



Flow-Based Community Search Approach for Functionally Cohesive Building Group Recognition: A Case Study on Commercial Complexes

Abstract
1. Introduction
- A case-driven, flow-based community search approach is innovatively applied to the task of recognizing functionally cohesive building groups. Using commercial complex recognition as a case study, our approach demonstrates a 5.4% improvement in F1 score over the second-best method.
- An incremental graph propagation network is applied in our study to integrate the geometric features, semantic attributes, and spatial relationships of buildings. This integration effectively mitigates the decoupling of geometric and semantic features—an issue that commonly arises in building group recognition tasks.
- We designed three synergistic modules that integrate feature computation, iterative node selection, and quality evaluation mechanisms. These components enable our method to maintain robust performance even with limited training data, demonstrating its practical applicability in data-scarce scenarios.
2. Related Works
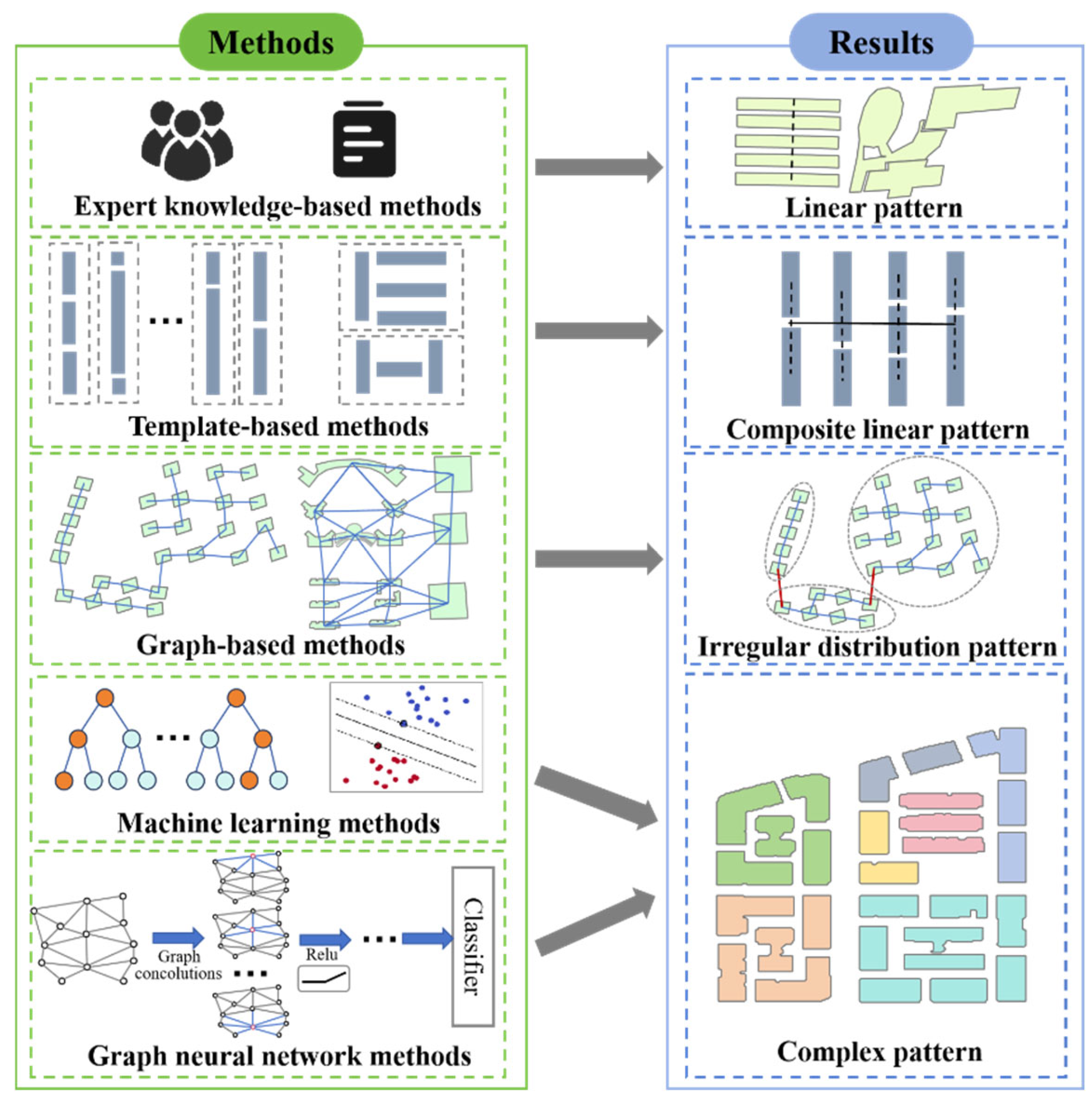
2.1. Recognition of Building Groups
2.2. Community Search
3. Study Area and Dataset
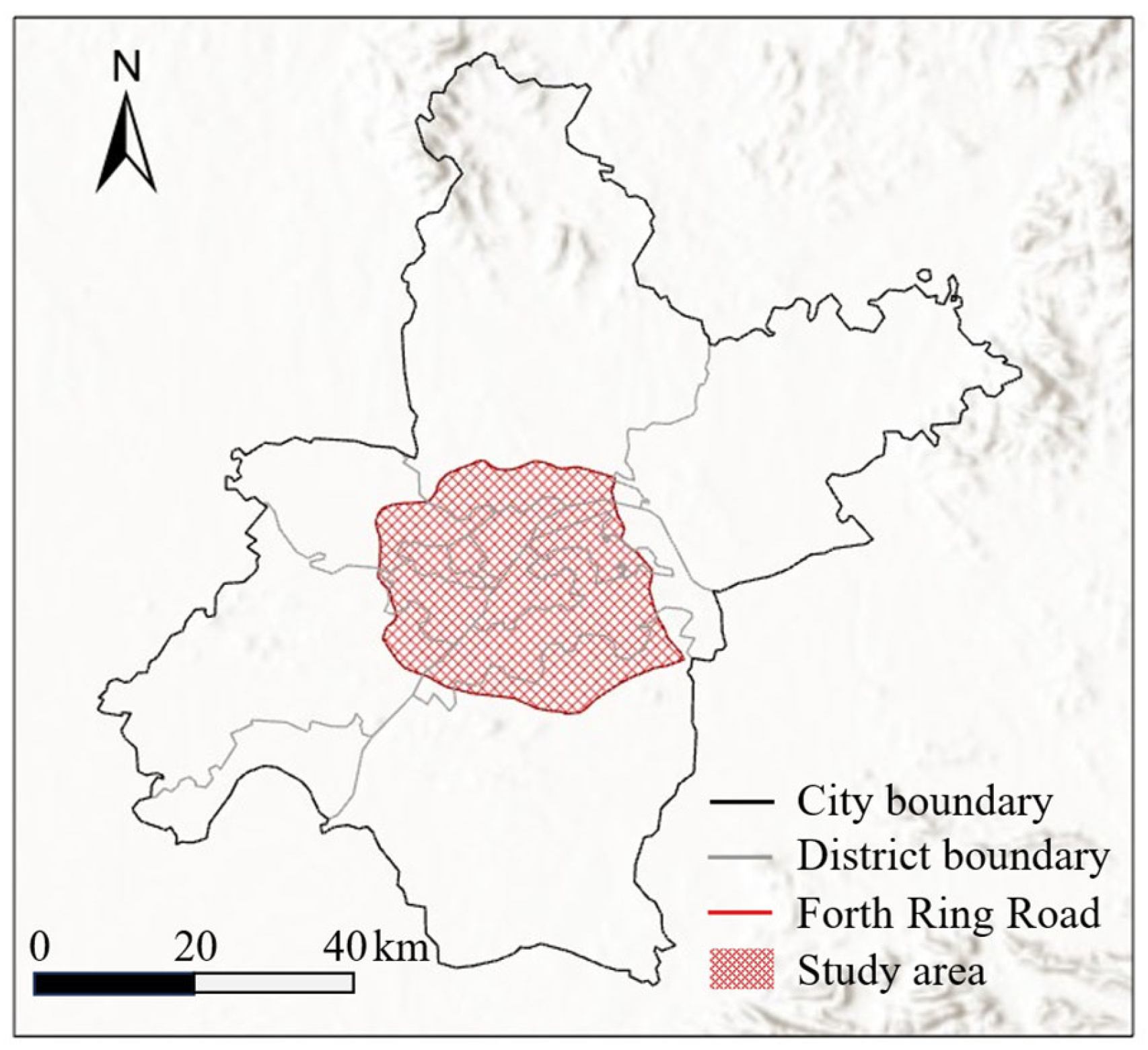
3.1. Study Area
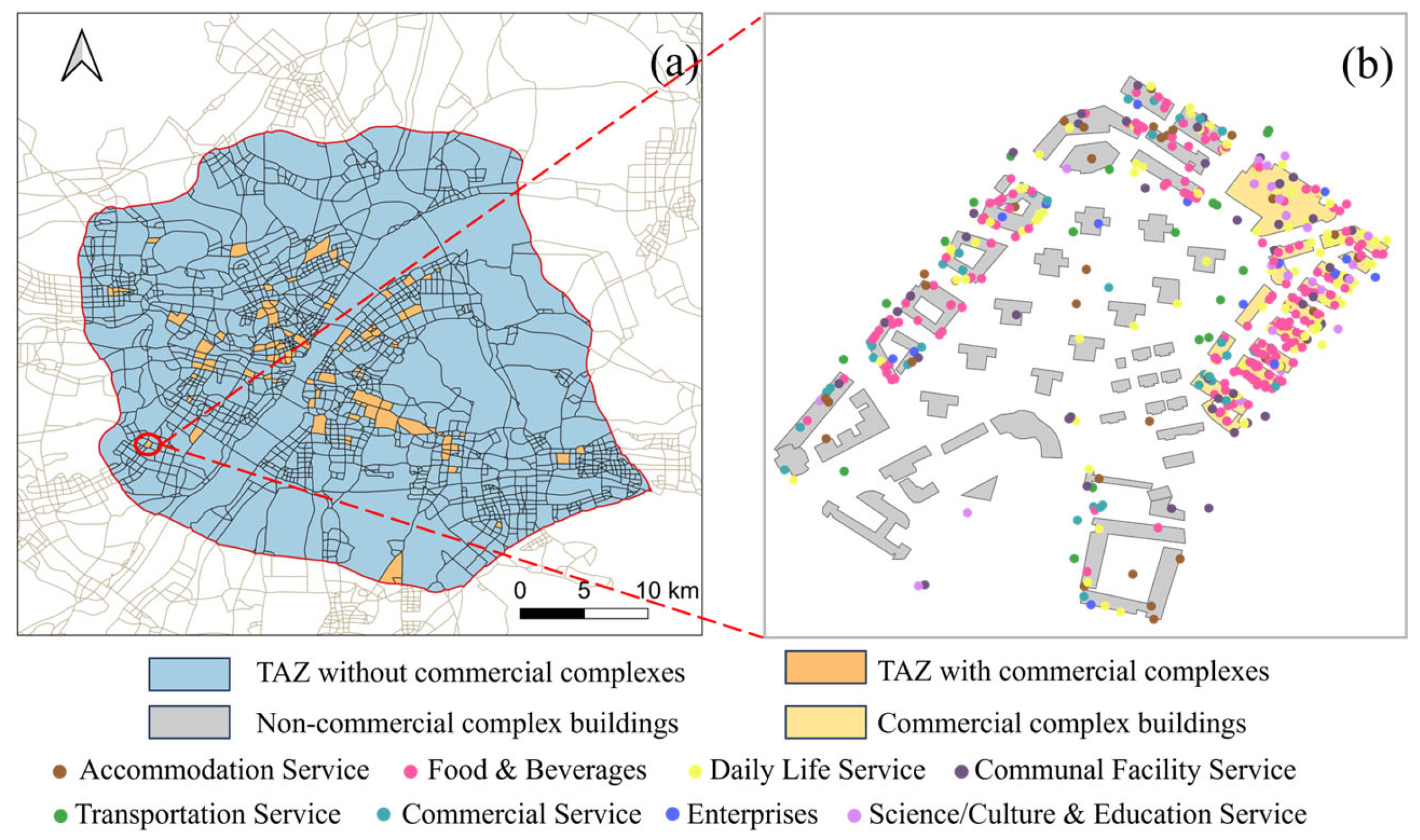
3.2. Data Sources and Preprocessing
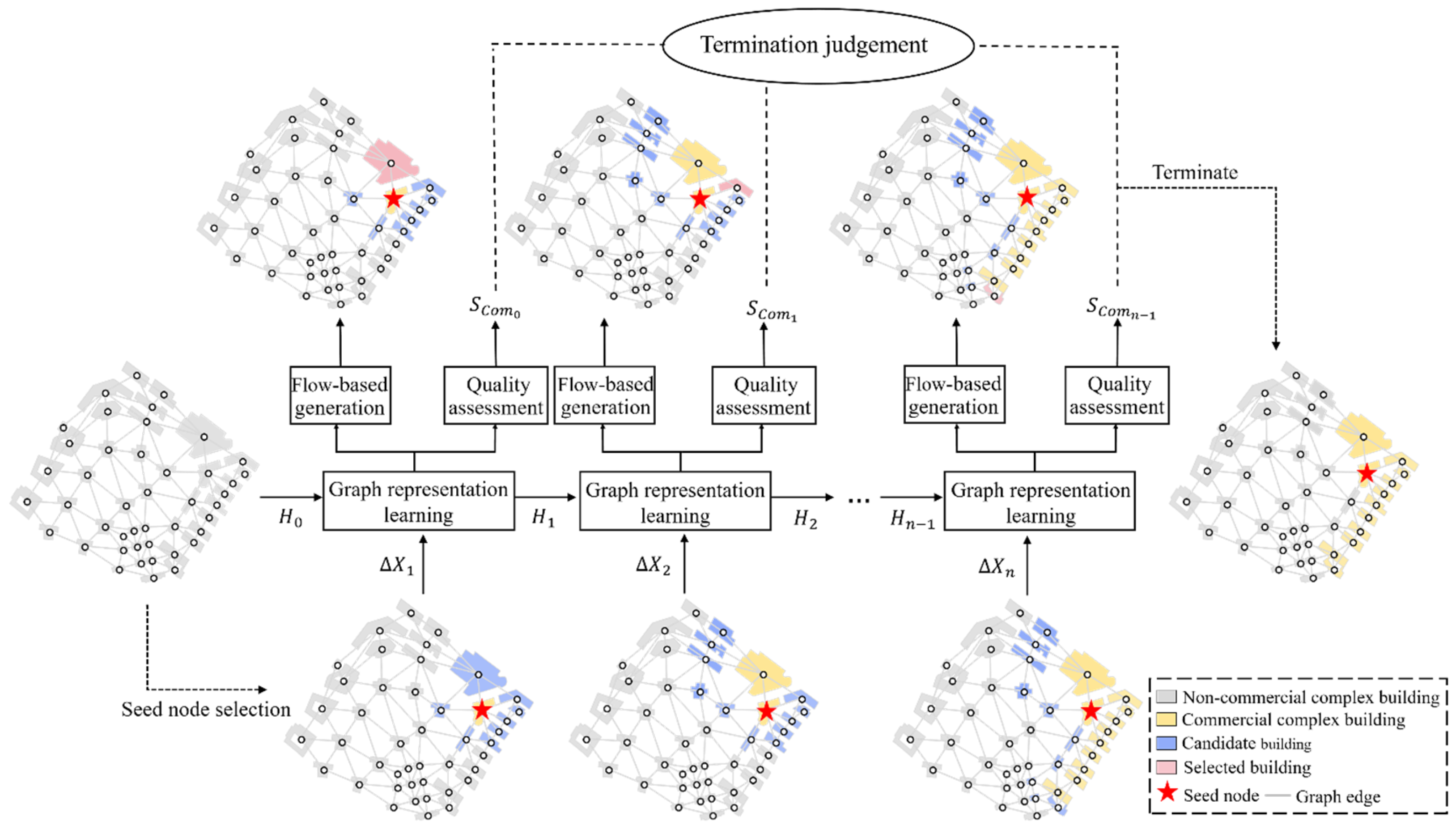
4. Methodology
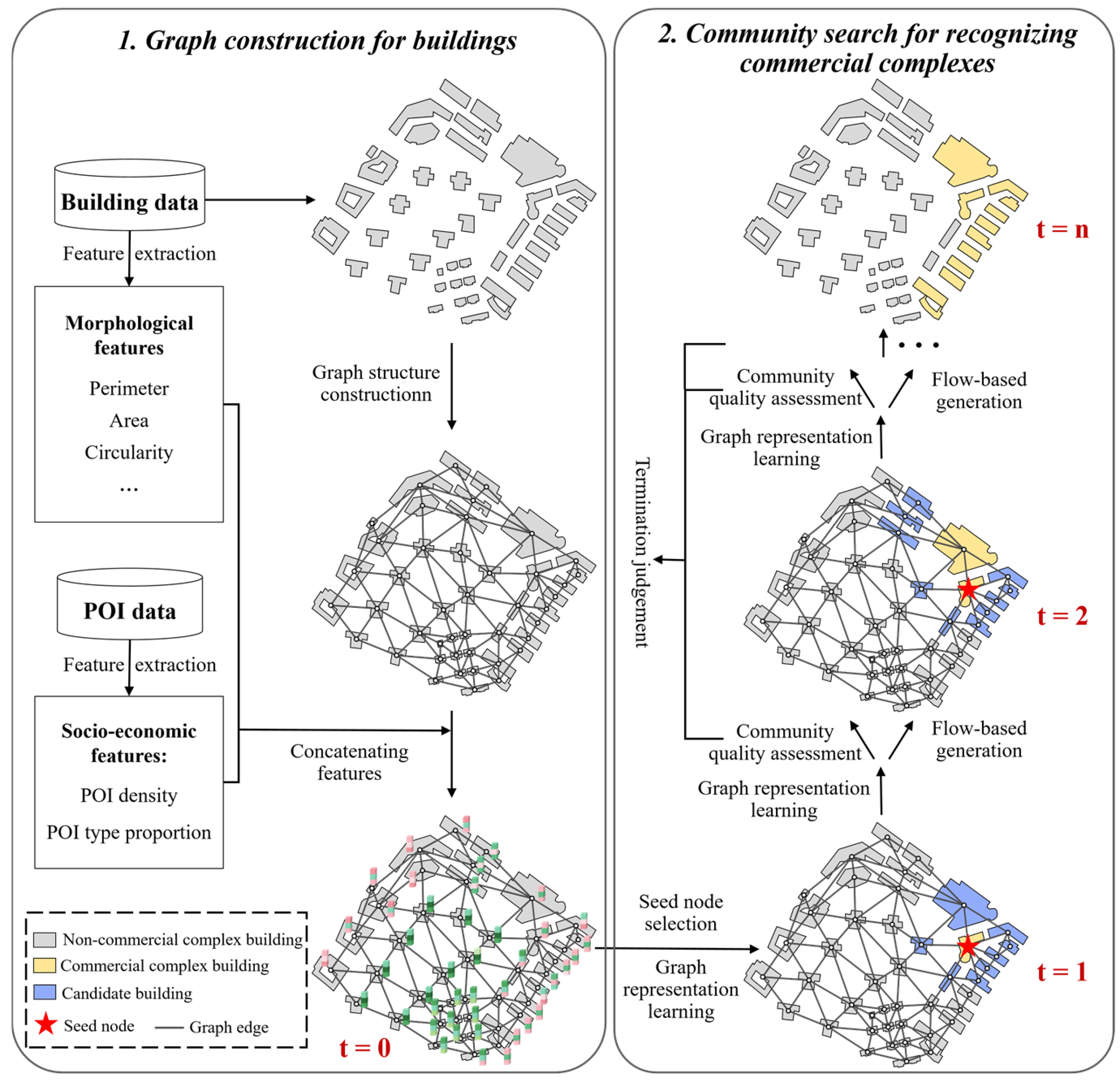
4.1. Graph Construction for Buildings
4.1.1. Node Feature Extraction
- Morphological features
- Socio-economic features
4.1.2. Graph Structure Construction
4.2. Community Search Approach for Recognizing Commercial Complexes
4.2.1. Graph Representation Learning Module
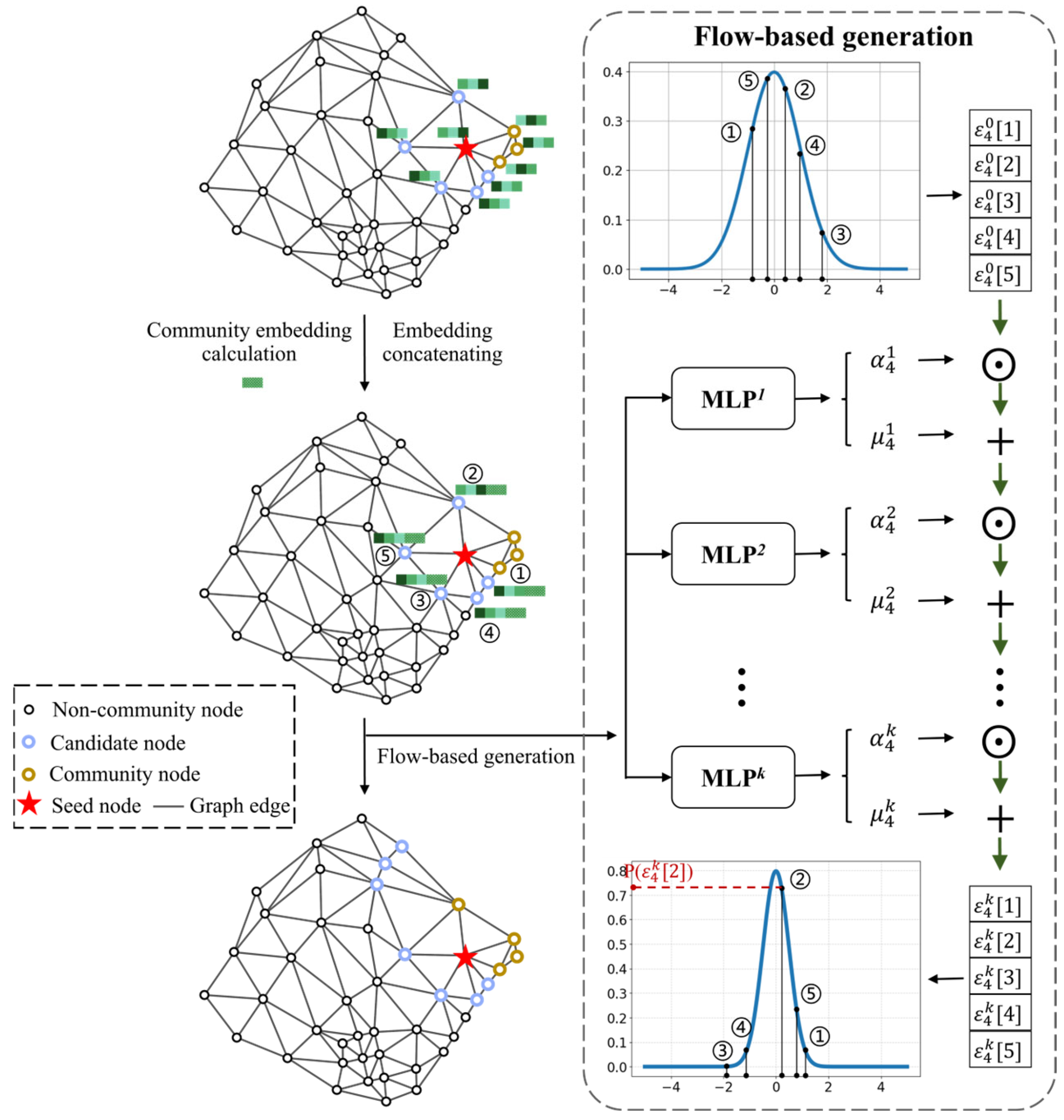
4.2.2. Flow-Based Generation Module
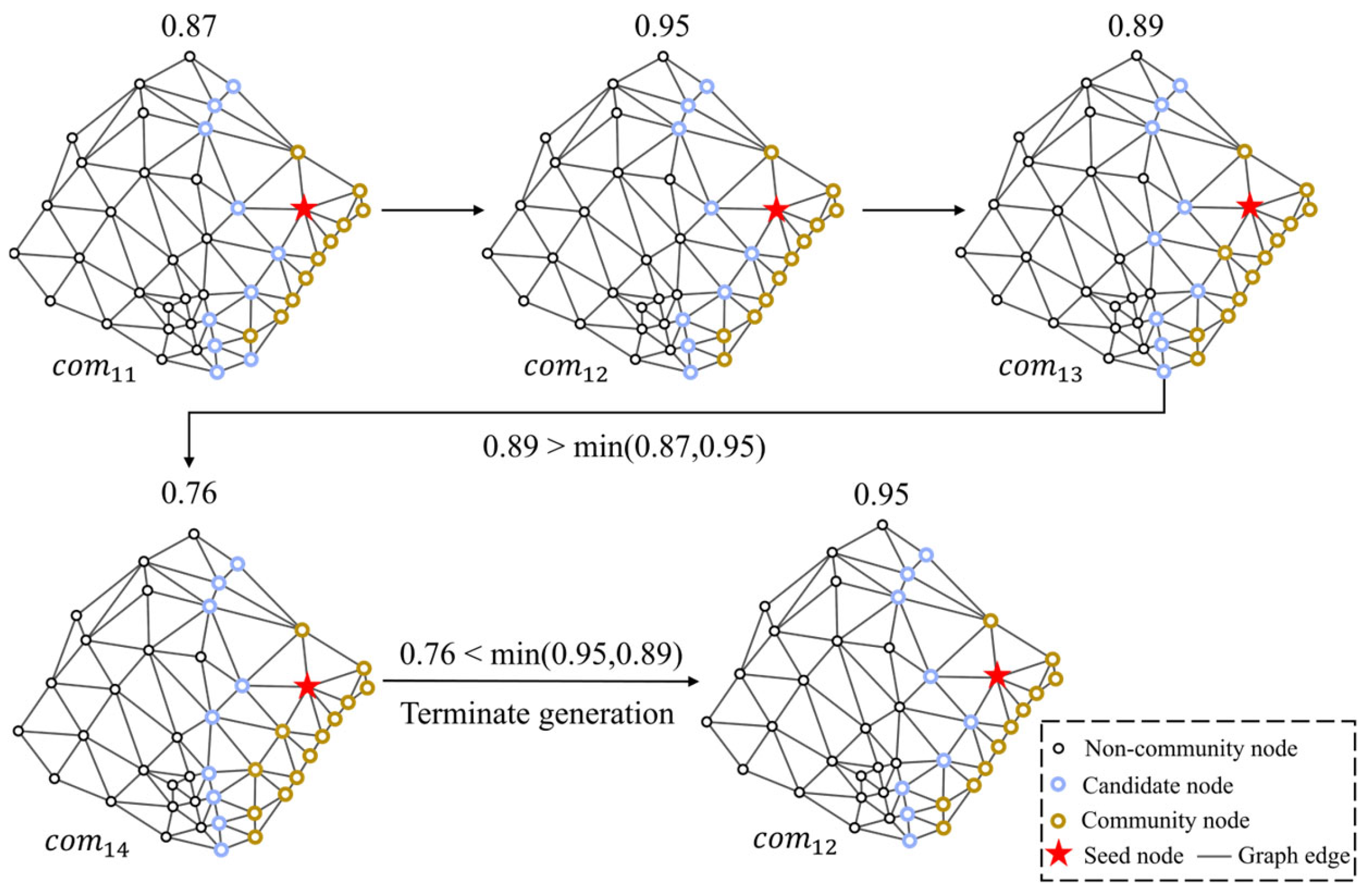
