
Adaptive Spatio-Temporal Query Strategies in Blockchain


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Spatio-Temporal Index
2.2. Blockchain
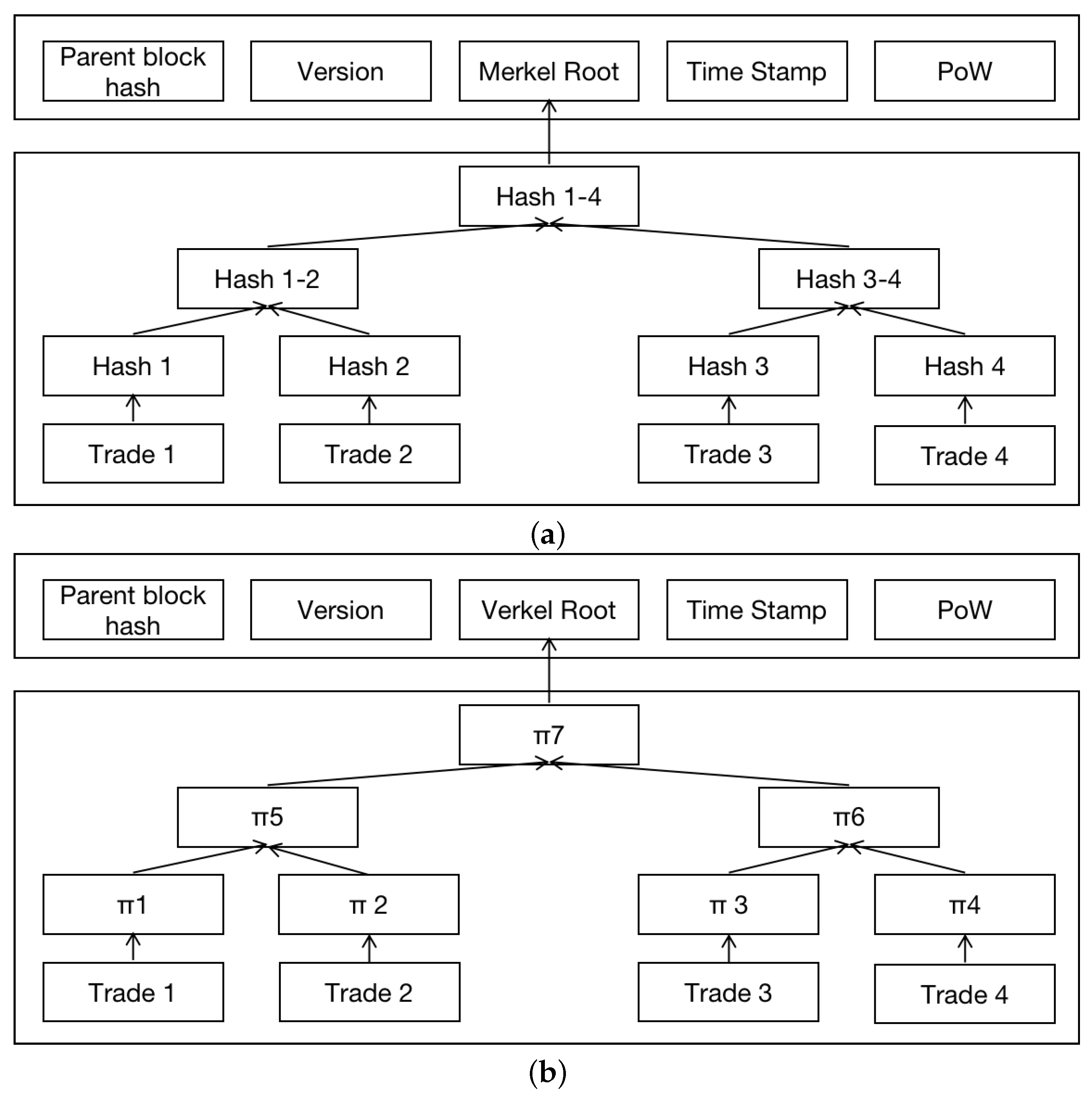
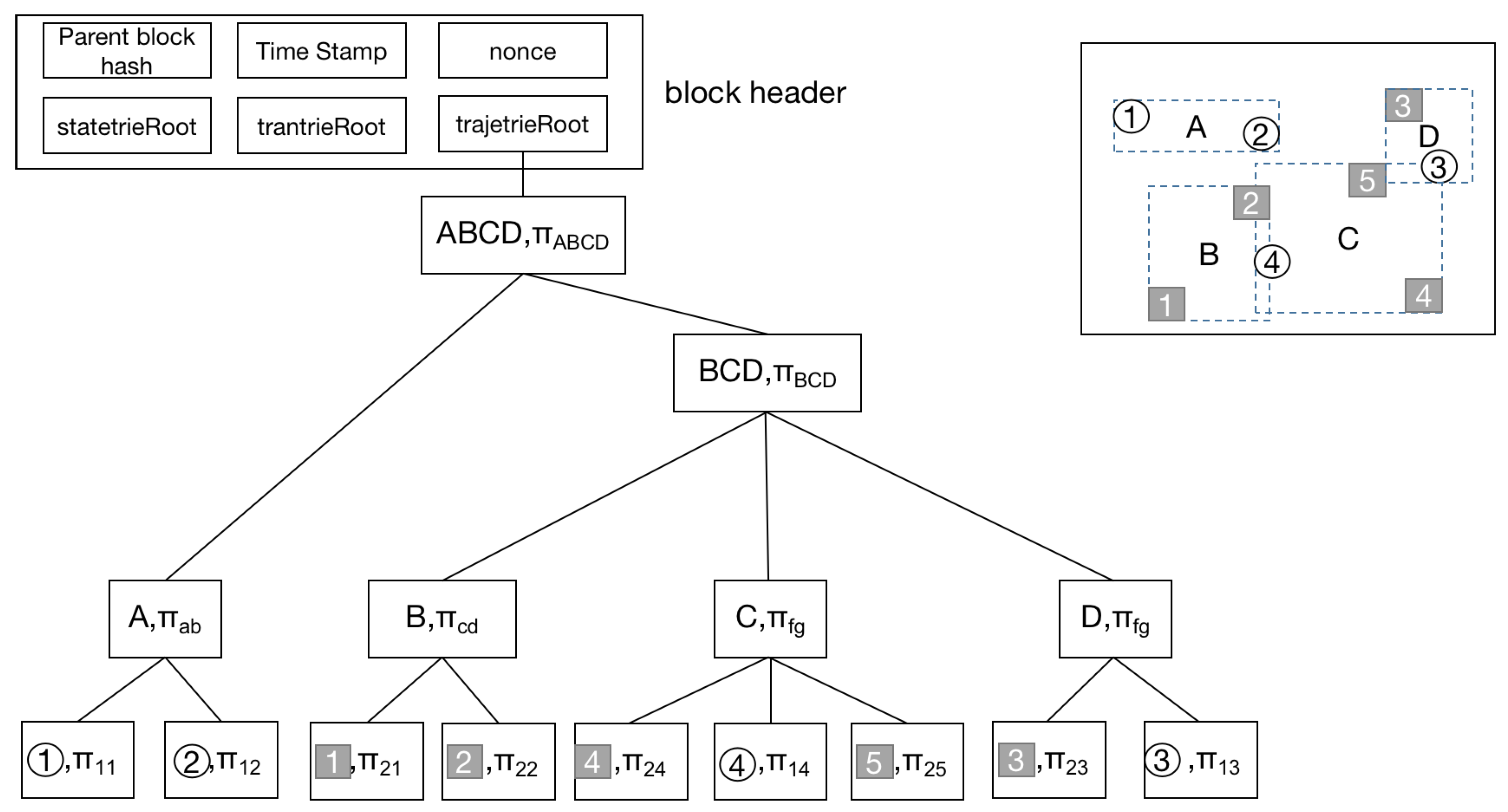
2.2.1. Architecture of Blockchain
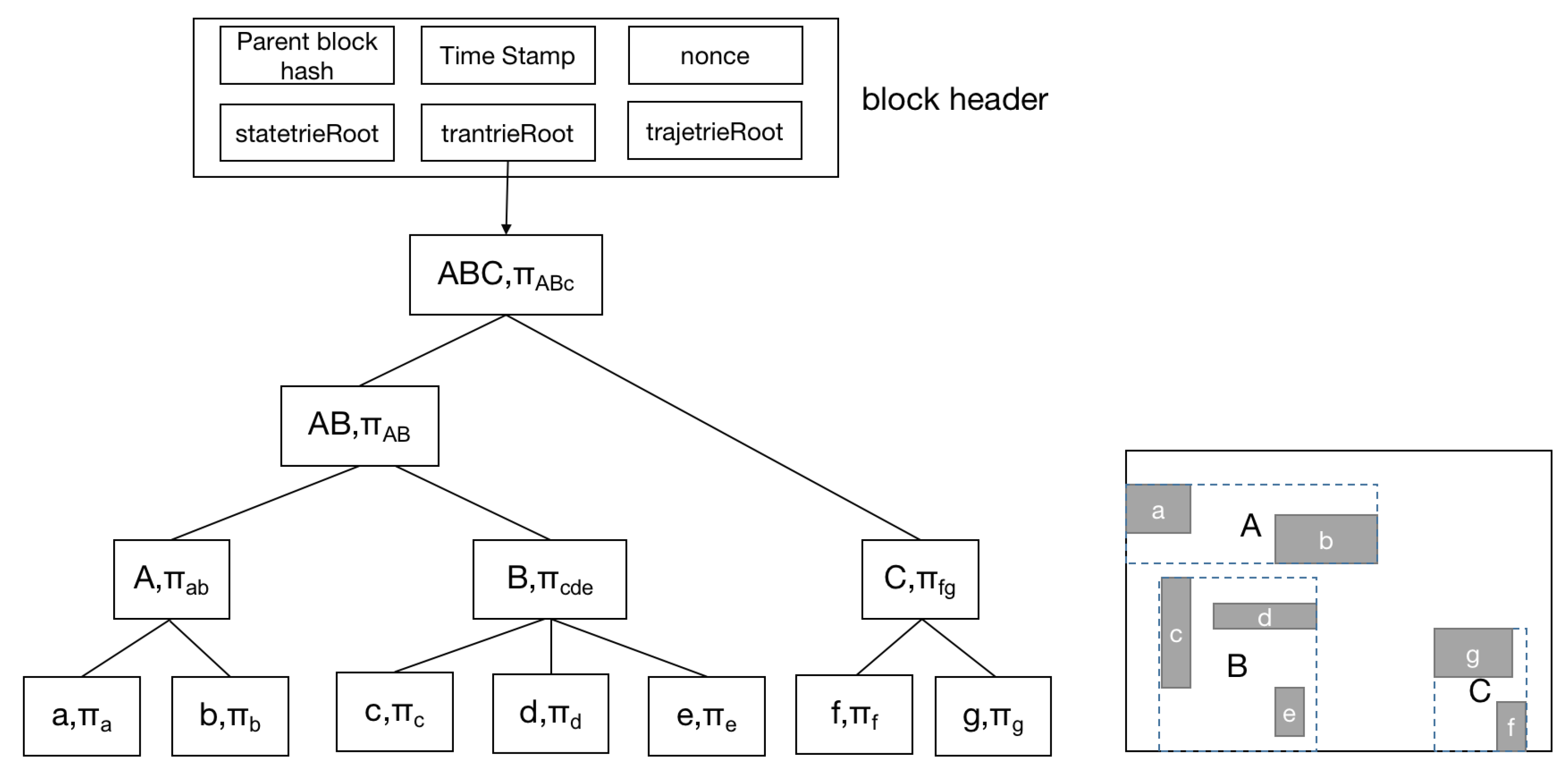
2.2.2. Merkle Trees and Verkle Trees
2.2.3. Spatio-Temporal Index in Blockchain
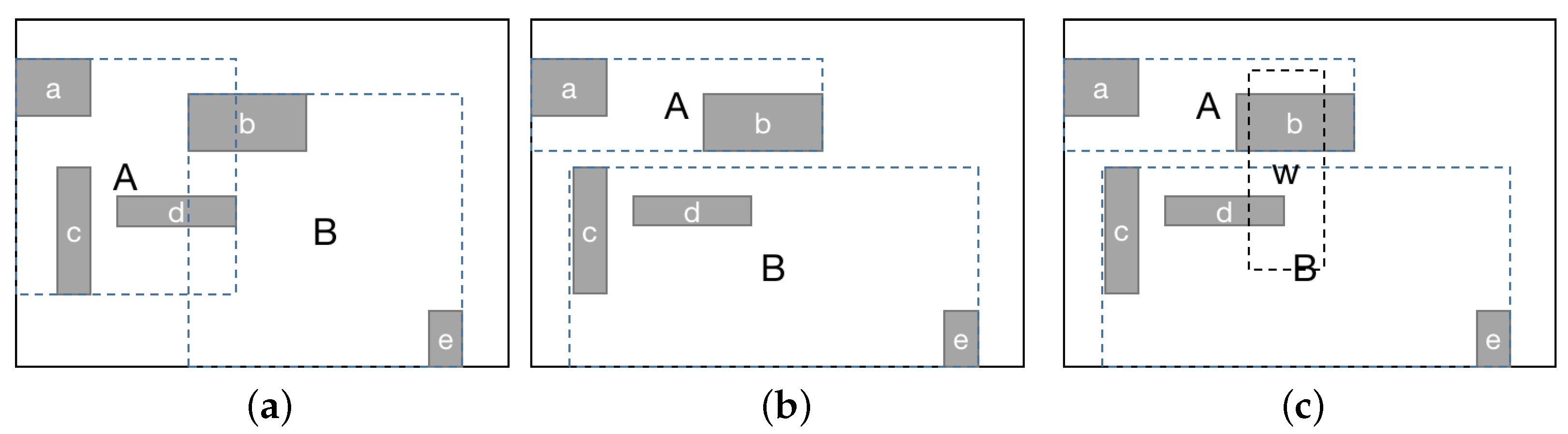
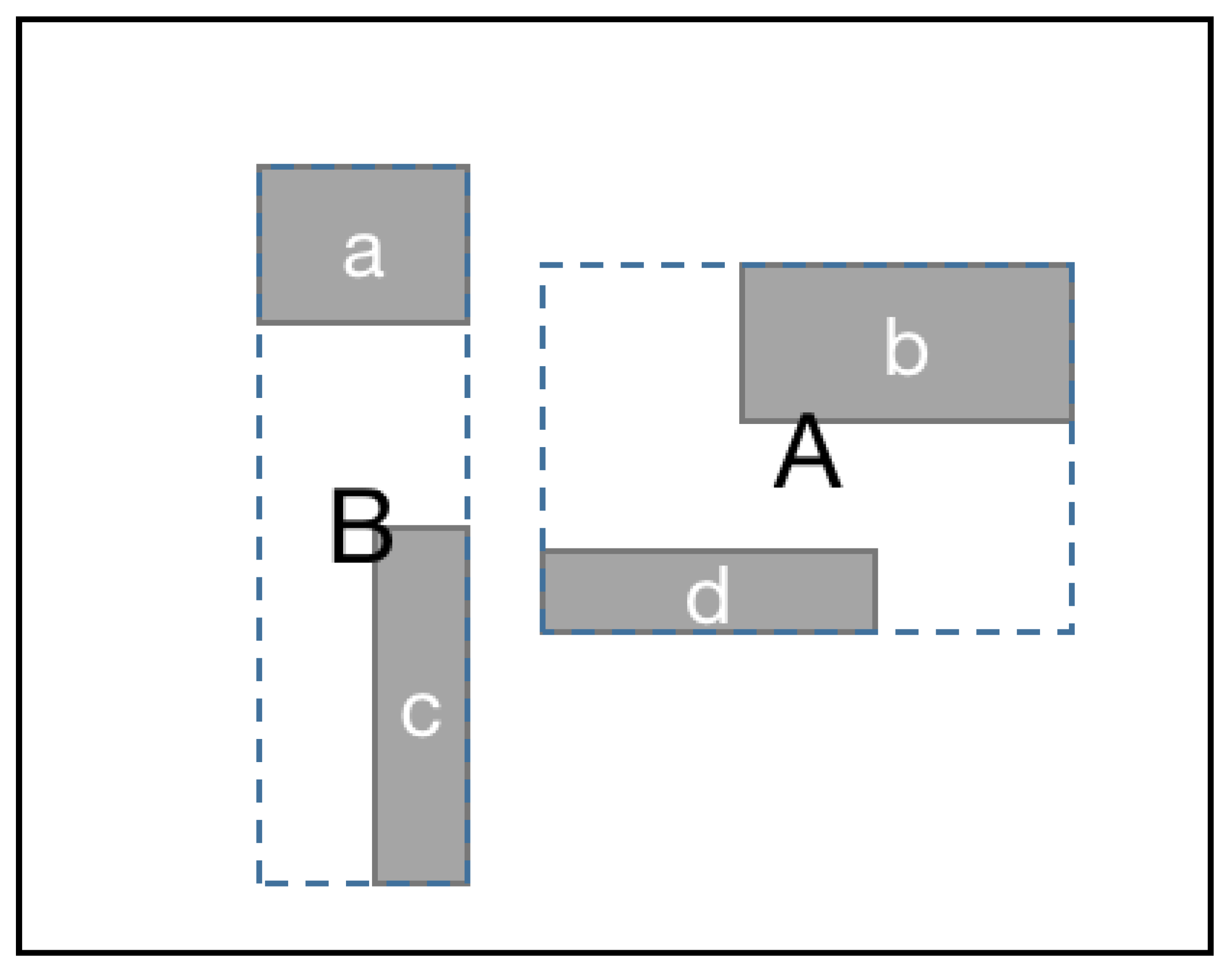
3. Verkle AR*-Tree in Spatio-Temporal Blockchain
3.1. Preliminary
3.2. Verkle AR*-Tree
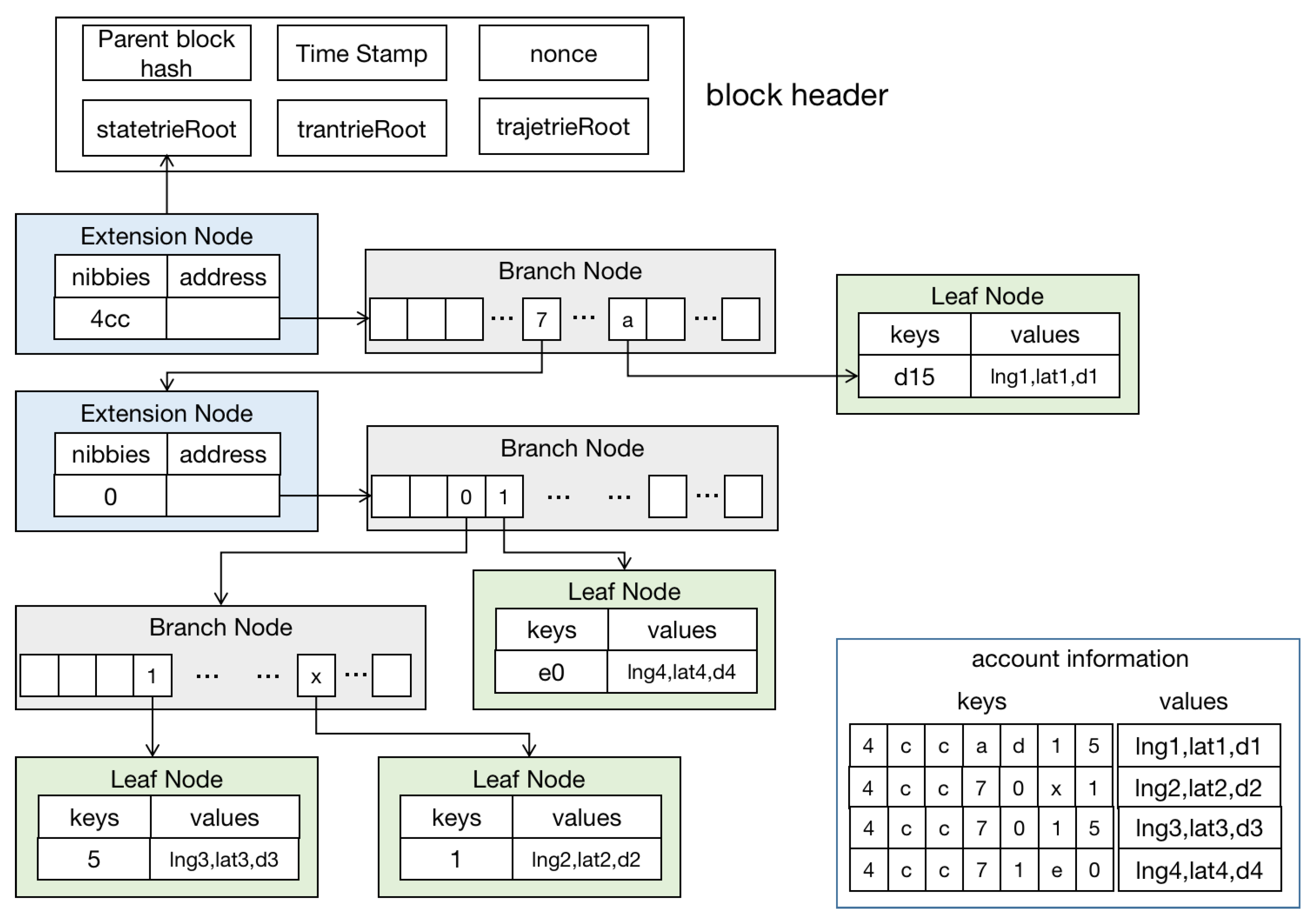
3.2.1. Index of Account with the Last location
| Algorithm 1 Update algorithm of VPT. |
| Input: |
| vpt: a Verkle patricia trie |
| node: current node in VPT |
| acc(keys,values): account information to be updated |
