
Landslide Susceptibility Assessment Considering Spatial Agglomeration and Dispersion Characteristics: A Case Study of Bijie City in Guizhou Province, China


Abstract
:1. Introduction
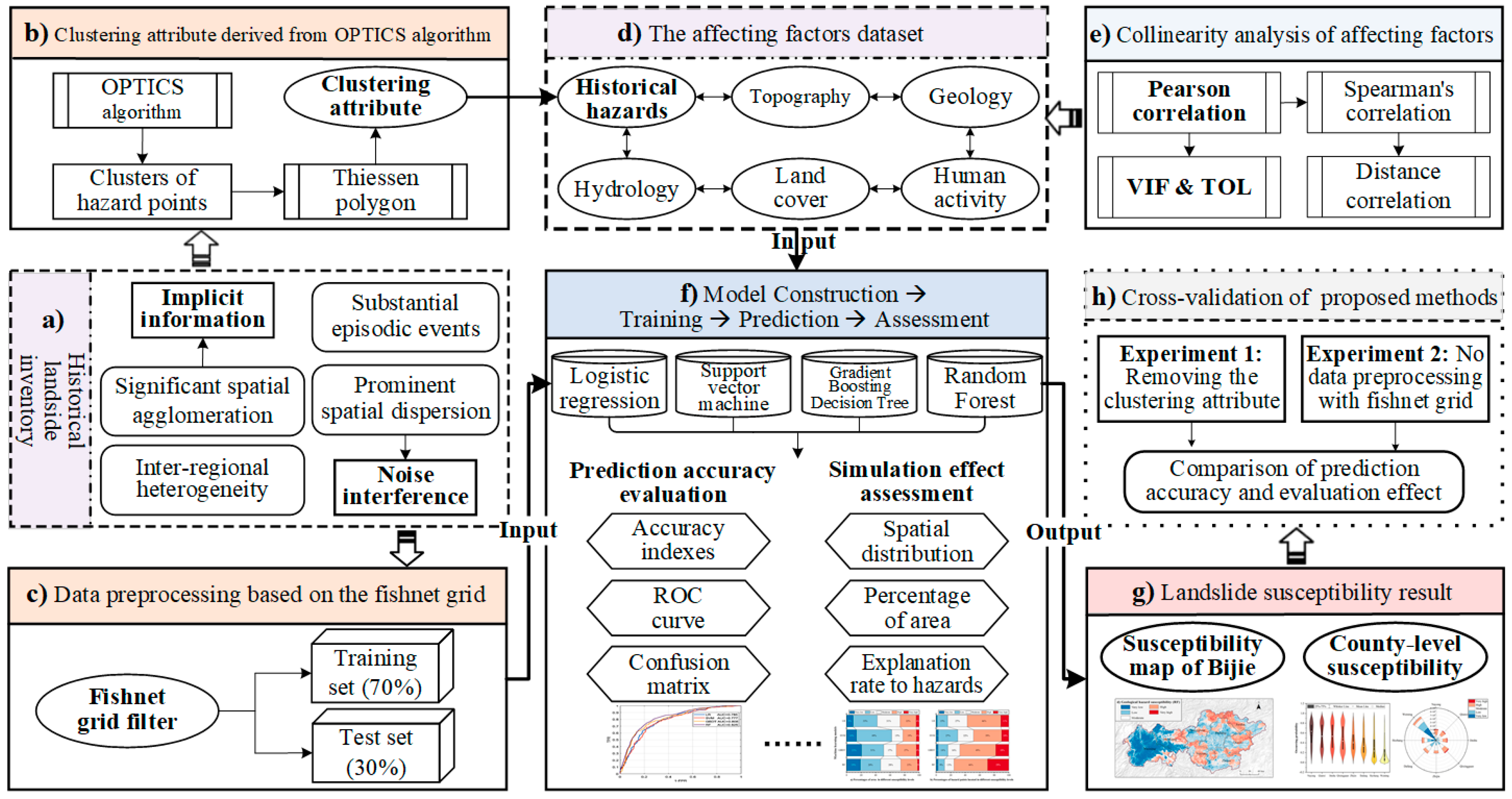
2. Materials and Methods
2.1. Study Area and Data
2.2. Methodology
2.2.1. Machine Learning Models
2.2.2. Accuracy Evaluation Indexes
2.3. Strategies Considering the Spatial Characteristics of Landslides
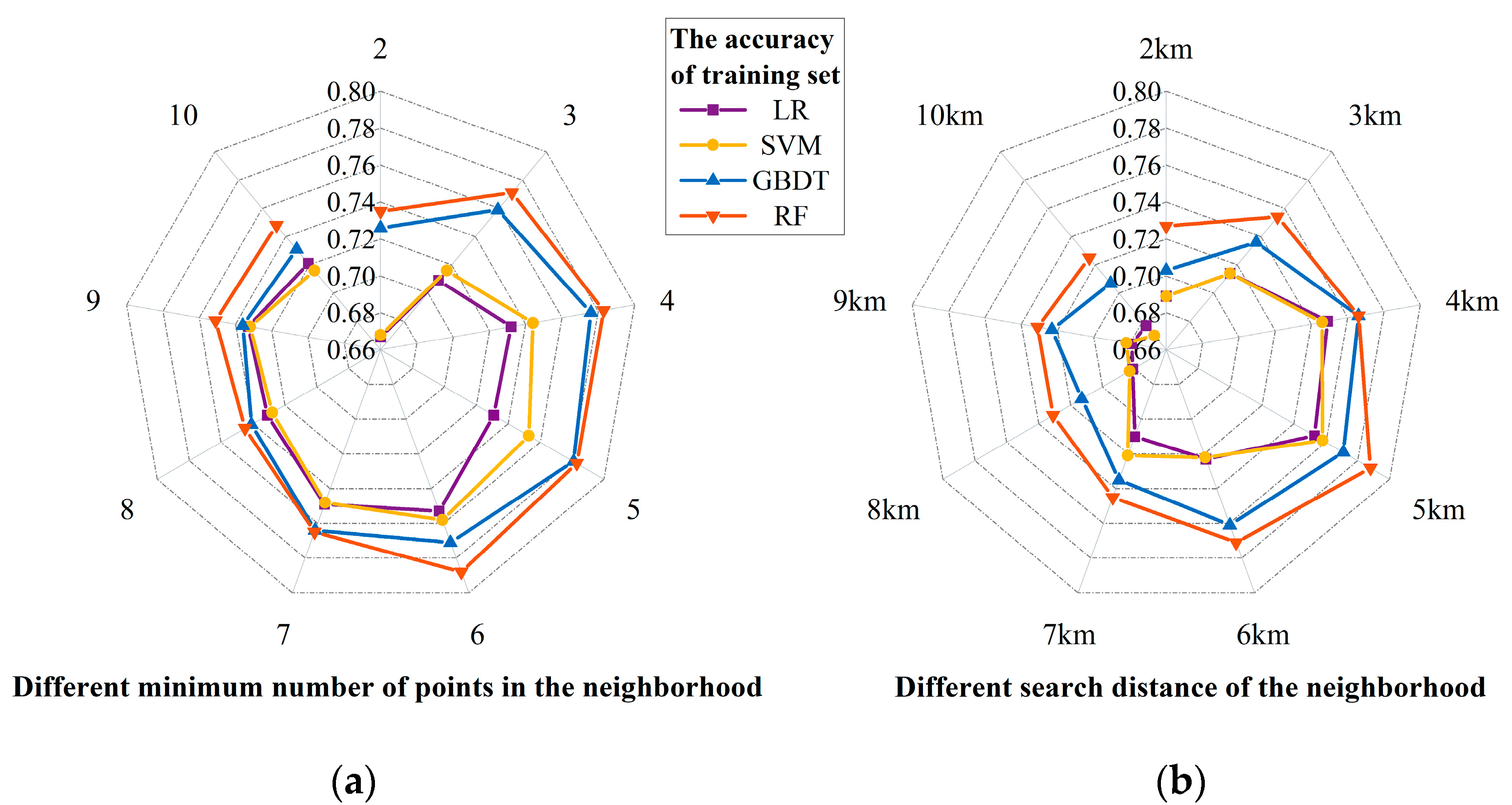
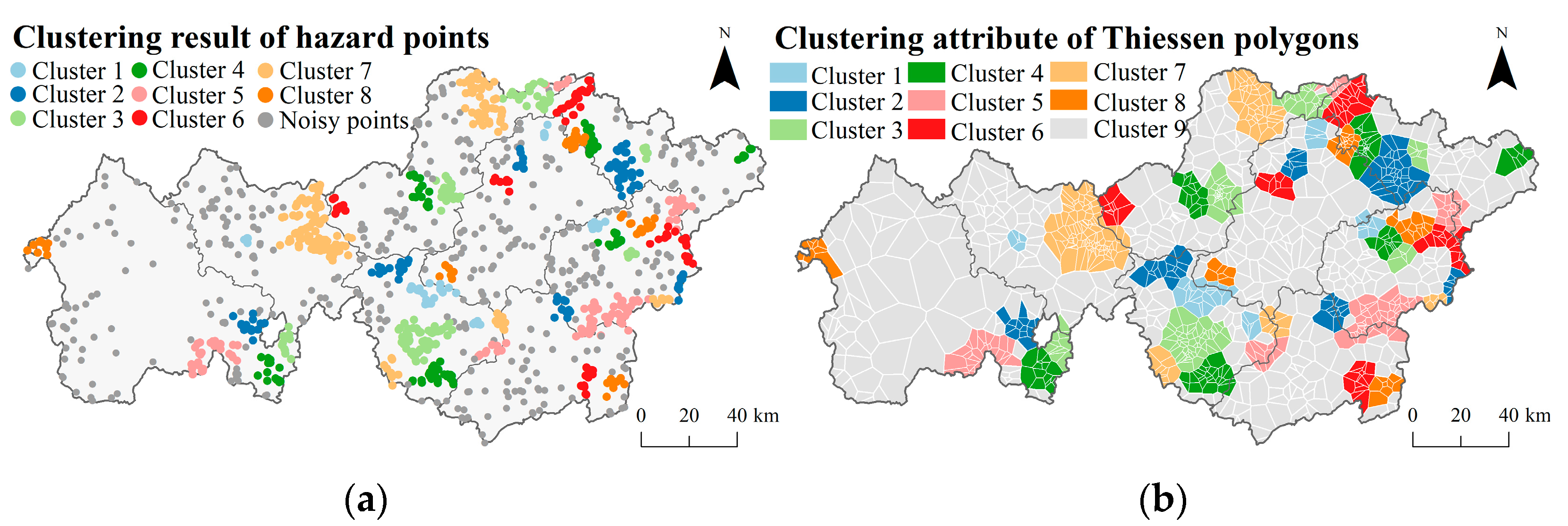
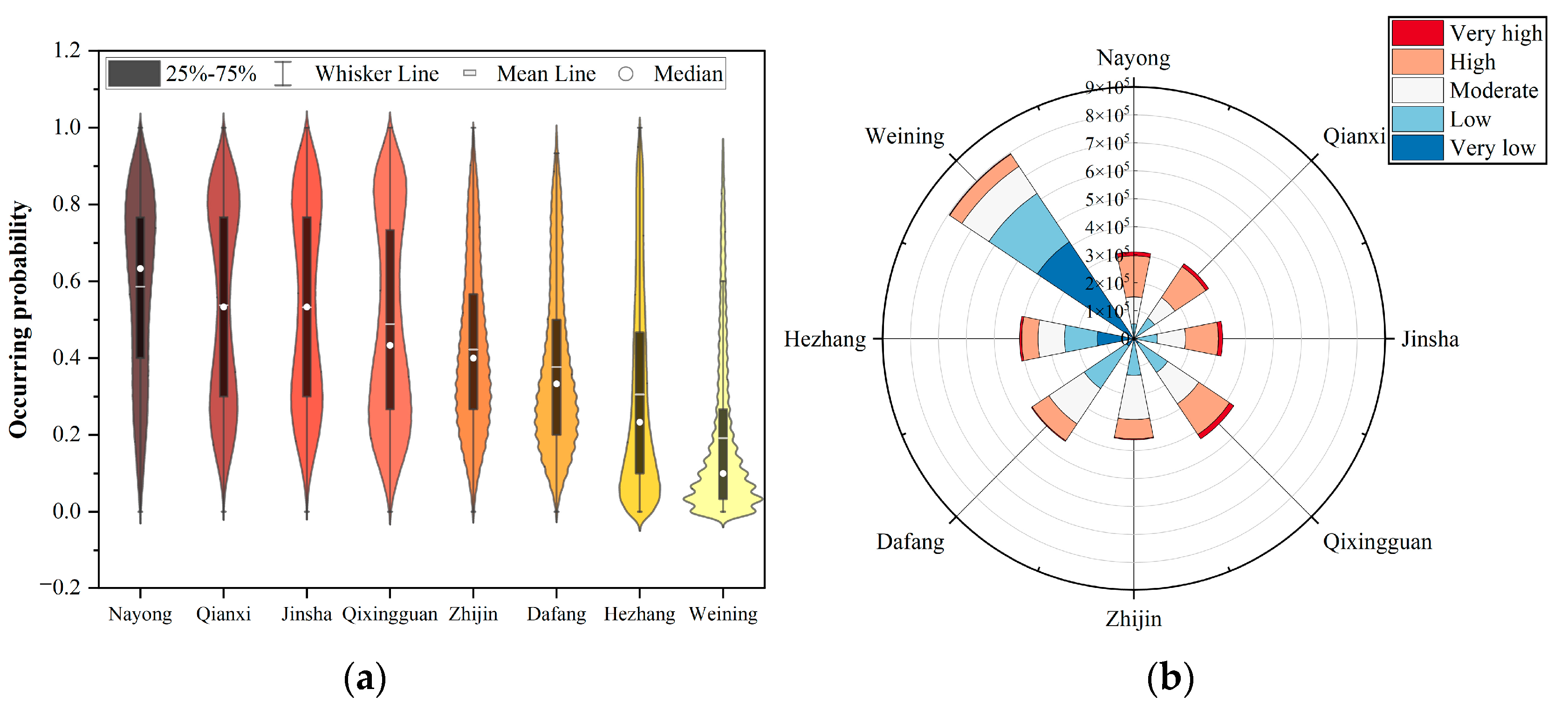
2.3.1. Clustering Attribute Derived from Spatial Agglomeration
