1. Introduction
Maps provide visual information about geographic features and locations and are an important visual representation of geographic data. Map labels and other textual details are referred to as map annotations. They are essential components of a map and are vital in assisting users with their geographic queries, thereby helping them find the locations that the map covers and understand its contents. Geographic information science (GIS) technology combines spatial analysis tools and computer science methods with the distinctive visual effects of maps. The functionality of maps is enhanced by this connection. However, at the moment, maps are frequently offered as digital picture files, scanned maps, or paper maps. Information about map annotations cannot be readily extracted by computers from these formats [
1]. A key stage in enabling computer intelligence to interpret map information is the extraction of annotations from map pictures. This process is also essential for attaining intelligent map information retrieval.
The extraction of map annotations relied heavily on manual visual interpretation in its early phases. This method was time-consuming, labor-intensive, and inefficient, even if it provided excellent accuracy. This operation would become very difficult and possibly impossible when dealing with a large number of annotations to be taken from maps [
1].
Some researchers have suggested a technique where annotations are first identified within maps using computer technology, followed by manual interpretation and conversion, in order to minimize the need for human participation. In the early stages of map annotation localization, techniques such as cluster analysis [
2], morphological operations [
3], segmentation [
4], labeling connected components [
2] and the use of image pyramid methods have been used [
5]. Even though these techniques are capable of automatically locating map annotations, the extraction of such annotations is less precise when they are intertwined and overlapped with other elements on the map. Li et al. [
6] introduced an interactive annotation extraction tool that lets users choose the criteria for character grouping and color separation. The accuracy of extracting map annotations has been somewhat enhanced by this utility. These techniques can automatically position annotations, but the positioning procedure is prone to interference from other map features, which reduces the precision of the map annotation extraction. Additionally, these techniques still rely heavily on manual labor for annotation interpretation and conversion, which leaves the problem of extracting annotations from a large number of maps unresolved.
Some academics have suggested integrating optical character recognition (OCR) technology to address the problem of automatic interpretation and the conversion of map annotations. OCR technology can examine and identify text-based image files, thereby extracting the text and layout information. In order to do this, the text must be identified inside the image and returned in textual form. Pouderoux et al. [
7] and Pezeshk et al. [
1] used OCR software to identify discovered map notes. However, due to the limits of conventional OCR recognition techniques, input images must be at least 300 dpi, and characters must be sufficiently large for conventional OCR technology to recognize them [
7]. Furthermore, the problem of problematic annotation localization when annotations overlap and tangle with other map characteristics is still unaddressed by current methods. Chiang et al. [
8] suggested using a manual user acquisition of map annotations to obtain user labels as part of a supervised learning technique. The characteristics of the annotations are learned by making use of the acquired user labels. Although it might not be appropriate for supporting jobs requiring the extraction of a sizable number of annotations, this method improves annotation extraction accuracy through user involvement.
The completion of OCR tasks has advanced significantly with the advent and development of deep learning, as well as through the effective combination of OCR technology and deep learning [
9,
10]. It was proposed by Li et al. [
11] to use the FRCNN model for annotation localization. Through graph segmentation and clustering processes, annotations were subsequently isolated from other map features. In order to automate the extraction of map annotations, the Google Tesseract OCR Engine was then used to recognize the annotations. The recognition was then improved using a geographic database. Additionally, Zhai et al. [
12] effectively constructed a model and dataset integrated transfer learning strategy to identify unstructured map text.
In conclusion, the available study raises the following problems: (1) The majority of recent research has been devoted to extracting annotations from English maps. Chinese characters are numerous and structurally difficult compared to English characters, which has hindered research on Chinese annotation extraction. (2) When compared to other types of text extraction (such as text from handwritten notes, documents, scenes, etc.), map annotation extraction is distinguished by its high quantity, nonuniform distribution, and susceptibility to influence from map line features. (3) There are not enough publicly accessible datasets of Chinese maps that can be used to train deep learning models at the moment.
The paper offers a deep-learning-based method for the automatic extraction of annotations from scanned Chinese maps in order to overcome the aforementioned problems. For detecting annotations in scanned Chinese maps and identifying them in scanned Chinese maps, this method principally uses an improved EAST model and a CRNN model based on transfer learning. Among them, annotation detection is used to locate the position of the annotation in the image and return the general extent of the annotated area; annotation recognition refers to the conversion of the annotated image in the scanned map into text, i.e., the text in the image is converted from the form of a picture into the form of a computer-readable text.
2. Materials and Methods
2.1. Dataset Construction
Chinese scanned map databases were not readily available; therefore, this study’s dataset had to be made. Real scanned map datasets and simulated map datasets make up the majority of the dataset. While the simulated map dataset was largely used for model training, the real scanned map data was mostly used for model validation and evaluation.
2.1.1. Real Scanned Map Dataset Construction
The Chinese maps used in this study are from the “Atlas of Yunnan Province 2002 Edition”. From this source, a total of 45 maps were chosen, and they were manually scanned to produce the Chinese scanned map images. A total of 45 different Chinese scanned map images were created after manually filtering and cropping the acquired Chinese scanned map photos, which contained some useless information. The resulting Chinese scanned map images were then manually annotated using the labeling program. After completing these stages, the final dataset of actual scanned map images was obtained and mainly used for the model’s evaluation and validation.
2.1.2. Simulated Scanned Map Dataset Construction
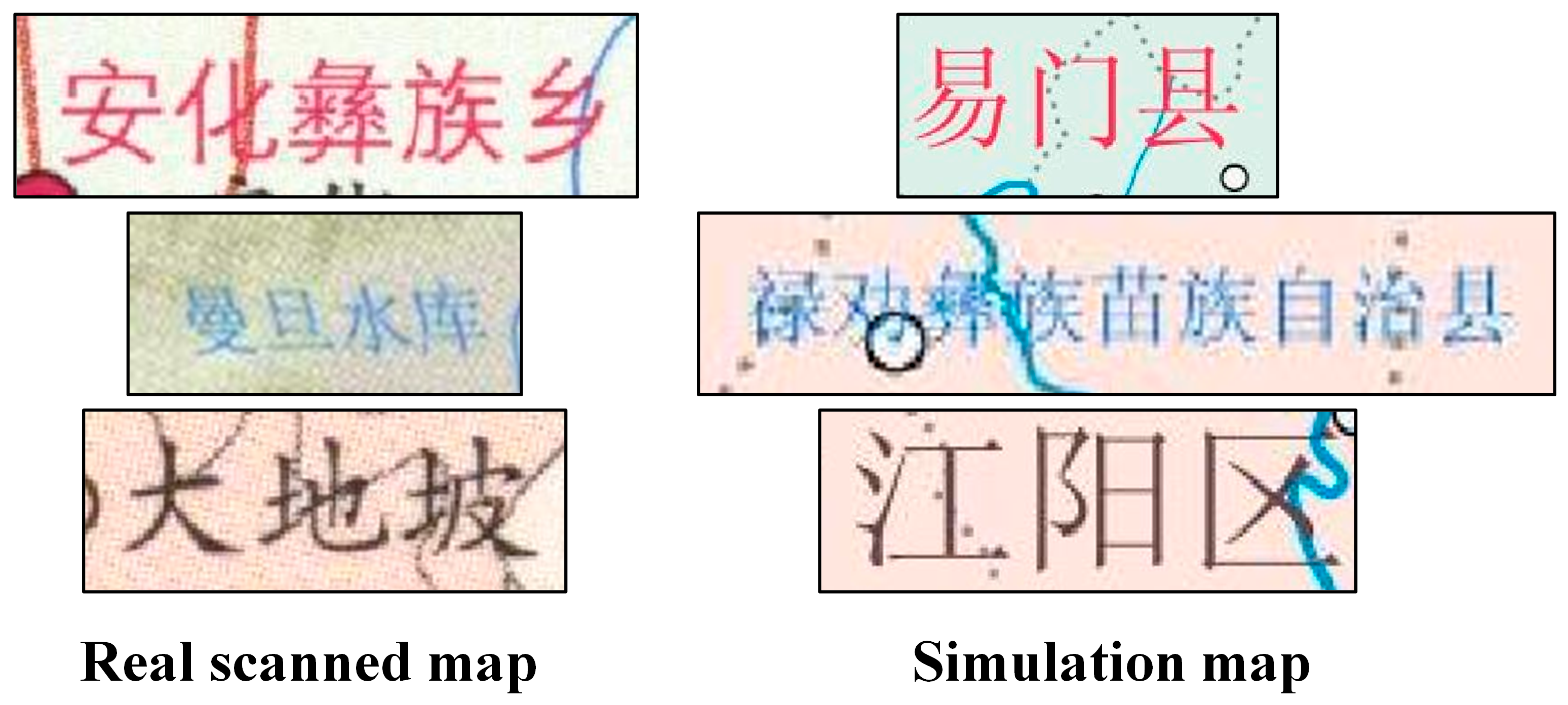
It is challenging to obtain simulation maps with the same style as all of the genuine scanned maps in this work, since the real scanned maps in this study comprise a variety of map styles. Given that the majority of the actual scanned maps in this study are from the standard cartography, which adheres to a set of specifications, and that their annotation styles are similar, this paper complicated the other elements while creating simulation maps to make the trained models as adaptable to as many various map styles as possible.
