
Quality Assurance for Spatial Research Data


Abstract
:1. Introduction
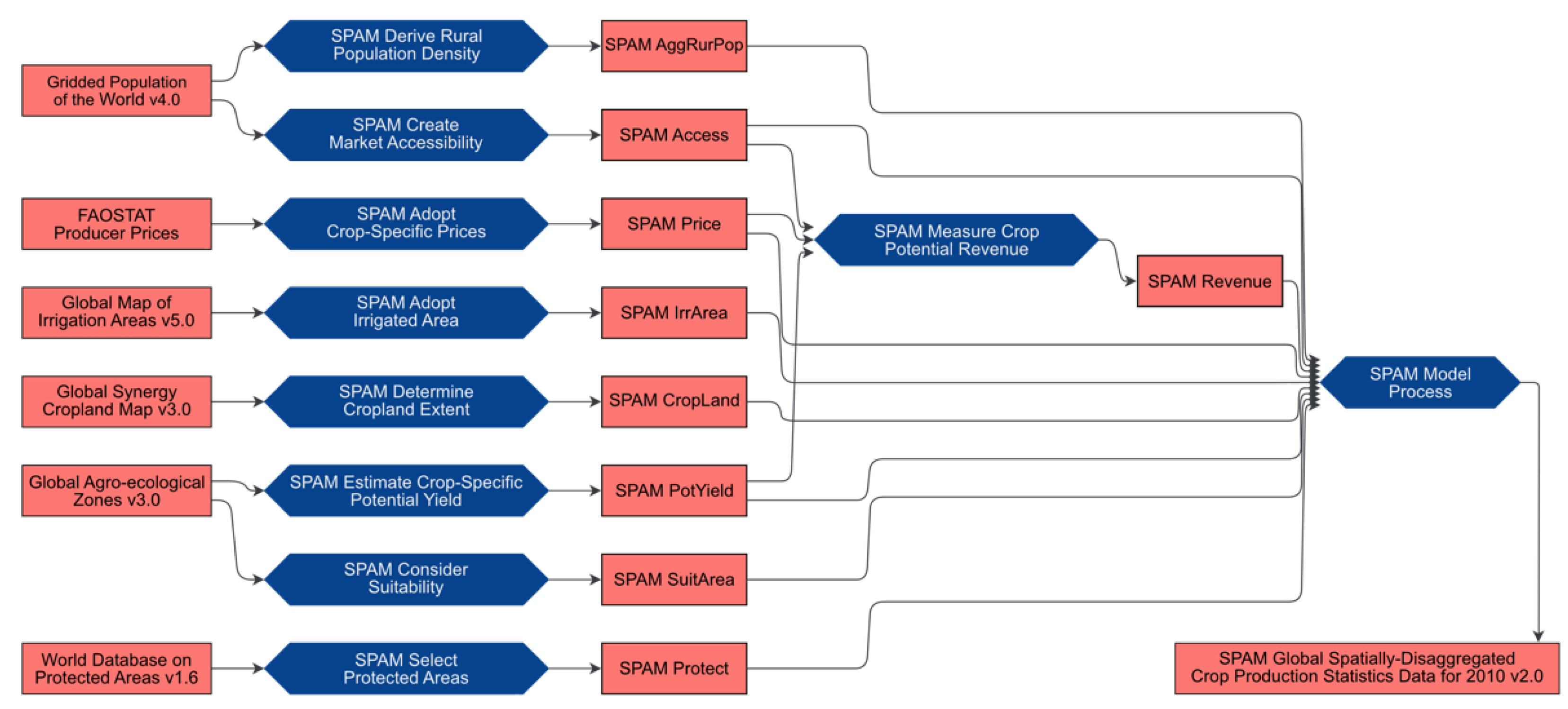
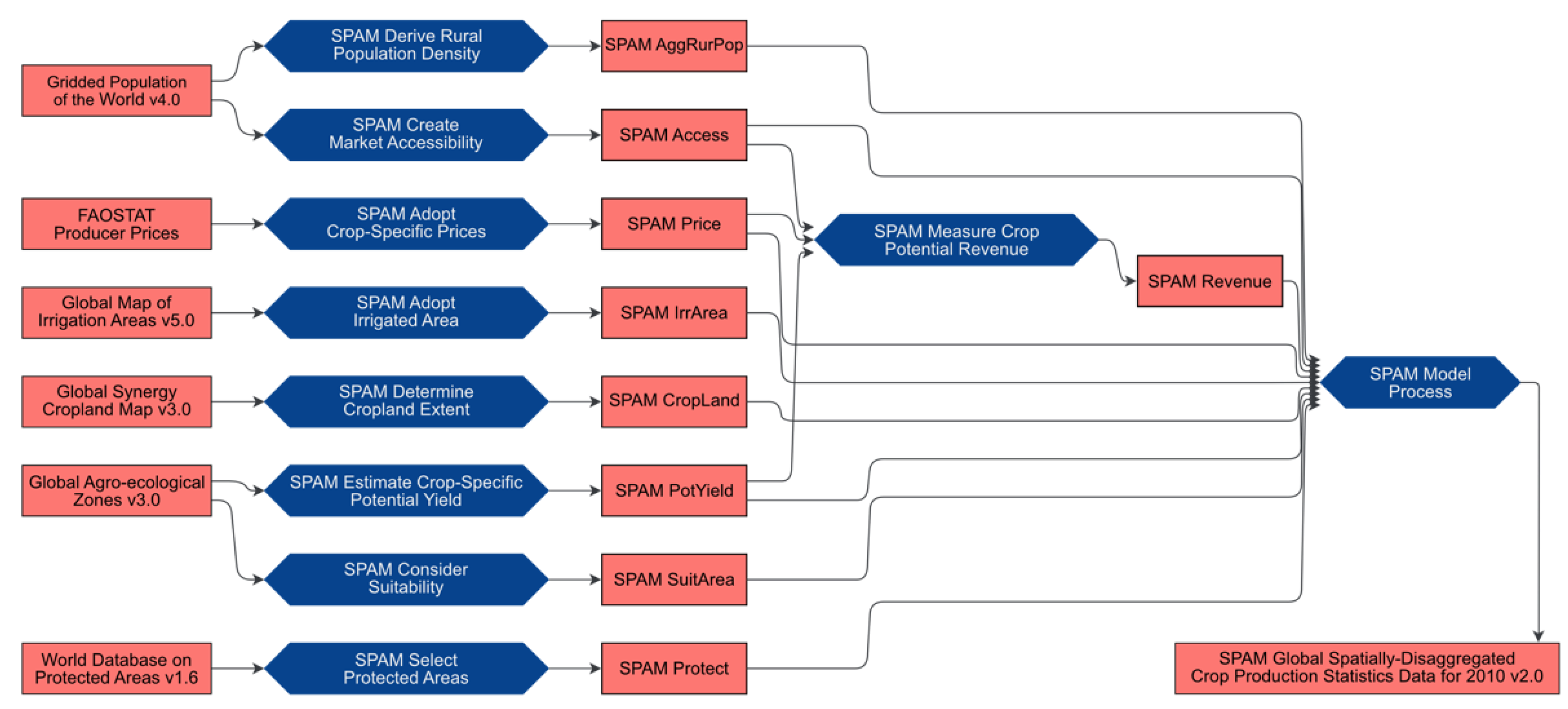
1.1. Example Dataset
- Physical area: area for a crop in the grid cell;
- Harvested area: physical area multiplied with crop intensity to take into account possible multiple harvests per plot;
- Yield: crop production per harvested area—the total yield is the weighted average of the four different farming systems;
- Production: harvested area multiplied with yield—is equal to the whole yield biomass;
- Value of production: crop price per grid cell—prices are globally harmonized and taken from average international crop prices of the Food and Agriculture Organization (FAO).
