

A Semantic Partition Algorithm Based on Improved K-Means Clustering for Large-Scale Indoor Areas


Abstract
1. Introduction
- 1.
- Our algorithm, distinct from traditional K-means and DBSCAN algorithms, incorporates semantic information from known indoor room node attributes. This approach leads to partitioning results that exhibit lower values in evaluation functions. Most notably, it eliminates the need to grapple with a multitude of redundant and intricate variables, enabling swift and automated generation of partitioning outcomes. This not only leads to cost savings but also yields partition results that closely align with manual partitioning results.
- 2.
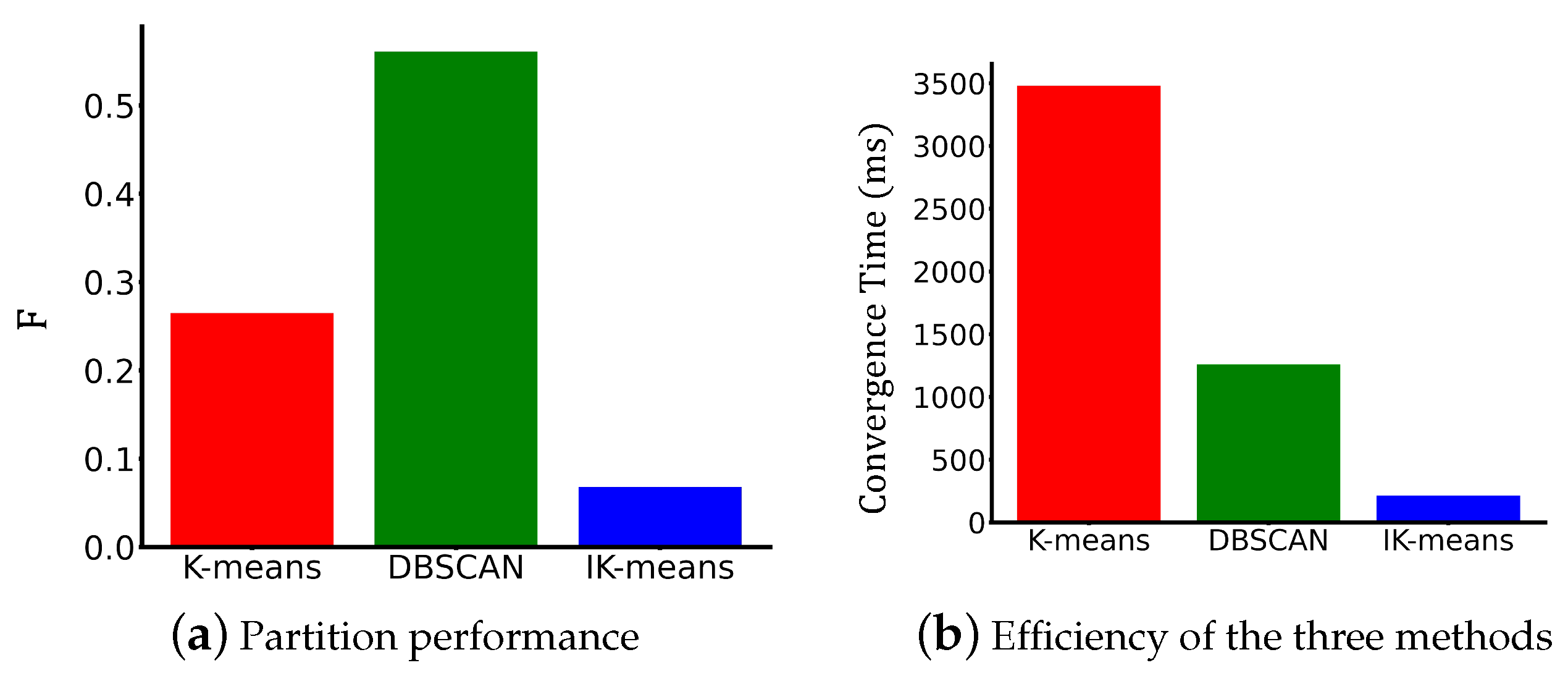
- In comparison to K-means and DBSCAN algorithms, our algorithm exhibits faster convergence rates. Experimental results demonstrate that our algorithm, IK-means, achieves a remarkable 93.85% faster convergence than traditional K-means and an impressive 83.29% faster convergence than DBSCAN.
- 3.
- The IK-means algorithm offers a more streamlined process for parameterization. Traditionally, selecting the optimal value for K in K-means clustering has been a significant challenge. In contrast, the