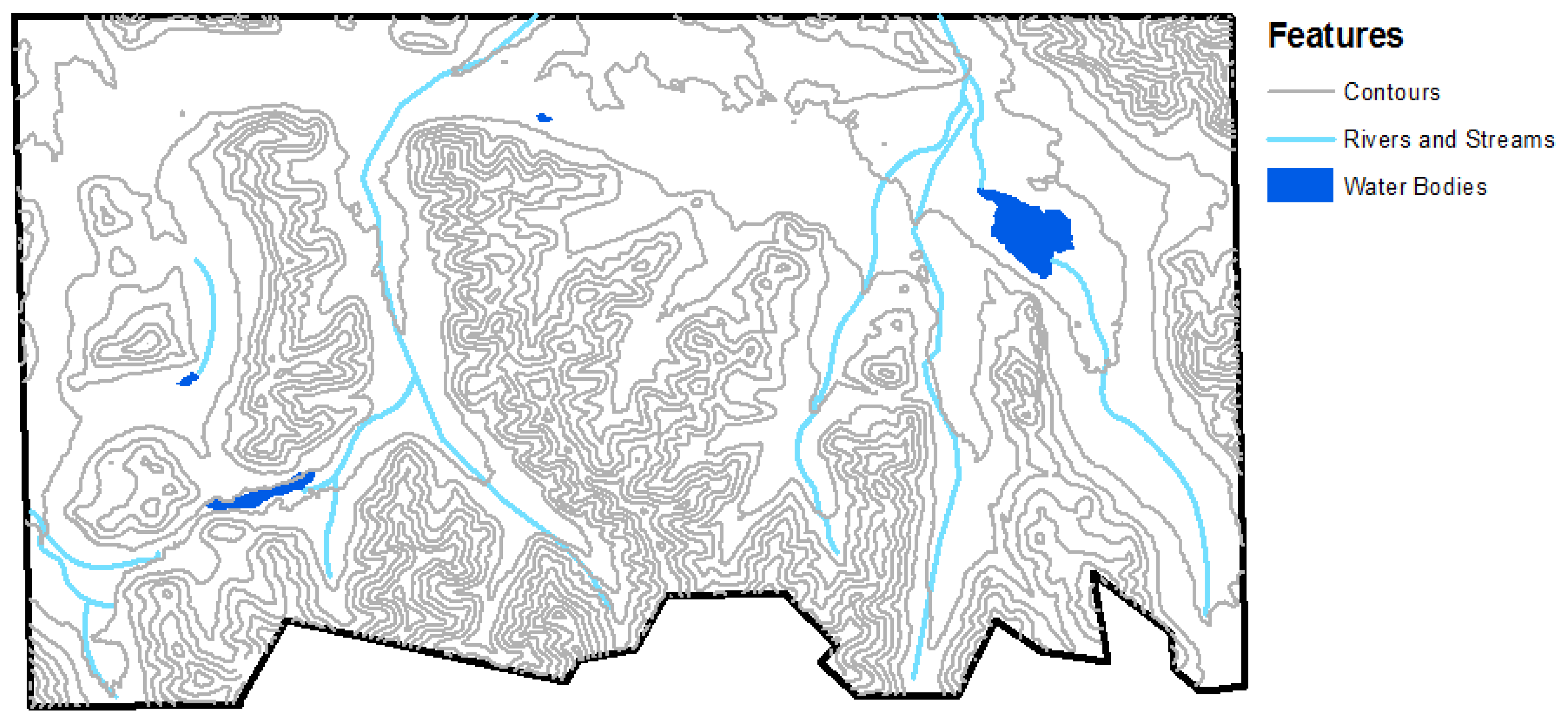
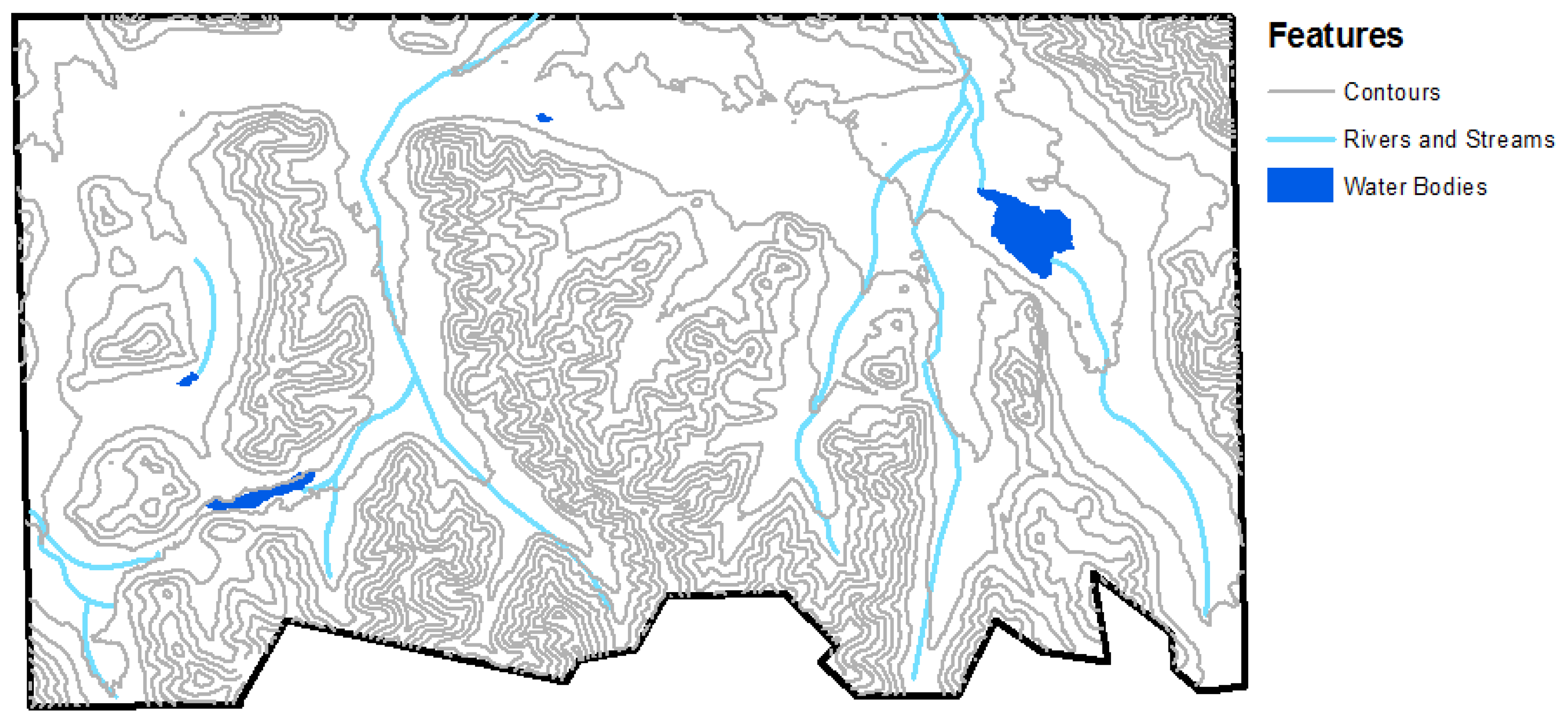
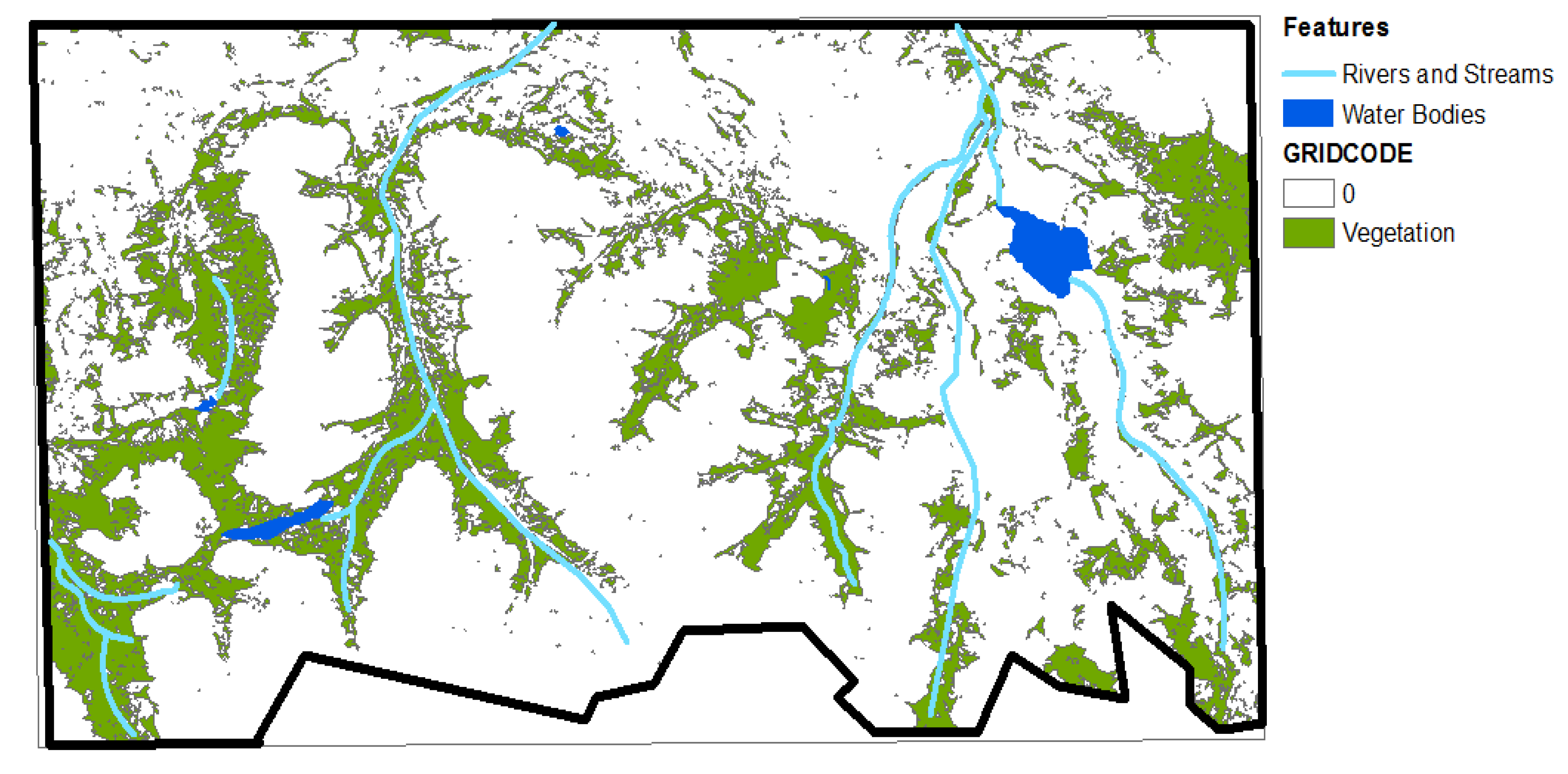
The list of layers we derived and analyzed were rivers and streams, water bodies, topography, and vegetation cover. In this report, rivers and streams refer to riparian areas, which may not have flowing water throughout the year. A layer for human settlements was not included as nothing was detected in the study area. We tabulated the results of our analysis.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}