1.2. Related Work and Concepts
1.2.1. Openness Measures
| * | Data available on the Web under an open license; |
| ** | Data provided as structured data; |
| *** | Data available in a non-proprietary open format; |
| **** | Usage of URIs to denote things, so that links to the data are possible; |
| ***** | Link the data to other data to provide context. |
1.2.2. FAIR Indication
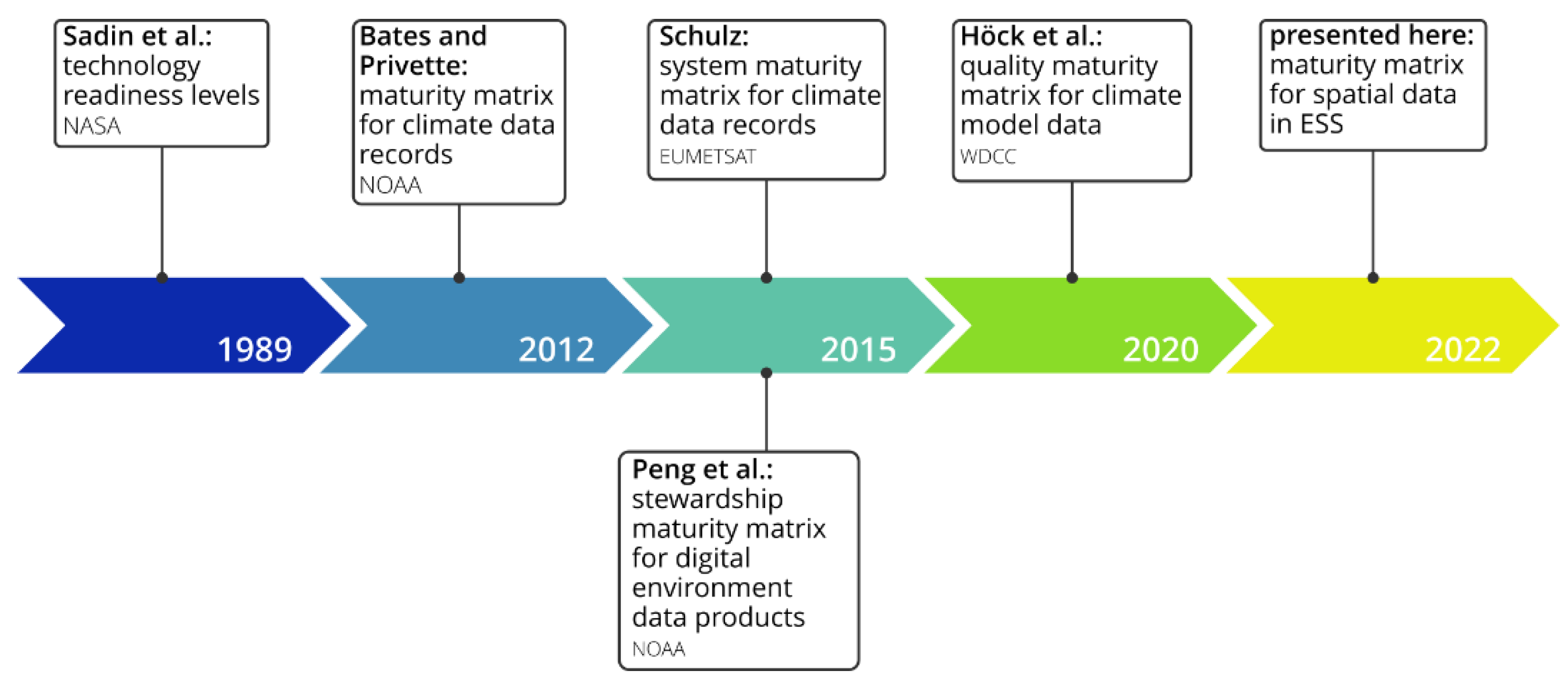
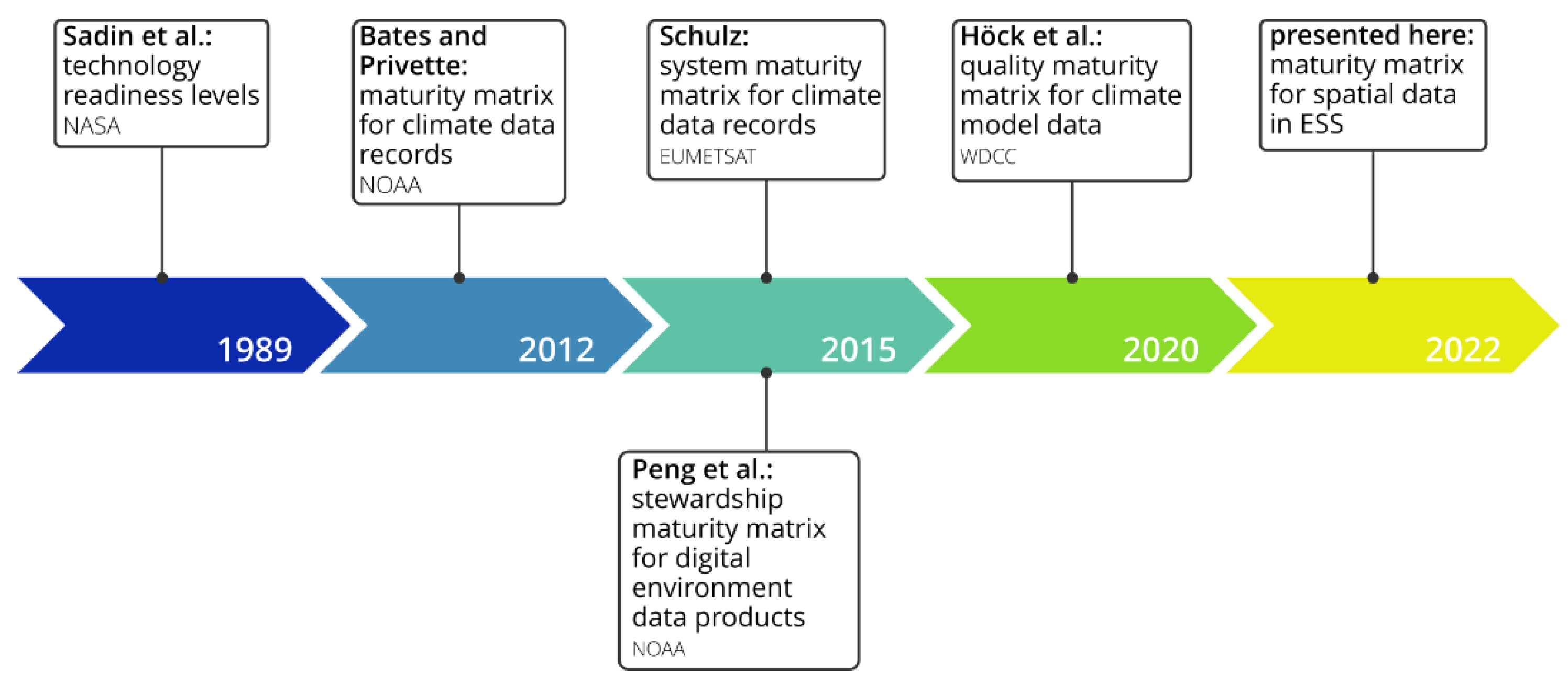
1.2.3. Data Maturity Modelling
1.2.4. Data Quality Measures
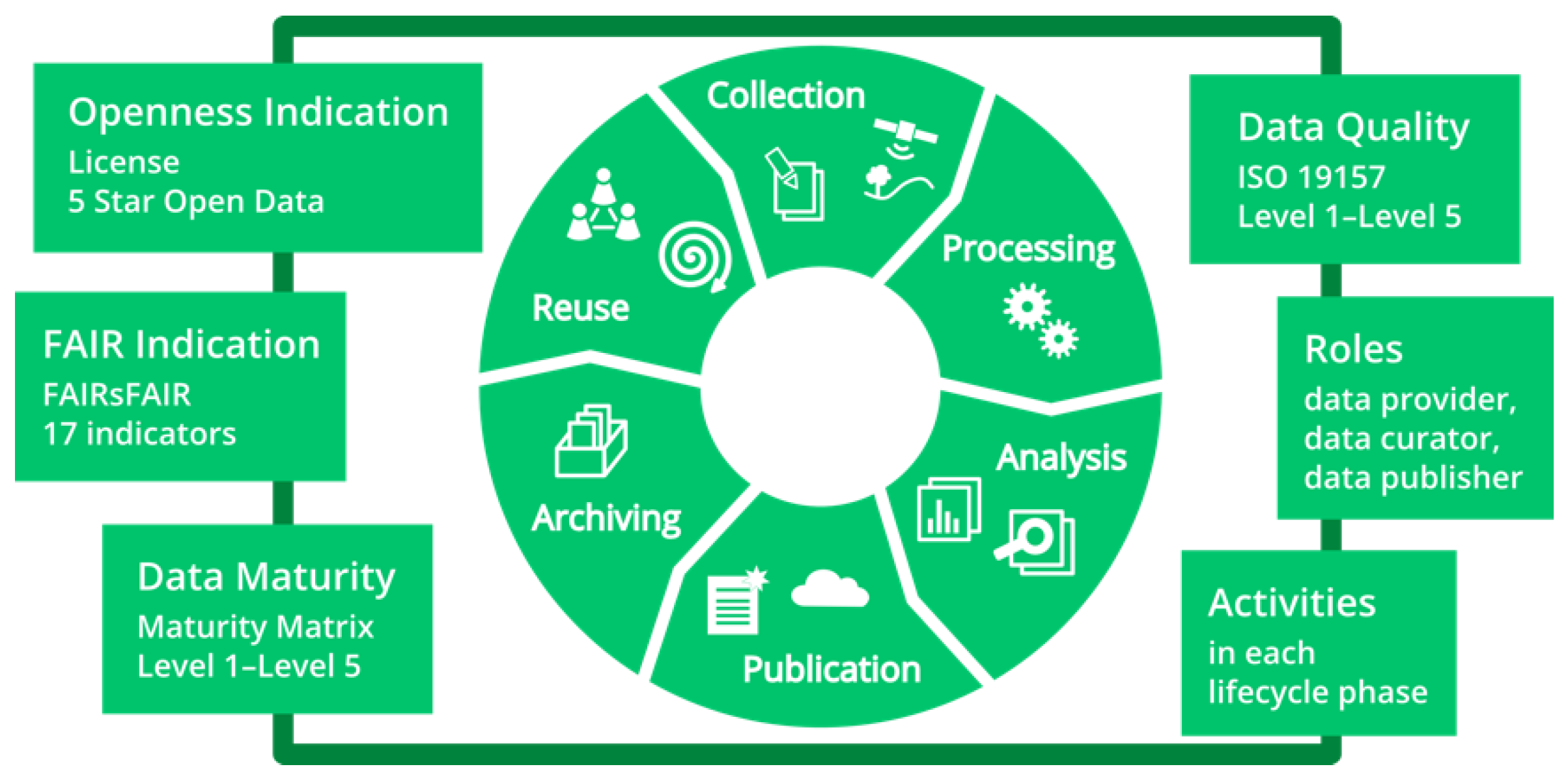
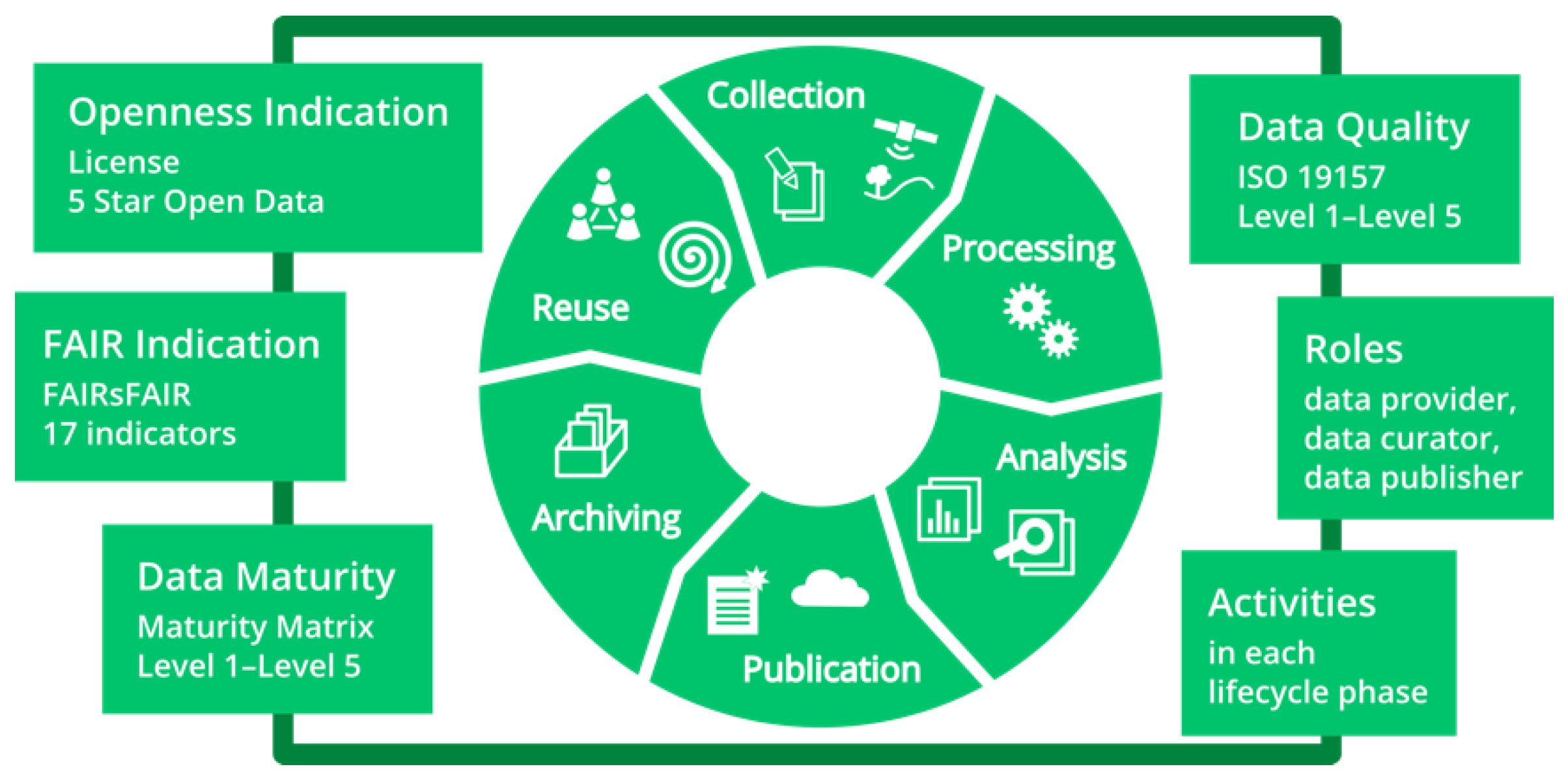
2. Methods—ESS Quality Assurance Concept
2.1. General Quality Assurance
2.1.1. Openness Measures
2.1.2. FAIR Indication
2.2. Discipline-Specific Quality Assurance
2.2.1. Data Maturity Modelling
2.2.2. Spatial Data Quality Matrix
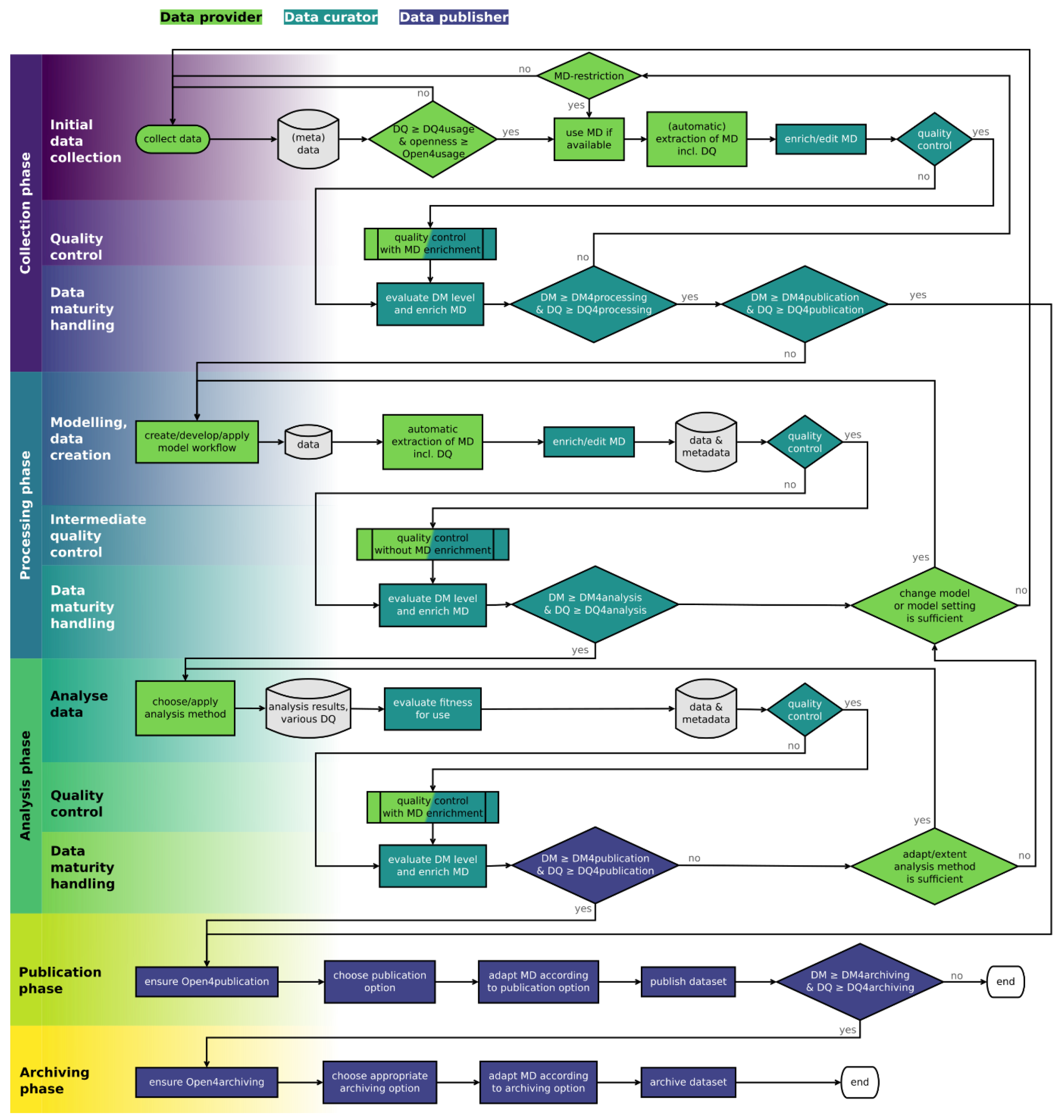
2.3. Roles, Activities, and Descriptions along the Data Life Cycle
2.3.1. Preliminary Phase
2.3.2. Predefined Quality Control Process
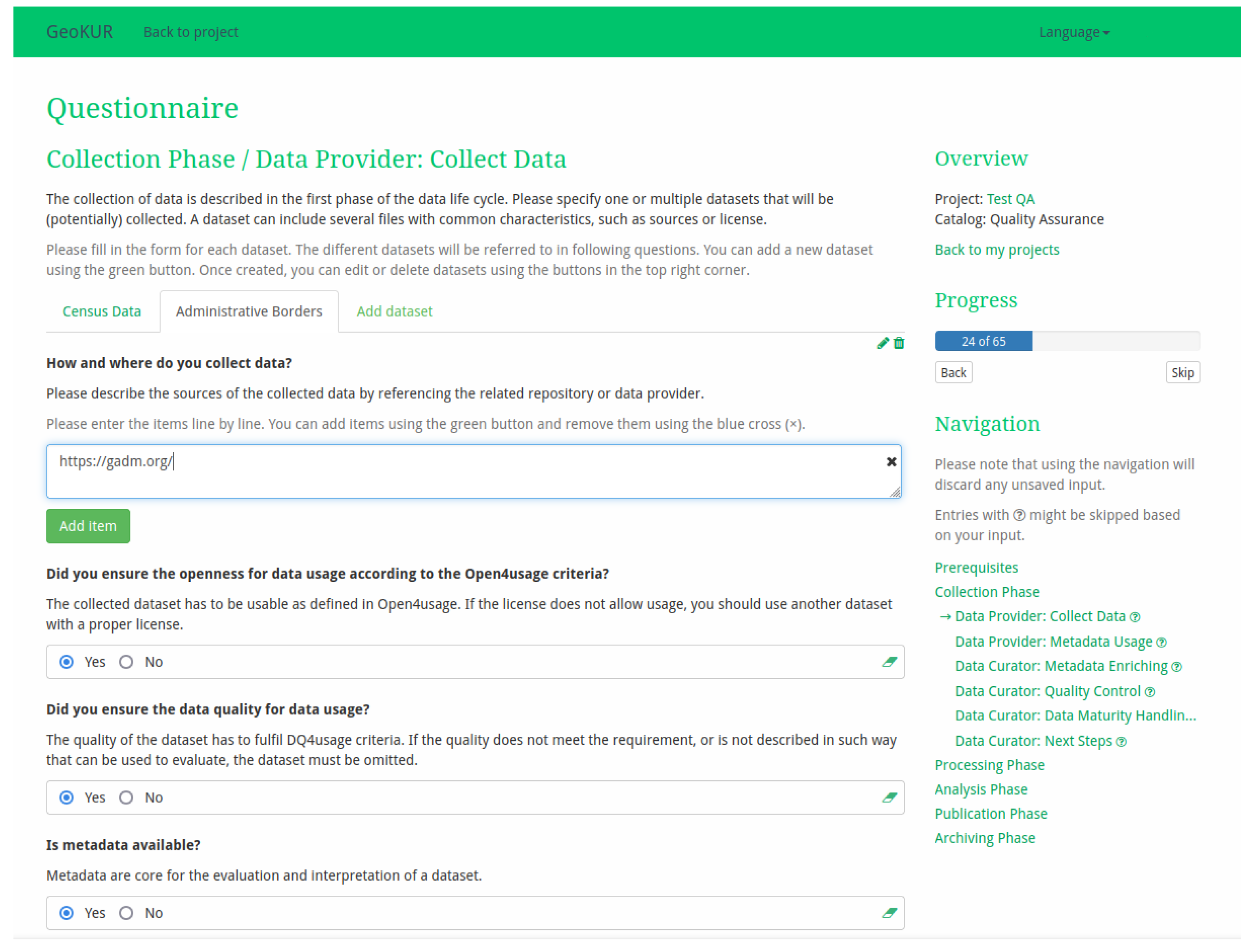
2.3.3. Collection Phase
2.3.4. Processing Phase
2.3.5. Analysis Phase
2.3.6. Publication Phase
2.3.7. Archiving phase
3. Results—Application to a Land-Use Dataset
3.1. Openness Evaluation for the SPAM2010 Dataset
3.2. Evaluation of FAIR Indication for the SPAM2010 Dataset
3.3. Data Maturity Evaluation for the SPAM2010 Dataset
3.4. Data Quality Evaluation for the SPAM2010 Dataset
4. Discussion/Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Data Maturity Matrix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Level 2 DM4processing | Level 3 DM4analysis | Level 4 DM4publication | Level 5 DM4archiving |
|---|---|---|---|---|
| Data formats | File extensions are consistent | Data sizes are consistent | ||
| FsF-R1.3-02D * conform to well-defined rules, e.g., discipline-specific standards | Conform to interdisciplinary standards | |||
| Versioning follows/is | Internal rules informal documented | Systematic corresponds to project requirements | Systematic collection including documentation of enhancement conform to well-defined rules, e.g., discipline-specific standards | Systematic collection including documentation of enhancement conform to well-defined rules |
| Data labelled with controlled vocabularies (CVs) conform to | Informal CVs if feasible | Formal project defined CVs if feasible | Discipline-specific standards | Interdisciplinary standard |
| Aspect | Level 2 DM4processing | Level 3 DM4analysis | Level 4 DM4publication | Level 5 DM4archiving |
|---|---|---|---|---|
| Data Access by | File names | Internal unique identifier corresponds to project requirements | FsF-F1-02D permanent identifier (expiration documented) | FsF-F1-01D global resolvable identifier registered |
