1. Introduction
Recent advancements in mobile technologies—including smartphones, wireless communication systems, and low-cost sensor networks—have significantly enhanced the ability to monitor various types of moving objects within geographic space. Moving objects encompass a broad range of entities, such as individuals, animals, vehicles (e.g., cars, buses), maritime vessels, and even meteorological phenomena like hurricanes.
Currently, Global Positioning System (GPS) remains the predominant technology for capturing the trajectories of moving objects [
1]. A raw trajectory is typically represented as an ordered sequence of spatiotemporal points, each consisting of a timestamp and spatial coordinates such as latitude, longitude, and optionally, altitude [
2].
Trajectory data plays a critical role in understanding the dynamics and behavior of moving objects. Through trajectory analysis, it is possible to extract valuable insights across a range of application domains—for example, identifying traffic congestion zones, analyzing human mobility patterns, determining optimal routing strategies, locating productive fishing areas, studying animal migration paths, and tracking the evolution of weather systems such as hurricanes [
3].
While raw trajectories typically consist only of the object’s identifier, spatial coordinates, and timestamp at each recorded location, such data alone may be insufficient for complex analytical tasks. To support more advanced and semantically meaningful analysis, many contemporary applications enrich raw trajectory data with semantic information, capturing contextual attributes that describe the environment in which the movement occurred.
As defined by Emmanouilidis et al., a semantic aspect refers to any contextual information that may influence the delivery or quality of a service [
4]. Such information can be derived from various sources, including environmental conditions, user profiles, or external systems. When trajectory data is enriched with semantic aspects, the resulting dataset is referred to as a semantic trajectory [
5,
6].
Semantic enrichment enables a deeper understanding of the behavior of moving objects by providing contextual details that are not captured by raw spatiotemporal data alone [
7]. For instance, while a raw trajectory may describe the spatial and temporal sequence of visited locations, a semantic trajectory can reveal additional attributes such as points of interest (POIs) visited, transportation modes employed, or even the purpose of the movement. These enriched datasets facilitate high-level reasoning and advanced analytical tasks that extend beyond the simple mapping of positions between an origin and a destination.
A semantic trajectory is typically composed of a sequence of spatiotemporal points, each annotated with relevant semantic metadata. For example,
Figure 1 depicts the semantic trajectory of an individual throughout a typical workday. In addition to location and time, the trajectory was annotated with physiological and behavioral data. The individual departed from her residence at 9:00 a.m. with a recorded heart rate of 75 bpm. She boarded a bus and arrived at her workplace approximately one hour later, during which her heart rate increased to 80 bpm. Her workday lasted from 10:00 a.m. to 5:00 p.m. Subsequently, she took the metro to a supermarket, at which point her heart rate measured 73 bpm. The day concluded with a walk home, during which her heart rate decreased to 70 bpm.
This example demonstrated how semantically enriched trajectories offered multi-faceted insights into mobility patterns, enabling researchers and decision-support systems to interpret user behavior within a richer and more meaningful context.
A semantic element associated with a point in a trajectory is referred to as aspect [
8]. Aspects can describe contextual information related either to the environment or to the moving object itself. Representative examples of aspects include the name and category of a point of interest (POI), weather conditions, mode of transportation, and physiological indicators such as the user’s heart rate [
9]. Once aspect information is annotated onto a trajectory, the result is a complex, multi-dimensional object in which each point is enriched with semantically relevant attributes, providing a more comprehensive representation of the movement context. Efficient storage and analysis of such semantically enriched trajectory data is essential to supporting advanced query processing and to extract actionable insights. While traditional spatial database systems are capable of processing spatiotemporal queries—such as “What is the average speed of individuals who departed from home and used public transport to visit a church?” or “What was the total distance traveled by individuals in New York City in 2012 who stopped at least once in Central Park on a rainy day?”—the complexity and computational cost associated with these queries may render conventional systems inadequate for handling large-scale or high-dimensional datasets.
To address these challenges, trajectory data can be managed using either moving object databases (MODs) or data warehouses (DWs). In particular, trajectory data warehouses (TDWs) have gained prominence for their ability to support complex, analytical queries with improved performance. This is achieved through a multidimensional modeling approach, in which data from various operational sources undergoes an extract–transform–load (ETL) process. During ETL, data is semantically transformed and temporally organized into fact tables and dimension tables, adhering to either star or snowflake schema [
10].
In this model, facts represent numerical measures or key performance indicators relevant to analytical tasks (e.g., travel time, distance, number of stops), while dimensions provide descriptive attributes used to contextualize and aggregate the facts (e.g., location, time, aspect type). These dimensions are commonly organized into hierarchies, enabling data abstraction at multiple levels of granularity.
Analytical queries over TDWs are typically executed using online analytical processing (OLAP) tools. OLAP enables multidimensional exploration through operations such as drill-down and roll-up, which navigate the dimension hierarchies. The drill-down operation transitions from aggregated data at a higher hierarchical level to more detailed, fine-grained data. Conversely, the roll-up operation aggregates data by ascending to a more general level within the same hierarchy.
When tailored specifically to handle spatiotemporal and semantic aspects of trajectory data, such DWs are referred to as TDWs [
11]. They provide a robust infrastructure for decision support systems that analyze mobility behavior in semantically rich contexts.
A significant limitation of traditional TDWs lies in their inability to effectively represent and process semantic trajectories. To overcome this shortcoming, the concept of semantic trajectory data warehouses (STrDWs) has emerged, offering support for both raw spatiotemporal data and associated semantic attributes [
12,
13].