| Output: |
| vpt: updated VPT |
| 1: if node is nil then |
| 2: node ← createLeafNode(acc) |
| 3: vpt.root ← node |
| 4: else |
| 5: if node.type is LeftNode then |
| 6: p ← maxLengthPrefix(acc.keys, node.keys) |
| 7: newe, newb ← createExtensionNode(p), createBranchNode() |
| 8: newb.children[node.keys[len(p)]] ← node |
| 9: newb.children[acc.keys(len(p))] ← createLeftNode(acc) |
| 10: newb.parent, newe.parent ← newe, node.parent |
| 11: else if node.type is ExtensionNode then |
| 12: p ← maxLengthPrefix(acc.keys, node.nibbs) |
| 13: if p == node.nibbs then |
| 14: acc.keys = acc.keys[len(p):] |
| 15: Update(vpt,node.next,acc) |
| 16: else if node.nibbs.startWith(p) then |
| 17: newe, newb ← createExtensionNode(p), createBranchNode() |
| 18: newb.children[node.nibbs[len(p)]] getsnode |
| 19: newb.children[acc.keys(len(p))] ← createLeftNode(acc) |
| 20: newb.parent, newe.parent ← newe, node.parent |
| 21: else |
| 22: newb ← createBranchNode() |
| 23: newb.parent ← node.parent |
| 24: newb.children[acc.keys[0]] ← createLeftNode(acc) |
| 25: newb.children[node.nibbs[0]] ← node |
| 26: node.nibbs ← node.nibbs[1:] |
| 27: end if |
| 28: else if node.type is BranchNode then |
| 29: if node.children[acc.keys[0]] is nil then |
| 30: node.children[acc.keys[0]] ← createLeftNode(acc) |
| 31: else |
| 32: acc.keys ← acc.keys[1:] |
| 33: Update(vpt,node.children[acc.keys[0]],acc) |
| 34: end if |
| 35: end if |
| 36: end if |
3.2.2. Index of Transaction Information
| Algorithm 2 ReCreate. |
| Input: |
| tree: R*-tree |
| Output: |
| tree: the reconstructed R*-tree |
| 1: entries ← tree.allentries() |
