
Landslide Susceptibility Prediction Based on High-Trust Non-Landslide Point Selection

Abstract
:1. Introduction
2. Overview and Data of the Study Area
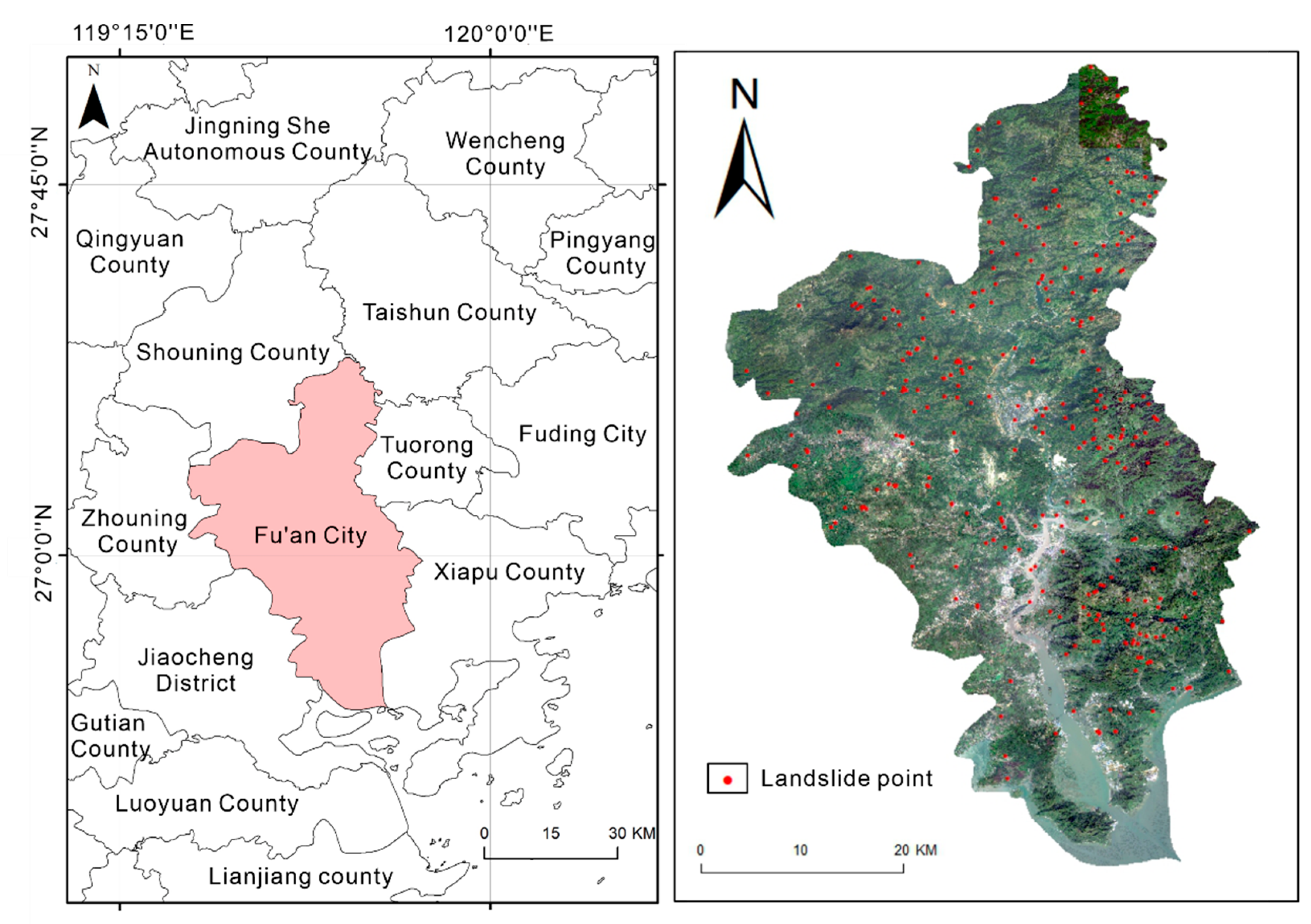
2.1. Study Area
2.2. Data Sources
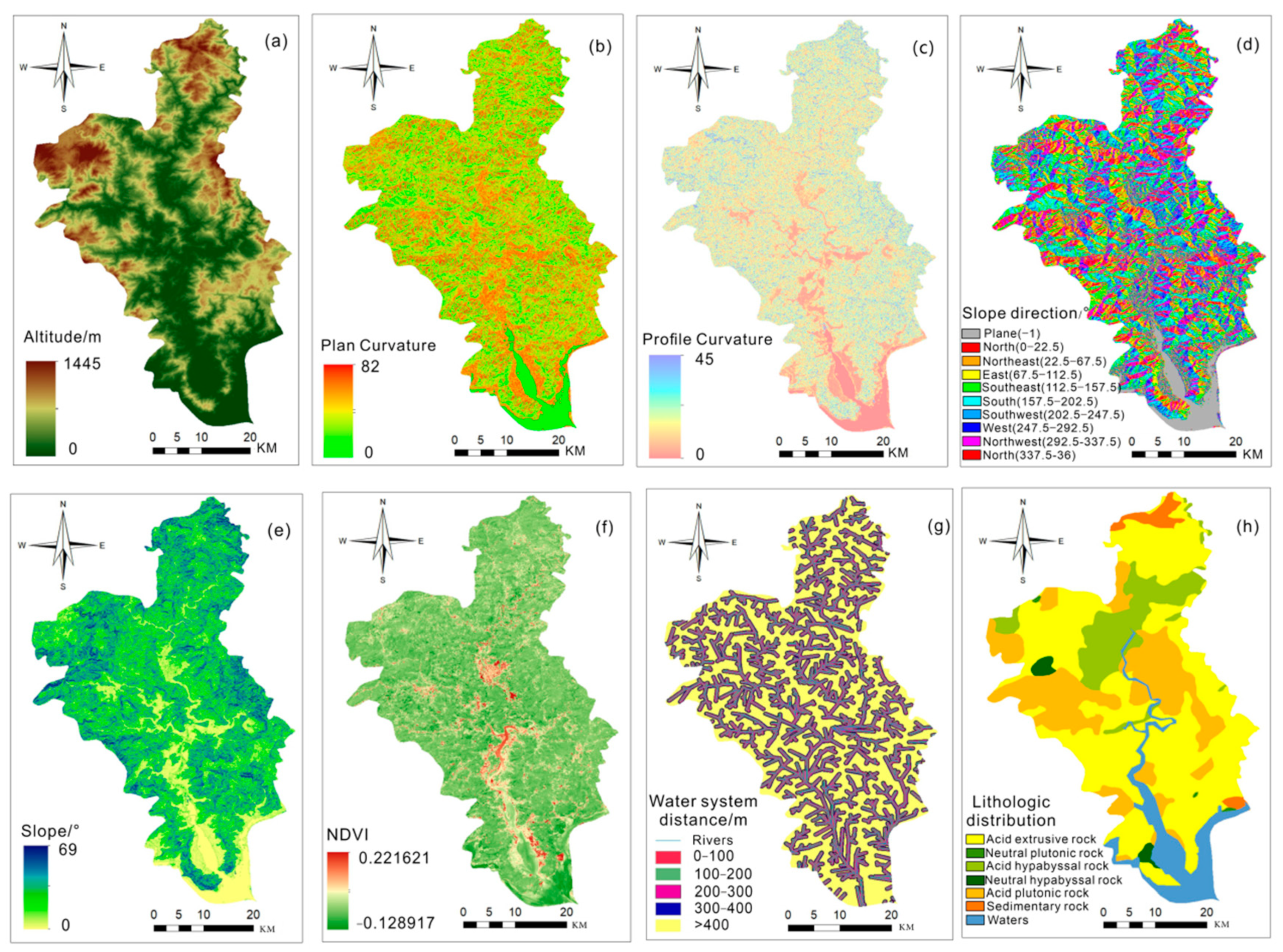
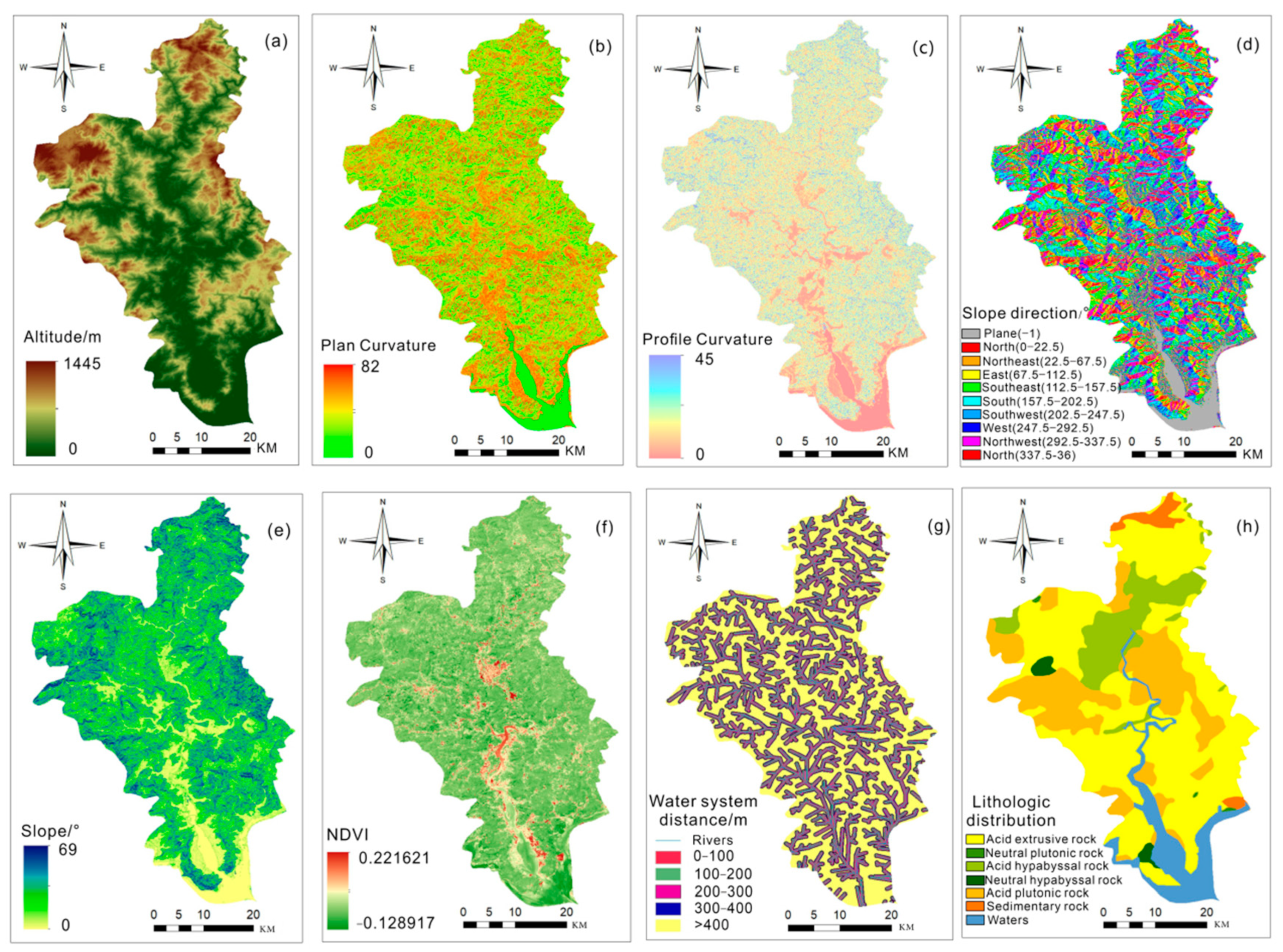
2.3. Environmental Factors
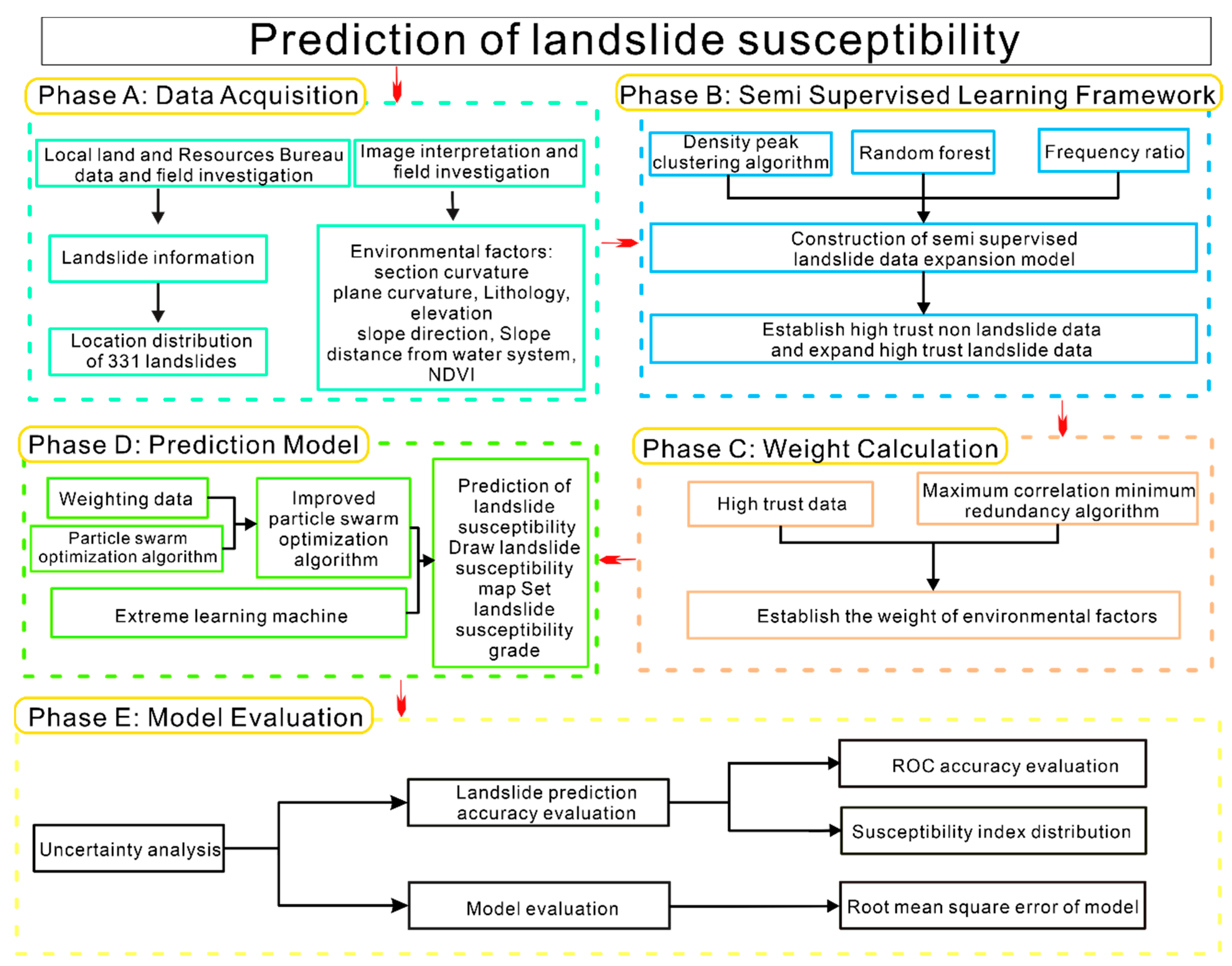
3. Methods
