From this study and the analysis of the state-of-the-art research, we created an initial road map for experimentation and methods. The work can be divided into sections with the final goal being, with CDRs as input, to output a detailed table of routine areas and their classification.
4.1. CDR Pre-Processing
Pre-processing the dataset included retrieving and inferring additional data columns (e.g., the day of the week, workday/weekend) from the existing ones. This was intended to ease the detection of spatio-temporal patterns in the records. An integer for the day of the week (from 0 for Monday to 6 for Sunday) and a Boolean value for the workday or weekend (0 being a workday) were obtained from the timestamp columns. Furthermore, we adopted the time segment division found in [
22]. For each entry, taking the timestamp, we verified the corresponding interval. One day is divided into eight time segments to capture the intraday variations in activity participation: early morning (3–6 a.m.); morning—peak hour (6–9 a.m.); morning—work (9 a.m.–12 p.m.); noon (12–2 p.m.); afternoon—work(2–5 p.m.); afternoon—peak hour (5–8 p.m.); night (8 p.m.–12 a.m.); and midnight (12–3 a.m.) [
22].
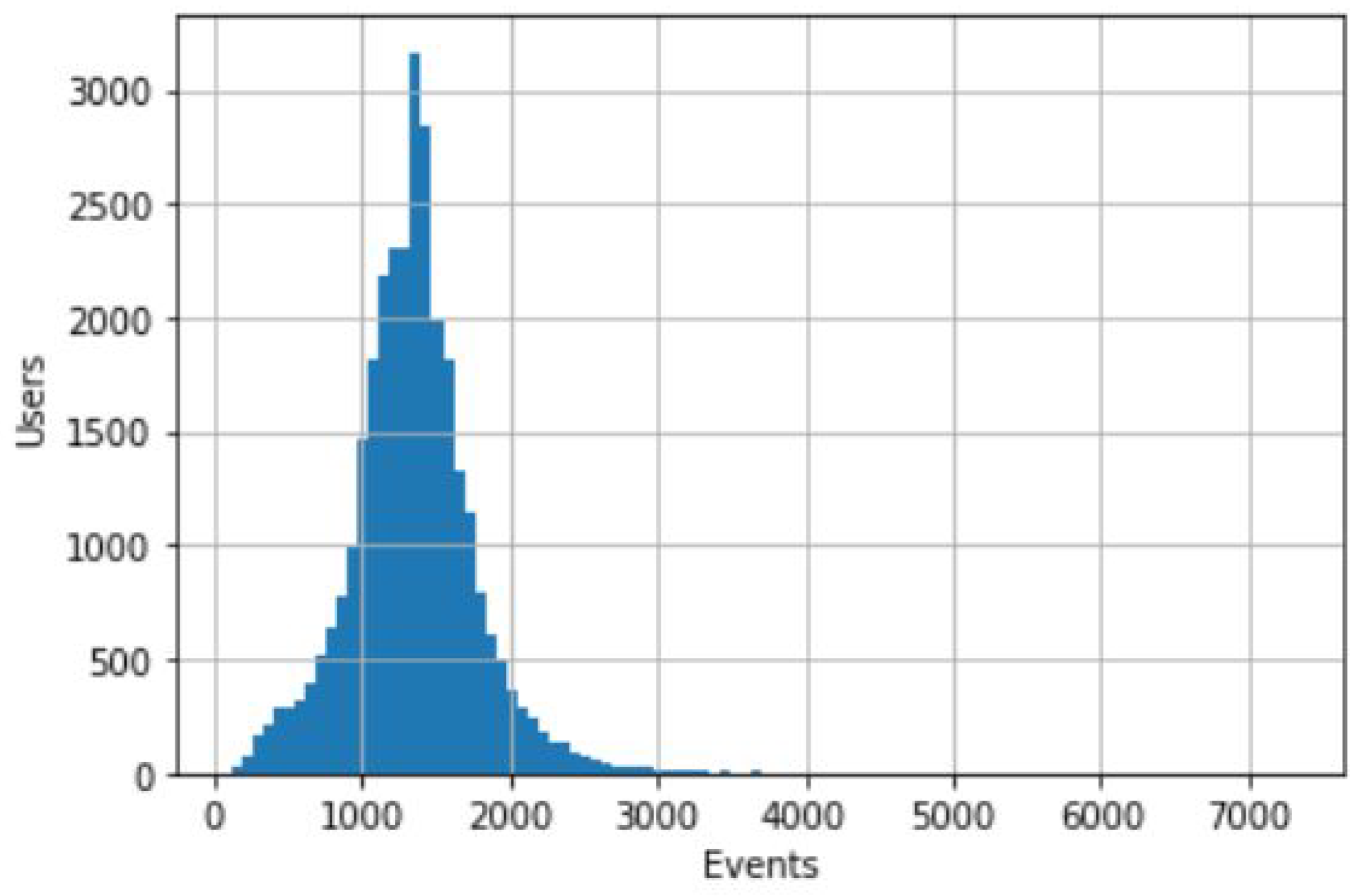
As seen by data exploration in the CDR data description section, there were some cases where users had a lower number of events than average—even those users with less than one event per day. As expected, these will add little to no information for our research purpose, since we seek a higher number of events in order to infer spatial patterns. Thus, we created a simple function that, taking as input an event threshold, filters out all users with a number of events below that threshold. For example, removing users with less than one event per day resulted in a reduction of 0.12% of the dataset or 25,858 unique events.