IK-means approach predefines the parameter K based on the semantic information of the rooms, thereby obviating the need to assess the impact of K on the partition results. This method effectively addresses and mitigates the issue of parameter dependence that is prevalent in the standard K-means algorithm and its variants.
2. Related Work
3. The Improved K-Means Clustering Algorithm for Semantic-Based Partition
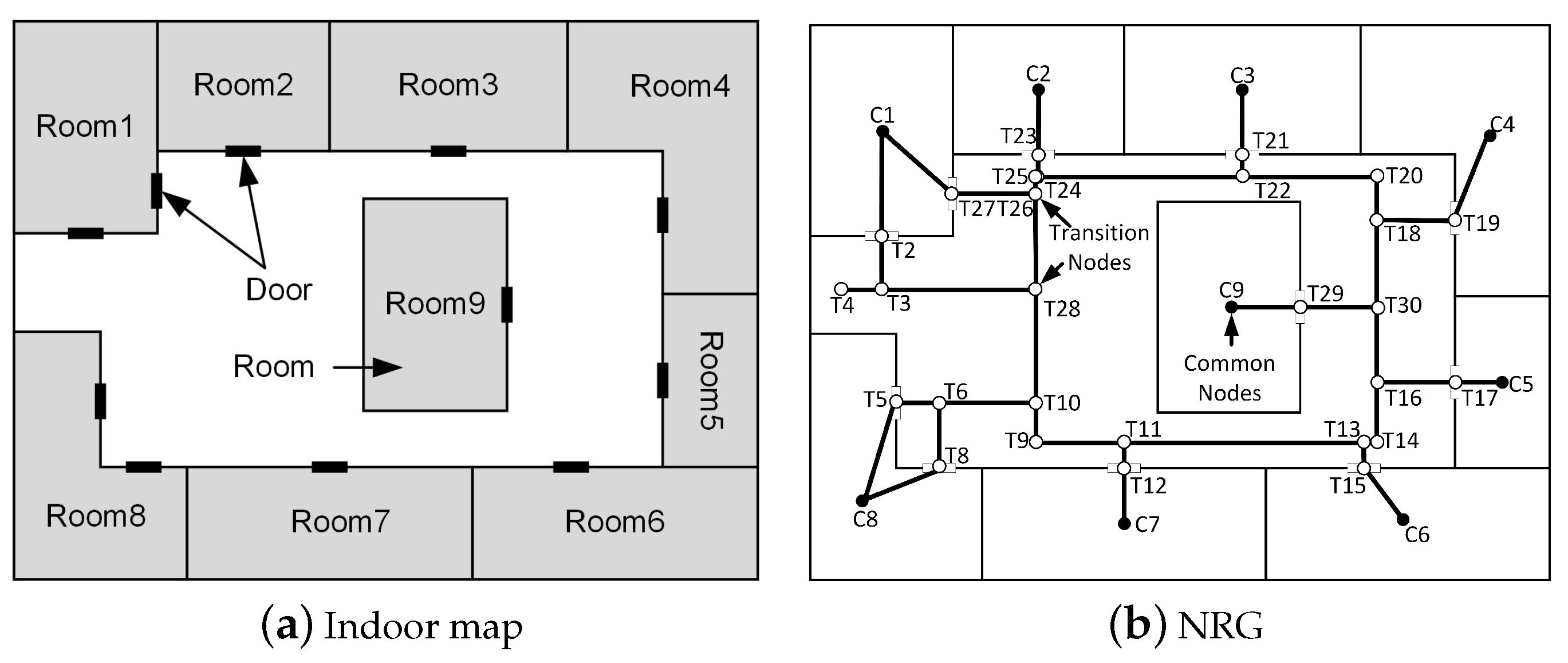
3.1. Concepts and Parameters
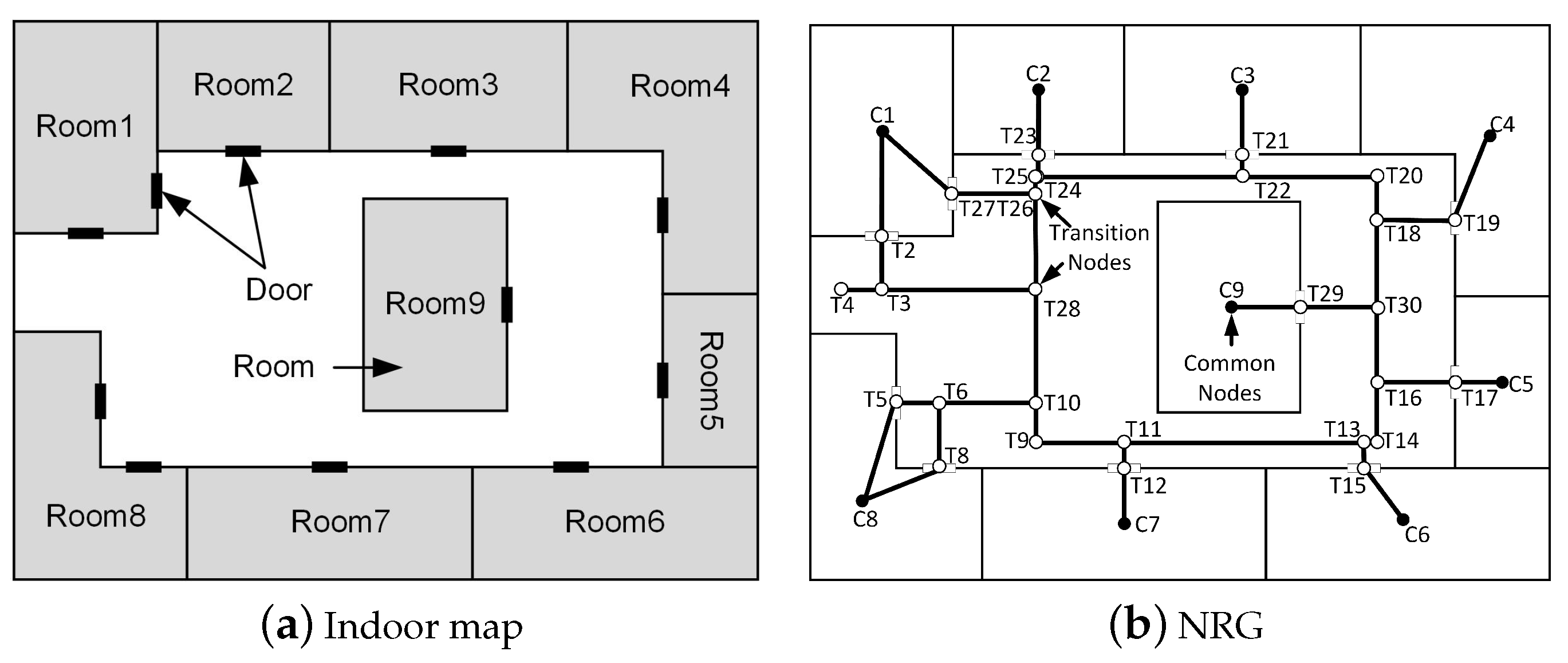
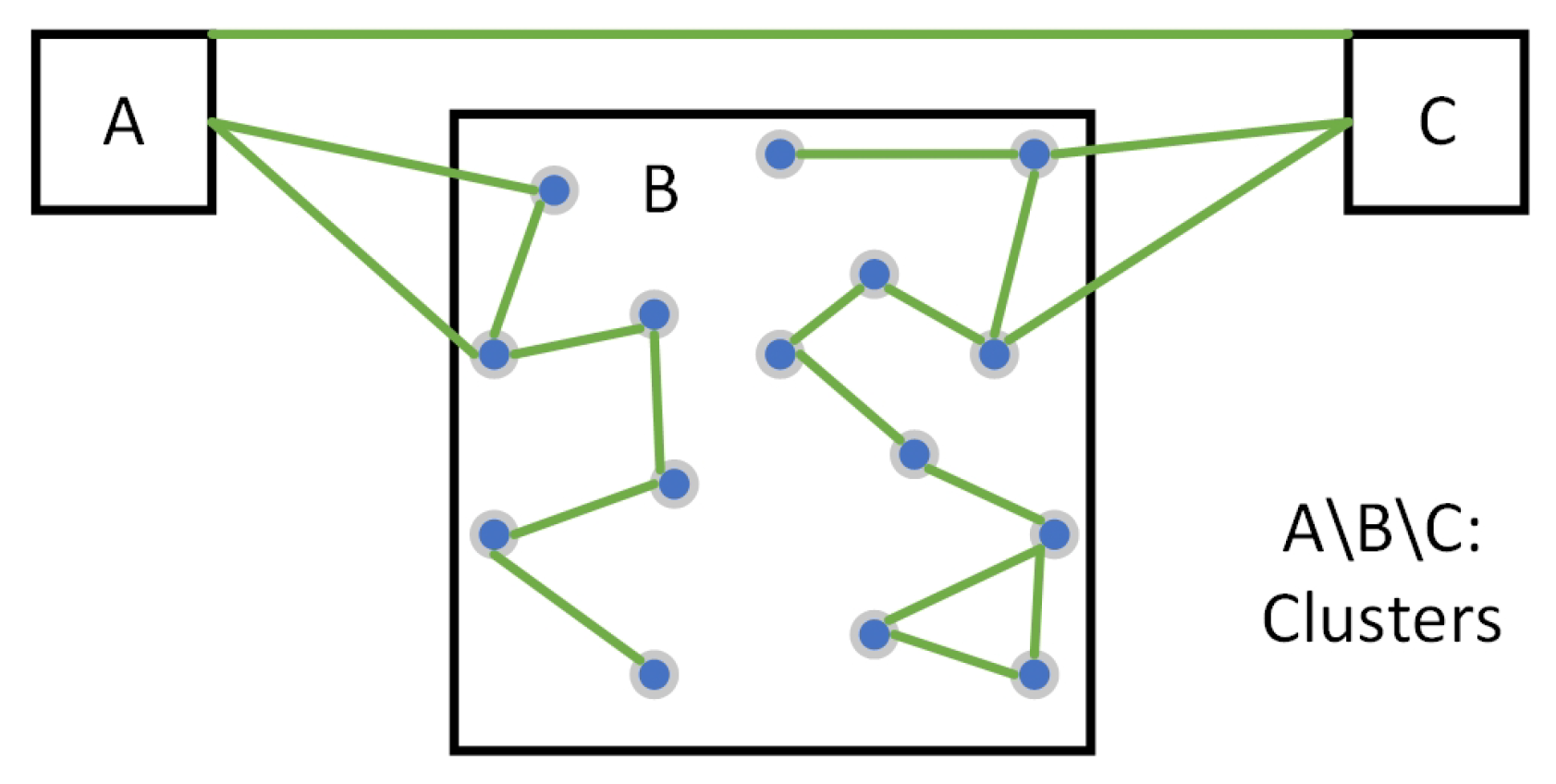
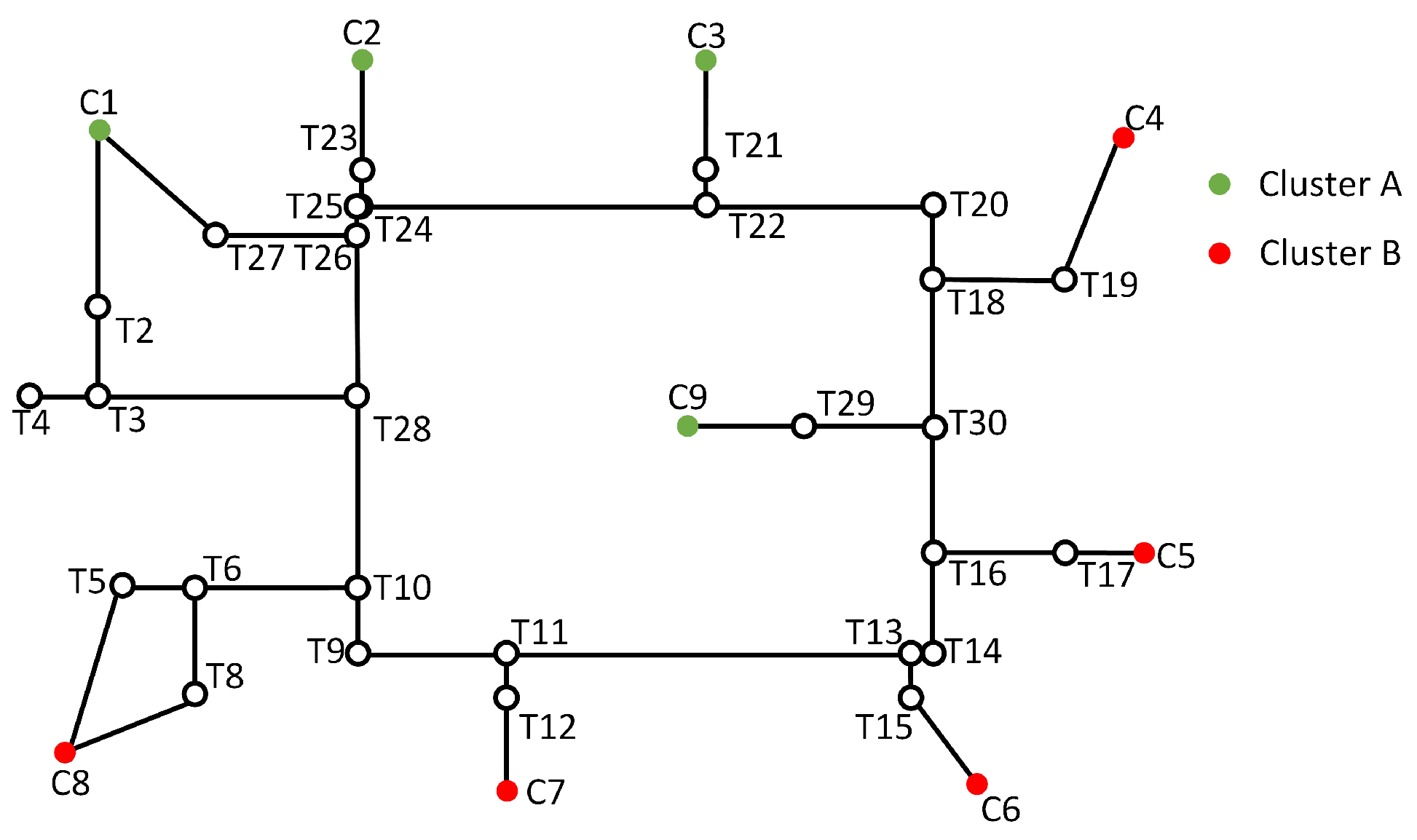
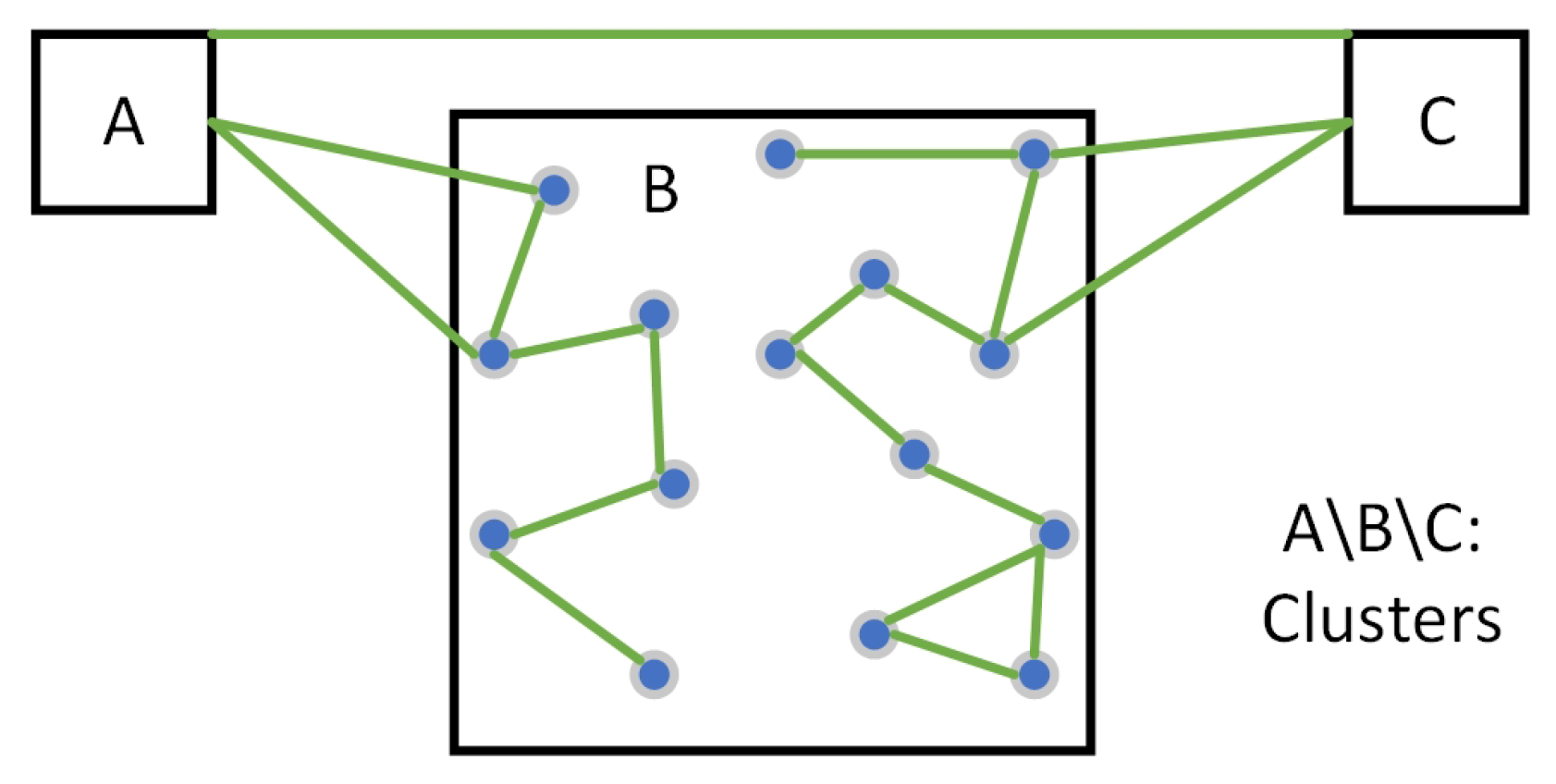
- Common nodes (): These nodes have specific functional attributes, such as room, elevator/stairs/escalator nodes. Common nodes are characterized by attributes, including identification numbers, semantic information, geometric coordinates, and connected edges. The semantics of common nodes come from the usage of the spaces that they represent. For instance, in a hospital, these usages of spaces may include wards, consultation rooms, and functional areas. During the process of IK-means, common nodes serve as the sample set and participate in the entire process.