- The integrated algorithms such as GBDT and RF significantly outperformed the traditional machine learning algorithms such as LR and SVM in this study.
- No matter which parameter was taken as the independent variable, the accuracies of the models presented a linear trend of increasing first and then decreasing with the increase in the variable. This pattern implies the potential clustering feature in the spatial distribution of landslides, as we speculated. Meanwhile, the agglomeration reflected here represents the group-occurring characteristic of landslides.
- Demonstrated by the value and variation of the training accuracy, the models were more sensitive to the parameter of the search distance than the minimum number of points, which also manifested the spatial heterogeneity among different polygon blocks in the study area.
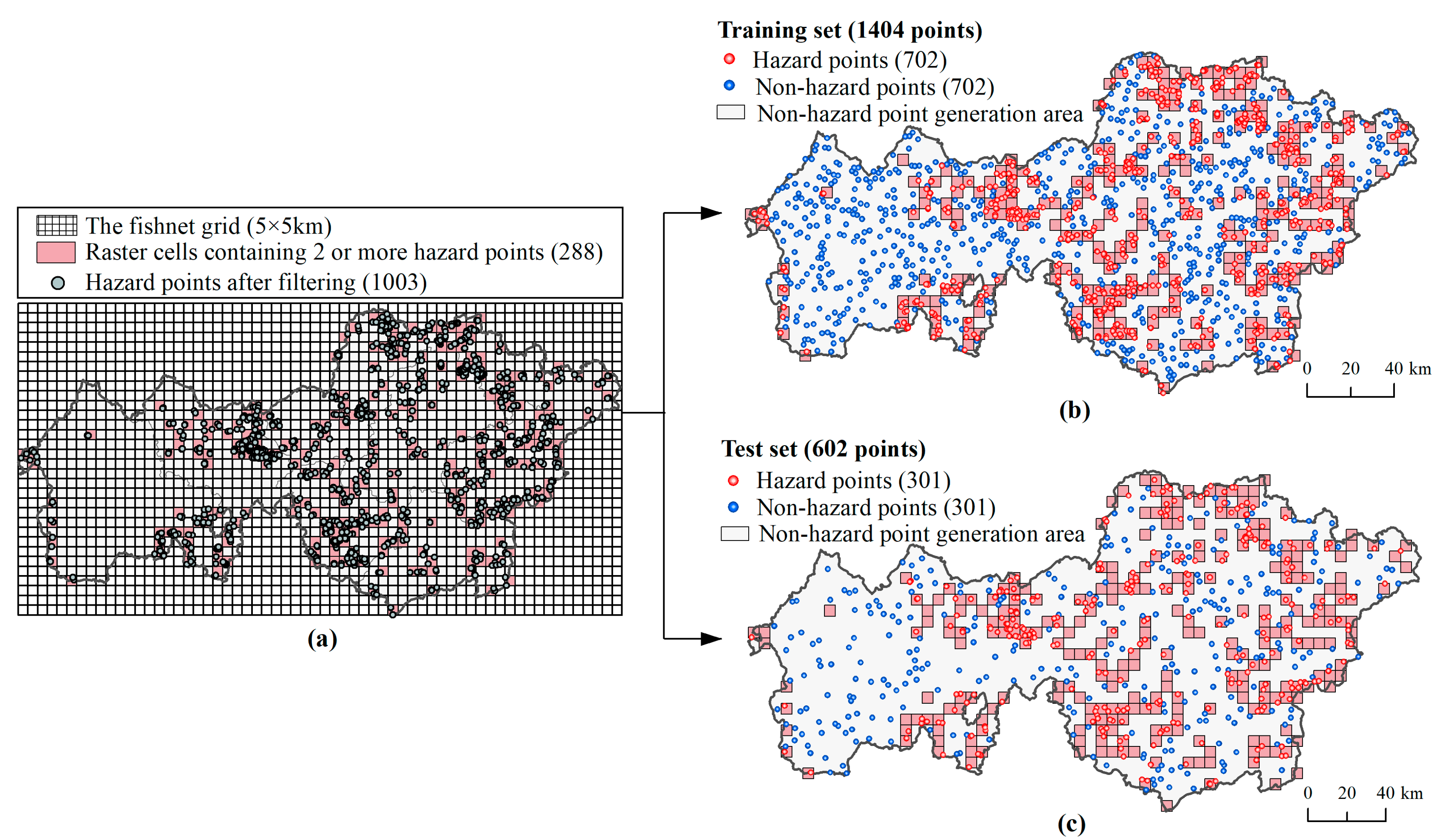
2.3.2. Training and Test Set Generated by the Fishnet Grid
- Generate the fishnet grid with a 5-km side length to filter the research area. Here, the basis for 5 km is the optimal search distance of 5 km from the clustering in Section 2.3.1, which most effectively reflects the inter-regional heterogeneity and intra-regional homogeneity of susceptibility and obtained the highest accuracy;
- For each raster cell of the fishnet, if there is only one hazard point in the cell, then this point is excluded; otherwise, it is retained (Figure 5a).