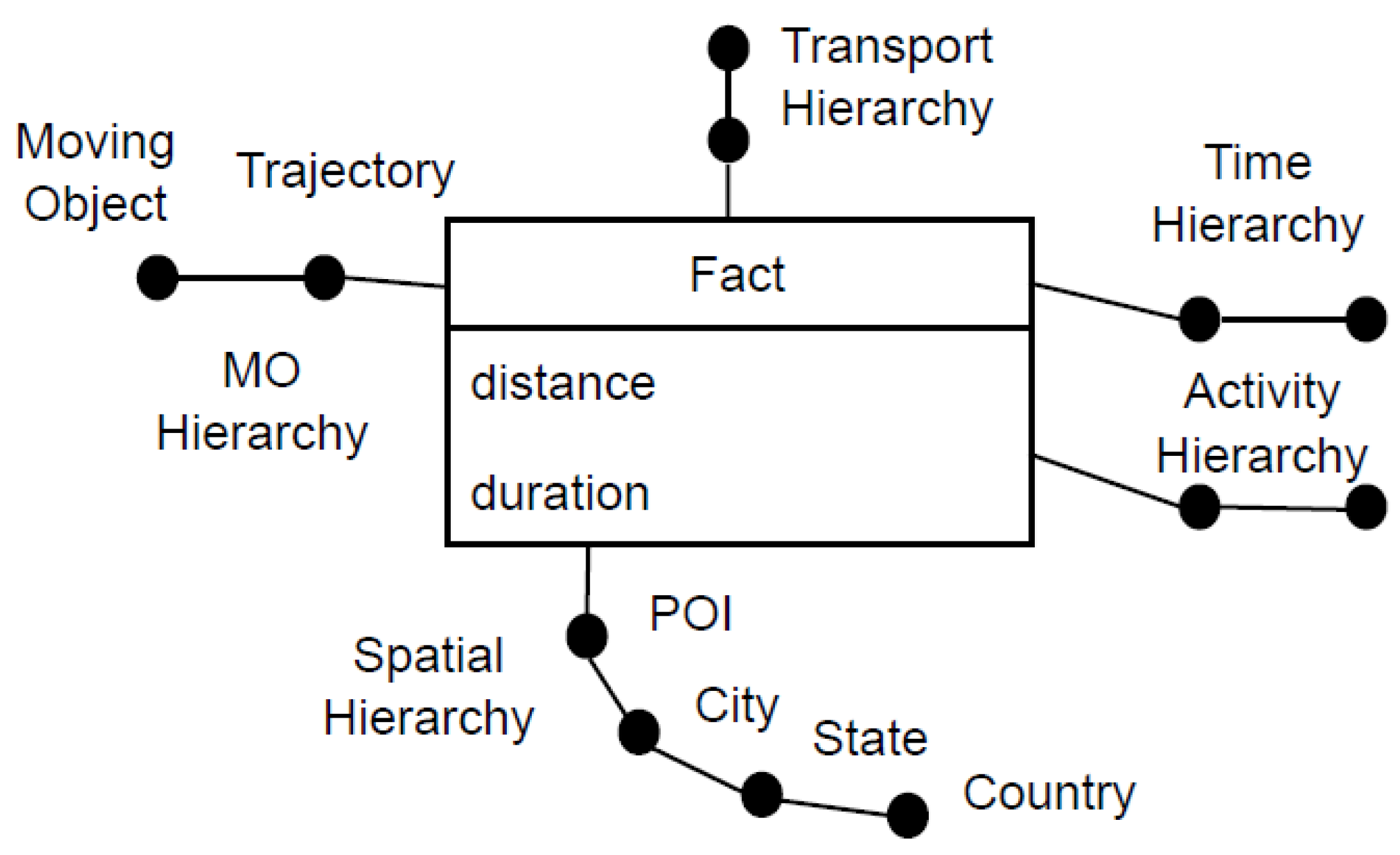
Conventional STrDWs typically address semantic aspects by introducing a distinct dimension for each aspect type represented in the trajectory data. For example,
Figure 2 illustrates the conceptual schema of a representative STrDW, composed of five dimensions—means of transportation, time, activity, space, and moving object—and two measures: distance and duration. In this design, semantic aspects such as transportation mode and activity type are modeled as individual dimensions. Although effective in fixed-schema scenarios, this approach presents a fundamental limitation: the schema becomes rigid and domain-specific, thereby limiting its adaptability to applications that require new semantic aspects.
As an illustration, the schema in
Figure 2 cannot accommodate queries involving other relevant aspects such as weather conditions or physiological indicators (e.g., heart rate) without requiring modifications to the underlying DW schema. Furthermore, the continual introduction of new dimensions for emerging semantic attributes can significantly increase schema complexity, leading to higher maintenance overhead and reduced portability. To address these challenges, this article proposes a novel STrDW architecture, termed the aspect trajectory data warehouse (ATrDW), specifically designed to promote schema extensibility, semantic generality, and cross-domain adaptability.
Our Main Contributions
The proposed ATrDW introduces several key innovations that collectively address the limitations of existing STrDWs. The major contributions of this work are as follows:
A flexible and extensible data warehouse model for semantic trajectories: we present a novel TDW architecture that supports the integration of an unbounded variety of semantic aspects without requiring schema modification. Unlike traditional STrDW approaches, which rigidly bind each semantic aspect to a dedicated dimension, our model decouples semantic attributes from the DW schema structure. This design enables users to enrich trajectory data with new types of contextual information—such as weather, physiological data, social context, or events—without altering the core schema. This substantially enhances the flexibility, maintainability, and reusability of the warehouse across multiple application domains, and significantly reduces the structural coupling that commonly limits conventional TDW architectures.
A unified text-based representation for semantic aspects enabling NLP-driven analytics: in a departure from classical dimension-based modeling, we propose a text-oriented abstraction layer for representing semantic aspects of trajectory data. All aspects—regardless of source, structure, or semantic category—are encoded as free-form text. This design enables the execution of semantic queries over enriched trajectory data. By incorporating natural language processing (NLP) techniques—such as the use of regular expressions, pattern matching, and textual similarity metrics—the model supports semantic-aware querying and analytics that transcend the capabilities of traditional OLAP operations. This approach enables new analytical opportunities in trajectory-based decision support systems.
An integrated and extensible framework for heterogeneous trajectory data management: we implemented a complete framework that operationalizes the ATrDW model through a robust ETL pipeline, capable of ingesting and processing trajectory data from diverse sources. The framework supports the extraction of raw spatiotemporal data and semantic annotations, the semantic enrichment of trajectory points, and the seamless integration of this data into a single, unified ATrDW schema. It is designed to handle heterogeneous datasets with varying formats and semantic structures. This enables researchers and practitioners to deploy the ATrDW in real-world scenarios without requiring extensive customization or schema redesign. This framework was validated with two different data sets.
Collectively, these contributions represent a significant advancement in the field of semantic trajectory data management, offering a more adaptive, semantically rich, and analytically powerful solution for a wide range of domains, including urban analytics, mobility intelligence, health monitoring, and environmental tracking.
In software engineering, a framework is a reusable, semi-complete structure that provides generic functionality which can be selectively specialized through user written code to build specific applications [
14]. To demonstrate the extensibility and applicability of the proposed framework, we conducted an experimental evaluation using two real-world datasets: the Foursquare dataset [
9] and the TripBuilder dataset [
15]. These datasets vary in both structure and semantic richness, enabling the validation of the framework’s capability to integrate heterogeneous semantic aspects without requiring modifications to the schema. Furthermore, we executed a set of analytical queries employing OLAP operations, including roll-up and drill-down, to assess the framework’s capability to support multidimensional navigation and semantic-aware analytical tasks.