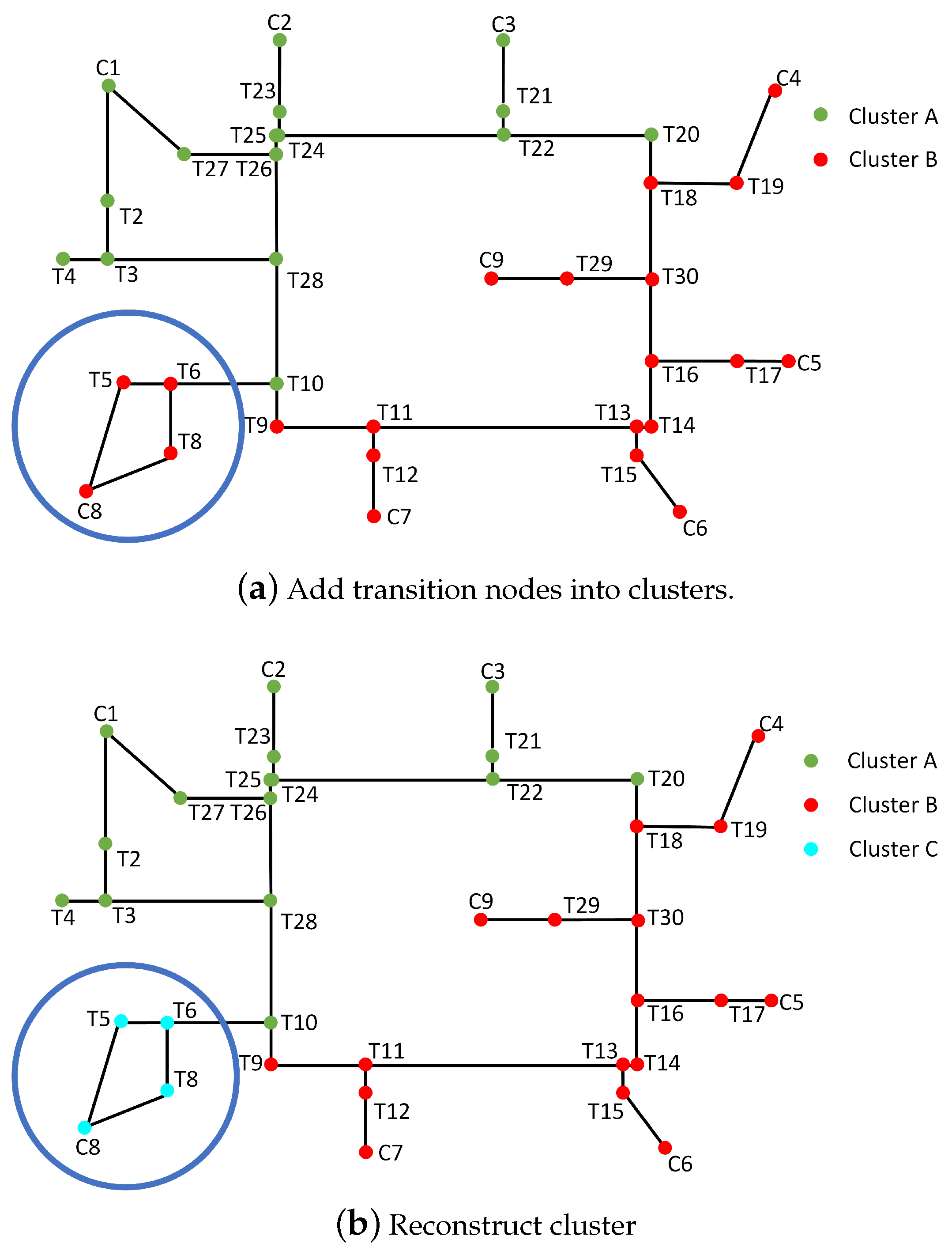
- Transition nodes (): Unlike common nodes, these nodes are intermediate nodes that serve to connect common nodes, representing locations without specific meaning. Examples of transition nodes include door nodes and corridor nodes. Transition nodes typically lack special attributes but possess attributes like identification numbers, geometric coordinates, and connected edges.
- Edges: Edges typically represent the connections between room nodes, door nodes, and corridor nodes. They are characterized by attributes such as identification numbers and information about the nodes they connect. The presence of edges is crucial in determining the existence of any orphans or disconnections within the resulting clusters after partitioning.
- Maximum number of iterations (): This parameter sets the upper limit for the number of iterations the algorithm will undergo. It is an important factor in controlling convergence and algorithm termination.
- Control parameters (): These parameters govern the influence of nominal attributes and the physical distance metric. They allow the fine-tuning of attribute importance within the clustering process.
- Number of nearest neighbor nodes (): This parameter determines the number of nearest neighbor nodes considered during cluster transition node grouping.
- Minimum number of nodes in a cluster (): This parameter sets the minimum threshold for the number of nodes within a cluster. Clusters with fewer than this number of nodes are not retained during the cluster reconstruction phase.