3. Results
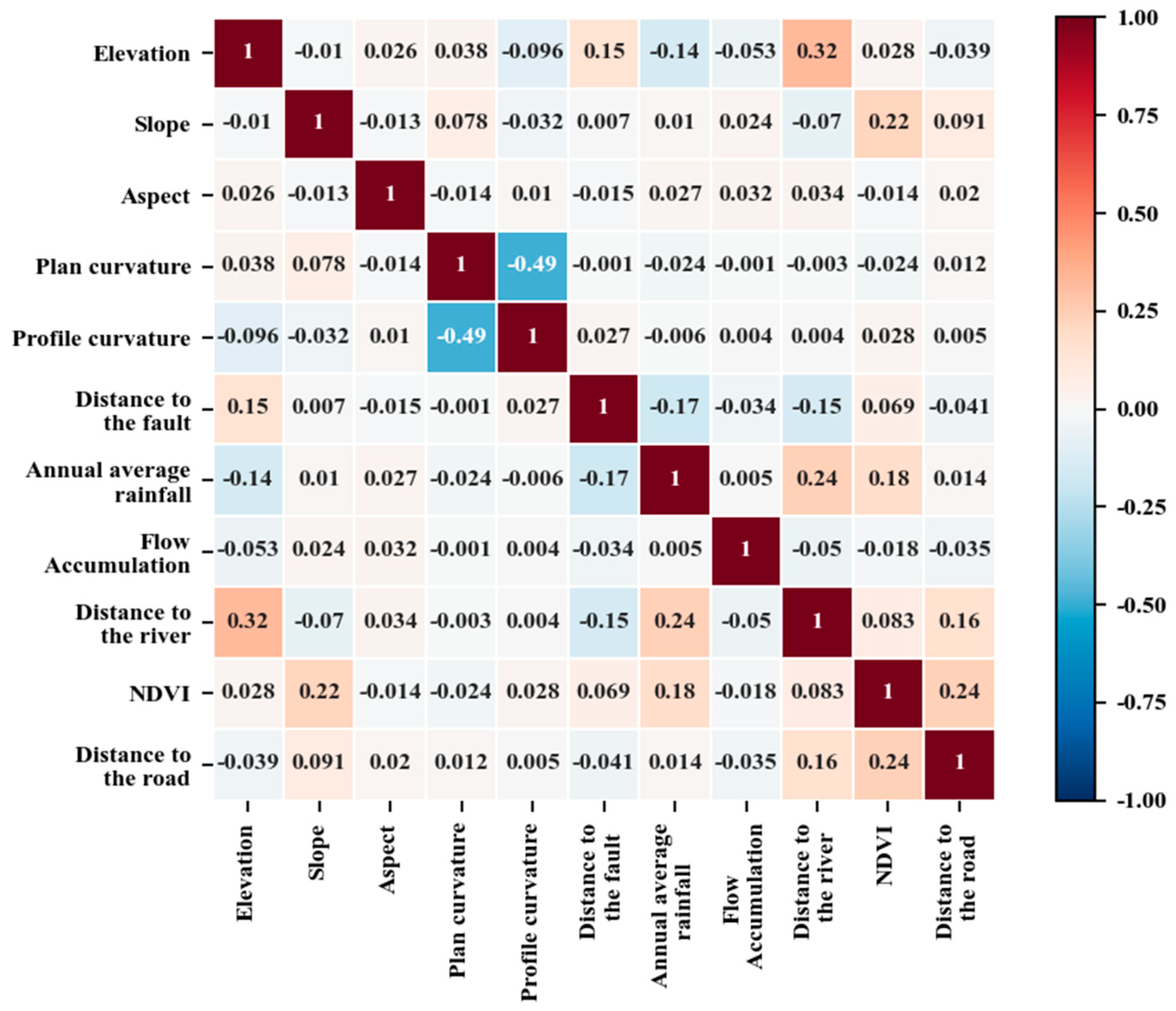
3.1. Constructing the Affecting Factors Data Set
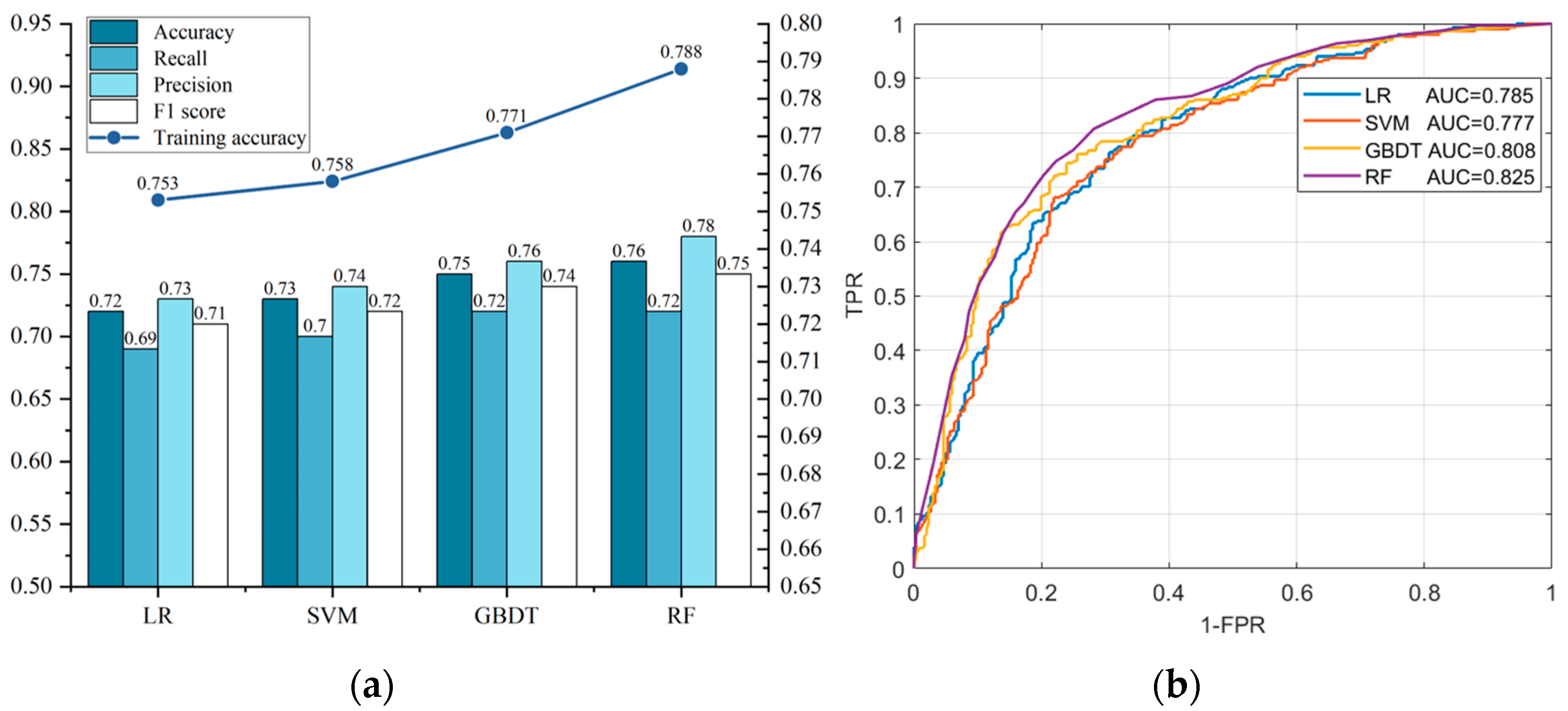
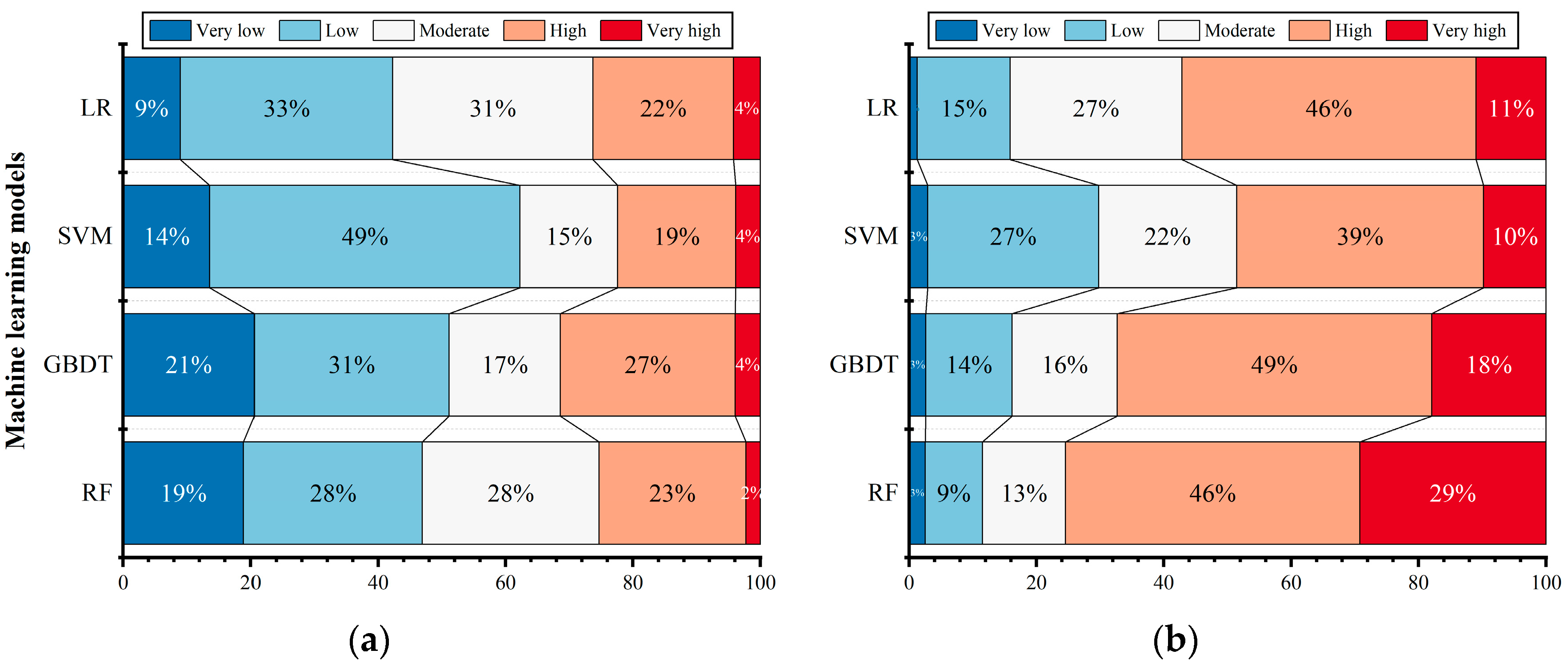
3.2. Evaluation of Model Prediction Accuracy
3.3. Mapping the Landslide Susceptibility
- At the global scale, the spatial distribution and area shares of different levels of susceptibility were more reasonable than those of other methods. For example, the very high susceptibility areas were moderately distributed among the high-value areas of each county (Figure 9d), whereas for LR and the SVM, the very high susceptibility areas were concentrated in blocks in the northernmost areas of Bijie, southwest of Dafang, and northeast of central Qianxi, featuring a local exaggeration which was biased from reality, being especially overestimated in the southwest of Dafang, where there were only six hazard points (Figure 9a,b). For GBDT, the percentage of moderately prone areas was underrepresented, accounting for 17% (Figure 10a).