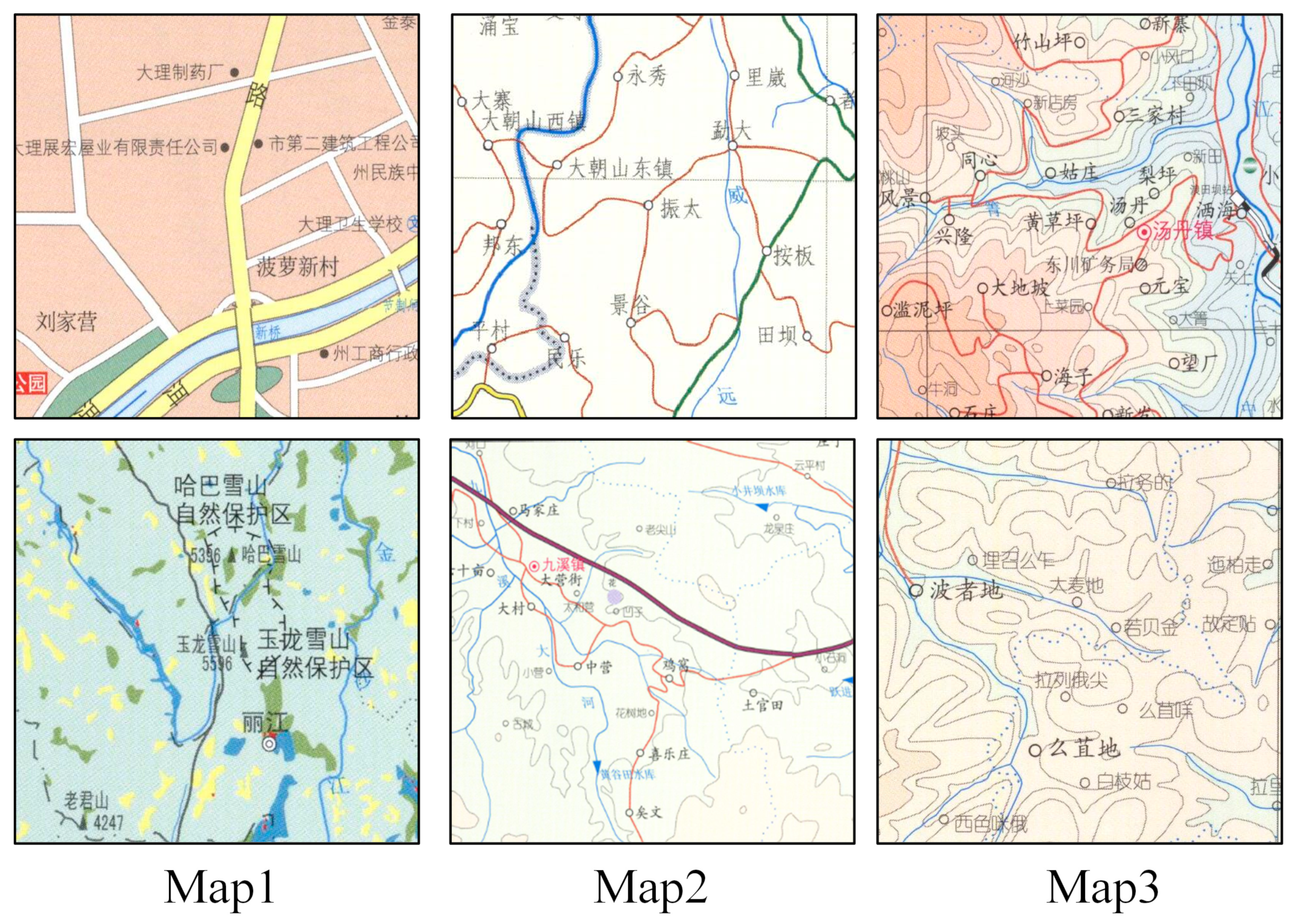
Figure 1 shows a comparison of the annotation styles of some of the real scanned maps and the simulated maps.
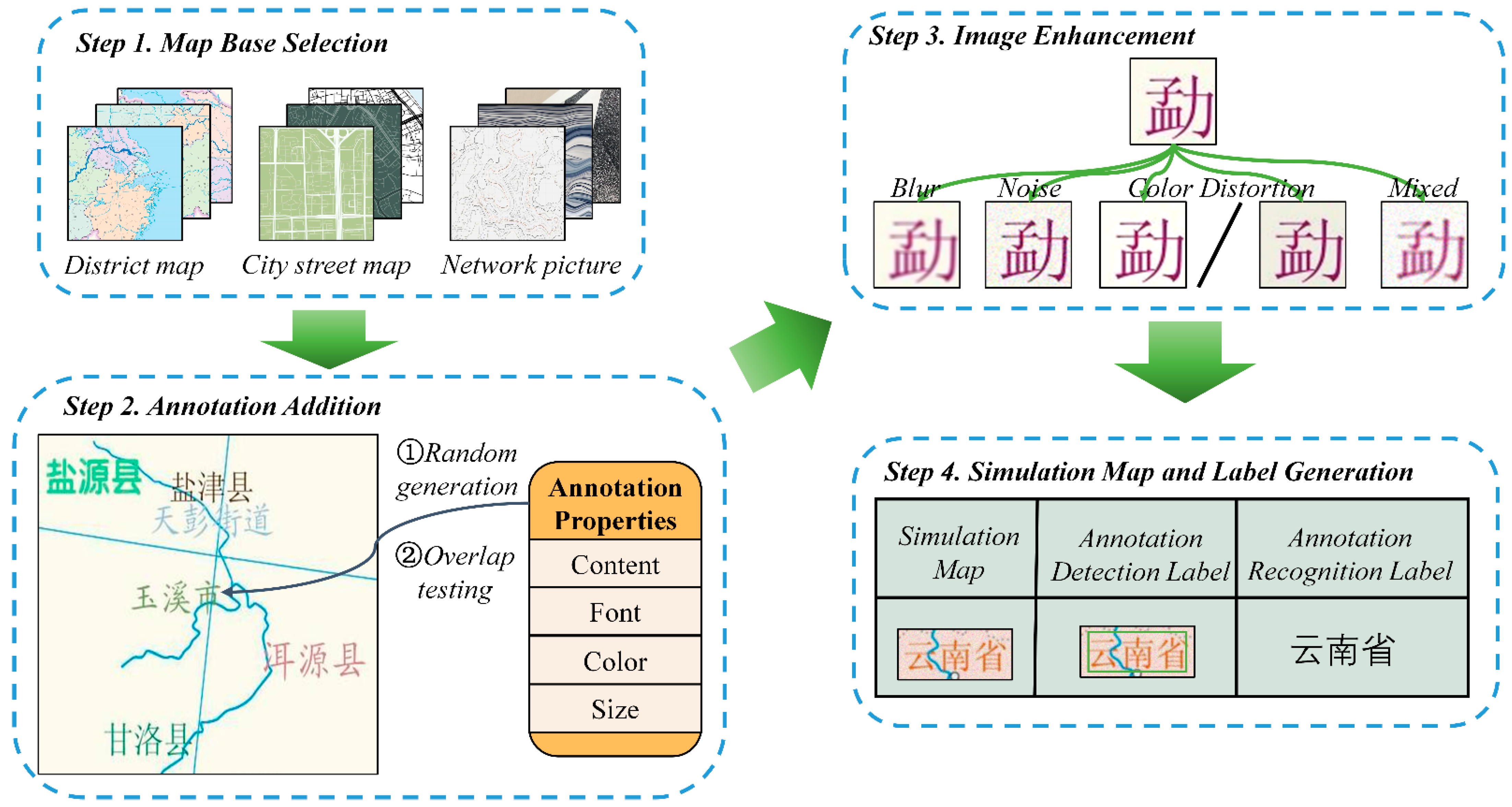
The paper developed a simulated map generator to produce simulated map datasets in batches in accordance with the properties of the maps.