4.2.3. Community Quality Assessment Module
4.3. Model Training
5. Experimental Results and Discussion
5.1. Evaluation Indicators
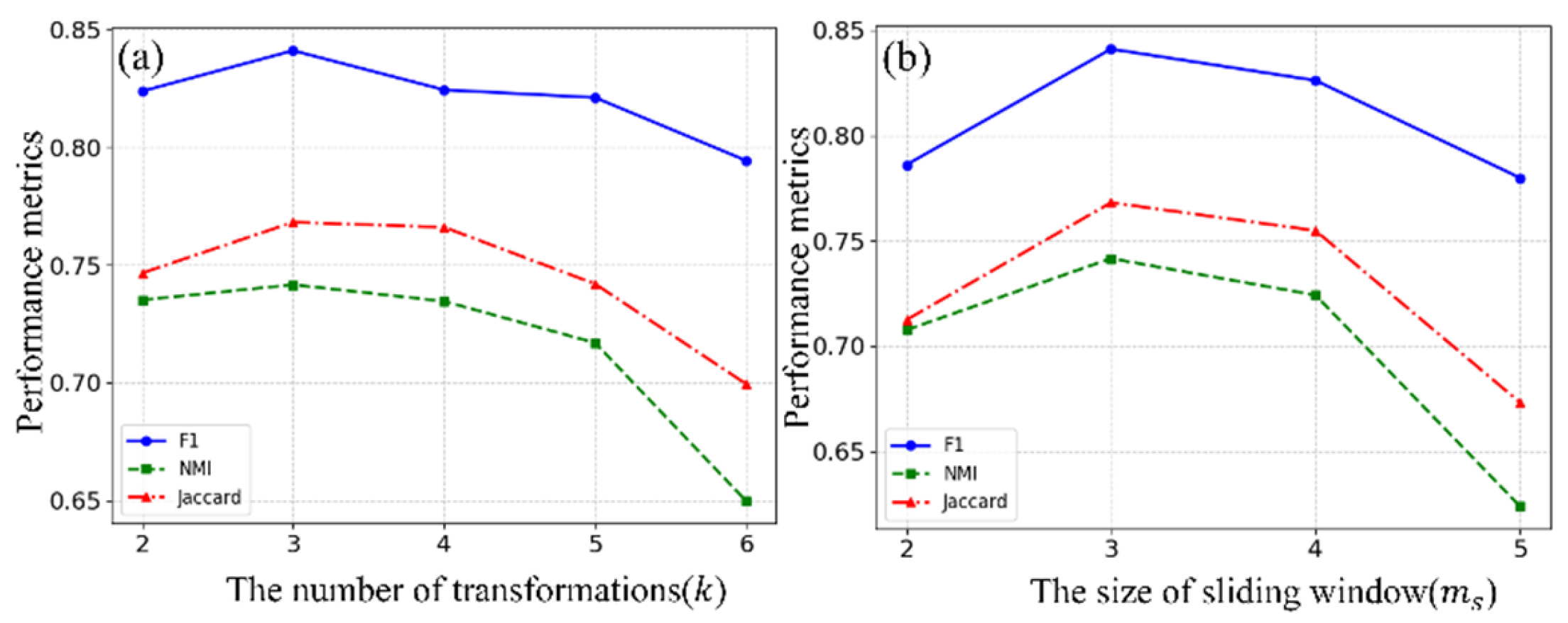
5.2. Experimental Settings
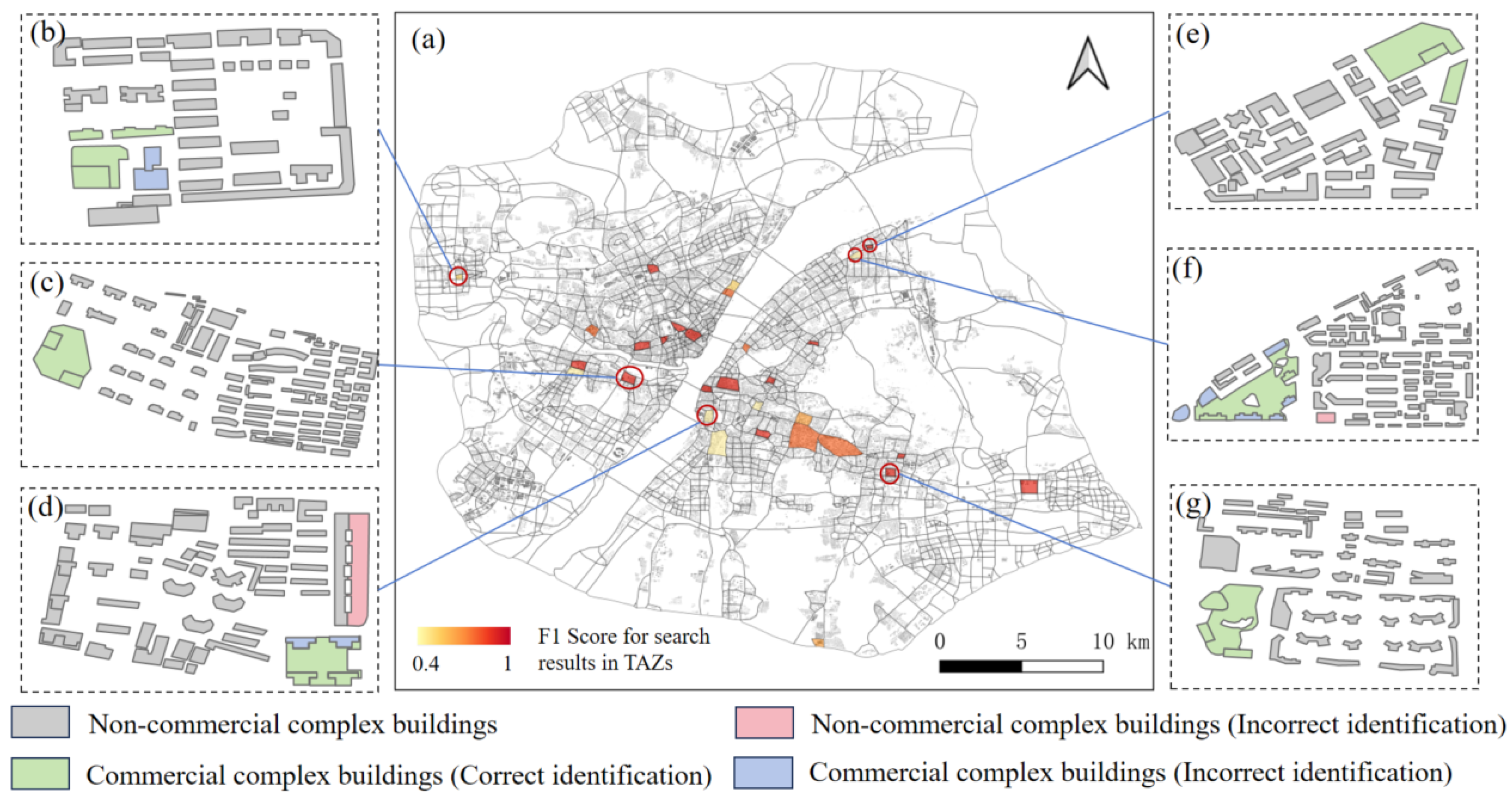
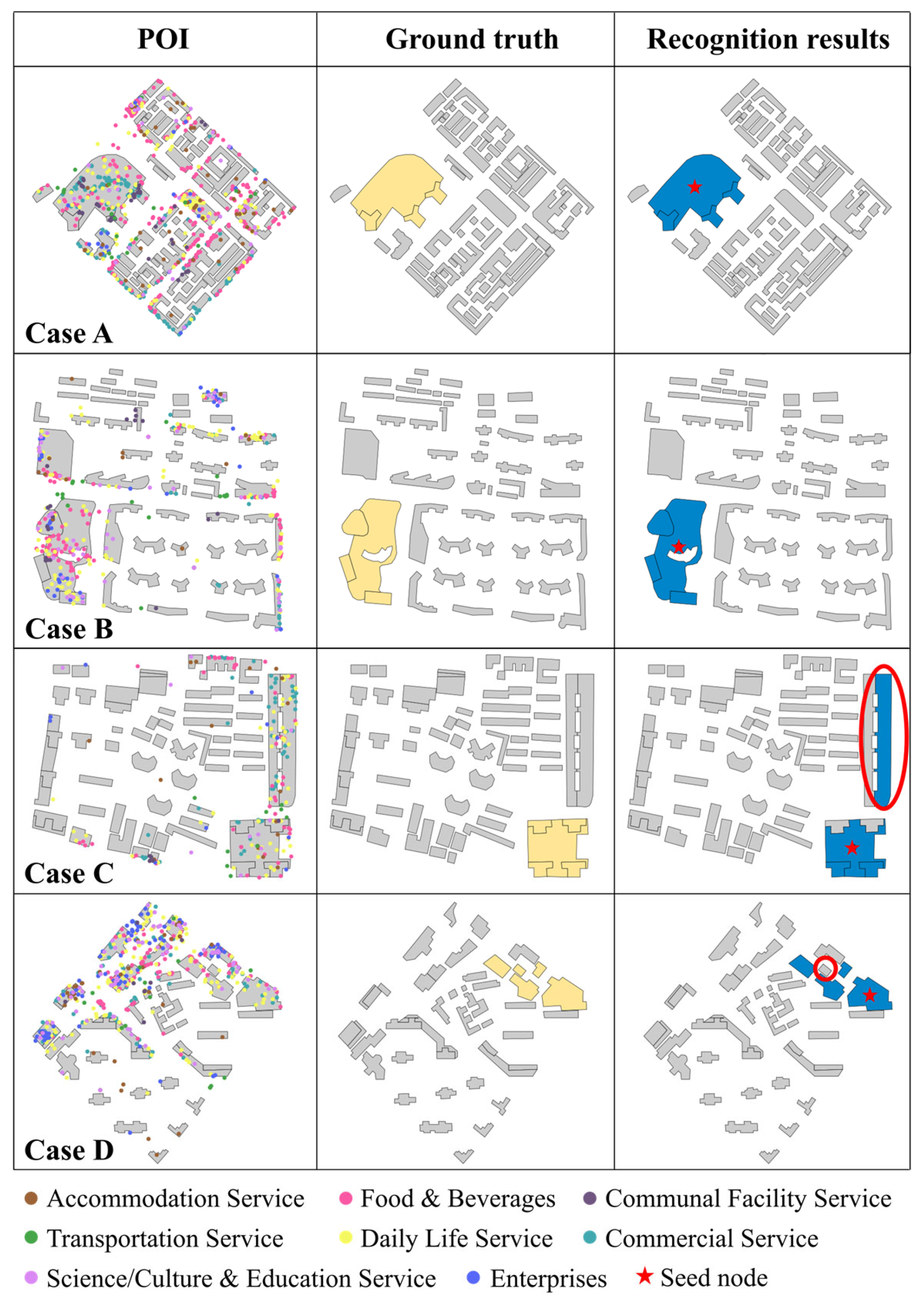
5.3. Results of Commercial Complex Recognition
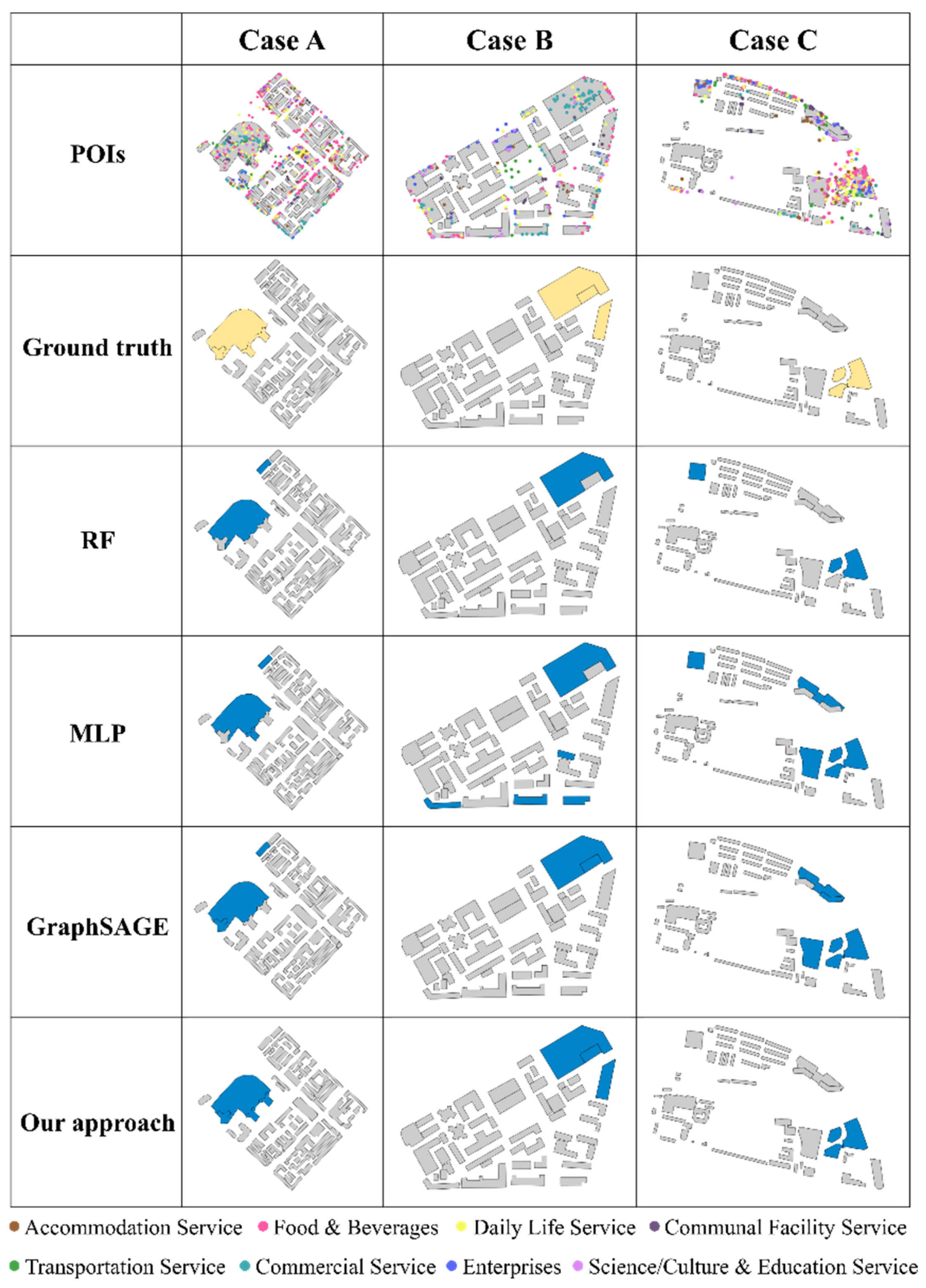
5.4. Comparison of Model Performance
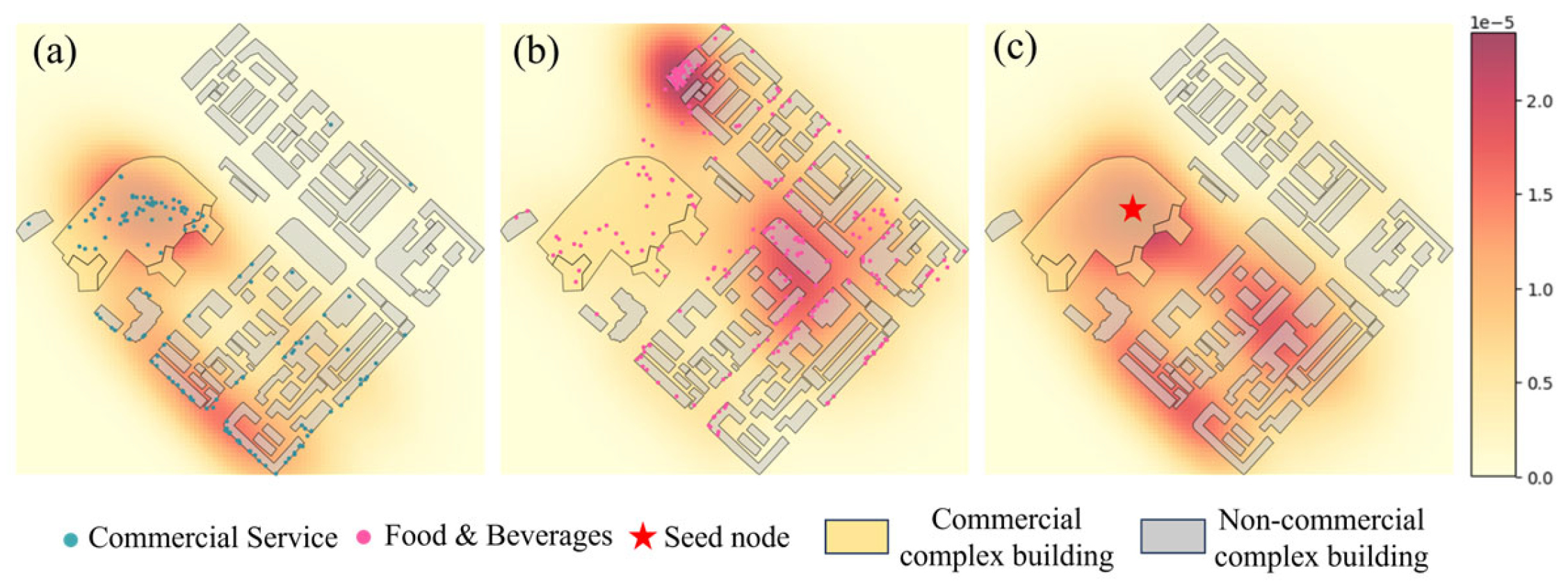
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wei, Z.; Ding, S.; Cheng, L.; Xu, W.; Wang, Y.; Zhang, L. Linear Building Pattern Recognition in Topographical Maps Combining Convex Polygon Decomposition. Geocarto Int. 2022, 37, 11365–11389. [Google Scholar] [CrossRef]
- He, X.; Deng, M.; Luo, G. Recognizing Building Group Patterns in Topographic Maps by Integrating Building Functional and Geometric Information. ISPRS Int. J. Geo Inf. 2022, 11, 332. [Google Scholar] [CrossRef]
- Zhang, L.; Hao, D.; Dong, C.; Zhen, W. A Spatial Cognition-Based Urban Building Clustering Approach and Its Applications. Int. J. Geogr. Inf. Sci. 2013, 27, 721–740. [Google Scholar] [CrossRef]
- Che, W.; Zhuang, W. Integrating Vertical Greenery for Complex Building Patterns towards Sustainable Urban Environment. Sustain. Cities Soc. 2024, 113, 105684. [Google Scholar] [CrossRef]
- Gong, X.; Wu, F. A Typification Method for Linear Pattern in Urban Building Generalisation. Geocarto Int. 2018, 33, 189–207. [Google Scholar] [CrossRef]
- Li, Z.; Yan, H.; Ai, T.; Chen, J. Automated Building Generalization Based on Urban Morphology and Gestalt Theory. Int. J. Geogr. Inf. Sci. 2004, 18, 513–534. [Google Scholar] [CrossRef]
- Mao, B.; Harrie, L.; Ban, Y. Detection and Typification of Linear Structures for Dynamic Visualization of 3D City Models. Comput. Environ. Urban Syst. 2012, 36, 233–244. [Google Scholar] [CrossRef]