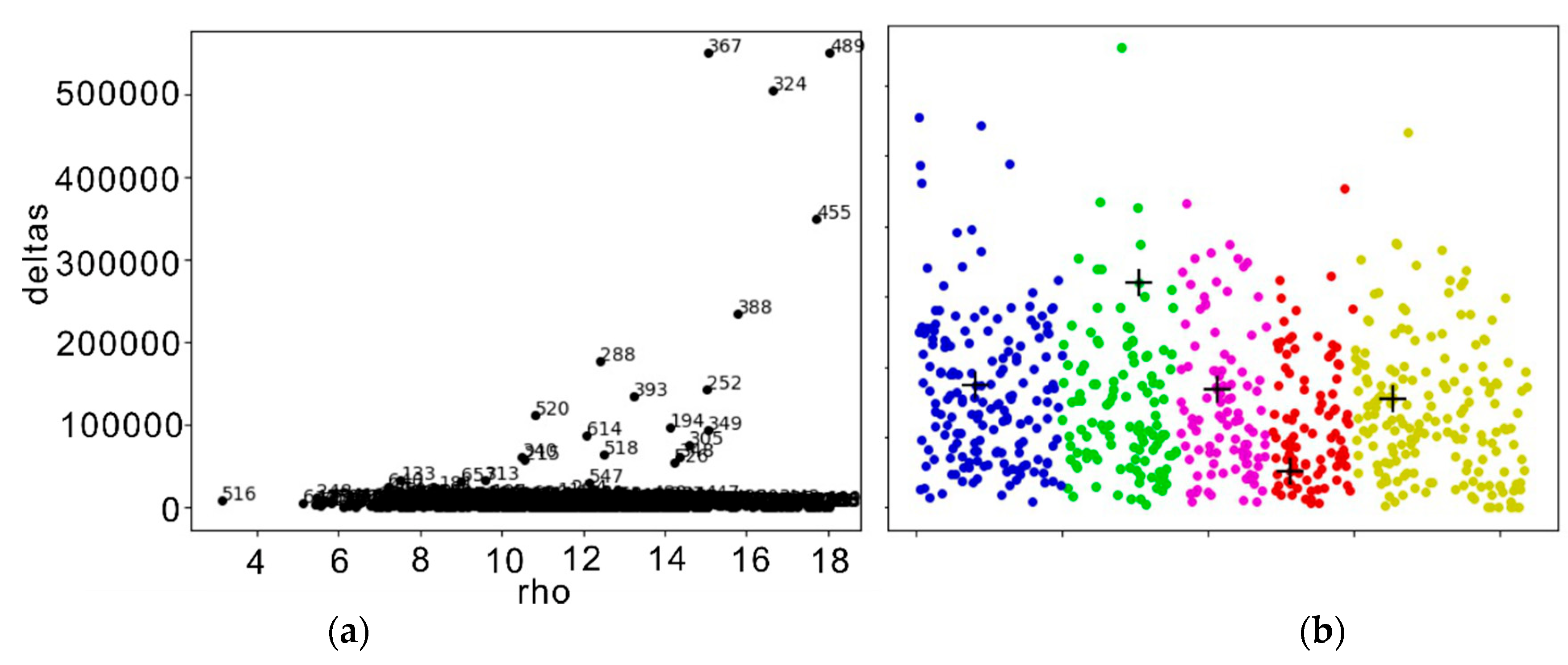
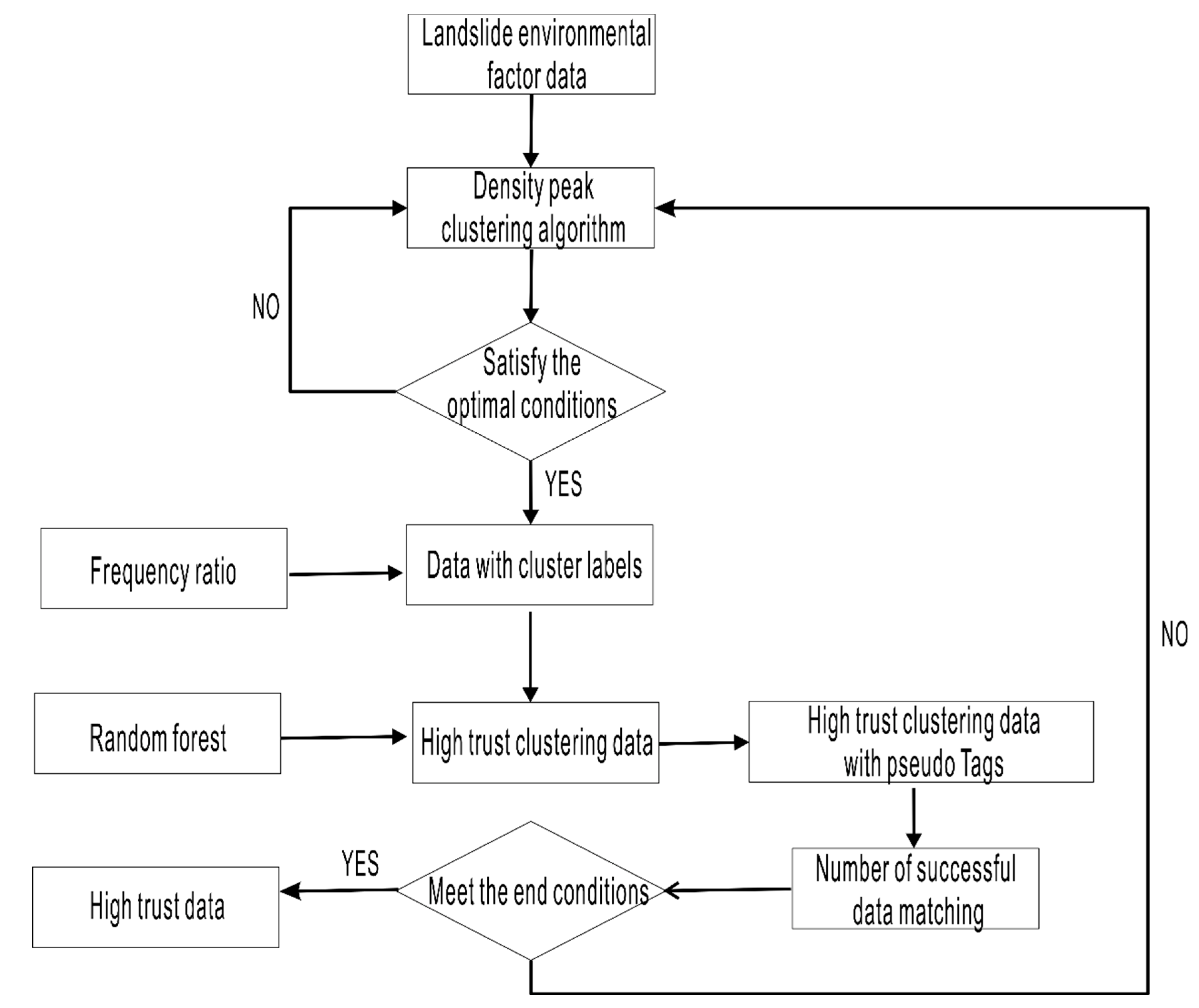
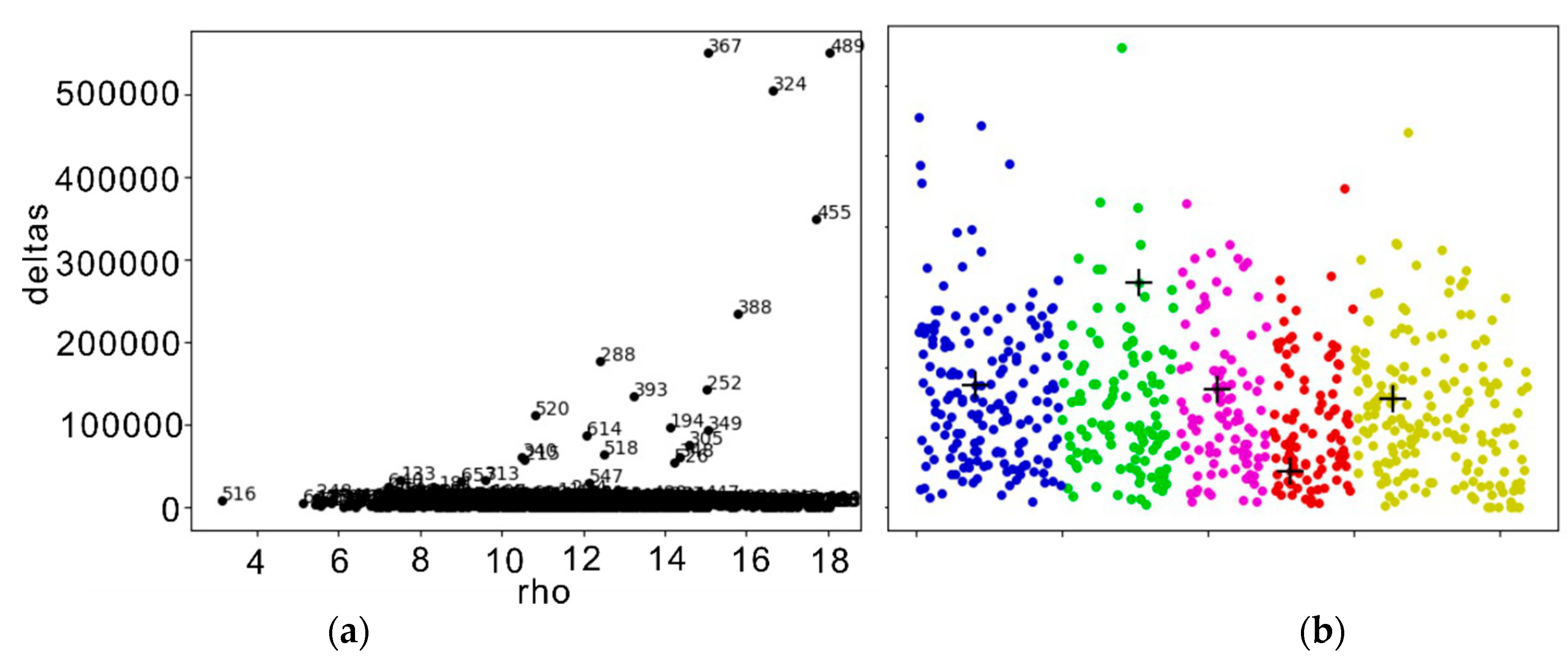
3.1. Density Peak Clustering Algorithm
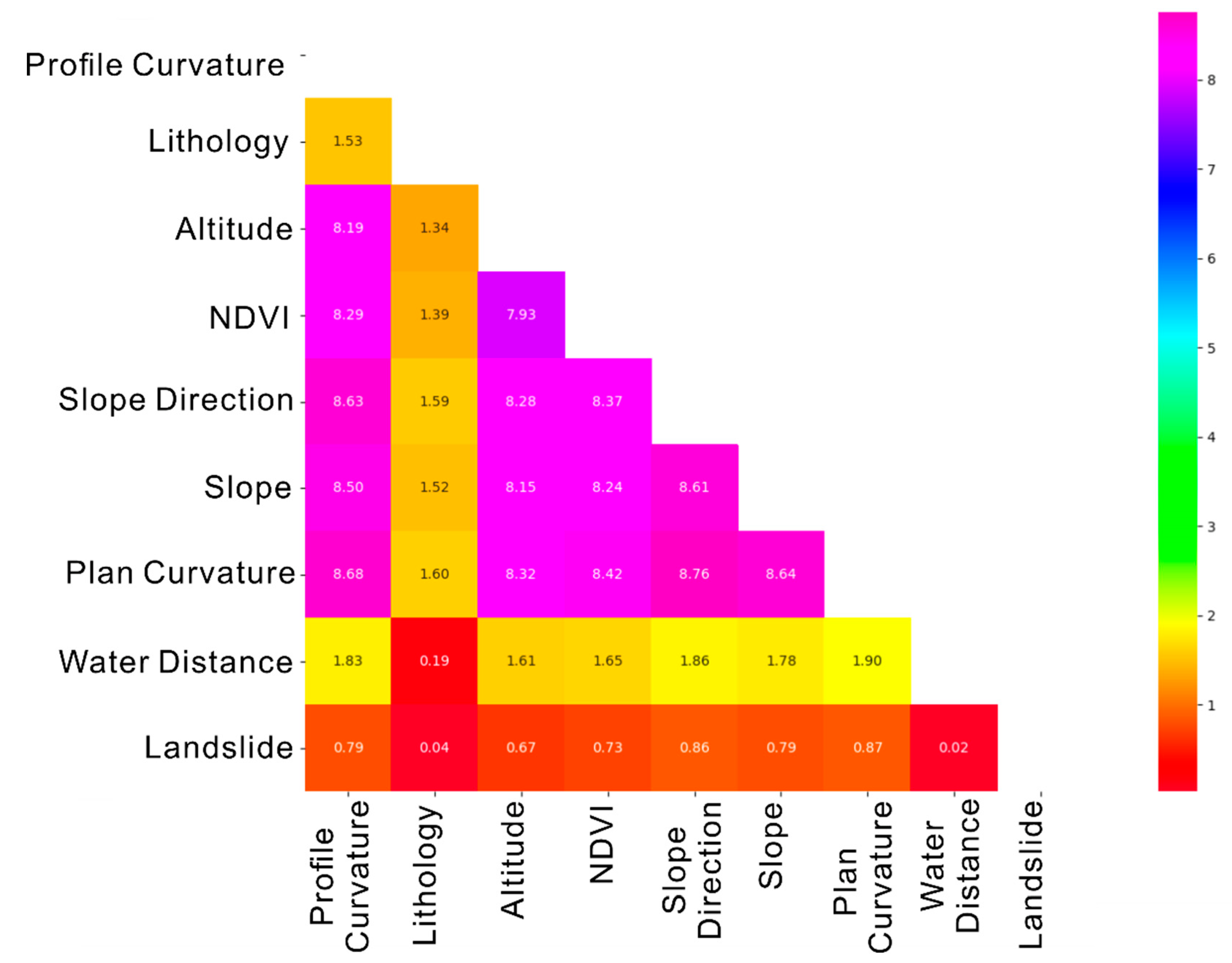
3.2. Max-Correlation Min-Redundancy Algorithm
3.3. Extreme Learning Machine
3.4. Random Forest
3.5. Particle Swarm Optimization Algorithm
3.6. Uncertainty Analysis Method
3.6.1. ROC Curve Precision Analysis
