
Development of Big Data-Analysis Pipeline for Mobile Phone Data with Mobipack and Spatial Enhancement


Abstract
:1. Introduction
- How can a large-scale data platform that requires efficient resource allocation for managing data be built as well as used and maintained in a sustainable manner, given that collecting up-to-date data on populations is a challenge in developing countries?
- How can we help enhance the capacity of CDR data analysis, which requires a specific skill set and is time-intensive to implement, if we desire to start from scratch where human resources are limited?
2. Call Detail Record (CDR) Data
2.1. Data Components
2.2. Data Representativeness
2.3. Spatial Granularity
2.4. Data Frequency
3. Concepts and Related Work
3.1. Data Pipeline
3.2. Large-Scale Data Platform
3.2.1. Apache Hadoop
3.2.2. Apache Spark and Databricks
3.3. Existing Open-Source Analytical Tools
3.3.1. The WB COVID-19 Mobility Indicator
3.3.2. FlowKit
4. Materials and Methods
4.1. Key Requirements
- The data pipeline comprises data acquisition, data recording, data pre-processing with cleaning, data processing with integration, data analysis with an analytics model, and data interpretation with visualization [26].
- The data requirements and data formats are clearly defined to ensure a standardized system that can be replicated by any country and run on an operational basis [13].
- The details of the recommended hardware and software specifications are provided [13].
- A large-scale platform that can accommodate huge datasets with scalability support and minimum effort to scale is necessary.
- The system covers all processes, starting from raw data to the output of indicators that can be utilized by other research groups/domains [12].
- The system includes analysis software with algorithms that are ready to use and able to run on large-scale platforms with parallel processing to minimize the processing time on huge datasets.
- The system is cost-effective and requires no license to enable CDR analysis capability in developing countries [13].
