

Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal

 , ,
, ,  ,
,  , , ,
, , ,  , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
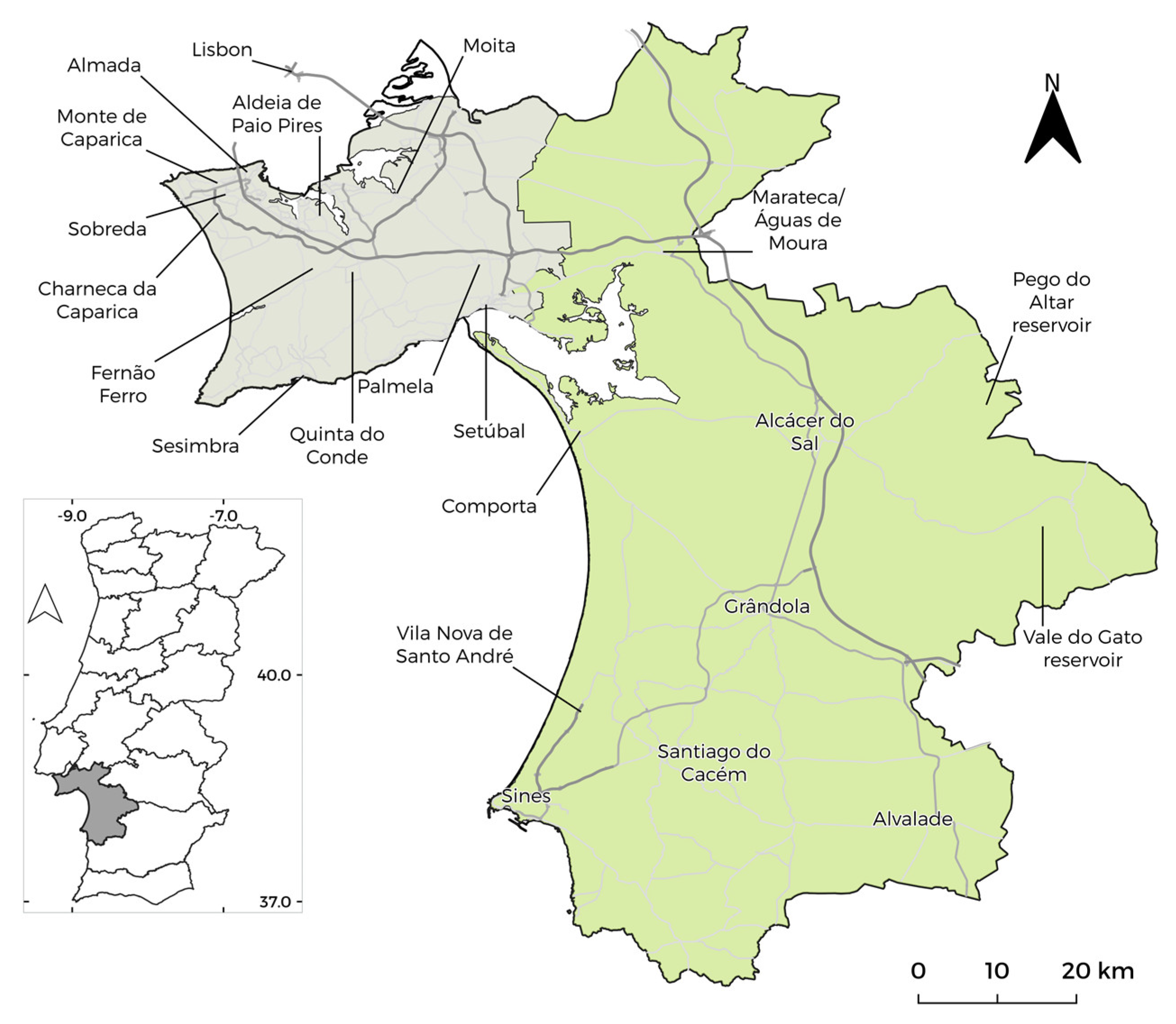