- Wang, X.; Burghardt, D. A Mesh-Based Typification Method for Building Groups with Grid Patterns. ISPRS Int. J. Geo Inf. 2019, 8, 168. [Google Scholar] [CrossRef]
- Sahbaz, K.; Basaraner, M. A Zonal Displacement Approach via Grid Point Weighting in Building Generalization. ISPRS Int. J. Geo Inf. 2021, 10, 105. [Google Scholar] [CrossRef]
- Wei, Z.; Xu, W.; Xiao, Y.; Shu, M.; Cheng, L.; Wang, Y.; Liu, C. Enhancing Building Pattern Recognition through Multi-Scale Data and Knowledge Graph: A Case Study of C-Shaped Patterns. Int. J. Digit. Earth 2023, 16, 3860–3881. [Google Scholar] [CrossRef]
- Trudelle, C.; Claramunt, C. A Graph-Based Modelling Approach for the Representation and Analysis of Urban Conflicts. Comput. Environ. Urban Syst. 2024, 114, 102201. [Google Scholar] [CrossRef]
- Zhang, P.; Yang, M.; Wang, Y.; Yang, T.; Yu, H.; Yan, X. Integrating Metro Passenger Flow Data to Improve the Classification of Urban Functional Regions Using a Heterogeneous Graph Neural Network. Int. J. Digit. Earth 2024, 17, 2443468. [Google Scholar] [CrossRef]
- Chen, J.; Xia, Y.; Gao, J. CommunityAF: An Example-Based Community Search Method via Autoregressive Flow. Proc. VLDB Endow. 2023, 16, 2565–2577. [Google Scholar] [CrossRef]
- Rainsford, D.; Mackaness, W. Template Matching in Support of Generalisation of Rural Buildings. In Advances in Spatial Data Handling; Richardson, D.E., Van Oosterom, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 137–151. ISBN 978-3-642-62859-7. [Google Scholar]
- Xing, R.; Wu, F.; Gong, X.; Du, J.; Liu, C. The template matching approach to combined collinear pattern recognition in building groups. Acta Geod. Cartogr. 2021, 50, 800–811. [Google Scholar] [CrossRef]