- At the local scale, the RF map was richer in spatial details and retained a gradual change in susceptibility from high to low in the high-value areas, which is realistic. In contrast, the other three maps were more distinctly patchy, with coarser portrayals of the highly and less prone areas.
- In terms of the interpretation effect of historical hazards, the more-prone areas (including high and very high areas, the same as those shown below) representing 25% of the RF map area contained 75% of the historical hazard points, and the less-prone areas (including low and very low areas, the same as those shown below) representing 47% of the RF area contained only 12% of the hazard points (Figure 10). This strongly proves the capability of the RF map to effectively reflect the true state of susceptibility. However, other maps did not perform as well, such as the GBDT map with a larger proportion of more-prone areas (31%) which explained only 67% of the historical hazards, while the SVM map with less-prone areas (63%) over-explained 30% of the hazards.
4. Discussion
4.1. Impact of the Spatial Clustering Attribute on the Models
4.2. Impact of the Spatial Dispersion Characteristic on the Models
- There was an unreasonable allocation of area for the different susceptibility levels, which was reflected both in the area percentage and the spatial distribution. Specifically, the area percentages of the more- and less-prone areas distinctly decreased by 6% and 13%, respectively, while that of the moderate susceptibility areas increased steeply to 47% (Figure 13d). Combined with reality, it seems to be too aggressive to state that nearly half the area of Bijie is moderately susceptible. Secondly, the overall spatial distribution also suffered from the problem of overestimation in the less-prone areas and underestimation in the more-prone areas, as shown in Figure 12c, and could not portray the gradual change in susceptibility between neighborhoods, as shown in Figure 9d.
- There was weakening of the interpretation effect on historical hazards. This manifested in the sharp 11% reduction in the interpretation of the very high susceptibility areas. Despite an 8% increase in the interpretation of the more-prone areas, there was an unexpected decrease in the relative proportion of very high susceptibility areas in the more-prone areas in the interpretation rate from 39% to 22%, as this went against the nature of more hazards occurring at the very high susceptibility level. However, the interpretation effect of the less-prone areas improved with a 10% reduction. The reason behind this was that without preprocessing for filtering, those isolated hazard points representing less-prone levels were fully learned by the model, thus contributing a better interpretation for the less-prone areas but at the expense of the overall accuracy. The loss of the interpretation rate of low susceptibility areas actually reflected the loss of data due to the filtration of isolated points. Compared with the improvement to the whole evaluation’s effectiveness, especially in the high susceptibility area, the data loss was acceptable.
5. Conclusions
- Indicator selection: Adding a spatial clustering attribute as one affecting factor can effectively enhance the model’s ability to recognize non-hazard points and in turn increase the model’s accuracy by nearly 5%. Most importantly, it corrects for the formerly unnoticed systematic assessment bias. The improvements in accurate identification in higher susceptibility areas and interpretation to historical hazards will help optimize the deployment of disaster prevention structures.
- Data processing: When using the fishnet grid as a mask to process the original data, the entire spatial pattern of susceptibility will not change, the training and testing accuracies will be improved by about 10%, and the spatial division of each susceptibility level will be more in line with the historical data, which may better serve disaster monitoring and control in the real world.
- Model construction: The integrated algorithms represented by the RF and GBDT algorithms outperformed the traditional ones such as LR and the SVM. Among them, the RF model was the best, with its of up to 76% and of up to 78%. Moreover, the superiority of the RF map lies in the more accurate positioning of higher susceptibility areas globally and the richer spatial portrayal of susceptibility locally, which reflects the necessary spatial group-occurring, inter-regional heterogeneity, and gradual variability characteristics of susceptibility.
- Management suggestion: The landslide susceptibility in Bijie presented a high susceptibility in the east, low susceptibility in the west, and a regional clustering pattern, with its central, northeastern, eastern edge, and southwestern areas having a high susceptibility level. The counties in Bijie can be divided into three echelons in descending order of susceptibility. For the first echelon, with a wide range and large proportion of more-prone areas, an adequate professional inspection of the geological environment should be implemented in place as a priority before regular slope monitoring and stabilization measures. Despite a moderate reduction in the susceptibility degree for the second and third echelons, the regional concentrations of high-susceptibility areas still deserve particular attention and warrant relevant authorities taking actions to develop adaptive development strategies for balancing human activities and the natural environment.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aleotti, P.; Chowdhury, R. Landslide hazard assessment: Summary review and new perspectives. Bull. Eng. Geol. Environ. 1999, 58, 21–44. [Google Scholar] [CrossRef]
- Sepúlveda, S.A.; Rebolledo, S.; Vargas, G. Recent catastrophic debris flows in Chile: Geological hazard, climatic relationships and human response. Quatern. Int. 2006, 158, 83–95. [Google Scholar] [CrossRef]