| Checksums available | ||||
| Metadata Access by | Internal unique identifier corresponds to project requirements | Permanent identifier (expiration documented) | FsF-A2-01M global resolvable identifier complete data citation is persistent | |
| FsF-F3-01M mapping between metadata and data identifiers implemented |
| Aspect | Level 2 DM4processing | Level 3 DM4analysis | Level 4 DM4publication | Level 5 DM4archiving |
|---|---|---|---|---|
| Plausibility | Documented procedure about technical sources of errors and deviation/inaccuracy exists (data header and content is consistent) | |||
| Documented procedure with validation against independent data exists | ||||
| Statistical Anomalies | Missing values are indicated, e.g., with fill values | |||
| Documented procedure of statistical quality control is available | ||||
| Scientific consistency among multiple datasets and their relationships is documented if feasible |
Appendix B. Spatial Data Quality Matrix
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| absolute external positional accuracy | mean Euclidean distance | |||
| mean bias | ||||
| radius around measured point, in which the true point is located in 95% | ||||
| relative internal positional accuracy | relative horizontal error (bias) as standard deviation in error space | |||
| gridded data positional accuracy | mean Euclidean distance | |||
| mean bias | ||||
| radius around given centre, in which the true centre is located in 95% |
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| accuracy of a time measurement | time half interval in which the true value lies in 95% | |||
| temporal consistency | chronological order (Boolean value) | |||
| temporal validity | number of items in non-conformance (integer for whole dataset) | |||
| value domain non-conformance rate (real for whole dataset) |
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| conceptual consistency | number of items in non-compliance (integer for whole dataset) | |||
| number of invalid overlaps of surfaces (integer for whole dataset) | ||||
| non-compliance rate (real for whole dataset) | ||||
| domain consistency | number of items in non-conformance (integer for whole dataset) | |||
| value domain non-conformance rate (real for whole dataset) | ||||
| format consistency | physical structure conflicts (Boolean for each item) | |||
| physical structure conflicts number (integer for whole dataset) | ||||
| physical structure conflict rate (real for whole dataset) | ||||
| topological consistency | number of invalid slivers | |||
| number of invalid self-intersect errors | ||||
| number of invalid self-overlap errors |
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| completeness commission | number of excess items | |||