Another step was the detection of cellular tower reselection in the middle of calls, or in very quick succession, creating impossible trajectories when taking in account the speed of movement. This is due to automatic network load balancing, a phenomenon often called load sharing [
7]. With this in mind, distances between the network towers were computed and, consequently, the traveling speeds of users were estimated in consecutive records. For the detection of the load sharing effect, a speed-based method was implemented. A sequence is identified if the tower switching speed exceeds a given threshold. We set the value at 200 km/h inspired by the work of Iovan et al. [
27].
After these initial steps and before we could search for routine activity patterns, we needed an accurate identification of each user’s home and workplace locations. These are most likely the places where people spend the majority of their time and represent a large portion of their mobile records. Finding these locations first is important because it allows us to focus our attention on relevant records for our research of habits outside of these places. Thankfully this topic has been a subject of many prior studies and there are proven methods with good accuracy.
4.2. Home and Workplace Detection
Motivated by Vanhoof et al.’s work [
6], a mixed approach of time filtering and density-based clustering is proposed. Firstly, we selected the temporal intervals of search when someone is not likely to be found in the places we want to identify. In this case, the home time interval was defined as the period from 7 p.m. to 9 a.m. as per [
6]. However, because they did not try their method for workplace detection, we defined working hours as the period from 9 a.m. to 5 p.m., a common schedule of 8 h for day workers. Additionally, workplace CDRs were constrained to workdays. Given the state-of-the-art research, we opted for density-based spatial clustering, or DBSCAN, as per the works of [
7,
8]. DBSCAN is still to this day considered a competent algorithm for grouping CDRs and finding important areas. Its recurrent appearance throughout the literature supported our choice to use it our methodology.
After identifying and excluding homes and workplaces from the individual user’s data, we are left with the remaining locations. From these, we then need to understand which are the most relevant to the daily routine, i.e., the most visited ones that account for a substantial time expenditure.
4.3. Other Routine Locations