3.6.2. Frequency Ratio
3.6.3. Root Mean Square Error Analysis
4. Modeling of Landslide Susceptibility Assessment in Fu’an
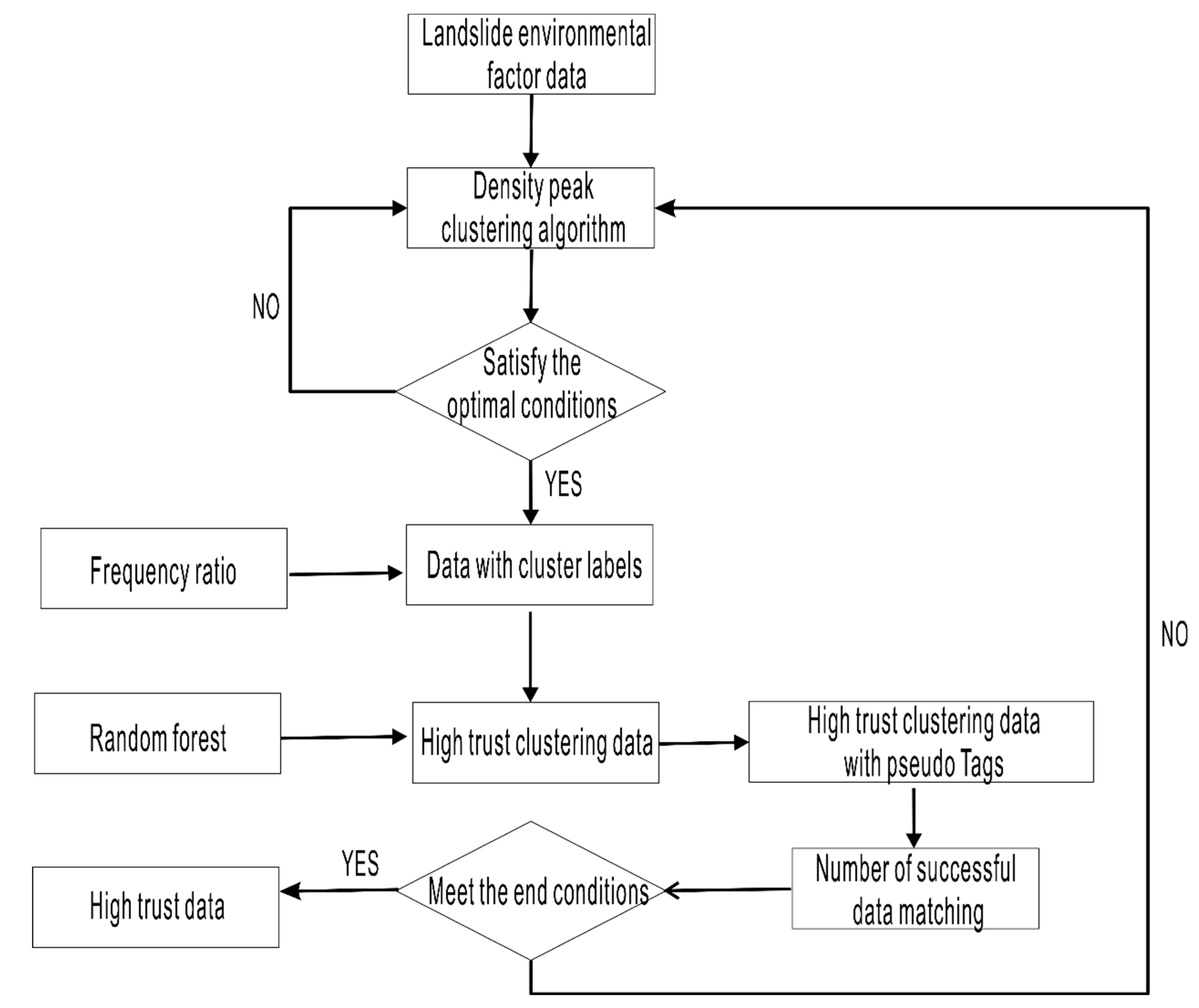
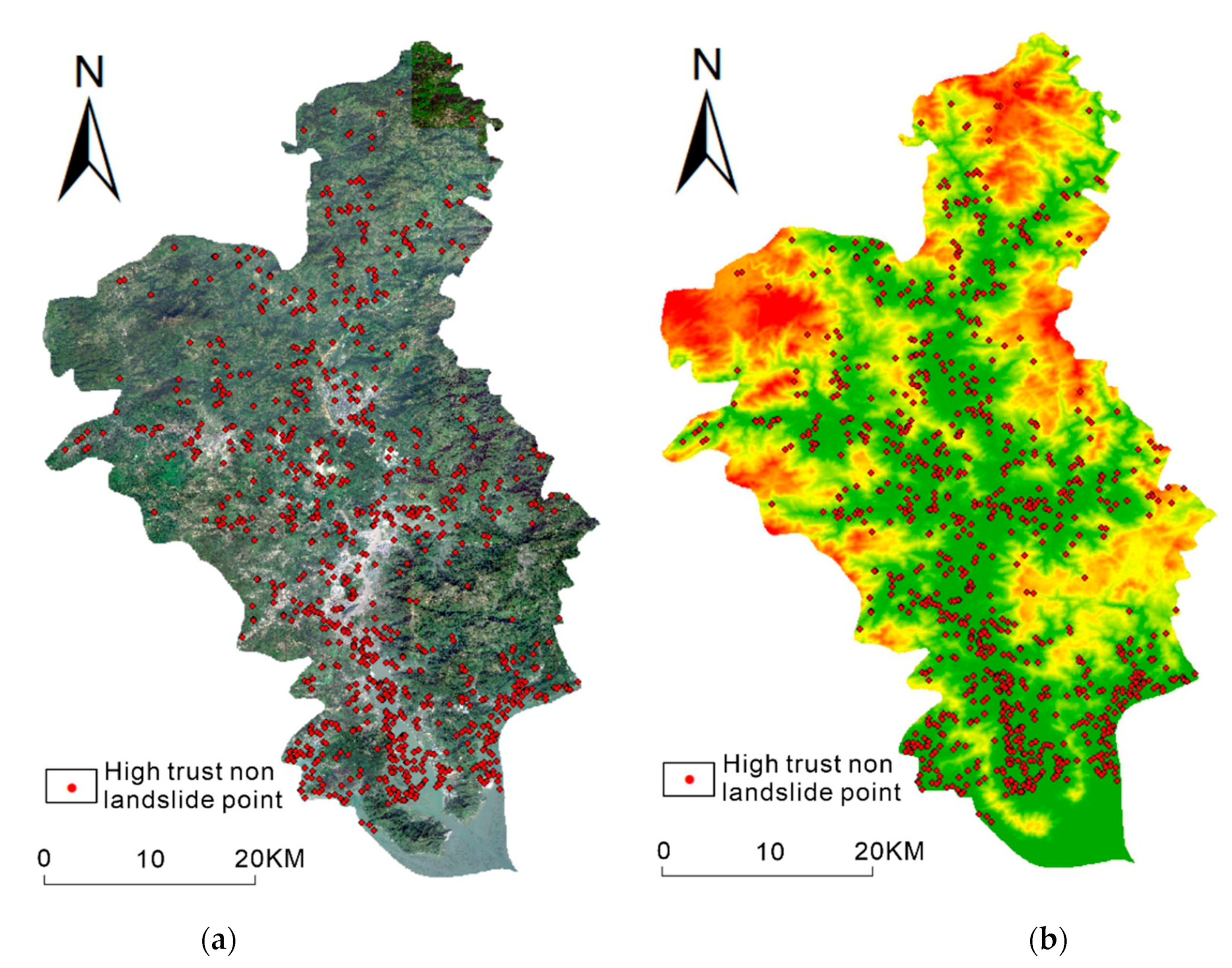
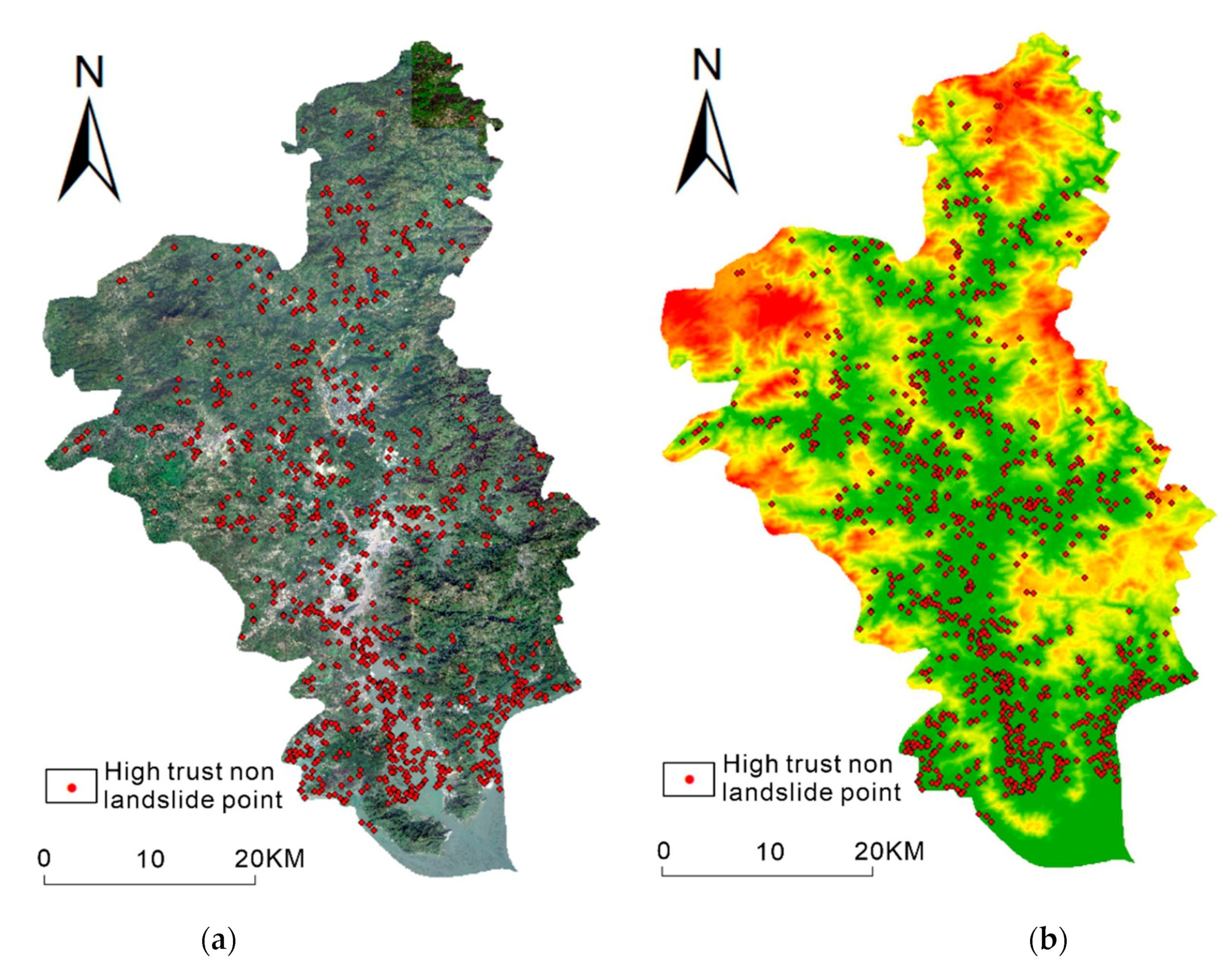
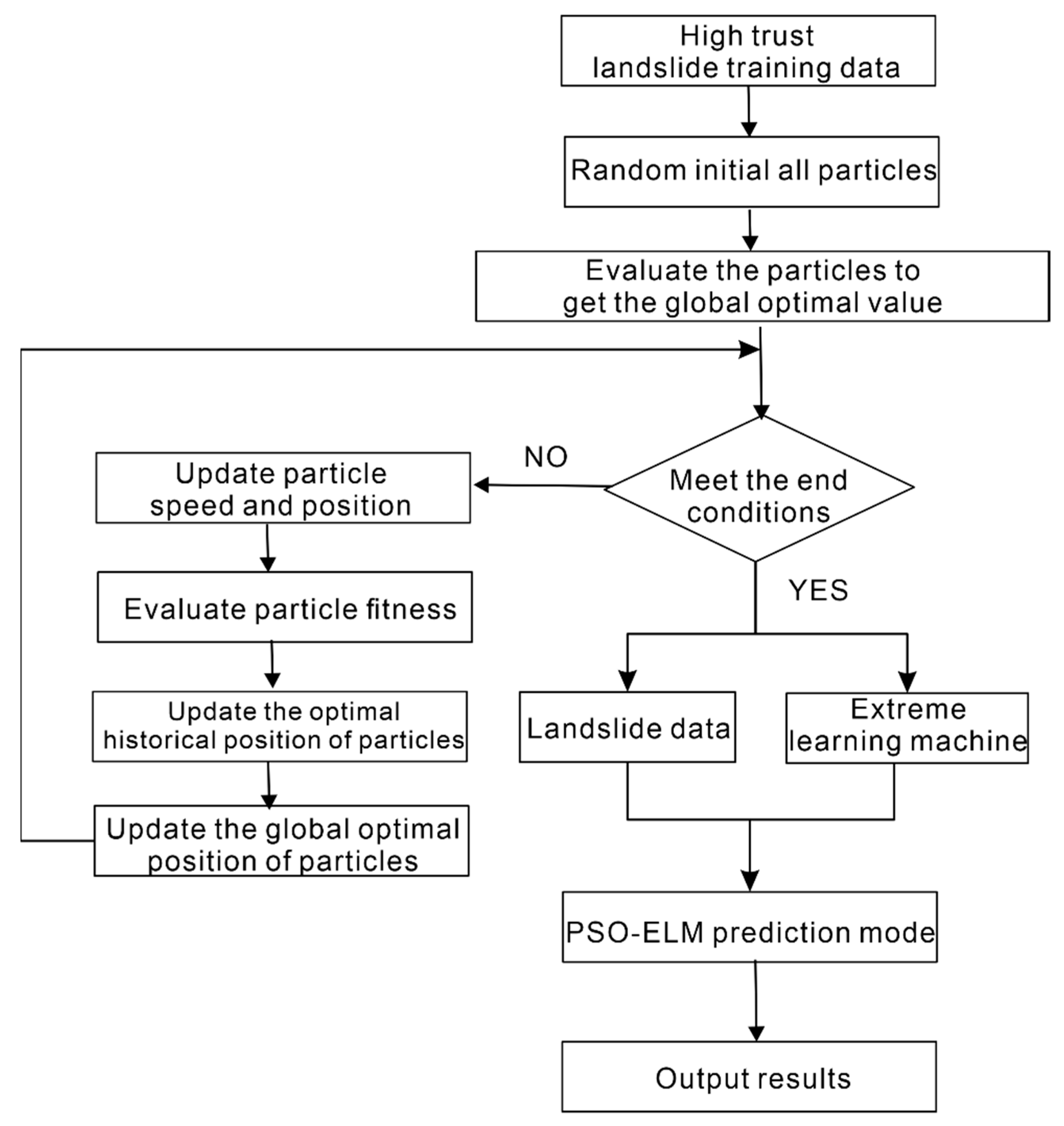
4.1. Semi-Supervised Learning Framework Construction
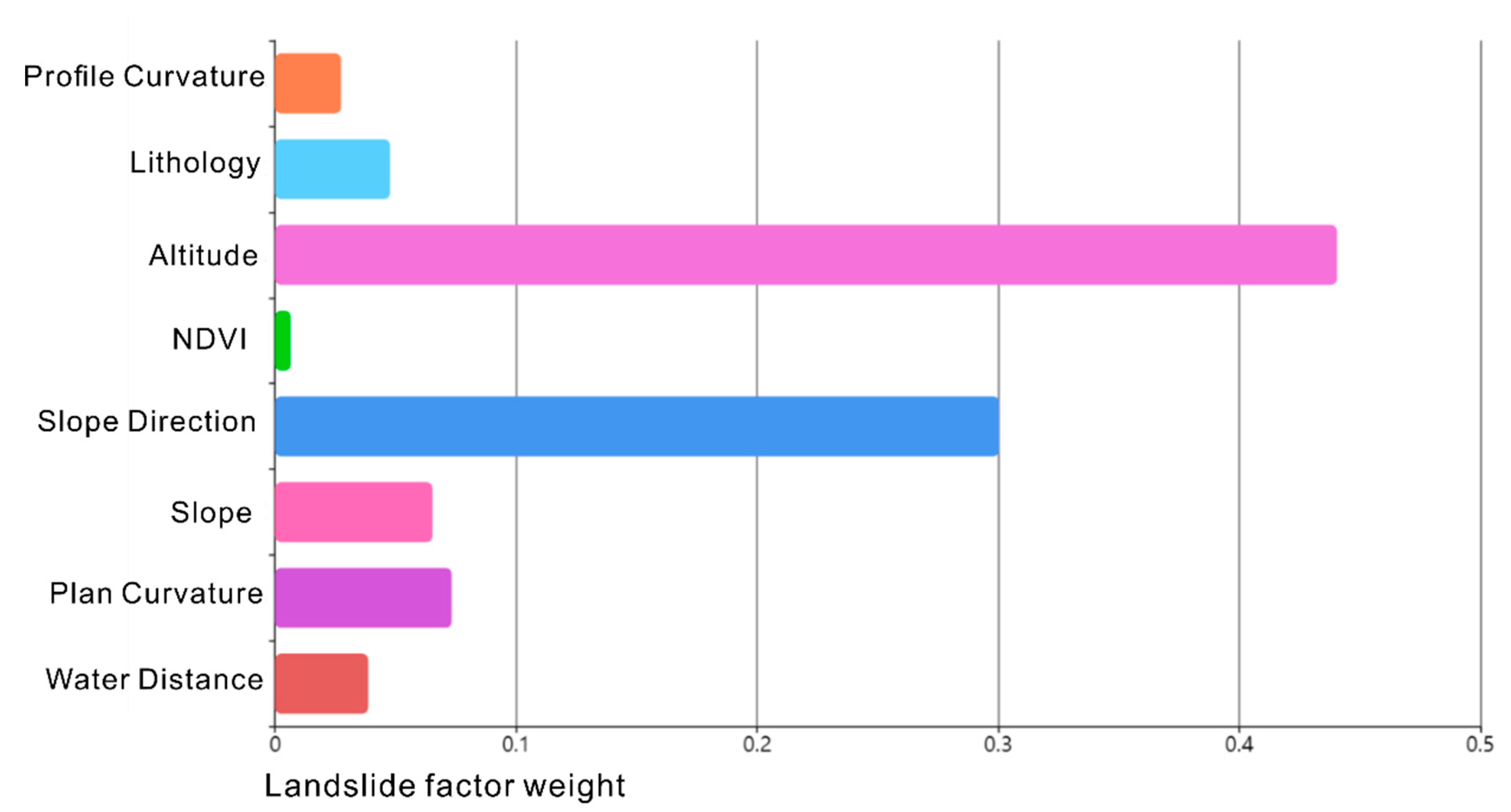
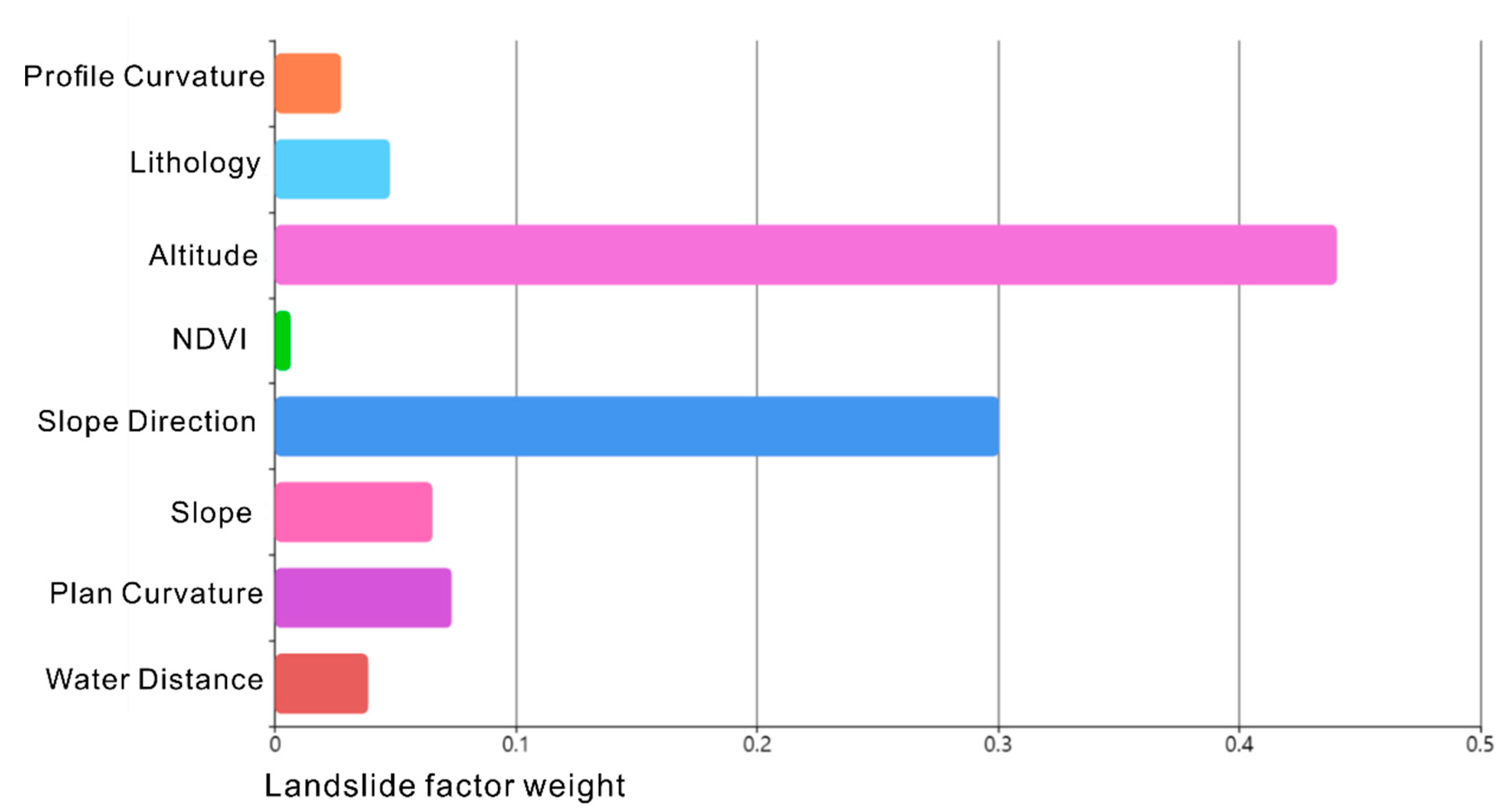