3.2. Determination of K
3.3. Clustering of Common Nodes
| Algorithm 1 IK-means clustering |
|
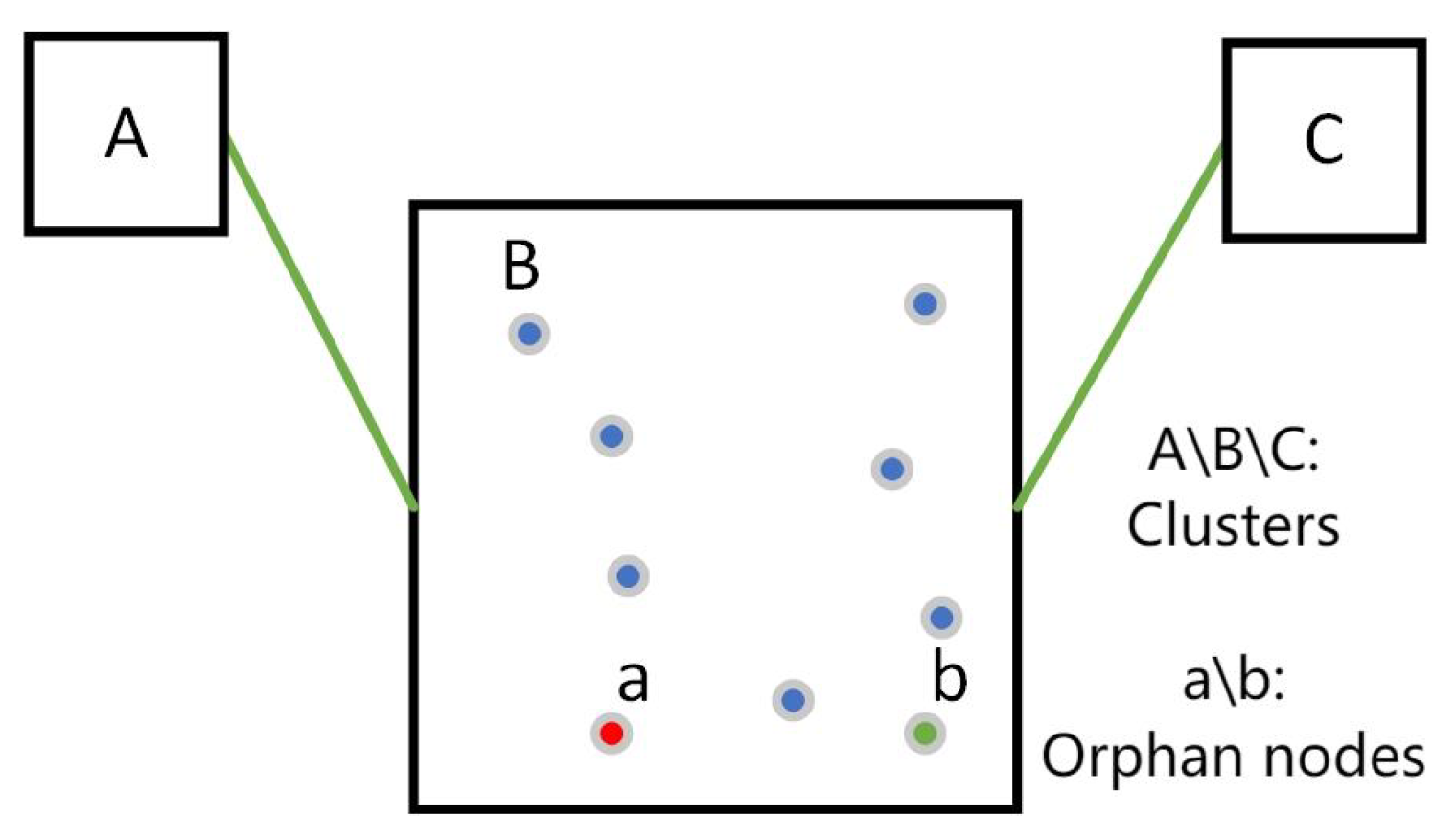
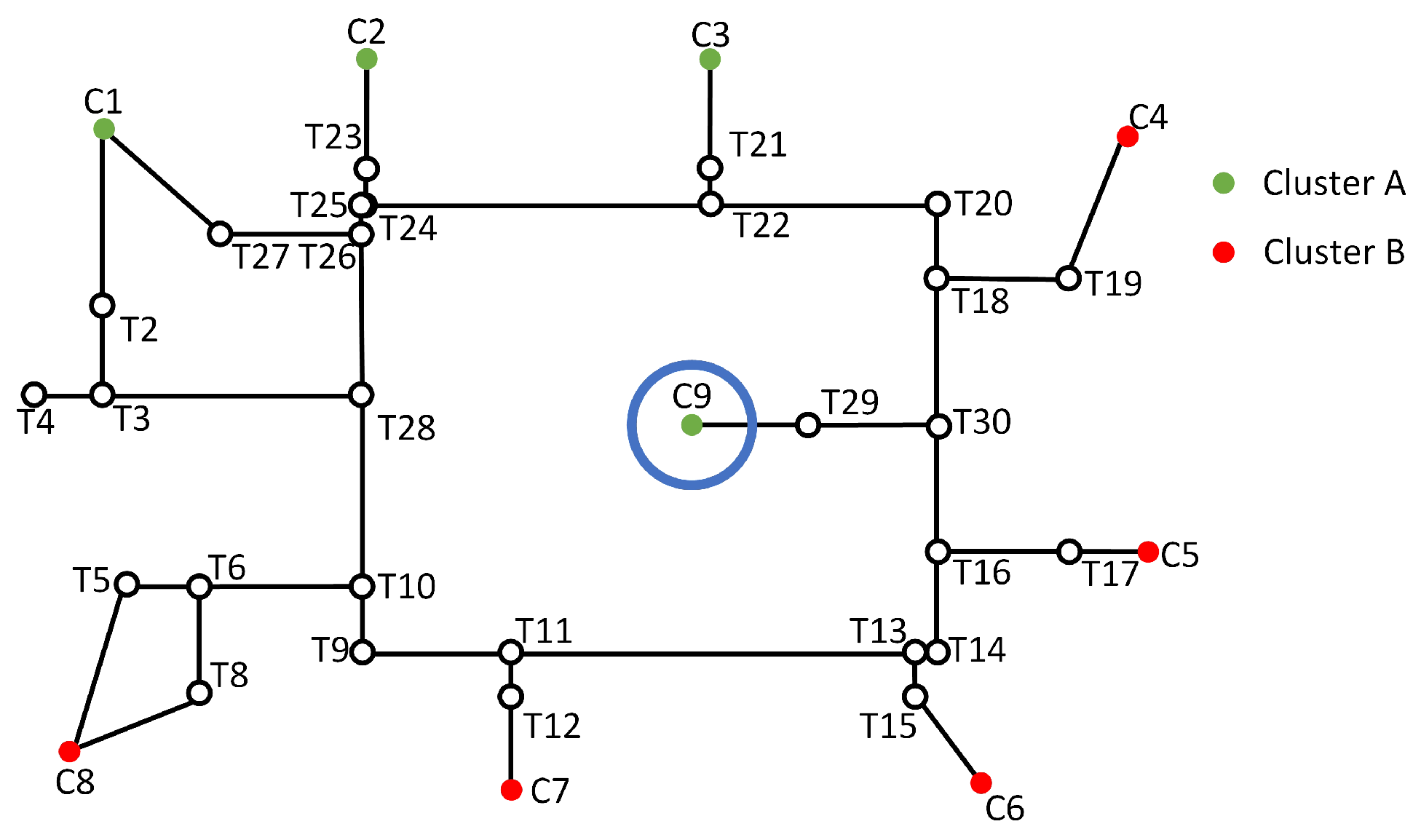
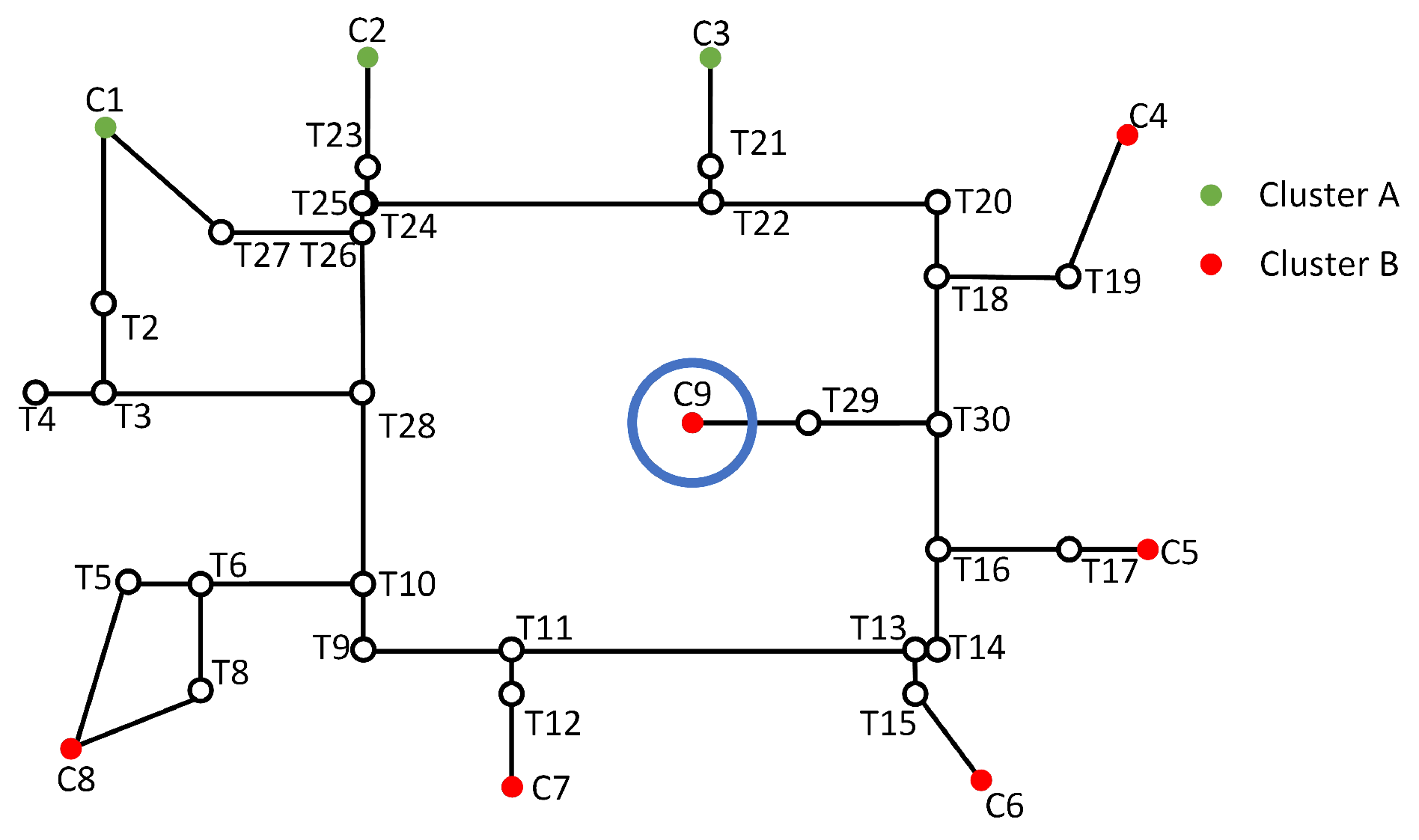
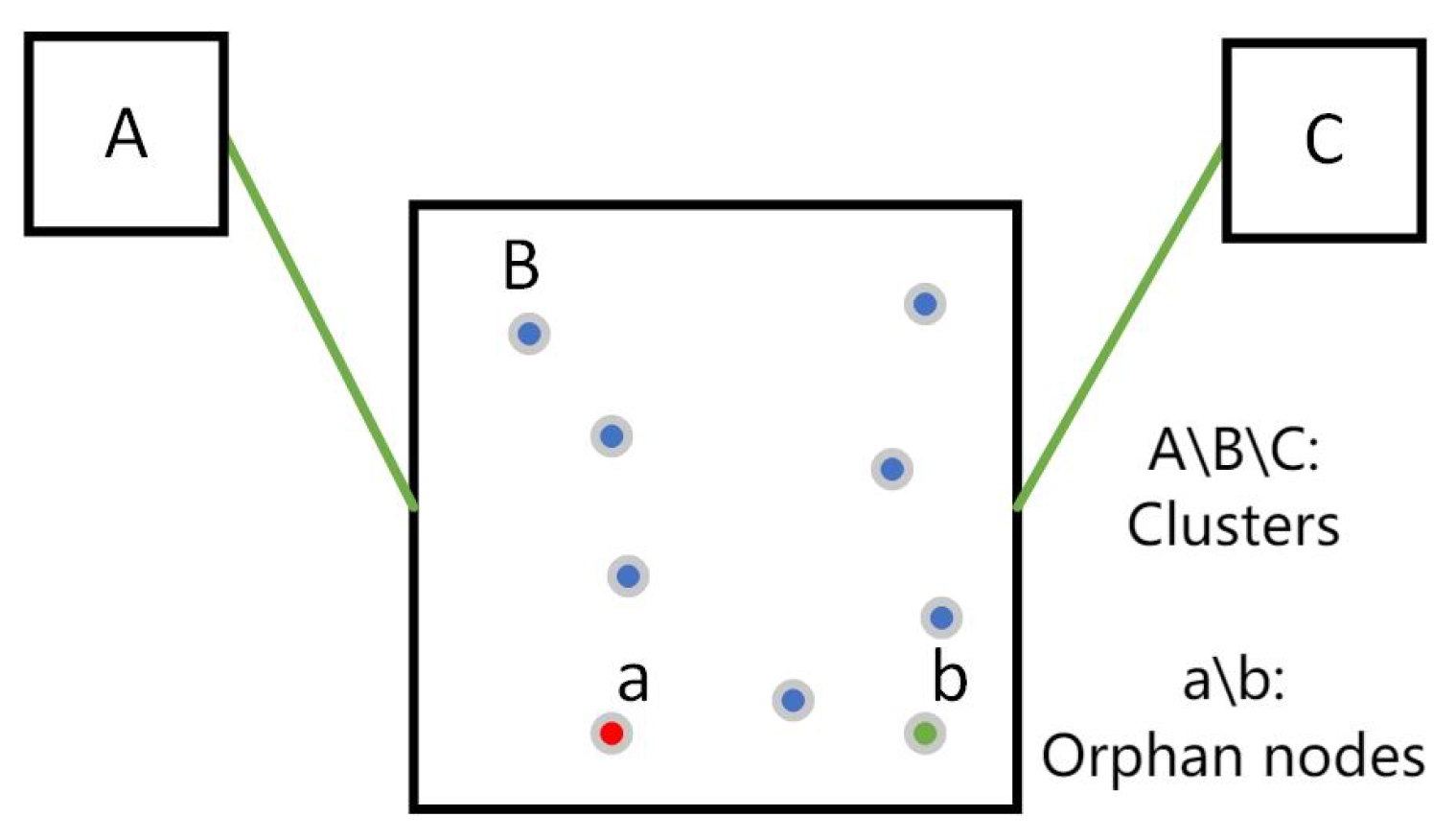
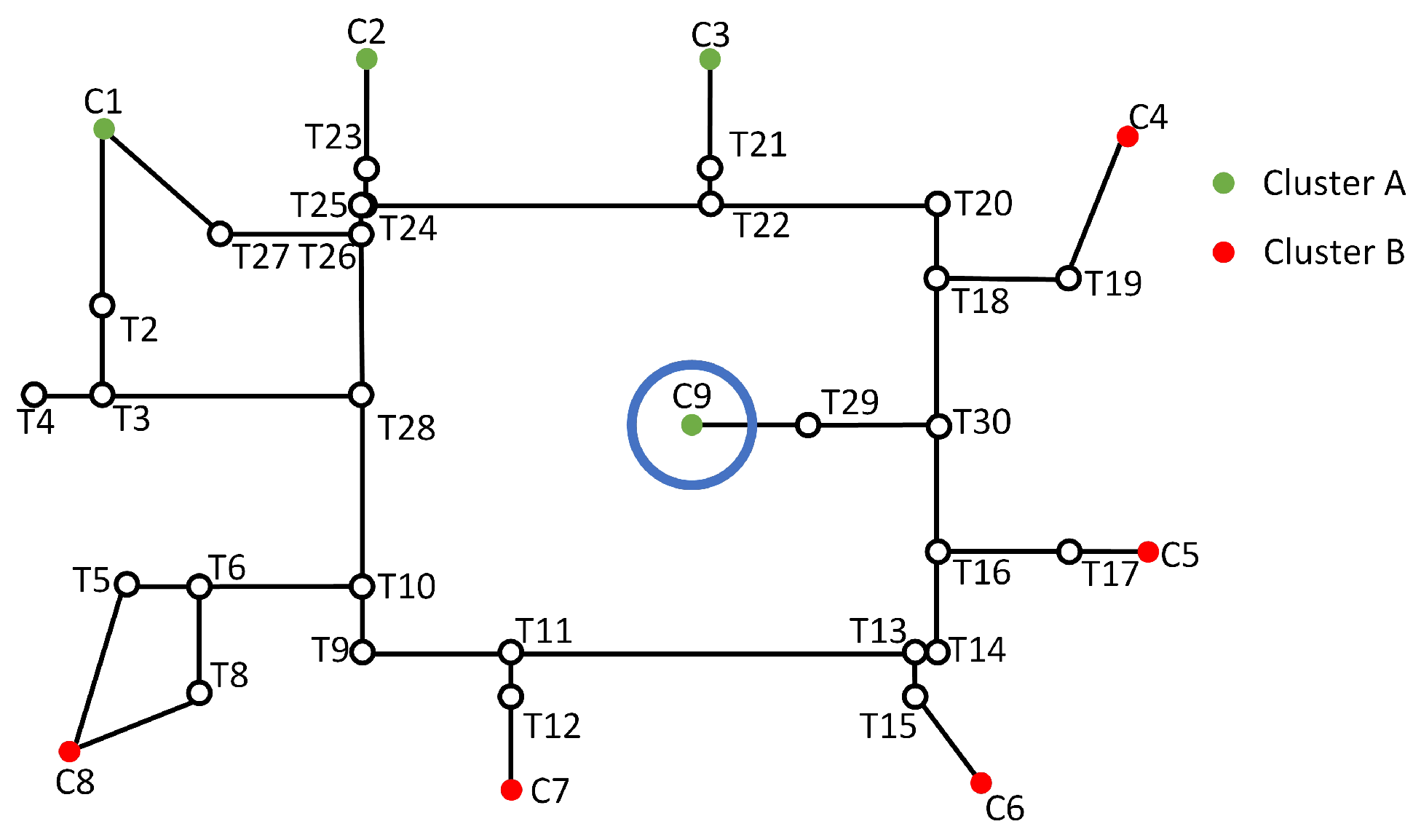
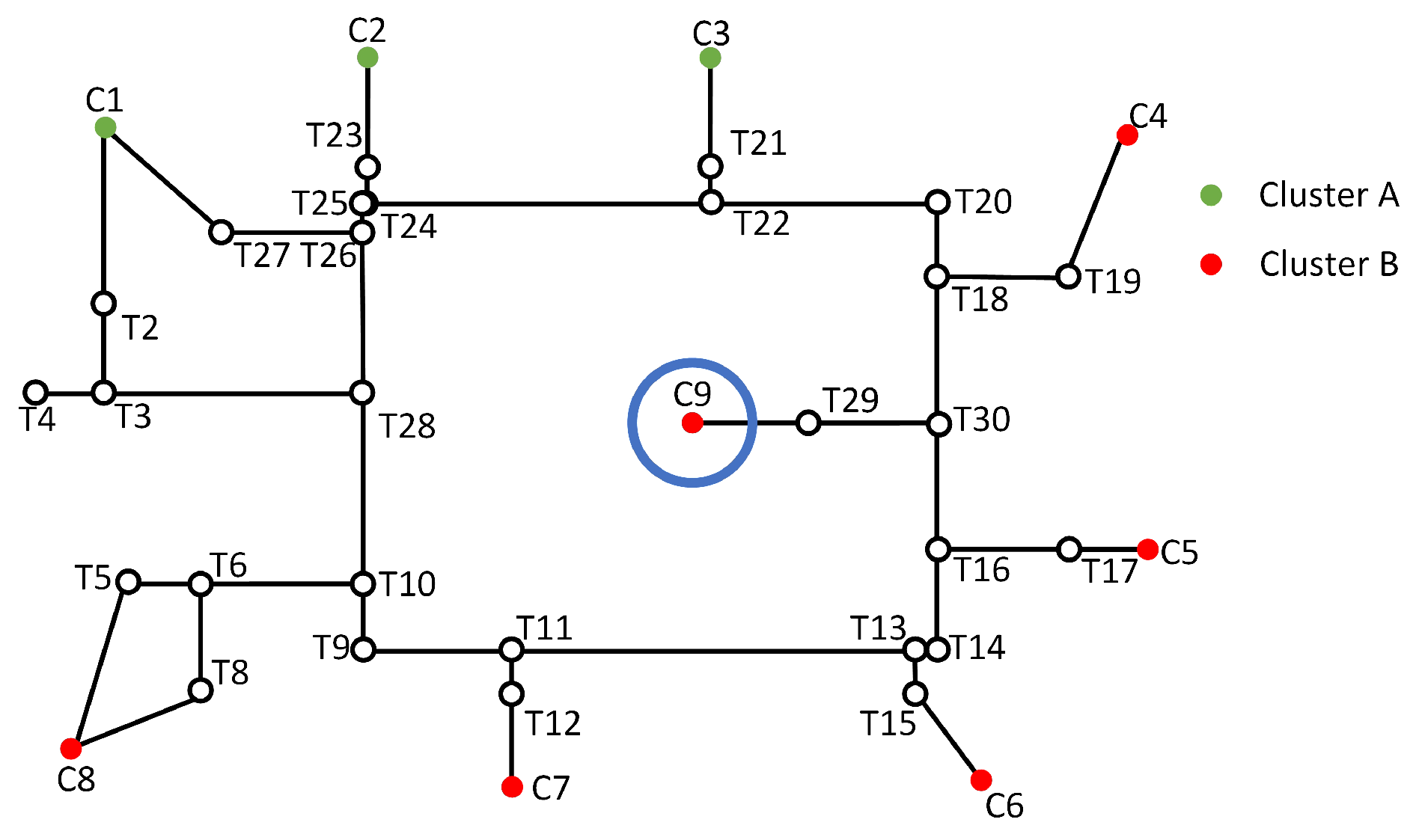
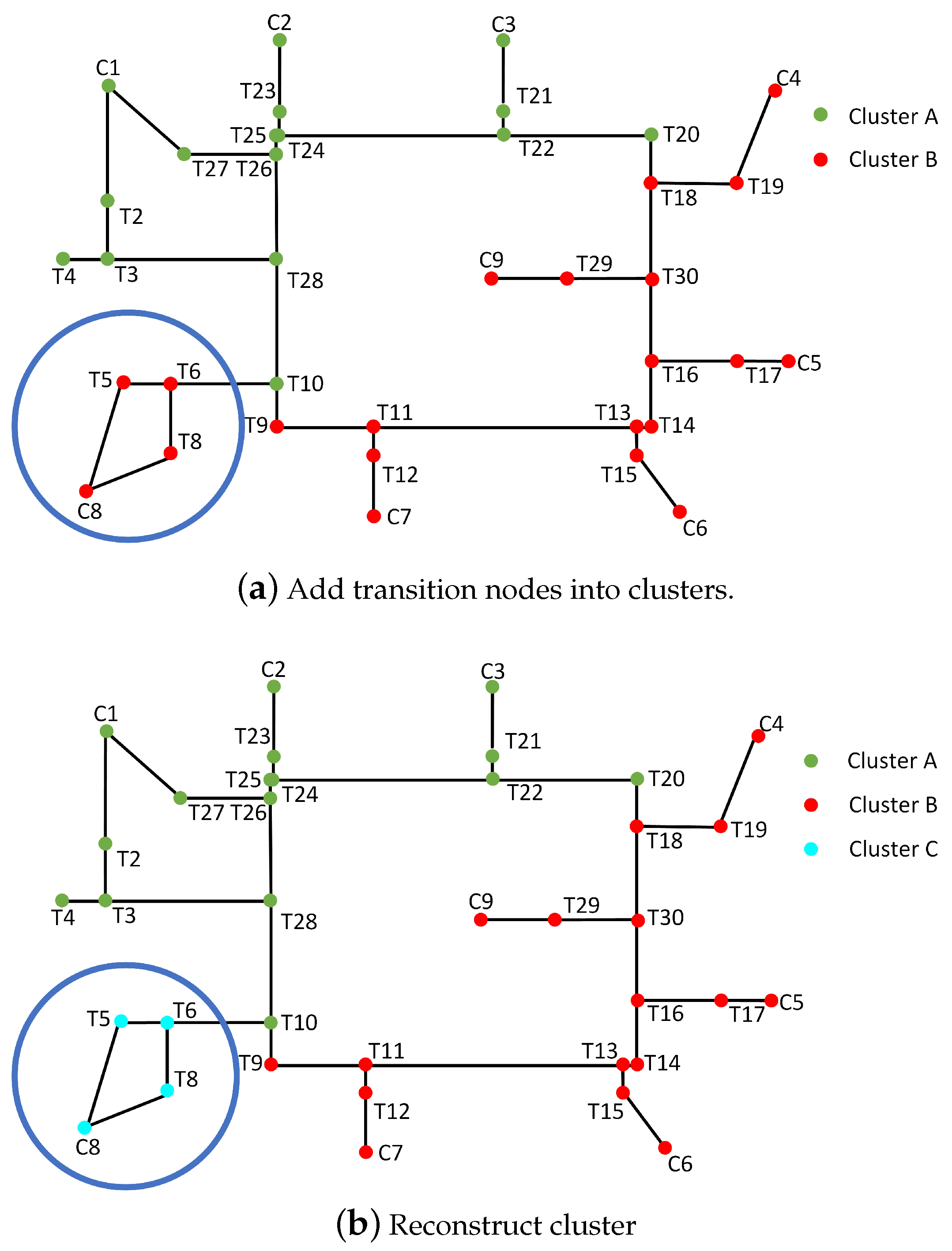
3.4. Fixing of Orphan Nodes
3.5. Clustering Transition Nodes and Reconstructing of Clusters
4. Implementation and Case Study
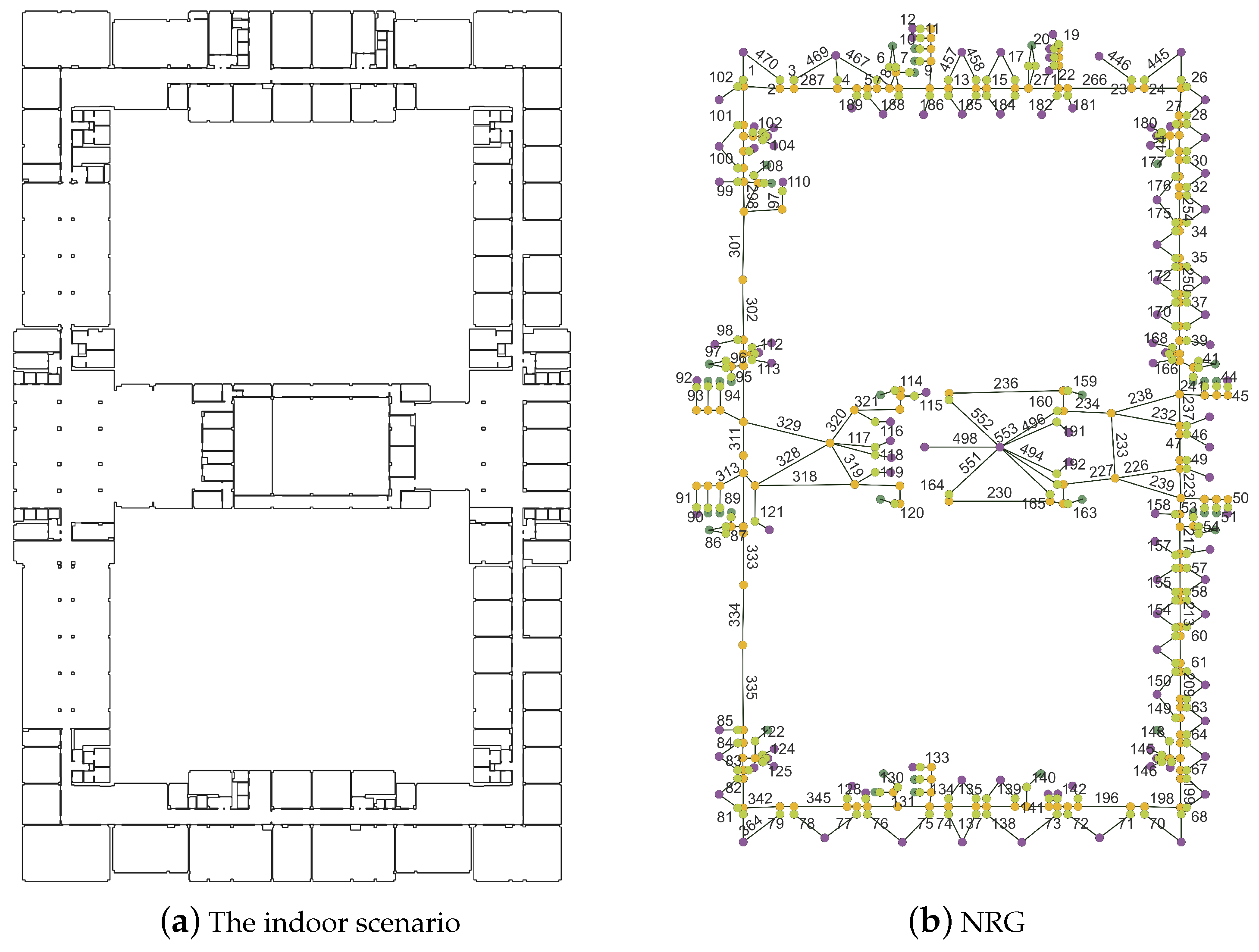
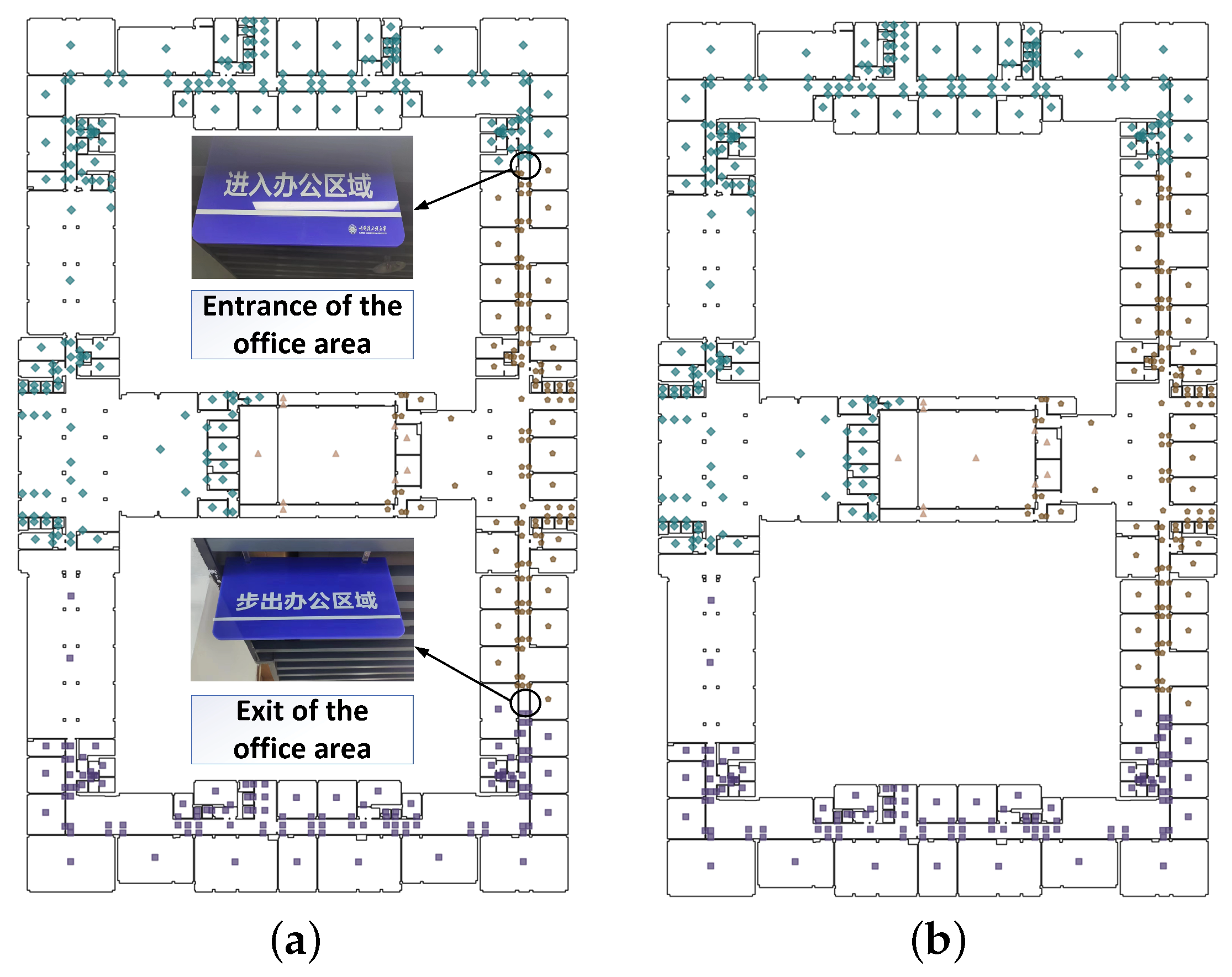
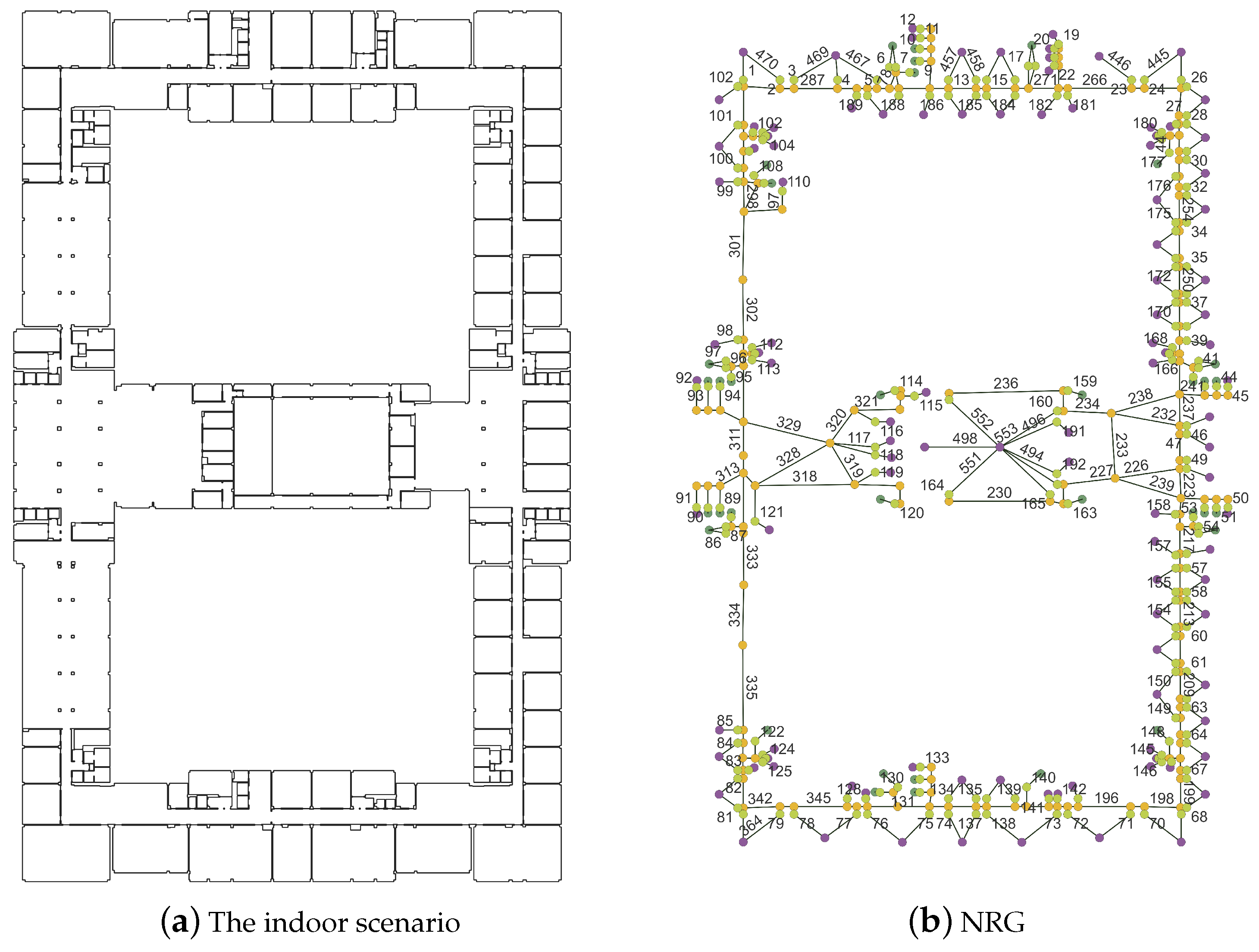
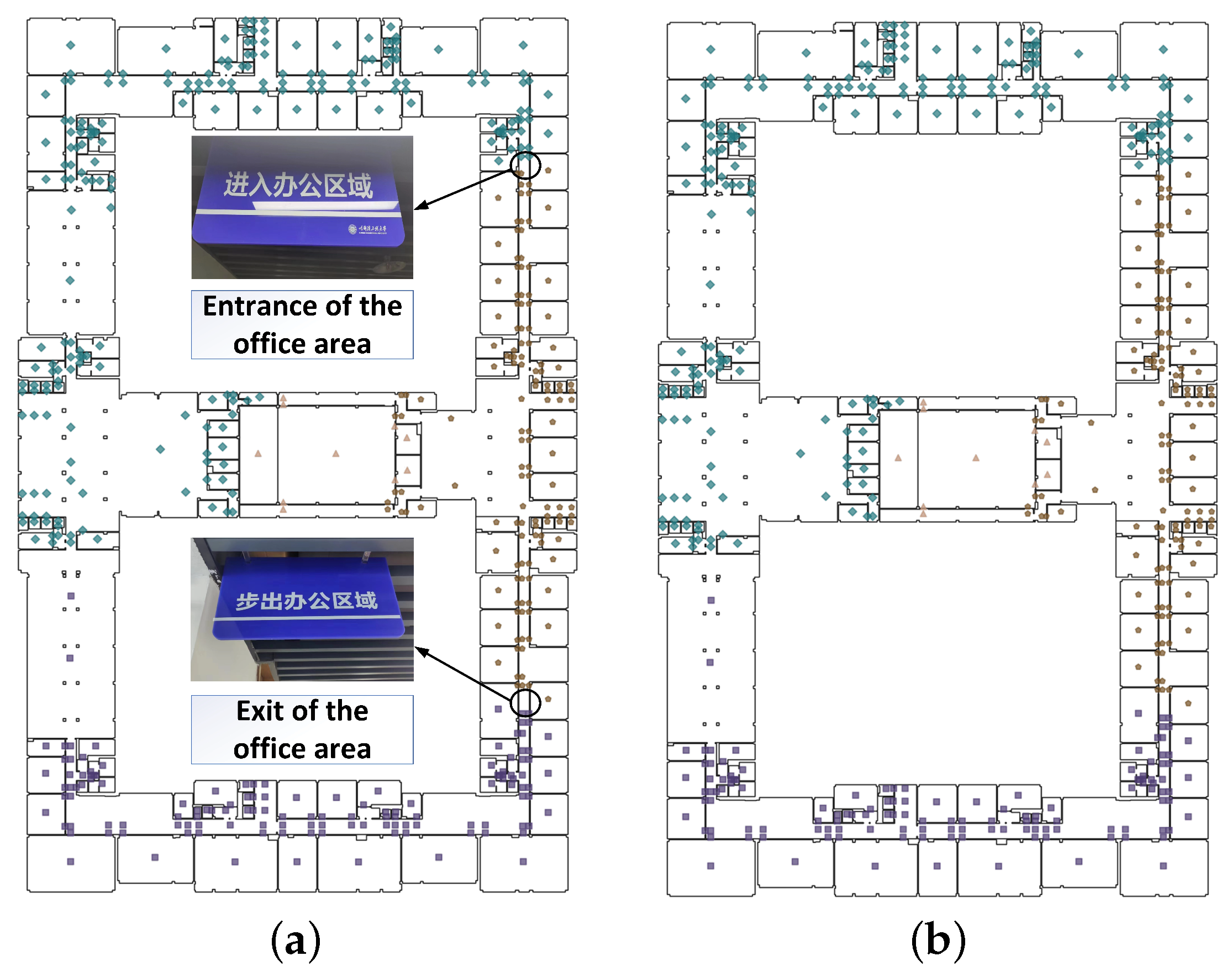
4.1. Case Description and Data Preparation
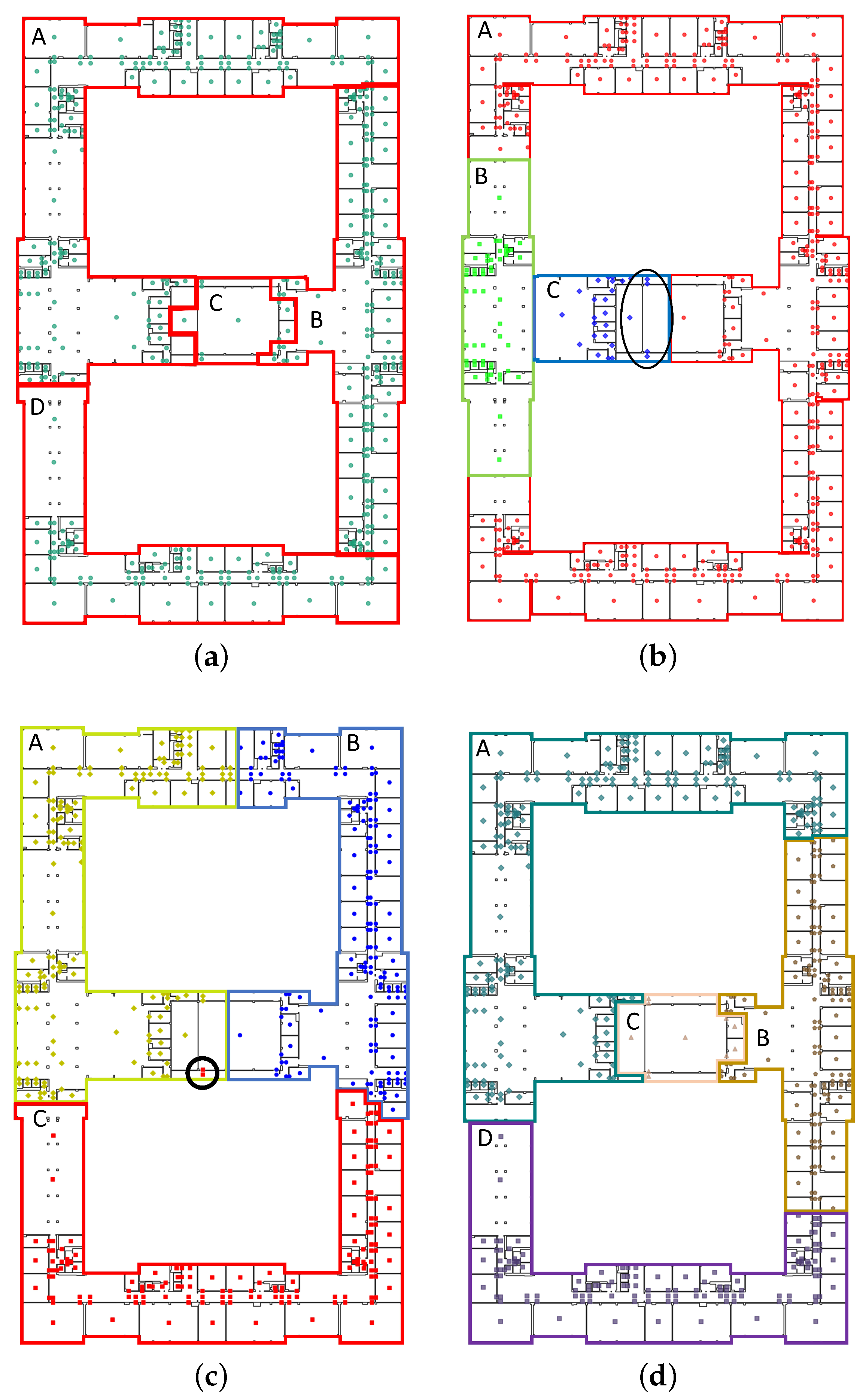
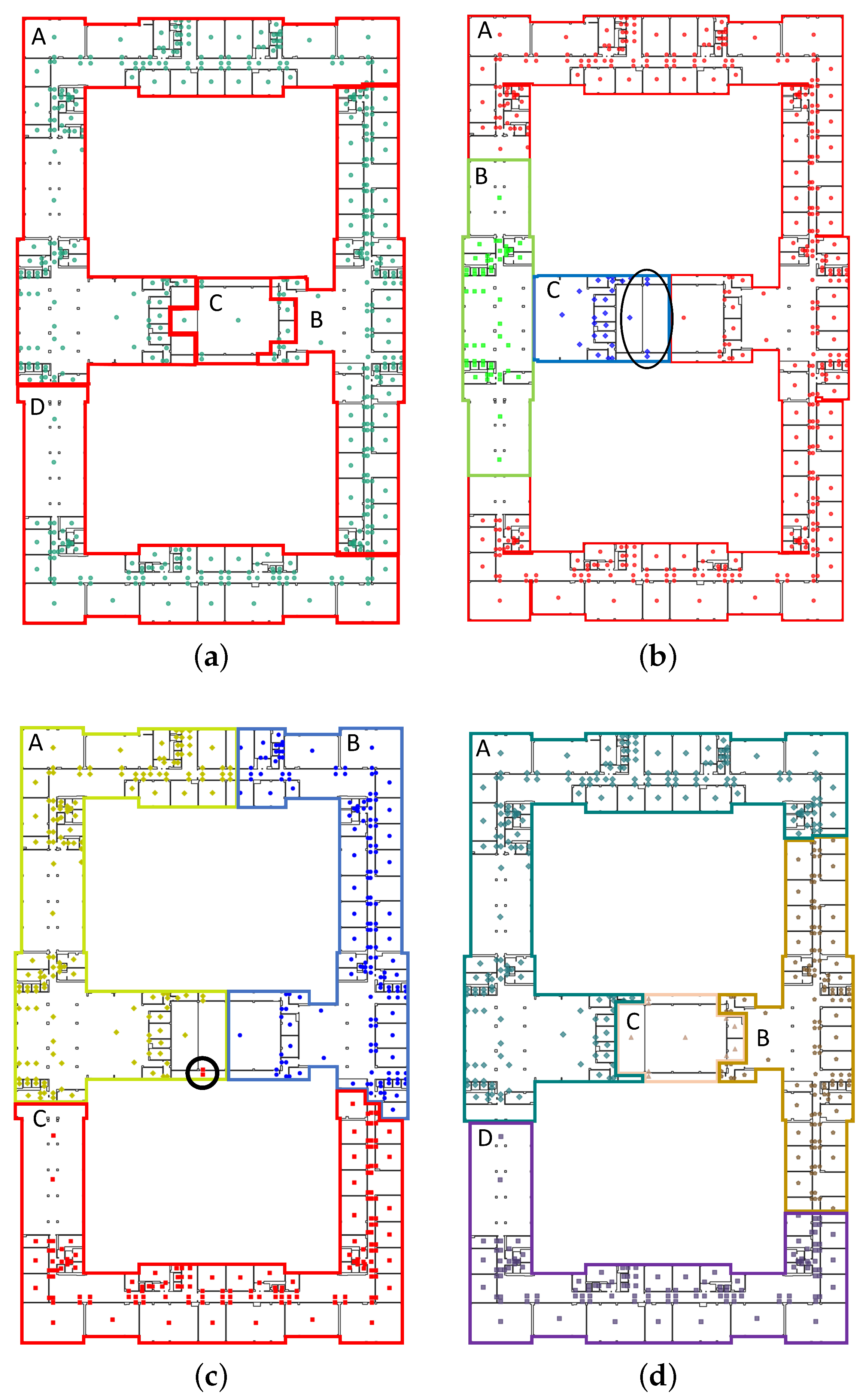
4.2. Area Partition Based on IK-Means
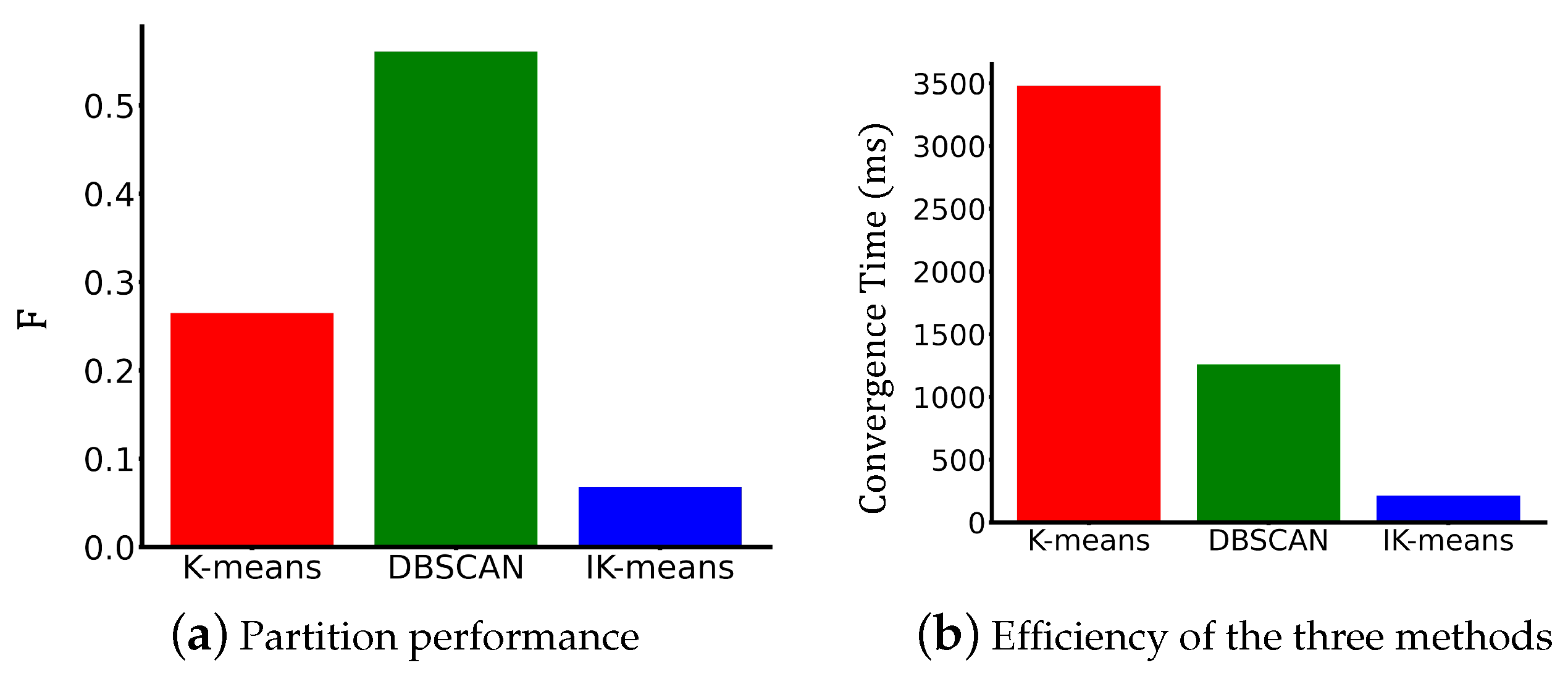
4.3. Results Analysis
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Zhang, Y.; Chen, L.; Chen, R. Intelligent Fusion Structure for Wi-Fi/BLE/QR/MEMS Sensor-Based Indoor Localization. Remote Sens. 2023, 15, 1202. [Google Scholar] [CrossRef]
- Yan, J.; Diakité, A.A.; Zlatanova, S. A generic space definition framework to support seamless indoor/outdoor navigation systems. Trans. GIS 2019, 23, 1273–1295. [Google Scholar] [CrossRef]
- Malinen, M.I.; Fränti, P. Balanced k-means for clustering. In Proceedings of the Structural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshop, S+ SSPR 2014, Joensuu, Finland, 20–22 August 2014; Proceedings. Springer: Berlin/Heidelberg, Germany, 2014; pp. 32–41. [Google Scholar]