The chosen method to detect the home and workplace using DBSCAN could also be used to find other routine locations. Without the time restrictions of home/workplace hours and by keeping all the clusters, rather than highlighting the one with the most events, it would be a good candidate solution. The issue found with using this density-based clustering is that we would lose additional precision in pinpointing the exact user position. Antenna locations already have great uncertainty when it comes to matching the user position, and clusters consisting of several antennas would substantially increase the challenge. For routine locations, we want to retain the maximum precision possible. The larger the area, the more difficult it will be to match a specific activity.
Inspired by the work of Quadri et al’s [
10], which divided users’ locations in classes of importance with respect to the number of unique visit days, a similar approach was used. The three classes are: most visited places (MVPs), locations most frequently visited by the user; occasionally visited places (OVP), locations of interest for the user, but only visited occasionally; exceptionally visited places (EVP): non-routine places. To classify places in these classes, a relevance metric was calculated for each place in the user’s records. The initial relevance of a location
l for a certain user
u:
was calculated by the number of unique days that the user visited the location
over their total number of active days
. As our main goal is not only to detect routine locations but also to infer activities, the relevance metric was modified to accommodate the need for a time window and day type. We separated user places by coordinates, time interval and type of day (workday/weekend). The final metric for calculating the relevance of a location,
, is that presented in Equation
1. Instead of counting the unique days that the user visited location
l, we counted the unique days that the user visited
l in time interval
and type of day
d:
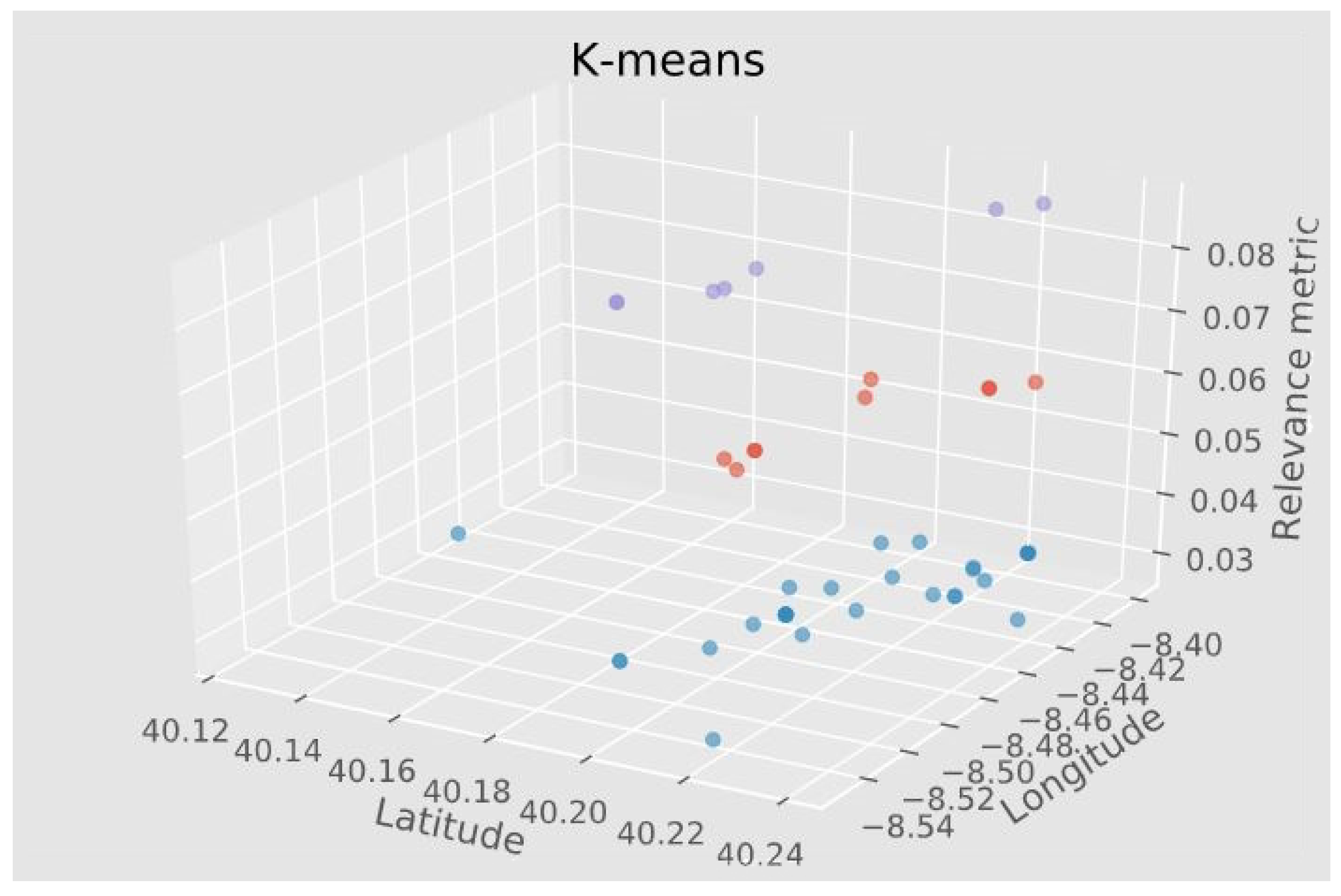
We used the calculated metric as input to a K-means clustering algorithm, this time with input value k = 3 to obtain the three distinct groups.
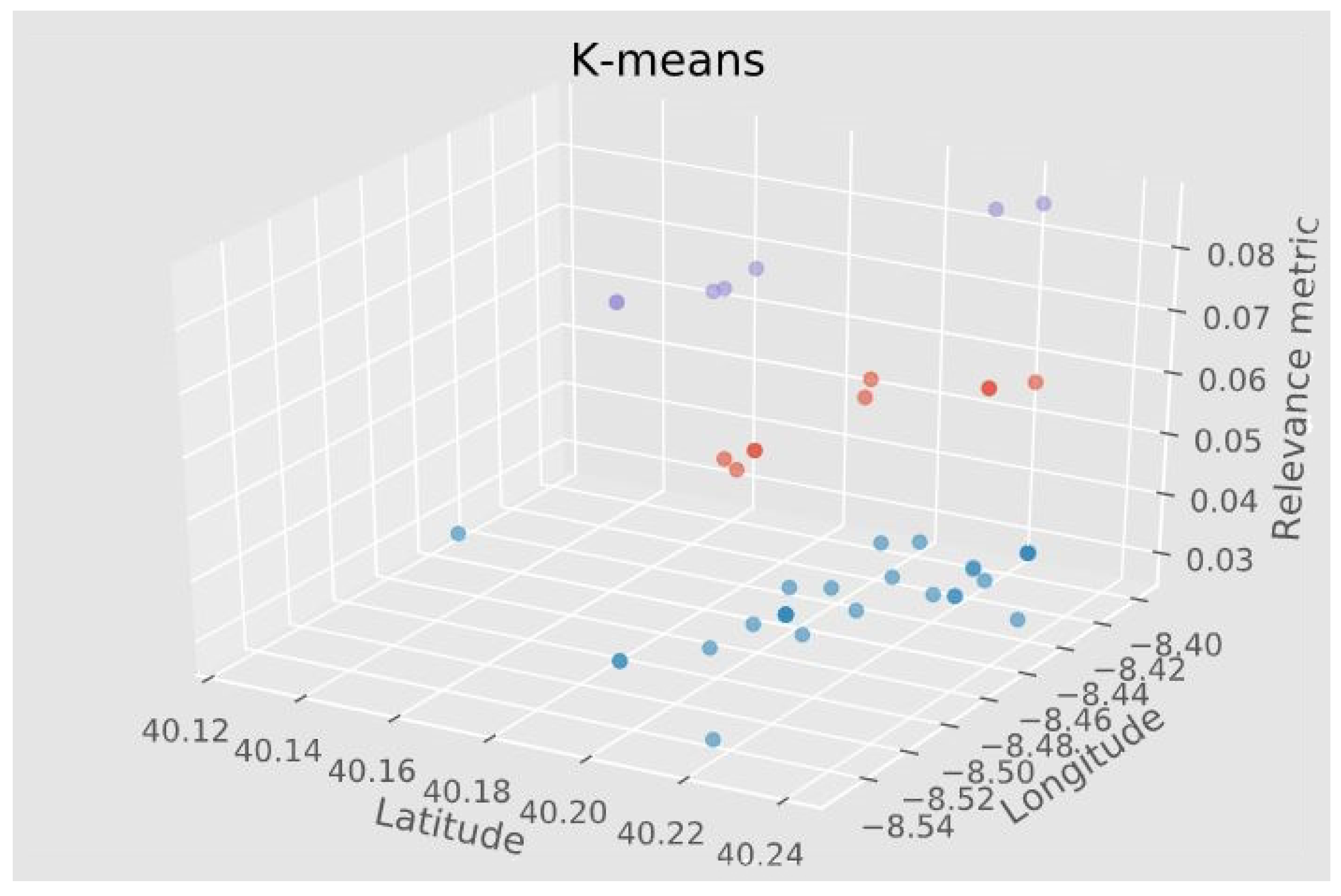
Figure 3, a 3D scatter plot, shows coordinate points clustering by the relevance metric for one selected person in the data. Note that the Z axis represents the relevance metric while the X and Y are latitude and longitude, respectively. Purple color coded point, with the highest relevance score are MVPs, with orange points being OVPs and blue points EVPs.