4.2. Weight Determination Analysis
4.3. PSO-ELM Prediction Model
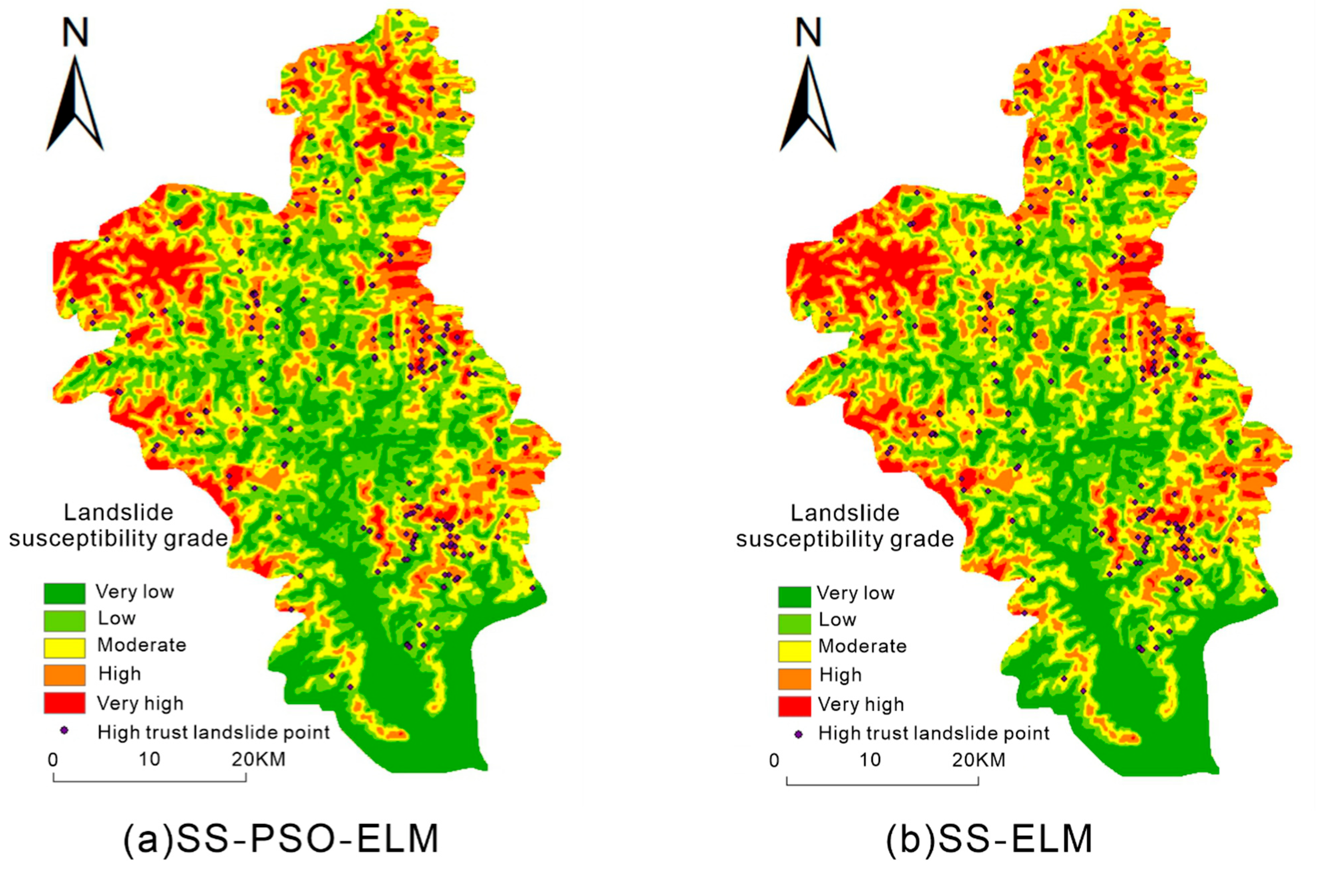
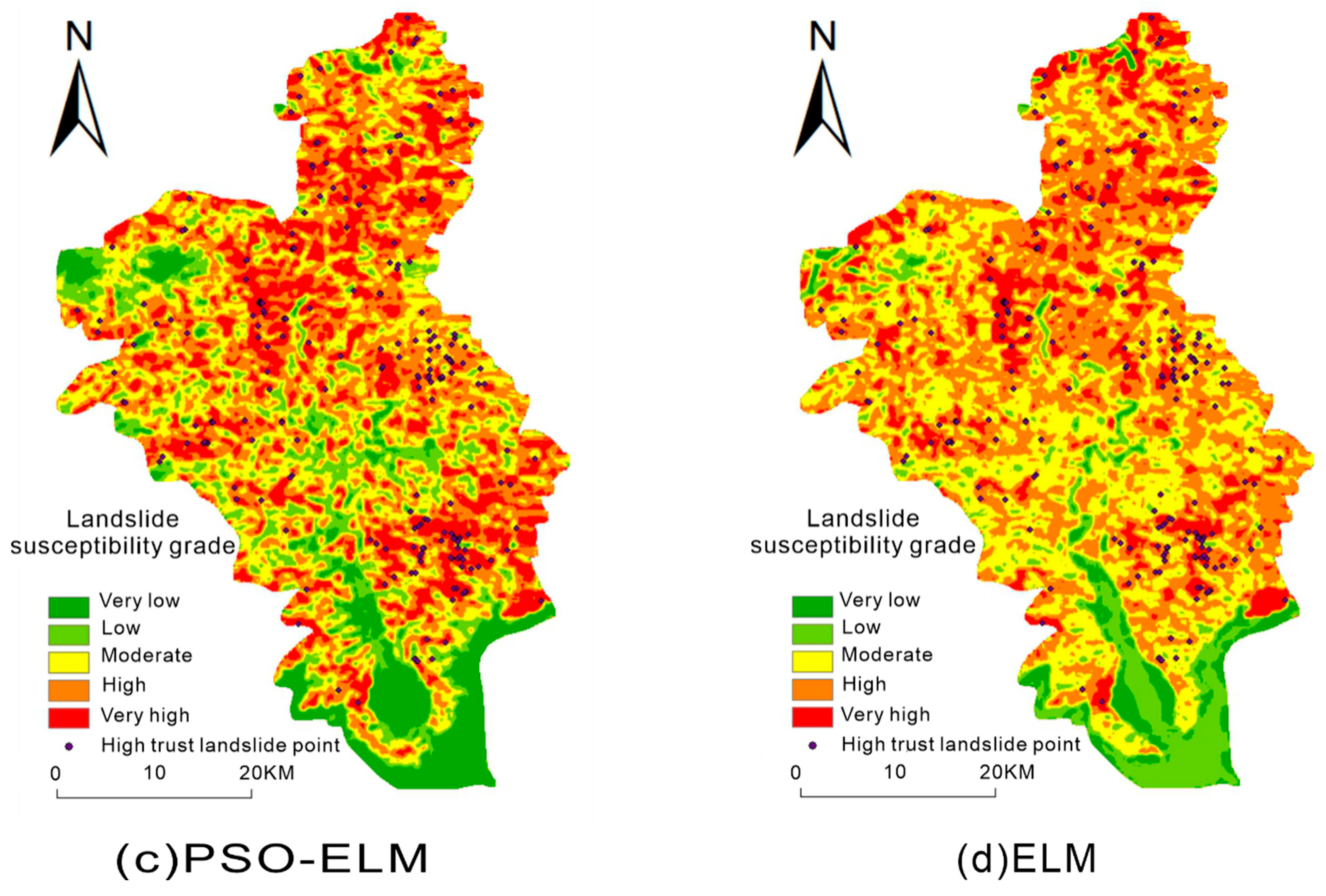
4.4. Landslide Susceptibility Mapping
- (1)
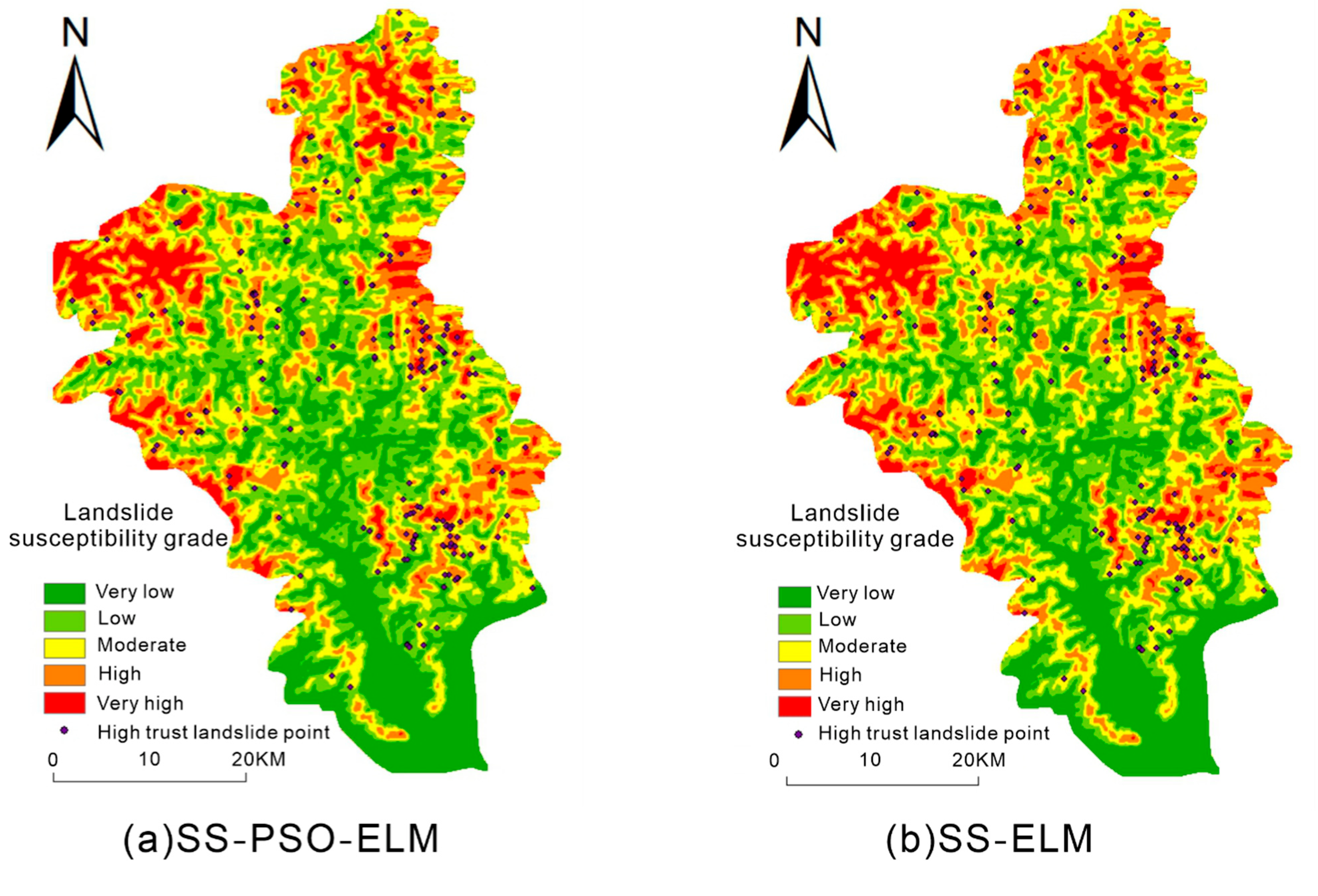
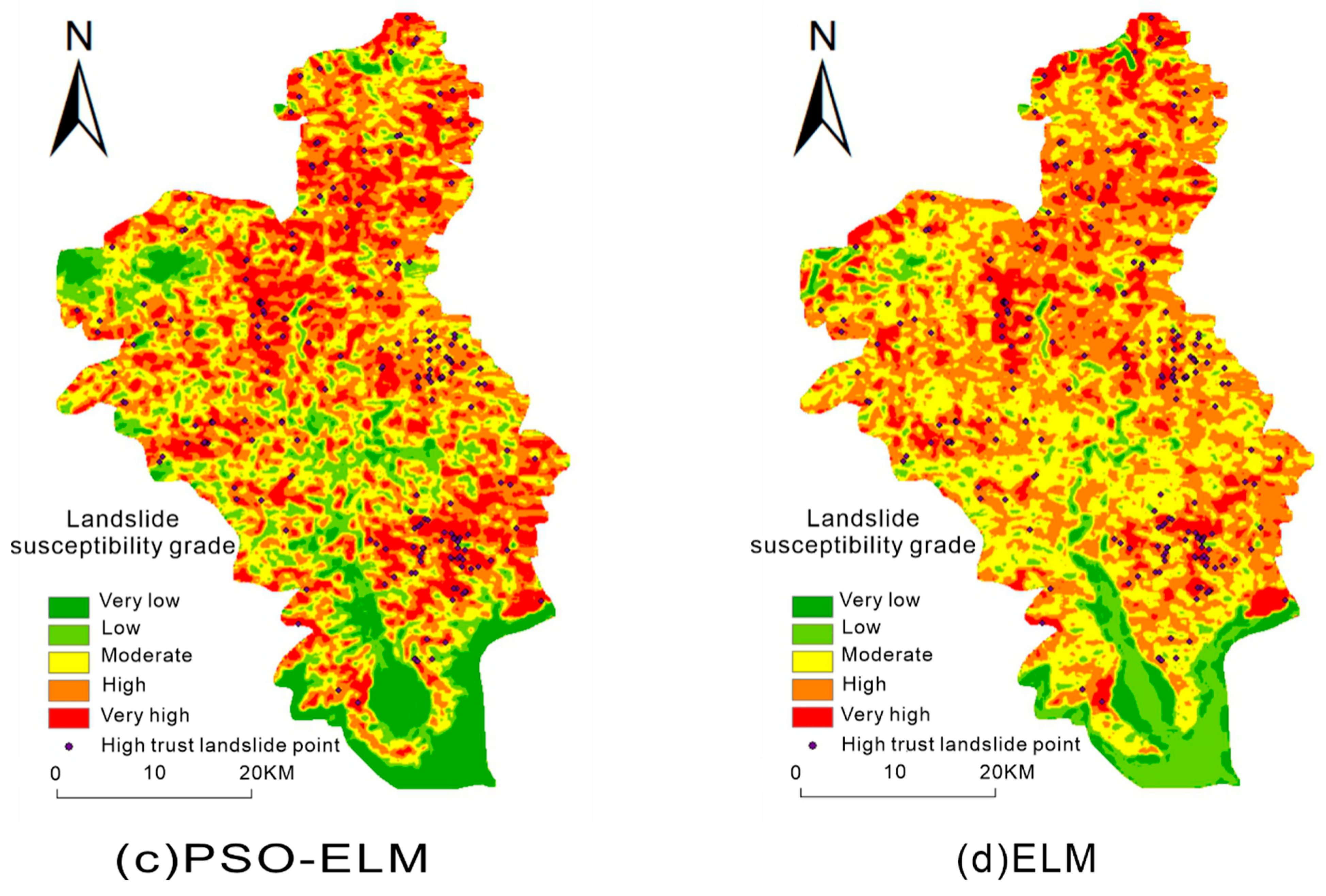
- The landslide points in the figure are landslide high-trust points expanded by the semi-supervised learning