

Micro-Terrain Recognition Method of Transmission Lines Based on Improved UNet++
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Description
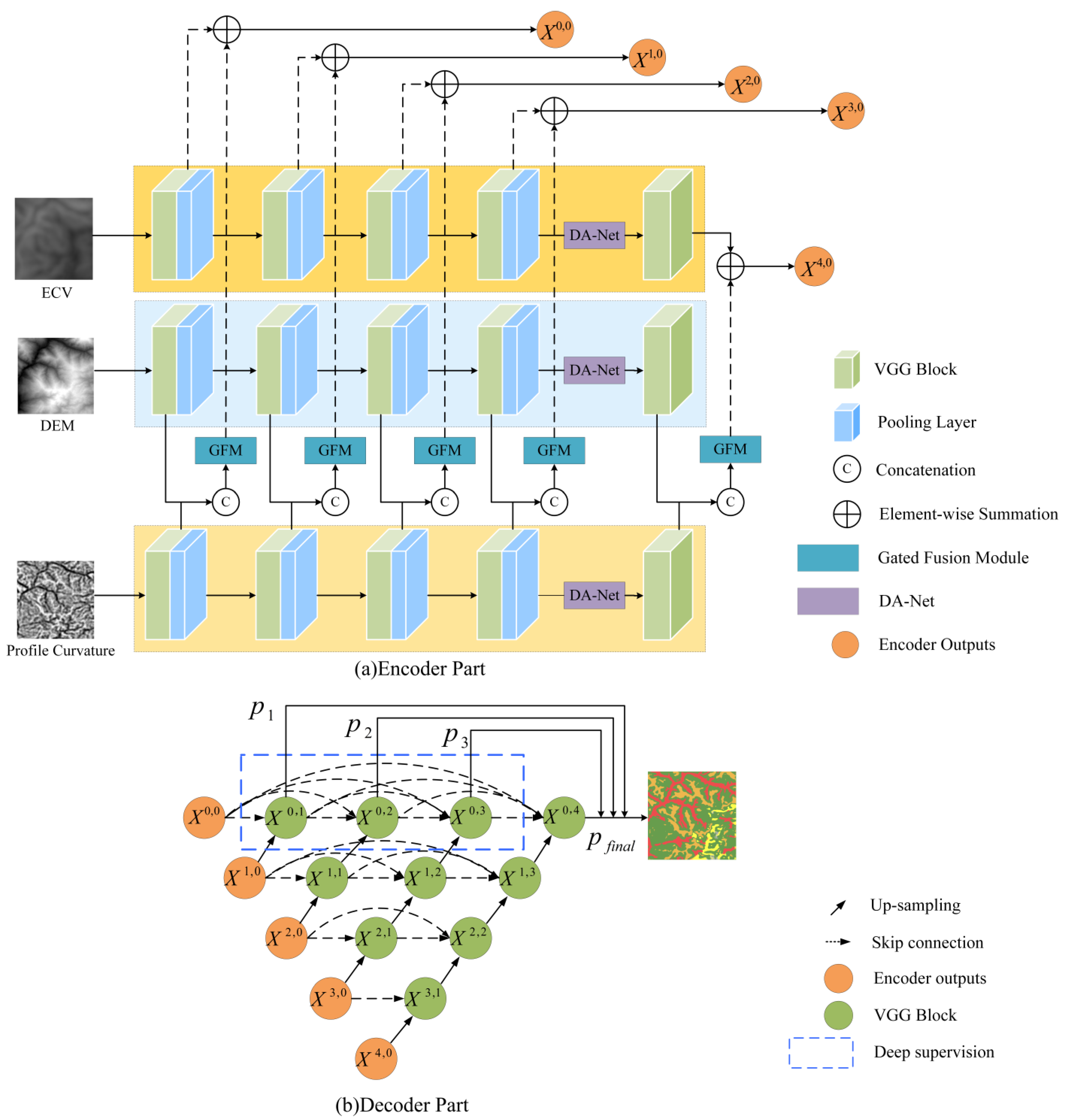
2.2. Improved UNet++ Model
2.3. Gated Fusion Module
2.4. DA-Net
2.5. Deep Supervision Strategy
2.6. Experimental Environment and Parameter Settings
2.7. Model Evaluation Metrics
3. Results
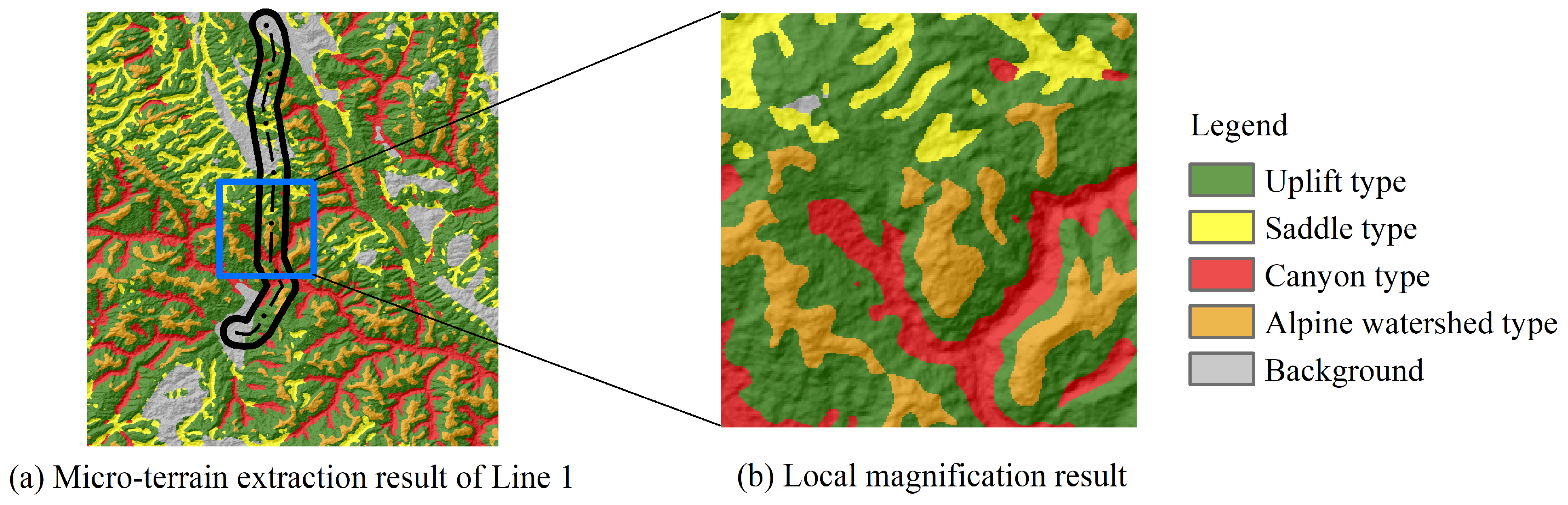
3.1. Experimental Results of the Improved Model
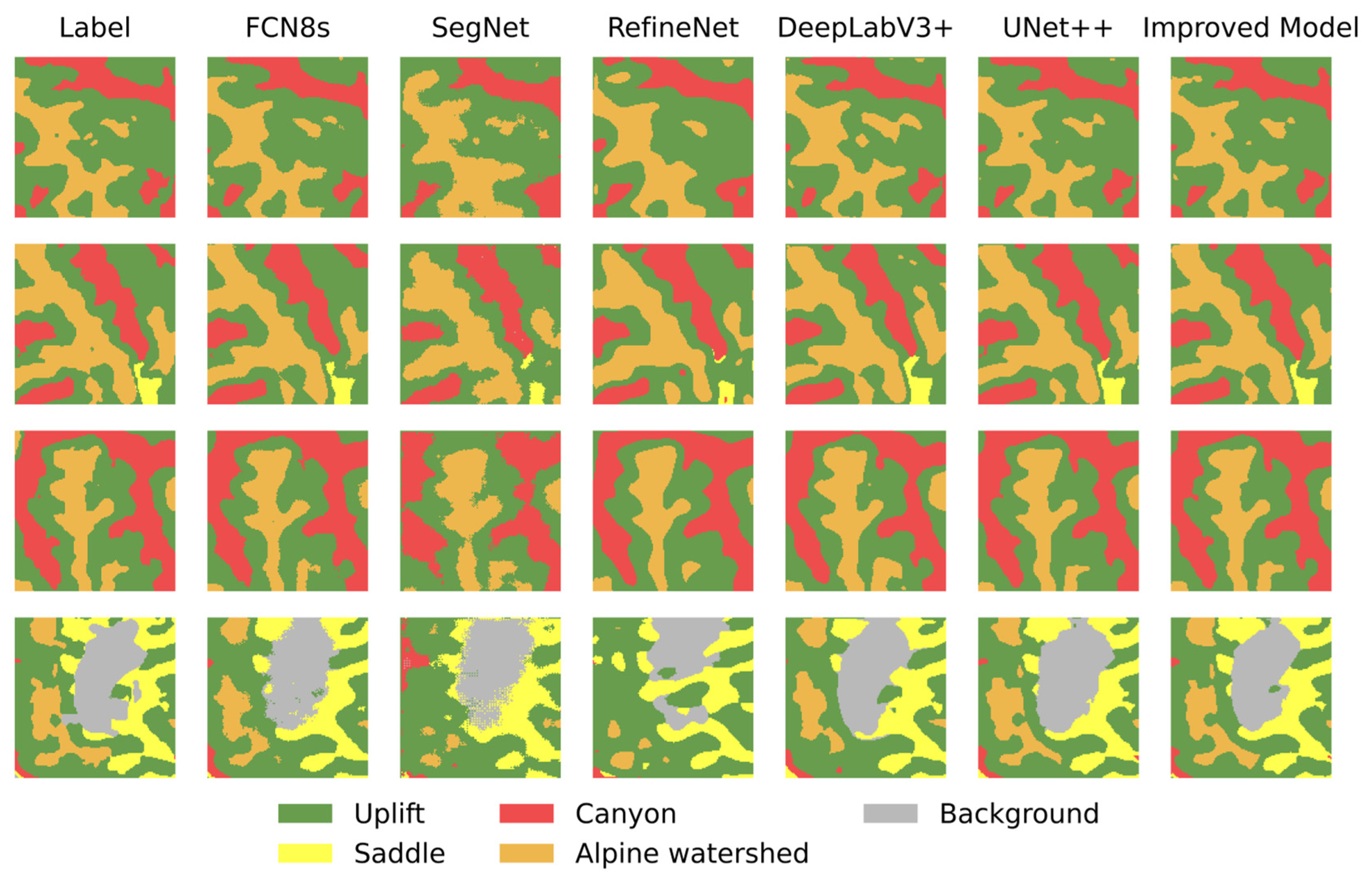
3.2. Experimental Results of the Model Comparison Experiment
3.3. Experimental Results of the Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, X.; Cao, W. Review of the disaster mechanism of transmission lines. J. Xi’an Polytech. Univ. 2017, 31, 589–605. [Google Scholar]
- Hu, J.; Deng, Y.; Jiang, X.; Zeng, Y. Feature extraction and identification method of ice-covered saddle mircotopography for transmission lines. Electr. Power 2022, 55, 135–142. [Google Scholar]
- Zhou, F.; Meng, F.; Zou, L.; Li, Z.; Wang, J. Automatic extraction of digital micro landform for transmission lines. Geomat. Inf. Sci. Wuhan Univ. 2022, 47, 1398–1405. [Google Scholar]
- Weiss, A.D. Topographic Position and Landforms Analysis; Semantic Scholar: Seattle, WA, USA, 2001. [Google Scholar]
- Zou, L. Micro Landform Classification Method of Grid DEM Based on Artificial Intelligence. Master’s Thesis, Changsha University of Science & Technology, Changsha, China, 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5168–5177. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. CoRR 2014, 40, 834–848. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Du, L. Research on Geomorphology Recognition and Classification Based on Multi-Modal Data Fusion. Ph.D. Thesis, Information Engineering University, Zhengzhou, China, 2019. [Google Scholar]
- Bajaj, A.; Bhardwaj, A.; Tuteja, Y.; Abraham, A. Landform segmentation in terrain images using image translation neural network architectures. In Intelligent Systems Design and Applications; Abraham, A., Bajaj, A., Hanne, T., Siarry, P., Ma, K., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 493–505. [Google Scholar]
- Yang, J.; Xu, J.; Lv, Y.; Zhou, C.; Zhu, Y.; Cheng, W. Deep learning-based automated terrain classification using high-resolution dem data. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103249. [Google Scholar] [CrossRef]
- Ouyang, S.; Xu, J.; Chen, W.; Dong, Y.; Li, X.; Li, J. A fine-grained genetic landform classification network based on multimodal feature extraction and regional geological context. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. CMGFNet: A deep cross-modal gated fusion network for building extraction from very high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 184, 96–115. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3141–3149. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. arXiv 2014, arXiv:1409.5185. [Google Scholar]
- He, X.; Kong, T.; Dong, N.; Cheng, J.; Yu, F.; Feng, X.; Meng, L.; She, L. Impact of several typical micro-terrain and micro-meteorological areas on electric transmission lines. Hubei Electr. Power 2020, 44, 33–38. [Google Scholar]