Figure 2 depicts the workflow of the generator, which can be distilled into four key steps:
- (1)
Map base selection: For this study, three different types of map bases were selected: web photos, maps of urban street scenes, and maps of administrative areas. The latter was picked to improve the dataset, whereas the first two were mostly selected to imitate popular map types. Annotations can be affected by other map components (particularly line features) during the extraction process. The robustness of the learned model was increased by including more complicated backdrops during training.
- (2)
Annotation addition: Specific properties (content, font, text color, and size) were used to introduce annotations. Annotations on standard maps typically fall under a number of predefined categories that are present on the same map, though these categories may vary from one map to another. In particular, rather than employing a few predetermined categories of characteristics during the development of training set maps, annotation attributes were produced randomly to improve model generalization. The placement of the annotations on the maps was random, and a straightforward overlap detection algorithm was developed to avoid overlap and covering between generated annotations:
Create an image of the annotation region that is the same size as the target map in order to capture the locations of the created annotations.
Create predefined annotation areas after obtaining annotation attributes.
Evaluate the annotation area image against the predefined areas until there is no intersection between the predefined area and the annotation area image; acquire a new predefined area if they do.
In the annotation area image, note the predefined area.
- (3)
Image Augmentation: Images created by computers frequently have superior quality and less noise interference. However, when it comes to scanned maps, the scanning procedure can be impacted by human or mechanical mistakes, with measurable effects on the quality of the scanned map. Several problems that are frequently encountered during scanning were identified and introduced as disturbances to the simulated maps in order to more accurately reflect the conditions of real scanned map images:
Blurriness is one issue that can arise from low scanning resolution, which makes it challenging to show details accurately.
Color shifts: Scanned images may show color shifts, in which the image’s colors differ from those of the actual object. This is frequently caused by problems with the scanner’s or scanning software’s color calibration. Another issue that could arise during scanning is shadows or reflections.
Noise: Patterns might become distorted and grainy due to random noise brought on by elements such as the scanner’s light source, optical path, and sensor.
Different forms of disturbances were randomly blended and added to the simulated maps after annotations had been added.
- (4)
Simulated map and label generation: Both the content and spatial details of the annotations that were created in step (2) were recorded. To develop labels for annotation detection and identification, these were later combined. In parallel, a new picture was created by copying all annotation characteristics to it, with the exception of text color. The annotation separation label was made using this newly constructed image. The final simulated maps were obtained once image augmentation step (3) was finished. These final simulated maps were linked to the generated labels. In the end, the output included the simulated maps and the labels that went with them.
Figure 2.
Flowchart of the simulation map generator.
Figure 2.
Flowchart of the simulation map generator.
2.2. Scanned Map Annotation Extraction Framework
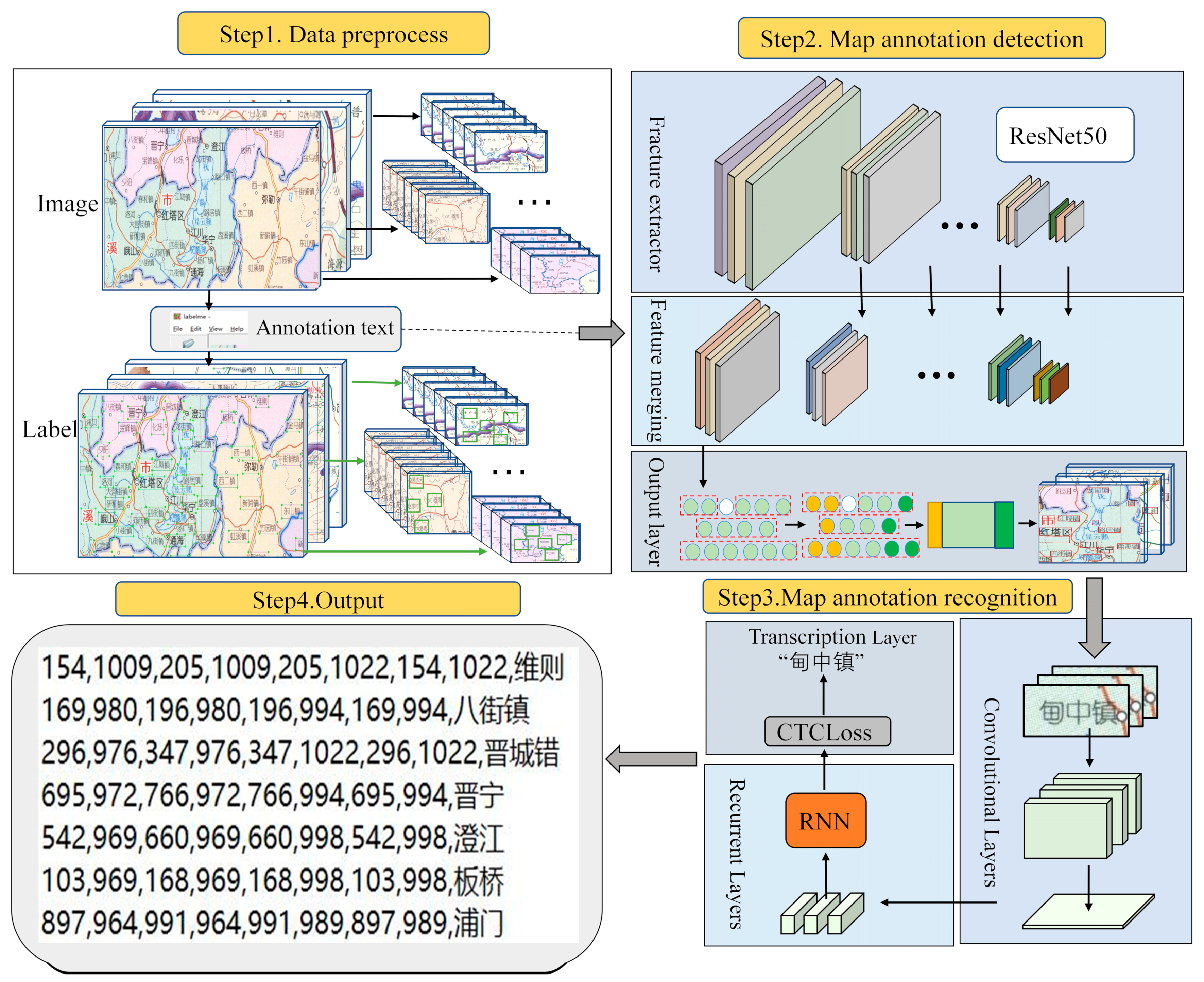
This paper accomplished the extraction of Chinese scanned map annotations through three steps, as illustrated in
Figure 3. The process involves three steps. In the first step, data preprocessing is carried out, which involves cropping or resizing the scanned map to meet the requirements of the annotation detection model. This is because, in the process of scanning, there will be a lot of unavoidable factors that lead to poor image quality, and each scanning according to the impact is not the same, which produces a wide range of image noise categories, thereby leading to the fact that it is difficult to ensure that the scanning of the map quality is consistent; therefore, this method is not set to denoise the process, but rather the impact of the noise is added to the model training, such as was performed in this paper in the generation of simulated maps when the interference of the noise was added. In the second step, annotation detection is performed using a trained model, which is applied to the preprocessed scanned map to detect annotations. This yields the coordinates of the annotations (if cropping was performed during preprocessing, it is recommended to adjust the coordinate offsets based on cropping rules). In the third step, annotation recognition is conducted. A trained annotation recognition model is applied to the results of the annotation detection step to recognize the annotations, thereby producing corresponding recognition outcomes. By combining these results with the annotation detection outcomes, the final extracted annotation results are ultimately generated.