- The system supports spatial-related operations such as finding distances between coordinates or identifying boundaries on which points are located. These kinds of functions are typically used in the analyses [37].
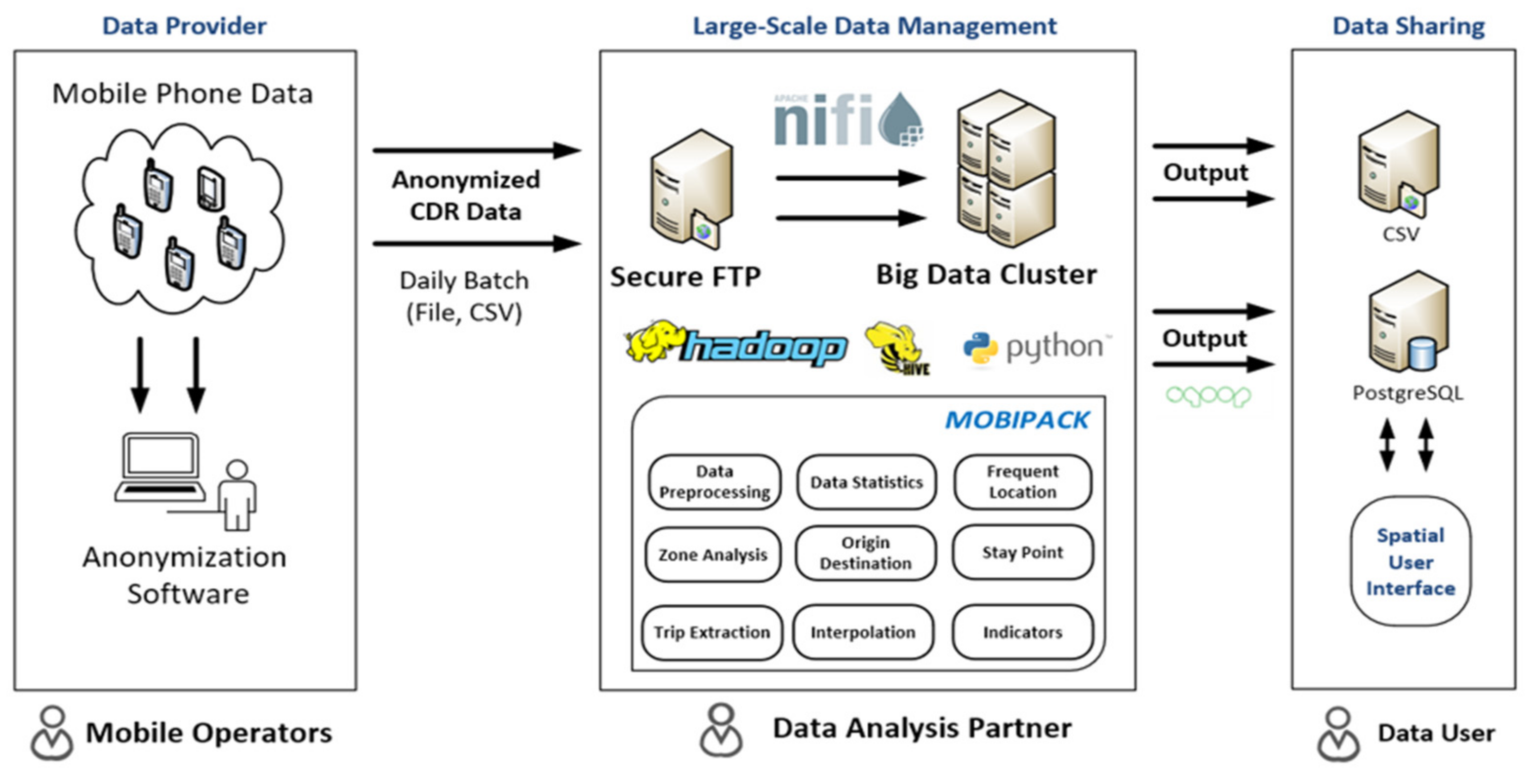
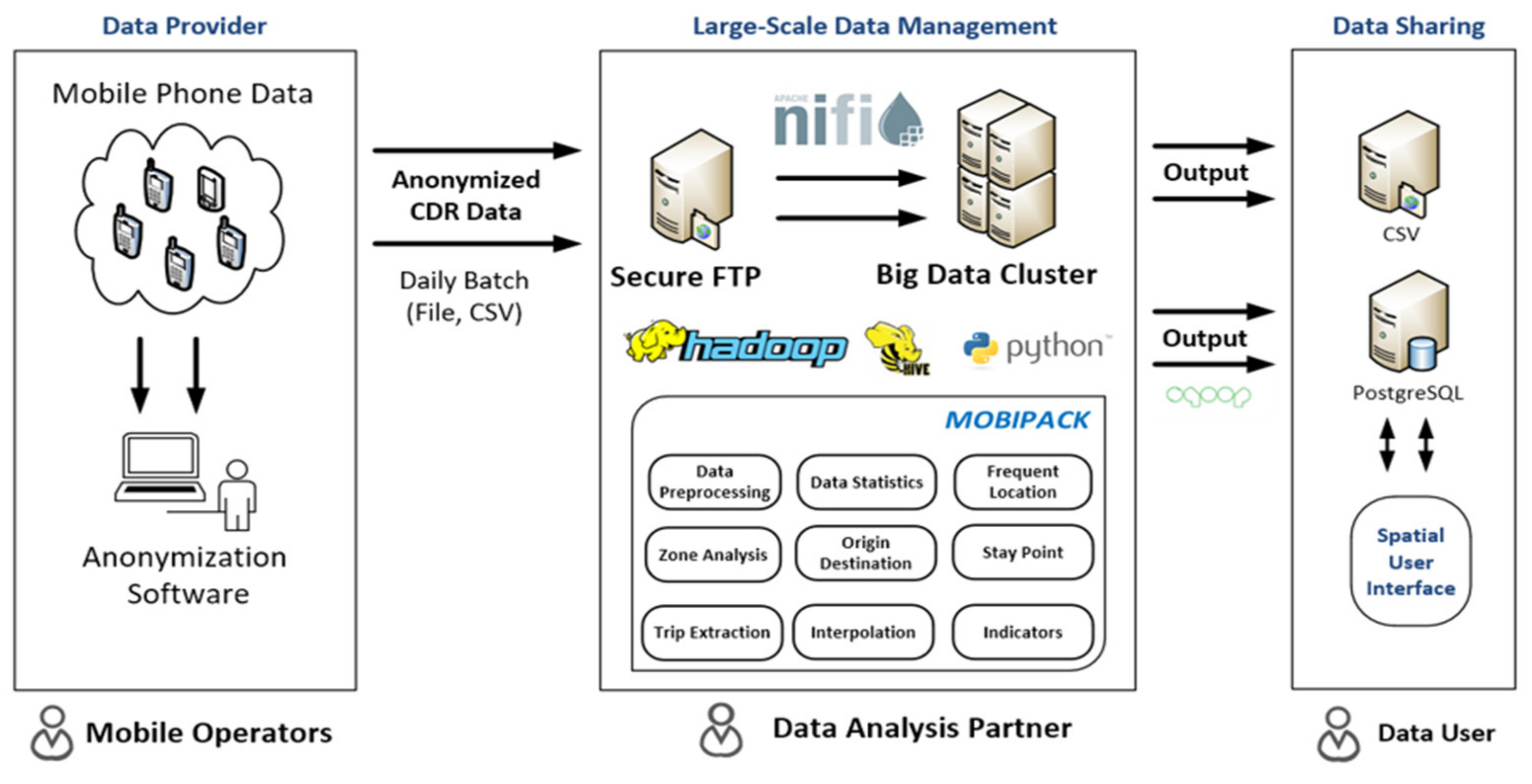
4.2. An Overview of the Data Analytics Pipeline
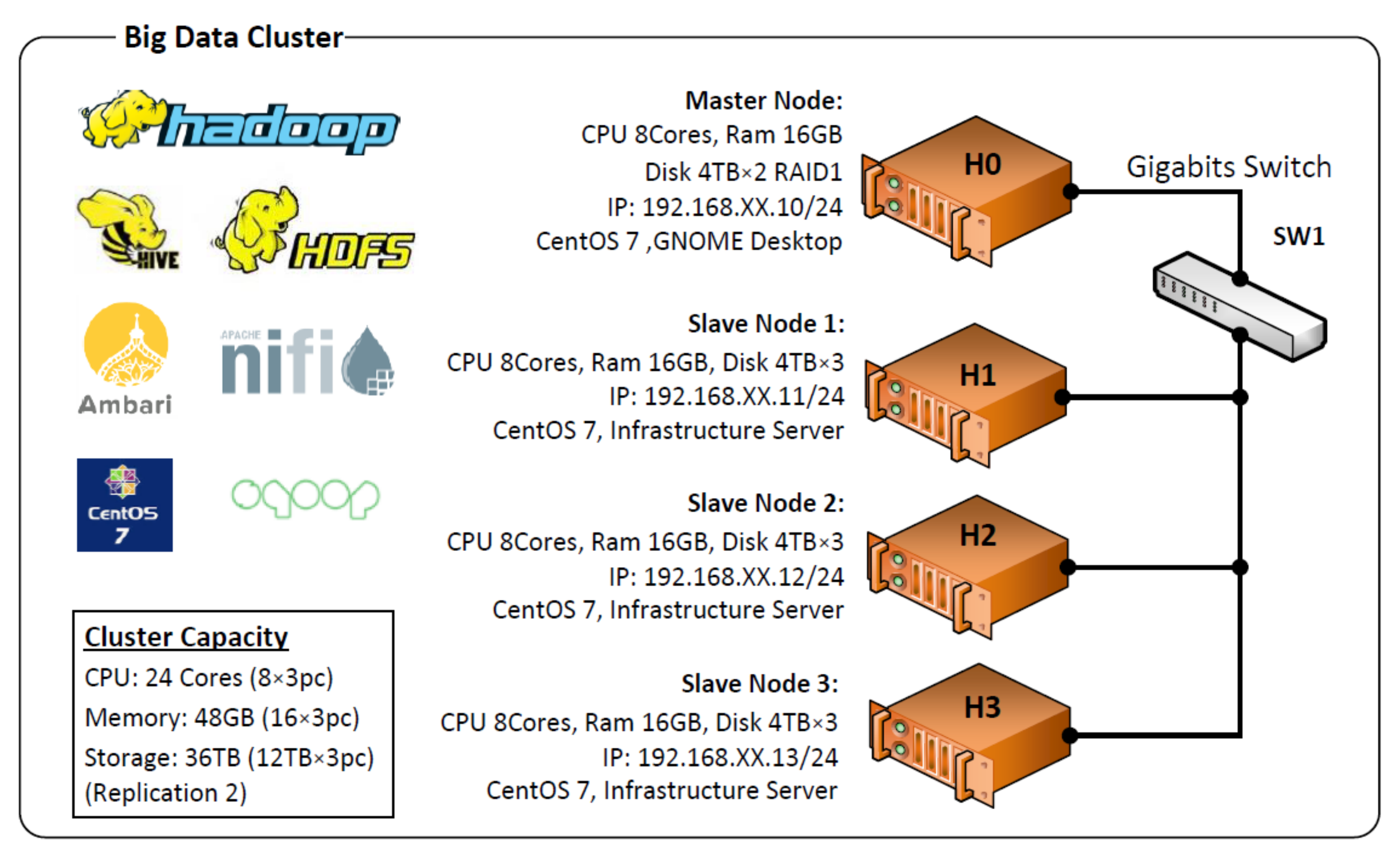
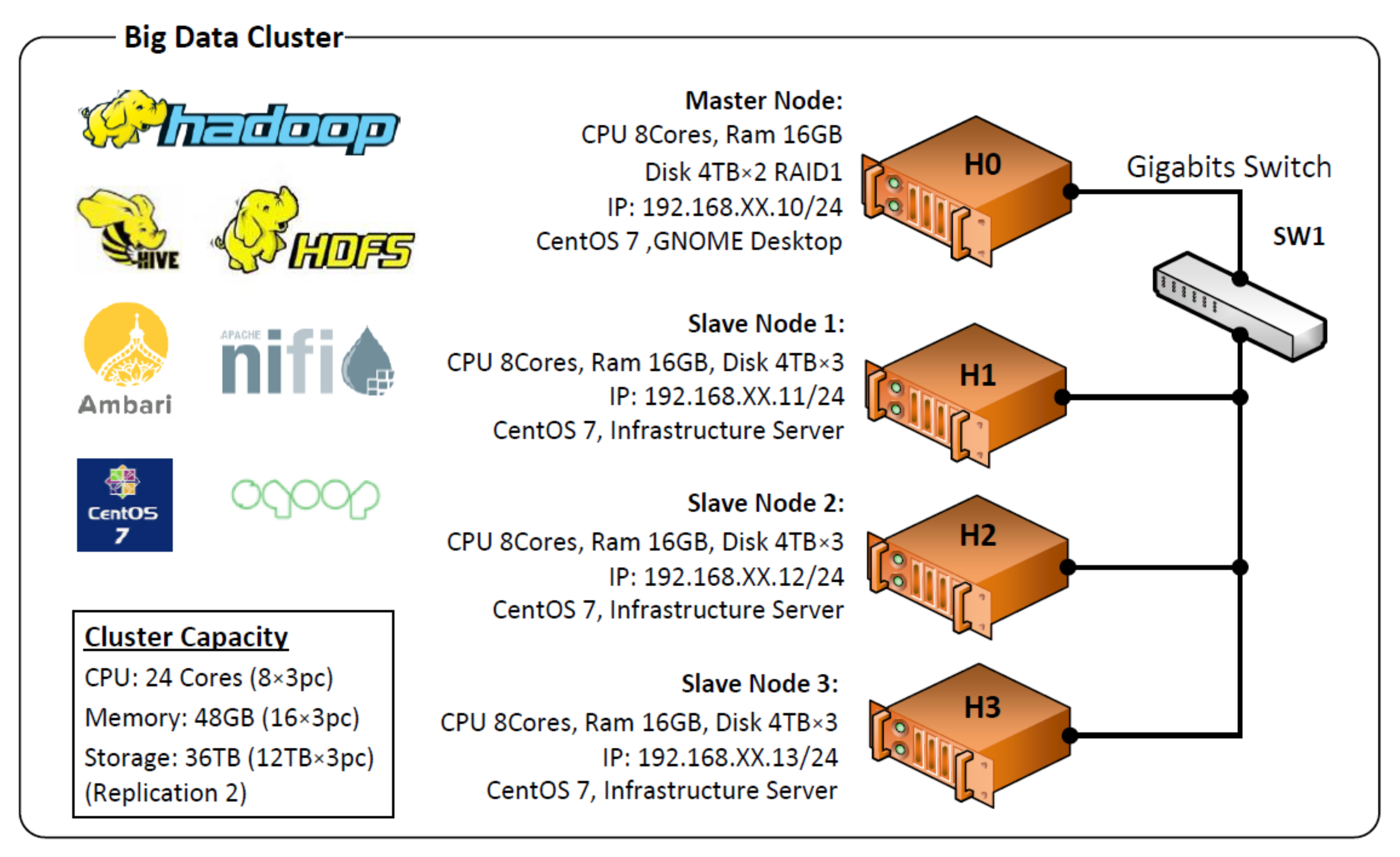
4.3. Big Data Cluster
4.4. An Analysis Tool: Mobipack
4.4.1. Anonymization Software
4.4.2. Cell Tower Mapping Tool
4.4.3. Statistical Data for Quality Assurance
4.4.4. Frequent Locations
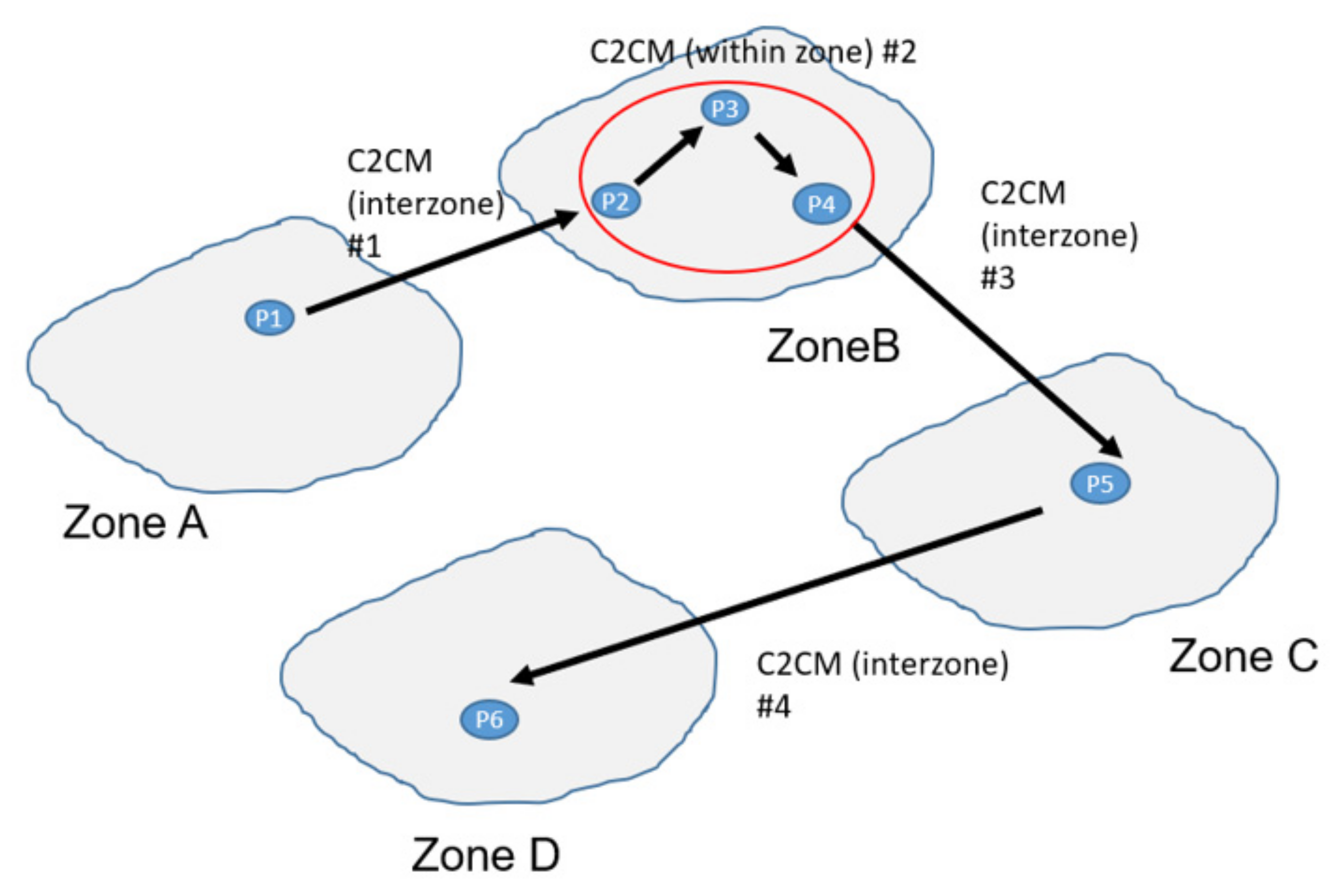
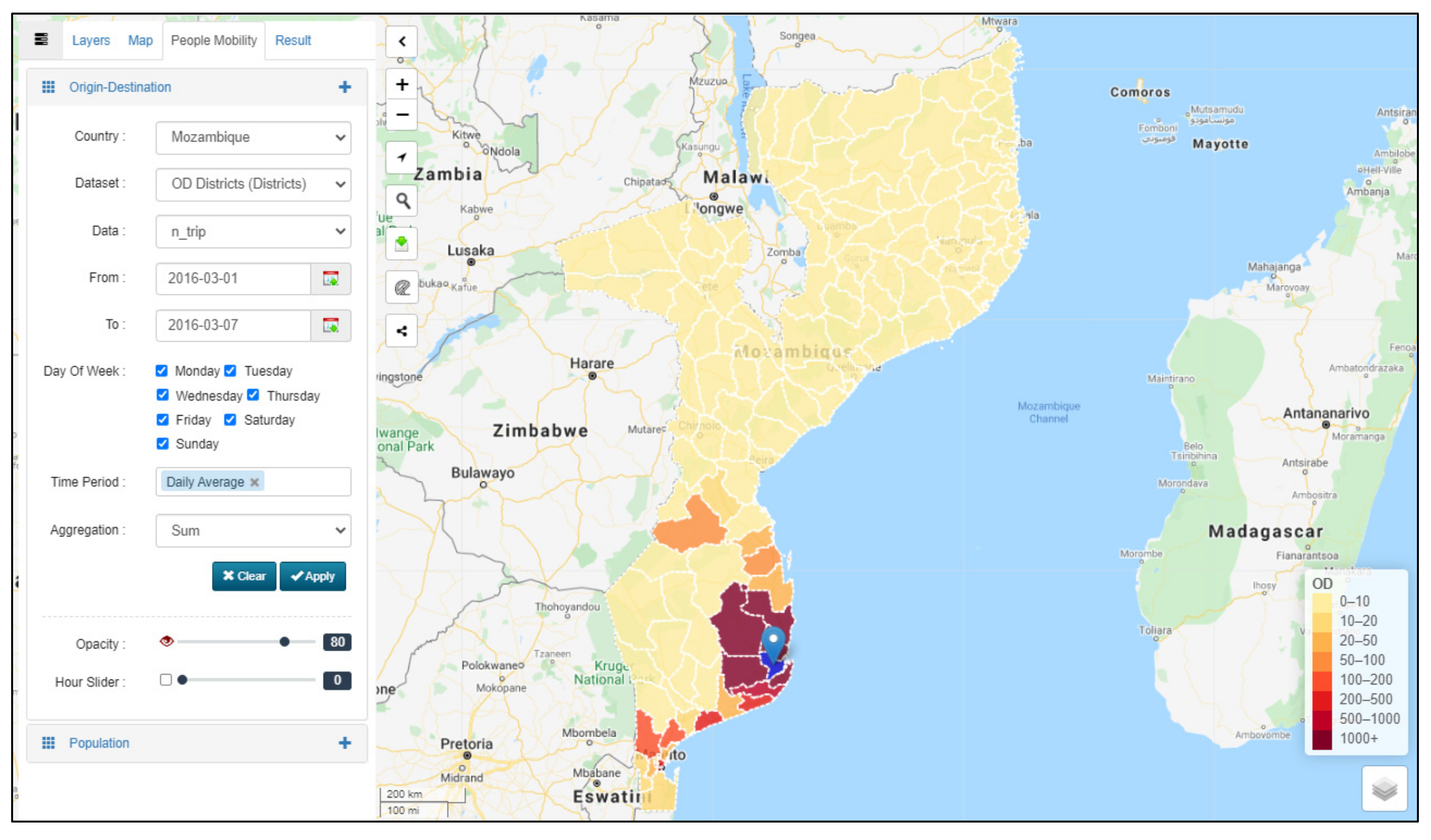
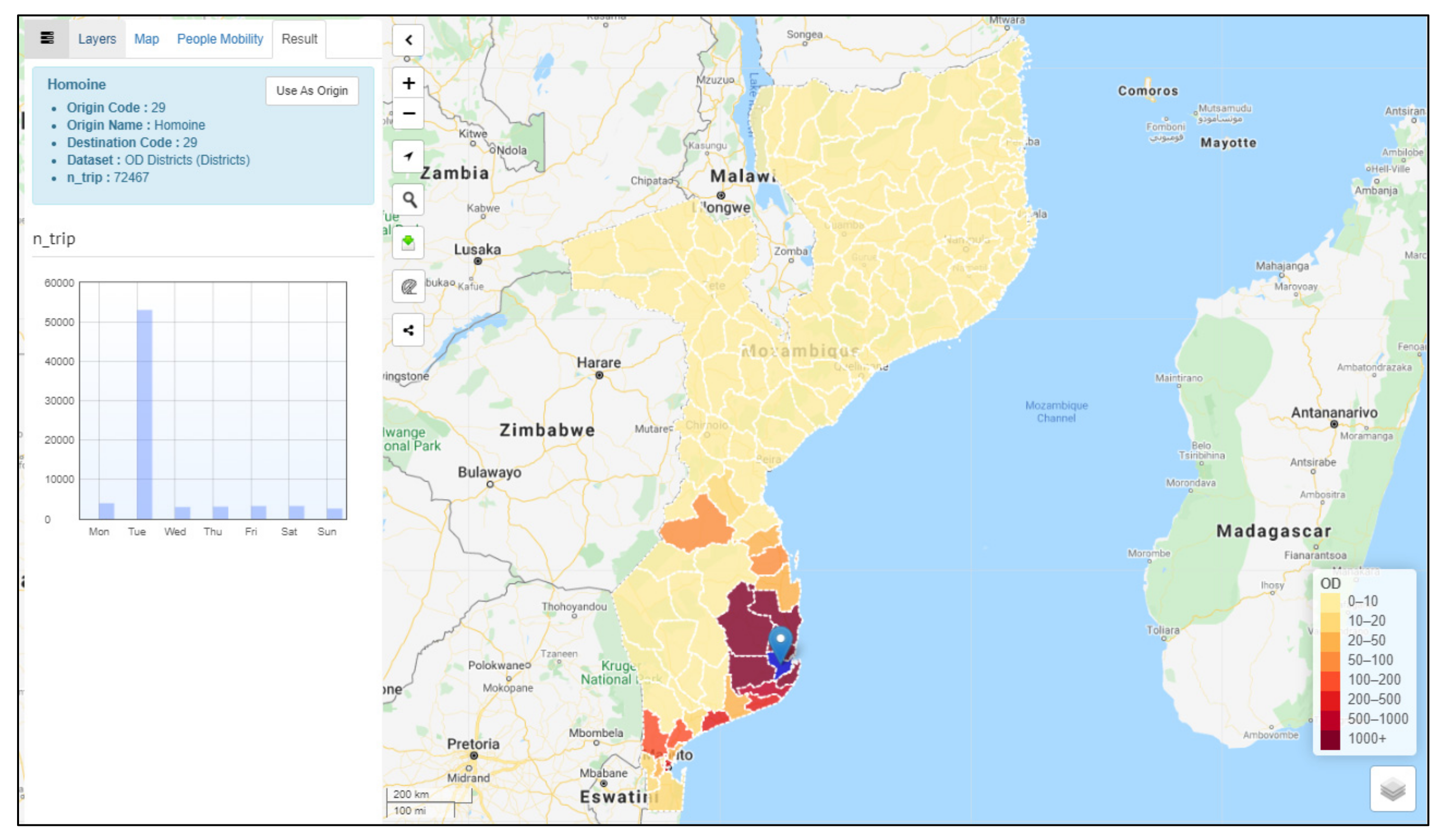
4.4.5. Origin–Destination
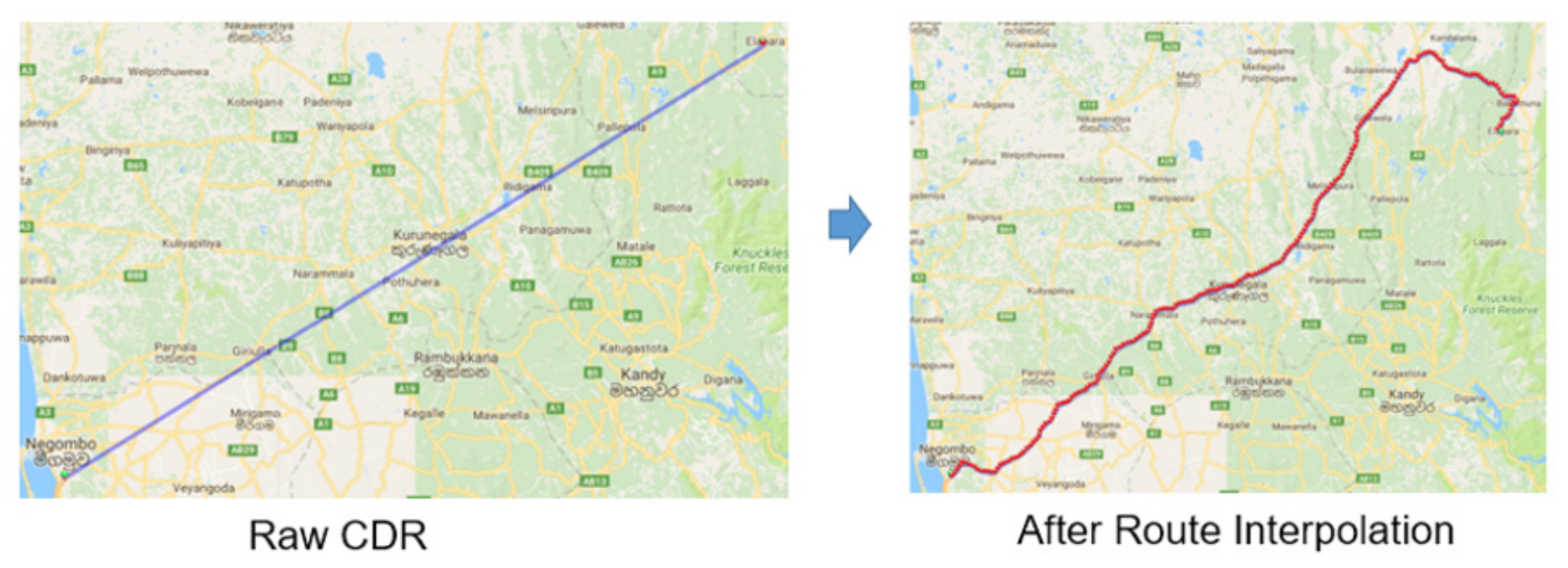
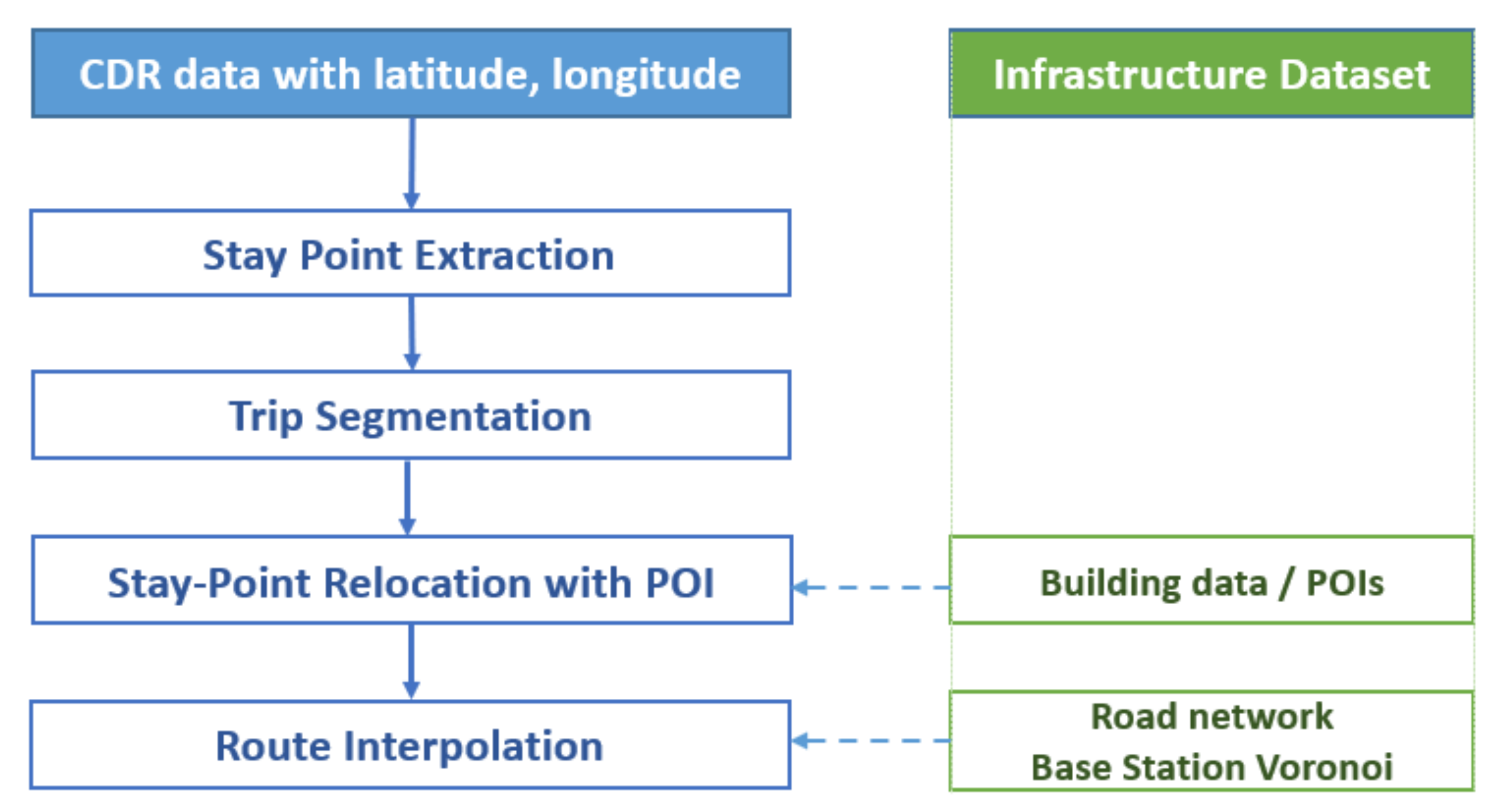
4.4.6. Route Interpolation
4.4.7. Indicator Series: Mobility Indicators
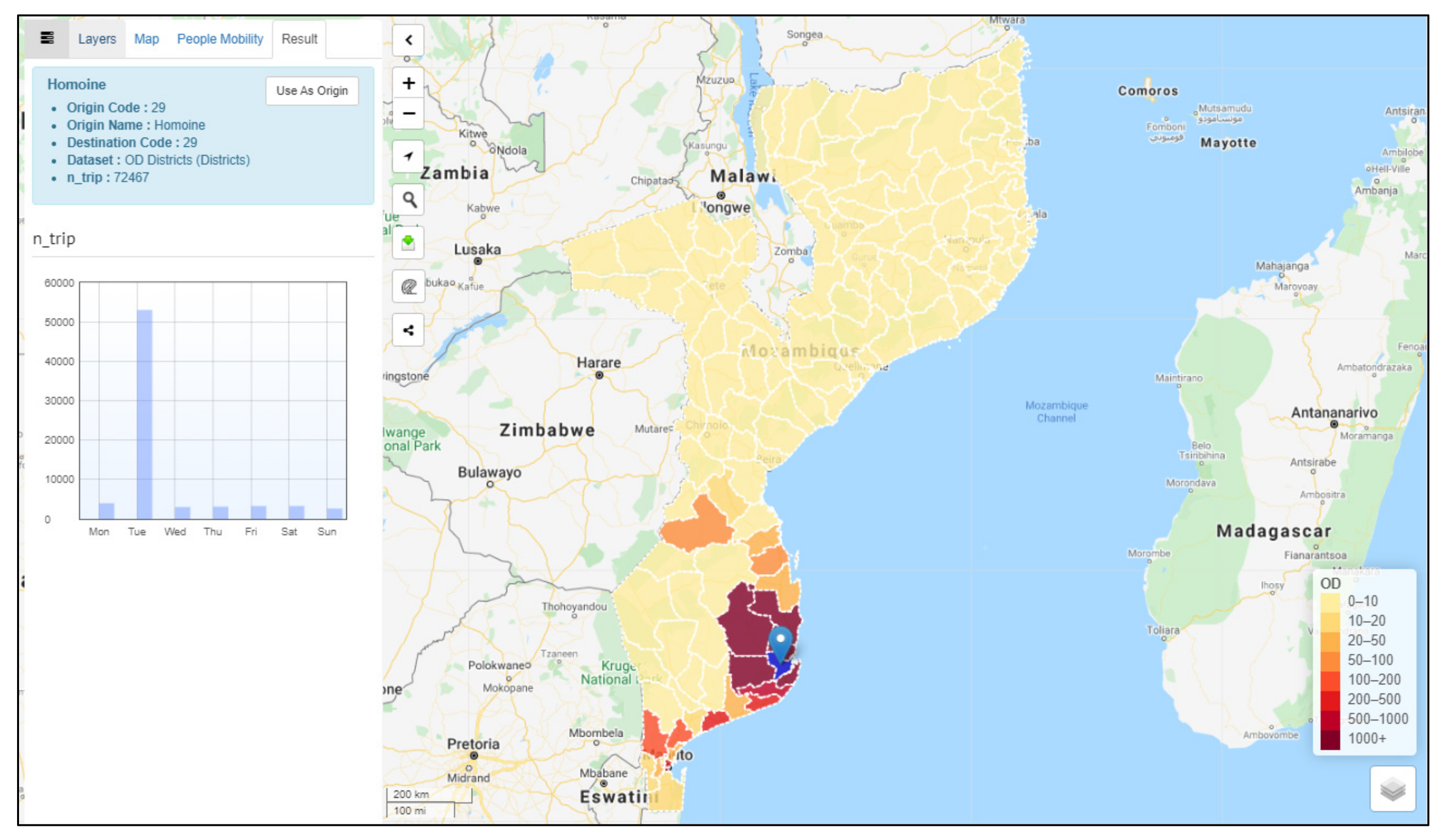
4.5. Visual Analytics Toolset
5. Results and Discussion
5.1. System Implementation and Scalability
5.2. Performance Evaluation
5.3. Comparison with the Existing Platforms
5.4. Model Limitation