- Wu, Z.; Luo, M.; Zhai, C.; Liu, Y. Analysis methods and application of landslide susceptibility in transmission line area. Shanxi Archit. 2023, 49, 58–62. [Google Scholar]
- Jiao, B.; Shi, P.; Liu, C.; Chen, L.; Liu, H. The distribution of rural settlements in relation to land form factors in low hilly land on the Loess Plateau. Resour. Sci. 2013, 35, 1719–1727. [Google Scholar]
- Guo, Z.; Yin, K.; Huang, F.; Fu, S.; Zhang, W. Evaluation of landslide susceptibility based on landslide classification and weighted frequency ratio model. Chin. J. Rock Mech. Eng. 2019, 38, 287–300. [Google Scholar]
- Yang, Q.; Zhao, M.; Liu, Y.; Guo, W.; Wang, L.; Li, R. Application of DEMs in regional soil erosion modeling. Geomat. World 2009, 7, 25–32. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Li, W.; Li, K.; Chen, S. Multi-modal fusion based method for high resolution remote sensing image segmentation. J. South-Cent. Univ. Natl. 2020, 137, 405–412. [Google Scholar]
- Sun, H.; Pan, C.; He, L.; Xu, Z. Remote sensing image semantic segmentation network based on multimodal feature fusion. Comput. Eng. Appl. 2022, 58, 256–264. [Google Scholar]
- Li, M.; Xu, C.; Li, X.; Liu, H.; Yan, C.; Liao, W. Multimodal fusion for video captioning on urban road scene. Appl. Res. Comput. 2023, 40, 607–611+640. [Google Scholar]
- Hu, Y.; Yu, C.; Gao, M. Remote Sensing image semantic segmentation network based on multimodal fusion. Comput. Eng. Appl. 2024, 60, 234–242. [Google Scholar]