- González-Banos, H.H.; Latombe, J.C. Navigation strategies for exploring indoor environments. Int. J. Robot. Res. 2002, 21, 829–848. [Google Scholar] [CrossRef]
- Diakité, A.A.; Zlatanova, S. Spatial subdivision of complex indoor environments for 3D indoor navigation. Int. J. Geogr. Inf. Sci. 2018, 32, 213–235. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, C.; Yang, S.; Xu, H.; Hu, B. Anomaly detection based on zone partition for security protection of industrial cyber-physical systems. IEEE Trans. Ind. Electron. 2017, 65, 4257–4267. [Google Scholar] [CrossRef]
- Lu, S.; Bharghavan, V. Adaptive resource management algorithms for indoor mobile computing environments. In Proceedings of the Conference Proceedings on Applications, Technologies, Architectures, and Protocols for Computer Communications, Palo Alto, CA, USA, 28–30 August 1996; pp. 231–242. [Google Scholar]
- Zhong, R.; Liu, X.; Liu, Y.; Chen, Y.; Wang, X. Path design and resource management for NOMA enhanced indoor intelligent robots. IEEE Trans. Wirel. Commun. 2022, 21, 8007–8021. [Google Scholar] [CrossRef]
- Li, J.; Gao, X.; Hu, Z.; Wang, H.; Cao, T.; Yu, L. Indoor localization method based on regional division with IFCM. Electronics 2019, 8, 559. [Google Scholar] [CrossRef]
- Oti, E.U.; Olusola, M.O.; Eze, F.C.; Enogwe, S.U. Comprehensive review of K-Means clustering algorithms. Criterion 2021, 12, 22–23. [Google Scholar] [CrossRef]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. arXiv 2013, arXiv:1301.3572. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Amoozandeh, K.; Winter, S.; Tomko, M. Granularity of origins and clustering destinations in indoor wayfinding. Comput. Environ. Urban Syst. 2023, 99, 101891. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Brodschneider, R.; Schlagbauer, J.; Arakelyan, I.; Ballis, A.; Brus, J.; Brusbardis, V.; Cadahía, L.; Charrière, J.D.; Chlebo, R.; Coffey, M.F.; et al. Spatial clusters of Varroa destructor control strategies in Europe. J. Pest Sci. 2023, 96, 759–783. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Aliguliyev, R.M.; Sultanova, N. Finding compact and well-separated clusters: Clustering using silhouette coefficients. Pattern Recognit. 2023, 135, 109144. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Yu, D.; Liu, G.; Guo, M.; Liu, X. An improved K-medoids algorithm based on step increasing and optimizing medoids. Expert Syst. Appl. 2018, 92, 464–473. [Google Scholar] [CrossRef]
- Liu, X.; Zhu, X.; Li, M.; Wang, L.; Zhu, E.; Liu, T.; Kloft, M.; Shen, D.; Yin, J.; Gao, W. Multiple kernel k k-means with incomplete kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1191–1204. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Khan, K.; Rehman, S.U.; Aziz, K.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. In Proceedings of the the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Bangalore, India, 17–19 February 2014; pp. 232–238. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview, II. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1219. [Google Scholar] [CrossRef]