| rate of excess items | ||||
| number of duplicates | ||||
| completeness omission | number of missing items | |||
| rate of missing items |
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| thematic classification correctness | number of incorrectly classified features | |||
| misclassification matrix (matrix spanning between data and classes) | ||||
| kappa coefficient (the better D65, the closer kappa- > 1, ergo one parameter to assess D65) | ||||
| non-quantitative attribute correctness | number of incorrect attribute values | |||
| rate of incorrect attribute values | ||||
| quantitative attribute accuracy | half length of an interval in which the true value lies in 95% |
| Sub Class | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|
| confidence | standard deviation of quantitative attribute values based on the model used | |||
| confidence intervals of quantitative attribute values | ||||
| representativity | number of polygons/points/lines per area | |||
| number of temporal units | ||||
| number of thematic units | ||||
| empirical distribution parameters of various combinations in spatial-temporal-thematic space | ||||
| homogeneity | RMSE from comparison of results from different operators |
References
- Devillers, R.; Stein, A.; Bédard, Y.; Chrisman, N.; Fisher, P.; Shi, W. Thirty Years of Research on Spatial Data Quality: Achievements, Failures, and Opportunities: Thirty Years of Research on Spatial Data Quality. Trans. GIS 2010, 14, 387–400. [Google Scholar] [CrossRef]
- Peng, G.; Lacagnina, C.; Ivánová, I.; Downs, R.R.; Ramapriyan, H.; Ganske, A.; Jones, D.; Bastin, L.; Wyborn, L.; Bastrakova, I.; et al. International Community Guidelines for Sharing and Reusing Quality Information of Individual Earth Science Datasets; Updated: 2022, Version: v01r02 20220326, Open Science Framework. 2021. Available online: https://osf.io/xsu4p/ (accessed on 22 March 2022).
- Nightingale, J.; Boersma, K.; Muller, J.-P.; Compernolle, S.; Lambert, J.-C.; Blessing, S.; Giering, R.; Gobron, N.; De Smedt, I.; Coheur, P.; et al. Quality Assurance Framework Development Based on Six New ECV Data Products to Enhance User Confidence for Climate Applications. Remote Sens. 2018, 10, 1254. [Google Scholar] [CrossRef] [Green Version]
- RfII–German Council for Scientific Information Infrastructures. The Data Quality Challenge. Recommendations for Sustainable Research in the Digital Turn; RfII Head Office: Göttingen, Germany, 2020. [Google Scholar]
- Rüegg, J.; Gries, C.; Bond-Lamberty, B.; Bowen, G.J.; Felzer, B.S.; McIntyre, N.E.; Soranno, P.A.; Vanderbilt, K.L.; Weathers, K.C. Completing the Data Life Cycle: Using Information Management in Macrosystems Ecology Research. Front. Ecol. Environ. 2014, 12, 24–30. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. CODATA 2015, 14, 2. [Google Scholar] [CrossRef]