The remainder of this article is organized as follows.
Section 2 introduces the foundational concepts essential for understanding the problem domain addressed in this study.
Section 3 reviews related work in the fields of trajectory data warehousing and semantic enrichment.
Section 4 provides a comprehensive and detailed description of the proposed ATrDW model.
Section 5 addresses the ETL process responsible for populating the ATrDW with raw and semantic trajectory data.
Section 6 focuses on the experimental evaluation, showcasing the model’s extensibility and analytical capabilities using the aforementioned datasets. Finally,
Section 7 concludes the paper and outlines directions for future research.
2. Basic Concepts
Spaccapietra and Parent define a semantic trajectory as a temporally ordered sequence of spatial positions, each annotated with contextual information [
16]. Expanding on this concept, Chen et al. [
17] and Zheng et al. [
18] introduce the POI-based semantic trajectory, which models movement as a finite sequence of POIs, where each POI is a geo-textual object encapsulating both its geographical location and a textual description. Furthermore, Mello et al. characterize aspects as contextual attributes associated with a trajectory, which may reflect environmental conditions, user-specific data, or other domain-relevant metadata [
8].
Building upon these foundational models, we introduce the notion of a multi-aspect POI-based semantic trajectory, which enriches POI-based trajectories with multiple semantic aspects. This structure is formally defined below.
Definition 1. A multi-aspect POI-based semantic trajectory AT is a chronologically ordered sequence of POIs, represented as AT = , where each point is a tuple defined assuch that MO = {id, type} identifies the moving object, including its unique identifier and type (e.g., person, vehicle, animal);
trajID is the unique trajectory identifier;
location denotes the geographical coordinates (latitude and longitude) of the POI;
name and category specify the POI’s descriptive metadata;
time indicates the timestamp at which the mobile object visited ;
is the set of semantic aspects associated with the POI.
For conciseness, we henceforth refer to a multi-aspect POI-based semantic trajectory as simply a semantic trajectory.
A collection of semantic trajectories {, , …, } serves as the input for the ETL process, which integrates this enriched trajectory data into an STrDW. An STrDW extends the classical data warehouse (DW) architecture by incorporating spatial, non-spatial, and semantic dimensions.
Conceptually, a DW is modeled as a multidimensional data cube, comprised of fact and dimension tables. Each dimension may contain one or more hierarchies, which are composed of levels representing varying granularities of data.
Each level consists of a set of members, each characterized by a set of attributes. Fact records reference one member from each dimension and are associated with measures, which are quantitative variables that can be aggregated (e.g., distance, duration, count).
A dimension is classified as a spatial dimension if it includes at least one spatial hierarchy [
11]. For instance, a spatial hierarchy can be defined as
=
municipality <
region <
state, where the symbol “<” denotes a topological containment or generalization relationship between hierarchical levels.
In contrast, the semantic dimension stores the semantic enrichment data associated with trajectories. Multiple STrDW models have been proposed to represent diverse types of semantic dimensions. These include models that capture event-based semantics along trajectories [
19], representations based on the 5W1H framework (Who, What, When, Where, Why, and How) [
12,
13], and models that encode specific contextual attributes such as weather conditions, transportation modes, and device types used during movement [
3].
These multidimensional structures support powerful analytical operations, enabling rich and flexible querying of spatiotemporal and contextual mobility data for decision support, behavior analysis, and pattern discovery.
3. Related Work
One of the foremost challenges in contemporary trajectory analytics lies in the semantic enrichment of raw trajectory data [
20]. Various methodologies have been proposed to address this issue by incorporating annotations into spatiotemporal data streams. For instance, VISTA facilitates visual analysis of vessel trajectories, allowing domain experts to manually annotate trajectory segments [
21]. In contrast, ANALYTiC employs machine learning techniques to automatically generate semantic labels over trajectory datasets [
22]. Similarly, Zheng et al. [
23] infer transportation modes by analyzing mobility features such as velocity, acceleration, directionality, and stop rates. Yan et al. [
24] extend this approach by utilizing a geographic map correspondence algorithm to deduce transportation means, categorize visited geographical regions such as residential and commercial areas, and identify points of interest types including home, office, and marketplace.
An influential model for semantic representation is the 5W1H framework, widely adopted in journalism and adapted for mobility analysis. This model characterizes trajectories through six dimensions:
Who, representing the identifier of the moving object;
Where, indicating the spatial location;
When, specifying the temporal marker;
What, describing the activity or object involved;
Why, reflecting the purpose of the movement; and
How, denoting the mode of transportation or movement pattern, such as either solitary or group-based behavior [
25].
Research works such as Baquara [
7] and CONSTAnT [
26] have operationalized the 5W1H model to semantically represent mobility data. Baquara provides a framework for trajectory enrichment through ontological annotations, whereas CONSTAnT introduces a conceptual model that leverages classes, relationships, and semantic attributes (e.g., context, mobile object properties, and domain-specific events) to facilitate rich semantic interpretation and advanced mobility analysis.
MASTER [
8] proposes a generic conceptual model that extends beyond 5W1H by representing multiple aspects of trajectories using RDF graphs. In this model, an aspect is any real-world fact relevant to interpreting movement behavior. Despite their expressiveness, these models operate within the paradigm of MODs and are not inherently designed for TDW.
Initial work on TDWs, such as that by Leonardi et al. [
27,
28], focused on spatial and temporal formalization of trajectory data. These models aimed to compute aggregate measures efficiently and leverage visualization for behavioral pattern analysis, without incorporating semantic annotations. Mob-Warehouse [
13] constituted a significant advancement by proposing a conceptual model for semantic trajectory data warehouses (STrDWs) grounded in the 5W1H framework, in which the fact table incorporates two primary measures: the duration and the displacement distance between trajectory points.
Manaa and Akaichi [
29] introduced a global ontology-based framework for the design, integration, and analysis of semantic trajectory data in a DW environment. Their approach supports the creation of a multidimensional ontology, encompassing dimensions, facts, and measures, to consolidate heterogeneous data sources. Similarly, Fileto et al. [
2] extended Mob-Warehouse by incorporating semantic data harvested from Twitter, Foursquare, and LinkedGeoData.
