



XT-SECA: An Efficient and Accurate XGBoost–Transformer Model for Urban Functional Zone Classification

Abstract
1. Introduction
- 1.
- Global spatial interaction modeling: Transformers inherently possess a global receptive field, enabling the model to learn long-distance spatial dependencies and semantic relationships across fragmented or spatially disjoint urban areas. This is especially valuable in functional zone classification, where similar functions may exist in non-contiguous regions [15].
- 2.
- High compatibility with heterogeneous data: The self-attention mechanism can simultaneously model relationships across multiple modalities, such as spectral features from remote sensing images and POI-based density distributions, offering a unified representation of both physical structure and human activity patterns [42,43].
- 3.
- Superior performance in complex urban zoning tasks: Recent studies have shown that Transformer-based networks significantly outperform CNNs and other deep architectures in large-scale, fine-grained urban classification tasks. For example, Lu et al. [15] demonstrated that a Transformer-based framework improved boundary recognition and classification accuracy across mixed-use zones. Fan et al. [36] also confirmed the robustness of Transformer backbones in mapping informal settlements under diverse environmental conditions.
2. Study Areas and Data
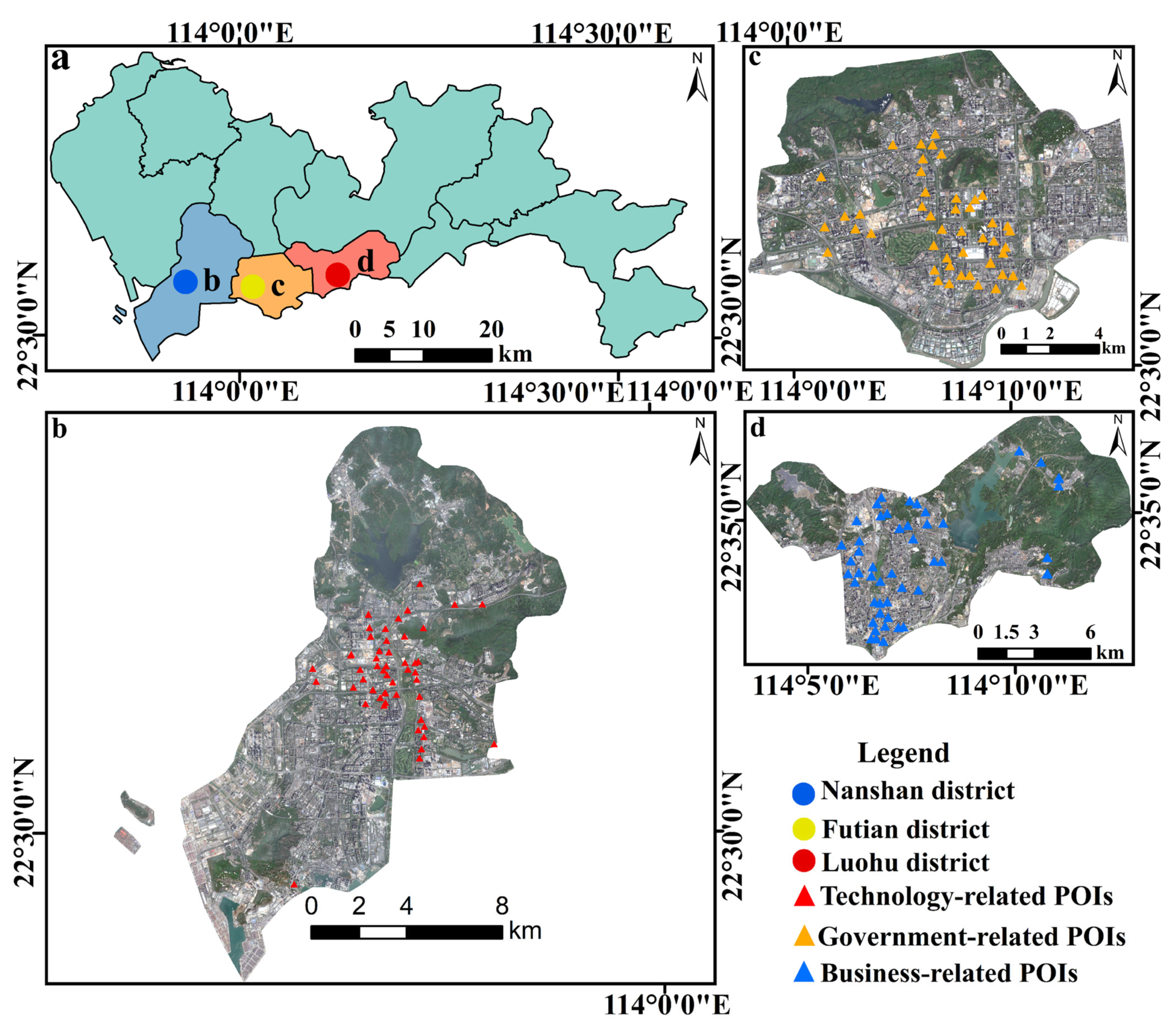
2.1. Study Areas
2.2. Data
2.2.1. Data Processing
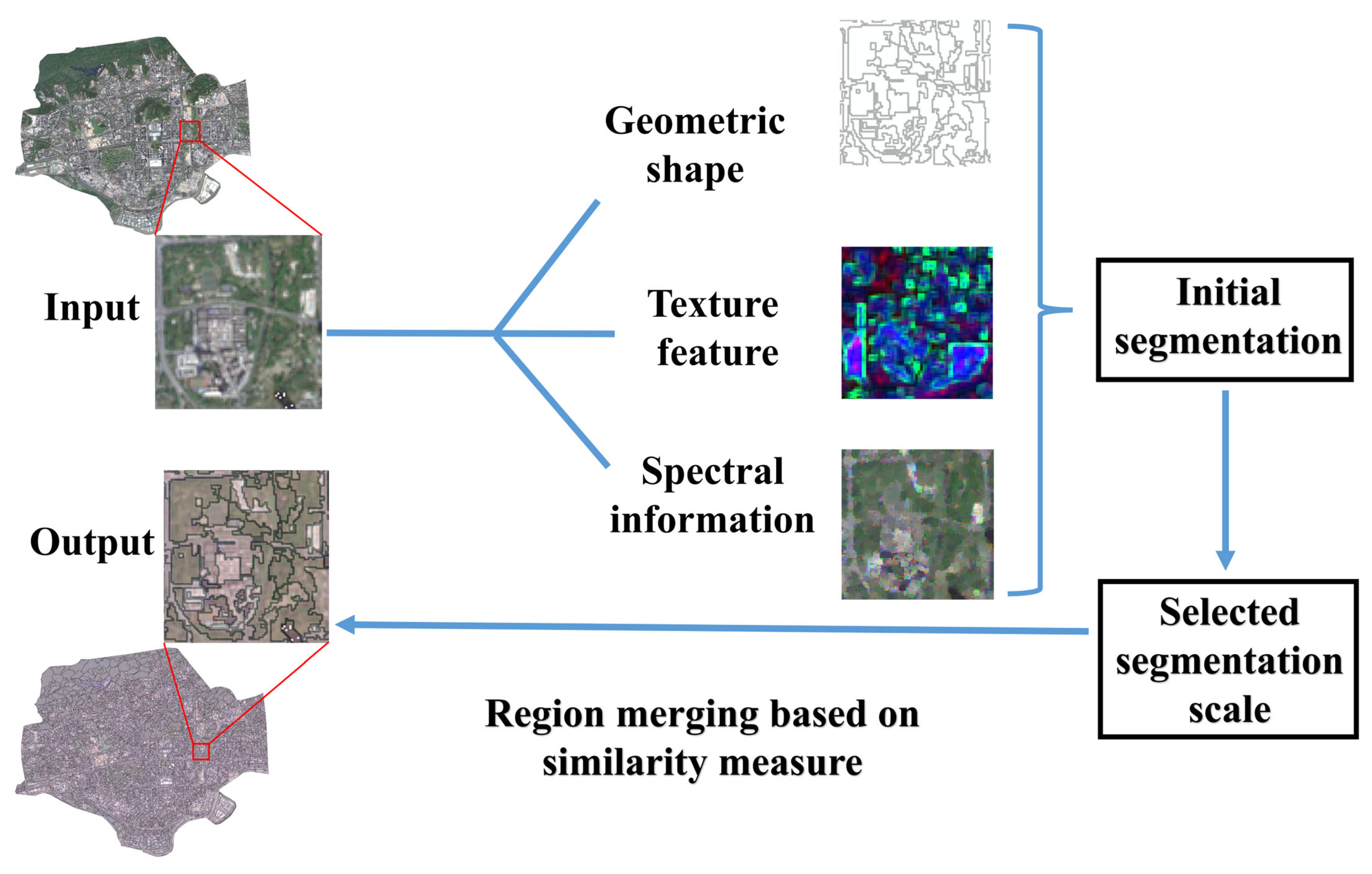
Multiscale Segmentation of Remote Sensing Images
POI Kernel Density Analysis
3. Method
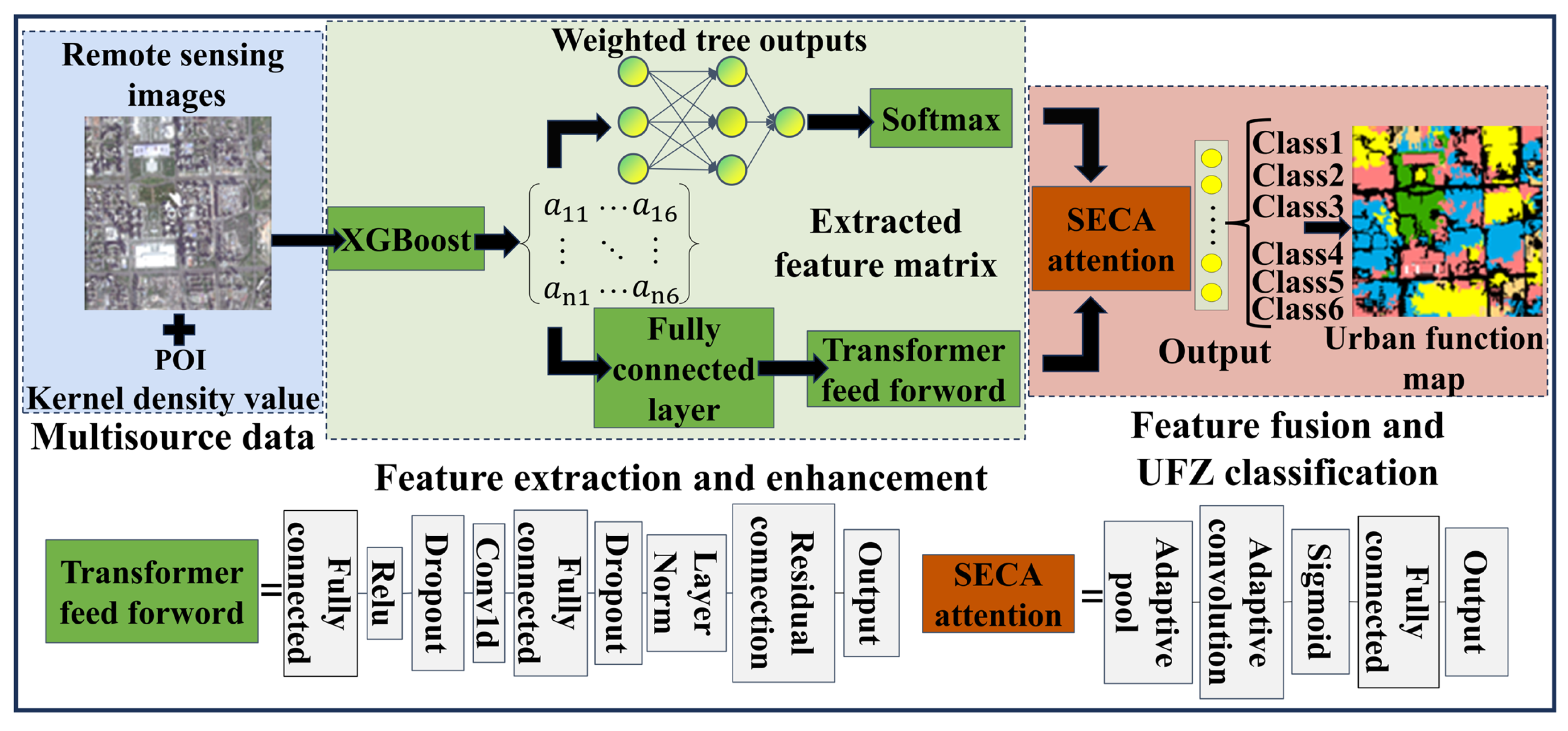
3.1. Feature Reconstruction Modules
3.1.1. Feature-Extraction Branch
3.1.2. Feature-Enhancement Branch
- 1.