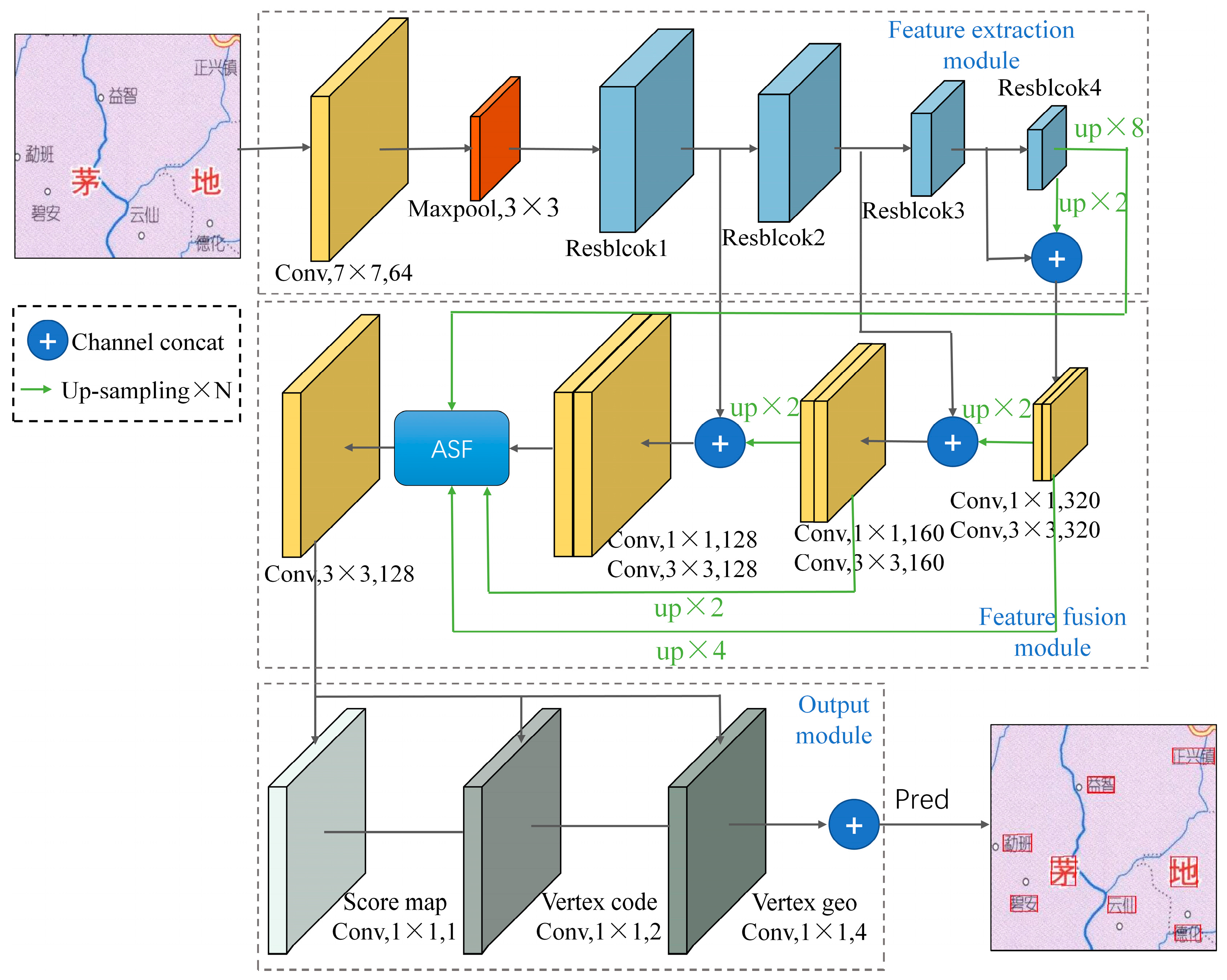
2.3. Improved EAST Annotation Detection Model
The EAST [
13] model’s structure was adopted by the annotation detection model in this paper. Three modules—feature extraction, feature fusion, and output—make up the overall model, as shown in
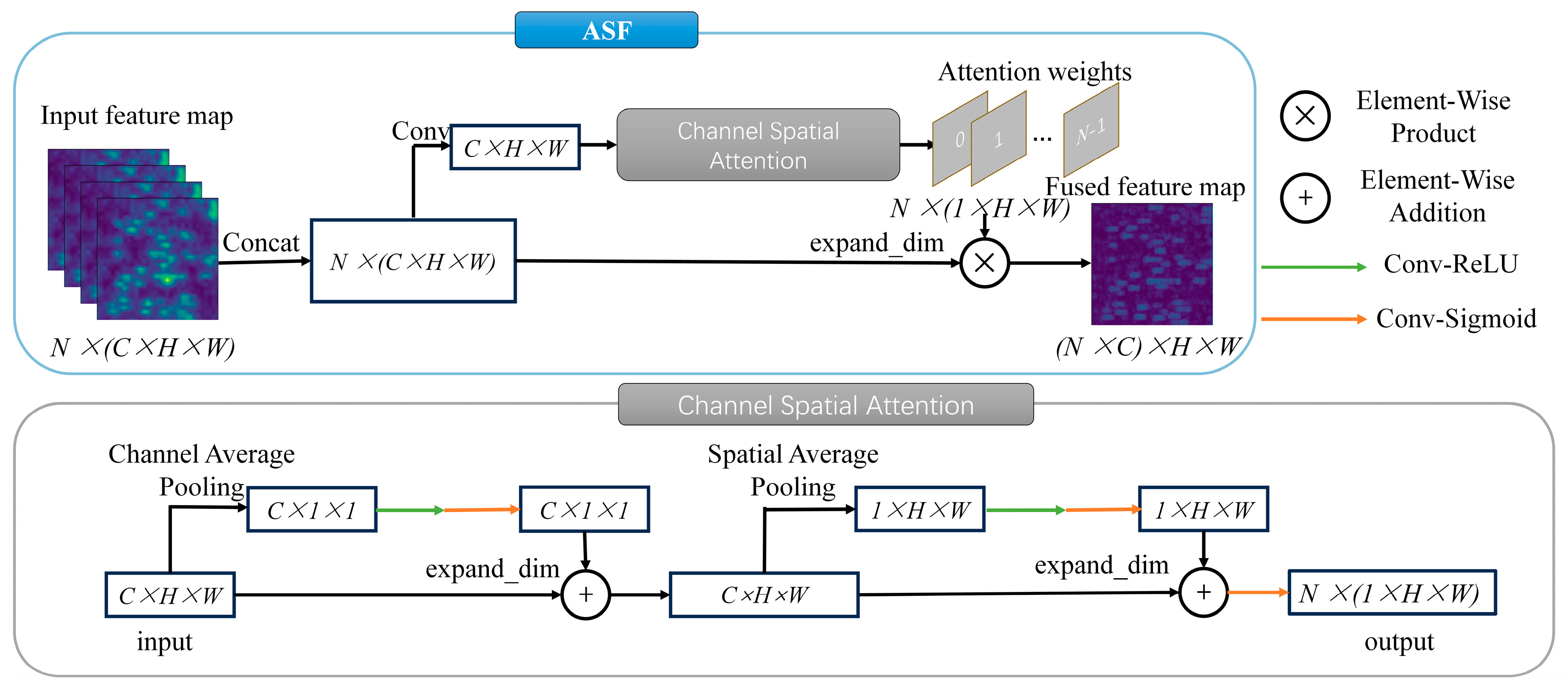
Figure 4. The EAST model’s basis is the foundation upon which the main alterations in this study have been made. A ResNet was used to extract deep image features in the feature extraction module, thereby allowing for the acquisition of profound picture characteristics. An ASF (adaptive spatial fusion) module was added to the feature fusion module to fuse features from different levels and create multiscale annotation features. Additionally, the output module incorporated the AdvancedEAST structure to improve the detection effectiveness for lengthier texts.