- Liu, J.; Han, J. Spectral clustering. In Data Clustering; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 177–200. [Google Scholar]
- Munkres, J.R. Elements of Algebraic Topology; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Hamerly, G.; Elkan, C. Learning the k in k-means. Adv. Neural Inf. Process. Syst. 2003, 16. [Google Scholar]
- Kodinariya, T.M.; Makwana, P.R. Review on determining number of Cluster in K-Means Clustering. Int. J. 2013, 1, 90–95. [Google Scholar]
- Khan, S.S.; Ahmad, A. Cluster center initialization algorithm for K-means clustering. Pattern Recognit. Lett. 2004, 25, 1293–1302. [Google Scholar] [CrossRef]
- Rosenbaum, M.S.; Otalora, M.L.; Ramírez, G.C. The restorative potential of shopping malls. J. Retail. Consum. Serv. 2016, 31, 157–165. [Google Scholar] [CrossRef]
- Lee, H.J.; Lee, K.H.; Kim, D.K. Evaluation and comparison of the indoor air quality in different areas of the hospital. Medicine 2020, 99, e23942. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
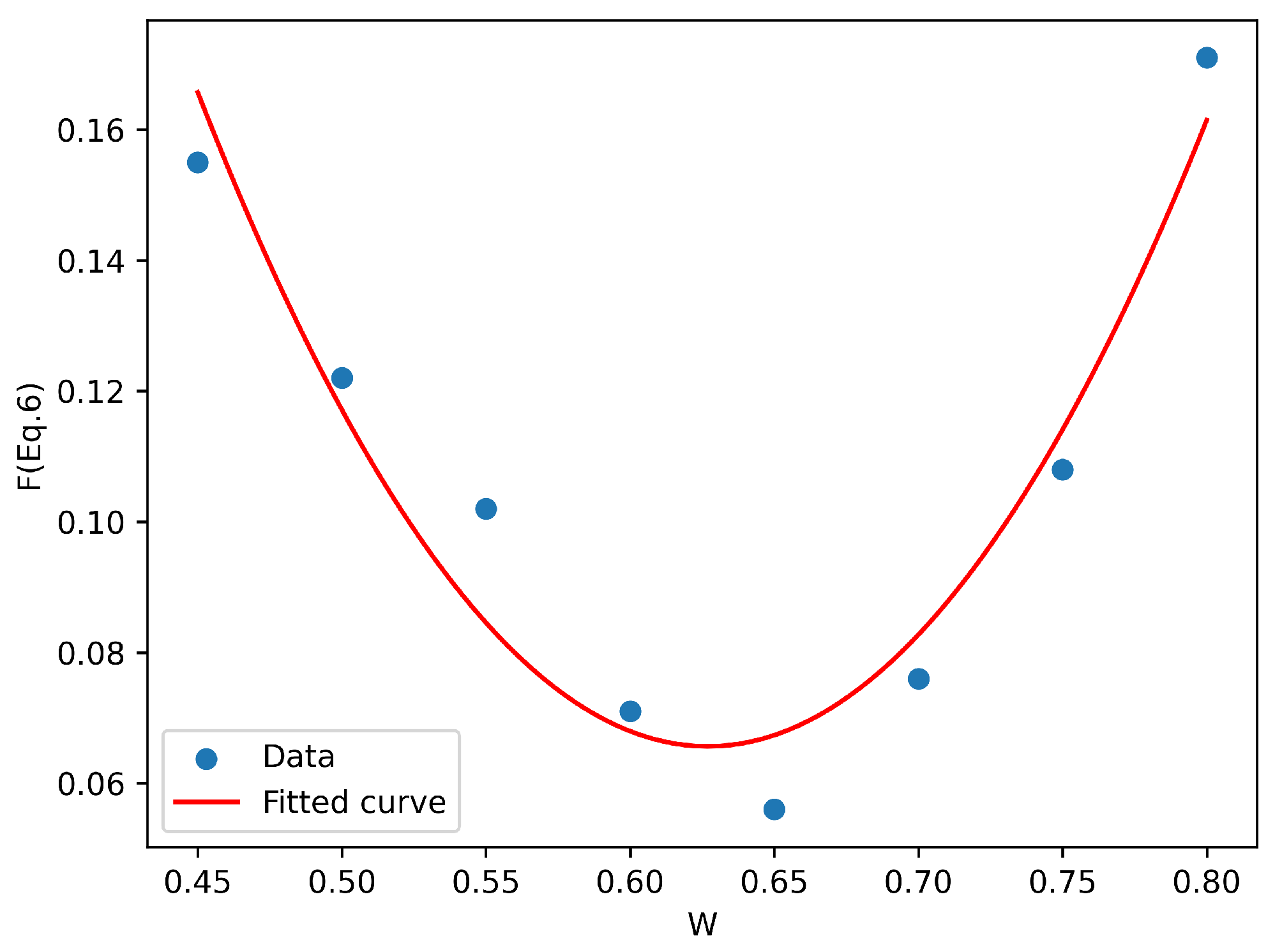
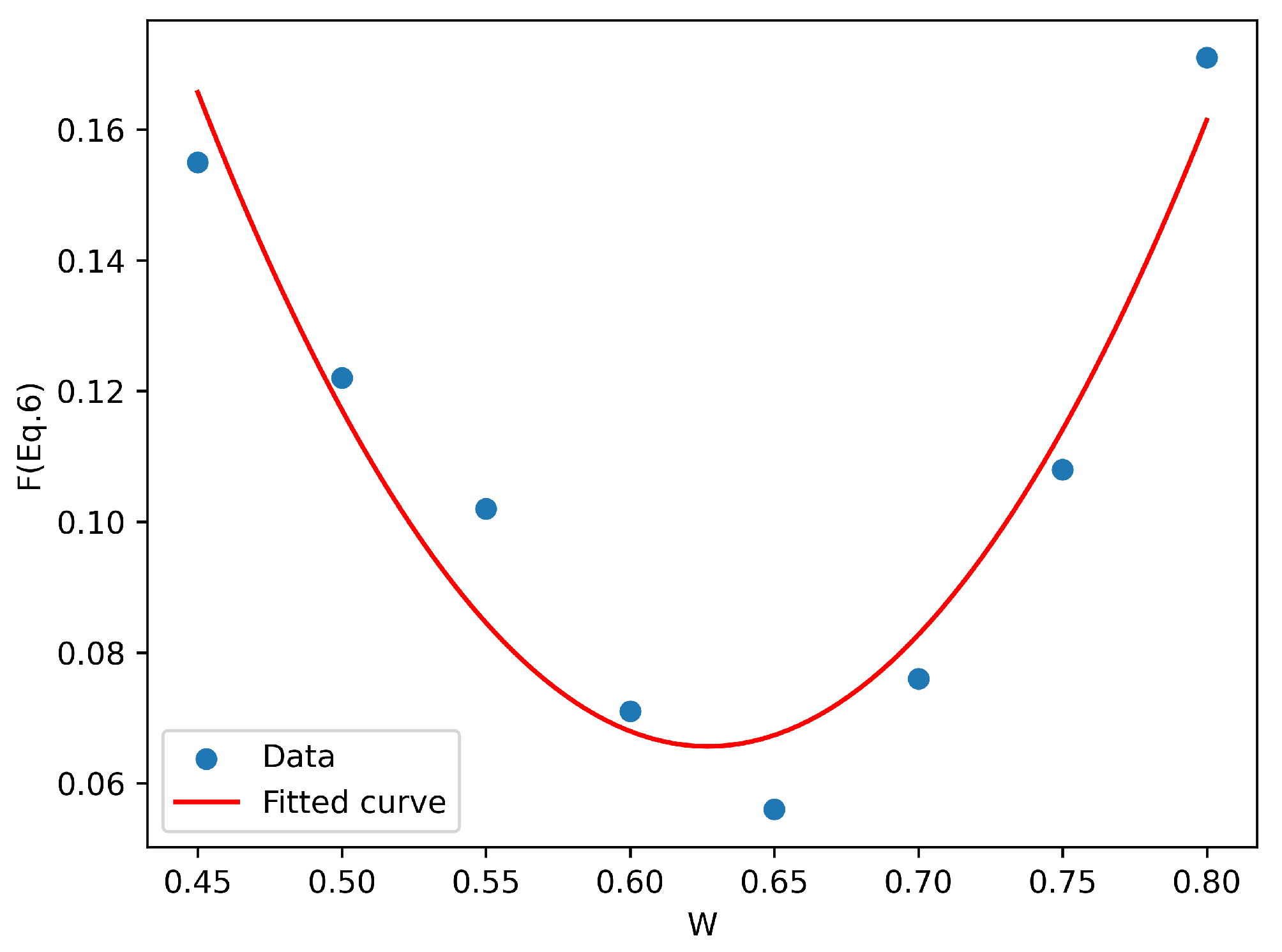
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| W | 0.8 | 0.75 | 0.7 | 0.65 | 0.6 | 0.55 | 0.5 | 0.45 |
| (1 − W) | 0.2 | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 | 0.5 | 0.55 |
| F (Equation (6)) | 0.171 | 0.108 | 0.076 | 0.056 | 0.071 | 0.102 | 0.122 | 0.155 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Average | |
|---|---|---|---|---|---|---|---|---|---|
| K-means | 4040.29 | 3169.19 | 3203.23 | 4151.75 | 3506.62 | 3182.59 | 3329.38 | 3262.34 | 3480.67 |