Recent advancements further explore semantic trajectory modeling and querying. Wu et al. [
30] propose a composite similarity metric integrating spatial, temporal, and semantic dimensions using WordNet for keyword-based queries. Sun et al. [
31] introduce ST-LSTM, a deep learning model that predicts future locations by learning embeddings of semantic place attributes and user behavior. Almeida et al. [
32] present SETHE, a text-based trajectory similarity framework leveraging vector space models for POIs, outperforming traditional SPARQL-based querying. Garani et al. [
33] propose S-TrODW, a logical data warehouse model employing nested object-relational tables to represent trajectory segments. Luo et al. [
34] utilize large language models (LLMs) to infer fine-grained semantics from raw GPS data, such as user occupation and movement narratives. Seep [
35] applies extended finite state machines (EFSMs) for modeling semantic trajectory patterns, incorporating k-means clustering to discover semantically coherent trajectory groups. Pugliese et al. [
36,
37,
38] propose tools such as MAT-Builder for trajectory enrichment and MAT-Sum for summarizing contextual information from raw mobility data to enhance trajectory representation. These tools support diverse use cases, including mobility behavior classification and routine pattern recognition. Hamann & Hagen [
39] develop an unsupervised machine learning approach for inferring trip purposes from unlabeled GPS trajectories, enabling scalable mobility analysis without manual annotations.
Despite these developments, all existing STrDW implementations primarily rely on fixed semantic schemas. This rigid structure limits their applicability in scenarios that demand more granular or domain-specific semantic descriptors, particularly in the context of multi-aspect trajectory representations. Notably, these research efforts do not address the evolution of semantic aspect schemas.
To the best of our knowledge, the model proposed in this work is the first STrDW capable of accommodating an extensible set of semantic aspects without necessitating modifications to the underlying schema. By eliminating the need to redesign the schema with each new aspect type, our proposed STrDW substantially improves the maintainability, scalability, and generalizability of semantic trajectory warehousing systems, enabling smooth evolution of schemas, particularly with respect to semantic aspects. This architectural flexibility enables our model to accommodate heterogeneous semantic attributes across diverse application domains, thereby significantly advancing the state of the art in StrDW. Our semantic extensibility is achieved through a unified, text-based representation of semantic aspects, allowing the flexible integration of diverse contextual information. Rather than encoding each semantic dimension separately within the schema, all contextual annotations—regardless of type or source—are stored as free-form text. This design simplifies the model structure and enables the use of NLP techniques for advanced trajectory analytics, supporting expressive semantic queries beyond traditional OLAP.
4. The Aspect Trajectory Data Warehouse Model
This section introduces the proposed model, designated as ATrDW, which enables the representation of diverse semantic aspects without requiring the creation of additional dimension tables for each new aspect type.
In the ATrDW architecture, semantic extensibility is achieved by consolidating all aspect-related information into a single, unified dimension called the AspectDimension. This model includes at least four core dimensions: (i) a spatial dimension capturing the geolocation of each trajectory point, (ii) a temporal dimension representing timestamps, (iii) a moving object dimension identifying the mobile entity, and (iv) the AspectDimension, which encapsulates contextual or semantic data associated with each trajectory point.
Formally, the AspectDimension is defined as follows:
Definition 2. Let be a set of aspect tuples, where each , with representing the set of aspect types, and the corresponding aspect values such that and , .
The
AspectDimension is designed to model contextual information associated with a mobile object’s behavior. For example, consider a semantic trajectory representing a tourist visiting multiple POIs within New York City. At the time of visiting Central Park, the associated context comprises weather conditions marked as “clear”, a temperature of 69.1 °F, a heart rate of 70 bpm, and a transportation mode identified as “subway”. These values are modeled as a single entry in the
AspectDimension:
As the tourist continues her journey, subsequent aspect entries are generated. For example, an AspectDimension instance may include:
= 〈 weather, temperature, heartbeat, transport 〉
= 〈 clear, 69.1, 70, subway 〉
= 〈 rain, 67.4, 60, taxi 〉
= 〈 cloud, 68.5, 65, walk 〉
This concise and adaptable representation facilitates the seamless integration of heterogeneous semantic data without necessitating modifications to the underlying schema.
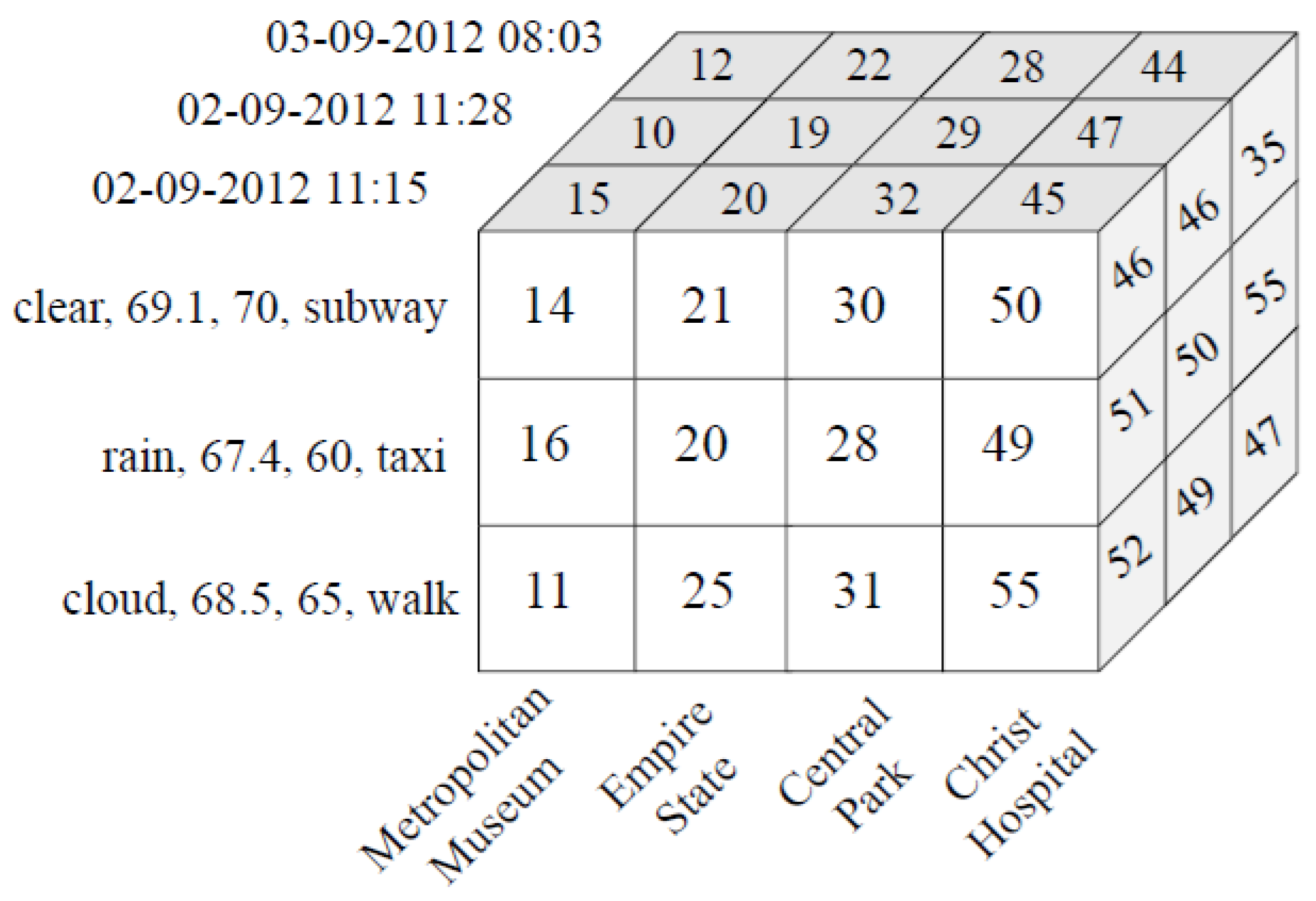
Figure 3 illustrates the integration of the
AspectDimension within a multidimensional data cube. The cube includes three dimensions: POI, time, and aspect, and a single measure: the number of visitors. Notably, only the values
of the
AspectDimension tuples are used in the cube’s analytical operations.