- (i)
Feature Extraction Module
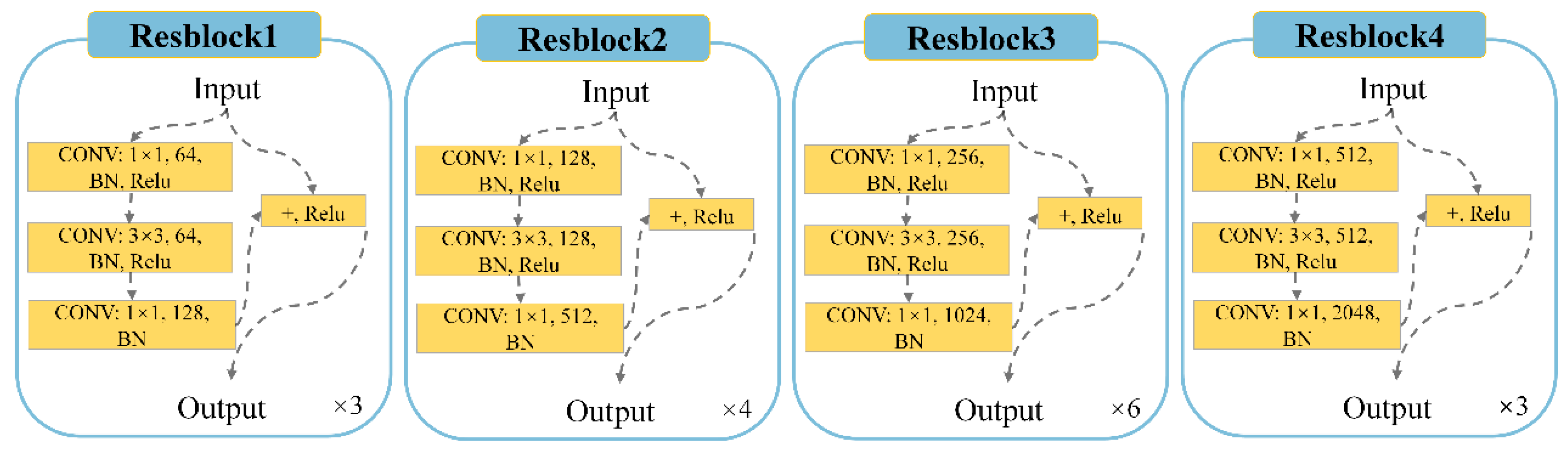
ResNet50 [
14] was used in this study as the feature extraction network. Through the utilization of residual structures, ResNet reduces the problems of disappearing gradients and network deterioration brought on by excessively deep networks. Deeper networks can be used to extract features, thereby allowing for the capture of features at several levels. The retrieved features grow increasingly abstract and semantically rich as the network depth rises.
The ResNet50 average pooling layer and fully connected layer, which are employed for classification tasks, were not included in the model. Instead, the feature fusion section used the outputs of the four residual modules within ResNet50 as its inputs.
Figure 5 shows the generated residual modules.
- (ii)
Feature Fusion Module
The main characteristics of map annotations are their designs and styles. These traits are mostly represented in channel features and spatial features in image processing. As a result, the feature fusion module in this article included an ASF module [
15]. With this feature, the model’s annotation detection accuracy was aimed to be improved.
Figure 6 depicts the layout of the adaptive spatial fusion (ASF) module. It should be noted that only the spatial attention module was used in the [
15] study. However, this work also included a channel attention module because of the unique qualities of map annotations. The findings of Ref. [
15] from 2022 are consistent with the underlying ideas. The channel spatial attention module is where the difference is found. In the channel spatial attention module, the intermediate feature
undergoes channelwise feature computation, thus yielding the channel feature
; this feature is elementwise multiplied with
, thereby resulting in an intermediate feature
that incorporates channel weights. Subsequently, spatial feature computation is performed on
, thereby producing the spatial feature
. Finally,
is elementwise multiplied with
, thereby generating the weighted feature map
. Here, the definitions of the features are as follows:
- (iii)
Output Module
The method used in this study incorporated the output module from AdvancedEAST (
https://github.com/huoyijie/AdvancedEAST accessed on 1 July 2023), wherein it took into account that longer texts are frequently found inside maps and that the EAST model’s performance with respect to identifying long texts may not be as good as it could be. This was done to improve the model’s ability to detect and handle lengthy textual comments in map pictures.
AdvancedEAST is an enhanced text detection algorithm built upon the foundation of the EAST model. It addresses the limitations of EAST in detecting long texts. By leveraging the EAST network architecture, AdvancedEAST cleverly designs a loss function based on text bounding boxes. This transformation shifts the challenge of long text detection into the task of detecting the boundaries of the text’s head and tail.
In contrast to EAST, AdvancedEAST’s output structure is made up of three primary parts: the score map, vertex code, and vertex geometry.
Figure 4 provides an illustration of this architecture. The score map represents the confidence level, thereby indicating the probability of a point being within the text box. The vertex code consists of two parameters. The first parameter signifies the confidence level that a point is a boundary element. The second parameter indicates whether the point belongs to the head or tail of a text element. Vertex geometry provides the coordinates of two predictable vertices for boundary pixels. All pixels together constitute the shape of the text box. Regression vertex coordinates are predicted only for boundary pixels. Boundary pixels encompass all pixels belonging to the head and tail. The prediction of the vertex coordinates for the short sides of the head or tail is achieved through the weighted average of the predicted values of all boundary pixels. Two vertices each are predicted for the boundary pixels of the head and tail, thereby resulting in a total of four vertex coordinates. Since the input image dimensions may not match the dimensions of the original image, the XY coordinates obtained here are not actual coordinates. Instead, they represent the offset of the current point’s XY coordinates.