- Wang, X.; Burghardt, D. Using Stroke and Mesh to Recognize Building Group Patterns. Int. J. Cartogr. 2020, 6, 71–98. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, Q.; Zhao, R. A Heuristic Approach to the Generalization of Complex Building Groups in Urban Villages. Geocarto Int. 2021, 36, 155–179. [Google Scholar] [CrossRef]
- Zhang, X.; Ai, T.; Stoter, J.; Kraak, M.-J.; Molenaar, M. Building Pattern Recognition in Topographic Data: Examples on Collinear and Curvilinear Alignments. GeoInformatica 2013, 17, 1–33. [Google Scholar] [CrossRef]
- Gong, X.; Wu, F. The Graph Theory Approach to Grid Pattern Recognition in Urban Building Groups. Acta Geod. Cartogr. 2014, 43, 960–968. [Google Scholar] [CrossRef]
- He, X.; Deng, M.; Luo, G. Recognizing Linear Building Patterns in Topographic Data by Using Two New Indices Based on Delaunay Triangulation. ISPRS Int. J. Geo Inf. 2020, 9, 231. [Google Scholar] [CrossRef]
- He, X.; Zhang, X.; Xin, Q. Recognition of Building Group Patterns in Topographic Maps Based on Graph Partitioning and Random Forest. ISPRS J. Photogramm. Remote Sens. 2018, 136, 26–40. [Google Scholar] [CrossRef]
- Yan, X.; Ai, T.; Yang, M.; Yin, H. A Graph Convolutional Neural Network for Classification of Building Patterns Using Spatial Vector Data. ISPRS J. Photogramm. Remote Sens. 2019, 150, 259–273. [Google Scholar] [CrossRef]
- Bei, W.; Guo, M.; Huang, Y. A Spatial Adaptive Algorithm Framework for Building Pattern Recognition Using Graph Convolutional Networks. Sensors 2019, 19, 5518. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Ai, T.; Yu, W.; He, Y.; Shen, Y. Recognition of Building Group Patterns Using Graph Convolutional Network. Cartogr. Geogr. Inf. Sci. 2020, 47, 400–417. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, X.; Qin, L.; Zhang, Y.; Zhang, W.; Cheng, R.; Lin, X. A Survey of Community Search over Big Graphs. VLDB J. 2020, 29, 353–392. [Google Scholar] [CrossRef]