Exploration or holiday-related activities (EVPs) do not entail a significant pattern in the data to be considered and are not analyzed further. The idea is that excluding home and work, we find other frequently visited places including MVPs and OVPs, that have significant importance for each user.
4.4. Geographic Regions Classification
To provide better insight into the motivations behind the mobility, at this point, we opted to subdivide the study area and classify the resulting geographic regions with the most likely activity. This is an important step in order to obtain the user’s classified routine locations.
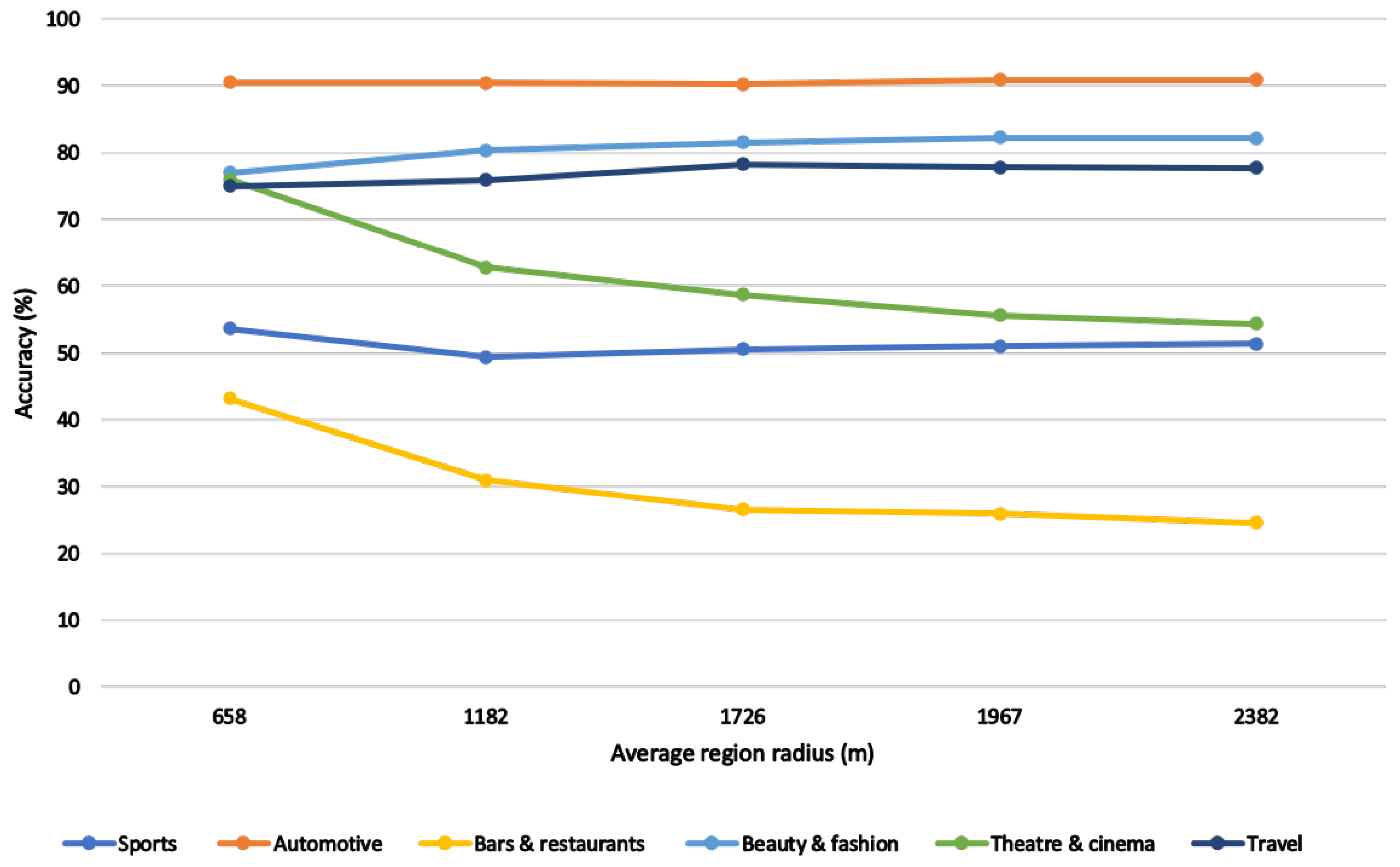
The selection of the regions is important as the size and shape can influence the final results. A slightly larger or differently shaped region can encompass more POIs, skewing the activity classification. We needed well-defined region boundaries that represented the search area in order for a function to return all contained POIs. Several approaches were considered, including fixed size ([
19,
20,
21,
22]) and dynamically sized [
23]; however, we proposed a new type of region for activity classification using the antenna’s signal attributes.