2.4. CRNN Annotation Recognition Model Based on Transfer Learning
Chinese scanned map recognition presents two distinct difficulties when compared to typical document text recognition tasks: Chinese scanned maps have more complex background interference and line element interference, especially with line elements, than English letters do. Chinese characters, in contrast to English letters, are more complex and numerous, with over 2500 commonly used characters and over 1000 less frequently used characters. It can be challenging to tell these line element attributes apart from annotation features because they frequently resemble one another. Chinese characters have a lot of visual similarities, unlike English letters; therefore, even a small bit of interference can rapidly result in skewed recognition results.
CRNN [
16] is a deep learning model for processing sequence data, especially for text recognition and OCR tasks. CRNN combines the strengths of the convolutional neural network (CNN) and recurrent neural network (RNN) to make it excellent at processing variable length sequence data (such as lines of text or paragraphs).
Transfer learning is a machine learning method that assists algorithms in acquiring new knowledge by leveraging the similarity between prior knowledge and new knowledge. Transfer learning algorithms can be classified into four categories [
17]: Instance-based transfer is the first category—this approach aims to build a reliable learning model by selecting instances from a source domain; feature-based transfer is the second category—in this category, attempts are made to discover shared feature representations between the source and target domains; parameter-based transfer is the third category—this involves identifying common parameters or prior distributions between source and target data to achieve knowledge transfer; and elation-based transfer is the fourth category—this type mainly deals with nonindependent and identically distributed data that have existing relationships.
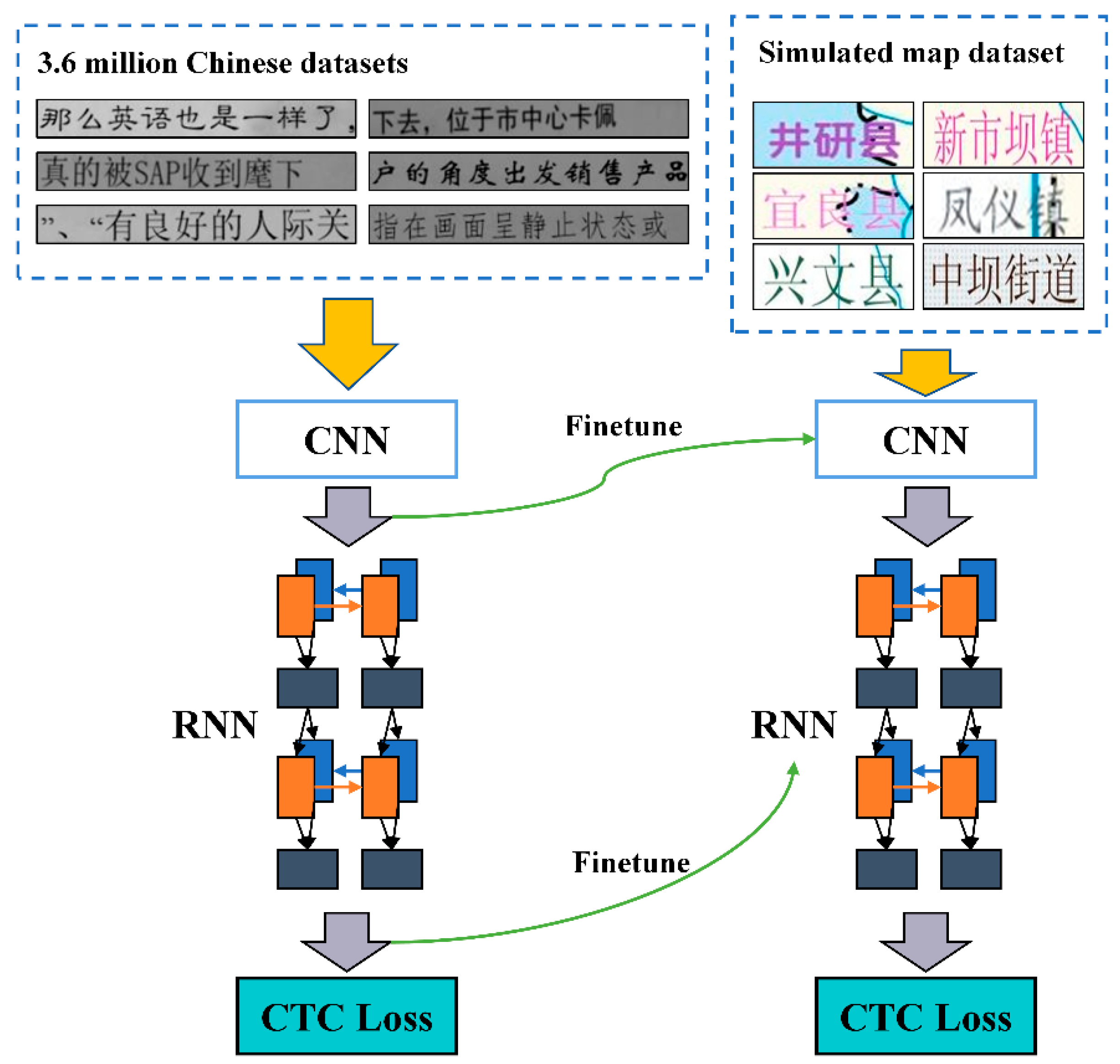
The method used in this paper is parameter-based transfer learning. A dataset of 3.6 million Chinese characters can be found in the source domain at (
https://github.com/senlinuc/caffe_ocr accessed on 1 July 2023). To create a pretrained model, the method begins with pretraining on the source domain. Then, the model of the target domain is given the parameters from the first n layers of this pretrained model. The subsequent layers are then adjusted using information from the target domain. The model’s performance on the target domain is improved, and the discrepancies between source and target domain data are decreased as a result of the fine-tuning procedure.
Figure 7 depicts the transfer learning process.
2.5. Evaluation Metrics
In order to assess the performance of the model, this paper employs three evaluation metrics: precision, recall, and h mean. Their definitions are as follows:
Among these, TP represents the count of correctly predicted positive samples, FP represents the count of incorrectly predicted positive samples, and FN represents the count of incorrectly predicted negative samples. In annotation detection evaluation, when the predicted region aligns with the actual region, it is considered to be a correct prediction. Specifically, due to the typically large dimensions of complete scanned maps, annotation detection models cannot predict the entire image at once. Instead, they require a sliding window approach for prediction. This unavoidably results in some complete annotations being divided into multiple parts, thus causing the number of predicted annotations to be greater than or equal to the number of annotations in the label data. As a result, the accuracy of annotation identification would not be accurately reflected if conventional text recognition criteria were used (where the entire label must be predicted properly to be considered valid). Additionally, given that the majority of annotations lack strong semantic information, even if they are divided into numerous separate characters, as long as their spatial placements on the map are identical, this would not have an impact on how users read and comprehend the annotations. As a result, this paper proposes the criterion that successfully predicting independent characters is deemed as a correct prediction for the evaluation of annotation recognition.
4. Results and Discussion
Because the size of the whole scanned map is much larger than the input to the model, if the whole image is directly input to the model, it does not obtain the expected results. Therefore, it is necessary to split the whole scanned map into several parts for prediction and then merge the prediction results to get the final prediction results. In addition, in order to prevent certain annotations from being split when cropping, which affects the prediction results, this paper chose to use two sliding windows for cropping, which have different starting points and the same step size and dimensions; it predicted the results obtained from both of the sliding windows and combined the results obtained from the two sliding windows to obtain the final prediction results.