5.5. Usefulness and Applied Use Cases
5.6. Challenges of CDR Data
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gomez, T.P.; Lokanathan, S. Leveraging big data to support measurement of the sustainable development goals. SSRN Electron. J. 2017, 1, 1–14. [Google Scholar] [CrossRef]
- Kishore, N.; Kiang, M.V.; Engø-Monsen, K.; Vembar, N.; Schroeder, A.; Balsari, S.; Buckee, C.O. Measuring mobility to monitor travel and physical distancing interventions: A common framework for mobile phone data analysis. Lancet Digit. Health 2020, 2, E622–E628. [Google Scholar] [CrossRef]
- ITU. Measuring Digital Development: Facts and Figures 2020; ITU Publication: Geneva, Switzerland, 2020. [Google Scholar]
- Olle, J.; Rein, A.; Frank, W. Understanding monthly variability in human activity spaces: A twelve-month study using mobile phone call detail records. Transp. Res. Part C: Emerg. Technol. 2014, 38, 122–135. [Google Scholar]
- Rien, A.; Anto, A.; Antti, R.; Ülar, M.; Siiri, S. Evaluating passive mobile positioning data for tourism surveys: An Estonian case study. Tour. Manag. 2008, 29, 469–486. [Google Scholar]
- González, M.C.; Hidalgo, C.A.; Barabási, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef]
- United Nations. The Sustainable Development Goals Report 2020; United Nations Publications: New York, NY, USA, 2020. [Google Scholar]
- UN Global Working Group on Big Data for Official Statistics. Handbook on the Use of Mobile Phone Data for Official Statistics; United Nations Publications: New York, NY, USA, 2019. [Google Scholar]
- Bachir, D.; Khodabandelou, G.; Gauthier, V.; Yacoubi, M.E.; Puchinger, J. Inferring dynamic origin-destination flows by transport mode using mobile phone data. Transp. Res. Part C Emerg. Technol. 2019, 101, 254–275. [Google Scholar] [CrossRef] [Green Version]
- Buckee, C.O.; Wesolowski, A.; Eagle, N.N.; Hansen, E.; Snow, R.W. Mobile phones and malaria: Modeling human and parasite travel. Travel Med. Infect. Dis. 2013, 11, 15–22. [Google Scholar] [CrossRef] [Green Version]