| 2: nodes ← earragenodes(entries) |
| 3: while True do |
| 4: results ← rearragenodes(nodes) |
| 5: parent ← [createNode(children = r) forrinresults] |
| 6: if parent.length ≤ context.maxchildrennum then |
| 7: tree.root ← createNode(children = parent) |
| 8: return |
| 9: end if |
| 10: results, nodes ← [], parents |
| 10: end while |
| Algorithm 3 Rearragenodes. |
| Input: |
| tree: R*-tree |
| nodes: all nodes of a layer |
| Output: |
| groups: node groups |
| 1: for node ∈ nodes do |
| 2: for d = 0 to node.dimension do |
| 3: for j = 0 to 1 do |
| 4: g1, g2 ← split(nodes, d, node, j) |
| 5: plans.add(g1,g2) |
| 6: end for |
| 7: end for |
| 8: end for |
| 9: plans ← sorted(plans, ‘cov’, reversed) |
| 10: maxcov ← plans[0].cov |
| 11: plans ← plans[cov == maxcov] |
| 12: plans ← sorted(plan, ‘overlop’) |
| 13: return plans[0] |
| Algorithm 4 Split. |
| Input: |
| entries: entries to be split |
| Output: |
| nodes: the split node set |
| 1: for entry ∈ entries do |
| 2: for d = 0 to entry.dimension do |
| 3: for j = 0 to 1 do |
| 4: g1, g2 ← split(entries, d, entry, j) |
| 5: plans.add(g1,g2) |
| 6: end for |
| 7: end for |
| 8: end for |
| 9: plans ← sorted(plans, ‘cov’, reversed) |
| 10: maxcov ← plans[0].cov |
| 11: plans ← plans[cov == maxcov] |
| 12: plans ← sorted(plans, ‘minarea’) |
| 13: minarea ← plans[0].area |
| 14: plans ← plans.trim(minarea, 0.) |
| 15: plans ← sorted(plans, ‘overlop’) |
| 16: optima ← plans[0] |
| 17: returnoptima |
3.2.3. Index of Trajectory
4. Experiment
4.1. Experimental Setup
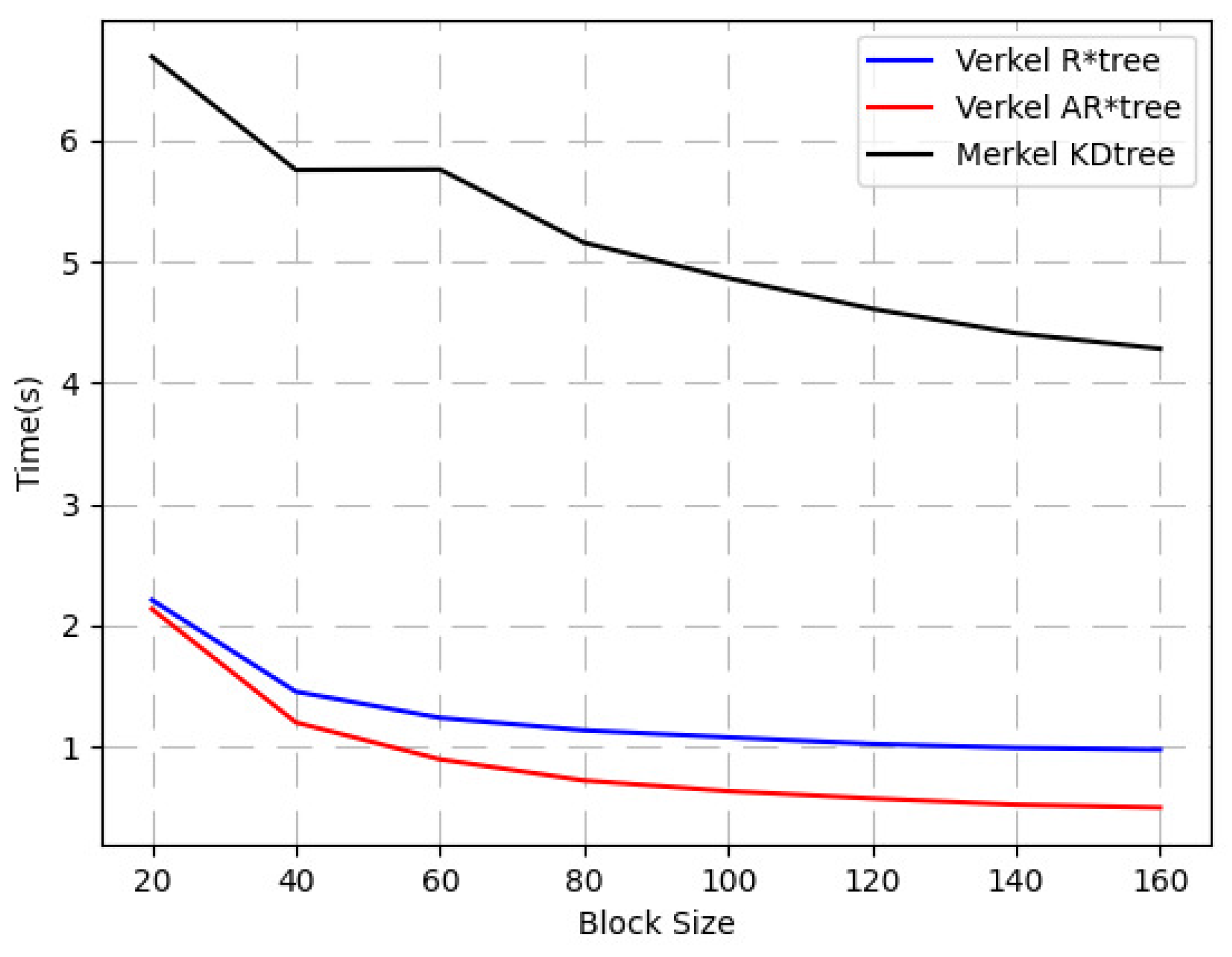
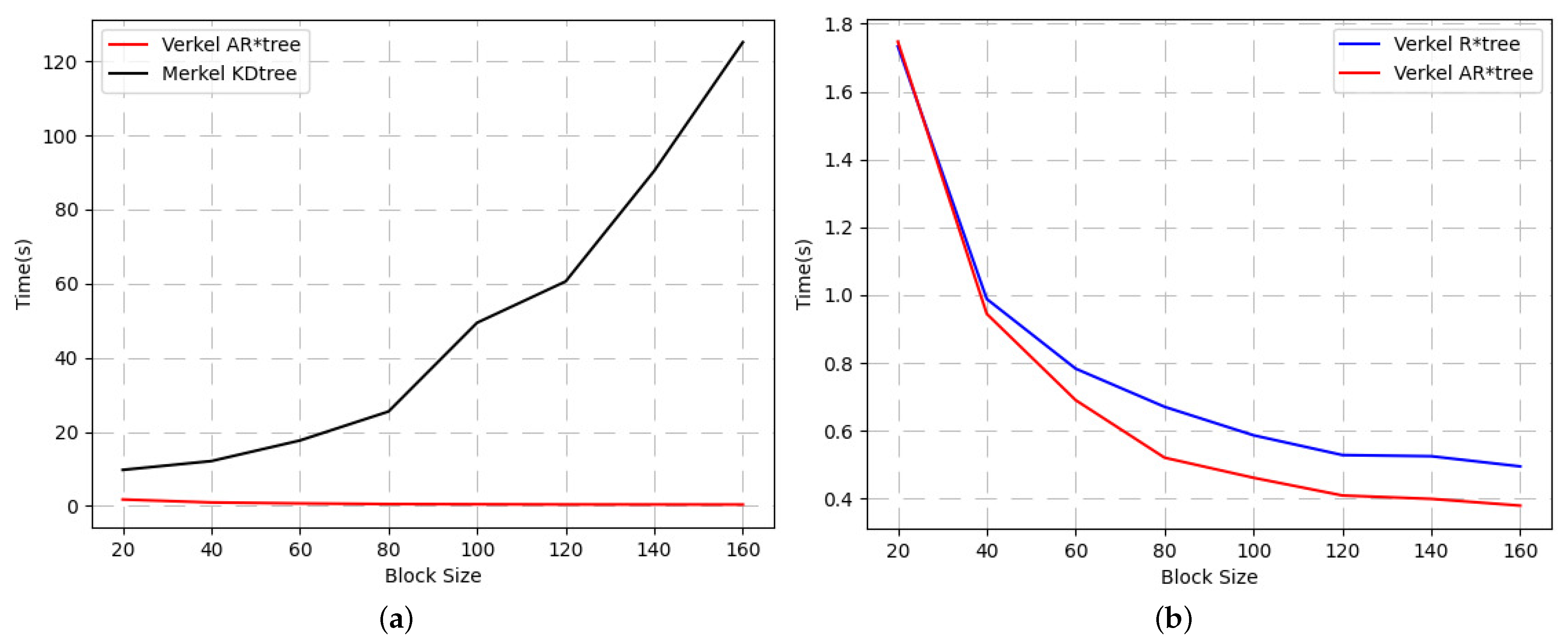