- Second-order optimization enhances feature stability and interpretability: Unlike other boosting methods that rely solely on first-order gradients or heuristic splits, XGBoost utilizes both the first- and second-order derivatives of the loss function. This leads to more stable and theoretically grounded decisions during feature splits. In this study, where fused features from spectral data and POI density are highly nonlinear and potentially redundant, this second-order gain-based mechanism effectively filters irrelevant attributes, enhancing both classification accuracy and interpretability.
- 2.
- Integrated regularization ensures model generalization in multimodal settings: XGBoost incorporates explicit L2 regularization to penalize model complexity, which is crucial for the UFZ classification scenario involving multi-source and high-dimensional inputs. This strategy helps control overfitting while maintaining model performance. In comparison, LightGBM tends to generate deeper trees due to its leaf-wise splitting, increasing overfitting risk, and CatBoost focuses more on categorical bias reduction, which is less applicable to the continuous input features in this work.
- 3.
- Gain-driven feature selection boosts efficiency and discriminative power: The core mechanism of XGBoost involves maximizing the expected reduction in loss (“Gain”) at each tree split, thereby prioritizing the most relevant features. This is especially valuable in remote sensing imagery where many features may be weakly correlated with the target classes. In contrast, Random Forest employs random feature sampling without loss optimization, and LightGBM’s histogram approximation may cause precision loss in split decisions.