- Bengtsson, L.; Lu, X.; Thorson, A.; Garfield, R.; Schreeb, J.V. Improved response to disasters and outbreaks by tracking population movements with mobile phone network data: A post-earthquake geospatial study in Haiti. PLoS Med. 2011, 8, e1001083. [Google Scholar] [CrossRef]
- Ronald, J.; Kovacs, K.; Esko, S.; Saluveer, E.; Sõstra, K.; Bengtsson, L.; Li, T.; Adewole, W.A.; Nester, J.; Arai, A.; et al. Guiding Principles to Maintain Public Trust in the Use of Mobile Operator Data for Policy Purposes. Data Policy 2021, 3, E24. [Google Scholar] [CrossRef]
- Milusheva, S.; Lewin, A.; Gomez, T.B.; Matekenya, D.; Reid, K. Challenges and opportunities in accessing mobile phone data for COVID-19 response in developing countries. Data Policy 2021, 3, e20. [Google Scholar] [CrossRef]
- Ayumi, A.; Witayangkurn, A.; Kanasugi, H.; Fan, Z.; Ohira, W.; Cumbane, S.P.; Shibasaki, R. Building a data ecosystem for using telecom data to inform the COVID-19 response effort. In Proceedings of the 5th International Data for Policy Conference 2020, London, UK, 15–17 September 2020. [Google Scholar]
- Flowminder. FlowKit. Available online: https://github.com/Flowminder/FlowKit (accessed on 1 August 2021).