4.1. Experimental Results of Chinese Scanned Map Annotation Detection
Table 1 displays the final annotation detection findings. It is clear from
Table 1 that the upgraded EAST model suggested in this paper performed significantly better than the original EAST model. With improvements of 0.4 or greater, the improvement was significant across all metrics. Among the comparable models, the model suggested in this research received the highest overall results in terms of the recall and h mean. Additionally, it had excellent precise performance.
Additionally, text detection models are typically divided into segmentation- and regression-based text detection models. Both EAST and the suggested model fit into the category of regression-based annotation identification models in the experiments carried out in this research. On the other side, segmentation-based annotation detection models include the PSE, FCE, SAST, DBNet, DBNet++ and TCM-DBNet. It is clear that segmentation-based annotation detection models, with the exception of PSE, typically have higher precision but lower recall, which results in lower total h mean scores. This paper makes an educated guess as to the reasons for the performance disparities between most segmentation-based annotation detection models and regression-based models by examining the model structures. Predictions are frequently pixel-based in segmentation-based models, which in certain cases results in more accurate final predicted regions. This strategy could, however, result in the loss of some macroscopic data. Given that lines and annotations at the local level resemble each other quite a bit, the models may unintentionally forecast certain lines as annotations, which would lower the recall value. Regression-based models, on the other hand, frequently use nonmaximum suppression (NMS) algorithms to combine and filter several prediction boxes, thereby resulting in a final prediction box. The precision of this method may not be as high as that of segmentation-based models, but it is less prone to interference from lines, thus producing a more stable recall value. Despite its overall effectiveness, the EAST had a recall value that was substantially higher than its precision value. Although the PSE is a segmentation-based detection model, no other segmentation-based detection model had a lower recall. It is hypothesized that this is because the multiscale prediction method, which is similar to NMS, was utilized in the prediction stage, which accounted for the precision and recall values being reasonably steady and near.
The results of several annotation detection models applied to diverse annotation styles are shown in
Figure 9. Overall, the suggested annotation detection model’s detection findings in this research were the most similar to the labels found in the real world. Different styles of map annotations could be successfully detected. While the other annotation identification algorithms are capable of recognizing annotations with a variety of styles, they performed poorly when it came to detecting map annotations with blue text, which frequently designates rivers or lakes.
The results of several annotation detection models under varied background interferences are shown in
Figure 10. It can be seen that many annotation detection techniques struggled to accurately detect map annotations when the map background was complicated, especially when the annotations overlapped and tangled with the line characteristics. The proposed annotation detection model in this paper, however, successfully resolved this problem. Even in situations where the interference from the map background was severe, it could reliably recognize map annotations.
4.2. Experimental Results of Chinese Scanned Map Annotation Recognition
Table 2 displays the final annotation recognition outcomes. The performance of the CRNN model with transfer learning was better than that of the CRNN model without transfer learning, as can be seen in
Table 2. There could be two primary causes for this enhancement: (1) Interference from the lines: One of the main factors impacting its performance is the interference brought on by the lines. While annotation images and document text annotation images are similar, annotation photos frequently have more interference from lines. Due to the similarities between lines and annotations, the CRNN model’s lack of transfer learning results in subpar annotation recognition accuracy. (2) Limited character dictionary: Because there are so many Chinese characters, even training on a dataset of 3.6 million Chinese characters might not completely cover all of the characters that could be used. The map dataset chosen for this study contains a number of uncommon Chinese characters that are not frequently used in spoken Chinese. As a result, the CRNN model without transfer learning finds it challenging to infer the appropriate Chinese characters.
Among all of the control groups, the annotation recognition model utilized in this study performed the best in terms of the various assessment criteria, both at the local and global levels. Additionally, the ddddOCR outperformed the other two OCR projects by more than 0.12 points across all evaluation metrics. The fact that the CnOCR and EasyOCR are both general-purpose OCR systems with a focus on scene text and document text recognition is probably the cause of this success. However, the ddddOCR concentrates mostly on CAPTCHA recognition. Images used for CAPTCHAs and annotations are similar in that they both frequently have a lot of lines and background distractions. Because CAPTCHAs and annotation images are comparable, this is likely one of the reasons why the ddddOCR’s recognition performance outperformed that of the other two OCR systems and closely resembled the model employed in this study.
The recognition outcomes of several annotation recognition algorithms under varied background interference situations are principally shown in
Figure 11. In the first image, the character ‘镇’ partially overlapped with map line features, thereby leading to incorrect recognition by some of the recognition models. In the second image, the character ‘楞’ overlapped with two different types of map line features, with significant overlap on its left side. In this case, some recognition models exhibited varying degrees of misrecognition. In the third image, despite the presence of only a few lines as interference, the left-side line caused some recognition models to mistake the character ‘老’ for ‘佬’. In the fourth image, the character ‘广’ was extensively covered by line features, thus causing some recognition models to fail to recognize it as a character. However, the model put forward in this paper was able to correctly identify annotation data in the aforementioned situations.
4.3. Chinese Scanned Map Annotation Extraction Error Analysis
The ultimate approach for extracting Chinese scanned map annotations can be accomplished by integrating the models that were obtained in accordance with
Figure 3. The whole results of the Chinese scanned map annotation detection are shown in
Figure 12, while the partial results of the Chinese scanned map annotation recognition are shown in
Figure 12, where the red box indicates a correct detection, the blue box indicates an incorrect detection, and the green box indicates a missed detection.
From
Figure 12, it can be observed that the model proposed in this paper was capable of accurately detecting the positions of most of the annotations. However, the annotation detection results for larger annotations were not as satisfactory, as seen in annotations such as ‘江’, ‘川’, and ‘县’ on the far right of
Figure 12. This could potentially be attributed to the significant differences between these types of annotations and others. Insufficient samples of this particular annotation style in the training dataset might have contributed to this issue.
In addition, in the middle of
Figure 12, we can see that there is a large number of annotations gathered, which was also a region of a high frequency of leakage detection. After analyzing, there are two main reasons for this situation: firstly, because the simulation maps generated in this paper almost did not have this kind of large number of concentrated annotations, this made the training for this case incomplete; secondly, because of the characteristics of the NMS algorithm, some annotations were too close together, which led to the removal of lower scoring prediction frames in the filtering of the prediction boxes so that the lower scoring prediction boxes were removed.