| DBSCAN | 1084.18 | 1269.31 | 1280.51 | 1220.46 | 1288.78 | 1311.52 | 1364.64 | 1265.18 | 1260.57 |
| IK-means | 242.77 | 236.35 | 220.61 | 224.88 | 191.49 | 198.47 | 188.11 | 209.44 | 214.01 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Average | |
|---|---|---|---|---|---|---|---|---|---|
| K-means | 0.208 | 0.304 | 0.217 | 0.225 | 0.473 | 0.284 | 0.209 | 0.203 | 0.265 |
| DBSCAN | 0.576 | 0.674 | 0.478 | 0.488 | 0.525 | 0.538 | 0.592 | 0.618 | 0.561 |
| IK-means | 0.044 | 0.056 | 0.072 | 0.124 | 0.032 | 0.054 | 0.073 | 0.092 | 0.068 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, K.; Yan, J.; Yang, J. A Semantic Partition Algorithm Based on Improved K-Means Clustering for Large-Scale Indoor Areas. ISPRS Int. J. Geo-Inf. 2024, 13, 41. https://doi.org/10.3390/ijgi13020041
Shi K, Yan J, Yang J. A Semantic Partition Algorithm Based on Improved K-Means Clustering for Large-Scale Indoor Areas. ISPRS International Journal of Geo-Information. 2024; 13(2):41. https://doi.org/10.3390/ijgi13020041
Chicago/Turabian StyleShi, Kegong, Jinjin Yan, and Jinquan Yang. 2024. "A Semantic Partition Algorithm Based on Improved K-Means Clustering for Large-Scale Indoor Areas" ISPRS International Journal of Geo-Information 13, no. 2: 41. https://doi.org/10.3390/ijgi13020041
APA StyleShi, K., Yan, J., & Yang, J. (2024). A Semantic Partition Algorithm Based on Improved K-Means Clustering for Large-Scale Indoor Areas. ISPRS International Journal of Geo-Information, 13(2), 41. https://doi.org/10.3390/ijgi13020041