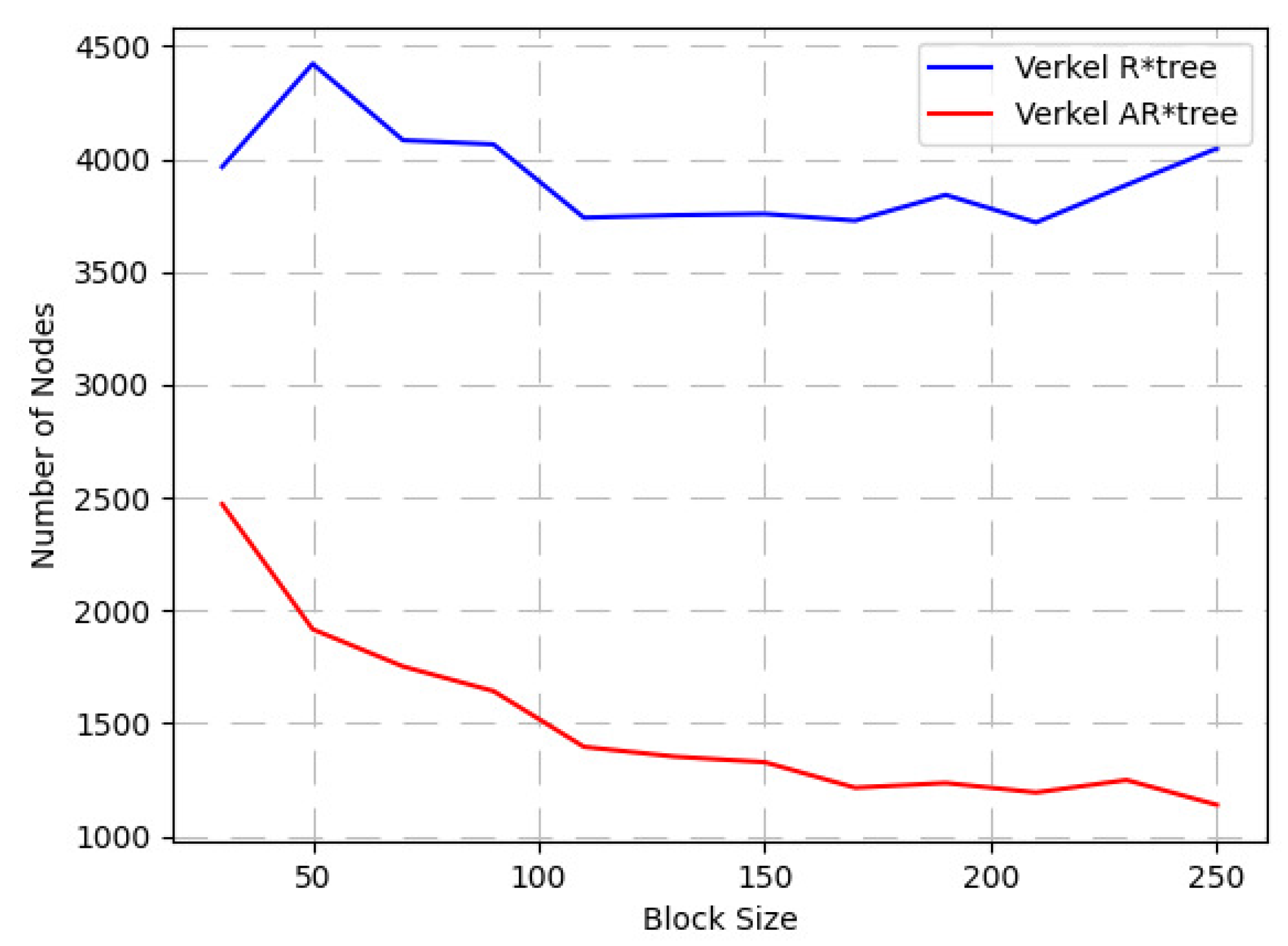
- Whether the spatio-temporal query performance of Verkle AR*-tree proposed in our work is better than the benchmark in [9] which reports that the spatio-temporal query performance is greatly affected by the block size, so we use different block sizes to compare the query performance.
- Performance comparison between adaptive AR*-tree and R*-tree in the blockchain.
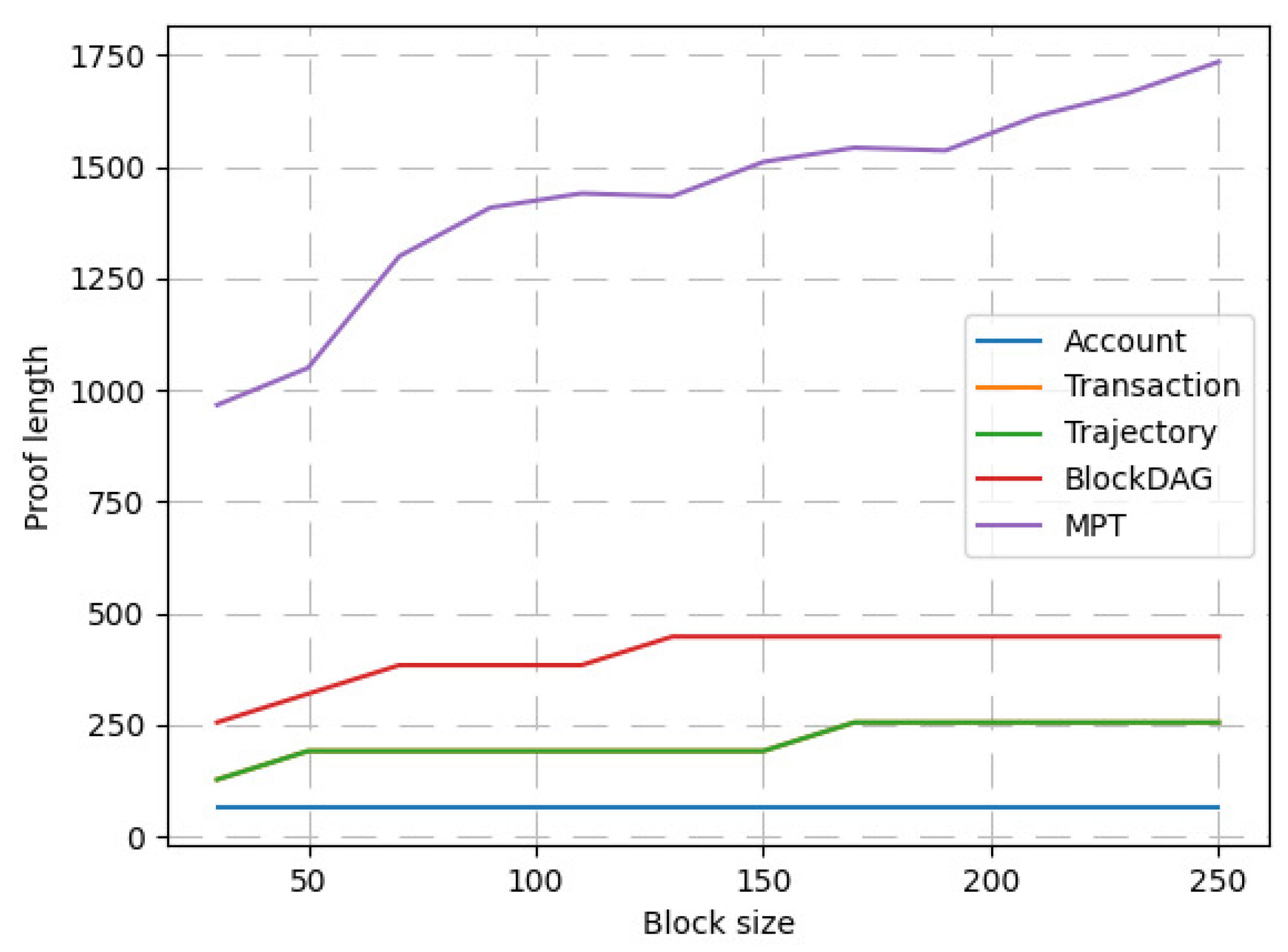
- The length of vector commitment provided by the Verkle tree is related to the depth of the tree, but independent of the width of the tree. Therefore, it should be better than the Merkle tree in performance. However, it is unclear about the difference in proving the performance of Verkle AR*-trees of various sizes, which needs to be further compared in experiments.