- Hassenstein, M.J.; Vanella, P. Data Quality—Concepts and Problems. Encyclopedia 2022, 2, 498–510. [Google Scholar] [CrossRef]
- ISO/DIS 19157-1. Geographic Information-Data Quality-Part 1: General Requirements. Available online: https://www.iso.org/standard/78900.html (accessed on 22 March 2022).
- GeoDCAT-AP-Version 2.0.0. Available online: https://semiceu.github.io/GeoDCAT-AP/drafts/latest/ (accessed on 16 March 2022).
- International Organization for Standardization. Geographic Information–Data Quality (ISO 19157:2013); ISO copyright office: Geneva, Switzerland, 2013. [Google Scholar]
- International Organization for Standardization. Quality Management Systems–Fundamentals and Vocabulary (ISO 9000:2015); ISO Copyright Office: Geneva, Switzerland, 2015. [Google Scholar]
- Henzen, C. GeoKur-Curation and Quality Assurance of Environmental Research Data for the Use Case of Global Land Use Data. Zenodo 2021, 1–10. Available online: https://geokur.geo.tu-dresden.de/ (accessed on 22 March 2022).
- Home of the Spatial Production Allocation Model. Available online: https://www.mapspam.info/ (accessed on 16 March 2022).
- International Food Policy Research Institute. Global Spatially-Disaggregated Crop Production Statistics Data for 2010 Version 2.0; Harvard Dataverse: Harvard, MA, USA, 2019. [Google Scholar] [CrossRef]
- Yu, Q.; You, L.; Wood-Sichra, U.; Ru, Y.; Joglekar, A.K.B.; Fritz, S.; Xiong, W.; Lu, M.; Wu, W.; Yang, P. A Cultivated Planet in 2010—Part 2: The Global Gridded Agricultural-Production Maps. Earth Syst. Sci. Data 2020, 12, 3545–3572. [Google Scholar] [CrossRef]
- Agricultural Producer Prices (Global-National-Annual/Monthly-FAOSTAT). Available online: https://data.apps.fao.org/catalog/dataset/faostat-pp (accessed on 22 March 2022).
- Protected Areas (WDPA). Available online: https://www.protectedplanet.net/en/thematic-areas/wdpa?tab=WDPA (accessed on 22 March 2022).
- Peng, G.; Lacagnina, C.; Downs, R.R.; Ganske, A.; Ramapriyan, H.K.; Ivánová, I.; Wyborn, L.; Jones, D.; Bastin, L.; Shie, C.; et al. Global Community Guidelines for Documenting, Sharing, and Reusing Quality Information of Individual Digital Datasets. Data Sci. J. 2022, 21, 8. [Google Scholar] [CrossRef]
- 5-Star Open Data. Available online: https://5stardata.info/ (accessed on 16 March 2022).
- About CC Licenses. Available online: https://creativecommons.org/about/cclicenses/ (accessed on 16 March 2022).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Research Data Alliance FAIR Data Maturity Model Working Group FAIR Data Maturity Model: Specification and Guidelines. Zenodo 2020, 1–47. [CrossRef]
- FAIRsFAIR. Available online: https://fairsfair.eu/ (accessed on 16 March 2022).