- Xie, S.; Chen, Z.; Shen, B. Detail-enhanced rgb-ir multichannel feature fusion network for semantic segmentation. Comput. Eng. 2022, 48, 230. [Google Scholar]
- Arevalo, J.; Solorio, T.; Montes-y-Gómez, M.; González, F.A. Gated multimodal networks. Neural. Comput. Appl. 2020, 32, 10209–10228. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, L.; Yu, L. Review of attention mechanism in convolutional neural networks. Comput. Eng. Appl. 2021, 57, 64–72. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11531–11539. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 510–519. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-attention networks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2735–2745. [Google Scholar]
- Wang, Y.; Wang, H.; Peng, Z. Rice diseases detection and classification using attention based neural network and bayesian optimization. Expert Syst. Appl. 2021, 178, 114770. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, P.; Fu, Q.; Kou, R.; Wu, W.; Liu, T. Survey of Evaluation Metrics and Methods for Semantic Segmentation. Comput. Eng. Appl. 2023, 59, 57. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | PA (%) | CPA (%) | IoU (%) | ||||
|---|---|---|---|---|---|---|---|
| Uplift | Saddle | Canyon | Alpine Watershed | Background | |||
| FCN8s | 87.84 | 91.31 | 83.62 | 89.86 | 79.15 | 84.12 | 78.01 |
| SegNet | 76.62 | 78.83 | 69.64 | 81.88 | 67.38 | 75.98 | 62.10 |
| RefineNet | 80.37 | 86.07 | 57.16 | 83.47 | 68.06 | 81.79 | 67.18 |
| DeepLabV3+ | 89.19 | 91.16 | 88.28 | 90.09 | 82.91 | 87.77 | 80.50 |
| UNet++ | 90.51 | 91.57 | 88.84 | 95.26 | 84.47 | 88.45 | 82.67 |