4.2. Result
4.2.1. Spatio-Temporal Query Performance of Verkle AR*-Tree
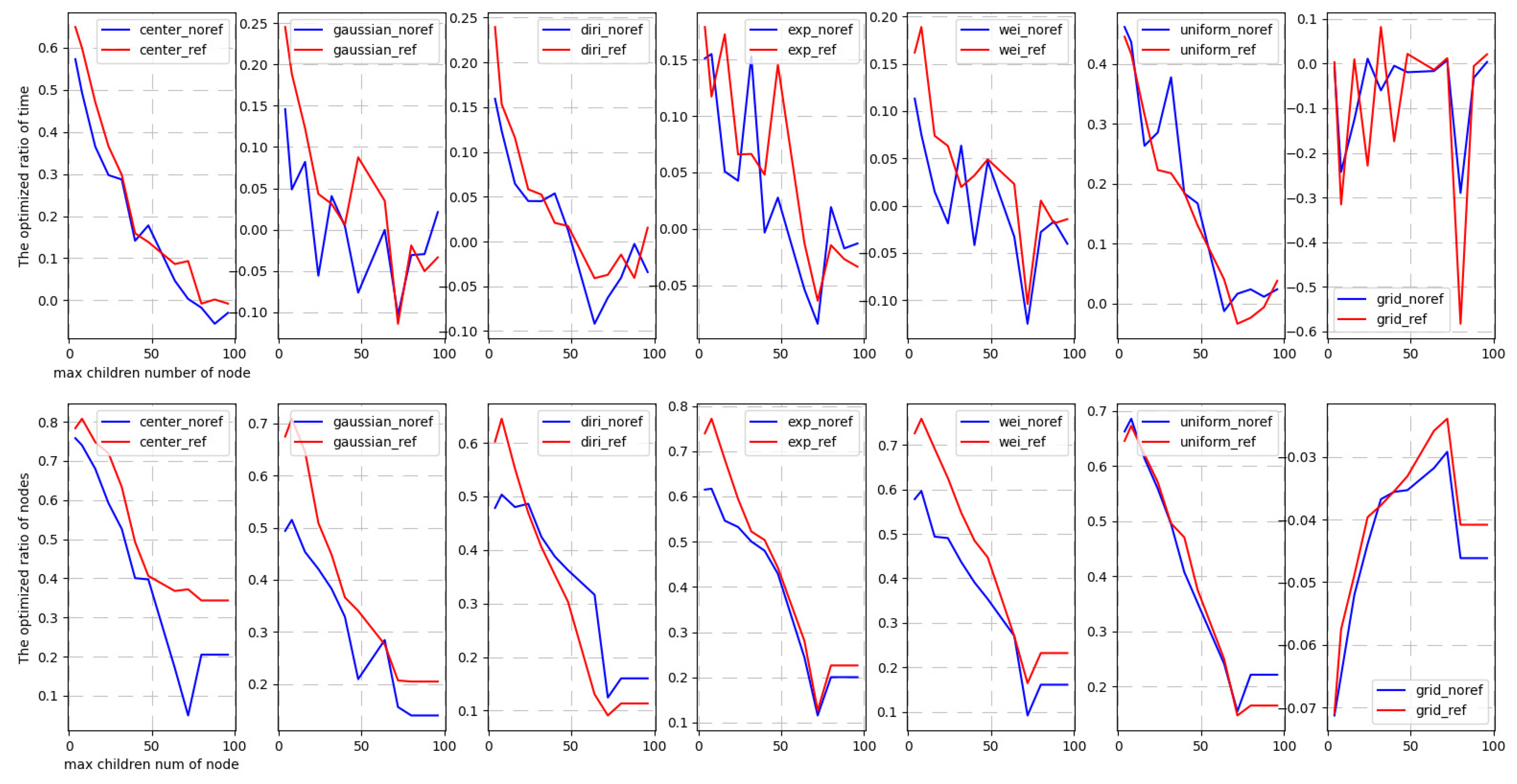
4.2.2. Adaptive Performance Analysis
- Center sampling. The center of all query windows is fixed in the center of the whole space-time region. the width of each dimension of the query window is obtained by sampling on Gaussian distribution N(0.3,0.05). The exception is that the width of the query window’s time dimension (third dimension) is fixed at 0.5 to allow more blocks to be effectively queried.
- Gaussian sampling. the query distribution is a Gaussian function(the number of center points is 9, and the width of the query window follows the normal distribution with a center value of 0.1 and a variance of 0.05).
- Dirichlet sampling. Both the central position and width of the query window follow the Dirichlet distribution with alpha = 3 and k = 4.
- Exponential sampling: The query center point follows the multivariate exponential distribution with scale = 2, and the width of the query window follows the normal distribution with a center value of 0.1 and variance of 0.05.
- Weibull sampling: The position of the query center follows the Weibull distribution with shape = 5, and the width of the query window follows the normal distribution with a center value of 0.1 and a variance of 0.05.
- Uniform sampling. The uniform sampling generates the center of the query with uniform distribution in the whole spatio-temporal region, and the width of each dimension of the query window is 0.05.
- Grid sampling. We fix a total number of queries, and then divide the whole space into grids according to the number of queries. Each grid just corresponds to a query window. This is an absolute uniform sampling, where uniform sampling is sampling with probability distribution.
4.2.3. Performance Analysis of Vector Commitment
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, M.; Chen, X.; Kou, G. A systematic review of blockchain. Financ. Innov. 2019, 5, 27. [Google Scholar] [CrossRef] [Green Version]
- Casino, F.; Dasaklis, T.K.; Patsakis, C. A systematic literature review of blockchain-based applications: Current status, classification and open issues. Telemat. Inform. 2019, 36, 55–81. [Google Scholar] [CrossRef]
- Worley, C.; Skjellum, A. Blockchain Tradeoffs and Challenges for Current and Emerging Applications: Generalization, Fragmentation, Sidechains, and Scalability. In Proceedings of the 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Halifax, NS, Canada, 30 July–3 August 2018; pp. 1582–1587. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 22 May 2022).
- Back, A.; Corallo, M.; Dashjr, L.; Friedenbach, M.; Maxwell, G.; Miller, A.; Poelstra, A.; Timón, J.; Wuille, P. Enabling Blockchain Innovations with Pegged Sidechains. Available online: https://blockstream.com/sidechains.pdf (accessed on 22 May 2022).
- Vujičić, D.; Jagodić, D.; Ranđić, S. Blockchain technology, bitcoin, and Ethereum: A brief overview. In Proceedings of the 2018 17th International Symposium Infoteh-Jahorina (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 21–23 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Helmer, S.; Roggia, M.; El Ioini, N.; Pahl, C. EthernityDB – Integrating Database Functionality into a Blockchain. In Proceedings of the European Conference on Advances in Databases and Information Systems, Budapest, Hungary, 2–5 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 37–44. [Google Scholar] [CrossRef]
- Sompolinsky, Y.; Wyborski, S.; Zohar, A. PHANTOM GHOSTDAG: A Scalable Generalization of Nakamoto Consensus: September 2, 2021. In Proceedings of the 3rd ACM Conference on Advances in Financial Technologies, Arlington, VA, USA, 26–28 September 2021; pp. 57–70. [Google Scholar]
- Nurgaliev, I.; Muzammal, M.; Qu, Q. Enabling Blockchain for Efficient Spatio-Temporal Query Processing. In Proceedings of the International Conference on Web Information Systems Engineering, Melbourne, VIC, Australia, 20–24 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 36–51. [Google Scholar]
- Kuszmaul, J. Verkle trees. Available online: https://math.mit.edu/research/highschool/primes/materials/2018/Kuszmaul.pdf (accessed on 22 May 2022).