- Devaraju, A.; Huber, R.; Mokrane, M.; Herterich, P.; Cepinskas, L.; de Vries, J.; L’Hours, H.; Davidson, J.; White, A. FAIRsFAIR Data Object Assessment Metrics. Zenodo 2020, 1–25. [Google Scholar] [CrossRef]
- Lacagnina, C.; Doblas-Reyes, F.; Larnicol, G.; Buontempo, C.; Obregón, A.; Costa-Surós, M.; San-Martín, D.; Bretonnière, P.-A.; Polade, S.D.; Romanova, V.; et al. Quality Management Framework for Climate Datasets. CODATA 2022, 21, 10. [Google Scholar] [CrossRef]
- Peng, G. The State of Assessing Data Stewardship Maturity–An Overview. Data Sci. J. 2018, 17, 7. [Google Scholar] [CrossRef] [Green Version]
- National Research Council. Environmental Data Management at NOAA: Archiving, Stewardship, and Access; National Academies Press: Washington, DC, USA, 2007; p. 12017. ISBN 978-0-309-11209-3.
- Sadin, S.R.; Povinelli, F.P.; Rosen, R. The NASA Technology Push towards Future Space Mission Systems. Acta Astronaut. 1989, 20, 73–77. [Google Scholar] [CrossRef]
- Technology Readiness Levels (TRLs). Available online: https://esto.nasa.gov/trl/ (accessed on 16 March 2022).
- Bates, J.J.; Privette, J.L. A Maturity Model for Assessing the Completeness of Climate Data Records. Eos Trans. AGU 2012, 93, 441. [Google Scholar] [CrossRef]
- Bates, J.J.; Privette, J.L.; Kearns, E.J.; Glance, W.; Zhao, X. Sustained Production of Multidecadal Climate Records: Lessons from the NOAA Climate Data Record Program. Bull. Am. Meteorol. Soc. 2016, 97, 1573–1581. [Google Scholar] [CrossRef]
- Schulz, J. System Maturity Assessment. Presented at the Copernicus Workshop on Climate Observation Requirements, ECMWF, Reading. 2015. Available online: https://www.ecmwf.int/sites/default/files/elibrary/2015/13474-system-maturity-assesment.pdf (accessed on 16 March 2022).
- Peng, G.; Privette, J.L.; Kearns, E.J.; Ritchey, N.A.; Ansari, S. A Unified Framework for Measuring Stewardship Practices Applied to Digital Environmental Datasets. Data Sci. J. 2015, 13, 231–252. [Google Scholar] [CrossRef] [Green Version]
- Höck, H.; Toussaint, F.; Thiemann, H. Fitness for Use of Data Objects Described with Quality Maturity Matrix at Different Phases of Data Production. Data Sci. J. 2020, 19, 45. [Google Scholar] [CrossRef]
- Best Practices—Quality Assurance. Available online: https://www.komfor.net/qa.html (accessed on 16 March 2022).
- Yang, X.; Blower, J.D.; Bastin, L.; Lush, V.; Zabala, A.; Masó, J.; Cornford, D.; Díaz, P.; Lumsden, J. An Integrated View of Data Quality in Earth Observation. Phil. Trans. R. Soc. A 2013, 371, 20120072. [Google Scholar] [CrossRef] [PubMed]
- DCMI Metadata Terms. Available online: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ (accessed on 16 March 2022).
- Data on the Web Best Practices: Data Quality Vocabulary. Available online: https://www.w3.org/TR/vocab-dqv/ (accessed on 16 March 2022).
- International Organization for Standardization Space Data and Information Transfer Systems–Open Archival Information System (OAIS)–Reference Model (ISO 14721:2012); ISO copyright office: Geneva, Switzerland, 2012.
- Attribution 4.0 International (CC BY 4.0). Available online: https://creativecommons.org/licenses/by/4.0/ (accessed on 16 March 2022).
- ORCID. Available online: https://orcid.org/ (accessed on 16 March 2022).
- ROR. Available online: https://ror.org/ (accessed on 16 March 2022).
- International Organization for Standardization Geographic Information–Metadata–Part 1: Fundamentals (ISO 19115-1:2014); ISO copyright office: Geneva, Switzerland, 2014.
- AGROVOC. Available online: https://www.fao.org/agrovoc/ (accessed on 16 March 2022).
- Hunter, G.J.; Wachowicz, M.; Bregt, A.K. Understanding Spatial Data Usability. Data Sci. J. 2003, 2, 79–89. [Google Scholar] [CrossRef] [Green Version]
- RDMO—Research Data Management Organiser. Available online: https://github.com/rdmorganiser/rdmo (accessed on 16 March 2022).
- RDMO Catalog Builder. Available online: https://github.com/GeoinformationSystems/RDMOCatalogBuilder (accessed on 16 March 2022).
- Open Geospatial Consortium Data Quality Domain Working Group. Available online: https://www.ogc.org/projects/groups/dqdwg (accessed on 22 March 2022).


| Identifier | Description |
|---|---|
| FsF-F1-01D | Data are assigned a globally unique identifier |
| FsF-F1-02D | Data are assigned a persistent identifier |
| FsF-F2-01M | Metadata include descriptive core elements (creator, title, data identifier, publisher, publication date, summary, and keywords) to support data findability |
| FsF-F3-01M | Metadata include the identifier of the data it describes |
| FsF-F4-01M | Metadata are offered in such a way that it can be retrieved by machines |
| FsF-A1-01M | Metadata contain access level and access conditions of the data |
| FsF-A1-02M | Metadata are accessible through a standardized communication protocol |
| FsF-A1-03D | Data are accessible through a standardized communication protocol |
| FsF-A2-01M | Metadata remain available, even if the data are no longer available |
| FsF-I1-01M | Metadata are represented using a formal knowledge representation language |
| FsF-I1-02M | Metadata use semantic resources |
| FsF-I3-01M | Metadata include links between the data and its related entities |
| FsF-R1-01M | Metadata specify the content of the data |
| FsF-R1.1-01M | Metadata include license information under which data can be reused |
| FsF-R1.2-01M | Metadata include provenance information about data creation or generation |
| FsF-R1.3-01M | Metadata follow a standard recommended by the target research community of the data |
| FsF-R1.3-02D | Data are available in a file format recommended by the target research community |
| Level | Level Objective | Data Life Cycle Phase | Level Conditions |
|---|---|---|---|
| 1 | Conceptualizing data creation and usage | Collection | Open4usage pr, DQ4usage pr |
| 2 | Processing data | Processing | DM4processing cu, DQ4processing cu |
| 3 | Providing data suitable for project collaboration | Analysis | DM4analysis cu, DQ4analysis cu |
| 4 | Prepare data for publication | Publication | Open4publication pu, DM4publication pu, DQ4publication pu |
| 5 | Provide data suitable for impact research and long-term archiving | Archiving | Open4archiving pu, DM4archiving pu, DQ4archiving pu |
| Level Condition | Definition |
|---|---|
| Open4usage | CC license that allows usage of data and dissemination of derived data (e.g., CC0 1.0 or CC BY 4.0); 2-star open data |
| Open4publication | CC license that allows reusability of data (e.g., CC BY-SA 4.0); 3-star open data |
| Open4archiving | CC license that allows non-commercial and commercial reusability of data for other parties (e.g., CC BY 4.0); 4-star open data |
| Criterion | Name in QMM Concept | Aspect |
|---|---|---|
| Technicality | Consistency | Data Formats |
| Versioning follows/is | ||
| Controlled Vocabularies | ||
| Integrity | Completeness | Existence of Data |
| Existence of Metadata | ||
| Accessibility | Accessibility | Data Access by |
| Metadata Access by | ||
| Validation | Accuracy | Plausibility |
| Statistical Anomalies |
| Aspect | Level 2 DM4processing | Level 3 DM4analysis | Level 4 DM4publication | Level 5 DM4archiving |
|---|---|---|---|---|