- The COVID19 Mobility Task Force. COVID-Mobile-Data. Available online: https://github.com/worldbank/covid-mobile-data (accessed on 1 August 2021).
- Wesolowski, A.; Eagle, N.; Noor, A.M.; Snow, R.W.; Buckee, C.O. The impact of biases in mobile phone ownership on estimates of human mobility. J. R. Soc. Interface 2013, 10, 20120986. [Google Scholar] [CrossRef] [PubMed]
- Couper, M.P. Is the sky falling? New technology, changing media, and the future of surveys. Surv. Res. Methods 2013, 7, 145–156. [Google Scholar]
- Deville, P.; Linard, C.; Martin, S.; Gilbert, M.; Stevens, F.R.; Gaughan, A.E.; Tatem, A.J. Dynamic population mapping using mobile phone data. Proc. Natl. Acad. Sci. USA 2014, 111, 15888–15893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Sui, Z.; Kang, C.; Gao, Y. Uncovering patterns of inter-urban trip and spatial interaction from social media check-in data. PLoS ONE 2014, 9, e86026. [Google Scholar] [CrossRef]
- Rein, A.; Siiri, S.; Olle, J.; Erki, S.; Margus, T. Using Mobile Positioning Data to Model Locations Meaningful to Users of Mobile Phones. J. Urban Technol. 2010, 17, 3–27. [Google Scholar]
- Wilson, R.; Erbach-Schoenberg, E.Z.; Albert, M.; Power, D.; Tudge, S.; Gonzalez, M.; Bengtsson, L. Rapid and near real-time assessments of population displacement using mobile phone data following disasters: The 2015 Nepal earthquake. PLoS Curr. 2016, 8. [Google Scholar] [CrossRef]
- Liu, J.; Braun, E.; Düpmeier, C.; Kuckertz, P.; Ryberg, D.S.; Robinius, M.; Hagenmeyer, V. Architectural concept and evaluation of a framework for the efficient automation of computational scientific work flows: An energy systems analysis example. Appl. Sci. 2019, 9, 728. [Google Scholar] [CrossRef] [Green Version]
- Isah, H.; Zulkernine, F. A Scalable and Robust Framework for Data Stream Ingestion. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 2900–2905. [Google Scholar]
- Liu, J.; Braun, E.; Dupmeier, C.; Kuckertz, P.; Ryberg, D.S.; Robinius, M.; Hagenmeyer, V. A Generic and Highly Scalable Framework for the Automation and Execution of Scientific Data Processing and Simulation Workflows. In Proceedings of the IEEE 15th International Conference on Software Architecture, Seattle, WA, USA, 30 April–4 May 2018; pp. 145–155. [Google Scholar]
- Sebei, H.; Taieb, M.A.H.; Aouicha, M.B. Review of social media analytics process and Big Data pipeline. Soc. Netw. Anal. Min. 2018, 8, 30. [Google Scholar] [CrossRef]
- Pervaiz, F.; Vashistha, A.; Anderson, R. Examining the challenges in development data pipeline. In Proceedings of the 2019 Conference on Computing and Sustainable Societies, Accra, Ghana, 3–5 July 2019; pp. 13–21. [Google Scholar]
- Omidvar-Tehrani, B.; Amer-Yahia, S. Data pipelines for user group analytics. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Amsterdam, the Netherlands, 30 June–5 July 2019; pp. 2048–2053. [Google Scholar]
- Misale, C.; Drocco, M.; Tremblay, G.; Martinelli, A.R.; Aldinucci, M. PiCo: High-performance data analytics pipelines in modern C++. Future Gener. Comput. Syst. 2018, 87, 392–403. [Google Scholar] [CrossRef] [Green Version]
- Aung, T.; Min, H.Y.; Maw, A.H. Performance Evaluation for Real-Time Messaging System in Big Data Pipeline Architecture. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Zhengzhou, China, 18–20 October 2018; pp. 198–204. [Google Scholar]
- Yang, J.; Dash, M.; Teo, S.G. PPTPF: Privacy-Preserving Trajectory Publication Framework for CDR Mobile Trajectories. ISPRS Int. J. Geo-Inf. 2021, 10, 224. [Google Scholar] [CrossRef]
- Abdallah, H.S.; Khafagy, M.H.; Omara, F.A. Case study: Spark GPU-enabled framework to control COVID-19 spread using cell-phone spatio-temporal data. Computers. Mater. Contin. 2020, 65, 1303–1320. [Google Scholar] [CrossRef]
- Qin, S.; Man, J.; Wang, X.; Li, C.; Dong, H.; Ge, X. Applying Big Data Analytics to Monitor Tourist Flow for the Scenic Area Operation Management. Discret. Dyn. Nat. Soc. 2019, 2019, 8239047. [Google Scholar] [CrossRef] [Green Version]
- Novović, O.; Brdar, S.; Mesaroš, M.; Crnojević, V.N.; Papadopoulos, A. Uncovering the Relationship between Human Connectivity Dynamics and Land Use. ISPRS Int. J. Geo-Inf. 2020, 9, 140. [Google Scholar] [CrossRef] [Green Version]
- ITU. Call Detail Record (CDR) Analysis: Republic of Guinea; ITU Report: Geneva, Switzerland, 2017. [Google Scholar]
- Shangguan, B.; Yue, P.; Wu, Z.; Jiang, L. Big spatial data processing with Apache Spark. In Proceedings of the Sixth International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–4. [Google Scholar]
- Witayangkurn, A.; Horanont, T.; Shibasaki, R. Performance comparisons of spatial data processing techniques for a large-scale mobile phone dataset. In Proceedings of the 3rd International Conference on Computing for Geospatial Research and Applications, Washington, DC, USA, 1–3 July 2012; p. 1. [Google Scholar]
- Apache Software Foundation. Hadoop. Available online: https://hadoop.apache.org (accessed on 1 August 2021).
- Apache Software Foundation. Spark. Available online: https://spark.apache.org (accessed on 1 August 2021).
- The Mobipack Software. Spatial Data Commons. Available online: https://github.com/SpatialDataCommons (accessed on 1 August 2021).