1.1. Location
1.2. Determinants for RTAs in Setúbal District
2. State of the Art
3. Methodology
3.1. Data Collection
3.2. Data Validation, Cleaning and Filtering
3.3. Kernel Density Estimation (KDE)
3.4. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
3.5. Getis-Ord Gi* and Local Moran-I
4. Results
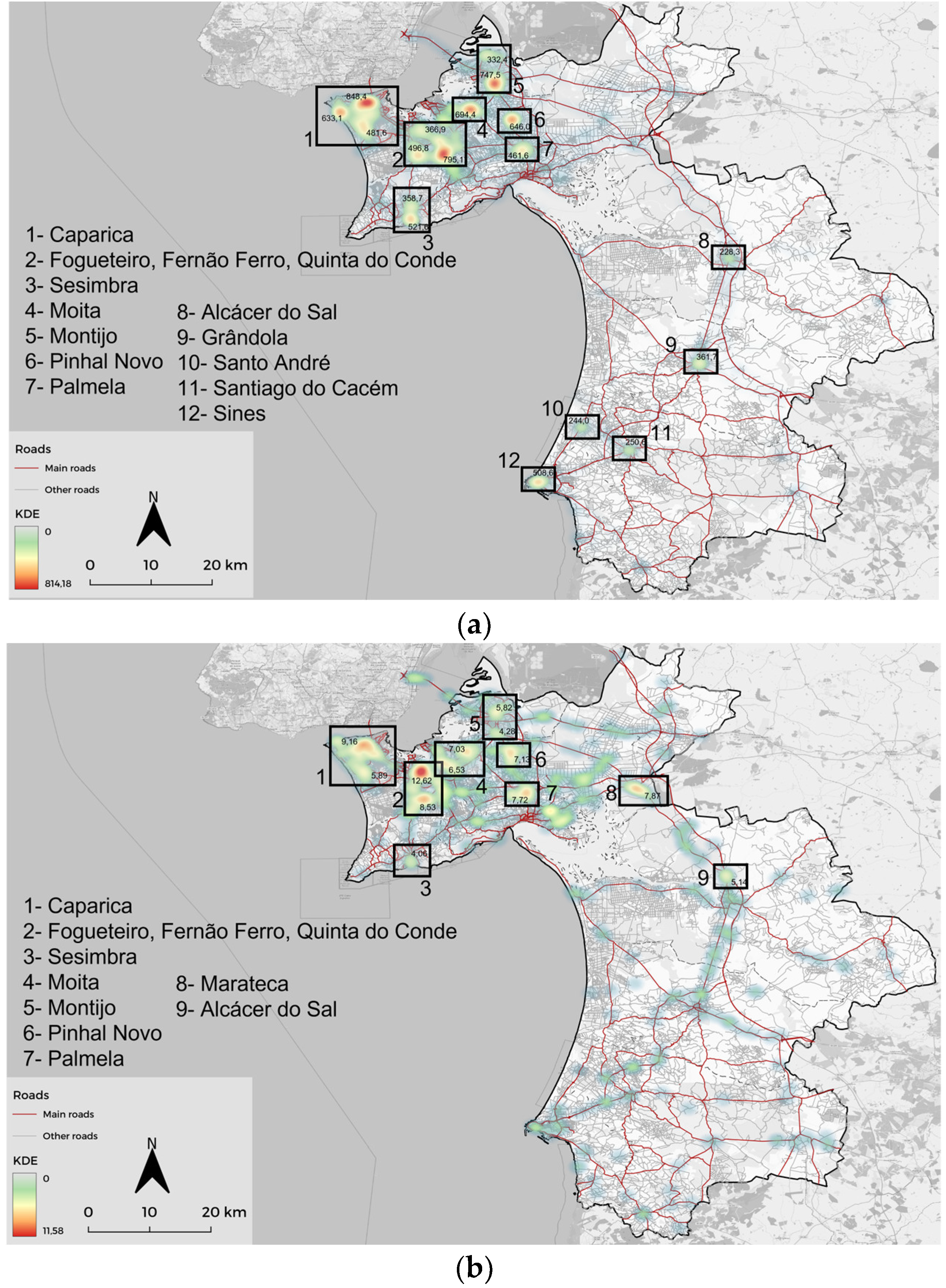