- Li, R.-H.; Qin, L.; Yu, J.X.; Mao, R. Influential Community Search in Large Networks. Proc. VLDB Endow. 2015, 8, 509–520. [Google Scholar] [CrossRef]
- Huang, X.; Cheng, H.; Qin, L.; Tian, W.; Yu, J.X. Querying K-Truss Community in Large and Dynamic Graphs. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 1311–1322. [Google Scholar]
- Yuan, L.; Qin, L.; Zhang, W.; Chang, L.; Yang, J. Index-Based Densest Clique Percolation Community Search in Networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 922–935. [Google Scholar] [CrossRef]
- Fang, Y.; Cheng, R.; Luo, S.; Hu, J. Effective Community Search for Large Attributed Graphs. Proc. VLDB Endow. 2016, 9, 1233–1244. [Google Scholar] [CrossRef]
- Huang, X.; Lakshmanan, L.V.S. Attribute-Driven Community Search. Proc. VLDB Endow. 2017, 10, 949–960. [Google Scholar] [CrossRef]
- Li, Y.; He, K.; Kloster, K.; Bindel, D.; Hopcroft, J. Local Spectral Clustering for Overlapping Community Detection. ACM Trans. Knowl. Discov. Data 2018, 12, 1–27. [Google Scholar] [CrossRef]
- Li, Q.; Ma, H.; Li, Z.; Chang, L. Local Spectral for Multiresolution Community Search in Attributed Graph. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Zhang, Y.; Xiong, Y.; Ye, Y.; Liu, T.; Wang, W.; Zhu, Y.; Yu, P.S. SEAL: Learning Heuristics for Community Detection with Generative Adversarial Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 23–27 August 2020; pp. 1103–1113. [Google Scholar]
- Radicchi, F.; Castellano, C.; Cecconi, F.; Loreto, V.; Parisi, D. Defining and Identifying Communities in Networks. Proc. Natl. Acad. Sci. USA 2004, 101, 2658–2663. [Google Scholar] [CrossRef]