- 4.
- Structural compatibility with the dual-branch design: XGBoost naturally complements the dual-branch model structure. Beyond acting as a classifier, its outputs provide interpretable and structured feature representations that can be directly fed into the Transformer module. This facilitates a seamless integration between explicit tree-based modeling and implicit contextual learning. Conversely, models like CatBoost and LightGBM encapsulate internal representations more tightly, making it difficult to extract structured intermediate features, while Random Forest lacks the granularity needed for downstream Transformer-based refinement.
3.1.3. Strengthened Efficient Channel Attention Mechanism
- 1.
- MLP-free attention computation: Instead of a two-layer fully connected network for channel recalibration, SECA employs a parameter-efficient 1D convolution (as in Equation (10)) to directly model local cross-channel interactions. This avoids the quadratic parameter growth of MLPs and enables fast inference [49].
- 2.
- Dynamic kernel adaptivity: The convolution kernel adapts to the feature channel dimension via a logarithmic function, enabling SECA to flexibly adjust its attention scope while maintaining low parameter counts [49].
- 3.
- No bottleneck distortion: SECA avoids the reduction–expansion process common in SE blocks, preventing the distortion of intermediate feature representations and reducing memory overhead [49].
- 4.
- Multiscale spatial perception: Dynamic pooling (Equations (8) and (9)) allows the attention mechanism to adapt to different urban spatial types, capturing fine-grained features in small areas and broader contexts in larger functional zones, improving interpretability and robustness.
3.2. Accuracy Evaluation Metrics
4. Results and Discussion
4.1. Experimental Setup
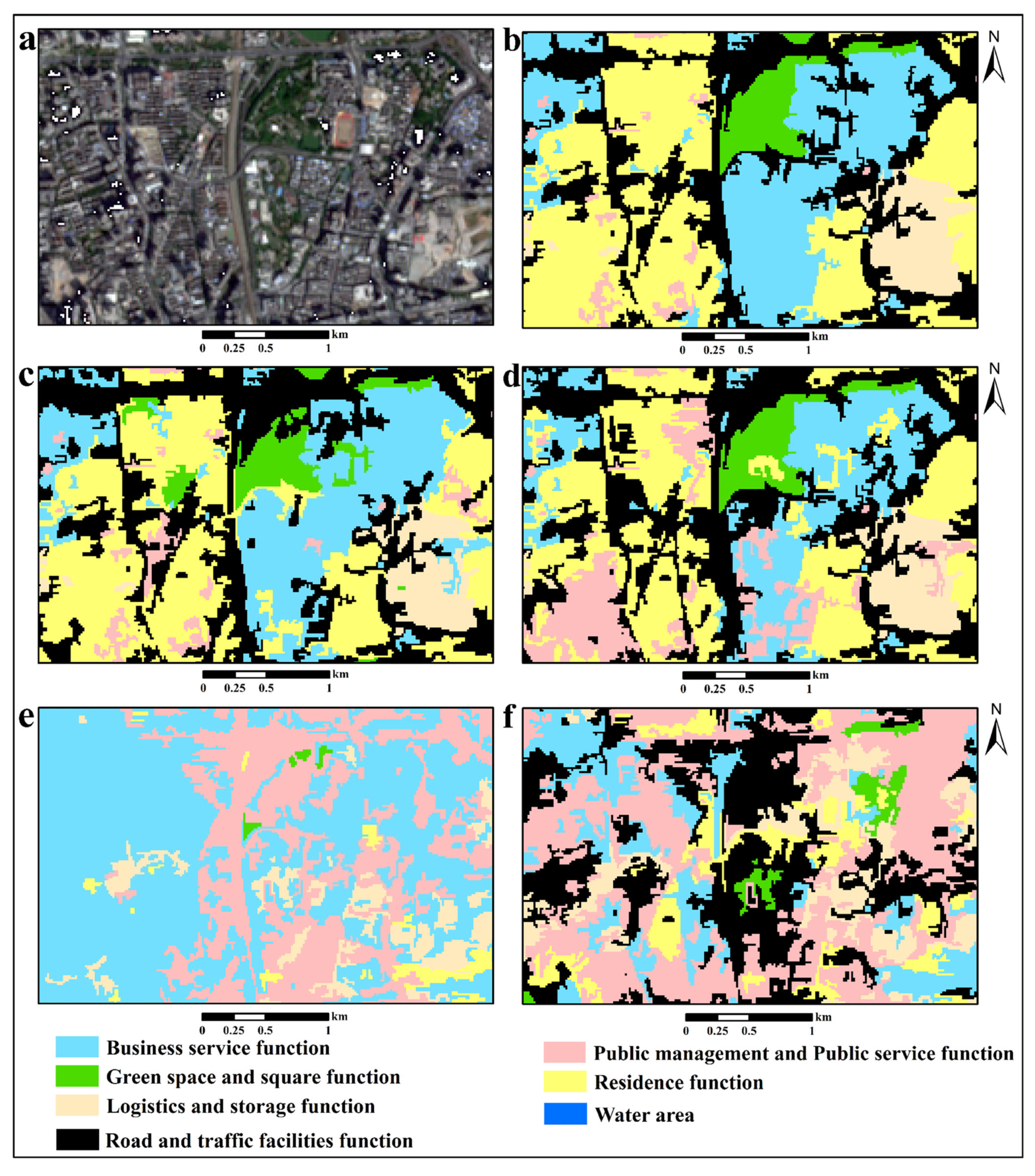
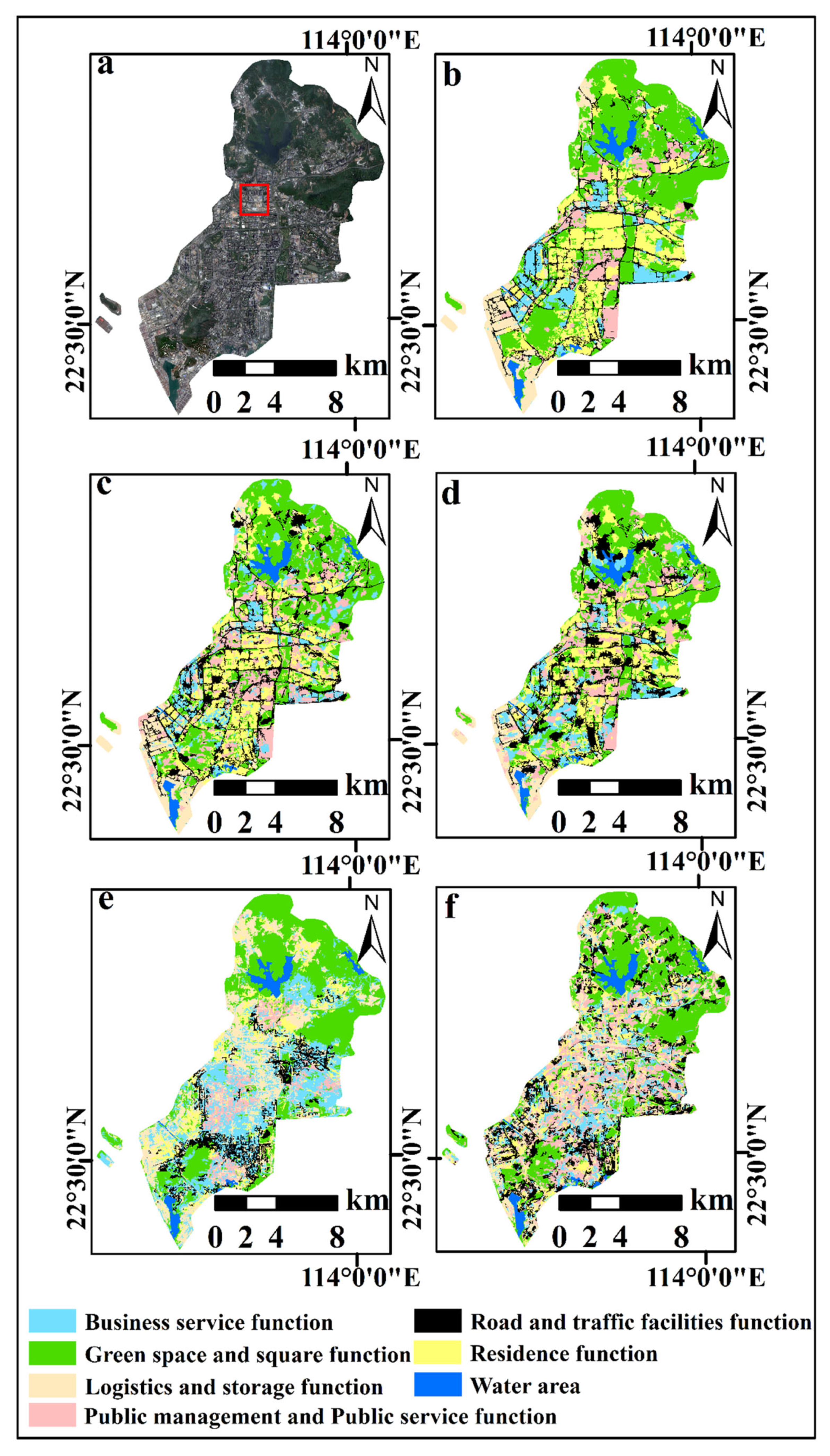
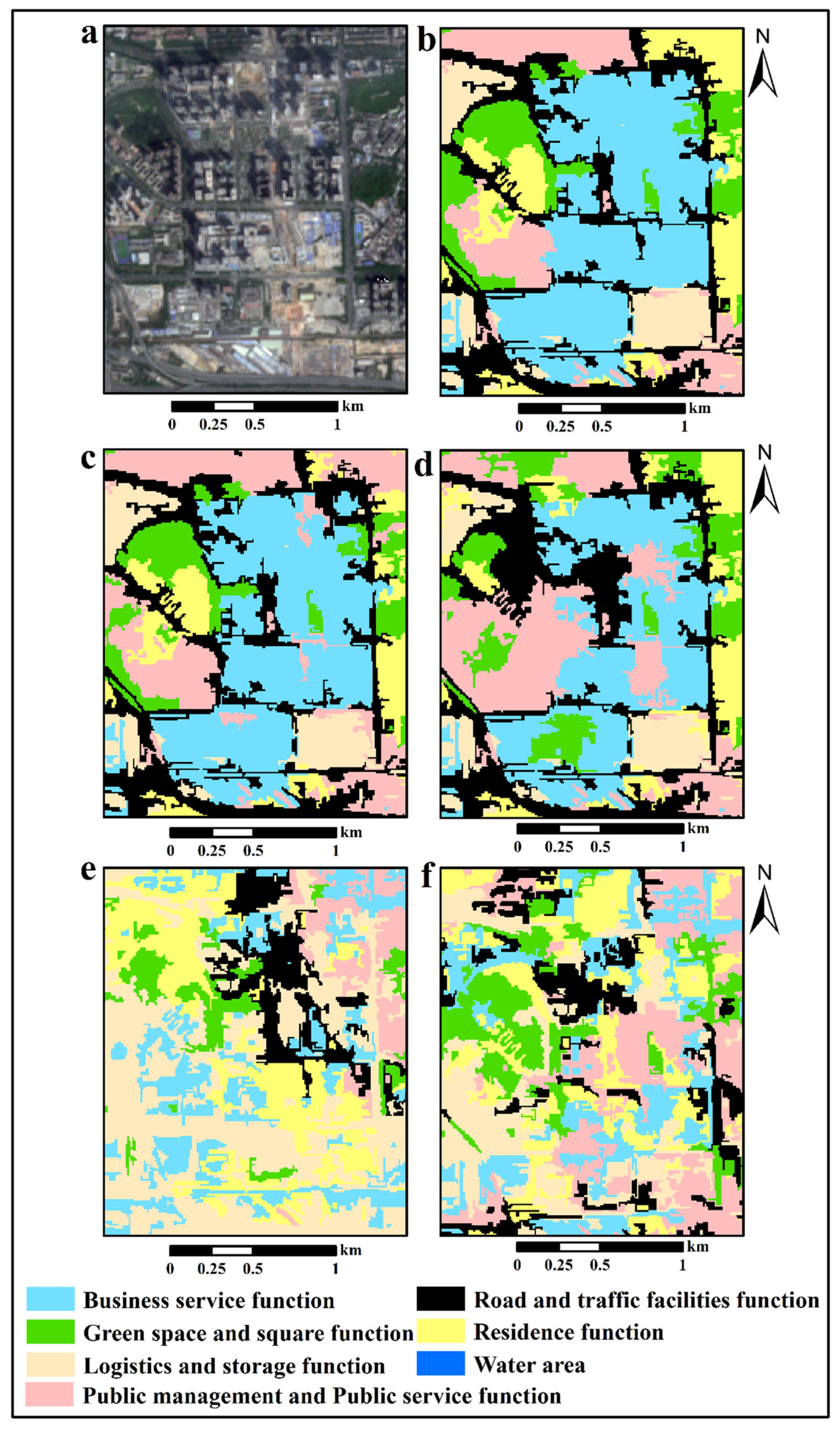
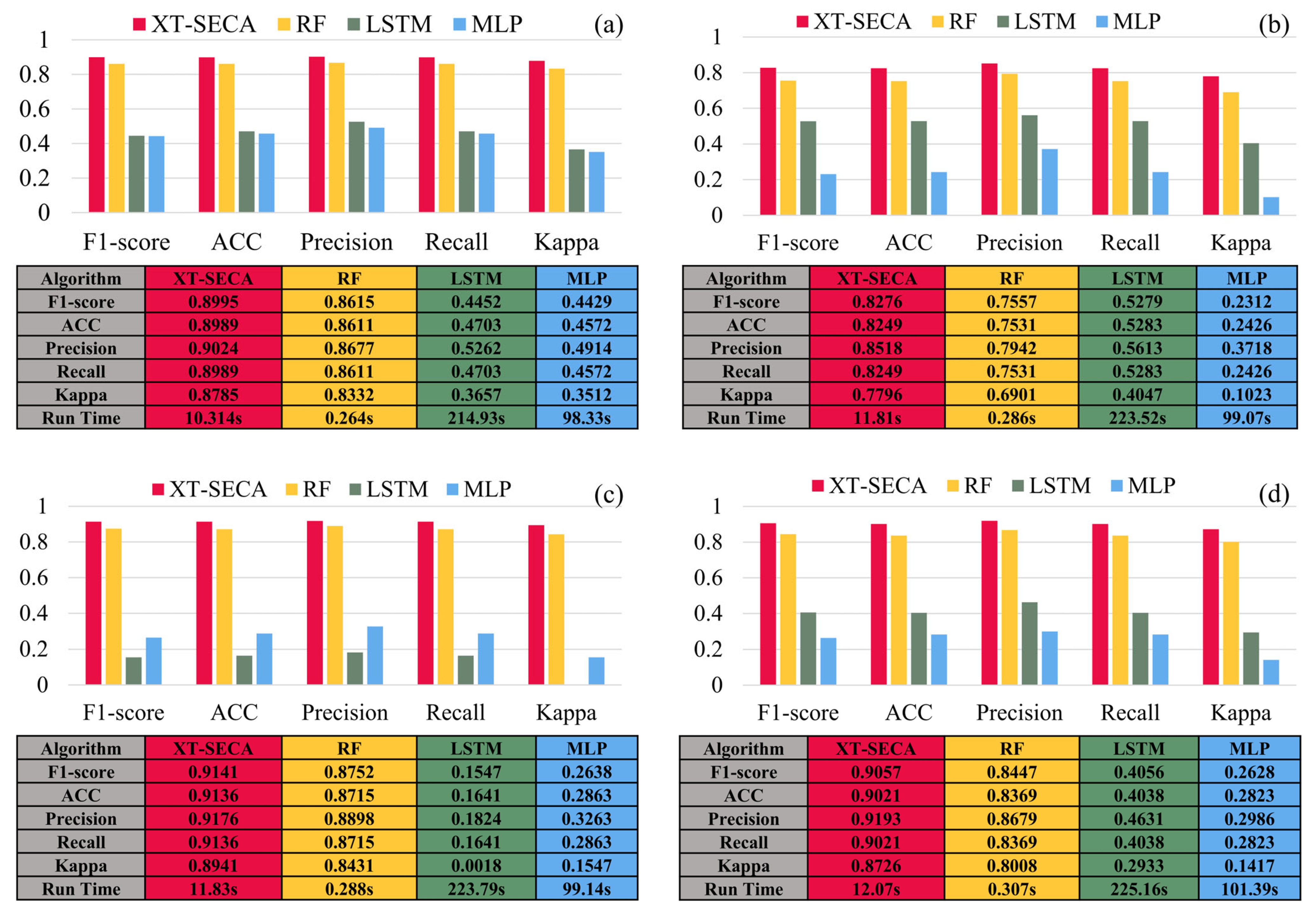
4.2. Urban Functional Zone Classification Results
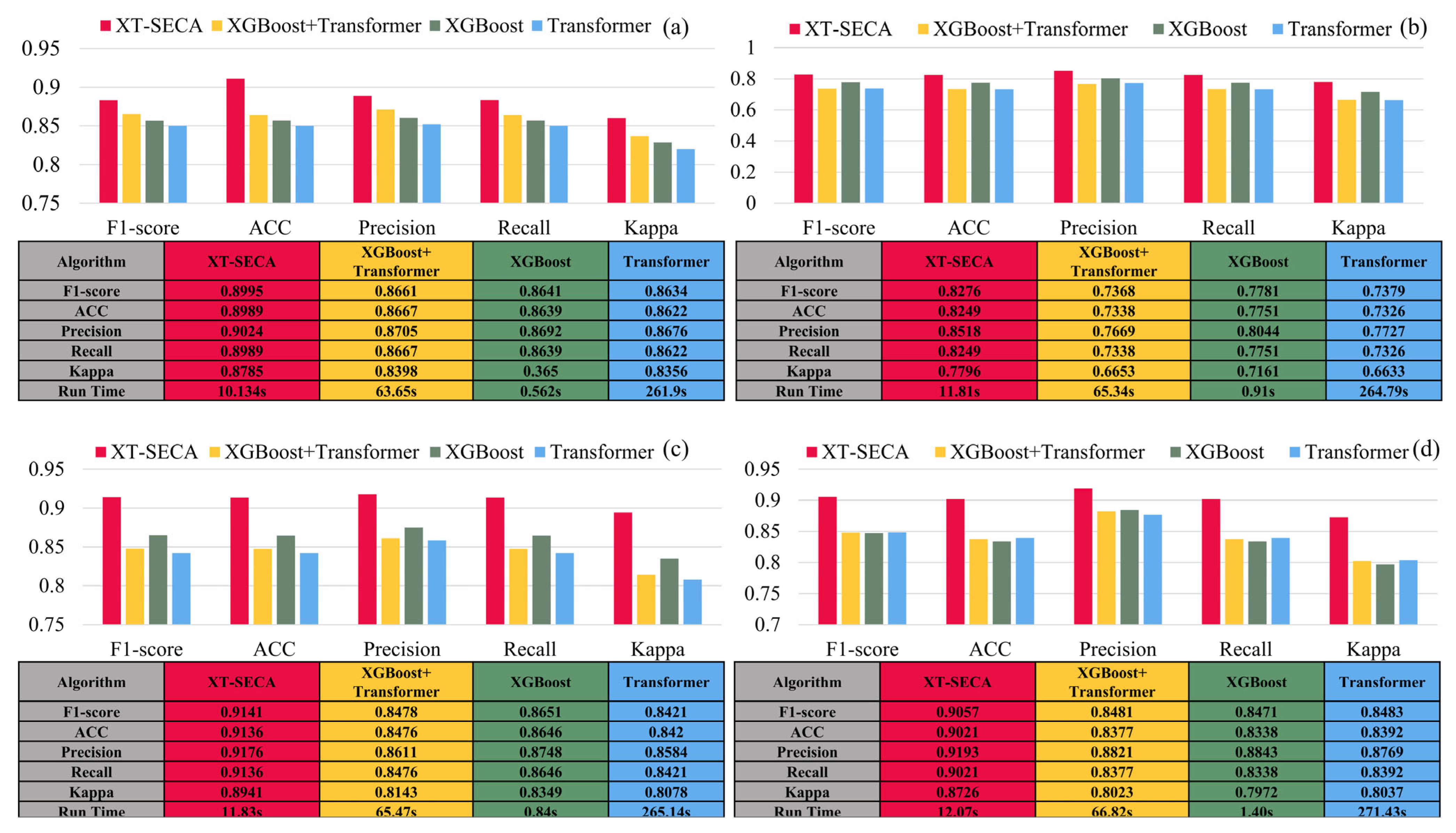
4.2.1. Algorithm Comparison
4.2.2. Ablation Experiment
- 1.
- Incorporation of spatial heterogeneity-aware modules. Urban areas across the globe exhibit substantial diversity in morphological and functional patterns, shaped by socio-economic, cultural, and climatic conditions. To enhance the model’s transferability across continents and varying urban structures (e.g., monocentric vs. polycentric cities), domain-adaptive components, such as adaptive normalization layers or attention-based spatial priors, could be integrated into the network. These modules would allow for dynamic adjustment to region-specific urban characteristics, thereby reducing the dependence on extensive fine-tuning when applied to new geographic regions.
- 2.
- Integration of multi-source data and hierarchical supervision mechanisms. In global applications, the availability and reliability of POI and ancillary datasets often vary significantly. To address this, a semi-supervised or multi-task learning framework that incorporates