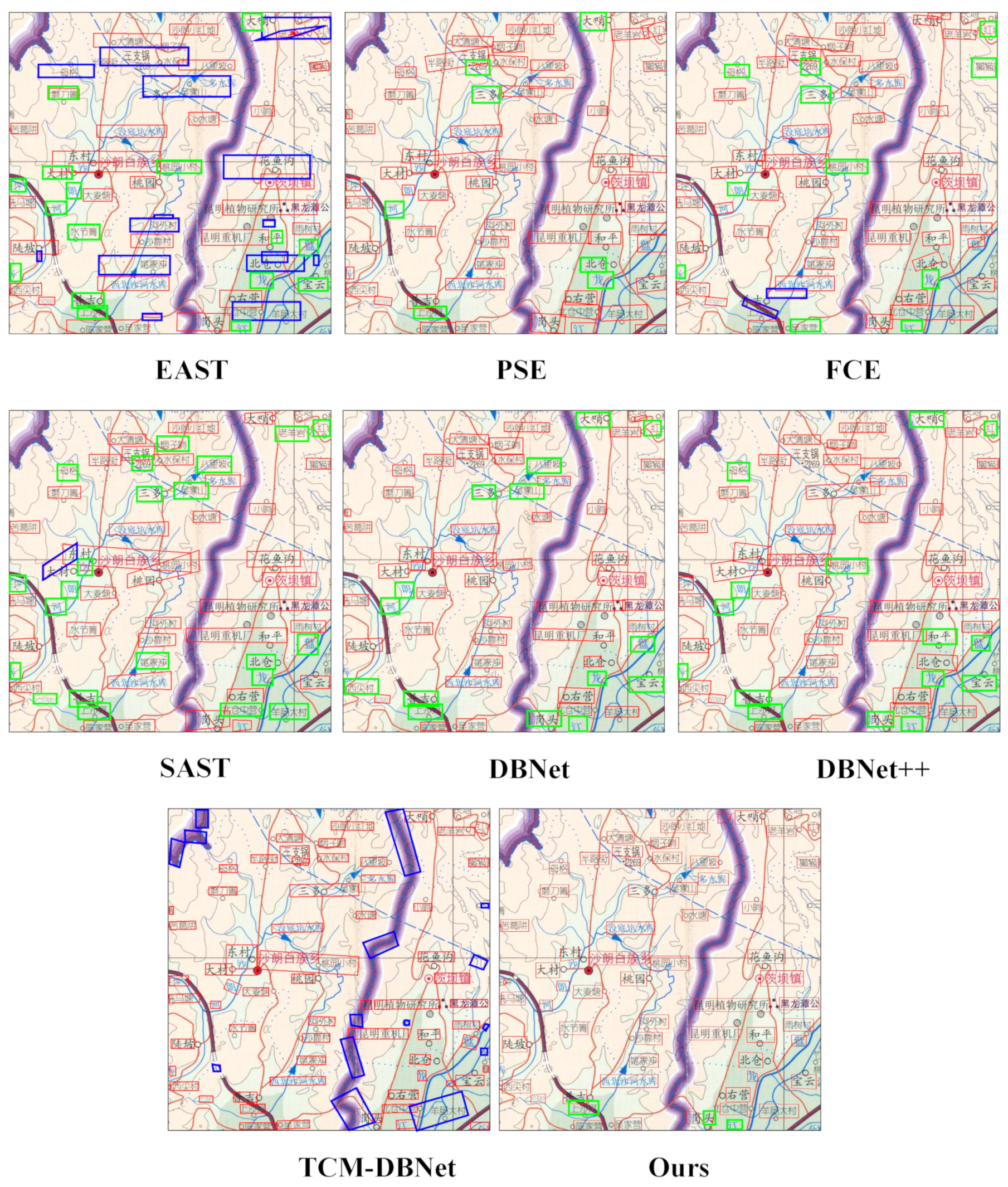
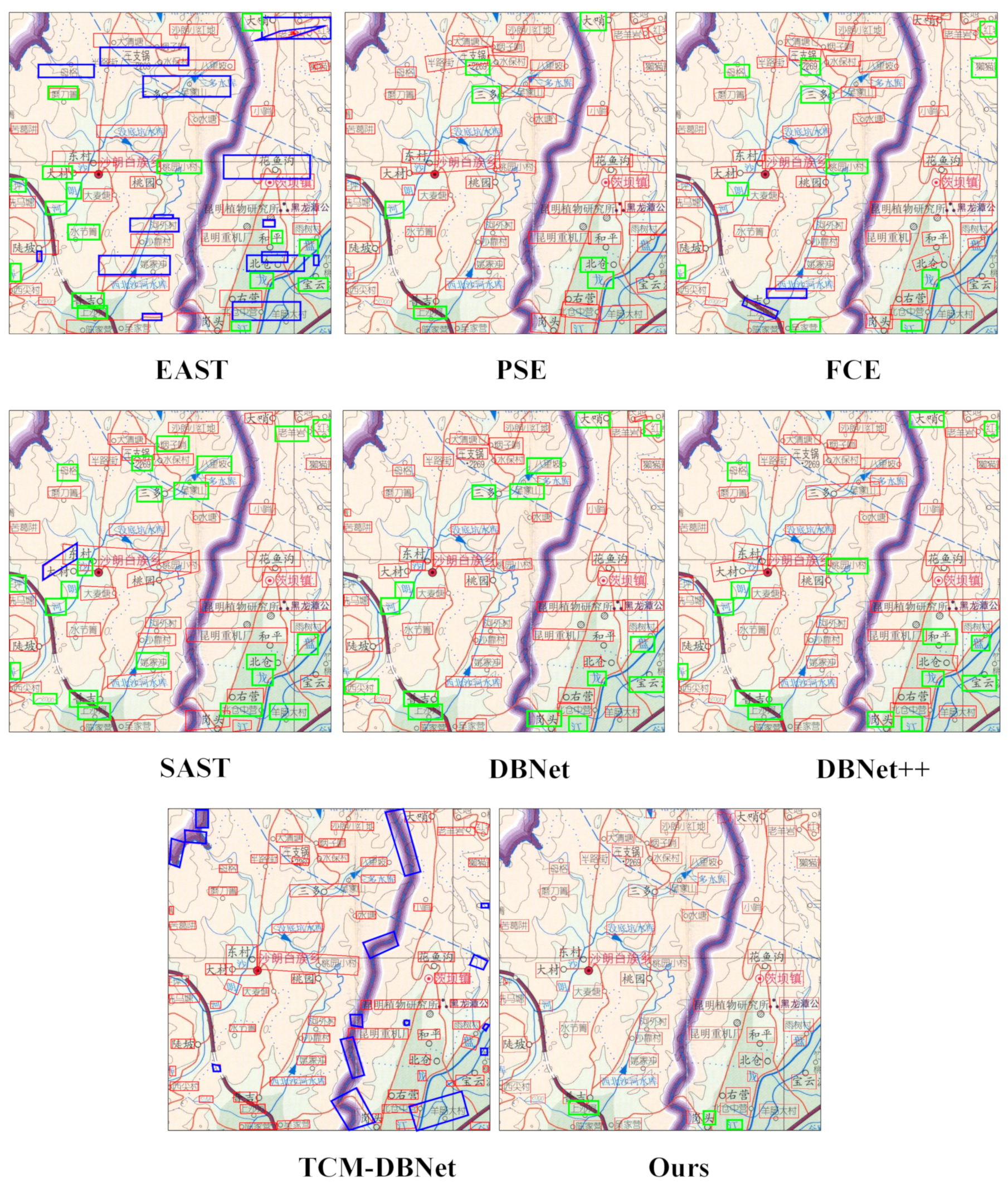
Figure 13 shows the annotation detection results of different annotation detection models, with red boxes indicating correct detection, blue boxes indicating wrong detection, and green boxes indicating missed detection. From the figure, it can be seen that the EAST had a large number of misdetections and missed detections, and the PSE, FCE, SAST, DBNet, and DBNet++ had almost no misdetections, but all of them had quite a lot of missed detections. The TCM-DBNet had almost no missed detections, but quite a lot of misdetections, presumably because the introduction of the TCM made the model’s learning capability. It is worth mentioning that the misdetections of the TCM-DBNet can be divided into two cases: the first is a small misdetection box, which covers less content; the second is a large misdetection box, which contains some rough lines without much information. These two cases will not be recognized when the annotation recognition takes place, i.e., the recognition result is empty, which has little effect on the final extraction effect, but will increase the load and efficiency of the whole method. The model proposed in this paper had only a small number of missed cases, and the overall effect was better than the other comparison models, which is also basically consistent with the results in
Table 1.
The results of the annotated image recognition are shown in
Figure 14. It is clear that the model used in this work exhibited comparatively accurate annotation picture recognition. The two most common categories of recognition errors were the following: (1) Interference from lines or other map features: The fifth annotation image in
Figure 14 best illustrates this type of error. The recognition result contains an additional character or characters, because the detection area also included some other map elements. (2) Complex characters or similar-looking characters: For instance, in the sixth annotation image in
Figure 11, the character that should have been recognized as ‘彝’ was instead recognized as ‘舞’. These two characters are visually similar and belong to the category of similar-looking characters. In cases where the image resolution is not high, the model is more prone to making recognition errors.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}