- Choudhary, S.; Malik, S.; Yadav, R.K. Analyze the Techniques of Community Detection in Social Networks and Their Applications. In Proceedings of the 2024 4th International Conference on Advancement in Electronics & Communication Engineering (AECE), Ghaziabad, India, 22–23 November 2024; pp. 42–47. [Google Scholar]
- Paoletti, G.; Gioacchini, L.; Mellia, M.; Vassio, L.; Almeida, J. CoDÆN: Benchmarks and Comparison of Evolutionary Community Detection Algorithms for Dynamic Networks. ACM Trans. Web 2025, 3718988. [Google Scholar] [CrossRef]
- Clark, W.A.V.; Rushton, R. Models of Intra Urban Consumer Behavior and Their Implications for Central Place Theory. Econ. Geogr. 1970, 46, 486–497. [Google Scholar] [CrossRef]
- Chan, S.H.Y.; Donner, R.V.; Lämmer, S. Urban Road Networks—Spatial Networks with Universal Geometric Features?: A Case Study on Germany’s Largest Cities. Eur. Phys. J. B 2011, 84, 563–577. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering Regions of Different Functions in a City Using Human Mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Li, W.; Yan, H.; Lu, X.; Shen, Y. A Heuristic Approach for Resolving Spatial Conflicts of Buildings in Urban Villages. ISPRS Int. J. Geo Inf. 2023, 12, 392. [Google Scholar] [CrossRef]
- Bertin, J. Semiology of Graphics: Diagrams, Networks, Maps; University of Wisconsin Press: Madison, WI, USA, 1983. [Google Scholar]
- Ai, T.; Zhang, X. The aggregation of urban building clusters based on the skeleton partitioning of gap space. In The European Information Society; Fabrikant, S.I., Wachowicz, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 153–170. [Google Scholar]
- Kong, B.; Ai, T.; Zou, X.; Yan, X.; Yang, M. A Graph-Based Neural Network Approach to Integrate Multi-Source Data for Urban Building Function Classification. Comput. Environ. Urban Syst. 2024, 110, 102094. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, X.; Ou, J.; Liu, X. Identifying Building Function Using Multisource Data: A Case Study of China’s Three Major Urban Agglomerations. Sustain. Cities Soc. 2024, 108, 105498. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Stanford Infolab: Monterrey, Mexico, 1999. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Reclassified POI Categories | Filtered POI Categories | Proportion |
|---|---|---|---|
| 1 | Commercial Service | Shopping, Auto Dealers, Auto Service, Finance & Insurance Services | 19.58% |
| 2 | Food & Beverages | Food & Beverages | 18.63% |
| 3 | Accommodation Service | Accommodation Service, Commercial House | 6.43% |
| 4 | Communal Facility Service | Public Facility, Governmental Organization & Social Group, Medical Service, Sports & Recreation | 8.28% |
| 5 | Transportation Service | Transportation Service, Pass Facilities, Road Furniture | 5.92% |
| 6 | Daily Life Service | Daily Life Service | 20.23% |
| 7 | Science/Culture & Education Service | Science/Culture & Education Service | 9.11% |
| 8 | Enterprises | Enterprises | 11.80% |
| Variable | Metrics | Formulas and Annotations |
|---|---|---|
| Size | Perimeter | — |
| Area | — | |
| Height | — | |
| Mean radius | ( indicates average distance from the i-th building’s vertexes to its centroid) | |
| Orientation | Orientation of the smallest bounding rectangle (SBR) | — |
| Shape | Elongation | ( and indicate the length and width of the i-th building’s SBR, respectively) |
| Circularity | ( and indicate the area and perimeter of the i-th building) | |
| Convexity | ( indicates the convex hull area of the i-th building) | |
| Rectangularity | (indicates the area of the i-th building’s SBR) | |
| Equivalent rectangular index (ERI) | ( indicates the perimeter of the i-th building’s equal-area rectangle) | |