weak labels (e.g., nighttime light intensity, land-use codes, crowd-sourced annotations) could improve model robustness in data-scarce regions. Furthermore, designing a hierarchical classification pipeline, initially distinguishing coarse land-use categories before refining them into specific functional subtypes, would better align with the heterogeneous granularity of global UFZ definitions while maintaining computational efficiency.
5. Conclusions
- 1.
- XT-SECA improves the performance and efficiency of UFZ classification through the effective combination of XGBoost, Transformer, and SECA. It significantly enhances the robustness of classification performance in the presence of complex and overlapping UFZs (such as residential, commercial, and public service areas), effectively addressing the issue of class confusion.
- 2.
- The XT-SECA algorithm was applied to key areas in Shenzhen: the science and technology innovation center (Nanshan District), commercial and financial center (Luohu District), and administrative center (Futian District). XT-SECA outperformed several widely used UFZ classification algorithms. Taking precision as an evaluation metric, the model achieved a precision of 0.8518 in the Futian District, exceeding RF, LSTM, and MLP by 5.8%, 29.1%, and 48.0%, respectively. In the Luohu District, XT-SECA reached a precision of 0.9176, with respective improvements of 2.8%, 73.5%, and 59.1% over the same algorithms. In the Nanshan District, the model achieved the highest precision of 0.9193, surpassing RF, LSTM, and MLP by 5.1%, 45.6%, and 62.1%, respectively.
- 3.