This structure enables expressive and semantically rich queries. For instance, one may query: “How many visits were recorded at the Empire State Building during rainy days in November?” or “How many individuals visited Central Park when the temperature exceeded 68 °F and the weather conditions were clear?” Such queries are supported by applying pattern matching and textual filtering techniques over the
AspectDimension values. These techniques are further detailed in
Section 4.1.
4.1. Pattern Matching
Given the heterogeneous nature of values encapsulated within the
AspectDimension, it becomes essential to isolate and extract each individual element
. To achieve this, we leverage regular expressions (regex)—a foundational technique in NLP for identifying patterns within textual data [
40]. For instance, to extract the first aspect type
∈
and its corresponding
∈
, the following application of the substring function with regular expressions can be employed:
|
|
The regular expression [+−]?\w + [.]?\w* defines a pattern capable of matching both alphanumeric tokens and numeric values, including those with optional signs and decimal points. This expression can be used to identify textual elements ranging from categorical labels (e.g., “weather”) to numerical values such as 70, +5.3, or −1.0. For conciseness, we denote this pattern as .
To extract the first value from a comma-separated string sequence, one may simply retrieve the substring that precedes the first delimiter (,). However, accessing an element at an arbitrary position i-th within the sequence necessitates a more refined approach, as it involves counting and matching the i-th delimited entry.
Extracting any value at the
i-th position requires counting the number of elements in the sequence until the desired position is reached. To achieve this in a textual representation of a sequence of aspects, we use a regular expression construct known as lookbehind. The lookbehind expression is written in the form
(?<=Y) X, which specifies that the query should match an element
X that is preceded by a pattern
Y. For example, to extract the heartbeat rate value, which is located at position
of
V, we can verify that it is preceded by two elements and their separators, using a regular expression such as
Any value
∈
or
can be extracted using Algorithm 1. This algorithm describes the behavior of the regexLookbehind() function. It takes as input the index of the element to be extracted and the corresponding sequence (
or
V). The function (lines 4 to 8) dynamically constructs a lookbehind regular expression, where the number of repeated
patterns depends on the index parameter i. Finally, in line 9, the substring function applies the constructed lookbehind expression to extract the element at the specified position i from the sequence.
| Algorithm 1 Create lookbehind expression. |
- 1:
function regexLookbehind(i, ) - 2:
- 3:
- 4:
- 5:
for to do - 6:
regex + - 7:
end for - 8:
(regex)) + - 9:
return substring(S from - 10:
end function
|
Table 1 illustrates how to use the function from Algorithm 1 to extract all values from
. These extracted values are presented in a tabular format, as shown in
Table 2. First, the query retrieves the names of each aspect in
, which form the header of
Table 2. The first, second, and third rows of
Table 2 correspond to the results of applying the regexLookbehind function to
,
, and
, respectively.
Operations for extracting values from textual representations are especially valuable when the objective is to display specific aspect values or conduct comparative analysis. For example, consider the query: “What are the most frequently used means of transportation when the temperature exceeds 60 °F?” In this case, it is necessary to first extract the temperature aspect value to evaluate it against the 60 °F threshold and subsequently extract the corresponding value of the means of transportation aspect. However, there are scenarios in which explicit value extraction is not required, as certain queries can be resolved using pattern-matching operations alone. For example, in the query “How many individuals arrived at college by subway on a clear day?” two aspects must be evaluated: the transportation mode being “subway” and the weather condition being “clear.” These aspects can be verified using the SQL LIKE operator.
Table 3 illustrates how to construct expressions with the SQL LIKE operator to match the weather and transportation aspects within the tuple
= 〈clear, 69.1, 70, subway〉. The first row demonstrates the expression used to verify whether the weather is “clear,” while the second row checks if the transportation mode is “subway.” The second column in the table presents the outcome of evaluating each expression.
Nonetheless, the SQL LIKE operator lacks support for regular expressions and provides only a limited set of wildcard characters, thereby limiting its effectiveness in identifying complex patterns within textual data. Although the SQL LIKE can be conveniently employed to validate values at the boundaries of a sequence—specifically
and
—it is inadequate for accessing intermediate values
where 1 < i < n. For example, in
Table 3, the aspects “weather” and “means of transportation” correspond to the first and last elements of
, respectively. Attempting to evaluate intermediate values using
LIKE may lead to incorrect results.
Consider the query: “What are the most frequently used means of transportation on days when the ambient temperature is 60 °F?”. Evaluating this using the expression LIKE %60%, where = 〈“rain, 67.4, 60, taxi”〉, would mistakenly match the “heartbeat rate” rather than the intended “temperature” aspect, thereby yielding a false positive.