| Existence of Data | Data are in production and may be deleted or overwritten | Datasets exist, not complete and may be deleted, but not overwritten unless explicitly specified | FsF-A1-03D data entities conform to discipline-specific standards; data are persistent as long as expiration date requires | Data entities conform to interdisciplinary standards; data are persistent as long as expiration date requires |
| Existence of Metadata | FsF-R1.2-01M provenance documented in well-defined format | Provenance documented in interdisciplinary standard | ||
| FsF-R1-01M basic metadata, e.g., from automatic extraction | FsF-F2-01M metadata enriched by non-automatically derivable elements | FsF-A1-01M metadata contain access rights information | Metadata conform to interdisciplinary standards | |
| Data quality as part of metadata included, e.g., from automatic extraction | Data quality as part of metadata enriched | |||
| FsF-F4-01M metadata are machine-readable | FsF-A1-02M metadata accessible through standardized protocol | |||
| FsF-I1-02M metadata use semantic resources | ||||
| FsF-I3-01M metadata reference to related entities | ||||
| FsF-I1-01M metadata in formal knowledge representation language | ||||
| FsF-R1.3-01M metadata conform to discipline-specific standards | ||||
| FsF-R1.1-01M metadata contain reuse license |
| Data Quality Class | Data Quality Sub Class | Description | Data Quality Level + Condition |
|---|---|---|---|
| Positional accuracy | Absolute external positional accuracy | Closeness of reported coordinate values to values accepted as or being true | 3-DQ4analysis |
| Relative internal positional accuracy | Evaluation of random errors in the relative position of one feature to another in the same dataset | 4-DQ4publication | |
| Gridded data positional accuracy | Closeness of gridded data position values to values accepted as or being true | 3-DQ4analysis | |
| Temporal quality | Accuracy of a time measurement | Correctness of the temporal references of an item (reporting of error in time measurement) | 5-DQ4archiving |
| Temporal consistency | Correctness of ordered events or sequences, if reported | 3-DQ4analysis | |
| Temporal validity | Validity of data specified by the scope with respect to time | 3-DQ4analysis | |
| Logical consistency | Conceptual consistency | Adherence to rules of the conceptual schema | 2-DQ4processing |
| Domain consistency | Adherence of values to the value domains | 4-DQ4publication | |
| Format consistency | Degree to which data are stored in accordance with the physical structure of the dataset, as described by the scope | 4-DQ4publication | |
| Topological consistency | Correctness of the explicitly encoded topological characteristics of the dataset, as described by the scope | 5-DQ4archiving | |
| Completeness | Completeness commission | Excess data present in the dataset, as described by the scope | 3-DQ4analysis |
| Completeness omission | Data absent from the dataset, as described by the scope | 3-DQ4analysis | |
| Thematic accuracy | Thematic classification correctness | Comparison of the classes assigned to features or their attributes to a universe of discourse | 2-DQ4processing |
| Non-quantitative attribute correctness | Correctness of non-quantitative attributes | 4-DQ4publication | |
| Quantitative attribute accuracy | Accuracy of quantitative attributes | 2-DQ4processing | |
| Metaquality | Confidence | Trustworthiness of a data quality result | 4-DQ4publication |
| Representativity | Degree to which the sample used has produced a result which is representative of the data within the data quality scope | 3-DQ4analysis | |
| Homogeneity | Expected or tested uniformity of the results obtained for a data quality evaluation | 2-DQ4processing | |
| Usability element | Based on user requirements | Usability, user perspectives, data use indices, what was the data used for | 2-DQ4processing |
| Data Quality Class | Data Quality Sub Class | Level 3 to 5 Measure | Threshold |
|---|---|---|---|
| Completeness | Completeness commission | number of excess items | n < 0.05 * n_all |
| rate of excess items | r < 5% | ||
| number of duplicates | n < 0.05 * n_all | ||
| Completeness omission | number of missing items | n < 0.05 * n_all | |
| rate of missing items | r < 5% |
| Role | Activity | Description | Phase—Step |
|---|---|---|---|
| Data provider | Define data quality (DQ) level conditions | Definition of level conditions for DQ for data usage at collection phase: DQ4usage | Preliminary |
| Define openness of data | Definition of the required openness of the data: Open4usage | Preliminary | |
| Data curator | Define data maturity (DM) and data quality (DQ) level conditions | Definition of level conditions for DM and DQ for data usage at processing, analysis, or publication phases: DM4processing, DM4analysis, DQ4processing, DQ4analysis | Preliminary |
| Data publisher | Define data maturity (DM) and data quality (DQ) level conditions | Definition of level conditions for DM and DQ for data usage in publication and archiving phases: DM4publication, DM4archiving, DQ4publication, DQ4archiving | Preliminary |
| Define openness of data | Definition of the required openness of the data at publication and archiving phases: Open4publication, Open4archiving | Preliminary |
| Role | Activity | Description | Phase—Step |
|---|---|---|---|
| Data provider | Choose/apply quality control method | Select and apply suitable quality control procedure, measures, and thresholds for the data with respect to the use case. | Multiple |
| Data curator | Evaluate fitness for next phase | Evaluate the results of the data quality assessment with regard to the fitness for the next phase. | Multiple |
| Add indicators/descriptions to metadata | Add the result of the fitness for the next phase evaluation in the metadata set to facilitate visibility of the assessment, and in the end, reuse of the data. | Multiple |
| Role | Activity | Description | Phase—Step |
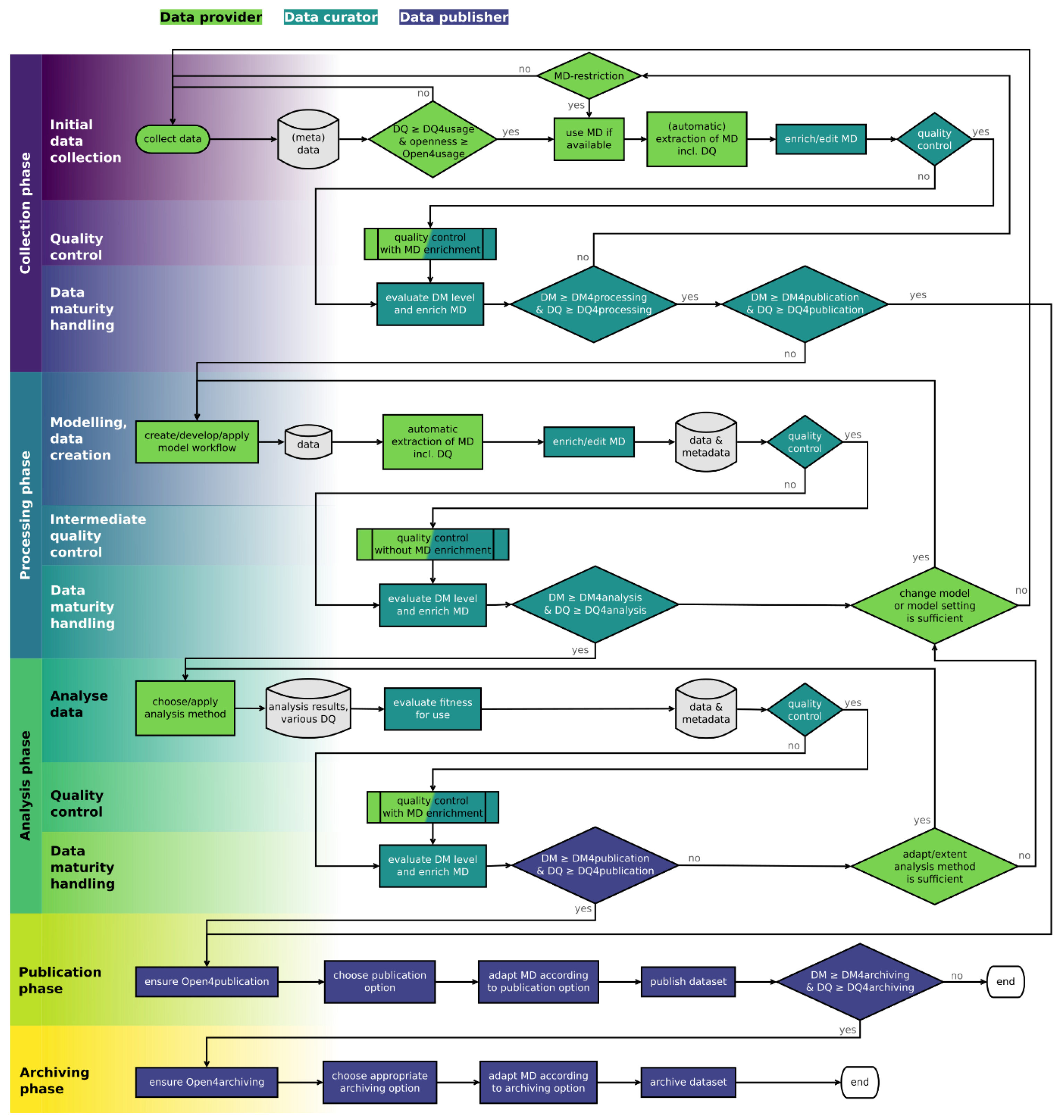
|---|---|---|---|
| Data provider | Collect data | Discover and collect data and metadata from repositories. | Collection—initial collection |
| (Automatic) extraction of metadata including data quality | Obtain a metadata set including data quality information by using an extraction tool (automatically) or analysing the data or publications (manually). Automatic metadata extraction is only available for data provided in structured file formats. | Collection—initial collection | |
| Quality control with metadata enrichment | Apply quality control (Section 2.3.2) and enrich metadata with its results. | Collection—quality control | |
| Data curator | Enrich/edit metadata | Extend or correct the existing metadata set to better fit evaluation needs (mostly manually). | Collection—initial collection |
| Evaluate data maturity level and enrich metadata | Evaluate the data maturity based on available data and metadata. Add the results of the data maturity assessment, the data maturity level, in the metadata. | Collection—data maturity handling |
| Role | Activity | Description | Phase—Step |
|---|---|---|---|