- Ahn, H.K.; Mamoulis, N.; Wong, H. A Survey on Multidimensional Access Methods. Available online: https://dspace.library.uu.nl/bitstream/handle/1874/2491/2001-14.pdf (accessed on 22 May 2022).
- Samet, H. The Quadtree and Related Hierarchical Data Structures. ACM Comput. Surv. 1984, 16, 187–260. [Google Scholar] [CrossRef] [Green Version]
- Ooi, B.; Mcdonell, K.; Sacks-davis, R. Spatial kd-tree: An indexing mechanism for spatial databases. In Proceedings of the IEEE International Computer Software and Applications Conference, Tokyo, Japan, 5–6 October 1987; pp. 433–438. [Google Scholar]
- Ohsawa, Y.; Sakauchi, M. The BD-Tree - A New N-Dimensional Data Structure with Highly Efficient Dynamic Characteristics. In Proceedings of the IFIP 9th World Computer Congress, Paris, France, 19–23 September 1983; pp. 539–544. [Google Scholar]
- Tao, Z.; Cheng, C.; Pan, Z.; Shi, J. Generation and applications of a multi-resolution BSP tree. J. Softw. 2001, 12, 117–125. [Google Scholar]
- Li, C.; Wu, Z.; Wu, P.; Zhao, Z. An Adaptive Construction Method of Hierarchical Spatio-Temporal Index for Vector Data under Peer-to-Peer Networks. ISPRS Int. J. Geo-Inf. 2019, 8, 512. [Google Scholar] [CrossRef] [Green Version]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. ACM SIGMOD 1990, 19, 322–331. [Google Scholar] [CrossRef]
- Šumák, M.; Gurský, P. R++-Tree: An Efficient Spatial Access Method for Highly Redundant Point Data. In New Trends in Databases and Information Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 37–44. [Google Scholar]
- Shekhar, S.; Xiong, H.; Zhou, X. (Eds.) R-Tree. In Encyclopedia of GIS; Springer: Berlin/Heidelberg, Germany, 2017; p. 1805. [Google Scholar] [CrossRef]
- Gunther, O. The design of the cell tree: An object-oriented index structure for geometric databases. In Proceedings of the Fifth International Conference on Data Engineering, Los Angeles, CA, USA, 6–10 February 1989; pp. 598–605. [Google Scholar] [CrossRef]
- Kamel, I.; Faloutsos, C. Hilbert R-Tree: An Improved R-Tree Using Fractals. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB ’94), Santiago de Chile, Chile, 12–15 September 1994; pp. 500–509. [Google Scholar]
- Altarawneh, A.; Herschberg, T.; Medury, S.; Kandah, F.; Skjellum, A. Buterin’s Scalability Trilemma viewed through a State-change-based Classification for Common Consensus Algorithms. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 727–736. [Google Scholar] [CrossRef]
- Wan, L. A Query Optimization Method of Blockchain Electronic Transaction Based on Group Account. In Proceedings of the International Conference on Big Data Analytics for Cyber-Physical-Systems, Shanghai, China, 28–29 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1358–1364. [Google Scholar] [CrossRef]
- Sompolinsky, Y.; Zohar, A. PHANTOM: A Scalable BlockDAG Protocol. In Proceedings of the 3rd ACM Conference on Advances in Financial Technologies, Arlington, VA, USA, 26–28 September 2021. [Google Scholar]
- Szydlo, M. Merkle Tree Traversal in Log Space and Time. In International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2004; pp. 541–554. [Google Scholar]
- Kamel Boulos, M.N.; Wilson, J.T.; Clauson, K.A. Geospatial blockchain: Promises, challenges, and scenarios in health and healthcare. Int. J. Health Geogr. 2018, 17, 25. [Google Scholar]
- Liu, H.; Tai, W.; Wang, Y.; Wang, S. A Blockchain-Based Spatial Data Trading Framework. Preprint. 2021. Available online: https://www.researchgate.net/publication/348709925_A_Blockchain-Based_Spatial_Data_Trading_Framework (accessed on 22 May 2022).
- Sun, Y.; Zhang, L.; Feng, G.; Yang, B.; Cao, B.; Imran, M. Performance Analysis for Blockchain Driven Wireless IoT Systems Based on Tempo-Spatial Model. In Proceedings of the 2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Guilin, China, 17–19 October 2019; pp. 348–353. [Google Scholar] [CrossRef]
- Demenkov, M.; Demenkova, E.; Shishmanova, S. Application of blockchain technology for storage information on spatial objects. Vestn. Astrakhan State Tech. Univ. Ser. Manag. Comput. Sci. Inform. 2019, 1, 61–72. [Google Scholar] [CrossRef]
- Qu, Q.; Nurgaliev, I.; Muzammal, M.; Jensen, C.S.; Fan, J. On spatio-temporal blockchain query processing. Future Gener. Comput. Syst. 2019, 98, 208–218. [Google Scholar] [CrossRef]
- Mouratidis, K.; Sacharidis, D.; Pang, H.H. Partially materialized digest scheme: An efficient verification method for outsourced databases. VLDB J. 2009, 18, 363–381. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Kunath, P.; Renz, M. R*-Tree. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 987–992. [Google Scholar] [CrossRef]
- Pagel, B.U.; Six, H.W.; Toben, H.; Widmayer, P. Towards an Analysis of Range Query Performance in Spatial Data Structures. In Proceedings of the Twelfth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Washington, DC, USA, 25–28 May 1993; pp. 214–221. [Google Scholar] [CrossRef]
- Greene, D. An implementation and performance analysis of spatial data access methods. In Proceedings of the Fifth International Conference on Data Engineering, Los Angeles, CA, USA, 6–10 February 1989; pp. 606–615. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Liang, D. Adaptive Spatio-Temporal Query Strategies in Blockchain. ISPRS Int. J. Geo-Inf. 2022, 11, 409. https://doi.org/10.3390/ijgi11070409
Chen H, Liang D. Adaptive Spatio-Temporal Query Strategies in Blockchain. ISPRS International Journal of Geo-Information. 2022; 11(7):409. https://doi.org/10.3390/ijgi11070409
Chicago/Turabian StyleChen, Haibo, and Daolei Liang. 2022. "Adaptive Spatio-Temporal Query Strategies in Blockchain" ISPRS International Journal of Geo-Information 11, no. 7: 409. https://doi.org/10.3390/ijgi11070409
APA StyleChen, H., & Liang, D. (2022). Adaptive Spatio-Temporal Query Strategies in Blockchain. ISPRS International Journal of Geo-Information, 11(7), 409. https://doi.org/10.3390/ijgi11070409