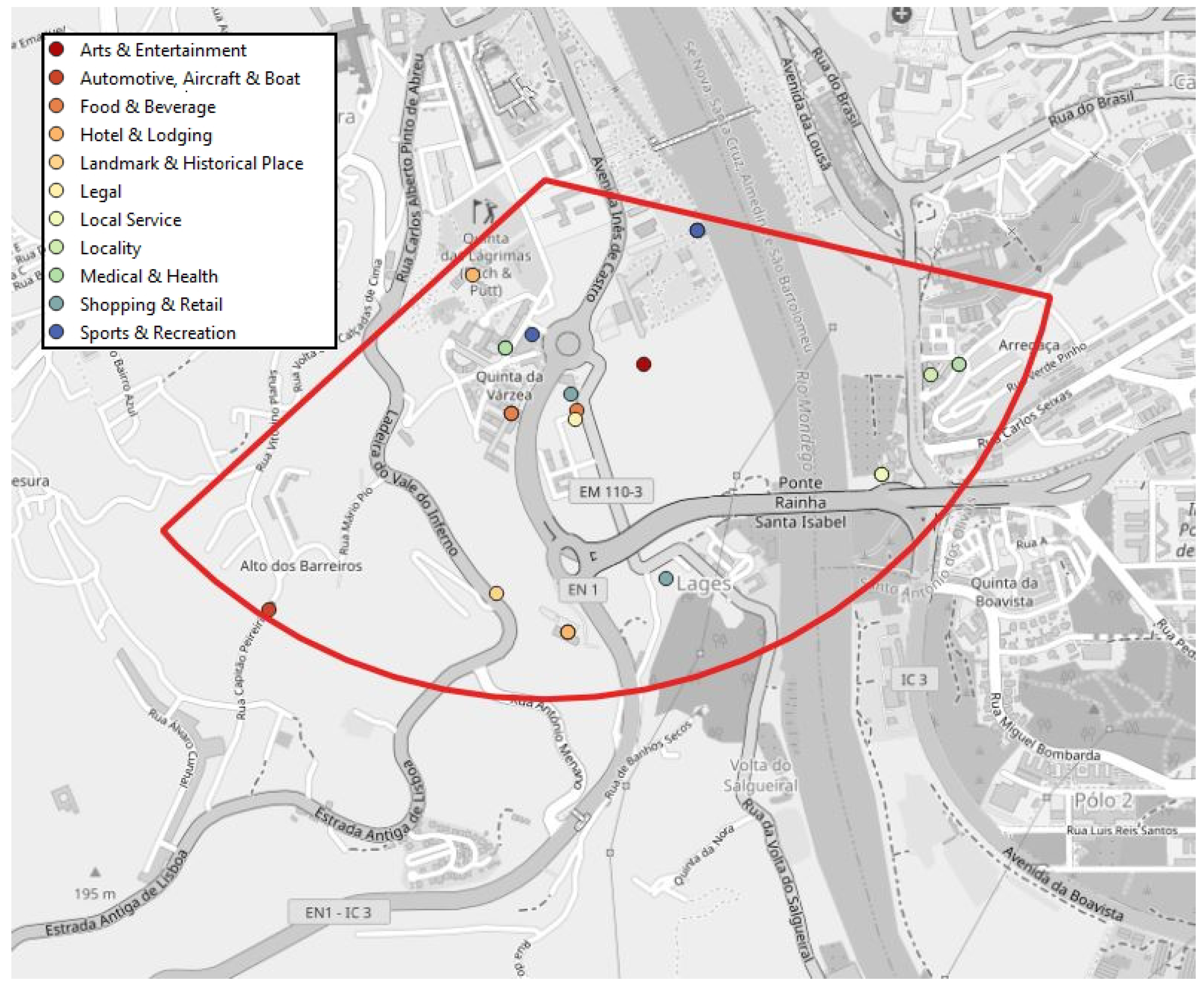
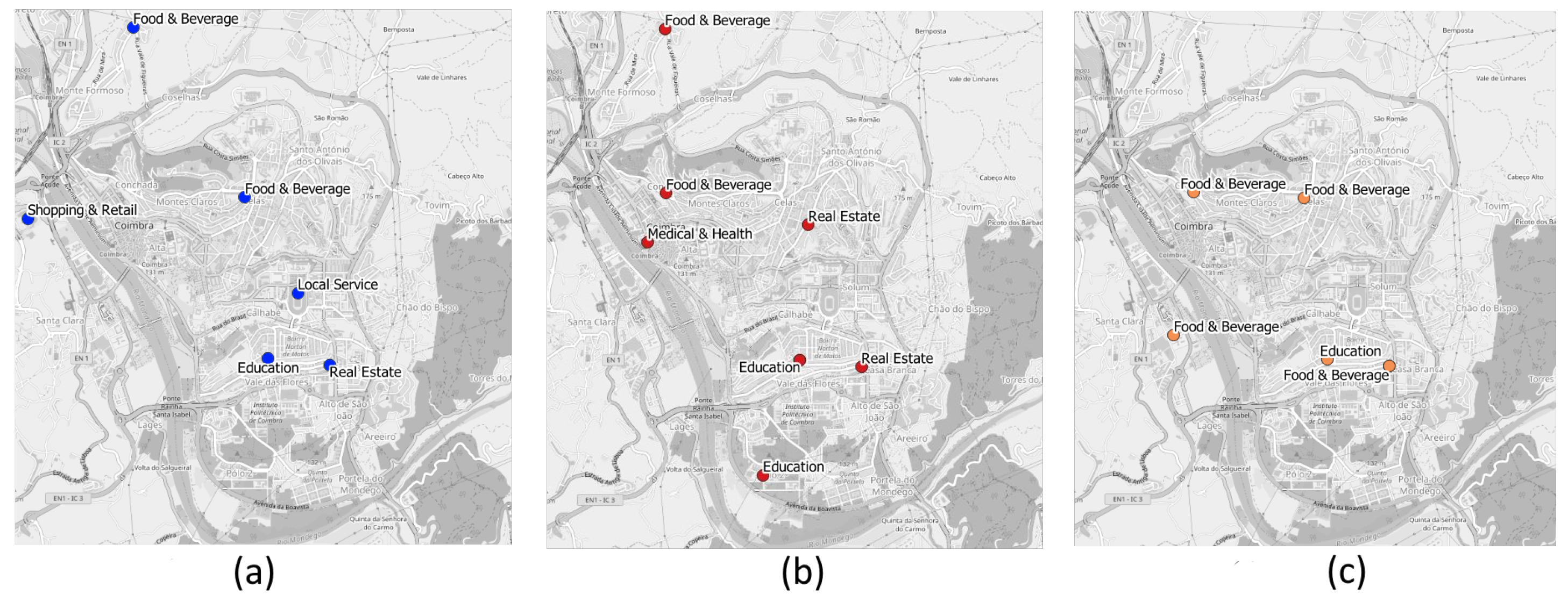
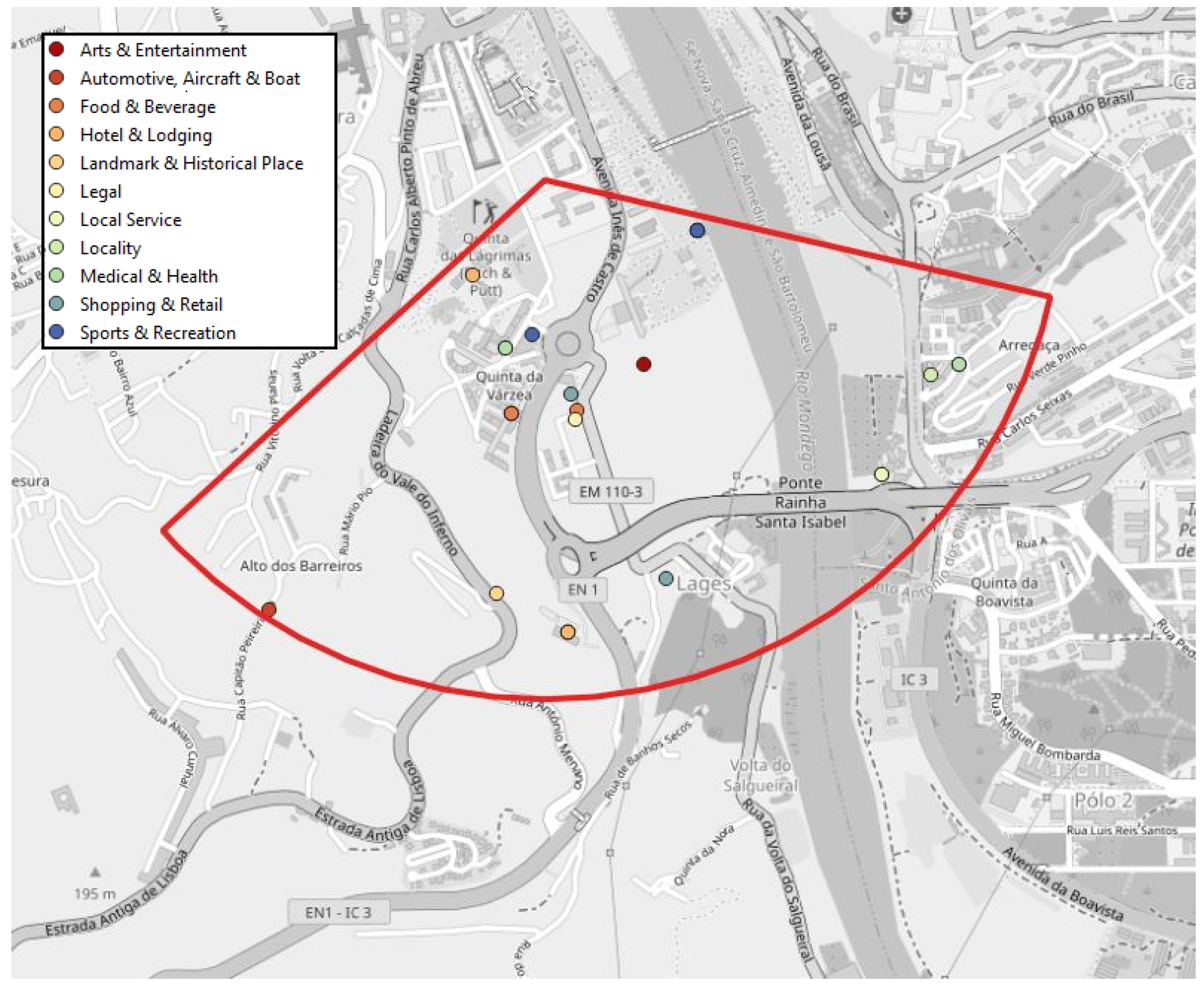
In our data, we accessed the values of the angle of coverage and the maximum expected range of each telecommunications antenna located in the study area. This resulted in the creation of circular sectors, corresponding to the antenna signal. In our understanding, these regions represent the user position with good estimation, as the user has to be within the boundaries of the signal range in order to connect to the corresponding antenna. Additionally, matching with the routine locations will be easier as these locations are also identified at the antenna level. The identified routine locations are associated with the antenna to which the user is connected, so we can infer that they must be within antenna’s signal. An example of an antenna signal area and contained POIs can be seen in
Figure 4.