4.1. KDE Analysis
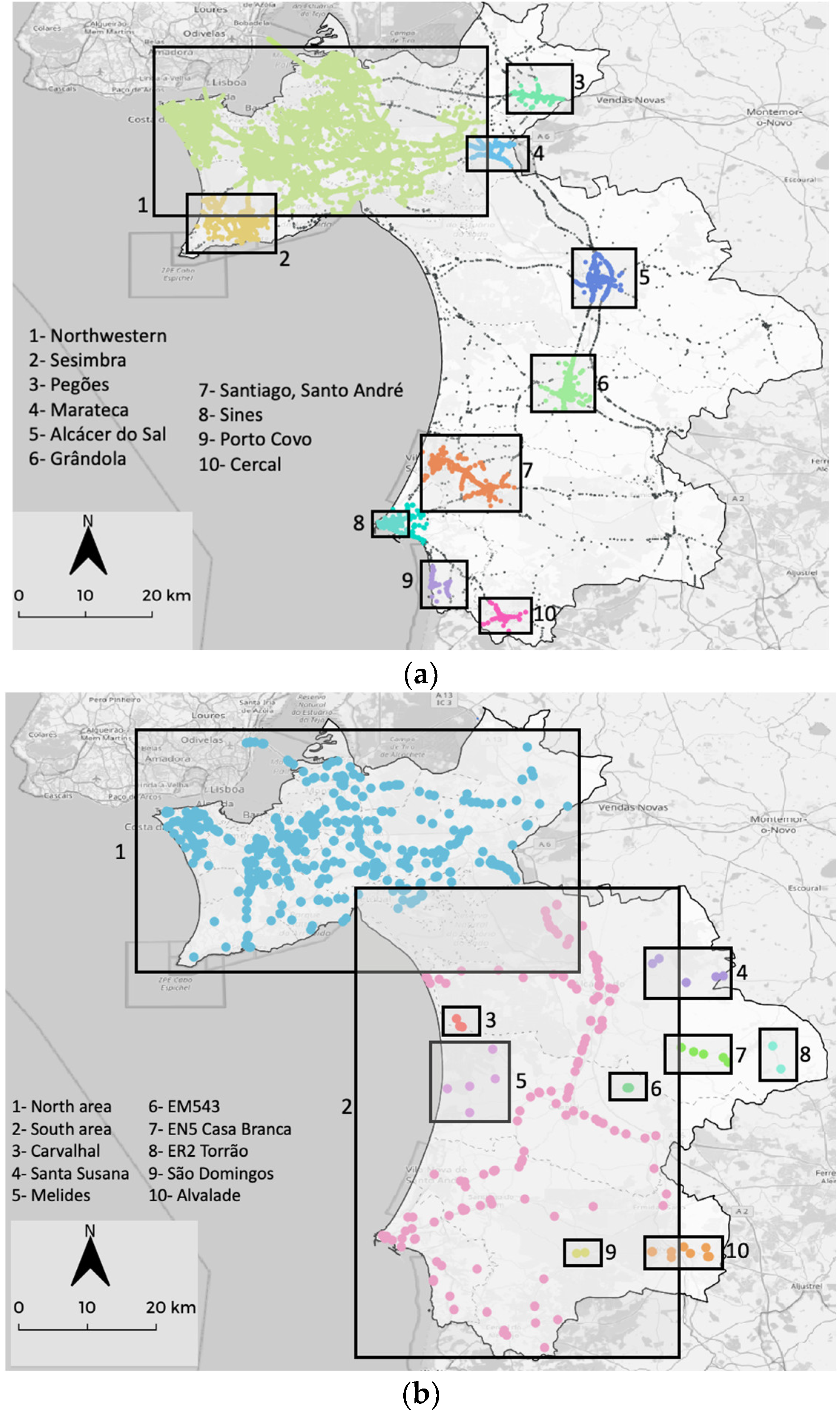
4.2. DBSCAN Analysis
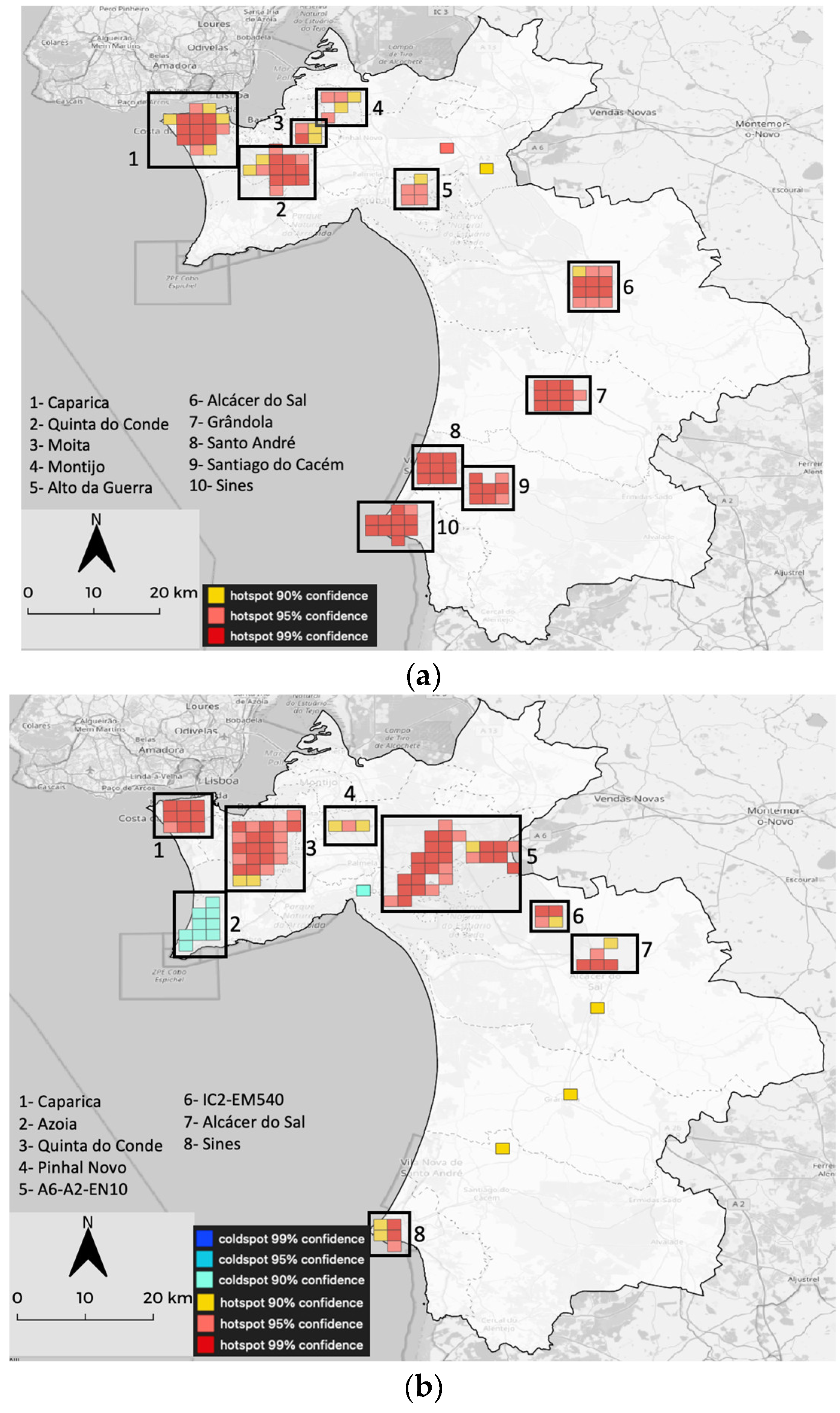
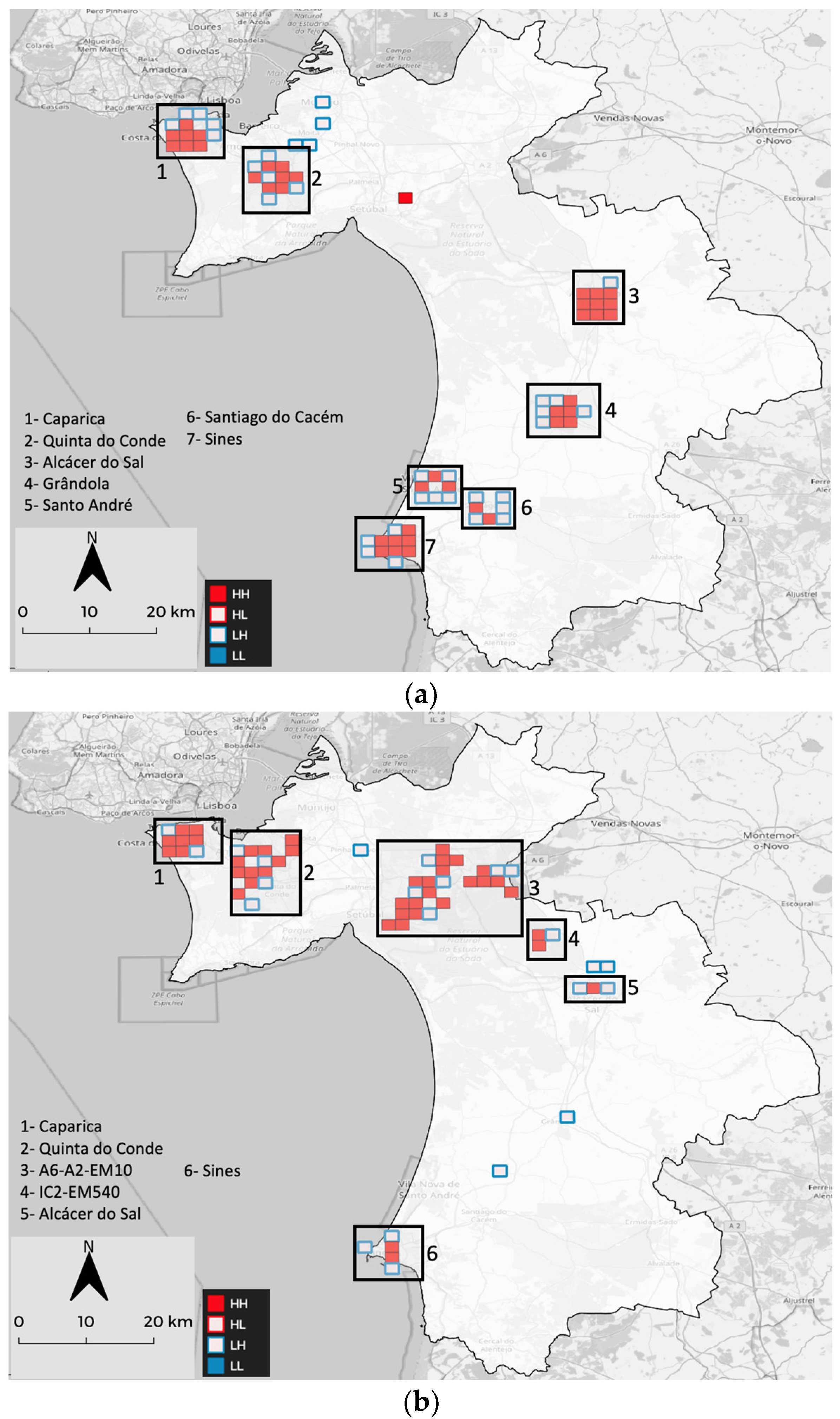
4.3. Getis-Ord Gi* and Local Moran-i Analysis
5. Discussion
6. Final Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Factsheets. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 22 November 2022).