Performing such checks accurately requires the use of operators or functions that support Boolean regular expression matching. One such example is the ~ operator in PostgreSQL, which enables regex-based evaluation.
Table 4 demonstrates how to access the
and
of the
sequence using regular expressions. The first column describes the semantics of the operation, the second provides the corresponding SQL expression, and the third shows the evaluation result. The first row in
Table 4 verifies whether
= 60, while the second row checks whether
= 60. The regular expression “ˆ
,” instructs the query engine to skip over
, and “ˆ
,
,” directs it to bypass both
and
, enabling accurate extraction of the desired values.
4.2. The ATrDW Logical Model
After establishing how multiple aspects can be represented within a single dimension and detailing the extraction of
and
V values, this subsection outlines the integration of the
AspectDimension within the ATrDW model.
Figure 4 illustrates the multidimensional structure of the ATrDW, which adheres to the star schema architecture [
41]. The model comprises four dimensions and a central fact table. The notation * in the diagram means that each tuple in the dimension tables can be related to many tuples in the fact table.
The first dimension represents the moving object and is modeled by the MovingObject entity. The temporal dimension is modeled by the time entity, which records the timestamp at which the moving object arrived at a specific POI, , within the semantic trajectory. The spatial dimension is captured by the POI entity. The aspect entity models the AspectDimension.
The AspectDimension functions as an additional criterion for aggregation for the measures recorded in the fact table. Unlike conventional dimensions, the AspectDimension provides flexibility regarding both the types and number of values it can accommodate. This is achieved by associating each dimension member with a sequence of aspect types, denoted by , which defines the semantic structure of the corresponding aspect values. This design allows heterogeneous types of semantic aspects to be represented compactly within a single attribute.
The fact table stores the measures associated with each event, where a moving object is observed at a specific POI and time, along with its corresponding semantic context captured in the AspectDimension.
The measures stored in the fact table are as follows:
num_trajectory: identifies the trajectory to which the POI belongs;
distance: represents the distance between the current POI and its immediate predecessor. This value is set to zero for the first POI in the trajectory;
total_distance: denotes the cumulative distance from the starting POI of the trajectory to the current POI. This value is zero for the initial POI;
duration: represents the total elapsed time from the beginning of the trajectory to the current POI. This value is zero for the initial POI;
total_duration: means the total displacement duration since the beginning of the trajectory. This value is 0 (zero) for the first POI of the trajectory;
position: specifies the ordinal position of the POI within the trajectory sequence.
5. An Analytical Semantic Trajectory Framework Architecture
This section presents the framework responsible for transforming semantically enriched trajectories into the proposed ATrDW model. To assess the effectiveness of our framework, we utilized two distinct datasets. The first is derived from the geosocial network Foursquare [
9], comprising user trajectory data from the states of New York and New Jersey in the United States. The second dataset originates from the TripBuilder project [
15] and consists of user trajectories in Italy, constructed by integrating geotagged Flickr data with semantic information from Wikipedia.
The ATrDW Framework Architecture
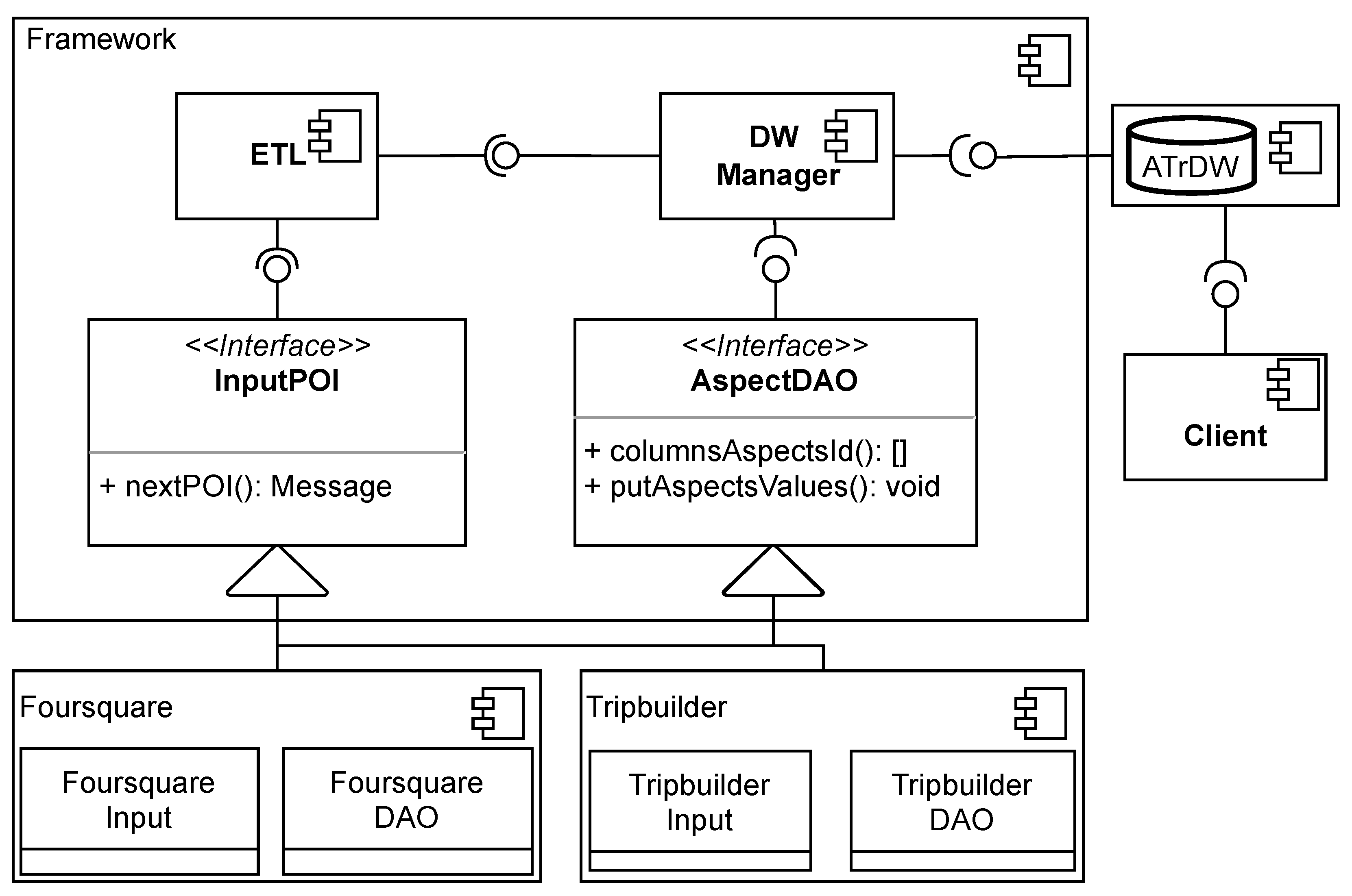
The proposed framework is capable of ingesting semantic trajectory data from heterogeneous datasets and generating a data warehouse according to the logical schema illustrated in
Figure 4. Each dataset may include a distinct set of semantic aspects, and the framework is designed to accommodate and manage this variability effectively. To address diverse application scenarios, the framework provides two extension points: the first is the
interface, and the second is the
interface. The overall architecture of the framework is depicted in
Figure 5.