- The ablation experiment validated the effectiveness of each module. The XGBoost component explicitly captures nonlinear feature interactions using decision trees, while the Transformer feedforward network captures nonlinear spatial features and implicitly models complex relationships. The SECA mechanism integrates features through dynamic pooling and convolution, enhancing the model’s ability to leverage both explicit and implicit nonlinear features. Taking the precision metric in the Futian District as an example, XT-SECA outperformed XGBoost + Transformer, XGBoost, and Transformer by 8.5%, 4.7%, and 7.9%, respectively. In the Luohu District, the improvements were 5.7%, 4.3%, and 5.9%; in the Nanshan District, they were 3.7%, 3.5%, and 4.2%, respectively. In terms of time, XT-SECA reduced processing duration from 65.34 s, 65.47 s, and 66.82 s in Futian, Luohu, and Nanshan, respectively, to 11.81 s, 11.83 s, and 12.07 s.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, L.; Huang, Z.; Song, M.; Li, L.; Zhang, L. Mixed-use of industrial land: Foreign experience and practical implications. Urban Plann. Int. 2023, 3, 20–21. [Google Scholar] [CrossRef]
- Luo, G.; Ye, J.; Wang, J.; Wei, Y. Urban functional zone classification based on POI data and machine learning. Sustainability 2023, 15, 4631. [Google Scholar] [CrossRef]
- Du, S.; Du, S.; Liu, B.; Zhang, X.; Zheng, Z. Large-scale urban functional zone mapping by integrating remote sensing images and open social data. GISci. Remote Sens. 2020, 57, 411–430. [Google Scholar] [CrossRef]
- Long, J.; Zhang, J.; Wang, M. Semantic-aware urban functional area recognition from multi-source data: A deep embedding approach. ISPRS J. Photogramm. Remote Sens. 2023, 198, 156–170. [Google Scholar]
- Zhao, W.; Peng, S.; Chen, J.; Zhang, H.; Lin, S. Exploring urban functional zones based on multi-source semantic knowledge and cross-modal network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 48, 1337–1342. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Y.; Zheng, Z.; Ling, Z.; Meng, X. Urban functional zone classification based on high-resolution remote sensing imagery and nighttime light imagery. Remote Sens. 2025, 17, 1588. [Google Scholar] [CrossRef]
- Zhang, K.; Ming, D.; Du, S.; Xu, L.; Ling, X.; Zeng, B.; Lv, X. Distance weight–graph attention model–based high-resolution remote sensing urban functional zone identification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5608518. [Google Scholar] [CrossRef]
- Yu, M.; Xu, H.; Zhou, F.; Xu, S.; Yin, H. A deep-learning-based multimodal data fusion framework for urban region function recognition. ISPRS Int. J. Geo-Inf. 2023, 12, 468. [Google Scholar] [CrossRef]
- Xu, W.; Wang, J.; Wu, Y. Multi-Dimension Geospatial Feature Learning for Urban Region Function Recognition. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 5832–5835. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, H.; Yang, H. Urban Functional Zone Recognition Integrating Multisource Geographic Data. Remote Sens. 2021, 13, 4732. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, Y.; Gao, J.; Zhao, Z.; Sun, J.; Mu, F. Urban functional zone identification based on multimodal data fusion: A case study of Chongqing’s central urban area. Remote Sens. 2025, 17, 990. [Google Scholar] [CrossRef]
- Liu, T.; Chen, H.; Ren, J.; Zhang, L.; Chen, H.; Hong, R.; Li, C.; Cui, W.; Guo, W.; Wen, C. Urban Functional Zone Classification via Advanced Multi-Modal Data Fusion. Sustainability 2024, 16, 11145. [Google Scholar] [CrossRef]
- GB 50137-2011; China Academy of Urban Planning and Design, Urban Land Use Classification and Planning and Construction Land Use Standards. Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2010.
- Batty, M. The size; scale, and shape of cities. Science 2008, 319, 769–771. [Google Scholar] [CrossRef]
- Lu, W.P.; He, Q.K.; Li, J.L.; Li, S.Y.; Tao, C. Object units and Transformer networks combined with urban functional zone classification method. Natl. Remote Sens. Bull. 2024, 28, 1927–1939. [Google Scholar] [CrossRef]
- Wang, K.-J.; Xu, W.-M.; Li, C.-Y.; Shao, E.-H.; Yang, H. A study on the function and structure of mixed land use in urban built-up areas from the perspective of spatial governance. J. Nat. Resour. 2023, 38, 1496–1516. [Google Scholar] [CrossRef]
- Das, S.; Sarkar, R. Predicting the land use and land cover change using Markov model: A catchment level analysis of the Bhagirathi-Hugli River. Spat. Inf. Res. 2019, 27, 439–452. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Tsou, M.-H.; Li, H.; Jiang, W.; Guo, F. Mapping dynamic urban land use patterns with crowdsourced geo-tagged social media (Sina-Weibo) and commercial points of interest collections in Beijing, China. Sustainability 2016, 8, 1202. [Google Scholar] [CrossRef]
- Memarsadeghi, N.; Mount, D.M.; Netanyahu, N.S.; Le Moigne, J. A fast implementation of the ISODATA clustering algo-rithm. Int. J. Comput. Geom. Appl. 2007, 17, 71–103. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, R.; Chen, B.; Hou, Y.; Qu, D. Dynamic identification of urban functional areas and visual analysis of time-varying patterns based on trajectory data and POIs. J. Comput.-Aided Des. Comput. Graph. 2018, 30, 1728–1740. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Zhou, P.C.; Cheng, G.; Yao, X.W.; Han, J.W. Machine learning paradigms in high-resolution remote sensing image in-terpretation. Natl. Remote Sens. Bull. 2021, 25, 182–197. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘16), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Li, X.; Deng, Y.; Liu, B.; Yang, J.; Li, M.; Jing, W.; Chen, Z. GDP spatial differentiation in the perspective of urban functional zones. Cities 2024, 151, 105126. [Google Scholar] [CrossRef]
- Ågren, A.M.; Lin, Y. A fully automated model for land use classification from historical maps using machine learning. Remote Sens. Appl. Soc. Environ. 2024, 36, 101349. [Google Scholar] [CrossRef]
- Shao, Z.; Ahmad, M.N.; Javed, A. Comparison of random forest and XGBoost classifiers using integrated optical and SAR features for mapping urban impervious surface. Remote Sens. 2024, 16, 665. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Oukawa, G.Y.; Krecl, P.; Targino, A.C. Fine-scale modeling of the urban heat island: A comparison of multiple linear regression and random forest approaches. Sci. Total Environ. 2022, 815, 152836. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, W.; Liu, W.; Tan, Z.; Hu, S.; Ao, Z.; Li, J.; Xing, H. Exploring the seasonal effects of urban morphology on land surface temperature in urban functional zones. Sustain. Cities Soc. 2024, 103, 105268. [Google Scholar] [CrossRef]