framework. Because the original landslide point may be accidental, it may be difficult for subsequent landslides to occur in this area over time. Therefore, this paper uses the expanded landslide high-confidence points to test the landslide susceptibility mapping.
- (2)
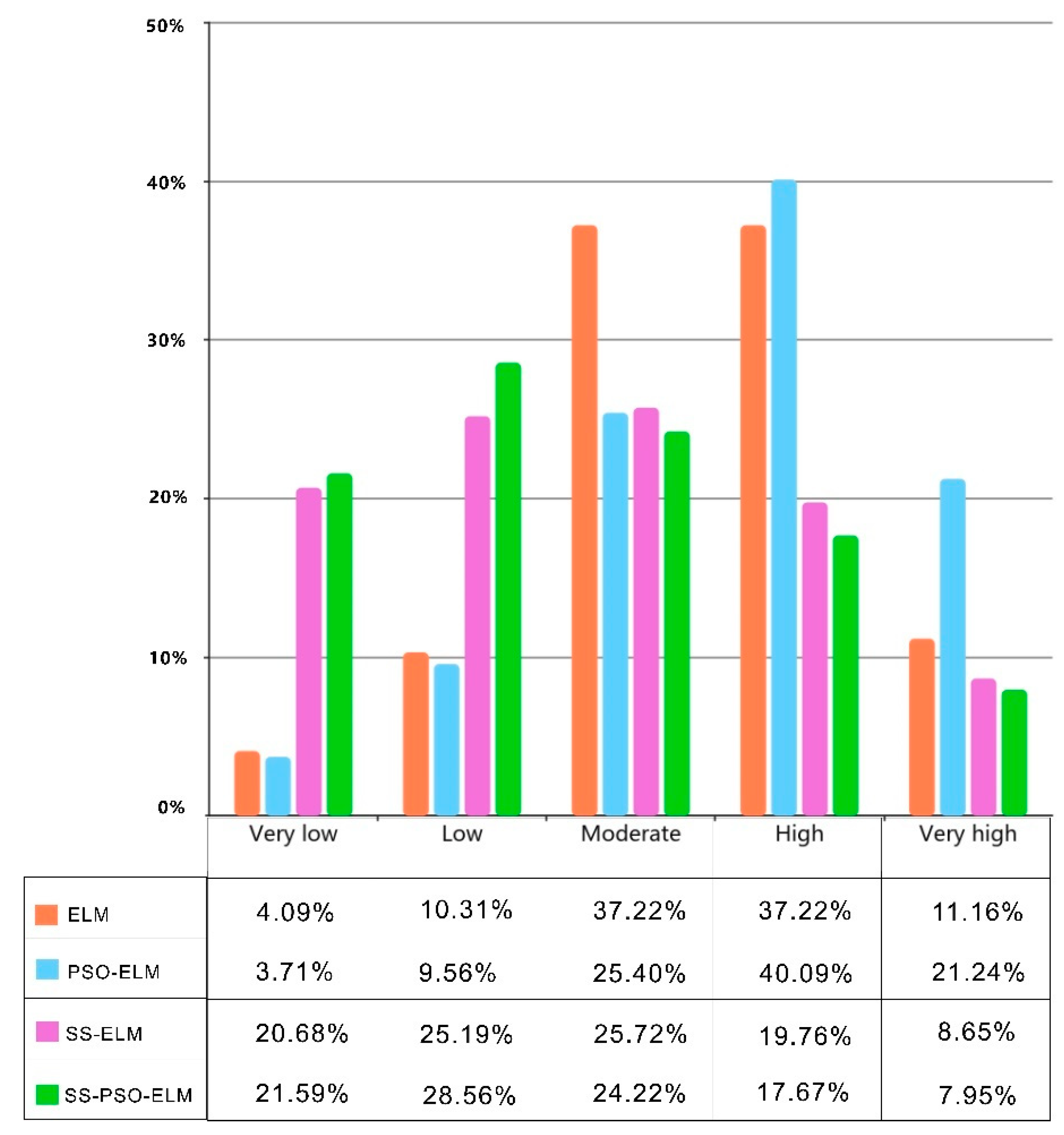
- The results of the four models, SS-PSO-ELM, SS-ELM, PSO-ELM, and ELM, are shown in the figure. The high-trust landslide points all fall in the high-risk and very high-risk areas, proving that the four models can effectively predict landslides. However, in the PSO-ELM model and the ELM model, the high-risk and very high-risk areas account for a large proportion of the entire study area, which is inconsistent with reality. The SS-PSO-ELM model and the SS-ELM model are more realistic.