| Data provider | Create/develop model workflow | The data from the collection phase serves as input for a model workflow. Here, the data provider creates and implements the model and defines related parameters. | Processing—modelling, data creation |
| Automatic extraction of metadata including data quality | Obtain a metadata set including data quality information by using an extraction tool (automatically) or analysing the data or publications (manually). Automatic metadata extraction is only available for data provided in structured file formats. | Processing—modelling, data creation | |
| Quality control without metadata enrichment | Apply quality control (Section 2.3.2). | Processing—intermediate quality control | |
| Data curator | Enrich/edit metadata | Extend or correct the existing metadata set to better fit evaluation needs (mostly manually). | Processing—modelling, data creation |
| Evaluate data maturity level and enrich metadata | Evaluate the data maturity based on available data and metadata. Add the results of the data maturity assessment, the data maturity level, in the metadata. | Processing—data maturity handling |
| Role | Activity | Description | Phase—Step |
|---|---|---|---|
| Data provider | Choose analysis method | Data provider selects proper analysis method that covers research interests and use case/project aspects. | Analysis—analyse data |
| Quality control with metadata enrichment | Apply quality control (Section 2.3.2) and enrich metadata with its results. | Analysis—quality control | |
| Data curator | Evaluate fitness for use | Data curator assesses the fitness for use based on the analysis results. | Analysis—analyse data |
| Evaluate data maturity level and enrich metadata | Evaluate the data maturity based on available data and metadata. Add the results of the data maturity assessment, the data maturity level, in the metadata. | Analysis—data maturity handling |
| Role | Activity | Description | Phase–Step |
|---|---|---|---|
| Data publisher | Ensure Open4publication | Check and—if necessary—change the openness of the data to meet the Open4publication requirement. | Publication |
| Choose publication option | Choose a proper option for data publication. The target repository can be a local, project-specific, or institutional data management system or a well-known repository. | ||
| Adapt metadata according to publication option | To meet the metadata requirements of the target repository, the data publisher will perform minor transformations of metadata elements to meet the target schema/profile, e.g., renaming metadata elements. | Publication | |
| Publish dataset | Publish the dataset and metadata. | Publication |
| Role | Activity | Description | Phase—Step |
|---|---|---|---|
| Data publisher | Ensure Open4archiving | Check and—if necessary—change the openness of the data to meet the Open4archiving requirement. | Archiving |
| Choose appropriate archiving option | Choose an appropriate option for data archiving. The archiving can be a mid-term archiving in a well-known repository or even a long-term archiving including possible alterations in the file format. | Archiving | |
| Adapt MD according to archiving option | The archiving option might have own demands for a metadata schema. In this case, adapt the metadata to the needs of the used archiving option. | Archiving | |
| Archive dataset | Archive the dataset. | Archiving |
| Identifier | Implemented in SPAM2010 | Comment |
|---|---|---|
| FsF-F1-01D | Yes | DOI is available |
| FsF-F1-02D | Yes | DOI is persistent |
| FsF-F2-01M | Yes | Descriptive core metadata (e.g., title) are available |
| FsF-F3-01M | Yes | Data DOI is included in metadata |
| FsF-F4-01M | Yes | The Harvard Dataverse repository provides machine-readable metadata access |
| FsF-A1-01M | Yes | Metadata contain information about accessibility of data |
| FsF-A1-02M | Yes | The Dataverse repository allows API access |
| FsF-A1-03D | Yes | The Dataverse repository allows API or direct file access |
| FsF-A2-01M | Yes | The Dataverse repository supports a bit-level preservation |
| FsF-I1-01M | Yes | The Dataverse repository allows, e.g., JSON-LD (JSON for linked data) |
| FsF-I1-02M | Yes | Metadata contain semantic information, e.g., keyword vocabularies |
| FsF-I3-01M | Yes/No | Links to previous versions SPAM2005 and SPAM2000 are available, but links to input datasets are not given |
| FsF-R1-01M | Yes | Metadata contain data description element |
| FsF-R1.1-01M | Yes | Metadata include the license information |
| FsF-R1.2-01M | No | Provenance information is not available |
| FsF-R1.3-01M | Yes/No | Metadata schema includes some Dublin Core elements, but ISO 19157:2013 or GeoDCAT standards are not applied |
| FsF-R1.3-02D | Yes | Available formats are csv, dbf, and GeoTIFF |
| Criterion | Aspect | Reached Measure | Reached Level | Comment |
|---|---|---|---|---|
| Technicality | Data Formats | Data sizes consistent | 5 | |
| FsF-R1.3-02D | 4 | |||
| Versioning follows/is | Project requirements | 3 | ||
| Controlled Vocabularies (CVs) | Formal project defined CVs | 3 | Crop types mostly follow Agrovoc [44] | |
| Integrity | Existence of Data | FsF-A1-03D; discipline-specific standard | 4 | |
| Existence of Metadata | No provenance in metadata | 1 | Input data and methodology are described, but information is not available in metadata | |
| FsF-A1-01M | 4 | |||
| No data quality in metadata | 1 | Some data quality described in publication (subjective uncertainty rating, local validation against existing datasets) | ||
| FsF-A1-02M | 5 | |||
| FsF-I1-02M | 5 | |||
| No references to related entities | 2 | References to thematic vocabulary for keywords, publication, producer available, but not to input data | ||
| FsF-I1-01M | 5 | |||
| FsF-R1.3-01M | 5 | |||
| FsF-R1.1-01M | 5 | |||
| Accessibility | Data Access by | FsF-F1-01D | 5 | |
| No checksums given | 2 | |||
| Metadata Access by | FsF-A2-01M | 5 | ||
| FsF-F3-01M | 5 | |||
| Validation | Plausibility | Documented technical sources of errors exist | 5 | In publication |
| Documented validation against independent data | 5 | In publication | ||
| Statistical Anomalies | No missing values indicated | 1/5 | No missing values in data | |
| Documented statistical quality control | 5 | Subjective uncertainty rating of data in publication [15] | ||
| Consistency among multiple datasets | 5 | Comparison of different SPAM versions in the publication |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wagner, M.; Henzen, C. Quality Assurance for Spatial Research Data. ISPRS Int. J. Geo-Inf. 2022, 11, 334. https://doi.org/10.3390/ijgi11060334
Wagner M, Henzen C. Quality Assurance for Spatial Research Data. ISPRS International Journal of Geo-Information. 2022; 11(6):334. https://doi.org/10.3390/ijgi11060334
Chicago/Turabian StyleWagner, Michael, and Christin Henzen. 2022. "Quality Assurance for Spatial Research Data" ISPRS International Journal of Geo-Information 11, no. 6: 334. https://doi.org/10.3390/ijgi11060334
APA StyleWagner, M., & Henzen, C. (2022). Quality Assurance for Spatial Research Data. ISPRS International Journal of Geo-Information, 11(6), 334. https://doi.org/10.3390/ijgi11060334