- Du, S.; Zhang, Y.; Sun, W.; Liu, B. Quantifying heterogeneous impacts of 2D/3D built environment on carbon emissions across urban functional zones: A case study in Beijing, China. Energy Build. 2024, 319, 114513. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Mo, Y.; Guo, Z.; Zhong, R.; Song, W.; Cao, S. Urban functional zone classification using light-detection-and-ranging point clouds, aerial images, and point-of-interest data. Remote Sens. 2024, 16, 386. [Google Scholar] [CrossRef]
- Sanlang, S.; Siji, S.; Cao, S.; Du, M.; Mo, Y.; Chen, Q.; He, W. Integrating aerial LiDAR and very-high-resolution images for urban functional zone mapping. Remote Sens. 2021, 13, 2573. [Google Scholar] [CrossRef]
- Deng, Y.; He, R. Refined urban functional zone mapping by integrating open-source data. ISPRS Int. J. Geo-Inf. 2022, 11, 421. [Google Scholar] [CrossRef]
- Teh, W.Y.; Tan, I.K.T. TransUNet for cross-domain semantic segmentation of urban scenery. In Proceedings of the 2022 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Penang, Malaysia, 22–25 November 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Fan, R.; Li, J.; Song, W.; Han, W.; Yan, J.; Wang, L. Urban informal settlements classification via a transformer-based spa-tial-temporal fusion network using multimodal remote sensing and time-series human activity data. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102831. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Guo, Z.; Wen, J.; Xu, R. A shape and size free-CNN for urban functional zone mapping with high-resolution satellite images and POI data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622117. [Google Scholar] [CrossRef]
- Ouyang, S.; Du, S.; Zhang, X.; Du, S.; Bai, L. MDFF: A method for fine-grained UFZ mapping with multimodal geographic data and deep network. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 9951–9966. [Google Scholar] [CrossRef]
- Ramana, K.; Srivastava, G.; Kumar, M.R.; Gadekallu, T.R.; Lin, J.C.-W.; Alazab, M.; Iwendi, C. A vision transformer approach for traffic congestion prediction in urban areas. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3922–3934. [Google Scholar] [CrossRef]
- Afrin, S.; Machida, F. Exploiting transformer models in three-version image classification systems. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 2–4 July 2024; pp. 662–669. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Shenzhen Municipal Bureau of Statistics, Shenzhen Statistic Yearbook 2021; Shenzhen Municipal Bureau of Statistics: Shenzhen, China, 2021.
- Chen, J.; Chang, K.; Karacsonyi, D.; Zhang, X. Comparing urban land expansion and its driving factors in Shenzhen and Dongguan, China. Habitat Int. 2014, 43, 61–71. [Google Scholar] [CrossRef]
- Baatz, M.; Schape, A. Multiresolution segmentation—An optimization approach for high quality multi-scale image seg-mentation. In Angewandte Geographische Information Sverarbeitung; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Wichmann-Verlag: Heidelberg, Germany, 2000; pp. 12–23. [Google Scholar]
- Huang, Z.; Qi, H.; Kang, C.; Su, Y.; Liu, Y. An ensemble learning approach for urban land use mapping based on remote sensing imagery and social sensing data. Remote Sens. 2020, 12, 3254. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. arXiv 2019, arXiv:1910.03151. [Google Scholar] [CrossRef]
- Wang, L.; Yang, M.; Li, Q. Dynamic pooling for remote sensing image classification using attention mechanisms. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 7851–7863. [Google Scholar]
- Nguyen, H.; Pham, T.; Doan, T.; Tran, P. Land use/land cover change prediction using multi-temporal satellite imagery and multi-layer perceptron Markov model. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 44, 99–105. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Data | Time | Data Source | Spacial Resolution |
|---|---|---|---|---|
| Remote sensing image | Sentinel-2 multispectral image | 23 February 2023 | European Space Agency | 10 m |
| POI data | POI types: dining, shopping, services, transportation, living facilities, entertainment, attractions, accommodation, offices, and government and public services | December 2022 | Gaode Map | - |
| Function Category | POI Type |
|---|---|
| Business and services | Cafes, fast-food restaurants, convenient hotels, shopping centers, travel agencies, publishers, companies, banks, cinemas, training institutions, car dealers, etc. |
| Residence | Real estate, community housing, etc. |
| Public management and services | Government agencies, administrative units, higher education institutions, elementary schools, secondary schools, exhibition halls, convention centers, museums, stadiums, hospitals, etc. |
| Green spaces and squares | Parks, scenic spots, tourist attractions, etc. |
| Logistics and storage | Logistics companies, logistics courier stations, distribution centers, etc. |
| Road and traffic facilities | Parking lots, driving schools, railway stations, subway stations, bus stations, port terminals, etc. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Wang, X.; Cao, L.; Guo, H.; Chen, W.; Zhai, X. XT-SECA: An Efficient and Accurate XGBoost–Transformer Model for Urban Functional Zone Classification. ISPRS Int. J. Geo-Inf. 2025, 14, 290. https://doi.org/10.3390/ijgi14080290
Gao X, Wang X, Cao L, Guo H, Chen W, Zhai X. XT-SECA: An Efficient and Accurate XGBoost–Transformer Model for Urban Functional Zone Classification. ISPRS International Journal of Geo-Information. 2025; 14(8):290. https://doi.org/10.3390/ijgi14080290
Chicago/Turabian StyleGao, Xin, Xianmin Wang, Li Cao, Haixiang Guo, Wenxue Chen, and Xing Zhai. 2025. "XT-SECA: An Efficient and Accurate XGBoost–Transformer Model for Urban Functional Zone Classification" ISPRS International Journal of Geo-Information 14, no. 8: 290. https://doi.org/10.3390/ijgi14080290
APA StyleGao, X., Wang, X., Cao, L., Guo, H., Chen, W., & Zhai, X. (2025). XT-SECA: An Efficient and Accurate XGBoost–Transformer Model for Urban Functional Zone Classification. ISPRS International Journal of Geo-Information, 14(8), 290. https://doi.org/10.3390/ijgi14080290