The interface is responsible for ingesting semantic trajectory data. Each application must implement this interface to enable the transformation of native data structures into a format that is both compatible with the framework and compliant with the ATrDW schema specification. The function is invoked by the framework to iterate over each point of interest (POI) in the data source. It returns an object of type Message, an abstract Java class that encapsulates the necessary information for constructing instances of the ATrDW. The encapsulated information includes categories, POI names, location details (city, state, and country), and timestamps. The Message class defines two key abstract methods essential to the ETL process: , which returns the available aspects, and , which retrieves the value of a specified aspect.
The implementation of these methods depends on the specific context in which the framework is applied. For instance, the TripBuilder and Foursquare datasets rely on different sets of aspects. In the Foursquare dataset, aspects include weather, rating, price, and day, while TripBuilder focuses solely on the aspect related to the means of transport. When extending the framework, developers must implement the and methods in accordance with the requirements of the target scenario.
The component diagram in
Figure 5 depicts the application of the framework in two distinct scenarios: processing trajectories from the Foursquare and TripBuilder datasets. The ETL component interacts with implementations of the
interface to extract and transform the information associated with each point of interest (POI) from the input datasets. It then populates the corresponding dimensions of the ATrDW and computes the measures to be stored in the fact table. After completing these operations, the
component is responsible for persisting the processed data into the target database.
The second extension point of the proposed framework is the interface, which is invoked by the data warehouse (DW) manager during the persistence of aspect data in the database. This interface defines the set of functions that must be implemented for each specific scenario, enabling the ETL component to construct the corresponding in the database according to scenario-specific requirements.
For each scenario—whether Foursquare, TripBuilder, or other datasets—the developer must implement two functions. The function defines the sequence of aspect types (the sequence), while the function is called by the DW manager to persist the aspect values (the V sequence) within the ATrDW.
The implementation of is straightforward: it involves converting the aspects into textual format by retrieving each aspect and its corresponding value from the Message object. Once the aspect types and their values are obtained as text, the is responsible for storing this data in the ATrDW.
Algorithm 2 provides a detailed description of the ETL process workflow. To facilitate the computation of fact measures, certain trajectory-related data are temporarily stored in a status set defined as status = {, , d, D, , , }, where the elements represent:
firstPOI: the initial point of interest (POI) in the trajectory;
lastPOI: the most recent POI processed in the trajectory;
d: the spatial distance between the and the preceding POI;
D: the cumulative distance traveled by the mobile object up to ;
du: the elapsed time duration between the and its preceding POI;
Du: the total elapsed time from to ;
pos: the ordinal position of within the trajectory sequence.
The status values are updated incrementally as the ETL process ingests new trajectory points. All trajectory-related statuses are maintained in a dictionary structure, denoted as , where the primary key corresponds to the trajectory identifier (). Algorithm 2 processes one Point of Interest (POI) at a time and is invoked whenever the data input component receives a new POI.
The algorithm takes as input an instance of , the dictionary representing the current status of each trajectory, and the responsible for persisting data into the warehouse. The instance provides semantically enriched trajectory data, already sorted and organized according to Definition 1.
In line 3, the algorithm iterates over each POI P while there is input data available. From lines 4 to 7, the algorithm extracts the necessary information to construct each dimension within the ATrDW. Each dimension provides a method responsible for generating its hierarchy, levels, and members based on the current POI P. These methods return the primary keys for their respective dimensions, which are subsequently used as foreign keys in the fact table.
The status values are updated as the ETL process processes new trajectory points. All the trajectory statuses are stored in a dictionary, called
, where the primary key is the trajectory identifier (
). Algorithm 2 processes one POI of the trajectory at a time. It is invoked each time the data input component receives a new POI. Algorithm 2 takes as input an instance of
, the dictionary
representing the status, and the
. In
, trajectory data has already been sorted and organized according to Definition 1. Line 3 of the algorithm iterates through each POI
P as long as data is in the input. From lines 4 to 7, the algorithm extracts the necessary data to create each dimension in the ATrDW. Each dimension possesses a function responsible for constructing the hierarchies, levels, and members from the POI
P. These functions return the primary key of each dimension, which serve as foreign keys in the fact table.
| Algorithm 2 ETL algorithm |
- 1:
Input: InputPOI , Dictionary , DWManager - 2:
while
do - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
- 9:
if == then - 10:
- 11:
- 12:
- 13:
else - 14:
- 15:
- 16:
- 17:
- 18:
- 19:
- 20:
- 21:
end if - 22:
- 23:
- 24:
- 25:
- 26:
- 27:
end while
|
In line 8, the algorithm retrieves the current status of the trajectory from the dictionary. From lines 10 to 11, if no prior status exists for the given trajectory, a new status object is initialized with all measure values set to zero. In line 12, this new status is stored in the dictionary using as the key.
From lines 14 to 20, the status object is updated with new values derived from the latest trajectory point. In line 25, a Fact object is created, containing both the dimension keys and the computed measures. In line 26, the component persists the fact data—comprising dimension references and associated measures—into the ATrDW schema.
Once the ATrDW construction process is complete, external clients with appropriate credentials may perform analytical queries over the warehouse using standard OLAP operations such as roll-up, drill-down, slice, and dice [
41].
6. Experiments
This section presents a set of analytical queries used to validate the proposed ATrDW model. The evaluation was performed using two datasets: Foursquare and TripBuilder.
The Foursquare dataset comprises 3079 trajectories, 15,402 POIs, and 193 users. In this context, the sequence is defined as . The weather domain includes the values: clear, clouds, fog, rain, and snow. The rating represents a score from 0 to 10, assigned by the user to each visited POI, with higher scores indicating more favorable evaluations. The price is a score ranging from 1 to 4, where higher values reflect greater perceived cost to visit the POI, according to the user’s judgment.