- Cui, P. Progress and prospects in research on mountain hazards in China. Prog. Geogr. 2014, 33, 145–152. [Google Scholar]
- Donat, M.G.; Lowry, A.L.; Alexander, L.V.; O Gorman, P.A.; Maher, N. More extreme precipitation in the world’s dry and wet regions. Nat. Clim Chang. 2016, 6, 508–513. [Google Scholar] [CrossRef]
- Shi, P.; Yang, W. Compound effects of earthquakes and extreme weathers on geo-hazards in mountains. Clim. Chang. Res. 2020, 16, 405. [Google Scholar]
- Yesilnacar, E.; Topal, T. Landslide susceptibility mapping: A comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng. Geol. 2005, 79, 251–266. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Yilmaz, I.; Keskin, I. GIS based statistical and physical approaches to landslide susceptibility mapping (Sebinkarahisar, Turkey). Bull. Eng. Geol. Environ. 2009, 68, 459–471. [Google Scholar] [CrossRef]
- Stamatopoulos, C.A.; Di, B. Analytical and approximate expressions predicting post-failure landslide displacement using the multi-block model and energy methods. Landslides 2015, 12, 1207–1213. [Google Scholar] [CrossRef]
- Nie, Y.; Li, X.; Zhou, W.; Xu, R. Dynamic hazard assessment of group-occurring debris flows based on a coupled model. Nat. Hazards 2021, 106, 2635–2661. [Google Scholar] [CrossRef]
- Goetz, J.N.; Guthrie, R.H.; Brenning, A. Integrating physical and empirical landslide susceptibility models using generalized additive models. Geomorphology 2011, 129, 376–386. [Google Scholar] [CrossRef]
- Liu, C.; Li, W.; Wu, H.; Lu, P.; Sang, K.; Sun, W.; Chen, W.; Hong, Y.; Li, R. Susceptibility evaluation and mapping of China’s landslides based on multi-source data. Nat. Hazards 2013, 69, 1477–1495. [Google Scholar] [CrossRef]
- Tan, Y.; Guo, D.; Xu, B. A geospatial information quantity model for regional landslide risk assessment. Nat. Hazards 2015, 79, 1385–1398. [Google Scholar] [CrossRef]
- Panchal, S.; Shrivastava, A.K. A comparative study of frequency ratio, Shannon’s entropy and analytic hierarchy process (AHP) models for landslide susceptibility assessment. ISPRS Int. J. Geo-Inf. 2021, 10, 603. [Google Scholar] [CrossRef]
- Ding, Q.; Chen, W.; Hong, H. Application of frequency ratio, weights of evidence and evidential belief function models in landslide susceptibility mapping. Geocarto Int. 2017, 32, 619–639. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C.; Mohammadi, M.; Moradi, H.R. Application of weights-of-evidence and certainty factor models and their comparison in landslide susceptibility mapping at Haraz watershed, Iran. Arab. J. Geosci. 2013, 6, 2351–2365. [Google Scholar] [CrossRef]
- He, S.; Pan, P.; Dai, L.; Wang, H.; Liu, J. Application of kernel-based Fisher discriminant analysis to map landslide susceptibility in the Qinggan River delta, Three Gorges, China. Geomorphology 2012, 171, 30–41. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Du, J.; Zhang, L.; Song, Y.; Sun, G. Multi-geohazards susceptibility mapping based on machine learning—a case study in Jiuzhaigou, China. Nat. Hazards 2020, 102, 851–871. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Gao, R.; Wang, C.; Liang, Z.; Han, S.; Li, B. A Research on Susceptibility Mapping of Multiple Geological Hazards in Yanzi River Basin, China. ISPRS Int. J. Geo-Inf. 2021, 10, 218. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Wang, C.; Liu, J.; Zhang, L. Susceptibility assessment of landslides triggered by earthquakes in the Western Sichuan Plateau. Catena 2019, 175, 63–76. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, C.; Hong, H.; Zhou, Q.; Wang, D. Mapping earthquake-triggered landslide susceptibility by use of artificial neural network (ANN) models: An example of the 2013 Minxian (China) Mw 5.9 event. Geomat. Nat. Hazards Risk 2019, 10, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Zhang, X.; Li, P.; Li, Z.B.; Yu, G. Characteristics and formation mechanism of the July 25, 2013, Tianshui group-occurring geohazards. Environ. Earth Sci. 2017, 76, 219. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Minaei, M.; Shahabi, H.; Hagenauer, J. Big data in geohazard; pattern mining and large scale analysis of landslides in Iran. Earth Sci. Inform. 2019, 12, 1–17. [Google Scholar] [CrossRef]
- Qiu, H.J. Study on the Regional Landslide Characteristic Analysis and Hazard Assessment: A Case Study of Ningqiang County. Ph.D. Thesis, Northwest University, Xi’an, China, 2012. [Google Scholar]
- Wang, Y.; Feng, L.; Li, S.; Ren, F.; Du, Q. A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China. Catena 2020, 188, 104425. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, J.; Xu, C.; Xu, C.; Song, C. Local-scale landslide susceptibility mapping using the B-GeoSVC model. Landslides 2019, 16, 1301–1312. [Google Scholar] [CrossRef]
- Jacobs, L.; Kervyn, M.; Reichenbach, P.; Rossi, M.; Marchesini, I.; Alvioli, M.; Dewitte, O. Regional susceptibility assessments with heterogeneous landslide information: Slope unit-vs. pixel-based approach. Geomorphology 2020, 356, 107084. [Google Scholar] [CrossRef]
- Qiu, H.; Cao, M.; Liu, W.; Hao, J.; Wang, Y. Research on the spatial point pattern of geo-hazard—A case of Ningqiang county. J. Arid. Land Resour. Environ. 2014, 28, 107–111. [Google Scholar]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Lin, J.; Zhang, A.; Deng, C.; Chen, W.; Liang, C. Sensitivity Assessment of Geological Hazards in Urban Agglomeration of Fujian Delta Region. J. Geo-Inf. Sci. 2018, 20, 1286–1297. [Google Scholar]
- Chen, W.; Li, R.; Yin, Z.; Tang, Z. A study of evaluation of resources and environment carrying capacity of Qixingguan District in Bijie City, Wumeng Mountain, Guizhou Province. Geol. Bull. China 2020, 39, 114–123. [Google Scholar]
- ESRI. ArcGIS Desktop; Version 10.6; Environmental Systems Research Institute: Redlands, CA, USA, 2018; Available online: https://www.arcgis.com/ (accessed on 17 March 2022).