- Peden, M.; Scurfield, R.; Sleet, D.; Mohan, D.; Hyder, A.A.; Jarawan, E.; Mathers, C. World Report on Road Traffic Injury Prevention; World Health Organization: Geneva, Switzerland, 2004; 244p. [Google Scholar]
- Ashraf, I.; Hur, S.; Shafiq, M.; Park, Y. Catastrophic factors involved in road accidents: Underlying causes and descriptive analysis. PLoS ONE 2019, 14, e0223473. [Google Scholar] [CrossRef] [PubMed]
- Cabrera-Arnau, C.; Curiel, R.; Bishop, S. Uncovering the behaviour of road accidents in urban areas. R. Soc. Open Sci. 2020, 7, 191739. [Google Scholar] [CrossRef] [PubMed]
- Eksler, V.; Lassare, S.; Thomas, I. Regional analysis of road mortality in Europe. Public Health 2008, 122, 826–837. [Google Scholar] [CrossRef] [PubMed]
- Noland, R.; Quddus, M. A spatially disaggregate analysis of road casualties in England. Accid. Anal. Prev. 2004, 36, 973–984. [Google Scholar] [CrossRef] [PubMed]
- Spoerri, A.; Egger, M.; von Elm, E. Mortality from road traffic accidents in Switzerland: Longitudinal and spatial analyses. Accid. Anal. Prev. 2011, 43, 40–48. [Google Scholar] [CrossRef]
- Infante, P.; Jacinto, G.; Afonso, A.; Rego, L.; Nogueira, V.; Quaresma, P.; Saias, J.; Santos, D.; Nogueira, P.; Silva, M.; et al. Comparison of Statistical and Machine-Learning Models on Road Traffic Accident Severity Classification. Computers 2022, 11, 80. [Google Scholar] [CrossRef]
- Waldon, M.; Ibingira, T.; Andrade, L.; Mmbaga, B.; Mvungi, M.V.; Staton, C. Built environment analysis for road traffic hotspot locations in Moshi, Tanzania. Int. J. Inj. Control. Saf. Promot. 2018, 25, 272–278. [Google Scholar] [CrossRef]
- Chen, X.; Huang, L.; Dai, D.; Zhu, M.; Jin, K. Hotspots of road traffic crashes in a redeveloping area of Shanghai. Int. J. Inj. Contr. Saf Promot. 2018, 25, 293–302. [Google Scholar] [CrossRef]
- Wang, X.; Qu, X.; Jin, S. Hotspot identification considering daily variability of traffic flow and crash record: A case study. J. Transp. Saf. Secur. 2020, 12, 275–291. [Google Scholar] [CrossRef]
- Le, K.; Liu, P.; Lin, L.-T. Determining the road traffic accident hotspots using GIS-based temporal-spatial statistical analytic techniques in Hanoi, Vietnam. Geo-Spat. Inf. Sci. 2020, 23, 153–164. [Google Scholar] [CrossRef]
- Le, K.; Liu, P.; Lin, L.-T. Traffic accident hotspot identification by integrating kernel density estimation and spatial autocorrelation analysis: A case study. Int. J. Crashworthiness 2022, 27, 543–553. [Google Scholar] [CrossRef]
- Zahran, E.; Tan, S.; Tan, E.; Putra, N.; Yap, Y.; Rahman, E. Spatial analysis of road traffic accident hotspots: Evaluation and validation of recent approaches using road safety audit. J. Transp. Saf. Secur. 2021, 13, 575–604. [Google Scholar] [CrossRef]
- Alotaibi, A. Density-based clustering for road accident data analysis. Int. J. Adv. Appl. Sci. 2018, 5, 113–121. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Ord, J.; Getis, A. Local spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Anselin, L. Local indicators of spatial association–LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- QGIS Development Team. QGIS Geographic Information System. Open Source Geospatial Foundation Project. 2022. Available online: http://qgis.osgeo.org (accessed on 9 December 2022).
- Xie, Z.; Yan, J. Kernel density estimation of traffic accidents in a network space. Comput. Environ. Urban Syst. 2008, 32, 396–406. [Google Scholar] [CrossRef]
- Hart, T.; Zandbergen, P. Kernel density estimation and hotspot mapping: Examining the influence of interpolation method, grid cell size, and bandwidth on crime forecasting. Polic. Int. J. Police Strateg. Manag. 2014, 37, 305–323. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland, OR, USA, 2–4 August 1996; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Verma, M.; Srivastava, M.; Chack, N.; Diswar, A.K.; Gupta, N. A Comparative Study of Various Clustering Algorithms in Data Minin. Int. J. Eng. Res. Appl. 2014, 2, 1379–1384. [Google Scholar]