In contrast, the TripBuilder dataset contains 55,474 trajectories and 2466 POIs. It includes a single aspect—means of transport—with the corresponding sequence defined as .
All experiments were executed on a computing environment equipped with an Intel Core i7-7700 3.60GHz processor, 32 GB of RAM, and a 500 GB hard disk drive, running the GNU/Linux Ubuntu 18.04 operating system.
The ETL process required approximately 7.9 min to extract, transform, and load the entire set of trajectories into the ATrDW. To evaluate the analytical capabilities of the proposed ATrDW framework, a total of 12 aggregation queries were formulated. These queries primarily focus on typical OLAP operations, including roll-up and drill-down, and aim to demonstrate the model’s ability to support analytical reasoning over semantic trajectory data.
The set of queries is presented in
Table 5. They were inspired by analytical tasks proposed in prior research on STrDW [
2,
12,
13]. Queries Q1, Q2, and Q11 are answered using aspects derived from the TripBuilder dataset, whereas the remaining queries are addressed using data from the Foursquare dataset. The queries are organized according to the type of analytical operation and semantic criterion involved.
Queries Q1 and Q2 illustrate drill-down operations from POI categories to specific POI names.
Queries Q3 and Q4 demonstrate roll-up operations, aggregating data from POI names to their corresponding categories.
Queries Q5 and Q6 perform temporal drill-down operations, disaggregating data from the year level to the semester level.
Queries Q7 and Q8 examine semantic transitions, specifically user movements between different POI categories.
Query Q9 analyzes mobility patterns involving trajectories that traverse three non-consecutive POIs.
Query Q10 investigates user movement between two POIs, with both locations filtered by name.
Query Q11 performs a similar analysis but filters the origin POI by name and the destination POI by category.
Query Q12 focuses on mobility involving a source POI filtered by name and a destination POI constrained by semantic aspects—specifically, rating and price.
These queries collectively validate the expressiveness and flexibility of the ATrDW in supporting complex semantic and spatiotemporal analysis tasks.
While the snowflake schema provides a robust mechanism for modeling complex hierarchical relationships, the star schema is generally more efficient for analytical query processing due to its simplified structure, which minimizes the number of join operations required—thereby improving query performance [
39]. For this reason, we adopted the star schema for the physical implementation of the ATrDW, as illustrated in
Figure 4. All analytical queries were implemented and executed against this schema.
To illustrate how analytical queries can be expressed using SQL—particularly those involving pattern-matching techniques discussed in
Section 4—we present three representative examples.
Table 6 provides the complete SQL formulations for these queries. For instance, in Query Q3, the objective is to compute the number of trajectories occurring within the geographic boundaries of New York City, where the average speed exceeds 25 mph. The weather condition is incorporated as a filtering criterion using the SQL
operator. As detailed in
Section 4, this operator is suitable in the given context because the weather attribute occupies the first position within the AspectDimension tuple, enabling direct textual pattern matching.
Query Q8 analyzes trajectories that intersect two specific categories of POIs: Entertainment and Restaurant. To minimize structural complexity and enhance query clarity, a temporary table named entertainment was utilized. This table preselects all trajectories that include at least one entertainment-related POI. Using the position attribute, it becomes possible to determine whether the entertainment and restaurant POIs occur consecutively within the trajectory sequence. Furthermore, Q8 leverages the function to extract the evaluation score of a POI, which corresponds to the second aspect in the ordered set defined by the .
Query Q10 presents an additional use case involving the analysis of consecutive POIs; however, rather than filtering by category, it targets specific POI names. In this case, aspect values are evaluated using the SQL regular expression match operator ~, which supports full regex semantics for binary true/false evaluation.
All queries were executed ten times to ensure consistent performance metrics.
Table 7 reports the average execution time for each query. As demonstrated, the relatively short duration required for the ETL process is offset by the efficient execution of analytical queries enabled by the ATrDW structure.
Figure 6 presents ranking queries in descending order of execution time. Notably, Q12, Q6, Q9, and Q11 exhibit the highest execution times, primarily due to their increased computational complexity and semantic filtering requirements.
7. Conclusions
Trajectory data can be semantically enriched through a wide variety of contextual information, commonly referred to as semantic aspects. Prior studies have consolidated semantic trajectory data within STrDWs, typically modeling each aspect as a dedicated dimension. However, the inclusion of multiple semantic aspects often results in highly complex warehouse schemas, which can hinder adaptability and scalability across diverse application domains.
This work introduces a novel and extensible multidimensional model—ATrDW—that simplifies the integration and representation of heterogeneous semantic aspects. Our ATrDW model represents all aspect types within a single, flexible dimension termed the AspectDimension. Aspects are encoded in free-form text, enabling their retrieval and analysis through pattern-matching techniques such as regular expressions, embedded within SQL queries. We demonstrated that our proposed design not only enhances schema maintainability but also facilitates semantically rich analytical queries without requiring structural modifications. We faced significant challenges in reproducing related work approaches due to the unavailability of source code and limited access to data sources in related work. These constraints hindered our ability to perform a fair and consistent comparative study.
Our primary focus was on extending the aspect dimension, which we identified as the most variable and application-dependent. This dimension can encompass a wide range of data types, including physiological signals (e.g., heart rate, blood pressure, emotional state), environmental parameters (e.g., weather conditions, temperature), and socioeconomic information (e.g., income, user ratings, price evaluations, transportation modes). Given this high degree of heterogeneity and relevance to diverse application domains, we prioritized addressing the extensibility of this dimension. The core dimensions—namely temporal and spatial—remain statically defined and do not support extensible or dynamic schema evolution. In future work, we plan to enhance our framework by incorporating extensibility in both the spatial and temporal dimensions.
Another important direction for future work involves addressing the linguistic diversity of end users. In real-world applications—particularly those deployed in multilingual regions or global platforms—trajectory data analysis systems must exhibit robustness to variations in language, dialect, and syntactic expression. Ensuring semantic interoperability across linguistic boundaries is critical for supporting inclusive and globally accessible analytical environments. Recent advancements in NLP, including pre-trained multilingual language models and cross-lingual embedding techniques, offer promising solutions to mitigate language-dependent limitations. Integrating such models into the ATrDW framework would enhance its capacity to interpret and process semantically annotated data across diverse linguistic contexts, thereby improving usability, accessibility, and internationalization support.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}