- Zhang, N.; Xu, Y.; Yan, H. A study of the instability mechanism and investigation methods of shallow bedrock landslides in Karst mountain areas: Taking the Jinxing landslide in Dafang County as an example. Hydrogeol. Eng. Geol. 2017, 44, 142–146. [Google Scholar]
- Zheng, G.; Xu, Q.; Ju, Y. The pusacun rockavalanche on August 28, 2017 in Zhanggjiawan Nayongxian, Guizhou: Characteristics and failure mechanism. J. Eng. Geol. 2018, 26, 223–240. [Google Scholar]
- Xu, S.; Liu, J.; Wang, X. Landslide susceptibility assessment method incorporating index of entropy based on support vector machine: A case study of Shaanxi Province. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1214–1222. [Google Scholar]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Jiang, W.; Rao, P.; Cao, R.; Tang, Z.; Chen, K. Comparative evaluation of geological disaster susceptibility using multi-regression methods and spatial accuracy validation. J. Geogr. Sci. 2017, 27, 439–462. [Google Scholar] [CrossRef] [Green Version]
- Lucchese, L.V.; de Oliveira, G.G.; Pedrollo, O.C. Investigation of the influence of nonoccurrence sampling on landslide susceptibility assessment using Artificial Neural Networks. Catena 2021, 198, 105067. [Google Scholar] [CrossRef]
- Hartmann, J.; Moosdorf, N. The new global lithological map database GLiM: A representation of rock properties at the Earth surface. Geochem. Geophys. Geosyst. 2012, 13, 12. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- He, Q.; Wang, M.; Liu, K. Rapidly assessing earthquake-induced landslide susceptibility on a global scale using random forest. Geomorphology 2021, 391, 107889. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Moradi, H.R.; Fatemi Aghda, S.M. Landslide susceptibility mapping by binary logistic regression, analytical hierarchy process, and statistical index models and assessment of their performances. Nat. Hazards 2013, 69, 749–779. [Google Scholar] [CrossRef]
- The Math Works, Inc. MATLAB Version 2020b; The Math Works, Inc.: Natick, MA, USA, 2020; Available online: https://www.mathworks.com/ (accessed on 17 March 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimensions | Affecting Factor | Original Resolution | Resampling Technique | Data Source |
|---|---|---|---|---|
| Topography | Elevation | 90 m | - | SRTMDEM (90 m) from Geospatial Data Cloud (http://www.gscloud.cn/ (accessed on 16 April 2022)) |
| Slope | - | - | Calculated from elevation | |
| Aspect | - | - | ||
| Plan curvature | - | - | ||
| Profile curvature | - | - | ||
| Geology | Distance to the fault | - | - | Fault data from Seismic Active Fault Survey Data Center (http://www.activefault-datacenter.cn/ (accessed on 16 April 2022)) |
| Lithology | Vector | - | The global lithological map database GLiM (https://doi.org/10.1594/PANGAEA.788537 (accessed on 16 April 2022)) [47] | |
| Soil type | Vector | - | Resource and Environment Science and Data Center (https://www.resdc.cn/ (accessed on 16 April 2022)) | |
| Hydrology | Annual average rainfall | 1 km | Bilinear interpolation | Resource and Environment Science and Data Center |
| Flow accumulation | - | - | Calculated from elevation | |
| Distance to the river | - | - | River data from OpenStreetMap (https://www.openstreetmap.org/ (accessed on 16 April 2022)) | |
| Land cover | Land use | 10 m | Nearest neighbor | Finer Resolution Observation and Monitoring-Global Land Cover (http://data.ess.tsinghua.edu.cn/ (accessed on 16 April 2022)) [48] |
| NDVI | 1 km | Bilinear interpolation | Resource and Environment Science and Data Center | |
| Human activity | Distance to the road | - | - | Road data from OpenStreetMap (https://www.openstreetmap.org/ (accessed on 16 April 2022)) |
| Historical hazards | Clustering attribute | - | - | Calculated from historical hazard points |
| Affecting Factor | TOL | VIF | Affecting Factor | TOL | VIF |
|---|---|---|---|---|---|
| Elevation | 0.425 | 2.353 | Annual average rainfall | 0.453 | 2.207 |
| Slope | 0.771 | 1.297 | Flow accumulation | 0.984 | 1.016 |
| Aspect | 0.994 | 1.006 | Distance to the river | 0.448 | 2.234 |
| Plan curvature | 0.362 | 2.762 | NDVI | 0.545 | 1.835 |
| Profile curvature | 0.356 | 2.807 | Distance to the road | 0.781 | 1.280 |
| Distance to the fault | 0.791 | 1.264 | - | - | - |
| Number | |||||
|---|---|---|---|---|---|
| Model | |||||
| LR | 208 | 93 | 225 | 76 | |
| SVM | 210 | 91 | 227 | 74 | |
| GBDT | 218 | 83 | 232 | 69 | |
| RF | 217 | 84 | 240 | 61 | |
| Number | Before | After | Index | Before | After |
|---|---|---|---|---|---|
| 217 | 216 | 0.76 | 0.71 | ||
| 84 | 85 | 0.72 | 0.72 | ||
| 240 | 214 | 0.78 | 0.71 | ||
| 61 | 87 | 0.75 | 0.72 |
| Number | With | Without | Index | With | Without |
|---|---|---|---|---|---|
| 217 | 250 | 0.76 | 0.66 | ||
| 84 | 130 | 0.72 | 0.66 | ||
| 240 | 251 | 0.78 | 0.66 | ||
| 61 | 129 | 0.75 | 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, K.; Yang, S.; Wu, S.; Tong, B. Landslide Susceptibility Assessment Considering Spatial Agglomeration and Dispersion Characteristics: A Case Study of Bijie City in Guizhou Province, China. ISPRS Int. J. Geo-Inf. 2022, 11, 269. https://doi.org/10.3390/ijgi11050269
Yao K, Yang S, Wu S, Tong B. Landslide Susceptibility Assessment Considering Spatial Agglomeration and Dispersion Characteristics: A Case Study of Bijie City in Guizhou Province, China. ISPRS International Journal of Geo-Information. 2022; 11(5):269. https://doi.org/10.3390/ijgi11050269
Chicago/Turabian StyleYao, Kezhen, Saini Yang, Shengnan Wu, and Bin Tong. 2022. "Landslide Susceptibility Assessment Considering Spatial Agglomeration and Dispersion Characteristics: A Case Study of Bijie City in Guizhou Province, China" ISPRS International Journal of Geo-Information 11, no. 5: 269. https://doi.org/10.3390/ijgi11050269
APA StyleYao, K., Yang, S., Wu, S., & Tong, B. (2022). Landslide Susceptibility Assessment Considering Spatial Agglomeration and Dispersion Characteristics: A Case Study of Bijie City in Guizhou Province, China. ISPRS International Journal of Geo-Information, 11(5), 269. https://doi.org/10.3390/ijgi11050269