- (3)
- In the northwest corner of the study area, the SS-PSO-ELM model and the SS-ELM model predicted a very high-risk area. The prediction results in the PSO-ELM and ELM models are low-risk and very low-risk areas. After data inspection and analysis, the reason is that the non-landslide points of the model without the semi-supervised learning framework are randomly selected in the study area. However, randomly selected points within the study area do not guarantee that they are credible non-landslide points. As shown in this case, the area that was initially a high risk of the landslide was used as a sample to enter the training data into non-landslide points, resulting in a large discrepancy between the results and the actual results.
5. Modeling Uncertainty Analysis
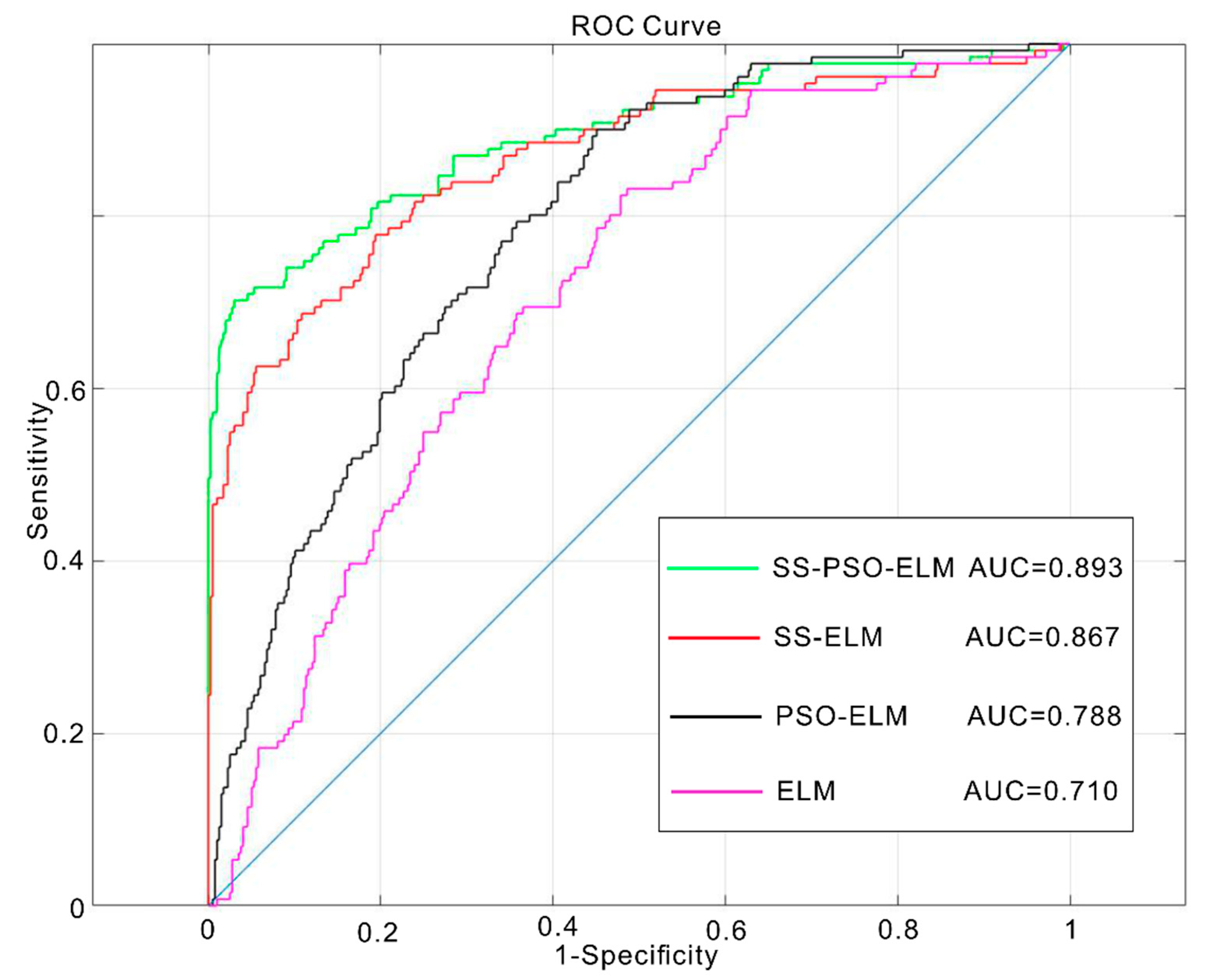
5.1. ROC Accuracy Evaluation
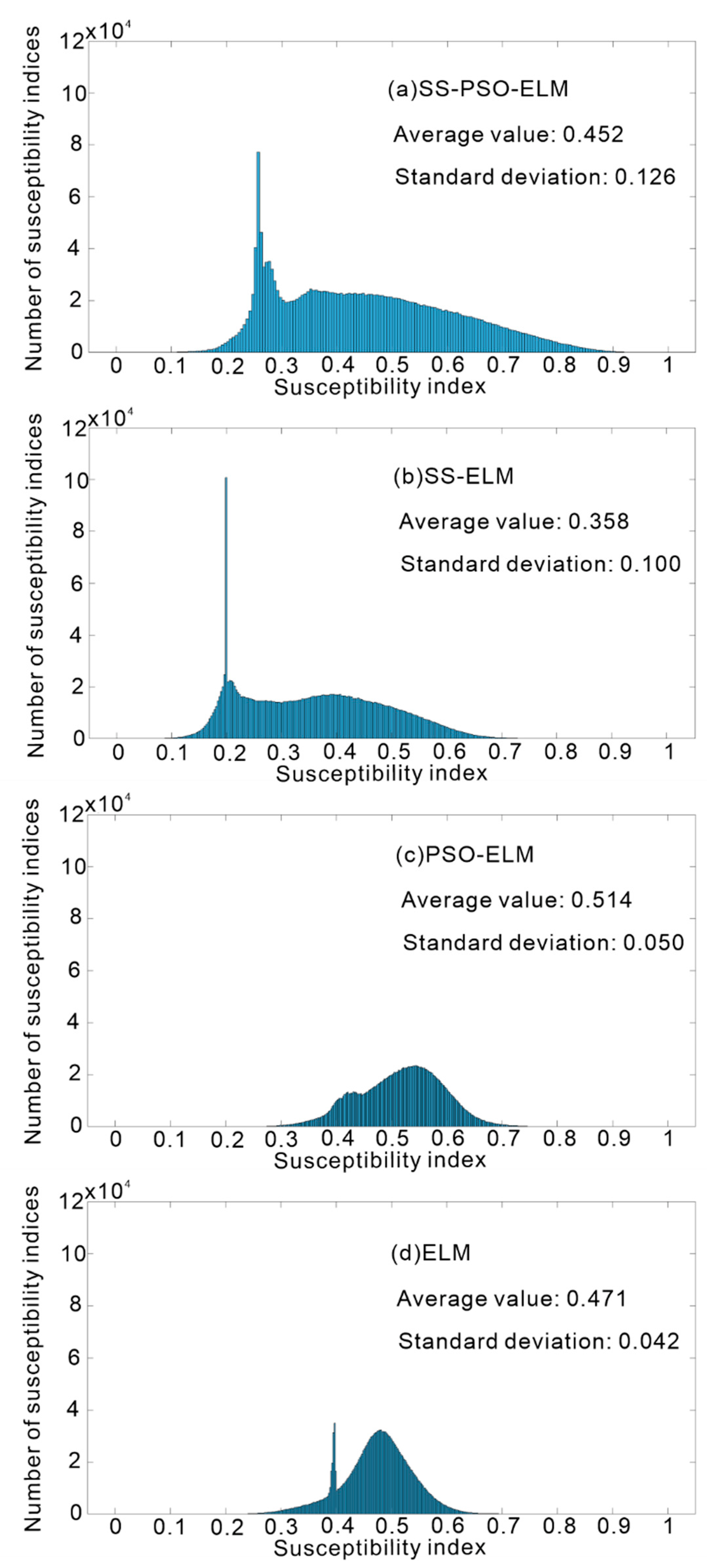
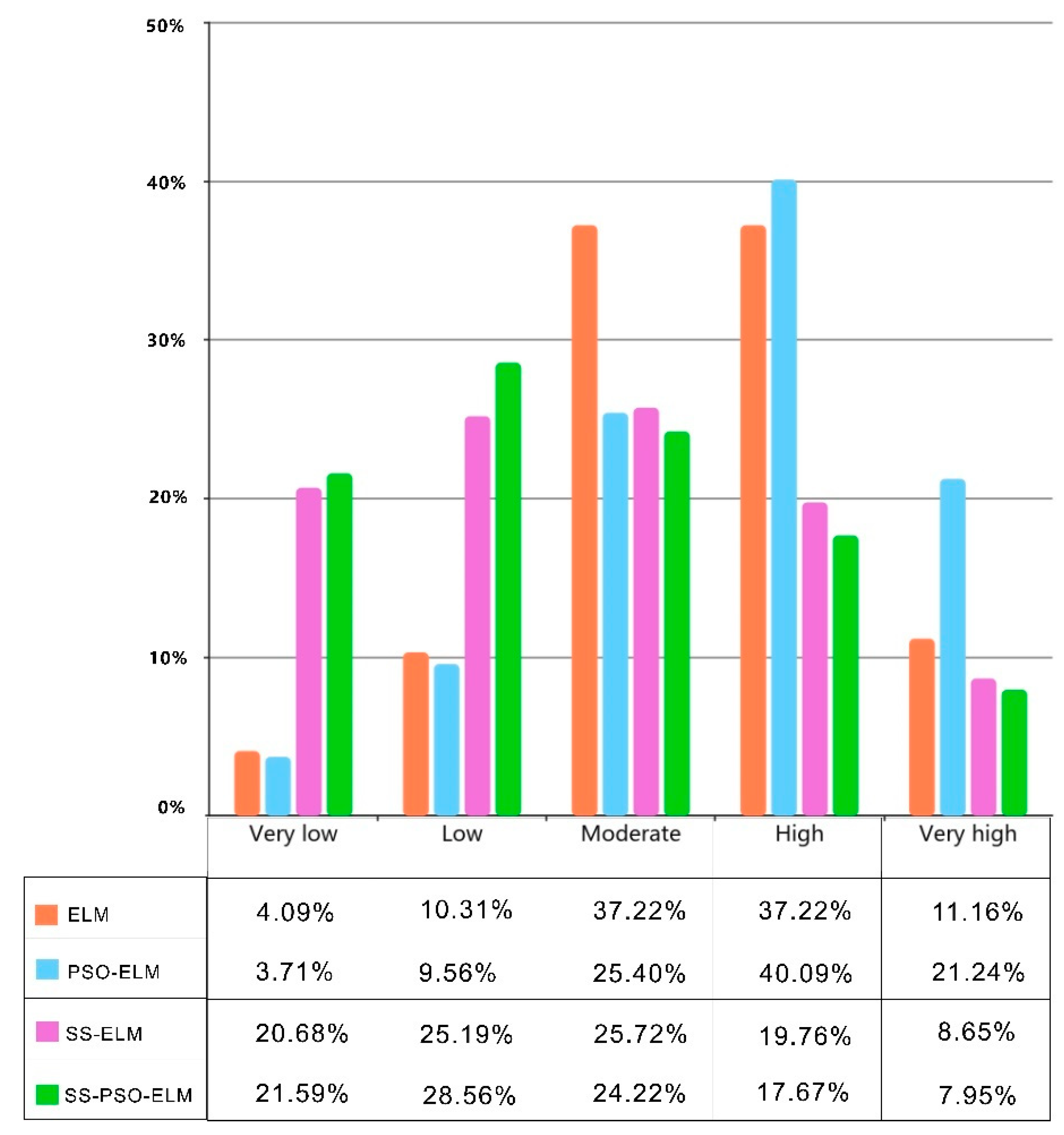
5.2. Susceptibility Index Distribution
- (1)
- The landslide risk areas of the SS-PSO-ELM model and the SS-ELM model are concentrated in low-risk and very low-risk areas and less in high-risk and very high-risk areas. The overall trend of landslide susceptibility is that the area from low risk to high risk gradually decreases, which is more in line with reality.