| Improved Model | 92.26 | 93.93 | 90.64 | 94.75 | 88.00 | 88.73 | 85.63 |
| Model | Params | Average Training Time per Epoch/s |
|---|---|---|
| FCN8s | 49.67 M | 71.08 |
| SegNet | 49.37 M | 83.19 |
| RefineNet | 17.29 M | 41.37 |
| DeepLabV3+ | 33.65 M | 142.28 |
| UNet++ | 18.59 M | 81.19 |
| Improved Model | 22.51 M | 88.17 |
| Base | DA-Net | Fusion | Deep Supervision | PA (%) | IoU (%) |
|---|---|---|---|---|---|
| ✓ | × | × | × | 90.51 | 82.67 |
| ✓ | ✓ | × | × | 90.99 | 83.46 |
| ✓ | × | ✓ | × | 90.91 | 83.34 |
| ✓ | × | × | ✓ | 91.94 | 85.08 |
| ✓ | ✓ | ✓ | × | 91.33 | 84.04 |
| ✓ | ✓ | × | ✓ | 92.11 | 85.38 |
| ✓ | × | ✓ | ✓ | 92.20 | 85.53 |
| ✓ | ✓ | ✓ | ✓ | 92.26 | 85.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, F.; Hu, C. Micro-Terrain Recognition Method of Transmission Lines Based on Improved UNet++. ISPRS Int. J. Geo-Inf. 2025, 14, 216. https://doi.org/10.3390/ijgi14060216
Yi F, Hu C. Micro-Terrain Recognition Method of Transmission Lines Based on Improved UNet++. ISPRS International Journal of Geo-Information. 2025; 14(6):216. https://doi.org/10.3390/ijgi14060216
Chicago/Turabian StyleYi, Feng, and Chunchun Hu. 2025. "Micro-Terrain Recognition Method of Transmission Lines Based on Improved UNet++" ISPRS International Journal of Geo-Information 14, no. 6: 216. https://doi.org/10.3390/ijgi14060216
APA StyleYi, F., & Hu, C. (2025). Micro-Terrain Recognition Method of Transmission Lines Based on Improved UNet++. ISPRS International Journal of Geo-Information, 14(6), 216. https://doi.org/10.3390/ijgi14060216