| Roughness index (RI) | ( indicates the mean radius of the i-th building, and 42.6 is used as the coefficient to scale a circle’s RI to 1) | |
| Density | Area ratio (AR) | ( indicates the area of the i-th building’s Voronoi-like polygon) |
| Metric | Proportion of Training Samples | ||||
|---|---|---|---|---|---|
| 20% | 40% | 60% | 80% | 100% | |
| F1 | 0.7048 | 0.7802 | 0.8070 | 0.8122 | 0.8294 |
| NMI | 0.5805 | 0.6534 | 0.7096 | 0.7240 | 0.7356 |
| Jaccard | 0.6134 | 0.7030 | 0.7243 | 0.7496 | 0.7606 |
| Model | F1 | NMI | Jaccard |
|---|---|---|---|
| RF | 0.6516 | 0.5732 | 0.5690 |
| FNN | 0.7118 | 0.6281 | 0.6395 |
| GraphSAGE | 0.7559 | 0.6754 | 0.6394 |
| Ours | 0.8294 | 0.7356 | 0.7606 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, T.; Zhang, P.; Xu, D.; Liu, P.; Yang, M. Flow-Based Community Search Approach for Functionally Cohesive Building Group Recognition: A Case Study on Commercial Complexes. ISPRS Int. J. Geo-Inf. 2025, 14, 213. https://doi.org/10.3390/ijgi14060213
Yang T, Zhang P, Xu D, Liu P, Yang M. Flow-Based Community Search Approach for Functionally Cohesive Building Group Recognition: A Case Study on Commercial Complexes. ISPRS International Journal of Geo-Information. 2025; 14(6):213. https://doi.org/10.3390/ijgi14060213
Chicago/Turabian StyleYang, Taiyang, Pengxin Zhang, Daozhu Xu, Pengcheng Liu, and Min Yang. 2025. "Flow-Based Community Search Approach for Functionally Cohesive Building Group Recognition: A Case Study on Commercial Complexes" ISPRS International Journal of Geo-Information 14, no. 6: 213. https://doi.org/10.3390/ijgi14060213
APA StyleYang, T., Zhang, P., Xu, D., Liu, P., & Yang, M. (2025). Flow-Based Community Search Approach for Functionally Cohesive Building Group Recognition: A Case Study on Commercial Complexes. ISPRS International Journal of Geo-Information, 14(6), 213. https://doi.org/10.3390/ijgi14060213