- (2)
- The mean value of landslide occurrence probability of SS-PSO-ELM and SS-ELM models is smaller than that of the PSO-ELM model and ELM model. It is proved that the semi-supervised learning framework’s prediction of landslide susceptibility is in line with reality, and the extremely low-susceptibility and low-susceptibility areas of landslides are the mainstream in the study area.
- (3)
- In Figure 12, the standard deviations of the four models are compared from large to small, namely SS-PSO-ELM, SS-ELM, PSO-ELM, and ELM. The SS-PSO-ELM standard deviation is the largest, proving that the SS-PSO-ELM model can distinguish and identify landslides and better reflect the differences in landslide susceptibility to the study area. However, since the PSO-ELM and ELM models do not use high-trust non-landslide points as training data, the probability of landslides in most places is concentrated between 0.4 and 0.6, and there is no good ability to discriminate landslides. Furthermore, most of the predicted areas are in the high-risk prone regions to landslides, which is inconsistent with the actual situation.
5.3. Model Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Paola, R. Landslide hazard evaluation: A review of currenttechniques and their application in a multi-scale study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Nadim, F.; Kjekstad, O.; Peduzzi, P.; Herold, C.; Jaedicke, C. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Assilzadeh, H.; Levy, J.K.; Wang, X. Landslide catastrophes and disaster risk reduction:a GISframework for landslide prevention and management. Remote Sens. 2010, 2, 2259–2273. [Google Scholar] [CrossRef] [Green Version]
- Guzzetti, F.; Reichenbach, P.; Ardizzone, F.; Cardinali, M.; Galli, M. Estimating the quality of landslide susceptibility models. Geomorphology 2006, 81, 166–184. [Google Scholar] [CrossRef]
- Montgomery, D.R.; Dietrich, W.E. A physically based model for the topographic control onshallow landsliding. Water Resour. Res. 1994, 30, 1153–1171. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef] [Green Version]
- Aleotti, P.; Chowdhury, R. Landslide hazard assessment: Summary review and newperspectives. Bull. Eng. Geol. Environ. 1999, 58, 21–44. [Google Scholar] [CrossRef]
- Ruff, M.; Czurda, K. Landslide susceptibility analysis with a heuristic approach in theEastern Alps (Vorarlberg, Austria). Geomorphology 2008, 94, 314–324. [Google Scholar] [CrossRef]
- Lin, S.Y.; Lin, C.W.; Gasselt, S.V. Processing Framework for Landslide Detection Based on Synthetic Aperture Radar (SAR) Intensity-Image Analysis. Remote Sens. 2021, 13, 644. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Hai-Min, L.; Jack, S.; Arul, A. Assessment of Geohazards and Preventative Countermeasures Using AHP Incorporated with GIS in Lanzhou, China. Sustainability 2018, 10, 304. [Google Scholar]
- Khan, H.; Shafique, M.; Khan, M.A.; Bacha, M.A.; Shah, S.U.; Calligaris, C. Landslide susceptibility assessment using Frequency Ratio, a case study of northern Pakistan. Egypt. J. Remote Sens. Space Sci. 2018, 22, 11–24. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O. BLandslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput. Geosci. 2011, 45, 199–211. [Google Scholar]
- Ghorbanzadeh, O.; Shahabi, H.; Crivellari, A.; Homayouni, S.; Blaschke, T.; Ghamisi, P. Landslide detection using deep learning and object-based image analysis. Landslides 2022, 19, 929–939. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Xu, Y.; Ghamis, P.; Kopp, M.; Kreil, D. Landslide4Sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection. arXiv 2022, arXiv:2206.00515. [Google Scholar]
- Alb, A.; Frb, C.; Qbp, D.; Gigović, L.; Drobnjak, S.; Aina, Y.A.; Panahi, M.; Yekeen, S.T.; Lee, S. Spatial prediction of landslide susceptibility in western Serbia using hybrid support vector regression (SVR) with with GWO, BAT and COA algorithms. Geosci. Front. 2020, 12, 101104. [Google Scholar]
- Depina, I.; Oguz, E.A.; Thakur, V. Novel Bayesian framework for calibration of spatially distributed physical-based landslide prediction models. Comput. Geotech. 2020, 125, 103660. [Google Scholar] [CrossRef]
- Guo, Z.; Chen, L.; Gui, L.; Du, J.; Yin, K.; Do, H.M. Landslide displacement prediction based on variational mode decomposition and WA-GWO-BP model. Landslides 2019, 17, 567–583, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Zhang, Y.G.; Tang, J.; Liao, R.P.; Zhang, M.F.; Zhang, Y.; Wang, X.M.; Su, Z.Y. Application of an enhanced BP neural network model with water cycle algorithm on landslide prediction. Stoch. Environ. Res. Risk Assess. 2021, 35, 1273–1291. [Google Scholar] [CrossRef]
- Benbouras, M.A. Hybrid meta-heuristic machine learning methods applied to landslide susceptibility mapping in the Sahel-Algiers. Int. J. Sediment Res. 2022, 37, 601–618. [Google Scholar] [CrossRef]
- Huang, F.M.; Pan, L.H.; Yao, C.; Zhou, C.; Huang, J.; Guo, Z. Prediction Model of Landslide Susceptibility Based on Semi-Supervised Machine Learning. J. Zhejiang Univ. (Eng. Ed.) 2021, 55, 1705–1713, (In Chinese with English abstract). [Google Scholar]
- Huang, F.M.; Wang, Y.; Dong, Z.L.; Wu, L.Z.; Guo, Z.Z.; Zhang, T.L. Sensitivity Evaluation of Regional Landslide Based on Grey Relational Grade Model. Earth Sci. 2019, 44, 664–676, (In Chinese with English abstract). [Google Scholar]
- Ito, R.; Nakae, K.; Hata, J.; Okano, H.; Ishii, S. Semi-supervised deep learning of brain tissue segmentation. Neural Netw. 2019, 116, 25–34. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.; Gupta, J.N.; Wu, C. Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 2014, 44, 2405–2417. [Google Scholar] [CrossRef]
- Jin, G.; Liu, C.; Chen, X. Adversarial network integrating dual attention and sparse representation for semi-supervised semantic segmentation. Inf. Processing Manag. 2021, 58, 102680. [Google Scholar] [CrossRef]
- Jian, C.; Yang, K.; Ao, Y. Industrial fault diagnosis based on active learning and semi-supervised learning using small training set. Eng. Appl. Artif. Intell. 2021, 104, 104365. [Google Scholar] [CrossRef]
- Xu, L.; Cui, L.; Weise, T.; Li, X.; Wu, Z.; Nie, F.; Chen, E.; Tang, Y. Semi-Supervised Multi-Layer Convolution Kernel Learning in Credit Evaluation. Pattern Recognit. 2021, 120, 108125. [Google Scholar] [CrossRef]
- Yao, J.; Qin, S.; Qiao, S.; Che, W.; Chen, Y.; Su, G.; Miao, Q. Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China. Appl. Sci. 2020, 10, 5640. [Google Scholar] [CrossRef]
- Hu, H.; Wang, C.; Liang, Z.; Gao, R.; Li, B. Exploring Complementary Models Consisting of Machine Learning Algorithms for Landslide Susceptibility Mapping. ISPRS Int. J. Geo-Inf. 2021, 10, 639. [Google Scholar] [CrossRef]
- Shahabi, H.; Rahimzad, M.; Tavakkoli Piralilou, S.; Ghorbanzadeh, O.; Homayouni, S.; Blaschke, T.; Lim, S.; Ghamisi, P. Unsupervised Deep Learning for Landslide Detection from Multispectral Sentinel-2 Imagery. Remote Sens. 2021, 13, 4698. [Google Scholar] [CrossRef]
- Liang, L.H. Analysis of Influencing Factors of Geological Hazards in Fu’an City. Fujian Geol. 2012, 31, 185–190, (In Chinese with English abstract). [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492. [Google Scholar] [CrossRef] [Green Version]
- Qian, L.X.; Wang, H.R.; Dang, S.Z.; Hong, M.; Zhao, Z.Y.; Deng, C.Y. A coupling Model of Water Resources Shortage Risk Assessment and its Application. Syst. Eng. 2021, 41m, 1319–1327, (In Chinese with English abstract). [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R.C. Particle Swarm Optimization. In Proceedings of the International Conference on Neural Networks (ICNN’95), Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Eberhart, R.C.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the MHS95 Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Zhang, S.; Qian, X.M.; Lou, P.H.; Wu, X.; Sun, C. Path Planning Optimization of Large-Scale Agv System Based on Improved Particle Swarm Optimization Algorithm. Comput.-Integr. Manuf. 2020, 26, 2484–2496, (In Chinese with English abstract). [Google Scholar]
- Li, W.B.; Fan, X.M.; Huang, F.M.; Wu, X.L.; Yin, K.; Chang, Z. Uncertainty of Landslide Susceptibility Modeling Based on Different Environmental Factors Linkage and Prediction Models. Earth Sci. 2021, 46, 3777–3795, (In Chinese with English abstract). [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid Cell Number | Elevation (m) | Slope Direction (°) | Slope (°) | Distance from Water System (m) | Cluster Labels | Match Count |
|---|---|---|---|---|---|---|
| 1,994,470 | 0 | −1.00 | 0.00 | 0 | No landslide | 10 |
| 392,364 | 93 | 343.98 | 25.87 | 100 | No landslide | 10 |
| 1,160,375 | 30 | 282.52 | 4.27 | 200 | No landslide | 6 |
| 1,161,694 | 37 | 67.28 | 20.70 | 100 | No landslide | 5 |
| 153,813 | 478 | 109.13 | 11.87 | 500 | Landslide | 10 |
| 888,368 | 429 | 135.66 | 44.76 | 300 | Landslide | 10 |
| 1,784,541 | 271 | 203.08 | 28.26 | 100 | Landslide | 5 |
| Model | Mean | Standard Deviation | AUC | RMSE |
|---|---|---|---|---|
| SS-PSO-ELM | 0.452 | 0.126 | 0.893 | 0.370 |
| SS-ELM | 0.358 | 0.100 | 0.867 | 0.438 |
| PSO-ELM | 0.514 | 0.050 | 0.788 | 0.417 |
| ELM | 0.471 | 0.042 | 0.710 | 0.442 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yan, Q. Landslide Susceptibility Prediction Based on High-Trust Non-Landslide Point Selection. ISPRS Int. J. Geo-Inf. 2022, 11, 398. https://doi.org/10.3390/ijgi11070398
Zhang Y, Yan Q. Landslide Susceptibility Prediction Based on High-Trust Non-Landslide Point Selection. ISPRS International Journal of Geo-Information. 2022; 11(7):398. https://doi.org/10.3390/ijgi11070398
Chicago/Turabian StyleZhang, Yizhun, and Qisheng Yan. 2022. "Landslide Susceptibility Prediction Based on High-Trust Non-Landslide Point Selection" ISPRS International Journal of Geo-Information 11, no. 7: 398. https://doi.org/10.3390/ijgi11070398
APA StyleZhang, Y., & Yan, Q. (2022). Landslide Susceptibility Prediction Based on High-Trust Non-Landslide Point Selection. ISPRS International Journal of Geo-Information, 11(7), 398. https://doi.org/10.3390/ijgi11070398