It was necessary to use a specialized points of interest (POIs) dataset as the base data for the region POI mapping. We chose to use Facebook Places, a location-based social network (LSBN) that offers detailed information on 221,724 unique points spread over hundreds of categories of different hierarchies in Portugal [
26]. The main attributes of each POI are: the name, Cartesian coordinates, city, opening and closing hours for both workdays and weekends as well as bottom-level category, top-level category and number of check-ins. POIs positioning is defined by the Cartesian coordinates present in the Facebook Places dataset. Although large POIs could theoretically encompass more than one antenna’s signal, we only use a single pair of coordinates to infer its presence in those areas. An excerpt of the POI dataset can be seen in
Table 3.
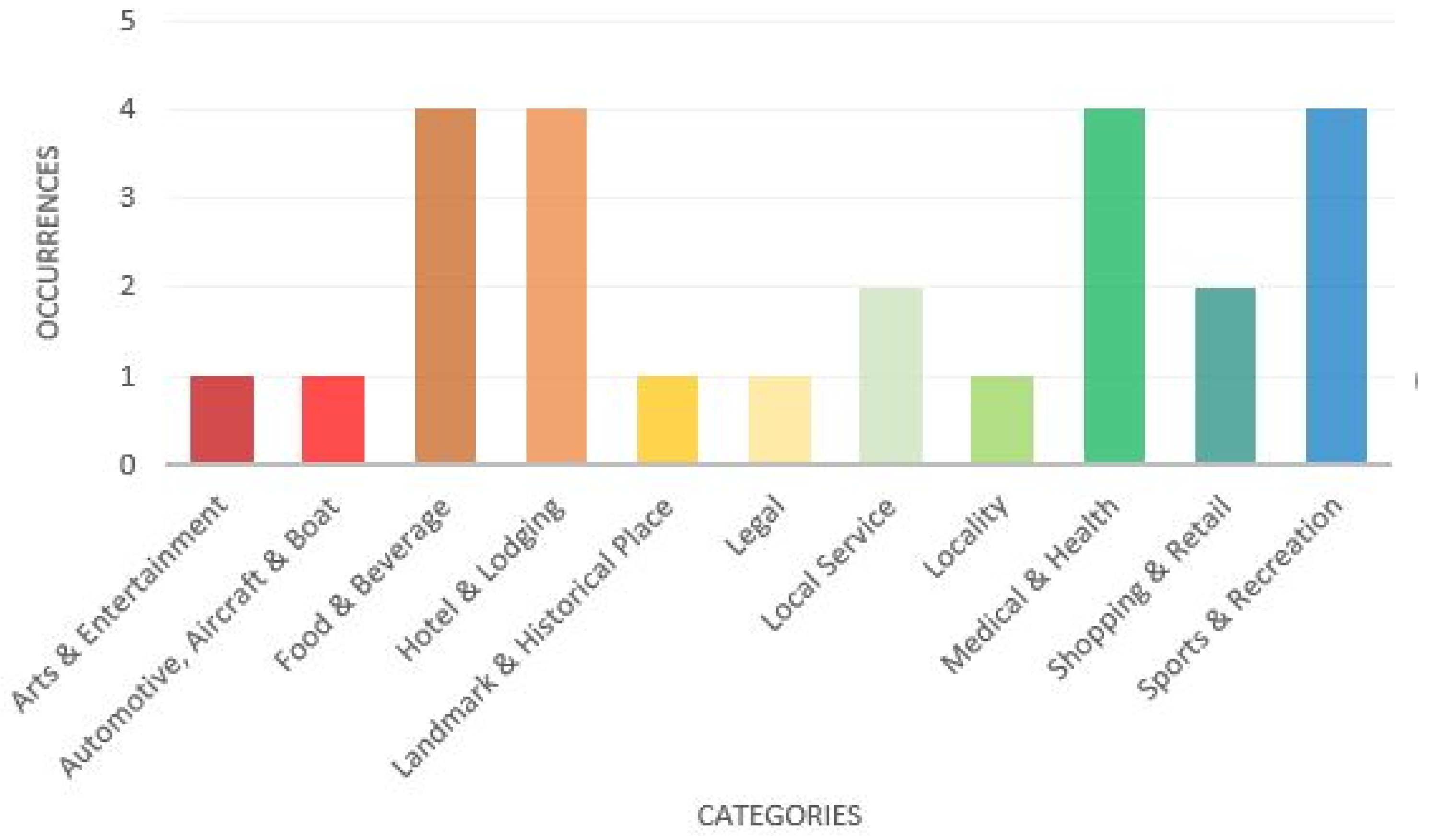
Running a search function on the POI dataset, we managed to obtain a table with all contained points and respective attributes for each region. To obtain the final output of the classified regions, we need to filter and extract some information from the POIs.