- Anasari, S.; Kale, K. Mapping and analysis of crime in Aurangabad city using GIS. IOSR J. Comput. Eng. 2014, 16, 67–76. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Y.; Sun, B.; Wen, L.; An, X. Epidemiological study of scarlet fever in Shenyang, China. BMC Infect. Dis. 2019, 19, 1074. [Google Scholar] [CrossRef] [PubMed]
- Erdoğan, S.; Derelí, M.; Yalçin, M. Spatial analysis of five crime statistics in Turkey. In Proceedings of the FIG Working Week 2011: Bridging the Gap between Cultures, Marrakech, Morocco, 18–22 May 2011; pp. 18–20. [Google Scholar]
- Lui, K.; Cai, J.; Wang, S.; Wu, Z.; Li, L.; Jiang, T.; Chen, B.; Cai, G.; Jiang, Z.; Chen, Y.; et al. Identification of distribution characteristics and epidemic trends of Hepatitis E in Zhejiang Province, China from 2007 to 2012. Sci. Rep. 2016, 6, 25407. [Google Scholar]
- Malvisi, L.; Troisi, C.; Selwin, B. Analysis of the spatial and temporal distribution of malaria in an area of Northern Guatemala with seasonal malaria transmission. Parasitol. Res. 2018, 117, 2807–2822. [Google Scholar] [CrossRef] [PubMed]
- Tholiya, J. Crime mapping: A GIS based spatial optimization approach in Toledo, Ohio, USA. Inst. Town Plan. India J. 2016, 13, 1–14. [Google Scholar]
- Soltani, A.; Askari, S. Exploring spatial autocorrelation of traffic crashes based on severity. Inj. Int. J. Care Inj. 2017, 48, 637–647. [Google Scholar] [CrossRef]
- Songchitruksa, P.; Zeng, X. Getis–Ord spatial statistics to identify hotspots by using incident management data. J. Transp. Res. Board 2010, 2165, 42–51. [Google Scholar] [CrossRef]
- Oxoli, D.; Prestifilippo, G.; Bertocchi, D.; Zurbaràn, M. Enabling spatial autocorrelation mapping in QGIS: The Hotspot Analysis Plugin. Geam. Geoing. Ambient. E Min. 2017, 151, 45–50. [Google Scholar]
- Santos, D.; Saias, J.; Quaresma, P.; Nogueira, V. Machine Learning Approaches to Traffic Accident Analysis and Hotspot Prediction. Computers 2021, 10, 157. [Google Scholar] [CrossRef]
- Infante, P.; Jacinto, G.; Afonso, A.; Rego, L.; Nogueira, P.; Silva, M.; Nogueira, V.; Saias, J.; Quaresma, P.; Santos, D.; et al. Factors That Influence the Type of Road Traffic Accidents: A Case Study in a District of Portugal. Sustainability 2023, 15, 2352. [Google Scholar] [CrossRef]
- Infante, P.; Nogueira, V.; Manuel, P.; Gois, P.; Afonso, A.; Santos, D.; Jacinto, G.; Saias, J.; Rego, L.; Silva, M.; et al. A Sinistralidade Rodoviária no Distrito de Setúbal; Imprensa da Universidade de Évora: Évora, Portugal, 2023; ISBN 978-972-778-300-7. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogueira, P.; Silva, M.; Infante, P.; Nogueira, V.; Manuel, P.; Afonso, A.; Jacinto, G.; Rego, L.; Quaresma, P.; Saias, J.; et al. Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal. ISPRS Int. J. Geo-Inf. 2023, 12, 93. https://doi.org/10.3390/ijgi12030093
Nogueira P, Silva M, Infante P, Nogueira V, Manuel P, Afonso A, Jacinto G, Rego L, Quaresma P, Saias J, et al. Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal. ISPRS International Journal of Geo-Information. 2023; 12(3):93. https://doi.org/10.3390/ijgi12030093
Chicago/Turabian StyleNogueira, Pedro, Marcelo Silva, Paulo Infante, Vitor Nogueira, Paulo Manuel, Anabela Afonso, Gonçalo Jacinto, Leonor Rego, Paulo Quaresma, José Saias, and et al. 2023. "Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal" ISPRS International Journal of Geo-Information 12, no. 3: 93. https://doi.org/10.3390/ijgi12030093
APA StyleNogueira, P., Silva, M., Infante, P., Nogueira, V., Manuel, P., Afonso, A., Jacinto, G., Rego, L., Quaresma, P., Saias, J., Santos, D., & Gois, P. (2023). Learning from Accidents: Spatial Intelligence Applied to Road Accidents with Insights from a Case Study in Setúbal District, Portugal. ISPRS International Journal of Geo-Information, 12(3), 93. https://doi.org/10.3390/ijgi12030093