- GSMA. GSMA Guidelines on the Protection of Privacy in the Use of Mobile Phone Data for Responding to the Ebola Outbreak; GSMA Guidelines: London, UK, 2014. [Google Scholar]
- Vanhoof, M.; Lee, C.; Smoreda, Z. Performance and sensitivities of home detection on mobile phone data. In Big Data Meets Survey Science 2020: A Collection of Innovative Methods; Wiley: Hoboken, NJ, USA, 2020; pp. 245–271. [Google Scholar]
- Bhandari, D.M.; Witayangkurn, A.; Shibasaki, R.; Rahman, M.M. Estimation of Origin-Destination using Mobile Phone Call Data: A Case Study of Greater Dhaka, Bangladesh. In Proceedings of the Thirteenth International Conference on Knowledge, Information and Creativity Support Systems (KICSS), Pattaya, Thailand, 15–17 November 2018; pp. 1–7. [Google Scholar]
- Kanasugi, H.; Sekimoto, Y.; Kurokawa, M.; Watanabe, T.; Muramatsu, S.; Shibasaki, R. Spatiotemporal Route Estimation Consistent with Human Mobility Using Cellular Network Data. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications Workshops (DERCOM Workshops), San Diego, CA, USA, 18–22 March 2013; pp. 267–272. [Google Scholar]
- Arai, A.; Knippenberg, E.; Meyer, M.; Witayangkurn, A. The hidden potential of call detail records in The Gambia. Data Policy 2021, 3, E9. [Google Scholar] [CrossRef]
- ITU. Call Detail Record (CDR) Analysis: Republic of Liberia; ITU Report: Geneva, Switzerland, 2017. [Google Scholar]
- ITU. Call Detail Record (CDR) Analysis: Sierra Leone; ITU Report: Geneva, Switzerland, 2017. [Google Scholar]
- Batran, M.; Arai, A.; Kanasugi, H.; Cumbane, S.P.; Grachane, C.; Sekimoto, Y.; Shibasaki, R. Urban Travel Time Estimation in Greater Maputo Using Mobile Phone Big Data. In Proceedings of the 2018 IEEE 20th Conference on Business Informatics (CBI), Vienna, Austria, 11–14 July 2018; pp. 122–127. [Google Scholar] [CrossRef]
- GSMA. Utilising Mobile Big Data and AI to Benefit Society: Insights from the COVID-19 Response; GSMA Report: London, UK, 2021. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Apache Hadoop | Apache Spark |
|---|---|---|
| Data Processing | Batch processing | Batch, real-time, streaming |
| Processing Speed | High | Higher by a factor of 10–100 (limited by memory) |
| Processing mode | On-disk | In-memory |
| Storage | Apache Hadoop Distributed File System (HDFS) | Uses existing platform |
| Scalability | Easily scalable by adding more nodes to the cluster | Same; however, memory-intensive nodes are required |
| Components | Functionalities | Use Cases |
|---|---|---|
| Standalone package | Anonymization Stay-point extraction Trip segmentation Route interpolation | To be run on personal computers (PCs) with small datasets |
| Apache Hadoop package | Cell tower mapping Data quality assurance Frequent locations Zone analysis Origin–destination matrix Stay-point extraction Trip segmentation Route interpolation | For processing big data Built as part of a data pipeline Requires Apache Hadoop cluster |
| Indicator series | Mobility indicator | Computation of necessary statistics of big data Requires Apache Hadoop cluster |
| Data | Call Detail Record Data | Cell Tower Data |
|---|---|---|
| Mapping components | Location area code (LAC) Cell identification (ID) | Location area code (LAC) Cell ID |
| Other Components | Anonymized identifiers Event timestamp Activity type | Geographic coordinates of cell towers (latitude and longitude) |
| No. | Name | Unit |
|---|---|---|
| 1 | Total records, total unique identifier | Per dataset |
| 2 | Total records, total unique identifier | Per day |
| 3 | Average usage per day for each unique identifier | Per dataset |
| 4 | Average number of unique locations per day | Per unique identifier |
| 5 | Hourly usage for each administrative zone | Per weekday, weekend |
| 6 | Footprint data for each administrative zone: total usage and total unique identifier. | Per dataset |
| 7 | Ratio of international mobile equipment identity (IMEI) to international mobile subscriber identity (IMSI) | Per dataset |
| Indicator | Name | Unit |
|---|---|---|
| 1 | Count of all CDR data | Day/hour |
| 2 | Count of unique handsets | Day/hour |
| 3 | Count of unique handsets | Day |
| 4 | The ratio of residents active on a given day based on those present at baseline | Day |
| 5 | Origin–destination matrix–trips between two regions | Day |
| 6 | Residents living in the area | Week |
| 7 | Mean and standard deviation (SD) of distance traveled (from home location) | Day |
| 8 | Mean and standard deviation of distance traveled (from home location) | Week |
| 9 | Daily locations based on home region with average stay time and SD of stay time | Day |
| 10 | Simple origin–destination matrix–trips between consecutive in time regions with duration | Day |
| 11 | Residents living in the area | Month |
| Module | No. of Records (Million) | No. of Concurrent Tasks | Execution Time (min) |
|---|---|---|---|
| Data Anonymization | 50 | 4 | 8.10 |
| 50 | 8 | 3.13 | |
| 100 | 4 | 13.58 | |
| 100 | 8 | 7.5 |
| Module | No. of Records (Million) | No. of Concurrent Tasks | Execution Time (min) |
|---|---|---|---|
| Data Preparation (Load, Pre-process, Cleaning, Mapping) | 50 | 10 | 7.93 |
| 50 | 20 | 4.62 | |
| 100 | 10 | 11.62 | |
| 100 | 20 | 7.39 | |
| Data Statistics (Daily and Summary Stats, Histogram, Zone-based Aggregation) | 50 | 10 | 30.32 |
| 50 | 20 | 25.27 | |
| 100 | 10 | 51.03 | |
| 100 | 20 | 40.78 | |
| Frequent Location | 50 | 10 | 3.30 |
| 50 | 20 | 2.28 | |
| 100 | 10 | 6.84 | |
| 100 | 20 | 3.93 | |
| Origin–Destination | 50 | 10 | 1.16 |
| 50 | 20 | 1.00 | |
| 100 | 10 | 2.39 | |
| 100 | 20 | 1.37 | |
| Route Interpolation | 50 | 10 | 349.07 |
| 50 | 20 | 179.77 | |
| 100 | 10 | 558.51 | |
| 100 | 20 | 226.89 | |
| Mobility Indicators | 50 | 10 | 60.60 |
| 50 | 20 | 37.77 | |
| 100 | 10 | 186.67 | |
| 100 | 20 | 73.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Witayangkurn, A.; Arai, A.; Shibasaki, R. Development of Big Data-Analysis Pipeline for Mobile Phone Data with Mobipack and Spatial Enhancement. ISPRS Int. J. Geo-Inf. 2022, 11, 196. https://doi.org/10.3390/ijgi11030196
Witayangkurn A, Arai A, Shibasaki R. Development of Big Data-Analysis Pipeline for Mobile Phone Data with Mobipack and Spatial Enhancement. ISPRS International Journal of Geo-Information. 2022; 11(3):196. https://doi.org/10.3390/ijgi11030196
Chicago/Turabian StyleWitayangkurn, Apichon, Ayumi Arai, and Ryosuke Shibasaki. 2022. "Development of Big Data-Analysis Pipeline for Mobile Phone Data with Mobipack and Spatial Enhancement" ISPRS International Journal of Geo-Information 11, no. 3: 196. https://doi.org/10.3390/ijgi11030196
APA StyleWitayangkurn, A., Arai, A., & Shibasaki, R. (2022). Development of Big Data-Analysis Pipeline for Mobile Phone Data with Mobipack and Spatial Enhancement. ISPRS International Journal of Geo-Information, 11(3), 196. https://doi.org/10.3390/ijgi11030196