As previously mentioned, in the pre-processing phase, a field was created to divide the CDRs into eight time intervals, as the time of day was taken into account and having a limited number of possible times instead of a continuous timeline facilitates classification. This means that we could classify all regions, at each specific time interval, for each day type (workday/weekend). To filter the POIs, we created a function to check for an intersection between each time interval and the opening hours of each POI. Let symbolize the POI opening and closing hours and the CDRs time interval; the base rule is to find the cases in which x is in-between and the cases where a is in-between .
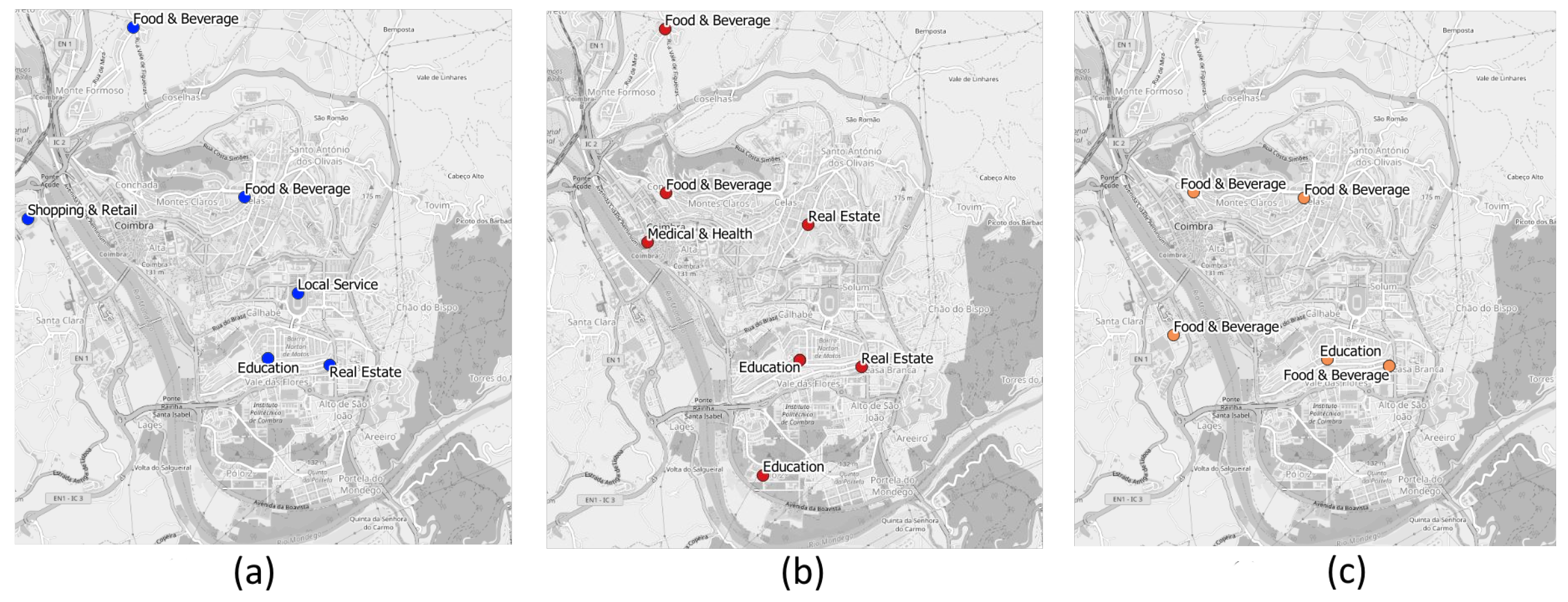
In our approach, we do not try to match the sparse user positioning with a single POI or a specific visit. We instead indicate the activity that the user is more exposed to in these locations, depending on the time of visitation and day of the week. Thus, we take into account the percentage of POIs of each category inside the area we are trying to classify. As such, the number of POIs is relevant but only when taking into account the relative percentage of a category when compared with the others. Our confidence measure for classification takes additional features such as opening hours and the popularity of each given POI. This also means that overlapping antennas should have the same activity for the same time periods and not affect the activity prediction for a user.
As points were already assigned to a category by the POI data source, we started by using those as our class labels. There is a problem, however. Lower level categories are sometimes over-specific and need to be grouped into broader classes to increase our chance of an accurate classification. For example, several types of restaurants (e.g., fast-food, Portuguese, Asian) can be grouped under one class label, food and beverage. This is the main reason why we decided to reclassify each POI according to the higher-level Facebook Places categories.
There was still one more value present in the POIs dataset that we could use in the hope of improving results, namely the number of check-ins. A check-in is a user registration of their presence in the location via a social network. As this value is related to the popularity of a given location, it could be inserted into the classification as a weight applied to that class.
From the region POI table, we counted the number of POIs from each label
l. Those individual values were then divided by the total number of POIs in the region
R, giving us a new area table with the label’s percentage. In addition, for each class label
l in region
R, we sum the number of check-ins and then divided the individual results by the total number of check-ins in the region
R. A new column was then added with this percentage to the existing table as can be seen in
Table 4. To use both values in the calculation, we multiply the label percentage by the label check-ins to obtain our metric for classification. The resulting equation is written in Equation (
2):
Once we had the regions classified, including all time intervals and day possibilities, we reached the final step where we merged this information with the previous step. The matching key was the corresponding antenna identifier, the cell id. This identifier is present in both the region classification table, because regions are associated with an antenna, as well as the identified routine locations. From this merge, we can have a good idea of the user’s routine patterns throughout the day, during workdays and weekends.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}